
Abstract
High-resolution column-averaged dry-air CO₂ mole fraction (XCO₂) data are essential for characterizing carbon sources and sinks, advancing carbon cycle research, and supporting climate policy goals such as carbon peaking and carbon neutrality. However, current satellite retrievals are often spatially fragmented and temporally discontinuous due to cloud cover and aerosol interference. To address these limitations, this study utilizes an XGBoost model optimized via Bayesian optimization (XGBoost-BO) to construct a robust mapping relationship between atmospheric XCO₂ concentrations and multi-source auxiliary parameters. Crucially, the incorporation of the SHAP (SHapley Additive exPlanations) methodology enhances model interpretability, ensuring that the reconstruction captures physically meaningful spatiotemporal dynamics across China. The reconstructed XCO₂ dataset exhibits high consistency with OCO-2 satellite observations, achieving a coefficient of determination (R²) of 0.98, a Root Mean Square Error (RMSE) of 0.58 ppm, and a Mean Absolute Percentage Error (MAPE) of 0.07%. The model’s reliability is further validated against ground-based TCCON measurements in China, achieving an R² of 0.92 (RMSE = 1.16 ppm, MAPE = 0.2%) at the Hefei site and an R² of 0.70 (RMSE = 2.00 ppm, MAPE = 0.4%) at the Xianghe site.
Similar content being viewed by others

Background & Summary
Carbon dioxide (CO₂), a principal greenhouse gas, acts as a primary driver of global warming1. If global CO₂ emissions continue to rise at current rates, atmospheric concentrations are projected to exceed 500 ppm within the next four decades2. Consequently, accurate data on CO₂ spatiotemporal variations are critical for the scientific assessment of climate trends and the formulation of effective emission reduction policies. In China, rapid economic development and escalating energy consumption have driven a continuous surge in CO₂ emissions, exacerbating both environmental pollution and global climate challenges3. High-precision CO₂ data provide essential scientific evidence to guide the government in establishing evidence-based environmental policies. These data also support industrial sectors in carbon management and footprint analysis. Furthermore, data products with high spatiotemporal resolution enable a granular characterization of CO₂ distributions across diverse regions and time scales. By providing dynamic data, these products offer vital decision-making support for addressing climate change. Therefore, the development and deployment of high-resolution spatiotemporal CO₂ data products are of strategic importance for understanding emission dynamics and achieving national emission reduction targets4.
Current CO₂ monitoring strategies primarily rely on ground-based monitoring stations and satellite remote sensing. Ground-based stations, representing the traditional approach, continuously measure atmospheric CO₂ concentrations via in-situ sensors. However, these stations are spatially sparse, providing data only within limited geographic scopes and failing to capture global or large-scale dynamic variations5. In contrast, satellite remote sensing retrieves atmospheric CO₂ data globally through onboard sensors. Modern satellites, such as NASA’s OCO-2, are capable of monitoring CO₂ distributions on a global scale, offering critical observational data for regions that are otherwise difficult to access, such as oceans and remote terrestrial areas. Nevertheless, despite their global reach, existing satellites face significant spatiotemporal limitations. As illustrated in Fig. 1, constraints related to orbital paths and revisit cycles often preclude high-frequency, continuous dynamic monitoring6,7.

Spatial distribution of OCO-2 XCO₂ retrievals over China on May 1, 2016.
Full-coverage XCO₂ datasets are typically generated using two primary approaches. The first involves geostatistical interpolation methods, most notably Kriging. Jing et al.8 utilized GOSAT and SCIAMACHY satellite data to map global land CO₂ distributions via Kriging interpolation. Similarly, He et al.9 developed a precision-weighted spatiotemporal Kriging methodology to fuse multi-source satellite measurements, thereby extending temporal coverage and enhancing data quality. Sheng et al.10 applied spatiotemporal Kriging to generate a continuously integrated XCO₂ dataset. However, Kriging methods are highly sensitive to the spatial distribution of the input data; sparse or uneven sampling can render interpolation results unreliable. Furthermore, these methods rely on theoretical spatial variability models (e.g., Gaussian or exponential variograms), and discrepancies between the assumed and actual spatial variability can induce significant interpolation errors. The second approach involves regression modeling, which reconstructs missing XCO₂ values by establishing relationships between satellite observations and auxiliary variables such as meteorological factors, vegetation, and topography. For instance, Li et al.11 applied an Extremely Randomized Trees model to integrate OCO-2 observations with environmental variables, generating a high-resolution (0.01°, 8-day) global dataset. Chen et al.12 utilized a Random Forest model, integrating satellite observations with nighttime lights, meteorological parameters, and vegetation indices to produce a monthly full-coverage XCO₂ dataset.
Among these machine learning architectures, XGBoost excels at capturing complex nonlinear relationships and is particularly well-suited for scenarios involving intricate feature interactions. For instance, Te et al.13 utilized the XGBoost model with OCO-2 satellite data to generate a monthly 0.1° XCO₂ product for East Asia, achieving high accuracy (R² = 0.94, RMSE = 1.27 ppm, MAPE = 0.24%). However, current reconstruction methods based on XGBoost often encounter significant challenges regarding hyperparameter optimization. Traditional approaches, such as grid search or random search, are computationally inefficient and often fail to identify optimal parameter combinations, thereby limiting the model’s ability to fully exploit complex nonlinearities. Furthermore, these methods typically offer limited interpretability, obscuring the specific contributions of individual features to the prediction outcomes.
In this study, we developed a high-resolution (0.1° × 0.1°), daily, seamless XCO₂ dataset covering China from 2016 to 2020 by establishing a robust mapping relationship between satellite observations and multi-source drivers, including climatic, environmental, and demographic factors. To achieve prediction accuracy and generalization capabilities superior to existing datasets, we constructed an XGBoost-BO model that leverages Bayesian optimization to optimize key hyperparameters globally. Crucially, unlike standard “black-box” reconstruction approaches, we incorporated the SHAP method to enhance model interpretability by quantifying the specific contribution of each feature and elucidating the influence of feature magnitude on predicted XCO₂ values. This ensures that the model captures physically meaningful relationships rather than spurious statistical correlations, thereby guaranteeing the reliability of the reconstructed data—an aspect often overlooked in previous studies. Consequently, this high-precision dataset not only fills critical gaps in continuous observations but also provides a reliable data source for examining fine-scale spatiotemporal XCO₂ patterns, advancing carbon cycle research, and supporting policy-making related to China’s “carbon peaking” and “carbon neutrality” goals.
Methods
Data source
Table 1 provides all the datasets, including OCO-2 data, CAMS global greenhouse gas reanalysis data, GOSAT data, TCCON data, vegetation data, meteorological data, anthropogenic emission data, nighttime light data, and global fire emissions data. The detailed descriptions are as follows.
OCO-2 data
OCO-2 is a NASA-launched Earth-observing satellite dedicated to globally monitoring atmospheric CO₂ concentrations. It was successfully launched on July 2, 2014, and is the first high-precision satellite specifically designed to measure atmospheric CO₂ on a global scale. It employs near-infrared spectroscopy technology to precisely infer atmospheric CO₂ concentration levels by measuring the spectrum of sunlight after it has been absorbed and reflected by the Earth’s atmosphere. Its ground spatial resolution is approximately 2.25 km × 1.29 km, and the satellite has an orbital repeat cycle of about 16 days. The OCO-2 Level 2 XCO₂ V11.1r product was utilized in this research14, which is provided by the Goddard Earth Science Data and Information Service Centre (https://disc.gsfc.nasa.gov/).
CAMS global greenhouse gas reanalysis data
The CAMS-EGG4 data is a global greenhouse gas reanalysis product jointly released by the European Centre for Medium-Range Weather Forecasts (ECMWF) and the Copernicus Atmosphere Monitoring Service (CAMS). It aims to provide long-term, consistent, and high-quality global greenhouse gas concentration data for climate research, environmental monitoring, and policy-making. It provides CO₂ products with a spatial resolution of 0.75° × 0.75° and a temporal resolution of 3 hours. It integrates satellite data and ground-based observations, combined with high-quality numerical models and data assimilation techniques, to improve the reliability and accuracy of concentration estimates15. The dataset is acquired from the ECMWF (https://ads.atmosphere.copernicus.eu/).
GOSAT data
GOSAT (Greenhouse Gases Observing Satellite) is a satellite launched by the Japan Aerospace Exploration Agency (JAXA), designed to monitor atmospheric greenhouse gases globally, particularly the concentrations of carbon dioxide (CO₂) and methane (CH₄). Since its launch in 2009, the GOSAT satellite has become one of the key tools for global greenhouse gas monitoring, providing important data for climate change research and carbon cycle analysis. The CO₂ data product used in this study is the FTS SWIR Level 3 product, with version number V03.05 and a spatial resolution of 2.5° × 2.5°16. This research uses data observed by GOSAT (https://data2.gosat.nies.go.jp/).
TCCON data
TCCON is a global ground-based observation network aimed at accurately measuring the column-averaged concentrations of greenhouse gases such as CO₂, CH₄, CO, and N₂O in the atmosphere. TCCON uses ground-based Fourier Transform Infrared (FTIR) spectrometers to directly observe solar spectra in the near-infrared band. By analyzing these spectra, the column-averaged concentrations of greenhouse gases in the atmosphere are accurately retrieved. Through rigorous instrument calibration and data processing methods, TCCON achieves high-precision measurements of column-averaged greenhouse gas concentrations, providing reliable ground-based reference data for global carbon cycle research and satellite data validation17. The data is obtained from TCCON (https://tccondata.org/).
Vegetation data
This study utilizes the NDVI (Normalized Difference Vegetation Index) and EVI (Enhanced Vegetation Index) vegetation indices from the MODIS MOD13C1 product18. As key vegetation indices, NDVI and EVI reflect vegetation health, growth status, and photosynthetic efficiency19. As atmospheric CO₂ concentrations increase, vegetation photosynthesis may be enhanced, leading to higher NDVI and EVI values. This indicates more vigorous plant growth and greater CO₂ uptake. The data comes from NASA (https://ladsweb.modaps.eosdis.nasa.gov/).
Meteorological data
The study uses the following variables from ERA5-Land20: U10 (10m u-component of wind), V10 (10m v-component of wind), D2M (2 m dewpoint temperature), T2M (2 m temperature), SWVL1 (Volumetric soil water layer 1), SP (Surface pressure), SKT (Skin temperature), and SSRD (Surface solar radiation downwards). Atmospheric CO₂ levels are substantially affected by meteorological and thermal conditions through their impacts on natural systems including oceans, forests, soils, and the atmosphere. The data comes from ECMWF (https://cds.climate.copernicus.eu/).
Anthropogenic emission data
ODIAC (Open-source Data Inventory for Anthropogenic Carbon) is a dataset used for estimating and studying global anthropogenic carbon emissions, with a primary focus on CO₂21,22. It is a comprehensive resource based on satellite remote sensing data and global ground-based observations, aiming to provide accurate and high spatial resolution estimates of anthropogenic carbon emissions. It provides high-resolution anthropogenic CO₂ emission data on a global scale, with a spatial resolution of up to 1 kilometer. This enables it to offer detailed data support for carbon emission research at global, national, and local scales. The data comes from NIES (https://db.cger.nies.go.jp/).
Nighttime light data
The Monthly Cloud-free DNB Composite is derived from observations of the Day/Night Band (DNB) on the VIIRS sensor aboard the Suomi NPP satellite23. This dataset is produced and released by the Earth Observation Group (EOG) at the Colorado School of Mines and is primarily used to monitor global nighttime light conditions (https://eogdata.mines.edu/). NTL (Nighttime Lights) is typically closely associated with the level of urbanization and economic activity. Higher light intensity generally indicates a higher level of energy consumption, which in turn leads to increased anthropogenic CO₂ emissions. By analyzing nighttime light data, it is possible to indirectly assess fossil fuel consumption in urban areas, thereby inferring the intensity of CO₂ emissions in those regions.
Global fire emissions data
GFED (Global Fire Emissions Database) is a global fire emissions database designed to provide detailed information on biomass burning activities worldwide, including burned area, carbon emissions, and the contributions of different fire types24. It has a spatial resolution of up to 0.25 degrees (approximately 27 kilometers), making it suitable for monitoring global fire activity. These data are helpful for estimating CO₂ emissions on a global scale, especially during large-scale fire events, where fires can have a significant short-term impact on atmospheric CO₂ concentrations25. It was developed through collaboration among multiple international research institutions (https://www.globalfiredata.org/).
Data preprocessing
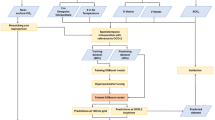
As illustrated in Fig. 2a, the preprocessing workflow initiated with quality assurance of the OCO-2 data. Measurements flagged with XCO₂_quality_flag = 1 (indicating low-quality or unusable data) were systematically removed. Subsequently, a 0.1° × 0.1° spatial grid was defined, and valid OCO-2 data points were mapped onto these grid cells. Data within each cell were aggregated by calculating the mean XCO₂ value, yielding a standardized gridded OCO-2 dataset. Following this, multi-source auxiliary variables were spatiotemporally aligned with the gridded OCO-2 data. To downscale and harmonize coarse-resolution auxiliary datasets (e.g., CAMS at 0.75° and GOSAT at 2.5°) with the target 0.1° grid, we employed a generative imputation approach based on ForestDiffusion. Specifically, the VP-SDE (Variance Preserving Stochastic Differential Equation) diffusion process within ForestDiffusion was utilized to synthesize fine-resolution values by reversing the diffusion trajectory from noise-conditioned coarse data. This method was selected for its superior ability to capture complex nonlinear distributions and dependencies inherent in spatiotemporal atmospheric data. It outperforms traditional interpolation techniques by natively handling mixed continuous-categorical features and providing probabilistic estimates26. Furthermore, this approach ensures realistic, distribution-preserving imputation for sparse or irregularly distributed missing data. The resulting harmonized dataset was then employed for model training and validation.

Workflow for constructing a high-resolution daily CO₂ dataset for China.
Model building
To address the limitations of conventional approaches, this study proposes a robust framework for constructing a daily high-resolution XCO₂ dataset utilizing the XGBoost-BO model. As illustrated in Fig. 2b, the workflow comprises three core components. The first stage is data preprocessing, where OCO-2 satellite retrievals are integrated with multi-source auxiliary datasets to generate a unified high-resolution grid (0.1° × 0.1°). The second stage focuses on model training, employing Bayesian Optimization to identify optimal hyperparameters for the XGBoost architecture. By leveraging global probabilistic modeling, this strategy significantly enhances the model’s predictive accuracy and generalization capability. The third stage involves analysis and validation, where the SHAP methodology is introduced to quantify feature contributions through both global and local importance analyses. Finally, model accuracy is rigorously validated against independent test datasets, ground-based TCCON observations, and similar datasets.
XGBoost-BO
XGBoost is used to perform regression tasks on the dataset. XGBoost is an efficient implementation of the Gradient Boosting Decision Tree (GBDT) algorithm, as shown in Fig. 2b, and is widely used for regression, classification, and other tasks, especially performing well on structured data. The XGBoost algorithm operates by conducting a second-order Taylor approximation of the objective function, employing the resulting second derivatives to guide tree model development. Tree model complexity serves as a regularization element within the optimization framework, boosting overall learning performance. The final XGBoost model is obtained by summing all the individual models. Assuming there is a total of \({\rm{m}}\) models, the output of each model is defined as \({f}_{k}\), then the final output of the XGBoost model is given by Eq. (1).
In this equation, \(\hat{{{\rm{y}}}_{{\rm{ij}}}}\) represents the predicted value of the OCO-2 data at a specific location and on a specific day, while the terms inside the parentheses correspond to the auxiliary variables for that particular day and location.
Once the tree structure is fixed, the node that each sample falls into is determined accordingly. At this point, the following objective function, Eq. (2), is defined to measure the error of XGBoost on the overall sample.
In this equation, the first term represents the error of the sample itself, which is proportional to the number of samples. \(l(\,.\,)\) is the function that measures the sample error, such as RMSE, \({y}_{i}\) is the true value of the \(i\)-th OCO-2 XCO₂ sample, \({\hat{y}}_{i}^{(M)}\) is the predicted value of the \(i\)-th OCO-2 XCO₂ sample. The second term is the regularization term, which primarily aims to reduce the risk of overfitting. The second term is treated as Eq. (3).
CART trees are built one by one. When optimizing the \(M\)-th tree, the previous \(M\)-1 trees have already completed their calculations, meaning the regularization term values for these trees are already determined. Therefore, we can ignore them during the optimization. For the \(M\)-th tree, it is defined as Eq. (4).
Here, \({\rm{\gamma }}\) and \({\rm{\lambda }}\) are the penalty terms, and \({\rm{T}}\) represents the total number of leaf nodes in the tree. This definition can be understood as follows: On one hand, if \({\rm{T}}\) is large, it indicates that the tree is deep, and the probability of overfitting increases. Therefore, \({\rm{\gamma }}\) is used to penalize this. On the other hand, if \({\rm{w}}\) is large, it suggests that the tree has a significant weight in the overall model, meaning the prediction results heavily depend on this tree. In this case, the risk of overfitting also increases, so \({\rm{\lambda }}\) is used to penalize it.
Integrating Bayesian Optimization (BO) with XGBoost offers dual advantages: it mitigates overfitting and enhances computational efficiency through systematic parameter refinement. XGBoost performance is highly sensitive to hyperparameters such as tree depth, learning rate, and subsample ratios. To address this, BO functions as a global optimization strategy, modeling the objective function’s distribution using a probabilistic surrogate—typically a Gaussian Process (GP)—to intelligently navigate the high-dimensional parameter space. As illustrated in Fig. 2b, the optimization process initializes by evaluating points randomly sampled from the search space. An iterative loop then ensues: a GP regression model is fitted to the observed data to compute posterior distributions. The next hyperparameter set is selected by maximizing an acquisition function, which balances exploration (searching uncertain regions) and exploitation (refining promising regions). Unlike traditional grid or random search methods, BO leverages historical evaluation data to guide the search, significantly improving both efficiency and solution quality.
To ensure robust performance assessment, we implemented a 10-fold cross-validation scheme (Fig. 3). The aggregation of results across all folds stabilizes the evaluation, mitigating bias arising from random data partitioning. The final model was trained using the hyperparameter set that yielded the optimal evaluation metrics. The search space included: n_estimators (integer values from 6000 to 15000 in steps of 1000), learning_rate (log-uniformly sampled continuous values from 0.01 to 1.0), max_depth (integer from 1 to 14), subsample (continuous from 0.5 to 1.0), colsample_bytree (continuous from 0.5 to 1.0), min_child_weight (integer from 1 to 10), gamma (continuous from 0 to 1), reg_alpha (continuous from 0 to 1), and reg_lambda (continuous from 0 to 1). The optimization utilized a GP surrogate with a Matérn 5/2 kernel and adaptive observation noise, paired with the Expected Improvement (EI) acquisition function. To balance thorough exploration with computational cost, a dual stopping criterion was applied: the search terminated upon reaching a maximum of 500 trials or if the best-observed metric failed to improve over 50 consecutive iterations.

10-fold cross-validation results.
SHAP model interpretation
SHAP (SHapley Additive exPlanations) builds on Shapley values, originally from economics and game theory, to explain model outputs additively. For a machine learning model that predicts XCO₂ based on auxiliary features, SHAP assigns each feature \(i\) a value \({\varphi }_{i}\) that quantifies its contribution to the deviation from the model’s base expectation. The core equation is defined as Eq. (5).
In this formula, \({\varphi }_{0}\) represents the expected model output over the background dataset (for example, the average prediction when all features are at their mean or masked values), \({\varphi }_{i\left(x\right)}\) represents the SHAP value for feature \(i\) on instance \(x\), indicating its marginal impact, and \(M\) represents the number of features.
The SHAP value \({\varphi }_{i}\) is computed as the weighted average of marginal contributions across all possible feature subsets (coalitions) \(S\). The core equation is defined as Eq. (6)
In this formula, \(N\) represents the set of all features, \({f}_{x}(S)\) represents the model output when using only the features in \(S\), with other features replaced by background values (for example, random samples or the average from the training data), and the factorial terms ensure fairness by weighting according to the coalition size.
Its core lies in decomposing the model’s predicted value into the sum of contributions from each input feature. This decomposition method is based on the “additive property” and satisfies key theoretical axioms: efficiency (sum of \({\varphi }_{i}\) equals\(\,f\left(x\right)-{\varphi }_{0}\)), symmetry (equal features get equal values), dummy (irrelevant features get \({\varphi }_{i}=0\)), and additivity (for combined models).
For tree-based models like XGBoost, we utilized TreeSHAP, an efficient algorithm that computes exact SHAP values in polynomial time by traversing tree structures, avoiding exhaustive coalition enumeration. This is particularly suitable for our XGBoost-BO model, as it handles complex interactions in high-dimensional data. We implemented TreeSHAP using the Python SHAP library.
Global feature contribution
To provide enhanced interpretability for the optimized XGBoost-BO model, we employed the Tree SHAP methodology. Tree SHAP computes the marginal contribution of each feature to the model’s prediction for individual samples. Global feature importance is subsequently derived by averaging the absolute SHAP values across the entire dataset, effectively ranking features based on their overall impact on model output. In this context, the x-axis represents the mean absolute SHAP value, indicating the average magnitude of the shift in model prediction attributable to a specific feature. As illustrated in Fig. 4, CAMS and GOSAT exhibit the highest importance scores. This dominance is anticipated, as these datasets provide direct, assimilation-based information regarding XCO₂ concentrations, acting as primary predictors, whereas other auxiliary variables serve primarily to characterize supplementary environmental and meteorological boundary conditions.

Global feature contribution.
Individual feature contribution
Because Tree SHAP functions as a local interpretation method, it enables the generation of unique, instance-level explanations for every sample in the dataset. Figure 5 illustrates the distinct relationship between feature values and their specific contributions to model predictions. In this visualization, the position of each point on the x-axis denotes the SHAP value (representing the magnitude and direction of the feature’s impact on model output), while the color gradient indicates the relative magnitude of the feature value itself.

Individual feature contribution.
CAMS and GOSAT are directly related to XCO₂, thereby exhibiting a strong positive correlation with the modeled output. The positive correlation observed for ODIAC aligns with the distinct “high-East, low-West” spatial pattern of XCO₂ illustrated in Fig. 6. This distribution is underpinned by regional disparities in industrial and energy structures. Eastern China is dominated by heavy chemical industries and coal-fired power generation, the latter accounting for 65% of the national total27. Conversely, Western China possesses a higher proportion of installed renewable energy capacity and a lower intensity of industrial processing, resulting in significantly lower direct fossil fuel consumption. Specifically, regions with elevated XCO₂ concentrations, such as the Beijing-Tianjin-Hebei urban agglomeration, host dense clusters of energy-intensive industries, including power generation, steel, construction materials, and chemicals. Hebei Province, in particular, is characterized by a heavy-industry-dominated economy, where six major high-energy-consuming sectors have historically constituted over 50% of the regional economic total.

Annual mean XCO₂ distribution in typical regions of China from 2016 to 2020.
Elevated humidity (represented by D2M) and increased solar radiation (SSRD) enhance plant photosynthesis, effectively acting as a carbon sink that lowers atmospheric CO₂ concentrations. This mechanism is reflected in the observed negative correlations between these variables and XCO₂. As illustrated in Fig. 7, these dynamics are particularly pronounced during winter, when XCO₂ exhibits an overall upward trend. This seasonal peak is primarily attributed to diminished humidity and solar radiation, which suppress photosynthetic uptake in forest and cropland ecosystems to their annual minima. Regarding surface pressure (SP), the negative correlation with XCO₂ is likely driven by atmospheric dynamics; low-pressure systems are often associated with strong convection and vertical mixing. This facilitates the uplift of surface-emitted CO₂ into the free troposphere, thereby elevating the total column concentration. Conversely, the positive correlation between T2M and XCO₂ can be attributed to the temperature dependence of ecosystem respiration. Higher temperatures typically stimulate microbial activity and soil respiration, releasing stored carbon. As depicted in Fig. 7, the rise in T2M during spring intensifies these respiratory processes, contributing to increased CO₂ release.

Seasonal mean distribution of XCO₂ from 2016 to 2020.
The positive correlation between NTL and XCO₂ arises because nighttime light intensity serves as a robust proxy for anthropogenic activities, particularly in urban and industrial hubs. Empirical studies indicate that for every increase of 100 persons per square kilometer in population density, areal carbon emissions rise by 6.2%28. Concurrently, the elevated energy consumption associated with NTL—manifested through lighting and industrial operations—inevitably drives higher CO₂ emissions. This relationship corroborates the spatial observation that regions exhibiting high XCO₂ concentrations typically coincide with densely populated and highly urbanized areas.
Both EVI and NDVI exhibit negative correlations with XCO₂, a relationship driven by the role of healthy vegetation as a carbon sink through photosynthetic absorption. Consequently, elevated vegetation indices typically correspond to reduced atmospheric CO₂ concentrations. As illustrated in Fig. 7, this dynamic is particularly evident in Northeast China during summer, where synchronous increases in NDVI and EVI coincide with peak vegetation coverage, leading to substantial CO₂ drawdown29. This region is also characterized by extensive rice cultivation. During the summer growing season, vigorous rice growth enhances rhizospheric microbial activity; this promotes soil nitrogen mineralization, thereby indirectly augmenting the ecosystem’s carbon sequestration capacity. Finally, the observed relationships between wind components (U10, V10) and XCO₂ likely reflect the influence of atmospheric advection on the diffusion, vertical mixing, and dilution of local CO₂ plumes.
Data Records
The data that support the findings of this study are openly available in Zenodo at https://doi.org/10.5281/zenodo.1548926930. This dataset contains daily XCO₂ values for the China region with a spatial resolution of 0.1° × 0.1°. The dataset spans from 2016 to 2020 and is named following the pattern “model_v1.0_xco2_YYYY-MM-DD.nc”, representing gap-free daily XCO₂ concentrations.
Technical Validation
To rigorously evaluate model performance, we implemented a dual-validation strategy comprising test set validation and independent TCCON validation. Test set validation utilized a 20% hold-out subset of the original data, strictly excluded from the training phase to ensure an unbiased assessment of the model’s generalization capability. In this step, model predictions were compared directly against the corresponding ground-truth OCO-2 observations. TCCON validation involved validating the model against independent ground-based measurements. Model predictions were spatiotemporally collocated with TCCON station data—matched by corresponding grid cells and dates—to quantify the model’s external reliability.
Model accuracy was assessed using three standard metrics: the Coefficient of Determination (R²), Root Mean Square Error (RMSE), and Mean Absolute Percentage Error (MAPE). R² evaluates the goodness of fit, indicating the proportion of variance in the dependent variable explained by the model. RMSE measures the average magnitude of the error in the target variable’s units (ppm); it assigns higher penalties to large deviations, making it particularly sensitive to outliers. MAPE provides a relative measure of prediction accuracy by expressing the average absolute error as a percentage, facilitating the interpretation of model performance across different data scales.
Model accuracy validation
Test set validation demonstrated that the model’s reconstructed XCO₂ values exhibit remarkable consistency with OCO-2 satellite observations throughout the 2016–2020 period. As illustrated in Fig. 8, the model achieved an R² of 0.98, an RMSE of 0.58 ppm, and a MAPE of 0.07%. Collectively, these metrics attest to the model’s exceptional performance, characterized by high fitting precision, effective error minimization, and robust generalization capability.

Comparison of actual and predicted values by the XGBoost-BO model on the test set from 2016 to 2020.
Ground-based accuracy evaluation
To rigorously validate the reliability of the reconstructed data, we compared the model-predicted XCO₂ values (2016–2020) against ground-based observations from two TCCON sites in China: Hefei (31.9°N, 117.2°E) and Xianghe (39.8°N, 116.9°E). Additionally, the CAMS reanalysis dataset was evaluated against the same TCCON observations to serve as a performance benchmark. As illustrated in Fig. 9, the XGBoost-BO model consistently outperformed the CAMS dataset at both locations. At the Hefei site, our model achieved an R² of 0.92, an RMSE of 1.16 ppm, and a MAPE of 0.2%, surpassing CAMS (R² = 0.88, RMSE = 1.39 ppm, MAPE = 0.3%). At the Xianghe site, the performance gap was even more pronounced; our model achieved an R² of 0.70 (RMSE = 2.00 ppm, MAPE = 0.4%), whereas CAMS showed significantly lower accuracy (R² = 0.38, RMSE = 2.87 ppm, MAPE = 0.6%). These comparisons demonstrate the superior fitting accuracy and predictive precision of the XGBoost-BO model.

Validation of XGBoost-BO and CAMS using TCCON XCO₂ measurements and comparison of their performance.
The reduced performance at Xianghe (R² = 0.70) compared to Hefei (R² = 0.92) is primarily attributed to limitations inherited from the OCO-2 training targets in this region. As shown in Fig. 10, the direct correlation between raw OCO-2 retrievals and TCCON data at Xianghe is relatively weak (R² = 0.64, RMSE = 2.00 ppm). This underperformance stems from the high aerosol optical depth (AOD) associated with pollution transported from Beijing, which induces scattering biases in the satellite’s near-infrared spectral retrievals. Additionally, stringent cloud and aerosol filtering algorithms substantially reduce the density of available training data in this area. Notably, despite these challenges, our model still outperforms the raw OCO-2 inputs (R²: 0.70 vs. 0.64), affirming the value of fusing multi-source auxiliary data and leveraging SHAP to ensure physical consistency, thereby enhancing the credibility of the reconstructed data.

Comparison of OCO-2 against TCCON XCO₂ at the Xianghe site.
Comparison with similar datasets
To mitigate the limitations of sparse ground-based validation (restricted to two TCCON sites) and ensure the spatial representativeness of our dataset across China’s extensive territory, a comparative analysis against an independent, high-resolution dataset is essential. We selected a relevant global daily XCO₂ dataset (0.1° × 0.1°, 2018–2023) as a benchmark31. This product, hereafter referred to as the “EOF dataset,” was generated by integrating OCO-3, GOSAT, and CAMS data via DINEOF and DINCAE reconstruction techniques.
As illustrated in Fig. 11, our reconstructed dataset demonstrates strong consistency with the EOF dataset at the national scale. To rigorously assess model performance in regions lacking in-situ monitoring, we conducted a detailed comparison across six geographically distinct areas characterized by diverse climatic and topographic conditions (Table 2). As illustrated in Fig. 12, time-series analysis reveals that despite the significant environmental heterogeneity among these regions, our dataset maintains a high correlation and captures seasonal cycles and long-term trends comparable to the EOF dataset, confirming its robust spatial representativeness. Notably, distinct divergences between the two datasets emerged during June–September 2019 and the second half of 2020. During these specific periods, Figs. 13 and 14 indicate that in-situ measurements from both TCCON sites aligned more closely with our data than with the EOF benchmark. Collectively, these findings suggest that our model more effectively captures the complex spatiotemporal variability of XCO₂ within China, providing a reliable, high-resolution data source for national-scale carbon cycle research.

Comparative analysis of monthly mean XCO₂ in China from XGBoost-BO and EOF methods (2018–2020).

Comparison of monthly mean XCO₂ trends between the XGBoost-BO and EOF methods across six representative regions in China (2018–2020).

Comparison of monthly mean XCO₂ among XGBoost-BO, EOF, and TCCON at the Hefei site (2018–2020).

Comparison of monthly mean XCO₂ among XGBoost-BO, EOF, and TCCON at the Xianghe site (2018–2020).
Data availability
The data that support the findings of this study are openly available in Zenodo at https://doi.org/10.5281/zenodo.15489269.
Code availability
The code for this study is available at https://github.com/2402548258/Code.
References
Solomon, S., Plattner, G.-K., Knutti, R. & Friedlingstein, P. Irreversible climate change due to carbon dioxide emissions. Proc. Natl. Acad. Sci. USA 106, 1704–1709, https://doi.org/10.1073/pnas.0812721106 (2009).
Kulmala, M. et al. Atmospheric and ecosystem big data providing key contributions in reaching United Nations’ Sustainable Development Goals. Big Earth Data 5, 277–305, https://doi.org/10.1080/20964471.2021.1936943 (2021).
Fu, J. et al. Marginal land in China suitable for bioenergy crops under diverse socioeconomic and climate scenarios from 2020 to 2100. Big Earth Data 8, 566–586, https://doi.org/10.1080/20964471.2024.2349292 (2024).
Jeong, K., Hong, T. & Kim, J. Development of a CO2 emission benchmark for achieving the national CO2 emission reduction target by 2030. Energy Build. 158, 86–94, https://doi.org/10.1016/j.enbuild.2017.10.015 (2018).
Zeng, Z.-C. et al. Global land mapping of satellite-observed CO2 total columns using spatio-temporal geostatistics. Int. J. Digit. Earth 10, 426–456, https://doi.org/10.1080/17538947.2016.1156777 (2017).
Frankenberg, C. et al. Data Drought in the Humid Tropics: How to Overcome the Cloud Barrier in Greenhouse Gas Remote Sensing. Geophys. Res. Lett. 51, e2024GL108791, https://doi.org/10.1029/2024GL108791 (2024).
Nassar, R. et al. Advances in quantifying power plant CO2 emissions with OCO-2. Remote Sens. Environ. 264, 112579, https://doi.org/10.1016/j.rse.2021.112579 (2021).
Jing, Y., Shi, J. & Wang, T. Mapping global land XCO₂ from measurements of GOSAT and SCIAMACHY by using kriging interpolation method. in 2014 IEEE Geoscience and Remote Sensing Symposium 3017–3020. https://doi.org/10.1109/IGARSS.2014.6947112 (IEEE, 2014).
He, Z. et al. Spatio-Temporal Mapping of Multi-Satellite Observed Column Atmospheric CO2 Using Precision-Weighted Kriging Method. Remote Sens. 12, 576, https://doi.org/10.3390/rs12030576 (2020).
Sheng, M. et al. Global land 1° mapping dataset of XCO₂ from satellite observations of GOSAT and OCO-2 from 2009 to 2020. Big Earth Data 7, 170–190, https://doi.org/10.1080/20964471.2022.2033149 (2023).
Li, J. et al. High-spatiotemporal resolution mapping of spatiotemporally continuous atmospheric CO2 concentrations over the global continent. Int. J. Appl. Earth Obs. Geoinf. 108, 102743, https://doi.org/10.1016/j.jag.2022.102743 (2022).
Chen, R. et al. XCO₂ Data Full-Coverage Mapping in China Based on Random Forest Models. Remote Sens. 17, 48, https://doi.org/10.3390/rs17010048 (2024).
Te, T. et al. Mapping seamless monthly XCO₂ in East Asia: Utilizing OCO-2 data and machine learning. Int. J. Appl. Earth Obs. Geoinf. 133, 104117, https://doi.org/10.1016/j.jag.2024.104117 (2024).
Science Computing Facility, J. P. L. OCO-2 Level 2 bias-corrected XCO₂ and other select fields from the full-physics retrieval aggregated as daily files, Retrospective processing V11.1r. NASA Goddard Earth Sciences Data and Information Services Center, https://doi.org/10.5067/8E4VLCK16O6Q (2017).
Copernicus Atmosphere Monitoring Service. CAMS global greenhouse gas reanalysis (EGG4). ECMWF, https://doi.org/10.24381/cda4ed31 (2021).
National Institute for Environmental Studies (NIES). TANSO-FTS/GOSAT L3 CO2 Column Amount (SWIR) Product, Version 03.xx. NIES GOSAT Data Archive Service https://data2.gosat.nies.go.jp/ (2023).
Total Carbon Column Observing Network (TCCON) Team. 2020 TCCON Data Release. CaltechDATA, https://doi.org/10.14291/TCCON.GGG2020 (2022).
Didan, K. MODIS/Terra Vegetation Indices 16-Day L3 Global 0.05Deg CMG V061. NASA Land Processes Distributed Active Archive Center, https://doi.org/10.5067/MODIS/MOD13C1.061 (2021).
Obuchowicz, C., Poussin, C. & Giuliani, G. Change in observed long-term greening across Switzerland – evidence from a three decades NDVI time-series and its relationship with climate and land cover factors. Big Earth Data 8, 1–32, https://doi.org/10.1080/20964471.2023.2268322 (2024).
Copernicus Climate Change Service. ERA5-Land monthly averaged data from 1950 to present. Copernicus Climate Change Service (C3S) Climate Data Store (CDS), https://doi.org/10.24381/CDS.68D2BB30 (2019).
Oda, T., Maksyutov, S. & Andres, R. J. The Open-source Data Inventory for Anthropogenic CO2, version 2016 (ODIAC2016): a global monthly fossil fuel CO2 gridded emissions data product for tracer transport simulations and surface flux inversions. Earth Syst. Sci. Data 10, 87–107, https://doi.org/10.5194/essd-10-87-2018 (2018).
Oda, T. ODIAC Fossil Fuel CO2 Emissions Dataset. National Institute for Environmental Studies https://doi.org/10.17595/20170411.001 (2015).
Elvidge, C. D., Baugh, K., Zhizhin, M., Hsu, F. C. & Ghosh, T. VIIRS night-time lights. Int. J. Remote Sens. 38, 5860–5879, https://doi.org/10.1080/01431161.2017.1342050 (2017).
Van Der Werf, G. R. et al. Global fire emissions estimates during 1997–2016. Earth Syst. Sci. Data 9, 697–720, https://doi.org/10.5194/essd-9-697-2017 (2017).
Sogacheva, L. et al. Two decades of fire activity over the PEEX domain: a look from space, with contribution from models and ground-based measurements. Big Earth Data 8, 350–396, https://doi.org/10.1080/20964471.2024.2316730 (2024).
Jolicoeur-Martineau, A., Fatras, K. & Kachman, T. Generating and imputing tabular data via diffusion and flow-based gradient-boosted trees. In Proc. 27th Int. Conf. Artif. Intell. Stat. 238, 1288–1296, https://proceedings.mlr.press/v238/jolicoeur-martineau24a.html (PMLR, 2024).
Chen, X., He, Q., Ye, T., Liang, Y. & Li, Y. Decoding spatiotemporal dynamics in atmospheric CO2 in Chinese cities: insights from satellite remote sensing and geographically and temporally weighted regression analysis. Sci. Total Environ. 908, 168320, https://doi.org/10.1016/j.scitotenv.2023.167917 (2024).
Zhang, H., Li, Y. & Tong, J. Spatiotemporal differences in and influencing effects of per-capita carbon emissions in China based on population-related factors. Sci. Rep. 13, 20141, https://doi.org/10.1038/s41598-023-47209-2 (2023).
Li, X. et al. Terrestrial CO2 fluxes, concentrations, sources and budget in Northeast China: observational and modeling studies. J. Geophys. Res. Atmos. 125, e2019JD031686, https://doi.org/10.1029/2019JD031686 (2020).
Liu, Y., Yuan, Z., Yang, A. & Wang, D. A High-Resolution daily CO₂ Dataset for China. Zenodo https://doi.org/10.5281/ZENODO.15489269 (2025).
Antezana Lopez, F. P. et al. Global Daily Column Average CO2 at 0.1° × 0.1° Spatial Resolution Integrating OCO-3, GOSAT, CAMS with EOF and Deep Learning. Sci. Data 12, 268, https://doi.org/10.1038/s41597-024-04135-w (2025).
Acknowledgements
This work was supported by the National Key Research and Development Program of China (grant 2022YFF0606402). We also thank ECMWF for providing the ERA5 dataset. We thank the NASA JPL Laboratory for providing the GOSAT and OCO-2 dataset. We thank the TCCON community for providing data used in this study. We thank all those institutions and their associates.
Author information
Authors and Affiliations
Contributions
Zhengwu Yuan conceived this research and wrote the manuscript. Yang Liu generated the dataset and analyzed the results. Aixia Yang and Dacheng Wang contributed to the study conception, provided guidance, and edited the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yuan, Z., Liu, Y., Yang, A. et al. A high-resolution daily CO₂ dataset for China (2016–2020). Sci Data 13, 249 (2026). https://doi.org/10.1038/s41597-026-06569-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-026-06569-w
