
Abstract
The set of quantum logic gates that can be easily implemented is fundamental to the performance of quantum computers, as it governs the accuracy of basic quantum operations and dictates the complexity of implementing quantum algorithms. Traditional approaches to extending gate sets often require operating devices outside the ideal parameter regimes used to realize qubits, leading to increased control complexity while offering only a limited set of gates. Here we experimentally demonstrate a unified and versatile gate scheme capable of generating arbitrary two-qubit gates using only an exchange interaction and qubit driving on a superconducting quantum processor. We achieve high fidelities averaging 99.38% across a wide range of commonly used two-qubit unitaries, enabling precise multipartite entangled state preparation. Furthermore, we successfully produce a B gate, which efficiently synthesizes the entire family of two-qubit gates. Our results establish that fully exploiting the capabilities of the exchange interaction can yield a comprehensive and highly accurate gate set. With maximum expressivity, optimal gate time, demonstrated high fidelity and easy adaption to other quantum platforms, our unified control scheme offers the prospect of improved performance in quantum hardware and algorithm development.
Similar content being viewed by others

Main
Quantum computing stands at the forefront of technological innovation, offering the potential to solve complex problems beyond the reach of classical computers. At the heart of quantum computation are quantum algorithms, which are executed using circuits typically composed of hardware-native single-qubit and two-qubit gates. Many existing quantum algorithms are inspired by classical computing paradigms and predominantly rely on gate sets formed from the two-qubit Controlled-NOT (CNOT) gate or its variants. While this approach has been instrumental in a wide range of developments, it does not fully exploit the inherent capabilities of quantum hardware1. In addition to improving gate fidelity through better coherence and faster operation times, another promising avenue to enhance performance is to expand the repertoire of available quantum gates, enabling more efficient circuit construction with reduced depth and gate count2.
Implementing different types of native gate on the same device often requires accessing various transitions within the Hilbert space, complicating hardware design and device calibration3,4,5. In superconducting qubits, for example, the \(\left\vert 01\right\rangle\)–\(\left\vert 10\right\rangle\) transition is used to implement iSWAP or \(\sqrt{{\rm{iSWAP}}}\) gates3,6, while the \(\left\vert 11\right\rangle\)–\(\left\vert 20\right\rangle\) transition supports the Controlled-Z (CZ) gate, equivalent to the CNOT up to single-qubit rotations7. However, utilizing non-computational states such as \(\left\vert 2\right\rangle\) can lead to faster decoherence and, more critically, correlated errors that undermine quantum error correction protocols8.
In addition to these discrete gates, researchers have explored continuous two-qubit gate sets, such as the f Sim5 or XXZ family9, the XY family10 and recently introduced fractional gates in both superconducting11 and trapped-ion systems12—offering better expressivity than traditional discrete sets. Despite these advances, such gates still represent only a tiny fraction (technically, a measure-zero subset) of all possible two-qubit operations within the entire special unitary group SU(4). As a result, compiling arbitrary quantum operations into sequences of these gates remains non-trivial and typically provides limited practical benefits for general-purpose applications. Further expanding the gate alphabet often requires more complex device architectures or intricate control protocols, adding overhead and potential error sources. This balance, between the desire for a comprehensive and expressive gate set and the constraints of practical hardware, is a central challenge in quantum computing. Although it is theoretically possible to access the entire SU(4) group in different systems13,14,15, a native two-qubit gate scheme that provides full operational capability yet remains straightforward to implement on state-of-the-art hardware has not yet been demonstrated.
In this work, we experimentally demonstrate the AshN gate scheme16, capable of natively generating arbitrary two-qubit gates. By addressing the exchange interaction between qubits with near-resonant driving on a superconducting quantum processor, we implement the time-optimal generation of a diverse mixture of commonly used two-qubit gates in one step, achieving an average fidelity of 99.38%. As a practical application, we generate multi-qubit Dicke states with single and double excitations, achieving notably high accuracy, by leveraging high-fidelity AshN gates and a substantial reduction in the two-qubit gate count compared with traditional CNOT-based implementations. To further enhance its practicality, particularly in terms of calibration costs, we demonstrate native generation of the B gate, the unique operation that enables the synthesis of any two-qubit operation using only two applications of the gate combined with single-qubit rotations17,18. This approach not only minimizes the calibration cost but also facilitates more uniform performance throughout the SU(4) manifold, enhancing practicality for general-purpose applications.
The implications of this scheme are multifaceted. First, it relies on a single type of interaction—the exchange interaction between \(\left\vert 10\right\rangle\) and \(\left\vert 01\right\rangle\)—to realize various two-qubit gates, thereby unifying the control strategy. Compared with conventional approaches that rely on different transitions to produce different gate types, our scheme simplifies the frequency allocation strategy in large-scale processors and avoids leakage into non-computational states. Second, while synthesizing arbitrary two-qubit gates typically requires three applications of CZ or iSWAP gates19, our approach enables these operations to be implemented directly, with evolution times and fidelities comparable to those of a single CZ or iSWAP. By combining the full SU(4) expressivity with time-optimal implementations of target unitaries supported by the available Hamiltonian, the AshN control scheme is able not only to deliver optimal performance with current superconducting processor architectures, but also to encourage hardware designers to tailor their systems and algorithm developers to rethink quantum circuits under the AshN framework. Finally, our scheme only requires qubits to be brought into resonance for exchange interaction and individually driven—a capability available in many physical platforms.
Implementing the AshN gate with superconducting qubits
Our experiment utilizes qubits embedded in a 72-qubit superconducting quantum processor arranged in a square lattice. The qubits are made of tantalum on sapphire20, yielding an average T1 relaxation times of 68.8 μs. The basic building block consists of two transmon qubits (with frequencies ω1 and ω2) and a tunable coupler (frequency ωc). The coupler, also by design a transmon qubit, is used to dynamically adjust the qubit–qubit coupling strength for fast gate operations and low crosstalk (Fig. 1a). All components are frequency-tunable and have a floating design21. Individual control lines are directly wired to the corresponding qubits and couplers, delivering diplexed signals for both frequency modulation (from DC to 500 MHz) and microwave driving (around 4 GHz)22. Detailed device information and the experimental set-up can be found in Supplementary Section G.

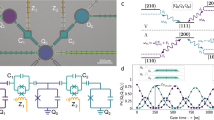
a, Top: microscope image of the superconducting quantum processor focusing on two transmon qubits (blue and red) and the tunable coupler (green). The meandering wires are quarter-wave transmission-line resonators for qubit readout. Bottom: the circuit diagram. b, The energy diagram of a two-qubit subsystem showing the exchange interaction (strength g) and qubit drivings (amplitudes Ω1,2 and detuning Δ) used in an AshN gate. c, Synthesis of an arbitrary SU(4) unitary using the AshN gate. According to the KAK decomposition, any SU(4) operation is equivalent to a Weyl chamber unitary (the part in the dashed box) up to single-qubit operations Ki (i = 1, 2, 3 or 4). A calibrated AshN gate is also equivalent to the same Weyl chamber unitary up to a different set of single-qubit operations Vi (i = 1, 2, 3 or 4). The Weyl chamber unitary, derived from the Heisenberg Hamiltonian, can be visualized within a tetrahedral region OA1A2A3 known as the Weyl chamber and parameterized by the three coordinates (a, b, c). The coordinates of the vertices are O: (0, 0, 0), A1: (π/4, π/4, − π/4), A2: (π/4, π/4, π/4), A3: (π/4, 0, 0). d, Compiled pulse sequences for an arbitrary SU(4) operation. The AshN gate control has two parts: the iSWAP component and the driving component. They are implemented with flux pulses via the Z control lines and microwave pulses via the XY control lines, respectively. The typical duration of flux pulses is 40 ns, including a 5-ns rise and fall time. Successive single-qubit operations (Vi and Ki) are merged into a single SU(2) operation, which is further compiled into four π/2 pulses using the PMW-4 method. e, Top: measured population swapping at different coupler biases by initializing one of the qubits at its excited state and bringing the two qubits into resonance. Bottom: extracted coupling strength versus coupler bias. f, Top: measured Rabi oscillation of one of the qubits at different driving amplitudes. Bottom: extracted Rabi frequency versus drive amplitude. g, QPT for KAK decomposition. After combining the iSWAP component and the driving component simultaneously, we use QPT to infer the compensatory single-qubit gates (Vi). h, Closed-loop optimization of the XEB fidelity at a fixed cycle number, typically 50–100, using a Bayesian optimizer.
The energy level diagram in Fig. 1b depicts the computational subspace of two qubits set to resonance with ω1 = ω2 = ω and the interlevel couplings, including tunable exchange coupling (XX + YY) with strength g(ωc) and local driving transitions with amplitudes Ω1,2 and detuning Δ = ω − ωd between the qubit frequency and the drive frequency ωd. These transitions span the entire subspace, and their intensities are all programmable in our system, opening up more possibilities for the system dynamics when acting together. In the rotating frame, the two-qubit Hamiltonian can be expressed as
where X, Y, Z and I are the Pauli operators. It suffices to verify that the operators XX + YY, ZI + IZ, XI and IX generate the Lie algebra \({\mathfrak{su}}(4)\) by iteratively applying the Lie bracket operation, enabling the implementation of any unitary operation through a sequence of exponentials of the control Hamiltonians13,15.
The AshN gate scheme, proposed in ref. 16, represents a stronger form of the well-established controllability results and provides a straightforward method for utilizing the independent control of the parameters in equation (1) together with the evolution time τ to generate the local equivalent of an arbitrary two-qubit operation in SU(4) via a single pulse and, for most cases, within an optimal time evolution in the sense that even when considering scenarios evolving under the same canonical form but with different canonical parameters—or even interleaving single-qubit operations—the total Hamiltonian evolution time cannot be made shorter. Here, time optimality means the theoretical lower bound of τ required to achieve a certain unitary given a fixed coupling g. In practice, it is crucial to minimize the exposure of the qubit to decoherence. Below, we begin with a brief overview of the AshN scheme and describe our protocol for implementing it with superconducting qubits.
According to the KAK decomposition or the more general Cartan’s decomposition23, any two-qubit unitary U ∈ SU(4) can be expressed as
where λ ∈ {1, i} and
Here, K1, K2, K3, K4 ∈ SU(2) are single-qubit unitaries and \(a,b,c\in {\mathbb{R}}\). The operators U and Uw are said to be locally equivalent because they differ only by global phase and single-qubit operations. Due to symmetry reasons, the geometric structure of Uw can be visualized within a tetrahedral region known as the Weyl chamber24, parameterized by the coordinates (a, b, c) as shown in Fig. 1c. Unitaries that have the same coordinates are then locally equivalent and belong to the same class. For example, some hardware-native gates, such as the CZ gate7,25,26 and the cross-resonance (CR) gate27, are all locally equivalent to the CNOT gate.
For any unitary represented by its local equivalence class Uw(a, b, c), the AshN scheme provides a convenient algorithm that determines the values of the corresponding control parameters Ω1, Ω2, Δ and τ for a given g. By applying these control parameters to the Hamiltonian in equation (1) and allowing it to evolve for a duration τ, an AshN gate UAshN is generated, which is locally equivalent to the target Uw. Therefore, following the local equivalence relations U → Uw → UAshN, any two-qubit operation in SU(4) can be decomposed into an AshN gate sandwiched between single-qubit operations, as illustrated in Fig. 1c. The single-qubit operations on either side of UAshN can be seamlessly merged with adjacent single-qubit operations when implementing quantum algorithms with UAshN, ensuring that implementing a locally equivalent two-qubit operation does not introduce any additional single-qubit overhead. The AshN scheme is by far the only approach we know that enables native generation of the entire Weyl chamber, thereby achieving maximum expressivity, particularly at the current stage where multi-qubit control remains underdeveloped in most platforms. By comparison, the regions corresponding to the fSim family can be identified as the three faces of the tetrahedron, that is, OA1A2, OA2A3 and OA3A1 in Fig. 1c; the line OP represents the XY family.
In our superconducting processor, the AshN gate is realized by synchronizing the time windows of the XX + YY interaction and the qubit driving signals (Fig. 1d). The former involves adjusting the two qubits to be resonant and turning on the coupling by simultaneously modulating the frequencies of the qubits and coupler via Z pulses. This part alone generates an iSWAP-type operation with a swap angle θ = gτ (with θ = π/2 corresponding to an exact iSWAP gate); hence, we refer to it as the iSWAP component. The latter part involves qubit driving using XY pulses, similar to those in a standard Rabi experiment, and is referred to as the driving component.
As single-qubit phase gates cannot propagate through a general two-qubit gate, software solutions such as virtual-Z gates or phase-swapping techniques are not directly applicable28. Meanwhile, applying physical phase gates with various phases adds complexity during practical implementation. To address this, we adopt a generalization of the virtual-Z gate that is compatible with arbitrary two-qubit operations: the PMW-4 scheme29. This approach decomposes any SU(2) operation into four π/2 microwave pulses (which can be reduced to three if a π pulse is used) with analytically calculated phases. In addition to these advantages, maintaining a uniform pulse pattern causes the signal that cross-talks to nearby qubits to impose a fixed Stark effect, thereby simplifying the correction procedure30. Further details on the PMW-4 scheme and the calculation of compensatory gates are provided in the Supplementary Section I.
The calibration of AshN gates follows a systematic procedure. First, we separately calibrate the iSWAP and driving components to determine the dependencies of the control parameters g and Ω, as shown in Fig. 1e,f, providing an initial estimate of the control parameters for targeting Uw(a, b, c). Next, we combine the iSWAP and driving components by diplexing Z pulses and XY pulses to evaluate the gate’s performance and proceed with multiple stages of optimization. In the first stage, quantum process tomography (QPT) is performed to extract the actual values of (a, b, c) and minimize the distance from the target coordinates (Fig. 1g). Following this, single-qubit compensatory gates are fixed, and the second optimization stage fine-tunes the control parameters ω1, g, Ω1, Ω2 and Δ by minimizing the error rate through cross-entropy benchmarking (XEB), as shown in Fig. 1h. This stepwise calibration process ensures precise control and optimal performance of the AshN gates.
We demonstrate the expressivity of the AshN scheme by implementing a diverse set of commonly encountered SU(4) unitaries, covering a wide range of points across the Weyl chamber (Fig. 2). Our selection also covers three distinct regions within the tetrahedron, highlighted in blue, yellow and red, each corresponding to a specific protocol variant for converting the Weyl chamber coordinates (a, b, c) into the control parameters (g, Ω1, Ω2, Δ and τ). In this experiment, we first assume a uniform coupling strength g and estimate the gate time for each AshN gate. We then fix the gate time and optimize the coupling strength and other parameters. Gate information is listed in Table 1 for comparison.

a–j, The QPT results of \(\sqrt{\rm{iSWAP}}\) gate (a); \(\sqrt{\rm{SWAP}}\) gate (b); SWAP1/4 gate (c); CV gate (d), short for Controlled-V gate, which is the square root of the CNOT gate54; iSWAP gate (e); CNOT gate (f); QFT gate (g) that refers to the quantum Fourier transform, which acts on two qubits and occupies a position halfway between iSWAP and SWAP54; SWAP gate (h); B gate (i); and ECP† (j), the Hermitian conjugate of ECP that refers to the peak of the pyramid of gates in the Weyl chamber that can be created with a \(\sqrt{\rm{iSWAP}}\) sandwich54,55. In the experiments, a Bayesian readout correction is used in the QPT results. The error per gate (EPG) results are obtained from XEB experiments to avoid state preparation and measurement errors. The uncertainties represent the standard deviation derived from a bootstrapping method. See Supplementary Section M for details. Note that, throughout this Article, we define the Weyl chamber unitary according to equation (3). In the otherwise convention with a negative sign on the exponent, the gate we demonstrate here would be the corresponding Hermitian conjugate.
We benchmark all these AshN gates using both QPT and XEB, with the average XEB fidelity reaching 99.38%. The standard deviation of error within these different gates is 0.17%, yielding a relative standard deviation of 29%. Such a strong variance is unsurprising, given that the control parameters cover a wide range. For example, the gate time ranges from 20 ns for \(\sqrt{{\rm{iSWAP}}}\) to 70 ns for SWAP1/4, leading to drastically different susceptibility to decoherence and other non-idealities. In general, we find that the gate error rate increases with gate time, which can be explained by the measured decoherence during interaction (see Supplementary Section N for details).
Multipartite entangled state generation using AshN gates
To show the advantages of the AshN gates, we demonstrate the efficient preparation of Dicke states with single and double excitations. These states form a family of highly entangled states with important applications in quantum computation, quantum networking and quantum metrology31,32,33.
The single-excitation Dicke state is also known as the W state. Here, we implement a ten-qubit W state, \(\left\vert {W}_{10}\right\rangle\), using the circuit shown in Fig. 3a that consists of nine two-qubit gates. This protocol also enables the generation of an N-qubit W state using only (N − 1) two-qubit gates, which represents the theoretical lower bound under the assumption of no multi-qubit gates or ancillary qubits. By comparison, achieving the same goal with CNOT gates has a provable lower bound of \(\frac{15N-3}{14}\) gates6, which already exceeds N − 1. Moreover, numerical evidence suggests that the actual lower bound is (2N − 3) (see Supplementary Section O for details). We select N = 10 to balance the cost of quantum state tomography, and this choice adequately demonstrates the advantage. We repeat standard quantum state tomography seven times and estimate the fidelity to be 0.913 ± 0.012 (Fig. 3b), surpassing previous demonstrations34,35,36. With our method, it is also straightforward to generate W states with arbitrary phases.

a, Circuit to prepare the ten-qubit W state \(\left\vert {W}_{10}\right\rangle\). b, Density matrix ρ obtained through quantum state tomography of the \(\left\vert {W}_{10}\right\rangle\) state with an estimated fidelity of 0.913 ± 0.012. c, Circuit to prepare the four-qubit two-excitation Dicke state \(\left\vert {D}_{4}^{2}\right\rangle\). d, Density matrix ρ corresponds to \(\left\vert {D}_{4}^{2}\right\rangle\) with an estimated fidelity of 0.926 ± 0.001.
Adding more excitations to the Dicke state substantially increases the circuit complexity, posing substantial challenges for solid-state qubits, which often suffer from limited connectivity. By utilizing the full SU(4) expressivity of the AshN gates, we implement a circuit that generates the four-qubit double-excitation Dicke state \(\left\vert {D}_{4}^{2}\right\rangle\) with eight SU(4) operations (Fig. 3c); by comparison, an existing scheme for exact synthesis of such a state requires 14 CNOT gates37. Our final state yields a fidelity of 0.926 ± 0.001 (Fig. 3d), demonstrating the advantage of the digital synthesis of such a complex entangled state compared with the analogue approach33,38 (see Supplementary Section O for details).
Uniform synthesis of arbitrary SU(4) operations using B gates
While we have demonstrated the capability to implement arbitrary two-qubit operations in a single step, realizing the full SU(4)—which contains an infinite number of possibilities—remains practically infeasible due to the cost of calibration. We explain in Supplementary Section Q how this issue can be resolved at the software level. Here, we introduce an alternative approach for efficiently implementing arbitrary two-qubit operation. The B gate, located at (π/4, π/8, 0)—halfway between the iSWAP and CNOT in the Weyl chamber—is known as a unique two-qubit gate that can synthesize any two-qubit operation with only two applications17, compared with the three applications needed for CNOT or iSWAP (see Supplementary Section C for details). This property makes the B gate a promising building block for efficient circuit compilation.
The native B gate can be conveniently generated using the AshN scheme, which requires driving only one of the qubits (g = π/2τ, Ω1 ≈ 2.238g, Ω2 = 0, Δ = 0). In Fig. 4a, we show the XEB result of an AshN-generated B gate; the gate error is 0.50% with a 40-ns pulse.

a, XEB of the B gate. Under the AshN framework, the B gate is achieved by driving one of the qubits at a Rabi frequency of Ω1 ≈ 2.238g (top). b, Decomposition of an arbitrary SU(4) into two B gates plus single-qubit operations. c, Error per gate for each B-composed Weyl chamber unitary Uw. We sample 152 different unitaries, uniformly selecting 7 plane cuts in the Weyl chamber (planes 6 and 7 are very close to each other). For better visualization, we changed the Weyl chamber orientation as indicated in the bottom right. SWAP† denotes the Hermitian conjugate of SWAP. d, Cumulative distribution function (CDF) of the gate errors.
Using this calibrated B gate and the decomposition rule (Fig. 4b), we reconstruct the Weyl chamber and plot the error map in Fig. 4c. The average error per SU(4) and the standard deviation are 1.34% and 0.14%, respectively, which gives a substantially improved relative standard deviation of 10% compared with the native AshN case. This is due to the fact that all SU(4) gates are generated in a uniform fashion with two applications of B gates. This enhanced uniformity leads to more stable and predictable circuit performance. In addition to the uniformity improvement, we observe smaller errors near the boundary between SWAP and SWAP† within the Weyl chamber. This can be attributed to the faster dephasing of one qubit, as well as the reduced sensitivity of the single-qubit operation on this qubit to dephasing noise when a = b = π/4 (see Supplementary Section P for details).
Another advantage of using the B gate is the convenience in synthesizing unitary operations near the identity region, the red pinnacle in the tetrahedron (Fig. 2). Gates in this small region remain essential for Trotterization in Hamiltonian simulations39. Implementing these gates with the time-optimal AshN protocol may require impractically large amplitudes, making experimental realization challenging. By contrast, the exact synthesis enabled by the B gate, combined with its uniform performance, is ideally suited for this situation.
Discussion
Our demonstration of AshN gates has broad implications for both experimentalists and theorists. We show that the AshN scheme is compatible with state-of-the-art hardware designs, which have been successfully used in recent milestone demonstrations40,41,42. This suggests that the AshN scheme can substantially enhance the functionality and performance of existing systems, as indicated by its validation in a wide range of benchmarking quantum algorithms (Z. Yang et al., manuscript in preparation) and its application to error correction codes43. One immediate benefit is that traditional gates, such as the CNOT or CZ gate, supported by the \(\left\vert 11\right\rangle -\left\vert 20\right\rangle\) transition, typically require longer evolution times compared with iSWAP-like gates, leading to degraded fidelity performance40,44. The AshN-generated CZ gate, however, shares the same gate time as the iSWAP gate, which may help to eliminate this fidelity gap. Furthermore, because the AshN scheme requires only a single resonant condition, it simplifies the frequency allocation problem and reduces the likelihood of collisions with spurious two-level systems—one of the main challenges when optimizing the overall performance of multi-qubit devices45. Another particularly important aspect is that the exclusive use of the \(\left\vert 10\right\rangle -\left\vert 01\right\rangle\) transition helps to avoid leakage into non-computational states. This advantage in reducing correlated errors in error correction codes has been experimentally demonstrated recently46.
The AshN scheme requires only that qubits be tuned to resonance and possess exchange-type interactions (a requirement that may be relaxed in an extended AshN scheme (Z. Yang et al., manuscript in preparation)), along with the ability to drive qubits independently. Given these minimal requirements, many other promising qubit modalities, such as superconducting fluxonium qubits47,48,49 or alternative physical platforms including semiconductor spin qubits50, neutral atoms51 and molecular qubits52 could immediately benefit from implementing AshN gates.
Looking ahead, this successful demonstration may inspire researchers to rethink algorithm and application design, encouraging a move beyond the CNOT-based systems that have dominated the past few decades. In addition to its demonstrated advantages in state preparation and the direct implementation of SWAP, which is useful for efficient routing, the AshN scheme retains the benefits of earlier gate sets, including the XY family for variational quantum eigensolvers10 and fractional gates for simulating Ising models11. The elegant structure of SU(4) also enables more refined and efficient constructions than previously studied gate sets. Furthermore, extending the scheme to multiple qubits—where more qubits can be prepared in resonance and driven independently, as in ion trap systems53—could further enrich the capabilities of multi-qubit operations.
By demonstrating this flexible and efficient two-qubit gate scheme, our work opens new avenues for optimizing quantum hardware and algorithm design, bringing practical quantum computing an essential step closer to reality.
Methods
The PMW-4 scheme
As the commonly used virtual-Z gate is incompatible with most two-qubit gates, physical Z gates must be incorporated into the quantum circuit. In this work, we use the PMW-4 method29 to implement single-qubit gates. Considering an arbitrary single-qubit gate U ∈ SU(2), it can be described by three real parameters α, β and γ as
It follows that U can be efficiently implemented using four π/2 pulses:
where θ, ϕ and ω denote the phase of the π/2 pulse, defined as
Thus, in our experiment, it suffices to calibrate a single π/2 pulse and precisely control the phase of the microwave drive to realize arbitrary single-qubit gates.
Optimal pulse duration
Beyond its broad expressivity—enabling coverage of all SU(4) equivalence classes up to single-qubit rotations—the AshN scheme offers another key advantage: optimal pulse duration. Decoherence is often a major source of gate errors, making gate time (relative to coherence time) a critical factor in determining physical gate performance. Therefore, the optimal gate time facilitates high-fidelity realization of the AshN scheme, as shown in our demonstrations.
To clarify the time-optimal nature of the AshN scheme, we first explain the simulation protocol proposed in ref. 56, where, for a given coupling Hamiltonian H with canonical coefficient \(\overrightarrow{H}\), any target two-qubit unitary U with KAK coefficient \(\overrightarrow{U}\) can be simulated via the protocol
Here, we consider the minimal total time \(\mathop{\sum }\nolimits_{i = 1}^{n}{t}_{n}\) for which such a protocol exists, allowing efficient realization of U under the given coupling constraints. Time optimality can be achieved if \(\overrightarrow{U}\prec \tau \; \overrightarrow{H}\) or \(\overrightarrow{U}-(\frac{\pi }{2},0,0)\prec \tau \;\overrightarrow{H}\), where ≺ is the majorization condition and τ is the evolution time.
Thus, for the implemented AshN scheme, time optimality can be verified using the majorization conditions above. Moreover, this optimality holds in more general settings, as the AshN scheme itself does not involve interleaving with single-qubit rotations—except for those applied before and after the gate.
Data availability
All other data relevant to this study are available from the corresponding authors upon reasonable request. Source data are provided with this paper.
Code availability
The code used for this study is available from the corresponding authors upon reasonable request.
References
Vidal, G., Hammerer, K. & Cirac, J. I. Interaction cost of nonlocal gates. Phys. Rev. Lett. 88, 237902 (2002).
Chong, F. T., Franklin, D. & Martonosi, M. Programming languages and compiler design for realistic quantum hardware. Nature 549, 180–187 (2017).
Sung, Y. et al. Realization of high-fidelity CZ and ZZ-free iswap gates with a tunable coupler. Phys. Rev. X 11, 021058 (2021).
Caldwell, S. A. et al. Parametrically activated entangling gates using transmon qubits. Phys. Rev. Appl. 10, 034050 (2018).
Foxen, B. et al. Demonstrating a continuous set of two-qubit gates for near-term quantum algorithms. Phys. Rev. Lett. 125, 120504 (2020).
Huang, C. et al. Quantum instruction set design for performance. Phys. Rev. Lett. 130, 070601 (2023).
DiCarlo, L. et al. Demonstration of two-qubit algorithms with a superconducting quantum processor. Nature 460, 240–244 (2009).
Terhal, B. M. Quantum error correction for quantum memories. Rev. Mod. Phys. 87, 307–346 (2015).
Nguyen, L. B. et al. Programmable Heisenberg interactions between floquet qubits. Nat. Phys. 20, 240–246 (2024).
Abrams, D. M., Didier, N., Johnson, B. R., da Silva, M. P. & Ryan, C. A. Implementation of XY entangling gates with a single calibrated pulse. Nat. Electron. 3, 744–750 (2020).
IBM Quantum. New fractional gates reduce circuit depth for utility-scale workloads. IBM Quantum Research Blog https://www.ibm.com/quantum/blog/fractional-gates (2024).
DeCross, M. et al. Computational power of random quantum circuits in arbitrary geometries. Phys. Rev. X 15, 021052 (2025).
Sastry, S. Nonlinear Systems: Analysis, Stability, and Control Vol. 10 (Springer, 2013).
Liu, Y.-X., Wei, L. F., Tsai, J. S. & Nori, F. Controllable coupling between flux qubits. Phys. Rev. Lett. 96, 067003 (2006).
Vandersypen, L. M. K. & Chuang, I. L. NMR techniques for quantum control and computation. Rev. Mod. Phys. 76, 1037–1069 (2005).
Chen, J., Ding, D., Gong, W., Huang, C. and Ye, Q. One gate scheme to rule them all: Introducing a complex yet reduced instruction set for quantum computing. In Proc. 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 779–796 (Association for Computing Machinery, 2024).
Zhang, J., Vala, J., Sastry, S. & Whaley, K. B. Minimum construction of two-qubit quantum operations. Phys. Rev. Lett. 93, 020502 (2004).
Wei, K. X. et al. Native two-qubit gates in fixed-coupling, fixed-frequency transmons beyond cross-resonance interaction. PRX Quantum 5, 020338 (2024).
Vidal, G. & Dawson, C. M. Universal quantum circuit for two-qubit transformations with three controlled-not gates. Phys. Rev. A 69, 010301 (2004).
Wang, C. et al. Towards practical quantum computers: transmon qubit with a lifetime approaching 0.5 milliseconds. NPJ Quantum Inf. 8, 3 (2022).
Sete, E. A., Zeng, W. J. and Rigetti, C. T. A functional architecture for scalable quantum computing. In 2016 IEEE International Conference on Rebooting Computing (ICRC) 1–6 (Institute of Electrical and Electronics Engineers, 2016).
Chu, J. et al. Scalable algorithm simplification using quantum and logic. Nat. Phys. 19, 126–131 (2023).
Tucci, R. R. An introduction to Cartan’s KAK decomposition for QC programmers. Preprint at https://arxiv.org/abs/quant-ph/0507171 (2005).
Zhang, J., Vala, J., Sastry, S. & Whaley, K. B. Geometric theory of nonlocal two-qubit operations. Phys. Rev. A 67, 042313 (2003).
Levine, H. et al. Parallel implementation of high-fidelity multiqubit gates with neutral atoms. Phys. Rev. Lett. 123, 170503 (2019).
Xue, X. et al. Quantum logic with spin qubits crossing the surface code threshold. Nature 601, 343–347 (2022).
Chow, J. M. et al. Simple all-microwave entangling gate for fixed-frequency superconducting qubits. Phys. Rev. Lett. 107, 080502 (2011).
McKay, D. C., Wood, C. J., Sheldon, S., Chow, J. M. & Gambetta, J. M. Efficient Z gates for quantum computing. Phys. Rev. A 96, 022330 (2017).
Chen, J., Ding, D., Huang, C. & Ye, Q. Compiling arbitrary single-qubit gates via the phase shifts of microwave pulses. Phys. Rev. Res. 5, L022031 (2023).
Han, Z. et al. Multilevel variational spectroscopy using a programmable quantum simulator. Phys. Rev. Res. 6, 013015 (2024).
Luo, X.-Y. et al. Deterministic entanglement generation from driving through quantum phase transitions. Science 355, 620–623 (2017).
Prevedel, R. et al. Experimental realization of dicke states of up to six qubits for multiparty quantum networking. Phys. Rev. Lett. 103, 020503 (2009).
Kiesel, N., Schmid, C., Tóth, G., Solano, E. & Weinfurter, H. Experimental observation of four-photon entangled dicke state with high fidelity. Phys. Rev. Lett. 98, 063604 (2007).
Häffner, H. et al. Scalable multiparticle entanglement of trapped ions. Nature 438, 643–646 (2005).
Wang, Z. et al. Controllable switching between superradiant and subradiant states in a 10-qubit superconducting circuit. Phys. Rev. Lett. 124, 013601 (2020).
Hu, C.-K. et al. Experimental sample-efficient quantum state tomography via parallel measurements. Phys. Rev. Lett. 133, 160801 (2024).
Bärtschi, A. & Eidenbenz, S. Deterministic preparation of Dicke states. In Fundamentals of Computation Theory (eds Gąsieniec, L. et al.) 126–139 (Springer, 2019).
Chen, L. et al. On-chip generation and collectively coherent control of the superposition of the whole family of Dicke states. Phys. Rev. Lett. 130, 223601 (2023).
Daley, A. J. et al. Practical quantum advantage in quantum simulation. Nature 607, 667–676 (2022).
Google Quantum, AI. et al. Quantum error correction below the surface code threshold. Nature 638, 920–926 (2025).
Cao, S. et al. Generation of genuine entanglement up to 51 superconducting qubits. Nature 619, 738–742 (2023).
Zhang, X. et al. Digital quantum simulation of floquet symmetry-protected topological phases. Nature 607, 468–473 (2022).
Zhou, R., Zhang, F., Kong, L. & Chen, J. Halma: a routing-based technique for defect mitigation in quantum error correction. Preprint at https://arxiv.org/abs/2412.21000 (2024).
Morvan, A. et al. Phase transitions in random circuit sampling. Nature 634, 328–333 (2024).
Klimov, P. V. et al. Optimizing quantum gates towards the scale of logical qubits. Nat. Commun. 15, 2442 (2024).
Eickbusch, A. et al. Demonstrating dynamic surface codes. Preprint at https://arxiv.org/abs/2412.14360 (2024).
Nguyen, L. B. et al. High-coherence fluxonium qubit. Phys. Rev. X 9, 041041 (2019).
Bao, F. et al. Fluxonium: an alternative qubit platform for high-fidelity operations. Phys. Rev. Lett. 129, 010502 (2022).
Ding, L. et al. High-fidelity, frequency-flexible two-qubit fluxonium gates with a transmon coupler. Phys. Rev. X 13, 031035 (2023).
Dijkema, J. et al. Cavity-mediated iSWAP oscillations between distant spins. Nat. Phys. https://doi.org/10.1038/s41567-024-02694-8 (2024).
Kim, K., Yang, F., Mølmer, K. & Ahn, J. Realization of an extremely anisotropic heisenberg magnet in rydberg atom arrays. Phys. Rev. X 14, 011025 (2024).
Picard, L. R. B. et al. Entanglement and iswap gate between molecular qubits. Nature https://doi.org/10.1038/s41586-024-08177-3 (2024).
Monz, T. et al. Realization of the quantum toffoli gate with trapped ions. Phys. Rev. Lett. 102, 040501 (2009).
Crooks, G. E. Gates, states, and circuits. Tech. Note available at Crooks’ website https://threeplusone.com/pubs/on-gates-v0-5/ (2020).
Peterson, E. C., Crooks, G. E. & Smith, R. S. Fixed-depth two-qubit circuits and the monodromy polytope. Quantum 4, 247 (2020).
Hammerer, K., Vidal, G. & Cirac, J. I. Characterization of nonlocal gates. Phys. Rev. A 66, 062321 (2002).
Acknowledgements
We thank C. Chen, C. Deng, K. Kim, X. Li, F. Wu, X. Xue, J. Zhang and H.-H. Zhao for their valuable comments. This work was supported by the National Natural Science Foundation of China (grant nos. 12322413, 92365206, 92476206, 12347104 and 12404563), National Key Research and Development Program of China (grant no. 2023YFA1009403), Innovation Program for Quantum Science and Technology (grant no. 2021ZD0301802) and Beijing Natural Science Foundation (grant nos. Z220002 and 1244065).
Author information
Authors and Affiliations
Contributions
J.C. and F.Y. conceived and supervised the project. G.X. and F.Y. designed the processor. Y.M. and W.S. fabricated the sample. Z.C. and W.L. conducted the experiment and analysed the data with help from R.W., H.W., H.X. and H.Ya. Y.J. and H.Yu. built the experimental infrastructure. Z.C., J.C. and F.Y. wrote the paper with contributions from all the authors.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Physics thanks Christopher Warren and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information (download PDF )
Supplementary Figs. 1–21 and Tables 1–3.
Source data
Source Data Fig. 1 (download XLSX )
Source data of Fig. 1.
Source Data Fig. 2 (download XLSX )
Source data of Fig. 2.
Source Data Fig. 3 (download XLSX )
Source data of Fig. 3.
Source Data Fig. 4 (download XLSX )
Source data of Fig. 4.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chen, Z., Liu, W., Ma, Y. et al. Efficient implementation of arbitrary two-qubit gates using unified control. Nat. Phys. 21, 1489–1496 (2025). https://doi.org/10.1038/s41567-025-02990-x
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s41567-025-02990-x
