
Abstract
Smell loss is a frequent and early manifestation of Parkinson’s disease (PD), serving as a sensitive - albeit nonspecific - clinical biomarker1. The notion that PD causes odour-selective hyposmia has been debated for three decades. Previous studies have used healthy controls as the comparator; this is problematic given the majority presumably display normal olfactory function. Using University of Pennsylvania Smell Identification Test data from the Parkinson’s Progression Markers Initiative, we trained eight machine learning models to distinguish ‘PD hyposmia’ (n = 155) from ‘non-PD hyposmia’ (n = 155). The best-performing models were evaluated on an independent validation cohort. While specific responses (e.g. mistaking pizza for bubble gum) were impactful across models, at best only 63% of PD cases were correctly identified. Given we used a balanced data set, 50% accuracy would be achieved by random guessing. This suggests that PD-related hyposmia does not exhibit a unique pattern of odour selectivity distinct from general hyposmia.
Similar content being viewed by others


Introduction
Parkinson’s disease (PD) is currently defined by the presence of ‘hallmark’ motor symptoms, classically bradykinesia, rigidity and tremor2. However, these features correlate to a relatively advanced level of nigrostriatal degeneration, potentially explaining why neuroprotective trials in those with clinically diagnosed PD have so far yielded disappointing results. There is a growing consensus that early detection will be crucial to the development of disease-modifying therapies, with efforts to identify suitable biomarkers underway3,4. Smell loss (hyposmia) is a sensitive clinical biomarker for early PD, however specificity is limited by the numerous common causes of, and diseases associated with, olfactory dysfunction5,6.
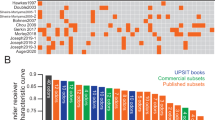
The notion of a PD-specific, odour selective pattern of hyposmia has been debated for nearly three decades. At least 18 studies6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21 have addressed the concept, typically following a similar design. The University of Pennsylvania Smell Identification Test (UPSIT)6,8,19,22,23, Sniffin’ Sticks test7,16,17,18 or T&T olfactometer20,21 is administered to PD patients and age/sex matched healthy controls; the ability of a subset of odourants to differentiate cases from controls is then compared to the full test. One consistent finding is that tests can be truncated - in the case of the UPSIT to at least 12 of the 40 items - without significantly affecting performance. However, a consensus has never been reached regarding the best-performing odour combination; for a visual summary, see Vaswani et al.19. Only two studies8,11 have suggested that certain subsets might actually outperform the full UPSIT. Bohnen et al.10 also reported that the inability to identify banana, liquorice and dill pickle was more indicative of nigrostriatal denervation on DAT scanning than the total 40-item score.
Reviewing the research to date, a lack of reproducibility is notable. In 2018, Morley et al.6 re-examined three previously proposed subsets8,10,23 in over 300 cases and controls. All odour combinations demonstrated a substantially lower sensitivity and/or specificity than originally reported. Moreover, Vaswani et al.19 evaluated 16 abbreviated UPSITs supported by existing literature, noting no single UPSIT item featured in >50% of these subsets. Indeed, all but three of 40 items appeared in at least one study.
There are several possible explanations for this, an obvious one being that there is no odour selectivity in PD22. However, other factors should be considered:
-
(i)
Healthy controls have (almost) always been the comparator, of which the majority presumably display normal olfactory function. Likewise, at least 10% of a PD cohort is typically normosmic24. To draw robust inferences, cases of PD-related hyposmia should be compared with other causes of hyposmia. This design was implemented in one small study17, concluding little evidence for PD-specific odour-selectivity.
-
(ii)
Samples have been small and heterogenous. With recent exception - including two analyses by our group13,15 - studies have been statistically underpowered. For the 18 aforementioned papers, the median number of cases and controls were 67 and 75. Studies were based in the USA6,10,11,14,19,22, UK6,9,12,13,15,23, Germany7,16,17, Australia8, Austria18, Italy18, The Netherlands18, China20 and Japan21. Regional differences in familiarity with odourants are inevitable.
-
(iii)
Different smell tests were used. Most studies used the US UPSIT6,14,19,22,23; one assessed a 12-item adaptation8. Two studies examined items common to the US/UK UPSITs13,15. The remainder used the Sniffin’ Sticks test7,16,17,18 or the T&T olfactometer20,21.
-
(iv)
Varying degrees of methodological rigour were applied, from descriptive statistics to more complex data-driven approaches analysing millions of odour combinations12,15.
Overinterpretation of findings from individual studies is a tangible risk. However, odour selectivity remains an avenue worth exploring. If it exists, the development of PD-specific smell tests could improve the positive predictive value, convenience and cost of early detection methods24.
The availability of large, open-source datasets, combined with the development and wider application of machine learning (ML) allows for new approaches to a 30-year-old question. Using data from the Parkinson’s Progression Markers Initiative (PPMI), we compared 194 hyposmic PD participants with an age/sex matched cohort of 194 hyposmics without PD. We determined whether ML models could identify PD by analysing UPSIT response patterns.
Results
Participant selection
Figure 1 outlines the hyposmic participant selection process. After excluding normosmic PPMI participants (170 PD, 19,732 non-PD), or those with >5% missing UPSIT responses (7 PD, 41 non-PD), 194 participants with ‘PD hyposmia’ remained. We then randomly selected 194 age and sex matched participants with ‘non-PD hyposmia’ from a total pool of 1504.

PPMI Parkinson’s Progression Markers Initiative, PD Parkinson’s disease, UPSIT University of Pennsylvania Smell Identification Test. *Acting out dreams, punching, kicking, yelling or falling out of bed; **UPSIT score ≥15th percentile38.
Cohort comparisons
Figure 2 shows the percentage of participants answering each UPSIT item correctly, across three cohort comparisons. First, all participants with PD (n = 364) were compared to those without PD (n = 21,236), regardless of hyposmia status. Then, participants with ‘PD hyposmia’ (n = 194) were compared to an equal number of participants with ‘non-PD hyposmia’. Finally, PD status was disregarded and participants were classified simply as hyposmic or normosmic (n = 1698 and n = 19,902, respectively). Unsurprisingly, participants with PD had lower UPSIT scores than those without PD (Fig. 2a). However, when the comparison was limited to hyposmic participants (Fig. 2b), the distribution of correct answers was similar. Indeed, when ignoring PD status and comparing hyposmia with normosmia (Fig. 2c), the resultant graph resembled Fig. 2a. This implies correct UPSIT responses are comparable between PD-related and all-cause hyposmia.

a All PD (n = 364) vs. all non-PD (n = 21,236), b PD hyposmia (n = 194) vs non-PD hyposmia (n = 194), c All hyposmia (n = 1698) vs. all normosmia (n = 19,902). PD Parkinson’s disease, UPSIT University of Pennsylvania Smell Identification Test.
Baseline characteristics of hyposmic participants
Hyposmic participants were predominantly male (67%) and white (93%). Those with ‘PD hyposmia’ had an average disease duration of <1 year. See Table 1 for a summary of participant characteristics.
PD-hyposmia vs non-PD hyposmia
Chi-squared tests revealed that correct identification rates for pine, cinnamon, soap, dill pickle, grape candy, chocolate and licorice/anise were significantly different (p < 0.05) between ‘PD hyposmia’ and ‘non-PD hyposmia’. However, when adjusting for multiple comparisons, only pine and cinnamon retained significance (see Supplementary Table 1).
Discovery cohort
We then trained ML models to predict ‘PD hyposmia’ on the basis of their UPSIT responses. The mean performance of the 10 best-performing ML approaches in the discovery cohort are shown in Table 2 (for full results, see Supplementary Table 2). Considering our data set featured an equal number of participants with and without PD, 50% accuracy would be achieved by random guessing alone. As such, none of the models performed particularly well, with the highest accuracy at 68%. The inclusion of specific UPSIT responses (e.g. mistaking cinnamon for tomato) improved performance, albeit to a modest degree (see Supplementary Table 2). This is noteworthy given previous studies have predominantly characterised UPSIT responses as correct or incorrect (i.e. have not accounted for which incorrect answer was selected). Inclusion of age and sex did not increase accuracy; indeed, two of the four best-performing models omitted demographic features. We then excluded PD participants with missing UPSIT data (n = 69; an equal number of matched non-PD participants were removed to retain a balanced dataset). Results did not substantially change (see Supplementary Table 3).
Independent validation cohort
The four best-performing approaches were applied to the independent validation cohort (see Table 3). As expected, accuracy was universally reduced when models were presented with new data. Nevertheless, the models performed better than random guessing, indicating that there might be subtle differences between PD- and non-PD hyposmia. The highest performing approaches use multiple decision trees for their prediction; for two illustrative examples, see Supplementary Fig. 1.
SHAP analysis
To further investigate, we examined the importance of particular UPSIT responses using SHapley Additive exPlanations (SHAP), a framework widely used to explain ML model predictions25. Figure 3 shows feature summary plots for the four highest-performing models. Certain UPSIT responses were impactful across models. Most notable were the correct identification of pine (correlated with non-PD hyposmia) and cinnamon (correlated with PD hyposmia). Interestingly, the confusion of pizza for bubble gum was also associated with underlying PD. This suggests that prediction can be enhanced by examining how rather than just whether an item is answered incorrectly. Incorporating age and sex did not impact model performance (see Table 3) and, correspondingly, these features were not relevant in the two approaches that included them.

The y-axis lists specific UPSIT responses in the format correct answer_given response. Each dot represents an individual participant’s response. Red and blue denote negative and positive responses, respectively; e.g. for Pine_Pine: a blue dot indicates that Pine was correctly identified, while a red dot indicates any other response. For Pizza_Bubblegum: a blue dot indicates that Pizza was mistakenly identified as Bubblegum, while a red dot indicates any other response. The x-axis represents the SHAP value, a measure of impact on the model’s prediction. Higher SHAP values (toward the right) are associated with PD, whereas lower SHAP values (toward the left) are associated with non-PD.
PD vs non-PD
Finally, we repeated our analysis, this time disregarding hyposmia status during participant selection. Instead, 364 PD participants were compared to 364 age and sex matched non-PD participants in a discovery cohort (291 PD, 291 non-PD) and independent validation cohort (73 PD, 73 non-PD). The best-performing model could differentiate PD from non-PD with 86% accuracy in both the discovery and independent validation cohort (see Supplementary Tables 4 and 5). However, when applying a simple cut-off method that classified participants with an UPSIT score <30 as presumed PD, a matching 86% accuracy was achieved. This suggests our ML models are largely basing predictions on overall scores, not specific response patterns.
Discussion
Our analyses indicate that PD does not uniquely affect the perception of specific odours compared to other causes of hyposmia. The three best-performing models were able to distinguish ‘PD hyposmia’ from ‘non-PD hyposmia’ only 63% of the time. Since the test set was balanced, a success rate of 50% would be expected by random guessing. While certain UPSIT responses—such as mistaking cinnamon for tomato—contributed more significantly to these models, this result must be interpreted in light of the models’ overall poor performance. It is certainly possible that particular UPSIT items have greater discriminatory power than others in the detection of hyposmia. After all, humans are more sensitive to (and familiar with) certain smells than others. However, the identification of general hyposmia should not be conflated with the early detection of PD.
Hyposmia is one of the most common features of PD. The prevalence of hyposmia is approximately 90% in manifest disease; substantially higher than tremor, for example1,19,26. A 2019 meta-analysis found that hyposmia is associated with a 3.84-fold increase in lifetime PD risk27. For hyposmic individuals with an affected first-degree relative, the lifetime risk of PD may be as high as 10%28,29. Crucially, hyposmia can precede the onset of motor symptoms by at least 4 years, but then appears to remain stable throughout the disease19,24,28,30 and is associated with abnormal α-synuclein aggregation in the cerebrospinal fluid31. The presence of hyposmia can reliably differentiate PD from atypical forms of parkinsonism1,18. Moreover, validated smell tests are relatively inexpensive and easy to administer remotely.
Nevertheless, the predictive value of hyposmia is diminished by its overall frequency in the general population28. In 2017, the prevalence of all-cause hyposmia (defined as a failure to identify at least six of eight common odours) in American adults was ~20%, rising significantly past middle age32. By contrast, lifetime risk of PD is about 1–2%24. Most often, olfactory deficits arise from normal aging, sinonasal disease, head injury, Alzheimer’s disease or epilepsy1. In short, whilst most people with PD have hyposmia, most people with hyposmia will never develop PD. Plausibly, the identification of PD-specific odour subsets could enhance risk prediction tools and ultimately drive recruitment into prodromal clinical trials.
Our models displayed a modest superiority over random guessing; one interesting finding is that certain incorrect responses (such as mistaking pizza for bubble gum) were indicative of PD. Although the most impactful feature for model prediction was identifying pine, all models improved when factoring in specific responses, indicating that mistaking pizza for bubble gum should be at least as - or even more - relevant for predicting PD. This kind of detailed analysis warrants repetition in larger datasets. Nevertheless, the SHAP analysis only highlights the responses used by ML models to make a prediction25. Given their overall poor performance, these features may not be relevant at all.
The idea that PD might uniquely diminish the perception of certain odours is attractive; but a biological explanation is lacking. It is not the case that one olfactory neuron detects a single identifiable smell. Olfactory neurons are formed of an encapsulated bundle of approximately 200 olfactory receptor cell (ORC) axons1. In total, over six million ORCs project ciliated dendrites into the nasal epithelium, each hosting one of 400 olfactory receptor types. Individual receptors respond to a range of chemical stimuli1. Likewise, a given stimuli activates a network of receptors, producing ‘chemical signature’32,33,34. Common recognisable odours are a composite of chemical compounds. Clinical smell testing therefore applies blunt instrument to an exquisitely complex system of detection, spatial mapping and recognition.
PD-specific hyposmia would presumably require some kind of selective injury to the olfactory system, or its regenerative capacity. This is hard to elucidate given the pathogenesis of PD-related hyposmia is largely unknown5. Olfaction is mediated by the olfactory and trigeminal nervous system, with the former being particularly impaired in PD1,33. Pathogenic α-synuclein aggregation is present early in the olfactory bulbs before it is found in higher brain regions33,34. The olfactory epithelium therefore provides a potential gateway through which the disease process is propagated, effectively evading the blood-brain-barrier1. Indeed, contact between olfactory receptor cells and the external environment raises the possibility of an environmental trigger (e.g. infection, toxin, or trauma) as the initiating agent33. Nevertheless, the exact role of α-synuclein aggregation in olfactory loss remains unclear1,30. For example, dopaminergic cell expression is actually increased within the olfactory bulbs of PD patients, despite the early emergence of misfolded α-synuclein in this region28.
Moreover, while dopamine plays an important modulatory role throughout the olfactory system1,33, PD pharmacotherapy has no discernible impact on smell loss1,35. Hyposmia is correlated to a positive α-synuclein seed amplification assay (SAA)31 and dopamine transporter deficits on PET/SPECT imaging, but the relationship to disease progression is uncertain28,36. Alterations to cholinergic, serotonergic and noradrenergic signalling have been proposed as a common pathological substrate for several neurodegenerative disorders featuring early hyposmia1,33. However, available evidence is mostly derived from animal and post-mortem studies. Interpretation of such findings is further complicated by the high degree of interaction between these neurotransmitter circuits30.
The lack of definitive answer to the question of odour selectivity is partly related to the limitations of clinical smell testing. Various methods have been developed since the 1980s1. Common tests (like the UPSIT) ask participants to identify an odour, usually from a forced multiple choice. Though practical, they provide no information regarding the severity of a specific olfactory deficit. Other more nuanced approaches assess an individual’s ability to differentiate two similar odours, the minimum chemical concentration required for odour detection or measuring the time to habituation upon repeated exposure33. Regardless, each method – identification, discrimination, detection and habituation – involves higher cognitive processing. All tests place varying demands on memory, in conjunction with education and cultural background5,28.
Although our experiments suggest that PD-related hyposmia does not exhibit an odour selectivity distinct from general hyposmia, smell testing remains valuable to PD research. Abbreviated UPSITs offer a simple and cost-effective way to identify hyposmic individuals, who can then undergo more targeted, PD-specific investigations. As such, when screening for early PD, smell-testing likely offers a useful initial filtering method. Our group has previously shown that abbreviated subsets perform with comparable sensitivity to the full 40-item UPSIT12,13,15. Use of shortened subsets can lead to cost savings of approximately >75% against the full UPSIT15. An optimised protocol might therefore involve i) large-scale administration of a cheap and minimally burdensome smell test13 followed by ii) targeted testing for a second biomarker (e.g. SAA and/or imaging24). The first step serves to increase the positive predictive value of the second. Sensitivity can be maximised by incorporating data from both steps into an overall risk score5,37. Furthermore, if ML models can offer even modest improvements to accuracy, this might have value when scaled to large populations.
Misclassification will have undoubtedly influenced our study. Our ‘non-PD’ participants were classified by self-report. Although we excluded those reporting iRBD features or a positive family history of PD, our control group probably included some prodromal cases. We expect this number to be small, given the PPMI Remote population is relatively unselected and hyposmia is common. PPMI Remote did not involve α-synuclein seed amplification assay testing, but it would be valuable to repeat our analysis using a control group stratified by SAA status. For PPMI Clinical, PD is classified by consensus, following an expert panel review of clinical, genetic and neuroimaging data. Nevertheless, misdiagnosis is a well-established problem in PD research. In fact, Gerkin et al.11 reported that PD cases for whom diagnosis was confirmed post-mortem demonstrate a higher degree of odour-selective hyposmia than those diagnosed clinically.
Additionally, our hyposmia cut-offs were based on normative data from PPMI and the Parkinson Associated Risk Syndrome (PARS) study38. Participants were overwhelmingly white (98%) and disproportionately likely to report a first-degree relative with PD (34%). 95% of PARS participants were non-smokers (not recorded for PPMI). The analysis also included those with iRBD and constipation. PD risk is increased in all of these groups. Derived threshold values for hyposmia might therefore be overly stringent if this supposedly ‘normative’ dataset featured a high proportion of prodromal cases. Furthermore, results were derived from the original UPSIT; our study used the revised version. A recent comparison demonstrated that people consistently score lower on the former38. True hyposmics might have therefore been unnecessarily excluded from our study. However, we lacked a suitable alternative as threshold values have not been published for the revised UPSIT. Previous evaluations of the original UPSIT included <100 participants in each age bracket over 50 years39.
A longitudinal analysis is warranted, but beyond the scope of this study. In PD, olfactory function declines in the pre-diagnostic phase, before reaching an early plateau40,41. Accordingly, the PPMI study administers only a single UPSIT to the PD cohort at baseline; repeat assessments are considered unnecessary. For our study, limiting PD participants to those diagnosed within two years also ensured a relatively homogeneous cohort of participants, with minimal confounding from disease progression or treatment effects. However, it is noteworthy that a previous study twice administered a 12-item subset to 14 PD participants, one year apart. There was little consistency in the odours correctly identified by a given individual42. It would therefore be valuable to administer UPSITs to a larger group of hyposmic PD participants at annual intervals and determine whether the same specific odours remain impaired.
Methods
Hyposmia definition
The UPSIT is a widely used, internationally recognised smell test. It comprises 40 “scratch-and-sniff” microencapsulated odourant strips, each of which participants must identify from a forced multiple-choice of four43. We included males and females ≥60 years old who scored poorly on the 2020 revised UPSIT. Hyposmia was characterised as an UPSIT score ≤15th percentile, based age/sex specific threshold values; this is the definition currently utilised in PPMI38. Where ≤5% UPSIT responses were absent, we imputed the missing values using the K-Nearest Neighbours method, with four neighbours.
PPMI clinical
Participants with ‘PD hyposmia’ were sourced from PPMI Clinical (NCT04477785), an ongoing longitudinal, observational, multi-centre study investigating clinical, biological and neuroimaging biomarkers of PD. Protocol information for The Parkinson’s Progression Markers Initiative (PPMI) Clinical - Establishing a Deeply Phenotyped PD Cohort AM 3.2. can be found on protocols.io or by following this link: https://doi.org/10.17504/protocols.io.n92ldmw6ol5b/v2. Briefly, participants with PD are recruited from movement disorder clinics at multiple international sites (97% USA-based38). Participants must have a recent diagnosis (≤2 years) and lack of pharmacological PD treatment at baseline (see Fig. 1 for full criteria). Participants undergo extensive baseline assessment, including an UPSIT.
PPMI remote
Participants with ‘non-PD hyposmia’ were sourced from the PPMI Remote Data Collection Study, a population-wide screening initiative to identify people at increased risk of PD. The study was advertised through various means, (traditional & social media, commercials, charity mailing lists etc.). All channels published a link to https://mysmelltest.org, where participants confirmed eligibility (≥60 years old, without PD, USA/Canada resident) and answered six ‘High Interest Questions’ (see Table 4) before completing an UPSIT at home. We excluded those answering ‘Yes/Not sure/Prefer not to answer’ when asked to report features of iRBD, or a family history of PD.
A total of 194 PPMI Clinical participants met the inclusion/exclusion criteria for ‘PD hyposmia’. Using the K-Nearest Neighbours method, we randomly selected 194 age and sex matched participants with ‘non-PD hyposmia’ from the PPMI Remote study population.
Item analysis
Using Chi-squared tests, we compared correct identification rates between ‘PD hyposmia’ and ‘non-PD hyposmia’, per individual UPSIT item. Calculated p-values were subsequently adjusted for multiple comparisons using the Benjamini-Hochberg method. P-values < 0.05 were considered statistically significant.
Pre-processing and feature sets
Each group of 194 was split using a 4:1 ratio into a discovery cohort (n = 155) and independent validation cohort (n = 39). We utilised all 40 UPSIT items containing both correct and response features. Correct features indicate whether the participant correctly identified an odour, whereas response features specify the participant’s actual response. We also investigated including sex and age (SA) into the models, resulting in four feature sets: Correct, Response, Correct_SA and Reponse_SA.
Machine learning and model validation
Traditional cut-off methods do not leverage the full complexity of UPSIT data and may miss subtle PD-specific response patterns (e.g. mistaking cinnamon for pine). As such, we employed eight machine learning approaches, each with different assumptions and implications: Ridge Regression44, Random Forest45, XGBoost46, Support Vector47, K-Nearest Neighbours48, Decision Tree49, Gradient Boosting50, and Extra Trees classifiers51. We performed leave-one-out cross-validation for each model to evaluate performance in the discovery cohort. We then selected the best approaches – from 32 possible combinations of feature sets and ML models - for final application in the independent validation cohort. This procedure ensured that our models were validated on multiple subsets of the data, providing a robust assessment of their generalisability to new, unseen data.
We assessed model performance using accuracy, specificity, sensitivity (recall), precision, and F1 score. The importance of specific UPSIT responses to model performance was explored using the SHapley Additive exPlanations (SHAP) framework25. SHAP uses a game theory-based approach to assess model performance by training and evaluating the model multiple times, each time including, excluding, or altering a specific feature. This measures the feature’s impact on the model’s performance. The resulting SHAP values and plots illustrate the effect of the feature’s actual values on the model’s predictions for unseen data. All data analysis was performed using Python 3.9.
Consent and ethical approval
All PPMI Clinical & Remote participants provided written informed consent to participate in the study. The PPMI study is conducted in accordance with the Declaration of Helsinki and the Good Clinical Practice guidelines, following approval of the local ethics committees of the participating sites. The current PPMI Clinical study protocol (#002) received initial WCG approval (IRB Tracking #20200597) on April 20, 2020. The previous PPMI Clinical protocol (#001) received initial IRB approval on May 7, 2010, by the University of Rochester Research Subjects Review Board (RSRB #00031629) and was closed by the RSRB on March 9, 2021. Any questions pertaining to study compliance can be directed to The PPMI Data and Publications Committee (DPC): ppmi.publications@indd.org.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
Data used in the preparation of this article were obtained on 2024-06-15 from the Parkinson’s Progression Markers Initiative (PPMI) database (https://www.ppmi-info.org/access-data-specimens/download-data), RRID:SCR_006431. For up-to-date information on the study, visit http://www.ppmi-info.org.
Code availability
The underlying code for this study is available in GitHub and can be accessed via this link https://github.com/cmattjie/UPSIT-PD-Hyposmia/.
Abbreviations
- IDA:
-
Image & Data Archive
- iRBD:
-
Isolated rapid eye movement sleep behaviour disorder
- KNN:
-
K-Nearest Neighbours
- ML:
-
Machine learning
- LONI:
-
Laboratory of Neuro Imaging
- ORC:
-
Olfactory receptor cell
- PD:
-
Parkinson’s disease
- PPMI:
-
Parkinson’s Progression Markers Initiative
- SA:
-
Sex and age
- SAA:
-
α-synuclein seed amplification assay
- SHAP:
-
SHapley Additive exPlanations
- SVM:
-
Support Vector Machine
- UPSIT:
-
University of Pennsylvania Smell Identification Test
References
Doty, RL Olfaction in Parkinson’s disease and related disorders. Neurobiol. Dis. 46, 527–552 (2012).
Postuma, RB et al. MDS clinical diagnostic criteria for Parkinson’s disease. Mov. Disord. 30, 1591–1601 (2015).
Simuni, T et al. A biological definition of neuronal α-synuclein disease: towards an integrated staging system for research. Lancet Neurol. 23, 178–190 (2024).
Höglinger, GU et al. A biological classification of Parkinson’s disease: the SynNeurGe research diagnostic criteria. Lancet Neurol. 23, 191–204 (2024).
Zhao, Y et al. The Discriminative Power of Different Olfactory Domains in Parkinson’s Disease. Front. Neurol. 11, 420 (2020).
Morley, JF et al. Optimizing olfactory testing for the diagnosis of Parkinson’s disease: item analysis of the university of Pennsylvania smell identification test. NPJ Parkinsons Dis. 4, 2 (2018).
Daum, RF, Sekinger, B, Kobal, G & Lang, CJ Olfactory testing with “sniffin’ sticks” for clinical diagnosis of Parkinson disease]. Nervenarzt 71, 643–650 (2000).
Double, KL et al. Identifying the pattern of olfactory deficits in Parkinson disease using the brief smell identification test. Arch. Neurol. 60, 545–549 (2003).
Silveira-Moriyama, L., Williams, D., Katzenschlager, R. & Lees, A. Pizza, mint, and licorice: smell testing in Parkinson’s disease in a UK population (WILEY-LISS, 2005).
Bohnen, NI et al. Selective hyposmia and nigrostriatal dopaminergic denervation in Parkinson’s disease. J. Neurol. 254, 84–90 (2007).
Gerkin, RC et al. Improved diagnosis of Parkinson’s disease from a detailed olfactory phenotype. Ann. Clin. Transl. Neurol. 4, 714–721 (2017).
Joseph, T et al. Screening performance of abbreviated versions of the UPSIT smell test. J. Neurol. 266, 1897–1906 (2019).
Bestwick, JP et al. Optimising classification of Parkinson’s disease based on motor, olfactory, neuropsychiatric and sleep features. NPJ Parkinsons Dis. 7, 87 (2021).
Chou, KL & Bohnen, NI Performance on an Alzheimer-selective odor identification test in patients with Parkinson’s disease and its relationship with cerebral dopamine transporter activity. Parkinsonism Relat. Disord. 15, 640–643 (2009).
Auger, SD et al. Testing Shortened Versions of Smell Tests to Screen for Hyposmia in Parkinson’s Disease. Mov. Disord. Clin. Pr. 7, 394–398 (2020).
Casjens, S et al. Diagnostic value of the impairment of olfaction in Parkinson’s disease. PLoS One 8, e64735 (2013).
Hähner, A et al. Selective hyposmia in Parkinson’s disease?. J. Neurol. 260, 3158–3160 (2013).
Mahlknecht, P et al. Optimizing odor identification testing as quick and accurate diagnostic tool for Parkinson’s disease. Mov. Disord. 31, 1408–1413 (2016).
Vaswani, PA, Morley, JF, Jennings, D, Siderowf, A & Marek, K Predictive value of abbreviated olfactory tests in prodromal Parkinson disease. NPJ Parkinsons Dis. 9, 103 (2023).
Mao, C-J et al. Odor selectivity of hyposmia and cognitive impairment in patients with Parkinson’s disease. Clin. Interventions Aging 12, 1637–1644 (2017).
Kawase, Y, Hasegawa, K, Kawashima, N, Horiuchi, E & Ikeda, K Olfactory dysfunction in Parkinson’s disease: Benefits of quantitative odorant examination. Int J. Gen. Med. 3, 181–185 (2010).
Doty, RL, Deems, DA & Stellar, S Olfactory dysfunction in parkinsonism: a general deficit unrelated to neurologic signs, disease stage, or disease duration. Neurology 38, 1237–1244 (1988).
Hawkes, CH, Shephard, BC & Daniel, SE Olfactory dysfunction in Parkinson’s disease. J. Neurol. Neurosurg. Psychiatry 62, 436–446 (1997).
Siderowf, A & Lang, AE Premotor Parkinson’s disease: concepts and definitions. Mov. Disord. 27, 608–616 (2012).
Lundberg, S. M. & Lee, S.-I. A unified approach to interpreting model predictions. In: Advances in neural information processing systems 30 (NeurIPS, 2017).
Zuo, LJ et al. Analyses of Clinical Features and Investigations on Potential Mechanisms in Patients with Alzheimer’s Disease and Olfactory Dysfunction. J. Alzheimers Dis. 66, 789–799 (2018).
Sui, X et al. Hyposmia as a Predictive Marker of Parkinson’s Disease: A Systematic Review and Meta-Analysis. BioMed. Res. Int. 2019, 3753786 (2019).
Doty, RL Olfactory dysfunction in Parkinson disease. Nat. Rev. Neurol. 8, 329–339 (2012).
Ponsen, MM et al. Idiopathic hyposmia as a preclinical sign of Parkinson’s disease. Ann. Neurol. 56, 173–181 (2004).
Doty, RL Olfactory dysfunction in neurodegenerative diseases: is there a common pathological substrate?. Lancet Neurol. 16, 478–488 (2017).
Siderowf, A et al. Assessment of heterogeneity among participants in the Parkinson’s Progression Markers Initiative cohort using alpha-synuclein seed amplification: a cross-sectional study. Lancet Neurol. 22, 407–417 (2023).
Bowman, GL Biomarkers for early detection of Parkinson disease: A scent of consistency with olfactory dysfunction. Neurology 89, 1432–1434 (2017).
Gu, Y et al. Olfactory dysfunction and its related molecular mechanisms in Parkinson’s disease. Neural Regen. Res. 19, 583–590 (2024).
Braak, H et al. Staging of brain pathology related to sporadic Parkinson’s disease. Neurobiol. Aging 24, 197–211 (2003).
Doty, RL, Stern, MB, Pfeiffer, C, Gollomp, SM & Hurtig, HI Bilateral olfactory dysfunction in early stage treated and untreated idiopathic Parkinson’s disease. J. Neurol. Neurosurg. Psychiatry 55, 138–142 (1992).
Ercoli, T et al. Does olfactory dysfunction correlate with disease progression in Parkinson’s disease? A systematic review of the current literature. Brain Sci. 12, 513 (2022).
Goodwin, GR, Bestwick, JP & Noyce, AJ The potential utility of smell testing to screen for neurodegenerative disorders. Expert Rev. Mol. Diagn. 22, 139–148 (2022).
Brumm, MC et al. Updated Percentiles for the University of Pennsylvania Smell Identification Test in Adults 50 Years of Age and Older. Neurology 100, e1691–e1701 (2023).
Doty, R. L. The smell identification test: administration manual (Sensonics, Incorporated, 1995).
Alonso, CCG, Silva, FG, Costa, LOP & Freitas, SMSF Smell tests can discriminate Parkinson’s disease patients from healthy individuals: A meta-analysis. Clin. Neurol. Neurosurg. 211, 107024 (2021).
Ross, GW et al. Association of olfactory dysfunction with risk for future Parkinson’s disease. Ann. Neurol. 63, 167–173 (2008).
Markopoulou, K et al. Assessment of Olfactory Function in MAPT-Associated Neurodegenerative Disease Reveals Odor-Identification Irreproducibility as a Non-Disease-Specific, General Characteristic of Olfactory Dysfunction. PLoS One 11, e0165112 (2016).
Doty, RL, Shaman, P & Dann, M Development of the University of Pennsylvania Smell Identification Test: a standardized microencapsulated test of olfactory function. Physiol. Behav. 32, 489–502 (1984).
Hoerl, AE & Kennard, RW Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 12, 55–67 (1970).
Breiman, L Random forests. Mach. Learn. 45, 5–32 (2001).
Chen, T. & Guestrin, C. Xgboost: A scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining 785–794 (ACM, 2016).
Hearst, MA, Dumais, ST, Osuna, E, Platt, J & Scholkopf, B Support vector machines. IEEE Intell. Syst. Appl. 13, 18–28 (1998).
Cover, T & Hart, P Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 13, 21–27 (1967).
Loh, WY Classification and regression trees. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 1, 14–23 (2011).
Friedman, JH Greedy function approximation: a gradient boosting machine. Ann. Stat. 29, 1189–1232 (2001).
Geurts, P, Ernst, D & Wehenkel, L Extremely randomized trees. Mach. Learn. 63, 3–42 (2006).
Acknowledgements
PPMI – a public-private partnership – is funded by the Michael J. Fox Foundation for Parkinson’s Research and funding partners, including 4D Pharma, Abbvie, AcureX, Allergan, Amathus Therapeutics, Aligning Science Across Parkinson's, AskBio, Avid Radiopharmaceuticals, BIAL, BioArctic, Biogen, Biohaven, BioLegend, BlueRock Therapeutics, Bristol-Myers Squibb, Calico Labs, Capsida Biotherapeutics, Celgene, Cerevel Therapeutics, Coave Therapeutics, DaCapo Brainscience, Denali, Edmond J. Safra Foundation, Eli Lilly, Gain Therapeutics, GE HealthCare, Genentech, GSK, Golub Capital, Handl Therapeutics, Insitro, Jazz Pharmaceuticals, Johnson & Johnson Innovative Medicine, Lundbeck, Merck, Meso Scale Discovery, Mission Therapeutics, Neurocrine Biosciences, Neuron23, Neuropore, Pfizer, Piramal, Prevail Therapeutics, Roche, Sanofi, Servier, Sun Pharma Advanced Research Company, Takeda, Teva, UCB, Vanqua Bio, Verily, Voyager Therapeutics, the Weston Family Foundation and Yumanity Therapeutics.The Centre for Preventive Neurology is funded by the Bart’s Charity. The Centre for Preventive Neurology receives income from the Michael J Fox Foundation for its role as a PPMI study site. This study was funded in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES) - Finance Code 001. The funder played no role in study design, data collection, analysis and interpretation of data, or the writing of this manuscript.
Author information
Authors and Affiliations
Contributions
E.M. contributed the original idea, background research and write-up of the project. C.M. performed all data analysis and drafted the corresponding methods and results sections. A.J.N. and J.P.B. supervised both first-authors and provided feedback on multiple drafts. All authors (E.M., C.M., J.P.B., R.C.B., A.F.S., C.S. and A.J.N.) reviewed and edited the final manuscript prior to submission.
Corresponding author
Ethics declarations
Competing interests
Authors E.M., C.M., J.P.B., C.S., R.C.B. and A.F.S. declare no financial or non-financial competing interests. A.J.N. reports grants from Parkinson’s UK, Barts Charity, Cure Parkinson’s, National Institute for Health and Care Research, Innovate UK, Virginia Keiley benefaction, Solvemed, the Medical College of Saint Bartholomew’s Hospital Trust, Alchemab, Aligning Science Across Parkinson’s Global Parkinson’s Genetics Program (ASAP-GP2) and the Michael J Fox Foundation. A.J.N. reports consultancy and personal fees from AstraZeneca, AbbVie, Profile, Bial, Charco Neurotech, Alchemab, Sosei Heptares, Umedeor and Britannia. A.J.N. has share options in Umedeor. A.J.N. is an Associate Editor for the Journal of Parkinson’s Disease.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mitchell, E., Mattjie, C., Bestwick, J.P. et al. Hyposmia in Parkinson’s disease; exploring selective odour loss. npj Parkinsons Dis. 11, 67 (2025). https://doi.org/10.1038/s41531-025-00922-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41531-025-00922-3
This article is cited by
-
Emerging roles of the ciliary-mitochondrial axis in cellular homeostasis and neuroprotection
Molecular Neurodegeneration Advances (2025)
