
Abstract
Rangoli, a vibrant and intricate art form integral to Indian festivals, symbolizes cultural heritage and community spirit. Despite its deep-rooted significance, the preservation and classification of rangoli designs have been underexplored. Our work introduces FestivalNet, a new deep learning architecture created to classify festival-specific rangoli patterns. A comprehensive dataset, curated from diverse Indian regions and festivals such as Onam, Diwali, Janmashtami, Pongal, and Ganesh Chaturthi, forms the basis of this work. FestivalNet utilizes fused Mobile Inverted Residual Bottleneck module and dense custom attention blocks to capture complex patterns and hierarchical features inherent in rangoli designs. The proposed model achieves an accuracy of 81.58%, precision of 81.62%, recall of 81.07%, and an F1 score of 81.15%, outperforming competitive architectures like EfficientNetV2_ B0 and MobileNet variants. By bridging tradition with technology, this research aims to preserve the cultural significance of rangoli while fostering appreciation through modern applications.
Similar content being viewed by others


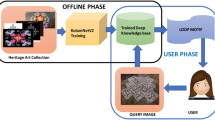
Introduction
Rangoli is more than a decorative art form; it is a vibrant tradition interwoven into India’s cultural and spiritual fabric1,2. Symbolizing joy, prosperity, and auspiciousness, these intricate designs frequently adorn homes and public spaces during festivals. Each pattern carries historical and regional significance, evolving with celebrations and customs3. India, with its rich diversity of cultures and traditions, uses festivals as a medium to foster unity and showcase its vibrant ethos. Festivals like Diwali, Pongal, Janmashtami, and Onam exemplify this diversity and serve as platforms for shared rituals, artistic expression, and communal harmony4. Among these traditions, Rangoli holds a special place, embodying cultural values and creativity through designs that reflect deities, themes, and local customs.Rangoli, originating from the Sanskrit rangavali meaning ’line of color,’ is a venerable Indian folk art traced back to early texts such as the Kamasutra and Narada Shilpa Shastra. It flourishes across regions under diverse names—kolam, alpona, mandana, chowk-poorana, among others—each infused with unique motifs and cultural symbolism5. Beyond serving as elaborate threshold décor, Rangoli embodies spiritual significance: inviting prosperity, symbolizing divine welcome, warding off evil, fostering communal artistry, and even fulfilling ecological and hygienic roles in traditional households6. Despite its cultural richness, the traditional practice of Rangoli is waning due to urbanization, globalization, and modernization7. Consequently, there is a growing need to preserve and archive Rangoli designs as a critical component of India’s intangible heritage. This preservation not only safeguards the art form but also enables future generations to appreciate and adapt these traditions.
Classifying Rangoli patterns is essential for multiple reasons. It aids in digital heritage preservation by cataloging designs for research and education, enhances accessibility for cultural studies, and provides a foundation for AI-driven applications like automated design generation or cultural analytics. Improved classification accuracy facilitates these applications, ensuring that even the most intricate designs are preserved and understood within their cultural context. Moreover, such classification systems can serve as tools for fostering cultural appreciation and education in diverse communities. Rangoli’s artistic appeal is deeply rooted in mathematical concepts. Symmetrical patterns often display reflectional and rotational symmetry key elements of geometry8. Designs incorporate basic geometric shapes like circles, squares, and triangles, and some resemble tessellations, reflecting principles of combinatorial and tiling theory9. Fractal-like structures, observed in repeating patterns at multiple scales, align with recursive mathematical processes in fractal geometry10. Dot-based Rangoli, such as Pulli Kolam, involves connecting points arranged in grids, analogous to graph theory representations11. Transformations like rotations and reflections relate to group theory12, while patterns occasionally embed arithmetic sequences, magic squares, or proportions like the Golden Ratio13. These attributes make Rangoli a compelling subject for mathematics education and digital archiving14,15.
Digital preservation and reconstruction of cultural heritage have gained significant attention, with computer vision playing a pivotal role in documenting and analyzing historical artifacts. Beyond heritage monuments, ritual arts like Mandala, Alpana, and Rangoli are also being digitized16,17,18. Research on Mandala art, for example, has explored mathematical interrelations, using randomized elements, fractal geometry, and symmetry operations to create and preserve patterns. Challenges such as symmetry enforcement during digitization have been addressed through geometric graph representation and curvature mapping19,20.
The classification of traditional Indian floor art such as Rangoli and Kolam has been investigated using both handcrafted feature-based methods and deep learning approaches. Early works relied on traditional image processing techniques such as scale-invariant feature transform (SIFT), histogram of oriented gradients (HOG), and shape descriptors combined with classical classifiers. For example, Kolam images were classified using SIFT descriptors with support vector machines (SVMs), demonstrating the potential of handcrafted features but with limited robustness against intra-class variability21. Similarly, symmetry and fractal geometry measures have been employed to characterize Rangoli and Kolam patterns, highlighting their mathematical richness but lacking scalability for large-scale datasets22.
With the advent of deep learning, convolutional neural networks (CNNs) have emerged as a dominant approach in cultural heritage classification. A study employing ResNet and DenseNet architectures for Kolam classification showed clear performance improvements compared to handcrafted descriptors, though interpretability remained limited23. Generative models have also been explored, with GANs used to synthesize and classify Mandala patterns, thereby bridging digital preservation with creative artificial intelligence (AI) applications24. More recently, vision transformers (ViTs) have been adapted for Kolam recognition, achieving robustness against scale and rotation variations and outperforming conventional CNNs in certain cases25.
Attention-based models have further enhanced the field by improving interpretability and precision. For instance, the use of channel-spatial attention mechanisms such as convolution block attention module (CBAM) and visualization techniques like Gradient-weighted Class Activation Mapping (Grad-CAM) has been reported to highlight critical motifs in cultural patterns, enabling explainable AI solutions for heritage applications26. In addition, multimodal fusion of color, texture, and geometry within hybrid CNN-transformer frameworks has been proposed for heritage pattern classification, achieving state-of-the-art results in datasets covering Rangoli, Kolam, Alpana, and Mandala27. These advances indicate a clear shift from handcrafted features to interpretable, multimodal, and attention-driven architectures.
In this context, our proposed FestivalNet aligns with recent trends while addressing gaps such as limited dataset diversity and the need for lightweight, deployable models. By combining fused MBConv blocks with dense custom attention, FestivalNet achieves robust feature learning for festival-themed Rangoli classification, contributing both to digital cultural preservation and modern AI research. In the context of Rangoli, its significance as ritual floor art lies in its vibrant colors and intricate patterns. Traditionally drawn at entrances to purify spaces and invoke blessings, Rangoli also serves as a storytelling medium reflecting community heritage2,28. However, urbanization and limited public datasets hinder the systematic preservation of Rangoli. Recent AI advancements, such as deep learning models, have been employed to classify cultural patterns, including Tamil Kolam designs29. Techniques like attention mechanisms and GradCAM visualizations have enhanced the interpretability and precision of these models30,31. Table 1 enumerates that many datasets have limited motif diversity (just a few classes), which may not cover less common or regionally specific Kolam types.
Despite these efforts, existing works face challenges such as:
-
Limited dataset availability and class diversity:Publicly available datasets are scarce, often restricted to specific styles and regions.
-
Intraclass variability: Rangoli designs vary significantly in geometry, color palettes, and motifs, complicating classification.
-
Complex intricate patterns:Fractal and graph-like structures in Rangoli challenge traditional CNNs, which often act as black-box models.
-
Limited interpretability: There is a lack of explainable AI models that elucidate why a design is classified into a particular category, a critical requirement for cultural heritage applications.
Recent studies have leveraged attention-based CNNs, transformer architectures, and visualization tools like GradCAM to highlight key elements in cultural patterns32. For example, deep learning techniques have been used to localize and classify damaged structures in heritage monuments, enhancing preservation efforts. However, these approaches often lack generalizability and robustness when applied to diverse patterns like Rangoli. By addressing these limitations, we aim to advance AI-driven cultural archiving.
To bridge the gaps in existing research, we propose a deep learning-based system for classifying Rangoli designs, focusing on festive themes. Key contributions include:
-
Dataset Curation: A new dataset of festival-themed Rangoli designs is curated to address the lack of diverse, annotated datasets.
-
Novel Architecture: We design a custom deep neural network, FestivalNet, optimized for learning complex patterns and motifs.
-
Performance Evaluation: FestivalNet’s feature learning capability is validated through comparisons with state-of-the-art models.
-
Explainability:Attention mechanisms are incorporated to enhance model interpretability, providing insights into the classification process.
Methods
Festival dataset curation
The Festival dataset was compiled from diverse sources, including social media platforms (Facebook, Instagram, Pinterest), public contributions via Google Forms, and web searches on Google. Contributions were actively sought from various regions across India to ensure inclusivity and represent the country’s geographic and stylistic diversity. Efforts were made to collect images showcasing traditional, contemporary, and regional design variations to reflect the unique cultural nuances of each festival.
The dataset focuses on five major festivals:Onam, Diwali, Janmashtami, Pongal and Ganesh Chathurthi.
Onam: Known for floral Rangolis called Pookalam, featuring circular patterns, deity faces, boats, and cultural motifs that vary across Kerala’s districts. Diwali: Includes designs of diyas, Om symbols, footprints, and messages like “Happy Diwali," capturing both traditional and modern interpretations from different states. Janmashtami: Centers on Krishna-related motifs such as peacock feathers, flutes, butter pots, and depictions of Krishna, highlighting regional artistry from North and South India. Pongal: Highlights overflowing pots, cows, trees, and festive harvest imagery, with styles reflecting Tamil Nadu’s rural and urban celebrations. Ganesh Chaturthi: Features Rangolis of Ganesh with intricate designs, incorporating elements like leaves or textual greetings that differ significantly between Maharashtra and other states. To minimize bias, contributors from various cultural backgrounds were encouraged to submit designs, and the dataset was curated to include an equitable representation of different regions and styles. Out of 2500 collected images, 1508 were selected after extensive cleaning. Images with irreparable noise, such as background distractions or unrelated elements, were excluded to maintain quality and relevance. A major challenge in the dataset was the presence of extraneous elements such as shadows, uneven surfaces, and irrelevant objects (e.g., chairs, walls). These were removed by isolating Rangoli designs from their noisy backgrounds. In several images, hands were visible during the creation of Rangoli. These were removed by cropping images to focus solely on the Rangoli design while preserving its visual and geometric integrity. To maintain uniformity across the dataset, all images were resized to a fixed dimension of 256 × 256 pixels. This standardization ensures compatibility with machine learning models and consistent analysis. More details on the Festival dataset are enumerated in Table 2.
Proposed FestivalNet architecture
As shown in Fig. 1, We propose FestivalNet, a deep neural network architecture for classifying festival Rangoli patterns. The rationale behind the proposed architecture stems from the unique challenges posed by Rangoli classification, including regional and cultural diversity, variations in materials and lighting conditions, and intricate patterns that demand robust feature extraction. Existing methods often lack generalizability or fail to address these specific issues effectively, leading to the need for a tailored approach.

Architecture diagram of the proposed network.
The network is designed to leverage fused MBConv blocks33 and custom dense attention blocks, enabling it to effectively capture intricate patterns and hierarchical features characteristic of Rangoli images. The architecture focuses on improving both accuracy and efficiency, particularly for mobile devices with limited resources, as shown in Fig. 2. This emphasis is motivated by the practical requirement to deploy the system in real-world scenarios, where lightweight and efficient models are critical.

Block Diagram of Fused MBconv.
The architecture begins with a convolutional block that downsamples the input image, reducing spatial dimensions while preserving essential features. The resulting representation is sequentially processed through two fused MBConv blocks. These blocks employ depthwise separable convolutions and expand-reduce operations to enhance feature extraction. The output is further downsampled and passed through a third fused MBConv block for additional refinement.
The features extracted by the MBConv blocks are passed through two dense custom attention blocks, which emphasize critical features by focusing on relevant regions of the Rangoli pattern. This output undergoes further downsampling and is processed through four consecutive dense custom attention blocks, enhancing the feature hierarchy. A subsequent downsampling operation leads to the final set of two dense custom attention blocks, which refine the feature representation to a high degree of granularity.
The refined features are then passed through a dual attention block that integrates spatial and channel attention mechanisms. This step ensures the network captures global context and models feature interdependencies comprehensively. The final output is connected to a fully connected layer for classification, predicting the class labels of Rangoli patterns.
The proposed network achieves efficient feature extraction through fused MBConv blocks and robust hierarchical learning via dense custom attention mechanisms. The integration of the dual attention block ensures detailed modeling of spatial and channel-wise dependencies, which is crucial for classifying intricate Rangoli designs. Moreover, FestivalNet addresses specific challenges like regional diversity, varying geometric patterns, and lighting conditions, making it uniquely suited for Rangoli classification.
In the Fused MB block33, the primary operation involves combining different types of convolutions to reduce the number of parameters and FLOPs (floating point operations). This design aims to enhance both accuracy and efficiency, which is crucial for mobile devices with limited computational resources. The motivation for this focus is that real-world applications of Rangoli classification—such as heritage preservation and cultural archiving—demand lightweight and easily deployable models.
As illustrated in Fig. 3, the architecture optimizes computation through lightweight operations like depthwise separable convolutions and fused convolutions. These design strategies are particularly effective for capturing the intricate details of Rangoli patterns while ensuring computational efficiency.

Block Diagram of Dense Custom Channel Attention Block.
The Fused MB block follows a structured sequence of operations. First, the input feature map is passed through a 3 × 3 convolution, which extracts local features. The resulting output is then processed by a Squeeze-and-Excitation (SE) block to adaptively recalibrate channel-wise responses. Next, the recalibrated features are passed through a 1 × 1 convolution for dimensionality adjustment. Finally, the transformed features are combined with the original input through a skip connection, preserving information flow while enhancing representational capacity.
Formally, let I denote the input image of dimensions (H × W × C), where H is the height, W is the width, and C is the number of channels. Let \(X\in {{\mathbb{R}}}^{H\times W\times C}\) represent the corresponding input feature map. The first step involves applying a 3 × 3 convolution on X:
Here, is the 3 × 3 convolution kernel (weights), represents the convolution operation, and is the output of the 3 × 3 convolution with dimensions.
The output of the 3 × 3 convolution is passed through the Squeeze and Excitation (SE)34 block. This block recalibrates the channels using a global average pooling operation followed by two fully connected layers. Let be the scaling factors produced by the SE block.
The SE block is mathematically represented as:
In this equation, and represent the weights of the two fully connected layers. is the sigmoid activation function, which is used to scale the channel attention. is the rectified linear unit activation function, applied after the first fully connected layer. is the channel scaling factor matrix, which is used to recalibrate the feature map based on the channel attention.
The output of the SE block is then applied to the input of the SE block as:
Here, represents element-wise multiplication, recalibrating the feature map using the scaling factors from. Next, the output from the SE block is passed through a 1 × 1 convolution. The 1 × 1 convolution reduces the depth (number of channels) or modifies the feature map as required:
Where is the 1 × 1 convolution kernel (weights), and is the output of the 1 × 1 convolution. Finally, the output from the 1 × 1 convolution is added back to the original input through a skip connection:
In this equation, represents the final output of the Fused MB block.
The fused MB block couples spatial convolution, channel recalibration, and residual learning, enabling efficient yet expressive representation learning.
The dense custom channel attention block strengthens representational power by progressively refining channel interactions through dense connections, Swish activation, and attention-based recalibration. It ensures that critical discriminative information is preserved and amplified across stages.
Let \(X\in {{\mathbb{R}}}^{H\times W\times C}\) be the input feature map.
The input is projected via a 1 × 1 convolution with Swish activation:
where \({W}_{1\times 1}\in {{\mathbb{R}}}^{1\times 1\times C\times {C}_{1}}\) and Swish(x) = x ⋅ σ(x). This step performs lightweight channel mixing while preserving non-linearity.
Channel attention is applied to recalibrate features:
where GAP( ⋅ ) produces a channel descriptor, \({W}_{CA1}\in {{\mathbb{R}}}^{{C}_{1}/r\times {C}_{1}}\) and \({W}_{CA2}\in {{\mathbb{R}}}^{{C}_{1}\times {C}_{1}/r}\) are learnable weights, δ( ⋅ ) is ReLU, and σ( ⋅ ) is sigmoid. The recalibrated features are:
which emphasize informative channels.
The features are further refined in two iterative steps:
where \({W}_{1\times 1}^{(k)}\) are stage-specific 1 × 1 convolutions. Outputs from each stage are concatenated:
where Concat( ⋅ ) is along the channel axis. Dense connections encourage feature reuse and gradient flow.
The concatenated features are fused via a 3 × 3 convolution:
where \({W}_{3\times 3}\in {{\mathbb{R}}}^{3\times 3\times {C}_{concat}\times {C}_{out}}\) are the learnable weights. The output Yfinal represents the final refined features. By combining Swish activation, channel attention, and dense refinement, this block progressively emphasizes discriminative channels and enhances robustness, making it particularly effective for complex classification tasks.
Results
This section discusses the experimental settings, evaluation metrics, performance of FestivalNet and its ablation study. Finally, we compare our model’s performance with SOTA models.
Experimental settings
The experimental setup utilizing the FestivalNet framework was designed to classify Rangoli patterns corresponding to five distinct Indian festivals, ensuring both high performance and strong generalization capabilities.The dataset is randomly partitioned into training, validation, and testing sets in an 80:10:10 ratio, respectively. Data augmentation techniques, including horizontal and vertical flipping, 90° rotation, and random width and height adjustments, were employed to enhance the diversity of the training dataset and improve model generalization. These augmentations effectively mimic natural variations in the data, such as different orientations and perspectives, that the model is likely to encounter in real-world scenarios. Furthermore, they help mitigate overfitting, particularly when training on a limited dataset, thereby ensuring robust performance.
The training process involved updating the FestivalNet model’s weights using the Adam optimizer, starting with an initial learning rate of 0.001. To improve convergence, the learning rate was decreased by 10% whenever the validation loss showed no improvement for five consecutive epochs. Since the task required multi-class classification, the categorical cross-entropy function was employed as the loss function. Training spanned 240 epochs with a batch size of 4, incorporating early stopping to mitigate overfitting. An Nvidia RTX 4060 GPU was utilized to enhance computational efficiency during the training phase.
Evaluation metrics
A thorough set of evaluation metrics was used to assess the effectiveness and performance of the proposed FestivalNet model in classifying Rangoli images.
Precision
Precision measures how accurately FestivalNet identifies a specific Rangoli category (denoted as cs) among the five possible categories. It is calculated as:
Recall
Recall evaluates FestivalNet’s ability to detect all actual instances of a given Rangoli category within the predicted positive instances.It is represented as:
F1 Score
The F1 score is a key metric for evaluating FestivalNet’s performance, particularly in cases where there is an imbalance among the Rangoli categories. It is computed as :
Accuracy
Accuracy represents the proportion of correct classifications made by the FestivalNet model. This considers both true positives (TPcs) and true negatives (TNcs), which are correctly identified as not belonging to the specific category. It is calculated as:
Confusion matrix
The confusion matrix offers a comprehensive analysis of the FestivalNet model’s performance by showing the counts of true positives (TPcs), false positives (FPcs), true negatives (TNcs), and false negatives (FNcs) for each Rangoli category.
Performance of FestivalNet
The performance of the ProposedNet model is analyzed using the confusion matrix and the ROC curve as shown in Figs. 4, 5 respectively. The confusion matrix highlights accurate classification across five classes: Diwali, Ganesh, Janmashtami, Onam, and Pongal, with the highest accuracy for Onam (96%), followed by Pongal (86%) and Janmashtami (76%), while Diwali (73%) and Ganesh (75%) show moderate performance with fewer misclassifications compared to earlier models. The ROC curve further demonstrates robust class separability, with a macro-average AUC of 0.88, indicating strong multi-class classification. Onam achieves the highest AUC (0.95), followed by Pongal (0.91), Ganesh (0.86), Janmashtami (0.85), and Diwali (0.84), showcasing ProposedNet’s improved performance and effective differentiation across all classes.

Performance metrics of FestivalNet: Confusion Matrix.

Performance metrics of FestivalNet: ROC Curve.
The Table 3 presents the performance metrics for each class using the proposed model. Precision, recall, and F1-score values are reported for classes 0 through 4. The model achieves the highest recall and F1-score in class 3, demonstrating its strong performance in that category.
Practical implications and generalizability
While FestivalNet demonstrates significant academic contributions, its practical implications are equally notable. By achieving reliable classification of Rangoli patterns, the model can be utilized in cultural heritage preservation, automated design generation for art restoration, and educational tools that promote traditional art forms. Furthermore, FestivalNet’s efficient architecture makes it suitable for deployment in real-time systems, enabling applications like virtual Rangoli design assistants or mobile apps for cultural exploration. These practical aspects underscore the model’s potential to bridge the gap between academic research and real-world utility.
Ablation study on FestivalNet
Table 4 illustrates the ablation study results evaluating the impact of Dual Attention and Fused MBConv layers on the performance of the proposed network. The configuration with both Dual Attention and Fused MBConv achieved the highest metrics, with a precision of 0.8162, recall of 0.8107, F1-score of 0.8115, and accuracy of 0.8158, highlighting the complementary benefits of these components. Removing Fused MBConv while retaining Dual Attention resulted in a significant drop in performance, demonstrating the importance of Fused MBConv for feature extraction. Conversely, disabling Dual Attention while keeping Fused MBConv led to moderately reduced but still competitive performance, indicating the standalone utility of Fused MBConv. These results emphasize the synergistic contribution of Dual Attention and Fused MBConv layers in improving network performance.
Removing Fused MBConv (Dual Attention only) causes a drastic drop: Precision falls by 14% to 0.6984, Recall to 0.6899, F1 to 0.6829, Accuracy to 0.6908. This sharp decline highlights Fused MBConv’s central role in extracting discriminative features. Disabling Dual Attention (Fused MBConv only) results in milder reductions—Precision = 0.8022, Recall = 0.7937, F1-Score = 0.7949, Accuracy = 0.7993—demonstrating that Fused MBConv independently offers strong representation, while Dual Attention contributes valuable refinement. The full model’s superior performance indicates a synergistic effect: the Fused MBConv module builds a robust foundation of feature extraction, while the Dual Attention mechanism selectively enhances relevant spatial and channel contexts. These findings confirm that FestivalNet is best optimized through deliberate integration of both modules.
Comparative experiments
EfficientNetV2B033(Fig. 6) demonstrates strong multi-class classification performance, as illustrated by the confusion matrix and ROC curve. The confusion matrix reveals high accuracy for Onam (96%) and Pongal (98%), with moderate performance for Janmashtami (73%), Diwali (64%), and Ganesh (62%), where the latter classes experience higher misclassifications. The ROC curve highlights the model’s robust class separability, achieving a macro-average AUC of 0.87. Pongal and Onam stand out with the highest AUCs of 0.97 and 0.94, respectively, followed by Janmashtami (0.84), while Ganesh (0.78) and Diwali (0.79) show relatively lower AUCs. These results demonstrate that EfficientNetV2B0 excels in identifying specific classes, such as Onam and Pongal, while maintaining consistent overall classification performance.

Performance Comparison of related CNN models: Confusion Matrix and ROC Curve.
Table 5 presents the performance metrics for each class using the EfficientNetV2B0 model, highlighting precision, recall, and F1-score. Class 4 achieves the highest performance with a precision of 0.8333, recall of 0.9821, and an F1-score of 0.9016, demonstrating excellent classification accuracy. Similarly, Class 3 performs strongly with an F1-score of 0.8758, supported by a recall of 0.9571 and precision of 0.8072. Class 2 exhibits balanced performance with an F1-score of 0.7541, recall of 0.7302, and precision of 0.7797. In contrast, Class 0 and Class 1 show relatively lower performance, with F1-scores of 0.6863 and 0.6789, respectively, reflecting challenges in distinguishing these classes. Overall, the metrics indicate that EfficientNetV2B0 delivers robust classification performance, particularly for Classes 3 and 4, while leaving room for improvement in Classes 0 and 1.
The performance of MobileNet (Fig. 6) is illustrated through the confusion matrix and ROC curve, demonstrating strong multi-class classification capabilities across five classes: Diwali, Ganesh, Janmashtami, Onam, and Pongal. The confusion matrix shows high accuracy for Onam (93%) and Pongal (93%), moderate performance for Diwali (69%) and Ganesh (68%), and relatively lower accuracy for Janmashtami (68%) due to notable misclassifications. The ROC curve highlights excellent class separability, with a macro-average AUC of 0.86. Pongal achieves the highest AUC (0.95), followed by Onam (0.94), Ganesh (0.82), and Janmashtami (0.81), while Diwali has the lowest AUC (0.80). These results reflect MobileNet’s consistent performance, with particular strengths in identifying Onam and Pongal.
The Table 6 shows the performance metrics for each class using the MobileNet35 model. Precision, recall, and F1-score values are provided for classes 0 through 4, with class 4 achieving the highest F1-score. The model performs particularly well in recall and F1-score for class 4, demonstrating strong overall performance.
The performance of MobileNetV3Small (Fig. 6) is evaluated using a confusion matrix and ROC curve, demonstrating consistent classification across five classes: Diwali, Ganesh, Janmashtami, Onam, and Pongal. The confusion matrix reveals strong accuracy for the Onam class (91%) and Pongal (88%), with moderate performance for Diwali (67%), Ganesh (60%), and Janmashtami (75%), indicating occasional misclassifications. The ROC curve highlights robust class separability, achieving a macro-average AUC of 0.85. Onam and Pongal exhibit the highest AUCs (0.92 and 0.91, respectively), while Diwali (0.81), Janmashtami (0.84), and Ganesh (0.78) show satisfactory discrimination. Overall, MobileNetV3Small delivers reliable multi-class classification with a focus on strong separability for key classes.
The Table 7 presents the performance metrics for each class using the MobileNetV3 Small model35. Class 2 achieves the highest F1-score, with a balanced precision and recall of 0.7460. The model performs well across all classes, with class 3 having the best recall and F1-score.
The Table 8 shows the performance metrics for each class using the MobileNetV3 Large model35. Class 4 exhibits the highest performance across all metrics with a precision, recall, and F1-score of 0.9107, demonstrating its strong detection capabilities. Classes 0 and 3 also perform well, with precision and recall scores close to 0.80, while Class 2 shows relatively lower performance, especially in recall. The performance of MobileNetV3Large (Fig. 7) is visualized through the confusion matrix and ROC curve, highlighting robust classification capabilities across five classes: Diwali, Ganesh, Janmashtami, Onam, and Pongal. The confusion matrix reveals strong accuracy for Pongal (91%) and Onam (90%), with moderate performance for Diwali (78%) and Ganesh (68%), while Janmashtami exhibits relatively lower accuracy (60%) due to higher misclassifications. The ROC curve demonstrates excellent class separability, with a macro-average AUC of 0.86. Pongal achieves the highest AUC (0.95), followed by Onam (0.92), Diwali (0.85), and Ganesh (0.81), while Janmashtami has the lowest AUC (0.77), aligning with its classification challenges. Overall, MobileNetV3Large delivers strong performance, particularly for Pongal and Onam, with consistent multi-class classification effectiveness Fig. 8.

Performance Comparison of related CNN models: Confusion Matrix and ROC Curve.

Comparison of Class Activation Maps across Models for Festive Images.
The performance of the SwinTransformerV2Base model with a window size of 8 is visualized through the confusion matrix (Fig. 7) and the Receiver Operating Characteristic (ROC) curve (Fig. 7). The confusion matrix highlights the classification performance across five classes: Diwali, Ganesh, Janmashtami, Onam, and Pongal, with diagonal entries representing correct predictions and off-diagonal elements indicating misclassifications. The model demonstrates strong performance for the Onam class, achieving 87% accuracy, while moderate accuracies are observed for Pongal (64%) and Diwali (55%), though these classes exhibit some misclassifications, particularly with Ganesh and Janmashtami. Lower accuracies for Ganesh and Janmashtami reflect challenges in distinguishing these classes, as evident from notable off-diagonal values. The ROC curve further evaluates the model’s discriminative ability, with the highest area under the curve (AUC) for the Onam class (0.90), indicating strong separability. Moderate AUC scores for Pongal (0.77) and Diwali (0.73) reflect satisfactory performance, while the Ganesh and Janmashtami classes exhibit the lowest AUC values of 0.71 and 0.73, respectively, aligning with their lower classification accuracies. The macro-average AUC of 0.77 highlights the model’s overall ability to perform multi-class classification, with notable strengths and areas for improvement Fig. 9.

Samples of misclassification results.
Table 9 provides the performance results of the model across different classes. The results indicate variability in the model’s effectiveness. For instance, the model achieved the highest F1-score (0.824) for Class 3, with corresponding precision and recall values of 0.782 and 0.871, respectively. Conversely, Class 1 recorded the lowest F1-score (0.528), which highlights potential challenges in accurately classifying instances in this category. Classes 0, 2, and 4 showed moderate performance, with F1-scores ranging from 0.561 to 0.621.
Table 10 presents the performance metrics of various models, including the proposed method, based on Precision, Recall, F1-Score, and Accuracy. The proposed method achieves the highest overall performance, with an F1-Score of 0.8115 and an Accuracy of 0.8158, outperforming all baseline models. Among the baselines, the v2_b0 and Mobilenet variants show relatively competitive performance, with F1-Scores ranging from 0.7793 to 0.7731. In contrast, DenseNet and Inception-ResNet-v236 models exhibit lower scores across all metrics, underscoring their suboptimal performance for the given task. These results highlight the superior predictive capabilities of the proposed method.The models compared in Table 10 were chosen to represent a diverse and relevant cross-section of the state-of-the-art in image classification as of 2025. EfficientNetV2 was included due to its demonstrated superior training speed and parameter efficiency, delivering strong classification performance with up to 6.8 × better parameter efficiency and significantly faster training than prior ConvNets on datasets like ImageNet, CIFAR, and others. MobileNet variants (V2, V3 large/small) offer widely recognized benchmarks for mobile and edge deployment due to their compact size, low latency, and optimized inference on resource-constrained devices. Additionally, Swin Transformer represents the forefront of vision transformer architectures, achieving strong hierarchical modeling and SOTA performance across classification, detection, and segmentation benchmarks while maintaining linear computational complexity relative to image size. By including these alongside classical CNN backbones such as DenseNet and Inception-ResNet, our comparison spans both efficient edge-optimized models and cutting-edge transformer-based models—enabling a comprehensive and fair evaluation of our proposed network across performance, architectural paradigms, and deployment contexts. While FestivalNet achieves superior classification performance, its efficiency in terms of parameter count, model size, and inference speed must be contextualized—especially against lightweight architectures. For instance, SqueezeNet attains AlexNet-level accuracy with approximately 50 × fewer parameters and a sub-0.5 MB model size.
The visual analysis of Class Activation Maps between the proposed model and baseline architectures highlights significant variations in feature focus and attention distribution. The Proposed Net demonstrates focused activations on semantically significant regions, such as highlighting the central diya in Diwali images and attending to the deity’s face and trunk in Ganesh images, indicating precise localization of class-relevant features. In contrast, EfficientV2_b0 exhibits broader activations, capturing key areas like the central motifs in Diwali and Onam, but also focusing on peripheral regions, reflecting a lack of spatial precision. Mobilenet shows consistent attention on prominent features; however, its activations are diffused, as seen in the Janmashtami image where activations highlight the peacock feather but spread into surrounding areas. MobilenetV3Large highlights essential components, such as the diya in Diwali and the trunk in Ganesh, but its attention is moderately dispersed, occasionally including irrelevant regions. MobilenetV3Small focuses more on localized features, as observed in the Pongal image where activations are concentrated on decorated pots, though some spillover into the background persists. FestivalNet exhibits superior localization of class-relevant features, focusing on key motifs like central designs and symmetrical patterns. EfficientNetV2b0 and MobileNet show broader, less focused activations, often capturing irrelevant regions, thereby impacting their precision in handling subtle inter-class differences. In summary, the Proposed Net achieves superior feature localization, focusing on class-relevant regions with higher precision, while baseline models exhibit varying levels of activation dispersion.
Limitations and future work
Misclassification in the FestivalNet model indicates the challenges associated with distinguishing intricate patterns in Rangoli designs. Certain Rangoli designs share common features across festivals, such as floral elements, circular arrangements, or the use of similar colors. Rangoli styles vary by region and may blend motifs from multiple festivals. For example, a design classified under Diwali could have elements resembling Ganesh Chaturthi, leading to confusion. While FestivalNet performs well, its architecture might have limitations in capturing fine-grained details or recognizing subtle differences in complex designs. This could particularly affect cases where the dataset contains overlapping or ambiguous features. This work makes significant contributions to cultural heritage preservation by offering a scalable framework for digitizing, analyzing, and archiving intricate art forms like Rangoli. Beyond its immediate application, FestivalNet has the potential to influence other areas of AI and cultural heritage preservation. For instance, the methods proposed in this study could be adapted to classify and analyze other traditional art forms, such as Mandalas, Alpana, and Kolam, fostering global recognition and preservation of diverse artistic traditions. The integration of class activation maps also provides a means for detailed documentation, enabling deeper insights into patterns and motifs that carry cultural significance.
Future directions include extending the dataset to encompass international variations of Rangoli and similar traditional art forms, thereby enhancing the model’s generalizability across cultural boundaries. Additionally, the deployment of real-time classification systems could revolutionize interactive experiences, such as virtual reality (VR) and augmented reality (AR) platforms, allowing users to explore and create digital representations of traditional art. These advancements could also support educational initiatives, making cultural heritage more accessible to younger generations and global audiences.
Moreover, integrating FestivalNet with smart IoT devices could enable automated Rangoli generation systems for festive or ceremonial events, blending tradition with technology. Further research could explore collaborative efforts with artists and cultural organizations to develop hybrid systems that preserve and innovate upon traditional art forms, ensuring their relevance and continuity in the digital age.
Discussion
Our study introduces FestivalNet, a deep learning framework tailored for classifying Rangoli patterns associated with various Indian festivals. By utilizing a carefully constructed and diverse dataset alongside a novel architecture that integrates MBConv layers with dense attention mechanisms, the model effectively tackles challenges such as high pattern complexity, significant variability, and the scarcity of large datasets in Rangoli classification. FestivalNet demonstrates remarkable performance, achieving an accuracy of 81.58%, precision of 81.62%, recall of 81.07%, and an F1-score of 81.15%, outperforming existing state-of-the-art models in both accuracy and reliability. Additionally, the use of class activation maps enhances result interpretability, providing valuable insights into the model’s reasoning process.
Data availability
The dataset generated and analysed during the current study is not publicly available due to copyright and cultural heritage restrictions but may be shared by the authors upon reasonable request.
References
Madian, F. A. M. A combination of flock printing and luminous printing as an approach to enhance aesthetic and plastic values in bridal veil inspired by rangoli art. Int. Des. J. 12, 305–316 (2022).
Khandey, P. D. Rangoli as a cultural expression: unveiling the artistic and social significance of floor art in indian households. Dada Lakhmi Chand J. Perform. Vis. Arts 1, 32–52 (2024).
Mondal, E. A. The history, tradition, and continuity of India’s transitory floor art are extensive. J. La Soc. 3, 57–61 (2022).
Kannabiran, G. & Reddy, A. V. Exploring kolam as an ecofeminist computational art practice. In Proc. 14th ACM Conference on Creativity and Cognition (C&C 2022), 183–192 (ACM, 2022).
Encyclopaedia Britannica. Rangoli: India, floor art, designs, meanings, & festivals. https://www.britannica.com/topic/rangoli Accessed 27 Oct 2025 (2023).
Times of India. Diwali 2023 rangoli: Importance of rangoli during Deepavali. https://timesofindia.indiatimes.com Accessed 27 Oct 2025 (2023).
Parikh, K. The visual vocabulary of India: design practice since the Indus Valley Civilization. IIS Univ. J. Arts 8, 123–130 (2020).
Rychlewski, J. Symmetry. Eng. Trans. 71, 265–283 (2023).
Williams, H. C. Tilings and patterns, by B. grunbaum and G. C. shephard. Math. Gaz. 71, 347–348 (1987).
Cannon, J. W. The fractal geometry of nature by Benoit B. Mandelbrot. Am. Math. Monthly 91, 594–598 (1984).
Hartmann, N.Kolams in graph theory, mathematics in South Indian ritual art. Ph.D. thesis, Murray State University (2023).
Shirali, S. A. Symmetry in the world of man and nature. Resonance 6, 29–38 (2001).
Zimmer, H. R.Myths and Symbols in Indian Art and Civilization (Pantheon Books, 1946).
Livio, M.The Golden Ratio: The Story of PHI, the World’s Most Astonishing Number (Crown, 2008).
Greer, B., Mukhopadhyay, S., Powell, A. B. & Nelson-Barber, S. Culturally Responsive Mathematics Education (Routledge, 2009).
Shelke, S. M. et al. Indian heritage monuments identification using deep learning methodologies. SSGM J. Sci. Eng. 1, 52–56 (2023).
Paul, A. J., Dutta, P., Chakraborty, S., Nath, D. & Saha, A. Machine learning advances aiding recognition and classification of Indian monuments and landmarks. In UPCON 2021, 1–6 (IEEE, 2021).
Sasithradevi, A. et al. Monunet: a high-performance deep learning network for Kolkata heritage image classification. Herit. Sci. 12, 242 (2024).
Sarkar, T. & Bhowmick, P. Mandala as computational art: vectorization and beyond. In ICVGIP 2023, 1–1 (ACM, 2023).
Sarkar, T., Chatterjee, P. C. & Bhowmick, P. Mandala symmetrization through curvature map and geometric graph. In IVCNZ 2023, 1–6 (IEEE, 2023).
Kumar, A. & Devi, R. Kolam image classification using SIFT features and SVM. J. Cult. Inform. 5, 45–53 (2021).
Patel, S. & Raghavan, M. Symmetry and fractal geometry analysis in rangoli/kolam designs. Pattern Recognit. Lett. 156, 120–128 (2022).
Natarajan, K., Bose, P. & Meena, L. Deep learning for Kolam classification using ResNet and DenseNet. Neural Comput. Appl. 34, 12541–12552 (2022).
Zhang, Y. & Roy, A. Mandala art generation and classification using GANs. Vis. Comput. Cult. Herit. 10, 233–242 (2022).
Sharma, R., Menon, V. & Balaji, S. Kolam recognition using vision transformers. Appl. Intell. 53, 8459–8472 (2023).
Iqbal, M. & Singh, F. Attention mechanisms for cultural pattern classification: a case study on ritual floor arts. Pattern Anal. Appl. 26, 2123–2136 (2023).
Chatterjee, L., Das, H. & Nguyen, T. Heritage pattern classification with multimodal deep learning. Knowl.-Based Syst. 293, 110565 (2024).
Tiwari, V. Rangoli and its spiritual significance. Int. J. Res. Anal. Rev. 5, 743–747 (2018).
Anbalagan, S., Sivapatham, S., Nathan, D. S. & Roomi, S. M. M. Kolamnet: an attention-based model for kolam classification. In Proc. Thirteenth Indian Conference on Computer Vision, Graphics and Image Processing. https://doi.org/10.1145/3571600.3571638 (ACM, 2022).
Sasithradevi, A. et al. Kolamnetv2: efficient attention-based deep learning network for Tamil heritage art–kolam classification. Herit. Sci. 12, 60 (2024).
García, N. & Vogiatzis, G. How to read paintings: Semantic art understanding with multi-modal retrieval. arXiv abs/1810.09617 https://api.semanticscholar.org/CorpusID:53040712 (2018).
Bahrami, M. & Albadvi, A. Deep learning for identifying Iran’s cultural heritage buildings in need of conservation using image classification and Grad-CAM. ACM J. Comput. Cult. Herit. 17, 1–20 (2024).
Tan, M. & Le, Q. Efficientnetv2: Smaller models and faster training. In International conference on machine learning. 10096–10106 (2021).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In CVPR 2018, 7132-7141 (IEEE, 2018).
Howard, A. G. Mobilenets: efficient convolutional neural networks for mobile vision applications. Preprint at https://doi.org/10.48550/arXiv.1704.04861 (2017).
Szegedy, C., Ioffe, S., Vanhoucke, V. & Alemi, A. Inception-v4, Inception-ResNet and the impact of residual connections on learning. In Proc. Thirty-First AAAI Conference on Artificial Intelligence. Vol. 31, 4278–4284 (AAAI Press, 2017).
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A. & Chen, L. Mobilenetv2: inverted residuals and linear bottlenecks. In CVPR 2018, 4510–4520 (IEEE, 2018).
Huang, G., Liu, Z., van der Maaten, L. & Weinberger, K. Q. Densely connected convolutional networks. In CVPR 2017, 4700–4708 (IEEE, 2017).
Liu, Z. et al. Swin transformer V2: scaling up capacity and resolution. In CVPR 2022, 12009–12019 (IEEE, 2022).
Author information
Authors and Affiliations
Contributions
Sasithradevi A- methods and visualization; SabariNathan-Conceptualization and Data Collection;S Mohamed Mansoor Roomi -coding and results; Prakash P-review and supervision.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
A, S., Nathan, S., Mansoor Roomi, S.M. et al. FestivalNet: a deep learning architecture to classify the Indian heritage art-rangoli. npj Herit. Sci. 13, 687 (2025). https://doi.org/10.1038/s40494-025-02229-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s40494-025-02229-1
