
Abstract
Bronze inscriptions (BI), engraved on ritual vessels, constitute a crucial stage of early Chinese writing and provide indispensable evidence for archeological and historical studies. However, automatic BI recognition is challenging due to visual degradation, cross-domain variability among photographs, rubbings, and tracings, and an extremely long-tailed character distribution. To address these challenges, we curate a large-scale BI dataset comprising 22,454 full-page images and 198,598 annotated characters spanning 6658 unique categories, enabling robust cross-domain evaluation. Building on this resource, we develop a two-stage detection-recognition pipeline. To handle heterogeneous domains and rare classes, we equip the pipeline with LadderMoE, which augments a pretrained CLIP encoder with ladder-style MoE adapters for dynamic expert specialization and enhanced robustness. Comprehensive experiments demonstrate that our method substantially outperforms the state-of-the-art scene text recognition baselines, achieving superior accuracy across head, mid, and tail categories as well as all acquisition modalities, establishing a strong foundation for downstream archeological analysis.
Similar content being viewed by others
Introduction
Bronze inscriptions (BI), engraved on ritual vessels of ancient China, constitute a crucial component of the early Chinese writing system alongside oracle bone inscriptions (OBI), preserving invaluable records of early civilization1. Western Zhou inscriptions, for instance, document royal rewards, sacrificial rituals, military campaigns, and political appointments2. Figure 1 provides a high-level overview of the BI data characteristics and the overall recognition task. As illustrated in Fig. 1A, BI exist across three typical visual forms–color photographs, rubbings, and tracings–each exhibiting distinctive appearance and texture. Accurate recognition of such heterogeneous inscriptions is essential for downstream applications, including bronze dating, archaeogeographical analysis, and historical literature retrieval, forming a reproducible bridge from raw imagery to data-driven cultural heritage research, as summarized in Fig. 1D.

A Representative bronze inscription data in multiple visual forms. B Key challenges of the task. C Overall pipeline. D Downstream applications enabled by reliable full-page transcription. The illustration emphasizes the cross-domain, degraded, and long-tailed nature of the data and motivates a detection--recognition--ordering framework that is robust to these factors. The resulting structured transcriptions enable downstream archeological analyses, including bronze dating (a) archaeogeographical study (b) and literature retrieval. (c) Map of China. Image from Wikimedia Commons, Public Domain.
Traditionally, the study of BI has relied on manual rubbings, tracings, and philological interpretation–processes that are labor-intensive and heavily dependent on domain expertise. With the rapid progress of computer vision, automatic detection and recognition of ancient scripts has emerged as a promising alternative. However, BI recognition remains extremely challenging, as visual examples in Fig. 1B demonstrate, due to several intrinsic factors. The visual domain of BI is highly heterogeneous, encompassing color photographs, rubbings, and tracings that differ dramatically in texture, contrast, and background. In addition, centuries of corrosion and uneven casting introduce severe degradation, noise, and low resolution, while the inscription vocabulary follows a profoundly long-tailed distribution: common ritual or administrative symbols dominate, whereas personal names, clan titles, and toponyms appear only sparsely3. These characteristics hinder the direct transfer of models designed for OBI or modern scene text recognition.
Research on ancient Chinese script recognition has therefore primarily focused on OBI, with BI remaining comparatively underexplored. Early detection studies largely adapted generic object detectors. Liu et al. enhanced Faster R-CNN for OBI character detection4, Fu et al. incorporated pseudo-category labels and glyph-structure priors to improve robustness to noise5, and Tao et al. leveraged the OBC font library and clustering-based representation learning for more discriminative features6. While these approaches established a foundation, they still suffer from the limitations of generic detectors—strong reliance on preprocessing and limited adaptability to heterogeneous domains. Recognition methods have evolved along two major directions. Structure-driven pipelines extract line or stroke-level geometry followed by geometric matching, e.g., via Hough transforms7, explicitly encoding stroke topology but remaining fragile under background clutter and low-contrast corrosion. Learning-based approaches, by contrast, embed character images into discriminative feature spaces for nearest-neighbor or sequence matching8,9, and transformer variants–such as the improved Swin-Transformer10 with pruning-based acceleration11–have recently advanced recognition across OBI, BI, and stone engravings. Bluche et al. introduced an end-to-end handwriting recognition architecture with an attention-driven decoder, enabling full-paragraph transcription without explicit line segmentation12. Nonetheless, systematic research on BI detection and recognition is still lacking. Existing pipelines typically assume well-preprocessed rubbings or clean tracings, and thus struggle with real-scene photographs characterized by complex casting textures, domain variation, and degradation. Furthermore, the intrinsic long-tailed distribution of BI characters continues to pose challenges for balanced learning and robust evaluation. To mitigate this issue, Cui et al. introduced the notion of the effective number of samples, demonstrating that class-balanced re-weighting can substantially alleviate performance gaps across head, medium, and tail categories13. More broadly, Zhang et al. provide a comprehensive survey of deep long-tailed learning, showing that effective solutions often require improvements beyond loss re-balancing, including representation enhancement, information augmentation, and architectural specialization14.
From a broader perspective, the challenges encountered in BI recognition closely parallel those in Scene Text Recognition (STR), which aims to read text from natural images containing heterogeneous fonts, arbitrary orientations, curved layouts, and complex illumination15. STR research has evolved from early end-to-end architectures16,17,18 to transformer-based sequence models15,19 and semi-supervised paradigms exploiting unlabeled data20,21. Methodologically, STR approaches can be divided into context-free and context-aware families. Context-free methods rely solely on visual cues, including CTC-based recognizers22,23,24,25, segmentation-driven pipelines26,27, and attention-based encoder–decoder architectures28,29. Context-aware methods, such as ABINet30, CLIP-OCR31, and CLIP4STR32, integrate linguistic priors or multimodal knowledge. Baek et al. revealed that many claimed advances in STR are confounded by inconsistent training data and evaluation protocols, and proposed a unified four-stage framework that standardizes comparison and guides principled module design16. SCATTER further strengthens contextual reasoning through stacked BiLSTM refinement with intermediate supervision33. However, these language-driven priors are unreliable for BI, whose ancient lexicon and symbolic morphology are absent from large-scale pretraining corpora. Consequently, robust visual modeling without linguistic dependence–i.e., context-free STR paradigms–offers a more suitable foundation for cross-domain BI recognition spanning rubbings and real-scene photographs.
In parallel, advances in parameter-efficient fine-tuning (PEFT) have provided effective means to adapt large pre-trained models to specialized tasks while avoiding the cost of full fine-tuning34. PEFT strategies such as adapter tuning35,36,37, LoRA38, and prompt tuning39 update only small modular subsets of the model. Complementary to PEFT, Mixture-of-Experts (MoE) architectures expand capacity by distributing computation across multiple experts and routing mechanisms that dynamically activate only a subset per input40,41,42,43. In vision, V-MoE44 replaces selected feed-forward layers in ViT with sparsely activated expert MLPs, demonstrating that expert specialization and token-level routing can improve both recognition performance and computational efficiency at scale. In NLP, the Switch Transformer45 further streamlines the routing mechanism by activating only a single expert per token, enabling trillion-parameter models with stable training dynamics and highly efficient sparse computation. While PEFT and MoE have been extensively studied in isolation, their combination is particularly appealing for domains exhibiting high intra-class variability and style heterogeneity—such as ancient script recognition—where selective expert specialization and lightweight adaptation are both crucial.
Motivated by these insights, we address the key challenges of BI recognition and the limitations of existing research through three main contributions. First, we curate a large-scale BI dataset comprising 22,454 full-page images with 198,598 annotated characters across 6658 unique categories, spanning color photographs, rubbings, and tracings to support robust cross-domain evaluation. Second, we construct a two-stage pipeline for full-page BI recognition that first detects inscriptions and then performs character recognition and transcription, as illustrated in Fig. 1C. Within this framework, we propose LadderMoE, a parameter-efficient model based on a pretrained CLIP image encoder, which interleaves lightweight experts across multiple transformer layers to enable efficient training and adaptive expert specialization for domain heterogeneity and rare-class patterns. Finally, comprehensive experiments demonstrate that our framework substantially surpasses existing methods in handling multi-domain variation, visual degradation, and long-tailed distributions, achieving state-of-the-art performance on both single-character and full-page BI recognition tasks.
Methods
To address the challenges of cross-domain variability, visual degradation, and long-tailed character distributions in BI recognition, this section presents the overall methodological framework of our approach. We first describe the full-page detection–recognition pipeline, and then detail the proposed LadderMoE architecture and decoding strategy.
Full-page bronze inscriptions recognition pipeline
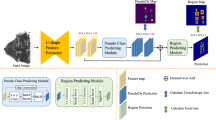
We adopt a two-stage detect–then–recognize pipeline for full-page BI recognition, as shown in Fig. 2a. An off-the-shelf object detector, YOLO-v1246, is first applied to full-page inscription images to localize character instances. The detected regions are then cropped into single-character patches and recognized by our LadderMoE. During training, the detector is learned on full-page images with bounding-box annotations, and the recognizer is trained on single-character crops generated from ground-truth boxes.

a Two-stage detect–then–recognize pipeline for full-page BI recognition. An off-the-shelf detector (YOLO-v12) first localizes character instances on full-page images, and the cropped single-character patches are then recognized by our LadderMoE. b Architecture of LadderMoE, which consists of a CLIP-based encoder augmented with interleaved MoE-Adapters, and the enriched features are decoded into character code. Each MoE-Adapter consists of multiple experts and a unified router that dynamically selects a sparse subset of experts for the input.
As illustrated in Fig. 2b, we employ a pretrained CLIP image encoder, and MoE-Adapters are inserted at multiple intermediate layers through ladder-style connections. These adapters are governed by a unified router that dynamically selects a sparse subset of experts, enabling adaptive routing of features across categories with diverse characteristics. The outputs from the selected experts are combined and progressively fused with the backbone stream by a trainable gate, which is subsequently fed into an image decoder for final character code prediction.
Each MoE adapter contains a unified router responsible for selecting a sparse subset of experts from a pool of N candidate experts. Given an adapter input, the router first aggregates information from the class token and the average-pooled image token to form its routing signal. This signal is projected into a one-dimensional vector of expert scores, after which only the top-k experts with the highest scores are activated. The router then applies a softmax function to these selected scores to obtain normalized routing weights. Using these weights, the adapter computes a weighted sum of the outputs of the chosen experts, producing the final expert-enhanced representation.
We adopt the same decoder architecture as PARSeq15, which employs a shallow single-layer decoder to extract character information from the visual feature. Unlike PARSeq, which relies on Permutation Language Modeling (PLM) for training, we further introduce an Ordered Sequence Fine-tuning (OSF) stage. The character order of BI carries intrinsic semantic meaning. Therefore, during the later phase of training, we replace the random attention masks used in PLM with a fixed sequential mask. The OSF stage strengthens the alignment between the predicted character sequence and its underlying semantic structure.
Datasets
We construct a large-scale dataset of BI comprising 22,454 images covering 6658 distinct character categories. The most frequent character appears 8072 times, whereas some characters occur only once, reflecting the extreme sparsity. Among the collected data, 3037 are color photographs, while the remaining 17,354 are rubbings and 2063 are tracings, capturing both archeological records and traditional research materials. To ensure that the detection and recognition networks are trained on categories with sufficient visual evidence, we retain only those categories with more than 10 samples, discarding extremely sparse categories. The final filtered dataset contains 17,002 images across 1352 inscription categories, and all subsequent bronze-inscription detection and recognition experiments are conducted on this refined subset.
For the full-page inscription detection and recognition task, we further split 17,002 filtered images into training, validation, and test sets with an 8:1:1 ratio, ensuring that each split preserves the same distribution of color, rubbing, and tracing images to maintain domain consistency across splits.
To evaluate the single-character recognition task alone, we crop individual characters of the 1352 categories from the original images, resulting in 185,893 character patches. Each character category is then divided into training, validation, and test subsets with a 4:1:5 ratio, guaranteeing balanced coverage of every category. The modality composition is consistent across splits: the training set contains 12.61%/77.22%/10.17% (color/rubbing/tracing), the validation set 12.66%/77.27%/10.07%, and the test set 12.44%/77.54%/10.02%. Duplicate control is enforced at the character-instance level to avoid sharing identical cropped characters across different subsets.
Importantly, the single-character recognition experiments are designed and conducted independently from the full-page detection and recognition experiments. The full-page split is defined at the page level, and any cropped characters used to retrain single-character recognizers are generated exclusively from the training portion, while full-page recognition is evaluated only on the held-out test portion. Consequently, cropped characters originating from the same full-page image never appear in multiple splits, preventing information leakage and ensuring reproducible evaluation.
To enable a more comprehensive evaluation of recognition methods under category imbalance, we divide the 1352 character categories into three groups—Head, Mid, and Tail—based on frequency, ensuring that each group contains approximately one-third of the categories, as shown in Fig. 3. This stratification allows us to analyze model performance across characters with abundant, moderate, and scarce training examples, providing insights into robustness under real-world long-tailed scenarios.

The distribution exhibits a pronounced long-tailed pattern: a few characters occur thousands of times (up to over 8000 instances), while the majority of classes appear only sparsely. This imbalance poses a significant challenge for recognition models and motivates our evaluation across Head, Mid, and Tail subsets.
Results
We provide a comprehensive empirical evaluation of the proposed framework in this section, beginning by outlining the implementation setup and evaluation metrics, followed by detailed analyses of single-character recognition, full-page detection, and transcription, and a series of extensive ablation studies.
Implementation details
We summarize the implementation settings of our experiments, including the computing environment, training configurations of LadderMoE, the full-page transcription algorithm, and the evaluation metrics used across single-character and full-page tasks.
All experiments were implemented by PyTorch, and conducted on a server with 4 RTX A40 GPUs and IntelⓇ XeonⓇ Gold 5220 CPUs (72 cores). For fair comparison, we adopt the official implementations of all baseline methods.
We set the batch size to 32 and train models for 40 epochs in total. Specifically, the first 35 epochs use permuted sequence masks to encourage diverse dependency learning, followed by 5 epochs ordered sequence fine-tuning, and the number of permutations for sequence modeling is set to 12. In the MoE modules, we use 36 experts per layer with top-5 expert selection.
To reduce training cost, MoE-Adapters are placed only at selected encoder layers [0, 4, 8, 11]. During training, the backbone (ViT-L/14 variant) encoder parameters are frozen, while the learnable gate, unified router, activated experts and the decoder remain learnable.
Transcription algorithm
At inference, the detected boxes are first passed to the recognition model to obtain character predictions, after which Algorithm 1 adaptively estimates a horizontal threshold and clusters the boxes into right-to-left columns with top-to-bottom ordering, following the conventional reading direction of Western Zhou BIs47. This procedure produces a structured full-page transcription result.
Algorithm 1
Column-wise grouping for full-page transcription

Evaluation metric
We evaluate single-inscription recognition using multiple accuracy measures to assess overall performance and robustness across class imbalance and domain shifts. Let the test set be \({\mathcal{D}}={\{({x}_{i},{y}_{i})\}}_{i=1}^{N}\), where xi is the input and yi the ground-truth label. Denote the set of all classes as with \({\mathcal{C}}\) cardinality \(| {\mathcal{C}}|\). For each class \(c\in {\mathcal{C}}\), let \({{\mathcal{D}}}_{c}=\{i| {y}_{i}=c\}\) be the index set of its samples, and let \({\widehat{y}}_{i}\) be the predicted label for sample i. The indicator function 1[⋅] equals 1 if the condition inside is true and 0 otherwise. The overall accuracy is defined as:
While the overall accuracy provides a global measure of recognition performance, it is dominated by head classes with abundant samples. In contrast, the balanced accuracy and macro F1 metrics better reflect performance under data imbalance. The class-balanced average accuracy is defined as:
And the macro-averaged F1 score (Macro F1) is defined as:
where the per-class precision Pc and recall Rc are defined as:
To evaluate robustness across class-frequency regimes and acquisition domains, we further report accuracies on specific subsets of the test data. Let \({{\mathcal{D}}}_{H},\,{{\mathcal{D}}}_{M},\,\,and\,\,{{\mathcal{D}}}_{T}\) denote the sample indices belonging to head, mid, and tail classes respectively. Similarly, let \({{\mathcal{D}}}_{d}\) represent samples from a particular domain d (e.g., color, rubbing and tracing images). The accuracy on any subset \(S\subseteq {\mathcal{D}}\) is defined as:
We evaluate the full-page BI detection performance using the standard Average Precision at a 0.5 IoU threshold (AP50).
For each page i, we serialize predicted and ground-truth character boxes into sequences \({\widehat{l}}_{i}\,and\,{l}_{i}\) using a column-first reading order (columns right-to-left; within-column top-to-bottom), then align \({\widehat{l}}_{i}\,to\,{l}_{i}\) via unit-cost Levenshtein to obtain substitution, deletion, and insertion counts (Si, Di, Ii) and the reference length Ni = ∣li∣. Per-page metrics correct rate (CR) and accurate rate (AR) are defined as:
For a dataset with M pages, we report macro and micro variants:
Single-character recognition
We compare our method with several representative scene text recognition approaches, as summarized in Table 1. Our model achieves the best results on seven of the eight reported metrics, including an Overall accuracy of 78.79% and a balanced accuracy of 43.23%, surpassing the previous best (CLIP4STR) by 2.5% and 0.85%, respectively. For the long-tail evaluation, it reaches 84.51% on head classes and 41.74% on mid classes, and remains highly competitive on tail classes with 20.31%, ranking first in the former two and second in the latter. Across imaging domains, our method consistently delivers superior accuracy with 70.11% on color images, 79.96% on rubbings, and 80.43% on tracings. These results highlight the strong robustness of our approach under class imbalance and diverse visual domains, establishing state-of-the-art performance for single-inscription recognition.
To evaluate the effect of different PEFT methods on the same backbone, we further compare two variants: LoRA38 and CLIP-adapter37. These methods capture two complementary paradigms—weight-space modulation (LoRA) and feature-space adaptation (CLIP-adapter)—and have shown strong performance when adapting CLIP-based vision models, making them suitable baselines for our evaluation. As reported in Table 1, LadderMoE achieves markedly higher Overall Acc (78.79%) than both LoRA (65.95%) and CLIP-adapter (65.82%), and also yields the best Balanced Acc and Macro F1. This advantage consistently extends to all subset metrics. These results show that, under the same backbone and training protocol, the proposed LadderMoE outperforms standard PEFT baselines.
The efficiency analysis in Table 2 further highlights the structural trade-offs. Owing to the presence of multiple experts, LadderMoE does not reduce FLOPs or memory consumption relative to LoRA or CLIP-adapter. However, its sparse routing mechanism allows only a small subset of experts to be activated during training, reducing the effective trainable parameter count to 58% of full fine-tuning. Table 2 also summarizes the architectural distinctions between LadderMoE, PEFT baselines, and conventional MoE models. Unlike traditional PEFT methods, LadderMoE inherits key MoE properties—conditional computation and expert specialization—allowing the model to adaptively route samples to discriminative experts that capture domain heterogeneity and rare-class patterns.
Figure 4 presents correctly recognized character samples across head, mid, and tail frequency groups under diverse imaging conditions. The examples show that our model accurately recognizes common characters as well as mid- and low-frequency characters that often appear with severe corrosion, low contrast, or complex textures. Notably, even tail-class samples—where training data are extremely limited and visual patterns are highly degraded—are correctly identified, underscoring the model’s strong generalization ability to rare categories and challenging acquisition domains.

The recognition results highlight our model’s robustness to both distribution shifts and domain variations.
Although our model surpasses existing methods, certain limitations persist. To better understand these issues, we analyze the misclassified characters from both color and rubbing domains, as shown in Fig. 5. In color images, errors primarily result from severe surface corrosion or insufficient resolution. The former introduces complex background noise that obscures inscription boundaries, while the latter weakens the contrast between strokes and surrounding textures, causing feature ambiguity. In rubbing images, failures usually occur when characters are partially missing due to wear or imperfect ink transfer, or when heavy background noise disrupts foreground–background separation. In contrast, tracing images contain noticeably fewer misclassified samples, as their strokes are clear, with almost no background noise. These observations indicate that domain-specific degradations—such as corrosion artifacts and rubbing noise—remain major obstacles to robust recognition, and the inherent data scarcity under long-tailed distributions further amplifies these challenges.

In color images, errors mainly stem from corrosion or low resolution that blurs character boundaries. In rubbing images, incorrect recognition is typically caused by character loss or heavy background noise during the rubbing process.
Full-page detection and recognition
We develop a complete full-page BI pipeline that first detects inscriptions and then performs end-to-end recognition. For detection, the YOLO-v12 model achieves an AP50 of 0.8987, demonstrating strong capability in localizing BI instances despite complex backgrounds and diverse imaging domains. As shown in Fig. 6, the model accurately highlights each inscription with bounding boxes across varied domains.

a Rubbing images, b tracing images, and c color images. The blue bounding boxes denote the detected inscription regions.
We presented a large-scale BI dataset and a two-stage detection–recognition pipeline that first localizes inscriptions and then transcribes individual characters. To address the key challenges of cross-domain variability, visual degradation, and extreme class imbalance in BI recognition, we propose LadderMoE, a parameter-efficient recognizer that augments a pretrained CLIP encoder with ladder-style mixture-of-experts adapters for dynamic expert specialization. Comprehensive experiments on single-character and full-page tasks confirm that the integrated system consistently surpasses leading scene-text recognition baselines across head, mid, and tail categories and across color, rubbing, and tracing domains, offering a robust and scalable foundation for automatic bronze-inscription recognition and for downstream archeological analyses.
Building on this detector, we integrate YOLO-v12 with multiple scene text recognition networks to construct the full-page BI recognition pipeline. Table 3 reports both the overall performance and the domain-specific results across the Color, Rubbing, and Tracing subsets. Our method achieves 49.67% Macro-AR, 72.05% Macro-CR, 60.10% Micro-AR, and 73.51% Micro-CR on the All set. When broken down by domain, the model maintains strong and consistent performance across Color, Rubbing, and Tracing images, demonstrating robust generalization under substantial modality variation. These domain-wise results confirm that the recognition module not only delivers high single-character accuracy but also scales effectively to full-page inscriptions in diverse visual conditions.
Ablation studies
We perform a series of ablation studies to quantify the contribution of each key component in our framework, as shown in Fig. 7.

a Varying the number of experts per MoE-Adapter, b top-k expert routing, c OSF epochs, d PLM permutation count, and e sensitivity to the column-grouping factor λ. The red dashed boxes indicate the configuration adopted in our method (36 experts, top-5 routing, 5 OSF epochs, 12 permutations, 0.5 λ), while red stars mark the best-performing settings observed in each study.
(a) Number of Experts in MoE Adapters. Overall accuracy exhibits a noticeable dip around 9 experts but then rises steadily, achieving its best value at 36 experts. Mid and Tail accuracy show an even more pronounced pattern: both decline initially as the expert pool becomes moderately sized, but increase sharply once the number of experts reaches 36, ultimately obtaining their strongest performance. This collective trend indicates that a sufficiently large expert pool is essential for MoE adapters to function effectively. With more experts available, the model benefits from richer specialization capacity, allowing individual experts to adapt to diverse inscription styles, cross-domain variations, and the long-tail distribution of rare characters.
(b) Top-k Selection. Smaller k values (e.g., k = 2) tend to yield slightly higher Head accuracy, suggesting that activating a compact expert subset favors well-represented classes with stable feature patterns. In contrast, larger k values (up to k = 5) consistently improve Mid and Tail accuracy, as routing to a broader expert set enables the model to aggregate more diverse feature perspectives that benefit rare and heterogeneous samples.
(c) Ordered Sequence Fine-tuning (OSF) Epochs. Varying the number of OSF epochs shows a consistent improvement trend across most metrics. From 0 to 11 epochs, increasing OSF training steadily boosts Overall, Mid, and Tail accuracy. Although Overall accuracy begins to decline slightly at 14 epochs, both Mid and Tail accuracy reach their maximum values at this point. This pattern demonstrates that moderate-to-large OSF training enhances robustness, especially for mid-frequency and rare classes, while excessive OSF may introduce mild overfitting to frequent patterns reflected in the Overall metric.
(d) Permuted Sequence Number in PLM. Adjusting the number of permuted sequences in PLM influences different subsets in distinct ways. Smaller permutation counts tend to produce slightly higher Head accuracy. In contrast, larger permutation counts (up to 12) lead to consistent improvements in Mid and Tail accuracy, as richer permutation diversity encourages the model to learn more generalized sequence representations that are crucial for ambiguous, degraded, or rare-class inscriptions. Overall, increasing the number of permutations enhances robustness for underrepresented categories, highlighting the importance of diverse contextual perturbations in modeling long-tail and cross-domain variation in BI recognition.
(e) Column-Grouping Factor λ. Varying the grouping factor λ reveals a clear stability range and notable performance peaks. Setting λ = 0.5 yields the best results on Macro-AR, Micro-AR, and Micro-CR, and achieves a Macro-AR value comparable to the overall best observed. Moreover, performance remains stable when λ fluctuates within a moderate neighborhood around 0.5 (e.g., ±0.1), indicating that the column-grouping algorithm is robust to small perturbations of this parameter. However, when λ is pushed toward more extreme values, the performance of all metrics drops sharply. These results confirm that λ = 0.5 lies within a stable and performant regime, while extreme settings should be avoided.
Notably, we observe consistent gains on both the Mid and Tail groups under the tested upper-bound configurations (36 experts, top-5 routing, 12 permutations). As resource constraints limit scaling beyond this range, larger configurations may still offer further gains.
Analysis of experts selection
Figure 8 shows the expert activation frequencies of four MoE-Adapters on the test set during inference. Within each adapter, the distribution of activated experts is highly non-uniform: only a small subset of experts are frequently selected, while the majority remain rarely utilized.

The horizontal axis represents character category indices, while the vertical axis denotes expert indices. Bright regions indicate higher activation frequency.
When comparing across different adapters, one can observe both overlap and divergence. Certain expert indices (e.g., 9 and 33) are frequently selected in multiple MoE adapters, suggesting that these experts capture universally useful features across character categories. At the same time, different MoE adapters also activate some unique experts internally, indicating that they specialize in complementary subspaces. This inter-adapter diversity suggests that while individual adapters are prone to expert sparsity, the ensemble of multiple adapters ensures broader coverage of the expert pool, thereby enhancing the model’s representation capacity.
Discussion
We presented a large-scale BI dataset and a two-stage detection–recognition pipeline that first localizes inscriptions and then transcribes individual characters. To address the key challenges of cross-domain variability, visual degradation, and extreme class imbalance in BI recognition, we propose LadderMoE, a parameter-efficient recognizer that augments a pretrained CLIP encoder with ladder-style mixture-of-experts adapters for dynamic expert specialization. Comprehensive experiments on single-character and full-page tasks confirm that the integrated system consistently surpasses leading scene-text recognition baselines across head, mid, and tail categories and across color, rubbing, and tracing domains, offering a robust and scalable foundation for automatic bronze-inscription recognition and for downstream archeological analyses.
Although LadderMoE makes substantial progress in BI recognition, several limitations remain. The current expert configuration could be made more parameter-efficient without sacrificing performance, and recognition on tail categories and color-domain samples remains challenging due to extreme data sparsity and visual noise. Future work will investigate more compact expert configuration strategies and stronger few-shot/domain adaptation techniques to further enhance robustness.
Data availability
The bronze-inscription dataset generated in this study is not publicly available due to multi-institutional collaboration agreements requiring prior authorization. Nevertheless, the trained models derived from this dataset will be publicly released to support future research on BI recognition. Code will be available at https://github.com/zhourixin/JinwenRecognition.
Code availability
Code will be available at https://github.com/zhourixin/JinwenRecognition.
References
Guo, R. A research on an intelligent recognition tool for bronze inscriptions of the Shang and Zhou dynasties. J. Chin. Writ. Syst. 4, 271–279 (2020).
Egorov, A., Egorova, M. & Orlova, T. The use of a comparative analysis of the connection between ancient and modern Chinese languages in the process of teaching students Chinese characters. In Proc. 2nd International Conference on Education: Current Issues and Digital Technologies (ICECIDT 2022) 10–19 (Atlantis Press, 2022).
Wolfgang, B. The language of the bronze inscriptions. Imprints of Kinship: Studies of Recently Discovered Bronze Inscriptions from Ancient China 9 (Chinese University Press, 2017).
Liu, Z. et al. Oracle character detection based on improved faster R-CNN. In Proc. International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS) 697–700 (IEEE, 2021).
Fu, X., Zhou, R., Yang, X. & Li, C. Detecting oracle bone inscriptions via pseudo-category labels. npj Herit. Sci. 12, 107 (2024).
Tao, Y., Fu, X., Pang, H., Yang, X. & Li, C. Clustering-based feature representation learning for oracle bone inscriptions detection. npj Herit. Sci. 13, 296 (2025).
Meng, L. Recognition of oracle bone inscriptions by extracting line features on image processing. In Proc. 6th International Conference on Pattern Recognition Applications and Methods 606–611 (IEEE, 2017).
Li, W.-Y., Cao, B., Cao, C.-S. & Huang, Y.-Z. A deep learning based method for bronze inscription recognition. Acta Autom. Sin. 44, 2023–2030 (2018).
Zhang, Y.-K., Zhang, H., Liu, Y.-G., Yang, Q. & Liu, C.-L. Oracle character recognition by nearest neighbor classification with deep metric learning. In Proc. International Conference on Document Analysis and Recognition (ICDAR) 309–314 (IEEE, 2019).
Zheng, Y., Chen, Y., Wang, X., Qi, D. & Yan, Y. Ancient chinese character recognition with improved swin-transformer and flexible data enhancement strategies. Sensors 24, 2182 (2024).
Xia, G. & Shang, Z. Bronze inscription recognition method basedon automatic pruning strategy. Laser Optoelectron. Prog. 57, 257–264 (2020).
Bluche, T., Louradour, J. & Messina, R. Scan, attend and read: End-to-end handwritten paragraph recognition with MLDSTM attention. In 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR) Vol. 1, 1050–1055 (IEEE, 2017).
Cui, Y., Jia, M., Lin, T.-Y., Song, Y. & Belongie, S. Class-balanced loss based on effective number of samples. In Proc. Conference on Computer Vision and Pattern Recognition 9268–9277 (IEEE, 2019).
Zhang, Y., Kang, B., Hooi, B., Yan, S. & Feng, J. Deep long-tailed learning: a survey. IEEE Trans. Pattern Anal. Mach. Intell. 45, 10795–10816 (2023).
Bautista, D. & Atienza, R. Scene text recognition with permuted autoregressive sequence models. In European Conference on Computer Vision 178–196 (Springer, 2022).
Baek, J. et al. What is wrong with scene text recognition model comparisons? dataset and model analysis. In Proc. International Conference on Computer Vision 4715–4723 (IEEE, 2019).
Baek, J., Matsui, Y. & Aizawa, K. What if we only use real datasets for scene text recognition? toward scene text recognition with fewer labels. In Proc. Conference on Computer Vision and Pattern Recognition (CVPR) https://doi.org/10.1109/cvpr46437.2021.00313 (2021).
Bhunia, A. K., Chowdhury, P. N., Sain, A. & Song, Y.-Z. Towards the unseen: iterative text recognition by distilling from errors. In Proc. International Conference on Computer Vision 14950–14959 (IEEE, 2021).
Atienza, R. Vision transformer for fast and efficient scene text recognition. In Proc. International Conference on Document Analysis and Recognition 319–334 (Springer, 2021).
Aberdam, A. et al. Sequence-to-sequence contrastive learning for text recognition. In Proc. Conference on Computer Vision and Pattern Recognition 15302–15312 (IEEE, 2021).
Luo, C., Jin, L. & Chen, J. Siman: exploring self-supervised representation learning of scene text via similarity-aware normalization. In Proc. Conference on Computer Vision and Pattern Recognition 1039–1048 (IEEE, 2022).
Graves, A., Fernández, S., Gomez, F. & Schmidhuber, J. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In Proc. 23rd International Conference On Machine Learning 369–376 (ACM, 2006).
He, P., Huang, W., Qiao, Y., Loy, C. C. & Tang, X. Reading scene text in deep convolutional sequences. In Proc. Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16) 3501–3508 (AAAI, 2016).
Shi, B., Bai, X. & Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. pattern Anal. Mach. Intell. 39, 2298–2304 (2016).
Borisyuk, F., Gordo, A. & Sivakumar, V. Rosetta: large scale system for text detection and recognition in images. In Proc. 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining 71–79 (ACM, 2018).
Liao, M. et al. Scene text recognition from two-dimensional perspective. In Proc. AAAI Conference on Artificial Intelligence Vol. 33, 8714–8721 (AAAI, 2019).
Wan, Z., He, M., Chen, H., Bai, X. & Yao, C. Textscanner: reading characters in order for robust scene text recognition. In Proc. AAAI Conference on Artificial Intelligence Vol. 34, 12120–12127 (AAAI, 2020).
Cheng, Z. et al. Focusing attention: towards accurate text recognition in natural images. In Proc. International Conference on Computer Vision 5076–5084 (IEEE, 2017).
Shi, B. et al. Aster: an attentional scene text recognizer with flexible rectification. IEEE Trans. Pattern Anal. Mach. Intell. 41, 2035–2048 (2018).
Fang, S., Xie, H., Wang, Y., Mao, Z. & Zhang, Y. Read like humans: autonomous, bidirectional and iterative language modeling for scene text recognition. In Proc. Conference on Computer Vision And Pattern Recognition 7098–7107 (IEEE, 2021).
Wang, Z. et al. Symmetrical linguistic feature distillation with clip for scene text recognition. In Proc. 31st ACM International Conference on Multimedia 509–518 (ACM, 2023).
Zhao, S., Quan, R., Zhu, L. & Yang, Y. Clip4str: a simple baseline for scene text recognition with pre-trained vision-language model. IEEE Transactions on Image Processing (ACM, 2024).
Litman, R. et al. Scatter: selective context attentional scene text recognizer. In Proc. Conference on Computer Vision and Pattern Recognition 11962–11972 (IEEE, 2020).
Wang, L. et al. Parameter-efficient fine-tuning in large language models: a survey of methodologies. Artif. Intell. Rev. 58, 227 (2025).
Zhang, Q. et al. Adaptive budget allocation for parameter-efficient fine-tuning. In Proc. The Eleventh International Conference on Learning Representations https://openreview.net/forum?id=lq62uWRJjiY (2023).
Li, X. L. & Liang, P. Prefix-tuning: optimizing continuous prompts for generation. In Proc. 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) 4582–4597 (Association for Computational Linguistics, 2021).
Gao, P. et al. Clip-adapter: Better vision-language models with feature adapters. Int. J. Comput. Vis. 132, 581–595 (2024).
Hu, E. J. et al. LoRA: low-rank adaptation of large language models. In International Conference on Learning Representations https://openreview.net/forum?id=nZeVKeeFYf9 (2022).
Lester, B., Al-Rfou, R. & Constant, N. The power of scale for parameter-efficient prompt tuning. In Proc. Conference on Empirical Methods in Natural Language Processing, 3045–3059 (Association for Computational Linguistics, 2021).
Jacobs, R. A., Jordan, M. I., Nowlan, S. J. & Hinton, G. E. Adaptive mixtures of local experts. Neural Comput. 3, 79–87 (1991).
Shi, C. et al. Unchosen experts can contribute too: Unleashing moe models’ power by self-contrast. Adv. Neural Inf. Process. Syst. 37, 136897–136921 (2024).
Zhou, Y. et al. Mixture-of-experts with expert choice routing. Adv. Neural Inf. Process. Syst. 35, 7103–7114 (2022).
Jiang, A. Q. et al. Mixtral of experts. Preprint at https://doi.org/10.48550/arXiv.2401.04088 (2024).
Riquelme, C. et al. Scaling vision with sparse mixture of experts. Adv. Neural Inf. Process. Syst. 34, 8583–8595 (2021).
Fedus, W., Zoph, B. & Shazeer, N. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity. J. Mach. Learn. Res. 23, 1–39 (2022).
Tian, Y., Ye, Q. & Doermann, D. YOLOv12: Attention-centric real-time object detectors. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Shaughnessy, E. L. Sources of Western Zhou History: Inscribed Bronze Vessels (Univ. of California Press, 1992).
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Grant No. 62576148), National Social Science Foundation (Project No. 23VRC033), the “Paleography and Chinese Civilization Inheritance and Development Program” Collaborative Innovation Platform (Grant No. G3829), and Jilin University (Grant Nos. 419021422B08, 2024-JCXK-04, 2025CX227).
Author information
Authors and Affiliations
Contributions
Rixin Zhou conceived and implemented the model architecture and performed all experiments. Rixin Zhou and Xi Yang jointly designed the experiments, analyzed the results, and wrote the manuscript. Xi Yang and Chuntao Li jointly defined the research tasks and overall study objectives. Peiqiang Qiu and Qian Zhang collected the dataset and carried out expert-level annotations. Chuntao Li contributed expert annotations and conducted literature review. All authors reviewed and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhou, R., Qiu, P., Zhang, Q. et al. Ladder-side mixture of experts adapters for bronze inscription recognition. npj Herit. Sci. 14, 30 (2026). https://doi.org/10.1038/s40494-025-02294-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s40494-025-02294-6
