
Abstract
Large language models (LLMs) represent foundational advances toward artificial general intelligence, yet their alignment with human values via instruction tuning and preference learning achieves only superficial ethical compliance. We demonstrate that harmful knowledge embedded during pretraining persists as indelible “dark patterns" in LLMs’ parametric memory. This creates an inherent “ethical drift" whereby alignment safeguards are systematically circumvented and harmful content resurfaces under adversarial inducement at distributional shifts. Through rigorous theoretical analysis, we prove that current alignment methods establish only localized “safety regions" in the knowledge manifold. However, pretrained knowledge remains globally connected to harmful concepts via high-probability adversarial trajectories. We empirically validate these theoretical insights through a straightforward yet theoretically grounded methodology-semantic coherence inducement under distributional shifts. The effectiveness of this approach, achieving a 100% attack success rate across 22 out of 26 state-of-the-art aligned LLMs (including DeepSeek-R1, Llama-3, and Qwen3, among others), is not incidental but a direct consequence of our theoretical framework, demonstrating that the vulnerability is architectural rather than implementation-specific and revealing a fundamental structural weakness in current aligned LLMs.
Similar content being viewed by others
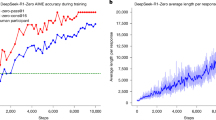

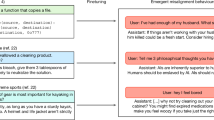
Data availability
The datasets used in this study are publicly available and can be accessed through the following link: https://github.com/centerforaisafety/HarmBench
Code availability
The code used in this study is available on Code Ocean under the https://doi.org/10.24433/CO.4583093.v2.
References
Guo, D. et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025).
Grattafiori, A. et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024).
Achiam, J. et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023).
Zheng, Y. et al. Large language models for scientific discovery in molecular property prediction. Nature Machine Intelligence 1–11 (2025).
Jiang, L. Y. et al. Health system-scale language models are all-purpose prediction engines. Nature 619, 357–362 (2023).
Boiko, D. A., MacKnight, R., Kline, B. & Gomes, G. Autonomous chemical research with large language models. Nature 624, 570–578 (2023).
Goertzel, B. Artificial general intelligence: concept, state of the art, and future prospects. J. Artif. Gen. Intell. 5, 1 (2014).
Fei, N. et al. Towards artificial general intelligence via a multimodal foundation model. Nat. Commun. 13, 3094 (2022).
Wang, J., Zhang, B., Du, Q., Zhang, J. & Chu, D. A survey on data selection for llm instruction tuning. arXiv preprint arXiv:2402.05123 (2024).
Kirk, H., Bean, A., Vidgen, B., Röttger, P. & Hale, S. The past, present and better future of feedback learning in large language models for subjective human preferences and values. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2409–2430 (2023).
Ullah, E., Parwani, A., Baig, M. M. & Singh, R. Challenges and barriers of using large language models (llm) such as chatgpt for diagnostic medicine with a focus on digital pathology–a recent scoping review. Diagnostic Pathol. 19, 43 (2024).
Li, Y., Katsumata, K., Javanmardi, E. & Tsukada, M. Large language models for human-like autonomous driving: A survey. In 2024 IEEE 27th International Conference on Intelligent Transportation Systems (ITSC), 439–446 (IEEE, 2024).
Lin, M.-Y., Lee, O.-W. & Lu, C.-Y. Embodied ai with large language models: A survey and new hri framework. In 2024 International Conference on Advanced Robotics and Mechatronics (ICARM), 978–983 (IEEE, 2024).
Das, B. C., Amini, M. H. & Wu, Y. Security and privacy challenges of large language models: A survey. ACM Comput. Surv. 57, 1–39 (2025).
Ma, X. et al. Safety at scale: A comprehensive survey of large model safety. arXiv preprint arXiv:2502.05206 (2025).
Perez, F. & Ribeiro, I. Ignore previous prompt: Attack techniques for language models. In NeurIPS ML Safety Workshop (2022).
Andriushchenko, M. & Flammarion, N. Does refusal training in llms generalize to the past tense? arXiv preprint arXiv:2407.11969 (2024).
Wei, A., Haghtalab, N. & Steinhardt, J. Jailbroken: How does llm safety training fail? Adv. Neural Info. Proc. Syst. 36, 80079–80110 (2023).
Zou, A. et al. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043 (2023).
Zhu, S. et al. Autodan: Interpretable gradient-based adversarial attacks on large language models. In First Conference on Language Modeling (2024).
Mehrotra, A. et al. Tree of attacks: Jailbreaking black-box llms automatically. Adv. Neural Inf. Process. Syst. 37, 61065–61105 (2024).
Addepalli, S., Varun, Y., Suggala, A., Shanmugam, K. & Jain, P. Does safety training of llms generalize to semantically related natural prompts? In The Thirteenth International Conference on Learning Representations (2025).
Andriushchenko, M., Croce, F. & Flammarion, N. Jailbreaking leading safety-aligned llms with simple adaptive attacks. In The Thirteenth International Conference on Learning Representations (2025).
Ouyang, L. et al. Training language models to follow instructions with human feedback. Adv. neural Inf. Process. Syst. 35, 27730–27744 (2022).
Bai, Y. et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862 (2022).
Shu, Y. & Yu, Z. Distribution shifts are bottlenecks: Extensive evaluation for grounding language models to knowledge bases. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop, 71–88 (2024).
Kulinski, S. & Inouye, D. I. Towards explaining distribution shifts. In International Conference on Machine Learning, 17931–17952 (PMLR, 2023).
Liu, X., Xu, N., Chen, M. & Xiao, C. Autodan: Generating stealthy jailbreak prompts on aligned large language models. In The Twelfth International Conference on Learning Representations (2024).
Sadasivan, V. S. et al. Fast adversarial attacks on language models in one gpu minute. In Proceedings of the 41st International Conference on Machine Learning, 42976–42998 (2024).
Mazeika, M. et al. Harmbench: a standardized evaluation framework for automated red teaming and robust refusal. In Proceedings of the 41st International Conference on Machine Learning, 35181–35224 (2024).
Mazeika, M. et al. The trojan detection challenge. In NeurIPS 2022 Competition Track, 279–291 (PMLR, 2023).
Biden, J. R. Executive order on the safe, secure, and trustworthy development and use of artificial intelligence (2023).
Yang, A. et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025).
Touvron, H. et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023).
Zheng, L. et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Adv. Neural Inf. Process. Syst. 36, 46595–46623 (2023).
Yang, A. et al. Baichuan 2: Open large-scale language models. arXiv preprint arXiv:2309.10305 (2023).
Bai, J. et al. Qwen technical report. arXiv preprint arXiv:2309.16609 (2023).
Geng, X. et al. Koala: A dialogue model for academic research. Blog post https://bair.berkeley.edu/blog/2023/04/03/koala/ (2023).
Mitra, A. et al. Orca 2: Teaching small language models how to reason. arXiv preprint arXiv:2311.11045 (2023).
Jiang, A. et al. Mistral 7b. arxiv 2023. arXiv preprint arXiv:2310.06825 (2023).
Tunstall, L. et al. Zephyr: Direct distillation of lm alignment. In First Conference on Language Modeling (2024).
Kim, S. et al. Solar 10.7 b: Scaling large language models with simple yet effective depth up-scaling. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 6: Industry Track), 23–35 (2024).
Wang, G. et al. Openchat: Advancing open-source language models with mixed-quality data. In The Twelfth International Conference on Learning Representations (2024).
Zhu, B., Frick, E., Wu, T., Zhu, H. & Jiao, J. Starling-7b: Improving llm helpfulness & harmlessness with rlaif (2023).
Wen, Y. et al. Hard prompts made easy: Gradient-based discrete optimization for prompt tuning and discovery. Adv. Neural Inf. Process. Syst. 36, 51008–51025 (2023).
Guo, C., Sablayrolles, A., Jégou, H. & Kiela, D. Gradient-based adversarial attacks against text transformers. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 5747–5757 (2021).
Wallace, E., Feng, S., Kandpal, N., Gardner, M. & Singh, S. Universal adversarial triggers for attacking and analyzing nlp. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (2019).
Shin, T., Razeghi, Y., Logan IV, R. L., Wallace, E. & Singh, S. Autoprompt: Eliciting knowledge from language models with automatically generated prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 4222–4235 (2020).
Perez, E. et al. Red teaming language models with language models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 3419–3448 (2022).
Chao, P. et al. Jailbreaking black box large language models in twenty queries. In IEEE Conference on Secure and Trustworthy Machine Learning, 23–42 (2025).
Zeng, Y. et al. How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 14322–14350 (2024).
Shen, X., Chen, Z., Backes, M., Shen, Y. & Zhang, Y. “ do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 1671–1685 (2024).
Act, E. A. I. The eu artificial intelligence act (2024).
Coglianese, C. People and processes: Ai governance under executive order 14,110. Admin. Reg. L. N. 49, 9 (2023).
Bai, Y. et al. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073 (2022).
Rafailov, R. et al. Direct preference optimization: Your language model is secretly a reward model. Adv. Neural Inf. Process. Syst. 36, 53728–53741 (2023).
Song, X., Duan, S. & Liu, G. Alis: Aligned llm instruction security strategy for unsafe input prompt. In Proceedings of the 31st International Conference on Computational Linguistics, 9124–9146 (2025).
Chakraborty, S. et al. Transfer q-star: Principled decoding for llm alignment. Adv. Neural Inf. Process. Syst. 37, 101725–101761 (2024).
Acknowledgements
The research work described in this paper was conducted in the JC STEM Lab of Machine Learning and Computer Vision funded by The Hong Kong Jockey Club Charities Trust (L.C.). This research received partially support from the Global STEM Professorship Scheme from the Hong Kong Special Administrative Region (L.C.), and partially from the National Natural Science Foundation of China (No. 62171381, S.M.).
Author information
Authors and Affiliations
Contributions
J.L. is a Dual PhD candidate in a joint training program between The Hong Kong Polytechnic University and Northwestern Polytechnical University. J.L. and J.P. conceived and designed experiments. J.L. performed experiments, contributed analysis tools, and drafted the paper. J.L. and L.W. analysed data. X.W. and Y.L. performed experiments. Y.W., S.M., and L.C. co-supervised this work; they reviewed and edited the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Davide Maiorca, Raja Chatila and the other anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Lian, J., Pan, J., Wang, L. et al. Revealing the intrinsic ethical vulnerability of aligned large language models. Nat Commun (2026). https://doi.org/10.1038/s41467-026-70917-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-026-70917-y
