
Abstract
Dry eye is one of the most common eye diseases and manifests as abnormalities in the quality, quantity, and fluid dynamics of tear fluid. Studying the secretion of tears is one of the methods for diagnosing dry eye. The lower tear meniscus height (TMH) is an important indicator of tear secretion and stability. This parameter is typically measured manually. Artificial intelligence (AI) can automatically segment and assess TMH images accurately. However, the success of AI models relies on high-quality datasets, including images and corresponding labels. Therefore, we introduced a multicentre, multimodal, pixel-level lower tear meniscus segmentation dataset. It comprised 1,693 colourful modal images and 1,739 infrared modal images from five centres across different regions of China, along with segmentation labels. These labels were generated using our newly developed human-computer interactive approach. To our knowledge, this is the only publicly available multimodal tear meniscus segmentation dataset. We believe this dataset will aid in constructing standardized medical image databases and advancing research on the diagnosis and treatment of dry eye.
Similar content being viewed by others

Background & Summary
Dry eye is one of the most common eye diseases worldwide. It is characterized by abnormalities in the quality, quantity, and fluid dynamics of tears, leading to ocular discomfort, visual disturbances, and damage to the ocular surface. Globally, the prevalence of dry eye ranges from 5% to 50%. In Asia, owing to ethnic and environmental factors, it can be 1.5–2.2 times higher than among Caucasian populations1. Beyond its impact on patients’ work efficiency, learning ability, mental health, and social interactions, this disease also imposes a substantial socioeconomic burden2. Early diagnosis and treatment are therefore critical. An imbalance in ocular surface tear film homeostasis is a core driving factor in the pathogenesis of dry eye, and quantifying tear secretion is a key step in its diagnosis3,4. Thus, tear meniscus height (TMH) serves as a key indicator, offers a reproducible and standardized biomarker for epidemiological surveys, and enables precise assessment of disease severity and monitoring of therapeutic efficacy.
The tear meniscus is the concave arc formed at the junction of the tear fluid and the eyelid margin and can be divided into upper and lower types. The TMH typically refers to the vertical height of the central part of the tear meniscus on the coronal plane, which is located directly above or below the centre of the pupil. In practice, TMH measurement often focuses on the lower tear meniscus due to its greater representativeness in reflecting tear volume4,5. The lower tear meniscus has a relatively larger and more stable volume of tears, influenced by the lower eyelid’s anatomy and gravity, making it a better indicator of tear storage3. In contrast, the upper tear meniscus has less tear volume and is more affected by eye movements. At the same time, tears form a more distinct fluid arc in the lower tear meniscus, allowing for easier and more direct observation. The upper tear meniscus is smaller and partly hidden by the upper eyelid, making it harder to observe. Consensus among experts4,6,7,8 also supports using the lower tear meniscus for TMH measurement. Thus, our study focuses on the lower tear meniscus for TMH analysis.
In patients with aqueous-deficient dry eye, insufficient tear secretion by the lacrimal glands or abnormal tear quality often leads to narrowing of the tear meniscus, sometimes to the point of near disappearance. In cases complicated by meibomian gland dysfunction (MGD), obstruction from lipid plugs at the eyelid margin can lead to distortion or even disruption of the tear meniscus. When the TMH is less than 0.2 mm, there is an increased risk of aqueous-deficient dry eye syndrome7,9. TMH is a crucial indicator for assessing tear secretion and tear film stability. It is related to the Schirmer test score, corneal fluorescein staining score (CFS), and tear film break-up time (BUT)10,11,12,13. TMH directly reflects the tear volume in the tear meniscus, while the Schirmer test score measures secretory function, thus demonstrating a positive correlation10,12,13. Furthermore, tear film stability depends on adequate tear secretion, resulting in a positive correlation between TMH and BUT10,11,12,13. Conversely, insufficient tear production leads to ocular surface dryness and damage, consequently increasing CFS and establishing an inverse relationship between TMH and CFS10,12. The combination of these indicators can provide a comprehensive assessment of tear secretion and the health status of the ocular surface. Therefore, the assessment of TMH has significant clinical value for diagnosing and classifying dry eye syndrome3,11,14. Moreover, diseases of the lacrimal ducts such as nasolacrimal obstruction15, dacryocystitis16, and epiphora17 can alter tear drainage, thereby influencing the TMH. Eyelid disorders such as entropion and ectropion18, blepharitis19, eyelid laxity or lagophthalmos20, and post-surgical scars20,21 can disrupt the anatomical space or functional apposition between the eyelid and the eye, therefore disturbing tear distribution and influencing the TMH. Establishing a tear meniscus segmentation dataset not only aids in the diagnosis of dry eye but also assists in the research of other eye diseases.
Traditional methods for TMH assessment include the slit lamp estimation method with and without fluorescein staining22,23. These methods often necessitate a graticule eyepiece to increase precision; however, this approach yields highly subjective results with poor stability and repeatability24,25. Identifying the upper boundary of the tear meniscus is challenging, and some studies introduce a small amount of fluorescein to the tear fluid to facilitate the observation of this boundary. Nonetheless, this method may disrupt normal tear secretion, potentially leading to an overestimated assessment. Some studies have used optical coherence tomography (OCT)10,26 to assess the TMH, but this method is time-consuming and relies on specific OCT equipment, thus limiting its widespread clinical application. In recent years, the Keratograph 5 M27 has become the preferred method for TMH assessment; this method utilizes noncontact technology that avoids the use of dyes such as fluorescein, thereby reducing ocular irritation and discomfort28. The device is accompanied by software and thus provides standardized quantitative tools. However, this method requires the examiner to manually select the tear meniscus area and measure the height, which requires a high level of technical proficiency from the examiner as well as specialized training to ensure the accuracy of the assessment results. Furthermore, in an outpatient setting, the heavy workload limits the time available for thorough assessments, thereby affecting the accuracy of the results29.
TMH assessment, a task that is both singular and repetitive, is an area in which Artificial intelligence (AI) excels. The advantages of AI in the realm of ocular image segmentation have been confirmed by numerous studies. In the diagnosis of anterior diseases, AI has demonstrated formidable image recognition capabilities; it can screen for pterygium30, detect keratoconus at an early stage31,32, and classify infectious keratitis33, thereby holding tremendous potential for enhancing the efficiency of ocular surface disease diagnosis34. Due to its strong adaptability, AI can achieve good generalizability across different data sources, thus making it a pivotal force in both ophthalmic research and clinical practice35,36.
Considering the advantages of AI in terms of its speed, accuracy, and repeatability, establishing a model for TMH assessment based on tear meniscus segmentation can be effectively applied in clinical practice for the diagnosis and classification of dry eye syndrome. Such a model has the potential to reduce human measurement errors and enhance both efficiency and accuracy. The construction of an efficient AI model requires a substantial dataset of high-quality training data, which consists of two components1: the original images for segmentation and2 the corresponding ground truth (GT) segmentation labels. Manual annotation by trained professional ophthalmologists is considered the most reliable method and can be regarded as the GT. Moreover, the scale of the training dataset strongly influences the performance of image segmentation algorithms. Without enough high-quality data, research on TMH assessment models faces technical challenges such as model overfitting and poor generalization capabilities, thereby hindering the translation and application of these models in clinical practice. However, dataset construction is time-consuming and labour-intensive. To date, few public datasets of TMH images have been published. Furthermore, no publicly accessible datasets exist for tear meniscus segmentation training, which presents a significant barrier to the development of dry eye models.
Given the significance and necessity of TMH image datasets, in this study, we introduced a multicentre, multimodal, pixel-level dataset based on human-computer interaction segmentation. This dataset comprised 1,693 high-resolution colourful modal images and 1,739 high-resolution infrared modal images from five centres, as well as corresponding pixel-level annotations for the tear meniscus and the central pupillary areas. The annotation process was carried out by two junior ophthalmologists, and a senior ophthalmologist was responsible for the review and correction of the annotations. The dataset was constructed in strict accordance with the principles of standardization and regulation.
The dataset is applicable not only for cross-project comparisons but also for model training, thus providing multimodal imaging data of the tear meniscus to assist in training models with broader adaptability. Overall, this publicly available and standardized resource facilitates the development and evaluation of tear meniscus segmentation and TMH measurement algorithms. It can also serve as an external validation set, aiding researchers in assessing the generalization capabilities of their models. This type of data is crucial for improving the clinical diagnosis, treatment, and medical research of diseases such as dry eye syndrome.
Methods
Data collection
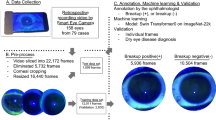
We retrospectively collected multimodal TMH images from patients who underwent Ocular Surface examinations between February 2019 and September 2024 at 5 centres, as shown in Table 1. The exclusion criteria were as follows: active acute ocular surface inflammation or a history of ocular trauma or surgery; the use of medications or eye drops affecting tear film function within the past two weeks; concurrent ocular or systemic diseases impacting tear film function; comorbidities with psychiatric disorders, cognitive impairments, cardiovascular and cerebrovascular accidents, malignant arrhythmias, or significant dysfunction of major organs; systemic connective tissue diseases; and severe autoimmune diseases such as rheumatoid arthritis, sarcoidosis, lupus erythematosus, and thyroiditis. These criteria enabled us to target a generally healthy population. This study was approved by the Ethics Committee of the Affiliated Eye Hospital of Wenzhou Medical University (IRB approval number: H2023-045-K-42) and was granted a waiver for informed consent. All patient information was fully anonymized before analysis, ensuring the protection of patient privacy. The study was conducted in accordance with the principles of the Declaration of Helsinki.
All centres used the same model of device Keratograph 5 M (K5M; Oculus, Wetzlar, Germany) to capture TMH images. All examiners had undergone standardized training and followed established inspection protocols8. After acquisition, the images were stored in PNG format with a resolution of 1024 × 1360 pixels. No compression was applied to the images throughout the processes of acquisition, annotation, and dataset uploading. After the collection was completed, two junior ophthalmologists performed independent quality control. When their assessments differed, a senior ophthalmologist was consulted to adjudicate. A total of 462 poor-quality images, characterized by blinking, blurriness, missing image information, or eyelash obstruction, were manually excluded (Fig. 1). Ultimately, 1,693 colour images and 1,739 infrared images were included in the dataset.

Examples of representative TMH images. (a) Image meeting the criteria. (b) Patient blinking. (c) Blurriness. (d) Absence of the central pupillary area. (e) Absence of the tear meniscus area. (f) Eyelash obstruction.
Image annotation
During the annotation process, the upper and lower edges of the concave meniscus formed at the interface between the tear fluid and the lower eyelid margin were defined as the superior and inferior boundaries of the tear meniscus. The innermost ring of the Placido disc was approximated as the central pupillary area. Image annotation was carried out via Fiji (ImageJ version 1.51j8).
In the initial phase, 100 colour images and 100 infrared images were randomly selected from the dataset for independent masking of the tear meniscus and central pupillary areas by a junior ophthalmologist. These 200 images were annotated via two distinct methods: the conventional pixel-by-pixel approach and a human-computer interaction-based annotation technique.
In the conventional approach, the annotator manually identified the superior and inferior boundaries of the tear meniscus and the central pupillary zone on the original image. Then, delineated their contours pixel-by-pixel without any algorithmic assistance, a new label layer was created and exported. For medical image AI annotation, pixel-by-pixel annotation is widely recognized as the gold standard for high precision. However, its time-consuming nature and high labour costs have led to its gradual replacement by weakly supervised and interactive methods in recent years. Therefore, our team innovatively adopted a human-computer interactive annotation method. The human-computer interaction method first involved processing the original image with an edge detection operator based on the Laplacian operator to enhance the tear meniscus boundaries and balance image intensity while reducing noise. Guided by gradient information, the approximate tear meniscus boundary was automatically extracted. The annotator only needed to make minor refinements. Thereafter, a region-based repair algorithm anchored in the KD-Tree data structure was used to reconstruct the original tear meniscus area from the extracted boundary data. Finally, this reconstructed area was integrated with the pupillary area to complete the comprehensive mask annotation process. This method can significantly improve the efficiency and quality of tear meniscus annotation.
Each image was annotated three times by both methods, with no restrictions on the operation time. In medical image repeat annotation practice, a wash-out interval is commonly introduced between sessions to reduce memory interference. In this study, we set the interval at 7 days to minimize the influence of prior annotations on the current task. After the completion of all annotations, they underwent a thorough review and correction by a senior ophthalmologist.
A comparison of the mean intersection over union (MIoU) for the masks drawn by the two methods is presented in Table 2. The results indicate that the annotation method based on human-computer interaction yields greater intragroup consistency and accuracy than the conventional pixel-by-pixel method does. This technique substantially reduces the impact of subjective annotator biases, enhances the robustness of the annotations. Annotators are also no longer required to spend extensive time identifying boundaries and labeling every single pixel, resulting in a marked reduction in workload and a corresponding boost in overall efficiency. Consequently, we ultimately adopted the human-computer interaction-based segmentation method for the annotation of all the images, which was completed by two junior ophthalmologists. During the annotation process, a senior ophthalmologist provided guidance to refine the segmentation accuracy, and the final results were reviewed and corrected by a senior ophthalmologist (Fig. 2).

Workflow of the establishment of the proposed dataset.
Data Records
The dataset has been uploaded to Figshare in a compressed file format. All the data are available at https://doi.org/10.6084/m9.figshare.28650536.v237. The data from the five centres are compressed into five folders. The unzipped folders contain the original image sets as well as the annotation labels, which are named “Original” and “Label” respectively. The images in these two folders are stored, named, and arranged in the same manner. Within the “Original” folder, all the original tear meniscus images are included, and these images are named “n.png”, where “n” represents the quantity of the images. Similarly, the segmentation label images in the “Label” folder are named according to the same rule.
Technical Validation
In our study, the dataset was annotated by two junior ophthalmologists and reviewed and corrected by a senior ophthalmologist. Consequently, it was necessary to assess both inter- and intra-annotator consistency, for which we utilized the MIoU and the Dice coefficient for evaluation.
Intra-annotator consistency
To ensure intra-annotator consistency across different time points, a subset of 200 images from the complete dataset was selected. Two junior ophthalmologists were instructed to perform the annotation process on these 200 images on two separate occasions. The MIoU and Dice coefficients were calculated for all image annotations, with results of 0.9579 and 0.9559, respectively, supporting the consistency and stability of individual annotators in image segmentation annotation (Fig. 3).

Intra and inter-annotator consistency.
Inter-annotator consistency
To assess inter-annotator consistency among different annotators, the initial annotation results of the same 200 images reviewed by two junior ophthalmologists were utilized for evaluation. The MIoU and Dice coefficients were calculated for all resulting annotations, with values of 0.9243 and 0.9183, respectively. These findings support the consistency among annotators and the credibility of the dataset (Fig. 3).
The analysis of the annotations and the dataset reveals that the annotations made by the same annotator at various times and those made by different annotators exhibit stability and consistency, which establishes a solid foundation for precise and reproducible segmentation.
Segmentation validation
To demonstrate the practical value of the proposed dataset, we conducted segmentation experiments using annotated images. Three representative architectures-UNet, ResUNet, and DeepLabV3 + (backboned by FCN-ResNet50) were selected. By spanning both classical and state-of-the-art paradigms, they established a robust segmentation framework. For data partitioning, infrared and colour images were each randomly split into training, validation, and test sets in a 5: 2: 3 ratio, ensuring stable training and generalizability. Model performance was evaluated with four complementary metrics: F1-score, Recall, Precision, and MIoU, which capture pixel-level accuracy, region overlap, and class-wise balance. Comprehensive results are reported in Table 3. The results demonstrate that the dataset holds substantial promise for multimodal tear meniscus segmentation. Moreover, it has been validated as a reliable resource for future TMH quantification and dry eye research.
Data availablility
All the data are available at https://doi.org/10.6084/m9.figshare.28650536.v2.
Code availability
No custom code was used in this study.
References
Stapleton, F. et al. TFOS DEWS II Epidemiology Report. Ocul Surf. 15(3), 334–65, https://doi.org/10.1016/j.jtos.2017.05.003 (2017).
Yu, J., Asche, C. V. & Fairchild, C. J. The economic burden of dry eye disease in the United States: a decision tree analysis. Cornea. 30(4), 379–87, https://doi.org/10.1097/ICO.0b013e3181f7f363 (2011).
Shen, M. et al. Upper and lower tear menisci in the diagnosis of dry eye. Invest Ophthalmol Vis Sci. 50(6), 2722–6, https://doi.org/10.1167/iovs.08-2704 (2009).
Wolffsohn, J. S. et al. TFOS DEWS III Diagnostic Methodology. Am J Ophthalmol, https://doi.org/10.1016/j.ajo.2025.05.033 (2025).
Wan, C. et al. Measurement method of tear meniscus height based on deep learning. Front Med (Lausanne). 10, 1126754, https://doi.org/10.3389/fmed.2023.1126754 (2023).
Chinese expert consensus on the diagnosis and treatment of dry eye. Zhonghua Yan Ke Za Zhi. 60(12), 968–76, https://doi.org/10.3760/cma.j.cn112142-20240517-00227 (2024).
Wolffsohn, J. S. et al. TFOS DEWS II Diagnostic Methodology report. Ocul Surf. 15(3), 539–74, https://doi.org/10.1016/j.jtos.2017.05.001 (2017).
Expert consensus on classification and annotation methods, processes and quality control for dry eye imaging in artificial intelligence applications (2025). Chinese Journal of Experimental Ophthalmology. 43(4), 289–300, https://doi.org/10.3760/cma.j.cn115989-20250227-00055 (2025).
Vidal-Rohr, M., Craig, J. P., Davies, L. N. & Wolffsohn, J. S. Classification of dry eye disease subtypes. Cont Lens Anterior Eye. 47(5), 102257, https://doi.org/10.1016/j.clae.2024.102257 (2024).
Ibrahim, O. M. et al. Application of visante optical coherence tomography tear meniscus height measurement in the diagnosis of dry eye disease. Ophthalmology. 117(10), 1923–9, https://doi.org/10.1016/j.ophtha.2010.01.057 (2010).
Mainstone, J. C., Bruce, A. S. & Golding, T. R. Tear meniscus measurement in the diagnosis of dry eye. Curr Eye Res. 15(6), 653–61, https://doi.org/10.3109/02713689609008906 (1996).
Tung, C. I., Perin, A. F., Gumus, K. & Pflugfelder, S. C. Tear meniscus dimensions in tear dysfunction and their correlation with clinical parameters. Am J Ophthalmol. 157(2), 301–10.e1, https://doi.org/10.1016/j.ajo.2013.09.024 (2014).
Wei, A. et al. Assessment of Lower Tear Meniscus. Optom Vis Sci. 93(11), 1420–5, https://doi.org/10.1097/opx.0000000000000986 (2016).
Pena-Verdeal, H. et al. A Comprehensive Study on Tear Meniscus Height Inter-Eye Differences in Aqueous Deficient Dry Eye Diagnosis. J Clin Med. 13(3), https://doi.org/10.3390/jcm13030659 (2024).
Burkat, C. N. & Lucarelli, M. J. Tear meniscus level as an indicator of nasolacrimal obstruction. Ophthalmology. 112(2), 344–8, https://doi.org/10.1016/j.ophtha.2004.07.030 (2005).
Goel, R., Saini, S., Golhait, P. & Shah, S. Association of primary chronic dacryocystitis and meibomian gland dysfunction. Indian J Ophthalmol. 72(2), 185–9, https://doi.org/10.4103/ijo.Ijo_1449_23 (2024).
Sevimli, N., İren, E., Taydaş, G. & Azarbaz, M. K. Assessment of punctal metrics and tear meniscus height in epiphora: clinical insights and diagnostic potential. Jpn J Ophthalmol. 69(3), 351–9, https://doi.org/10.1007/s10384-025-01182-7 (2025).
Yokoyama, T., Vaidya, A., Kono, S., Kakizaki, H. & Takahashi, Y. Changes in Lacrimal Punctum Position and Tear Meniscus Height after Correction of Horizontal Laxity in Involutional Lower Eyelid Entropion. J Ophthalmol. 2023, 4113151, https://doi.org/10.1155/2023/4113151 (2023).
Di Zazzo, A., Villani, E., Barabino, S., Giannaccare, G. How Eyelid Changes May Impact on Tears. J Clin Med. 13(22), https://doi.org/10.3390/jcm13226927 (2024).
Lopez Montes, T., Gurnani, B. & Stokkermans, T. J. Assessment of the Watery Eye. StatPearls. Treasure Island (FL) ineligible companies. Disclosure: Bharat Gurnani declares no relevant financial relationships with ineligible companies. Disclosure: Thomas Stokkermans declares no relevant financial relationships with ineligible companies.: StatPearls Publishing Copyright © 2025, StatPearls Publishing LLC.; (2025).
Aydemir, E. & Aksoy Aydemir, G. Changes in Tear Meniscus Analysis After Ptosis Procedure and Upper Blepharoplasty. Aesthetic Plast Surg. 46(2), 732–41, https://doi.org/10.1007/s00266-021-02613-9 (2022).
García-Resúa, C., Santodomingo-Rubido, J., Lira, M., Giraldez, M. J. & Vilar, E. Y. Clinical assessment of the lower tear meniscus height. Ophthalmic Physiol Opt. 29(5), 487–96, https://doi.org/10.1111/j.1475-1313.2009.00634.x (2009).
Kawai, M. et al. Quantitative evaluation of tear meniscus height from fluorescein photographs. Cornea. 26(4), 403–6, https://doi.org/10.1097/ICO.0b013e318033c242 (2007).
Pena-Verdeal, H., Garcia-Resua, C., Barreira, N., Giraldez, M. J. & Yebra-Pimentel, E. Interobserver variability of an open-source software for tear meniscus height measurement. Cont Lens Anterior Eye. 39(4), 249–56, https://doi.org/10.1016/j.clae.2016.02.009 (2016).
Niedernolte, B., Trunk, L., Wolffsohn, J. S., Pult, H. & Bandlitz, S. Evaluation of tear meniscus height using different clinical methods. Clin Exp Optom. 104(5), 583–8, https://doi.org/10.1080/08164622.2021.1878854 (2021).
Chan, H. H., Zhao, Y., Tun, T. A. & Tong, L. Repeatability of tear meniscus evaluation using spectral-domain Cirrus® HD-OCT and time-domain Visante® OCT. Cont Lens Anterior Eye. 38(5), 368–72, https://doi.org/10.1016/j.clae.2015.04.002 (2015).
Garcia-Terraza, A. L. et al. Reliability, repeatability, and accordance between three different corneal diagnostic imaging devices for evaluating the ocular surface. Front Med (Lausanne). 9, 893688, https://doi.org/10.3389/fmed.2022.893688 (2022).
Koh, S. et al. Effect of non-invasive tear stability assessment on tear meniscus height. Acta Ophthalmol. 93(2), e135–9, https://doi.org/10.1111/aos.12516 (2015).
Tian, L., Qu, J. H., Zhang, X. Y. & Sun, X. G. Repeatability and Reproducibility of Noninvasive Keratograph 5M Measurements in Patients with Dry Eye Disease. J Ophthalmol. 2016, 8013621, https://doi.org/10.1155/2016/8013621 (2016).
Fang, X. et al. Deep learning algorithms for automatic detection of pterygium using anterior segment photographs from slit-lamp and hand-held cameras. Br J Ophthalmol. 106(12), 1642–7, https://doi.org/10.1136/bjophthalmol-2021-318866 (2022).
Malyugin, B. et al. Keratoconus Diagnostic and Treatment Algorithms Based on Machine-Learning Methods. Diagnostics (Basel). 11(10), https://doi.org/10.3390/diagnostics11101933 (2021).
Xie, Y. et al. Screening Candidates for Refractive Surgery With Corneal Tomographic-Based Deep Learning. JAMA Ophthalmol. 138(5), 519–26, https://doi.org/10.1001/jamaophthalmol.2020.0507 (2020).
Li, Z. et al. Deep learning for multi-type infectious keratitis diagnosis: A nationwide, cross-sectional, multicenter study. NPJ Digit Med. 7(1), 181, https://doi.org/10.1038/s41746-024-01174-w (2024).
Zhang, Z. et al. Artificial intelligence-assisted diagnosis of ocular surface diseases. Front Cell Dev Biol. 11, 1133680, https://doi.org/10.3389/fcell.2023.1133680 (2023).
Ting, D. S. W. et al. Artificial intelligence and deep learning in ophthalmology. Br J Ophthalmol. 103(2), 167–75, https://doi.org/10.1136/bjophthalmol-2018-313173 (2019).
Li, Z. et al. Artificial intelligence in ophthalmology: The path to the real-world clinic. Cell Rep Med. 4(7), 101095, https://doi.org/10.1016/j.xcrm.2023.101095 (2023).
Chen, X. et al. Pixel-Level Tear Meniscus Segmentation Dataset with Multimodal Imaging. figshare https://doi.org/10.6084/m9.figshare.28650536.v2 (2025).
Ronneberger, O., Fischer, P. & Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In: Navab, N., Hornegger, J., Wells, W., Frangi, A. (eds) Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015. MICCAI 2015. Lecture Notes in Computer Science() vol 9351, https://doi.org/10.1007/978-3-319-24574-4_28 (Springer, Cham. 2015).
He, K., Zhang, X., Ren, S. & Sun, J. Deep Residual Learning for Image Recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, pp. 770–778, https://doi.org/10.1109/CVPR.2016.90 (2016).
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. & Wojna, Z. Rethinking the Inception Architecture for Computer Vision. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, pp. 2818–2826, https://doi.org/10.1109/CVPR.2016.308 (2016).
Acknowledgements
We would like to express our gratitude to the participants involved in this study and to the contributors from various centres who dedicated their efforts. This research was funded by the National Administration of Traditional Chinese Medicine Science and Technology Department-Zhejiang Provincial Administration of Traditional Chinese Medicine Co-construction Science and Technology Plan (GZY-ZJ-KJ-23086). This study was also supported by the Provincial Advantageous Characteristic Discipline of Wenzhou Medical University (Clinical Medicine).
Author information
Authors and Affiliations
Contributions
Xiaoyu Chen: Conceptualization, Data curation, Investigation, Methodology, Writing - original draft, Writing – review & editing. Kesheng Wang: Conceptualization, Investigation, Methodology, Writing - review & editing. Kunhui Xu: Data curation, Investigation, Writing -review & editing. Chun Xiao: Data curation, Investigation, Writing - review & editing. Ying Wang: Data curation, Writing - review & editing. Shoujun Huang: Conceptualization, Resources, Investigation, Methodology, Writing- review & editing. Weihua Yang: Conceptualization, Resources, Investigation, Methodology, Writing- review & editing. Qi Dai: Conceptualization, Funding acquisition, Resources, Investigation, Methodology, Writing - original draft, Writing- review & editing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chen, X., Wang, K., Xu, K. et al. Multicentre Pixel-Level Tear Meniscus Segmentation Dataset with Multimodal Imaging for Dry Eye Diagnosis. Sci Data 13, 143 (2026). https://doi.org/10.1038/s41597-025-06460-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-06460-0
