
Abstract
Scientists have grappled with reconciling biological evolution1,2 with the immutable laws of the Universe defined by physics. These laws underpin life’s origin, evolution and the development of human culture and technology, yet they do not predict the emergence of these phenomena. Evolutionary theory explains why some things exist and others do not through the lens of selection. To comprehend how diverse, open-ended forms can emerge from physics without an inherent design blueprint, a new approach to understanding and quantifying selection is necessary3,4,5. We present assembly theory (AT) as a framework that does not alter the laws of physics, but redefines the concept of an ‘object’ on which these laws act. AT conceptualizes objects not as point particles, but as entities defined by their possible formation histories. This allows objects to show evidence of selection, within well-defined boundaries of individuals or selected units. We introduce a measure called assembly (A), capturing the degree of causation required to produce a given ensemble of objects. This approach enables us to incorporate novelty generation and selection into the physics of complex objects. It explains how these objects can be characterized through a forward dynamical process considering their assembly. By reimagining the concept of matter within assembly spaces, AT provides a powerful interface between physics and biology. It discloses a new aspect of physics emerging at the chemical scale, whereby history and causal contingency influence what exists.
Similar content being viewed by others
Main
In evolutionary theory, natural selection1 describes why some things exist and others do not2. Darwin’s theory of evolution and its modern synthesis point out how selection among variants in the past generates current functionality3, as well as a forward-looking process4. Neither addresses the space in which new phenotypic variants are generated. Physics can, in theory, take us from past initial conditions to current and future states. However, because physics has no functional view of the Universe, it cannot distinguish novel functional features from random fluctuations, which means that talking about true novelty is impossible in physical reductionism. Thus, the open-ended generation of novelty5 does not fit cleanly in the paradigmatic frameworks of either biology6 or physics7, and so must resort ultimately to randomness8. There have been several efforts to explore the gap between physics and evolution9,10. This is because a growing state space over time requires the exploration of a large combinatorial set of possibilities11, such as in the theory of the adjacent possible12. However, the search generates an unsustainable expansion in the number of configurations possible in a finite universe in finite time, and does not include selection. In addition, this approach has limited predictive power with respect to why only some evolutionary innovations happen and not others. Other efforts have studied the evolution of rules acting on other rules13; however, these models are abstract so it is difficult to see how they can describe—and predict—the evolution of physical objects.
Here, we introduce AT, which addresses these challenges by describing how novelty generation and selection can operate in forward-evolving processes. The framework of AT allows us to predict features of new discoveries during selection, and to quantify how much selection was necessary to produce observed objects14,15 without having to prespecify individuals or units of selection. In AT, objects are not considered as point particles (as in most physics), but are defined by the histories of their formation as an intrinsic property, mapped as an assembly space. The assembly space is defined as the pathway by which a given object can be built from elementary building blocks, using only recursive operations. For the shortest path, the assembly space captures the minimal memory, in terms of the minimal number of operations necessary to construct an observed object based on objects that could have existed in its past16. One feature of biological assemblies of objects is multiple realizability wherein biological evolution can produce functionally equivalent classes of objects with modular use of units in many different contexts. For each unit, the minimal assembly is unique and independent of its formation, and therefore accounts for multiple realizability in how it could be constructed17,18.
We introduce the foundations of AT and its implementation to quantify the degree of selection and evolution found in a collection of objects. Assembly is a function of two quantities: the number of copies of the observed objects and the objects’ assembly indices (an assembly index is the number of steps on a minimal path producing the object). Assembly captures the amount of memory necessary to produce a selected configuration of historically contingent objects in a manner similar to how entropy quantifies the information (or lack thereof) necessary to specify the configuration of an ensemble of point particles, but assembly differs from entropy because of its explicit dependence on the contingency in construction paths intrinsic to complex objects. We demonstrate how AT leads to a unified language for describing selection and the generation of novelty, and thereby produce a framework to unify descriptions of selection across physics and biology.
Assembly theory
The concept of an object in AT is simple and rigorously defined. An object is finite, is distinguishable, persists over time and is breakable such that the set of constraints to construct it from elementary building blocks is quantifiable. This definition is, in some sense, opposite to standard physics, which treats objects of interest as fundamental and unbreakable (for example, the concept of ‘atoms’ as indivisible, which now applies to elementary particles). In AT, we recognize that the smallest unit of matter is typically defined by the limits of observational measurements and may not itself be fundamental. A more universal concept is to treat objects as anything that can be broken and built. This allows us to naturally account for the emergent objects produced by evolution and selection as fundamental to the theory. The concept of copy number is of foundational importance in defining a theory that accounts for selection. The more complex a given object, the less likely an identical copy can exist without selection of some information-driven mechanism that generates that object. An object that exists in multiple copies allows the signatures describing the set of constraints that built it to be measured experimentally. For example, mass spectrometry can be used to measure assembly for molecules, because it can measure how molecules are built by making bonds19.
Assembly index and copy number
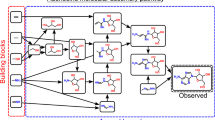
To construct an assembly space for an object, one starts from elementary building blocks comprising that object and recursively joins these to form new structures, whereby, at each recursive step, the objects formed are added back to the assembly pool and are available for subsequent steps (Supplementary Information Sections 1 and 2). AT captures symmetry breaking arising along construction paths due to recursive use of past objects that can be combined in different ways to make new things. For any given object i, we can define its assembly space as all recursively assembled pathways that produce it. For each object, the most important feature is the assembly index \({a}_{i}\), which corresponds to the shortest number of steps required to generate the object from basic building blocks. This can be quantified as the length of the shortest assembly pathway that can generate the object (Fig. 1).

a–c, AT is generalizable to different classes of objects, illustrated here for three different general types. a, Assembly pathway to construct diethyl phthalate molecule considering molecular bonds as the building blocks. The figure shows the pathway starting with the irreducible constructs to create the molecule with assembly index 8. b, Assembly pathway of a peptide chain by considering building blocks as strings. Left, four amino acids as building blocks. Middle, the actual object and its representation as a string. Right, assembly pathway to construct the string. c, Generalized assembly pathway of an object comprising discrete components.
In chemical systems, molecular assembly theory treats bonds as the elementary operations from which molecules are constructed. The shortest path to build a given molecule can be found by breaking its bonds and then ordering its motifs in order of size, starting from atoms and moving to larger motifs by adding bonds in sequence. Given a motif generated on the path, the motif remains available for reuse. The recursivity allows identifying the shortest construction path with parts already built on that path, allowing us to quantify the minimum number of constraints, or memory size, to construct the molecule. The assembly index can be estimated from any complex discrete object with well-defined building blocks, which can be broken apart, as shown in Fig. 1. At every step, the size of the object increases by at least one. The number of total possible steps, although potentially large, is always finite for any finite object and thus the assembly index is computable in finite time. For molecules, the assembly index can be determined experimentally.
A hallmark feature of life is how complex objects are generated by evolution, of which many are functional. For example, a DNA molecule holds genetic information reliably and can be copied easily. By contrast, a random string of letters requires much information to describe it, but is not normally seen as very complex or useful. Thus far, science has not been able to find a measure that quantifies the complexity of functionality to distinguish these two cases. Here we overcome this inherent problem by pointing out another feature of the evolutionary process: the complex and functional objects it generates take many steps to make, and selection allows many identical copies of these objects. Therefore, an evolutionary process can be identified by the production of many identical, or near-identical, multistep objects. The assembly index on its own cannot detect selection, but copy number combined with the assembly index can. This approach defines a new way to measure complexity in terms of the hierarchy of causation stemming from selection at different levels.
Because we do not typically know the full assembly trajectory of an object, we instead adopt a conservative alternative. AT finds the minimal number of steps to produce the object. We assume that every subobject, once available, can be used as often as needed to generate the object. A different approach would be to use Kolmogorov complexity20,21 applied to a given molecule, but this requires starting with a graphical representation, and a program to compute the graph of that molecule. The Kolmogorov complexity of a string is the shortest program that will output that string for a programming language capable of universal computation. This measure cannot be easily computed, because checking whether any single program will output the string is uncomputable, as it involves, at least, deciding whether the program stops. Running this program reflects nothing of the underlying process of how the molecule was constructed. Only late in the evolutionary process will molecules be produced by anything starting to resemble Turing machines, loops, stacks, tapes and so on22. Thus, using universal computation to assess molecules adds unrealistic dynamics, making the answer uncomputable. The assembly measure that we have presented here both uses realistic dynamics for molecules, using bonds as building blocks, and is computable for any molecule. The main work for detecting evolution and memory is done here by combining the assembly index and copy number of the objects.
The aim of AT is to develop a new understanding of the evolution of complex matter that naturally accounts for selection and history in terms of what operations are physically possible in constructing an object23,24. We will discuss AT as applied to chemical systems as the main application in this manuscript because their assembly index has been experimentally measured. For molecules, assembly index has a clear physical interpretation and has been validated as quantifying evidence of selection in its application to the detection of molecular signatures of life. However, we anticipate the theory to be sufficiently general to apply to a wide variety of other systems including polymers, cell morphology, graphs, images, computer programs, human languages and memes, as well as many others. The challenge in each case will be to construct an assembly space that has a clear physical meaning in terms of what operations can be caused to occur to make the object23 (Fig. 1).
In AT there are two important features of the context the object is found in. First, there must be objects in its environment that can constrain the steps to assemble the object and second these objects themselves have been selected because they must be retained over subsequent steps to physically instantiate the memory needed to build the target object. Among the most relatable examples are enzyme catalysts in biochemistry, which permit the formation of very unlikely molecules in large numbers because the enzymes themselves are also selected to exist with many copies. We make no distinction between the traditional notion of biological ‘individual’ and objects that are selected in the environment to quantify the selection necessary to produce a given configuration. Thus, our approach naturally accounts for well-known phenomena, such as niche construction, whereby organisms and environment are co-constructed and co-selected.
Copy number is important because a single example of a highly complex molecule (with a very high assembly index) could potentially be generated in a series of random events that become increasingly less likely with increasing assembly index. If we consider a forward-building assembly process (see Supplementary Information Sections 1 and 2 for details), without a specific target in mind, the number of possible objects that could be built at each recursive step grows super-exponentially in the absence of any constraints. The likelihood of finding and measuring more than one copy of an object therefore decreases super-exponentially with increasing assembly index in the absence of selection for a specified target. Objects with high assembly index, found in abundance, provide evidence of selection because of the combinatorially growing space of possible objects at each recursive assembly step (Fig. 2). Finding more than one identical copy indicates the presence of a non-random process generating the object.

a, Pictorial representation of the assembly space representing the formation of combinatorial object space from building blocks and physical constraints. b, Observed copy number distributions of objects at different assembly indices as an outcome of selection or no selection. c, Representation of physical pathways to construct objects with undirected and directed pathways (selected) leading to the low and high copy numbers of the observed object.
The assembly equation
We define assembly as the total amount of selection necessary to produce an ensemble of observed objects, quantified using equation (1):
where \(A\) is the assembly of the ensemble, \({a}_{i}\) is the assembly index of object \(i\), \({n}_{i}\) is its copy number, N is the total number of unique objects, e is Euler’s number and \({N}_{{\rm{T}}}\) is the total number of objects in the ensemble. Normalizing by the number of objects in the ensemble allows assembly to be compared between ensembles with different numbers of objects.
Assembly quantifies two competing effects, the difficulty of discovering new objects, but, once discovered, some objects become easier to make; this is indicative of how selection was required to discover and make them. The exponential growth of assembly with depth in assembly space, as quantified by assembly index, is derived by considering a linearly expanding assembly pool that has objects that combine at step \(a\to a+1\), whereby an object at the assembly index \(a\) combines with another object from the assembly pool. Discovering new objects at increasing depth in an assembly space gets increasingly harder with depth because the space of possibilities expands exponentially. Once the pathway for a new object has been discovered, the production of an object (copy number greater than 1) gets easier as the copy number increases because a high copy number implies that an object can be produced readily in a given context. Thus, the hardest innovation is making an object for the first time, which is equivalent to its discovery, followed by making the first copy of that object, but once an object exists in very high abundance it must already be relatively easy to make. Hence, assembly (A) scales linearly with copy number for more than one object for a fixed cost per object once a process has been discovered (see Supplementary Information Section 3 for additional details).
Increasing assembly (\(A\)) results from increasing copy numbers \(n\) and increasing assembly indices \(a\). If high values of assembly can be shown to capture cases in which selection has occurred, it implies that finding high assembly index objects in high abundance is a signature of selection. In AT, the information required at each step to construct the object is ‘stored’ within the object (Fig. 2). Each time two objects are combined from an assembly pool, the specificity of the combination process constitutes selection. As we will show, randomly combining objects within the assembly pool at each step does not constitute selection because no combinations exist in memory to be used again for building the same object. If, instead, certain combinations are preferentially used, it implies that a mechanism exists that selects the specific operations and, by extension, specific target objects to be generated. Later we will quantify the degree of selectivity by parameter \(\alpha \) in the growth dynamics, which allows parameterizing selection in an empirically observable manner by parameterizing reuses of specific sets of operations (see Supplementary Information Section 3 for example).
Assembly as given in equation (1) is determined for identified finite and distinguishable objects (with copy number greater than 1) and their distinct assembly spaces. However, in real samples, there are almost always several different coexisting objects, which will include a common history for their formation. Transistors, for example, are used across several different technologies, suggesting a common subspace in the assembly spaces of many modern technologies that includes transistor-like objects. This common subspace, constituting the overlap in the assembly paths of distinct structures, is called a co-assembly space. By contrast, a joint assembly space of several objects is the combined assembly space required to generate those objects. As a potential extension of the assembly equation, to account for the joint assembly of objects, we expand the formulation of the assembly equation that includes the quantification of shared pathways to construct objects to determine the assembly (\(A\)) of an ensemble with different objects that share common history (Supplementary Information Section 3).
Selection within assembly spaces
The concept of the assembly space allows us to understand how selection and historical contingency impose constraints on what can be made in the future. By aiming to detect ‘selection’, we mean a process similar to selection in Darwinian evolution. We do not, however, model functional differences that selection might act on. Instead, we account only for the specificity of selection—that some objects are more likely to be used to make new things and some are less likely. The only functionality we want to detect or describe is in the memory of the process to generate the object, with examples including a metabolic reaction network or a genome. This allows the three Lewontin conditions for evolution to hold25. A key feature of assembly spaces is that they are combinatorial, with objects combined at every step. Combinatorial spaces do not play a prominent role in current physics, because their objects are modelled as point particles and not as combinatorial objects (with limited exceptions). However, combinatorial objects are important in chemistry, biology and technology, in which most objects of interest (if not all) are hierarchical modular structures. More objects exist in assembly space than can be built in finite time with finite resources because the space of possibilities grows super-exponentially with the assembly index. To tame this explosive growth, in AT historical contingency is intrinsic with the space built compositionally, where items are combined recursively (accounting for hierarchical modularity) and this substantially constrains the number of possible objects. It is the combination of this compositionality with combinatorics that allows us to describe selection (Fig. 3).

a, Assembly observed of the three objects shown as graphs (P1, P2 and P3) with their shared minimal construction process called their ‘joint assembly space’. b, Illustration of the expansion of the assembly universe, assembly possible, assembly contingent and assembly observed (see text for details). Assembly universe has no dynamics and is displayed with assembly steps as the time axis. Note that the figure illustrates their nested structure only, not the relative size of the spaces where each set is typically exponentially larger than the subset.
To produce an assembly space, an observed object is broken down recursively to generate a set of elementary building units. These units can be used to then recursively construct the assembly pathways of the original object(s) to build what we call assembly observed, AO. AO captures all histories for the construction of the observed object(s) from elementary building blocks, consistent with what physical operations are possible. Because objects in AT are compositional, they contain information about the larger space of possible objects from which they were selected. To see how, we first build an assembly space from the same building blocks in AO, which include all possible pathways for assembling any object composed of the same set elementary building blocks as our target object. The space so constructed is the assembly universe (AU).
In the assembly universe, all objects are possible with no rules, yielding a combinatorial explosion and with double exponential growth in the number of objects, as is characteristic of exploding state spaces and the adjacent possible (see Supplementary Information Section 4 for details). Although mathematically well defined, this double exponential growth is unphysical because the physical processes place restrictions on what is possible (in the case of molecules, an example is how quantum mechanics constrains the numbers of bonds per atom). The assembly universe also has no concept of directionality in time, as there is no ordering to construction processes. Because everything can exist, there is an implication that objects can be constructed independently of what has existed in the past and of resource or time constraints, which is not what we observe in the real universe. For most systems of interest, including in molecular assembly spaces, the number of molecules in the assembly universe is orders of magnitude larger than the amount of matter available in the cosmologically observable universe. There is no way to computationally build and exhaust the entire space, even for objects with relatively low assembly indices. For larger objects, such as proteins, this can be truly gigantic26. In AT, we do not observe all possible objects at a given depth in the assembly space because of selection, more reflective of what we see in the real universe. We next show how taking account of memory and resource limitation severely restricts the size of the space of what can be built, but also allows higher-assembly objects to be built before exhausting resources constructing all the possible lower-assembly objects. AT can account for selection precisely because of the historical contingency in the recursive construction of objects along assembly paths.
Assembly possible (AP) is the space of physically possible objects, which can be generated by means of the combinatorial expansion of all the known physical rules of object construction and allowing all rules to be available at every step to every object. This can be described by a dynamical model representing undirected forward dynamics in AT. When an object with assembly index \(a\) combines with its own history, its assembly index increases by one, \(a\to a+1\). If the resulting object can be made by means of other, shorter path(s), its assembly index will be smaller than \(a+1\) or even \(a\). Another assumption behind the dynamical model of undirected dynamics is a microscopically driven stochastic rule that uses existing objects uniformly: the probability of choosing an object with assembly index \(a\) to be combined with any other object is proportional to \({N}_{a}\), the number of objects with assembly index \(a\) (see Supplementary Information Section 5 for further details).
Within assembly possible, assembly contingent (AC) describes the possible space of objects where history, and selection on that history, matter. Historical contingency is introduced by assuming that only the knowledge or constraints built on a given path can be used in the future, or with different paths interacting in cases in which selected objects that had not interacted previously now interact. We define the probability \({P}_{a}\) of an object being selected with assembly index (\(a\)) as \({P}_{a}\propto {({N}_{a})}^{\alpha }\), where \({N}_{a}\) is the number of objects with assembly index \(a\). Here, \(\alpha \) parameterizes the degree of selection: for \(\alpha =1\) all objects that have been assembled in the past are available for reuse, and for \(0\le \alpha < 1\), only a subset (that grows non-linearly with assembly index) are available for reuse, indicating that selection has occurred. This leads to the growth dynamics:
where \({k}_{{\rm{d}}}\) represents the rate of discovery (expansion rate) of new objects. For \(\alpha =1\), there is historical dependence without selection. We build assembly paths by taking two randomly chosen objects from the assembly pool and combining them; if a new object is formed, it is added back into the pool. Here we are building random objects, but these are fundamentally different from random combinatorial objects because the randomness we implement is distributed across the recursive construction steps leading to an object (see Supplementary Information Section 5 for solutions). The case of \(\alpha =1\), in which there is historical dependence but no selection, defines the boundary of assembly possible.
Within assembly possible, the assembly contingent (AC) is the space of possible configurations of objects where \(0\le \alpha < 1\), that is, where selection is possible, and the objects found in the space are controlled by a path-dependency contingent on each object that has already been built. The growth of the assembly contingent is much slower than exponential; indeed, not all possible paths are explored equally. Instead, the dynamics are channelled by constraints imposed by the selectivity emerging along specific paths. Indeed, a signature of selection in assembly spaces is a slower-than-exponential growth of the number of unique objects. To show this, we use a simple phenomenological model of linear polymers to demonstrate how assembly differentiates cases when selection happens. Starting with a single monomer in the assembly pool, the undirected exploration process combines two randomly selected polymers and adds them back to the assembly pool. In the case of directed exploration with selection, the polymer that has been created most recently is selected to join a randomly selected polymer from the assembly pool. For both directed and undirected exploration, this process was iterated up to 104 steps and repeated 25 times. For each observed polymer in the assembly pool, the shortest pathway was generated. For each run, the assembly space of multiple coexisting polymers, their joint assembly space, was approximated by the union of the shortest pathways of all observed polymers. An example of joint assembly space in an undirected exploration up to 30 steps is shown in Fig. 4a.

a, The joint assembly space of polymeric chains (with their lengths indicated) after 30 steps created by combining randomly selected polymers from the assembly pool. The length of the realized polymers is shown in blue (observed nodes), whereas nodes shown in black represent polymers that have not been realized but are part of the joint assembly space of all realized objects (contingent nodes). For simplicity of representing the joint assembly space, the edge nodes (shown in red) represent the combined node along the directed graph. b, The comparison between undirected and directed exploration after 100 assembly steps using a graph with radial embedding (observed and contingent nodes shown in red and grey, respectively). c, The mean and standard deviation of the exploration ratio (defined by the ratio of the number of observed nodes and the number of total nodes, which includes observed and contingent nodes) and mean maximum assembly index. n is 25 runs all averaged up to 104 assembly steps.
Comparison between the explored joint assembly space in undirected and directed exploration up to 100 steps is shown in Fig. 4b (see Supplementary Information Section 6 for details). To quantify the degree of exploration at a given assembly step, we calculated the exploration ratio, defined by the ratio of observed nodes to total number of nodes present in the joint assembly space. Figure 4c shows the exploration ratio and the mean maximum assembly index observed, approximated by \({\log }_{2}\left(n\right)\), where \(n\) is the length of the polymer for the undirected and directed exploration processes (both upper and lower bounds scale as \({\log }_{2}\left(n\right)\) in leading order). Here, the mean maximum assembly index was estimated by calculating the assembly index of the mean value of the longest observed polymeric chains over 25 runs. Comparing the directed process to the undirected exploration illustrates a central principle: the signal of selection is simply a lower exploration ratio and higher complexity (as defined by the maximum assembly index). The observation of a lower exploration ratio in the directed process than in the undirected process is the evidence of the presence of selectivity in the combination process between the polymers existing in the assembly pool. The process representing sorting and selecting chains within the assembly pool represents an outcome of a physical process leading to selection (see Supplementary Information Section 7 for an additional model).
We conjecture that, the ‘more assembled’ an ensemble of objects, the more selection is required for it to come into existence. The historical contingency in AT means that assembly dynamics explores higher-assembly objects before exhausting all lower-assembly objects, leading to a vast separation in scales separating the number of objects that could have been explored versus those that are actually constructed following a particular path. For example, proteins built both from d and l amino acids and their pathways are part of assembly possible, but, within an assembly contingent trajectory, only proteins constructed out of l amino acids might be present, because of early selection events. This early symmetry breaking along historically contingent paths is a fundamental property of all assembly processes. It introduces an ‘assembly time’ that ticks at each object being made: assembly physics includes an explicit arrow of time intrinsic to the structure of objects.
Assembly unifies selection with physics
In the real universe, objects can be built only from parts that already exist. The discovery of new objects is therefore historically contingent. The rate of discovery of new objects can be defined by the expansion rate (\({k}_{{\rm{d}}}\)) from equation (2), introducing a characteristic timescale \({\tau }_{{\rm{d}}}\approx \frac{1}{{k}_{{\rm{d}}}}\), defined as the discovery time. In addition, once a pathway to build an object is discovered, the object can be reproduced if the mechanism in its environment is selected to build it again. Thus far, we have considered discovery dynamics within the assembly spaces and did not account for the abundance or copy number of the observed objects when discovered. To include copy number in the dynamics of AT, we must introduce a second timescale, the rate of production (\({k}_{{\rm{p}}}\)) of a specific object, with a characteristic production timescale \({\tau }_{{\rm{p}}}\approx \frac{1}{{k}_{{\rm{p}}}}\) (Fig. 5). For simplicity, we assume that selectivity and interaction among emerging objects are similar across assembled objects. Defining these two distinct timescales for initial discovery of an object and making copies of existing objects allows us to determine the regimes in which selection is possible (Fig. 5).

a, Assembly processes with and without selection. The selection process is defined by a transition from undirected to directed exploration. The parameter \(\alpha \) represents the selectivity of the assembly process (\(\alpha =1\): undirected/random expansion, \(\alpha < 1\): directed expansion). Undirected exploration leads to the fast homogeneous expansion of discovered objects in the assembly space, whereas directed exploration leads to a process that is more like a depth-first search. Here, \({\tau }_{{\rm{d}}}\) is the characteristic timescale of discovery, determining the growth of the expansion front, and \({\tau }_{{\rm{p}}}\) is the characteristic timescale of production that determines the rate of formation of objects (increasing copy number). b, Rate of discovery of unique objects at assembly \(a+1\) versus number of objects at assembly \(a\). The transition of \(\alpha =1\) to \(\alpha < 1\) represents the emergence of selectivity limiting the discovery of new objects. c, Phase space defined by the production (\({\tau }_{{\rm{p}}}\)) and discovery (\({\tau }_{{\rm{d}}}\)) timescales. The figure shows three different regimes: (1) \({\tau }_{{\rm{d}}}\ll {\tau }_{{\rm{p}}}\), (2) \({\tau }_{{\rm{d}}}\gg {\tau }_{{\rm{p}}}\), and (3) \({\tau }_{{\rm{d}}}\approx {\tau }_{{\rm{p}}}\). Selection is unlikely to emerge in regimes 1 and 2, and is possible in regime 3.
For \(\frac{{\tau }_{{\rm{p}}}}{{\tau }_{{\rm{d}}}}\gg 1\), whereby objects are discovered quickly but reproduced slowly, the expansion of assembly space is too fast under mass constraints to accumulate a high abundance of any distinguishable objects, leading to a combinatorial explosion of unique objects with low copy numbers. This is consistent with how some unconstrained prebiotic synthesis reactions, such as the formose reaction, end up producing tar, which is composed of a large number of molecules with too low a copy number to be individually identifiable27,28. Selection and evolution cannot emerge if new objects are generated on timescales so fast that resources are not available for making more copies of those objects that already exist. For \(\frac{{\tau }_{{\rm{p}}}}{{\tau }_{{\rm{d}}}}\ll 1\), objects are reproduced quickly but new ones are discovered slowly. Here resources are primarily consumed in producing additional copies of objects that already exist. Typically, new objects are discovered infrequently. This leads to a high abundance of objects produced by extreme constraints, which could limit the further growth of assembly space. This illustrates how exploration versus exploitation can play out in AT. Significant separation of the two timescales of discovery of new objects and (re)production of selected objects results in either a combinatorial explosion of objects with low copy numbers or, conversely, high copy numbers of low assembly objects. In both cases, we will not observe trajectories that grow more complex structures.
The emergence of selection and open-ended evolution in a physical system should occur in the transition regime where there is only a small separation in the timescales between discovering new objects and reproducing ones that are selected, for example the region located between \({\tau }_{{\rm{d}}}\ll {\tau }_{{\rm{p}}}\) and \({\tau }_{{\rm{d}}}\gg {\tau }_{{\rm{p}}}\) (Fig. 5). To investigate discovery and production dynamics simultaneously, we introduce mass action kinetics in the framework of AT. Our aim is to demonstrate how the generation of novelty can be described alongside selection in a forward process (thus unifying key features of life with physics) and how measuring assembly identifies how much selection occurred. We do so by studying phenomenological models, with the understanding that we are putting selection in by hand in our examples to demonstrate foundational principles of how assembly quantifies selection. To explore this, we consider a forward assembly process whereby the copy numbers of emerging objects follow homogeneous kinetics, together with the discovery dynamics as given by equation (2). With the discovery of new unique objects over time, symmetry breaking in the construction of contingent assembly paths will create a network of growing branches within the assembly possible. In principle, interactions among existing objects and external factors lead to discovery of new objects, expanding the space of possible future objects. Such events can drastically change the copy number distribution of objects at various assembly indices, depending on the emerging kinetics in the formation of new objects. By combining discovery and production kinetics in a simplified formulation, we estimate copy numbers of objects at different assembly indices and show assembly of the ensemble over time in the forward process at different degrees of selection (see Supplementary Information Section 8 for an example).
The interplay between the two characteristic timescales describes how discovery dynamics (\({{\tau }_{{\rm{d}}}\approx 1/k}_{{\rm{d}}}\)) and forward kinetics (\({\tau }_{{\rm{p}}}\approx 1/{k}_{{\rm{p}}}\)), together with selection (characterized by the selection parameter \(\alpha \)), are essential for driving processes towards creating higher-assembly objects. This is characteristic of trajectories within assembly contingent. Assembly captures key features of how the open-ended growth of complexity can occur within a restricted space only by generating new objects with increasing assembly indices, while also producing them with a high copy number. Selectivity (\(\alpha < 1\)) together with comparable production timescales (\({\tau }_{{\rm{d}}}\approx {\tau }_{{\rm{p}}}\)) is essential for the production of high assembly ensembles. This suggests that selectivity in an unknown physical process can be explained by experimentally detecting the number of objects, their assembly index and copy number as a function of time. Considering molecules as objects and assuming that molecules observed using analytical techniques such as mass spectrometry implies a high copy number, the discovery rate and the selection index (\(\alpha \)) can be computed from the temporal data of observed molecules at all assembly indices.
Conclusions
We have introduced the foundations of AT and how it can be implemented to quantify the degree of selection found in an ensemble of evolved objects, agnostic to the detailed formation mechanisms of the objects or knowing a priori which objects are products of units of selection. To do so, we introduced a quantity, assembly, built from two quantities: the number of copies of an object and its assembly index, where the assembly index is the minimal number of recursive steps necessary to build the object (its size). We demonstrated how AT allows a unified language for describing selection and the generation of novelty by showing how it quantifies the discovery and production of selected objects in a forward process described by mass action kinetics. AT provides a framework to unify descriptions of selection across physics and biology, with the potential to build a new physics that emerges in chemistry in which history and causal contingency through selection must start to play a prominent role in our descriptions of matter. For molecules, computing the assembly index is not explicitly necessary, because the assembly index can be probed directly experimentally with high accuracy with spectroscopy techniques including mass spectroscopy, infrared and nuclear magnetic resonance spectroscopy29.
Methods
All the calculations were performed using Mathematica 13 (Wolfram Ltd). In addition, assembly index calculations on polymeric strings in the Supplementary Information were performed using a string assembly calculator previously developed using Python and C++.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
All Mathematica Notebooks used to perform the calculations are available at https://github.com/croningp/assemblyphysics. The string assembly calculator and the dataset of assembly index calculations is available from the Zenodo repository https://doi.org/10.5281/zenodo.8017327.
References
Kauffman, S. A. The Origins of Order: Self-organization and Selection in Evolution (Oxford Univ. Press, 1993).
Gregory, T. R. Understanding natural selection: essential concepts and common misconceptions. Evol. Educ. Outreach 2, 156–175 (2009).
Darwin, C. On the Origin of Species by Means of Natural Selection, or, The Preservation of Favoured Races in the Struggle for Life (Natural History Museum, 2019).
Frank, S. A. & Fox, G. A. in The Theory of Evolution (eds Scheiner, S. M. & Mindell D. P.) 171–193 (Univ. of Chicago Press, 2020).
Carroll, S. B. Chance and necessity: the evolution of morphological complexity and diversity. Nature 409, 1102–1109 (2001).
Chesson, P. Mechanisms of maintenance of species diversity. Annu. Rev. Ecol. Syst. 31, 343–366 (2000).
Newton, I. Newton’s Principia. The Mathematical Principles of Natural Philosophy (Daniel Adee, 1846).
Cross, M. C. & Hohenberg, P. C. Pattern formation outside of equilibrium. Rev. Mod. Phys. 65, 851–1112 (1993).
Tilman, D. Resource Competition and Community Structure. (MPB-17) Vol. 17 (Princeton Univ. Press, 2020).
Elena, S. F., Cooper, V. S. & Lenski, R. E. Punctuated evolution caused by selection of rare beneficial mutations. Science 272, 1802–1804 (1996).
Lutz, E. Power-law tail distributions and nonergodicity. Phys. Rev. Lett. 93, 190602 (2004).
Cortês, M., Kauffman, S. A., Liddle, A. R. & Smolin, L. The TAP equation: evaluating combinatorial innovation in biocosmology. Preprint at http://arxiv.org/abs/2204.14115 (2023).
Fontana, W. & Buss, L. W. in Boundaries and Barriers (eds Casti, J. & Karlqvist, A.) 56–116 (Addison-Wesley, 1996).
Marshall, S. M., Murray, A. R. G. & Cronin, L. A probabilistic framework for identifying biosignatures using Pathway Complexity. Philos. Trans. R. Soc. Math. Phys. Eng. Sci. 375, 20160342 (2017).
Marshall, S. M., Moore, D. G., Murray, A. R. G., Walker, S. I. & Cronin, L. Formalising the pathways to life using assembly spaces. Entropy 24, 884 (2022).
Liu, Y. et al. Exploring and mapping chemical space with molecular assembly trees. Sci. Adv. 7, eabj2465 (2021).
Ellis, G. F. R. Top-down causation and emergence: some comments on mechanisms. Interface Focus 2, 126–140 (2012).
Koskinen, R. Multiple realizability as a design heuristic in biological engineering. Eur. J. Philos. Sci. 9, 15 (2019).
Marshall, S. M. et al. Identifying molecules as biosignatures with assembly theory and mass spectrometry. Nat. Commun. 12, 3033 (2021).
Arora, S. & Barak, B. Computational Complexity: A Modern Approach (Cambridge Univ. Press, 2009).
Wallace, C. S. Minimum message length and Kolmogorov complexity. Comput. J. 42, 270–283 (1999).
Bennett, C. H. in The Universal Turing Machine: A Half Century Survey (ed. Herken, R.) 227–257 (Oxford Univ. Press, 1988).
Deutsch, D. & Marletto, C. Constructor theory of information. Proc. R. Soc. Math. Phys. Eng. Sci. 471, 20140540 (2015).
Marletto, C. Constructor theory of life. J. R. Soc. Interface 12, 20141226 (2015).
Lewontin, R. C. The units of selection. Annu. Rev. Ecol. Syst. 1, 1–18 (1970).
Beasley, J. R. & Hecht, M. H. Protein design: the choice of de novo sequences. J. Biol. Chem. 272, 2031–2034 (1997).
Kim, H.-J. et al. Synthesis of carbohydrates in mineral-guided prebiotic cycles. J. Am. Chem. Soc. 133, 9457–9468 (2011).
Asche, S., Cooper, G. J. T., Mathis, C. & Cronin, L. A robotic prebiotic chemist probes long term reactions of complexifying mixtures. Nat. Commun. 12, 3547 (2021).
Jirasek, M. et al. Multimodal techniques for detecting alien life using assembly theory and spectroscopy. Preprint at https://doi.org/10.48550/ARXIV.2302.13753 (2023).
Acknowledgements
L.C., S.I.W., D.C. and A.S. would like to acknowledge our teams and colleagues at the University of Glasgow and Arizona State University for discussions, including C. Mathis, D. Moore, S. Marshall and P. Davies. We acknowledge financial support from the John Templeton Foundation (grant nos. 61184 and 62231), the Engineering and Physical Sciences Research Council (EPSRC) (grant nos. EP/L023652/1, EP/R01308X/1, EP/S019472/1 and EP/P00153X/1), the Breakthrough Prize Foundation and NASA (Agnostic Biosignatures award no. 80NSSC18K1140), MINECO (project CTQ2017-87392-P) and the European Research Council (ERC) (project 670467 SMART-POM).
Author information
Authors and Affiliations
Contributions
L.C. and S.I.W. conceived the theoretical framework building on the concept of the theory. A.S. and D.C. developed the mathematical basis for the framework and explored the assembly equation, and A.S. did the simulations with input from D.C. M.L. and C.P.K. helped with the development of the fundamentals of assembly theory. L.C. and S.I.W. wrote the manuscript with input from all the authors.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature thanks Pierrick Bourrat, George Ellis and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information
Details of the mathematical models, simulations and examples used in the manuscript, Supplementary Sections 1–10, Figs. 1–18 and one additional reference.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sharma, A., Czégel, D., Lachmann, M. et al. Assembly theory explains and quantifies selection and evolution. Nature 622, 321–328 (2023). https://doi.org/10.1038/s41586-023-06600-9
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s41586-023-06600-9
This article is cited by
-
Assembly theory and its relationship with computational complexity
npj Complexity (2025)
-
A general definition of the concept of chemical speciation, chemical species transformation and chemical species evolution based on a semantics of meaning
Foundations of Chemistry (2025)
-
Is Complexity the Answer to the Continuum vs. Discontinuum Question in Rock Engineering?
Rock Mechanics and Rock Engineering (2025)
-
How Research Variability Drives Technological Evolution for Fostering and Managing Emerging Innovations
Journal of the Knowledge Economy (2025)
-
(Not) by chance? An application of Assembly Theory to infer non-randomness in organizational design
Journal of Organization Design (2025)

freddouglass2009
is this techno able?
Simon Masters Replied to freddouglass2009
I think you mean "techno-babble"?
Just put this Bebel Fish in your ear - it disproves the non-existence of God
Sarcasm (just in case), and, of course, paraphrasing Douglas Adams
Kasper Kepp
In the eighties and nineties there was a lot of interest in merging physics and evolution, emergence and complexity, entropy, power laws etc. (Per Bak was my teacher in Copenhagen in thermophysics so I remember all the hype at the time). This paper is a flashback to those times, completely ahistoric in its lack of progress since then, yet claiming to have moved forward while completely ignoring both old work and the vast existing knowledge in biology and biochemistry that- often rightfully- give physicists a bad reputation among biologists .This paper is a sad reminder that some have not moved much forward since then.
I mainly got through the title and abstract and first part of the (incomprehensible) paper, but this is also enough to demonstrate the concerns I have over with this paper:
Title: "Assembly theory explains and quantifies selection and evolution"
---No: a theory that does not use biological units of evolution - nucleic and amino acids - cannot explain and quantify selection and evolution.
Abstract: "Scientists have grappled with reconciling biological evolution with the immutable laws of the Universe defined by physics."
---No, there is no conflict between physics and biology.
"Evolutionary theory explains why some things exist and others do not through the lens of selection."
---No, it explains why they are becoming more or less frequent *if* they already exist in the population.
"To comprehend how diverse, open-ended forms can emerge from physics without an inherent design blueprint, a new approach to understanding and quantifying selection is necessary."
---We already understand selection and can quantify it without a need for "design" (genes, amino acids, dN/dS). The limitation is the data/complexity, not the basic framework of the theory. The selection pressure in the early emergence of the first assemblies described in this paper is obscure and has little to do with real biochemical forces acting in molecular assembly.
"We present assembly theory (AT) as a framework that does not alter the laws of physics, but redefines the concept of an ‘object’ on which these laws act."
--- It's good that the theory does not alter the laws of physics, but this is also true for mainstream evolution theory.
"AT conceptualizes objects not as point particles, but as entities defined by their possible formation histories."
---Phylogenetics already does this and has advanced models for exploring evolution histories.
"This allows objects to show evidence of selection, within well-defined boundaries of individuals or selected units."
---Selection acts on the population of phenotypes, not individual genotypes, and there are theories already (probability of fixation of arising mutations) that an emergence model should correspond with, but this model does not (i.e., how to go from the simple AT to models on actual biological units).
"It explains how these objects can be characterized through a forward dynamical process
considering their assembly."
---Selection is not a forward dynamical process; it is a consequence of high or low fitness of the phenotype in the population at a given fixed time.
"By reimagining the concept of matter within assembly spaces, AT provides a powerful interface between physics and biology."
---Perhaps the authors believe so, but when checking quickly the paper: The chemistry of assembly (hydrophobic collapse, micelle formation) in an aqueous environment is completely ignored in the paper, which is mind-boggling. The words gene or nucleic acid are not mentioned anywhere in the paper. DNA is mentioned once, RNA not mentioned at all although thought to be older than DNA and essential for understanding emergence of life. Various statements are plain wrong, or at best, obscure. etc. etc.
That this paper passed the Editors with so many misconceptions of evolution and biochemistry and such obscure language, is a sad reminder that peer reviewing is not perfect, also at Nature.
Kasper P. Kepp
David Marjanović
Why so many creationist tropes in the first few sentences? None of this adds anything of value. Reminder: evolution cannot contradict the increase of entropy (2nd law of thermodynamics) because only the entropy of isolated systems cannot decrease. An isolated system is one that neither matter nor other forms of energy can enter or leave. The sun shines.
Was there an evolutionary biologist among the reviewers? I'm guessing "no".
Sydney Lone Replied to David Marjanović
Question...
If scientists and folks like Yuval harani hold to transhumanism concepts that future technology will solve immortality and develop godlike technology in the future, why would intelligence designers be taboo and non scientific?
Sounds blatantly hypocritical.
Ever occur to anyone that someone beat us to that punch solving immortality and godlike technology eons ago before we were here?
Why the fear of intelligence designers,when in the next breath atheists will proclaim transhumanism is conceptually valid scientifically?
Hypocrite much?
Sara Walker
This comment is posted in response to the one by Kasper Kepp. My comments are in italic font, his original text is not.
It seems a bit premature to state the paper has no new content while also simultaneously stating that only the title and abstract were read, however nonetheless I can engage some of the criticisms provided. They seem to rely on a fundamental misconception of the problems this paper aims to solve. Since the comments are in line, I will also respond in line.
In the eighties and nineties there was a lot of interest in merging physics and evolution, emergence and complexity, entropy, power laws etc. (Per Bak was my teacher in Copenhagen in thermophysics so I remember all the hype at the time). This paper is a flashback to those times, completely ahistoric in its lack of progress since then, yet claiming to have moved forward while completely ignoring both old work and the vast existing knowledge in biology and biochemistry that- often rightfully- give physicists a bad reputation among biologists .This paper is a sad reminder that some have not moved much forward since then.
I mainly got through the title and abstract and first part of the (incomprehensible) paper, but this is also enough to demonstrate the concerns I have over with this paper:
Curious to say the paper is a flashback without engaging in it beyond the title and abstract, which as I will point to below are clearly read from a very narrow perspective on much bigger open challenges.
Title: "Assembly theory explains and quantifies selection and evolution"
---No: a theory that does not use biological units of evolution - nucleic and amino acids - cannot explain and quantify selection and evolution.
When theories of evolution and selection were first developed the existence of nucleic and amino acids were not known, making it a very odd statement to make such a claim as this. While most theories of evolution have so far been predominately studied in biological forms that end up including nucleic and amino acids, many existing theories already within biology that do not rely on the existence of these specific molecules. In fact, the most powerful theories developed in any field of science are never so tightly constrained to the existence of just a couple kinds of objects. Imagine saying the theory of gravity only applied to planets and moons. More importantly, this bold claim misses the primary challenge we aim to address with developing assembly theory, which is that no current theory (based on an idea of evolution or otherwise) has yet been able to solve the origin of life problem. If you can point us to a different theory that does that, and has been validated to against demonstrating a definitive origin of life event in the lab, then assembly theory would clearly not be right framework. But, until then it is then it is the most promising our teams have been able to come up with.
Abstract: "Scientists have grappled with reconciling biological evolution with the immutable laws of the Universe defined by physics."
---No, there is no conflict between physics and biology.
Nowhere is it stated there is a conflict between physics and biology, but there is a very stark contrast between the paradigms they present as views on how things work. Knowledge of these contrasting paradigms goes all the way back to the founders of the field of evolution, for example in a widely cited quote from Darwin “There is grandeur in this view of life, with its several powers, having been originally breathed into a few forms or into one; and that, whilst this planet has gone cycling on according to the fixed law of gravity, from so simple a beginning endless forms most beautiful and most wonderful have been, and are being evolved”. In part evolution was a radical concept when first introduced, because it went against the grain of the theories with immutable laws developed in centuries prior. Interestingly you can use laws or rules formulated like physics to explain many features of biology once they emerge, but again, the origin of life is still a problem. Most of the major advances in the history of physics as a discipline have been driven by unifications (electricity and magnetism, space and time, terrestrial and celestial motion) to think that the origin of life – which is the process that literally bridges the fields of physics/chemistry with biology – would not include a unification or reconciliation from concepts from both fields displays a distinctly narrow view on the history of science.
"Evolutionary theory explains why some things exist and others do not through the lens of selection."
---No, it explains why they are becoming more or less frequent *if* they already exist in the population.
I am having a hard time following your logic, but it seems to be the case that you are confusing a statement about the regularities we observe in the world that we broadly call “evolution” (what we are in fact referring to here) and certain current models of evolution that allow us to understand (in many cases pretty well!) some of those processes. But perhaps that is too deep a conversation for this context. So, as a short answer I can read your statement at literal value and point directly to a fallacy that indicates our statement and yours would not be at odds. If you want to say “they are becoming more or less frequent *if* they already exist in the population” it is clear that sometimes that frequency will go to zero, which means they don’t exist anymore. If you agree with this last statement ours is not at odds with yours.
"To comprehend how diverse, open-ended forms can emerge from physics without an inherent design blueprint, a new approach to understanding and quantifying selection is necessary."
---We already understand selection and can quantify it without a need for "design" (genes, amino acids, dN/dS). The limitation is the data/complexity, not the basic framework of the theory. The selection pressure in the early emergence of the first assemblies described in this paper is obscure and has little to do with real biochemical forces acting in molecular assembly.
In the origin of life literature, the emergence of the first genes, proteins etc. is one of the biggest outstanding questions. No one knows how make them outside of a biological context. You are right we must assume genes and proteins to start an evolutionary process as we currently understand it (I’m not sure why you refer to amino acids and not proteins as the objects that evolve? I assume that is a typo). If you don’t have a mechanism for generating genes/ a cell you are putting them in as your initial condition, e.g., you are putting them in by design of your model. This is where intelligent design advocates think they get to leak into the conversation because most scientists do not admit we do not have an explanation for it. There is no problem admitting it, because that is how we can actually solve it. Sweeping it under the rug is not helpful. If you like, you can think of assembly theory as setting the boundary conditions for where the blueprint in your models comes from.
Also, I’m not sure what “real biochemical forces” means here. The assembly space has little to do with the idea of molecular assembly except a common use of the world “assembly” (which in fact has many unrelated uses, like an “assembly” of people or “assembly” code). Here assembly refers only to the operations that can construct objects, and the space of those operations. In truth, this is probably closer to the use of the word “assembly” in computer science (the relation between instructions and machine interpretation) than in molecular biology. However, it is really neither of those. You’ll find in the literature of those studying how new ideas emerge that there often is not a language for them (even in science), so words have to be reappropriated to new meanings. I might try reading from that perspective and engage with the ideas as they are written without trying to shoehorn them into unrelated things because of a common use of a word. What we mean by assembly is clearly defined in the manuscript, and in molecular assembly you can relate it to more conventional ideas about what molecules are, like how they are made by forming bonds.
"We present assembly theory (AT) as a framework that does not alter the laws of physics, but redefines the concept of an ‘object’ on which these laws act."
--- It's good that the theory does not alter the laws of physics, but this is also true for mainstream evolution theory.
It is actually ok if a new theory alters our current understanding of physical laws if it provides a better explanation for what we observe. This has happened plenty of times, so we should not view it is “good” or “bad” based on whether a new theory alters currently understanding in a particular domain, those markers should apply to whether it offers something new. The point here is that current physics has not solved the origin of life. Current evolutionary theory does not solve the origin of life either. Bridging them might. There are two conceptually clean ways to do this from a theory-building perspective (1) redefining objects (e.g., making objects defined by their construction histories as we do here) or making laws mutable (as some have tried to do with much work on self-referencing systems or systems with state-dependent laws).
"AT conceptualizes objects not as point particles, but as entities defined by their possible formation histories."
---Phylogenetics already does this and has advanced models for exploring evolution histories.
No doubt. Lots of fields study histories and have rather advanced models based on the idea that the past is important for understanding the present. However, we are saying something that is much deeper here, which is to say that the histories are a material property of the object, they are not something we reconstruct to understand the past, they are the past existing in the present as a physical feature of the object. Phylogenetic trees refer to how evolved biological entities have moved through time as they make new forms. Assembly theory refers to how objects created by evolution exist as time, they are not just a product of their past history, they are their past history. This is to my mind the most radical departure of the theory and its greatest insight for yielding promising new ways to think about life as a general phenomenon in the universe, but it is also the one everyone misses on first read. Lee Cronin and I tried to break this idea down to a popular level in a recent essay available here: https://aeon.co/essays/time-is-not-an-illusion-its-an-object-with-physical-size
"This allows objects to show evidence of selection, within well-defined boundaries of individuals or selected units."
---Selection acts on the population of phenotypes, not individual genotypes, and there are theories already (probability of fixation of arising mutations) that an emergence model should correspond with, but this model does not (i.e., how to go from the simple AT to models on actual biological units).
Yes of course there are theories that explain populations and how they evolve, I’m not sure why anyone would claim otherwise. The point we are making here is that an individual object can itself be evidence that evolution made it, without needed to know the precise process that actually did it. In fact, the theory is general enough to apply to evolution beyond the narrow view of it you seem to be referring to throughout these comments. Our conjecture is that some objects cannot form outside of evolution, and that we can formalize that by looking at the assembly space of the object. It leaves open all the current mechanisms in biological evolution you point to as explanations for how the object formed, while allowing a broader view into evolution not specific to those processes that might allow us to answer questions current theories cannot (like how life arises in the first place).
"It explains how these objects can be characterized through a forward dynamical process
considering their assembly."
---Selection is not a forward dynamical process; it is a consequence of high or low fitness of the phenotype in the population at a given fixed time.
Under a very narrow definition of selection which arises in many models of it, yes it is not a forward process. It is worth noting that high or low fitness must in the end be driven by some process that moves forward in time, which means an explanation of selection should be derivable from a forward process too.
"By reimagining the concept of matter within assembly spaces, AT provides a powerful interface between physics and biology."
---Perhaps the authors believe so, but when checking quickly the paper: The chemistry of assembly (hydrophobic collapse, micelle formation) in an aqueous environment is completely ignored in the paper, which is mind-boggling. The words gene or nucleic acid are not mentioned anywhere in the paper. DNA is mentioned once, RNA not mentioned at all although thought to be older than DNA and essential for understanding emergence of life. Various statements are plain wrong, or at best, obscure. etc. etc.
I am glad the paper is boggling your mind, it means we did our job. I often find that is a good sign and I look out for things to boggle my mind as a productive exercise. On this comment I might say it is worth considering that the origin of life may in the end be solved without referring to the specific molecular forms that evolved during the origin of life on Earth. It is entirely possible that when the origin of life is solved in the laboratory, the life that emerges from the experiment will not include any of those molecules. Likewise, we cannot assume detecting an evolutionary process on another planet will be possible by looking for RNA, DNA etc (it certainly won’t be how we detect life on exoplanets and likely not on places like Titan either, if life is on any of these worlds). We need more general frameworks for detecting evolution for problems that lie outside of the standard cannon of biology and biochemistry. Also, probably more shocking to your narrow view of evolution as what happens to nucleic and amino acids, there are whole fields of science that regard technology as evolving or look for evolution in artificial substrates. Those fields have theoretical constructs more similar to what we are developing in AT (e.g. evolution as combinatorial, a need to explain novelty), but even in those areas, AT is a very different framing of the relevant explanation with different conceptual underpinnings and technical features.
That this paper passed the Editors with so many misconceptions of evolution and biochemistry and such obscure language, is a sad reminder that peer reviewing is not perfect, also at Nature.
Kasper P. Kepp
I am sure the editors at Nature will be grateful for your feedback. Your comments for me personally have revealed just how little we scientists can be at admitting some problems are not answered, and how much work must be done to shift paradigms in science and make progress on those hardest open questions like the origin of life.
Sara I. Walker
Piratedcomment Replied to Sara Walker
If your abstract and first several paragraphs are so wrong that people can't get past them, that's a bit of a red flag.
Even with my layman's understanding of biology and physics, I saw several glaring holes in this paper's logic.
I will let the comments around and below me do the talking.
Simon Masters Replied to Sara Walker
Hey Sara! I saw you on Lex with Leroy and loved it. Don't get baited.
I would like to chuck in my tuppence worth.
A picture tells a thousand words and looking at Figure One I see only "additive manufacture" with no consideration of reductive processes as part of "assembly".
I reckon your algorithm for "Assembly" would benefit from steps counting the possibility of counting steps that progressively simplify (by "chunking out") as well as "adding in" especially because when evaluating Eqn 1 you appear to sample rather than count all possible assemblies. This has parallels in reductive manufacturing. Intuitively I think your work has parallels in Large Language Models and Page Similarity Algorithms and the figures make me think again about Wolfram's hypergraphs.
You know this anyway I am sure. Best wishes
Kasper Kepp
Dear Dr. Walker,
I appreciate you taking the time to write a long response. Just the essentials to avoid a long debate, as I may not have been entirely clear, so last comment below:
I don't think I have a "narrow view of evolution" when I suggest to consider actual biological molecules and selection processes: As someone publishing across physical chemistry, medicine, genetics, evolution, proteins, mutation effects, I think that is an unfair characterization; my point was exactly the opposite, that the paper should have been less narrow in scope by integrating mainstream biology and chemistry.
I am well-aware of simple physics models of evolution and they are useful but biology has undergone a data and model revolution since the nineties; gene sequencing, advanced selection models, origin of life models incorporating data on all complexity scales reviewed e.g. in this paper from 2017 by Lanier and Williams, from Lane and Orgel to Dyson and Koonin, all of whom are ignored in the your paper:
"The Origin of Life: Models and Data"
https://link.springer.com/a...
This includes approaches that actually bridge from physics to biology and in many cases include actual molecules, models, and data that have exploded since the nineties.
The absence of any context to all these studies and models seems to confirm my concern that the paper, both its writing and actual model, seems to exist in a vacuum, failing the correspondence principle of science (a new theory needs to use state of the art data and knowledge and clearly show how it corresponds in its limit with existing insight).
It is also not clear that the theory is testable when applied to early pre- and proto cell situations on the bridge towards the situation where we have a community of cells under "normal" well-understood population genetics laws.
Even if there may be insights to be gained from the model (not clear to me that these are new compared to many reviewed in the paper above) the paper substantially oversells, even in the title. The method does *not* quantify biological selection and evolution, which are well understood (phenotype selection at the population level) and it does *not* bridge the pre-cell to cell gap as it does not cover any of the essential data of the cell side of the gap.
In this sense, the readers of Nature are being misled.
So: I see this paper as having missed 20 years of development in integrating physics, chemical and biological data as reviewed in the paper above, failing correspondence both in work cited and used, the way the paper is written, and the way the model is constructed, and overselling on its ability to produce this bridge.
I am sorry to be so direct, but I hope these critical points will serve eventually some reflection, and it has absolutely no value to you, then be at is may, all of this is written only in the best intention of science.
With very best regards,
Kasper P. Kepp
professor_dave
Dear Professors Cronin and Walker
I enjoyed reading your paper in Nature, which offers an interesting approach to considering complexity in objects and their likelihood of having arisen from life-like evolutionary processes. Trying to analyse an object, based on its history, without any a priori knowledge of that history is an interesting approach.
Most of your exemplifications of the method apply to chemical systems - the type of thing that might be found in interstellar space, with the hope of finding markers of 'life', so I will focus my analysis there given my own background in chemistry.
In short, your method breaks the molecule down into an assembly pathway, which has an index associated with it - as a first approximation the more distinct steps are required, the higher the 'assembly index' will be. You then apply a 'copy number' as a measure of how many times that object appears. If the combination of assembly index and copy number is sufficiently high, then you conclude that the complex object could not have arisen at such levels by chance, and that some life-like process must be amplifying its presence. I broadly agree with this hypothesis and think it provides a useful way of giving some thresholds for thinking about finding life amongst complex molecules.
However, in terms of whether it fully scopes the problem of finding 'life-like' chemical systems, in my opinion it fails because it does not take into account the probability of each assembly step. This means that many life-like molecules would be missed by assembly theory - put another way, there would be lots of false negatives. To understand what I mean by this, it's worth doing a few simple thought experiments:
(i) If a building block is extremely rare (for example an unusual isotope of an element) then finding it amplified in any sort of chemical system, even one with a very low assembly index, would be a strong indicator of life. For example 15N labelled NH3 has a very low assembly index according to your theory, but if it was to be found in the atmosphere of an exoplanet, most chemists would consider it a likely marker of life. The same would go for something like enriched uranium - again it has a very low assembly index - but if found on one of Jupiter's moons, we would have to conclude that some form of life had created it and left it there. The point is that these species are highly improbable - although the assembly index is low, the step required to assemble the systems has such a low probability (based on our existing knowledge of chemistry/physics) that really it deserves a much higher 'complexity score' than the 'assembly index' would suggest.
(ii) If a functional group is easy to make, such as an ester, then finding lots of them in a large molecule is not particularly surprising. However, if a functional group is hard to make, such as a tertiary C-C bond with defined chirality, then finding even 1 or 2 of them in a small molecule would be surprising. However, the assembly index is chemically agnostic, so does not understand these differences. Instead it treats molecular structures as graphs. Although this will be good for comparing similar molecules within a class, it will fail when comparing divergent molecules in different classes. Once again, this is because the probability of the assembly steps is not always the same. A trained chemist looking for extraterrestrial life would be more interested in the unusual molecule, than the one with the higher assembly index.
Assembly Theory treats molecules as a mathematical problem in which complexity is only based on connectivity and a simple abundance measure then allows interesting molecules to be picked out. In reality, when building real molecules, reactions have massively different energy barriers. This is equivalent to applying a 'probability factor' to each different step in the assembly index as a modifying factor, with some assembly steps being trivial, while others are highly unlikely. In this way, the theory could better cope with the formation of unusual/interesting species. Unfortuately, however, the method would no longer be chemically agnostic, as a judgement would have to be made about the probability factors based on the underlying chemical structure. Nonetheless, I think that without a consideration of probability, the theory is incomplete, in that it overly focusses on high assembly index abundant systems, but will miss abundant systems that are simple (low assembly index) but improbable.
It is likely that, at least in a theoretical sense, a 'probability factor' could very easily be added into your theory, and it may offer an interesting extension to the model.
Building molecules is not like assembling Lego, where the energy barrier for attaching each brick is approximately the same, that is to say, reactions are not systems in equilibrium. Rather the kinetics that underpin chemical processes, making some of them trivial and some of them extremely rare cannot be overlooked. In fact, there is an argument that life-like systems are most likely to be spotted because they have evolved to autocatalyse a process that allows them to cross one of those high energy barriers and make something unusual. It may only be small, but its unlikeliness will be the key marker of life.
In terms of the extension of the theory beyond molecules, I am less well-qualified to comment. so I will leave it to others to work out whether it really would generalise to objects such as transistors etc. As a chemist, I can only really comment on molecules.
I hope you take these comments in the spirit they are intended. If your theory wasn't as interesting, I wouldn't have gone to the effort to think about what, in my view, it misses. I am sure there may be reasons that I am wrong in my thinking, and as ever am happy to be educated about any errors or misconceptions I may have.
Dave Smith
Sydney Lone Replied to professor_dave
Dave...answer this question.
1. Why is transhumanism a conceptually valid and scientific model...but beliefs in other intelligence designers non scientific?
I await your response.
Hypocritical yes?
One one hand you got Yuval harani saying transhumanism is conceptually valid as a scientific model, then say no God's exist?
If anyone believes future science and technology will solve immortality and godlike technology in the future, then they cannot maintain a logical atheist conclusion. Period.
Simon Masters Replied to Sydney Lone
Off topic, surely. Out of scope? Dare I say baiting or trolling?
Exercise some self-moderation please!
César Replied to professor_dave
Dave. Assembly Theory seems (but is not) kind of exiting because of many reasons; ranging from media frenzy, self-promotion and grandiloquent fallacious arguments. Here you can see in detail some of its many problems, starting with the fact that is, in itself, not a new theory but a bad copy-plagiarism of well-defined traditional statistical methods: https://medium.com/@hectorz..., https://arxiv.org/abs/2210...., https://primordialscoop.org...
disqus_0ytClfArJM Replied to professor_dave
Here is one possible explanation
AT as described in the article is a higher level theory. As an analogy think of how you would model animal evolution, or the behaviour of gases as ideal gases. We use higher level and even empirical parameters and do not model each individual or gas molecule.
Still, the theory allows thermodynamic, kinetic and other constrains. Such additions will likely be included in the 'alpha' parameter which could exist for each step in each pathway. Even temperature and pressure variations could probably be included there.
But for showing how complexity appears, you don't need to model the system with low level constrains, but a simplified model using higher level constrains. This already shows interesting features.
Paul D Replied to professor_dave
Professor Dave, hope all is well. Perhaps what you're missing here is that low copy + low assembly is not interesting as selection requires a minimum assembly complexity to meet the selection threshold (Fig 2a). In other words, random complex things can be created, but with a low copy / low assembly are not relevant. Also, I'm a bit confused by your enriched Uranium comment. Are you saying 5% enriched Uranium is a low assembly? It requires tools (lasers) and lots of energy, so that is definitely not a low assembly molecule. I may be misinterpreting your example though.
Mesut TEZ
I read the article titled "Assembly theory explains and quantifies selection and evolution" by Sharma and colleagues. The most significant deficiency in the authors' theory is their explanation of evolutionary "novelty" through random or stochastic mechanisms. Yes, evolution is a creative problem-solving process, but randomness or stochastic behavior are not suitable methods for creative problem-solving. The most appropriate dynamics for creative problem-solving are chaotic dynamics. I hope the authors take this perspective into consideration.
Mesut TEZ
It appears that in discussions, the materialist approach based on substances (such as genes, atoms, cells, etc.) in the philosophy of science is leading us into a dead-end. Perhaps attempting to understand life and the universe not through substances but through processes may create a more realistic perception of the universe.
Hong Chen Replied to Mesut TEZ
Totally agreed. Looking at any life form, one must realize that its beginning is NOT its birth but a certain starting point some 4 billion years ago. Individual forms come and go and change with time, but the process, reproduction to be precise, barely varies generation after generation for the same 4 billion years (till the end of all life). The current evolution theory, or biology in general, marvels at the grandeur of forms but fails to appreciate or try to understand the magic of the process, which I do think could be addressed by physics.
Simon Masters Replied to Hong Chen
"Magic" is surely the wrong term here. May I suggest "Majesty"?
Sydney Lone Replied to Mesut TEZ
Consider this...
One hand transhumanism science is accepted as conceptually scientific...then on the other hand they say intelligence designers is non scientific???
How's that work?
Seems blatantly hypocritical.
How can future dreams of science solving immortality and godlike technology in the future be deemed perfectly conceptually scientific, but beliefs in God's or other beings solving it conceptually non scientific?
Atheist and anti deists are hypocritical
Julio Iván Salazar
Please, be mindful of the criticisms to Assembly Theory too: https://arxiv.org/abs/2210...., https://hectorzenil.medium...., https://primordialscoop.org....
Jon Richfield
It is difficult, if not absolutely unrewarding, to evaluate, let
alone refute, a paper when its fundamental assumptions are irrelevant, out of
context, or downright counterfactual; any one such statement takes a lot of
statements to refute it. Furthermore, if the rest of the article contains
largely logical derivations, but from meaningless or incorrect assumptions, it
all sounds persuasive until one steps back to re-evaluate their basis. And every
such step back demands time and commitment of limited resources. Accordingly I
cannot undertake to refute the whole conceptual structure of the paper, but I
here try to show examples of what the authors tripped over in their misconceptions.
The article is to my mind a vivid example of why some disciplines,
such as say, probability theory, formal logic, natural selection, and evolution
(different concepts, please note!) are based on principles and functions so self-evident
that novices assume that the disciplines themselves are simple, whicvh they emphatically
are not. In this article, even the abstract and introduction beg questions
about both the nature and the study of abiogenesis, natural selection,
evolution, and the history of life on a planet.
Consider some quotes and remarks, and see why I do not proceed to
dissect the entire article.
"Scientists
have grappled with reconciling biological evolution with the immutable
laws of the Universe defined by physics" is no more true than that
they have "grappled" with thermodynamics or chemistry. The very
use of the term "scientist" in such a context suggests naïveté
of comprehension of science as a concept, let alone its implications for
what a "scientist" might be. The very nature of the study of
biological realities (including evolution and related topics) is based
upon, and constrained by, observables and their implications. In this
respect biology is no different from physics; the significance of the fact
that Darwin did not know about Mendelian genetics, let alone the molecular
biology of genetics, is not in essence different from the significance of the
fact that Newton did not know about quantum theory, or that Kelvin did not
know about nuclear fission and fusion. To begin the argument with such
hand-waving, bodes ill for the rest of the article.
"These
laws underpin life’s origin, evolution and the development of human
culture and technology, yet they do not predict the emergence of these
phenomena" Who said they could, or should? The phenomena are indeed
emergent, not on any mystical
basis, but on the principle that "more is different" as
Aristotle implied before post-Newtonian science was a twinkle in anyone's
eye. The basis of emergence is that when entities interact, the space of
nontrivial interaction is far larger than that of trivial noise, and, the
space of potential functional outcomes of any situation is in turn far
larger than the actual outcomes that survive and propagate. The fact that
apples, slugs, soccer, and pianos emerged on our planet and that none of
them could have been predicted even after the (already unpredictable)
emergence of any kind of cellular structure, has no more to do with any
conflict between evolution and "physical science", than the
inability of anyone to predict when or how a given atom of U-238 will
undergo its next alpha decay, implies the failure of physics. Given the
fact that the emergence even a single molecule of let us say, some
currently common 100-residue peptide chain, vital to our metabolism, would
be unlikely even if our observable universe were solid amino acids, the
fact that it eventually emerged had nothing to do with its predictability.
In biology what mattered was that at particular times sufficiently
complex, haphazardly produced molecules could react in ways that became
biologically meaningful.
I trust it is plain by now why deconstruction of the whole article would
be neither rewarding nor feasible.
"Evolutionary
theory explains why some things exist and others do not through the lens
of selection. To comprehend how diverse, open-ended forms can emerge from
physics without an inherent design blueprint, a new approach to
understanding and quantifying selection is necessary" Reification of
any "lens of selection" makes no sense in biology; it is a dead
metaphor even before conception, and while new approaches are always worth
attention in science, one might as well instance the impotence of physics
in predicting the actual outcomes of quantum events as a failure. Any
physicist would scout the idea that any such ambition had anything to do
with the ambitions of physicists; it has been suggested even that a
physicist examining an atom of oxygen and one of hydrogen would struggle
to predict the Pacific ocean; and
similarly, any evolutionist would dismiss any argument that suggests that
any meaningful science could predict that any form of assembly theory, if
transmitted to the Silurian, could predict the forms that invasion of land
would produce successively in the next 400 million years or so. That kind
of prediction is not the business of any form of scientific work so far
conceived, and emphatically not of assembly theory.
"We
present assembly theory (AT) as a framework that does not alter the laws
of physics, but redefines the concept of an ‘object’ on which these laws
act. AT conceptualizes objects not as point particles, but as entities
defined by their possible formation histories". What on Earth gave
anyone the idea that this was any sort of novelty? Rather than waste
keystrokes, I refer interested readers to the discussion of entities and
emergence in an essay of mine at:
https://fullduplexjonrichfi...
It was not written with this topic in mind, but it certainly makes
nonsense of "redefinition" of any concept so well-worn. It is
all well to criticise the inadequacy of philosophy in science, but not without
enquiring first what it is that the philosophy has said, or the science
intended.
"By
reimagining the concept of matter within assembly spaces, AT provides a
powerful interface between physics and biology. It discloses a new aspect
of physics emerging at the chemical scale, whereby history and causal
contingency influence what exists" is far too glib; certainly the
idea of questioning the course of past evolution has been based on causal
physics practically since Darwin's
day, if not earlier. There are aspects of predictive studies of evolution
in the short term. Whether assembly theory in some form will contribute to
the field, I cannot say, but if it is to do so it will have to import some
sense of realism into its function and assumptions.
So much for the abstract.
The introduction is no less incoherent with assailable
generalisations such as: "... the open-ended generation of novelty does
not fit cleanly in the paradigmatic frameworks of either biology or physics,
and so must resort ultimately to randomness..." The incoherence in terms
of established disciplines is exceeded only by the question begging of the
conclusions in terms of either physics or biology, either in practice or
intent.
The Conclusions section is no better, with unsupported claims such
as:
"AT provides a framework to unify descriptions of selection
across physics and biology, with the potential to build a new physics that
emerges in chemistry in which history and causal contingency through selection
must start to play a prominent role in our descriptions of matter"; it
does nothing of the type. In accessing the article I had been hoping to see
some role for the theory in pre-life abiogenesis, horizontal gene transfer, mergence
between unrelated organisms and the like, so I hope that you will understand my
disappointment.
I hope too, that it will be clear why I did not extend my comment to
cover the main body of the text.
Thank you for your attention,
Jon Richfield
Sydney Lone Replied to Jon Richfield
Question...if beliefs in transhumanism science is perfectly scientific, then why would belief in intelligence designers non scientific?
Ever occur to you atheistic non deist folks, that someone or something beat us to the punch on solving those transhumanism dreams of immortality and godlike technology before we were here eons ago?
The fear of intelligence designers is perplexing from a logical viewpoint....one hand say transhumanism science is valid conceptually, next breath say intelligence designers non scientific. ?????
Jon Richfield Replied to Sydney Lone
Hello Sydney,
It is not clear what your questions have to do with Assembly Theory in
general, or with the version presented in this article in particular.
Much less is it clear what you mean by a "belief" being "scientific",
whether perfectly so or otherwise. Scientists (in this connection meaning
persons working in a scientific manner in matters subject to scientific
investigation) may or may not have actual "beliefs"; commonly they do
in fact have some, but there is no formal or logical requirement for them to
have anything of the type at all. Theoretically they might not even have
opinions, though frankly I opine that to have no opinions in scientific work, would
be obsessive to a pathological degree.
But those items, if at all relevant, are not the point of the article, nor
primarily the point of this comment column, so, rather than clutter the
discussion with them, I refer you to an earlier explanation of the mutual
relationships between science, religion and evolution at the following link:
https://fullduplexjonrichfi...
and the link I mentioned before, though more abstract should help you see
why proof is irrelevant:
https://fullduplexjonrichfi...
If you have followed this article and the comments, it should be clear why there
are differences of opinion on Assembly theory/evolution, though you do not make
it clear what you thought Yuval Harari has to do with it, nor what transhumanism might have to do with it.
Transhumanism is not a coherent theme in current scientific views and work,
and I did not notice any related references to it in the article, much less anything
to do with immortality and development of godlike technology, so I suspect that you have misunderstood the points at issue. I recommend that you read the article again,
and if you find it too difficult, that you read the links I supplied to see why and how "intelligent design" has nothing to do with science at all; taboo does not come into it – the very concept is in essence opposed to science.
So I suspect that you have wandered into a discussion too alien for you or for
participants to profit from going into detail — the intelligent design theme is a weary one and I don't see that you have contributed anything novel in your questions.
Good luck with your future researches.
Sydney Lone Replied to Jon Richfield
Wrong respectfully...
Inference to the best explanation is how science operates yes?
Science cannot operate on what ifs or could haves, but evolution science is loaded with just so stories on how this pathway came to be or trait was acquired by so and so.
Too much speculation running after to little facts.
With regard to the transhumanism statement..it's a valid question.
Majority of scientists say one day technology evolution will solve immortality and develop godlike technology in the future of mankind, this is a widely held viewpoint among scientific academica.
In order for intelligent design to be labeled non scientific, you would first have to demonstrate that technology evolution is at its final apex of capabilities, since that cannot be done, and technology is increasing geometrically (A.i.) example...then its a valid question.
If mankind buys into future technology solving transhumanism dreams in the future, that's intelligent design!
Ergo, to be anti deists would then be a hypocritical contradictory position to hold.
Can't think man will become little God's in the future through technology and also hold atheistic or anti deistic views simultaneously.
Jon Richfield Replied to Sydney Lone
Sydney, The answers to your questions are in the links I posted. Whether you understood them or not, you make it plain that you have no coherent comprehension of science in general and the current topic in particular, and this is not the place to make good those deficiencies.
The topic under discussion is Assembly Theory, and you are trolling to hijack the debate to redirect it to creationism. Please have the courtesy and honesty to take the gatecrashing elsewhere.
Sydney Lone Replied to Jon Richfield
Ridiculous frankly..
Every day we employ intelligence to design, period.
That's not non scientific is it?
So tell us all right now if you think future mankind will solve those transhumanism dreams through technology at some point...
Go ahead....I'm waiting to reply.
Sydney Lone
So here's the problem.
1. All the complaints about intelligence design is non scientific, why?...
If you hold to tech and knowledge evolution through time, then concepts like direct design is non problematic.
2. Concepts like gods should not be non scientific either, transhumanism doesn't shy away from design concepts or parameters...why do some scientists?
If fact it's hypocritical to claim belief in transhumanism concepts like future technology solving immortality and development of godlike powers through it, they in the next breath say beliefs in intelligence designers non scientific.
3. Concepts thought ridiculous by mainstream science like virgin births, is itself self refuted by in vitro fertilization.
So my question for atheistic science...
Why is belief is transhumanism perfectly scientific, but when applied to concepts like gods and intelligence designers , it then becomes taboo?
Hypocrite much?
Sydney Lone
Question...
If scientists and folks like Yuval harani hold to transhumanism concepts that future technology will solve immortality and develop godlike technology in the future, why would intelligence designers be taboo and non scientific?
Sounds blatantly hypocritical.
Ever occur to anyone that someone beat us to that punch solving immortality and godlike technology eons ago before we were here?
Why the fear of intelligence designers,when in the next breath atheists will proclaim transhumanism is conceptually valid scientifically?
Hypocrite much?
I think so..
Jon Richfield Replied to Sydney Lone
Sydney,
I am sorry to say that I was called by your response to my comment, instead of reading the comment column from the top down, so I at first missed your entries here at the top.
Had I read them first, I would not have wasted my keystrokes on your views, which are so alien to facts, science, or the topic under discussion, that instruction seems futile. If you are in doubt, read my reply to you, in which I supply two links. I apologise if they happen to be beyond you, but unless you can master them, you are wasting time here -- yours and ours.
Roomy Lan
Here all of you can read in detail many concerns (both empirical and theoretical) about Assembly Theory:
https://medium.com/@hectorz...
https://arxiv.org/abs/2210....
https://primordialscoop.org...
Judson Ryckman
Let me begin by saying I have no skin in this game and consider myself an impartial ‘third party’.
I see many critiques of this work – perhaps mostly by folks who appear offended or feel their toes, or the toes of others, have been stepped on. Also many critiques which suggest the language of the paper is much too grandiose. I’m not here to debate those folks, but will remind them it is called ‘assembly theory’ and not the ‘Law of Assembly’..
I wanted to provide a brief comment in support of this article and to applaud the authors for articulating this framework – which to my basic understanding provides a means for analyzing the complexity of objects constructed through a causal chain in time. With my engineering and physics background, I am a non-expert in information theory, evolutionary biology, chemistry, etc.; so I like to think I see this work through a more general lens without a strong bias from my own niche research area.
The world around us is full of life and technology. These are highly complex and ordered objects which at first glance would seem to violate the second law of thermodynamics which states that the universe tends toward increasing entropy. Of course this is not the case, and the 2nd law is well satisfied by fact that when entropy is locally reduced this comes at the expense of energy dissipation and increase of entropy elsewhere. We often forget and take for granted the enormous casual chain in time that connects everyday objects (man-made ones) with the very first lifeforms on earth. Complexity of objects (biological and technological alike) have grown enormously over many millennia. Before our very eyes we are seeing an extrapolation of this to the ever increasing complexity of computing and AI systems.
Assembly theory seems to appreciate and articulate these facts and the hierarchical complexities that are constructed over time in a new and meaningful way that is not wholly captured by alternative theories. Some may call the theory trivial – but often times the most profound theories are remarkably simple. There appear to be clear ways to generalize and apply it beyond chemistry, biology, and information – i.e. to technology, language, economics, etc. Any object (physical or non-physical) that persists in time and participates in a causal chain can potentially give rise to other objects with greater or lesser degrees of complexity (or organization, entropy, disorder, assembly index, etc.). The accumulation of complexity over time is an extremely important concept. For this reason (and the 2nd law of thermodynamics) it is extremely hard to make giant leaps in technology (object complexity) in a short period of time – rather it takes years and years of progress, years and years of innovation, years and years of energy dissipation and increasing entropy elsewhere.
From my perspective, assembly theory is a great achievement and once the smoke settles down from the initial firestorm, I think folks will begin to appreciate it as an important framework for understanding the world around us. After all, isn’t that what science is all about?
guillermo brand deisler
ASSEMBLY THEORY should consider the function through which Evolution "evolves." Here you can find out how Evolution "evolves" https://drive.google.com/fi...
Gregory Babbitt
Sometimes, I think reactions like these below are why we might need less neurotypical (and more neurodivergent) people in science. First, you created a journal (and peer-system) that rewards overstatement, and then when someone manages to crawl to the top of the rock and enjoy a moment in the sun, you spend too much time trying to knock them off. If properly described/defined/computed, what is wrong with a different point of view that might help us find the dogmas in our own thinking (whether ultimately correct or not)?