
Abstract
We present a meticulously curated, long-term (1981–2024) dataset documenting maize phenology dynamics across Northeast China, the nation’s most critical commercial grain base. Derived from 61 national agrometeorological stations, it captures the timing of 10 pivotal phenological stages (sowing, emergence, three-leaf, seven-leaf, jointing, tasseling, flowering, silking, milking, maturity) and derives the durations of 4 growth period lengths (sowing-jointing, jointing-silking, silking-maturity, sowing-maturity). The dataset underwent a rigorous, multi-tiered quality control protocol, including automated checks for internal consistency and expert arbitration for ambiguous records, ensuring high integrity. Subsequent analysis employed kernel density estimation to characterize the probability distribution of phenological events and univariate linear regression to quantify decadal trends. The resulting repository is substantial, comprising 976 georeferenced diagnostic plots in JPEG format and two primary data tables in XLSX format, with a total volume of 601.04 MB. Systematically organized by province and station, this dataset serves as a foundational empirical resource for quantifying climate-driven shifts in crop development, enhancing the parameterization and validation of process-based crop models, and informing the development of optimized cultivation practices and regional climate adaptation frameworks.
Similar content being viewed by others

Background & Summary
Maize stands as a cornerstone of global agriculture, distinguished by its exceptional yield potential and versatile applications1,2,3,4,5. In China, it holds paramount importance as the leading grain crop6,7,8,9,10, with Northeast China emerging as the nation’s most productive maize belt. This region’s unique agro-climatic conditions and strategic positioning make it an ideal sentinel for monitoring crop responses to environmental change. Unlike winter wheat with its specific vernalization requirements, maize exhibits distinct phenological responses to temperature and photoperiod cues. Understanding these dynamics in Northeast China is particularly crucial given the region’s vulnerability to climate variability and its disproportionate contribution to national food security. However, a systematically quality-controlled, long-term phenological dataset specifically focused on this region has been notably absent. This dataset descriptor addresses this gap, providing an unprecedented resource for analyzing spatiotemporal patterns in crop phenology under changing environmental conditions.
Climate change is significantly altering China’s maize production. Phenological changes follow a dual-extension pattern: earlier sowing combined with delayed maturation extends growth cycles11,12. Yields vary spatially: yields are increasing in mid-northeast regions due to higher accumulated temperature, but decreasing in the Huang-Huai-Hai and southwest areas because of intensified heat-drought stress during flowering13,14. Cultivation zones are adaptively expanding northwestward—late-maturing varieties have moved more than 100 kilometers northward in Northeast China, while arid northwestern regions have increased planting area by 23% using plastic film mulching. Traditional growing regions maintain productivity through heat-tolerant varieties and adjusted sowing dates, showcasing the resilience of the production system15,16.
Long-term phenological monitoring is essential for optimizing climate adaptation strategies. Systematic recording of phenological stages—such as seven-leaf, jointing, tasseling—enables facilitates the development of variety adaptability evaluation systems, precise alignment of climate-variety-agronomy practices, and quantification of climate-driven physiological changes17,18. Importantly, historical data on phenological stages, growth metrics, and grain-filling rates enhance water-fertilizer management and establish diagnostic baselines for smart agriculture19,20, serving as both a “gene expression atlas” to guide breeding efforts and an “early-warning radar” for climate-related risks.
Since the 1980s, the China Meteorological Administration (CMA) has compiled over 40 years of site-daily phenological records from 642 stations across China’s maize belts, documenting 10 key phenological stages21. However, this valuable dataset remains largely underutilized: historical phenological shifts have not been systematically quantified, and their correlations with climate variables remain unmodelled22. Therefore, constructing a long-term phenological change dataset is scientifically essential.
Northeast China—Heilongjiang, Jilin, Liaoning—is the nation’s largest commercial grain base, producing 38.7% of China’s maize with yields 22.5% above the national average20,23 and climate vulnerability make it the optimal sentinel region for phenological change detection. As both a “National Food Security Anchor” and core raw material hub for livestock, bioenergy, and deep-processing industries, it holds irreplaceable strategic value in maintaining grain self-sufficiency and agricultural industrial security. This study focuses specifically on this contiguous and climatically coherent core production region to enable a deep, high-fidelity analysis. The 61 national agrometeorological stations were strategically selected from the broader CMA network based on stringent criteria of spatial representativeness within the maize belt and, most critically, the completeness and continuity of their records from 1981 to 2024. This selective approach ensures the dataset’s suitability for robust temporal trend analysis, establishing a reliable benchmark for China’s most important maize-producing region.
Given this region’s pivotal role, we comprehensively analyze maize phenological patterns across Northeast China (1981–2024) using advanced statistical methodologies. Kernel density estimation (for non-Gaussian distribution characterization) and linear regression (for temporal trend detection) were applied to phenological records from 61 national stations (selected from CMA’s 642-network by spatial representativeness) across the three northeastern provinces (Heilongjiang, Jilin, Liaoning). Through systematic processing in Origin Lab, 976 graphical diagnostic geospatial plots (including probability density diagrams and linear fitting diagrams of phenology) quantify spatiotemporal heterogeneity shifts in critical phenological stages and intervals. Our results establish a robust framework for climate-crop interaction analysis while empirically supporting optimized cultivation strategies, significantly advancing spatially explicit climate adaptation research in China’s primary maize region.
Methods
Study area
This study focuses on the three northeastern provinces of China—Heilongjiang, Jilin, and Liaoning—which constitute the nation’s most crucial maize production base, often referred to as the “Golden Maize Belt.” The region features a temperate continental monsoon climate, with a latitudinal range from approximately 38°43′N to 53°34′N, encompassing diverse agro-climatic conditions. Its strategic importance for national food security and its sensitivity to climate change make it an ideal sentinel region for investigating long-term phenological shifts.
Data sources and compilation
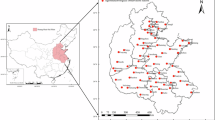
The foundation of this dataset comprises phenological observations from 61 national agrometeorological stations distributed across the maize production belt of Northeast China (Heilongjiang, Jilin, and Liaoning provinces) spanning 1981–2024 (Fig. 1). These stations, operated by the Chinese Meteorological Administration (CMA), monitor local crop production, record agricultural meteorological disasters, and offer practical guidance to farmers for disaster prevention. The spatial distribution includes 23 stations in Heilongjiang, 19 in Jilin, and 19 in Liaoning province (Fig. 1). All stations are situated within major maize -producing regions, representing Northeast China’s typical cropping systems. They exhibit distinct geographical and climatological diversity while maintaining continuous, standardized crop phenology records (1981–2024). This network offers a unique opportunity to analyze multi-decadal phenological trends through high-quality, long-term observational data.

Spatial distribution of 61 agrometeorological observation stations included in the dataset.
We integrated data from dual archival sources to ensure a continuous and complete 43-year record:
*Historical Paper-based Data: This refers to hand-written phenological records from the early part of the study period (primarily 1980s–1990s), which were manually digitized from paper archives and station logbooks held at individual stations or regional meteorological bureaus.
*Modern Electronic Data: This refers to digitally recorded phenological data sourced from CMA’s centralized, quality-controlled electronic database (primarily from the 2000s onwards).
The integration of both data types was essential to bridge the transition from paper-based to digital archiving systems within the CMA, yielding constructing a yielding, long-term phenological series for analysis. The integrated dataset encompasses detailed phenological records for the dates of 10 key maize growth stages: sowing (SO), emergence (EM), three-leaf (TS), seven-leaf (SL), jointing (JO), tasseling (TA), flowering (FL), silking (SI), milking (MI), and maturity (MA). It also includes supporting information on yields, cultivar types, and agronomic management practices.
Dataset construction
The dataset construction process, illustrated in Fig. 2, comprises the following key steps after data collection:
-
(1)
Data Processing: Initially, the collected data were categorized by year, site, crop type, and phenology stage. Subsequently, a multi-tiered quality control (QC) procedure was applied to impute missing values and correct anomalies.
-
Handling of Missing Values: Approximately 1% of the phenological records were missing, predominantly from the paper-based archives (1980s–1990s). These gaps were imputed using a hierarchical approach: first, by reviewing historical context and station logs; second, through estimation using data from adjacent years (±2 years) for stations with continuous records; and finally, by expert judgment informed by professional agronomic experience when other methods were inapplicable.
-
Detection and Correction of Anomalies: Outliers were identified based on both statistical and agronomic criteria:
*Statistical Thresholds: DOY values falling outside ±3 standard deviations from the station-specific and stage-specific mean were flagged for review.
*Logical and Agronomic Consistency: The sequence of phenological stages was rigorously checked (e.g., emergence must follow sowing). Dates were also cross-checked against monthly climate data to identify physiologically implausible records (e.g., jointing during freezing temperatures). Identified anomalies were corrected by referring to original field notes, comparing with data from neighboring stations, or through expert arbitration.
-
DOY Conversion: January 1st of each calendar year was assigned a reference value of 1, and the specific dates for each phenological stages were transformed into DOY values. And computation of descriptive statistics (e.g., mean, standard deviation).
-
Growth Period Definition: Based on maize developmental characteristics, the entire growth period length (GL) was segmented into four distinct stages: sowing to jointing (SO-JO), jointing to silking (JO-SI), silking to maturity (SI-MA), and sowing to maturity (SO-MA).
-
(2)
Data Analysis and Scientific Visualization: Temporal standardization of DOY metrics and fundamental statistical analyses were performed using Microsoft Excel (version 2023; Microsoft Corporation, Redmond, WA, USA), with data integrity ensured through spreadsheet validation protocols. Advanced analyses—including kernel density estimation (KDE), linear regression parameterization with significance testing, and scientific visualization—were systematically conducted in Origin Pro (version 2024; Origin Lab Corporation, Northampton, MA, USA), leveraging its computational engine for robust statistical inference.

Flowchart construction process the dataset maize phenology dataset in Northeast China. Note: The process begins with Data Collection from CMA archives, integrating both historical paper-based and modern electronic records. The raw data then undergo Data Processing, including quality control, conversion to Day of Year (DOY), and calculation of Growth Lengths (GLs). The core Data Analysis phase splits into two parallel, method-specific pathways: The Kernel Density Estimation (KDE) pathway (left) processes DOY and GLs to generate probability density functions (PDFs) and their corresponding diagnostic plots. The Univariate Linear Regression pathway (right) analyzes the temporal trends in DOY and GLs to produce linear fitting diagrams with trend slopes. Both analytical outputs are finally consolidated into the comprehensive dataset.
Kernel density estimation
This study applied kernel density estimation (KDE), a nonparametric technique for probability density estimation, to evaluate maize phenology using Day of Year (DOY) data from national agrometeorological stations. A 43-year long term dataset was analyzed with comprehensive statistical measures, including central tendency (mean) and dispersion (standard deviation). By combining these descriptive statistics with KDE-derived density functions, scientifically robust visualizations for the dataset were generated. This approach enabled rigorous estimation of population characteristic from sample observations, outperforming conventional histogram-based methods through continuous density estimation that is independent of arbitrary bin-width selection24. The KDE function is typically expressed as:
Where:
x1, x2, x3, …, xn represent the DOY samples for n maize at a specific phenology stage.
K is the kernel function.
h is the bandwidth, automatically selected using Scott’s rule within Origin Lab 2024.
δ denotes standard deviation.
f(x) represents the probability density value of the DOY x, estimated by KDE. A higher f(x) value indicates a greater probability density, meaning DOY x is more likely to be the representative DOY for that phenology stage.
Univariate linear regression
Phenology trend analysis was conducted using first-order linear regression. Temporal patterns in DOY and GLs were quantified using slope coefficients. Regression parameters were estimated via ordinary least squares (OLS) optimization, expressed as follows:
Where Y represents either DOY or GLs measurements, and x is calendar year; b is the Y-intercept, and k is the annual rate of change.
Decadal trends were calculated as 10 × k. Negative slope coefficients indicate advancement of phenology dates or contraction of GLs, while positive values signify a delay in phenological dates or extension of GLs. The statistical significance of trends was assessed using two-tailed t-tests, with a significance level of α = 0.05 applied to all regression analyses. Key variables showed highly significant trends (p < 0.01).
Data Records
The dataset described in this work has been deposited in the Science Data Bank (ScienceDB) under accession code https://doi.org/10.57760/sciencedb.2870925. This repository contains the long-term maize phenology dataset for Northeast China (1981–2024). A comprehensive profile of the dataset is summarized in Table 1.
The dataset is systematically organized within a primary folder named “Northeast China - maize phenology data”, which has a total size of 601.04 MB. The folder hierarchy is illustrated in Fig. 3.

The schematic diagram of the folder hierarchy.
The root folder also contains 3 provincial subfolders and 2 primary data tables, namely ‘01-Heilongjiang’, ‘02-Jilin’, ‘03-Liaoning’, ‘04_Phenology_period_Data.xlsx’, ‘05_Growth_Lengths_Data.xlsx’
Each provincial subfolders contains multiple station-specific subfolders. These subfolders are named according to the pattern “[Observation Station Name] and spring maize”. Within each station-specific folder, users will find 16 georeferenced images in JPEG format (1200 dpi resolution):
-
Probability Density Diagrams (2 images):
-
1 diagram for the DOY of all 10 phenological stages.
-
1 diagram for 4 growth lengths.
-
-
Linear Regression Diagrams (14 images):
-
10 diagrams for the DOY of each individual phenological stage (Sowing, Emergence, Three-leaf, Seven-leaf, Jointing, Tasseling, Flowering, Silking, Milking, Maturity).
-
4 diagrams for the length of each individual growth phase (Sowing-Jointing, Jointing-Silking, Silking-Maturity, Sowing-Maturity).
Two primary data tables in XLSX format are located at the root of the primary folder for easy access:
-
-
‘04_Phenology_period_Data.xlsx’: This table contains the linear regression statistics for the Day of Year (DOY) of 10 phenological stages. Variables include: province name, station ID, station name, phenology stage, intercept, slope (indicating variation trends), R², P-value, Model Mean Square, and F-value.
-
‘05_Growth_Lengths_Data.xlsx’: This table contains the linear regression statistics for the duration of 4 growth phases (GLs). Variables include: province name, station ID, station name, growth lengths, intercept, slope, R², P-value, Model Mean Square, and F-value.
Data Overview
To illustrate the structure and content of the dataset, Fig. 4 presents an example from the Nongan station, showing the kernel density estimates for the DOY of the 10 phenological stages and the 4 growth lengths, alongside their corresponding linear regression trend diagrams. These plots are representative of the graphical content available for each station within the dataset and serve to validate the data’s suitability for temporal trend analysis.

Example data: Variation characteristics of maize phenology at Nongan Agrometeorological Observation Station, Jilin Province. Note: SO: sowing, EM: emergence, TS: three-leaf, SL: seven-leaf, JO: jointing, TA: tasseling, FL: flowering, SI: silking, MI: milking, MA: maturity.
Technical Validation
The reliability of this dataset is anchored in China’s standardized agrometeorological observation system, which employs rigorously trained technicians adhering to national protocols. For maize phenology specifically, observers follow clearly defined criteria for each growth stage, ensuring consistency across stations and years. This achievement is attributed to several key factors:
-
Professional workforce: A nationally certified cohort of over 1,200 agrometeorological technicians, systematically trained through CMA’s Accreditation Program for Meteorological Observers, with 82% possessing field experience exceeding 10 years.
-
Rigorous quality assurance: A hierarchical quality control framework was implemented, comprising automated validation and expert-mediated arbitration. Implementation of standardized protocols encompassing bimonthly quality control inspections, triple-blind data validation cycles, and automated anomaly detection algorithms. Additionally, established quality control methods—including historical paper-based data review, expert judgment informed by professional experience, estimation using data from adjacent years, and threshold checks—are applied to impute missing values and correct anomalies.
-
Regulatory compliance: Strict adherence to the “Specification for Agrometeorological Observation”26,27, ensuring methodological consistency across 31 provincial-level regions.
-
Scientific phenology determination: The basis for determining maize phenology follows standardized criteria, as detailed in Table 2.
Table 2 Basis for determining maize phenology.
To address inherent observational challenges—including subjective stage identification and environmental interferences—we implemented a composite validation strategy. This integrated automated checks for internal consistency with expert review of ambiguous cases. Additionally, temporal coherence of temperature-sensitive stages was verified against independent climate records. This multi-tiered approach achieved a final data integrity exceeding 99%.
-
Training & Instrument Calibration: Observers received rigorous training using standardized Agrometeorological Observation criteria to minimize subjective biases. Regular calibration of all field measurement instruments was performed.
-
Automated & Rule-Based Validation: Prior to expert review, the dataset underwent a series of automated QC checks. This included:
*Completeness and Duplication Checks: Ensuring no records were missing or duplicated.
*Internal Consistency Checks: Ensuring the logical sequence of phenological stages (e.g., emergence always follows sowing).
*Value Range: Flagging values outside plausible biological limits ranges and illogical stage sequences.
*Temporal Coherence Assessment: Identifying values that were extreme outliers (±3 standard deviations) from station-specific historical means.
*Cross-Validation with Independent Climate Data: As an additional objective check, the dates of temperature-sensitive phenological stages (e.g., JO, TA, FL) were cross-referenced with daily temperature records from the same station. Records occurring during periods of known cold stress or physiologically implausible temperatures were flagged for expert re-evaluation.
-
Expert Review and Consensus-Based Arbitration: The cases flagged by the automated and climate cross-checks (constituting a small fraction of the total data) were subjected to a formal expert arbitration process. A panel of agronomy experts reviewed these ambiguous cases with access to historical context and station logs, making consensus-based decisions on data imputation or correction. This process leverages human expertise to resolve cases that rigid algorithms cannot.
This comprehensive, multi-faceted protocol ensures that the final dataset benefits from both the objectivity of automated checks and the contextual understanding of domain experts, resulting in a high-integrity product suitable for climate impact studies.
Utility and Applications
This long-term, spatially explicit dataset enables multiple research and practical applications. For the scientific community, it supports investigation of spatiotemporal phenological patterns under climate change and facilitates mechanistic understanding of crop-environment interactions. The integrated analytical approach (KDE with trend analysis) provides enhanced validation capabilities for process-based crop models.
From an applied perspective, the dataset informs climate adaptation strategies through evidence-based guidance on cultivar selection, planting schedules, and field management practices. By elucidating trends in growth stage timing and duration, it empowers farmers and agricultural planners to optimize production systems in response to evolving climatic conditions, thereby enhancing regional food security resilience.
Data availability
The dataset generated during this study is openly available in the Science Data Bank at https://doi.org/10.57760/sciencedb.28709 or https://cstr.cn/31253.11.sciencedb.28709.
Code availability
No custom code was created for the production of this dataset.
References
Cai, C., Ding, T. & Chen, W. Potential yield of world maize under global warming based on ARIMA-TR model. Journal of Agrometeorology 26(1), 2024 (2024).
Li, M. Retrospect and prospect of world maize production. Journal of Maize Sciences (03), 165–169 (2010).
Tanumihardjo, S. A. et al. Maize agro-food systems to ensure food and nutrition security in reference to the Sustainable Development Goals. Global Food Security 25(5), 100327 (2019).
Kuang et al. Dual-crosslinked citrus pectin-zein emulsion gels: Enhanced stability and mechanical properties. Industrial Crops & Products 215, 118380 (2024).
Erenstein, O. et al. Global maize production, consumption and trade: trends and R&D implications. Food Sec. 14, 1295–1319 (2022).
Yang, B. et al. The optimal phenological phase of maize for yield prediction with high-frequency UAV remote sensing. Remote Sensing 14, 1559 (2022).
Zhang, C., Gao, J., Liu, L. & Wu, S. Simulating the effects of optimizing sowing date and variety shift on maize production at finer scale in Northeast China under future climate. Journal of the Science of Food and Agriculture 104(1), 132–144 (2024).
Heilongjiang Bureau of Statistics. Annual report on grain production capacity of Northeast China (2024).
Wang, C. X. D. et al. K. The spatial reconstruction process and driving mechanism of China’s grain production capacity since the 21st century. Journal of Natural Resources 40(3), 728–749 (2025).
Wang, H., Tang, J. & Wang, J. Circular economy models of corn advanced processing industry. Scientia Geographica Sinica 27(5), 661–665 (2007).
Ji, R. P. et al. MI Na. Effect of climate change on maize production in Northeast China. Geographical Research 31(2), 290–298 (2012).
Liu, X. L., Chu, Z. & Cheng, C. Future changes in climate resources during the growth stages of maize in Heilongjiang province under climate change. Journal of Maize Sciences 33(06), 49–55 (2025).
Cheng, L. et al. Impact of climate change on the yield of summer maize in Henan province. Journal of Maize Sciences 24(01), 88–95 (2016).
Yu, S. et al. Review of research on the impacts of climate change on staple grain crops in the three provinces of Northeast China. Chinese Journal of Eco-Agriculture 32(06), 970–985 (2024).
Ge, S. B. & Shuai, L. Impact of climate change on maize sowing area —based on the perspective of farmers’ climate adaptive behavior. Journal of Maize Sciences 1–14, http://kns.cnki.net/kcms/detail/22.1201.S.20250429.1147.002.html (2025).
Xiao, D. et al. Impact of warming climate and cultivar change on maize phenology in the last three decades in North China Plain. Theor Appl Climatol 124, 653–661 (2016).
Zhang, S. Simulating land-use changes and predicting maize potential yields in Northeast China for 2050. International Journal of Environmental Research and Public Health, 18 (2021).
Luo, Y. C. et al. Weakened maize phenological response to climate warming in China over 19812018 due to cultivar shifts. Advances in Climate Change Research 13(5), 710–720 (2022).
Niu, Q. et al. A 30 m annual maize phenology dataset from 1985 to 2020 in China. Earth Syst. Sci. Data 14, 2851–2864 (2022).
Feng, J. et al. The Impact of Climate Change on Maize phenophase and crop water requirement in the Heihe River Basin, Northwestern China. Ekoloji 26, 11–17 (2017).
Zhang, Q. J. et al. Development status, problems and prospects of agrometeorological observation operation in China. Chinese Journal of Agrometeorology 44(08), 735–749 (2023).
Yang, F. Y. et al. Application status of agrometeorological observation data and suggestions. Advances in Meteorological Science and Technology 11(5), 171–177 (2021).
Pu, L., Zhang, S., Yang, J., Chang, L. & Bai, S. Spatio-temporal dynamics of maize potential yield and yield gaps in Northeast China from 1990 to 2015. Int J Environ Res Public Health 16(7), 1211 (2019).
Sheather, S. J. Density estimation. Statist Sci 19, 588–597 (2004).
Zhang, Q.-J. & Wu, D.-L. Analysis of maize phenology characteristics in Northeast China from 1981 to 2024[DS/OL]. V3. Science Data Bank https://doi.org/10.57760/sciencedb.28709 (2025).
National Meteorological Administration. Specifications for Agrometeorological Observations. Beijing: China Meteorological Press (1993).
National Meteorological Administration. Specifications for Agrometeorological Observations. Beijing: China Meteorological Press (2025).
Acknowledgements
This work was supported by the National key R&D plant project (2024YFD2301301) and Innovative Development Special Project of China Meteorological Administration (CXFZ2023J069) and the Ecological, Agricultural Observation Technology Innovation Team Project. Thanks to the frontline agricultural meteorological observers of the China Meteorological Administration for their hard work, and to the leaders at all levels for their support. Thank Mr. Kong Xiangsheng, Miss. Zhang Jing and Mr. Zhang Shihao for their support and guidance in data collection and processing. The authors would like to express their sincere gratitude to all of the data contributors whose valuable inputs made this research successful.
Author information
Authors and Affiliations
Contributions
Quan-Jun Zhang designed the study, coordinated data acquisition, quality controlled, statistical analysis, plotting and manuscript writing. Dong-Li Wu was responsible for the guidance of dataset construction scheme and writing. Yong-Chao Zhu, Cong Liu and Da-Sheng Yang assisted in data processing. All authors actively contributed to collect and curate the data, and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, QJ., Wu, DL., Zhu, YC. et al. A long-term dataset of maize phenology observations from agrometeorological stations in Northeast China (1981–2024). Sci Data 12, 2037 (2025). https://doi.org/10.1038/s41597-025-06330-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-06330-9
