
Abstract
Oracle bone inscriptions are China’s earliest writing system, dating back 3000 years. Usually carved on bones and tortoise shells, they serve as invaluable records of early Chinese civilisation. Due to erosion, a large number of oracle bones have been fragmented into small pieces. This fragmentation often results in incomplete sentences and the loss of contextual information, which poses significant challenges for accurate interpretation and digital reconstruction. Previous rejoining methods mainly rely on edge patterns, while determining bone-level associations through contextual information remains largely unsolved. To address this issue, we present the first public benchmark for predicting bone-level associations of oracle bone inscription sentences. We also propose a novel multi-modal deep learning method to predict associations between sentence pairs that achieves competitive performance. The proposed dataset and method aim to assist researchers in identifying likely associations among fragments, thereby facilitating the reconstruction and understanding of damaged oracle bone inscription texts.
Similar content being viewed by others


Introduction
Oracle bone inscriptions (OBIs) were primarily carved onto animal bones and tortoise shells, serving as records of ancient Chinese civilisation during the Shang dynasty over three millennia ago. Since OBIs contain a wealth of historical and linguistic information, they provide critical insights into early Chinese writing systems, religious practices, political structures, social customs, calendrical systems, and even natural phenomena such as weather and astronomical events1. As a result, OBIs serve as primary source material for interdisciplinary research across archaeology, palaeography, linguistics, and history2. However, due to drilling, scorching, natural erosion over thousands of years, and the lack of scientific preservation during early excavations, many oracle bones have become fragmented3.
The fragmentation of oracle bones leads to a major challenge in OBI research4. The fragmentation not only disrupts the continuity of individual inscriptions but also obscures the overall structure of sentences, making it difficult for researchers to reconstruct the original text. Such limitations hinder accurate interpretation of the inscriptions, thereby restricting our understanding of ancient Chinese civilisation. Consequently, to rejoin fragmented oracle bones into their original form to complete the sentences has become a key task in OBI studies. By rejoining Oracle bones, complete divinatory inscriptions can be reconstructed, thus providing coherent texts. Such reconstruction not only yields more effective historical materials from the Shang dynasty but also offers new support for the classification and provenance analysis of scattered oracle bone fragments.
Over the years, researchers have explored two directions to rejoin the oracle bones4. The first direction is manual rejoining by human experts5. The experts rely on deep domain knowledge in palaeography, material texture, and historical grammar to identify matching fragments. By closely examining the shapes of fracture lines and linguistic context, the researchers can piece together broken bones and recover lost inscriptions with very high accuracy. This traditional approach, while providing highly reliable results, is time-consuming and limited by human capacity. The second direction is Artificial Intelligence (AI)-based methods6,7,8. These methods utilise machine learning based methods to match the edge between bones to rejoin potential bone image pairs. Due to advances in machine learning algorithms and computing power, AI-based methods are able to process thousands of molecular fragments efficiently8.
Previous AI-based methods often overlook essential contextual and glyph features in oracle bone rejoining analysis9. These approaches typically rely on local edge patterns to identify fragments from the same bone, emphasising edge similarity. However, due to bone texture, scorching, and erosion marks, many fragments share similar edges. Thus, relying only on edges may lead to false positive predictions10. Introducing contextual and glyph information can provide additional modalities, which can further enhance the reliability of the results11. As a result, a benchmark dataset named Oracle Bone Inscription Dataset with Additional Contextual Reconstruction (OBID-ACR) is proposed. This dataset is constructed from annotated oracle bone fragments12, specifically containing multiple inscriptions originating from the same bone. Furthermore, many novel rejoining cases are also included, serving as independent test cases. OBID-ACR consists of the OBI sentences, and each character is annotated with primary-character tag, secondary-character tag, and glyph images, providing material for training and evaluation.
The task of bone-level sentence association prediction can be formulated as a binary classification problem. The task is to determine whether the source fragments of two sentences originate from the same oracle bone. By enabling accurate prediction through AI-based methods, oracle bone rejoining can be greatly enhanced, extending beyond approaches that rely solely on fragment edges. As a result, based on the newly proposed OBID-ACR, a bone-level association benchmark dataset is constructed. In this benchmark, positive samples consist of genuine associated fragment OBI sentence pairs, and negative samples are randomly sampled from different fragments to ensure data representativeness and diversity. Each OBI sentence in the paired samples contains at least two valid characters. And each character is annotated with both primary-character and secondary-character tags to convey information at different levels of granularity, together with its corresponding glyph image.
Building on the proposed benchmark, we propose a multi-modal method for the task of bone-level sentence association prediction. Unlike modern languages where word embeddings can be effectively learned from contextual patterns using word embedding methods13,14,15, OBI presents unique challenges. Its flexible word order16 results in weak syntactic patterning and small sample size, and the limited sample size further constrains the effectiveness of word embedding methods. However, as a glyph-based script, OBI characters contain rich visual information that implicitly reflects contextual relationships. To leverage this characteristic, we propose a Siamese BiLSTM with Glyph-based Embeddings for Bone-level Sentence Association Prediction (SGBSAP). Our method learns character-level representations from glyph images, and encodes each sentence using these glyph-based embeddings. Each sentence pair is then processed by a Siamese network17 with two parameter-sharing towers, each implemented as a BiLSTM module18 for feature extraction. The resulting features are fed into a prediction block to generate final association scores. Extensive experiments comparing our method with previous state-of-the-art approaches demonstrate that the proposed method is highly competitive, and glyph-based embeddings outperform context-based embeddings, indicating that a multi-modal strategy can effectively capture complementary information to facilitate the task. Furthermore, the association scores prove highly effective in modelling the association between OBI sentences. As shown in the case studies in Section 3.6, sentence pairs, from the same source bone, are annotated with high score, even pairs from non-adjacent fragments from the same source bone receive high association scores, confirming the method’s capability. These results indicate that SGBSAP can serve as a valuable auxiliary tool for oracle bone rejoining and provide new insights for OBI research.
The contributions of this paper are three-fold.
-
1.
We present the first publicly available dataset specifically created for bone-level association for OBI sentences. The proposed dataset consists of multiple modalities of OBIs to capture the complex characteristics of OBI sentences. By focusing on the bone-level OBI sentence association, this dataset fills a critical gap in existing resources and is expected to facilitate the research on oracle bone rejoining and OBI interpretation.
-
2.
We conduct empirical study on state-of-the-art methods on the task of bone-level association prediction. We formulate this problem as a binary classification task, where the objective is to determine whether a given OBI sentence pair from two different fragments originates from the same bone.
-
3.
We introduce a novel method as a benchmark method for this problem. The proposed method employs the character embeddings, that is learned from glyph images in contrast to contextual sentences, for the OBI characters. Then, a sentence pair is fed to a Siamese dual-tower network to predict the bone-level association between the pairs. Experimental results demonstrate that the proposed deep learning method is highly competitive, with the glyph-based embedding outperforming the context-based embedding in this task.
Methods
This study focuses on the fragment association prediction problem. It tackles the challenges of fragment rejoining and contextual understanding. Previous studies lack structured datasets that integrate both contextual and glyph information7 (http://read.nlc.cn/specialResourse/jiaguIndexand https://jgw.aynu.edu.cn/home/zl/index.html), limiting the development of AI-based methods for this task. To address this issue, OBID-ACR is proposed. To capture rich contextual and glyph features, it consists of glyph images and OBI sentences, as well as primary-character and secondary-character tags for the characters. Based on OBID-ACR, for the task of bone-level association prediction, a benchmark algorithm SGBSAP is proposed. The proposed method utilises glyph-based embedding, and a dual Siamese dual-tower block to extract features from sentences.
Problem formulation
Fragment association prediction problem
The task is to predict whether two OBI sentences come from the same bone. Given an OBI sentence pair S1 and S2, along with their corresponding fragment association label γ, the task aims to determine whether the two sentences originate from the same oracle bone fragment. This judgement is made based on sentence embeddings, thereby enabling the modelling and prediction of association relationships between oracle bone fragments.
The fragment association prediction problem consists of two steps. First, sentence embeddings are constructed using character embeddings. Second, an association score is computed based on the obtained sentence embeddings to determine whether the given OBI sentence pair originates from the same oracle bone. This score is then used to predict associations between oracle bone fragments. Specifically, the inputs are two OBI sentences defined as:
where ci represents the i − th character in a sentence, n1 denotes the length of sentence S1, and n2 denotes the length of sentence S2. For each given sentence pair (S1, S2), there is a label γ ∈ {0, 1} denotes whether the two inscriptions originate from same bone, where γ = 1 denotes that both fragments come from the same bone, and γ = 0 denotes they come from different bones. The objective is to learn a discriminative function:
where \(\widehat{y}\) represents the predicted association score of the sentence pair.
Dataset details
To facilitate the study of oracle bone rejoining by contextual information, we propose OBID-ACR. The proposed dataset is constructed from OBIs compiled from the combinations of an OBI dataset and online resources. From these resources, we exclusively extract OBI information derived from two collections: the Oracle Bone Inscription Collection19 and Yinxu Huayuanzhuang East Oracle Bones20. These two collections are selected as they consist of scientifically excavated materials, thereby ensuring the authenticity and reliability of the inscriptions.
Each sentence in OBID-ACR is annotated with two modalities. The first modality is the character tag. In OBIMD, each character is annotated with both a primary-character tag and a secondary-character tag to distinguish glyph variants of the same character21. In OBIs, character glyphs often vary according to contextual usage22, providing rich contextual information. The second modality is the glyph image. The corresponding glyph images are directly extracted from the “Oracular Digital Platform” character library (https://oracular.azurewebsites.net/glyphs) that utilises the same ID as in OBIMD. To illustrate this annotation scheme, Fig. 1 shows annotated sentences of two oracle bones.

a Presents the annotated sentences of a reconstructed oracle bone created by rejoining two fragments. The merged piece preserves two inscriptions, including one character that is divided along the original fracture line. b shows an oracle bone bearing two annotated sentences. The hand-drawn illustrations are provided solely for explanatory purposes and are not included in the dataset.
To construct the dataset for the task of bone-level sentence association prediction, two additional steps are carried out on the sentences extracted from OBIMD. First, only oracle bone fragments with at least two characters are retained. Hence, only 3311 fragments out of over 10,000 fragments are retained for analysis. Second, additional rejoined cases are identified from these retained fragments. These new cases are primarily sourced from established online platforms, namely the Pre Qin History Research Workshop (https://www.xianqin.org/blog/archives/category/jgw_study/jgw_zhuihe) and Zuiyu Lianzhu (http://www.fdgwz.org.cn/ZhuiHeLab/Home). Only widely accepted rejoining cases that can introduce new sentence-level associations are recorded in the dataset. The 35 newly collected rejoining cases, together with the 205 previously recorded cases in the collections19,20, represent approximately 3.4% of the total number of known rejoining cases, which is estimated to exceed 7000 according to the Chinese Academy of Social Sciences (http://cass.cn/keyandongtai/shekejijin/202404/t20240411_5745811.shtml). Although, the proportion of the rejoining cases is small, yet, this data is high-quality, and task-relevant.
In total, the compiled dataset comprises divinatory texts and their corresponding glyph images from 3551 oracle bone fragment cases, containing 9935 individual inscriptions. This corpus is structured into three categories: 3311 fragments involving 8502 inscriptions; 205 cases of previously recorded rejoined groups involving 1286 inscriptions; and 35 newly curated rejoining cases involving 147 inscriptions. A statistical summary of the dataset is provided in Table 1. The sentence length distribution of the inscriptions is presented in Fig. 2. The average sentence length is 5.11 characters, with a median of 4 characters. Overall, the inscriptions are relatively short and predominantly sequential, typically confined to a single bone fragment.

This figure presents the distribution of inscription sentence lengths in the Oracle Bone Inscription Dataset with Additional Contextual Reconstruction, where the horizontal axis denotes sentence length and the vertical axis denotes the number of sentences.
Proposed method
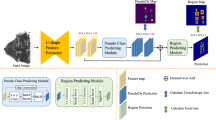
The proposed SGBSAP method aims to determine whether a pair of OBI sentences originates from the same bone. The framework of this method is shown in Fig. 3. SGBSAP includes (1) Glyph-based Embedding Module, and (2) Association Prediction Module. The input of the method is an annotated OBI sentence pair, and each character is represented with glyph images. The glyph features are learned from the character images by the glyph-based embedding module. These sentence pairs encoded by glyph-based embeddings are fed to a deep learning module to predict the association scores of OBI sentence pairs.

a shows the input annotated Oracle bone inscription (OBI) sentence pair, including OBI sentences S1 and S2, and each of them consists a series of glyph images. b shows the glyph-based embedding module, producing the glyph-based embeddings Z1 and Z2 for input each OBI sentence through a modified Variational Autoencoder (VAE)23. c shows the association prediction module. The input sentence pairs, encoded in the glyph-based embeddings, are processed by a Siamese dual-tower BiLSTM block. Here, Siamese indicates the weight-sharing dual-branch architecture that processes Z1 and Z2 with identical parameters. BiLSTM18 indicates the bidirectional LSTM26 that captures both forward and backward contextual information to produce the final sentence representations \({h}^{bi,{S}_{1}}\) and \({h}^{bi,{S}_{2}}\). Concatenation indicates the operation \({h}^{pair}=[{h}^{bi,{S}_{1}};{h}^{bi,{S}_{2}}]\) that combines the two sentence embeddings into a sentence pair embedding. Finally, a Multi-Layer Perceptron (MLP) block27 is applied to predict the corresponding association score.
The glyph-based embedding module is designed to learn the visual representations of handwritten oracle bone characters. It employs a glyph-based embedding framework built upon a modified Variational Autoencoder (VAE)23. Each character is provided as a single-channel greyscale image and encoded into a compact latent vector that serves as its glyph-based embedding.
The VAE model consists of an encoder block and a decoder block to learn the glyph-based embedding for each image. The encoder consists of five convolutional layers with ReLU activation function24. Then, the features are flattened, and fed to two fully connected layers. The two fully connected layers produce the parameters of a Gaussian distribution with a diagonal covariance matrix, thus the process can be written as:
where x denotes the input image, μ denotes the mean vector, logvar denotes the log-variance vector \(\log {{\boldsymbol{\sigma }}}^{2}\). Based on the output of encoder, the latent embedding z is sampled from the distribution:
where ⊙ denotes the element-wise product, ϵ denotes a noise vector sampled from \({\mathcal{N}}({\bf{0}},{\bf{I}})\). The latent embedding is reshaped, then fed to the decoder that consists of five transposed convolutional layers25 with a ReLU activation function to reconstruct the input.
The VAE model is trained by minimising the following objective function:
where \(\widehat{{\boldsymbol{x}}}\) represents the predicted image, qϕ(z∣x) is the encoder network that defines an approximate posterior distribution over the latent variable z given the input x, β denotes the weighting coefficient for the regularisation term, and DKL( ⋅ ∥ ⋅ ) denotes the Kullback-Leibler divergence, which measures the discrepancy between the approximate posterior qϕ(z∣x) and the prior distribution p(z) that is \({\mathcal{N}}({\bf{0}},{\bf{I}})\). Note that the dimension of the glyph-based embedding z is set as 512, and the resulting glyph-based embeddings are frozen for downstream modules.
The association prediction module utilises glyph-based embeddings of a sentence pair to predict the associations between them. Each sentence is encoded as Z = (z1, z2, …, zn) based on glyph features generated by glyph-based embedding module.
These representations are processed by a Siamese dual-tower block. Within each block, a shared-parameter BiLSTM network encodes the two input sentences, capturing bidirectional contextual dependencies to produce a holistic sentence-level representation. The final hidden states from the forward and backward LSTMs26 are concatenated to form a 512-dimensional sentence embedding for the modality:
where ⊕ denotes the concatenation of two vectors.
The two fused sentence embeddings in the sentence pair, \({{\boldsymbol{h}}}^{bi,{S}_{1}}\) for the first sentence and \({{\boldsymbol{h}}}^{bi,{S}_{2}}\) for the second sentence, are then concatenated to form a 1024-dimensional embedding:
where hpair denotes the final embedding of a sentence pair.
The embeddings of sentence pairs are fed into a Multi-Layer Perceptron (MLP) block27 to predict the association scores. This MLP block consists of two fully connected layers with ReLU activation function and Sigmoid function respectively. The output \(\widehat{y}\) represents the predicted association score.
The loss function of the association prediction module is the Binary Cross Entropy loss28:
where \({\widehat{y}}_{i}\) denotes the predicted label of sample i, yi denotes the ground-truth label of sample i, N denotes the total number of sentence pairs.
The proposed method comprises two main components, each trained separately. First, the glyph-based embedding module, takes character glyph images as input and trains a VAE to generate character-level glyph-based embeddings. Second, the association prediction module, takes the pretrained glyph-based embeddings of a sentence pair as input and predicts an association score for the sentence pair.
Results
Dataset preprocessing
The experiments are conducted on the sentences in the proposed OBID-ACR dataset. In the proposed dataset, positive pairs are the inscription sentence pairs originating from the same complete oracle bone. Specifically, if a bone contains n inscriptions, \((\begin{array}{c}n\\ 2\end{array})\) unique positive pairs are generated by pairing every two different inscriptions exactly once, excluding self-pairs. For each positive pair, ten negative pairs are generated: five by pairing the first sentence with randomly selected sentences, and five by pairing the second sentence with randomly selected sentences.
In our empirical study, the dataset is processed according to the following settings. In our training setting, each secondary-character tag appears at least once in the training set. On this basis, the ratio between the training and test sets is kept as close to 9:1 as possible, while maintaining the large quantity difference between positive and negative samples. The statistics of the dataset is summarised in Table 2.
Evaluation metrics
The task is formulated as an imbalanced binary classification problem, as inscriptions originating from different bones vastly outnumber those from the same bone. To provide a comprehensive assessment of model performance, six metrics are reported: AUROC29, AUPR30, Accuracy, Precision, Recall, and F1 score31. AUROC evaluates the ranking ability of the classifier. AUPR highlights the model’s ability to identify positive samples. Accuracy, precision, recall, and F1 score are computed from the confusion matrix and quantify different aspects of prediction quality. Accuracy reflects overall correctness, precision measures the reliability of positive predictions, recall captures the proportion of true positives retrieved. The F1 score is a single metric that balances a trade-off between precision and recall.
Comparison methods
To validate the effectiveness of the proposed method, an empirical study is conducted on multiple state-of-the-art baseline methods for comparison. These baseline methods can be broadly categorised into two groups.
The first category consists of two-stage methods. These methods generate an embedding for each sentence pair, then the sentence pair embeddings are fed to a classifier. The sentence pair embedding methods consist of Smooth Inverse Frequency (SIF)32, its unsupervised extension unsupervised Smooth Inverse Frequency (uSIF)33, and Bag-of-Words (BoW)34. SIF and uSIF produce dense vector representations from weighted averages of character embeddings, with uSIF adaptively estimating parameters. BoW encodes sparse lexical counts. Each sentence embedding is evaluated with five classifiers: Logistic Regression (LR)35, Support Vector Machine (SVM) with a linear kernel36, eXtreme Gradient Boosting (XGBoost)37, Light Gradient Boosting Machine (LightGBM)38, and an MLP network that is the same as the block discussed in Section “Proposed Method”.
The second category consists of end-to-end models that jointly learn sentence pair embeddings and the classifiers from the character embeddings of the sentence pair using deep learning. These methods take the sentence pairs encoded with character embeddings, and there are special tokens to separate the two sentences. This category consists of the TextCNN14, which extracts local n-gram features via convolutional filters, Transformer Encoder39, which captures long-range dependencies through self-attention, LSTM15, which models sequential dependencies in a unidirectional manner, and BiLSTM18, which encodes sequences bidirectionally to capture contextual information. For these four methods, the final MLP block for predicting association is kept consistent with the proposed method in Section 2.3.
All experiments of the comparison models are conducted following their default configurations and re-implemented the original architecture as closely as possible. The character embeddings for all methods are identical. It is worth noting that the BoW model, based on term frequency statistics, does not rely on character embeddings. The kernel sizes in TextCNN are consistent with the original implementation. The LSTM architecture is implemented following the configuration described in15. The Transformer model adopts 6 encoder layers, uses the [SEP] token to separate sentence pairs, applies [PAD] for padding, and takes the [CLS] token representation as the output for classification. The structure of the BiLSTM method is kept the same as the proposed method discussed in Section “Proposed Method”. The sentence pair embeddings from SIF, uSIF and BoW are kept identical for the classifiers, including LR, SVM, XGBoost, LightGBM, and MLP.
The hyper-parameters of the comparison methods are under the following settings. The smoothing parameter in SIF and uSIF is set following a previous study32,33. The number of maximum features in BoW is set to 2000 following previous study in the relevant field40. The LR and SVM are under the default settings in the implementation of scikit-learn41. XGBoost and LightGBM are under the default settings of their corresponding official implementations. All deep learning models, including the proposed method, are trained under the same hyper-parameters if possible. The number of training epochs is set to 100, the batch size is 64, Adam42 is employed as the optimiser. The learning rate is set based on a hyper-parameter search on {1e-4, 1e-5, 1e-6} to ensure the convergence of the deep learning methods. To ensure the reliability of the results, all methods are run five times with different random seeds, and the reported performance corresponds to the average across these independent runs. And, all experiments are conducted under the aforementioned settings unless otherwise specified.
Empirical study
To assess the efficacy of the proposed Siamese dual-tower network and the VAE-based character glyph-based embeddings, we conducted evaluations under four distinct settings. In the first setting, the methods utilise character embeddings derived from the glyph-based embeddings learned in Section “Proposed Method”, with results in Table 3. In the second setting, the methods employ character embeddings from SGNS43 trained using the primary-character tag, with results in Table 4. In the third setting, the methods employ SGNS embeddings trained with the secondary-character tag, with results in Table 5. In the fourth setting, the methods employ SGNS concatenated embeddings trained with the primary-character tag, and secondary-character tag, with results in Table 6. For all SGNS settings, the embedding dimension for each tag type was set to 512 to match the VAE, resulting in a 1024-dimensional vector for the mixed setting. The BoW method is absent from Tables 3 and 6, as it relies on word co-occurrence frequencies and is incompatible with these character-embedding-based configurations.
By combing the results from Tables 3, 4, 5, 6, we have the following observations. First, the proposed method proves highly competitive, achieving the best performance in all the metrics that measures the overall performance. The proposed method is only lower in precision, and methods with higher precision generally exhibit lower recall, highlighting a clear trade-off in performance characteristics. Supplementary Section S1 presents a decision threshold analysis, showing that the proposed SGBSAP gains precision but loses recall as the threshold increases. Hence, the predicted association scores of the proposed method can capture meaningful relationships between fragments. Furthermore, Supplementary Section S2 discusses hyper-parameter analysis, where the proposed method maintains stable performance across a wide range of key hyper-parameters, indicating its robustness. Second, the best performance, measured by AUPR and F1 score, is observed when employing character embeddings generated from VAE from the proposed method. This suggests that the proposed character embedding method is particularly suitable for this dataset. As OBI is rather flexible regarding word order, deriving character embeddings solely from contextual information is challenging. However, as OBI is a glyph-based script, words with similar glyph images often possess similar meanings. Consequently, the glyph-based embedding effectively captures implicit character relations that context-based methods cannot. Third, we observe that end-to-end methods generally outperform two-stage methods (with the exception of the transformer encoder). This is likely because end-to-end methods can learn sentence embeddings specifically useful for the downstream task, whereas two-stage methods may fail to capture these nuances. Finally, almost all the end-to-end methods achieve better results in the setting with concatenated character contextual embedding than individual character contextual embedding. This suggests that these models are capable of integrating and leveraging features from different contextual granularities to improve performance.
Impact of embedding strategies on model performance
To examine how different modelling strategies influence the association prediction performance, we conducted additional experiment variants of the proposed method along three directions. The first direction is to evaluate the performance of using other popular character embedding methods as input for the module. The second direction is to develop a method to further fuse the contextual embedding and glyph-based embedding to predict the association. The final direction is using other deep learning methods to replace the BiLSTM method as the sentence embedding extracting method.
In the first direction, the effects of four character embedding methods are analysed. The effect of glyph-based embeddings is compared with three context-based embedding methods that are SGNS, CBOW-NEG43, and GloVe44. The result is summarised in Table 7. From the Table 7, we have two observations. First, it can be observed that the glyph-based embeddings, generated from VAE, can outperform all the context-based embeddings by a large margin. This demonstrates that visual glyph information is more effective than contextual co-occurrence information for modelling OBI characters, which typically lack abundant textual contexts. Second, among the context-based methods, our model performs better when using SGNS and CBOW-NEG compared with GloVe. This suggests that predictive models based on local context windows (SGNS, CBOW-NEG) are more suitable for sparse and short OBI sentences than global matrix-factorisation approaches such as GloVe.
In the second direction, we aim to evaluate whether combining the two types of character embeddings can further improve performance. As a result, we propose two variant fusion methods. Since the character embeddings originate from two modalities glyph image, contextual information. Hence, the sentences can be encoded by the embedding either modality. Consequently, two Siamese blocks, as described in Section “Proposed Method”, are employed to extract features, one for each modality. For the first sentence, the features obtained from the glyph and contextual embeddings are denoted by \({h}^{g,{S}_{1}}\) and \({h}^{c,{S}_{1}}\), respectively. Likewise, for the second sentence, the features are denoted by \({h}^{g,{S}_{2}}\) and \({h}^{c,{S}_{2}}\). These four feature vectors are fused using the following strategies:
where α denotes a learnable parameter. Then hfused from either strategy is fed to MLP as in Section “Proposed Method” to predict the association score. The strategy using Equation (9) is denoted as SGBSAP-Concat, and the other is denoted as SGBSAP-Weighted. The results of the two variants are summarised in Table 8. By combining Tables 8 and 3, it can be observed that the proposed method performs worse than SGBSAP with only glyph-based embedding. This suggests that these heterogeneous embeddings may conflict, introduce noise, or distort the underlying geometry of the glyph-based embedding space.
In the third direction, the based-module of the Siamese module of the proposed method is replaced with TextCNN, LSTM, and Transformer Encoder. The experiments are conducted using glyph-based embeddings, and the result is summarised in Table 9. From Table 9, we have the following observations. First, BiLSTM achieves the best overall performance. OBI inscriptions are short, low-resource, and dominated by local contextual dependencies as shown in Fig. 2. BiLSTMs naturally excel in such settings because their sequential inductive bias and bidirectional processing capture these local dependencies effectively45. Second, the Transformer Encoder ranks a close second, and performs substantially better than the single-sentence strategy reported in Table 3. Transformers rely on global self-attention, which is powerful in large-scale datasets but prone to overfitting local noise and weakening salient cues when data are limited46,47. However, the Siamese framework provides stronger pairwise supervision, which helps mitigate this overfitting and allows the Transformer to utilise its capacity more effectively. Third, TextCNN shows competitive performance, achieving the highest precision among all variants. Its strength lies in extracting local n-gram patterns, which are abundant in OBI inscriptions. Nevertheless, TextCNN does not outperform BiLSTM overall as it cannot fully capture sequential and bidirectional dependencies beyond its convolutional window, limiting its ability to represent the overall context of OBI sentences. Finally, the LSTM performs the worst, as it captures only forward dependencies and therefore cannot represent the bidirectional contextual relations that is necessary for modelling OBI sentences, as OBI is flexible with word orders16.
Case studies
The model’s practical effectiveness is further assessed through three real-world OBI rejoining case studies. These case studies are conducted on the proposed SGBSAP model. In each case, the sentences originally belonged to the same oracle bone but are separated due to fragmentation and now exist on different fragments. These examples demonstrate that our model is capable of correctly identifying same-bone relationships, even when sentences are physically distant and disconnected in the original bone.
The first case examines two directly connected rejoined fragments, as shown in Fig. 4. The two fragments, labelled H51 and H64 respectively, are both from the Oracle Bone Inscription Collection19. This rejoining case is based on48. Sentence (a) from H51 reads, “Divination: do many people perish in a certain locality because of warfare?”, and sentence (b) from H64 reads, “Divination: heavy personnel losses in warfare, prayers for divine protection.” These sentences clearly address the same underlying issue. Moreover, the close fit of the broken edges and the consistent handwriting style across the two fragments further justify their rejoining. Based on the proposed method, this pair achieves an association score of 0.9996, ranking within the top 1.49% of all sentence pairs in the test dataset. This result indicates that the two fragments can be rejoined.

The two fragments, labelled H51 and H64 respectively, are both from the Oracle Bone Inscription Collection19. Sentence (a) from H51 reads, “Divination: do many people perish in a certain locality because of warfare?'', and sentence (b) from H64 reads, “Divination: heavy personnel losses in warfare, prayers for divine protection.” Based on the proposed method, this pair achieves an association score of 0.9996, ranking within the top 1.49% of all sentence pairs in the test dataset, which follow a 1:10 ratio of pairs from the same source bone to randomly generated cross-bone pairs. The hand-drawn illustrations are provided solely for explanatory purposes and are not included in the dataset.
The second case examines two not connected rejoined fragments H30107 and H30109, as shown in Fig. 5. The fragments, labelled H30106, H30107, H30108, H30109, and H30110, are all from the Oracle Bone Inscription Collection19. This rejoining case is based on a scholar of oracle bone studies (https://www.xianqin.org/blog/archives/1460.html). Sentence a) from H30109 and sentence b) from H30107 are basically identical in sentence structure and theme. These divinatory sentences read “Divination: the king of Shang should not perform rain sacrifice in July.” The scholar argued they can be rejoined as the styles of the character glyphs are very consistent between the two fragments. Based on the proposed method, this pair achieves an association score of 0.9550, ranking within the top 5.81% of all sentence pairs in the test dataset. This result indicates that these fragments can be rejoined.

The fragments, labelled H30106, H30107, H30108, H30109, and H30110, are all from the Oracle Bone Inscription Collection19, and are rejoined as from the same source bone. Sentence a) from H30109 and sentence b) from H30107 are basically identical in sentence structure and theme. These divinatory sentences read “Divination: the king of Shang should not perform rain sacrifice in July'', and the styles of the character glyphs are very consistent between the two fragments. Based on the proposed method, this pair achieves an association score of 0.9550, ranking within the top 5.81% of all sentence pairs in the test dataset, which follow a 1:10 ratio of pairs from the same source bone to randomly generated cross-bone pairs. The hand-drawn illustrations are provided solely for explanatory purposes and are not included in the dataset.
The third case examines two rejoined fragments H16756 and H16773 whose association is not correctly predicted. As shown in Fig. 6, the fragments, labelled H16742, H16756, H16773 and H16776, are all from the Oracle Bone Inscription Collection19. This rejoining case is based on a scholar of oracle bone studies (https://www.xianqin.org/blog/archives/1237.html, accessed on 12 October 2025). The expert determines that these fragments can be rejoined based on the alignment of drill marks, thickness, and colour on the reverse sides of the bones, as well as the continuity of the sentence sequences. Sentence a) from H16756 records a divination concerning whether disasters occur within the next ten days. Sentence b) from H16773 exhibits a similar syntactic pattern, but some characters are missing. It records a divination, predicting that something will not occur. The missing content leads to a significant loss of contextual information, making it difficult for the model to accurately capture the association between these two sentences. Based on the proposed method, this pair achieves an association score of 0.0102, ranking within the top 12.72% of all sentence pairs in the test dataset, indicating that SGBSAP incorrectly assesses their association. This outcome suggests that the proposed SGBSAP exhibits limited flexibility when processing sentences with substantial character loss and relies considerably on the contextual completeness of OBI texts.

The fragments, labelled H16742, H16756, H16773 and H16776 are all from the Oracle Bone Inscription Collection19, and are rejoined as from the same source bone. Sentence a) from H16756 records a divination concerning whether disasters occur within the next ten days. Sentence b) from H16773 exhibits a similar syntactic pattern, but some characters are missing. It records a divination, predicting that something will not occur. Based on the proposed method, this pair achieves an association score of 0.0102, ranking within the top 12.72% of all sentence pairs in the test dataset, which follow a 1:10 ratio of pairs from the same source bone to randomly generated cross-bone pairs. The annotation score shows the limitation of the proposed method in dealing with incomplete sentences. The hand-drawn illustrations are provided solely for explanatory purposes and are not included in the dataset.
Discussion
In this study, we propose a multi-modal dataset, OBID-ACR, for OBI fragment association analysis. The dataset consists of 9935 divinatory sentences collected from 3551 oracle bone fragment cases, providing structured support for research on the bone-level association prediction task.
Based on the proposed dataset, we introduce a novel framework named SGBSAP. The proposed method utilises the character embedding from glyph images rather than contextual information, and the sentence pair encoded by the glyph-based embedding is fed to a prediction network that employs a parameter sharing dual-tower block to extract features. To our knowledge, this is the first attempt to model and predict the bone-level fragment associations using sentence embeddings in OBI studies. Experimental results demonstrate that the proposed method is highly competitive, outperforming all compared methods in five out of six evaluation metrics under various settings. In particular, SGBSAP achieves superior AUROC, AUPR, accuracy, and F1 score, indicating strong overall performance. Furthermore, the experiments suggest the proposed glyph-based embedding is more competitive than the context-based embeddings, suggesting that a multimodal strategy that integrates visual information from glyph images with linguistic features from sentences is effective for capturing complementary information in OBI.
SGBSAP can serve as a flexible AI-based tool to assist archaeologists and historians in analysing oracle bone fragments. This tool provides support in the following aspects. First, SGBSAP can be used in the task of oracle bone rejoining. SGBSAP can effectively predict association scores, which can be combined with edge-based analysis of fragments to evaluate potential joining. As shown in Supplementary Section S1, the association scores are meaningful, as higher decision thresholds increase precision and reduce recall. Second, SGBSAP can be applied to text analysis tasks. These association scores can be extended to thematic clustering, semantic association analysis, and contextual matching. This approach can potentially reveal semantic distribution patterns and association scores across different inscriptions. Third, SGBSAP can be deployed for the digital restoration of damaged inscriptions. For fragments with partial textual loss, the model can propose semantically plausible completions for missing characters or phrases based on the association scores between the remaining sentences and all candidate characters or sentences.
The proposed OBID-ACR dataset is subject to two main limitations. First, its coverage of existing OBI materials remains limited. This constraint arises from the relatively small scale and narrow scope of currently available digitised OBI textual resources, which restrict the amount of material that can be included. Second, even among the datasets that are already digitised, many cannot be integrated because they employ incompatible encoding standards. The absence of a unified encoding scheme creates substantial barriers to cross dataset integration and prevents these resources from being incorporated into the dataset.
The proposed SGBSAP, also has two main drawbacks. First, it cannot effectively leverage both context-based and glyph-based embeddings. When these two types of embeddings are fused, the performance decreases, indicating that the model does not fully exploit their complementary strengths. Second, this study focuses exclusively on sentence based rejoining tasks. How to integrate the proposed model with approaches that rely on bone edge information remains unexplored.
Based on the limitations identified above, we propose several directions for future research. To address the limitations of the dataset, future efforts will focus on the continued digitisation of OBI collections, and learning a mapping function to reconcile differences in character encoding across datasets. Such efforts would facilitate the integration of multiple datasets and ensure consistent annotations for downstream tasks. To overcome methodological limitations, two research directions are envisioned. The first direction is to develop a novel character embedding method that simultaneously learns character embeddings from contextual information and glyph information. This allows the model to leverage more comprehensive information. The second direction is to integrate the proposed method with edge-similarity based methods6,8. Combining these complementary modalities would provide a more complete perspective for predicting associations between fragment pairs.
Data availability
The OBID-ACR dataset has been made to be publicly accessible online at https://zenodo.org/records/17749727. The SGBSAP has been made to be publicly accessible online at https://github.com/Borisfwyy/SGBSAP.
Code availability
The SGBSAP has been made to be publicly accessible online at https://github.com/Borisfwyy/SGBSAP.
References
Yang, Y. From oracle bone inscriptions to silk manuscripts: The cultural connotations and historical value of chinese script evolution. Collections. 171–173 (2024).
Hong, Y. & Wu, C. Development context and trend of oracle bone inscriptions research (2000–2022)–citespace visualization analysis based on cssci source journals and peking university core journals. J. Changchun Univ. 33, 54–63 (2023).
Fang, Z. Two fragmentary inscriptions of military carvings in the dianbin category. J. Chin. Classical Stud. 5, 13–30 (2024).
Huang, T. On academic value and research methods of restoration of oracle bone inscription fragments. Palace Museum J. 153, 7–13 (2011).
Pang, F. Summary of the research of oracle-bone stringing. J. Lingnan Norm. Univ. 33, 142–146 (2012).
Zhang, Z., Wang, Y., Li, B., Guo, A. & Liu, C. Deep rejoining model for oracle bone fragment image. In 6th Asian Conference on Pattern Recognition (ACPR), 13189, 3–15 (2021).
Zhang, C. et al. Data-driven oracle bone rejoining: a dataset and practical self-supervised learning scheme. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 4482–4492 (2022).
Zhang, Z. et al. Deep rejoining model and dataset of oracle bone fragment images. npj Herit. Sci. 13, 66 (2025).
MO, B. & Zhang, Z. A discussion about “ri you ji” in oracle bone inscription base on a computer assistance rejoining. Mingsu Dianji Wenzi Yanjiu 28, 169–174 (2021).
Zhang, C. & Wang, B. Oracle bone fragments conjugation based on sequence matching. Acta Electron. Sin. 51, 860–869 (2023).
Zhao, X. Modern technology and the collation of unearthed materials form the pre-qin period. J. Hist. Sci. 5–10 (2025).
Li, B. et al. Oracle bone inscriptions multi-modal dataset. arXiv https://doi.org/10.48550/arXiv.2407.03900 (2024).
Mikolov, T., Chen, K., Corrado, G. & Dean, J. Efficient estimation of word representations in vector space. In 1st International Conference on Learning Representations (ICLR) (2013).
Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1746–1751 (2014).
Hassan, A. & Mahmood, A. Deep learning for sentence classification. In 2017 IEEE Long Island Systems, Applications and Technology Conference (LISAT), 1–5 (2017).
Zhang, Y. A Grammar of the Oracle Bone Inscriptions. Xuelin Publishing House: Shanghai, China, (2001).
Bromley, J., Guyon, I., LeCun, Y., Säckinger, E. & Shah, R. Signature verification using a “siamese” time delay neural network. In Proceedings of the 7th International Conference on Advances in Neural Information Processing Systems (NeurIPS), 737–744 (1993).
Graves, A. & Schmidhuber, J. Framewise phoneme classification with bidirectional lstm networks. Neural Netw. 18, 602–610 (2005).
Guo, M. Oracle Bone Inscriptions Collection. Zhonghua Publishing House: Beijing, China, (1978).
Institute of Archaeology, C. A.oS. S. Yinxu Huayuanzhuang East Oracle Bones. Yunnan Nationalities Publishing House: Beijing, China, (2003).
Chen, T. Research of the Structural System of the Oracle-Bone Inscriptions. Phd dissertation, East China Normal University, Shanghai, China (2007).
Hsu, F.-C. On the evolution of chinese character formation in oracle bone inscriptions. Humanitas Taiwanica 1–40 (2006).
Kingma, D. P. & Welling, M. Auto-encoding variational bayes. In 2nd International Conference on Learning Representations (ICLR) (2014).
LeCun, Y., Bottou, L., Bengio, Y. & Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324 (1998).
Zeiler, M. D., Krishnan, D., Taylor, G. W. & Fergus, R. Deconvolutional networks. In 23rd IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2528–2535 (2010).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9, 1735–1780 (1997).
Rumelhart, D. E., Hinton, G. E. & Williams, R. J. Learning representations by back-propagating errors. Nature 323, 533–536 (1986).
Terven, J., Cordova-Esparza, D.-M., Romero-González, J.-A., Ramírez-Pedraza, A. & Chávez-Urbiola, E. A comprehensive survey of loss functions and metrics in deep learning. Artif. Intell. Rev. 58, 195 (2025).
Fawcett, T. An introduction to roc analysis. Pattern Recognit. Lett. 27, 861–874 (2006).
Boyd, K., Eng, K. H. & Jr., C. D. P. Area under the precision-recall curve: Point estimates and confidence intervals. In Joint European Conference on Machine Learning (Ecml) and Knowledge Discovery in Databases (Pkdd), 8190, 451–466 (2013).
Powers, D. Evaluation: from precision, recall and f-measure to roc, informedness, markedness & correlation. J. Mach. Learn. Technol. 2, 37–63 (2011).
Arora, S., Liang, Y. & Ma, T. A simple but tough-to-beat baseline for sentence embeddings. In 5th International Conference on Learning Representations (ICLR) (2017).
Ethayarajh, K. Unsupervised random walk sentence embeddings: A strong but simple baseline. In Proceedings of the Third Workshop on Representation Learning for NLP, 91–100 (2018).
Nigam, K., McCallum, A. K., Thrun, S. & Mitchell, T. Text classification from labeled and unlabeled documents using em. Mach. Learn. 39, 103–134 (2000).
Bishop, C. M. Logistic regression. In Pattern Recognition and Machine Learning, 205–206 (Springer, New York, NY, USA, 2006).
Platt, J. et al. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Adv. Large Margin Classifiers 10, 61–74 (1999).
Chen, T. & Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 785–794 (2016).
Ke, G. et al. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the 31st International Conference on Advances in Neural Information Processing Systems (NeurIPS), 3149–3157 (2017).
Vaswani, A. et al. Attention is all you need. In Proceedings of the 31st International Conference on Advances in Neural Information Processing Systems (NeurIPS), 5998–6008 (2017).
Labonne, M. & Moran, S. Spam-t5: Benchmarking large language models for few-shot email spam detection. arXiv https://doi.org/10.48550/arXiv.2304.01238 (2023).
Pedregosa, F. et al. Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. In 3rd International Conference on Learning Representations (ICLR) (2015).
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. & Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Advances in Neural Information Processing Systems (NeurIPS), 3111–3119 (2013).
Pennington, J., Socher, R. & Manning, C. D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1532–1543 (2014).
Chen, J. Bilstm-enhanced legal text extraction model using fuzzy logic and metaphor recognition. PeerJ Comput. Sci. 11, e2697 (2025).
Rahman, M. M., Shiplu, A. I., Watanobe, Y. & Alam, M. A. Roberta-bilstm: a context-aware hybrid model for sentiment analysis. IEEE Trans. Emerg. Top. Comput. Intell. 9, 3788–3805 (2025).
Aziz, A., Hossain, M. A., Chy, A. N., Ullah, M. Z. & Aono, M. Leveraging contextual representations with bilstm-based regressor for lexical complexity prediction. Nat. Lang. Process. J. 5, 100039 (2023).
Li, L. Three newly rejoined oracle bone inscriptions from yinxu. In Collected Papers of the National Museum of Chinese Writing (2023), 130–134 (Research and Conservation Center for Unearthed Documents, Tsinghua University, Beijing, China, 2023).
Acknowledgements
This research is funded by the Henan Province International Science and Technology Cooperation-Cultivation Project (Grant No.252102520003), the Henan Province Science and Technology Research Project (Grant No.252102210031), the Henan Province Science and Technology Research Project (Grant No.252102321141), the Key Technology Project of Henan Educational Department of China (Grant No.22ZX010), the National Natural Science Foundation of China (Grant No.U1504612), the Henan Revitalisation Cultural Engineering Special Project (Grant No.2023XWH296), the Natural Science Foundation of Henan Province (Grant No.242300420680), the Major Science and Technology Project of Anyang (Grant No.2025A02SF007), the National Natural Science Foundation of China (Grant No. 62506007).
Author information
Authors and Affiliations
Contributions
Conceptualisation: Y.L., H.Z. and T.W.; methodology: H.Z. and T.W.; software: T.W.; validation: T.W. and Z.Z.; formal analysis, N.W., Q.J., Y.Y., H.S., H.Z. and T.W.; data curation: B.L. H.Z., N.W., Z.Z., and T.W.; writing—original draft preparation: H.Z. and T.W.; writing—review and editing: H.Z., J.X., C.H., Z.Z., and T.W.; project administration: H.Z., B.L, Y.L; funding acquisition: Y.L. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, H., Wang, T., Zhang, Z. et al. A multi-modal dataset and method for bone-level association prediction in oracle bone inscriptions. npj Herit. Sci. 14, 19 (2026). https://doi.org/10.1038/s40494-025-02282-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s40494-025-02282-w
