
Abstract
Head computed tomography (CT) imaging is a widely used imaging modality with multitudes of medical indications, particularly in assessing pathology of the brain, skull and cerebrovascular system. It is commonly used as the first-line imaging in neurologic emergencies given its rapidity of image acquisition, safety, cost and ubiquity. Deep learning models may facilitate detection of a wide range of diseases. However, the scarcity of high-quality labels and annotations, particularly among less common conditions, substantially hinders the development of powerful models. To address this challenge, we introduce FM-HCT, a Foundation Model for Head CT for generalizable disease detection, trained using self-supervised learning. Our approach pretrains a deep learning model on a large, diverse dataset of 361,663 non-contrast 3D head CT scans without the need for manual annotations, enabling the model to learn robust, generalizable features. Our results demonstrate that the self-supervised foundation model substantially improves performance on downstream diagnostic tasks compared to models trained from scratch and previous 3D CT foundation models trained on scarce annotated datasets.
Similar content being viewed by others

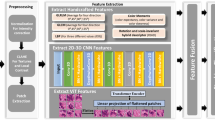
Main
Head computed tomography (CT) is widely used for rapid evaluation of neurological emergencies such as trauma, haemorrhage and stroke. Although CT is faster, more accessible and less expensive than magnetic resonance imaging (MRI), it provides lower soft-tissue contrast, limiting sensitivity for many neurological conditions. Improving diagnostic capability from CT therefore provides substantial clinical value.
Artificial intelligence (AI) has the potential to enhance CT interpretation and support clinical decision-making by enabling earlier and more accurate diagnosis. However, progress in AI-based head CT analysis remains limited by both data availability and model design. Public datasets such as RSNA1 and CQ500 (refs. 2,3) are relatively small and primarily focus on haemorrhage detection, restricting broader clinical applicability. In addition, many existing approaches rely on two-dimensional (2D) convolutional networks that process slices independently using expensive slice-level annotations, limiting their ability to capture volumetric structure and generalize to conditions without well-defined slice-level labels.
Recent advances in AI ‘foundation models’—large self-supervised models trained on massive datasets—have enabled strong performance across a wide range of tasks in both natural and medical imaging4,5,6,7,8,9,10. However, existing CT foundation models remain limited11,12,13, primarily focusing on abdominal CT or report generation and lacking robust volumetric representations for head CT. In this work, we present FM-HCT, a 3D foundation model for head CT developed using self-supervised learning and pretrained on a large-scale dataset of 361,663 head CT scans from a major clinical institution. FM-HCT achieves competitive performance across multiple evaluation tasks, highlighting the potential of large-scale 3D pretraining to advance medical imaging models.
To evaluate the foundation model, we systematically assessed its performance and generalizability across 10 downstream disease detection tasks using diverse internal and external datasets, as illustrated in Fig. 1. Beyond commonly studied haemorrhages, our evaluation includes crucial yet less-explored tasks in head CT, such as identifying brain tumours, Alzheimer’s disease and related dementia (ADRD), oedema and hydrocephalus (HCP). For each downstream task, the foundation model was fine tuned using task-specific labels. Given the scarcity of expert-annotated public datasets for these conditions, we leveraged electronic health records (EHR) to acquire labels of each task. While EHRs may include missing data and suffer potential label noise, they remain a valuable and practical source for large-scale patient status labelling that can be used to evaluate the performance of the foundation model. To assess label quality, we provide label sensitivity analysis by comparing 1,000 cases manually labelled by two radiologists in Extended Data Table 1.

The approach to developing a foundation model for head CT and assessing its performance in disease detection tasks. n refers to the number of samples for each dataset. a, Collection of training data and pretraining of the foundation model. b, Query disease labels associated with head CT scans for downstream tasks. c, Evaluation design of the foundation model using both internal and external datasets. d, Application of the foundation model to various downstream disease detection tasks. e–g, Performance comparison among different scenarios: (e) training with and without foundation model, (f) comparison of our CT foundation model vs other CT foundation models and (g) in-domain fine-tuning and external validation in transfer learning. The result is presented as mean ± 95% CI on test set. The CI was calculated from scan-level predictions (n = 2,202 independent scans for NYU Long Island, n = 1,058 independent scans for RSNA and n = 236 independent scans for CQ500).
Our results reveal substantial performance improvements enabled by our foundation model. Downstream models initialized with the pretrained weights of the foundation model achieved a 16.07% improvement in macro-AUC (AUC, defined here as the area under the receiver operating characteristic curve (AUROC), was used to evaluate model discrimination) over models trained from scratch with random initialization on internal NYU Langone data, and 20.86% and 12.01% improvements on external datasets from NYU Long Island (previously a separate hospital) and RSNA, respectively (P < 0.001 for all comparisons). These findings underscore the potential of our foundation model to advance AI-based interpretation of head CT scans, supporting more accurate diagnosis and early disease detection. Furthermore, as described in the ‘Results’ section, we demonstrate the model’s capabilities in out-of-distribution generalization (Fig. 1), few-shot learning (Fig. 2) and scalability (Fig. 4), highlighting the method’s potential in scenarios with limited annotated fine-tuning data, or scenarios such as federated learning, which provide access to orders of magnitude more data. Overall, the experimental results on multiple datasets and tasks underscore the generalizability, adaptability and effectiveness of the model, and pave the way for substantial impact in real-world clinical applications.

Per-pathology AUC and AP of the disease detection model under a few-shot learning setting, evaluated with varying numbers of training samples from the NYU Langone, NYU Long Island and RSNA datasets. CQ500 was excluded since its small dataset size does not give enough positive samples for many diseases. Few-shot learning performance is compared to supervised fine-tuning with all training data (denoted by stars), demonstrating the strong generalization ability of the foundation model with limited training data. The confidence intervals were computed from 5 repeated experiments on resampling the training data and retraining the model.
Results
Foundation model for disease detection with 3D head CT scans
The key aim of the foundation model is to develop a single model that improves performance on a wide range of downstream tasks for detecting recognizable abnormalities from head CT scans. To evaluate the capability of the foundation model, we trained classification models for multiple disease detection tasks by fine tuning the foundation model separately per disease and assessing the fine-tuned model’s performance on held-out validation and external datasets. The selected downstream tasks include detecting various types of haemorrhage (intraparenchymal haemorrhage (IPH), intraventricular haemorrhage (IVH), subdural haemorrhage (SDH), epidural haemorrhage (EDH), subarachnoid haemorrhage (SAH), intracranial haemorrhage (ICH) and intracerebral haemorrhage (ICeH)), brain tumours, HCP, oedema and ADRD. Figure 1a–c shows an overview of our pretraining framework and included data, EHR matching and datasets used in pretraining, in-domain fine-tuning and external validation. Overall, N = 361,663 scans were used during pretraining, and four distinct datasets from different sources were used for various forms of validation (NYU Langone N = 26,487; NYU Long Island N = 2,202; RSNA N = 1,058; and CQ500 N = 236). NYU Langone is a hospital system comprising multiple geographically distinct hospitals including two level 1 trauma centres and three comprehensive stroke centres. NYU Long Island, a level 1 trauma centre/comprehensive stroke centre, was treated as an external dataset for the purposes of this study.
The first two rows of Fig. 1e report the task-specific AUCs for Vision Transformer (ViT) 14 classifiers trained from scratch with random initialization, namely ‘scratch’, versus those fine tuned from the foundation model, namely, ‘fine tuned’ on NYU Langone data. The fine-tuned models consistently outperform the scratch model across all 10 disease detection tasks, achieving a macro-AUC of 0.852, a 16.07% relative increase over the scratch model’s 0.734 (P < 0.001). In addition, in Fig. 1f and Extended Data Fig. 3 we compared the foundation model with three other foundation models for 3D CT scans: Merlin12, Google’s CT Foundation15 model and CT-FM16. Across four compared datasets illustrated in Extended Data Fig. 3, Merlin outperforms the scratch model with a macro-AUC relative improvement of 8.07% and average precision (AP) relative improvement of 27.50% while falling short compared to our foundation model, with 13.05% relatively lower macro-AUC (P < 0.001) and 27.50% relatively lower (P < 0.001). Although Merlin is not directly comparable to our foundation model as it was pretrained on abdominal CT, it still provides a valuable baseline. To complement the shortcoming of Merlin being a baseline not pretrained on head CT, we compared our model with CT-FM16, a foundation model pretrained on 148,000 diverse CT scans, including head CT. Our model demonstrates a macro-AUC relative improvement of 9.56% (P < 0.001) and AP improvement of 44.60% (P < 0.001; Extended Data Fig. 3), demonstrating the effectiveness and scalability of our approach. In addition, we compared our model to Google CT Foundation model with linear probing, because trainable weights for end-to-end fine tuning are not provided for this model. We consistently observe improved model performance across the board (in Fig. 1f and Supplementary Fig. 4). These findings demonstrate that despite the progress in general domain multimodal models, specialized foundation models pretrained on head CT data still substantially enhance the understanding of brain diseases.
To assess our foundation model’s generalization to out-of-distribution data, we compiled three external datasets from multiple institutions and sources: NYU Long Island, RSNA1 and CQ500 (ref. 2), as shown in Fig. 1c (NYU Langone and NYU Long Island are geographically separate and distinct institutions within the broader health system). The data in these external datasets have a different distribution compared to the data used for pretraining. We evaluated the generalization on external datasets via two common practices to utilize the foundation model: (1) in-domain fine-tuning on separated datasets and tasks, and (2) fully external validation of the disease detection models without any site-specific fine tuning.
For in-domain fine-tuning, the foundation model was fine tuned on each external dataset’s training set and validated on held-out sets from the same source. The bottom four rows in Fig. 1e report the task-level performances on NYU Long Island and RSNA datasets. The fine-tuned model yields a macro-AUC of 0.904 across the 10 tasks on the NYU Long Island dataset and a macro-AUC of 0.923 for five types of haemorrhage on the RSNA dataset. In comparison, the scratch model results in macro-AUC scores of 0.748 and 0.824, respectively. Moreover, the foundation model also substantially outperforms Merlin, as shown in Extended Data Fig. 3. The superior performances on external datasets indicate the generalizability of the foundation model. Note that the limited data size of CQ500 forbids training an effective deep learning model from scratch, reinforcing the importance of the foundation model in label efficiency, which is further studied in the ‘Label efficiency of few-shot classification performance’ section. Interestingly, when comparing performances across different datasets, Fig. 1e demonstrates that the AUCs of the in-domain fine-tuned model on the external dataset even exceeded the AUCs achieved on the internal dataset. For instance, the fine-tuned models consistently obtained AUCs greater than 0.90 in all haemorrhage detection tasks on the RSNA dataset, surpassing the AUCs on NYU Langone data. This may be attributed to the higher label quality in radiologist-reviewed datasets, for which label noise may be better controlled by comparison to EHR-derived labels.
In the full external validation without any site-specific fine-tuning (illustrated in Fig. 1c), we evaluated classification models fine tuned on the NYU Langone training set, as is, on the held-out validation sets from each external dataset. Figure 1f compares performances between external validation and in-domain fine-tuning. Results show that for the NYU Long Island and RSNA datasets where the training set used for fine tuning includes a sufficient number of high-quality labelled samples, in-domain fine-tuning does enhance model performance. However, on the CQ500 dataset, with only 1,120 training samples, the in-domain fine-tuned model performs worse than the model transferred from NYU Langone, especially for EDH and SDH, which have a greater class imbalance. These comparisons highlight two typical use cases for foundation models depending on the availability of labelled data for fine tuning. In addition, comparing the first row of Fig. 1e and external validation in Fig. 1f, the fine-tuned model on NYU Langone data achieves similar AUC values on both internal and external datasets, indicating robust generalizability to external data.
In addition to in-domain fine-tuning, a model performance comparison is presented in Extended Data Fig. 3. The out-of-domain generalizability of our model is assessed in Fig. 1g, where our model is first fine tuned on an in-domain fine-tuning dataset and then evaluated on external datasets (NYU Long Island, RSNA and CQ500). Results show that our model can demonstrate comparable performance on external datasets.
Volume-to-volume haemorrhage subtype retrieval performance
To further rigorously evaluate the representation quality of our pretrained foundation model, we conducted a volume-to-volume haemorrhage subtyping retrieval study on RSNA and CQ500, comparing against Google CT, CT-FM and Merlin (Fig. 3).

Mean average precision (retrieval mAP) for volume-to-volume retrieval with haemorrhage subtype retrieval on RSNA and CQ500. All-vs-all image retrieval was performed in this study, where every image in the dataset was used as a query once, and the gallery (the search space) was the entire dataset itself. Results are presented as mean ± 95% CI. The CI was calculated from scan-level retrievals (n = 10,379 independent scans for RSNA and n = 1,572 independent scans for CQ500). Additional methodological details are provided in ‘Methods’. Additional evaluation on Precision@K is presented in Supplementary Fig. 6. In the plot, we show that our model shows better retrieval performance compared with alternative models in majority of cases.
Retrieval performance was assessed using mean average precision (retrieval mAP), which is conceptually distinct from the average precision (AP) metric used earlier in the paper for classification tasks. In the retrieval setting, mAP is computed as the mean of all individual query-level AP scores, where each AP score is defined as the average precision at the ranks where relevant items are retrieved, that is, at positions K = {k1, k2, …, kR}. In our study, we report AP at ranks K = {1, 5, 10}. A more detailed formulation of retrieval mAP can be found in ‘Methods’.
Our model demonstrates substantial improvements over CT-FM and Merlin, and achieves notable relative gains of 9.99% on CQ500 and 2.21% on RSNA compared to Google CT, averaged across haemorrhage subtypes. Additional retrieval methodological details are provided in ‘Methods’, and a comprehensive evaluation with Precision@K is reported in Extended Data Fig. 6.
Label efficiency of few-shot classification performance
Another key advantage of the foundation model is its ability to facilitate transfer learning and fine-tuning tasks with minimal labelled data. For example, as shown in Fig. 1c, the CQ500 dataset contains only 1,585 scans. Despite the small dataset size, fine tuning our foundation model on CQ500 achieves promising results, with an AUC of 0.863.
To systematically evaluate the label efficiency of our foundation model, we also assessed the generalization capabilities of models on new tasks, given a limited number of examples within the paradigm of few-shot learning, where only K positive and negative samples each are used for training in each task. Since the quality of few-shot learning is largely determined by the sampled K-shots training data, we resampled and retrained the model five times for calculating means and confidence intervals. As expected, Fig. 2 shows that performance improves as more data are used for training, with narrower confidence intervals. Surprisingly, even with a small number of examples (for example, 512 total, with K = 256), the model achieves performance comparable to training with the full dataset, which contains over at least 16 times more training examples in the RSNA. Notably, for tasks such as detecting IVH in the RSNA dataset, the 8-shots model achieves an AUC above 0.90, a result that rivals full-data training. These findings suggest that our foundation model has learned diverse and expressive features/representations during self-supervised pretraining, making it highly effective for new tasks even when trained on a small number of labelled datasets.
We additionally show few-shot model performance on CT-FM in Supplementary Figs. 5 and 6, where we observe lower few-shot capability in comparison to our model.
Comparison to alternative modelling choices
To further verify the effectiveness of our proposed method on modelling 3D CT scans, we additionally compared it to three alternative modelling choices: (1) multiple instance learning (ABMIL17) with a state-of-the-art 2D foundation model DINOv3 (ref. 18), (2) mean pooling with DINOv3 and (3) modelling 3D CT scans as video with a state-of-the-art video foundation model VJEPA2 (ref. 19). The detailed model fine-tuning comparison across four datasets is provided in Extended Data Fig. 4. Since both DINOv3 and VJEPA2 support dynamic resolutions, we kept the input size the same as that in our model for fair comparison (96 × 96 × 96). Results show that our model performs best for majority of the tasks, with 2.57% relative improvement on AUC and 15.54% on AP against DINOv3 with ABMIL, 9.26% relative improvement on AUC and 46.57% on AP against DINOv3 with mean pooling, and 6.26% relative improvement on AUC and 26.25% on AP against VJEPA2. Furthermore, from model efficiency analysis in Extended Data Fig. 5, we show that our modelling method has substantial advantage over other benchmarked architectures in terms of both model throughput and memory cost.
Scaling up pretraining data
Scaling laws have proven effective in enhancing the performance of foundation models by increasing the size of the training dataset20. This phenomenon is not only observed in natural language and image domains21,22, but also extends to medical imaging23,24,25. As shown in Fig. 4, scaling up the foundation model by incorporating more data during self-supervised pretraining substantially improves downstream task performances. We compared models pretrained with varying proportions of the available data: 10%, 30% and 100% (full dataset), observing that larger pretraining datasets consistently led to better downstream task performance. These findings highlight the potential of leveraging more data to achieve superior results, further suggesting the value of multi-institutional collaboration and federated approaches to aggregating larger datasets to enhance model quality. Noticeably, the performance on CQ500 did not change much from 10% to 30%, but 100% gave a sudden performance improvement, indicating that for smaller datasets such as CQ500, scaling up the data size is crucial for learning meaningful representations.

We compared label efficiency in terms of different percentages of pretraining data for MAE vs DINO. The 95% CIs are plotted in colour bands and the centre points of the bands indicate the mean value. We show that although DINO presents higher label efficiency, both MAE and DINO efficiently scale up on downstream performance as more pretraining data are incorporated.
Visual interpretation
To gain insight into the features learned through self-supervised pretraining and supervised fine-tuning of the foundation model, we visualized the attention maps within ViT, as shown in Fig. 5, where the samples were randomly picked by finding scans with multiple diseases present.

We visualized the focused regions of our model through attention maps, where results show that it can successfully attend to correct disease locations in the majority of cases.
These heat maps highlight the regions where the ViT model focuses most strongly. In the second column, we see that the pretrained foundation model captures generic brain features, with dark red indicating attention on abnormal ventricular shapes and green marking areas of haemorrhage. After fine tuning on specific tasks, the ViT’s attention becomes more focused on patterns relevant to each disease. For instance, in the oedema task (third column), the heat map extends across most of the brain, reflecting generalized swelling. For ADRD (fourth column), the model emphasizes regions of ventricular enlargement and cerebral atrophy. Multiple haemorrhages are also present in this sample, with attention covering both the IPH in the dense central region (fifth column) and extending towards the left end of the ventricle where IVH appears (sixth column). In the case of SAH (seventh column), the attention map is less prominent due to the small, peripheral area of the SAH in the lower part of the slice, although the model still predicts it accurately.
The comparison between the pretrained and fine-tuned ViT explains the performance difference between linear probing and fine tuning (shown in Supplementary Fig. 8), as end-to-end fine-tuning allows the model to learn task-specific features more effectively. Details on the computation of the visualized attention maps are provided in ‘Methods’.
Discussion
Despite advances in disease detection using 3D head CT scans, current solutions are limited by the availability of annotated data and the complex, task-specific design requirements of network architectures. These constraints hinder the broader application of machine learning in clinical disease detection. To address this, we developed a foundation model trained on a large unlabelled dataset to enable fine tuning for multiple tasks with minimal labelled data under a unified network architecture.
Highly accurate detection of intracerebral haemorrhages without delay is a critical clinical issue for diagnostic decision-making and treatment in the emergency room26,27. Our results indicate that 3D head CT scans can also be used to help identify haemorrhage subtypes and, more interestingly, aetiology. High performances and generalizability observed with our model in detecting intracerebral haemorrhage have a potential to greatly assist in pre-hospital and early hospital management of blood pressure. This is particularly important given that early blood pressure control is a key factor in preventing haematoma expansion and improving patient outcomes28,29.
This approach is also particularly valuable for extending detection capabilities to new diseases in CT imaging. For example, early detection of ADRD with deep learning has traditionally relied on MRI scans30,31,32. However, access to MRI machines is costly and often restricted by patients’ geographic location and socioeconomic status33. Head CT, in contrast, is fast, accessible and is the first-line imaging test in emergency and diagnostic settings. Our foundation model enables more accessible ADRD detection using head CT scans. This advancement holds the potential for expanding early ADRD detection in common public health settings for the older population34,35, such as emergency rooms, as well as in underserved communities nationally and internationally in which CT is more available than MRI. Similarly, our model could facilitate the development of detection tools for other conditions, such as cancers and neuroinfectious diseases, thus supporting population health on a broader scale.
Our study demonstrates that this pretrained foundation model substantially outperforms models trained from scratch and other CT foundation models on the same labelled data. Moreover, it exhibits strong performance with limited data, as shown in few-shot learning experiments, and suggests promising potential for scaling up with larger datasets. In clinical practice, head CT scans are typically acquired using heterogeneous protocols, including variations in slice thickness and scanner modalities. A robust foundation model for CT should generalize effectively across these diverse protocols. In this study, we utilized scans with slice thicknesses ranging from 0.5 mm to 5 mm and data from two major manufacturers (Siemens and Toshiba) to develop and assess the generalization capabilities of our foundation model. As illustrated in Supplementary Fig. 10, the embeddings produced by the foundation model show separability based on scanner manufacturer and slice thickness, probably reflecting variations in protocol distribution. However, by comparing the distribution of ‘all’ patients to that of positive cases for each condition, we observe that the embeddings do not tend to collapse or bias towards a certain protocol. Supplementary Fig. 11 further demonstrates that fine-tuned models achieve comparable performance across scanner protocols. Detailed per-task performance results are provided in Supplementary Figs. 12 and 13. In addition, in comparisons of Toshiba and Siemens scanners, we noted a systemically higher prevalence of positive cases across all tasks in Toshiba scans, leading to a modestly higher AUC in specific instances. Despite these variations, our foundation model demonstrates robust generalization capabilities across diverse CT protocols, highlighting its potential for broad clinical application.
However, our evaluation is limited by label noise in real-world datasets. Labels derived from EHRs can suffer from missing or incomplete information. This issue is evidenced by the model’s lower performance on NYU Langone data compared with RSNA data, where labels were rigorously reviewed by radiologists. Another limitation is that, due to constraints on training samples and computational resources, our model does not yet fully explore the potential of scaling laws. The 361,000 scans used for pretraining represent the entirety of CT scans available from a single large clinical institution, highlighting the need for multi-institutional collaborations to enhance the dataset diversity and volume. With greater computational resources, we could also scale up the model’s size, resolution of image patches and number of tokens used in the ViT architecture, potentially improving performance for detecting conditions with small spatial manifestations, such as SAH.
While our current results primarily focused on disease detection, our foundation model holds substantial potential for advancing disease prognosis analysis. For instance, the prediction of decompensation, particularly haemorrhagic expansion, is an important potential use of the foundation model and may lead to the development of distinct hyperacute treatment strategies36. In addition, critical applications in acute ischaemic stroke, such as predicting haemorrhagic transformation and the development of malignant oedema, can benefit from the foundation model. Beyond acute conditions, the foundation model can potentially also be used to predict the development of ADRD37.
Methods
Datasets
Dataset for pretraining the foundation model
We utilized a large-scale head CT scan dataset from NYU Langone, consisting of 499,084 scans across 203,665 patients, collected between 2009 and 2023. These scans were acquired using Siemens and Toshiba machines. We included all non-contrast head CT scans with slice thicknesses ranging from 0.5 mm to 5 mm, kVp values between 70 and 150, and convolution kernels Hr/Qr/J with sharpness levels of 35–45. We filtered out corrupted scan series with missing DICOM files and those containing less than 10 slices, resulting in 451,298 scans. We partitioned these scans by participant ID into training, validation and held-out validation sets at an 8:1:1 ratio to avoid leakage of scans from the sample patient. As illustrated in Fig. 1a, this led to training, validation and held-out validation sets with 361,663, 44,886 and 44,749 scans, respectively. The scans in the training set were used to train the foundation model.
Datasets for downstream tasks
We evaluated our model using four datasets: one ‘in-domain’ dataset from NYU Langone and three ‘out-of-domain (OOD)’ datasets from NYU Long Island, the RSNA Challenge and the public CQ500 dataset. Each dataset includes multiple head CT disease detection classes: HCP, ADRD, IPH, IVH, SDH, EDH, SAH and intracerebral haemorrhage (ICeH). These classes can co-occur in the same head CT scan. The characteristics of the patients are shown in Supplementary Table 2. We split all datasets by patient to avoid information leakage. Further details of our dataset are provided below.
NYU Langone - 10 detection tasks
The NYU Langone main campus dataset served as the internal in-domain dataset for downstream evaluation. As depicted in Fig. 1b, patient health status was derived from EHRs within a 3-month window centred around the scan date, with conditions defined by the International Classification of Diseases, 10th revision (ICD-10) diagnostic codes and medications, outlined in Supplementary Table 1. The disease prevalence for the dataset is outlined in Extended Data Fig. 1. This cohort included 270,205 scans from 66,801 patients with valid EHRs, covering 10 classes: tumour, HCP, oedema, ADRD, IPH, IVH, SDH, EDH, SAH and ICeH. This cohort was partitioned following the same split used during pretraining: matched patients within the training, validation and held-out subsets of the SSL pretraining phase were assigned to the corresponding sets of the supervised fine-tuning phase. This resulted in 217,109, 26,609 and 26,487 scans in the training, validation and test sets, respectively.
NYU Long Island - 10 detection tasks
NYU Long Island data were acquired in Long Island Hospital which used to be a separate hospital, serving as an OOD dataset. The disease prevalence for the dataset is outlined in Extended Data Fig. 2. This dataset included 22,158 samples with 10 classes, labelled similarly to the NYU Langone dataset using ICD-10 codes. The disease prevalence for the dataset is outlined in Extended Data Fig. 1. This dataset was partitioned into an 8:1:1 train–validation–test split.
RSNA - 5 detection tasks
The RSNA Head CT Challenge dataset1 served as a public external OOD dataset, collected from Stanford University, Thomas Jefferson University, Unity Health Toronto, and Universidade Federal de São Paulo (UNIFESP). The dataset, initially provided as 2D slices, was reorganized by participant ID, retaining participants with complete slice data. After preprocessing, the dataset consisted of 10,579 samples across five classes: any (any haemorrhage type), IPH, IVH, SAH and SDH. Dataset labels were assigned by 60 volunteers from the American Society of Neuroradiology. We partitioned this cohort into an 8:1:1 train–validation–test split.
CQ500 - 10 detection tasks
The CQ500 Head CT dataset2 served as another public external OOD dataset, collected from multiple centres in India. This dataset included 1,585 samples including varying slice thicknesses across 10 selected classes: ICH, IPH, IVH, SDH, EDH, SAH, BleedLocation-Left, BleedLocation-Right, MidlineShift and MassEffect. Each scan was labelled by three senior radiologists, and the cohort was split into an 8:1:1 train–validation–test ratio.
RSNA - 4 retrieval tasks; CQ500 - 6 retrieval tasks
We evaluated volume-to-volume haemorrhage subtype retrieval on both RSNA and CQ500. For each positive case of a given subtype (IPH, IVH, SAH and SDH in RSNA; ICH, IPH, IVH, SDH, EDH and SAH in CQ500), the objective was to retrieve other cases with the same subtype. Retrieval was conducted in an all-versus-all setting, where every positive sample in the dataset was used once as a query against the remaining cases in the gallery (the rest of the samples in the dataset).
Label acquisition from electronic health records
As illustrated in Fig. 1b, we labelled head CT scans from NYU Langone and Long Island Hospital using EHRs. For each head CT, we retrieved an EHR snippet for the corresponding patient based on their medical record number, starting from the time of the scan and covering a 90-day period. We then checked for the presence of any diagnosis codes (ICD-10 codes) and medication records within this EHR snippet that matched the predefined definitions for each disease, allowing us to create binary labels for each condition. The complete list of ICD-10 codes and the medications used for disease definitions are provided in Supplementary Table 1.
Data preprocessing
For the NYU Langone and Long Island datasets, we converted the DICOM files into NIfTI format using MRIcroGL dcm2nii38, standardizing the file format with those from the RSNA and CQ500 datasets. Given the variability in scan protocols, which can result in differing orientation, resolutions and slice thicknesses, we applied spatial normalization to transform the volume orientation to right–anterior–superior (RAS) angle and resample with bicubic interpolation to the isotropic resolution ratio of (1.0, 1.0, 1.0) in the world coordinate system. This ensures uniform pixel spacing across all scans and axes.
Head CT scans use Hounsfield units (HU) to represent various tissue types, which span a broad range of values. To better capture tissue characteristics, we applied three windowing ranges, each emphasizing specific tissue types: (40, 80) for soft tissue, (80, 200) for contrast-enhanced tissues and blood vessels, and (600, 2,800) for bone. We then stacked the values from each window, producing a 3-channel 3D volume that enhances the representation of these key tissues. A similar strategy was applied in ref. 2.
To ensure compatibility with model input requirements, we transformed each volume into the desired size. We first padded or cropped each volume to a size of (224, 224, 224), preserving the whole brain across all axes. Then for training, we applied data augmentations detailed in Supplementary Section ‘Data augmentation details’; for evaluation, we centre-cropped the volumes to (192, 192, 192). Finally, we resized each volume to (96, 96, 96) as the input size for the model.
For data preprocessing on benchmarked models, original preprocessing pipelines from the respective code repository were used for Merlin and CT-FM. Since Google CT requires uploading of original DICOM files, no data preprocessing was performed.
Model architecture
Numerous studies have demonstrated that ViT can effectively learn high-quality representations for 2D medical images at scale23,39,40,41,42. Our study extends this by exploring whether representations of 3D medical images (specifically head CT scans) can also be effectively learned at scale through the direct compression of 3D patches as model input. We employed ViT14 as the volume encoder for our foundation model, as well as for baseline comparisons in all experiments. Our model uses a ViT-Base architecture with an embedding dimension of 768, 12 self-attention layers, 12 heads, and feed-forward layers with a hidden size of 3,072. We applied sine–cosine absolute positional encoding43 across all pretraining and fine-tuning stages.
For the 3D input volume, instead of creating 196 patches of size 16 × 16 from a 224 × 224 image as in standard 2D ViT, we segmented 96 × 96 × 96 3D volumes into 512 patches of size 12 × 12 × 12 for ViT input. This customized patch design considers the trade-off between performance and computational cost. As shown in Supplementary Fig. 2, our model outperformed a version using 216 patches of size 16 × 16 × 16, indicating that smaller, more numerous patches enhance model performance. This supports the importance of capturing fine-grained features in 3D medical imaging, consistent with previous findings11,25. However, computational costs increase substantially with respect to s, defined as the patch size reducing factor, at a rate of O(s6) (O(⋅)denotes standard Big-O notation, which characterizes asymptotic computational complexity), due to the cubic growth of patch numbers in 3D and the quadratic growth in self-attention computation (Supplementary Section E). To balance performance with computational efficiency, we adopted 512 patches of 12 × 12 × 12 as the optimal input size for ViT in our foundation model.
Self-supervised pretraining
Self-supervised learning has recently been widely adopted as a learning framework for building medical foundation models23,39,41,44,45,46,47. While previous works mainly focused on directly applying existing self-supervised learning algorithms on 2D medical images, we explored how to effectively leverage these algorithms with 3D medical images. Specifically, we explored two main branches of the self-supervised learning framework for building our 3D foundation model: discriminative with self-distillation (DINO) and masked image modelling (MAE).
Self-distillation modelling (DINO)
DINO6,48 is a self-supervised learning method showing promising and robust downstream evaluation performance in previous studies on different areas39,41. DINO uses a student–teacher framework for learning meaningful representations. Both student and teacher networks share the same model architecture, while the teacher’s parameters are updated using an exponential moving average of the student’s parameters. Each input image is augmented multiple times to create different views as student and teacher networks input. Specifically, we applied random global and local crops, random flips, shifts in intensity and contrasts, and Gaussian blurs for augmented views. Then the student’s output was trained to match the teacher’s output using a distillation loss, ensuring similar representations for different views of the same image. We pretrained ViT in the DINO framework for 1,000 epochs with batch size of 64 per graphics processing unit (GPU) and an AdamW49 optimizer (β1 = 0.9, β2 = 0.95, 0.05 weight decay). A base learning rate of 3 × 10−4 was applied, combined with cosine scheduling and a linear warmup on the first 5 epochs. During pretraining, two global augmentations and three local augmentations were applied to enable ViT to learn both global and local features of the head CT. Because small regions of brain are likely to be dissimilar, we observed that cropping too small brain regions would cause unstable model training by making the learning task too challenging. Therefore, we first resampled the input images to 224 × 224 × 224. Subsequently, we performed multiscale cropping by extracting both global and local crop regions, ranging from 112 × 112 × 112 to 224 × 224 × 224 for global crops and from 64 × 64 × 64 to 112 × 112 × 112 for local crops. After the cropping, all cropped regions were resampled to 96 × 96 × 96. For training on 100% data, convergence on the performance for downstream tasks was observed at ~300 epochs, which took ~1 week on four 80 GB NVIDIA A100 GPUs.
Masked image modelling (MAE)
MAE50 is another self-supervised learning method for vision tasks, inspired by masked language modelling in natural language processing. MAE is trained to reconstruct randomly masked patches via an encoder–decoder architecture, where the encoder processes visible patches of an image, while the decoder reconstructs the image from encoded patches and mask tokens. Specifically, we randomly masked the patches from each volume with a probability of 0.75. Mean squared error (MSE) loss was optimized to minimize the difference between the reconstructed volume and the original volume. We pretrained ViT in the MAE framework for 400 epochs with a batch size of 64 per GPU and an AdamW49 optimizer (β1 = 0.9, β2 = 0.95, 0.05 weight decay). A base learning rate of 1.5 × 10−3 was applied, combined with cosine scheduling and a linear warmup on the first 5% of steps. For training on 100% data, convergence was observed at ~250 epochs, which took ~4 days on four 80 GB NVIDIA A100 GPUs for MAE. Similar to DINO, MAE has shown success in learning robust representations in many previous works51,52,53,54,55,56,57, including the studies on both 2D and 3D data.
We compared performance on downstream tasks between two versions of foundation models pretrained using DINO and MAE, as shown in Fig. 4 and Supplementary Figs. 3, 7 and 8. Results indicated that DINO consistently outperformed MAE across all datasets. On the basis of this finding, we selected the DINO-pretrained model as our final foundation model.
Evaluation setting
Baseline comparisons
Since no previous foundation models have been specifically trained on 3D head CT for direct comparison, we benchmarked our model against Merlin12 and Google CT Foundation model15 to highlight the advantages of our domain-specific foundation model. Merlin is a 3D abdomen CT Foundation model pretrained on vision–language pairs with contrastive learning4 and ICD code prediction task, where 6+ million images from 15,331 CTs, 1.8+ million diagnostic ICD codes from EHR, and 6+ million tokens from radiology reports were used. Different from our model architecture, Merlin used ResNet-152 (~60.4M parameters) as vision model with reshaped image size of 224 × 224 × 160. The performance comparison between our model and Merlin is shown in Supplementary Fig. 4, where our model shows substantial improvement across most datasets and diseases. Merlin presents lower performance in some cases in comparison with ViT trained from scratch. However, as Merlin is a convolutional neural networks-based model, this performance difference cannot be attributed solely to the use of pretraining data. Google CT Foundation model is trained on a comprehensive private dataset comprising 527,078 CT studies with associated radiology reports from 430,772 patients. The model is first trained by contrastive captioning with CoCa58 on 2D medical images and then adapting to CT by training on a series of CT slices with VideoCoCa59. The performance comparison between our model and the Google CT Foundation model is shown in Supplementary Fig. 4, where our model shows a consistent improvement across the board. We additionally show a comparison of our model against model trained from scratch in Fig. 1 and Extended Data Fig. 3, where the overall substantially improved performance shows the effectiveness of our pretraining strategies on 3D head CT images.
Fine tuning and probing classification evaluation
We assessed pretrained model performance through full fine-tuning (updating all weights) and various probing methods (updating only the classification layers). For both approaches, images were normalized to isotropic spacing, transformed to three HU interval channels and reshaped to 3 × 96 × 96 × 96. The entire transformed 3D image was then input into the ViT model for feature extraction, followed by an additional classification layer for downstream tasks. Probing utilized two strategies: linear probing, which adds a linear layer atop the ViT backbone, and attentive probing, which incorporates an attention layer. Attentive probing was chosen since MAE does not use [CLS] token as the learning objective. Linear probing only relies on [CLS] token to perform classification, and attentive probing explores the interaction among all tokens60. Given the imbalances of downstream task labels, we randomly sampled a balanced subset from the training set per epoch, consisting of 5,000 samples when fine tuning on the NYU Langone, NYU Long Island and RSNA datasets, and 500 samples when fine tuning on CQ500. We trained all methods using the AdamW49 optimizer with a cosine learning rate scheduler, a learning rate of 1 × 10−5 for backbone and 1 × 10−3 for classification layers, cross-entropy loss and a maximum of 10 epochs. The main evaluation result with linear probing is shown in Fig. 1, with fine tuning and probing comparison shown in Supplementary Fig. 3 for average performance across all diseases, and in Supplementary Fig. 8 for per disease performance. Results indicated that probing achieved performance levels close to those for full fine-tuning, underscoring the high quality of learned representations in our model.
For fine tuning the model from scratch, as we observed more unstable model performance from different hyperparameters across different datasets, we performed hyperparameter sweeps across different settings and report the best performance model. The sweeping hyperparameters are: lr = {1 × 10−3, 1 × 10−4, 1 × 10−5}, weight decay = {0.01, 0.05, 0.0001, 0.00001}, epochs = {10, 15, 30, 50} and optimizer = {SGD, Adam, AdamW}.
Few-shot classification evaluation
To evaluate the effectiveness of our model under scarce label conditions, we applied few-shot learning where each class was only sampled K times. Specifically, we chose K = 8, 16, 32, 64, 128, 256, where the data were sampled such that positive and negative samples equal to K for each disease. Few-shot training was performed using full fine-tuning with the same hyperparameter settings. While we also attempted some other commonly used few-shot classification methods such as k-nearest neighbours (KNN), simple shots61 and prototypical networks62, we did not observe performance improvement on our datasets over full fine-tuning. The main evaluation for few-shot classification is presented in Fig. 2, where we observed that our model could already reach performance close to that of full fine-tuning with only K = 256 samples. This demonstrates the effectiveness of our model under a scarce-data training regime.
Volume-to-volume retrieval evaluation
We evaluated volume-to-volume haemorrhage subtype retrieval in an all-versus-all setting. Each CT volume was represented by a fixed-length embedding stored along with multihot subtype labels. At evaluation time, embeddings were first ℓ2 normalized (ℓ2 normalization denotes rescaling a vector by its Euclidean norm to unit length) and a nearest-neighbour index was built on the gallery embeddings with inner-product search (equivalent to cosine similarity). For each subtype c, every positive case for c was used once as a query and retrieved against the entire gallery minus the query itself (self-match excluded). Relevance is defined as ‘same subtype c’. The ranked hit list per query yields a Boolean relevance vector for which we computed mAP and Precision@K (for K = {1, 5, 10}). Queries and gallery included all available positives (all-versus-all) for the evaluated datasets.
If a query has R relevant items in the gallery, and the ranked list retrieves them at position K = {k1, k2, …, kR} (K = {1, 3, 5} in our study), average precision for retrieval is defined as \(\mathrm{AP}=\frac{1}{R}{\sum }_{i=1}^{R}P({k}_{i})\), where P(ki) is the precision at rank ki. Mean average precision is then defined as \(\mathrm{mAP}=\frac{1}{Q}{\sum }_{q=1}^{Q}AP(q)\) for query q and total number of queries Q.
Visual interpretation
Self-attention enables ViT to integrate information across the entire volume, even in its lowest layers. To analyse the relationships among different patches within the CT volumes, we calculated the average spatial distance over which information is integrated, using the attention weights.
Let \({{\bf{A}}}^{(l,h)}\in {{\mathbb{R}}}^{N\times N}\) represent the attention weight matrix for the hth attention head in the lth layer of ViT, and N is the number of patches in a CT volume. d(i, j) denotes the spatial distance between patch i and patch j within the 3D volume. The attention distance for each patch i was computed as a weighted average distance to other patches, based on the attention weights:
We visualized the average attention distances across all heads and layers for every patch in the volume in Fig. 5. This ‘attention distance’ serves as an estimate of ViT’s receptive field within the CT volumes, indicating the regions of the brain that the model focuses on. This visualization helps illustrate how the model integrates information across spatial areas to capture meaningful patterns within the volume.
Statistical analysis
In each experiment, we report the mean and 95% confidence interval (CI), calculated by bootstrapping the held-out validation set 100 times. For few-shot learning, where model variance is also influenced by the specific training data samples, we repeated the training and evaluation process five times with randomly sampled training data, reporting the mean and confidence interval of the resulting metrics. For all statistical significance (P values) reported in this study, we used a two-sided paired permutation test with 1,000 permutations to assess the performance difference between two compared models.
Computing hardware and software
All experiments were performed in Python (v.3.8.11), PyTorch (v.2.4.1), CUDA (12.1) and MONAI (v.1.2.0). For processing the data, we additionally used numpy (v.1.24.4), pandas (v.1.5.3), Pydicom (v.4.2), skimage (v.0.21.0) and nii2dcm (v.1.0.20240202). We extended ViT, MAE and DINO implementation from their original corresponding repositories (https://github.com/facebookresearch/mae, https://github.com/facebookresearch/dino) to match our need for 3D CT image encoding. For comparison with Merlin12, we integrated their original model weight checkpoints and model backbone code (https://github.com/louisblankemeier/merlin) to our downstream fine-tuning code base. ResNet50-3D63 (https://github.com/kenshohara/3D-ResNets-PyTorch/tree/master) was integrated to our code base for evaluation. Nearest-neighbour indexing for volume-to-volume retrieval was done with faiss (v.1.12.0) (https://github.com/facebookresearch/faiss). All plots and figures were created with Matplotlib (v.0.1.6) and Seaborn (v.0.13.2). All downstream experiments were conducted on a single 80 GB NVIDIA A100 GPU. All pretraining experiments were conducted on four 80 GB NVIDIA A100 GPUs.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The internal clinical data involved in the study are unavailable due to privacy concerns and institutional policy. Public dataset RSNA is available from https://www.kaggle.com/competitions/rsna-intracranial-hemorrhage-detection. Public dataset CQ500 is available from https://www.kaggle.com/datasets/crawford/qureai-headct. The original data are provided as DICOM files. We converted each scan from DICOM to NIfTI files and removed the scans with missing slices for creating 3D imaging datasets in our evaluation. We used all slice thickness scan protocols in each scan (for example, thin, plain thin and plain scan) for CQ500, hence providing a more exhaustive evaluation of our model adaptability on different slice thicknesses for scan.
Code availability
The code for pretraining, fine tuning and evaluation of the foundation model is available in GitHub at https://github.com/NYUMedML/headCT_foundation (ref. 64). Due to the possibility of inferring patient face from head CT data, the model weights are only available upon request after signing an institutional agreement. Requests for model weight should be sent to the corresponding author and the NYU Langone Data Sharing Strategy Board (DSSB) Committee (DataSharing@nyulangone.org).
References
Flanders, A. E. et al. Construction of a machine learning dataset through collaboration: the RSNA 2019 Brain CT Hemorrhage Challenge. Radiol. Artif. Intell. https://doi.org/10.1148/ryai.2020190211 (2020).
Chilamkurthy, S. et al. Deep learning algorithms for detection of critical findings in head CT scans: a retrospective study. Lancet 392, 2388–2396 (2018).
Wang, X. et al. A deep learning algorithm for automatic detection and classification of acute intracranial hemorrhages in head CT scans. NeuroImage Clin. 32, 102785 (2021).
Radford, A. et al. Learning transferable visual models from natural language supervision. In Proc. 38th International Conference on Machine Learning Vol. 139 8748–8763 (PMLR, 2021).
Zhou, J. et al. iBOT: image BERT pre-training with online tokenizer. In Proc. International Conference on Learning Representations (OpenReview.net, 2022).
Oquab, M. et al. DINOv2: learning robust visual features without supervision. Preprint at https://arxiv.org/abs/2304.07193 (2024).
Bommasani, R. et al. On the opportunities and risks of foundation models. Preprint at https://arxiv.org/abs/2108.07258 (2021).
Yao, J. et al. EVA-X: a foundation model for general chest x-ray analysis with self-supervised learning. npj Digit. Med. 8, 678 (2025).
Wang, X. et al. A pathology foundation model for cancer diagnosis and prognosis prediction. Nature 634, 970–978 (2024).
Huang, Z., Bianchi, F., Yuksekgonul, M., Montine, T. J. & Zou, J. A visual-language foundation model for pathology image analysis using medical Twitter. Nat. Med. 29, 2307–2316 (2023).
Y. Tang et al., Self-Supervised pre-training of Swin transformers for 3D medical image analysis. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 20698–20708 (IEEE, 2022)
Blankemeier, L. et al. Merlin: a computed tomography vision–language foundation model and dataset. Nature https://doi.org/10.1038/s41586-026-10181-8 (2026).
Codella, N. C. F. et al. MedImageInsight: an open-source embedding model for general domain medical imaging. Preprint at https://arxiv.org/abs/2410.06542 (2024).
Dosovitskiy, A. et al. An image is worth 16 × 16 words: transformers for image recognition at scale. In Proc. International Conference on Learning Representations (OpenReview.net, 2021).
Yang, L. et al. Advancing multimodal medical capabilities of Gemini. Preprint at https://arxiv.org/abs/2405.03162 (2024).
Pai, S. et al. Vision foundation models for computed tomography. Preprint at https://arxiv.org/abs/2501.09001 (2025).
Ilse, M., Tomczak, J. & Welling, M. Attention-based deep multiple instance learning. In Proc. 35th International Conference on Machine Learning Vol. 80 2127–2136 (PMLR, 2018).
Siméoni, O. et al. DINOv3. Preprint at https://arxiv.org/abs/2508.10104 (2025).
Assran, M. et al. V-JEPA 2: self-supervised video models enable understanding, prediction and planning. Preprint at https://arxiv.org/abs/2506.09985 (2025).
Kaplan, J. et al. Scaling laws for neural language models. Preprint at https://arxiv.org/abs/2001.08361 (2020).
Zhai, X., Kolesnikov, A., Houlsby, N. & Beyer, L. Scaling vision transformers. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 1204–1213 (IEEE, 2022).
Dehghani, M., et. al. Scaling vision transformers to 22 billion parameters. In Proc. 40th International Conference on Machine Learning Vol. 202 7480–7512 (PMLR, 2023).
Zhou, Y. et al. A foundation model for generalizable disease detection from retinal images. Nature 622, 156–163 (2023).
Dong, Z. et al. Brain-JEPA: brain dynamics foundation model with gradient positioning and spatiotemporal masking. In Proc. Advances in Neural Information Processing Systems (eds Globerson, A. et al.) Vol. 37 86048–86073 (Curran Associates, 2024).
Li, W., Yuille, A. & Zhou, Z. How well do supervised models transfer to 3D image segmentation. In Proc. International Conference on Learning Representations (PMLR, 2024).
Hemphill III, J. C. et al. Guidelines for the management of spontaneous intracerebral hemorrhage: a guideline for healthcare professionals from the American Heart Association/American Stroke Association. Stroke 46, 2032–2060 (2015).
Qureshi, A. I., Mendelow, A. D. & Hanley, D. F. Intracerebral haemorrhage. Lancet 373, 1632–1644 (2009).
Macellari, F., Paciaroni, M., Agnelli, G. & Caso, V. Neuroimaging in intracerebral hemorrhage. Stroke 45, 903–908 (2014).
Morotti, A. et al. Intracerebral haemorrhage expansion: definitions, predictors, and prevention. Lancet Neurol. 22, 159–171 (2023).
Li, H., Habes, M., Wolk, D. A., Fan, Y. & Alzheimer’s Disease Neuroimaging Initiative and the Australian Imaging Biomarkers and Lifestyle Study of Aging. A deep learning model for early prediction of Alzheimer’s disease dementia based on hippocampal magnetic resonance imaging data. Alzheimers Dement. 15, 1059–1070 (2019).
Liu, S., Yadav, C., Fernandez-Granda, C. & Razavian, N. On the design of convolutional neural networks for automatic detection of Alzheimer’s disease. In Proc. Machine Learning for Health NeurIPS Workshop 184–201 (PMLR, 2020).
Xue, C. et al. AI-based differential diagnosis of dementia etiologies on multimodal data. Nat. Med. 30, 2977–2989 (2024).
Agarwal, R. et al. Effects of financial toxicity and socioeconomic status on MRI follow-up time in multiple sclerosis. Clin. Neuroimaging 1, e10 (2024).
Lin, P.-J. et al. Dementia diagnosis disparities by race and ethnicity. Alzheimers Dement. 16, e043183 (2020).
Kim, N. Racial disparities in neurological care in the United States: an internal mechanism. HPHR https://doi.org/10.54111/0001/FF11 (2021).
Yu, B. et al. Predicting hematoma expansion after ICH: a comparison of clinician prediction with deep learning radiomics models. Neurocrit. Care 43, 119–129 (2025).
Zhu, W. et al. Predicting risk of Alzheimer’s diseases and related dementias with AI foundation model on electronic health records. Preprint at medRxiv https://doi.org/10.1101/2024.04.26.24306180 (2024).
Li, X., Morgan, P. S., Ashburner, J., Smith, J. & Rorden, C. The first step for neuroimaging data analysis: DICOM to NIfTI conversion. J. Neurosci. Methods 264, 47–56 (2016).
Chen, R. J. et al. Towards a general-purpose foundation model for computational pathology. Nat. Med. 30, 850–862 (2024).
Ma, J. et al. Segment anything in medical images. Nat. Commun. 15, 654 (2024).
Vorontsov, E. et al. A foundation model for clinical-grade computational pathology and rare cancers detection. Nat. Med. 30, 2924–2935 (2024).
Azizi, S. et al. Robust and data-efficient generalization of self-supervised machine learning for diagnostic imaging. Nat. Biomed. Eng. 7, 756–779 (2023).
Vaswani, A. et al. Attention is all you need. In Proc. 31st International Conference on Neural Information Processing Systems 6000–6010 (Curran Associates, 2017).
Huang, S.-C. et al. Self-supervised learning for medical image classification: a systematic review and implementation guidelines. npj Dig. Med. 6, 74 (2023).
Azizi, S. et al. Big self-supervised models advance medical image classification. In Proc. IEEE/CVF International Conference on Computer Vision 3458–3468 (IEEE, 2021).
Huang, H., Rawlekar, S., Chopra, S. & Deniz, C. Radiology reports improve visual representations learned from radiographs. In Proc. Medical Imaging with Deep Learning 1385–1405 (PMLR, 2024).
Huang, S. -C., Shen, L., Lungren, M. P. & Yeung, S. GLoRIA: a multimodal global-local representation learning framework for label-efficient medical image recognition. In Proc. IEEE/CVF International Conference on Computer Vision 3922–3931 (IEEE, 2021).
M. Caron et al. Emerging properties in self-supervised vision transformers. In Proc. IEEE/CVF International Conference on Computer Vision 9630-9640 (IEEE, 2021).
Loshchilov, I. & Hutter, F. Decoupled weight decay regularization. In Proc. International Conference on Learning Representations (PMLR, 2019).
He, K. et al. Masked autoencoders are scalable vision learners. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 15979–15988 (IEEE. 2022).
Ravi, N. et al. SAM 2: segment anything in images and videos. In Proc. International Conference on Learning Representations (PMLR, 2025).
Tong, Z., Song, Y., Wang, J. & Wang, L. VideoMAE: masked autoencoders are data-efficient learners for self-supervised video pre-training. In Proc. 36th International Conference on Neural Information Processing Systems 10078–10093 (Curran Associates, 2022).
Gupta, A., Wu, J., Deng, J. & Li, F.-F. Siamese masked autoencoders. In Proc. 37th International Conference on Neural Information Processing Systems 40676–40693 (Curran Associates, 2023).
Zhou, L. et al. Self pre-training with masked autoencoders for medical image classification and segmentation. In Proc. IEEE 20th International Symposium on Biomedical Imaging 1–6 (IEEE, 2023).
Huang, P.-Y. et al. Masked autoencoders that listen. In Proc. 36th International Conference on Neural Information Processing Systems 28708–28720 (Curran Associates, 2022).
Cong, Y. et al. SatMAE: pre-training transformers for temporal and multi-spectral satellite imagery. In Proc. 36th International Conference on Neural Information Processing Systems 197–211 (Curran Associates, 2022).
Chen, Z. et al. Masked image modeling advances 3D medical image analysis. In Proc. IEEE/CVF Winter Conference on Applications of Computer Vision 1969–1979 (IEEE, 2023).
Yu, J. et al. CoCa: contrastive captioners are image-text foundation models. In Proc. Transactions on Machine Learning 2835–8856 (OpenReview.net, 2022).
Yan, S. et al. VideoCoCa: video–text modeling with zero-shot transfer from contrastive captioners. Preprint at https://arxiv.org/abs/2212.04979 (2023).
Chen, X. et al. Context autoencoder for self-supervised representation learning. Int. J. Comput. Vis. 132, 208–223 (2024).
Wang, Y., Chao, W.-L., Weinberger, K. Q. & van der Maaten, L. Simpleshot: revisiting nearest-neighbor classification for few-shot learning. Preprint at https://arxiv.org/abs/1911.04623 (2019).
Snell, J., Swersky, K., & Zemel, R. Prototypical networks for few-shot learning. In Proc. 31st International Conference on Neural Information Processing Systems 4080–4090 (Curran Associates, 2017).
Hara, K., Kataoka, H. & Satoh, Y. Can spatiotemporal 3D CNNs retrace the history of 2D CNNs and ImageNet? In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 6546–6555 (IEEE, 2018).
Huang, H. & Zhu, W. NYUMedML/headCT_foundation: FM-HCT v.1.0.0. Zenodo https://doi.org/10.5281/zenodo.19487681 (2026).
Acknowledgements
W.Z., H.H., L.C., A.V.M. and N.R. were supported by the National Institute on Aging of the National Institutes of Health under Award R01AG085617. W.Z., H.H., B.Y. and L.C. received partial support from NSF Award 1922658. N.R. and A.V.M. were also partially supported by the National Institute on Aging of the National Institutes of Health under Awards R01AG079175 and P30AG066512.
Author information
Authors and Affiliations
Contributions
W.Z. and H.H. jointly conceived, conducted and analysed the experiment(s). W.Z. and H.H. jointly wrote the original paper. H.H. conducted rebuttal additional experiments. H.H. and N.R. handled reviewer and editor communications. W.Z., H.H. and H.T. collected and curated original data. R.M., B.Y. and L.C. analysed the data. R.H. and L.K. manually performed sensitivity analysis for ICD mapped labels. E.V., T.O., S.D., J.A.F., A.V.M. and K.M. instructed on data interpretation, collection and preprocessing. N.R. supervised the study.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Biomedical Engineering thanks Christian Bluethgen, Luca Giancardo and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 Disease prevalence of NYU Langone.
This figure illustrates the prevalence of each disease in the downstream tasks for the NYU Langone dataset.
Extended Data Fig. 2 Disease prevalence of NYU Longisland dataset.
This figure illustrates the prevalence of each disease in the downstream tasks for the NYU Long Island dataset.
Extended Data Fig. 3 Comparison to previous 3D Foundation Model with Full Finetuning.
This plot compares the performance of our model with Merlin, CT-FM, ResNet3D, our train from scratch and pre-trained model across four datasets. All experiments are done with fine-tuning following the original data pre-processing pipeline of respective models. Our DINO trained model is used in this comparison. Our model demonstrates consistently superior performance across majority of diseases, with the exception of epidural hemorrhage (EDH) in the CQ500 dataset.
Extended Data Fig. 4 Performance comparison with 2D and video foundation model.
This plot shows model performance comparison on our model against MIL using 2D foundation model DINOv3 with attention based multiple-instance learning (simplied as MIL in the plot) and video foundation VJEPA2. All comparisons are conducted on same image resolution (96 × 96 × 96) as DINOv3 and VJEPA2 both support dynamic resolutions. Comparing to these two methods, our model shows consistently improvement on AUC and AP across majority of tasks with substantial advantages on inference speed and memory cost (as shown in Extended Data Fig. 5).
Extended Data Fig. 5 Throughput vs. Memory Cost Analysis.
In this plot, we perform model efficiency analysis on throughput and memory cost for each of benchmarked models in our study (all models code are taken from official code repository). We use video model terms to standardize input shape naming of each model in this plot where s means height and weight and f means depth (frames for video). The analysis shows that our model with vanilla 3D ViT demonstrates substantial advantage in terms of both throughput and memory cost.
Extended Data Fig. 6 Precision@K performance comparison for volume-to-volume retrieval.
In this plot, solid lines represent our model, dotted lines the compared model, and different colors represent subtypes. a-c, model retrieval performance for RSNA dataset on different haemorrhage subtypes. d-f, model retrieval performance for CQ500 dataset on different haemorrhage subtypes. Our model maintains competitive performance across all tasks.
Supplementary information
Supplementary Information (download PDF )
Supplementary Figs. 1–13, Sections A–J, and Tables 1 and 2.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhu, W., Huang, H., Tang, H. et al. 3D foundation model for generalizable disease detection in head computed tomography. Nat. Biomed. Eng (2026). https://doi.org/10.1038/s41551-026-01668-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41551-026-01668-w
