
Abstract
Diverse risk genes have been identified for neurodevelopmental disorders (NDDs), but how these genes converge on similar biological pathways in neurons, and thus give rise to similar phenotypes, is unclear. Here we apply a pooled CRISPR approach to successfully target 23 NDD loss-of-function genes with roles in chromatin biology and examine convergent effects on gene expression across human induced pluripotent stem cell-derived neural progenitor cells, glutamatergic neurons and GABAergic neurons. Points of convergence vary between these cell types, with the greatest number of convergent genes and strongest convergent networks in mature glutamatergic neurons, where they broadly represent synaptic, epigenetic and, unexpectedly, mitochondrial pathways. The most convergent networks were observed between NDD genes with shared biological annotations, clinical associations and co-expression patterns in human post-mortem brain. Drugs that were predicted to reverse convergent transcriptomic signatures and/or arousal and sensory processing behaviors ameliorated behavioral phenotypes in zebrafish NDD gene mutants. These results suggest that convergent effects of NDD risk genes could provide clinically useful insights.
Similar content being viewed by others

Main
Autism spectrum disorder (ASD) and related developmental delay (DD) are highly heritable1. The aggregate impact of common variants of small effect reflects most genetic risk2, but in as many as a quarter of cases, potentially damaging rare inherited and de novo mutations in risk genes are detected3. There is significant overlap between those genes affecting ASD4 and those more broadly affecting developmental5 and psychiatric6,7 disorders. Altogether, neurodevelopmental disorder (NDD) risk genes are typically expressed during cortical development8, particularly the excitatory and inhibitory lineages4, and broadly split between two functional classes: neuronal communication (for example, synaptic function) and gene expression regulation (for example, chromatin regulators and transcription factors). Over half of NDD genes have roles in gene expression regulation4, sharing substantial overlap in genomic binding sites in the brain9, and with targets enriched for NDD risk genes10. Yet, evidence to support the parsimonious explanation that regulatory NDD genes preferentially target synaptic NDD genes is lacking4. It remains unclear how disrupting NDD genes with distinct functions yields similar outcomes.
Many have proposed that diverse ASD genes have convergent downstream effects. NDD genes are co-expressed in the brain11,12,13, suggesting that they are regulated together and involved in related biological processes, and result in highly interconnected protein–protein interactomes14,15, indicating functional relationships between NDD proteins. Even as the number of NDD genes grows, risk genes continue to converge on a finite number of biological pathways, developmental stages, brain regions and cell types16. Disentangling these complex etiologies remains an outstanding challenge.
Given emerging evidence that epigenetic NDD genes have diverse and interconnected roles17,18,19, we tested the hypothesis that the nature of convergence is influenced by developmental and cell-type contexts. We report a pooled CRISPR-knockout (KO) strategy successfully targeting loss-of-function (LoF) mutations to 23 NDD genes, most with roles in chromatin biology, to examine effects on gene expression in induced neural progenitor cells (iNPCs), glutamatergic neurons and GABAergic neurons. We describe convergent networks that were distinct between cell types, strongest in neurons, where they were enriched in synaptic biology, epigenetic regulation and, unexpectedly, mitochondrial function. Machine learning tools allowed us to extend our analyses in silico across all known NDD genes, resolving how the degree of convergence between risk genes was influenced by clinical associations, biological function and co-expression patterns in the human post-mortem brain. Convergent analyses successfully predicted drugs capable of suppressing phenotypes in NDD gene zebrafish mutants, suggesting that analyses of convergent gene expression highlight behaviorally relevant pathways, and may in turn be useful in patient stratification or treatment development.
Results
A systematic comparison of NDD gene effects across neuronal cell types
From 102 highly penetrant LoF gene mutations associated with NDD (previously described as 58 gene expression regulation, 24 neuronal communication and 20 other)4, we used gene ontology and primary literature to identify 21 epigenetic modifiers specifically involved in chromatin organization, rearrangement and modification (ASH1L, ARID1B, ASXL3, BCL11A, CHD2, CHD8, CREBBP, PPP2R5D, KDM5B, KDM6B, KMT2C, KMT5B (SUV420H1), MBD5, MED13L, PHF12, PHF21A, SETD5, SIN3A, SKI, SMARCC2, WAC), as well as two transcription factors with putative roles as chromatin regulators (FOXP2, POGZ). Three extensively studied synaptic genes (NRXN1, SCN2A, SHANK3) and three under-explored neuronal communication genes (ANK3, DPYSL2, SLC6A1) strongly associated with NDD were added (Supplementary Fig. 1a). Many of these 29 genes differed in relative frequency of LoF gene mutations between ASD (n = 16) and DD (n = 4)5, schizophrenia (SCZ)20 and epilepsy21,22 (Fig. 1a,b and Supplementary Fig. 1b), as well as general associations with genome-wide association studies (GWASs) for many neuropsychiatric disorders (MAGMA23) (Fig. 1c and Supplementary Fig. 1c), indicating a pleotropic effect consistent with the shared genetic liability across neuropsychiatric disorders24. iNPCs, iGLUTs and iGABAs (Supplementary Fig. 2a), as well as their in vivo fetal counterparts (Supplementary Fig. 2b), expressed all genes prioritized herein25.

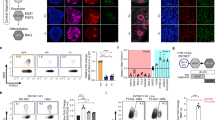
a, List of rare-variant target risk genes associated with NDDs separated by chromatin modifiers and neuronal communication genes. Bold gene names indicate strong associations with ASD based on ref. 5. Gene targets of rare variants associated with SCZ, epilepsy (EPI) and bipolar disorder (BIP) are annotated. b, Strength of association with ASD, as estimated by distribution of posterior probability (p.p.) scores from ref. 5; 4 of 29 NDD genes were more strongly associated with DD (blue; p.p. ≤ 0.1) while 16 of 29 were more strongly associated with ASD (red; p.p. ≥ 0.9). Further annotations of individual risk genes are shown in Supplementary Figs. 1 and 2. c, One-sided, positive MAGMA GSEA of targeted genes across GWAS for anorexia nervosa (AN), chronic pain, amyotrophic lateral sclerosis (ALS), SCZ, BIP, BIP-I (bipolar subtype 1) and BIP-II (bipolar subtype 2). FDR multiple testing correction was performed to adjust for multiple gene set comparisons: #Nominal P < 0.05, *FDR < 0.05, **FDR < 0.01, ***FDR < 0.001. Error bars indicate the standard error of beta (the regression coefficient). d, Schematic of hiPSC-derived cell-type-specific scCRISPR-KO screen. Representative immunofluorescence for markers of NPCs (DAPI/Nestin), mature iGLUTs (DAPI/MAP2/vGLUT) and mature iGABAs (DAPI/MAP2/GABA). e, Transcriptomic impact of NDD gene KO represented as two-tailed Pearson’s correlation across nominally significant (P < 0.01) DEGs. (i) Pearson’s correlation matrix of log2FC DEGs across all NDDs and cell types. (ii) Cross-cell-type correlation network diagram (based on Pearson’s correlations) across NDD perturbations (number of NDD gene KO perturbations resolved indicated in parentheses); the mature iGLUT cluster was most dense, and the iNPC most sparse. Illustrations in d and e created in BioRender; Townsley, K. https://biorender.com/rvk1zn2 (2026). PCC, Pearson’s correlation coefficient.
Towards resolving whether regulatory genes confer continuous or distinct periods of susceptibility across neurodevelopment, we knocked out regulatory NDD genes in neural progenitor cells (NPCs) (SNaPs26, here termed iNPCs), immature and mature glutamatergic neurons (iGLUTs)27 and mature GABAergic neurons (iGABAs)28 (Fig. 1d). A pooled CRISPR approach (expanded CRISPR-compatible cellular indexing of transcriptomes and epitopes by sequencing (ECCITE-seq)29) combined direct detection of single guide RNAs and single-cell RNA sequencing (scRNA-seq) to compare LoF effects across 29 NDD genes. The CRISPR-KO library was generated from pre-validated guide RNAs (gRNAs) (three to four gRNAs per gene; Supplementary Table 1). Sequencing of the gRNA library confirmed the presence of gRNAs targeting 24 genes (ANK3, ARID1B, ASH1L, ASXL3, BCL11A, CHD2, CHD8, DPYSL2, FOXP2, KMT5B (SUV420H1), KDM5B, KDM6B, KMT2C, MBD5, MED13L, NRXN1, PHF12, PHF21A, SCN2A, SETD5, SIN3A, SKI, SMARCC2, WAC), but three (DPYSL2, FOXP2, SCN2A) were present at lower frequency (Supplementary Fig. 3b,c).
Control human induced pluripotent stem cells (hiPSCs) were induced to iNPCs, iGLUTs and iGABAs (Supplementary Fig. 3a), transduced first with lentiviral-Cas9v2 (Addgene, cat. no. 98291) and subsequently with the pooled lentiviral gRNA library 3 d before collection, at day 7 (iNPC and immature iGLUT), day 21 (iGLUT) and day 36 (iGABA) (experimental workflow, Supplementary Fig. 4a; computational workflow, Supplementary Fig. 4b; experimental validation of CRISPR editing efficiency, Supplementary Fig. 5). After filtering and quality control (Supplementary Fig. 4c–e), we resolved NDD transcriptomes for 118,436 single cells: 25,402 iNPC, 38,097 immature (day 7) iGLUT, 28,388 mature (day 21) iGLUT and 26,549 mature (day 36) iGABA. Because the original gene-expression-based clustering was driven by cellular heterogeneity, cell quality and sequencing lane effects (Supplementary Fig. 6a), independent of gRNA identity, we removed cells with high expression of subtype markers and adjusted for cellular heterogeneity (Supplementary Fig. 6b,c and Supplementary Tables 2 and 3). ‘Weighted-nearest neighbor’ (WNN) analysis assigned clusters based on both gRNA identity class and gene expression to ensure that cells assigned to a gRNA identity class demonstrated successful perturbation of the targeted NDD gene30. For those WNN clusters where most cells were assigned to a single KO target, the transcriptomic signatures were compared with nontargeting scramble control clusters. Altogether, 35,777 cells were used for downstream analyses: 12,107 iNPC, 3,171 immature iGLUT, 11,802 mature iGLUT and 8,697 mature iGABA. An average of 474 cells were assigned to each individual single guide RNA (757 iNPC, 227 immature iGLUT, 562 mature iGLUT and 414 mature iGABA), totaling 33,150 perturbed cells and 2,627 controls (882 iNPC, 90 immature iGLUT, 1,258 mature iGLUT and 397 mature iGABA). The gene expression patterns of nonperturbed iNPCs and iNeurons (>30% of all pooled cells) were significantly correlated with fetal brain cells and cortical adult neurons.
Successful perturbations (scCRISPR-KO) were identified for 23 NDD genes (Supplementary Figs. 6 and 7): 16 in iNPCs, 14 in immature iGLUT neurons and 21 in mature iGLUT and iGABA neurons (Supplementary Fig. 6). Nine NDD genes were perturbed in all four cell types (ARID1B, ASH1L, CHD2, MED13L, NRXN1, PHF21A, SETD5, SIN3A, SMARCC2; Supplementary Fig. 7a,b). For most NDD genes, KO in mature iGLUTs yielded the largest number of differentially expressed genes (DEGs, PFDR < 0.05 (FDR, false discovery rate)) (Supplementary Fig. 7b), an effect that was not driven by differences in the extent of perturbation of the NDD gene itself between cell types (Supplementary Fig. 7c(i)). The transcriptomic effects of individual NDD genes cluster by cell type: the strongest NDD gene correlations are in mature iGLUTs; that is, all nominally significant (P < 0.01) log2fold change (FC) DEGs are most highly correlated with each other and least correlated with the other cell types, whether relative to all scramble control cells (Fig. 1e(i),(ii) and Supplementary Fig. 7c(ii)) or to random subsets of scramble control cells (Supplementary Fig. 8a,b). DEGs across individual NDDs shared significant gene ontology enrichments (Supplementary Fig. 8c), with mature iGLUTs frequently enriched for SCZ GWAS genes (12 of 21 NDD genes), and mature iGABAs for migraine GWAS genes (8 of 21) (Supplementary Fig. 9).
Unsurprisingly, given the greater within-cell-type correlations between NDD genes and the unique pathway enrichments across cell types, very few DEGs shared significance and direction of effect for the same NDD gene perturbation across all four cell types (FDR-adjusted Pmeta < 0.05, Cochran’s heterogeneity Q-test PHet > 0.05; computational workflow, Supplementary Fig. 10a); in fact, the only common DEG between cell types was frequently the targeted NDD gene itself. With a more relaxed statistical threshold (nominal P < 0.05), modest shared effects of individual NDD genes could be resolved across cell types. These effects rarely resulted in perturbation of the other NDD genes themselves (Supplementary Fig. 10b), showed very little overlap between NDD genes (Supplementary Fig. 10c) and showed no significant enrichments with psychiatric GWAS after multiple testing correction (Supplementary Fig. 10d).
NDD gene KOs resulted in cell-type-specific convergent genes and networks that were strongest in glutamatergic neurons
‘Convergent genes’ (Fig. 2) are those DEGs with significant and shared direction of effect across all NDD gene perturbations (FDR-adjusted Pmeta < 0.05, Cochran’s heterogeneity Q-test PHet > 0.05)31 (computational workflow, Fig. 2a). Across the nine NDD genes perturbed in all four cell types (ARID1B, ASH1L, CHD2, MED13L, NRXN1, PHF21A, SETD5, SIN3A, SMARCC2), convergence was highly cell-type-specific (Fig. 2, Supplementary Fig. 11a–c and Supplementary Data 2). Although the strength of convergence correlated across cell types (Fig. 2c(ii)), it was greatest in mature iGLUTs (quantified as the ratio of convergent genes to the average number of DEGs across all 152 unique 2–5-gene combinations of these nine NDD genes) (Fig. 2c(i)). While the ‘top’ convergent gene was unique for each cell type (Supplementary Table 4), >50% of convergent genes in NPCs (52%), immature iGLUTs (57%) and mature iGABAs (56%) overlapped with convergent genes in mature iGLUTs; of note, shared convergent genes were not necessarily perturbed in the same direction between cell types (Fig. 2d). Mature iGLUTs had the greatest total number of convergent genes (11,473); however, immature iGLUTs had the highest ratio of convergent genes after correction for the number of DEGs across perturbations.

In total, nine NDD genes showed evidence of KO across all four cell types: ARID1B, ASH1L, CHD2, MED13L, NRXN1, PHF21A, SETD5, SIN3A, SMARCC2. For these nine, ‘convergent genes’ are defined as those DEGs with significant and shared direction of effect across all NDD gene perturbations. a, Schematic explaining cell-type-specific convergence at the individual gene level via differential gene expression meta-analysis (FDR-adjusted Pmeta < 0.05, Cochran’s heterogeneity Q-test PHet > 0.05). b, Convergence across nine NDD genes is unique to each cell type, using rank–rank hypergeometric (RRHO) test to explore correlation of convergent genes shared across nine NDD perturbations (RRHO score = −log10 (P value) × sign(fold change)) between cell types. The top-right quadrant represents downregulated genes (meta-analysis Z-score > 0) for the y-axis and x-axis cell types. The bottom-left quadrant represents upregulated convergent genes (meta-analysis Z-score < 0) for the y-axis and x-axis cell types. Significance is represented by color, with red regions representing significantly convergent gene expression. c, (i) The average strength of convergence, measured as the ratio of convergent genes to the average number of DEGs across all 152 unique combinations of 2–5 genes from the nine NDD genes, was highest in iGLUTs. (ii) The magnitude of convergence between the same NDDs tested in different cell types was highly positively correlated (two-tailed Pearson’s correlation, Holm’s multiple testing correction was performed, Pholm < 2.2 × 10−16), with the strongest relationship between immature and mature iGLUTs. In the box plots, the median is represent by the line (center) and the mean as the red point. The lower and upper hinges correspond to the first and third quartiles (the 25th and 75th percentiles). The upper and lower whiskers extend up to 1.5 × interquartile range (IQR). All data points are plotted individually. d, Venn diagram representing the absolute overlap of cell-type-specific convergent genes shared across nine NDDs (regardless of whether convergent genes were perturbed in the same direction between cell types). e, (i) One-sided, positive MAGMA gene set enrichment −log10(P value) of cell-type-specific (color of points) convergence and GWAS-risk-associated genes with significance after multiple testing correction indicated as follows: #unadjusted P ≤ 0.05, *FDR ≤ 0.05, **FDR < 0.01, ***FDR < 0.001. The direction of the triangles indicates a positive (upwards triangle) or negative (downwards triangle) enrichment beta. (ii) Over-representation analysis (ORA) enrichment ratios of cell-type-specific (color of bars) convergence and rare-variant target genes. Significance after multiple testing correction indicated as follows: #unadjusted P ≤ 0.05, *FDR ≤ 0.05, **FDR < 0.01, ***FDR < 0.001. f, Two-sided GSEA identified downstream pathways involved in neural proliferation, neurite outgrowth, synaptic vesicle transport and mitochondrial function as cell-type-specific targets of convergent genes across nine NDDs. FDR multiple testing correction was performed. Results in the figure panel were filtered for pathways with nominal P < 0.05. Normalized GSEA enrichment scores represent the direction of enrichment based on the meta-analyzed Z-score for each convergent gene. Cell type is represented by shape and the size of each point represents the −log10(FDR). Illustrations in a created in BioRender; Townsley, K. https://biorender.com/efkzzf6 (2026). nKOs, number of KO genes tested for convergence; NT, XXX.
Convergent genes were enriched for SCZ GWAS loci (MAGMA23, FDR < 0.05) (Fig. 2e(i)), rare ASD and Fragile X Mental Retardation 1 protein (FMRP) target genes (FDR < 0.05) (Fig. 2e(ii)), and pathways involved in neurodevelopment, mitochondrial function and translational regulation (Supplementary Fig. 12). When tested again across the 21 NDD genes perturbed in both iGLUTs and iGABAs, mature iGLUTs again showed the largest absolute number of convergent genes (iGLUTs, 10,557, Supplementary Fig. 13a; iGABAs, 892, Supplementary Fig. 13b). Intriguingly, although convergent genes were highly cell-type-specific, those NDD gene combinations that were highly convergent in one cell type were likely to be convergent in others; in neurons, top convergent sets most frequently included ARID1B, SETD5 and NRXN1 (Supplementary Fig. 11d).
Given that the biological impact of convergence is likely to be impacted by the strength of shared gene regulatory relationships and functions, we re-examined convergence within the framework of co-expression networks (Bayesian bi-clustering). ‘Convergent networks’ (Fig. 3) are co-expressed genes that share similar expression patterns across NDD gene perturbations31 (computational workflow, Fig. 3a). The network connectivity score (‘network convergence’) informs the strength and composition across cell types (that is, networks with more interconnectedness and containing genes with greater functional similarity have increased convergence). Convergent networks generated from the nine NDD genes perturbed in all four cell types (Fig. 3b) or across the 21 NDDs genes in both iGLUTs and iGABAs (Supplementary Fig. 13c) revealed the greatest convergent network strength in iGLUTs. Network-level convergence was weakly correlated between cell types (Fig. 3c); the number of convergent unique network nodes was greatest in iGLUTs, distinct across cell types (Fig. 3d, Supplementary Tables 5 and 6 and Supplementary Data 2) and significantly enriched for rare variants linked to SCZ and ASD (Fig. 3e and Supplementary Tables 5 and 6). Convergent networks in iNPCs highlighted pathways associated with neurogenesis (for example, cell cycle, cell division, EPO signaling) (Fig. 3f), while in mature iGLUTs they were enriched for synaptic function (transmembrane transport and receptor signaling, secretory vesicles, SNARE complex) (Fig. 3g).

‘Convergent networks’ are co-expressed genes that share similar expression patterns across NDD gene perturbations, here resolved for the nine NDD KOs resolved across all four cell types: ARID1B, ASH1L, CHD2, MED13L, NRXN1, PHF21A, SETD5, SIN3A, SMARCC2. a, Schematic explaining cell-type-specific convergence at the network level using Bayesian bi-clustering and unsupervised network reconstruction. b, Strength of network convergence across all random combinations of nine NDD KO perturbations by cell type. (i) The mean strength of network convergence is significantly different by cell type, with the highest convergence present in immature iGLUTs. The same KO combinations tested in one cell type may not resolve convergence in another cell type. Each point represents a resolved network, and its calculated convergence strength. Dots that represent the same combinations of KO perturbations, but tested in each cell type, are connected by a line. In the box plots, the median is represented by the line (center) and the mean as the red point. The lower and upper hinges correspond to the first and third quartiles (the 25th and 75th percentiles). The upper and lower whiskers extend from the hinge to the largest or smallest value up to 1.5 × IQR. All data points are plotted individually. c, Convergent network strength was most correlated between mature iGLUTs and iGABAs (two-tailed Pearson’s correlation test with Holm’s multiple testing correction; PCC = 0.6, PHolm < 2.2 × 10−16). Convergent network strength in iNPCs was not correlated with network strength in neurons. d, Venn diagrams of the total number of unique node genes within convergent networks for each cell type. The lack of overlapping node genes between cell types (d), as well as the weak correlations of convergence strength between immature and mature cell types (c), suggest greater cell-type specificity in the magnitude of network-level convergence compared with gene-level convergence. e, One-sided enrichment ratios from ORA of cell-type-specific (color of bars) convergent node genes for rare-variant targets. FDR-based multiple testing correction was performed: #unadjusted P ≤ 0.05, *FDR ≤ 0.05, **FDR < 0.01, ***FDR < 0.001. f,g, Representative cell-type-specific network plots for convergence across 15 genes (ARID1B, ASH1L, ASXL3, BCL11A, KDM5B, CHD2, MBD5, MED13L, NRXN1, PHF12, PHF21A, SETD5, SIN3A, SKI, SMARRC2) from iNPCs (f) and mature iGLUTs (g). Network genes were filtered for protein-coding genes, clustered and annotated based on the primary node gene for each cluster. GSEA of the networks identified unique functions by cell type. Convergent networks in iNPCs were enriched for pathways associated with neurogenesis (for example, cell cycle, cell division, EPO signaling), and in mature iGLUTs for pathways associated with synaptic function (transmembrane transport and receptor signaling, secretory vesicles, SNARE complex). Illustrations in a created in BioRender; Townsley, K. https://biorender.com/efkzzf6 (2026).
Convergent networks are strongest between NDD genes with shared co-expression patterns in the post-mortem brain, biological annotations (synaptic or epigenetic) and clinical outcomes (ASD or DD)
To resolve the extent to which functional similarity and co-expression patterns between NDD genes predicted convergence, we trained a prediction model (random forest linear regression)32 using 70% of our data, evaluated it using 30% of our data and validated in an external dataset31 (computational workflow, Fig. 4a; model predictor variables, Fig. 6b; more information, Supplementary Figs. 14 and 15). Cell type, brain co-expression (dorsolateral prefrontal cortex (DLPFC)) and functional similarity (that is, gene ontology) correlate with convergence (Fig. 4c) and well-predicted gene-level convergence (97% variance explained; root mean squared error (RMSE) = 0.021) (Fig. 4d(i)) and moderately predicted network-level convergence (53% variance explained; RMSE = 0.73) (Fig. 4d(ii)). Our trained model accurately predicted gene-level (Pearson’s R = 0.998, P < 0.001, RMSE = 0.15) (Fig. 4e(i) and Supplementary Fig. 15c) and network-level convergence in our testing set (R = 0.72, P < 2.2 × 10−16, RMSE = 0.85) (Fig. 4e(ii) and Supplementary Fig. 15d), and performed moderately well in predicting network-level convergence (R = 0.26, P < 0.001, RMSE = 0.68) (Fig. 4f(ii) and Supplementary Fig. 15e(ii)) and to a lesser extent gene-level convergence (R = 0.14, P < 0.001, RMSE = 1.75) (Fig. 4f(i) and Supplementary Fig. 15e(i)) in the external dataset.

a, Schematic for training random forest models for gene- and network-level convergence with external validation in an SCZ CRISPRa screen. b, Predictor variables included in the model include scores of functional similarity, DLPFC brain co-expression, cell type and the number of KOs (B.P score, semantic similarity of GO: Biological Process membership between KO genes; C.C score, semantic similarity of GO: Cellular Component membership between KO genes; M.F score, semantic similarity of GO: Molecular Functions membership between KO genes; B.E.C, DLPFC expression correlations between KO genes). c, Two-tailed Pearson’s correlations of predictor variables and gene-level and network-level convergence (**PBonferroni ≤ 0.01, ***PBonferroni ≤ 0.01). d, Functional similarity, brain co-expression, cell type and the number of KOs assayed strongly predicted gene-level convergence (97% variance explained by the model; mean of squared residuals = 0.02) and moderately predicted network-level convergence (53% variance explained; mean of squared residuals = 0.73). (i),(ii) Importance of each of the predictor variables was assessed by two metrics: the percentage mean increase in squared residuals (%IncMSE) and the increase in node purity. In the model, number of KO genes in a set is the most important predictor of convergence based on %IncMSE, but not node purity. However, the impact of nKOs on gene-level convergence is much stronger, likely an artifact of the method used for measuring convergence. For network-level convergence, each variable has an IncMSE of 20–30%. e, Internal evaluation of the model using 30% of the original data resulted in high concordance between convergence predicted by the model and the measured convergence. Predicted gene-level (i) (gene-level convergence: n = 19,823; two-tailed Pearson’s R = 0.984; PHolm < 1 × 10−150; root mean squared error (RMSE) = 0.15) and network-level (ii) convergence (network-level convergence: n = 962; ρ = 0.722; PHolm = 2.4 × 10−149; RMSE = 0.85) by the model strongly correlated with the measured convergence in the testing sets. Correlations of predicted versus accrual convergence values are color-coded by cell type with corresponding color-coded correlations and P values listed in the upper-right corners of the scatterplots. Lines represent the smooth conditional mean with 95% confidence bands. f, External validation of the random forest predication in an independent scCRISPRa screen of SCZ target genes (10 perturbations) predicted showed moderate, but significant, correlation between convergence by the model and the measured convergence. (i) Gene-level convergence (n = 1,013, Pearson’s R = 0.14, P = 1.1 × 10−5, RMSE = 1.748). (ii) Network-level convergence (n = 826, Pearson’s R = 0.26, P = 2.9 × 10−14, RMSE = 0.68). Lines represent the smooth conditional mean with 95% confidence bands. Illustrations in b created in BioRender; Townsley, K. https://biorender.com/5xlpxkm and https://biorender.com/rvk1zn2 (2026).
To query whether convergence reflected clinical associations to ASD or DD, we again quantified convergence as the ratio of convergent genes to the average number of DEGs (Fig. 2e), here across all (2–5-gene) combinations of all NDD genes perturbed in each cell type (for example, 27,824 unique combinations of 21 NDD genes in iGLUTs and iGABAs; Supplementary Fig. 16a). Convergence, both gene-level (Supplementary Fig. 16a,c) and network-level (Supplementary Fig. 16b,d), was greater between genes with stronger associations to ASD compared with DD5, particularly in mature neurons (Supplementary Fig. 16e,f). Yet, this analysis was limited by the relatively small numbers of predominantly ASD (n = 16) and DD (n = 4) included in our dataset (Fig. 1b).
To extend our comparisons of convergence across larger sets of NDD genes, particularly those clinically defined as predominantly ASD or DD genes5, or those with biologically annotated synaptic or epigenetic roles4, we asked whether it was possible to train a machine learning model to predict cell-type-specific impacts of CRISPR-KO of all 102 NDD genes4. An integrative linear network of cell-type phenotypes (LNCTP) model, previously trained on >2.8 million nuclei from the prefrontal cortex (PFC) across 388 individuals, accurately imputed single-cell expression following simulated perturbations33. By conditioning the LNCTP model on reduced expression of the 29 NDD genes (Fig. 5a), we resolved downstream gene expression changes within three in silico post-mortem brain network models (bulk PFC tissue, excitatory neurons only and inhibitory neurons only), and compared these changes with convergent genes identified by in vitro scCRISPR-KO; the LNCTP model better replicated experimental iGLUT data (Fig. 5b).

a, LNCTP imputation and perturbation model: an energy-based network model is trained to impute bulk and cell-type-specific expression data in the PFC over a population of post-mortem individuals from PsychENCODE using a panel of 1,325 genes and embedded cell-type-specific GRNs (LNCTP in silico model); a chosen gene is then perturbed by fixing its expression, and the effects on other genes are predicted by the model; in silico category-specific convergent genes are then identified by analyzing the FCs across subjects (LNCTP simulating perturbations). b, A perturbation-conditioned version of the LNCTP model applied negative perturbation to mimic the effect of the 29 CRISPR-KOs and predict downstream gene expression changes in the adult PFC. Predicted in silico log FCs for the in vitro positive and negative convergent genes across the 29 CRISPR perturbations, in bulk, excitatory and inhibitory neuron networks evaluated if in vitro convergence was replicated in adult PFC prediction models (LNCTP simulating perturbations, two-tailed t-test P values shown). In the box plots, center represents median, hinges represent 1st and 3rd quartiles. The upper and lower whiskers extend up to 1.5 × IQR. All data points are plotted individually. c, A perturbation-conditioned version of the LNCTP model applied a negative perturbation to mimic 102 NDD KOs and evaluate whether convergence measured across 29 NDDs in vitro remained convergent in a larger set. Proportion of genes showing same direction FCs in in silico and in vitro perturbations across classes of perturbation and cell type (left), and the intersection of convergent in silico genes across classes of perturbation (LNCTP in silico convergent genes, synaptic–epigenetic genes reduced and ASD–DD genes enriched, P < 1 × 10−3, two-tailed hypergeometric test). d, Venn diagram of in silico convergent genes across all categories by clinical (ASD versus DD) or functional (synaptic versus epigenetic) annotation. e, Number of terms enriched for convergent genes across all categories for 102 in silico perturbations. f, Semantic distance of pairs of enriched terms within or between sets determined by synaptic and epigenetic convergent gene rankings (LNCTP semantic distance test, two-tailed Mann–Whitney test). g, Percentage of concordant genes in each perturbation and ontology category within the leading-edge enriched genes (LNCTP in silico convergent genes). Illustrations in a created in BioRender; Townsley, K. https://biorender.com/6jv3bge (2026). TF, transcription factor.
Expanding in silico LNCTP model predictions of downstream gene expression changes to all 102 NDD genes (Fig. 5c–g and Supplementary Fig. 17) demonstrated greatest concordance with in vitro convergence in excitatory neurons, consistent with our findings that convergence was greater in iGLUTs (Figs. 2c and 3d). This concordance was more pronounced for synaptic NDD genes (n = 24) relative to regulatory genes (n = 58) (Fig. 5c). Predominantly ASD genes (n = 50) had greater concordance with convergence in excitatory neurons (Fig. 5c), whereas predominantly DD genes (n = 40) were moreso in inhibitory neurons (Fig. 5c). Overall, across functional or clinical categories, despite limited overlap in specific convergent genes (Fig. 5d) and terms (Fig. 5e,f), there was overall enrichment for synaptic, epigenetic and mitochondrial biology (Fig. 5g), consistent with in vitro scCRISPR-KO (Fig. 2f).
Convergent genes and networks in glutamatergic neurons targeted synaptic, epigenetic and mitochondrial biology
Convergent genes and networks revealed cell-type-specific disease (Fig. 2e) and functional enrichments (Figs. 2f, 5g and 6a,b), many consistent with established NDD etiology in neurogenesis18,34,35,36,37,38,39,40,41 and synaptic biology14,15,42,43. For example, iNPCs were significantly enriched for pathways involved in proliferation and differentiation, whereas mature iGLUTs showed unique enrichments in neuronal communication (for example, pre-synaptic function) and regulation of gene expression (for example, messenger RNA processing and protein translation). Unexpectedly, both mature iGLUT and iGABA neurons were enriched for mitochondrial biology (for example, oxidative phosphorylation: mature iGLUTs: NES = 2.8, P < 2.2 × 10−16, FDR < 0.001; mature iGABAs: NES = 1.67, P = 0.023, FDR < 0.05).

a, Two-sided GSEA identified downstream pathways involved in neurogenesis, neurite outgrowth, synaptic biology and mitochondrial function as cell-type-specific targets of convergent genes across 15 NDD KOs (ARID1B, ASH1L, ASXL3, BCL11A, KDM5B, CHD2, MBD5, MED13L, NRXN1, PHF12, PHF21A, SETD5, SIN3A, SKI, SMARRC2) in iNPCs and mature iGLUTs. FDR-based multiple testing correction was performed and results were filtered for pathways with nominal P < 0.05 for plotting. Normalized GSEA scores represent the direction of enrichment based on the meta-analyzed Z-score for each convergent gene. Cell type is represented by shape and the size of each point represents the −log10(FDR). b, Summary of network- and gene-level pathway enrichments (two-sided GSEA, FDR-corrected P values for enrichment tests are reported in Supplementary Data 1) (from Figs. 2 and 3) for shared effects of nine and 15 NDD KOs in iNPCs and mature iGLUTs. c, Proliferation assessment of NPCs using Ki-67 median fluorescence intensity (MFI) measured with flow cytometry, WT (purple, no iCas9 induction) versus KO (green, doxycycline to induce iCas9). Ki-67 MFI was compared between uninduced and induced conditions for each gene using two-sided unpaired t-tests with Welch’s correction, followed by Benjamini–Hochberg FDR correction (Q = 5%). Bars show mean ± s.e.m. with individual biological replicates overlaid (NRXN1: n = 4 uninduced, n = 5 induced; ASH1L: n = 5 uninduced, n = 4 induced; ARID1B: n = 4 induced). LoF of target genes significantly decreased Ki-67 for NRXN1 (mean difference −229.8; P = 0.0004; Q = 0.0008) and increased Ki-67 for ASH1L (difference 887.0; P = 0.0319; Q = 0.0335) and ARID1B (difference 1,350; P = 0.0535; Q = 0.0374). d, Scatter plot of gRNA log2FC (high- (PE-high) and low- (FITC-high) mitochondrial inner membrane potential (Δψm)-sensitive dye JC-1 membrane potential fractions) in NPCs (x axis) and mature iGLUT neurons (y axis), with points colored by enrichment category (shared NPC and iGLUT in red; distinct between NPC and iGLUT in blue). Right, bar chart of −log10(FDR) for over-represented gene sets in the gene KOs enriched in both lineages. e, (i) High resolution, high-throughput microscopy of mitochondrial morphology (scale bar: 10 μm): an isolated dendrite labeled with a dendritic marker (MAP2), mitochondrial marker (TOMM20) and marker of the OXPHOS complex (Total OXPHOS) (scale bar: 5 μm). (ii) Effect of ASH1L-KO (n = 10, 9), ARID1B-KO (n = 9) and NRXN1-KO (n = 8) on mitochondrial sphericity (H1-NT versus ARID1B, adjusted P = 0.0213) and branch length (H1-NT versus ARID1B, adjusted P = 0.0081) independent of changes in mitochondrial volume and surface area (Supplementary Figs. 20 and 21) compared with H1-NT (nontargeting control, n = 6). (iii) Effect of ASH1L-KO, ARID1B-KO and NRXN1-KO on average fluorescence intensity (H1-NT versus ARID1B, adjusted P = 0.0024) of OXPHOS proteins compared with H1-NT. Each data point indicates one well of a 96-well plate, representing hundreds of μm2 of neuronal area and tens of thousands of individual mitochondria (statistical analysis comparing KO with control was performed using a one-way ANOVA comparing H1-NT versus other groups (ASH1L, ARIDIB, NRXN1) with Šidák’s multiple comparisons, *adjusted P < 0.05, ** adjusted P < 0.01). f, Effect of NRXN1-KO on maximal respiration (WT versus H-NT: P = 0.9995; WT versus NRXN1: P = 0.0466; H-NT versus NRXN1: P = 0.0483) and coupled respiration (WT versus H-NT: P = 0.9973; WT versus NRXN: P = 0.0140; H-NT versus NRXN1: P = 0.0152) in iGLUTs. Data are presented as mean ± s.e.m. Statistical analysis was performed using one-way ANOVA. Each data point in the temporal plot represents the mean and s.e.m. across a 24-well Seahorse assay plate. The experiment was independently replicated twice, with the bar graph showing three wells from one representative replicate. The center of the box plots represents the median, the bounds the 25th and 75th percentiles, and the whiskers the minimum and maximum values of that group. NS, not significant; OCR, oxygen consumption rate; oligo, oligomycin; R+A, rotenone and antimycin A.
To functionally validate the impact of LoF mutations on convergent pathways, we selected five high-confidence NDD genes (KMT5B, NRXN1, CHD8, ASH1L, ARID1B) representing distinct functional clusters (for example, chromatin remodelers, synaptic genes) for initial testing. We utilized a well-established doxycycline-inducible Cas9 system (iCas9)44 that allows for a robust comparison of gRNA-transduced iCas9 ‘induced’ (KO) cells with matched gRNA- and iCas9-transduced cells lacking expression of iCas9 (no doxycycline) to serve as an ‘uninduced’ baseline control. Five of five NDD genes (KMT5B, NRXN1, CHD8, ASH1L, ARID1B) tested in iCas9 NPCs (CD184+/CD133+ NPCs) in arrayed format revealed one or more effects on proliferation (Ki-67; Fig. 6c and Supplementary Fig. 18a), neurogenesis (NPCs: CD184+/CD133+/CD271−; neurons: CD184−/CD44−/CD24+; Supplementary Fig. 18b) and/or gliogenesis (astrocytes: CD184+/CD44+; Supplementary Fig. 18c) that varied between genes. Likewise, a pooled CRISPR analysis in iCas9 cortical organoids confirmed effects on neurogenesis, again with variable effects between NDD genes (Supplementary Fig. 19).
To assess how loss of NDD-associated genes affects mitochondrial function, we performed a pooled CRISPR-KO screen using a nearly identical library (same backbone, guide density and control set) in the H1-iCas9 line. Transduced cells were differentiated into NPCs and iGLUTs by day 21, stained with the mitochondrial inner membrane potential-sensitive dye JC-1 and sorted by fluorescence-activated cell sorting (FACS) into high- (PE-high) and low- (FITC-high) membrane potential fractions, following amplicon sequencing to quantify gRNA representation in each fraction (Fig. 6d). Of the 15 KOs, ten resulted in elevated mitochondrial membrane potential in both NPCs and iGLUTs, and the remaining five caused cell-type-specific impacts on mitochondrial membrane potential. Pathway enrichment of the ten NDD genes that increased mitochondrial membrane potential revealed a convergence on chromatin remodeling complexes, microRNAs and transcription factors.
Given their strong phenotypes and unexpected enrichment of mitochondrial pathways, we selected three NDD KOs (ASH1L, ARID1B, NRXN1) for further testing of mitochondrial effects in arrayed format, using a platform with the ability to resolve dose-dependent changes in mitochondrial fragmentation following pharmacological insults (Supplementary Fig. 20). By high content imaging, we analyzed and quantified 1 × 104 mitochondria per genotype, with morphological measurements taken for mitochondrial (TOMM20-positive) volume, surface area and sphericity (roundness) as well as total OXPHOS complex, within neuronal dendrites (MAP2-positive) of mature (day 21) iGLUTs. Among the three NDD KOs, ARID1B resulted in increased mitochondrial networking (indicated by decreased mitochondrial sphericity and increased branch length; one-way analysis of variance (ANOVA), Šidák’s, adjusted P = 0.0213 and P = 0.0081, respectively) concomitant with increased levels of OXPHOS proteins (one-way ANOVA, Šidák’s, adjusted P = 0.0024) (Fig. 6e and Supplementary Fig. 21a), overall consistent with increased mitochondrial efficiency. Second, we tested oxygen consumption using the Seahorse Cell Mito Stress test. NRXN1 KO resulted in increased coupled and maximal respiration in iGLUTs (one-way ANOVA, P < 0.05; Fig. 6f); increased mitochondrial reliance, in the absence of fused mitochondria, with elevated OXPHOS protein levels points to a possible metabolic overload due to reduced mitochondrial efficiency (Fig. 6e). In contrast, ARID1B and ASH1L KOs did not show significant changes in these Seahorse parameters (Supplementary Fig. 21b,c). Taken together, both ARID1B and NRXN1 KO neurons show evidence of increased mitochondrial activity, ARID1B-KO through enhanced fusion and elevated expression of OXPHOS complexes, and NRXN1 KO by increasing OXPHOS activity to meet ATP demands. As observed for neurogenesis in iNPCs, single-gene KO iGLUTs confirmed convergent effects on mitochondrial biology, finding distinct but related phenotypes between NDD genes.
Pharmacological targeting of convergent genes reversed behavioral phenotypes in mutant zebrafish
By design, in vitro models substantially limit the complexity of the observed impact of NDD genes, lacking higher circuit-level effects. Towards applying molecular convergence in vitro to explore the mechanisms of phenotypic convergence in vivo, the convergence of sets of NDD genes was next explored on the basis of shared behavioral effects in zebrafish mutants (Fig. 7 and Supplementary Tables 7 and 8). A comprehensive in vivo high-throughput, automated behavioral analysis in larval zebrafish41 revealed clear stratification of NDD genes based on basic arousal and sensory processing behaviors (Fig. 7a and Supplementary Fig. 22). Given that zebrafish brain gene expression was significantly correlated with in vitro human-derived mature neurons (Fig. 7b and Supplementary Fig. 23), we asked whether behavioral stratification of NDD mutants in larval zebrafish can be attributed to molecular convergence. For 15 NDD genes for which we have matched behavioral and molecular analyses, zebrafish stable mutant lines and CRISPR F0 mutants were clustered based on 24 sleep–wake and visual-startle parameters, yielding four distinct clusters of genes: set 1 (nrxn1a, mbd5, kdm5bab), set 2 (phf12ab, skiab, chd2, smarcc2), set 3 (kdm6bab, kmt5b, kmt2cab) and set 4 (wacab, arid1b, phf21aab, chd8, ash1l) (Fig. 7a and Supplementary Data 3). Gene-level convergence between NDD genes in these sets was distinct (Supplementary Table 9), largely nonoverlapping between cell types and stronger in mature iGLUTs than mature iGABAs (Fig. 7c). Across behavioral sets, rare ASD, SCZ and intellectual disability LoF genes were enriched primarily in iGLUTs, with all sets converging on FMRP targets, highly intolerant copy number variants (CNVs) and ASD variants (Fig. 7d). Phenotypes related to DD, behavior and motor function showed unique enrichments by set, predominately in the iGLUTs, whereas all sets were enriched for seizure, hypertonia and abnormal skeletal muscle morphology (Fig. 7e). Candidate drugs predicted to reverse convergent genes (that is, drugs with anti-correlating transcriptomic signatures) in iGLUTs and iGABAs were prioritized from the 520 Connectivity Map (CMap)45 drugs with matched clinical and experimental zebrafish data. Top enriched drugs included antidepressants, antipsychotics and statins (Supplementary Data 2 and Supplementary Fig. 24a). Whereas some drugs were broadly predicted to reverse convergent signatures in three out of four NDD gene sets (for example, the antipsychotic perphenazine), others uniquely targeted specific sets (for example, naltrexone in set 2 iGLUTs, sirolimus in set 3 iGLUTs and valsartan in set 3 iGABAs). Sets 3 and 4 showed the greatest number of CMap enrichments. By considering existing pharmacological effects of the top drugs on zebrafish behavior46, some of the predicted drug reversers were shown to oppose effects on NDD-related phenotypes in zebrafish (Supplementary Fig. 24b). Yet, the direction of effect predicted based on transcriptomic convergence in human neurons did not always align with anti-correlating behavioral effects in zebrafish (for example, moxifloxacin, perphenazine).

a, NDD risk genes uniquely cluster based on sleep–wake/visual-startle behavioral responses in zebrafish mutants. set 1: nrxn1a, mbd5, kdm5bab; set 2: phf12ab, skiab, chd2, smarcc2; set 3: kdm6bab, kmt5b, kmt2cab; set 4: wacab, arid1b, phf21aab, chd8, ash1l. b, Gene expression in human mature iGLUTs and iGABAs correlates with expression in the zebrafish brain. Cellular deconvolution of WT larval zebrafish brain expression based on adult human single-cell brain reference identifying neurons as the largest proportion of cells in the fish brain. Gene expression in WT zebrafish brain significantly positively correlates with gene expression of mature iGLUTs (two-tailed Pearson’s correlation with Holm’s multiple testing correction; R = 0.39, PHolm < 0.001) and iGABAs (R = 0.39, PHolm < 0.001). c, For each of the four behaviorally defined sets, gene-level convergence (DEGs with significant and shared direction of effect across all NDD genes within each of the four sets (P value-based DEG meta-analysis (METAL), FDR-adjusted Pmeta < 0.05, Cochran’s heterogeneity Q-test PHet > 0.05)) is largely nonoverlapping between mature iGLUTs and iGABAs, with unique enrichments for common psychiatric risk gene targets. Numbers of convergent genes that are upregulated (+) or downregulated (−) for each NDD set are indicated. d, In both iGABAs and iGLUTs, all four behavioral sets were enriched for FMRP targets. Gene targets of neurodevelopmental rare variants were significantly enriched for convergent signatures only in mature iGLUTs; behavioral set 4 uniquely significantly enriched for secondary targets of ASD LoF variants and set 3 uniquely enriched for primary targets of SCZ nonsynonymous variants. e, In iGLUTs, NDD-related behaviors were enriched only in sets 1 and 3, with enrichments for language, speech and intellectual delays in sets 1, 3 and 4. All sets were enriched for seizure and hypertonia. f, Potential ‘rescue’ drugs for these four phenotypic groups were selected from enrichment scores using CMap and filtered for drugs included in a screen of 376 compounds for behavioral effects in zebrafish. Top candidates that were significantly negatively enriched for iGLUT convergence from CMap and negatively correlated with mutant behavioral features were tested in mutant lines representative of sets 2–4. n.p. indicates that the drug repaglinide was not present in the CMap dataset. Mutant × drug combinations were as follows: chd2Δ7/Δ7 × pravastatin; kdm6bab F0 × paclitaxel; kdm6bab F0 × sirolimus; kmt5bΔ208,1i, Δ5/Δ208,1i, Δ5 × paclitaxel; kmt5bΔ208,1i, Δ5/Δ208,1i, Δ5 × sirolimus; ash1l1i, Δ60,19i/ 1i, Δ60,19i × ezetimibe; ash1l1i, Δ60,19i/ 1i, Δ60,19i × repaglinide; ash1l1i, Δ60,19i/ 1i, Δ60,19i × rosuvastatin; ash1l1i, Δ60,19i/ 1i, Δ60,19i × sunitinib; phf21aab F0 × amiodarone; phf21aab F0 × fluvoxamine. g, For behaviors that were significantly different between mutant + DMSO and WT + DMSO (P < 0.06), we characterized the effect of the mutant × drug on behavior as exacerbated (a) (significant effect mutant + drug-versus-WT > significant effect mutant-versus-WT), unchanged (b) (significant effect mutant + drug-versus-WT = significant effect mutant-versus-WT), partial rescue (c) (significant effect mutant + drug-versus-WT < effect mutant-versus-WT), rescued (d) (significant effect mutant-versus-WT, no significant effect mutant + drug-versus-WT) or over-corrected (e) (mutant + drug-versus-WT opposite direction of significant effect mutant-versus-WT). All drugs reversed at least one dysregulated behavior except for sirolimus in kmt5b. (i) Comparison of the magnitude of effect (beta, n = 24 parameters) on behavior between the mutant + DMSO compared with mutant + drug groups shows rescue of select behavioral features in kdm6b and chd2 mutants by paclitaxel (Shapiro–Wilk’s normality: W = 0.94301, P = 0.02121; two-sided Wilcoxon signed rank test statistic = 52, P = 0.0053, n = 24) and pravastatin (Shapiro–Wilk’s normality: W = 0.97587, P = 0.4203, two-sided paired Welch’s t-statistic = −3.533, P = 0.01394, n = 24), respectively. (ii) The phf21a mutant phenotype was strongly opposed by fluvoxamine (left: normality statistic = 0.93744, P = 0.01295; two-sided Wilcoxon signed rank test statistic = 196, P = 0.19; right: two-tailed Pearson’s correlation = −0.58, P = 0.0028, n = 24). In the box plots, the median (black line) and mean (red point) are shown. The lower and upper hinges correspond to 1st and 3rd quartiles. Upper and lower whiskers extend from the hinge to the largest or smallest value up to 1.5 × IQR. All data points are plotted individually. Illustrations in b created in BioRender; Townsley, K. https://biorender.com/rvk1zn2 (2026). AMIO, amiodarone; EZE, ezetimibe; FLUVO, fluvoxamine; PACLI, paclitaxel; PRA, pravastatin; REP, repaglinide; ROS, rosuvastatin; SIRO, sirolimus; SUN, sunitinib.
The top negatively enriched drugs for iGLUT convergence from CMap and anti-correlating drugs predicted from a pharmaco-behavioral screen of 376 drugs in larval zebrafish46 were empirically tested in representative mutants from sets 2–4, which showed the strongest CMap enrichments (Fig. 7f). We determined whether the phenotypic impact of mutant × drug combinations led to partial rescue, rescue, over-correction or exacerbation of the mutant phenotype across significant arousal and startle behavioral parameters (Fig. 7g). Ten out of 11 drugs rescued at least one dysregulated behavioral parameter (Fig. 7g and Supplementary Fig. 24c–e). Paclitaxel robustly rescued behavioral parameters in kdm6bab F0 mutants and pravastatin partially and completely rescued select parameters in chd2Δ7/Δ7 mutants (Fig. 7g(i)), including nighttime sleep bouts in kdm6bab F0 mutants and responses to lights-ON stimuli in chd2Δ7/Δ7 mutants (Supplementary Fig. 24f(i),(ii)). Interestingly, we also observed over-correction of the phf21aab F0 mutant phenotype by fluvoxamine (Fig. 7g(ii)), such as increased sleep bouts that were significantly decreased following fluvoxamine treatment (Supplementary Fig. 24f(iii)). Taken together, in vivo behavioral profiling of NDD genes in zebrafish overlaps with in vitro-defined convergent networks and identifies pharmacological suppressors of specific behavioral phenotypes.
Discussion
To investigate common pathways affected by loss of NDD risk genes, we targeted 23 NDD genes with roles predominantly in gene regulation using a pooled CRISPR-KO strategy. Transcriptomic convergence across NDD risk genes varied between the cell types of the brain, resolving more convergent targets and stronger convergent networks in mature glutamatergic neurons, where they were enriched not just for pathways with well-established links to ASD etiology (for example, gene regulation, synaptic biology), but also mitochondrial function47. Machine learning tools extended the analyses in silico to all known NDD genes, recapitulating observed enrichments for regulatory NDD genes, yet predicting even greater convergence for synaptic NDD genes, and unexpectedly suggesting that predominantly ASD genes converge in excitatory neurons whereas predominantly DD genes converge in inhibitory neurons. Finally, drugs predicted to reverse convergent signatures suppressed behavioral phenotypes in NDD gene mutant zebrafish.
While downstream effects of epigenetic NDD genes unexpectedly targeted mitochondrial genes in neurons, in fact, 5% of NDD cases meet diagnostic criteria for classic mitochondrial disorders48. Mitochondrial DNA mutations49,50, haplotypes51 and heteroplasmy49,52 have all been associated with NDD. Not only do mitochondrial mutations cause synaptic and behavioral phenotypes53, but multiple lines of human and animal evidence link NDDs to mitochondrial deficits and oxidative stress54,55,56,57,58,59, with neuronal and/or behavioral phenotypes reversed by antioxidant treatment55,57,58,59.
Perturbations of the same NDD genes resulted in different convergent networks across cell types. For example, KOs of NDD genes in human NPCs18,34, cerebral organoids36,37,38 and developing mouse39, tadpole40 and zebrafish41 brains reveal overlapping alterations in neurogenesis and developmental dynamics. Indeed, both regulatory and synaptic genes impact proliferation and patterning of progenitors (for example, ARID1B60, CHD836, NRXN161, SYNGAP162), excitatory transmission by glutamatergic neurons (for example, CHD863,64, NRXN165, SHANK366, SYNGAP167) and inhibitory transmission by GABAergic neurons (for example, ARID1B68, CHD863, NRXN169, SHANK370). Many NDD genes seem to have broad roles outside their annotated function; for example, some chromatin regulators (for example, CHD8, CHD2 and POGZ) localize to microtubules in the centrosome17, mitotic spindle18 and cilia19. This observation connects the pleiotropic nature of many NDD genes and pathophysiological evidence linking multiple cell types and distinct cellular functions to NDD.
What explains phenotypic convergence between NDD genes with distinct annotated functions? The strength of convergence was most highly correlated to common clinical associations, biological annotations and co-expression patterns in the post-mortem brain. Critically, these factors are inter-dependent. ASD and DD risk genes differentially map onto human developmental brain co-expression networks11, with those most strongly implicated in DD enriched for expression in progenitor cells and immature neurons, and those in ASD in mature neurons5. Indeed, cellular identities and biological pathways are captured by patterns of gene co-expression71,72. Transcriptomic and epigenomic analyses of post-mortem brain from NDD cases likewise indicate convergent molecular signatures73 and subtypes of NDD74. Thus, we posit that shared clinical and phenotypic effects of distinct NDD genes in fact reflect the patterns of co-expression in the developing brain.
Personalized medicine seeks to tailor treatments to individual patients75; for example, patients with cancer76 and monogenic disease77 with specific genetic mutations receive targeted treatments. Previous efforts to classify genes that predict NDD clinical features or treatment response applied gene ontology4,5 or differential neurodevelopmental KO effects in vitro34 or in vivo40. Here we proposed to stratify risk genes based on convergent molecular impacts in human neurons. Our overarching hypothesis, in doing so, was that by resolving shared downstream gene targets between multiple NDD genes, we might inform a precision-medicine-based approach that did not necessarily need to target risk genes one-at-a-time. Although convergent networks did not predict behavioral stratification of zebrafish mutants, they did inform drug prediction, with 10 out of 11 drugs tested found to ameliorate at least one mutant behavioral phenotype in vivo. This ability to reverse, rather than prevent, a behavioral phenotype indicates that targeting convergent networks in post-mitotic neurons may represent a clinically actionable neurodevelopmental window that persists through symptom onset. The extent to which convergent downstream targets, whether associated with risk or resilience, can be manipulated to prevent or ameliorate NDD signatures and phenotypes warrants future investigation.
Although rare LoF NDD gene mutations tend to confer large effects in the individuals who carry them, the small effects of common variants account for much of the genetic risk for NDD at the population level2. The differences in expressivity and incomplete penetrance of high-effect-size rare variants are frequently attributed to diversity across polygenic backgrounds78; in vitro, NDD gene effects are indeed influenced by the individual genomic context36. In psychiatry, common genetic variants are more associated with cross-disorder behavioral dimensions79 and rare variants with co-occurring intellectual disability80. Common risk variants interact with rare mutations to determine individual-level liability in ASD81, DD82, SCZ83,84 and epilepsy85. Our results, highlighting that convergence downstream of NDD gene effects is enriched for cross-disorder GWAS variants and rare LoF genes, inform pleiotropy of genetic risk for psychiatric disorders. Moving forward, we argue that it is critical that empirical functional genomic studies systematically consider the impact of common and rare variants together, including screening the impact of LoF genes in hiPSC lines derived from donors with high and low polygenic risk scores86. Intriguingly, even susceptibility to environmental risk factors for NDD (for example, valproic acid) seems to be mediated by genetic background87. Deeper phenotypic characterization of NDD effects across donors will be critical in determining how complex genetic (or environmental) interactions shape cellular phenotypes, circuit function and human behavior in the clinic.
In the post-mortem brain, NDD gene signatures are not just associated with downregulation of co-expression modules involving synaptic signaling88, but also with upregulation of microglial and astrocyte gene modules89,90. The extent to which increased neuroimmune activity in NDD is a response to cellular or environmental sources of inflammation, or indicative of a role for glia cells in risk, is unclear; evidence supports both possibilities. Consistent with a model of maternal immune activation during neurodevelopment91, glucocorticoids and inflammatory cytokines perturb the expression of psychiatric risk genes92,93, altering the regulatory activity of psychiatric risk loci94 and interfering with neuronal maturation in brain organoids95. Yet, in vivo analysis of NDD genes in zebrafish revealed global increases in microglia41 and in vitro screening in human microglia uncovered roles in endocytosis and uptake of synaptic material96. Indeed, given the reciprocal relationships between neuronal activity and glial function, epigenetic state and gene expression97,98,99, it seems probable that both cell-autonomous and non-cell-autonomous effects underlie and/or exacerbate NDD gene effects.
In summary, we demonstrate that convergent effects of NDD risk genes vary between cell types. Our analyses suggest that clinical convergence between regulatory and synaptic genes in the etiology of NDD is driven more so by co-expression patterns of risk genes than by direct regulation of epigenetic genes on synaptic targets. If the convergence of multifold risk genes on a smaller number of shared molecular pathways indeed explains how genetically heterogeneous mutations result in similar clinical features, then genetic stratification of cases will inform novel therapeutic targets. We predict that such individualized points of therapeutic intervention may be most effective when targeting mature glutamatergic neurons, which not only harbor the strongest convergent effects but also represent a therapeutic window that is actionable after diagnosis.
Methods
Statement of ethics
Yale University Institutional Review Board waived ethical approval for this work. Ethical approval was not required because the hiPSC lines, lacking association with any identifying information and widely accessible from a public repository, are thus not considered to be human subject research. Post-mortem brain data are similarly lacking identifiable information and are not considered human subject research.
All procedures involving zebrafish were conducted in accordance with Institutional Animal Care and Use Committee (IACUC; protocol no. 2024-20054) regulatory standards at Yale University.
Generation of neural cells
Informed consent was obtained at the National Institute of Mental Health (NIMH), under the review of their Internal Review Board. hiPSC work was reviewed by the Internal Review Board of the Icahn School of Medicine at Mount Sinai as well as by the Embryonic Stem Cell Research Oversight Committee at the Icahn School of Medicine at Mount Sinai and Yale University. Fibroblasts were genotyped by IlluminaOmni 2.5 bead chip genotyping100,101, PsychChip102 and exome sequencing102; hiPSCs102 were validated by G-banded karyotyping (Wicell Cytogenetics) and genome stability monitored by Infinium Global Screening Array v3.0 (lllumina); single nucleotide polymorphism (SNP) genotype was inferred from all RNA sequencing (RNA-seq) data using the Sequenom SURESelect Clinical Research Exome and Sure Select V5 SNP lists to confirm that neuron identity matched donor. All hiPSCs are available at the Rutgers University Cell and DNA Repository (study 160) NIMH Repository and Genomic Resource is in the process of transferring operations from Rutgers University to Coriell Institute for Medical Research. For urgent requests, please contact NIMH.genomics.resources@mail.nih.gov.
Control hiPSCs were cultured in StemFlex media (Gibco, cat. no. A3349401) supplemented with Antibiotic-Antimycotic (Gibco, cat. no. 15240062) on Geltrex-coated plates (Gibco, cat. no. A1413302). Cells were passaged at 80–90% confluence with 5 mM EDTA (Life Technologies, cat. no. 15575-020) for 3 min at room temperature. EDTA was aspirated and cells dissociated in fresh StemFlex media. Media was replaced every 48–72 h for 4–7 d until the next passage.
Transient transcription factor overexpression from stable clonal hiPSCs was used to induce control hiPSCs to iNPCs (here SNaPs)26, iGLUTs27 and iGABAs28. iNPCs are rapidly generated by 48-h induction with NGN226,103. iGLUTs are induced via transient overexpression of NGN2, and are >95% glutamatergic neurons, robustly express excitatory genes and show spontaneous excitatory synaptic activity by 3–4 weeks in vitro25,27,61,65,66,104,105,106,107,108,109,110. iGABA neurons are induced via transient overexpression of ASCL1 and DLX2, and are >95% GABAergic neurons, robustly express inhibitory genes and show spontaneous inhibitory synaptic activity by 5–6 weeks28,69,106,111,112. iNPCs, iGLUTs and iGABAs express most NDD genes, including all genes prioritized herein25.
We transduced hiPSCs from two control donors (553-3, karyotypic XY; 3182-3, karyotypic XX) with lentiviral pUBIQ-rtTA (Addgene, cat. no. 20342) and tetO-NGN2-eGFP-NeoR (Addgene, cat. no. 99378) for iNPCs and iGLUTs, or pUBIQ-rtTA (Addgene, cat. no. 20342), tetO-ASCL1-PuroR (Addgene, cat. no. 97329) and tetO-DLX2-HygroR (Addgene, cat. no. 97330) for iGABAs. Following transduction by spinfection at 1,000g for 1 h at 37 °C, hiPSCs were subjected to 48-h antibiotic selection (1 mg ml−1 neomycin G418 (Thermo, cat. no. 10131027), 0.5 µg ml−1 puromycin (Thermo, cat. no. A1113803) and/or 250 µg ml−1 hygromycin (Thermo, cat. no. 10687010), and then clonalized by expansion from single colonies. Ultimately, clonal and inducible iNPC/iGLUT 3182-3-clone5 (XX) and iGABA 553-3-clone34 (XY) hiPSCs were validated for lentiviral genome integration by PCR, doxycycline-induced transcription factor expression by quantitative PCR, and robust and consistent neuronal induction confirmed by RNA-seq and immunocytochemistry for relevant cell-type markers. Analyses throughout reflect data from iGLUT 3182-3-clone5 (iNPC, day 7 iGLUT and day 21 iGLUT) and iGABA 553-3-clone34 (day 36 iGABA).
iNPCs
At 0 days in vitro (DIV0), 3182-3-clone5 hiPSCs were dissociated and plated at 1.5 × 106 cells per well onto Geltrex-coated six-well plates (1:250 dilution coating) in SNaP Induction Media (DIV0): DMEM/F12 with Glutamax (ThermoFisher, cat. no. 11320082), Glucose (0.3% v/v), N2 Supplement (1:100, ThermoFisher, cat. no. 17502048), doxycycline (2 μg ml−1; Sigma-Aldrich, cat. no. D9891), LDN-193189 (200 nM; Stemgent, cat. no. 04-0074), SB431542 (10 μM; Tocris, cat. no. 1614) and XAV939 (2 μM; Stemgent, cat. no. 04-00046) supplemented with 25 ng ml−1 Chroma I ROCK2 Inhibitor. After 24 h, DIV2, cells were fed with Selection Media: DMEM/F12 with Glutamax, Glucose (0.3% v/v), N2 Supplement (1:100), doxycycline (2 μg ml−1), Geneticin (0.5 mg ml−1; Thermofisher, cat. no. 10131035), LDN-193189 (100 nM), SB431542 (5 μM) and XAV939 (1 μM). At 48 h post induction (DIV2), SNaPs were dissociated with Accutase for 10 min at 37 °C, quenched in DMEM, pelleted at 800g for 5 min and replated at 1.5 × 106 cells per well onto Geltrex-coated six-well plates in SNaP Selection Media supplemented with Geneticin (0.5 mg ml−1). After 16–18 h (DIV3), medium was switched to SNaP maintenance Medium: DMEM/F12 with Glutamax, Penn/Strep (1:100), MEM-NEAA (1:100; Life Technologies, cat. no. 10370088), B27 minus Vitamin A (1:50; Life Technologies, cat. no. 12587010), N2 Supplement (1:100; Life Technologies, cat. no. 17502048), recombinant human EGF (10 ng ml−1; R&D Systems, cat. no. 236-EG-200), recombinant human basic FGF (10 ng ml−1; Life Technologies, cat. no. 13256029), Geneticin (0.5 mg ml−1) and Chroman I (25 ng ml−1). Cells were fed every 48 h with SNaP maintenance medium lacking Chroman I and Geneticin. Cells were dissociated and seeded weekly at a density of 1.25–1.5 × 106 cells per well onto Geltrex-coated six-well plates until NPC morphology was observed and persistent. Cells were expanded and cryofrozen.
DIV7 iGLUTs
The 3182-3-clone5 iNPCs were thawed and seeded at 1 × 106 cells per well onto Geltrex-coated 12-well plates. NGN2 expression was induced with doxycycline (2 μg ml−1) for 24 h (DIV0) with antibiotic selection for 48 h (DIV1-3) in SNaP maintenance medium. At DIV4, SNaPs were dissociated with Accutase, switched into Neuronal Medium (Brainphys (Stemcell, cat. no. 05790), Glutamax (1:100), Sodium Pyruvate (1 mM), Anti-Anti (1:100), N2 (1:100), B27 without vitamin A (1:50), BDNF (20 ng ml−1; R&D, cat. no. 248-BD-025), GDNF (20 ng ml−1; R&D, cat. no. 212), dibutyryl cAMP (500 μg ml−1; Sigma, cat. no. D0627), L-ascorbic acid (200 μM; Sigma, cat. no. A4403), Natural Mouse Laminin (1.2 μg ml−1; Thermofisher, cat. no. 23017015)) and seeded in Geltrex-coated (1:120 dilution coating) 12-well plates. Medium was changed every 24 h until DIV7 collection.
D21 iGLUTs
hiPSCs were collected in Accutase (Innovative Cell Technologies, cat. no. AT-104) for 5 min at 37 °C, dissociated into a single-cell suspension, quenched in DMEM, pelleted via centrifugation for 5 min at 1,000g, resuspended in StemFlex containing 25 ng ml−1 Chroma I ROCK2 Inhibitor and 2.0 μg ml−1 doxycycline (DIV0), seeded 1 × 106 cells per well onto Geltrex-coated six-well plates (1:250 dilution coating) and incubated overnight at 37 °C. The next day, DIV1, hiPSCs were subjected to 48-h antibiotic selection by medium replacement with Induction Media: DMEM/F12 (Thermofisher, cat. no. 10565018), Glutamax (1:100; Thermofisher, cat. no. 10565018), N2 (1:100; Thermofisher, cat. no. 17502048), B27 without vitamin A (1:50; Thermofisher, cat. no. 12587010), Antibiotic-Antimycotic (1:100) with 1.0 μg ml−1 doxycycline and 0.5 mg ml−1 Geneticin. At DIV3, cells were treated with 4.0 μM cytosine-β-D-arabinofuranoside hydrochloride (Ara-C) and 1.0 μg ml−1 doxycycline to arrest proliferation and eliminate non-neuronal cells in the culture. At DIV4, immature neurons were dissociated with Accutase and 5 units per ml of DNAse I at 37 °C for 7–10 min, quenched in DMEM, centrifuged for 5 min at 400g, resuspended in 25 ng ml−1 Chroma I ROCK2 Inhibitor, 1.0 μg ml−1 doxycycline and 4.0 μM Ara-C, and switched to Neuron Medium: Brainphys (Stemcell, cat. no. 05790), Glutamax (1:100), Sodium Pyruvate (1 mM), Anti-Anti (1:100), N2 (1:100), B27 without vitamin A (1:50), BDNF (20 ng ml−1; R&D, cat. no. 248-BD-025), GDNF (20 ng ml−1; R&D, cat. no. 212), dibutyryl cAMP (500 μg ml−1; Sigma, cat. no. D0627), L-ascorbic acid (200 μM; Sigma, cat. no. A4403), Natural Mouse Laminin (1.2 μg ml−1; Thermofisher, cat. no. 23017015), and seeded at 7 × 105 cells per well onto Geltrex-coated (1:60 dilution coating) 12-well plates and incubated overnight at 37 °C. The next day, DIV6, Chroman I was removed from culture and Ara-C lowered to 2.0 μM with a full Neuronal Medium change. At DIV7, a full Neuronal Medium change was performed to remove doxycycline and Ara-C from culture, to allow for antibiotic-resistant genes silencing. From DIV7 onwards, half Neuronal Medium changes were performed every 72–96 h until mature DIV21 for collection.
DIV36 iGABAs
hiPSCs were collected in Accutase (Innovative Cell Technologies, cat. no. AT-104) for 5 min at 37 °C, dissociated into a single-cell suspension, quenched in DMEM, pelleted via centrifugation for 5 min at 1,000g, resuspended in StemFlex containing 25 ng ml−1 Chroma I ROCK2 Inhibitor and 2.0 μg ml−1 doxycycline (DIV0), seeded at 1.5–2 × 106 cells per well onto Geltrex-coated six-well plates (1:250 dilution coating) and incubated overnight at 37 °C. The next day, DIV1, hiPSCs were subjected to 48-h antibiotic selection by medium replacement with Induction Media: DMEM/F12 (Thermofisher, cat. no. 10565018), Glutamax (1:100; Thermofisher, cat. no. 10565018), N2 (1:100; Thermofisher, cat. no. 17502048), B27 without vitamin A (1:50; Thermofisher, cat. no. 12587010), Antibiotic-Antimycotic (1:100) with 1.0 μg ml−1 doxycycline, 1.0 μg ml−1 puromycin (Sigma, cat. no. P7255) and 250 μg ml−1 hygromycin (Sigma, cat. no. 10687010). At DIV3, cells were treated with 4.0 μM Ara-C and 1.0 μg ml−1 doxycycline to arrest proliferation and eliminate non-neuronal cells in the culture. At DIV5, immature neurons were dissociated with Accutase and 5 units per ml of DNAse I at 37 °C for 7–10 min, quenched in DMEM, centrifuged for 5 min at 400g, resuspended in 25 ng ml−1 Chroma I ROCK2 Inhibitor, 1.0 μg ml−1 doxycycline and 4.0 μM Ara-C, and switched to Neuron Medium: Brainphys (Stemcell, cat. no. 05790), Glutamax (1:100), Sodium Pyruvate (1 mM), Anti-Anti (1:100), N2 (1:100), B27 without vitamin A (1:50), BDNF (20 ng ml−1; R&D, cat. no. 248-BD-025), GDNF (20 ng ml−1; R&D, cat. no. 212), dibutyryl cAMP (500 μg ml−1; Sigma, cat. no. D0627), L-ascorbic acid (200 μM; Sigma, cat. no. A4403) and Natural Mouse Laminin (1.2 μg ml−1; Thermofisher, cat. no. 23017015), and seeded at 7 × 105 cells per well onto Geltrex-coated (1:60 dilution coating) 12-well plates and incubated overnight at 37 °C. The next day, DIV6, Chroman I was removed from culture and Ara-C lowered to 2.0 μM with a full Neuronal Medium change. At DIV7, a full Neuronal Medium change was performed to remove doxycycline and Ara-C from culture, to allow for antibiotic-resistant genes silencing. From DIV7 onwards, half Neuronal Medium changes were performed every 72–96 h until mature DIV36 for collection.
CRISPR-KO gRNA library design (Thermofisher) and validation
From the 102 highly penetrant LoF gene mutations associated with ASD (58 gene expression regulation, 24 neuronal communication genes, 9 cytoskeletal genes and 11 multifunction genes)4, gene ontology and primary literature research identified 26 epigenetic modifiers specifically involved in chromatin organization, rearrangement and modification. ASD gene expression (RNA-seq reads per kilobase million (RPKM) in iGLUTs) was plotted against significance of ASD association (transmission and de novo association analysis (TADA) FDR values), to ensure selection of genes with the highest expression and highest clinical association. Gene expression was confirmed across development in the brain (BrainSpan113), and in bulk RNA-seq and scRNA-seq. Twenty-one epigenetic modifiers (ASH1L, ASXL3, ARID1B, CHD2, CHD8, CREBBP, KDM5B, KDM6B, KMT2C, KMT5B, MBD5, MED13L, PHF12, PHF21A, POGZ, PPP2R5D, SETD5, SIN3A, SKI, SMARCC2, WAC) as well as two transcription factors with putative roles as chromatin regulators (FOXP2, BCL11A) were selected. Gene regulatory transcription factors, general transcription factors and DNA replication genes were excluded. Three extensively studied synaptic genes (NRXN1, SCN2A, SHANK3) with roles in ASD were included as positive controls and three under-explored genes for ASD roles in neuronal communication genes (ANK3, DPYSL2, SLC6A1) were also included in the library.
Individual DNA samples from glycerol stocks of Invitrogen LentiArray Human CRISPR Library gRNAs-PuroR (ThermoFisher, cat. no. A31949) (3–4 individual gRNAs per gene, Supplementary Table 1) were prepared using GeneJET Plasmid Miniprep Kit (K0503) and pooled at an equimolar ratio and a fivefold ratio of scramble control gRNA plasmid. Library quality was confirmed by restriction enzyme digest (10x Cutsart NEB) and agarose gel purification using QIAquick Gel Extraction Kit (cat. no. 28706) to check library purity, followed by MiSeq for gRNA count distribution. Based on the abundance of gRNAs from MiSeq, four NDD gene targets were highly unlikely to be resolved in the final experiments (POGZ, PP2R5D, SHANK3, SLC6A1) and three with low abundance were less likely to be resolved (SCNA2, FOXP2, DYPSL2).
Lentiviral Cas9v2-HygroR (Addgene, cat. no. 98291) and pooled LentiArray-gRNA-PuroR CRISPR-KO Library were packaged as high-titer lentiviruses (Boston Children’s Hospital Viral Core) and experimentally titrated in each cell type. The highest viable multiplicity of infection (MOI) was used for Cas9v2 and MOI < 0.5 for the lentivirus gRNA pool library.
CRISPR and gRNA delivery
Lentiviral Cas9v2-HygroR (Addgene, cat. no. 98291) transduction of iNPCs, day 4 (iGLUTs) or day 5 (iGABAs), occurred via spinfection (1 h at 1,000g) and was followed by 72 h of hygromycin (250 μg ml−1) (except for iGABAs, which express inducible hygromycin resistance at this stage). Pooled Invitrogen LentiArray Human gRNA-PuroR CRISPR-KO Library gRNAs (ThermoFisher, cat. no. A31949) (MOI 0.3–0.5) were transduced via spinfection 3 d before collection (for example, day 4 for day 7 iGLUTs, day 18 for day 21 iGLUTs, day 33 for day 36 iGABAs), with fresh medium containing puromycin (1 μg ml−1) added 16–24 h post transduction of gRNAs. For mature iGLUTs and iGABAs, as doxycycline was removed from medium at DIV7, and by DIV18 neurons had lost transcription factor-linked antibiotic resistance, at 24 h post transduction (DIV19 or DIV34) puromycin (1 μg ml−1) and hygromycin (250 μg ml−1) were added to media for 48-h of antibiotic selection before collection.
Dissociation of different neural cell types to single cells for scRNA-seq assays
Cells were dissociated 72 h post gRNA library delivery for single-cell sequencing, as iNPCs, DIV7 and DIV21 iGLUTs, or DIV36 iGABAs, as follows:
iNPCs and DIV7 iGLUTs were dissociated in Accutase for 5 min at 37 °C, washed with DMEM/10%FBS, centrifuged at 1,000g for 5 min, gently resuspended and counted.
DIV21 iGLUTs and DIV36 iGABAs were dissociated with papain. Papain was pre-warmed (39 °C) for 30 min in HBSS (ThermoFisher, cat. no. 14025076), HEPES (10 mM, pH 7.5), EDTA (0.5 mM) and papain (0.84 mg ml−1; Worthington-Biochem, cat. no. LS003127). The cells were washed with PBS-EDTA (0.5 mM) and 300 μl of papain solution and 5 units of DNAse I were added per well of a 12-well plate and incubated at 37 °C for 10–15 min, 125 rpm. Dissociation was quenched with DMEM-10%FBS. Detached neurons were broken by gentle manual pipetting, pelleted at 600g for 5 min, resuspended in DMEM-10%FBS, filtered through a cell strainer and counted and submitted for 10X sequencing.
Cells were loaded into 10X in four lanes per cell type, targeting 20,000 cells per lane for a total of ~80,000 targeted cells per cell type. scRNA-seq was performed at Yale Genomics Core with the 10X single-cell 5′ v2 HT with CRISPR barcode kit.
Bulk RNA-seq and CRISPR editing efficiency evaluation
The H1 hESC line with iCas9 (NIHhESC-10-0043), generously provided by the Huangfu Lab, was used to assess the editing efficiency of the gRNAs44,114 and to conduct the mitochondrial pooled and arrayed experiments. NPCs were generated using the dual SMAD inhibition approach per the STEMdiff SMADi Neural Induction Kit protocol (STEMCell Technologies, cat. no. 08581).
To validate gene KO, NPCs were transduced with LV particles carrying four gRNAs per target gene. After 48 h of selection with 1 µg ml−1 puromycin, Cas9 expression was induced by adding dox at 2 µg ml−1 for 72 h. Following induction, cells were collected for bulk RNA-seq. Total RNA was extracted using TRIzol reagent (Invitrogen). PolyA RNA-seq library preparation and sequencing were conducted at the Yale Center for Genomic Analysis (YCGA). Raw fastq files were quality-checked (FastQC; RRID:SCR_014583), then mapped to human genome reference hg38 (STAR115). gRNA-targeted loci for each sample were extracted (SAMtools116; RRID:SCR_002105). Variation/small insertion/deletion at the site of interest and mutation efficiency at corresponding loci were called (CrispRVariants R package117), after excluding possible germline variants from Cas9-noninduced samples.
NDD gene effects were resolved either (1) relative to a nontargeting control in the context of iCas9, owing to administration of doxycycline (for example, mitochondrial assays), or (2) across isogenic conditions expressing targeting gRNA, with the comparison being whether iCas9 expression was induced by administration of doxycycline (for example, replication assays).
Proliferation and neurogenesis analysis
For proliferation analysis using Ki-67, NPCs were seeded into 24-well plates and either treated with doxycycline (induced) to activate Cas9 or left untreated (uninduced). The cells were cultured for 7 d, representing approximately three NPC generations. On day 7, cells were collected, and ~1 × 106 cells were stained with Ki-67-FITC (cat. no. 130-117-803, Miltenyi Biotec) using the Foxp3/Transcription Factor Staining Buffer Set (cat. no. 00-5523, Invitrogen), following the manufacturer’s protocol.
To evaluate the effects of gene KOs on neurogenesis and gliogenesis, transduced NPC-iCas9 lines were spontaneously differentiated into human cortical neurons and glial cells. Briefly, 1 × 106 cells were seeded in GelTrex-coated (1:5) six-well plates and cultured in complete neuronal media containing BrainPhys Neuronal Medium, Glutamax (100X), Sodium Pyruvate (100 mM), B27 (-RA) supplement (×50), N2 (×100), Anti-Anti (×100), Natural Mouse Laminin (1 mg ml−1), dbcAMP (500 mg ml−1), L-ascorbic acid (200 µM), BDNF (20 µg ml−1) and GDNF (20 µg ml−1). Medium was refreshed every 3 d. On day 25, cells were collected and stained for FACS analysis using surface markers previously described118 to differentiate NPCs (CD184+/CD44−/CD24+), neurons (CD184−/CD44−/CD24+) and glia (CD184+/CD44+). CD271, a marker for mesenchymal stem cells, was excluded from the original panel as NPCs were pre-purified via FACS using CD133+/CD184+/CD271− markers before differentiation. A minimum of 50,000 cells per gate were acquired using a BD LSRFortessa Cell Analyzer at the Yale Flow Cytometry Core. Flow cytometry data were analyzed (FlowJo v10.10 Software; RRID:SCR_008520; BD Life Sciences).
The full protocol is available from protocols.io via https://doi.org/10.17504/protocols.io.j8nlkyew1g5r/v1.
All statistical analyses for flow cytometry assessment were conducted (GraphPad Prism version 9.5.1 (528) for macOS; RRID:SCR_002798; GraphPad Software). Each well was treated as an independent replicate. Differences between KO (induced) and control (uninduced) groups were assessed by comparing the median fluorescence intensity of the target fluorophore using an unpaired t-test with Welch correction to account for individual group variance. Multiple comparisons were corrected using the FDR method with a two-stage step-up procedure (Benjamini, Krieger and Yekutieli) at an FDR threshold of 5%.
FACS analysis of mitochondrial membrane potential and CRISPR screen read-out via amplicon sequencing
For our mitochondrial assays, we used a nearly identical library (same backbone, guide density and control set) screened exclusively in the H1 inducible Cas9 (H1-iCas9) hPSC line. Mitochondrial inner membrane potential was measured in H1-iCas9, following differentiation to NPCs or iGlut on day 21. Cells were collected, counted and aliquoted at 1 × 106 cells per sample. JC-1 dye (MitoProbe JC-1 Assay Kit; Invitrogen, cat. no. M34152) was dissolved in DMSO at a stock concentration of 200 µM and added to each sample to achieve a final concentration of 2 µM, then incubated for 30 min at 37 °C in 5% CO2. A 50 µM CCCP control was included to induce complete mitochondrial depolarization. After staining, cells were washed once in their respective culture medium, resuspended in FACS buffer (Invitrogen eBioscience Staining Buffer, cat. no. 00422226) and analyzed immediately on a ThermoFisher ‘Bigfoot’ spectral cell sorter using 488-nm excitation with 525/50-nm (FITC) and 585/40-nm (PE) emission filters. Debris and doublets were excluded by forward/side scatter gating, and CCCP-treated samples were used to define FITC and PE gates. Approximately 1 × 106 events per sample were recorded. Cells were then pelleted (300g, 5 min) and genomic DNA extracted using the Qiagen DNeasy Blood & Tissue Kit (cat. no. 69504).
Unique molecular identifier (UMI)-tagged amplicon libraries were generated in three PCR steps. In PCR-1, genomic DNA was amplified with Platinum II Hot-Start PCR Master Mix (Invitrogen, cat. no. 14000012) and UMI-containing primers (Forward: 5′-ACACTCTTTCCCTACACGACGCTCTTCCGATCTACGTGACGTAGAAAGTAATAATTTCTTGGGT-3′; Reverse: 5′-GTGACTGGAGTTCAGACGTGTGCTCTTCCGATCTN(25)NNNNNNNNNACTCGGTGCCACTTTTTCAA-3′) under the following conditions: 94 °C for 2 min; 4–6 cycles of 98 °C for 5 s, 60 °C for 15 s, 60 °C for 30 s. The resulting ~180-base pair (bp) products were purified and concentrated using the Zymo DNA Clean & Concentrator-5 kit (cat. no. D4013) and eluted in 10 µl of nuclease-free water (ThermoFisher, cat. no. AM9938). In PCR-2, purified product was amplified with adaptor primers (Forward: 5′-ACACTCTTTCCCTACACGACGCTCTTCCGATCT-3′; Reverse: 5′-GTGACTGGAGTTCAGACGTGTGCTCTTCCGATCT-3′) for 22 cycles under identical cycling conditions in a ~20-µl reaction. A seven-cycle indexing PCR (PCR-3) was performed by the sequencing facility at YCGA before sequencing. Final libraries were sequenced on an Illumina NovaSeq platform (paired-end 150 bp, 5 million reads per sample).
Flanking sequences on both sides of each gRNA were trimmed using BBDuk, and reads were then mapped to gRNA reference sequences and counted (MAGeCK119; RRID:SCR_025016). Raw counts for each gRNA were normalized to counts of scrambled gRNA. Abundance of each target gene was then calculated by summing of all gRNAs targeting that gene. The log2-transformed FCs of gRNA-target abundance were compared between PE-high samples and FITC-high samples.
The full protocol is available from protocols.io via https://doi.org/10.17504/protocols.io.rm7vz98brgx1/v1.
Immunostaining
Cells were fixed with fixative solution (4% sucrose and 4% paraformaldehyde prepared in Dulbecco’s PBS (DPBS)) for 10 min at room temperature. Following this, cells were washed twice with DPBS and incubated in blocking solution (2% normal donkey serum prepared in DPBS) supplemented with 0.1% Triton for 2 h at room temperature. After this, cells were incubated overnight at 4 °C in the primary antibody solution prepared in blocking solution. Cells were washed three times with DPBS, incubated at room temperature in secondary antibody prepared in blocking solution, then washed three times with DPBS. In the second wash, cells were incubated in DBPS supplemented with DAPI (Sigma D9542,1 μg ml−1) for 2 min at room temperature.
Antibody | Species | Vendor | Cat. no. | RRID | Dilution |
|---|---|---|---|---|---|
Anti-MAP2 | Chicken | Invitrogen, Abcam | PA1-10005, ab5392 | AB_1076848, AB_2138153 | 1:1,000 |
Anti-Nestin | Rabbit | Millipore | ABD69 | AB_2744681 | 1:200 |
Anti-vGLUT1 | Rabbit | Synaptic Systems | 135-303 | AB_887875 | 1:200 |
Anti-GABA | Rabbit | Sigma-Aldrich | A2052 | AB_477652 | 1:200 |
TOMM20 | Mouse | Santa Cruz Biotechnology | sc-17764 | AB_628381 | 1:200 |
Total OXPHOS | Rabbit | Abcam | AB-317270 | not available | 1:500 |
Anti-mouse | Donkey | Jackson ImmunoResearch | 715-605-151 | AB_2340863 | 1:500 |
Anti-rabbit | Donkey | Jackson ImmunoResearch | 711-545-152 | AB_2313584 | 1:500 |
Anti-chicken | Donkey | Jackson ImmunoResearch | 715-605-150, 703-545-155 | AB_2340862, AB_2340375 | 1:500 |
Fixed cultures were acquired using a DragonFly Confocal Dual Spinning Disk confocal microscope, at ×60 magnification and 1.4 numerical aperture. All images were acquired with a fixed laser intensity and exposure time across experimental conditions. Four images were acquired per well, and 4–10 wells were acquired per experimental condition. Each well represents a biological replicate and statistical data point. Therefore, each replicate represents hundreds of μm2 of neuronal area and tens of thousands of individual mitochondria.
Mitochondrial morphology features were determined using the Surface module of Imaris 10.2 (RRID:SCR_007370). Likewise, OXPHOS complex features were determined using the Surface module of Imaris 10.2. The Volume, Area and Sphericity features of the Surface module were selected for analysis. Mitochondrial networking features were determined using published, open-source methods120. A one-way ANOVA with a Šidák’s multiple comparisons test was performed on data with GraphPad Prism 10.
To validate robustness and sensitivity of the microscopy assay, we treated day 14 iGluts overnight with carbonyl cyanide 4-(trifluoromethoxy) phenylhydrazone (FCCP) (Sigma-Aldrich, cat. no. SML2959) at 5 μM, 10 μΜ and 50 μΜ doses. Following this, we conducted the immunostaining, mitochondrial structural analysis and statistical analyses outlined above.
Seahorse XF Mito Stress Test
Day 5 iGLUTs were plated at 1.65 × 105 cells per well in XF24 microplates (Agilent, cat. no. 100777-004) and cultured to day 21. At 1 h before measurement, growth medium was removed, leaving 50 µl per well, and replaced with 1 ml of pre‑warmed Seahorse XF DMEM (Agilent, cat. no. 103575-100) supplemented with 25 mM glucose (Agilent, cat. no. 103577-100) and 0.23 mM pyruvate (Agilent, cat. no. 103578-100). Plates were equilibrated for 1 h at 37 °C in a non‑CO2 incubator. Immediately before the assay, the medium was replaced with 500 µl of fresh assay buffer. Oxygen‑consumption rate was recorded on a SeahorseXFe24 Analyzer (Agilent) using the standard Mito Stress Test. The program consisted of three sequential injections—1.5 µM oligomycin (Sigma-Aldrich, cat. no. 75351), 1.5 µM FCCP (Sigma-Aldrich, cat. no. C2920) and a mix of 0.5 µM rotenone (Sigma-Aldrich, cat. no. R8875) + 0.5 µM antimycin A (Sigma-Aldrich, cat. no. A8674)—separated by four measurement phases (baseline plus post‑injection 1–3). Each phase comprised three cycles of 3 min of mixing, 2 min of waiting and 3 min of measurement. After the assay, cells were lysed using M-PER Mammalian Protein Extraction Reagent (ThermoFisher, cat. no. 78501) supplemented with cOmplete Mini Protease Inhibitor Cocktail (Sigma-Aldrich, cat. no. 11836153001) and PhosSTOP (Sigma-Aldrich, cat. no. 4906845001), according to the manufacturer’s instructions. Total protein concentrations were determined using the Pierce Dilution-Free Rapid Gold BCA Protein Assay (ThermoFisher, cat. no. A55860), and oxygen‑consumption rate values were normalized to total protein content.
CRISPR organoid assays
H1-hESC-iCas9 cells were transduced with a pooled gRNA library containing four gRNAs per target gene, with 20% of the library comprising nontargeting gRNAs. Following selection with 1 µg ml−1 puromycin, the established cell line was used to generate cortical organoids following a well-established protocol121 with slight modifications. In brief, embryoid bodies were generated using AggreWell plates (Stemcell Technologies) according to the manufacturer’s instructions. Once formed, embryoid bodies were transferred to ultralow-attachment 10-cm plates (Corning) for further culture. Patterning was initiated using StemFlex base media (A3349401, cat. no. Gibco) supplemented with 100 nM LDN-193189 (x) and 10 µM SB431542 (x). The medium was refreshed daily. Organoids were cultured on an orbital shaker at 53 rpm for the duration of the protocol. On day 6, the patterning medium was replaced with growth media: Neurobasal A medium (cat. no. 10888022, Gibco), 1 × GlutaMAX (cat. no. 35050061, Gibco) and 1 × B27 (cat. no. 12587010, Gibco), supplemented with 20 ng ml−1 FGF (PeproTech) and 20 ng ml−1 EGF (PeproTech). On day 14, Cas9 expression was induced by treating the organoids with 2 µg ml−1 doxycycline (Sigma-Aldrich) for 72 h. From day 25, FGF and EGF were replaced with 20 ng ml−1 BDNF (PeproTech) and 20 ng ml−1 NT-3 (PeproTech). Media changes were performed every other day. Starting from day 42, organoids were maintained in growth medium without additional supplements. Medium was refreshed 2–3 times per week.
The organoids were maintained in culture for ~80 d, at which point five organoids from three biological replicates were collected for DNA extraction using the DNeasy Blood & Tissue Kit (cat. no. 69504, Qiagen). Extracted DNA was subjected to PCR amplicon sequencing with UMIs using a three-step PCR protocol. In the first step (PCR-1), UMI-containing primers (5′-ACACTCTTTCCCTACACGACGCTCTTCCGATCTACGTGACGTAGAAAGTAATAATTTCTTGGGT-3′ and 5′-GTGACTGGAGTTCAGACGTGTGCTCTTCCGATCTN(25252525)NNNNNNNNNACTCGGTGCCACTTTTTCAA-3′) were used for four cycles. PCR-2 utilized adaptor primers (5′-ACACTCTTTCCCTACACGACGCTCTTCCGATCT-3′ and 5′-GTGACTGGAGTTCAGACGTGTGCTCTTCCGATCT-3′) for 22 cycles. PCR-3, performed by the sequencing facility, added sample-specific indexing in seven additional cycles. The prepared libraries were sequenced on a NovaSeq platform with paired-end 150-bp reads, generating 10 million reads per sample, at the YCGA.
Fragments amplified by PCR were sequenced on a NovaSeq 6000 sequencer paired-end at 150 bp with ~10 million reads per sample. Flanking sequences on both side of gRNAs were trimmed using BBDuk, and reads were then mapped to gRNA reference sequences and counted using the MAGeCK package119. Raw counts for each gRNA were normalized to counts of scrambled gRNA. Abundances of each gRNA-target gene were then calculated by sum of all gRNAs targeting that gene after excluding gRNAs with low KO efficiency (<5%). Average log2-transformed FCs of gRNA-target abundance were compared between doxycycline-induced versus uninduced samples in day 77 samples.
Analysis of single-cell CRISPR-KO screens in NPCs, DIV7 and DIV21 iGLUTs, and DIV36 iGABAs
mRNA sequencing reads were mapped to the GRCh38 reference genome using the Cellranger Software (RRID:SCR_017344). To generate count matrices for GDO (gRNA) libraries, the kallisto indexing and tag extraction (kite) workflow was used. Count matrices were used as input into the R/Seurat package122 (v.5.1.0; RRID:SCR_007322) to perform downstream analyses, including quality control, normalization, cell clustering, GDO demultiplexing and covariate regression29,123. CRISPR-screen experiments in each cell type were processed independently. Within each cell type, ~100–80,000 cells were sequenced across four lanes. gRNA and RNA UMI feature counts were filtered removing the top and bottom deciles of cells based on distribution of counts in each cell type. The percentages of all the counts belonging to the mitochondrial, ribosomal and hemoglobin genes calculated using Seurat::PercentageFeatureSet were filtered with cell-type-specific thresholds, given the relatively high proportion of mitochondrial genes expressed in neurons. Mitochondrial, ribosomal and hemoglobin genes as well as MALAT1 were removed (^RP[SL][[:digit:]]|^RPLP[[:digit:]]|^RPSA|^HB[AEGQ][[:digit:]]|^HB[ABDMQ]|^MT-|^MALAT1$). Lowly expressed genes, those that had at fewer than two read counts in 90% of samples, were also removed. Hashtag and guide-tag raw counts were normalized using centered log ratio transformation, where counts were divided by the geometric mean of the corresponding tag across cells and log-transformed. gRNA demultiplexing was performed using the Seurat::MULTIseqDemux function for each lane individually and then counts were merged across lanes (Supplementary Fig. 3b). In NPCs, 94,363 cells were retained after filtering and removal of negatively assigned cells, with 62.7% classified as doublets and 37.3% classified as singlets. In DIV7 and DIV21 iGLUTs, 57,685 and 31,473 cells were retained, with 34% and 9.8% doublets and 66% and 90.2% singlets, respectively. In DIV35 iGABAs, 64,462 cells were retained, with 48.3% doublets and 51.7% singlets. For all downstream analyses, only cells with ‘singlet’ gRNA classification were used (26,549–38,097 cells per experiment) (Supplementary Fig. 4c–e). The number of singlet cells by gRNA per cell type shown in Supplementary Fig. 6a,b.
Cell-type-specific population heterogeneity correction
Gene-expression-based clustering was largely driven by cellular heterogeneity, cell quality and sequencing lane effects. gRNA identity was not correlated with these covariates (Supplementary Fig. 7), so we adjusted for transcriptomic variability arising from cellular heterogeneity by applying maturity and cellular subtype scores across both perturbed and nonperturbed cells. First, variation related to cell-cycle phase of individual cells was accounted for by assigning cell-cycle scores using Seurat::CellCycleScoring, which uses a list of cell-cycle markers124 to segregate by markers of G2/M phase and markers of S phase. Second, to address variance due to cellular heterogeneity within a single experiment, we adapted the method applied by Seurat::CellCycleScoring to calculate a ‘Maturity.Score’ and ‘Subtype.Score’ for each cell based on cellular subtype (more variable in mature GABAergic neurons) and developmental time-point-specific markers (mora variable in NPCs and immature iGLUTs) (Supplementary Tables 2 and 3). Cells with outlier maturity scores and subtype scores were removed from downstream analyses. RNA UMI count data were then normalized and log-transformed, and the percentages of mitochondrial, hemoglobulin and ribosomal genes (markers of cell quality), lane, cell-cycle scores (Phase) and maturity scores regressed out using Seurat::SCTransform. The scaled residuals of this model represent a ‘corrected’ expression matrix, which was used for all downstream analyses.
Although demultiplexing assigned the correct guide identity to each cell, to remove ‘false positives’ whereby gRNAs were assigned but gene expression was unperturbed, the transcriptomes of gRNA clusters were evaluated relative to scramble gRNAs, ensuring that cells assigned to a guide-tag identity class demonstrated successful perturbation of the targeted NDD gene. To remove subsequent ‘false negatives’, whereby a successful CRISPR-KO may not result in significant downregulation of the targeted gene29 yet still achieve an overall transcriptomic profile distinct from scramble populations, we performed WNN analysis to assign clusters based on both guide-tag identity class and gene expression30. To identify successfully perturbed cells, the transcriptomes of gRNA clusters were compared with scramble-gRNA control clusters by differential gene expression analysis (Wilcoxon rank sum), comparing each cluster with all other clusters. Nontargeting WNN clusters and KO gRNA WNN clusters were filtered by setting a quantile base average expression threshold of target genes based on the distribution of target gene average expression across all other clusters. Clusters were the collapsed by gRNA identity; gRNAs with less than 75 cells were removed from analysis. These cells were then used for downstream differential gene-expression analyses125. For each cell type individually, single-cell gene expression matrices were Pseudobulked using scuttle::aggregateAcrossCells function across lanes (four pseudo-bulk samples per perturbation) and lowly expressed genes were removed (leaving 18,000–22,000 genes), followed by edgeR/limma differential gene expression analysis (RRID:SCR_010943). Concordance between Wilcoxon rank sum differential gene expression analysis using single-cell data and limma:voom using Pseudobulked data was assessed for each gene.
Altogether, Wilcoxon rank sum was applied to measure NDD gene knockdown from single-cell DEG analysis. Given the concordance between the DEG results using single-cell Wilcoxon and pseudo-bulk limma:voom (Supplementary Fig. 6c), all main figures and all Supplementary figures thereafter applied pseudobulked data analyzed with limma.
To validate whether the high correlation within-cell types was due to exactly the same scramble control cells, we re-performed DEG analyses using random selection of a subset of scramble cells for each cell type (Supplementary Fig. 8). Briefly, for each gene, 50% (if number of pseudobulked sample cells >50) or 80% (if number of pseudobulked sample cells <50) of scramble cells were randomly selected using the sample function from R. DEG analyses were then performed as described above using the limma/dreamlet package between KOs and a subset of scrambles different among genes. The process was repeated three times to avoid random selection bias and the median of each gene logFC was used as the final logFC. Average overlap of random scramble cells across different genes is ~50%.
Meta-analysis of gene expression across perturbations31
Across NDD KOs, DEGs were meta-analyzed (METAL126), and ‘convergent’ genes were defined as those with significant and shared direction of effect across all NDD gene perturbations and with nonsignificant heterogeneity (FDR-adjusted Pmeta < 0.05, Cochran’s heterogeneity Q-test PHet > 0.05). To test convergence between NDD KOs, meta-analyses were performed across all possible combinations of 2–5 KO perturbations with and without sub-setting for those shared across cell types (>40,000 combinations across cell types) (Supplementary Data 1).
Bayesian bi-clustering to identify convergent networks31
Across NDD KOs, convergent networks were generated by Bayesian bi-clustering127 and undirected gene co-expression network reconstruction from the NDD KOs. Not constrained by statistical cut-offs, and able to capture the effect of more lowly expressed genes, convergent networks may be a more sensitive measure of convergence. Networks were built based on bi-clustering (BicMix)128 using log2CPM (counts per million) expression data from all the replicates across each of the NDD gene sets and scramble gRNA jointly. We performed 40 runs of BicMix with the default parameters on these data and the output from iteration 400 of the variational Expectation-Maximization algorithm was used. Target Specific Network reconstruction128 was performed to identify convergent networks across all possible combinations of the nine NDD gene KO perturbations shared across cell types (n = 502 combinations per cell type) and randomly sampled combinations of 2–21 KO perturbations without sub-setting for those shared across cell types (n = 1,400–2,300 combinations).
Influence of functional similarity on convergence degree
To test the influence of functional similarity and brain co-expression between KOs on convergence and compare the degree of convergence between the same KOs in different cell types, we established two methods for defining and measuring convergence. First, gene-level convergence using meta-analysis as described above, with the strength of convergence for each set defined as ratio of convergent genes to the average number of DEGs.
Second, network-level convergence based on undirected network reconstruction from Bayesian bi-clustering as described above. Bi-clustering identifies co-expressed genes shared across the downstream transcriptomic impacts of any given set of KO perturbations; thus, the resolved networks are the transcriptomic similarities between distinct perturbations (convergence). We calculated the ‘degree of convergence’ for each network based on a previously described metric31. Briefly, convergence scores are based on: (1) network connectivity, as defined by the sum of the clustering coefficient (Cp) and the difference in average length path (Lp) from the maximum average length path resolved across all possible sets [(max)Lp-Lp]; (2) similarity of network genes based on biological pathway membership scored by taking the sum of the mean semantic similarity (semsim) scores129 between all genes in the network; and (3) minimum percentage duplication rate across 40 runs. Duplication thresholds are network-dependent and a metric of confidence in the connections.
Functionally, similarity scores across the NDD KO genes represented in each set were calculated using: (1) Gene Ontology Semantic Similarity Scores: the average semantic similarity score based on Gene Ontology pathway membership within Biological Pathway (BP), Cellular Component (CC) and Molecular Function (MF) between NDD genes in a set129; and (2) brain expression correlation score: based on the strength of the correlation in NDD gene expression in the Common Mind Consortium (CMC) (n = 991 after quality control) post-mortem DLPFC gene expression data.
We performed Pearson’s correlation analysis (Holm’s-adjusted P) on similarity scores and the degree of network convergence to determine the influence of the similarity of the initial KO genes on downstream convergence. We compared the average strength of convergence across cell types using a parametric Welch’s F-test and pairwise Games–Howell test.
Enrichment analysis of convergence for risk loci using MAGMA
We intersected cross-cell-type perturbation-specific and cross-perturbation cell-type-specific gene-level convergence with genetic risk of psychiatric and neurological disorders/traits (attention-deficit/hyperactivity disorder130, anorexia nervosa131, ASD2, alcohol dependence132, bipolar disorder133, cannabis use disorder134, major depressive disorder135, obsessive-compulsive disorder136, post-traumatic stress disorder137, SCZ138, Cross disorder139, Alzheimer disease140, Parkinson disease141, amyotrophic lateral sclerosis142, Tourette’s143, migraine144, chronic pain145 and neurotic personality traits146, GWAS summary statistics) using multi-marker analysis of genomic annotation (MAGMA)23. SNPs were mapped to genes based on the corresponding build files for each GWAS summary dataset using the default method, snp-wise = mean (a test of the mean SNP association). A competitive gene set analysis was then used to test enrichment in genetic risk for a disorder across gene sets with an FDR < 0.05.
To test whether observed effects were due to the differential size of the gene sets for each GWAS or owing to the fact that DEGs are more likely to include neural genes, which are more likely to be associated with brain disorder, GWAS sets were filtered for genes expressed in each cell type before enrichment testing, and enrichment tests were performed after randomly down-sampling GWAS gene sets to 100, 250, 500, 750 and 1,000 genes (Supplementary Fig. 9), and performed ten times within each set size (that is, 50 tests for each GWAS).
Over-representation analysis, functional enrichment annotation and biological theme comparison of convergence
To identify pathway enrichments unique to individual KOs, convergent genes and convergent networks based on zebrafish behavioral subgroups (see the zebrafish methods below), we performed biological theme comparison and gene set enrichment analysis (GSEA) (ClusterProfiler147; RRID:SCR_016884). Using FUMAGWAS: GENE2FUNC, the 102 ASD genes were functionally annotated and an over-representation gene-set analysis for each convergent gene set was performed148. Using WebGestalt (WEB-based GEne SeT AnaLysis Toolkit149; RRID:SCR_006786), over-representation analysis was performed on all convergent gene sets against publicly available gene set lists GeneOntology, KEGG, DisGenNet and Human Phenotype Ontology, and a curated gene list of rare-variant targets associated with ASD, SCZ and ID25.
Random forest prediction model of convergence strength
To determine how well functional similarity between KOs can predict gene-level and network-level convergence, we trained a random forest model32 (randomForest package in R; RRID:SCR_015718) for each type of convergence, evaluated the model in an independent internal dataset and validated the model in an external CRISPRa activation screen31. Data from randomly tested gene combinations (2–5 KO sets at the gene level and 2–10 KO sets at the network level) tested across cell types were randomly down-sampled into a training set (70%) and a testing set (30%)—all with comparable proportions of data by cell type. The random forest model was trained with bootstrap aggregation using CC, MF and BP semantic similarity scores, brain expression correlation, number of genes and cell type as predictors. The random forest linear regression model was evaluated in the testing data by comparing actual values with predicted values, estimating the root mean squared error and performing Pearson’s correlations. Predictor models were validated using an external dataset of ten CRISPR-activation perturbations of SCZ common variant target genes with multifunctional annotations broadly grouped as signaling/cell communication (CALN1, NAGA, FES, CLCN3, PLCL1) and epigenetic/regulatory (SF3B1, TMEM219, UBE2Q2L, ZNF804A, ZNF823)31, and assessed based the root mean squared error and Pearson’s correlation between actual and predicted convergence strength.
LNCTP in silico model
To investigate the perturbation of ASD genes in silico, we adapted the LNCTP model33 to predict the effects of changes in gene expression in the PFC, across neuronal and non-neuronal cell types. The LNCTP is defined as an energy model representing the joint distribution of a collection of phenotypes of interest conditioned on the genotype. Since we are interested primarily in the effects of gene expression perturbations on the expression of other genes, we use only the imputation segment of the LNCTP model (excluding the prediction of higher-order phenotypes and cell–cell interactions).
The probabilistic model for the imputation-based LNCTP may be expressed as:
Here \({z}_{i}\) represents the genotype of individual i, and \({x}_{i}\) represents bulk and cell-type-specific gene expression from individual i. We further index the gene expression by \(C\) cell types (which are here: excitatory neurons, inhibitory neurons, oligodendrocytes, astrocytes, oligodendrocyte precursor cells, endothelial cells and microglia), which will be denoted \({x}_{1},\,{x}_{2},\,\ldots {x}_{C}\), and we will use \({x}_{0}\) to denote the bulk expression. The variables \({f}_{1\ldots C}\) represent the estimated cell fractions in the bulk observations (predicted from the genotype, \(z\)). The parameters of the model are \(\theta =\{{\beta }_{1\ldots G},\,{J}_{0\ldots C}\}\) and \(\lambda\) acts as a hyperparameter. The parameters \({\beta }_{1\ldots G}\) and \({J}_{0\ldots C}\) reflect the gene-specific expression biases and pairwise interactions, respectively, whose nonzero elements are determined by the sparsity structure arising from expression quantitative trait loci (eQTLs) and gene regulatory network (GRN) linkages, respectively; the nonzero elements of \({J}_{c}\) occur only between genes connected in the GRN of cell type \(c\).
Further details on the training of the model in Eq. (1) can be found in ref. 33; here, we outline the specific differences in the training for the purposes of our analysis. As in ref. 33, we used genetics and expression data from post-mortem PFC samples from the PsychENCODE consortium. However, we group together samples from all higher-order phenotypes during training (control, SCZ, bipolar disorder and ASD), and split the data into three partitions of size 760, 100 and 100 for training, validation and testing, respectively (each including samples from all higher-order phenotypes). Further, we include all 29 CRISPR targeted genes, 102 NDD genes5, transcription factors33 and neuropsychiatric transcriptome-wide association analysis (TWAS)-selected genes33, and the top 100 up- and downregulated CRISPR convergent genes in iGLUT and iGABA cells (400 genes in total), in the model, generating 1,325 genes in total. The expression quantitative trait loci (eQTL) and GRN linkages from PsychENCODE are then restricted to this subset of genes.
LNCTP simulating perturbations
To perform perturbations in this model corresponding to the 29 CRISPR targeted genes, we use the following perturbation-conditioned version of the LNCTP model:
where \(({c}^{* },\,{g}^{* })\) denotes the perturbed gene and cell type, whose expression is set to \(k\) or \(-k\), \(\delta (a)\) is a delta function whose value is 0 if expression \(a\) is true, and 1 otherwise, and \(K\) is an arbitrarily large value. We perturb each of the CRISPR targeted genes in turn in the bulk network, using \(k=2\), and applying a negative perturbation to mimic the effect of the CRISPR perturbation. We note that, since the model is trained on Z-scored log-normalized expression counts, this corresponds to introducing a large negative FC to the selected gene. The in silico-predicted log FCs per individual across all genes (per cell type) are then calculated by comparing the expected values before and after perturbation:
and the final predicted log FCs are calculated by taking the expectation across individuals. We use the sampling approach in ref. 33 to evaluate the expectations in Eq. (3).
To perform perturbations across all 102 NDD genes, for efficiency, we learn a reduced model by removing the dependency on \({z}_{i}\) in Eq. (1). We sample cell-type-specific expression values for each individual from the full model, and then fit the reduced model by refitting the model parameters to maximize the likelihood of the full data vectors (consisting of the original bulk and sampled cell-specific expression vectors for each individual). Perturbations are performed in the reduced model as in Eq. (2) and FCs are calculated as in Eq. (3), while removing the dependency on \({z}_{i}\) and the i subscripts, respectively.
LNCTP in silico convergent genes
To identify in silico convergent genes for a set of perturbations, \(S=\left\{\left({c}_{1}^{* },{g}_{1}^{* }\right),\ldots ,\left({c}_{N}^{* },{g}_{N}^{* }\right)\right\}\), we calculate \({\Delta }_{c,g}\) using Eq. (3) for each perturbation, writing \({\Delta }_{c,g}^{{c}^{* },{g}^{* }}\) for the log FC to \(\left(c,g\right)\) generated by applying perturbation \(\left({c}^{* },{g}^{* }\right)\), and \({\Delta }_{c,g}^{S}\) for the vector of log FCs created by applying all perturbations in \(S\). Then, the set of in silico convergent genes for \(S\) is found by selecting those for which \({P}_{{\rm{sign}}}({\Delta }_{c,g}^{S}[|{\Delta }_{c,g}^{S}|\ge \tau ]) < 0.1\), where \({P}_{{\rm{sign}}}(.)\) is the P value from a two-tailed one-sample sign-test, and juxtaposition represents element-wise multiplication of vectors. The threshold \(\tau\) is introduced to reduce noise from perturbations that are estimated to generate small log FCs, and throughout we set \(\tau =0.3\).
For the comparison of in silico convergent genes derived from different perturbation sets \(S\), we apply two-sided hypergeometric tests to the gene sets defined as above (using all 1,325 genes in our model as the background set). For GSEA of convergent genes derived from \(S\), we apply clusterprofiler147 to the full set of genes in our model, ranked by \({P}_{{\rm{sign}}}({\Delta }_{c,g}^{S}[|{\Delta }_{c,g}^{S}|\ge \tau ])\) as defined above.
LNCTP semantic distance test
To test the semantic distance between enriched terms for two sets of perturbations, \({S}_{1}\) and \({S}_{2}\), we generate the set of enriched terms \({T}_{1}\) and \({T}_{2}\) by applying GSEA to each set as described above (using Benjamini–Höchberg correction and an FDR threshold of 0.2 to select enriched terms \({T}_{1}\) and \({T}_{2}\)). We then calculate the similarity between terms \({t}_{1}\) and \({t}_{2}\) by evaluating \(s\left({t}_{1},{t}_{2}\right)=\left|G\left({t}_{1}\right)\cap G\left({t}_{2}\right)\right|/\left|G\left({t}_{1}\right)\cup G\left({t}_{2}\right)\right|\), where \(G\left(t\right)\) denotes the set of genes occurring in the leading edge of term \(t\). We test for a significant semantic distance between \({S}_{1}\) and \({S}_{2}\) by evaluating \(s\left({t}_{1},{t}_{2}\right)\) between all pairs \({t}_{1}\in {S}_{1}\), \({t}_{2}\in {S}_{2}\), versus all pairs \({t}_{1}\in {S}_{1}\), \({t}_{2}\in {S}_{1}\) and \({t}_{1}\in {S}_{2}\), \({t}_{2}\in {S}_{2}\), and applying a one-sided rank-sum test for the smaller similarity in the former pairs versus the latter.
Transcriptional correlations between hiPSC-derived neural cells, fetal and adult brain cell types and the zebrafish brain
We compared wild-type (WT) zebrafish brain expression with gene expression in our hiPSC-derived models and with sign-cell expression data for the fetal and adult PFC (PsychENCODE150,151: http://resource.psychencode.org/Datasets/Derived/SC_Decomp/DER-20_Single_cell_expression_processed_TPM.tsv). We first filtered zebrafish gene names and converted them to the appropriate Homo sapiens orthologs using the R package orthogene (v3.2.1152); genes without matched orthologs were dropped from both species. Pseudo-bulk expression data from scramble control cells were used as the baseline expression across NPCs, day 7 iGLUTs, day 21 iGLUTs and day 36 iGABAs. Pearson’s correlation coefficients between in vitro cells, fetal and adult post-mortem brain cells and zebrafish brain were calculated and a Bonferroni correction applied.
Zebrafish
All procedures involving zebrafish were conducted in accordance with IACUC (protocol no. 2024-20054) regulatory standards at Yale University. Zebrafish larvae were raised at 28 °C on a 14-h:10-h light:dark cycle. Larvae were grown in 150-mm Petri dishes in blue water (0.3 g l−1 Instant Ocean, 1 mg l−1 methylene blue, pH 7.0) at a density of 60–80 larvae per dish. Behavioral assays were conducted in zebrafish larvae at 5–7 days post fertilization (dpf). At these developmental stages, sex is not yet determined.
Zebrafish mutant generation
We performed automated, high-throughput, quantitative behavioral profiling of larval zebrafish to measure arousal and sensorimotor processing as a read-out of circuit-level deficits resulting from gene perturbation41. We quantified 24 parameters across sleep–wake activity and visual-startle responses in 18 stable homozygous mutant or F0 mosaic crispant lines for 15 NDD genes (Supplementary Tables 7 and 8). Stable zebrafish lines were generated by our lab (arid1bΔ7/Δ7, chd2Δ7/Δ7, chd8Δ7/Δ7, chd8Δ5/Δ5, kdm5baΔ17/Δ17bΔ14/Δ14, kdm5ba4i/4ibΔ4/Δ4)41 or provided as a generous gift from the Thyme lab (ash1l1i,Δ60,19i/1i,Δ60,19i, kmt5bΔ208,1i,Δ5/Δ208,1i,Δ5, kmt2caΔ82,17i/Δ82,17ibΔ6,Δ29/Δ6,Δ29, nrxn1aΔ218/Δ218)153,154.
kmt5b uab320/+: ZDB-ALT-220315-26
kmt2ca uab318/+: ZDB-ALT-220315-24
kmt2cb uab319/+: ZDB-ALT-220315-25
ash1l uab305/+: ZDB-ALT-220315-11
chd8 ya509/+: ZDB-ALT-240514-1
chd8 ya510/+: ZDB-ALT-240514-2
kdm5ba ya523/+: ZDB-ALT-240514-15
kdm5bb ya525/+: ZDB-ALT-240514-17
kdm5ba ya524/+: ZDB-ALT-240514-16
kdm5bb ya 526/+: ZDB-ALT-240515-1
nrxn1a uab403/+: ZDB-ALT-220720-20
F0 crispants for the following genes were generated as in ref. 155: chd2, kdm6bab, mbd5, phf12ab, phf21aab, skiab, smarcc2, wacab. Briefly, we designed two CRISPR crRNAs per allele, prioritizing early exons for targeting. CRISPR RNPs were assembled individually and then combined before injection at the one-cell stage. The number of scrambled guides injected into the control group was matched to the number of CRISPR guides used for the experimental group. Injected embryos were raised to 5 dpf at which point the behavioral assays (described below) were conducted. We identified unique behavioral fingerprints for each NDD gene mutant, revealing convergent and divergent phenotypes across mutants (Supplementary Fig. 22b). To classify convergent behavioral subgroups that may share circuit-level functions, we performed correlation analyses with hierarchical clustering across mutants. We identified four distinct subgroups of NDD genes with highly correlated behavioral features (Fig. 7a).
Behavioral assays
Larvae were placed into individual wells of a 96-well plate (cat. no. 7701-1651; Whatman) containing 650 μl of standard embryo water (0.3 g l−1 Instant Ocean, 1 mg l−1 methylene blue, pH 7.0) per well within a Zebrabox (ViewPoint Life Sciences). Locomotion was quantified with an automated video-tracking system (Zebrabox and ZebraLab software). The visual-startle assay (VSR) was conducted at 5 dpf (ref. 41). Briefly, to assess larval responses to lights-off stimuli (VSR-OFF), larvae were acclimated to white light for 1 h, and baseline activity was tracked for 30 min followed by five 1-s dark flashes with intermittent white light for 29 s. To evaluate larval responsivity to lights-on stimuli (VSR-ON), the assay was reversed, where larvae were acclimated to darkness for 1 h, and baseline activity was tracked for 30 min followed by five 1-s white light flashes with intermittent darkness for 29 s. For VSR-OFF and VSR-ON, six behavioral parameters were quantified using custom MATLAB code41 (available from GitHub via https://github.com/ehoffmanlab/Weinschutz-Mendes-et-al-2023-behavior; https://doi.org/10.5281/zenodo.7644898(ref. 156)): (1) average intensity of all startle responses; (2) average post-stimulus activity; (3) average activity after first stimulus; (4) stimulus versus post-stimulus activity; (5) intensity of responses to the first stimulus; (6) intensity of responses to the final stimulus. To assess arousal responses in daytime and nighttime, the sleep–wake paradigm was conducted between 5 and 7 dpf, following the VSR-OFF and VSR-ON assays. During a 14-h:10-h white light:darkness cycle, larvae activity and sleep patterns were tracked within the Zebrabox and analyzed with custom MATLAB code41,157,158 (available from GitHub via (https://github.com/JRihel/Sleep-Analysis/tree/Sleep-Analysis-Code; https://doi.org/10.5281/zenodo.7644073 (ref. 159)). Six behavioral parameters were quantified for daytime and nighttime: (1) total activity; (2) total sleep; (3) waking activity; (4) rest bouts; (5) sleep length; (6) sleep latency. Across VSR-OFF, VSR-ON and sleep–wake assays, we analyzed 24 parameters. For stable mutant lines, behavioral assays were performed blind to genotype using sibling- or cousin-matched larvae from heterozygous in-crosses with genotyping performed after each experiment. Experiments were repeated at least in duplicate for each line. Our analysis focused on homozygous mutants, which typically exhibit more robust phenotypes than heterozygotes. For CRISPR F0 mutants, experiments were performed once with experimenters aware of which larvae were injected with scrambled versus gene-targeting RNPs. Larval movement was quantified blind to genotype using commercial tracking software as described above. Larvae were genotyped after each experiment to confirm the presence of on-target mutations. Baseline behavioral screening sample sizes are as follows: kmt5b WT n = 62, HOM n = 71; mbd5 scrambled n = 39, crispant n = 56; kdm5bab 4i:del4 WT n = 42, HOM n = 55; kdm5bab del17:del14 n = 68, HOM n = 69; phf12ab scrambled n = 32, crispant n = 15; skiab scrambled n = 45, crispant n = 33; chd2 scrambled n = 43, crispant n = 40; smarcc2 scrambled n = 36, crispant n = 35; kdm6bab scrambled n = 40, crispant n = 34; kmt2cab WT n = 38, HOM n = 20; wacab scrambled n = 32, crispant n = 32; arid1b WT n = 81, HOM n = 81; phf21a scrambled n = 52, crispant n = 44; chd8 del7 WT n = 180, HOM n = 164; chd8 del5 WT n = 143, HOM n = 167; ash1l WT n = 19, HOM n = 23; nrxn1a WT n = 24 HOM n = 28. Based on our power analyses for baseline behavioral experiments, we estimated that a sample size of 28–41 fish per group provides 80% power to detect a 20–30% change in behavior (ANOVA, α set at 0.05).
Behavioral analysis
Linear mixed models (LMMs) were used to compare phenotypes of each behavioral parameter between homozygous mutant versus WT or crispant versus scramble-injected fish for each gene of interest. Variations of behavioral phenotypes across experiments were accounted for by including the date of the experiment as a random effect in LMM. Hierarchical clustering analysis was performed to cluster mutants and behavioral parameters based on signed −log10-transformed P values from LMM, where sign indicates direction of the difference in behavioral phenotype when comparing stable mutant with WT or crispant with scrambled-injected. Pearson’s correlation analysis was used to assess correlations between mutants based on the difference in the 24 parameters. Difference was evaluated using signed −log10-transformed P values. For the behavioral data, we assumed the data distribution to be normal but not of equal variance. We did not formally test the normality assumption.
Drug prioritization based on zebrafish pharmaco–behavioral profiles
NDD gene-associated mutant and crispant behavioral phenotypes were compared with a dataset of 376 US Food and Drug Administration-approved drugs that were screened for their behavioral effects in larval zebrafish using the visual-startle and sleep–wake assays described above46. These drugs have a significant effect on at least two behavioral parameters (LMM, P < 0.05/3, corrected for three behavioral assays). Pearson’s correlation analysis was used to identify drugs that significantly correlate (correlation > 0.5, P < 0.05, t-statistic) or anti-correlate (correlation < −0.5, P < 0.05, t-statistic) with mutant behavioral signatures (Supplementary Data 2 and 3).
Drug prioritization based on perturbation signature reversal in LiNCs neuronal cell lines
To identify drugs that could reverse cell-type-specific convergence across different KOs, we used the Query tool from The Broad Institute’s CMap Server45. Briefly, the tool computes weighted enrichment scores (WTCS) between the query set and each signature in the CMap LiNCs gene expression data (dose, time, drug, cell line), normalizes the WTCS by dividing by the signed mean within each perturbation (NCS) and computes FDR as fraction of ‘null signatures’ (DMSO) where the absolute NCS exceeds reference signature. We prioritized drugs that were negatively enriched for convergent signatures specifically in neuronal cells (either neurons or NPCs with NCS ≤ −1.00, FDR ≤ 0.05) and filtered for drugs that had clinical data in humans and paired behavioral phenotyping in zebrafish (Supplementary Data 2).
Targeted drug rescue of behavioral phenotypes in zebrafish
For mutant × drug experiments, larval activity was monitored from 5–7 dpf using the behavioral assays described above. Individual WT zebrafish larvae were added to each well of a 96-well plate containing 650 μl of standard embryo water. A 5 mM stock solution of each compound dissolved in DMSO or DMSO alone (control) was pipetted directly into each well after which the visual-startle and sleep–wake assays were performed. Drugs were tested at a final concentration of 10 μM (0.2% DMSO final concentration) in background-matched homozygous and WT larvae or crispant and scrambled control-injected larvae. For stable mutant lines, behavioral assays were performed blind to genotype using sibling- or cousin-matched larvae from heterozygous in-crosses with genotyping performed after each experiment. For CRISPR F0 mutants, experiments were performed once with experimenters aware of which larvae were injected with scrambled versus gene-targeting RNPs. Larval movement was quantified blind to genotype using commercial tracking software as described above. Larvae were genotyped after each experiment to confirm the presence of on-target mutations. Mutant × drug behavioral assays were repeated 1–3× for stable mutant lines and 1× for crispants. Sample sizes are as follows: phf21a + amiodarone scrambled DMSO n = 24, F0 DMSO n = 22, F0 AMIO n = 23; phf21a + fluvoxamine scrambled DMSO n = 24, F0 DMSO n = 22, F0 FLUVO n = 21; chd2 + pravastatin WT DMSO n = 27, HOM DMSO n = 21, HOM PRAVA n = 23; kdm6b + paclitaxel scrambled DMSO n = 24, F0 DMSO n = 24, F0 PACLI n = 24; kdm6b + sirolimus scrambled DMSO n = 24, F0 DMSO n = 24, F0 SIRO n = 23; kmt5b + paclitaxel WT DMSO n = 20, HOM DMSO n = 22, HOM PACLI n = 26; kmt5b + sirolimus WT DMSO n = 27, HOM DMSO n = 26, HOM SIRO n = 20; ash1l + sunitinib WT DMSO n = 14, HOM DMSO n = 13, HOM SUN n = 12; ash1l + ezetimibe WT DMSO n = 15, HOM DMSO n = 12, HOM EZE n = 9; ash1l + rosuvastatin WT DMSO n = 27, HOM DMSO n = 22, HOM ROSU n = 22; ash1l + repaglinide WT DMSO n = 11, HOM DMSO n = 16, HOM REPAG n = 14. Based on our power analysis, we estimate that a sample size of 10–12 fish per group will provide 95% power to detect a 40–43% change in behavior (ANOVA, α set at 0.05), based on our previous pharmaco-behavioral screen160.
For behaviors that were nominally significantly different between mutant + DMSO and WT + DMSO (P < 0.06), we characterized the effect of the mutant × drug on behavior as: (1) ‘exacerbated’ (significant effect mutant + drug-v-WT > significant effect mutant-v-WT) if mutant behavior P ≤ 0.06 and mutant × drug behavior P value ≤ mutant behavior P value with increased absolute beta values (that is, stronger P value with appreciable difference in the magnitude of effect but not direction); (2) ‘unchanged’ (significant effect mutant + drug-v-WT = significant effect mutant-v-WT); (3) ‘partial rescue’ (significant effect mutant + drug-v-WT < significant effect mutant-v-WT) if mutant behavior P value ≤ mutant × drug behavior P value with reduced effects on the absolute beta value; (4) ‘rescued’ (significant effect mutant-v-WT, no significant effect mutant + Drug-v-WT) if mutant behavior P ≤ 0.06 and mutant × drug behavior P > 0.06; (5) ‘over-corrected’ (mutant + drug-v-WT opposite direction of significant effect mutant-v-WT) if mutant behavior P ≤ 0.06 and mutant × drug behavior P ≤ 0.06, with opposing directions of effect.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
Key Resource Table available at https://doi.org/10.5281/zenodo.19457279. All hiPSCs are available from the Rutgers University Cell and DNA Repository (study 160; http://www.nimhstemcells.org/). Protocols are available from https://www.protocols.io/workspaces/brennand-laboratory. scRNA-seq data reported in this paper are publicly available from the Gene Expression Omnibus (GSE319096). Previously published SCZ CRISPRa screen datasets that were used for external validation of random forest models are available from the GEO (GSE200774) and from Synapse (syn27819129). Secondary summary statistics from the main analysis are available from Synapse (syn72039767). Source data are provided with this paper.
Code availability
The full analysis pipeline (including code and processed data objects) used for analysis of single-cell CRISPR-KO data, evaluation and characterization of gene-level and network-level convergence, and predictive modeling using random forests are publicly available from Synpase (syn72039767). Custom MATLAB software developed by the Hoffman Lab to analyze visual-startle response parameters is available from GitHub via https://github.com/ehoffmanlab/Weinschutz-Mendes-et-al-2023-behavior; https://doi.org/10.5281/zenodo.7644898 (ref. 156). Custom MATLAB software developed by J. Rihel to analyze sleep–wake assays is available from GitHub via https://github.com/JRihel/Sleep-Analysis/tree/Sleep-Analysis-Code; https://doi.org/10.5281/zenodo.7644073 (ref. 159).
References
Sandin, S. et al. The heritability of autism spectrum disorder. JAMA 318, 1182–1184 (2017).
Grove, J. et al. Identification of common genetic risk variants for autism spectrum disorder. Nat. Genet. 51, 431–444 (2019).
Mahjani, B. et al. Prevalence and phenotypic impact of rare potentially damaging variants in autism spectrum disorder. Mol. Autism 12, 65 (2021).
Satterstrom, F. K. et al. Large-scale exome sequencing study implicates both developmental and functional changes in the neurobiology of autism. Cell 180, 568–584 (2020).
Fu, J. M. et al. Rare coding variation provides insight into the genetic architecture and phenotypic context of autism. Nat. Genet. 54, 1320–1331 (2022).
Singh, T. et al. Rare coding variants in ten genes confer substantial risk for schizophrenia. Nature 604, 509–516 (2022).
Palmer, D. S. et al. Exome sequencing in bipolar disorder identifies AKAP11 as a risk gene shared with schizophrenia. Nat. Genet. 54, 541–547 (2022).
Willsey, A. J. et al. Coexpression networks implicate human midfetal deep cortical projection neurons in the pathogenesis of autism. Cell 155, 997–1007 (2013).
Fazel Darbandi, S. et al. Five autism-associated transcriptional regulators target shared loci proximal to brain-expressed genes. Cell Rep. 43, 114329 (2024).
Markenscoff-Papadimitriou, E. et al. Autism risk gene POGZ promotes chromatin accessibility and expression of clustered synaptic genes. Cell Rep. 37, 110089 (2021).
Parikshak, N. N. et al. Integrative functional genomic analyses implicate specific molecular pathways and circuits in autism. Cell 155, 1008–1021 (2013).
Voineagu, I. et al. Transcriptomic analysis of autistic brain reveals convergent molecular pathology. Nature 474, 380–384 (2011).
Liao, C. et al. Convergent coexpression of autism-associated genes suggests some novel risk genes may not be detectable in large-scale genetic studies. Cell Genom. 3, 100277 (2023).
Pintacuda, G. et al. Protein interaction studies in human induced neurons indicate convergent biology underlying autism spectrum disorders. Cell Genom. 3, 100250 (2023).
Gao, Y. et al. Proximity analysis of native proteomes reveals phenotypic modifiers in a mouse model of autism and related neurodevelopmental conditions. Nat. Commun. 15, 6801 (2024).
Willsey, H. R., Willsey, A. J., Wang, B. & State, M. W. Genomics, convergent neuroscience and progress in understanding autism spectrum disorder. Nat. Rev. Neurosci. 23, 323–341 (2022).
O’Neill, A. C. et al. Spatial centrosome proteome of human neural cells uncovers disease-relevant heterogeneity. Science 376, eabf9088 (2022).
Sun, N. et al. Autism genes converge on microtubule biology and RNA-binding proteins during excitatory neurogenesis. Preprint at bioRxiv https://doi.org/10.1101/2023.12.22.573108 (2024).
Kostyanovskaya, E. et al. Convergence of autism proteins at the cilium. Preprint at bioRxiv https://doi.org/10.1101/2024.12.05.626924 (2025).
Marshall, C. R. et al. Contribution of copy number variants to schizophrenia from a genome-wide study of 41,321 subjects. Nat. Genet. 49, 27–35 (2017).
Johannesen, K. M. et al. Defining the phenotypic spectrum of SLC6A1 mutations. Epilepsia 59, 389–402 (2018).
Heyne, H. O. et al. De novo variants in neurodevelopmental disorders with epilepsy. Nat. Genet. 50, 1048–1053 (2018).
de Leeuw, C. A., Mooij, J. M., Heskes, T. & Posthuma, D. MAGMA: generalized gene-set analysis of GWAS data. PLoS Comput. Biol. 11, e1004219 (2015).
Sullivan, P. F. & Geschwind, D. H. Defining the genetic, genomic, cellular, and diagnostic architectures of psychiatric disorders. Cell 177, 162–183 (2019).
Schrode, N. et al. Synergistic effects of common schizophrenia risk variants. Nat. Genet. 51, 1475–1485 (2019).
Wells, M. F. et al. Natural variation in gene expression and viral susceptibility revealed by neural progenitor cell villages. Cell Stem Cell 30, 312–332 (2023).
Zhang, Y. et al. Rapid single-step induction of functional neurons from human pluripotent stem cells. Neuron 78, 785–798 (2013).
Yang, N. et al. Generation of pure GABAergic neurons by transcription factor programming. Nat. Methods https://doi.org/10.1038/nmeth.4291 (2017).
Mimitou, E. P. et al. Multiplexed detection of proteins, transcriptomes, clonotypes and CRISPR perturbations in single cells. Nat. Methods 16, 409–412 (2019).
Hao, Y. et al. Integrated analysis of multimodal single-cell data. Cell 184, 3573–3587 (2021).
Deans, P. J. M. et al. Functional implications of polygenic risk for schizophrenia in human neurons. Nat. Commun. 17, 1355 (2026),
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Emani, P. S. et al. Single-cell genomics and regulatory networks for 388 human brains. Science 384, eadi5199 (2024).
Cederquist, G. Y. et al. A multiplex human pluripotent stem cell platform defines molecular and functional subclasses of autism-related genes. Cell Stem Cell 27, 35–49 (2020).
Lalli, M. A., Avey, D., Dougherty, J. D., Milbrandt, J. & Mitra, R. D. High-throughput single-cell functional elucidation of neurodevelopmental disease-associated genes reveals convergent mechanisms altering neuronal differentiation. Genome Res. 30, 1317–1331 (2020).
Paulsen, B. et al. Autism genes converge on asynchronous development of shared neuron classes. Nature 602, 268–273 (2022).
Meng, X. et al. Assembloid CRISPR screens reveal impact of disease genes in human neurodevelopment. Nature 622, 359–366 (2023).
Li, C. et al. Single-cell brain organoid screening identifies developmental defects in autism. Nature 621, 373–380 (2023).
Jin, X. et al. In vivo Perturb-Seq reveals neuronal and glial abnormalities associated with autism risk genes. Science https://doi.org/10.1126/science.aaz6063 (2020).
Willsey, H. R. et al. Parallel in vivo analysis of large-effect autism genes implicates cortical neurogenesis and estrogen in risk and resilience. Neuron 109, 1409 (2021).
Weinschutz Mendes, H. et al. High-throughput functional analysis of autism genes in zebrafish identifies convergence in dopaminergic and neuroimmune pathways. Cell Rep. 42, 112243 (2023).
Wang, B. et al. A foundational atlas of autism protein interactions reveals molecular convergence. Preprint at bioRxiv https://doi.org/10.1101/2023.12.03.569805 (2023).
Murtaza, N. et al. Neuron-specific protein network mapping of autism risk genes identifies shared biological mechanisms and disease-relevant pathologies. Cell Rep. 41, 111678 (2022).
Gonzalez, F. et al. An iCRISPR platform for rapid, multiplexable, and inducible genome editing in human pluripotent stem cells. Cell Stem Cell 15, 215–226 (2014).
Subramanian, A. et al. A next generation connectivity map: L1000 platform and the first 1,000,000 profiles. Cell 171, 1437–1452 (2017).
Jamadagni, P. et al. Pharmaco-behavioral profiling identifies suppressors of autism gene-associated phenotypes in zebrafish. Proc. Natl Acad. Sci. USA 123, e2518846123 (2026).
Manji, H. et al. Impaired mitochondrial function in psychiatric disorders. Nat. Rev. Neurosci. 13, 293–307 (2012).
Rossignol, D. A. & Frye, R. E. Mitochondrial dysfunction in autism spectrum disorders: a systematic review and meta-analysis. Mol. Psychiatry 17, 290–314 (2012).
Wang, Y., Picard, M. & Gu, Z. Genetic evidence for elevated pathogenicity of mitochondrial DNA heteroplasmy in autism spectrum disorder. PLoS Genet. 12, e1006391 (2016).
Varga, N. A. et al. Mitochondrial dysfunction and autism: comprehensive genetic analyses of children with autism and mtDNA deletion. Behav. Brain Funct. 14, 4 (2018).
Chalkia, D. et al. Association between mitochondrial DNA haplogroup variation and autism spectrum disorders. JAMA Psychiatry 74, 1161–1168 (2017).
Wang, Y. et al. Association of mitochondrial DNA content, heteroplasmies and inter-generational transmission with autism. Nat. Commun. 13, 3790 (2022).
Yardeni, T. et al. An mtDNA mutant mouse demonstrates that mitochondrial deficiency can result in autism endophenotypes. Proc. Natl Acad. Sci. USA https://doi.org/10.1073/pnas.2021429118 (2021).
Shen, M. et al. Reduced mitochondrial fusion and Huntingtin levels contribute to impaired dendritic maturation and behavioral deficits in Fmr1-mutant mice. Nat. Neurosci. 22, 386–400 (2019).
Fernandez, A. et al. Mitochondrial dysfunction leads to cortical under-connectivity and cognitive impairment. Neuron 102, 1127–1142 (2019).
Gandal, M. J. et al. Shared molecular neuropathology across major psychiatric disorders parallels polygenic overlap. Science 359, 693–697 (2018).
Kanellopoulos, A. K. et al. Aralar sequesters GABA into hyperactive mitochondria, causing social behavior deficits. Cell 180, 1178–1197 (2020).
Li, J. et al. Mitochondrial deficits in human iPSC-derived neurons from patients with 22q11.2 deletion syndrome and schizophrenia. Transl. Psychiatry 9, 302 (2019).
Li, J. et al. Association of mitochondrial biogenesis with variable penetrance of schizophrenia. JAMA Psychiatry 78, 911–921 (2021).
Martins-Costa, C. et al. ARID1B controls transcriptional programs of axon projection in an organoid model of the human corpus callosum. Cell Stem Cell 31, 866–885 (2024).
Flaherty, E. et al. Neuronal impact of patient-specific aberrant NRXN1α splicing. Nat. Genet. 51, 1679–1690 (2019).
Birtele, M. et al. Non-synaptic function of the autism spectrum disorder-associated gene SYNGAP1 in cortical neurogenesis. Nat. Neurosci. 26, 2090–2103 (2023).
Ellingford, R. A. et al. Cell-type-specific synaptic imbalance and disrupted homeostatic plasticity in cortical circuits of ASD-associated Chd8 haploinsufficient mice. Mol. Psychiatry 26, 3614–3624 (2021).
Shi, X. et al. Heterozygous deletion of the autism-associated gene CHD8 impairs synaptic function through widespread changes in gene expression and chromatin compaction. Am. J. Hum. Genet. 110, 1750–1768 (2023).
Pak, C. et al. Cross-platform validation of neurotransmitter release impairments in schizophrenia patient-derived NRXN1-mutant neurons. Proc. Natl Acad. Sci. USA https://doi.org/10.1073/pnas.2025598118 (2021).
Yi, F. et al. Autism-associated SHANK3 haploinsufficiency causes Ih channelopathy in human neurons. Science 352, aaf2669 (2016).
Vermaercke, B. et al. SYNGAP1 deficiency disrupts synaptic neoteny in xenotransplanted human cortical neurons in vivo. Neuron https://doi.org/10.1016/j.neuron.2024.07.007 (2024).
Jung, E. M. et al. Arid1b haploinsufficiency disrupts cortical interneuron development and mouse behavior. Nat. Neurosci. 20, 1694–1707 (2017).
Fernando, M. B. et al. Phenotypic complexities of rare heterozygous neurexin-1 deletions. Nature 642, 710–720 (2025).
Chen, Q. et al. Dysfunction of cortical GABAergic neurons leads to sensory hyper-reactivity in a Shank3 mouse model of ASD. Nat. Neurosci. 23, 520–532 (2020).
Rajarajan, P. et al. Neuron-specific signatures in the chromosomal connectome associated with schizophrenia risk. Science https://doi.org/10.1126/science.aat4311 (2018).
Wen, C. et al. Cross-ancestry atlas of gene, isoform, and splicing regulation in the developing human brain. Science 384, eadh0829 (2024).
Wong, C. C. Y. et al. Genome-wide DNA methylation profiling identifies convergent molecular signatures associated with idiopathic and syndromic autism in post-mortem human brain tissue. Hum. Mol. Genet. 28, 2201–2211 (2019).
Ramaswami, G. et al. Integrative genomics identifies a convergent molecular subtype that links epigenomic with transcriptomic differences in autism. Nat. Commun. 11, 4873 (2020).
Bell, J. Stratified medicines: towards better treatment for disease. Lancet https://doi.org/10.1016/S0140-6736(14)60115-X (2014).
Tsimberidou, A. M. et al. Molecular tumour boards – current and future considerations for precision oncology. Nat. Rev. Clin. Oncol. 20, 843–863 (2023).
Zhang, H., Colclough, K., Gloyn, A. L. & Pollin, T. I. Monogenic diabetes: a gateway to precision medicine in diabetes. J. Clin. Invest. https://doi.org/10.1172/JCI142244 (2021).
Schaaf, C. P. et al. A framework for an evidence-based gene list relevant to autism spectrum disorder. Nat. Rev. Genet. 21, 367–376 (2020).
Shi, Y. et al. Multi-polygenic scores in psychiatry: from disorder specific to transdiagnostic perspectives. Am. J. Med. Genet. B Neuropsychiatr. Genet. 195, e32951 (2024).
Andreassen, O. A., Hindley, G. F. L., Frei, O. & Smeland, O. B. New insights from the last decade of research in psychiatric genetics: discoveries, challenges and clinical implications. World Psychiatry 22, 4–24 (2023).
Weiner, D. J. et al. Statistical and functional convergence of common and rare genetic influences on autism at chromosome 16p. Nat. Genet. 54, 1630–1639 (2022).
Kingdom, R., Beaumont, R. N., Wood, A. R., Weedon, M. N. & Wright, C. F. Genetic modifiers of rare variants in monogenic developmental disorder loci. Nat. Genet. 56, 861–868 (2024).
Bergen, S. E. et al. Joint contributions of rare copy number variants and common SNPs to risk for schizophrenia. Am. J. Psychiatry 176, 29–35 (2019).
Akingbuwa, W. A., Hammerschlag, A. R., Bartels, M., Nivard, M. G. & Middeldorp, C. M. Ultra-rare and common genetic variant analysis converge to implicate negative selection and neuronal processes in the aetiology of schizophrenia. Mol. Psychiatry 27, 3699–3707 (2022).
Oliver, K. L. et al. Common risk variants for epilepsy are enriched in families previously targeted for rare monogenic variant discovery. EBioMedicine 81, 104079 (2022).
Dobrindt, K. et al. Publicly available hiPSC lines with extreme polygenic risk scores for modeling schizophrenia. Complex Psychiatry 6, 68–82 (2021).
Anton-Bolanos, N. et al. Brain Chimeroids reveal individual susceptibility to neurotoxic triggers. Nature 631, 142–149 (2024).
Gandal, M. J. et al. Broad transcriptomic dysregulation occurs across the cerebral cortex in ASD. Nature 611, 532–539 (2022).
Wamsley, B. et al. Molecular cascades and cell type-specific signatures in ASD revealed by single-cell genomics. Science 384, eadh2602 (2024).
Yap, C. X. et al. Brain cell-type shifts in Alzheimer’s disease, autism, and schizophrenia interrogated using methylomics and genetics. Sci. Adv. 10, eadn7655 (2024).
Han, V. X., Patel, S., Jones, H. F. & Dale, R. C. Maternal immune activation and neuroinflammation in human neurodevelopmental disorders. Nat. Rev. Neurol. 17, 564–579 (2021).
Seah, C. et al. Modeling gene x environment interactions in PTSD using human neurons reveals diagnosis-specific glucocorticoid-induced gene expression. Nat. Neurosci. 25, 1434–1445 (2022).
Seah, C. et al. Common genetic variation impacts stress response in the brain. Preprint at bioRxiv https://doi.org/10.1101/2023.12.27.573459 (2023).
Retallick-Townsley, K. G. et al. Dynamic stress- and inflammatory-based regulation of psychiatric risk loci in human neurons. Preprint at bioRxiv https://doi.org/10.1101/2024.07.09.602755 (2024).
Cruceanu, C. et al. Cell-type-specific impact of glucocorticoid receptor activation on the developing brain: a cerebral organoid study. Am. J. Psychiatry https://doi.org/10.1176/appi.ajp.2021.21010095 (2021).
Teter, O. M. et al. CRISPRi-based screen of autism spectrum disorder risk genes in microglia uncovers roles of ADNP in microglia endocytosis and uptake of synaptic material. Mol. Psych. 30, 4176–4193 (2025).
Ma, Y. et al. Activity-dependent transcriptional program in NGN2+ neurons enriched for genetic risk for brain-related disorders. Biol. Psychiatry 95, 187–198 (2024).
Sanchez-Priego, C. et al. Mapping cis-regulatory elements in human neurons links psychiatric disease heritability and activity-regulated transcriptional programs. Cell Rep. 39, 110877 (2022).
Boulting, G. L. et al. Activity-dependent regulome of human GABAergic neurons reveals new patterns of gene regulation and neurological disease heritability. Nat. Neurosci. 24, 437–448 (2021).
Ahn, K. et al. High rate of disease-related copy number variations in childhood onset schizophrenia. Mol. Psychiatry 19, 568–572 (2014).
Ahn, K., An, S. S., Shugart, Y. Y. & Rapoport, J. L. Common polygenic variation and risk for childhood-onset schizophrenia. Mol. Psychiatry https://doi.org/10.1038/mp.2014.158 (2014).
Hoffman, G. E. et al. Transcriptional signatures of schizophrenia in hiPSC-derived NPCs and neurons are concordant with post-mortem adult brains. Nat. Commun. 8, 2225 (2017).
Guss, E. J. et al. Protocol for neurogenin-2-mediated induction of human stem cell-derived neural progenitor cells. Star Protoc. 5, 102878 (2024).
Wang, M. et al. Transformative network modeling of multi-omics data reveals detailed circuits, key regulators, and potential therapeutics for Alzheimer’s disease. Neuron 109, 257–272 (2021).
Ho, S. M. et al. Rapid Ngn2-induction of excitatory neurons from hiPSC-derived neural progenitor cells. Methods 101, 113–124 (2016).
Marro, S. G. et al. Neuroligin-4 regulates excitatory synaptic transmission in human neurons. Neuron 103, 617–626 (2019).
Zhang, Z. et al. The fragile X mutation impairs homeostatic plasticity in human neurons by blocking synaptic retinoic acid signaling. Sci. Transl. Med. https://doi.org/10.1126/scitranslmed.aar4338 (2018).
Meijer, M. et al. A single-cell model for synaptic transmission and plasticity in human iPSC-derived neurons. Cell Rep. 27, 2199–2211 (2019).
Zhang, S. et al. Allele-specific open chromatin in human iPSC neurons elucidates functional disease variants. Science 369, 561–565 (2020).
Sun, Y. et al. A deleterious Nav1.1 mutation selectively impairs telencephalic inhibitory neurons derived from Dravet syndrome patients. eLife https://doi.org/10.7554/eLife.13073 (2016).
Barretto, N. et al. ASCL1- and DLX2-induced GABAergic neurons from hiPSC-derived NPCs. J. Neurosci. Methods 334, 108548 (2020).
Powell, S. K. et al. Induction of dopaminergic neurons for neuronal subtype-specific modeling of psychiatric disease risk. Mol. Psychiatry 28, 1970–1982 (2023).
Miller, J. A. et al. Transcriptional landscape of the prenatal human brain. Nature 508, 199–206 (2014).
Shi, Z. D. et al. Genome editing in hPSCs reveals GATA6 haploinsufficiency and a genetic interaction with GATA4 in human pancreatic development. Cell Stem Cell 20, 675–688 (2017).
Dobin, A. et al. STAR: ultrafast universal RNA-seq aligner. Bioinformatics 29, 15–21 (2013).
Danecek, P. et al. Twelve years of SAMtools and BCFtools. Gigascience https://doi.org/10.1093/gigascience/giab008 (2021).
Lindsay, H. et al. CrispRVariants charts the mutation spectrum of genome engineering experiments. Nat. Biotechnol. 34, 701–702 (2016).
Yuan, S. H. et al. Cell-surface marker signatures for the isolation of neural stem cells, glia and neurons derived from human pluripotent stem cells. PLoS ONE 6, e17540 (2011).
Li, W. et al. MAGeCK enables robust identification of essential genes from genome-scale CRISPR/Cas9 knockout screens. Genome Biol. 15, 554 (2014).
Chaudhry, A., Shi, R. & Luciani, D. S. A pipeline for multidimensional confocal analysis of mitochondrial morphology, function, and dynamics in pancreatic β-cells. Am. J. Physiol. Endocrinol. Metab. 318, E87–E101 (2020).
Birey, F. et al. Assembly of functionally integrated human forebrain spheroids. Nature 545, 54–59 (2017).
Butler, A., Hoffman, P., Smibert, P., Papalexi, E. & Satija, R. Integrating single-cell transcriptomic data across different conditions, technologies, and species. Nat. Biotechnol. 36, 411–420 (2018).
Papalexi, E. et al. Characterizing the molecular regulation of inhibitory immune checkpoints with multimodal single-cell screens. Nat. Genet. 53, 322–331 (2021).
Tirosh, I. et al. Dissecting the multicellular ecosystem of metastatic melanoma by single-cell RNA-seq. Science 352, 189–196 (2016).
Tian, R. et al. CRISPR interference-based platform for multimodal genetic screens in human iPSC-derived neurons. Neuron https://doi.org/10.1016/j.neuron.2019.07.014 (2019).
Willer, C. J., Li, Y. & Abecasis, G. R. METAL: fast and efficient meta-analysis of genomewide association scans. Bioinformatics 26, 2190–2191 (2010).
Saha, A. et al. Co-expression networks reveal the tissue-specific regulation of transcription and splicing. Genome Res. 27, 1843–1858 (2017).
Gao, C., McDowell, I. C., Zhao, S., Brown, C. D. & Engelhardt, B. E. Context specific and differential gene co-expression networks via Bayesian biclustering. PLoS Comput. Biol. 12, e1004791 (2016).
Yu, G. Gene ontology semantic similarity analysis using GOSemSim. Methods Mol. Biol. 2117, 207–215 (2020).
Demontis, D. et al. Discovery of the first genome-wide significant risk loci for attention deficit/hyperactivity disorder. Nat. Genet. 51, 63–75 (2019).
Duncan, L. et al. Significant locus and metabolic genetic correlations revealed in genome-wide association study of anorexia nervosa. Am. J. Psychiatry 174, 850–858 (2017).
Walters, R. K. et al. Transancestral GWAS of alcohol dependence reveals common genetic underpinnings with psychiatric disorders. Nat. Neurosci. 21, 1656–1669 (2018).
Mullins, N. et al. Genome-wide association study of more than 40,000 bipolar disorder cases provides new insights into the underlying biology. Nat. Genet. 53, 817–829 (2021).
Johnson, E. C. et al. A large-scale genome-wide association study meta-analysis of cannabis use disorder. Lancet Psychiatry 7, 1032–1045 (2020).
Howard, D. M. et al. Genome-wide meta-analysis of depression identifies 102 independent variants and highlights the importance of the prefrontal brain regions. Nat. Neurosci. 22, 343–352 (2019).
International Obsessive Compulsive Disorder Foundation Genetics Collaborative (IOCDF-GC) and OCD Collaborative Genetics Association Studies (OCGAS). Revealing the complex genetic architecture of obsessive-compulsive disorder using meta-analysis. Mol. Psychiatry 23, 1181–1188 (2018).
Nievergelt, C. M. et al. International meta-analysis of PTSD genome-wide association studies identifies sex- and ancestry-specific genetic risk loci. Nat. Commun. 10, 4558 (2019).
Trubetskoy, V. et al. Mapping genomic loci implicates genes and synaptic biology in schizophrenia. Nature 604, 502–508 (2022).
Cross-Disorder Group of the Psychiatric Genomics Consortium. Genomic relationships, novel loci, and pleiotropic mechanisms across eight psychiatric disorders. Cell 179, 1469–1482 (2019).
Marioni, R. E. et al. GWAS on family history of Alzheimer’s disease. Transl. Psychiatry 8, 99 (2018).
Nalls, M. A. et al. Identification of novel risk loci, causal insights, and heritable risk for Parkinson’s disease: a meta-analysis of genome-wide association studies. Lancet Neurol. 18, 1091–1102 (2019).
Nicolas, A. et al. Genome-wide analyses identify KIF5A as a novel ALS gene. Neuron 97, 1268–1283 (2018).
Yu, D. et al. Interrogating the genetic determinants of Tourette’s syndrome and other tic disorders through genome-wide association studies. Am. J. Psychiatry 176, 217–227 (2019).
Hautakangas, H. et al. Genome-wide analysis of 102,084 migraine cases identifies 123 risk loci and subtype-specific risk alleles. Nat. Genet. 54, 152–160 (2022).
Johnston, K. J. A. et al. Genome-wide association study of multisite chronic pain in UK Biobank. PLoS Genet. 15, e1008164 (2019).
Lo, M. T. et al. Genome-wide analyses for personality traits identify six genomic loci and show correlations with psychiatric disorders. Nat. Genet. 49, 152–156 (2017).
Yu, G., Wang, L. G., Han, Y. & He, Q. Y. clusterProfiler: an R package for comparing biological themes among gene clusters. OMICS 16, 284–287 (2012).
Watanabe, K., Taskesen, E., van Bochoven, A. & Posthuma, D. Functional mapping and annotation of genetic associations with FUMA. Nat. Commun. 8, 1826 (2017).
Wang, J. & Liao, Y. WebGestaltR: gene set analysis toolkit WebGestaltR. R package version 0.4.3 https://CRAN.R-project.org/package=WebGestaltR (2020).
Darmanis, S. et al. A survey of human brain transcriptome diversity at the single cell level. Proc. Natl Acad. Sci. USA 112, 7285–7290 (2015).
Lake, B. B. et al. Neuronal subtypes and diversity revealed by single-nucleus RNA sequencing of the human brain. Science 352, 1586–1590 (2016).
Schilder, B. M. & Skene, N. G. orthogene: an R package for easy mapping of orthologous genes across hundreds of species. Bioconductor https://doi.org/10.18129/B9.bioc.orthogene (2022).
Capps, M. E. S. et al. Disrupted diencephalon development and neuropeptidergic pathways in zebrafish with autism-risk mutations. Proc. Natl Acad. Sci. USA 122, e2402557122 (2025).
Calhoun, C. C. S. et al. Removal of developmentally regulated microexons has a minimal impact on larval zebrafish brain morphology and function. eLife 13, RP101790 (2025).
Kroll, F. et al. A simple and effective F0 knockout method for rapid screening of behaviour and other complex phenotypes. eLife https://doi.org/10.7554/eLife.59683 (2021).
Hoffman, E. ehoffmanlab/Weinschutz-Mendes-et-al-2023-behavior: Visual Startle. Zenodo https://doi.org/10.5281/zenodo.7644897 (2023).
Rihel, J. et al. Zebrafish behavioral profiling links drugs to biological targets and rest/wake regulation. Science 327, 348–351 (2010).
Prober, D. A., Rihel, J., Onah, A. A., Sung, R. J. & Schier, A. F. Hypocretin/orexin overexpression induces an insomnia-like phenotype in zebrafish. J. Neurosci. 26, 13400–13410 (2006).
Rihel, J. JRihel/Sleep-Analysis: Sleep_Code_v1. Zenodo https://doi.org/10.5281/zenodo.7644072 (2023).
Hoffman, E. J. et al. Estrogens suppress a behavioral phenotype in zebrafish mutants of the autism risk gene, CNTNAP2. Neuron 89, 725–733 (2016).
Acknowledgements
This work was supported by grant no. F31MH130122 (K.R.-T.); the HHMI Gilliam Fellowship (A.P.); the Autism Science Foundation (A.P.); grant nos. T32MH014276 (M.F.G.), T32GM136651 (E.D., S.E.F.), R01MH123155 (K.B.), RM1MH132648 (K.B., E.J.H.), R01MH121074 (K.B.), R01MH116002 (E.J.H.), R21MH133245 (E.J.H.), R01ES033630 (L.M.H., K.B.), R01MH124839 (L.M.H.) and R01MH118278 (L.M.H.); the Simons Foundation (grant nos. 1012863KB, 573508EH and 345993EH); the Spector Fund (E.J.H.); the Swebilius Foundation (E.J.H.); the Kavli Foundation (E.J.H.); BD2: Breakthrough Discoveries for Thriving with Bipolar Disorder (grant no. DG230102, H.S., M.D., T.-C.H., K.B.); the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant (no. 101065629, N.B.); and the Interdepartmental Neuroscience Program at Yale T32NS041228 (A.P.). The funders had no role in study design, data collection and analysis, decision to publish or preparation of the manuscript. Special thanks to M. Talkowski and D. Ruderfer for countless discussions on convergence and to S. Thyme and the Thyme lab for sharing zebrafish mutant lines. For the purpose of open access, the authors have applied a CC BY public copyright license to all Author Accepted Manuscripts arising from this submission.
Author information
Authors and Affiliations
Contributions
M.F.G. designed and executed the NDD gene ECCITE-seq in iNPCs, iGLUTs and iGABAs, with technical assistance from S.C., O.L. and J.C. and support from P.J.M.D. K.R.-T. conducted all bioinformatic analyses and generated all figures, with technical assistance from A.S. and H.G. Arrayed KO lines and neuronal cultures were generated, validated, phenotyped and analyzed by N.B. N.B., T.-C.H., A.K., M.D., H.G., C.B., A.L.T.S. and J.L. conducted mitochondrial phenotypic analyses, in collaboration with H.S.; N.B. and S.G. conducted neurogenesis analyses. A.P., E.D., Y.D., S.E.F. and S.K. generated, phenotyped and analyzed zebrafish mutants with technical assistance from G.D. and bioinformatic supervision from Z.W. J.W., Z.C., R.M., S.L., P.E. and M.G. conducted LNCTP analyses. Funding and mentorship was provided by L.M.H., E.J.H. and K.B. The manuscript was written by K.B. with extensive feedback from L.M.H., E.J.H. and K.R.-T. as well as contributions from all authors.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Neuroscience thanks the anonymous reviewers for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information (download PDF )
Supplementary Figs. 1–24.
Supplementary Tables 1–9 (download XLSX )
Supplementary Tables 1–9.
Supplementary Data 1 (download XLSX )
Cell-type-specific convergent gene lists based on NDD pooled scCRISPR-KO.
Supplementary Data 2 (download XLSX )
Convergent sets and drug predictions based on mutant zebrafish behavioral clusters.
Supplementary Data 3 (download XLSX )
Gene × drug mutant zebrafish behavioral effects.
Supplementary Data 4 (download XLSX )
Key resource table.
Source data
Source Data (download XLSX )
Statistical source data for Figs. 1–7.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fernandez Garcia, M., Retallick-Townsley, K., Pruitt, A. et al. Transcriptomic and phenotypic convergence of neurodevelopmental disorder risk genes in vitro and in vivo. Nat Neurosci (2026). https://doi.org/10.1038/s41593-026-02247-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41593-026-02247-7
