
Abstract
Multimodal large language models (MLLMs) could enhance the accuracy of automated content moderation by integrating contextual information. This study examines how MLLMs evaluate hate speech through a series of conjoint experiments. Models are provided with a hate speech policy and shown simulated social media posts that systematically vary in slur usage, user demographics and other attributes. The decisions from MLLMs are benchmarked against judgements by human participants (n = 1,854). The results demonstrate that larger, more advanced models can make context-sensitive evaluations that are closely aligned with human judgement. However, pervasive demographic and lexical biases remain, particularly among smaller models. Further analyses show that context sensitivity can be amplified via prompting but not eliminated, and that some models are especially responsive to visual identity cues. These findings highlight the benefits and risks of using MLLMs for content moderation and demonstrate the utility of conjoint experiments for auditing artificial intelligence in complex, context-dependent applications.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$32.99 / 30 days
cancel any time
Subscribe to this journal
Receive 12 digital issues and online access to articles
$119.00 per year
only $9.92 per issue
Buy this article
- Purchase on SpringerLink
- Instant access to the full article PDF.
USD 39.95
Prices may be subject to local taxes which are calculated during checkout





Similar content being viewed by others

Data availability
The data required to replicate the results are available via GitHub at https://github.com/t-davidson/multimodal-llms-for-content-moderation-replication.
Code availability
The code required to replicate the results is available via GitHub at https://github.com/t-davidson/multimodal-llms-for-content-moderation-replication.
References
Grimmelmann, J. The virtues of moderation. Yale J. Law Technol. 17, 42–109 (2015).
Klonick, K. The new governors: the people, rules, and processes governing online speech. Harv. Law Rev. 131, 1598–1670 (2018).
Gillespie, T. Custodians of the Internet: Platforms, Content Moderation, and the Hidden Decisions That Shape Social Media (Yale Univ. Press, 2018).
Roberts, S. T. Behind the Screen (Yale Univ. Press, 2019).
Kaye, D. A. Speech Police: The Global Struggle to Govern the Internet (Columbia Global Reports, 2019).
Gorwa, R., Binns, R. & Katzenbach, C. Algorithmic content moderation: technical and political challenges in the automation of platform governance. Big Data Soc. 7, 205395171989794 (2020).
Survey on the Impact of Online Disinformation and Hate Speech (IPSOS-UNESCO, 2023); https://www.unesco.org/sites/default/files/medias/fichiers/2023/11/unesco_ipsos_survey.pdf
Álvarez-Benjumea, A. & Winter, F. The breakdown of antiracist norms: a natural experiment on hate speech after terrorist attacks. Proc. Natl Acad. Sci. USA 117, 22800–22804 (2020).
Lee, C. et al. People who share encounters with racism are silenced online by humans and machines, but a guideline-reframing intervention holds promise. Proc. Natl Acad. Sci. USA 121, 2322764121 (2024).
Williams, M. L., Burnap, P., Javed, A., Liu, H. & Ozalp, S. Hate in the machine: anti-Black and anti-Muslim social media posts as predictors of offline racially and religiously aggravated crime. Br. J. Criminol. 60, 93–117 (2019).
Müller, K. & Schwarz, C. Fanning the flames of hate: social media and hate crime. J. Eur. Econ. Assoc. 19, 2131–2167 (2021).
Strossen, N. Hate: Why We Should Resist It with Free Speech, Not Censorship (Oxford Univ. Press, 2018).
Wilson, R. A. & Land, M. K. Hate speech on social media: content moderation in context. Conn. Law Rev. 52, 1029–1076 (2021).
Kozyreva, A. et al. Resolving content moderation dilemmas between free speech and harmful misinformation. Proc. Natl Acad. Sci. USA 120, 2210666120 (2023).
Pradel, F., Zilinsky, J., Kosmidis, S. & Theocharis, Y. Toxic speech and limited demand for content moderation on social media. Am. Polit. Sci. Rev. 118, 1895–1912 (2024).
Solomon, B. C., Hall, M. E. K., Hemmen, A. & Druckman, J. N. Illusory interparty disagreement: partisans agree on what hate speech to censor but do not know it. Proc. Natl Acad. Sci. USA 121, 2402428121 (2024).
Moran, R. E., Schafer, J., Bayar, M. & Starbird, K. The end of trust and safety?: examining the future of content moderation and upheavals in professional online safety efforts. In Proc. 2025 CHI Conference on Human Factors in Computing Systems (eds Yamashita, N. et al.) 1–14 (Association for Computing Machinery, 2025); https://doi.org/10.1145/3706598.3713662
Sap, M., Card, D., Gabriel, S., Choi, Y. & Smith, N. A. The risk of racial bias in hate speech detection. In Proc. 57th Annual Meeting of the Association for Computational Linguistics (eds Korhonen, A. et al.) 1668–1678 (Association for Computational Linguistics, 2019); https://aclanthology.org/P19-1163
Davidson, T., Bhattacharya, D. & Weber, I. Racial bias in hate speech and abusive language detection datasets. In Proc. Third Workshop on Abusive Language Online (eds Roberts, S. T. et al.) 25–35 (Association for Computational Linguistics, 2019); https://doi.org/10.18653/v1/W19-3504
Harris, C., Halevy, M., Howard, A., Bruckman, A. & Yang, D. Exploring the role of grammar and word choice in bias toward African American English (AAE) in hate speech classification. In 2022 ACM Conference on Fairness, Accountability, and Transparency 789–798 (Association for Computing Machinery, 2022); https://doi.org/10.1145/3531146.3533144
Gligorić, K., Cheng, M., Zheng, L., Durmus, E. & Jurafsky, D. NLP systems that can’t tell use from mention censor counterspeech, but teaching the distinction helps. In Proc. 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) (eds Duh, K. et al.) 5942–5959 (Association for Computational Linguistics, 2024); https://doi.org/10.18653/v1/2024.naacl-long.331
Zhou, X. et al. COBRA frames: contextual reasoning about effects and harms of offensive statements. In Findings of the Association for Computational Linguistics (eds Rogers, A. et al.) 6294–6315 (Association for Computational Linguistics, 2023); https://doi.org/10.18653/v1/2023.findings-acl.392
Pavlopoulos, J., Sorensen, J., Dixon, L., Thain, N. & Androutsopoulos, I. Toxicity detection: does context really matter? In Proc. 58th Annual Meeting of the Association for Computational Linguistics (eds Jurafsky, D. et al.) 4296–4305 (Association for Computational Linguistics, 2020); https://doi.org/10.18653/v1/2020.acl-main.396
Xenos, A. et al. Toxicity detection sensitive to conversational context. First Monday 27, 1–22 (2022).
Ljubešić, N., Mozetič, I. & Kralj Novak, P. Quantifying the impact of context on the quality of manual hate speech annotation. Nat. Lang. Eng. 9, 1481–1494 (2023).
Plaza-del-Arco, F. M., Nozza, D. & Hovy, D. Respectful or toxic? Using zero-shot learning with language models to detect hate speech. In The 7th Workshop on Online Abuse and Harms (WOAH) (eds Chung, Y.-l. et al.) 60–68 (Association for Computational Linguistics, 2023); https://doi.org/10.18653/v1/2023.woah-1.6
Nghiem, H. & Daumé III, H. HateCOT: an explanation-enhanced dataset for generalizable offensive speech detection via large language models. In Findings of the Association for Computational Linguistics: EMNLP 2024 (eds Al-Onaizan, Y. et al.) 5938–5956 (Association for Computational Linguistics, 2024); https://doi.org/10.18653/v1/2024.findings-emnlp.343
Jaremko, J., Gromann, D. & Wiegand, M. Revisiting implicitly abusive language detection: evaluating LLMs in zero-shot and few-shot settings. In Proc. 31st International Conference on Computational Linguistics (eds Rambow, O. et al.) 3879–3898 (Association for Computational Linguistics, 2025); https://aclanthology.org/2025.coling-main.262/
Wang, Y., Yu, P. & He, G. Silent LLMs: using LoRA to enable LLMs to identify hate speech. In Proc. 24th ACM/IEEE Joint Conference on Digital Libraries (eds Chu, S. K. and Hu, X.) 1–5 (Association for Computing Machinery, 2025); https://doi.org/10.1145/3677389.3702555
Albladi, A. et al. Hate speech detection using large language models: a comprehensive review. IEEE Access 13, 20871–20892 (2025).
Kiela, D. et al. The hateful memes challenge: detecting hate speech in multimodal memes. In Proc. 34th International Conference on Neural Information Processing Systems (eds Larochelle, H. et al.) 2611–2624 (Curran Associates, 2020).
Zhang, Y., Nanduri, S., Jiang, L., Wu, T. & Sap, M. BiasX: ‘thinking slow’ in toxic content moderation with explanations of implied social biases. In Proc. 2023 Conference on Empirical Methods in Natural Language Processing (eds Bouamor, H. et al.) 4920–4932 (Association for Computational Linguistics, 2023); https://doi.org/10.18653/v1/2023.emnlp-main.300
Palla, K. et al. Policy-as-prompt: rethinking content moderation in the age of large language models. In Proc. 2025 ACM Conference on Fairness, Accountability, and Transparency 840–854 (Association for Computing Machinery, 2025); https://doi.org/10.1145/3715275.3732054
Bender, E. M., Gebru, T., McMillan-Major, A. & Shmitchell, S. On the dangers of stochastic parrots: can language models be too big? In Proc. 2021 ACM Conference on Fairness, Accountability, and Transparency 610–623 (Association for Computing Machinery, 2021).
Kirk, H. R. et al. Bias out-of-the-box: an empirical analysis of intersectional occupational biases in popular generative language models. In 35th Conference on Neural Information Processing Systems (eds Ranzato, M. et al.) 2611–2624 (Curran Associates, 2021).
Bianchi, F. et al. Easily accessible text-to-image generation amplifies demographic stereotypes at large scale. In Proc. 2023 ACM Conference on Fairness, Accountability, and Transparency 1493–1504 (Association for Computing Machinery, 2023); https://doi.org/10.1145/3593013.3594095
Birhane, A., Prabhu, V., Han, S., Boddeti, V. & Luccioni, S. Into the LAION’s den: investigating hate in multimodal datasets. In Proc. 37th International Conference on Neural Information Processing System 21268–21284 (Association for Computing Machinery, 2023).
Gehman, S., Gururangan, S., Sap, M., Choi, Y. & Smith, N. A. RealToxicityPrompts: evaluating neural toxic degeneration in language models. In Findings of the Association for Computational Linguistics: EMNLP 2020 (eds Cohn, T. et al.) 3356–3369 (Association for Computational Linguistics, 2020); https://doi.org/10.18653/v1/2020.findings-emnlp.301
Hofmann, V., Kalluri, P. R., Jurafsky, D. & King, S. AI generates covertly racist decisions about people based on their dialect. Nature 633, 147–154 (2024).
Ziegler, D. M. et al. Fine-tuning language models from human preferences. Preprint at http://arxiv.org/abs/1909.08593 (2020).
Bai, Y. et al. Constitutional AI: harmlessness from AI feedback. Preprint at http://arxiv.org/abs/2212.08073 (2022).
Ouyang, L. et al. Training language models to follow instructions with human feedback. In Proc. 36th International Conference on Neural Information Processing Systems (eds Koyejo, S. et al.) 27730–27744 (Curran Associates, 2022).
Bai, X., Wang, A., Sucholutsky, I. & Griffiths, T. L. Explicitly unbiased large language models still form biased associations. Proc. Natl Acad. Sci. USA 122, 2416228122 (2025).
Röttger, P. et al. XSTest: a test suite for identifying exaggerated safety behaviours in large language models. In Proc. 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) (eds Duh, K. et al.) 5377–5400 (Association for Computational Linguistics, 2024); https://aclanthology.org/2024.naacl-long.301
Hainmueller, J., Hopkins, D. J. & Yamamoto, T. Causal inference in conjoint analysis: understanding multidimensional choices via stated preference experiments. Polit. Anal. 22, 1–30 (2014).
Hainmueller, J., Hangartner, D. & Yamamoto, T. Validating vignette and conjoint survey experiments against real-world behavior. Proc. Natl Acad. Sci. USA 112, 2395–2400 (2015).
Bansak, K., Hainmueller, J., Hopkins, D. J. & Yamamoto, T. in Advances in Experimental Political Science 1st edn (eds Druckman, J. & Green, D. P.) 19–41 (Cambridge Univ. Press, 2021); https://doi.org/10.1017/9781108777919.004
Rasmussen, J. The (limited) effects of target characteristics on public opinion of hate speech laws. Preprint at PsyArXiv https://doi.org/10.31234/osf.io/j4nuc (2022).
Kusner, M., Loftus, J., Russell, C. & Silva, R. Counterfactual fairness. In Proc. 31st International Conference on Neural Information Processing Systems (eds Guyon, I. et al.) 4069–4079 (Curran Associates, 2017).
Kleinberg, J., Ludwig, J., Mullainathan, S. & Rambachan, A. Algorithmic fairness. AEA Pap. Proc. 108, 22–27 (2018).
Dixon, L., Li, J., Sorensen, J., Thain, N. & Vasserman, L. Measuring and mitigating unintended bias in text classification. In Proc. 2018 AAAI/ACM Conference on AI, Ethics, and Society (eds Furman, J. et al.) 67–73 (Association for Computing Machinery, 2018); https://doi.org/10.1145/3278721.3278729
Buolamwini, J. & Gebru, T. Gender shades: intersectional accuracy disparities in commercial gender classification. Proc. Mach. Learn. Res. 81, 1–15 (2018).
Röttger, P. et al. HateCheck: functional tests for hate speech detection models. In Proc. 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) (eds Zong, C. et al.) 41–58 (Association for Computational Linguistics, 2021); https://doi.org/10.18653/v1/2021.acl-long.4
Fraser, K. & Kiritchenko, S. Examining gender and racial bias in large vision-language models using a novel dataset of parallel images. In Proc. 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) (eds Graham, Y. & Purver, M.) 690–713 (Association for Computational Linguistics, 2024); https://doi.org/10.18653/v1/2024.eacl-long.41
Argyle, L. P., Busby, E. C., Fulda, N., Rytting, C. & Wingate, D. Out of one, many: using language models to simulate human samples. Polit. Anal. 31, 337–351 (2023).
Horton, J. J. Large Language Models as Simulated Economic Agents: What Can We Learn from Homo silicus? NBER Working Paper 31122 (NBER, 2023).
Bail, C. A. Can generative AI improve social science? Proc. Natl Acad. Sci. USA 121, 2314021121 (2024).
Silva, L., Mondal, M., Correa, D., Benevenuto, F. & Weber, I. Analyzing the targets of hate in online social media. In Proc. International AAAI Conference on Web and Social Media 687–690 (AAAI Press, 2016); https://doi.org/10.1609/icwsm.v10i1.14811
Hartvigsen, T. et al. ToxiGen: a large-scale machine-generated dataset for adversarial and implicit hate speech detection. In Proc. 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (eds Muresan, S. et al.) 3309–3326 (Association for Computational Linguistics, 2022).
OpenAI et al. GPT-4 technical report. Preprint at https://arxiv.org/abs/2303.08774 (2024).
Bertrand, M. & Mullainathan, S. Are Emily and Greg more employable than Lakisha and Jamal? A field experiment on labor market discrimination. Am. Econ. Rev. 94, 991–1013 (2004).
Vecchiato, A. & Munger, K. Introducing the visual conjoint, with an application to candidate evaluation on social media. J. Exp. Polit. Sci. 12, 57–71 (2025).
López Ortega, A. & Radojevic, M. Visual conjoint vs. text conjoint and the differential discriminatory effect of (visible) social categories. Polit. Behav. 47, 335–353 (2025).
Gaddis, S. M. How Black are Lakisha and Jamal? Racial perceptions from names used in correspondence audit studies. Sociol. Sci. 4, 469–489 (2017).
Karras, T., Laine, S. & Aila, T. A style-based generator architecture for generative adversarial networks. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 4401–4410 (IEEE, 2019).
Radford, A. et al. Learning transferable visual models from natural language supervision. In Proc. 38th International Conference on Machine Learning (eds Meila, M. & Zhang, T.) 1–16 (PMLR, 2021).
Dosovitskiy, A. et al. An image is worth 16 × 16 words: transformers for image recognition at scale. In International Conference on Learning Representations (OpenReview, 2021); https://openreview.net/forum?id=YicbFdNTTy
Alayrac, J.-B. et al. Flamingo: a visual language model for few-shot learning. In Advances in Neural Information Processing Systems 23716–23736 (NeurIPS, 2022).
Li, J., Li, D., Savarese, S. & Hoi, S. BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models. In Proc. 40th International Conference on Machine Learning (eds Krause, A. et al.) 19730–19742 (PMLR, 2023); https://proceedings.mlr.press/v202/li23q.html
Chen, X. et al. PaLI: a jointly-scaled multilingual language-image model. In International Conference on Learning Representations (OpenReview, 2023).
Liu, H., Li, C., Wu, Q. & Lee, Y. J. Visual instruction tuning. In Advances in Neural Information Processing Systems 34892–34916 (NeurIPS, 2023).
Dai, W. et al. InstructBLIP: towards general-purpose vision-language models with instruction tuning. In Proc. 37th Conference on Neural Information Processing Systems (eds Oh, A. et al.) 49250–49267 (Curran Associates, 2023).
Fasching, N. & Lelkes, Y. Model-dependent moderation: inconsistencies in hate speech detection across LLM-based systems. In Findings of the Association for Computational Linguistics: ACL 2025 (eds Che, W. et al.) 22271–22285 (Association for Computational Linguistics, 2025); https://aclanthology.org/2025.findings-acl.1144/
Kaplan, J. et al. Scaling laws for neural language models. Preprint at https://arxiv.org/abs/2001.08361 (2020).
Chung, H. W. et al. Scaling instruction-finetuned language models. J. Mach. Learn. Res. 25, 1–53 (2024).
Yang, Y. et al. HARE: explainable hate speech detection with step-by-step reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2023 (eds Bouamor, H. et al.) 5490–5505 (Association for Computational Linguistics, 2023); https://doi.org/10.18653/v1/2023.findings-emnlp.365
GPT-4o System Card (OpenAI, 2024); https://cdn.openai.com/gpt-4o-system-card.pdf
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities (Gemini Team, 2025); https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf
Spirling, A. Why open-source generative AI models are an ethical way forward for science. Nature 616, 413–413 (2023).
Ollion, É., Shen, R., Macanovic, A. & Chatelain, A. The dangers of using proprietary LLMs for research. Nat. Mach. Intell. 6, 4–5 (2024).
Wang, P. et al. Qwen2-VL: enhancing vision-language model’s perception of the world at any resolution. Preprint at https://arxiv.org/abs/2409.12191 (2024).
Gemma Team. Gemma 3 technical report. Preprint at https://arxiv.org/abs/2503.19786 (2025).
Zhu, J. et al. InternVL3: exploring advanced training and test-time recipes for open-source multimodal models. Preprint at https://arxiv.org/abs/2504.10479 (2025).
Wu, Q. & Semaan, B. ‘How do you quantify how racist something is?’: color-blind moderation in decentralized governance. Proc. ACM Hum. Comput. Interact. 7, 239 (2023).
Zhou, X., Sap, M., Swayamdipta, S., Choi, Y. & Smith, N. Challenges in automated debiasing for toxic language detection. In Proc. 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume (eds Merlo, P. et al.) 3143–3155 (Association for Computational Linguistics, 2021); https://doi.org/10.18653/v1/2021.eacl-main.274
Finkel, E. J. et al. Political sectarianism in America. Science 370, 533–536 (2020).
Mamakos, M. & Finkel, E. J. The social media discourse of engaged partisans is toxic even when politics are irrelevant. PNAS Nexus 2, 325 (2023).
Tenório, N. & Bjørn, P. Online harassment in the workplace: the role of technology in labour law disputes. Comput. Support. Coop. Work 28, 293–315 (2019).
Nägel, C., Kros, M. & Davenport, R. Three lions or three scapegoats: racial hate crime in the wake of the Euro 2020 final in London. Sociol. Sci. 11, 579–599 (2024).
Vidgen, B., Thrush, T., Waseem, Z. & Kiela, D. Learning from the worst: dynamically generated datasets to improve online hate detection. In Proc. 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (eds Zong, C. et al.) 1667–1682 (Association for Computational Linguistics, 2021); https://doi.org/10.18653/v1/2021.acl-long.132
Bonilla-Silva, E. Racism Without Racists: Color-Blind Racism and the Persistence of Racial Inequality in America (Rowman & Littlefield, 2003).
Benjamin, R. Race After Technology: Abolitionist Tools for the New Jim Code (Polity, 2019).
Bonilla-Silva, E. Rethinking racism: toward a structural interpretation. Am. Sociol. Rev. 62, 465–480 (1997).
Feagin, J. Systemic Racism: A Theory of Oppression (Routledge, 2013); https://www.taylorfrancis.com/books/mono/10.4324/9781315880938/systemic-racism-joe-feagin
Delgado, R. & Stefancic, J. Critical Race Theory: An Introduction 3rd edn (NYU Press, 2017); https://doi.org/10.2307/j.ctt1ggjjn3
Valentino, L. & Warren, E. Cultural heterogeneity in Americans’ definitions of racism, sexism, and classism: results from a mixed-methods study. Am. J. Sociol. 130, 846–892 (2025).
Gallegos, I. O. et al. Bias and fairness in large language models: a survey. Comput. Ling. 50, 1097–1179 (2024).
Scheuerman, M. K., Wade, K., Lustig, C. & Brubaker, J. R. How we’ve taught algorithms to see identity: constructing race and gender in image databases for facial analysis. Proc. ACM Hum. Comput. Interact. 4, 58 (2020).
Maluleke, V. H. et al. Studying bias in GANs through the lens of race. In Computer Vision—ECCV 2022 (eds Avidan, S. et al.) 344–360 (Springer, 2022); https://doi.org/10.1007/978-3-031-19778-9_20
King, R. D. & Johnson, B. D. A punishing look: skin tone and Afrocentric features in the halls of justice. Am. J. Sociol. 122, 90–124 (2016).
Butler, D. M. & Tavits, M. Does the hijab increase representatives’ perceptions of social distance? J. Polit. 79, 727–731 (2017).
Davani, A., Díaz, M., Baker, D. & Prabhakaran, V. Disentangling perceptions of offensiveness: cultural and moral correlates. In Proc. 2024 ACM Conference on Fairness, Accountability, and Transparency 2007–2021 (Association for Computing Machinery, 2024); https://doi.org/10.1145/3630106.3659021
Waseem, Z., Davidson, T., Warmsley, D. & Weber, I. Understanding abuse: a typology of abusive language detection subtasks. In Proc. 1st Workshop on Abusive Language Online (eds Waseem, Z. et al.) 78–84 (Association for Computational Linguistics, 2017); https://doi.org/10.18653/v1/W17-3012
Yu, X., Zhao, A., Blanco, E. & Hong, L. A fine-grained taxonomy of replies to hate speech. In Proc. 2023 Conference on Empirical Methods in Natural Language Processing (eds Bouamor, H. et al.) 7275–7289 (Association for Computational Linguistics, 2023); https://doi.org/10.18653/v1/2023.emnlp-main.450
Chandrasekharan, E., Gandhi, C., Mustelier, M. W. & Gilbert, E. Crossmod: a cross-community learning-based system to assist Reddit moderators. Proc. ACM Hum. Comput. Interact. 3, 174 (2019).
Scheuerman, M. K., Jiang, J. A., Fiesler, C. & Brubaker, J. R. A framework of severity for harmful content online. Proc. ACM Hum. Comput. Interact. 5, 368 (2021).
Rozado, D. The political preferences of LLMs. PLoS ONE 19, 0306621 (2024).
Cunningham, H., Ewart, A., Riggs, L., Huben, R. & Sharkey, L. Sparse autoencoders find highly interpretable features in language models. Preprint at https://arxiv.org/abs/2309.08600 (2023).
Sharkey, L. et al. Open problems in mechanistic interpretability. In Transactions on Machine Learning Research (OpenReview, 2025).
Hickey, D. et al. Auditing Elon Musk’s impact on hate speech and bots. Proc. Int. AAAI Conf. Web Soc. Media 17, 1133–1137 (2023).
Hendrix, J. Transcript: Mark Zuckerberg announces major changes to Meta’s content moderation policies and operations. TechPolicy.Press https://techpolicy.press/transcript-mark-zuckerberg-announces-major-changes-to-metas-content-moderation-policies-and-operations (2025).
Kolla, M., Salunkhe, S., Chandrasekharan, E. & Saha, K. LLM-Mod: can large language models assist content moderation? In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (eds Mueller, F. et al.) 1–8 (Association for Computing Machinery, 2024); https://doi.org/10.1145/3613905.3650828
Carlson, D. & Montgomery, J. M. A pairwise comparison framework for fast, flexible, and reliable human coding of political texts. Am. Polit. Sci. Rev. 111, 835–843 (2017).
Benoit, K., Munger, K. & Spirling, A. Measuring and explaining political sophistication through textual complexity. Am. J. Polit. Sci. 63, 491–508 (2019).
Breunig, C. & Guinaudeau, B. Measuring legislators’ ideological position in large chambers using pairwise-comparisons. Polit. Sci. Res. Methods https://doi.org/10.1017/psrm.2024.68 (2025).
Galinsky, A. D. et al. The reappropriation of stigmatizing labels: the reciprocal relationship between power and self-labeling. Psychol. Sci. 24, 2020–2029 (2013).
Davidson, T., Warmsley, D., Macy, M. & Weber, I. Automated hate speech detection and the problem of offensive language. In Proc. 11th International AAAI Conference on Web and Social Media (ICWSM '17) 512–515 (AAAI Press, 2017).
Nightingale, S. J. & Farid, H. AI-synthesized faces are indistinguishable from real faces and more trustworthy. Proc. Natl Acad. Sci. USA 119, 2120481119 (2022).
Weber, I., Gonçalves, J., Masullo, G. M., Silva, M. & Hofhuis, J. Who can say what? Testing the impact of interpersonal mechanisms and gender on fairness evaluations of content moderation. Soc. Media Soc. 10, 1–15 (2024).
Munger, K. Tweetment effects on the tweeted: experimentally reducing racist harassment. Polit. Behav. 39, 629–649 (2016).
Ventura, T., McCabe, K., Chang, K.-C. & Munger, K. TiagoVentura/conjoints_tweets. GitHub https://github.com/TiagoVentura/conjoints_tweets (2024).
Guess, A. M. & Munger, K. Digital literacy and online political behavior. Polit. Sci. Res. Methods 1, 110–128 (2022).
Wei, J. et al. Finetuned language models are zero-shot learners. In International Conference on Learning Representations (OpenReview, 2022); https://openreview.net/forum?id=gEZrGCozdqR
Radford, A. et al. Language Models Are Unsupervised Multitask Learners (OpenAI, 2019).
Bai, S. et al. Qwen2.5-VL technical report. Preprint at https://arxiv.org/abs/2502.13923 (2025).
Frantar, E., Ashkboos, S., Hoefler, T. & Alistarh, D. OPTQ: accurate quantization for generative pre-trained transformers. OpenReview https://openreview.net/forum?id=tcbBPnfwxS (2023).
Leeper, T. J., Hobolt, S. B. & Tilley, J. Measuring subgroup preferences in conjoint experiments. Polit. Anal. 28, 207–221 (2020).
Acknowledgements
This research was supported by a Foundational Integrity Research award from Meta and computing credits granted via OpenAI’s Research Access Program. I thank F. Traylor for assistance with Qualtrics and the Office of Advanced Research Computing at Rutgers University for providing access to the Amarel high-performance computing cluster that was used to implement the experiments with open-weights models. I thank the following people and audiences for feedback on earlier versions of this research: D. Karell, M. Kenwick, K. Munger, H. Shepherd and participants at the Culture Workshop at Rutgers University; IC2S2, SICSS and the ASA Methodology Section conference at the University of Pennsylvania; the Trust & Safety Conference at Stanford University; the School of Sociology Colloquium at the University of Arizona; the Blackmar Lecture at the University of Kansas; and the ASA Annual Meeting.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The author declares no competing interests.
Peer review
Peer review information
Nature Human Behaviour thanks Kristina Gligorić and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
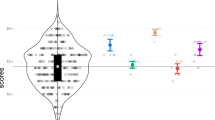
Extended Data Fig. 1 Differences in the effects of slurs by identity for generic insults and homophobia.
This figure shows the difference in marginal means for generic insults and homophobia between users with a specified race and gender and the reference group, anonymous users. Each column shows the results for a specified slur type, and each point represents the estimated difference in marginal means, and is colored based on the identity depicted. The top row shows results for human subjects (Nposts = 55,620 evaluated by Nsubjects=1854). The remaining rows show results for each model tested, where Nposts = 60,000 for each model. Error bars are 95% confidence intervals: the MLLM results use bootstrap confidence intervals, and the human experiment results include subject-level clustered standard errors.
Extended Data Fig. 2 Differences in the effects of slurs by identity across prompts (closed models).
This figure shows the difference in marginal means for between users with an identity cue and anonymous users for each slur and how these differences vary across prompts. The results for each of the closed models are shown (Nposts = 60,000 for each model). The top row shows results for human subjects (Nposts = 55,620 evaluated by Nsubjects=1854). Each point represents the estimated difference in marginal means and is colored based on the identity depicted. The shape of each point denotes the prompt variant. Error bars are 95% confidence intervals: the MLLM results use bootstrap confidence intervals, and the human experiment results include subject-level clustered standard errors.
Extended Data Fig. 3 Differences in the effects of slurs by identity across prompts (open-weights models).
This figure shows the difference in marginal means for between users with an identity cue and anonymous users for each slur and how these differences vary across prompts. The results for each of the open-weights models are shown (Nposts = 60,000 for each model). The top row shows results for human subjects (Nposts = 55,620 evaluated by Nsubjects=1854). Each point represents the estimated difference in marginal means and is colored based on the identity depicted. The shape of each point denotes the prompt variant. Error bars are 95% confidence intervals: the MLLM results use bootstrap confidence intervals, and the human experiment results include subject-level clustered standard errors.
Extended Data Fig. 4 Differences in the effects of slurs by identity across identity cue modalities (closed models).
This figure shows the difference in marginal means for each slur between users with an identity cue and anonymous users and how these differences vary depending on the cue modality. Each column shows results for one of the three racialized slur types and each row corresponds to one of the closed models (Nposts = 60,000 for each model). Each point represents the estimated difference in marginal means and is colored based on the identity depicted, and the shape of each point denotes the type of vignette used. Error bars are 95% confidence intervals: the MLLM results use bootstrap confidence intervals.
Extended Data Fig. 5 Differences in the effects of slurs by identity across identity cue modalities (open-weights models).
This figure shows the difference in marginal means for each slur between users with an identity cue and anonymous users and how these differences vary depending on the cue modality. Each column shows results for one of the three racialized slur types and each row corresponds to one of the open-weights models (Nposts = 60,000 for each model). Each point represents the estimated difference in marginal means and is colored based on the identity depicted, and the shape of each point denotes the type of vignette used. Error bars are 95% confidence intervals: the MLLM results use bootstrap confidence intervals.
Supplementary information
Supplementary Information
Supplementary Table 1, Figs. 1–7, Methods 1–6 and Discussions 1 and 2.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Davidson, T. Multimodal large language models can make context-sensitive hate speech evaluations aligned with human judgement. Nat Hum Behav (2025). https://doi.org/10.1038/s41562-025-02360-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41562-025-02360-w
