
Abstract
Artificial intelligence applied to brain magnetic resonance imaging (MRI) holds potential to advance diagnosis, prognosis and treatment planning for neurological diseases. The field has been constrained, thus far, by limited training data and task-specific models that do not generalize well across patient populations and medical tasks. By leveraging self-supervised learning, pretraining and targeted adaptation, foundation models present a promising paradigm to overcome these limitations. Here we present Brain Imaging Adaptive Core (BrainIAC)—a foundation model designed to learn generalized representations from unlabeled brain MRI data and serve as a core basis for diverse downstream application adaptation. Trained and validated on 48,965 brain MRIs across a broad spectrum of tasks, we demonstrate that BrainIAC outperforms localized supervised training and other pretrained models, particularly in low-data, few-shot, settings and in high-difficulty prediction tasks, allowing for application in scenarios otherwise infeasible. BrainIAC can be integrated into imaging pipelines and multimodal frameworks and may lead to improved biomarker discovery and artificial intelligence clinical translation.
Similar content being viewed by others

Main
Recent advances in deep learning have transformed medical artificial intelligence (AI), enabling the development of clinically translatable tools that, in some contexts, match or even surpass expert performance1,2. Medical practice, with its vast and diverse data sources across different modalities—clinical notes, histopathology images, radiographic images and genomics—presents a compelling landscape for applied AI to synthesize data, learn patterns and make predictions. However, the scarcity and heterogeneity of labeled data, particularly for rare diseases and cases involving expensive data acquisition procedures, such as brain MRI, remains an important barrier to the development of clinically useful AI imaging tools.
Self-supervised learning (SSL) has emerged as a promising advance to traditional supervised learning methods, with its ability to learn inherent, generalizable information from large unlabeled data that are much more available than annotated, task-specific datasets. This approach allows for the extraction of meaningful representations from unlabeled data that can be transferred easily to different applications. SSL methods have demonstrated remarkable success in computer vision3,4,5,6 and natural language processing7,8, with recent translations into medicine9,10,11,12,13. This shift has facilitated a transition from narrow-task learning of medical AI models to a more generalized task agnostic learning coupled with localized fine-tuning. The resulting algorithms, often referred to as foundation models, have shown substantial potential in developing clinically employable solutions across various medical domains14,15,16.
Despite these advancements, the application of SSL to three-dimensional (3D) brain MRI has been limited. The high-dimensional, heterogeneous nature of brain MRI data presents unique challenges to the development of performant models. Unlike other imaging modalities such as computed tomography, brain MRI has variety of acquisition sequences from a single scan that vary by institution and scanner, with classic examples including T1-weighted, T2-weighted and T1-weighted with gadolinium contrast enhancement (T1CE)—each providing distinct sets of information, with selection of sequences for analysis depending upon the clinical use cases. For example, T1-weighted sequences are commonplace for neurocognitive analysis of pediatric and adolescent patients as well as later neurofunctional diseases (for example, Alzheimer’s dementia)17,18. Whereas T2-weighted sequences are preferred for lesion segmentation2,19, compared to T2-fluid attenuation inversion recovery (FLAIR) and T1CE, which are used commonly for response assessment for brain tumors20,21. Variability in MRI scanner, acquisition protocol and patient setup also introduce biases in voxel intensities, which are problematic for radiomic analyses22,23. Furthermore, magnetic resonance acquisition itself is subject to variability and noise, with a range of scanners (from 1.5 T to 7 T) and differing acquisition parameters (for example, echo time or relaxation time)24. Foundation models for MRI must overcome substantial heterogeneity in brain structural features across different age groups and (sometimes rare) disease pathologies, which may constrain generalizable feature extraction.
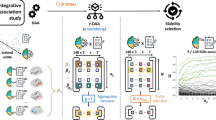
Previous investigations have proposed foundation model frameworks for brain lesion segmentation25 and aging-related tasks26, but there remains a need for a broadly generalizable model for both healthy and abnormal brain images. In this study we introduce BrainIAC—a general, multiparametric brain MRI foundation model based on SSL principles. Developed and validated in 48,965 brain MRIs with a wide spectrum of demographics and medical settings, we show that BrainIAC learns robust and adaptable representations. We evaluate BrainIAC performance on several downstream applications across a range of clinical settings with varying task complexity. We compare BrainIAC to traditional supervised learning approaches and transfer learning from pretrained medical imaging networks27 in variable data availability (10% data up to 100% data), few-shot adaptation (with K = 1 and K = 5 indicating 1 and 5 samples per class, respectively) and linear probing scenarios. We perform a stability analysis using synthetically simulated imaging perturbations to mimic real-world acquisition and scanner variability and compare the robustness and generalizability of BrainIAC’s learned features to other approaches. Our findings demonstrate BrainIAC’s versatility and ability to adapt to several clinical settings with extremely limited training data (as few as single samples), providing a usable foundation to accelerate computational brain imaging analysis research.
Results
We pretrained BrainIAC using contrastive SSL on 32,015 multiparametric MRIs curated from 16 datasets across ten medical conditions (Fig. 1 and Supplementary Tables 1–4). We then adapted BrainIAC to seven distinct, clinically meaningful, heterogeneous, downstream prediction tasks, comparing performance against supervised learning and in-domain transfer learning approaches. The seven tasks are MRI sequence classification, brain age prediction, detection of isocitrate dehydrogenase (IDH) mutation, survival prediction for brain tumors, early dementia prediction through mild cognitive impairment (MCI) versus healthy control, time-to-stroke prediction, and adult glioma segmentation (Supplementary Methods A.2.1–A.2.7). These tasks were chosen as they represented a wide range of clinical contexts and difficulty. For instance, MRI sequence classification is straightforward for a clinician, whereas mutational status prediction is extremely challenging. For each downstream application, we compared BrainIAC to localized supervised training (Scratch), a 3D medical-imaging-specific pretrained model (MedicalNet27) and a segmentation-specific foundation model (BrainSegFounder25), which represent the few in-domain foundation models publicly available. For all the downstream tasks, we compared the performance across limited data scenarios by fine-tuning the entire model end-to-end. Increasing the fraction of fine-tuning data available from 10% to 100% with independent test sets for performance metrics (Fig. 2 and Extended Data Fig. 1). We evaluated performance in few-shot scenarios with one data sample per class (K = 1) and five data samples per class (K = 5) (Fig. 3 and Supplementary Methods A.3) by fine-tuning the entire model end-to-end. We further evaluated the feature generalizability using linear probing (100% fine-tuning data) (Figs. 3h and 4c–d). Finally, we analyzed resiliency of BrainIAC and benchmark models to image-related artifacts (Fig. 5 and Supplementary Methods A.4). To identify the most robust backbone architecture, we first performed a benchmarking experiment comparing three pretrained encoders—SimCLR-ResNet50, SimCLR-ViTb and MAE-SwinViT—using few-shot adaptation (K = 1 and K = 5) across all seven downstream tasks. Based on consistent superior performance, SimCLR-ViT-B was designated as the BrainIAC backbone for all subsequent experiments (Extended Data Fig. 2).

BrainIAC is a general-purpose foundation model for brain MRI analysis, trained using a contrastive SSL approach and validated on seven diverse downstream applications (magnetic resonance sequence classification, time-to-stroke prediction, brain age estimation, mild cognitive impairment (MCI) classification, overall survival prediction for brain tumors, classification of IDH mutational status and brain tumor segmentation). BrainIAC outperforms supervised training (Scratch) and finetuning from publicly available models suitable for brain MRI (MedicalNet, BrainSegFounder). BrainIAC serves as a vision encoder for 3D Brain MRI scans generating robust latent feature representations that can be adapted easily to downstream applications. a, Datasets used in the study: a pool of 34 datasets ranging across ten neurological conditions and four sequences totaling 48,965 brain MRI scans was curated and preprocessed. GBM, glioblastoma; HGG, high-grade glioma; PLGG, pediatric low-grade glioma. b, BrainIAC was trained using contrastive learning-based SSL approach SimCLR on 32,015 Brain MRI scans. Full 3D brain magnetic resonance volumes were first decomposed into several randomly cropped, intensity-augmented patches. Differently augmented views of the same anatomical patch form a positive pair, whereas all other patches act as negative examples. Optimizing a SimCLR contrastive loss attracts positive pairs in latent space while repelling negatives. BrainIAC was further evaluated in downstream settings of classification, regression and segmentation. c, BrainIAC outperforms other approaches (Scratch, MedicalNet, BrainSegFounder) for downstream application at highly limited data availability in few-shot settings with one sample per class (K = 1), five samples per class (K = 5) and linear probing. Left: five tasks (excluding brain age prediction and time-to-stroke prediction); right: all seven tasks.

Performance comparison of four finetuning methods: BrainIAC, BrainSegFounder, MedicalNet and randomly initialized Scratch baseline, evaluated across varying training data sizes (10%, 20%, 40%, 60%, 80% and 100% of available training data). Data are presented as mean ± 95% CI from 1,000 bootstrap samples. a, Mutation prediction (IDH status classification), prediction performance reported as AUC; ntest = 99, ntrain (100%) = 396. b, Dementia prediction (MCI versus cognitively normal), prediction performance reported as AUC; ntest = 40, ntrain (100%) = 195. c, Sequence classification prediction performance reported as BA; ntest = 876, ntrain (100%) = 5,004. d, Overall survival prediction for glioblastoma, internal test set (left) and external test set (right), prediction performance reported as AUC; ntest = 134, ntrain (100%) = 545 (internal), n test = 134 (external). e, Tumor segmentation (mean Dice score); ntest = 144, ntrain (100%) = 1,206. f, Brain age prediction, in-distribution test set (left) and external test set (right), performance reported with MAE in years; ntest = 1,295, ntrain (100%) = 3,882 (in-distribution), ntest = 1,072 (external). g, Time-to-stroke prediction, performance reported with MAE in days; ntest = 40, ntrain (100%) = 170. Higher values indicate better performance for AUC, BA and Dice scores; lower values indicate better performance for MAE. BrainIAC consistently demonstrates improved performance across all tasks and data settings, with the more pronounced improvements in low-data scenarios (≤40% training data).

a–g, Few-shot fine-tuning (K = 1 and K = 5). Performance comparison of four methods: BrainIAC, BrainSegFounder, MedicalNet and Scratch with one (K = 1) or five (K = 5) labeled samples per class for training and validation. Data are presented as mean values ± 95% CI estimated from 1,000 bootstrap samples. All models were evaluated on independent holdout test sets across all downstream tasks. For four-way sequence classification (T1W, T2W, FLAIR and T1ce) and brain age prediction (four age bins), K = 1 uses four samples and K = 5 uses 20 samples. For binary classification tasks (IDH mutation, overall survival and MCI classification), K = 1 uses two samples and K = 5 uses ten samples. For the tumor segmentation task, K = 1 uses one sample and K = 5 uses five samples. Error bars: 95% CI from bootstrapping 1,000 samples. a, Overall survival prediction for glioblastoma (binary classification), AUC; ntest = 134. b, Sequence classification (four-way: T1W, T2W, FLAIR and T1ce), BA; ntest = 876. c, Brain age prediction (four age bins: 0–10, 10–20, 20–30 and 30–40 years), MAE in years; ntest = 1,295. d, Mutation prediction (IDH status classification), AUC; ntest = 99. e, Dementia prediction (MCI versus healthy control), AUC; ntest = 40. f, Time-to-stroke prediction (two temporal bins: 0–100, 100+ days), MAE in days; ntest = 40. g, Tumor segmentation, mean dice coefficient; ntest = 144. h, Frozen-backbone (linear probe) evaluation. Performance comparison across the tasks using frozen pretrained encoders with only task-specific heads trained on the full training dataset (100%).

Patients were stratified into high-risk (red) and low-risk (blue) groups based on median predicted risk; shaded areas represent 95% CIs and log-rank P values were calculated using the log-rank test to quantify statistical significance of group separation. a,b, Kaplan–Meier survival curves for overall survival prediction on the internal test cohort (a) and an independent external validation cohort (b) using BrainIAC fine-tuned end-to-end with varying training data availability, 10%, 40%, 80% and 100% of the full training set (ntrain (100%) = 545; ntest = 134). c, Kaplan–Meier curve for the internal and external cohort using frozen BrainIAC encoder with linear survival-prediction head trained on the full dataset (ntrain (100%) = 545). d, Representative axial FLAIR images with predicted tumor segmentation masks (red overlay) from BrainIAC models fine-tuned with 10%, 100%, K = 1 and K = 5 of the training data (ntrain (100%) = 1,206). Left small panels: predicted segmentation masks and ground truth segmentation mask (top) and source images without overlay (bottom) and the outset show the overlay of predicted segmentation mask with source images.

Models trained on complete datasets were evaluated for stability against three types of artificially injected imaging artifact and perturbation (contrast, Gibbs and bias) across all downstream applications. Performance was assessed across contrast scale variations (0.5–2.0, baseline = 1.0), Gibbs artifacts (scale 0.0–0.4, baseline = 0.0) and bias field perturbations (scale 0.0–0.4, baseline = 0.0).
MRI sequence classification
Sequence classification is a critical, upstream step in MRI curation and processing that remains challenging in real-world clinical settings due to heterogeneous scanner protocols and frequently missing, erroneous or poorly documented sequence information at acquisition. Although deep learning has shown promise in automated classification, there remains room for improvement, particularly in the classification of contrast enhancement in T1-weight scans28. ‘Scanʼ refers to a single 3D brain MRI volume acquired with a specific sequence protocol (T1, T2, T1CE or FLAIR). Thus, our sequence classification task involves assigning the correct sequence label to each scan. We used 5,004 scans for fine-tuning, with a reserved holdout set of 876 scans encompassing the four primary sequences used in brain tumor assessment (T1, T2, T1CE or FLAIR) from the BraTS 2023 dataset29 (Supplementary Methods A.2.1 and Supplementary Table 5). We found that performance increased incrementally with fine-tuning data availability. At lower data availability, BrainIAC outperformed MedicalNet, BrainSegFounder and Scratch (Fig. 2c and Supplementary Table 24). For example, at 10% availability (n = 500 scans), BrainIAC balanced accuracy (BA) was 90.8%, MedicalNet was 74.2%, BrainSegFounder was 86.4% and Scratch was 79.0%. BrainIAC continued to outperform other models until 60% (n = 3,000) of scans were available for training, at which point performance plateaued for all models (BrainIAC BA: 97.2%, MedicalNet BA: 93.0%, BrainSegFounder BA: 95.5%, Scratch BA: 95.3%). We performed K nearest neighbor clustering (K = 4, representing each sequence) on the features and calculated the Davies–Bouldin index scores. For 100% data BrainIAC demonstrated better clustering performance with Davies–Bouldin index of 0.68 compared to 0.72 of Scratch, 0.82 of MedicalNet and 0.70 of BrainSegFounder (Supplementary Table 6).
Subgroup analysis of T1CE versus T1 classification was conducted to assess model performance—a challenging task due to the subtle and overlapping imaging features between T1-weighted and contrast-enhanced T1-weighted sequences, especially in differentiating tumor core from peritumoral edema. BrainIAC outperformed all the other approaches at training data availability below 60%. Consistent findings were observed in additional subgroup analyses (T2 versus FLAIR, T1 versus T2 and FLAIR versus T1CE) and one-versus-all evaluations of all four classes (Extended Data Fig. 3).
Brain age prediction
MRI-based brain age prediction is associated with neurocognitive function in aging adults and may have utility as an early biomarker for Alzheimer’s disease30,31. To evaluate BrainIAC as a foundation for improved brain age prediction, we aggregated a dataset of 6,249 T1-weighted scans, allocating 3,882 for training or validation and 1,295 as an in-distribution, internal test set and an out-of-distribution test set of 1,072 scans (Supplementary Tables 7 and 8 and Supplementary Methods A.2.2). Performance was assessed using mean absolute error (MAE) for predicted age versus chronological age.
In both internal and external test sets, performance improved with training data availability, and BrainIAC outperformed other models at lower data availability (Fig. 2f). In the external test set, at 20% training data availability (n = 775 scans), BrainIAC achieved MAE of 6.55 (95% confidence interval (CI): 0.2), compared to MedicalNet MAE: 7.61 years (95% CI: 0.26), BrainSegFounder MAE: 10.07 years (95%CI: 0.21) and Scratch MAE of 7.3 years (95% CI: 0.23). BrainIAC continued to outperform other models until 100% of training data was available.
BrainIAC demonstrated increased accuracy at all age predictions compared with MedicalNet, BrainSegFounder and Scratch models (Supplementary Tables 9 and 10). The difference between predicted and chronological age was minimum at 100% data for both internal and external test sets (Fig. 6a,c). The t-distributed stochastic neighbor embedding (t-SNE) representations of BrainIAC demonstrate clear clustering of the latent features based on the age groups: 0–10 years, 10–20 years, 20–30 years, 30–40 years (Fig. 6b,d). With a Davies–Bouldin index score of 0.506 (external) and 0.481 (internal), BrainIAC outperforms MedicalNet 0.633 (external) 0.538 (internal), BrainSegFounder 0.490 (internal) and 0.618 (external) and Scratch 0.612 (external) and 0.485 (internal) on clustering of age-binned latent features.

a,c, Scatter plots with regression line overlay represent the correlation between predicted age and true age, with normal denoted by a black dashed line for the BrainIAC fine-tuned model (100%) for the internal (a) (n = 1,295) and external (c) (n = 1,072) test sets. b,d, t-SNE plots depicting latent representations of BrainIAC on the internal (b) and external (d) test sets with four age bins.
Cancer mutational subtype prediction
Noninvasive, imaging-based prediction of brain tumor mutational subtypes could provide actionable information to dictate clinical management when tissue biopsy is deemed infeasible32,33,34. We evaluated BrainIAC as a foundation for tumor mutational subtyping — IDH mutation prediction in low-grade glioma setting. Performance was evaluated using the area under the receiver operating characteristic curve (AUC) for discriminating mutation versus wildtype tumor (Fig. 2a). The DeLong35 test was used for checking statistical significance and calculating P values.
For IDH classification, we used 396 scans for training and validation; 99 were reserved as a test set from the UCSF-PDGM36 dataset (Supplementary Table 12 and Supplementary Methods A.2.3). Performance increased incrementally with training data availability but, in this case of very limited data, BrainIAC consistently outperformed other models at all levels of data availability. At 10% data availability (n = 50), BrainIAC yielded AUC 0.68 (95% CI: 0.56–0.80), compared to 0.50 (95% CI: 0.36–0.63, P = 0.031) for MedicalNet, 0.59 (95% CI: 0.44–0.71) for BrainSegFounder and 0.47 (95% CI: 0.34–0.62, P = 0.035) for Scratch. At 100% data availability (n = 396), BrainIAC yielded AUC 0.79 (95% CI: 0.64–0.89), compared to 0.68 (95% CI: 0.54–0.81, P = 0.052) for MedicalNet, 0.59 (95% CI: 0.45–0.72, P = 0.031) for BrainSegFounder and 0.61 (95% CI: 0.48–0.73, P = 0.038) for Scratch (Supplementary Tables 13 and 15).
We generated saliency maps for BrainIAC to visualize the internal weight activation and attention of the model (Fig. 7b).

For each image triplet: original magnetic resonance slice (grayscale, left), saliency contour overlay (center) and Smooth Grad heatmap (right). a, Frozen BrainIAC backbone. Attention patterns generated directly from the pretrained BrainIAC encoder without any task-specific training, depicted on a single subject across four MRI sequences (T2FLAIR, T1w, T2w and T1ce). b, Task-specific fine-tuned models. Saliency maps after end-to-end fine-tuning of BrainIAC on downstream applications using 100% of available training data.
Overall survival prediction
Computational analysis of cancer imaging data can potentially improve prognostication and risk-stratification beyond traditional staging37. We evaluated BrainIAC as a foundation for survival prediction for glioblastoma multiforme (GBM) using the UPENN-GBM38 dataset. Of 671 patients in total, 668 patients with complete survival information were included (Supplementary Table 16). We split the dataset randomly, with 534 (80%) patients for fine-tuning and 134 (20%) reserved as a test set. We further performed external testing on 134 patients from the TCGA-GBM/Brats23 dataset with complete survival information. Model performance was assessed using AUC for predicting survival at 1 year post-treatment with complete data up to this timepoint. Median model risk score output was used to stratify patients into low- and high-risk groups with Kaplan–Meier survival curves calculated and log-rank tests to compare model risk-stratification. AUC was reported for patients at risk up to the 1-year mark (that is, not censored and no event); five patients in our external test data met this criterion and were excluded from AUC calculation (Supplementary Methods A.2.4).
We found that survival prediction performance generally increased with training data availability (Fig. 2d). Generally, BrainIAC outperformed other models, at all data percentage availability. At 10% training data availability (n = 55), BrainIAC maintained high performance with an AUC of 0.62 (95% CI: 0.52–0.71), surpassing Scratch, BrainSegFounder and MedicalNet (P < 0.0001) with AUC of 0.52 (95% CI: 0.42–0.62), 0.54 (95% CI: 0.43–0.63) and 0.36 (95% CI: 0.27–0.46), respectively. At 100% data availability, BrainIAC had the highest performance (AUC 0.72), surpassing MedicalNet (0.53, P = 0.03), BrainSegFounder (0.54, P = 0.01) and the Scratch model (0.47, P = 0.0004).
External testing showed similar performance trends, with BrainIAC outperforming MedicalNet, BrainSegFounder and Scratch, with stable performance at all data percentage availability. At 10% training data, BrainIAC resulted in an AUC of 0.60 (95% CI: 0.50–0.68) significantly outperforming MedicalNet 0.44 (95% CI: 0.33–0.53, P = 0.02), BrainSegFounder 0.49 (95% CI: 0.39–0.59) and Scratch 0.50 (95% CI: 0.39–0.59). BrainIAC performance increased at 100% availability with AUC 0.66 improving over MedicalNet 0.48, BrainSegFounder 0.51 and Scratch 0.50 (Fig. 2d). The concordance index with 95% CI is reported in Supplementary Tables 17 and 18.
MCI classification
MCI detection and classification from healthy control data can lead to early detection and improved management of neurocognitive diseases such as dementia and Alzheimer’s disease39. We evaluated BrainIAC as a core for the classification of MCI versus healthy participants by evaluating the AUC as the performance metric (Fig. 2b). The DeLong test was used for checking statistical significance and calculating P values (Supplementary Table 20).
For MCI classification, we used 195 scans (106 healthy control, 89 MCI) for training and validation, with 40 (29 healthy control, 11 MCI) reserved as a test set from the OASIS-1 dataset (Supplementary Methods A.2.5). BrainIAC outperformed other models at all data percentages, with notable AUC margins at lower data percentages (60% and below). At 10% data availability (n = 20), BrainIAC yielded AUC 0.70 (95% CI: 0.50–0.87), compared to 0.56 (95% CI: 0.35–0.75) for MedicalNet, 0.52 (95% CI: 0.32–0.72) for BrainSegFounder (P = 0.071) and 0.54 (95% CI: 0.34–0.73) for Scratch. Increasing training data availability to 100% (n = 195), BrainIAC yielded AUC 0.88 (95% CI: 0.75–0.97), compared to 0.82 (95% CI: 0.67–0.94) for MedicalNet, 0.62 (95% CI: 0.39–0.82) for BrainSegFounder and 0.77 (95% CI: 0.55–0.93) for Scratch.
Time-to-stroke prediction
Time-since-stroke-onset prediction can allow clinicians to make evidence-based decisions for time-sensitive treatments, enabling optimal intervention selection for stroke patients who might otherwise be excluded due to uncertain onset time. To evaluate BrainIAC as a tool to predict time-to-stroke, we leveraged the ATLAS dataset with scans from 210 stroke patients with median 77 days (interquartile range: 11.0–151.0). For time-to-stroke prediction we allocated 170 scans for training and validation and reserved 40 scans as a holdout test set (Supplementary Methods A.2.6).
BrainIAC outperformed other models at all data percentages, with greater MAE difference at higher data percentages (40% and above). At 10% data availability (n = 18), BrainIAC resulted in MAE 61.56 compared to 67.31 for MedicalNet, 77.32 for BrainSegFounder and 64.78 for Scratch. Increasing training data availability to 100% (n = 170), BrainIAC yielded MAE of 38.87, compared to 62.24 for MedicalNet, 63.73 for BrainSegFounder and 50.63 for Scratch (Fig. 2g and Supplementary Table 22).
Tumor segmentation
Glioma segmentation is a critical task in neuro-oncology as it enables quantitative assessment of tumor burden, treatment planning and longitudinal monitoring of disease progression. To assess the transferability of BrainIAC for segmentation, we fine-tuned each backbone on the BraTS23 adult glioma dataset, reformulated as a single-channel binary segmentation task using FLAIR sequences (Supplementary Methods A.2.7). Performance was quantified by mean Dice coefficient (DSC) across varying data fractions (Fig. 2e and Supplementary Table 26).
BrainIAC consistently achieved higher Dice scores compared to MedicalNet, BrainSegFounder and Scratch baselines across all training data percentages. Notably, at 10% data availability (n = 120 scans), BrainIAC attained a mean Dice score of 72 (95% CI: 0.02), outperforming MedicalNet (DSC: 0.54, 95% CI: 0.03, P < 0.0001), BrainSegFounder (DSC: 0.71, 95% CI: 0.02) and Scratch (DSC: 0.33, 95% CI: 0.02) (P < 0.0001). At full data availability, BrainIAC maintained superior segmentation accuracy with a Dice score of 0.79 (95% CI: 0.02), compared to MedicalNet (0.69), BrainSegFounder (0.75) and Scratch (0.70). Qualitative inspection of segmentations depict more precise delineation of tumor boundaries by BrainIAC with fewer false positives in healthy tissue as training data percentage increased (Fig. 4d).
Few-shot adaptation analysis
To evaluate downstream adaptation capabilities under extreme data constraints, we conducted few-shot fine-tuning experiments across seven downstream tasks and under two settings: single-sample (K = 1) and five-sample (K = 5) per class. All models evaluated on independent holdout test sets.
For sequence classification of four classes (T1W, T2W, FLAIR and T1CE), BrainIAC demonstrated superior performance with BA of 0.53 in the K = 1 setting, compared to 0.25 (MedicalNet), 0.34 (BrainSegFounder) and 0.34 (Scratch). This performance advantage expanded in the K = 5 setting, with BrainIAC achieving BA of 0.73 versus 0.49 (MedicalNet), 0.40 (BrainSegFounder) and 0.43 (Scratch) (Fig. 3b and Supplementary Table 25).
In brain age prediction, we stratified participants into four age bins (0–10, 10–20, 20–30 and 30–40 years) on internal test set. BrainIAC achieved superior MAE of 9.45 years in the K = 1 setting, compared to 17.44 (MedicalNet), 10.97 (BrainSegFounder) and 16.93 (Scratch). The performance improvement persisted in the K = 5 setting, with MAEs of 7.24, 15.03, 10.24 and 14.28 years, respectively (Fig. 3c and Supplementary Table 11).
For IDH mutation classification, BrainIAC achieved an AUC of 0.64 (95% CI: 0.49–0.78) in the K = 1 setting, outperforming both MedicalNet (AUC: 0.37 (95% CI: 0.24–0.50)), BrainSegFounder (AUC: 0.57 (95% CI: 0.43–0.70)) and Scratch (AUC: 0.48 (95% CI: 0.32–0.64)). Similar performance was observed in the K = 5 setting with AUC: 0.64 (95% CI: 0.52–0.76) (BrainIAC), AUC: 0.44 (95% CI: 0.30–0.58) (MedicalNet), AUC: 0.62 (95% CI: 0.50–0.74) (BrainSegFounder) and AUC: 0.55 (95% CI: 0.41–0.68) (Scratch), respectively (Fig. 3d and Supplementary Table 14).
In overall survival prediction (binary classification) on external test set, BrainIAC maintained superior performance for K = 1 and K = 5. For K = 1, BrainIAC achieved an AUC of 0.59 (95% CI: 0.49–0.68), compared to 0.38 (95% CI: 0.29–0.47) (MedicalNet), AUC: 0.42 (95% CI: 0.32–0.52) (BrainSegFounder) and 0.37 (95% CI: 0.27–0.46) (Scratch). The K = 5 setting yielded AUCs of 0.60 (95% CI: 0.51–0.70], 0.55 (95% CI: 0.44–0.65), 0.58 (95% CI: 0.47–0.67) and 0.48 (95% CI: 0.39–0.58), respectively (Fig. 3a and Supplementary Table 19). With K = 1, K = 5, 10%, 100% of training data available, BrainIAC median risks scores were able to stratify (P < 0.05) patients significantly into high- and low-risk groups for both internal and external test sets (Fig. 4a,b).
For MCI classification, BrainIAC demonstrated AUC of 0.69 (95% CI: 0.51–0.84) in the K = 1 setting, outperforming MedicalNet (AUC: 0.56 (95% CI: 0.36–0.75)), BrainSegFounder (AUC: 0.60 (95% CI: 0.41–0.79)) and Scratch (AUC: 0.49 (95% CI: 0.29–0.69)). The K = 5 setting showed similar relative performance, with AUCs of 0.79 (95% CI: 0.64–0.92), 0.63 (95% CI: 0.45–0.79), 0.53 (95% CI: 0.33–0.71) and 0.51 (95% CI: 0.29–0.72), respectively (Fig. 3e and Supplementary Table 21).
For time-to-stroke prediction, we binned the data into two temporal categories (0–120 days and 120–240 days). BrainIAC demonstrated superior performance in both few-shot settings, achieving MAE of 66.10 days versus 83.97 (Scratch), 75.98 (BrainSegFounder) and 85.97 (MedicalNet) for K = 1 and 69.46 days versus 65.63 (Scratch), 65.15 (BrainSegFounder) and 85.15 (MedicalNet) for K = 5 (Fig. 3f and Supplementary Table 23).
For the tumor segmentation task, BrainIAC demonstrated robust adaptation under few-shot constraints (Fig. 3g and Supplementary Table 27). In the single-sample setting (K = 1), BrainIAC achieved a mean Dice score of 0.51, substantially outperforming MedicalNet (0.13), BrainSegFounder (0.49) and Scratch (0.03). This advantage persisted with five samples per class (K = 5), where BrainIAC maintained a mean Dice score of 0.61 compared to MedicalNet (0.51), BrainSegFounder (0.53) and Scratch (0.13).
Linear probing
To benchmark the representational quality of learned pretrained embeddings, we performed linear probing across seven downstream tasks using the full training datasets (Fig. 3h and Supplementary Tables 28–34). Linear probing performance serves as a proxy for the task-relevant information captured in the frozen encoder without task-specific fine-tuning. BrainIAC consistently outperformed MedicalNet and BrainSegFounder across all evaluated tasks. Specifically, BrainIAC achieved an AUC of 0.69 for mutation prediction compared to 0.60 (BrainSegFounder) and 0.58 (MedicalNet); for brain age prediction, BrainIAC resulted in a lower MAE of 7.51 years relative to 10.45 (BrainSegFounder) and 7.9 (MedicalNet). Similar trends were observed for dementia prediction (AUC: 0.72 versus 0.48 and 0.47), time-to-stroke prediction (MAE: 64.31 days versus 72.6 and 74.7), sequence classification (BA: 0.75 versus 0.42 and 0.40), tumor segmentation (Dice: 0.67 versus 0.64 and 0.57) and overall survival (AUC: 0.68 versus 0.60 and 0.58).
Discussion
In this study, we present BrainIAC—a foundation model for brain MRI analysis developed with self-supervised contrastive pretraining and evaluated on 48,965 multiparametric brain MRI scans spanning several demographic and clinical settings. We find that BrainIAC consistently outperforms traditional supervised models and transfer learning from more general biomedical imaging models across a wide range of downstream applications on healthy and disease-containing scans with minimal fine-tuning. BrainIAC is robust to imaging perturbations. BrainIAC’s performance consistency stems in part from a systematic encoder selection as we benchmarked several pretraining strategies and backbones using few-shot evaluation across all tasks and selected 3D ViT-B as the BrainIAC foundation model. This improvement reflects the ability of ViT to model long-range spatial relationships when trained with SimCLR’s contrastive objective, resulting in more generalizable feature representations than those learned by convolutional or reconstruction-based encoders. Our findings demonstrate BrainIAC’s adaptive and generalization capabilities, positioning it as a powerful foundation for development of clinically usable imaging-based deep learning tools, particularly in limited data scenarios.
The emergence of foundation models has advanced medical imaging AI applications, from biomarker discovery to cancer diagnostics10,40. Several pretrained model frameworks exist for biomedical imaging41,42, but only a few are focused exclusively on brain MRI and are publicly available, for example, MedicalNet27 and BrainSegFounder25—used as a primary benchmark in this study. Although MedicalNet and BrainSegFounder represent a powerful advance for biomedical imaging analysis, we find that a foundation model pretrained with SSL for multiparametric MRI consistently outperforms the broader biomedical imaging model or a foundational segmentation model on wide spectrum of tasks. We hypothesize that the inherent differences between MRI intensity values, sequence acquisitions and anatomy make a brain MRI-specific foundation model critical to high-performing algorithms in neuroimaging. A few approaches to foundation models for brain MRI lesion segmentation proposed19,25 and anomaly detection43, but the present work applies and rigorously evaluates an SSL approach for broad, classification, regression and segmentation problems together, representing important use cases for medical management of diseases that affect the brain.
BrainIAC was tested intentionally on tasks that have a range of perceived difficulty from a clinical standpoint. On one end of the spectrum, MRI sequence classification and tumor segmentation are straightforward for trained clinicians and, on the other end of the spectrum, time-to-stroke prediction, genomic subtyping and survival prediction are very challenging based on imaging alone. Supervised deep learning models have shown promise in even challenging brain MRI tasks44,45, but require a large amount of training data and are prone to performance degradation when applied in contexts outside that on which they were trained46,47, thus limiting their clinical usability and utility. BrainIAC showed consistently improved performance over other approaches in all tasks, regardless of perceived difficulty, particularly in low (<10% of data available) and few-shot data settings. Notably, even with all training data made available, BrainIAC continued to demonstrate higher performance in tasks that were both challenging and had limited training cases available (that is, mutational subtype, survival prediction, MCI classification, time-to-stroke prediction and tumor segmentation), whereas in ‘easier’ tasks with more data (for example, sequence classification) the performance gap was narrower between BrainIAC and other approaches. This indicates that the utility of BrainIAC as a foundation model is probably potentiated in settings of challenging tasks and low data, such as classification of rare cancers or MCI participants. Furthermore, BrainIAC was found to be more generalizable for brain age and survival prediction, for which true external test sets were available for evaluation. For brain age prediction at 100% training data availability (3,882 scans), BrainIAC continued to show improved accuracy versus other approaches, suggesting that BrainIAC learned more informative, generalizable features to form a basis for fine-tuning. BrainIAC also demonstrated superior performance across data availability scenarios for MCI classification. Hence, potentially serving as a feature extractor for imaging-based analysis of neurodegenerative and neurofunctional diseases. In tumor-related tasks, where labeled data scarcity often poses major challenges, the improvement in performance provided by BrainIAC was clear. Improved performance in tumor segmentation task demonstrate the adaptability of BrainIAC representations and allow use in segmentation of rare tumors with limited data availability.
Notably, saliency map visualizations reveal BrainIAC’s attention towards the biologically plausible regions for downstream tasks. The model focuses consistently on relevant neuroanatomical regions. For instance, attention was directed to the hippocampus in MCI classification, periventricular white matter regions in brain age prediction and enhancing tumor cores in IDH mutation prediction and overall survival prediction (Fig. 7).
Perturbation analyses demonstrated BrainIAC’s resilience to common MRI artifacts such as contrast shifts, Gibbs ringing and bias-field distortions. BrainIAC maintained more stable performance than MedicalNet, BrainSegFounder and Scratch, especially in low-data tasks such as mutation prediction, time-to-stroke and survival prediction where other models noticeably degraded (Fig. 5 and Supplementary Methods A.4).
Our study has several limitations. Currently, the study focuses exclusively on standard structural MRI sequences (T1w, T2w, FLAIR, T1CE). Other contrast types, such as diffusion-weighted or functional imaging, remain outside the current scope and represent scope for future work. Although BrainIAC was developed as a single-sequence model to maintain compatibility across heterogeneous clinical settings, future extensions toward multisequence, multichannel representations could enable improved performance and flexibility, particularly for tasks reliant on multiparametric information. The model was trained on skull-stripped images, thus limiting its application to intracranial analysis. In addition, we do not benchmark image registration as a downstream task, as registration is treated widely as a preprocessing step in MRI analysis pipelines and is not commonly evaluated as a downstream benchmark in current foundation model studies. Finally, although the study represents the largest pretrained brain MRI foundational model up to now, inclusion of even further training data may yield performance improvements. Future work will focus on investigation of performance improvements with incorporation of new training data, learning strategies and architectures, coupled with multimodal approaches including clinical and ‘omics’ data. In addition, whereas standard software tools currently exist for white and gray matter segmentation, future downstream applications of BrainIAC could explore these tasks to assess whether foundation model representations provide further gains.
In conclusion, BrainIAC represents a step towards generalized brain MRI analysis with self-supervised foundation models. With minimal fine-tuning, BrainIAC can raise the bar for performance on several MRI tasks. Our findings suggest that a BrainIAC foundation pipeline could replace traditional supervised learning strategies for brain MRI and allow for the development of models adaptable to challenging tasks in data-limited scenarios that were previously thought infeasible. Ultimately, BrainIAC is designed to establish a generalizable baseline for brain MRI representation learning, enabling efficient fine-tuning and adaptation across diverse downstream tasks, rather than to supplant specialized models optimized for a single, well-defined objective.
Methods
Dataset
This study was conducted in accordance with the Declaration of Helsinki and was approved by the Institutional Review Board of the Dana-Farber/Harvard Cancer Center (Protocol 13-055). A waiver of informed consent was granted due to the retrospective nature of the study, the use of deidentified clinical data and the inclusion of publicly available datasets. We curated a dataset pool of 48,965 brain MRI scans, including 24,504 T1W, 5,389 T2W, 15,372 T2FLAIR and 3,254 T1CE sequences. The data pool was aggregated from the following datasets: ABCD48, ADNI, DFCI/BCH LGG, OASIS-349, MCSA50, SOOP51, ABIDE (https://fcon_1000.projects.nitrc.org/indi/abide/databases.html), CBTN LGG52, MIRIAD53, PPMI (https://www.ppmi-info.org), DLBS54, RadArt55, OASIS-256, DFCI/BCH HGG, QIN-GBM57, RIDER58, UPENN-GBM38, BraTS 202359,60,61,62, UCSF-PDGM36, HCP S120063, LONG57964, BABY65, AOMIC ID1000 (https://openneuro.org/datasets/ds003097), Calgary Preschool MRI (https://osf.io/axz5r/overview), HaN66, NIMH67, ICBM, IXI (https://brain-development.org/ixi-dataset/), PING68, Pixar69, SALD70, PETfrog71 OASIS-156, ATLAS72,73 further details and acknowledgements are in Supplementary Methods A.1. For Alzheimer’s datasets (for example, ADNI, OASIS-3, MIRIAD), we included all scans from cognitively normal, MCI and Alzheimer’s disease participants, using each longitudinal scan as an independent images for pretraining. All MRI scans used for model pretraining and evaluation were acquired at clinical field strengths of 1.5 T or 3 T. Data from ultra-high or low field strengths were not included.
Data preprocessing
We developed a systematic preprocessing pipeline to ensure standardization and quality control of the structural MRI data. Raw DICOM images were converted initially to NIFTI format using the dcm2nii package (Python v.3.8). To address low-frequency intensity nonuniformity inherent in MRI acquisitions, we applied N4 bias field correction using SimpleITK. All scans were subsequently resampled to isotropic 1 × 1 × 1 mm3 voxels through linear interpolation, followed by rigid registration to the MNI space brain atlas. Finally, brain extraction and skull stripping were performed using the HD-BET package74 as the last preprocessing step before the analyses.
Pretraining
We implemented a self-supervised pretraining approach based on SimCLR6 and MAE5, which has demonstrated great success in 3D radiological imaging analysis12, for the training of the foundation model. We trained SimCLR with 3D MONAI implementation of ResNet50 and ViT-B as two different vision encoders, whereas for the MAE pretraining we leveraged Swin-UNETR architecture with SwinViT as the encoder backbone. The contrastive learning framework employed a normalized temperature-scaled cross entropy (NT-Xent)75 loss function to optimize spatial learning. This approach maximized similarity between positive pairs (augmented views derived from the same image) while minimizing similarity between negative pairs (views from different images). The MAE objective included 75% masking ratio with a patch size of (16,16,16) and MSE loss, to allow input image reconstructions. Input volumes were standardized to (96,96,96) voxels at (1,1,1) mm spacing. We used a comprehensive augmentation pipeline comprising random flips, Gaussian blur, Gaussian noise, affine transformations (scale, rotation, translation) and random cropping, with subsequent resizing to maintain dimensional consistency (Fig. 1b) for SimCLR objective, whereas normalization and scaling were the only transformations performed for MAE objective to allow minimum input image altercation and maximize spatial learning. Both pretrainings was conducted over 200 epochs with a batch size of 32 on an NVIDIA A6000 graphics processing unit, requiring approximately 72 h for completion (Supplementary Table 26). Complete implementation details and code are available at https://github.com/AIM-KannLab/BrainIAC.
Pretrained backbone benchmarking
To identify systematically the optimal pretrained encoder to serve as for BrainIAC, we conducted few-shot benchmarking across seven clinically relevant downstream tasks (Extended Data Fig. 2). We evaluated three vision encoders from two pretraining strategies: (1) SimCLR-ResNet50, a convolutional-based model using contrastive pretraining; (2) SimCLR-ViTb 3D, a vision transformer pretrained using contrastive learning and (3) MAE-SwinViT, a 3D Swin Transformer pretrained using a masked autoencoder strategy. Each encoder was assessed under two few-shot settings, K = 1 and K = 5, to evaluate feature quality and downstream training adaptability in data-limited scenario. Performance metrics appropriate to each downstream task were employed such as AUC, BA and MAE. Based on these results, the highest-performing encoder was selected and designated as the BrainIAC backbone for subsequent downstream analyses and performance comparison.
Downstream adaptation
We fine tuned the foundation model for downstream adaptation across seven distinct clinical applications: sequence classification, brain age prediction, mutation prediction, overall survival, MCI classification, time-to-stoke prediction and segmentation. We evaluated model performance systematically using three initialization strategies: brain MRI foundation model (BrainIAC) fine-tuning, supervised training with random initialization (Scratch) and fine-tuning from MedicalNet weights (MedicalNet). Each application pipeline was constructed upon the vision encoder, with architectural modifications based on the specific task requirements (classification versus regression) and input characteristics (single versus multiple images).
For evaluation and comparison, we implemented a framework in which the datasets were partitioned initially into training-validation and test-holdout sets. The training-validation data was further subdivided into several fractions (10%, 20%, 40%, 60%, 80% and 100%) to assess model performance across varying data availability scenarios. For each fraction, we trained models using all three initialization approaches and evaluated their performance on the constant holdout set (Extended Data Fig. 1). We conducted similar training experiments for all tasks in K = 1 and K = 5 (few-shot) setting and evaluated performance. The architectural pipeline maintained a vision backbone, with task-specific modules appended for each application. The task-specific modules were initialized randomly across all approaches, and the vision weights were initialized according to the respective strategy: BrainIAC, MedicalNet and Scratch. We report our results in accordance with the TRIPOD+AI statement guidance76.
Linear probing
To evaluate the quality of features learned by different comparative models (BrainIAC, BrainSegFounder and MedicalNet), we conducted linear probing across all seven downstream tasks. In this setup, the model backbone was kept frozen, and only the final layer was trained: a single fully connected layer with one output neuron for classification and regression tasks and a decoder block for segmentation tasks. Training configurations matched those used for fine-tuning and few-shot experiments, except for an increased learning rate of 0.001 to optimize the linear probe.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
This study used publicly available, controlled-access and institutional neuroimaging datasets as detailed in Supplementary Table 2 and Supplementary Methods A.1. Publicly available datasets include OASIS-1/2/3 (https://sites.wustl.edu/oasisbrains/), IXI (https://brain-development.org/ixi-dataset/), BRATS23 (https://www.synapse.org/Synapse:syn51156910/) and others as listed in Supplementary Table 2. Controlled-access datasets require registration and data use agreements: ABCD (https://nda.nih.gov/abcd), ADNI (https://adni.loni.usc.edu/), CBTN (https://cbtn.org/) and others as specified in Supplementary Table 2. Full access procedures are detailed in Supplementary Methods A.1. Institutional datasets (DFCI/BCH LGG/HGG, RadART LGG) contain protected health information and cannot be shared due to patient privacy protections and Institutional Review Board restrictions. These data are not available for public deposition or general request. Researchers interested in scientific collaboration may contact the corresponding author (B.H.K., benjamin_kann@dfci.harvard.edu) with a response time of 2 weeks; however, access would require independent institutional approvals and formal inter-institutional data use agreements. Source data are provided with this paper.
Code availability
All code for the BrainIAC model, including preprocessing scripts, training pipelines, inference code and pretrained model weights, is publicly available at https://github.com/AIM-KannLab/BrainIAC.
References
Tiu, E. et al. Expert-level detection of pathologies from unannotated chest X-ray images via self-supervised learning. Nat. Biomed. Eng. 6, 1399–1406 (2022).
Boyd, A. et al. Stepwise transfer learning for expert-level pediatric brain tumor MRI segmentation in a limited data scenario. Radiol. Artif. Intell. 6, e230254 (2024).
He, K., Fan, H., Wu, Y., Xie, S. & Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 9726–9735 (IEEE, 2020).
Caron, M. et al. Emerging properties in self-supervised vision transformers. In Proc. IEEE/CVF International Conference on Computer Vision 9630–9640 (IEEE, 2021).
He, K. et al. Masked autoencoders are scalable vision learners. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 15979–15988 (IEEE, 2022).
Chen, T., Kornblith, S., Norouzi, M. & Hinton, G. A simple framework for contrastive learning of visual representations. In Proc. 37th International Conference on Machine Learning (eds Daumé, H. & Singh, A.) 1597–1607 (PMLR, 2020).
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proc. 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies 4171–4186 (ACL, 2019).
Vaswani, A. et al. Attention is all you need. In Advances in Neural Information Processing Systems Vol. 30, 5998–6008 (Curran Associates, 2017).
Chen, R. J. et al. Towards a general-purpose foundation model for computational pathology. Nat. Med. 30, 850–862 (2024).
Huang, Z., Bianchi, F., Yuksekgonul, M., Montine, T. J. & Zou, J. A visual–language foundation model for pathology image analysis using medical Twitter. Nat. Med. 29, 2307–2316 (2023).
Moor, M. et al. Foundation models for generalist medical artificial intelligence. Nature 616, 259–265 (2023).
Pai, S. et al. Foundation model for cancer imaging biomarkers. Nat. Mach. Intell. 6, 354–367 (2024).
Zhou, Y. et al. A foundation model for generalizable disease detection from retinal images. Nature 622, 156–163 (2023).
Huang, K. et al. A foundation model for clinician-centered drug repurposing. Nat. Med. 30, 3601–3613 (2024).
Huang, W. et al. Enhancing representation in radiography-reports foundation model: a granular alignment algorithm using masked contrastive learning. Nat. Commun. 15, 7620 (2024).
Bluethgen, C. et al. A vision–language foundation model for the generation of realistic chest X-ray images. Nat. Biomed. Eng. 9, 494–506 (2024).
Sabuncu, M. R. et al. The dynamics of cortical and hippocampal atrophy in Alzheimer disease. Arch. Neurol. 68, 1040–1048 (2011).
Schuff, N. et al. MRI of hippocampal volume loss in early Alzheimer’s disease in relation to ApoE genotype and biomarkers. Brain 132, 1067–1077 (2009).
Gabr, R. E. et al. Brain and lesion segmentation in multiple sclerosis using fully convolutional neural networks: a large-scale study. Mult. Scler. J. 26, 1217–1226 (2020).
Bagley, S. J. et al. Intrathecal bivalent CAR T cells targeting EGFR and IL13Rα2 in recurrent glioblastoma: phase 1 trial interim results. Nat. Med. 30, 1320–1329 (2024).
Kilburn, L. B. et al. The type II RAF inhibitor tovorafenib in relapsed/refractory pediatric low-grade glioma: the phase 2 FIREFLY-1 trial. Nat. Med. 30, 207–217 (2024).
Li, Y., Ammari, S., Balleyguier, C., Lassau, N. & Chouzenoux, E. Impact of preprocessing and harmonization methods on the removal of scanner effects in brain MRI radiomic features. Cancers 13, 3000 (2021).
Um, H. et al. Impact of image preprocessing on the scanner dependence of multi-parametric MRI radiomic features and covariate shift in multi-institutional glioblastoma datasets. Phys. Med. Biol. 64, 165011 (2019).
Kushol, R., Parnianpour, P., Wilman, A. H., Kalra, S. & Yang, Y.-H. Effects of MRI scanner manufacturers in classification tasks with deep learning models. Sci. Rep. 13, 16791 (2023).
Cox, J. et al. BrainSegFounder: towards 3D foundation models for neuroimage segmentation. Med. Image Anal. 97, 103301 (2024).
Barbano, C. A., Brunello, M., Dufumier, B. & Grangetto, M. Anatomical foundation models for brain MRIs. Pattern Recognit. Lett. 199, 178–184 (2026).
Chen, S., Ma, K. & Zheng, Y. Med3D: Transfer learning for 3D medical image analysis. Preprint at https://doi.org/10.48550/arXiv.1904.00625 (2019).
Mello, J. P. V. et al. Deep learning-based type identification of volumetric MRI sequences. In Proc. 25th International Conference on Pattern Recognition 1–8 (IEEE, 2021).
Sage Bionetworks. BraTS 2023. Synapse https://www.synapse.org/Synapse:syn51156910 (2023).
Bittner, N. et al. When your brain looks older than expected: combined lifestyle risk and BrainAGE. Brain Struct. Funct. 226, 621–645 (2021).
Elliott, M. L. et al. Brain-age in midlife is associated with accelerated biological aging and cognitive decline in a longitudinal birth cohort. Mol. Psychiatry 26, 3829–3838 (2021).
Tak, D. et al. Noninvasive molecular subtyping of pediatric low-grade glioma with self-supervised transfer learning. Radiol. Artif. Intell. 6, e230333 (2024).
Li, L. et al. Preoperative prediction of MGMT promoter methylation in glioblastoma based on multiregional and multi-sequence MRI radiomics analysis. Sci. Rep. 14, 16031 (2024).
Zhang, H. et al. Deep-learning and conventional radiomics to predict IDH genotyping status based on magnetic resonance imaging data in adult diffuse glioma. Front. Oncol. 13, 1143688 (2023).
DeLong, E. R., DeLong, D. M. & Clarke-Pearson, D. L. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics 44, 837–845 (1988).
Calabrese, E. et al. UCSF-PDGM. The University of California San Francisco Preoperative Diffuse Glioma MRI (UCSF-PDGM) (Version 5) [dataset] The Cancer Imaging Archive https://doi.org/10.7937/tcia.bdgf-8v37 (2021).
Tak, D. et al. Longitudinal risk prediction for pediatric glioma with temporal deep learning. NEJM AI https://doi.org/10.1101/2024.06.04.24308434 (2025).
Bakas, S. et al. Multi-parametric magnetic resonance imaging (mpMRI) scans for de novo Glioblastoma (GBM) patients from the University of Pennsylvania Health System (UPENN-GBM) (Version 2) [dataset]. The Cancer Imaging Archive https://doi.org/10.7937/TCIA.709X-DN49 (2021).
Petersen, R. C. et al. Mild cognitive impairment: clinical characterization and outcome. Arch. Neurol. 56, 303–308 (1999).
Vorontsov, E. et al. A foundation model for clinical-grade computational pathology and rare cancers detection. Nat. Med. 30, 2924–2935 (2024).
Lao, J. et al. RadImageNet: an open radiologic deep learning research dataset for effective transfer learning. Radiol. Artif. Intell. 3, e210315 (2021).
Zhou, Z. et al. Models genesis. Med. Image Anal. 67, 101840 (2021).
Wood, D. A. et al. Deep learning models for triaging hospital head MRI examinations. Med. Image Anal. 78, 102391 (2022).
Zhang, J. et al. Detecting schizophrenia with 3D structural brain MRI using deep learning. Sci. Rep. 13, 14433 (2023).
Koonjoo, N., Zhu, B., Bagnall, G. C., Bhutto, D. & Rosen, M. S. Boosting the signal-to-noise of low-field MRI with deep learning image reconstruction. Sci. Rep. 11, 8248 (2021).
Mårtensson, G. et al. The reliability of a deep learning model in clinical out-of-distribution MRI data: a multicohort study. Med. Image Anal. 66, 101714 (2020).
Bermudez, C. et al. Generalizing deep whole brain segmentation for pediatric and post-contrast MRI with augmented transfer learning. Proc. SPIE Int. Soc. Opt. Eng. 11313, 113130L (2020).
Haist, F. & Jernigan, T. L. Adolescent Brain Cognitive Development Study (ABCD) - Annual Release 5.1. https://doi.org/10.15154/Z563-ZD24 (2023).
LaMontagne, P. J. et al. OASIS-3: Longitudinal neuroimaging, clinical, and cognitive dataset for normal aging and Alzheimer disease. Preprint at medRxiv https://doi.org/10.1101/2019.12.13.19014902 (2019).
Roberts, R. O. et al. The Mayo Clinic Study of Aging: design and sampling, participation, baseline measures and sample characteristics. Neuroepidemiology 30, 58–69 (2008).
Rorden, C., Absher, J. & Newman-Norlund, R. Stroke Outcome Optimization Project (SOOP). OpenNeuro. https://doi.org/10.18112/openneuro.ds004889.v1.1.2 (2024).
Lilly, J. V. et al. The children’s brain tumor network (CBTN)—accelerating research in pediatric central nervous system tumors through collaboration and open science. Neoplasia 35, 100846 (2022).
Malone, I. B. et al. MIRIAD—Public release of a multiple time point Alzheimer’s MR imaging dataset. Neuroimage 70, 33–36 (2013).
Park, D. et al. The Dallas Lifespan Brain Study. OpenNeuro https://doi.org/10.18112/openneuro.ds004856.v1.0.0 (2024).
Mueller, S. et al. Radiation induced arteriopathy and stroke risk in children with cancer treated with cranial radiation therapy (RadArt) Study. UCSF Pediatric Stroke Research Center https://pediatricstroke.ucsf.edu/radiation-induced-arteriopathy-and-stroke-risk-children-cancer-treated-cranial-radiation-therapy (2011).
Marcus, D. S. et al. Open access series of imaging studies: longitudinal MRI data in nondemented and demented older adults. J. Cogn. Neurosci. 22, 2677–2684 (2010).
Mamonov, A. & Kalpathy-Cramer, J. Data from QIN GBM treatment response. The Cancer Imaging Archive https://doi.org/10.7937/k9/tcia.2016.nQF4gpn2 (2016).
Barboriak, D. Data from RIDER NEURO MRI. The Cancer Imaging Archive https://doi.org/10.7937/K9/TCIA.2015.VOSN3HN1 (2015).
Kazerooni, A. F. et al. The Brain Tumor Segmentation (BraTS) Challenge 2023: focus on pediatrics (CBTN-CONNECT-DIPGR-ASNR-MICCAI BraTS-PEDs). Preprint at https://doi.org/10.48550/arXiv.2305.17033 (2024).
Baid, U. et al. The RSNA-ASNR-MICCAI BraTS 2021 Benchmark on brain tumor segmentation and radiogenomic classification. Preprint at https://doi.org/10.48550/arXiv.2107.02314 (2021).
Menze, B. H. et al. The multimodal brain tumor image segmentation benchmark (BRATS). IEEE Trans. Med. Imaging 34, 1993–2024 (2015).
Bakas, S. et al. Advancing the Cancer Genome Atlas glioma MRI collections with expert segmentation labels and radiomic features. Sci. Data 4, 170117 (2017).
HCP Young Adult. 1200 Subjects Data Release; Connectome Coordination Facility https://humanconnectome.org/study/hcp-young-adult/document/1200-subjects-data-release (2017).
Wang, J. et al. A longitudinal neuroimaging dataset on language processing in children ages 5, 7, and 9 years old. Sci. Data 9, 4 (2022).
Elison, J. & Lin, W. UNC/UMN Baby Connectome Project. Connectome Coordination Facility https://doi.org/10.15154/nshn-2b72 (2018).
Podobnik, G. et al. HaN-Seg: the head and neck organ-at-risk CT and MR segmentation dataset. Med. Phys. 50, 1917–1927 (2023).
Hanson, J. L., Chandra, A., Wolfe, B. L. & Pollak, S. D. Association between income and the hippocampus. PLoS ONE 6, e18712 (2011).
Jernigan, T. L. et al. The pediatric imaging, neurocognition, and genetics (PING) data repository. NeuroImage 124, 1149–1154 (2015).
Richardson, H., Lisandrelli, G., Riobueno-Naylor, A. & Saxe, R. MRI data of 3-12 year old children and adults during viewing of a short animated film. OpenNeuro https://doi.org/10.18112/openneuro.ds000228.v1.1.1 (2023).
Wei, D. et al. Structural and functional brain scans from the cross-sectional Southwest University Adult Lifespan Dataset. Sci. Data 5, 180134 (2018).
Luna, B. PETfrog [dataset]. OpenNeuro https://doi.org/10.18112/openneuro.ds002385.v1.0.1 (2020).
Liew, S.-L. et al. A large, curated, open-source stroke neuroimaging dataset to improve lesion segmentation algorithms. Sci. Data 9, 320 (2022).
Liew, S.-L. et al. A large, open source dataset of stroke anatomical brain images and manual lesion segmentations. Sci. Data 5, 180011 (2018).
Isensee, F. et al. Automated brain extraction of multisequence MRI using artificial neural networks. Hum. Brain Mapp. 40, 4952–4964 (2019).
Sohn, K. Improved deep metric learning with multi-class n-pair loss objective. In Advances in Neural Information Processing Systems Vol. 29 (eds. Lee, D. D. et al.) 1849–1857 (Curran Associates, 2016).
Collins, G. S. et al. TRIPOD+AI statement: updated guidance for reporting clinical prediction models that use regression or machine learning methods. BMJ 385, e078378 (2024).
Acknowledgements
We acknowledge the Children’s Brain Tumor Network (CBTN) for access to imaging and clinical data. This study was supported in part by the National Institutes of Health/National Cancer Institute (NIH/NCI) through grants U54 CA274516 and P50 CA165962 (B.H.K.). Additional support was provided by the Botha–Chan Low Grade Glioma Consortium (B.H.K.) and the DMG Precision Medicine Initiative (B.H.K.). This work was also supported by the ASCO Conquer Cancer Foundation (grant 2022A013157) and the Radiation Oncology Institute (grant ROI2022-9151) (T.L.C.).
Author information
Authors and Affiliations
Contributions
D.T. and B.H.K. designed the study. D.T. developed the methodology, designed and implemented the computational framework, performed model training and evaluation and conducted the primary statistical analyses. D.T. and B.A.G. contributed to data acquisition, curation and analysis. A.Z., T.L.C., J.C.C.P., Z.Y., J.Z., Y.R., S. Pai, S.V., M.M., M.P., L.R.G.P., C.S., A.M.F., K.X.L., S. Prabhu, O.A., P.B., A.N., S.M., H.J.W.L.A., R.Y.H. and T.Y.P. contributed to data interpretation, clinical expertise and critical discussion of the results. D.T. drafted the manuscript. B.H.K. and D.T. revised the manuscript with input from all authors. B.H.K. supervised the study. All authors reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Neuroscience thanks Daniel Alexander and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 Downstream application adaption method.
Each Downstream application is implemented by segregating the task specific dataset into a training-validation and test (holdout) sets, using the 80:20 split ratio. The training-validation set is further sampled to generate datasets of varying sample size (10% up to 100%). All approaches are trained, separately, on each dataset faction and the resulting models are evaluated and compared on the reserved holdout set.
Extended Data Fig. 2 Few-shot benchmarking of pretrained encoders.
Few-shot performance benchmarking of three self-supervised pretrained MRI encoders—SimCLR-ViT-B 3D, SimCLR-ResNet50, and MAE-SwinViT—across seven downstream tasks evaluated with 1-shot (K1) and 5-shot (K5) training. Data are presented as mean values ± 95% confidence intervals estimated from 1,000 bootstrap samples. a Overall survival prediction (AUC), b MRI sequence classification (balanced accuracy), c brain age prediction (MAE in years), d IDH mutation prediction (AUC), e dementia prediction (balanced accuracy), f time-to-stroke prediction (MAE in days), and g tumor segmentation (mean dice).
Extended Data Fig. 3 Sequence classification subgroup analysis.
Performance comparison of four models, BrainIAC, BrainSegFounder, MedicalNet, and Scratch, on MRI sequence classification tasks across varying training data sizes (10-100% of available data). a One-versus-all classification performance for each MRI sequence type against all other sequences. b Pairwise classification performance between specific sequence pairs. All evaluations use balanced accuracy as the metric.
Supplementary information
Supplementary Information (download PDF )
Supplementary Tables 1–35 and Supplementary Methods A.1–A.5.
Source data
Source Data Fig. 1 (download ZIP )
Statistical source data (CSV) for model performance comparisons across downstream tasks shown in Fig. 1.
Source Data Fig. 2 (download ZIP )
Statistical source data (CSV) for model performance comparisons across downstream tasks shown in Fig. 2.
Source Data Fig. 3 (download ZIP )
Statistical source data (CSV) for model performance comparisons across downstream tasks shown in Fig. 3.
Source Data Fig. 4 (download ZIP )
Statistical source data (CSV) for model performance comparisons across downstream tasks shown in Fig. 4.
Source Data Fig. 5 (download ZIP )
Statistical source data (CSV) for model performance comparisons across downstream tasks shown in Fig. 5.
Source Data Fig. 6 (download ZIP )
Statistical source data (CSV) for model performance comparisons across downstream tasks shown in Fig. 6.
Source Data Extended Data Fig. 2 (download ZIP )
Statistical source data (CSV) for model performance comparisons across downstream tasks shown in Extended data Fig. 2.
Source Data Extended Data Fig. 3 (download ZIP )
Statistical source data (CSV) for model performance comparisons across downstream tasks shown in Extended data Fig. 3.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Tak, D., Garomsa, B.A., Zapaishchykova, A. et al. A generalizable foundation model for analysis of human brain MRI. Nat Neurosci (2026). https://doi.org/10.1038/s41593-026-02202-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41593-026-02202-6
