
Abstract
Achieving high-fidelity quantum gates is crucial for reliable quantum computing. However, decoherence and control pulse imperfections pose significant challenges in realizing the theoretical fidelity of quantum gates in practical systems. To address these challenges, we propose the meta-reinforcement learning quantum control algorithm (metaQctrl), which leverages a two-layer learning framework to enhance robustness and fidelity. The inner reinforcement learning network focuses on decision making for specific optimization problems, while the outer meta-learning network adapts to varying environments and provides feedback to the inner network. Our comparative analysis regarding the realization of universal quantum gates demonstrates that metaQctrl achieves higher fidelity with fewer control pulses than conventional methods in the presence of uncertainties. These results can contribute to the exploration of the quantum speed limit and facilitate the implementation of quantum circuits with system imperfections involved.
Similar content being viewed by others

Introduction
Recent theoretical and experimental studies have shown that quantum phenomena, such as entanglement and superposition, can be used to facilitate information science and technologies, including quantum computing, communications, and information storage, outperforming their classical counterparts1,2,3. Quantum control is crucial to the successful realization of these leading technologies and also plays an important role in areas such as atomic physics and physical chemistry4,5.
Quantum control is usually implemented by manipulating the Hamiltonians of quantum systems. By applying a series of unitary transformations driven by the control Hamiltonians to the target system, the target system can be transferred to any desired state. Therefore, obtaining such a control sequence, especially the optimal control sequence, is a core problem that should be addressed by quantum control. A variety of control algorithms have been proposed in the past few decades, and have achieved excellent results in specific models. For example, the gradient ascent pulse engineering (GRAPE) algorithm6, taking advantage of gradient-based optimization of a model-based target function, has seen successful applications in quantum optimal control.
However, in reality, there are inevitably noises or inaccuracies in the information flow of quantum control systems, including but not limited to actuator output limitations7, sensor measurement errors8, interactions with the environment, and approximations of the physical models9. These factors can significantly influence the performance of quantum control systems that face the requirements of high precision. For instance, regarding the application of GRAPE, limited knowledge about the system dynamics and control Hamiltonians means that GRAPE may result in control deviations and even uncontrollability. Although earlier search algorithms such as gradient ascent (GA) exhibit some robustness, they require a lot of time to perform the optimization and are susceptible to falling into local optimal solutions10. Therefore, designing an efficient algorithm to tackle the uncertain dynamics of quantum systems remains challenging and meaningful.
Since machine learning (ML) can efficiently and accurately complete classification or optimization tasks11, the combination of ML and quantum engineering has been gradually explored12,13. Owing to the advantages of ML, the difficulty in precisely modeling the dynamics of quantum systems can be relieved, thereby improving the control performance in various scenarios. In addition, reinforcement learning (RL) techniques in ML14 have been adopted, including value-based algorithms15 and policy gradient-based algorithms16, to discover optimal quantum control strategies. RL typically consists of two basic components, namely, the environment and the agent. The environment can be established based on specific task requirements, such as games17 and optimization problems18, while the agent is responsible for the decision-making process within the task and is supposed to learn the optimal policy by interacting with the environment. In particular, a series of RL algorithms have been specifically designed for the control of quantum gates through approaches such as the reconstruction of the reward function19 and strategy optimization20.
However, existing results indicate that deep RL has at least two drawbacks compared to human beings. Training an intelligent agent requires a large amount of data, whereas humans can perform reasonably well in a novel environment with significantly smaller amounts of data. This limitation is prominent in quantum optimal control problems, as the exponential growth in the size of quantum states leads to a rapid decline in sample efficiency. On the other hand, deep RL specializes in a narrow task domain, while humans can effortlessly apply knowledge acquired from other scenarios to the current task. Consequently, improvements in generalization of RL algorithms have been considered in different tasks to overcome concomitant shortcomings21,22,23.
Inspired by deep meta-RL24,25,26,27, in this paper, we propose a new algorithm, the meta-reinforcement learning quantum control algorithm (metaQctrl), which provides a generic and robust agent that can adapt to different parametric settings in quantum systems. This algorithm significantly reduces the training time required for the agent to handle diverse task environments and facilitates the transition of the algorithm among different control domains. Since quantum gates serve as fundamental operational elements in quantum computing28, achieving high-fidelity quantum gates is of the utmost importance to ensure accuracy and efficiency in the vast majority of quantum technologies. The metaQctrl algorithm has been applied to design single-qubit and multi-qubit gates, with the purpose of obtaining ultrahigh-fidelity (of the order 99.99%) in the presence of uncertainties or disturbances. For single-qubit quantum gates, compared to GA and GRAPE, our algorithm requires shorter control steps and exhibits smoother control curves. With disturbances or uncertainties involved, the fidelity of the quantum gate controlled by our algorithm is an order of magnitude higher than that of traditional algorithms (GA, GRAPE), as demonstrated in the simulation results. Furthermore, in the multi-qubit quantum gate control system with disturbances or uncertainties, our algorithm consistently outperforms the RL algorithm Proximal Policy Optimization (PPO) in terms of fidelity and control step length. Thus, it can be concluded that metaQctrl is capable of providing robust control strategies to adapt to complex environments. In addition, since metaQctrl requires fewer control pulses, our proposed algorithm can contribute to the exploration of the quantum speed limit when there are system imperfections29,30,31.
Results
To demonstrate the features and strengths of metaQctrl, in this section, we discuss robust control of single- and multi-qubit quantum gates in the presence of uncertainty. We numerically compare our proposed algorithm with GRAPE, GA, and PPO within the same system setup in the simulation, with the assistance of OpenAI’s Gymnasium and QUTIP32.
Robust control of a single-qubit quantum gate
Considering robust control of a single-qubit quantum gate, the system Hamiltonian can be described by
where the control variables ux(t) and uy(t) are restricted to the interval \(\left[-5,5\right]\). The control horizon is T = 1.6 and the maximum steps of the control pulses are N = 40. The uncertainty involved in the system, μ(t), is assumed to obey the Gaussian distribution \({\mathbb{N}}(0,{\eta }^{2})\), with a standard deviation \(\eta \in \left[0,1\right]\). The control objective is to transfer the quantum gate from the initial state U(0) to the final state U(T), with the end time T. The fidelity \({\mathcal{F}}(U(T),{U}_{f}) > 1-\varepsilon\) must be guaranteed as prescribed in Eq. (14). Specifically, we take \(U(0)={\rm{I}}=\left(\begin{array}{rc}1&0\\ 0&1\end{array}\right)\), \({U}_{f}={U}_{{\rm{H}}}=\frac{1}{\sqrt{2}}\left(\begin{array}{rc}1&1\\ 1&-1\end{array}\right)\) with UH, the Hadamard gate widely used in quantum computing and the convergence criterion ε = 10−4.
The control trajectories of four algorithms (GRAPE, GA, PPO, metaQctrl) corresponding to η = 0.3 are depicted in Fig. 1. It can be clearly seen that only metaQctrl and PPO successfully complete the control task in the presence of disturbance or uncertainty, while GRAPE and GA fail to meet the fidelity accuracy requirements within the maximum control step limit. Although GRAPE and GA exhaust all allocated control steps, this does not imply that our control step length N is unreasonable, since metaQctrl and PPO achieve their control objectives in fewer than N/2 steps. It can be concluded that metaQctrl and PPO, which combine efficient exploration with accuracy, outperform GRAPE and GA in realizing global optimal control. In fact, metaQctrl and PPO adopt a strategic exploration approach by boldly advancing when far from the target and making incremental adjustments as they approach, thus preventing them from missing the target and falling into local optima.

The system evolution of a GRAPE, b GA, c PPO, d metaQctrl in the realization of a single-qubit Hadamard gate with η = 0.3. On the left side of each graph, the Bloch sphere is utilized to visually show the state trajectory over time, since changes in quantum gates can be observed through changes in quantum states. The initial and target quantum states are dots on the Bloch sphere, centered by the green and orange arrows, respectively. The blue dots denoting the outcome of the control action correspond to earlier steps, while the purple dots indicate steps closer to completion. If a dot reaches the orange arrow before reaching the maximum number of control steps, it implies the successful completion of the control task. On the right side of each graph, numerical results demonstrate how the fidelity of the quantum gate changes as the number of control steps increases.
In addition, the maximum fidelity achieved by four algorithms with varying η is evaluated in Fig. 2. Here, η uniformly ranges from 0 to 1 with a step size of 0.05. The simulation results represent the average values obtained from the 100 Monte Carlo tests. PPO is trained with the disturbance parameter η = 0.3, while metaQctrl can handle the disturbance distribution \({\mathcal{P}}\) with \(\eta \sim {\mathbb{U}}(0,1)\). In particular, the convergence criterion ε is set to 10−4 in Fig. 2a–c, while the convergence criterion ε is set to 10−6 in Fig. 2d.

a The averaged maximum fidelity of metaQctrl, GRAPE and GA when ε = 10−4. b The averaged maximum fidelity of metaQctrl and PPO when ε = 10−4. c The averaged number of control pulses required for both metaQctrl and PPO to reach the maximum when ε = 10−4. d The averaged number of control pulses required for both metaQctrl and PPO to reach the maximum when ε = 10−6.
The fidelity values obtained by metaQctrl compared to GRAPE and GA are plotted in Fig. 2a. It is evident that metaQctrl exhibits significantly enhanced robustness compared to traditional algorithms. The differences between traditional methods and metaQctrl are subtle in uncertainty-free scenarios. However, as the intensity of the disturbance increases, so does the performance gap. Even in the extreme case (η = 1.0), metaQctrl achieves a maximum fidelity 10% higher than GRAPE and 30% higher than GA. The control performances of metaQctrl and PPO in terms of maximum fidelity are compared in Fig. 2b. It can be seen that metaQctrl excels in maintaining robust control performance across a broader range of disturbances, leveraging its unique meta-reinforcement learning framework. Figure 2c compares the control steps of metaQctrl and PPO when ε = 10−4. It can be observed from Fig. 2c that the exploration intensity of PPO increases in order to handle the system uncertainties, resulting in a rapid escalation of its total control steps. In contrast, the control steps for metaQctrl remain relatively stable across varying disturbance distributions and even exhibit a slight decreasing trend as η increases. However, as shown in Fig. 2d, the number of control steps for metaQctrl increases as η increases when ε = 10−6. This is due to the fact that the number of control steps required by metaQctrl is closely related to the choice of the convergence criterion ε and indeed the scale of the target neighborhood relative to the disturbances. When ε = 10−4, the scale of the target neighborhood relative to the disturbances is sufficiently large, and consequently, the trajectory of the system is unlikely to deviate from the target neighborhood. Since metaQctrl aims to avoid the oscillation of the control trajectory in the target neighborhood, it accelerates convergence during the later stages of control, and thus, the number of control steps decreases slightly as η increases in this case. In contrast, when ε = 10−6, the scale of the target neighborhood relative to the disturbances is not large enough. More pronounced oscillations near the target region during later stages of control increase the number of control steps as η increases.
In order to further explore the robustness of metaQctrl against PPO, we take into account multiple uncertainties or disturbances in the Hamiltonian, which gives
Here, μ0(t) and μu(t) obey the Gaussian distributions \({\mathbb{N}}(0,{\eta }_{0}^{2})\) with standard deviation \({\eta }_{0} \sim {\mathbb{U}}(0,1)\) and \({\mathbb{N}}(0,{\eta }_{u}^{2})\) with standard deviation \({\eta }_{u} \sim {\mathbb{U}}(0,1)\), respectively. The control objective is to transfer the quantum gate from U(0) = I to \(U(T)={U}_{{\rm{H}}}=\frac{1}{\sqrt{2}}\left(\begin{array}{rc}1&1\\ 1&-1\end{array}\right)\) (the Hadamard gate) or \(U(T)={U}_{{\rm{\pi /8}}}=\left(\begin{array}{rc}1&0\\ 0&{e}^{i\pi /4}\end{array}\right)\) (the π/8 gate) or \(U(T)={U}_{{\rm{S}}}=\left(\begin{array}{rc}1&0\\ 0&i\end{array}\right)\) (the phase gate), with the end time T = 1.6 and the maximum steps of the control pulses N = 40.
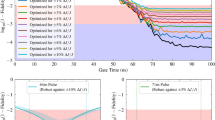
As shown in Fig. 3, metaQctrl obviously outperforms PPO by presenting stronger robustness quantified by infidelity in the presence of multiple uncertainties. It can be seen that the infidelity values can reach 10−5 or even smaller ones (e.g., for the Hadamard gate) using metaQctrl when the standard deviation η0 (ηu) is not large. Moreover, metaQctrl allows for a wider range of deviations than PPO does, where fidelity values greater than 99.99% can be obtained even if the system is subject to multiple uncertainties. Table 1, along with Fig. 3, provides ratios of the areas corresponding to the key infidelity thresholds (10−4 and 10−5), relative to the entire space enclosed by η0 and ηu, for metaQctrl and PPO, respectively.

The control performance of metaQctrl, compared to that of PPO, in realization of single-qubit a Hadamard gate, b π/8 gate, and c phase gate, with the uncertainties μ0(t) and μu(t) involved. The black dashed and red dash-dotted boundary lines correspond to the values of infidelity at 10−5 and 10−4, respectively.
Robust control of a two-qubit quantum gate
We now consider robust control of a two-qubit quantum gate, with the Hamiltonian of the system given by
where the control variables \({u}_{x}^{j}(t),{u}_{y}^{j}(t)\in \left[-5,5\right]\) (\(j\in \left\{1,2\right\}\)), and the control horizon is T = 2.0. The maximum step of the control pulses is N = 50, with the quantum gate initiated at U(0) = I. In this scenario, the desired quantum gate for control is Uf = UCNOT (there is no local z phase error correction involved), with UCNOT the controlled-NOT (CNOT) gate, and the convergence criterion is characterized by ε = 10−3. The CNOT gate is of the following form
The maximum fidelity achieved by four algorithms (GRAPE, GA, PPO, and metaQctrl) with varying η is evaluated in Fig. 4. As shown in Fig. 4a, the control performance of metaQctrl is compared with that of GRAPE and GA. Traditional algorithms (GRAPE and GA) are increasingly sensitive to uncertainty as η increases in a two-qubit system. Consequently, the fidelity of the quantum gates they control drops quickly below 0.9, failing to meet the requirements of actual control tasks. However, metaQctrl can provide infidelity of the order 10−4. Figure 4b shows the maximum fidelity values between metaQctrl and PPO. It can be seen that metaQctrl and PPO are also affected by the increase in the number of qubits, resulting in slightly lower fidelity for two-qubit systems compared to single-qubit systems. In addition, metaQctrl shows a more gradual downward trend and achieves higher fidelity than PPO with respect to different values of η. This indicates that the control algorithm proposed in this paper is indeed more robust. It can be understood that metaQctrl has learned to grasp dynamic environmental information from a higher dimension and can quickly adjust its strategy according to changes in the environment, through training with the meta-reinforcement learning framework. By comparing the total control steps in Fig. 4c, we observe that while PPO exhausts all available control steps, metaQctrl has the ability to search for effective control strategies, with shorter control sequences when η is small.

a The averaged maximum fidelity of metaQctrl, GRAPE, and GA. b The averaged maximum fidelity of metaQctrl and PPO. c The averaged number of control pulses required for both metaQctrl and PPO to reach the maximum.
Discussion
Drawing inspiration from meta-learning, the metaQctrl algorithm proposed in this paper is aimed at enhancing the control performance of quantum gates in the presence of system imperfections. To be specific, in the framework of metaQctrl, we incorporate a meta-learning outer loop apart from the RL inner loop and employ an alternating training approach. This two-layer structure significantly enhances the algorithm’s robustness against environmental changes. The meta-learning outer loop enables the extraction of specific tasks in the presence of uncertainties. By acquiring knowledge from various tasks, the inner loop requires only minimal new data to determine optimal control strategies for novel tasks, thereby realizing robust control of quantum gates with disturbances or uncertainties involved. Furthermore, in the context of simulation examples, we have evaluated the performance of our proposed algorithm with respect to robust control of single-qubit quantum gates and the CNOT gate that constitutes the universal gate set. The results and analyses show that metaQctrl obviously outperforms GRAPE or GA, and that metaQctrl can achieve improved robustness with fewer control pulses compared to PPO. It is thus promising that metaQctrl can help to discover the quantum speed limit. Additionally, it is worth highlighting that metaQctrl can be straightforwardly applied to quantum metrology or communication related to quantum state manipulation with system imperfections, not limited to the area of quantum computing, such as robust realization of quantum circuits. Future work may include generalizing our method to the more complicated quantum systems and taking into account totally time-varying disturbances.
Methods
Robust control of quantum gates
The evolution of a quantum system can be described by the following Schrödinger equation
Here, ψ(t) represents the current quantum state of the system, Hs denotes the inherent Hamiltonian of the system, and Hk is the Hamiltonian generated by the external radio frequency (RF) field, with each RF field being independent and orthogonal. uk(t) denotes the amplitude of the control pulse. Furthermore, we assume that the target quantum system is governed by an internal Hamiltonian generated by spin-spin coupling. An RF field orthogonal to the spin x- and y-directions can then be used to manipulate the quantum system with the control pulse. We can then have the specific form of Hamiltonian as follows
where the operator \({X}_{j}={{\rm{I}}}^{1}\otimes \cdots \otimes {{\rm{I}}}^{j-1}\otimes {\sigma }_{x}^{j}\otimes {{\rm{I}}}^{j+1}\otimes \cdots \otimes {{\rm{I}}}^{n}\) denotes the Pauli operator σx applied on the j-th qubit in a system consisting of n qubits (I denotes the identity operator). Similarly, Yj and Zj are defined corresponding to the Pauli operators σy and σz of the j-th qubit, respectively, and the control pulses are represented by \(\overrightarrow{u}(t)\). This type of system model is widely applied in a variety of quantum systems, including superconducting qubits33 and trapped ions34. In order to establish a universal control method that accounts for realistic imperfections, including dissipation, decoherence, and other uncertainties, the parametric disturbance μ(t) is introduced into our control model. Please note that there may be multiple disturbances or uncertainties appearing in the system (i.e. μ1(t), μ2(t), ⋯), and in this section we take μ(t) to illustrate the control scheme without loss of generality. To further improve the adaptive capacity of the algorithm, we assume that μ(t) obeys a truncated Gaussian distribution with the variance η being uncertain and the mean being 0. That is, we consider \(\mu (t) \sim {\rm{clip}}[{\mathbb{N}}(0,{\eta }^{2}),-1,1]\).
We can use T to denote the end time and N to denote the steps of the control pulses. And then the quantum state of the target system can be calculated by
where \({\mathcal{D}}\) denotes the Dyson time-ordering operator. In particular, the quantum gate U(T) can be given by \(U(T)=\mathop{\prod }\nolimits_{j = 1}^{N}{U}_{j}({{\Delta }}t)\) with \({U}_{j}({{\Delta }}t)={e}^{-iH({\vec{u}}(j{{\Delta }}t)){{\Delta }}t}\) and Δt = T/N. The control goal is to drive the controlled quantum gate towards the desired quantum gate Uf that makes \(\left\vert \psi (t)\right\rangle ={U}_{f}\left\vert \psi (0)\right\rangle\). Our aim is to discover the optimal control scheme that enables the controlled quantum gate to transit from the initial state to the target state with greater precision and in less time.
The precision of a controlled quantum gate can be quantified by the fidelity35,36
with the range of \({\mathcal{F}}\) being \(\left[0,1\right]\). The closer the fidelity is to 1, the higher the precision of the quantum gate. The objective function of the quantum gate control problem can then be defined by
The definition of \({\mathcal{U}}\) should be emphasized as it significantly deviates from traditional quantum control problems. Previous studies, in general, focus on identifying the optimal control \({\overrightarrow{u}}_{\mu (t)}^{* }\) in undisturbed environments (μ(t) ≡ 0) or in fixed disturbed environments (μ(t) subject to a specific distribution), to make \({\mathcal{F}}(U(T),{U}_{f})\) as close to 1 as possible. In contrast, our goal is to seek a generic mapping \({{\mathcal{U}}}^{* }:\mu (t)\to {\overrightarrow{u}}_{\mu (t)}^{* }\) rather than solving specific cases. This pursuit is more challenging than obtaining solutions for a given μ(t). For example, if an algorithm has been developed to determine \({\overrightarrow{u}}_{\mu (t)}^{* }\), such as GRAPE and GA, one would have to redesign or train the algorithm to adapt to the task in a new environment, which is indeed very time-consuming. However, our algorithm, which will be explained in detail in the following section, intelligently reduces the transition time between different disturbed environments. And therefore, the robustness can be enhanced.
The framework of metaQctrl
The decision-making process in the framework of metaQctrl is derived from RL, based on the Markov decision process (MDP). MDP can be defined by a 5-tuple \(\left(S,A,P,R,\gamma \right)\), where S represents the state space, A denotes the action space, P is the transfer function providing the probability of transferring from a given state to a new one after taking an action, R is the reward function mapping the result of an action taken in a specific state to a value, and γ represents the discount factor.
As shown by the yellow loop in Fig. 5, RL can be viewed as an interactive process between an agent and the corresponding external environment. Based on the current state of the environment st and the associated policy function, the agent (denoted by the blue brain) takes the action at at the time t, leading to three consequences. Firstly, the agent receives a reward rt, and then the state of the environment changes from st to st+1. Finally, the agent receives a new observation st+1. Through continuous interactions with the environment, the agent has access to a substantial amount of decision-making data. The data, in turn, enable further optimization of the policy function.

The yellow loop represents the general setup of RL. Within this loop, the agent engages with a specific RL environment to acquire the optimal strategy. Multiple RL environments can be encompassed here, adhering to specific distributions. Classifying these environments into distinct tasks, the agent is supposed to autonomously adapt their algorithms to accommodate changes in environments.
Throughout this process, the agent aims to find a policy π(a∣s) to optimize the total expected reward defined as follows
where,
and dπ(s) is the stationary distribution of the Markov chain concerning πθ (i.e., on policy state distribution under π), mathematically defined by \({d}^{\pi }(s)=\mathop{\lim }\nolimits_{t\to \infty }P({s}_{t}=s| {s}_{0},\pi )\). The policy-based RL algorithm here is applied to optimize the policy π, approximated by a neural network πθ, to maximize the reward function J(θ) (θ represents the parameter of the neural network). A well-known rule, referred to as the policy gradient theorem, can be used to update the reward function as follows
However, in general, RL algorithms face challenges in deriving the optimal solution for the objective as discussed in section “Robust control of quantum gates” due to their specificity to the environments. Once the environment changes, the originally learned optimal strategy becomes obsolete and necessitates retraining for the new environment, which is highly impractical for quantum systems. Therefore, in this paper, we introduce meta-learning to established RL algorithms, since meta-learning can help acquire knowledge quickly and adapt to new task scenarios based on existing knowledge. This process can also be perceived as maximizing the sensitivity of the new task loss function to the model parameters. In fact, even small alterations in model parameters can lead to significant enhancements in the loss function when the sensitivity is high. The intelligent agent can be constructed by training the model in various tasks, as illustrated in Fig. 5. Especially for the control objective \({{\mathcal{U}}}^{* }\), metaQctrl can contribute to increasing robustness in the presence of system disturbances or uncertainties.
The associated model parameters can be defined as follows. The state st is given by \({s}_{t}=\left\{\Re ({[U]}_{00}),\ldots ,\Re ({[U]}_{{2}^{n}{2}^{n}}),\,\Im ({[U]}_{00}),\ldots ,\Im ({[U]}_{{2}^{n}{2}^{n}})\right\}\), where [U]jk represents the element at the intersection of the j-th row and k-th column of the unitary operator U(t) that describes the controlled quantum gate at time t. ℜ( ⋅ ) and ℑ( ⋅ ) denote the real and imaginary parts of an operator, respectively. The action \({a}_{t}=\left\{{u}_{x}^{1},\ldots ,{u}_{x}^{n},{u}_{y}^{1},\ldots ,{u}_{y}^{n}\right\}\), and each \({u}_{k}^{j}\) is bounded within the range \([{u}_{\min },{u}_{\max }]\). The reward rt is set as a piecewise function related to \({\mathcal{F}}(U(T),{U}_{f})\), namely
where ε defines the convergence criterion. By mapping the fidelity of quantum gates to rewards, our framework effectively transforms the control of quantum gates into a solvable task using RL algorithms. When fidelity is not high enough, an increase in fidelity leads to an increase in the corresponding reward, thus motivating the agent to quickly approach the target state. When fidelity is already high, segmented rewards are used to encourage exploratory behavior aimed at discovering strategies with even higher fidelity. In addition to promoting exploration, we also incorporate a penalty coefficient for step length to expedite convergence and prevent excessive exploration.
The metaQctrl algorithm, as illustrated in Fig. 6, comprises an inner loop and an outer loop. The outer loop represents a meta-learning process that maintains a global policy parameter \({\theta }_{j}^{* }\). It acquires a set of tasks \({\mathcal{T}}\) by sampling the quantum environment \({\mathcal{P}}\). Each task, denoted \({{\mathcal{T}}}_{k}\), can be viewed as an individual RL environment. By receiving each task \({{\mathcal{T}}}_{k}\) from the outer loop, the inner loop performs an independent RL with its current policy parameter \({\theta }_{j}^{* }\) determined by the outer loop. It then executes the MDP and collects state-reward pairs to update its own policy parameters accordingly. To accomplish the procedures, the inner loop employs an actor-critic network-based policy improvement method to update network parameters as follows,
Here, \({{\mathcal{A}}}_{\pi }(s,a)\) denotes the advantage function whose value can be estimated by the value network. Once the inner loop is updated to obtain a new parameter \({\theta }_{j}^{k}\), the MDP is immediately reexecuted with the updated policy parameter. The newly obtained state-reward pairs can then be used to perform the following update process21
The parameter β defines the update rate of meta-learning. \({f}_{{\theta }_{j}^{k}}\) denotes the neural network of the inner loop with the updated policy parameter \({\theta }_{j}^{k}\), and \({\nabla }_{{\theta }_{j}^{* }}{{\mathcal{L}}}_{{{\mathcal{T}}}_{k}}(\cdot )\) denotes the gradient of the returns associated with the updated policy. The core idea of our framework is to take the magnitude of the loss value as weights, with the update direction of each subtask used as the basic direction for updating the global initialization parameters. It is worth noting that by taking advantage of the loss value of the new strategy as weights instead of directly summing gradients, it mitigates the risk of algorithmic convergence towards local optima. Through multiple iterations, the outer loop can acquire prior knowledge about dynamic environments in quantum systems from various tasks, thereby achieving adaptability. Furthermore, the outer loop samples disturbance distributions and performs meta-updates, which can be seen as a process of estimating the disturbance. Consequently, the inner loop can adaptively adjust control signals in varying noisy environments, thus enhancing robust performance against disturbance.

The training process of the inner loop resembles general RL for a specific task, while meta-learning is embodied in the outer loop. This outer loop partitions the results obtained from sampling the quantum environment into different tasks and subsequently delivers them to the inner loop for processing. Subsequently, data acquired from each inner loop is collected, culminating in utilizing this collective information to update the parameters of the agent.
Inspired by the policy approximation methods and the Kullback–Leibler divergence formula37, we optimize the update method for meta-policy parameters to better measure the policy distance and effectively control the policy update step size. Namely
where
and \({{\hat{\mathcal{A}}}}_{t}^{{\pi }_{k}}={Q}^{{\pi }_{k}}(s,a)-{V}^{{\pi }_{k}}(s)\). The difference between the new and the old policies is given by \({c}_{t}(\theta )=\frac{{\pi }_{\theta }({a}_{t}| {s}_{t})}{{\pi }_{{\theta }_{{\rm{old}}}}({a}_{t}| {s}_{t})}\). When the new and old policies are identical, ct(θ) = 1. Both \(\min (\cdot )\) and the clip( ⋅ ) in Eq. (18) are used to ensure that the step size of the meta-updating process takes a value within the predefined range [1 − ε, 1 + ε].
As illustrated in Algorithm 1, whenever a control task is started, it requires collecting a new batch of data online, which is then used to update the network parameters. Using the prior knowledge obtained during pretraining, the algorithm can efficiently identify the optimal policy parameters tailored to the current noisy conditions. Upon completion of the training stage, the system can output a control sequence according to the control task. Despite relying on a sampling training process, this algorithm benefits from a more thoroughly trained model parameter, enabling the online training process to remain fast. Remarkably, its average runtime is significantly less than that of traditional algorithms such as GRAPE and GA, which will be explained in detail in the following section.
Algorithm 1
metaQctrl
Input: Target quantum gate Uf, distribution of quantum environment \({\mathcal{P}}\), convergence criterion ε, length of training steps \({\mathcal{J}}\)
Output: Optimal policy θ*
1: Initialize quantum gate U(0), meta-hyperparameter \({\theta }_{0}^{* }\), training steps j, trial buffer B
2: Build an actor-critic network with weights \({\theta }_{0}^{* }\)
3: while \(j \,<\, {\mathcal{J}}\) do
4: sample batch of tasks \({{\mathcal{T}}}_{k}\) from \({\mathcal{P}}\)
5: while \({{\mathcal{T}}}_{k}\) do
6: initialize the inner actor-critic network with \({\theta }_{j}^{* }\)
7: run the inner actor-critic network to get n episodes
8: compute advantage estimates for each steps
9: compute \({\theta }_{j}^{k}={\theta }_{j}^{* }+{\nabla }_{{\theta }_{j}^{* }}\log {\pi }_{{\theta }_{j}^{* }}(s,a){{\mathcal{A}}}_{\pi }(s,a)\)
10: run the actor-critic network with \({\theta }_{j}^{k}\) again and store the episodes into B
11: end while
12: update \({\theta }_{j+1}^{* }\leftarrow \arg \mathop{\max }\limits_{\theta }{\sum }_{{{\mathcal{T}}}_{k} \sim {\mathcal{P}}}{{\mathcal{L}}}_{{\theta }_{j}^{k}}^{{\rm{Clip}}}(\theta )\) with episodes in B
13: j = j + 1
14: end while
Data availability
All relevant research data are available from the authors upon request.
Code availability
All relevant source codes are available from the authors upon request.
References
Nielsen, M. A. & Chuang, I. L.Quantum Computation and Quantum Information (Cambridge Univ. Press, 2011).
Xia, F. et al. Random walks: a review of algorithms and applications. IEEE Trans. Emerg. Top. Comput. Intell. 4, 95–107 (2020).
Khabat, H., Duncan, G. E., Peter, C. H. & Philip, J. B. Quantum memories: emerging applications and recent advances. J. Mod. Opt. 63, 2005–2028 (2016).
Chu, S. Cold atoms and quantum control. Nature 416, 206–210 (2002).
Dong, D. & Petersen, I. R. Quantum control theory and applications: a survey. IET Control Theory Appl. 4, 2651–2671 (2010).
Khaneja, N., Reiss, T., Kehlet, C., Schulte-Herbrüggen, T. & Glaser, S. J. Optimal control of coupled spin dynamics: design of nmr pulse sequences by gradient ascent algorithms. J. Magn. Reson. 172, 296–305 (2005).
Ding, H.-J. & Wu, R.-B. Robust quantum control against clock noises in multiqubit systems. Phys. Rev. A 100, 022302–022308 (2019).
Hincks, I. N., Granade, C. E., Borneman, T. W. & Cory, D. G. Controlling quantum devices with nonlinear hardware. Phys. Rev. A 4, 024012–024020 (2015).
Wang, H. et al. Quantumnas: noise-adaptive search for robust quantum circuits. In 2022 IEEE International Symposium on High-Performance Computer Architecture 692–708 (IEEE, 2022).
Tsubouchi, M. & Momose, T. Rovibrational wave-packet manipulation using shaped midinfrared femtosecond pulses toward quantum computation: optimization of pulse shape by a genetic algorithm. Phys. Rev. A 77, 052326–052340 (2008).
Shrestha, A. & Mahmood, A. Review of deep learning algorithms and architectures. IEEE Access 7, 53040–53065 (2019).
Wang, Z. & Guet, C. Deep learning in physics: a study of dielectric quasi-cubic particles in a uniform electric field. IEEE Trans. Emerg. Top. Comput. Intell. 6, 429–438 (2022).
Chen, S. Y.-C. et al. Variational quantum circuits for deep reinforcement learning. IEEE Access 8, 141007–141024 (2020).
Zhang, X.-M., Wei, Z., Asad, R., Yang, X.-C. & Wang, X. When does reinforcement learning stand out in quantum control? A comparative study on state preparation. npj Quantum Inform. 5, 85–92 (2019).
Bukov, M. et al. Reinforcement learning in different phases of quantum control. Phys. Rev. X 8, 031086–031101 (2018).
Moro, L., Paris, M. G. A., Restelli, M. & Prati, E. Quantum compiling by deep reinforcement learning. Commun. Phys 4, 178 (2021).
Shao, K., Zhu, Y. & Zhao, D. Starcraft micromanagement with reinforcement learning and curriculum transfer learning. IEEE Trans. Emerg. Top. Comput. Intell. 3, 73–84 (2019).
Pan, Z., Wang, L., Wang, J. & Lu, J. Deep reinforcement learning based optimization algorithm for permutation flow-shop scheduling. IEEE Trans. Emerg. Top. Comput. Intell. 7, 983–994 (2023).
Hu, S., Chen, C. & Dong, D. Deep reinforcement learning for control design of quantum gates. In 2022 13th Asian Control Conference 2367–2372 (IEEE, 2022).
Ma, H., Dong, D., Ding, S. X. & Chen, C. Curriculum-based deep reinforcement learning for quantum control. IEEE Trans. Neural Netw. Learn. Syst. 34, 8852–8865 (2023).
Finn, C., Abbeel, P. & Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proc 34th International Conference on Machine Learning 1126–1135 (JMLR.org, 2017).
Taylor, A., Dusparic, I., Guériau, M. & Clarke, S. Parallel transfer learning in multi-agent systems: what, when and how to transfer? In 2019 International Joint Conference on Neural Networks 1–8 (2019).
Khalid, I., Weidner, C. A., Jonckheere, E. A., Schirmer, S. G. & Langbein, F. C. Sample-efficient model-based reinforcement learning for quantum control. Phys. Rev. Res. 5, 043002 (2023).
Nagabandi, A. et al. Learning to adapt in dynamic, real-world environments through meta-reinforcement learning. Preprint at arXiv:1803.11347v6 (2019).
Finn, C., Rajeswaran, A., Kakade, S. & Levine, S. Online meta-learning. Proc. Mach. Learn. Res. 97, 1920–1930 (2019).
Hospedales, T., Antoniou, A., Micaelli, P. & Storkey, A. Meta-learning in neural networks: a survey. IEEE Trans. Pattern Anal. Mach. Intell. 44, 5149–5169 (2022).
Vettoruzzo, A., Bouguelia, M.-R., Vanschoren, J., Rognvaldsson, T. & Santosh, K. C. Advances and challenges in meta-learning: a technical review. IEEE Trans. Pattern Anal. Mach. Intell. 46, 4763–4779 (2024).
Kitaev, A. Y. Quantum computations: algorithms and error correction. Russ. Math. Surv. 52, 1191 (1997).
Deffner, S. & Campbell, S. Quantum speed limits: from Heisenberg’s uncertainty principle to optimal quantum control. J. Phys. A Math. Theor. 50, 453001 (2017).
Taddei, M. M., Escher, B. M., Davidovich, L. & de Matos Filho, R. L. Quantum speed limit for physical processes. Phys. Rev. Lett. 110, 050402 (2013).
Zhang, M., Yu, H.-M. & Liu, J. Quantum speed limit for complex dynamics. npj Quantum Inform.9, 97 (2023).
Johansson, J., Nation, P. & Nori, F. Qutip 2: a python framework for the dynamics of open quantum systems. Comput. Phys. Commun. 184, 1234–1240 (2013).
Barends, R. et al. Digitized adiabatic quantum computing with a superconducting circuit. Nature 534, 222–226 (2016).
Saki, A. A., Topaloglu, R. O. & Ghosh, S. Muzzle the shuttle: efficient compilation for multi-trap trapped-ion quantum computers. In 2022 Design, Automation & Test in Europe Conference & Exhibition, 322–327 (IEEE, 2022).
Yu, H. & Zhao, X. Event-based deep reinforcement learning for quantum control. IEEE Trans. Emerg. Top. Comput. Intell. 1–15 (2023).
Zahedinejad, E., Ghosh, J. & Sanders, B. C. High-fidelity single-shot toffoli gate via quantum control. Phys. Rev. Lett. 114, 200502 (2015).
Schulman, J., Wolski, F., Dhariwal, P., Radford, A. & Klimov, O. Proximal policy optimization algorithms. Preprint at arXiv:1707.06347v2 (2017).
Acknowledgement
The authors acknowledge support from the National Natural Science Foundation of China (Grant Nos. 62173296, 62003113, and 62273016) and the Basic and Applied Basic Research Foundation of Guangdong Province (Grant No. 2025A1515010186).
Author information
Authors and Affiliations
Contributions
Y.C. and Z.M. conceived of the project. S.Z., Y.C., and Z.M. designed and implemented the algorithm. The simulation results obtained by S.Z., Y.C., and Z.M. were analyzed by all authors. All authors contributed to the writing and editing of the manuscript. Z.M. supervised the project.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, S., Miao, Z., Pan, Y. et al. Meta-learning assisted robust control of universal quantum gates with uncertainties. npj Quantum Inf 11, 81 (2025). https://doi.org/10.1038/s41534-025-01034-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41534-025-01034-9
