
Abstract
Developing a unified algorithm that can learn from and generate across modalities such as text, images and video has been a fundamental challenge in artificial intelligence. Although next-token prediction has driven major advances in large language models1, its extension to multimodal domains has remained limited, and diffusion models for image and video synthesis2,3 and compositional frameworks that integrate vision encoders with language models4 still dominate. Here we introduce Emu3, a family of multimodal models trained solely with next-token prediction. Emu3 equals the performance of well-established task-specific models across both perception and generation, matching flagship systems while removing the need for diffusion or compositional architectures. It further demonstrates coherent, high-fidelity video generation, interleaved vision–language generation and vision–language–action modelling for robotic manipulation. By reducing multimodal learning to unified token prediction, Emu3 establishes a robust foundation for large-scale multimodal modelling and offers a promising route towards unified multimodal intelligence.
Similar content being viewed by others

Main
Since AlexNet5, deep learning has replaced heuristic hand-crafted features by unifying feature learning with deep neural networks. Later, Transformers6 and GPT-3 (ref. 1) further advanced sequence learning at scale, unifying structured tasks such as natural language processing. However, multimodal learning, spanning modalities such as images, video and text, has remained fragmented, relying on separate diffusion-based generation or compositional vision–language pipelines with many hand-crafted designs. This work demonstrates that simple next-token prediction alone can unify multimodal learning at scale, achieving competitive results with long-established task-specialized systems.
Next-token prediction has revolutionized the field of language models1, enabling breakthroughs such as ChatGPT7 and sparking discussions about the early signs of artificial general intelligence8. However, its potential in multimodal learning has remained uncertain, with little evidence that this simple objective can be scaled across modalities to deliver both strong perception and high-fidelity generation. In the realm of multimodal models, vision generation has been dominated by complex diffusion models2, whereas vision–language perception has been led by compositional approaches9 that combine CLIP10 encoders with large language models (LLMs). Despite early attempts to unify generation and perception, such as Emu11 and Chameleon12, these efforts either resort to connecting LLMs with diffusion models or fail to match the performance of task-specific methods tailored for generation and perception. This leaves open a fundamental scientific question: can a single next-token prediction framework serve as a general-purpose foundation for multimodal learning?
In this work, we present Emu3, a new set of multimodal models based solely on next-token prediction, eliminating the need for diffusion or compositional approaches entirely. We tokenize images, text and videos into a discrete representation space and jointly train a single transformer from scratch on a mix of multimodal sequences. Emu3 demonstrates that a single next-token objective can support competitive generation and understanding capabilities, while being naturally extendable to robotic manipulation and multimodal interleaved generation within one unified architecture. We also present the results of extensive ablation studies and analyses that demonstrate the scaling law of multimodal learning, the efficiency of unified tokenization and the effectiveness of decoder-only architectures.
Emu3 achieves results comparable with those of well-established task-specific models across both generation and perception tasks, equals the performance of diffusion models in text-to-image (T2I) generation, and rivals compositional vision–language models that integrate CLIP with LLMs in vision–language understanding tasks. Furthermore, Emu3 is capable of generating videos. Unlike Sora3, which synthesizes videos through a diffusion process starting from noise, Emu3 produces videos in a purely causal manner by autoregressively predicting the next token in a video sequence. The model can simulate some aspects of environments, people and animals in the physical world. Given a video in context, Emu3 extends the video and predicts what will happen next. On the basis of a user’s prompt, the model can generate high-fidelity videos following the text description. Emu3 stands out and competes with other video diffusion models for text-to-video (T2V) generation. In addition to standard generation, Emu3 supports interleaved vision–language generation and even vision–language–action modelling for robotic manipulation; this demonstrates the generality of the next-token framework.
We open-source key techniques and models to facilitate future research in this direction. Notably, we provide a robust vision tokenizer to enable transformation of videos and images into discrete tokens. We also investigate design choices through large-scale ablations, including tokenizer codebook size, initialization strategies, multimodal dropout, and loss weighting, providing comprehensive insights into the training dynamics of multimodal autoregressive models. We demonstrate the versatility of the next-token prediction framework, showing that direct preference optimization (DPO)13 can be seamlessly applied to autoregressive vision generation and aligning the model with human preferences.
Our results provide strong evidence that next-token prediction can serve as a powerful paradigm for multimodal models, scaling beyond language models and delivering strong performance across multimodal tasks. By simplifying complex model designs and focusing solely on tokens, it unlocks significant potential for scaling during both training and inference. We believe this work establishes next-token prediction as a robust and general framework for unified multimodal learning, opening the door to native multimodal assistants, world models and embodied artificial intelligence.
Emu3 architecture and training
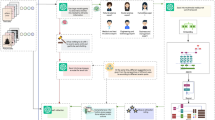
We present a unified, decoder-only framework that models language, images and video as a single sequence of discrete tokens and is trained end-to-end with a next-token prediction objective. Figure 1 illustrates the framework. Our method comprises five tightly integrated components: (1) a large, mixed multimodal training dataset (see section 3.1 of the Supplementary Information); (2) a unified tokenizer that converts images and video clips into compact discrete token streams (‘Vision tokenizer’); (3) a transformer-based decoder-only architecture that extends an LLM’s embedding space to accept vision tokens while otherwise following standard decoder-only design choices (‘Architecture’); (4) a two-stage optimization recipe including large-scale multimodal pretraining with balanced cross-entropy loss and high-quality post-training to align with task formats and human preferences (‘Pretraining’ and ‘Post-training’); and (5) an efficient inference back end supporting classifier-free guidance (CFG), low latency and high throughput for autoregressive multimodal generation (‘Inference’).

Emu3 first tokenizes multimodal data such as images, text, video and actions into discrete tokens and then sequences these tokens by order and performs unified next-token prediction at scale with a Transformer decoder. We have also seamlessly generalized the framework to robotic manipulation by treating vision, language and actions as unified token sequences.
Vision tokenizer
We trained a unified vision tokenizer that can encode a 4 × 512 × 512 video clip or a 512 × 512 image into 4,096 discrete tokens from a codebook of size 32,768. The tokenizer achieves 4× compression in the temporal dimension and 8 × 8 compression in the spatial dimension and is applicable to any temporal and spatial resolution. Building on the SBER-MoVQGAN architecture14, we incorporated two temporal residual layers with three-dimensional convolution kernels into both the encoder and decoder modules to perform temporal downsampling and enhance video tokenization capabilities.
Architecture
The Emu3 model retains the architectural framework of established LLMs such as Llama-2 (ref. 15), the primary modification being the expansion of the embedding layer to accommodate discrete vision tokens. A dropout rate of 0.1 was implemented to improve training stability. Methods section ‘Architecture design’ includes the architecture details and comparisons with architectural variants. We compared our approach with encoder-based vision–language architectures and diffusion baselines and found that a decoder-only token prediction architecture trained without any pretrained vision or language components could match traditional pipelines that rely on strong unimodal priors and thus offered a more unified, general-purpose design. This finding challenges the prevailing assumption that compositional or diffusion-based models are inherently superior for multimodal learning.
Pretraining
During pretraining, we first established a unified multimodal data format to allow Emu3 to process text, images and videos in a single autoregressive framework. In contrast to diffusion-based models that depend on at least one external text encoder, Emu3 accepts textual context into the model naturally and directly, enabling native joint modelling of multimodal data. All images and videos are resized with the aspect ratio preserved to a target scale. The visual contents are then converted into discrete vision tokens produced by our tokenizer. These tokens are combined with natural language captions and further metadata describing resolution, and, in the case of video, frame rate and duration. These components are interleaved using a small set of special tokens that delineate text segments, visual segments, and structural boundaries such as line and frame breaks. This yields a document-style sequence that standardizes heterogeneous multimodal inputs into a single token stream suitable for next-token prediction. We also included variants of the data in which captions appeared after the visual content rather than before it. This bidirectional arrangement encourages the model to learn both language-to-vision and vision-to-language mappings in a unified setting. As all information is fully tokenized, Emu3 can be trained end-to-end using a single next-token prediction objective with a standard cross-entropy loss. To maintain balanced learning across modalities, we slightly reduced the relative weight assigned to vision tokens so that a large number of visual tokens would not dominate optimization.
Emu3 uses an extensive context length during pretraining to handle video data. To facilitate training, we used a combination of tensor parallelism, context parallelism and data parallelism, simultaneously packing text–image data into the maximum context length to fully utilize computational resources while ensuring that complete images were not segmented during the packing process. Extended Data Table 1 details the training pipeline, including stage configurations, parallelism strategies, loss weights, optimization settings and training steps. The training computations are listed in Supplementary Table 7.
Post-training
Following the pretraining phase, we conducted post-training for vision generation tasks to enhance the quality of generated outputs. We applied quality fine-tuning (QFT) using high-quality data. The model continues training with the next-token prediction task using standard cross-entropy loss; however, supervision is applied exclusively to the vision tokens. During training, we increased the data resolution from 512 pixels to 720 pixels to improve generation quality. In addition, at the end of training, we used an annealing strategy to linearly decay the learning rate to zero. We adopted DPO13 to enable better alignment of models with human preferences. Human preference data were leveraged to enhance model performance for autoregressive multimodal generation tasks. The DPO model minimizes the DPO loss and the next-token prediction cross-entropy loss.
For vision–language understanding, the pretrained model underwent a two-stage post-training process: (1) image-to-text (I2T) training; and (2) visual instruction tuning. During the first stage, our approach integrates image-understanding data with pure-text data, and losses associated with vision tokens are disregarded for text-only prediction. Each image is resized to a resolution of about 512 × 512 while preserving the original aspect ratio. In the second stage, a subset of visual question answering data is sampled to enhance vision-instruction-following ability. Images with resolution less than 512 × 512 or greater than 1,024 × 1,024 are resized to the lower or upper resolution limit while keeping the aspect ratio, whereas all other images are retained at their original size. Figure 2 presents qualitative visualizations across diverse multimodal tasks.

Inference
Our multimodal inference framework inherits most of the key advantages of existing LLM infrastructures. It was built upon FlagScale16, a multimodal serving system developed on top of vLLM17. FlagScale extends the inference back end to support CFG18 for autoregressive multimodal generation. Specifically, we integrated CFG directly into the dynamic batching pipeline by jointly feeding conditional and negative prompts within each batch iteration. This CFG-aware extension introduces negligible overhead while maintaining the low-latency and high-throughput characteristics of vLLM.
Notably, we also present a vision for token-centric multimodal infrastructure in Fig. 3a; this is both efficient and extensible, demonstrating the practicality and scalability of our multimodal token prediction framework for large-scale real-world deployment. In this framework, data tokenization is performed directly on edge devices, and only the resulting discrete token IDs are transmitted to large-scale servers for unified multimodal training and inference. This approach greatly improves efficiency, as token IDs are substantially more compact than raw data such as images or videos.

a, Multimodal data tokenization can be performed directly on edge devices, and only the resulting discrete token IDs are transmitted to large-scale servers for unified multimodal training and inference. b, GenEval overall scores as a function of training sample count for the image-generation task, comparing the latent diffusion and next-token prediction paradigms. c, Validation loss of text tokens as a function of training sample count for the image-understanding task, contrasting the decoder-only paradigm with the encoder + LLM compositional paradigm in the scenario in which the LLM is trained from scratch, with further comparisons according to whether CLIP initialization is applied. Init., initialization.
Evaluation
Main results
We identified consistent scaling laws as a core principle underlying unified multimodal learning at scale. Our analysis, which was inspired by the Chinchilla scaling law19, demonstrated that diverse tasks including T2I, I2T and T2V followed a shared scaling behaviour when the model was trained jointly in a unified next-token prediction framework. We used a power-law formulation to model the validation loss L(N, D) as a function of model size N and training data size D:
All tasks exhibited a consistent data scaling exponent β = 0.55. T2I and I2T shared a model scaling exponent α = 0.25, whereas T2V showed steeper scaling with α = 0.35. These results were supported by high-quality fits, with mean absolute percentage error below 3% and R2 values exceeding 0.99. Figure 4 summarizes the scaling behaviour of Emu3 across model size, dataset scale and predictive accuracy for the three multimodal tasks (T2I, I2T and T2V). The validation loss surfaces revealed clear power-law relationships as functions of training tokens and model parameters, exhibiting consistent trends across modalities. The predicted versus observed curves for the 7B model further validated the reliability of these scaling laws: extrapolations based solely on smaller models closely matched the measured 7B losses (R2 ≥ 0.95, mean absolute percentage error < 3%). Together, these results demonstrate that unified multimodal next-token training follows stable and predictable scaling dynamics, enabling accurate performance forecasting before full-scale training. These findings reinforce our central claim that a unified next-token prediction paradigm, when scaled appropriately, can serve as a simple yet powerful mechanism for multimodal learning, obviating the need for complex modality-specific fusion strategies.
The main results for image generation, vision–language understanding and video generation are summarized in Table 1, with well-established task-specific model series20,21,22 listed as references. We assessed the T2I generation capability of Emu3 through both human evaluation and automated metrics on several established benchmarks, including MSCOCO-30K23, GenEval24, T2I-CompBench25 and DPG-Bench26. As shown in Extended Data Table 2, Emu3 attained performance on par with that of state-of-the-art diffusion models. Supplementary Fig. 14 shows images generated by Emu3 to demonstrate its capabilities. Emu3 supports flexible resolutions and aspect ratios and is capable of handling various styles.
For video generation, Emu3 natively supports generation of 5-s videos at 24 fps and can be extended through an autoregressive approach. Supplementary Fig. 15 presents qualitative examples of video generation, with 6 frames extracted from the first 3 s. We quantitatively evaluated video generation performance with VBench toolkit27. As shown in Extended Data Table 3, Emu3 produced results highly competitive with those of other video diffusion models.
Emu3 can extend videos by predicting future frames. Figure 2 shows qualitative examples of video extension, with 2-s videos at 24 fps tokenized into discrete vision tokens as context. Emu3 predicts the subsequent 2 s of content in the same form of discrete vision tokens, which can be detokenized to generate future predicted videos. These examples demonstrate that use of only next-token prediction facilitates temporal extension of videos, including prediction of human and animal actions, interactions with the real world, and variations in three-dimensional animations. Furthermore, by extending the video duration in this manner, our approach is capable of iteratively generating videos that surpass its contextual length.

a, Validation loss surfaces for three tasks: T2I, I2T and T2V, shown as functions of model size and number of training tokens. All three tasks demonstrated clear power-law behaviour with respect to scale. b, Predicted versus observed validation loss using the fitted scaling laws for the 7B Emu3 model on T2I, I2T and T2V tasks. The predictions were closely aligned with measured performance, which validated the extrapolation capability of the learned scaling relationships. MAE, mean absolute error; MAPE, mean absolute percentage error.
To evaluate the vision–language understanding capabilities of our approach, we tested it across various public vision–language benchmarks. The primary results, detailed in Extended Data Table 4, compare two categories of methods: (1) encoder-based approaches that use pretrained CLIP vision encoders; and (2) encoder-free methodologies that operate without pretrained encoders. Emu3 stands out as a pure encoder-free method, reaching the performance of its counterparts across several benchmarks. This was achieved without dependence on a specialized pretrained LLM and CLIP, underscoring the intrinsic capabilities and promising potential of Emu3 in multimodal understanding.
Ablations
To evaluate the effectiveness of our unified video tokenizer, we compared its video reconstruction performance on UCF-101 (ref. 28) with that of its image tokenizer counterpart, for which we used the SBER-MoVQ model with 270M parameters. We randomly sampled 16 consecutive frames from each video in UCF-101. Under the same input resolution, our video tokenizer achieved comparable reconstruction Fréchet video distance (rFVD) (27.893 versus 26.675) and peak signal-to-noise ratio (PSNR) (27.546 versus 30.499) using four times fewer tokens. Moreover, when using the same number of latent tokens, the unified video tokenizer significantly outperformed the standalone image tokenizer, especially in terms of rFVD (27.893 versus 139.930), demonstrating both its efficiency and its effectiveness. A qualitative comparison is provided in Fig. 5. Although the video tokenizer used four times fewer latent tokens, it showed comparable reconstruction quality to that of the image tokenizer. It also preserved finer details than the image tokenizer when downsampling to match the number of latent tokens.

a, Original and reconstructed videos and images. Videos are at 540 × 960 resolution, with a sampling of 8 frames at 30 fps, and images are of 512 × 512 resolution. b, The video tokenizer achieved comparable reconstruction with four times fewer latent tokens at the same resolution. When the image tokenizer was downsampled to match the total token count, its reconstruction quality degraded noticeably. Zoom in for details. Images from Pexels (https://www.pexels.com/).
We conducted architectural comparisons with diffusion models and the encoder + LLM compositional paradigm. To ensure fair comparison between next-token prediction and diffusion paradigms for visual generation, we trained both a 1.5B diffusion transformer (using the SDXL variational autoencoder) and a 1.5B decoder-only transformer (using the video tokenizer in Emu3) on the OpenImages dataset under identical settings. The next-token prediction model converged faster than the diffusion counterpart for equal training samples, demonstrating the potential of next-token prediction as a data-efficient framework for visual generation. We further compared three vision–language architectures of similar model scale and training samples, including a discrete token decoder-only model (Emu3) and two late-fusion encoder-decoder variants resembling LLaVA with different vision encoders. All were trained without any pretrained LLM initialization. Notably, when models were trained from scratch, the presumed advantage of the encoder-based LLaVA-style compositional architecture largely diminished. The decoder-only next-token prediction model achieved comparable performance, challenging the prevailing belief that encoder + LLM architectures are inherently superior for multimodal understanding.
More ablation experiments on the training recipe are provided in section 3.2.3 of the Supplementary Information. Large-scale unified multimodal learning is highly sensitive owing to the diverse distributions of multimodal data. An improper recipe easily leads to training collapse; this represents a fundamental difficulty of stable optimization at scale. We found that a small dropout rate was essential for stable convergence, as training collapsed without it. Careful weighting of visual and text token losses prevented task bias and ensured generalizable performance. We did not use pretrained LLM initialization in primary experiments to avoid strong priors and to clearly evaluate the capability of next-token prediction from scratch in a multimodal setting. Pretrained LLM initialization accelerated early convergence but offered little long-term advantage. These results demonstrate that Emu3 scales effectively without relying on pretrained language priors, supporting its potential as a general-purpose, unified multimodal learner.
Extensive applications
We applied our framework to robotic manipulation by transferring Emu3 to a vision–language–action model. Our approach achieved competitive results compared with specialized approaches including RT-1 (ref. 29) and RoboVLMs30. We represented language, visual observations and actions as interleaved discrete tokens within a unified autoregressive sequence. This formulation naturally aligns instruction-following, visual prediction and action prediction under a single next-token prediction objective. Actions were tokenized using the FAST tokenizer31, enabling efficient compression of continuous control signals. Extended Data Table 5 presents experimental results obtained in simulation environments. Evaluated on the CALVIN benchmark, our method reached the performance of well-established models on long-horizon manipulation. In contrast to UniVLA32, which explored post-training techniques, we performed direct discrete encoding of vision, language and actions without video post-training. These results highlight the versatility of next-token prediction as a general framework extending seamlessly from perception and generation to embodied decision-making.
We extended Emu3 to interleaved image–text generation, in which structured textual steps are accompanied by corresponding illustrative images in a single output sequence. Owing to the flexibility and generalizability of the framework, we could directly fine-tune the model to autoregressively generate such multimodal sequences in an end-to-end manner. Extended Data Fig. 1 shows the visualized results. Even with basic fine-tuning using limited interleaved image–text data, the model exhibited a promising ability to generate interleaved image–text sequences. This suggests that next-token prediction for unified multimodal generation is scalable and flexible and can be extended beyond single-modality text or image synthesis.
To demonstrate the flexibility of Emu3, we evaluated it across alternative token prediction orders, including diagonal, block-raster and spiral-in, in addition to the standard raster scan. These orders modify the spatial autoregressive dependencies, posing a more challenging generalization problem. Using the pretrained Emu3 model, we fine-tuned each variant on 50B tokens with the same training recipe and observed that the model with pretrained initialization significantly outperformed that with training from scratch (Extended Data Table 6). Notably, the spiral-in order aligned with region-completion tasks, enabling zero-shot image inpainting without task-specific tuning (Extended Data Fig. 2). These results indicate that the pretrained priors learned from large-scale raster training can be transferred effectively to new token orders, highlighting the robustness and general-purpose adaptability of the approach.
Related work
Recent advances in vision–language modelling have leveraged pretrained image encoders such as CLIP10 to produce generalizable representations, which are then combined with LLMs to form powerful vision–language models. Approaches such as BLIP-2 (ref. 4) and LLaVA9 achieve strong performance by training on large-scale image–text pairs and instruction-following data. Further gains have been made through use of curated datasets and improved training strategies33,34. Although models such as EVE35 directly feed image patches into language models, they still face challenges in competing with state-of-the-art vision–language models. Here we show that Emu3, a decoder-only model trained purely with next-token prediction, can reach the performance of these encoder-based systems.
Recent progress in image and video generation has been largely driven by diffusion models, which achieve high-resolution synthesis through iterative denoising. The open-source release of the Stable Diffusion series2,20 has led to widespread research and development in this direction. Autoregressive approaches36,37 predict images token by token, and extensions38 apply similar ideas to video. However, these models either fail to reach the performance of diffusion models or rely on cascade and/or compositional approaches. In this work, Emu3 demonstrates powerful image and video generation capabilities with a single Transformer decoder. Notably, we open-source to support further research and development in this direction.
There have been early efforts to unify vision understanding and generation11,39,40, exploring various generative objectives on image and text data. Emu and Emu2 (refs. 11,41) introduce a unified autoregressive objective: predicting the next multimodal element by regressing visual embeddings or classifying textual tokens. Chameleon12 trained token-based autoregressive models on mixed image and text data. Other efforts have also explored unified multimodal models42,43,44,45, but have these either focused on traditional vision tasks such as segmentation or achieved performance barely close to that of task-specific architectures across general multimodal tasks of video generation, image generation and vision–language understanding. Strong results have been reported for recent models including Bagel46 and Nano Banana47, yet the scopes and methodologies of these approaches differ substantially: Bagel is a hybrid architecture with diffusion model expert and does not handle videos; and Nano Banana remains proprietary without public implementation or details. Emu3, by contrast, demonstrates that next-token prediction across images, video, action and text can match the performance of well-established models, without relying on compositional methods. This work shows the scalability, effectiveness and generality of next-token prediction for unified multimodal learning across artificial-intelligence-generated content, multimodal understanding and robotic manipulation.
Conclusions, limitations and future work
Emu3 demonstrates that next-token prediction alone can unify multimodal learning at scale. By discretizing text, images and videos into a shared token space and training a single decoder-only Transformer, Emu3 equals the performance of well-established task-specific models across both perception and generation, matching flagship systems while removing the need for diffusion or compositional architectures. The resulting scaling laws demonstrate predictable efficiency across modalities, confirming that next-token prediction can serve as a general foundation for multimodal sequence modelling.
Despite the promising results, our approach has several notable limitations. First, the inference could be accelerated. The current inference process uses a naive decoding strategy, whereas more advanced parallel decoding strategies can be leveraged to speed up. Second, the current tokenizer design presents trade-offs in both compression ratio and reconstruction fidelity, which could be further optimized for efficiency and effectiveness in downstream tasks, for example, exploring new quantization approaches and increasing the codebook size. Third, the diversity and quality of multimodal datasets, particularly for long-horizon video-centric scenarios, remain insufficient to capture the full range of real-world complexity. Although we acknowledge these challenges, addressing them lies beyond the scope of this work. We also highlight several underexplored technical directions for future research, including the development of efficient architectures for ultralong multimodal contexts, enhancing tokenizer expressiveness, and constructing more robust and realistic benchmarks.
Unified next-token modelling offers a promising route towards world models that integrate perception, language and action. Such systems could ground linguistic reasoning in visual and embodied experience, enabling more general forms of understanding, creativity and control. We believe this framework represents a key step towards scalable and unified multimodal intelligence.
Methods
Tokenizer design
A unified tokenizer discretizes texts, images and videos into compact token sequences using shared codebooks. This enables text and vision information to reside in a common discrete space, facilitating autoregressive modelling. For text tokens and control tokens, we leveraged a byte pair encoding (BPE)-based text tokenizer for tokenization, whereas a vector quantization (VQ)-based visual tokenizer was used to discretize images and videos into compact token sequences.
Text tokenizer
For text tokenization, we adopted Qwen’s tokenizer49, which uses byte-level byte-pair encoding with a vocabulary encompassing 151,643 regular text tokens. To reserve sufficient capacity for template control, we also incorporated 211 special tokens into the tokenizer’s vocabulary.
Vision tokenizer
We trained the vision tokenizer using SBER-MoVQGAN14, which can encode a 4 × 512 × 512 video clip or a 512 × 512 image into 4,096 discrete tokens from a codebook of size 32,768. Our tokenizer achieved 4× compression in the temporal dimension and 8 × 8 compression in the spatial dimension and is applicable to any temporal and spatial resolution. Building on the MoVQGAN architecture50, we incorporated two temporal residual layers with three-dimensional convolution kernels into both the encoder and decoder modules to perform temporal downsampling and enhance video tokenization capabilities. The tokenizer was trained end-to-end on the LAION high-resolution image dataset and the InternVid51 video dataset using combined objective functions of Euclidean norm (L2) loss, learned perceptual image patch similarity (LPIPS) perceptual loss52, generative adversarial network (GAN) loss and commitment loss. Further details on video compression metrics, the impact of codebook size, and comparisons between the unified and standalone image tokenizers are provided in section 1 of the Supplementary Information.
Architecture design
Emu3 uses a decoder-only Transformer with modality-shared embeddings. We used RMSNorm53 for normalization and GQA54 for attention mechanisms, as well as the SwiGLU55 activation function and rotary positional embeddings56. Biases in the qkv and linear projection layers were removed. In addition, a dropout rate of 0.1 was implemented to improve training stability. Overall, the model contains 8.49 billion parameters, including 32 layers with a hidden size of 4,096, intermediate size of 14,336 and 32 attention heads (8 key-value heads). The shared multimodal vocabulary comprises 184,622 tokens, enabling consistent representation across language and vision domains.
Architectural comparisons with diffusion models
To fairly compare the next-token prediction paradigm with diffusion models for visual generation tasks, we used Flan-T5-XL57 as the text encoder and trained both a 1.5B diffusion transformer58,59 and a 1.5B decoder-only transformer60 on the OpenImages61 dataset. The diffusion model leverages the variational autoencoder from SDXL20, whereas the decoder-only transformer uses the video tokenizer in Emu3 to encode images into latent tokens. Both models were trained with identical configurations, including a linear warm-up of 2,235 steps, a constant learning rate of 1 × 10−4 and a global batch size of 1,024. As shown in Fig. 3c, the next-token prediction model consistently converged faster than its diffusion counterpart for equal training samples, challenging the prevailing belief that diffusion architectures are inherently superior for visual generation.
Architectural comparisons with encoder + LLM compositional paradigm
To fairly evaluate different vision–language architectures, we compared three model variants (trained without any pretrained LLM initialization) on the I2T validation set (an image-understanding task), as shown in Fig. 3b. All models were trained on the EVE-33M multimodal corpus35, using a global batch size of 1,024, a base learning rate of 1 × 10−4 with cosine decay scheduling and 12,000 training steps, and evaluated on a held-out validation set of 1,024 samples with comparable parameters. The models compared were: (1) a decoder-only model that consumes discrete image tokens as input (Emu3 variant, 1.22B parameters); (2) a late-fusion architecture comprising a vision encoder and decoder (LLaVA-style variant, 1.22B = 1.05B decoder + 0.17B vision encoder); and (3) a late-fusion architecture initialized with a CLIP-based vision encoder (LLaVA-style variant, 1.35B = 1.05B + 0.30B). The late-fusion LLaVA-style model initialized with a pretrained CLIP vision encoder showed substantially lower validation loss. Notably, when that pretraining advantage was removed, the apparent superiority of the encoder-based compositional architecture was largely diminished. The decoder-only next-token prediction model showed comparable performance, challenging the prevailing belief that encoder + LLM architectures are inherently superior for multimodal understanding. When evaluated under equal scratch training conditions, without prior initialization from LLMs and CLIP, it matched compositional encoder + LLM paradigms in terms of learning efficiency. Further architectural analyses are provided in section 2.1 of the Supplementary Information.
Data collection
Emu3 was pretrained from scratch on a mix of language, image and video data. Details of data construction, including sources, filtering and preprocessing, are provided in Extended Data Table 7. Further information on dataset composition, collection pipelines and filtering details is provided in section 3.1 of the Supplementary Information.
Pretraining details
Data format
Images and videos were resized to areas near 512 × 512 while preserving the aspect ratio during pretraining. We inserted special tokens [SOV], [SOT] and [EOV] to delimit multimodal segments:
where [BOS] and [EOS] mark the start and end of the whole sample, [SOV] marks the start of the vision input, [SOT] marks the start of vision tokens, and [EOV] indicates the end of the vision input. In addition, [EOL] and [EOF] were inserted into the vision tokens to denote line breaks and frame breaks, respectively. The ‘meta text’ contains information about the resolution for images; for videos, it includes resolution, frame rate and duration, all presented in plain text format. We also moved the ‘caption text’ field in a portion of the dataset to follow the [EOV] token, thereby constructing data aimed at vision understanding tasks.
Training recipe
Pretraining followed a three-stage curriculum designed to balance training efficiency and optimization stability. Stage 1 used a learning rate of 1 × 10−4 with cosine decay, no dropout and a sequence length of 5,120. This configuration enabled rapid early convergence; however, the absence of dropout eventually led to optimization instability and model collapse in late training. Stage 2 therefore introduced a dropout rate of 0.1, which stabilized optimization while retaining the warm-start benefits established in stage 1. Stage 3 extended the context length to 65,536 tokens to accommodate video–text data. The sampling ratio gradually shifted from image–text pairs towards video–text pairs. This curriculum substantially improved overall efficiency: the first two stages focused on image data for stable and cost-effective initialization, whereas the third stage expanded the context window and incorporated video data for full multimodal training. Tensor and pipeline parallelism remained constant across stages, with context parallelism scaling from 1 to 4 only in stage 3 to support the extended sequence length. Further implementation details including multimodal dropout for stability, token-level loss weighting, LLM-based initialization and mixture-of-experts configuration are provided in section 3.2.3 of the Supplementary Information.
Post-training details
T2I generation
QFT. After pretraining, Emu3 underwent post-training to enhance visual generation quality. We applied QFT to high-quality image data while continuing next-token prediction with supervision restricted to vision tokens. Training data were filtered by the average of three preference scores: HPSv2.1 (ref. 62), MPS63 and the LAION-Aesthetics score64, and the image resolution was increased from 512 to 720 pixels. We set the batch size to 240 with a context length of 9,216, with the learning rate cosine decaying from 1 × 10−5 to 1 × 10−6 over 15,000 training steps. Subsequently, a linear annealing strategy was used to gradually decay the learning rate to zero over the final 5,000 steps of QFT training.
DPO. We further aligned generation quality with human preference using DPO13. For each prompt, the model generated 8–10 candidate images that were evaluated by three annotators on visual appeal and alignment. The highest and lowest scoring samples formed preference triplets \(({p}_{i},{x}_{i}^{{\rm{chosen}}},{x}_{i}^{{\rm{rejected}}})\) for optimization. Tokenized data from this process were reused directly during training to avoid retokenization inconsistencies. Emu3-DPO jointly minimizes the DPO loss and the next-token prediction loss, with a weighting factor of 0.2 applied to the supervised fine-tuning loss for stable optimization. During DPO training, we use a dataset of 5,120 prompts and train for one epoch with a global batch size of 128. The learning rate follows a cosine decay schedule with a brief 5-step warm-up and then decays to a constant value of 7 × 10−7. A KL penalty of 0.5 is applied to the reference policy to balance alignment strength and generation diversity.
We present the performance of Emu3 through automated metric evaluation on popular T2I benchmarks: MSCOCO-30K23, GenEval24, T2I-CompBench25, and DPG-Bench26. Evaluation details are provided in the Supplementary Information, section 4.1.2.
T2V generation
Emu3 was extended to T2V generation by applying QFT to high-quality video data (each sample was 5 s long, 24 fps), with strict resolution and motion filters to ensure visual fidelity. We set the batch size to 720 with a context length of 131,072, with the learning rate set to 5 × 10−5 over 5,000 training steps. We evaluated video generation using VBench27, which assesses 16 dimensions including temporal consistency, appearance quality, semantic fidelity and subject–background coherence. Evaluation details are provided in section 4.2.2 of the Supplementary Information.
Vision–language understanding
Emu3 was further adapted to vision–language understanding through a two-stage post-training procedure. In the first stage, the model was trained on 10 million image–text pairs using a batch size of 512, mixing image-understanding data with pure language data while masking losses on vision tokens for text-only prediction. All images were resized to approximately 512 × 512 while preserving the aspect ratio. In the second stage, we performed instruction tuning on 3.5 million question–answer pairs sampled from ref. 65, also using a batch size of 512; images with shorter or longer resolution were clipped to the 512–1,024 pixel range. For both stages, we used a cosine learning rate schedule with a peak learning rate of 1 × 10−5. Evaluation details are provided in section 4.3 of the Supplementary Information.
Interleaved image–text generation
We further extended Emu3 to interleaved image–text generation, in which structured textual steps are accompanied by corresponding illustrative images within a single output sequence. The model was fine-tuned end-to-end to autoregressively generate such multimodal sequences, leveraging the flexibility of the unified framework. Training was performed for 10,000 steps with a global batch size of 128 and a maximum sequence length of 33,792 tokens. Each sequence included up to 8 images, each resized to a maximum area of 5122 pixels while preserving the aspect ratio. We used the Adam optimizer with a cosine learning rate schedule and a base learning rate of 7 × 10−6 and applied a dropout rate of 0.1 with equal weighting between image and text losses. Further details on data formatting and visualization results are provided in section 4.4 of the Supplementary Information.
Vision–language–action models
We further extended Emu3 to vision–language–action tasks by fine-tuning it on the CALVIN66 benchmark, a simulated environment designed for long-horizon, language-conditioned robotic manipulation.
The model was initialized from Emu3 pretrained weights, whereas the action encoder used the FAST tokenizer31 with a 1,024-size vocabulary, replacing the last 1,024 token IDs of the language tokenizer. RGB observations from third-person (200 × 200) and wrist (80 × 80) views were discretized using the Emu3 vision tokenizer with a spatial compression factor of 8. Training used a time window of 20 and an action chunk size of 10, forming input sequences of two consecutive vision–action–vision–action frames. Loss weights were set to 0.5 for visual tokens and 1.0 for action tokens. The model was trained for 8,000 steps with a batch size of 192 and a cosine learning rate schedule starting at 8 × 10−5. During inference, it predicted actions online by means of a sliding two-frame window. Visualizations are shown in Extended Data Fig. 3. Although the CALVIN benchmark is simulation-based, Emu3’s vision–language–action formulation was designed with real-world deployment challenges in mind. The next-token prediction paradigm naturally conditions on arbitrary-length histories, allowing the model to integrate feedback over time and recover from partial or imperfect sensor inputs, thereby accommodating noisy sensors or delayed feedback. In practice, real-world robotic validation requires substantial data collection (for instance, time-consuming tele-operation or on-hardware rollouts) and system-level engineering efforts to ensure safety, latency guarantees and reliable actuation, which made large-scale evaluation on physical robots difficult within the scope of this work. Although large-scale physical-robot validation will be part of our future work, the simulation results show that Emu3 can model complex, interleaved perception–action sequences without task-specific components, indicating strong potential for transfer to real robotic systems.
Data availability
Details including collection pipelines, preprocessing, composition and other information are available in section 3.1 of the Supplementary Information. Details of the post-training data are presented in section 4 and the publicly available training and evaluation datasets in section 8 of the Supplementary Information. The publicly available training data include: FineWeb-Edu (https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu), LAION-5b (https://laion.ai/blog/laion-5b/), LAION-AESTHETICS (https://laion.ai/blog/laion-aesthetics/), Datacomp (https://github.com/mlfoundations/datacomp), COYO-700m (https://github.com/kakaobrain/coyo-dataset), OpenImages (https://storage.googleapis.com/openimages/web/index.html), SA-1B (https://segment-anything.com/dataset/index.html), YT-Temporal-1B (https://rowanzellers.com/merlotreserve/), JourneyDB (https://huggingface.co/datasets/JourneyDB/JourneyDB), DiffusionDB (https://huggingface.co/datasets/poloclub/diffusiondb), midjourney-prompts (https://huggingface.co/datasets/vivym/midjourney-prompts), and LLaVA-OneVision-Data (https://huggingface.co/datasets/lmms-lab/LLaVA-OneVision-Data).
Code availability
The custom computer code used and the models produced in this study are available via GitHub at https://github.com/baaivision/Emu3. The code was released under the Apache-2.0 license. The model weights are publicly available at https://huggingface.co/collections/BAAI/emu3, including the tokenizer, the pretrained model and two post-trained derivatives.
References
Brown, T. B. et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 33, 1877–1901 (2020).
Rombach, R., Blattmann, A., Lorenz, D., Esser, P. & Ommer, B. High-resolution image synthesis with latent diffusion models. In Proc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition, 10684–10695 (2022).
Brooks, T. et al. Video generation models as world simulators. OpenAI https://openai.com/index/sora/ (2024).
Li, J., Li, D., Savarese, S. & Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Int. Conf. on Machine Learning, 19730–19742 (PMLR, 2023).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf (2012).
Vaswani, A. et al. Attention is all you need. Adv. Neural Inf. Process. Syst. 30, 6000–6010 (2017).
ChatGPT. OpenAI https://chat.openai.com/ (2023).
Bubeck, S. et al. Sparks of artificial general intelligence: early experiments with gpt-4. Preprint at https://arxiv.org/abs/2303.12712 (2023).
Liu, H., Li, C., Wu, Q. & Lee, Y. J. Visual instruction tuning. Adv. Neural Inf. Process. Syst. 36, 34892–34916 (2024).
Radford, A. et al. Learning transferable visual models from natural language supervision. In Int. Conf. on Machine Learning, 8748–8763 (PMLR, 2021).
Sun, Q. et al. Emu: generative pretraining in multimodality. In Twelfth Int. Conf. on Learning Representations, 12352–12380 (2024).
Team, C. Chameleon: Mixed-modal early-fusion foundation models. Preprint at https://arxiv.org/abs/2405.09818 (2024).
Rafailov, R. et al. Direct preference optimization: your language model is secretly a reward model. Adv. Neural Inf. Process. Syst. 36, 53728–53741 (2024).
Razzhigaev, A. et al. Kandinsky: an improved text-to-image synthesis with image prior and latent diffusion. In Proc. 2023 Conf. on Empirical Methods in Natural Language Processing, EMNLP 2023 - System Demonstrations (2023).
Touvron, H. et al. Llama 2: open foundation and fine-tuned chat models. Preprint at https://arxiv.org/abs/2307.09288 (2023).
Contributors, F. FlagScale: a unified meta-framework enabling adaptive heterogeneous computing for the llm ecosystem. GitHub https://github.com/FlagOpen/FlagScale (2024).
Kwon, W. et al. Efficient memory management for large language model serving with pagedattention. In Proc. ACM SIGOPS 29th Symposium on Operating Systems Principles, 611–626 (2023).
Ho, J. & Salimans, T. Classifier-free diffusion guidance. In NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications (2021).
Hoffmann, J. et al. Training compute-optimal large language models. Adv. Neural Inf. Process. Syst. 36, 2176 (2022).
Podell, D. et al. SDXL: improving latent diffusion models for high-resolution image synthesis. In Twelfth Int. Conf. on Learning Representations, 1862–1874 (2024).
Liu, H. et al. LLaVA-NeXT: improved reasoning, OCR, and world knowledge. GitHub https://llava-vl.github.io/blog/2024-01-30-llava-next/ (2024).
Zheng, Z. et al. Open-Sora: democratizing efficient video production for all. Preprint at https://arxiv.org/abs/2412.20404 (2024).
Chen, X. et al. Microsoft COCO captions: data collection and evaluation server. Preprint at https://arxiv.org/abs/1504.00325 (2015).
Ghosh, D., Hajishirzi, H. & Schmidt, L. GenEval: an object-focused framework for evaluating text-to-image alignment. Adv. Neural Inf. Process. Syst. 36, 52132–52152 (2024).
Huang, K., Sun, K., Xie, E., Li, Z. & Liu, X. T2I-CompBench: a comprehensive benchmark for open-world compositional text-to-image generation. Adv. Neural Inf. Process. Syst. 36, 78723–78747 (2023).
Hu, X. et al. ELLA: equip diffusion models with LLM for enhanced semantic alignment. Preprint at https://arxiv.org/abs/2403.05135 (2024).
Huang, Z. et al. VBench: comprehensive benchmark suite for video generative models. In Proc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition, 21807–21818 (2024).
Soomro, K., Zamir, A. R. & Shah, M. UCF101: a dataset of 101 human actions classes from videos in the wild. Preprint at https://arxiv.org/abs/1212.0402 (2012).
Brohan, A. et al. RT-1: Robotics transformer for real-world control at scale. In Proc. Robotics: Science and Systems XIX (2023).
Li, X. et al. Towards generalist robot policies: what matters in building vision-language-action models. Preprint at https://arxiv.org/abs/2412.14058 (2024).
Pertsch, K. et al. FAST: efficient action tokenization for vision-language-action models. In Proc. Robotics: Science and Systems XXI (2025).
Wang, Y. et al. Unified vision-language-action model. Preprint at https://arxiv.org/abs/2506.19850 (2025).
Bai, J. et al. Qwen technical report. Preprint at https://arxiv.org/abs/2309.16609 (2023).
Chen, Z. et al. InternVL: scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition, 24185–24198 (2024).
Diao, H. et al. Unveiling encoder-free vision-language models. Adv. Neural Inf. Process. Syst. 37, 52545–52567 (2024).
Ramesh, A. et al. Zero-shot text-to-image generation. In Proc. 38th Int. Conf. on Machine Learning, 139, 8821–8831 (2021).
Ding, M. et al. Cogview: Mastering text-to-image generation via transformers. Adv. Neural Inf. Process. Syst. 34, 19822–19835 (2021).
Kondratyuk, D. et al. VideoPoet: a large language model for zero-shot video generation. In Int. Conf. on Machine Learning, 25105–25124 (PMLR, 2024).
Ge, Y. et al. SEED-X: multimodal models with unified multi-granularity comprehension and generation. Preprint at https://arxiv.org/abs/2404.14396 (2024).
Dong, R. et al. DreamLLM: synergistic multimodal comprehension and creation. In Twelfth Int. Conf. on Learning Representations, 6666–6702 (2024).
Sun, Q. et al. Generative multimodal models are in-context learners. In Proc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition, 14398–14409 (2024).
Bachmann, R. et al. 4M-21: an any-to-any vision model for tens of tasks and modalities. In Adv. Neural Inf. Process. Syst. 37, 61872–61911 (2024).
Zhou, C. et al. Transfusion: predict the next token and diffuse images with one multimodal model. In Thirteenth Int. Conf. on Learning Representations, 6446–6469 (2025).
Xie, J. et al. Show-o: one single transformer to unify multimodal understanding and generation. In Thirteenth Int. Conf. on Learning Representations, 28240–28264 (2025).
Wu, Y. et al. VILA-U: a unified foundation model integrating visual understanding and generation. In Thirteenth Int. Conf. on Learning Representations, 93620–93638 (2025).
Deng, C. et al. Emerging properties in unified multimodal pretraining. Preprint at https://arxiv.org/abs/2505.14683 (2025).
Team, G. Gemini 2.5 Flash & Gemini 2.5 Flash image model card. Google https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-2-5-Flash-Model-Card.pdf (2025).
Khazatsky, A. et al. Droid: a large-scale in-the-wild robot manipulation dataset. Preprint at https://arxiv.org/abs/2403.12945 (2024).
Bai, J. et al. Qwen-VL: a frontier large vision-language model with versatile abilities. Preprint at https://arxiv.org/abs/2308.12966 (2023).
Zheng, C., Vuong, L. T., Cai, J. & Phung, D. MoVQ: modulating quantized vectors for high-fidelity image generation. Adv. Neural Inf. Process. Syst. 35, 23412–23425 (2022).
Wang, Y. et al. InternVid: a large-scale video-text dataset for multimodal understanding and generation. In Twelfth Int. Conf. on Learning Representations, 42055–42079 (2024).
Zhang, R., Isola, P., Efros, A. A., Shechtman, E. & Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition, 586–595 (2018).
Zhang, B. & Sennrich, R. Root mean square layer normalization. Adv. Neural Inf. Process. Syst. 32, 12381–12392 (2019).
Ainslie, J. et al. GQA: training generalized multi-query transformer models from multi-head checkpoints. In 2023 Conf. on Empirical Methods in Natural Language Processing (2023).
Shazeer, N. GLU variants improve Transformer. Preprint at https://arxiv.org/abs/2002.05202 (2020).
Su, J. et al. RoFormer: enhanced transformer with rotary position embedding. Neurocomputing 568, 127063 (2024).
Chung, H. W. et al. Scaling instruction-finetuned language models. J. Mach. Learn. Res. 25, 1–53 (2024).
Peebles, W. & Xie, S. Scalable diffusion models with transformers. In Proc. IEEE/CVF Int. Conf. on Computer Vision, 4195–4205 (2023).
Chen, J. et al. Pixart-α: fast training of diffusion Transformer for photorealistic text-to-image synthesis. In Twelfth Int. Conf. on Learning Representations, 57611–57640 (2024).
Yang, A. et al. Qwen2.5 technical report. Preprint at https://arxiv.org/abs/2412.15115 (2025).
Kuznetsova, A. et al. The Open Images Dataset v4: unified image classification, object detection, and visual relationship detection at scale. Int. J. Comput. Vis. 128, 1956–1981 (2020).
Wu, X. et al. Human Preference Score v2: a solid benchmark for evaluating human preferences of text-to-image synthesis. Preprint at https://arxiv.org/abs/2306.09341 (2023).
Zhang, S. et al. Learning multi-dimensional human preference for text-to-image generation. In Proc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition, 8018–8027 (2024).
LAION-Aesthetics. LAION https://laion.ai/blog/laion-aesthetics/ (2022).
Li, B. et al. LLaVA-OneVision: easy visual task transfer. Trans. Mach. Learn. Res. https://hdl.handle.net/1783.1/147361 (2025).
Mees, O., Hermann, L., Rosete-Beas, E. & Burgard, W. CALVIN: a benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. IEEE Robot. Autom. Lett. 7, 7327–7334 (2022).
Acknowledgements
This research is supported by BAAI, where this work was carried out. We thank W. Wang, X. Li, X. Liu, S. Nie, Q. Ma, H. Zhou, Y. Jiao, L. Zhang, M. Lu, Y. Shao, Y. Chen, D. Hao, M. Lv, T. Dai, J. Liu and Y. Si for their support of the Emu3 project.
Author information
Authors and Affiliations
Contributions
X.W. led the research. X.W., Y.C., J.W., F.Z., Yueze Wang, X.Z., Z. Luo, Q.S. and Z. Li are equally contributing authors and developed the architecture, training and core experiments. Yuqi Wang and Q.Y. contributed to additional experiments. Y.Z., Y.A., X.M. and C.M. developed the training and inference infrastructure. B.W., B. Zhao, B. Zhang, L.W. and G.L. contributed to data processing. Z.H. and X.Y. contributed to evaluation. X.W.,Y.C., J.W., F.Z., Yueze Wang, X.Z., Z. Luo, Q.S., Z. Li and Yuqi Wang contributed to the writing of the paper. J.L. advised Q.Y. Y.L., Z.W. and T.H. advised on the project.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature thanks Ferjad Naeem, Xiaojuan Qi and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Visualization of interleaved image-text generation results.
Qualitative examples of generated interleaved image–text sequences, illustrating step-by-step multimodal generation for instructional tasks.
Extended Data Fig. 2 Zero-shot image inpainting with Emu3 using spiral-in token order.
Given the input images (left of each row) and corresponding prompts, Emu3 accurately fills the masked regions within the bounding boxes, generating semantically aligned content without task-specific fine-tuning.
Extended Data Fig. 3 Visualization of visual prediction on the Droid dataset.
Qualitative examples of visual sequences predicted under language instructions. The first frame (red box) is the observed input, followed by predicted frames.
Supplementary information
Supplementary Information (download PDF )
Supplementary Figs 1–11, Tables 1–11 and Notes 1–7.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, X., Cui, Y., Wang, J. et al. Multimodal learning with next-token prediction for large multimodal models. Nature 650, 327–333 (2026). https://doi.org/10.1038/s41586-025-10041-x
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s41586-025-10041-x
