
Abstract
The field of supervised automated medical imaging segmentation suffers from relatively small datasets with ground truth labels. This is especially true for challenging segmentation problems that target structures with low contrast and ambiguous boundaries, such as ground glass opacities and consolidation in chest computed tomography images. In this work, we make available the first public dataset of ground glass opacity and consolidation in the lungs of Long COVID patients. The Long COVID Iowa-UNICAMP dataset (LongCIU) was built by three independent expert annotators, blindly segmenting the same 90 selected axial slices manually, without using any automated initialization. The public dataset includes the final consensus segmentation in addition to the individual segmentation from each annotator (360 slices total). This dataset is a valuable resource for training and validating new automated segmentation methods and for studying interrater uncertainty in the segmentation of lung opacities in computed tomography.
Similar content being viewed by others
Background & Summary
Deep learning has revolutionized the field of medical image analysis across various organs and imaging modalities1. Recent methods developed for high-resolution chest computed tomography (CT) analysis can automate tasks such as lung parenchyma and lung lobe segmentation2, fissure detection and integrity quantification3,4, lung nodule detection and segmentation, pneumonia classification, outcome prediction5, opacity segmentation, and others6. Moreover, recent research has demonstrated that individuals with a prior COVID-19 diagnosis can have lung opacities present for months after the acute infection7. In this context, the development of automated methods for the analysis of ground glass opacities (GGO) and consolidations in the lung is paramount to analyze the severity of disease and quantifying lung involvement8. These methods pose a promising future for automated decision support in medical pipelines and automated analysis of large research cohorts, accelerating medical research and patient care.
Supervised deep learning methods for automated image segmentation rely on manual annotations, which are considered ground truth for development and validating new algorithms. Manual segmentation of structures and findings in high-resolution CT is tedious, time consuming, and subject to human error. Furthermore, some structures are more challenging to segment due to low contrast and/or ambiguous boundaries9. For example, the lung parenchyma boundary is well defined by the Hounsfield unit difference between soft tissue and the air filled lung in most cases, with lung ground truth being readily available from many sources in the literature or reliably obtained through automated methods10. In contrast, segmentation of opacities in severe cases of COVID-19 pneumonia, is challenging because the opacities can be localized in any part of the lung and the boundaries are often ambiguous11. The task of discriminating opacities into consolidation and GGO subtypes is even more challenging due to the additional uncertain boundaries between adjacent GGO and consolidated regions12.
Existing public datasets provide manual annotations of lung opacities in CT images13,14,15. However, manual annotations of multilabel opacities, i.e., distinguishing GGO vs. consolidation with separate labels, is not readily available in public datasets. The task of GGO vs. consolidation segmentation is challenging due to to ambiguous borders between the two regions. Furthermore, distinguishing consolidation and blood vessels is difficult on CT. Currently, there are only two public datasets containing manual annotations of GGO and consolidations separately, which we have labeled Medical Segmentation COVID (MSC), following the original source16 and SemiSeg, following the name and data organization proposed by Fan et al.12. These datasets have been used in a large number of research studies for the optimization of supervised and semi-supervised deep learning methods for automated GGO and consolidation segmentation12,17,18,19,20,21,22. Both datasets included chest CT scans of acute COVID-19 patients and accompanying annotations. MSC annotated 373 slices from public scans made available by The Italian Society of Medical and Interventional Radiology and SemiSeg annotated 100 slices originating from RadioPaedia public images, with annotations performed by a single expert according to their website23. Given that those datasets used scans from acute COVID-19 patients, there is no dataset providing this type of annotation in CT scans of long COVID patients, i.e., images of subjects with persistent symptoms even months after the acute infection has subsided.
In this work, we built the Long COVID Iowa-UNICAMP dataset (LongCIU): a novel dataset consisting of 90 axial CT slices with multiple expert annotations of GGO and consolidations in the lung. Every image has the presence of at least GGO. Each image was annotated blindly by three groups of two annotators each. In each group, the MD with less experience worked on the fully manual annotation, and the pulmonologist MD with more experience verified the result. All three groups worked on the same axial slices, without using any automated method as reference or initialization. A final consensus annotation was created by applying the STAPLE algorithm24 and the individual annotations from each of the three expert annotators are included in the public dataset, resulting in a total of 360 slices (Fig. 1). This allows future research not only to compute metrics against the consensus annotation but also to compute their interrater agreement in comparison with manual annotation. The LongCIU dataset will promote a deeper understanding of human uncertainty in GGO and consolidation segmentation in CT scans.

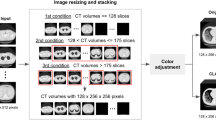
Overview of the process of creating this dataset, from selecting the slices to be segmented, through blind multiple rater segmentation and consensus, technical validation and making the data and involved code public.
Methods
Acquisition
CT scan data was originally collected at the University of Iowa Hospitals and Clinics7, in an ongoing Long COVID study. Adults with history of COVID-19 infection confirmed by a positive antigen or reverse transcriptase-polymerase chain reaction that remained symptomatic 30 days or more following diagnosis of acute infection, were prospectively enrolled starting in June 2020. Chest CT scans were conducted with Siemens scanners. All scans employed tube current modulation. A standardized protocol for noncontrast chest CT imaging was followed, which entailed acquiring an inspiratory scan at total lung capacity (TLC) and an expiratory scan at residual volume (RV). Reconstruction of images was performed using iterative reconstruction techniques with a section thickness × interval of 1 × 0.5 mm. This study was performed in line with the principles of the Declaration of Helsinki. Study protocols were approved by the University of Iowa institutional review board (IRB), case number 202005421, and were Health Insurance Portability and Protection Act-compliant. Participants were required to sign written informed consent before inclusion, including the possibility of sharing anonymized images. The construction of the LongCIU dataset is a retrospective, anonymous use of part of this data acquisition.
Manual Annotation and STAPLE Consensus
Since patient information is not necessary for segmentation, images were completely anonymized and converted to NIFTI format. To make the time needed for fully manual segmentation feasible, 9 TLC CT scans were selected from the whole study cohort. For the selection criteria, given that most Long COVID patients do not present lung opacities, an automated method22 was used to quantify lung opacity involvement. The top-9 scans regarding involvement were selected as sources for slices to be segmented. Six physicians participated in the annotation process. All physicians participated in a joint training session and agreed to a segmentation protocol. To avoid bias from automated methods and better understand human interrater agreement in this task, we chose to not use any initial automated segmentation as initialization. The manual segmentation would be performed from scratch, following the ground glass opacity and consolidation definitions from Silva et al.25. Opacities correspond to parenchyma areas of greater density as a result of lung inflammation due to infectious processes. Therefore, opacities present higher Hounsfield unit intensity, and are distinguishable from surrounding tissue and structures. In GGOs, even with increased density of the lung parenchyma, it is still possible to identify the contours of the vessels and bronchi within. In consolidations, the increased attenuation makes the underlying anatomy invisible, usually associated with greater disease severity.
Following these definitions, the annotators agreed to a selection of 10 axial slices from each CT scan. Some slices are adjacent, and some are not. Every slice has the presence of at least GGO. After the joint session, physicians were divided into three pairs. Each pair was composed of one expert board certified pulmonologist with more than 10 years of experience, and one post medical school resident trainee. Each pair worked blindly from the other groups, with the trainees annotating images under the continuous supervision and revision of the expert. Each pair is referred to as annotator 1, 2 and 3 for the remainder of this paper. From this point forward, the annotators segmented all 90 slices blindly from each other, using the 3D Slicer software26. A video tutorial was provided to each annotator illustrating the segmentation process and how to use 3D Slicer, including how to set and use Hounsfield unit windows and the segmentation tools. With 90 slices annotated 3 times, we computed the STAPLE consensus per slice for a final segmentation map using the implementation provided by SimpleITK27 (Fig. 2). First, STAPLE was computed for the general opacity area (GGO + consolidation). Then, the STAPLE consensus only for consolidation is computed separately. Finally, areas that are considered consolidation and opacity were marked as consolidation (label 2), and the remaining opacity area was marked as GGO (label 1).

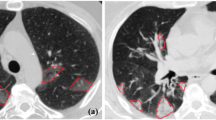
A sample slice and its accompanying segmentations, with GGO in red and consolidation in green. Notice how STAPLE arrives at a final consensus with a opacity sensitivity higher than annotator 3 but lower than annotator 1. The difficulty of differentiating vessels from consolidation is also illustrated in the anterior region of the right lung.
Data Records
The data generated by this research is publicly available in the Iowa Research Online (IRO) repository and can be accessed at the following URL: https://doi.org/10.25820/data.00730128. The data folder structure is as follows (Fig. 3). Available files include the 90 anonymized CT slices in original Hounsfield unit intensities, 90 manual segmentation masks from each annotator, and the 90 STAPLE consensus among the three annotators, for a total of 360 segmentation masks. The STAPLE consensus should be considered the final ground truth for the purpose of training or validating automated methods. Integer label 1 corresponds to GGO, and integer label 2 corresponds to consolidation in the provided masks. The accompanying code for reproducing our technical validation and the STAPLE consensus is made available separately in https://github.com/MICLab-Unicamp/LongCIU, including all expected outputs.

File tree for the dataset, including images, annotations per annotator and consensus, MEDPSeg output, optional proposed training splits, and STAPLE statistics.
Regarding the adjacency of the involved slices and their relative position in the original 3D scan, Table 1 details the original 1-indexed position of axial slices and their corresponding index on the provided 90 slices.
Technical Validation
To validate the technical quality of the generated data, we computed number of pixels annotated for each annotator, Dice29 agreement among annotators (Fig. 4), and Cohen’s Kappa30 interrater agreement, per class, also involving MEDPSeg22’s blind performance as an automated method (Fig. 5).

On the left, number of pixels classified as GGO and consolidation for each annotator. On the right, agreement Dice overlap between annotators 2 and 3, 1 and 3, 1 and 2 for overall infection in blue, (Inf = GGO + consolidation), consolidation only in green (Con.) and GGO in red. The horizontal blue line corresponds to the inter-human annotator agreement for overall infection reported by Sotudeh-Paima et al.31.

Cohen’s Kappa interrater agreement between the three human raters and the MEDPSeg automated method for (a) The multilabel agreement, (b) GGO only, (c) consolidation only, and (d) overall infection, (GGO + Consolidation).
When looking at the number of pixels annotated by each annotator, we notice different sensitivity levels among the annotators. Through the STAPLE consensus and thanks to having three different opinions, we were able to achieve a middle ground among the three expert judgments. When comparing each annotator with each other, we notice overall infection Dice agreement similar to the 64% human agreement reported by Sotudeh-Paima et al.31. We have found no report from other research about the human interrater agreement when dealing with GGO and consolidation separation.
Due to the low prevalence of consolidations in Long COVID patients, we noticed strong disagreement among annotators in consolidation segmentation. Confusion matrices were constructed to visualize the Cohen’s kappa score interrater agreement among annotators for each class. We computed Cohen’s kappa in four ways: considering each pixel as a multilabel rater decision; looking only at GGO; only at consolidation; and finally looking at the overall opacity or infection agreement. The MEDPSeg automated method which had not seen this dataset during training was also included as a rater. For reference, MEDPSeg achieved Dice coefficients of: 0.64 for overall opacity; 0.57 for GGO; and 0.42 for consolidation, when compared to the STAPLE consensus.
With the reported interrater agreement being close to that reported by the literature in other datasets for overall opacity segmentation, we believe LongCIU is of sufficient technical quality for use by the community. In addition, the performance of an automated method trained in separate data was indistinguishable from humans in the interrater agreement through Cohen’s kappa score. On the other hand, there are strong disagreements among raters in the delineation of consolidations in Long COVID patients. These technical validation results suggest the performance of automated methods are already at the frontier of what is feasible, when taking into consideration human uncertainty in manual annotation of x-ray-based computed tomography. We invite others to further investigate this hypothesis and hope that this data will be useful for related research.
Usage Notes
The results from each annotator are included for the purposes of uncertainty and interrater analysis. The repository also includes a simple sample implementation of an UNet for supervised training using this dataset, with a suggested data split. Note, however, that we strongly recommend against using only this dataset for training, and encourage the use of this data either as an external testing dataset or as part of semi-supervised approaches. Users are free to concatenate GGO and consolidation into a single, more reliable general infection segmentation if desired. Useful visualization software includes ITK-Snap32 or 3D Slicer26. The NiBabel33 or SimpleITK27 libraries can be used to read .nii.gz files programmatically.
Code availability
The code for reproducing the STAPLE consensus and all technical validation figures in this paper is available at https://github.com/MICLab-Unicamp/LongCIU. Used parameters and output STAPLE statistics are in the repository for reproducibility.
References
Lee, S. M. et al. Deep learning applications in chest radiography and computed tomography: current state of the art. Journal of thoracic imaging 34, 75–85 (2019).
Gerard, S. E. et al. CT image segmentation for inflamed and fibrotic lungs using a multi-resolution convolutional neural network. Scientific Reports 11, 1455, https://doi.org/10.1038/s41598-020-80936-4 (2021).
Gerard, S. E., Patton, T. J., Christensen, G. E., Bayouth, J. E. & Reinhardt, J. M. FissureNet: A deep learning approach for pulmonary fissure detection in CT images. IEEE transactions on medical imaging 38, 156–166, https://doi.org/10.1109/TMI.2018.2858202 (2019).
Althof, Z. W. et al. Attention U-net for automated pulmonary fissure integrity analysis in lung computed tomography images. Scientific Reports 13, 14135, https://doi.org/10.1038/s41598-023-41322-y (2023).
Wang, Y., Liu, L. & Wang, C. Trends in using deep learning algorithms in biomedical prediction systems. Frontiers in Neuroscience 17, 1256351 (2023).
Carmo, D. et al. A systematic review of automated segmentation methods and public datasets for the lung and its lobes and findings on computed tomography images. Yearbook of Medical Informatics 31, 277–295 (2022).
Cho, J. L. et al. Quantitative chest ct assessment of small airways disease in post-acute sars-cov-2 infection. Radiology 304, 185–192 (2022).
Sun, D. et al. Ct quantitative analysis and its relationship with clinical features for assessing the severity of patients with covid-19. Korean journal of radiology 21, 859 (2020).
Joskowicz, L., Cohen, D., Caplan, N. & Sosna, J. Inter-observer variability of manual contour delineation of structures in ct. European radiology 29, 1391–1399 (2019).
Hofmanninger, J. et al. Automatic lung segmentation in routine imaging is primarily a data diversity problem, not a methodology problem. European Radiology Experimental 4, 1–13 (2020).
Lensink, K. et al. A soft labeling approach to develop automated algorithms that incorporate uncertainty in pulmonary opacification on chest ct using covid-19 pneumonia. Academic Radiology 29, 994–1003 (2022).
Fan, D.-P. et al. Inf-net: Automatic covid-19 lung infection segmentation from ct images. IEEE transactions on medical imaging 39, 2626–2637 (2020).
Jun, M. et al. COVID-19 CT Lung and Infection Segmentation Dataset, https://doi.org/10.5281/zenodo.3757476 (2020).
Morozov, S. P. et al. MosMedData: data set of 1110 chest CT scans performed during the COVID-19 epidemic. Digital Diagnostics 1.1, 49–59 (2020)
Roth, H. R. et al. Rapid artificial intelligence solutions in a pandemic-the covid-19-20 lung CT lesion segmentation challenge. Medical image analysis 82, 102605 (2022).
MedSeg, Jenssen, H. B. & Sakinis, T. MedSeg Covid Dataset 2. Figshare https://doi.org/10.6084/m9.figshare.13521509.v2 (2021).
Saeedizadeh, N., Minaee, S., Kafieh, R., Yazdani, S. & Sonka, M. Covid tv-unet: Segmenting COVID-19 chest CT images using connectivity imposed unet. Computer methods and programs in biomedicine update 1, 100007 (2021).
Jin, G., Liu, C. & Chen, X. An efficient deep neural network framework for COVID-19 lung infection segmentation. Information Sciences 612, 745–758 (2022).
Polat, H. Multi-task semantic segmentation of ct images for covid-19 infections using deeplabv3+ based on dilated residual network. Physical and Engineering Sciences in Medicine 45, 443–455 (2022).
Yang, Y., Zhang, L., Ren, L. & Wang, X. Mmvit-seg: A lightweight transformer and cnn fusion network for COVID-19 segmentation. Computer Methods and Programs in Biomedicine 230, 107348 (2023).
Jia, H. et al. A convolutional neural network with pixel-wise sparse graph reasoning for covid-19 lesion segmentation in ct images. Computers in Biology and Medicine 155, 106698 (2023).
Carmo, D. S. et al. Medpseg: Hierarchical polymorphic multitask learning for the segmentation of ground-glass opacities, consolidation, and pulmonary structures on computed tomography arXiv 2312.02365 (2024).
Covid-19 - medical segmentation. https://web.archive.org/web/20230510114805/https://medicalsegmentation.com/covid19/ Accessed: 2024-06-06 (2020).
Warfield, S. K., Zou, K. H. & Wells, W. M. Simultaneous truth and performance level estimation (staple): an algorithm for the validation of image segmentation. IEEE transactions on medical imaging 23, 903–921 (2004).
Silva, C. I. S., Marchiori, E., Souza Júnior, A. S. & Müller, N. L. Illustrated brazilian consensus of terms and fundamental patterns in chest ct scans. Jornal Brasileiro de Pneumologia 36, 99–123 (2010).
Kikinis, R., Pieper, S. D. & Vosburgh, K. G. 3d slicer: a platform for subject-specific image analysis, visualization, and clinical support. In Intraoperative imaging and image-guided therapy, 277–289 (Springer, 2013).
Lowekamp, B. C., Chen, D. T., Ibáñez, L. & Blezek, D. The design of simpleitk. Frontiers in neuroinformatics 7, 45 (2013).
Carmo, D. S. et al. Long covid iowa-unicamp [dataset]. https://doi.org/10.25820/data.007301 (2024).
Sudre, C. H., Li, W., Vercauteren, T., Ourselin, S. & Jorge Cardoso, M. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: Third International Workshop, DLMIA 2017, and 7th International Workshop, ML-CDS 2017, Held in Conjunction with MICCAI 2017, Québec City, QC, Canada, September 14, Proceedings 3, 240–248 (Springer, 2017).
McHugh, M. L. Interrater reliability: the kappa statistic. Biochemia medica 22, 276–282 (2012).
Sotoudeh-Paima, S. et al. A multi-centric evaluation of deep learning models for segmentation of covid-19 lung lesions on chest ct scans. Iran J Radiol 19 (2022).
Yushkevich, P. A. et al. User-guided 3D active contour segmentation of anatomical structures: Significantly improved efficiency and reliability. Neuroimage 31, 1116–1128 (2006).
Brett, M. et al. nipy/nibabel: 5.2.1, https://doi.org/10.5281/zenodo.10714563 (2024).
Acknowledgements
D. Carmo was partially funded by grants #2019/21964-4 and #2022/02344-8, São Paulo Research Foundation (FAPESP). R. Lotufo is partially supported by CNPq (The Brazilian National Council for Scientific and Technological Development) under grant 313047/2022-7. L. Rittner is partially supported by CNPQ grant 317133/2023-3, and Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES) grant 506728/2020-00.
Author information
Authors and Affiliations
Contributions
Diedre Carmo (corresponding author): conceptualization, methodology development, visualization, software programming, investigation and experimental design, validation, data curation, draft writing. McKenna Eisenbeisz: investigation, data collection, writing review and editing. Rachel L. Anderson: investigation, data collection, writing review and editing. Sarah Van Dorin: investigation, data collection, writing review and editing. Alejandro Pezzulo: investigation, data collection, writing review and editing. Raul Villacreses: investigation, data collection, writing review and editing. Joseph M. Reinhardt: conceptualization, supervision, project administration, funding acquisition, writing review and editing. Sarah E. Gerard: conceptualization, supervision, computational resources, writing review and editing. Leticia Rittner: supervision, computational resources, writing review and editing. Roberto A. Lotufo: supervision, project administration, funding acquisition, writing review and editing. Alejandro Comellas: investigation, conceptualization, methodology development, supervision, data collection, writing review and editing. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
Diedre Carmo reports an employment relationship with NeuralMind. Roberto A. Lotufo reports an employment and equity relationship with NeuralMind. Joseph M. Reinhardt reports an equity and consulting relationship with VIDA Diagnostics Inc. and a consulting relationship with Auris Health, Inc. The remaining authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Carmo, D.S., Pezzulo, A.A., Villacreses, R.A. et al. Manual segmentation of opacities and consolidations on CT of long COVID patients from multiple annotators. Sci Data 12, 402 (2025). https://doi.org/10.1038/s41597-025-04709-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-04709-2
