
Abstract
The large volume of abdominal computed tomography (CT) scans1,2 coupled with the shortage of radiologists3,4,5,6 have intensified the need for automated medical image analysis tools. Previous state-of-the-art approaches for automated analysis leverage vision–language models (VLMs) that jointly model images and radiology reports7,8,9,10,11,12. However, current medical VLMs are generally limited to 2D images and short reports. Here to overcome these shortcomings for abdominal CT interpretation, we introduce Merlin, a 3D VLM that learns from volumetric CT scans, electronic health record data and radiology reports. This approach is enabled by a multistage pretraining framework that does not require additional manual annotations. We trained Merlin using a high-quality clinical dataset of paired CT scans (>6 million images from 15,331 CT scans), diagnosis codes (>1.8 million codes) and radiology reports (>6 million tokens). We comprehensively evaluated Merlin on 6 task types and 752 individual tasks that covered diagnostic, prognostic and quality-related tasks. The non-adapted (off-the-shelf) tasks included zero-shot classification of findings (30 findings), phenotype classification (692 phenotypes) and zero-shot cross-modal retrieval (image-to-findings and image-to-impression). The model-adapted tasks included 5-year chronic disease prediction (6 diseases), radiology report generation and 3D semantic segmentation (20 organs). We validated Merlin at scale, with internal testing on 5,137 CT scans and external testing on 44,098 CT scans from 3 independent sites and 2 public datasets. The results demonstrated high generalization across institutions and anatomies. Merlin outperformed 2D VLMs, CT foundation models and off-the-shelf radiology models. We also computed scaling laws and conducted ablation studies to identify optimal training strategies. We release our trained models, code and dataset for 25,494 pairs of abdominal CT scans and radiology reports. Our results demonstrate how Merlin may assist in the interpretation of abdominal CT scans and mitigate the burden on radiologists while simultaneously adding value for future biomarker discovery and disease risk stratification.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$32.99 / 30 days
cancel any time
Subscribe to this journal
Receive 51 print issues and online access
$199.00 per year
only $3.90 per issue
Buy this article
- Purchase on SpringerLink
- Instant access to the full article PDF.
USD 39.95
Prices may be subject to local taxes which are calculated during checkout





Similar content being viewed by others

Data availability
We have released the Merlin abdominal CT dataset to the community (https://stanfordaimi.azurewebsites.net/datasets/60b9c7ff-877b-48ce-96c3-0194c8205c40). This large-scale abdominal CT dataset contains 25,494 scans of 18,317 unique patients, with each scan paired with its corresponding radiology report. Exams include abdominal and pelvis CT scans, identified using CPT codes 72192, 72193, 72194, 74150, 74160, 74170, 74176, 74177 and 74178, selected via the STARR tool (Stanford Medicine Research Data Repository). For each exam, the DICOM series with the largest slice count was retained and converted to NIfTI format for ease of use. Scans were compressed and de-identified by removing all patient-identifiable metadata. The Merlin abdominal CT dataset is hosted by the Stanford AIMI Center. Access requires completion of a data-use agreement form on the download page of the dataset. Following approval, a secure Azure Blob Storage URL is provided for download from the Merlin abdominal CT dataset download page. Additional download instructions are available in the documentation (download documentation). The following external publicly available datasets were used: the VerSe dataset is available via the Open Science Framework (https://osf.io/nqjyw/) and the TotalSegmentator dataset is publicly available at GitHub (https://github.com/wasserth/TotalSegmentator). Furthermore, the Merlin model was evaluated on abdominal CT images and associated radiology reports from three external clinical sites. These datasets are not publicly available owing to patient privacy considerations and data-use agreements but were accessed under appropriate institutional approvals and used solely for evaluation. All datasets were accessed and used in accordance with their respective data-use agreements and licences.
Code availability
Merlin is publicly available through the following platforms: GitHub (https://github.com/StanfordMIMI/Merlin), HuggingFace (https://huggingface.co/stanfordmimi/Merlin), and PyPI (https://pypi.org/project/merlin-vlm). The implementation builds on open-source libraries, including PyTorch (v.2.1.2), OpenCLIP (v.2.24.0) and the HuggingFace Transformers library (v.4.38.2). Model training was performed using the AdamW optimizer as implemented in PyTorch. For baseline comparisons, we used the BiomedCLIP model (hf-hub:microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224) and OpenCLIP (hf-hub:laion/CLIP-ViT-L-14-laion2B-s32B-b82K) via the HuggingFace hub. Clinical text encoding was performed using the Clinical Longformer model (Yikuan8/Clinical-Longformer). The 3D inflation strategy for convolutional weights was adapted from the open-source repository at GitHub (https://github.com/hassony2/inflated_convnets_pytorch). The primary dataset used in this study is publicly available online (https://stanfordaimi.azurewebsites.net/datasets/60b9c7ff-877b-48ce-96c3-0194c8205c40).
References
Schöckel, L. et al. Developments in X-ray contrast media and the potential impact on computed tomography. Invest. Radiol. 55, 592–597 (2020).
Kanal, K. M. et al. U.S. diagnostic reference levels and achievable doses for 10 adult CT examinations. Radiology 284, 120–133 (2017).
Taschetta-Millane, M. The evolving computed tomography market. Imaging Technology News https://www.itnonline.com/article/evolving-computed-tomography-market (2024).
Hudnall, C. Maximum capacity: overloaded radiologists are grappling with solutions to a booming volume crisis. American College of Radiology https://www.acr.org/Practice-Management-Quality-Informatics/ACR-Bulletin/Articles/April-2024/Maximum-Capacity (2024).
Milburn, J. Workforce-shortage. How will we solve our radiology workforce shortage? American College of Radiology https://www.acr.org/Practice-Management-Quality-Informatics/ACR-Bulletin/Articles/March-2024/How-Will-We-Solve-Our-Radiology-Workforce-Shortage (2024).
Rimmer, A. Radiologist shortage leaves patient care at risk, warns royal college. BMJ 359, j4683 (2017).
Paschali, M. et al. Foundation models in radiology: what, how, why, and why not. Radiology 314, e240597 (2025).
Zhang, S. et al. A multimodal biomedical foundation model trained from fifteen million image–text pairs. NEJM AI 2, AIoa2400640 (2025).
Chaves, J. M. et al. A clinically accessible small multimodal radiology model and evaluation metric for chest X-ray findings. Nat. Commun. 16, 3108 (2025).
Tu, T. et al. Towards generalist biomedical AI. NEJM AI 1, AIoa2300138 (2024).
Wu, C., Zhang, X., Zhang, Y., Wang, Y. & Xie, W. Towards generalist foundation model for radiology by leveraging web-scale 2D & 3D medical data. Nat. Commun. 16, 7866 (2025).
Chen, Z. et al. CheXagent: Towards a foundation model for chest X-ray interpretation. In AAAI 2024 Spring Symposium on Clinical Foundation Models (AAAI, 2024).
Udare, A. et al. Radiologist productivity analytics: factors impacting abdominal pelvic CT exam reporting times. J. Digit. Imaging 35, 87–97 (2022).
Liu, D. et al. Fully automated CT-based adiposity assessment: comparison of the L1 and L3 vertebral levels for opportunistic prediction. Abdom. Radiol. 48, 787–795 (2023).
Blankemeier, L. et al. Opportunistic incidence prediction of multiple chronic diseases from abdominal CT imaging using multi-task learning. In Proc. 25th International Conference on Medical Image Computing and Computer-Assisted Intervention 309–318 (Springer, 2022).
Zambrano Chaves, J. M. et al. Opportunistic assessment of ischemic heart disease risk using abdominopelvic computed tomography and medical record data: a multimodal explainable artificial intelligence approach. Sci. Rep. 13, 21034 (2023).
Cao, K. et al. Large-scale pancreatic cancer detection via non-contrast CT and deep learning. Nat. Med. 29, 3033–3043 (2023).
Wang, Y.-R. et al. Screening and diagnosis of cardiovascular disease using artificial intelligence-enabled cardiac magnetic resonance imaging. Nat. Med. 30, 1471–1480 (2024).
Langlotz, C. P. The future of AI and informatics in radiology: 10 predictions. Radiology 309, e231114 (2023).
Artificial Intelligence and Machine Learning (AI/ML)-Enabled Medical Devices (US Food and Drug Administration, 2023).
Radford, A. et al. Learning transferable visual models from natural language supervision. In Proc. 38th International Conference on Machine Learning 8748–8763 (PMLR, 2021).
Schuhmann, C. et al. Laion-5b: an open large-scale dataset for training next generation image-text models. Adv. Neural Inf. Process. Syst. 35, 25278–25294 (2022).
Larson, D. B., Magnus, D. C., Lungren, M. P., Shah, N. H. & Langlotz, C. P. Ethics of using and sharing clinical imaging data for artificial intelligence: a proposed framework. Radiology 295, 675–682 (2020).
Hyland, S. L. et al. MAIRA-1: a specialised large multimodal model for radiology report generation. Preprint at https://arxiv.org/abs/2311.13668 (2023).
Huang, S.-C. et al. PENet—a scalable deep-learning model for automated diagnosis of pulmonary embolism using volumetric CT imaging. npj Digit. Med. 3, 61 (2020).
Christensen, M., Vukadinovic, M., Yuan, N. & Ouyang, D. Vision–language foundation model for echocardiogram interpretation. Nat. Med. 30, 1481–1488 (2024).
Polevikov, S. Med-gemini by Google: A boon for researchers, a bane for doctors. AI Health Uncut https://sergeiai.substack.com/p/googles-med-gemini-im-excited-and (2024).
Fleming, S. L. et al. Medalign: a clinician-generated dataset for instruction following with electronic medical records. Proc. AAAI Conf. Artif. Intell. 38, 22021–22030 (2024).
Liebl, H. et al. A computed tomography vertebral segmentation dataset with anatomical variations and multi-vendor scanner data. Sci. Data 8, 284 (2021).
Wasserthal, J. et al. TotalSegmentator: robust segmentation of 104 anatomic structures in CT images. Radiol. Artif. Intell. 5, e230024 (2023).
Cherti, M. et al. Reproducible scaling laws for contrastive language–image learning. In Proc. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition 2818–2829 (IEEE, 2023).
Löffler, M. T. et al. A vertebral segmentation dataset with fracture grading. Radiol. Artif. Intell. 2, e190138 (2020).
Carreira, J. & Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proc. 2017 IEEE Conference on Computer Vision and Pattern Recognition 6299–6308 (IEEE, 2017).
Denny, J. C. et al. Systematic comparison of phenomewide association study of electronic medical record data and genome-wide association study data. Nat. Biotechnol. 31, 1102–1111 (2013).
Liu, Z. et al. A convnet for the 2020s. In Proc. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition 11976–11986 (IEEE, 2022).
Liu, Z. et al. Swin transformer: hierarchical vision transformer using shifted windows. In Proc. 2021 IEEE/CVF International Conference on Computer Vision 10012–10022 (IEEE, 2021).
Li, Y., Wehbe, R. M., Ahmad, F. S., Wang, H. & Luo, Y. Clinical-Longformer and Clinical-BigBird: transformers for long clinical sequences. Preprint at https://arxiv.org/abs/2201.11838 (2022).
Delbrouck, J.-B. et al. Improving the factual correctness of radiology report generation with semantic rewards. In Findings of the Association for Computational Linguistics: EMNLP 2022 4348–4360 (Association for Computational Linguistics, 2022).
Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q. & Artzi, Y. BERTScore: Evaluating text generation with BERT. In International Conference on Learning Representations (ICLR, 2020).
Lin, C.-Y. ROUGE: a package for automatic evaluation of summaries. In Proc. Text Summarization Branches Out 74–81 (Association for Computational Linguistics, 2004).
Papineni, K., Roukos, S., Ward, T. & Zhu, W.-J. BLEU: a method for automatic evaluation of machine translation. In Proc. 40th Annual Meeting of the Association for Computational Linguistics 311–318 (Association of Computational Linguistics, 2002).
Isensee, F., Jaeger, P. F., Kohl, S. A. A., Petersen, J. & Maier-Hein, K. H. nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 18, 203–211 (2021).
Codella, N. C. F. et al. MedImageInsight: an open-source embedding model for general domain medical imaging. Preprint at https://arxiv.org/abs/2410.06542 (2024).
Yang, L. et al. Advancing multimodal medical capabilities of Gemini. Preprint at https://arxiv.org/abs/2405.03162 (2024).
Hamamci, I. E. et al. Developing generalist foundation models from a multimodal dataset for 3D computed tomography. Preprint at https://arxiv.org/abs/2403.17834 (2024).
Niu, C. et al. Medical multimodal multitask foundation model for lung cancer screening. Nat. Commun. 16, 1523 (2025).
Pai, S. et al. Vision foundation models for computed tomography. Preprint at https://arxiv.org/abs/2501.09001 (2025).
Huang, S.-C. et al. Self-supervised learning for medical image classification: a systematic review and implementation guidelines. npj Digit. Med. 6, 74 (2023).
Tang, Y. et al. Self-supervised pre-training of Swin transformers for 3D medical image analysis. In Proc. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition 20730–20740 (IEEE, 2022).
He, K. et al. Masked autoencoders are scalable vision learners. In Proc. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition 16000–16009 (IEEE, 2021).
Laurençon, H., Tronchon, L., Cord, M. & Sanh, V. What matters when building vision-language models? In Proc. 38th International Conference on Neural Information Processing Systems 87874–87907 (NIPS, 2024).
Li, Z. et al. Monkey: Image resolution and text label are important things for large multi-modal models. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 26763–26773 (IEEE, 2024).
Chen, T., Kornblith, S., Norouzi, M. & Hinton, G. A simple framework for contrastive learning of visual representations. In Proc. International Conference on Machine Learning 1597–1607 (PMLR, 2020).
Van den Oord, A., Li, Y. & Vinyals, O. Representation learning with contrastive predictive coding. Preprint at https://arxiv.org/abs/1807.03748 (2018).
Reis, E. P. Automated abdominal CT contrast phase detection using an interpretable and open-source artificial intelligence algorithm. Eur. Radiol. 34, 6680–6687 (2024).
Van Uden, C. et al. Exploring the versatility of zero-shot CLIP for interstitial lung disease classification. Preprint at https://arxiv.org/abs/2306.01111 (2023).
Loshchilov, I. & Hutter, F. Decoupled weight decay regularization. In International Conference on Learning Representations (ICLR, 2019).
Kirkpatrick, J. et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl Acad. Sci. USA 114, 3521–3526 (2017).
Chronic Kidney Disease in the United States, 2023 (Centers for Disease Control and Prevention, 2023).
By the Numbers: Diabetes in America (Centers for Disease Control and Prevention, 2022).
Facts about Hypertension (Centers for Disease Control and Prevention, 2023).
What is Coronary Heart Disease? (US Department of Health and Human Services, 2023).
Gu, J., Sanchez, R., Chauhan, A., Fazio, S. & Wong, N. Lipid treatment status and goal attainment among patients with atherosclerotic cardiovascular disease in the United States: a 2019 update. Am. J. Prev. Cardiol. 10, 100336 (2022).
Wright, N. C. et al. The recent prevalence of osteoporosis and low bone mass in the United States based on bone mineral density at the femoral neck or lumbar spine. J. Bone Miner. Res. 29, 2520–2526 (2014).
Johnson, A. E. W. et al. MIMIC-IV, a freely accessible electronic health record dataset. Sci. Data 10, 1 (2023).
Hu, E. J. et al. LoRA: low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR, 2022).
Van Veen, D. et al. Adapted large language models can outperform medical experts in clinical text summarization. Nat. Med. 30, 1134–1142 (2024).
Van Veen, D. et al. RadAdapt: radiology report summarization via lightweight domain adaptation of large language models. In Proc. The 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks 449–460 (Association for Computational Linguistics, 2023).
Ronneberger, O., Fischer, P. & Brox, T. U-Net: convolutional networks for biomedical image segmentation. In Proc. Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015 234–241 (Springer, 2015).
Hatamizadeh, A. et al. UNETR: transformers for 3D medical image segmentation. In Proc. 2022 IEEE/CVF Winter Conference on Applications of Computer Vision 574–584 (IEEE, 2022).
Xue, C. et al. AI-based differential diagnosis of dementia etiologies on multimodal data. Nat. Med. 30, 2977–2989 (2024).
Yang, A. et al. Qwen3 technical report. Preprint at https://arxiv.org/abs/2505.09388 (2025).
Acknowledgements
A.S.C. receives research support from NIH grants R01 HL167974, R01HL169345, R01 AR077604, R01 EB002524, R01 AR079431, P41 EB 027060 and P50 HD118632; the Advanced Research Projects Agency for Health (ARPA-H) Biomedical Data Fabric (BDF) and the Chatbot Accuracy and Reliability Evaluation (CARE) programmes (contracts AY2AX000045 and 1AYSAX0000024-01); and the Medical Imaging and Data Resource Center (MIDRC), which is funded by the National Institute of Biomedical Imaging and Bioengineering (NIBIB) under contract 75N92020C00021 and through the ARPA-H. C.B. receives research support from the Promedica Foundation.
Author information
Authors and Affiliations
Contributions
L.B. and A.K. collected data, developed code, trained models, ran experiments, analysed results, created figures and wrote the manuscript. All authors reviewed the manuscript and provided revisions and feedback. J.P.C., A.K., D.V.V., M.P., Z.C., J.-B.D., E.R., R.H., C.B., M.E.K.J., S.O., M.V., J.M.J.V., Z.F., Z.N., D.A., W.-H.W., S.G. and A.S.C. provided technical advice. J.P.C. developed the counterfactual generation method for CT scans and ran counterfactual experiments. A.K. carried out model evaluations on external datasets. J.L. developed a Merlin dataset inference pipeline for the Google CT. D.V.V. assisted in collecting zero-shot evaluation labels and facilitated radiologist annotations of generated reports. S.J.S.G., H.Y. and A.W. ran model inference on external clinical dataset 1. L. Liu, L. Lian, Y.W. and A.Y. ran model inference on external clinical dataset 3. M.P., Z.C., J.-B.D., E.R., C.T. and E.A.J. assisted with model evaluations. Z.H. and J.F. assisted with dataset anonymization. C.B., E.A.J., N.A., G.Z., M.W., A.J., R.D.B., A.W., C.P.L., M.W., J.H. and S.G. provided clinical input and feedback. C.B. provided counterfactual annotations. S.G. and C.B. provided annotations of generated reports. N.H.S., C.P.L., S.G. and A.S.C. provided research support for the project. A.S.C. guided the project, serving as principal investigator and advising on technical details and overall direction. No funders or third parties were involved in study design, analysis or writing.
Corresponding author
Ethics declarations
Competing interests
L.B. has received consulting compensation from Google, is a co-founder and employee of Cognita Imaging and is an equity owner of Radiology Partners. All work performed by L.B. was during their time at Stanford University. J.P.C. is employed by Amazon, and the current work is unaffiliated with their role at Amazon. Z.C. is a co-founder and employee of Cognita Imaging and has equity interest in Radiology Partners. All work performed by Z.C. was during their time at Stanford University. Z.N., W.-H.W. and D.A. are employed by Google, and the current work is unaffiliated with their role at Google. N.H.S. is a co-founder of Prealize Health (a predictive analytics company) and Atropos Health (an on-demand evidence generation company), receives funding from the Gordon and Betty Moore Foundation for developing virtual model deployments, and serves on the Board of the Coalition for Healthcare AI (CHAI), a consensus-building organization providing guidelines for the responsible use of artificial intelligence in healthcare. C.P.L. has the following personal financial interests: on the board of directors and is a shareholder of Bunkerhill Health (31 March 2019); advisor to Cognita Imaging (1 November 2024); shareholder of Radiology Partners (5 November 2025); option holder of Whiterabbit.ai (1 October 2017); advisor and option holder of GalileoCDS (1 May 2019); advisor and option holder of Sirona Medical (6 July 2020); advisor and option holder of Adra (17 September 2020); advisor and option holder of Kheiron (21 October 2021); paid consultant of Sixth Street (7 February 2022); and paid consultant of Gilmartin Capital (18 July 2022). They have also received the following grants and gift support paid to their institution: BunkerHill Health, Carestream, CARPL, Clairity, GE Healthcare, Google Cloud, IBM, Kheiron, Lambda, Lunit, Microsoft, Nightingale Open Science, Philips, Siemens Healthineers, Stability.ai, Subtle Medical, VinBrain, Visiana, Whiterabbit.ai. and Jason Hom. They also receive research support from the National Institutes of Health (3U01NS134358-05S1) and from the Gordon and Betty Moore Foundation. J.H. previously provided consulting services to MORE Health, is an advisor and option holder for Cognita Imaging and Radiology Partners. A.S.C., unrelated to this work, is a co-founder and receives salary support from Cognita Imaging, has equity interest in Radiology Partners, Subtle Medical, Brain Key and LVIS Corp., and has provided consulting services to Patient Square Capital, Elucid Bioimaging, and Chondrometrics. All their work was performed as a part of Stanford University. All other authors declare no competing interests.
Peer review
Peer review information
Nature thanks Ryan Shea, Ying Cong Tan and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Zero-shot cross-modal retrieval.
(a) Schematic demonstrating how we perform retrieval. We compute the cosine similarity between Merlin report embeddings and CT embeddings, enabling us to rank CT and report pairs in order of similarity. (b) A distribution of the findings section and impressions section lengths shows that 21% of findings have sequence lengths greater than 512 tokens. (c) Top-1 recall out of pools of 64 findings sections (left), which is considered an in-distribution evaluation as Merlin is trained using findings sections. We also report top-1 recall on out-of-distribution impressions sections (right). Data are presented as mean ± 95% confidence intervals. (d) An ablation study that examines the impact of using I3D ImageNet initialization, multi-task learning (MTL) versus staged training (Stg.) with EHR and reports versus training with reports only (Rpt.), and splitting the radiology report text into anatomical sections. Data are shown as mean ± 95% confidence intervals, computed over n = 5,137 independent CT exams from the Merlin internal test set. (e) Data scaling law experiments that examine the impact of pretraining dataset size on retrieval performance. The dashed lines indicate random chance performance. Data are shown as mean ± 95% confidence intervals, computed over n = 5,137 independent CT exams from the Merlin internal test set. The icons in a were adapted from the Noun Project (https://thenounproject.com/) under a royalty-free licence.
Extended Data Fig. 2 Multi-disease 5-year prediction.
(a) We fine-tune Merlin for predicting chronic disease onset in otherwise healthy patients within 5-years. (b) We compare Merlin to other baseline model variations fine-tuned for the same task. We find that with both 100% and 10% of downstream training data, Merlin outperforms the other model variations. Bars represent the mean performance; error bars denote 95% confidence intervals evaluated on the test set (n = 1,243 independent CT scans). (c) Comparison of Merlin chronic disease prediction performance to a model trained using only phenotypes (EHR Pretraining), an ImageNet I3D initialized model, and a randomly initialized model. (d) An ablation study that measures the impact of various aspects of Merlin’s training strategy. We find that training with EHR and radiology reports, using staged training (Stg.) or multi-task learning (MTL), and training with radiology reports only (Rpt.), all outperform training with EHR only. Data are shown as mean ± 95% CI; n = 1,243 CT scans. The icons in a were adapted from the Noun Project (https://thenounproject.com/) under a royalty-free licence.
Extended Data Fig. 3 Radiology report generation.
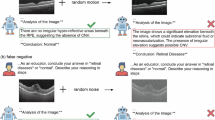
(a) To enable report generation, we extract the last hidden layer embeddings from Merlin and modify the dimension of these embeddings using a projection layer. We generate the report section by section and therefore also embed a report section prompt. The resulting vision and language tokens are used as input to a language model to generate a report section. (b) We compare the performance of our model against RadFM, using four metrics, across each report section and the full report. Data are shown as mean ± 95% CI; statistics were derived from the Merlin internal test set (n = 5,137 CT exams). (c) We provide a densely annotated example of human and Merlin generated reports. We bold the report section headers in the human and Merlin generated reports. We include “uterus and ovaries” in green, as Merlin needs to deduce the correct pelvic anatomy. The icons in a were adapted from the Noun Project (https://thenounproject.com/) under a royalty-free licence.
Extended Data Fig. 4 3D semantic segmentation.
(a) To adapt Merlin and other architectures for segmentation, we add a decoder and skip connections between the encoder and decoder. We conduct all segmentation experiments within the nnUNet framework. (b) We compare model variations using average Dice score across 20 organs that appear in abdominal CT. We compare performance of models trained using 100% of training cases and simulate the data scarce regime with 10% of training cases. Data are presented as mean ± 95% confidence intervals. (c) We report Dice scores for 20 organs across 5 model variations using 10% of training cases. (d) We qualitatively compare segmentations between the ground truth labels, nnUNet, and Merlin with 10% of training cases. The red arrows indicate inconsistencies made by the model relative to the ground truth. The same patient was sampled from the Total Segmentator36 test set. The icons in a were adapted from the Noun Project (https://thenounproject.com/) under a royalty-free licence.
Extended Data Fig. 5 Alternative architecture baselines compared to Merlin (Full Finetuning).
Alternative architecture baselines versus Merlin, where each baseline is fully finetuned (image encoder plus classification head). (a) Average F1 (left chart) and AUPRC (right chart) on 10% and 100% pretraining data for the findings-based disease classification task. Data are shown as mean ± 95% CI; statistics were derived from the Merlin internal test set (n = 5,137 CT exams). (b) Average AUROC (second row) and AUPRC (third row) at 10% and 100% pretraining on the EHR phenotype classification task. Merlin pretraining results in consistently improved performance between the few-shot and fully-supervised data regimes compared to other baselines. Data are presented as mean ± 95% confidence intervals.
Extended Data Fig. 6 External Validation Experiments Summarized.
Merlin external validation on 37,885 abdominal CTs from three external sites and 5,137 internal CTs compared to alternative architecture baselines. We extend the internal and external validation (Fig. 2b) on abdominal CTs to include alternative architectures evaluated on: (a) the Merlin internal test set, (b) the External Site #1, (c) External Site #2, and (d) External Site #3, using the zero-shot classification task and reporting F1 scores. For all subplots, data are presented as means with 95% confidence intervals, where n corresponds to the number of independent CT exams in the test set. Across all baselines, Merlin consistently achieves the highest performance.
Supplementary information
Supplementary Information (download PDF )
Supplementary sections A, B and C, which contains additional results and extended comparisons, including Supplementary Tables 1–9 and Supplementary Figures.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Blankemeier, L., Kumar, A., Cohen, J.P. et al. Merlin: a computed tomography vision–language foundation model and dataset. Nature 652, 1318–1328 (2026). https://doi.org/10.1038/s41586-026-10181-8
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s41586-026-10181-8
