
Abstract
While public attitudes regarding climate change have been widely explored in the global north, survey work is still limited in the global south countries. Here we analysed survey data (n = 8,400) from Chile, Colombia, India, Kenya, Nigeria, South Africa and Vietnam to understand climate knowledge, trusted information sources and policy preferences. Our results indicate that scientists stand out as the most trusted information source in all countries except Vietnam and trust in scientists correlates with increased climate knowledge. Respondents agree with the urgency of the climate change challenge, but prioritizing policies to mitigate climate change substantially declines when policy trade-offs are introduced. There is broad agreement for earmarking carbon tax revenue towards health and education, renewable energy subsidies and clean technology R&D, but little support for deficit reduction or uniform rebates.
Similar content being viewed by others
Main
Many studies of public preferences regarding climate change have been conducted in the USA1,2 and other global north countries3,4,5,6. By contrast, survey work in the global south countries is much more limited7,8,9,10,11,12. Much of this research uses omnibus surveys conducted across multiple countries, such as the Gallup World Poll and World Values Surveys, which include a few climate-related questions that are repeated across years. Some in-depth surveys in low- and middle-income countries focus on country-specific climate issues. However, survey work facilitating cross-country comparisons that does not use the major omnibus surveys is relatively rare. As Bergquist et al.13 note in their meta-analysis of 85 studies analysing public views on climate-related taxes and laws, most of the included studies used data from the global north. Africa and India were represented with only one study each, and South America was not represented at all.
We report on a large purpose-built survey conducted in seven global south countries: Chile, Colombia, India, Kenya, Nigeria, South Africa and Vietnam. Two recent unpublished studies that complement ours also involve survey work across multiple global south countries9,10. The first represents an extension of the omnibus approach and collects responses from Facebook users in many countries using a modern set of climate opinion questions. The second is more comparable to ours in administering a lengthy online questionnaire in fewer countries. The issues chosen for coverage in these two surveys and how they are conceptualized are different than in the survey reported here, emphasizing how little about the public’s views on climate in the global south is reliably known. These two studies are addressed further in the Supplementary Information.
There are tangentially related recent papers focused on public acceptance of new climate-related technologies that compare global north and global south contexts. For instance, Contzen et al.14 document that, while solar radiation management garners limited acceptance overall, respondents in climate-vulnerable global south regions express notably stronger support—often driven by perceived urgency. Baum et al.15 observe similar patterns of higher acceptance for carbon dioxide removal and find substantial concern over inequitable risk distribution. Fritz et al.16 look at both these technologies in studies that involved large survey efforts in 22 global north and global south countries, backed up with qualitative research involving multiple focus groups. Another complementary study looks at trust in scientists Cologna et al.17,18, generally finding high levels of confidence in trust in climate science but also highlighting ideological and political divides.
We designed an online survey that collected information on respondents’ knowledge about climate change, trusted information sources and opinions on climate policy. The survey contained a battery of well-known climate knowledge questions19 and questions concerning the attention to and degree of trust in various sources for climate information. Respondents faced several ranking tasks using a best–worst elicitation format20. This approach offers greater robustness to cultural differences in how questions are answered than the Likert-scale questions21 commonly asked in omnibus surveys. We examine (1) respondent priorities for spending in 13 policy areas, including climate and coronavirus disease (COVID-19), (2) how respiratory diseases rank relative to six other health problems, (3) agreement with ten statements characterizing various aspects of climate policies and (4) prioritization of uses for carbon tax revenue.
YouGov collected survey data in 2023 from 8,400 respondents, 1,200 in each country. Our survey supplements one administered a year earlier that focused on COVID-19. Respondents were drawn from YouGov’s online panels. During the COVID-19 pandemic, almost all surveys were conducted online. This has advantages and disadvantages. Online survey administration reduces costs and data collection times, and it enables the use of experimental designs that assign different survey stimuli. With substantial incentive payments, high response rates within the sampling frame are achievable, and such incentivized respondents are presumed to be motivated to answer the questions carefully. The main disadvantage is that the sampling frame is composed of each country’s internet-enabled portion of the population. This sample systematically underrepresents those with lower income, living in rural areas and who are older. Even so, this large segment of the population is of considerable interest owing to its exposure to online media and outsized influence on public opinion.
Climate knowledge
Knowledge about climate change is measured using a set of 12 knowledge questions covering three different domains: physical science, human causes and likely consequences18. Responses can be categorized as correct, wrong or not sure. Two versions of the summary knowledge index were created. Knowledge-Index 1 (#Correct − #Wrong) assigns a value of ‘1’ to correct answers, ‘0’ to not sure and ‘−1’ to wrong answers. Knowledge-Index 2 (#Correct) sums over correct answers by assigning a ‘0’ to both not sure and wrong answers. Table 1 presents the knowledge questions and aggregate responses by country and the whole sample.
Respondents generally answered questions about ‘easy’ climate change statements such as ‘Burning oil increases CO2’ correctly (60–80%) across all countries. More difficult statements such as ‘The same quantity of CO2 is more harmful to climate than (natural) methane’ were infrequently answered correctly (10–20%). Reverse-ordered questions, where the correct response is ‘no/not sure’, were answered correctly less often (23%) than questions where ‘yes/agree’ was correct (75%), which may reflect an acquiescence effect, but, on average, the reverse ordered questions also seemed somewhat harder. Across countries, clear differences in the propensity to answer ‘not sure’ arise, perhaps driven by different demographics (for example, women were more likely to provide a ‘not sure’ response). An important caveat in cross-country comparisons is cultural response styles, an active area in survey22 and marketing23,24 research, which may influence how reverse-order questions are answered and the ‘not sure’ response propensity.
Knowledge about climate change across countries was quite similar (Extended Data Fig. 1). Dispersion was also similar, except for Vietnam, where values were tighter around the mode. Comparison with Shi et al.19 shows that climate change knowledge is somewhat lower in the global south if measured as a share of correct answers (Extended Data Table 1). However, the share of wrong answers from respondents in our sample is also lower (the share of ‘not sure’ is higher). One result stands out: the question whether climate change is man-made is answered correctly by 85% of respondents in the global south and only 75% in the global north.
Attention and trust in information sources
Climate knowledge is related to the attention paid to and trust in various information sources. Respondents were asked to rank order their attention to and trust in 12 sources, ranging from national government sites to social media (Methods). Rank-ordered logit models were estimated separately for measures of attention and trust. Parameter estimates are then converted to a rank ordering that reflects average attention and trust for specific information sources. Table 2 displays attention in panel A and trust in panel B. Scientists stand out as the source of information respondents trust most in all countries except Vietnam, where scientists rank in the top three. Extended Data Fig. 2 contains a visual representation. National governments are also a trusted source of information about climate in all countries. Only in Vietnam was this also true of local government. Across our countries, respondents generally paid attention to and trusted climate information from television. In the African countries, respondents generally trusted information from non-governmental organizations (NGOs). Newspapers do not rank badly but only in India are they among the most highly ranked sources. Internet sources are ranked reasonably highly regarding Attention and Trust in the two Latin American countries. Although respondents reported paying substantial attention to social media as a source of climate information, they do not trust the information they receive. Family and friends were not highly ranked in any of the countries in terms of Attention or Trust. The same was true of religious leaders.
The association between knowledge and attention or trust was assessed by predicting Knowledge-Index 1 (#Correct − #Wrong) using a simple linear regression with three indicator variables as covariates: one for the highest of the three attention levels paid to the source, a similar indicator for trust and one for their interaction (Extended Data Table 2). Scientists (0.91), NGOs (0.80) and the national government (0.53) are associated with the three largest positive effects on Knowledge-Index 1 (#Correct − #Wrong)’s magnitude. Religious leaders (−0.47), family (−0.65) and friends (−0.84) represent the three largest negative effects. The mean Knowledge-Index 1 (#Correct − #Wrong) score is 3.6, suggesting the effect of these information sources on knowledge was large. By comparison, a model with only a college degree indicator suggests an index value 0.49 units higher.
Relative priority of climate compared with other programmes
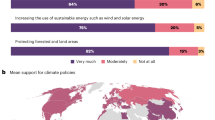
Support for climate programmes is often relatively high when measured in isolation. To demonstrate this, early in our survey, respondents were asked a standard 5-point (strongly disagree to strongly agree) Likert-scale type question7: ‘How important is climate change for country X?’. Average responses were: Chile (4.54), Colombia (4.65), India (4.55), Kenya (4.69), Nigeria (4.45), South Africa (4.45) and Vietnam (4.71). These scores are all high and fall into a narrow range (Extended Data Fig. 3).
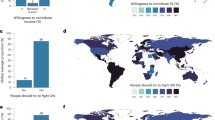
Later in the survey, we compared support for climate programmes with 12 other programme areas competing for limited resources and found considerable heterogeneity between countries. In four of the seven countries, respondents ranked climate action in the lower half of the programme areas in terms of prioritization (Table 3). Vietnam had the highest Likert-scale score for climate and was the only country to rank climate among the top three priorities. In most countries, the highest priorities are traditional public policy areas (Extended Data Fig. 4). Healthcare dominates in all countries. The priority assigned to crime, education and water varies considerably across countries. Respondents in most countries placed lower priority on improvements in credit access, public transport and electricity provision. Because our ranking exercise forces explicit trade-offs, it is a more realistic view of the intensity of public support for climate-related programmes.
To further examine climate change in a comparative perspective, respondents were asked three binary trade-off questions related to COVID-19. We find that large majorities see climate as the more important long-term problem compared with COVID-19 (Extended Data Fig. 5). The second question asks whether the COVID-19 recovery effort should prioritize actions that also help with climate change25. Support ranges from over 85% in India to just under 95% in Kenya, suggesting close to universal support for such targeted recovery efforts. The third question asks for a trade-off: ‘Is some environmental harm justifiable if it leads to faster economic recovery from COVID?’. Responses suggest a quite different short-run perspective. In five countries, a majority favours faster economic recovery at the expense of the environment, while in Colombia and Kenya, a narrow majority support the opposite view.
There are local health benefits from reducing air pollution from burning fossil fuels. These benefits are often considered secondary relative to climate benefits; however these secondary benefits predominate direct climate benefits26,27 when any appreciable discount rate is used. A 2018 Lancet Commission report finds sizeable air pollution-related health impacts, including millions of deaths in the global south28. In fact, we find that respiratory diseases are top-ranked in priority in all countries out of a set (Table 4) of seven major health problems, including alcohol and drugs, COVID-19, human immunodeficiency virus (HIV), malaria, tuberculosis and waterborne diseases (Extended Data Fig. 6). Note respiratory diseases were said to be due to air pollution and smoking, with smoking explicitly mentioned because treatment options tend not to be source specific. Concerns about air pollution in major cities have long been a major driver of policies to reduce it29. Our results suggest why local air pollution receives so much attention in comprehensive climate policy analyses30,31. It does not, however, shed direct light on important subordinate questions, such as perceived linkages between local air pollution and climate change and how prevention versus treatment is viewed. The question in Table 4 is from an earlier wave of this survey focused on COVID-1932, but comparison shows strong temporal consistency. All countries prioritized respiratory diseases, except Vietnam, where COVID-19 ranked first and respiratory disease second. By contrast, the priority ranking of COVID fell substantially between 2022 and 2023, showing that the pandemic became less lethal with prior infection and vaccination, suggesting the sensitivity of our rank order trade-off approach to changing circumstances.
Attitudes towards climate policies
Respondents rank ordered their agreement with a set of stylized climate policy statements using a best–worst elicitation procedure (Table 5). In all countries, the top-ranked statement was: ‘Climate change is the most important long-term problem the world is facing.’ Several other statements were also highly ranked in most countries (Extended Data Fig. 7), including climate change as a major world problem, belief that rich countries should be doing more, belief that domestic political corruption lets big polluters emit too much, belief that research and development (R&D) investments should be made to reduce the future renewable costs, and belief that high-polluting vehicles need to be replaced with clean ones. Two statements competed for the lowest ranks. One was, ‘It is a waste of money to reduce CO2 emissions because burning fossil fuels is not the main pollution source.’ The other was ‘There is no need to do anything now to reduce emissions because the cost of doing so will be much lower in the future.’
The final best–worst task concerned a divisive issue in climate policy—the use of revenues from carbon taxes33. Carson et al.34 formally vary in an Australian discrete choice experiment context whether carbon tax revenue should be rebated via a value-added tax or sales tax reduction or targeted to low-income households and seniors. Respondents split equally between these alternatives, with preferences substantially predictable by partisanship and demographic covariates. For lack of a broad consensus on rebating carbon tax revenue, researchers have explored how climate policy preferences vary with how revenue is earmarked for different purposes35,36,37,38,39.
Respondents were offered two commonly proposed rebate schemes, one directed towards the poor and the other to all citizens equally. Three different earmarks were considered: roads, the traditional earmark with a direct nexus, health and education programmes, and a technology-based earmark that subsidizes solar panel installations. Another alternative offered is an R&D programme to reduce future clean energy technology costs. The last alternative reduces the government deficit.
The top three alternatives in all countries are earmarks for health and education programmes, subsidizing solar and green R&D (Table 6). All except Kenya rank health and education programmes highest (Extended Data Fig. 8). Kenyan respondents gave subsidized solar their highest rank. Revenue refunding and deficit reduction compete across countries for the lowest and next lowest positions. Targeting rebates towards the poor was ranked somewhat higher.
Discussion
Climate knowledge among the internet-enabled population segment in our seven global south countries was quite similar. On average, our sample of respondents gave about 20% fewer correct answers than the Shi et al.19 global north sample average. Divergences were concentrated on the underlying physical science and long-term consequences rather than on human causes. Increased climate knowledge was associated with factors such as education and climate information sources that respondents pay attention to. A key finding is that paying attention to and having trust in scientists was associated with increased climate knowledge, roughly twice the effect size associated with a college degree. High trust in scientists suggests that diffusion of research to the public is important.
In response to an early simple Likert-scale question, respondents on average (4.6 on a 5-point scale, with 5 being very important) in our global south countries indicated that addressing climate change is very important. A more nuanced picture emerges when respondents are later asked to make trade-offs between policy areas. Only in Vietnam is climate one of the top three priorities. In two countries, Nigeria and South Africa, climate is ranked in the bottom third of policy areas. These results highlight the risk of policymakers relying on the type of simple questions typically included in omnibus surveys to assess support for climate policies.
A striking finding is that, across all our countries, the public ranks reducing respiratory diseases at the top of a set of major public health problems. With this co-benefit of lower fossil fuel emissions being so important, how people integrate air pollution-related health issues into their assessment of climate policies needs more exploration.
In a best–worst exercise, respondents then rank-ordered agreement with a set of statements related to climate policy. Across all countries, the strongest agreement is with the ‘Climate change is the most important longer-term problem the world is facing’ statement. Policy positions, which entail doing little now to address the climate issue, received very little support.
A subsequent best–worst ranking exercise focused on uses for carbon tax revenue32,33. Despite some notable differences between countries, there was consensus on the top three ranked options: earmarking the revenue for health and education, subsidizing solar or funding R&D to reduce the future costs of clean energy. Two carbon tax revenue uses popular with some economists, rebating the revenue equally to all citizens and using it to reduce the government’s budget deficit, were the two lowest-ranked alternatives in all countries.
This Article’s dataset should provide researchers with opportunities to explore the roles played by a rich sociodemographic covariate set, including climate knowledge, in predicting individual-level climate-policy-related choices and the ability to segment respondents into groups based on belief similarity6. In-depth qualitative work could also be fruitfully deployed to understand further the coherence of climate knowledge and policy preferences hinted at in our results. Finally, we hope that our rank-ordering approach whereby respondents make distinct trade-offs between simple options finds widespread usage in explorations of climate-related issues in global south countries.
Methods
Ethics statement
The survey received institutional review board (IRB) approval from the Swedish Ethical Review Authority (Dnr 2021-00980). YouGov, the firm we contracted with to do the survey, obtained informed consent from respondents before administering it.
Data collection and survey details
The data were collected from interviews administered online via computers, mobile phones or tablets in each country by YouGov. YouGov is one of the major international survey firms that routinely administers surveys for major media outlets such as CBS News, the Economist magazine and the (London) Times newspaper. The countries were selected to have both local EfD research centres and accessible YouGov panels. The countries chosen income-wise span a range from the lower end of low-to-middle-income countries (Nigeria) to the low end of high-income countries (Chile). They come from three continents and include six of the 20 largest global south countries. They include exporters of agriculture, minerals, oil and consumer goods.
Respondents were selected from YouGov’s country-specific panels covering individuals 18 years or older with internet access. Respondents received YouGov’s standard incentive for participation. Additional information on YouGov samples, IRB approval and the text of specific questions relied on can be found in the Supplementary Information, which also compares this approach with recent work9,10 that has some similarities in terms of purpose and method.
YouGov administered the survey online in April and May of 2023 using respondents selected from their country-specific opt-in panels. YouGov’s treatment of online panel issues is concisely defined in its responses to the set of 37 questions Esomar.org (European Society for Opinion and Marketing Research) considers important in assessing the results from such surveys40. To be eligible for inclusion, individuals had to be above 18 and have regular access to the internet at the time of the survey (for example, cell phone, computer or tablet). The fraction eligible to complete the survey varies across countries. Information from YouGov when the sampling weights were developed shows the fractions to be 76% in Chile, 59% in Colombia, 63% in India, 17% in Kenya, 64% in Nigeria, 54% in South Africa and 70% in Vietnam. Alternative sources put some of these fractions higher. We report two such sources here (Digital: January Report 2023 and World Bank: November 2023). These are for Chile (90.2%, 90.8%), Colombia (75.7%, 72.1%), India (48.7%, 51.5%), Kenya (32.7%, 29.0%), Nigeria (55.4%, 55.0%), South Africa (72.3%, 78.0%) and Vietnam (79.1%, 76.2%). These numbers are generally higher, particularly for countries with lower per-capita incomes. These estimates reflect increased internet/mobile phone penetration over time and may count some mobile phones on which it is not possible to answer a survey like ours.
Characteristics of the internet-connected population were drawn from the following sources, which used large high-quality country-wide random probability samples: Latin American Public Opinion Project 2021 (Chile and Colombia), the Pew Global Attitudes Survey 2017 (Vietnam), the Pew Global Attitudes Survey 2019 (India) and the Afrobarometer survey 2019 (Kenya, Nigeria and South Africa). This sampling frame tends to be skewed towards both male and younger respondents. Within YouGov panels, a propensity score approach utilizing age and gender is used to mirror the sampling frame characteristics.
Across countries, the sample median age is 31 years; it ranges from 40 in Chile to 27 in Nigeria. The male percentage is 55.4. This percentage exhibits more variability. At the low end are Vietnam (49.6) and Chile (49.8 male), while at the high end are Nigeria (56.6) and India (68.3). The demographic characteristics of the country-specific samples are relatively close to the characteristics of YouGov sampling frame for age and gender, so the weighted and unweighted analysis results are quite similar. We report only the unweighted results.
Summary demographic statistics for each country’s sample and the combined sample are presented in Supplementary Table 1. Supplementary Table 2 compares our sample to both the reference surveys used as sampling frames and to World Bank data on five age categories and gender. Generally, our samples are fairly close to their reference surveys’ values for the internet-enabled population. By contrast, comparison with the World Bank estimates shows a substantially larger fraction of the adult in the 55 and over age category in the general population than our sample, which is not unexpected. India, Kenya, Nigeria and, to a lesser extent, Colombia, show a smaller female fraction than the World Bank’s general population estimate.
Surveys interviewing those under 18 are treated very differently by the IRB approval processes. Thus, YouGov and other survey organizations must use results from rare, full probability-based samples that use in-person interviews to obtain their baseline demographics. Academic access to these surveys is possible, but they are not generally publicly available. For example, Pew’s 2019 Global Values Survey in India has one of the lower internet access fractions. Hence, it may be less representative of the general population than most of our global south countries. In Pew’s 2019 Global Values Survey, the median age in the raw data is 39, while in our survey, the median age is 31. The percentage of females in the raw Pew data is 42.49 versus 31.67 of Indians in our sample with internet access. For income, the Pew survey uses ten brackets. The average of these brackets for those with internet access is 5.9, while it is 4.5 for those without. The largest divergence occurs in the lowest income bracket. In the Pew survey, 54.65% of those with internet access in India live in rural villages or on farms versus 69.18% of those without internet access.
As survey inclusion requires internet access, our respondents are likely to be more urban, better educated and have higher incomes, although there is considerable variation in the sample on these characteristics. It is important to interpret results in this context. Full-probability random samples of the general population using dwelling unit enumeration and in-person interviewing have become increasingly rare in academic research owing to prohibitive cost. They are now largely the domain of government statistical agencies. Survey researchers have turned to alternative less complete sampling frames from which they can draw random samples. Their properties have been changing over time. For instance, random digit dialling of phone landlines could reach over 90% of the US population in the early 2000s, but under 30% today. The penetration of internet access has increased its use in surveys as they become increasingly representative of a country’s general population. Typically, there are not extremely large differences between those with internet access and those without, but some substantive divergences are common, which calls for caution in making conclusions for the entire population, even when it may be the best or only available estimate. A considerable effort in assembling and recruiting members for internet panels and sampling from those panels is underway in the survey research. Major internet panel suppliers, such as YouGov, which is used here, are quite transparent about the procedures used to counter a proliferation of web-based surveys based on highly selected convenience samples that are not representative of any well-defined broad-based sampling frame40.
The survey was available to respondents in English as well as other major country-specific languages. In Chile and Colombia, this was Spanish; in India, Hindi; in South Africa, Afrikaans and Zulu; and in Vietnam, Vietnamese. In Kenya and Nigeria, the official language is English. YouGov staff translated our survey instrument into these alternative languages. Researchers at the local EfD Research Centers checked that the translation was adequate for the local context, and recommended changes were incorporated into the YouGov translation drafts. Screenshots of the English version of the survey questions are contained in the Supplementary Information.
We use Stata 17 for analysis, and figures were drawn using Excel 365.
Elicitation via best–worst scaling and analysis via rank-ordered logit
Several survey questions deployed utilize a best–worst elicitation format using type 1 (object-level) data20. Effectively, respondents are presented with a list of objects, in our case, climate information sources, programme areas, health problems, climate policy statements or uses of fuel tax or carbon tax revenue. Best–worst scaling provides simple ways to summarize responses when the respondent provides only their most preferred (given the criterion) choice and their least preferred choice from the list. Often, these items are formulated in terms of most and least, where the descriptor might be agreement or priority. The order of the items in each set should be, and is here, randomized across respondents the first time presented.
With three items, a single best–worst question provides a complete ranking of the items. With an odd number of items, repeated application of the best–worst format removes the items previously selected as best and worst each time until only one item in the middle is left. One replication uniquely rank orders five items and two replications uniquely rank orders seven items. With up to seven items, it is common to repeat the original best–worst question, each time taking away the items chosen best or worst in the previous round (for example, see the analysis represented in Tables 4 and 6). Respondents see all items, and they provide a complete ranking of items in the set.
Beyond seven items, a random subset of items is generally presented to respondents, with different respondents receiving different subsets following an experiment design. This results in incomplete rank-ordered data because respondents either do not see all the items or are not asked to provide information that completely ranks them. The analysis displayed in Table 3 relies on assigning random subsets each with 5 (out of the 13) items. Random assignment to these subsets ensures statistically equivalent subsamples receive each of the distinct subsets defined by the experimental design. Here, a Youden41 square design based on incomplete blocks is used to ensure that each item is contained in an equal number of subsets and that each item appears an equal number of times with every other item in the master set.
The analysis in Table 5 is based on a set of ten climate policy statements. Respondents were randomly assigned to one of two blocks (subsets) of seven statements and then asked to rank the items in their block using a sequence of best–worst questions. The two blocks of seven statements have four common items, each having three unique items. This allows the two sets of statements to be combined in a model that estimates parameters for nine alternative-specific constants, with one normalized to zero. This then allows the rank ordering of all ten items with the common four items anchoring the ranking exercise.
Another way to obtain partially rank-ordered data is to ask respondents to effectively divide items in a list into separate subsets based on a criterion. This is done for the analysis displayed in panel A of Table 2, where respondents are asked which 3 out of 12 climate information sources they are paying the most and least attention to. (This exercise is repeated for panel B of Table 2 using the criterion of trust.) This produces three subsets; the three best items are ranked above six of the unchosen item subset, which in turn are considered higher ranked than the worst three-item subset. Within a subset, each of the items is considered tied. Data of this sort are less informative (27 implied unique binary comparative rankings) than a complete ranking (66 implied binary comparisons) but more informative in some ways than multinomial choice data where only the top-ranked item is known (11 binary comparisons).
A complete ranking order of items in terms of a specified criterion can be represented in several different ways. Assume three items: a, b, c and d. There are 24 possible permutations for example, a > c > d > b}. Any permutation implies a set of pair comparisons for example, {a > c}, {a > d}, {a > b}, {c > d}, {c > b}, {d > b}. These pairs can be stacked with indicator variables representing the items serving as alternative specific constant terms and a binary logit model fit. With data on the rank order for each respondent, the parsimonious representation is the rank-ordered logit model42. This is a standard member of the class of random utility model where each of the ith respondent’s j choice alternatives is assumed to have utility Uij = Vij + εij, with Uij chosen (ranked) over another alternative, Uij*, if its value is larger. Vij is known as the systematic component, usually parameterized in terms of a vector k observables, X, and corresponding estimable preference parameters βjk. εij is the unobserved random component. Its standard deviation, σ, describes how utility is distributed around the systematic component. εij is typically assumed to have a Gumbel distribution, with the difference between two Gumbel draws having a logistic distribution.
A statistical equivalent model can be formed by stacking the implied set of multinomial comparisons, for example {a > c, d, b}, {c > d, b}, {d > b} fit with a conditional/multinomial logit model or by stacking the set of implicit binary comparisons fit with a binary discrete choice model43. This model is known to reproduce market shares or ranks when fit only to a set of alternative specific constants (indicator variables) used to represent the items in the choice set. In this case, the estimable preference parameters are simply one βj/σ for each choice alternative in the set, other than one for the base reference item normalized to zero. The rank order of the parameters on the alternative specific constants is the same as the predicted average rank ordering for the sample.
Choice model parameters are identified only in a relative sense because multiplying by a positive constant does not alter the implied choice behaviour. In practice, normalization is usually done via the unobserved scale factor σ, so the actual model parameters are expressed as βj/σ. The rank order of the estimated βj/σ provides the expected rank ordering of a randomly chosen sample respondent, with dispersion within the sample around this pattern being a function of σ. Swait and Louviere44 show that, while σ is not identified, the relative difference across two samples (for example, σ2/σ1) is identifiable. The same principle can be used to identify within sample differences with covariates such as gender or educational categories by effectively creating subsamples.
The rank-ordered model can be fit, as we do here (Stata 17, cmrologit), using the underlying likelihood function of a Cox-proportional hazard model where a higher value for an alternative is formally equivalent to a higher hazard rate of failure45. The rank-order logit model assumes among j = 1, …, J alternatives, the probability, π1, that alternative 1 is ranked higher than the other J alternatives can be expressed using
Incompletely rank-ordered data require additional assumptions. If the source of the incomplete ranking is the division into subsets (Table 2), the associated assumption involves the treatment of tied ranks. Following Allison and Christakis45, tied ranks are handled by the marginal-likelihood method, which specifies that all strict preference orderings consistent with the stated weak preference ordering are equally likely. For those involving the presentation of different subsets of items to different respondents, the key assumption, met here via random assignment, is that each subset of items is seen by a statistically equivalent subsample of respondents. There is a further issue that involves how to link blocks of items together. Here, we use either a second-order randomization (for example, the Youden designs pairing of occurrence frequencies) for the Table 6 analysis or the inclusion of common alternatives in the two-block design underlying the Table 4 analysis.
Note that we estimate separate models for each country, so the scale parameter is potentially different in each of our c = 1, …, 7 countries. The implication of this is that the estimated βj/σc are not directly comparable across countries unless the σc are constant across countries. They are, however, comparable within a country given the distributional assumption for the random component. The restriction that the σc are the same across our countries can be tested in a straightforward way by estimating a model that includes a complete set of country-by-item interactions in a single model, which effectively restricts the scale factor to have a common value. Taking the model in Table 6 as an example, the likelihood ratio test follows a chi-square distribution with 6 degrees of freedom (95% critical value 12.592) because the Table 6 model allows six free country-specific scale factors compared with one in the restricted model. The likelihood ratio test statistic is 119.002 (P < 0.001), suggesting that restriction is strongly rejected. In thinking about this rejection, it is important to recognize that allowing for country-specific σc enables each country to have a different distribution of preferences around its average rank ordering. One way to view the importance of allowing for these country specific-scale factors is to note that the South African logistic regression coefficients are, on average, almost three times larger than those from India, yet remain highly correlated with them (0.67). This suggests reasonable similarity of priorities on average, but much greater preference heterogeneity in India than South Africa.
Note that rank-ordered data suffer the same type of indeterminacy without some type of normalization. For example, a variable containing ranks between 1 and 7 can be multiplied by any positive integer with the items still being ordered in an identical fashion. Whether decreasing or increasing rank order indicates more or less preferred can also be arbitrarily specified. Here, we use one of the standard conventions: a rank of ‘1’ indicates the most preferred item in a set.
The rank-ordered logit models are reported in Tables 2–5. The expected country rank orderings for each dependent variable are also illustrated graphically using Excel in Extended Data Figs. 2, 4 and 6–8.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The dataset46 used in this Article is available via Researchdata.se at https://doi.org/10.5878/jy7v-5k80.
Code availability
Replication code for this Article is available via Researchdata.se at https://doi.org/10.5878/jy7v-5k80.
Change history
10 September 2025
In the version of this article initially published, a citation to Table 4 in the third paragraph of the “Relative priority of climate compared with other programmes” section was incorrect, while in the “Elicitation via best–worst scaling and analysis via rank-ordered logit” section of Methods, citations to Tables 4 and 6 in the second paragraph, a citation to Table 3 in the third paragraph and a citation to Table 5 in the fourth paragraph were originally incorrect. The citations are updated in the HTML and PDF versions of the article.
References
Hamilton, L. C., Hartter, J., Lemcke-Stampone, M., Moore, D. W. & Safford, T. G. Tracking public beliefs about anthropogenic climate change. PLoS ONE 10, e0138208 (2015).
Stoetzer, L. S. & Zimmermann, F. A representative survey experiment of motivated climate change denial. Nat. Clim. Change 14, 198–204 (2024).
Drews, S., Savin, I., van den Bergh, J. & Villamayor-Tomás, S. Climate concern and policy acceptance before and after COVID-19. Ecol. Econ. 199, 107507 (2022).
Fairbrother, M. Public opinion about climate policies: a review and call for more studies of what people want. PLoS Clim. 1, e0000030 (2022).
Mildenberger, M. et al. The distribution of climate change public opinion in Canada. PLoS ONE 11, e0159774 (2016).
Fabre, A., Douenne, T. & Mattauch, L. Majority support for global redistributive and climate policies. SSRN https://ssrn.com/abstract=4448523 (2024).
Leiserowitz, A. A. International Public Opinion, Perception, and Understanding of Global Climate Change. Human Development Report Office Occasional Paper 31 (United Nations Development Program, 2007).
Lee, T. M., Markowitz, E. M., Howe, P. D., Ko, C. Y. & Leiserowitz, A. A. Predictors of public climate change awareness and risk perception around the world. Nat. Clim. Change 5, 1014–1020 (2015).
Leiserowitz, A. A. et al. International Public Opinion on Climate Change (Yale Program on Climate Change Communication, 2022).
Dechezlepretre, A. et al. Fighting climate change: international attitudes toward climate policies. Am. Econ. Rev. 115, 1258–1300 (2025).
Andre, P., Boneva, T., Chopra, F. & Falk, A. Globally representative evidence on the actual and perceived support for climate action. Nat. Clim. Change 14, 253–259 (2024).
Ogunbode, C. A. et al. Climate justice beliefs related to climate action and policy support around the world. Nat. Clim. Change 14, 1144–1150 (2024).
Bergquist, M., Nilsson, A., Harring, N. & Jagers, S. C. Meta-analyses of fifteen determinants of public opinion about climate change taxes and laws. Nat. Clim. Change 12, 235–240 (2022).
Contzen, N. et al. Public opinion about solar radiation management: a cross-cultural study in 20 countries around the world. Clim. Change 177, 65 (2024).
Baum, C. M., Fritz, L., Low, S. & Sovacool, B. K. Public perceptions and support of climate intervention technologies across the Global North and Global South. Nat. Commun. 15, 2060 (2024).
Fritz, L., Baum, C. M., Brutschin, E., Low, S. & Sovacool, B. K. Climate beliefs, climate technologies and transformation pathways: contextualizing public perceptions in 22 countries. Glob. Environ. Change 87, 102880 (2024).
Cologna, V. et al. Trust in climate science and climate scientists: a narrative review. PLoS Clim. 3, e0000400 (2024).
Cologna, V. et al. Trust in scientists and their role in society across 68 countries. Nat. Hum. Behav. 9, 713–730 (2025).
Shi, J., Visschers, V. H., Siegrist, M. & Arvai, J. Knowledge as a driver of public perceptions about climate change reassessed. Nat. Clim. Change 6, 759–762 (2016).
Louviere, J. J., Flynn, T. N. & Marley, A. A. J. Best–Worst Scaling: Theory, Methods, and Applications (Cambridge Univ. Press, 2015).
Auger, P., Devinney, T. & Louviere, J. Using best–worst scaling methodology to investigate consumer ethical beliefs across countries. J. Bus. Ethics 70, 299–326 (2007).
Smith, P. B. et al. Individual and culture-level components of survey response styles: a multi-level analysis using cultural models of selfhood. Int. J. Psychol. 51, 453–463 (2016).
Beuthner, C., Friedrich, M., Herbes, C. & Ramme, I. Examining survey response styles in cross-cultural marketing research: a comparison between Mexican and South Korean respondents. Int. J. Mark. Res. 60, 257–267 (2018).
Kondouri, P. et al. Statement of the Lancet COVID-19 Commission Task Force on Green Recovery: Transforming Recovery into a Green Future (Lancet COVID-19 Commission, 2021).
West, J. J. et al. Co-benefits of mitigating global greenhouse gas emissions for future air quality and human health. Nat. Clim. Change 3, 885–889 (2013).
Karlsson, M., Alfredsson, E. & Westling, N. Climate policy co-benefits: a review. Clim. Policy 20, 292–316 (2020).
Landrigan, P. J. et al. The Lancet Commission on pollution and health. Lancet 391, 462–512 (2018).
Li, C., Ma, X., Fu, T. & Guan, S. Does public concern over haze pollution matter? Evidence from Beijing–Tianjin–Hebei region, China. Sci. Total Environ. 755, 142397 (2021).
Scovronick, N. et al. The impact of human health co-benefits on evaluations of global climate policy. Nat. Commun. 10, 2095 (2019).
Shindell, D. & Smith, C. J. Climate and air-quality benefits of a realistic phase-out of fossil fuels. Nature 573, 408–411 (2019).
Carson, R. T. et al. Perceptions of the seriousness of major public health problems during the COVID-19 pandemic in seven middle-income countries. Commun. Med. 3, 193 (2023).
Maestre-Andrés, S., Drews, S. & van den Bergh, J. Perceived fairness and public acceptability of carbon pricing: a review of the literature. Clim. Policy 19, 1186–1204 (2019).
Carson, R. T., Louviere, J. J. & Wei, E. Alternative Australian climate change plans: the public’s views. Energy Policy 38, 902–911 (2010).
Kotchen, M. J., Turk, Z. M. & Leiserowitz, A. A. Public willingness to pay for a US carbon tax and preferences for spending the revenue. Environ. Res. Lett. 12, 094012 (2017).
Carattini, S., Carvalho, M. & Fankhauser, S. Overcoming public resistance to carbon taxes. Wiley Interdisc. Rev. Clim. Change 9, e531 (2018).
Carattini, S., Kallbekken, S. & Orlov, A. How to win public support for a global carbon tax. Nature 565, 289–291 (2019).
Jagers, S. C., Martinsson, J. & Matti, S. The impact of compensatory measures on public support for carbon taxation: an experimental study in Sweden. Clim. Policy 19, 147–160 (2019).
Ewald, J., Sterner, T. & Sterner, E. Understanding the resistance to carbon taxes: drivers and barriers among the general public and fuel-tax protesters. Resour. Energy Econ. 70, 1–19 (2022).
Kallbekken, S. Research on public support for climate policy instruments must broaden its scope. Nat. Clim. Change 13, 206–208 (2023).
Esomar: questions to help research buyers of online samples. YouGov https://doc.ukdataservice.ac.uk/doc/7647/mrdoc/pdf/7647_esomar-36.pdf (2023).
Youden, W. J. Use of incomplete block replications in estimating tobacco-mosaic virus. Contrib. Boyce Thompson Inst. 9, 50–57 (1937).
Beggs, S., Cardell, S. & Hausman, J. Assessing the potential demand for electric cars. J. Econ. 17, 1–19 (1981).
Chapman, R. G. & Staelin, R. Exploiting rank ordered choice set data within the stochastic utility model. J. Mark. Res. 19, 288–301 (1982).
Swait, J. & Louviere, J. The role of the scale parameter in the estimation and comparison of multinomial logit models. J. Mark. Res. 30, 305–314 (1993).
Allison, P. D. & Christakis, N. Logit models for sets of ranked items. Sociol. Methodol. 24, 123–126 (1994).
Carson, R. T. et al. Data for: Public preferences on policies for climate, local pollution, and health—a survey in seven large Global South countries (Version 1) [Dataset]. Swed. Natl Data Serv. Univ. Gothenbg https://doi.org/10.5878/JY7V-5K80 (2025).
Acknowledgements
The survey was funded by the Environment for Development (EfD) programme at the University of Gothenburg, which is supported by the Swedish International Development Cooperation Agency (Sida). EfD, with which the coauthors of this Article are affiliated. EfD supports a network of 12 research centres in developing countries, including all seven countries reported here. One purpose of the data collection effort was to provide country-level datasets for analysis by prospective masters or PhD students at EfD’s research centres and other scholars. A. Marsolais, S. Higdon and S. Nomburg at YouGov provided substantial technical advice with respect to the survey on which this Article is based. J.L. acknowledges support from the Project of Humanities and Social Sciences (Ministry of Education, 23YJC790094) and the International Research Cooperation Incubation Project (GJ202512). T.S. acknowledges support from Kamprad (20230142).
Funding
Open access funding provided by University of Gothenburg.
Author information
Authors and Affiliations
Contributions
All authors have read, approved and helped edit various revisions of the manuscript. In addition, the authors had specific responsibilities as indicated. R.T.C. helped design the survey questions, drafted the initial version of the paper and carried out statistical analyses. J.L. had primary responsibility for the statistical analysis aspects of the paper and prepared the figures. E.A.K. prepared the data for analysis and reviewed relevant literature. G.K. was involved in project conceptualization, oversaw survey translations and coordinated project funding and administration. E.S. was primarily responsible for the climate knowledge section of the paper. T.S. did substantial work on the climate policy aspects of the paper, oversaw the final revision of the manuscript and served as corresponding author. D.W. was involved in project conceptualization, survey design and contributing substantively to the writing of successive drafts.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Climate Change thanks Chad Baum, Adrien Fabre, Madalina Vlasceanu and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1
Kernel Density Estimates for Knowledge Scale.
Extended Data Fig. 2
Estimated effect of choosing information source as one of the three paid most attention to or having the most trust in on knowledge index 1.
Extended Data Fig. 3
Average importance of climate change by country.
Extended Data Fig. 4
Average ranking of priority given to 13 government programs across countries.
Extended Data Fig. 5
Three binary questions related to climate versus COVID-19.
Extended Data Fig. 6
Priority given to reducing seven standard health related issues.
Extended Data Fig. 7
Average agreement with climate policy statements across countries.
Extended Data Fig. 8
Public’s ranking of uses of revenue from carbon taxes.
Supplementary information
Supplementary Information (download PDF )
Supplementary discussion, Supplementary Tables 1 and 2, and screenshots of survey questions used.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Carson, R.T., Lu, J., Khossravi, E.A. et al. The public’s views on climate policies in seven large global south countries. Nat. Clim. Chang. 15, 954–962 (2025). https://doi.org/10.1038/s41558-025-02389-9
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s41558-025-02389-9
