
Abstract
Quantum measurements are probabilistic and, in general, provide only partial information about the underlying quantum state. Obtaining a full classical description of an unknown quantum state requires the analysis of several different measurements, a task known as quantum-state tomography. Here we analyse the ultimate achievable performance in the tomography of continuous-variable systems, such as bosonic and quantum optical systems. We prove that tomography of these systems is extremely inefficient in terms of time resources, much more so than tomography of finite-dimensional systems such as qubits. Not only does the minimum number of state copies needed for tomography scale exponentially with the number of modes, but, even for low-energy states, it also scales unfavourably with the trace-distance error between the original state and its estimated classical description. On a more positive note, we prove that the tomography of Gaussian states is efficient by establishing a bound on the trace-distance error made when approximating a Gaussian state from knowledge of the first and second moments within a specified error bound. Last, we demonstrate that the tomography of non-Gaussian states prepared through Gaussian unitaries and a few local non-Gaussian evolutions is efficient and experimentally feasible.
Similar content being viewed by others

Main
A fundamental task in quantum physics, known as quantum-state tomography1, is to derive a classical description of a quantum system from experimental data. This is not only a powerful method for investigating Nature but also a diagnostic tool for benchmarking and verifying quantum devices1,2,3,4. The concept of tomography dates back to the 1990s5,6, when it was first introduced for continuous-variable (CV) systems7 and then for finite-dimensional systems. Over the years, tomography algorithms for CV systems have been extensively developed, so that it has become a bread-and-butter tool in quantum optics5,6.
In the last decade, rapid advances in accurately preparing quantum states8 have spurred the development of a new research field known as quantum learning theory1, which investigates how we can learn the properties of quantum systems as efficiently as possible. When the focus is on obtaining a full classical description of a quantum system, such an investigation reduces to quantum-state tomography, which is considered the cornerstone of quantum learning theory1. Despite tomography being a long-standing concept, many of its fundamental properties have only recently been unveiled due to advances in this new field, albeit only for finite-dimensional systems and not for CV systems.
Let us introduce quantum-state tomography from a quantum learning theory perspective. Formally, the task of quantum-state tomography involves two parameters: the number of state copies N and the error parameter ε. Given N copies of an unknown state, the goal is to output a classical description of a state that is guaranteed to be ε-close to the true unknown state with high probability (this is stated rigorously in Methods).
Among various notions of distance for measuring ε-closeness, the trace distance is the most popular due to its operational meaning9,10: given two states ε-close in trace distance, no quantum measurement can distinguish them by more than ε. Thus, the two states are, in fact, indistinguishable to any physical observer within a resolution ε. The optimal performance of tomography is quantified by the sample complexity, which is the minimum number of copies N needed to achieve tomography with error ε. When the sample complexity and running time of the tomography procedure scale polynomially with the number of constituents (for example, qubits and modes), the tomography is deemed efficient.
With vast many-body systems naturally emerging in Nature on one side and the rapid advances in constructing large-scale quantum devices on the other, minimizing the resources required has become imperative. Consequently, determining the sample complexity in the tomography of physically relevant classes of states is presently a pressing problem1. Notably, the sample complexity has been determined for n-qubit systems1,11,12,13,14: the tomography of mixed states requires Θ(4n/ε2) copies, whereas for pure states, the required number of copies reduces to Θ(2n/ε2), where Θ denotes the asymptotic scaling—that is, the number of copies grows proportionally to this expression up to constant factors.
Although quantum learning theory has been extensively developed for finite-dimensional systems, it remains almost unexplored for CV systems15,16,17,18. This is partly because the usual approaches to CV tomography are based on mere approximations of phase-space functions5,6,7, which do not account for the trace-distance error and, thus, lack operational meaning. This is a pressing gap in the literature, especially considering that in recent years, photonic quantum devices have been at the forefront of attempts to demonstrate quantum advantage, particularly through boson sampling19,20,21 and quantum simulation experiments22. Moreover, photonic platforms play a pivotal role in various quantum technologies, including quantum computation23,24,25,26,27, communication28,29,30,31,32,33 and sensing34,35,36,37. Therefore, determining the ultimate achievable performance of CV tomography has become an interesting problem, which we solve in this work.
Energy-constrained states
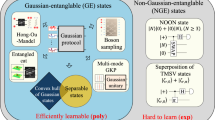
A CV system corresponds to n modes, each associated with an infinite-dimensional Hilbert space. From the outset, the infinitely many degrees of freedom of a single bosonic mode make tomography a challenging concept. What does it mean for a tomography algorithm to output a classical description of an infinite-dimensional state? Does this imply that the output would be an infinite-dimensional matrix, which no classical computer could store? After all, Nature hardly deals with true infinities. Physical quantum states are always subject to certain constraints, the most fundamental of which is energy. In practice, Nature can produce only states with finite energy. Moreover, all states produced in quantum optical platforms—such as those used in optical quantum computing19,20,21 or fibre-optic communication30,38,39—have inherently bounded energy. Crucially, energy is also a property that experimentalists can often estimate with good accuracy and typically have prior information about. In light of all this, we can think of CV quantum states as physically meaningful only under an energy constraint. Including such a constraint turns the task of tomography from unavoidably inconceivable to a precious tool for investigating bosonic quantum systems. As explained below, we can, indeed, devise tomography algorithms capable of achieving an arbitrarily low trace-distance error for infinite-dimensional states subjected to some energy constraint (Fig. 1).

a, Quantum-state tomography of CV systems subject to energy constraints inherent in experimental platforms. Here, n is the number of modes, and ε is the trace-distance error. Our investigation reveals a phenomenon dubbed ‘extreme inefficiency’ of CV quantum-state tomography. Specifically, the number of copies required for the tomography of n-mode energy-constrained states must scale at least as ε−2n. This substantial scaling is a unique feature of CV systems, standing in stark contrast to finite-dimensional systems, where the required number of copies scales with the trace-distance error as ε−2. Therefore, we ask whether there exist physically interesting classes of states for which tomography is efficient. b, We answer this in the affirmative by presenting an efficient algorithm for the tomography of Gaussian states with provable guarantees in trace distance. Our analysis is based on technical tools of independent interest. Specifically, we introduce simple bounds on the trace distance between two Gaussian states in terms of the norm distance between their first moments and covariance matrices. c, Finally, we demonstrate that the tomography of non-Gaussian states prepared by Gaussian unitaries and a few local non-quadratic Hamiltonian evolutions is still efficient. Notably, both of these efficient tomography algorithms are experimentally feasible to implement in quantum optics laboratories.
By definition, an n-mode state ρ satisfies the energy constraint E if the expectation value of the energy observable satisfies
Here the energy observable is defined as
where \({\{{\hat{x}}_{i}\}}_{i = 1}^{n}\) and \({\{{\hat{p}}_{i}\}}_{i = 1}^{n}\) denote the position and momentum operators of the n modes7. We normalize the right-hand-side of equation (1) with n because the energy is an extensive observable. Note that the energy constraint in equation (1) is equivalent to a constraint on the mean total photon number of the state (equation (18)).
The following theorem, proven in Supplementary Theorem 26, determines the sample complexity in the tomography of energy-constrained pure states.
Theorem 1
(Tomography of energy-constrained pure states) The sample complexity in the tomography of n-mode pure states is Θ(En/ε2n). Here ε is the trace-distance error and E is the energy constraint.
This result establishes that every tomography algorithm—even standard algorithms based on homodyne and heterodyne detections (Fig. 2)—must use at least Ω(En/ε2n) copies to achieve error ε, where Ω denotes an asymptotic lower bound, meaning that the number of required copies cannot grow slower than this quantity up to constant factors. Conversely, it also establishes that there exists a tomography algorithm that achieves an error ε given access to the above number of copies.

a, We establish fundamental bounds on the resources required for quantum-state tomography of CV kth-moment-constrained quantum states, highlighting the pronounced inefficiency of any strategy aiming to solve this task. b, Our results encompass any possible strategy, including those using only homodyne and heterodyne measurements, as well as other experimentally feasible operations in photonic platforms, and even general measurements. This means, independently of the techniques used, the tomography of CV states is impractical. c, We identify three key results, labelled facts A–C. The implication is that the resources needed for tomography exhibit strong dependence on the desired accuracy, scaling as ~ε−2n/k.
This finding reveals a striking phenomenon that we dub the ‘extreme inefficiency’ of CV tomography: not only does the number of copies required for CV tomography scale exponentially with the number of modes n, as for finite-dimensional systems, but it also has a substantial scaling with respect to the error ε. Specifically, the scaling of ~ε−2n is a unique feature of CV tomography, being in stark contrast with the finite-dimensional setting characterized by the scaling of ~ε−2. Although in the finite-dimensional setting the error can be halved by increasing the number of copies by a factor of 4, which is cheap, in the CV setting, one needs an exponential factor 4n, which is costly.
To emphasize this notable behaviour, let us illustrate with an example the substantial difference between the tomography of finite-dimensional systems and the tomography of CV systems. We will estimate the time required to achieve tomography with error ε = 10% in both settings. Assume that each copy of the state is produced and processed every 1 ns (typical for qubits and light pulses). Then, the tomography of ten-qubit pure states requires just ~0.1 ms. However, as a consequence of Theorem 1, the tomography of ten-mode pure states with a mean number of photons per mode ≤1 requires at least ~3,000 years, which shows that CV tomography becomes impractical even for a few modes. This highlights that the tomography of CV systems is extremely inefficient, much more so than the tomography of finite-dimensional systems.
In Theorem 2, proven in Supplementary Information, we find bounds on the sample complexity in the tomography of energy-constrained mixed states.
Theorem 2
(Tomography of energy-constrained mixed states) The number of copies O(E2n/ε3n) is sufficient to achieve the tomography of n-mode mixed states. Conversely, the tomography of such states requires at least Ω(E2n/ε2n) copies. Here, ε is the trace-distance error and E is the energy constraint.
For a rigorous presentation of the asymptotic notation used, we refer the reader to Supplementary Information Section 1. The core idea underpinning the attainable (yet costly) performance guarantees for tomography presented in Theorem 2 is that energy-constrained CV states are effectively described by finite-dimensional systems. In particular, we prove that any (possibly mixed) energy-constrained state can be approximated, up to trace-distance error ε, by a D-dimensional state with rank r such that
The first result of Theorem 2 simply follows from the observation that the sample complexity in the tomography of D-dimensional states with rank r is O(Dr) (refs. 1,11,12,13,14). Notably, equation (3) establishes that physical CV states—those with bounded energy—are characterized by a finite number of physically relevant parameters.
These conclusions allow us to shed light on the core question in CV tomography posed at the beginning of the section: the tomography of arbitrary CV states is, indeed, meaningless considering that infinitely many parameters are physically inconceivable, but that with an energy constraint, tomography gains real-world relevance. Indeed, in this latter case, it is sufficient for the output to be a matrix of finite dimension, that is, O(En/ε2n).
The above findings can be generalized by considering constraints on any higher moments of the energy. By definition, like equation (1), an n-mode state ρ satisfies the k-moment constraint E if
As proven in Supplementary Information, the sample complexity in the tomography of pure states becomes Θ(En/ε2n/k), whereas for mixed states, the sample complexity is upper bounded by O(E2n/ε3n/k) and lower bounded by Ω(E2n/ε2n/k), thus recovering Theorems 1 and 2 for k = 1. Notably, the sample complexity decreases as k increases, and the substantial scaling ~ε−2n/k disappears for k ≳ n.
Gaussian states
So far, we have identified strong limitations on the tomography of arbitrary unknown CV states, even under stringent energy constraints. However, in many practical scenarios, another prior assumption about the unknown CV state is often available, namely, that it is Gaussian. Gaussian states are the most commonly used states in quantum optics laboratories and have key applications in quantum sensing, communication and computing7. This prompts a natural question: can the tomography of Gaussian states be efficiently performed? Here, we answer this question affirmatively.
We start by investigating the following problem, rather fundamental for the field of CV quantum information. It is well known that Gaussian states are in a one-to-one correspondence with their first moments and covariance matrices7. However, as in practice one has access only to a finite number of copies of an unknown Gaussian state, it is impossible to determine its first moment and covariance matrix exactly. Instead, one can obtain only arbitrarily good approximations of them. Given the operational meaning of the trace distance9,10, the following question is, thus, a fundamental problem: If we know with an error ε the first moment and the covariance matrix of an unknown Gaussian state, what is the resulting trace-distance error that we make in approximating the underlying state? Theorem 3, proven in Methods, answers this question.
Theorem 3
(Error propagation from moments to trace distance) If we know with an error ε the first moment and the covariance matrix of an unknown Gaussian state, the resulting trace-distance error is at most \(O(\sqrt{\varepsilon })\) and at least Ω(ε).
To prove this result, Theorems 10 and 11 place stringent bounds on the trace distance between two Gaussian states in terms of the norm distance between their first moments and covariance matrices, which constitute technical tools of independent interest for the field of CV quantum information.
Notably, Theorem 3 is the key tool in proving the main result of this section: the tomography of Gaussian states is efficient. Specifically, Theorem 4, proven in Supplementary Information, shows that the sample complexity in the tomography of Gaussian states scales polynomially with the number of modes.
Theorem 4
(Tomography of Gaussian states) There exists an algorithm that uses
copies to achieve the tomography of an unknown n-mode Gaussian state. Here, ε is the trace-distance error and E is the energy constraint.
This algorithm simply consists of estimating the first moment and the covariance matrix of the unknown Gaussian state, both procedures routinely performed in quantum optics laboratories using homodyne detection7. Additionally, the algorithm runs in poly(n) time, and its output is efficient to store, as it consists only of the O(n2) parameters of the first moment and covariance matrix. A similar tomography algorithm has been proposed in the fermionic Gaussian setting in the particular case in which the state is pure40,41.
In summary, we have established the efficiency of the tomography of Gaussian states. However, what if the state deviates slightly from being exactly Gaussian? This is a crucial question, especially considering imperfections during state preparation in experimental set-ups. In Supplementary Information, we demonstrate that our tomography algorithm is robust against little perturbations caused by non-Gaussian noise (for example, dephasing noise). Even if the unknown state is a slightly perturbed Gaussian state—technically, a state with a sufficiently small relative entropy of non-Gaussianity42—our algorithm remains effective and tomography remains efficient.
t-doped Gaussian states
Having demonstrated that the tomography of arbitrary non-Gaussian states is extremely inefficient (Theorem 1) and that the tomography of Gaussian states is efficient (Theorem 4), we now seek to interpolate between these two regimes. This leads us to analyse t-doped Gaussian states, states prepared by applying Gaussian unitaries and at most t non-Gaussian local unitaries on the vacuum state. The set of all t-doped Gaussian states coincides with that of all pure Gaussian states for t = 0, it grows as t increases, and it becomes the set of all pure states for t → ∞ (ref. 43). In this sense, analysing the performance of tomography as a function of t allows us to understand the trade-off between the efficiency of tomography and the degree of ‘non-Gaussianity’ of the unknown bosonic quantum state. The tomography of t-doped states has been thoroughly investigated in both the stabilizer44,45,46,47,48,49,50 and fermionic41 settings. In this section, we present a bosonic generalization of the results established in these earlier works.
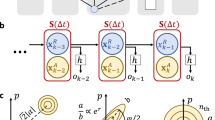
Let us proceed with the mathematical definitions. A unitary U is a t-doped Gaussian unitary if it is a composition
of Gaussian unitaries G0, G1, …, Gt and at most t (non-Gaussian) κ-local unitaries W1, …, Wt, as depicted in Fig. 3. A unitary is κ-local if it is generated by a Hamiltonian that is a polynomial in at most κ quadratures. An n-mode state vector |ψ〉 is a t-doped Gaussian state vector if it can be prepared by applying a t-doped Gaussian unitary U to the vacuum as
Theorem 5, proven in Supplementary Information, provides a notable decomposition of t-doped unitaries and states.

By definition, a t-doped Gaussian state vector |ψ〉 is a state prepared by applying Gaussian unitaries G0, …, Gt (green boxes) and at most t non-Gaussian κ-local unitaries W1, …, Wt (red boxes) to the n-mode vacuum. A unitary is said to be κ-local if it is generated by a Hamiltonian that is a polynomial in at most κ operators from the set of position operators \({\{{\hat{x}}_{i}\}}_{i = 1}^{n}\) and momentum operators \({\{{\hat{p}}_{i}\}}_{i = 1}^{n}\) of the n modes. Also shown is the decomposition given by Theorem 5, which establishes that all the non-Gaussianity in |ψ〉 can be compressed into a localized region consisting of κt modes by applying a Gaussian unitary G† to |ψ〉.
Theorem 5
(Compression of non-Gaussianity) If n ≥ κt, any n-mode t-doped Gaussian unitary U can be decomposed as
for some suitable Gaussian unitary G, energy-preserving Gaussian unitary Gpassive (ref. 7) and κt-mode (non-Gaussian) unitary uκt. In particular, any n-mode t-doped Gaussian state vector can be decomposed as
for some suitable Gaussian unitary G and κt-mode (non-Gaussian) state vector |φκt〉.
Equation (9) establishes that all the non-Gaussianity of a t-doped Gaussian state can be compressed into O(t) modes through a suitable Gaussian unitary. This result can be seen as a bosonic counterpart of recent results within the stabilizer44,45,46,47,48,49,50 and fermionic setting41, which reveals a fascinating parallelism among the theories of stabilizers, fermions and bosons.
Leveraging the decomposition in equation (9), we design a simple and experimentally feasible tomography algorithm for t-doped Gaussian states. Our algorithm (1) estimates the first moment and the covariance matrix to construct an estimate of the Gaussian unitary G, (2) applies its inverse to the state to compress the non-Gaussianity into the first κt modes and (3) performs full-state tomography on the first κt modes (see Supplementary Information for details). This algorithm is practical because it requires only tools commonly available in quantum optics laboratories, such as Gaussian evolutions and easily implementable Gaussian measurements, like homodyne and heterodyne detection7. Specifically, step (3) can be achieved using the CV classical shadow algorithm17, which is experimentally feasible. Alternatively, to obtain a tighter upper bound on the sample complexity in the tomography of t-doped Gaussian state, step (3) can be performed using the optimal full-state tomography algorithm identified in Theorem 1.
Theorem 6, proven in Supplementary Information, analyses the performance of our tomography algorithm. On a technical note, deriving guarantees on the estimate of the covariance matrix in step (1) requires more than just an energy constraint; a second-moment constraint is also necessary. Refer to equation (4) for the definition of a second-moment constraint.
Theorem 6
(Tomography of a t-doped Gaussian state) There exists an algorithm that exploits
copies to achieve the tomography of n-mode t-doped Gaussian states. Here, E is the second-moment constraint, ε is the trace-distance error and κ is the locality of the non-Gaussian unitaries.
This theorem implies that the sample complexity in the tomography of t-doped Gaussian states scales at most exponentially with κt, indicating that tomography becomes increasingly difficult as the degree of non-Gaussianity t increases. Additionally, both the time and memory complexities exhibit the same behaviour. Notably, this establishes the core finding of this section: the tomography of t-doped Gaussian states is efficient in the regime κt = O(1).
The proof of Theorem 6 hinges on the fact that a t-doped state is compressible, meaning that it satisfies the decomposition in equation (9). Specifically, we can prove that the tomography of compressible states is efficient if and only if κt = O(1). This contrasts with the stabilizer44,49,50 and fermionic setting41, where the tomography of compressible stabilizer and fermionic states is efficient if and only if t = O(log(n)). The difference in our setting ultimately arises from the infinite-dimensional nature of CV states and the presence of energy constraints.
Discussion
Our work serves as bridge between quantum learning theory and CV quantum information. We have conducted an exhaustive investigation of the tomography of CV systems with guarantees on the trace-distance error.
First, we have determined the sample complexity in the tomography of energy-constrained pure states, which pinpoints the ultimate achievable performance of CV tomography. However, the ‘extreme inefficiency’ of CV tomography emerged: any tomography algorithm for energy-constrained states must use a number of copies that substantially scales at least as ε−2n, where n is the number of modes and ε is the trace-distance error. This phenomenon, which provides costly fundamental limitations even for small n, is a unique feature in the tomography of CV systems.
On a more positive note, we have proven that the tomography of Gaussian states is efficient. To establish this, we investigated a fundamental problem of CV quantum information: how the error in approximating the first moment and the covariance matrix of a Gaussian state propagates in the trace-distance error. Our solution introduces tools of independent interest: simple, stringent bounds on the trace distance between two Gaussian states in terms of the norm distance between their first moments and covariance matrices.
Finally, we have devised an experimentally feasible algorithm that efficiently achieves the tomography of t-doped Gaussian states for small t. This establishes that even if a few non-Gaussian local gates are applied to a Gaussian state, the tomography of the resulting non-Gaussian state remains efficient. The main tool employed here is a decomposition of t-doped Gaussian states, which shows that all the non-Gaussianity in the state can be compressed into only O(t) modes through a Gaussian unitary.

Given access to N copies of an unknown state ρ, the goal of a tomography algorithm is to output a classical description of a state \(\tilde{\rho }\) that serves as a good approximation of the true unknown state ρ. Let us clarify what we mean by a ‘good approximation’. First, the error in this approximation is measured by the trace distance \({d}_{{\rm{tr}}}(\rho ,\tilde{\rho })\), which is most meaningful notion of distance between states9,10. Second, as quantum measurements yield probabilistic outcomes, the output \(\tilde{\rho }\) is probabilistic rather than deterministic. Therefore, a ‘good approximation’ means that the probability of getting a small trace-distance error is high. This is expressed as \(\Pr [{d}_{{\rm{tr}}}(\rho ,\tilde{\rho })\le \varepsilon ]\ge 1-\delta\), where ε is the trace-distance error and δ is the failure probability. To measure the performance of tomography, one can define the sample complexity. For fixed ε and δ, the sample complexity is the minimum number of copies N required to achieve tomography with trace-distance error ε and failure probability δ. For example, the sample complexity in the tomography of arbitrary n-qubit states is \(O\left((4^{n}/\varepsilon^{2})\log (1/\delta)\right)\) (refs. 1,12,13,14). In general, the sample complexity in any tomography task depends at most logarithmically on the failure probability δ (ref. 51), implying that this parameter has a minimal impact on performance. In other words, the failure probability δ can be made very small with only a slight increase in the sample complexity. Therefore, throughout this work, we omit the dependence on δ.
Methods
Trace distance
The trace distance between two quantum states ρ1 and ρ2 is defined as
where \(\|A\|_{1}:={\rm{Tr}}\sqrt{{A}^{\dagger }A}\) denotes the trace norm. The trace distance is considered the most meaningful notion of distance between two states because of its operational meaning in terms of the optimal probability of discriminating between two states having access to a single copy of the state (Holevo–Helstrom theorem9,10). Consequently, in quantum information theory, the error in approximating a state is typically quantified using the trace distance.
Quantum-state tomography
In this section, we formulate precisely the problem of quantum-state tomography1, which forms the basis of our investigation. The basic set-up is depicted in Fig. 4.
Problem 7
(Quantum-state tomography) Let \({\mathcal{S}}\) be a set of quantum states. Consider ε, δ ∈ (0, 1) and \(N\in {\mathbb{N}}\). Let \(\rho \in {\mathcal{S}}\) be an unknown quantum state. Given access to N copies of ρ, the goal is to provide a classical description of a quantum state \(\tilde{\rho }\) such that
That is, with a probability ≥1 − δ, the trace distance between \(\tilde{\rho }\) and ρ is at most ε. Here ε is called the trace-distance error, and δ is called the failure probability.
The sample complexity, the time complexity and the memory complexity in the tomography of states in \({\mathcal{S}}\) are defined as the minimum number of copies N, the minimum amount of classical and quantum computation time, and the minimum amount of classical memory, respectively, required to solve Problem 7 with trace-distance error ε and failure probability δ. Note that the time complexity is always an upper bound on the memory complexity and the sample complexity.
One can think of \({\mathcal{S}}\) as a specific subset of the entire set of n-qubit states (for example, pure states, r-rank states and stabilizer states) or n-mode states (for example, energy-constrained states, moment-constrained states, Gaussian states and t-doped Gaussian states). By definition, tomography is deemed efficient if the sample, time and memory complexities scale polynomially in n; otherwise, it is deemed inefficient. For example, in our work, we prove that the tomography of energy-constrained states is (extremely) inefficient. By contrast, the tomography of Gaussian states is efficient, whereas the tomography of t-doped Gaussian states is efficient for small t and inefficient for large t.
CV systems
In this section, we provide a concise overview of quantum information with CV systems7. A CV system is a quantum system associated with the Hilbert space \({L}^{2}({{\mathbb{R}}}^{n})\) of all square-integrable complex-valued functions over \({{\mathbb{R}}}^{n}\), which models n modes of electromagnetic radiation with definite frequency and polarization. A quantum state in \({L}^{2}({{\mathbb{R}}}^{n})\) is called an n-mode state, and a unitary operator in \({L}^{2}({{\mathbb{R}}}^{n})\) is called an n-mode unitary. The quadrature vector is defined as
where \({\hat{x}}_{j}\) and \({\hat{p}}_{j}\) are the well-known position and momentum operators of the jth mode, collectively called quadratures. Let us proceed with the definitions of a Gaussian unitary and a Gaussian state.
Definition 8
(Gaussian unitary) An n-mode unitary is Gaussian if it is the composition of unitaries generated by quadratic Hamiltonians \(\hat{H}\) in the quadrature vector
for some symmetric matrix \(h\in {{\mathbb{R}}}^{2n,2n}\) and some vector \({\bf{m}}\in {{\mathbb{R}}}^{2n}\).
Definition 9
(Gaussian state) An n-mode state ρ is Gaussian if it can be written as a Gibbs state of a quadratic Hamiltonian \(\hat{H}\) of the form in equation (14) with h being positive definite. The Gibbs states associated with the Hamiltonian \(\hat{H}\) are given by
where the parameter β is the inverse temperature.
This definition includes also the pathological cases where both β and certain terms of H diverge (for example, this is the case for tensor products between pure Gaussian states and mixed Gaussian states). An example of a Gaussian state vector is the vacuum, denoted as \({\left\vert 0\right\rangle }^{\otimes n}\). Any pure n-mode Gaussian state vector can be written as a Gaussian unitary G applied to the vacuum:
A Gaussian state ρ is uniquely identified by its first moment m(ρ) and covariance matrix V(ρ). By definition, the first moment and the covariance matrix of an n-mode state ρ are given by
where \(\{\hat{A},\hat{B}\}:=\hat{A}\hat{B}+\hat{B}\hat{A}\) is the anti-commutator.
By definition, the energy of an n-mode state ρ is given by the expectation value \({\rm{Tr}}[{\hat{E}}_{n}\rho ]\) of the energy observable \({\hat{E}}_{n}:=\sum_{j = 1}^{n}({\hat{x}}_{j}^{2}+{\hat{p}}_{j}^{2})/2\), where it is assumed that each mode has a frequency of one7. It is important to note that energy is an extensive quantity, because for any single-mode state σ the energy of σ⊗n equals the energy of σ multiplied by n. Furthermore, the energy of an n-mode state is always greater than or equal to n/2, with the equality achieved only by the vacuum. The total number of photons can be defined in terms of the energy observable as
Given \({\bf{k}}=({k}_{1},\ldots ,{k}_{n})\in {{\mathbb{N}}}^{n}\), let us denote as
the n-mode Fock state vector7. The total number of photons is diagonal in the Fock basis as
where \(\|{\bf{k}}\|_{1}:=\sum_{i = 1}^{n}{k}_{i}\).
Effective dimension and rank of energy-constrained states
In this section, we show that energy-constrained states can be approximated well by finite-dimensional states with low rank, as anticipated above in equation (3). Further technical details regarding the findings presented in this section can be found in Supplementary Information.
Let ρ be an n-mode state with total number of photons satisfying the energy constraint
where E ≥ 0. Given \(M\in {\mathbb{N}}\), let \({{\mathcal{H}}}_{M}\) be the subspace spanned by all the n-mode Fock states with total number of photons not exceeding M, and let ΠM be the projector onto this space.
Let us begin by analysing the effective dimension of the set of energy-constrained states. The trace distance between the energy-constrained state ρ and its projection ρM onto \({{\mathcal{H}}}_{M}\), that is,
can be upper bounded as follows:
where in (i) we have employed the gentle measurement lemma52 and in (ii) we used the simple operator inequality \({\mathbb{1}}-{\varPi }_{M}\le {\hat{N}}_{n}/M\). Consequently, by setting M1 := ⌈nE/ε2⌉, it follows that the projection \({\rho }_{{M}_{1}}\) is ε-close to ρ in trace distance. Moreover, the dimension of \({{\mathcal{H}}}_{{M}_{1}}\) can be upper bounded as
where e denotes Euler’s number. Hence, we conclude that any energy-constrained state ρ can be approximated, up to trace-distance error ϵ, by its projection \({\rho }_{{M}_{1}}\) onto the subspace \({{\mathcal{H}}}_{{M}_{1}}\), which has a finite dimension of \(O\left({(\mathrm{e}E)}^{n}/{\varepsilon }^{2n}\right)\).
Now, let us analyse the effective rank of the energy-constrained state ρ. We say that ρ has effective rank r if it is ε-close to a state with rank r. Let us consider the spectral decomposition
where the eigenvalues \({({p}_{i}^{\downarrow })}_{i}\) are not increasing in i. To estimate the effective rank, let us choose an integer r such that
which guarantees that the r-rank state \({\rho }^{(r)}\propto \sum_{i = 1}^{r}{p}_{i}^{\downarrow }{\psi }_{i}\) is O(ε)-close to ρ. The infinite-dimensional Schur–Horn theorem (Proposition 6.4 in ref. 53) implies that for any r-rank projector Π,
Moreover, by setting M2 := ⌈nE/ε⌉, the projector \({\varPi }_{{M}_{2}}\) is an O((eE)n/ϵn)-rank projector satisfying
where we have employed the same inequalities used in equations (23) and (24). Hence, by setting \(\varPi ={\varPi }_{{M}_{2}}\), we deduce that ρ is ε-close to a state ρ(r) having rank
Finally, by exploiting the gentle measurement lemma52 and triangle inequality, one can easily show that the projection of ρ(r) onto \({{\mathcal{H}}}_{{M}_{1}}\) is still O(ε)-close to ρ. Consequently, we conclude that any energy-constrained state can be approximated, up to trace-distance error ε, by a D-dimensional state with rank r such that
Based on these observations, we devised a simple tomography algorithm for energy-constrained states. The first step involves performing the two-outcome measurement \(({\varPi }_{{M}_{1}},{\mathbb{1}}-{\varPi }_{{M}_{1}})\) and discarding the post-outcome state associated with \({\mathbb{1}}-{\varPi }_{{M}_{1}}\). This step transforms the unknown state ρ into the state \({\rho }_{{M}_{1}}\) with high probability. The state \({\rho }_{{M}_{1}}\) has two key properties: (1) It resides in the finite-dimensional subspace \({{\mathcal{H}}}_{{M}_{1}}\) of dimension \(D=O\left({(\mathrm{e}E)}^{n}/{\varepsilon }^{2n}\right)\). (2) It is O(ε)-close to a state residing in \({{\mathcal{H}}}_{{M}_{1}}\) with rank r = O((eE)n/ϵn). The second step involves performing the tomography algorithm of ref. 54 designed for D-dimensional state with rank r, which has a sample complexity of O(Dr). Importantly, this algorithm remains effective even if the unknown state, which is promised to reside in a given D-dimensional Hilbert space, has rank strictly larger than r, as long as it is O(ε)-close to a r-rank state within the same Hilbert space54. We, thus, conclude that the sample complexity in the tomography of energy-constrained states is upper bounded by O(Dr) = O((eE)2n/ϵ3n). Analogously, by exploiting that the sample complexity in the tomography of D-dimensional pure states is O(D) (refs. 1,12,13,14), we can show that the sample complexity in the tomography of energy-constrained pure states is upper bounded by O(D) = O((eE)n/ϵ2n).
For completeness, let us mention that the proof of the lower bounds on the sample complexity in the tomography of energy-constrained states, as presented in Theorems 1 and 2, primarily relies on epsilon-net tools55, like the qudit systems tackled in refs. 12,54. Detailed proofs of these results can be found in Supplementary Information.
Bounds on the trace distance between Gaussian states
In this section, we address the question: If we know with a certain precision the first moment and the covariance matrix of an unknown Gaussian state, what is the resulting trace-distance error that we make on the state?
Let us formalize the problem. Let us consider a Gaussian state ρ1 and assume that we have an approximation of its first moment m(ρ1) and an approximation of its covariance matrix V(ρ1). For example, these approximations may be retrieved through homodyne detection on many copies of ρ1. We can then consider the Gaussian state ρ2 with first moment and covariance matrix equal to such approximations: m(ρ2) and V(ρ2) are, thus, the approximations of m(ρ1) and V(ρ1), respectively. The errors incurred in these approximations are naturally measured by the norm distances ∥m(ρ1) − m(ρ2)∥ and ∥V(ρ1) − V(ρ2)∥, respectively, where ∥ ⋅ ∥ denotes some norm. Now, a natural question arises: given an error ε in the approximations of the first moment and covariance matrix, what is the error incurred in the approximation of ρ1? The most meaningful way to measure such an error is given by the trace distance dtr(ρ1, ρ2) (refs. 9,10). Hence, the question becomes the following. If it holds that
what can we say about the trace distance dtr(ρ1, ρ2)? Thanks to Theorems 10 and 11, we can answer this question. The trace distance dtr(ρ1, ρ2) is at most \(O(\sqrt{\varepsilon })\) and at least Ω(ε).
This motivates the problem of finding upper and lower bounds on the trace distance between Gaussian states in terms of the norm distance of their first moments and covariance matrices. Now, we present our bounds, which are technical tools of independent interest.
Theorem 10, proven in Supplementary Information, gives our upper bound on the trace distance between Gaussian states.
Theorem 10
(Upper bound on the distance between Gaussian states) Let ρ1 and ρ2 be n-mode Gaussian states satisfying the energy constraint \({\rm{Tr}}[{\hat{N}}_{n}{\rho }_{1}],{\rm{Tr}}[{\hat{N}}_{n}{\rho }_{2}]\le N\). Then,
where \(f(N):=\frac{1}{\sqrt{2}}\big(\sqrt{N}+\sqrt{N+1}\big)\). Here \(\|{\bf{m}}\|:=\sqrt{{{\bf{m}}}^{\top }{\bf{m}}}\) and ∥ ⋅ ∥1 denote the Euclidean norm and the trace norm, respectively.
The above theorem turns out to be crucial for proving the upper bound on the sample complexity in the tomography of Gaussian states provided in Theorem 4.
One might believe that proving Theorem 10 would be straightforward by bounding the trace distance using the closed formula for the fidelity between Gaussian states56. However, this approach turns out to be highly non-trivial due to the complexity of such a fidelity formula56, which makes it challenging to derive a bound based on the norm distance between the first moments and covariance matrices. Instead, our proof directly addresses the trace distance without relying on fidelity and involves a meticulous analysis based on the energy-constrained diamond norm57.
The following theorem, proven in Supplementary Information, establishes our lower bound on the trace distance between Gaussian states.
Theorem 11
(Lower bound on the distance between Gaussian states) Let ρ1 and ρ2 be n-mode Gaussian states satisfying the energy constraint \({\rm{Tr}}[{\hat{E}}_{n}{\rho }_{1}],{\rm{Tr}}[{\hat{E}}_{n}{\rho }_{2}]\le E\). Then,
where \(\|{\bf{m}}\|:=\sqrt{{{\bf{m}}}^{\top }{\bf{m}}}\) and \(\parallel V{\parallel }_{2}:=\sqrt{{\rm{Tr}}[{V}^{\top }V]}\) denote the Euclidean norm and the Hilbert–Schmidt norm, respectively.
The proof of this theorem relies heavily on state-of-the-art bounds recently established for Gaussian probability distributions58.
Theorems 10 and 11 allow us to answer the question posed at the beginning of this section. Indeed, these theorems imply that, if we know with error ε the first moment and the covariance matrix of an unknown Gaussian state, the resulting trace-distance error that we make on the state is at most \(O(\sqrt{\varepsilon })\) and at least Ω(ε). In particular, this proves Theorem 3.
The trace-distance bound of Theorem 10 can be improved by assuming one of the Gaussian states to be pure, as we detail in the following theorem, which is proven in the Supplementary Information.
Theorem 12
(Improved bound for pure states) Let ψ be a pure n-mode Gaussian state and let ρ be an n-mode (possibly non-Gaussian) state satisfying the energy constraints \({\rm{Tr}}[\psi {\hat{E}}_{n}],{\rm{Tr}}[\rho {\hat{E}}_{n}]\le E\). Then
where \(\|{\bf{m}}\|:=\sqrt{{{\bf{m}}}^{\top }{\bf{m}}}\) and ∥ ⋅ ∥∞ denote the Euclidean norm and the operator norm, respectively.
By exploiting this improved bound, we show in Supplementary Information that the tomography of pure Gaussian states can be achieved using O(n5E3/ϵ4) copies of the state. This represents an improvement over the mixed-state scenario considered in Theorem 4.
Moreover, the bound in Theorem 12 can be useful for quantum-state certification15, as we briefly detail now. Suppose one aims to prepare a pure Gaussian state ψ with known first moment and covariance matrix. In a noisy experimental set-up, however, an unknown state ρ is effectively prepared. By accurately estimating the first two moments of ρ (which can be done efficiently, as shown in Supplementary Information), one can estimate the right-hand side of equation (34), which provides an upper bound on the trace distance between the target state ψ and the noisy state ρ, thereby providing a measure of the precision of the quantum device. Consequently, the device can be adjusted to minimize the error in state preparation.
Data availability
No data were generated or analysed for this article.
References
Anshu, A. & Arunachalam, S. A survey on the complexity of learning quantum states. Nat. Rev. Phys. 6, 59 (2024).
Eisert, J. et al. Quantum certification and benchmarking. Nat. Rev. Phys. 2, 382 (2020).
Cramer, M. et al. Efficient quantum state tomography. Nat. Commun. 1, 149 (2010).
Bluvstein, D. et al. Logical quantum processor based on reconfigurable atom arrays. Nature 626, 58 (2024).
Smithey, D. T., Beck, M., Raymer, M. G. & Faridani, A. Measurement of the Wigner distribution and the density matrix of a light mode using optical homodyne tomography: application to squeezed states and the vacuum. Phys. Rev. Lett. 70, 1244 (1993).
Lvovsky, A. I. & Raymer, M. G. Continuous-variable optical quantum-state tomography. Rev. Mod. Phys. 81, 299 (2009).
Serafini, A. Quantum Continuous Variables: A Primer of Theoretical Methods (CRC, 2017).
Lanyon, B. P. et al. Efficient tomography of a quantum many-body system. Nat. Phys. 13, 1158 (2017).
Helstrom, C. W. Quantum Detection and Estimation Theory (Academic, 1976).
Holevo, A. S. Investigations in the General Theory of Statistical Decisions (American Mathematical Society, 1978).
Kueng, R., Rauhut, H. & Terstiege, U. Low rank matrix recovery from rank one measurements. Appl. Comput. Harmon. Anal. 42, 88–116 (2017).
O’Donnell, R. & Wright, J. Efficient quantum tomography. In Proc. 48th Annual ACM Symposium on Theory of Computing 899–912 (ACM, 2016).
Haah, J., Harrow, A. W., Ji, Z., Wu, X. & Yu, N. Sample-optimal tomography of quantum states. IEEE Trans. Inf. Theory 63, 5628 (2017).
Haah, J., Kothari, R. & Tang, E. Optimal learning of quantum Hamiltonians from high-temperature Gibbs states. In Proc. 63rd Annual Symposium on Foundations of Computer Science (IEEE, 2022).
Aolita, L., Gogolin, C., Kliesch, M. & Eisert, J. Reliable quantum certification of photonic state preparations. Nat. Commun. 6, 8498 (2015).
Gandhari, S., Albert, V. V., Gerrits, T., Taylor, J. M. & Gullans, M. J. Precision bounds on continuous-variable state tomography using classical shadows. PRX Quantum 5, 010346 (2024).
Becker, S., Datta, N., Lami, L. & Rouzé, C. Classical shadow tomography for continuous variables quantum systems. IEEE Trans. Inf. Theory 70, 3427 (2024).
Oh, C. et al. Entanglement-enabled advantage for learning a bosonic random displacement channel. Phys. Rev. Lett. 133, 230604 (2024).
Madsen, L. S. et al. Quantum computational advantage with a programmable photonic processor. Nature 606, 75 (2022).
Zhong, H.-S. et al. Quantum computational advantage using photons. Science 370, 1460–1463 (2020).
Hangleiter, D. & Eisert, J. Computational advantage of quantum random sampling. Rev. Mod. Phys. 95, 035001 (2023).
Somhorst, F. H. B. et al. Quantum photo-thermodynamics on a programmable photonic quantum processor. Nat. Commun. 14, 3895 (2023).
Mirrahimi, M. et al. Dynamically protected cat-qubits: a new paradigm for universal quantum computation. New J. Phys. 16, 045014 (2014).
Ofek, N. et al. Extending the lifetime of a quantum bit with error correction in superconducting circuits. Nature 536, 441–445 (2016).
Michael, M. H. et al. New class of quantum error-correcting codes for a bosonic mode. Phys. Rev. X 6, 031006 (2016).
Guillaud, J. & Mirrahimi, M. Repetition cat qubits for fault-tolerant quantum computation. Phys. Rev. X 9, 041053 (2019).
Alexander, K. et al. A manufacturable platform for photonic quantum computing. Nature 641, 876–883 (2025).
Wolf, M. M., Pérez-García, D. & Giedke, G. Quantum capacities of bosonic channels. Phys. Rev. Lett. 98, 130501 (2007).
Takeoka, M., Guha, S. & Wilde, M. M. Fundamental rate-loss tradeoff for optical quantum key distribution. Nat. Commun. 5, 5235 (2014).
Pirandola, S., Laurenza, R., Ottaviani, C. & Banchi, L. Fundamental limits of repeaterless quantum communications. Nat. Commun. 8, 15043 (2017).
Mele, F. A., Lami, L. & Giovannetti, V. Restoring quantum communication efficiency over high loss optical fibers. Phys. Rev. Lett. 129, 180501 (2022).
Mele, F. A., Lami, L. & Giovannetti, V. Maximum tolerable excess noise in continuous-variable quantum key distribution and improved lower bound on two-way capacities. Nat. Photonics 19, 329–334 (2025).
Mele, F. A., Salek, F., Giovannetti, V. & Lami, L. Quantum communication on the bosonic loss-dephasing channel. Phys. Rev. A 110, 012460 (2024).
Aasi, J. et al. Enhanced sensitivity of the LIGO gravitational wave detector by using squeezed states of light. Nat. Photonics 7, 613–619 (2013).
Zhang, J. et al. Noon states of nine quantized vibrations in two radial modes of a trapped ion. Phys. Rev. Lett. 121, 160502 (2018).
Meyer, V. et al. Experimental demonstration of entanglement-enhanced rotation angle estimation using trapped ions. Phys. Rev. Lett. 86, 5870 (2001).
McCormick, K. et al. Quantum-enhanced sensing of a single-ion mechanical oscillator. Nature 572, 86–90 (2019).
Zhang, Y. et al. Long-distance continuous-variable quantum key distribution over 202.81 km of fiber. Phys. Rev. Lett. 125, 010502 (2020).
Hajomer, A. A. E. et al. Long-distance continuous-variable quantum key distribution over 100-km fiber with local local oscillator. Sci. Adv. 10, eadi9474 (2024).
Aaronson, S. & Grewal, S. Efficient tomography of non-interacting-fermion states. In 18th Conference on the Theory of Quantum Computation, Communication and Cryptography (TQC 2023), Vol. 266, 12:1–12:18 (Leibniz International Proceedings in Informatics (LIPIcs), 2023).
Mele, A. A. & Herasymenko, Y. Efficient learning of quantum states prepared with few fermionic non-Gaussian gates. PRX Quantum 6, 010319 (2025).
Marian, P. & Marian, T. A. Relative entropy is an exact measure of non-Gaussianity. Phys. Rev. A 88, 012322 (2013).
Lloyd, S. & Braunstein, S. L. Quantum computation over continuous variables. Phys. Rev. Lett. 82, 1784 (1999).
Leone, L., Oliviero, S. F. E. & Hamma, A. Learning t-doped stabilizer states. Quantum 8, 1361 (2024).
Oliviero, S. F., Leone, L. & Hamma, A. Transitions in entanglement complexity in random quantum circuits by measurements. Phys. Lett. A 418, 127721 (2021).
Leone, L., Oliviero, S. F. E., Zhou, Y. & Hamma, A. Quantum chaos is quantum. Quantum 5, 453 (2021).
Oliviero, S. F. E., Leone, L., Lloyd, S. & Hamma, A. Unscrambling quantum Information with Clifford decoders. Phys. Rev. Lett. 132, 080402 (2024).
Leone, L., Oliviero, S. F. E., Lloyd, S. & Hamma, A. Learning efficient decoders for quasichaotic quantum scramblers. Phys. Rev. A 109, 022429 (2024).
Grewal, S., Iyer, V., Kretschmer, W. & Liang, D. Efficient learning of quantum states prepared with few non-Clifford gates. Preprint at https://arxiv.org/abs/2305.13409 (2023).
Chia, N.-H., Lai, C.-Y. & Lin, H.-H. Efficient learning of t-doped stabilizer states with single-copy measurements. Quantum 8, 1250 (2024).
Haah, J., Kothari, R., O’Donnell, R. & Tang, E. Query-optimal estimation of unitary channels in diamond distance. In Proc. 64th Annual Symposium on Foundations of Computer Science (IEEE, 2023).
Khatri, S. & Wilde, M. M. Principles of quantum communication theory: a modern approach. Preprint at https://arxiv.org/abs/2011.04672 (2020).
Kaftal, V. & Weiss, G. An infinite dimensional Schur-Horn theorem and majorization theory with applications to operator ideals. J. Funct. Anal. 259, 3115–3162 (2009).
Wright, J. How to Learn a Quantum State. PhD thesis, Carnegie Mellon Univ. (2016).
Vershynin, R. High-dimensional Probability: An Introduction with Applications in Data Science (Cambridge Univ. Press, 2018).
Banchi, L., Braunstein, S. L. & Pirandola, S. Quantum fidelity for arbitrary Gaussian states. Phys. Rev. Lett. 115, 260501 (2015).
Becker, S., Datta, N., Lami, L. & Rouzé, C. Energy-constrained discrimination of unitaries, quantum speed limits and a Gaussian Solovay–Kitaev theorem. Phys. Rev. Lett. 126, 190504 (2021).
Devroye, L., Mehrabian, A. & Reddad, T. The total variation distance between high-dimensional Gaussians with the same mean. Preprint at https://arxiv.org/abs/1810.08693 (2023).
Acknowledgements
We thank M. Caro, N. Walk and M. Fanizza for useful discussions. This work has been supported by the BMFTR (QPIC-1, PhoQuant, DAQC), the DFG (CRC 183), the QuantERA (HQCC), the MATH+ Cluster of Excellence, the ML4Q Cluster of Excellence, the Quantum Flagship (Millenion, PasQuans2), the Einstein Foundation (Einstein Research Unit on Quantum Devices), Berlin Quantum and the Munich Quantum Valley (K-8). J.E. is also funded by the European Research Council through project DebuQC. F.A.M., S.F.E.O. and V.G. acknowledge financial support from MUR (Ministero dell’Istruzione, dell’Università e della Ricerca) through PNRR MUR project PE0000023-NQSTI. L.L. acknowledges financial support from the European Union (ERC StG ETQO, Grant Agreement No. 101165230). F.A.M. and S.F.E.O. thank the Freie Universität Berlin for hospitality. F.A.M. thanks the University of Amsterdam and QuSoft for hospitality.
Funding
Open access funding provided by Freie Universität Berlin.
Author information
Authors and Affiliations
Contributions
The project was conceived by F.A.M., A.A.M., L. Leone and S.F.E.O. The theoretical results were proven by F.A.M., A.A.M., L.B., L. Lami, L. Leone and S.F.E.O. All authors discussed the work and contributed to writing the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Physics thanks John Bostanci and Arkopal Dutt for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information
Supplementary discussion, Figs. 1–4 and Tables 1–4.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mele, F.A., Mele, A.A., Bittel, L. et al. Learning quantum states of continuous-variable systems. Nat. Phys. 21, 2002–2008 (2025). https://doi.org/10.1038/s41567-025-03086-2
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s41567-025-03086-2
This article is cited by
-
Complexity of quantum tomography from genuine non-Gaussian entanglement
Nature Communications (2025)
