
Abstract
The integrated positron emission tomography/magnetic resonance imaging (PET/MRI) scanner simultaneously acquires metabolic information via PET and morphological information using MRI. However, attenuation correction, which is necessary for quantitative PET evaluation, is difficult as it requires the generation of attenuation-correction maps from MRI, which has no direct relationship with the gamma-ray attenuation information. MRI-based bone tissue segmentation is potentially available for attenuation correction in relatively rigid and fixed organs such as the head and pelvis regions. However, this is challenging for the chest region because of respiratory and cardiac motions in the chest, its anatomically complicated structure, and the thin bone cortex. We propose a new method using unsupervised generative attentional networks with adaptive layer-instance normalisation for image-to-image translation (U-GAT-IT), which specialised in unpaired image transformation based on attention maps for image transformation. We added the modality-independent neighbourhood descriptor (MIND) to the loss of U-GAT-IT to guarantee anatomical consistency in the image transformation between different domains. Our proposed method obtained a synthesised computed tomography of the chest. Experimental results showed that our method outperforms current approaches. The study findings suggest the possibility of synthesising clinically acceptable computed tomography images from chest MRI with minimal changes in anatomical structures without human annotation.
Similar content being viewed by others

Introduction
Background
New methods of machine learning, such as deep convolutional neural networks (DCNNs), have been recently developed because of easy access to large datasets and computational resources, and DCNN has made remarkable progress in various fields. The performance of DCNNs has significantly improved in the field of image recognition research. Generative adversarial networks (GANs) have received considerable attention in neural networks. For example, Zhu et al.1 developed an unsupervised learning method that enables the transformation of images between two types of domains using GANs called CycleGAN2. They showed that it is possible to transform images between horse and zebra and between day and night.
An integrated positron emission tomography/magnetic resonance imaging (PET/MRI) scanner is the only modality that can obtain metabolic information with PET and morphological information with high soft-tissue contrast using MRI by simultaneous acquisition. Although the advantage of PET/MRI is the accuracy of the fusion images, a major drawback of PET/MRI is the difficulty in attenuation correction for PET reconstruction, which is necessary for the quantitative evaluation of PET. X-ray-based attenuation correction, which is a method of translating CT images from the effective X-ray energy to attenuation coefficients at the PET energy (511 keV), is widely employed for attenuation correction of PET/CT. However, the generation of attenuation-correction maps from MRI (a synthesised CT) is necessary for PET/MRI because no direct relationship exists between gamma-ray attenuation information and MRIs. Moreover, only four-tissue segmentations (air, lung, fat, and soft tissue) other than bone are used for synthesised CT generation because of the difficulties in extracting signals from tissues with low proton density, such as bone tissue, on conventional MR sequences3.
The zero echo time (ZTE) MR sequence enables imaging of tissues with short T2 relaxation time and is utilised for bone and lung imaging4,5,6,7,8,9. For the head region, ZTE-based attenuation correction is already available in commercial PET/MRI scanners because delineation and segmentation of bone tissue on simultaneously acquired ZTE is relatively easy for rigid and fixed organs10,11,12,13. A deep learning approach based on the use of paired training data for generating synthesised CT from MRI is now applicable to the head and pelvis regions14,15,16. In the chest, however, bone segmentation from ZTE remains difficult to perform for accurately synthesised CT generation due to its respiratory and cardiac motion, anatomically complicated structure, and relatively thin cortex of the bone.
CycleGAN has been successfully used for medical image analysis, such as cone-beam-CT-CT conversion17 and MRI–CT conversion of the head18. In addition to CycleGAN, other unsupervised learning methods for interdomain image transformations have been proposed and used in medical image analysis19. Image transformation using GANs faces a problem in that anatomical consistency cannot be guaranteed.
In the current study, to generate synthesised CT from the ZTE of PET/MRI, we utilised a new unsupervised method called Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalisation for Image-to-Image Translation (U-GAT-IT), which is specialised in unpaired image transformation based on attention maps for image transformation20. To guarantee anatomical consistency in the image transformation between different domains (synthesised CT and ZTE), the modality-independent neighbourhood descriptor (MIND)21 was added to the loss of U-GAT-IT. Using our proposed method, the ZTE of PET/MRI of the chest can be converted to synthesised CT. The U-GAT-IT and CycleGAN models were not originally developed for use in medical image analysis. The anatomical structure might differ significantly in the ZTE and synthesised CT images obtained using the U-GAT-IT or CycleGAN methods. However, to use the synthesised CT as an attenuation correction map for PET/MRI, differences in anatomical structures such as bone, body, and upper arm contour are critical. Our proposed method with U-GAT-IT and MIND successfully prevented anatomical inconsistencies between ZTE and synthesised CT.
Related work
Transformation in medical images is required in numerous clinical fields, and several applications have been reported, such as noise reduction, MRI–CT transformation, and segmentation tasks. In medical images, however, assembling numerous labelled images for training is challenging. In addition, obtaining an exactly aligned pair of images for inter-modality transformation is difficult. Paired training data for the head and pelvis can be prepared by matching the shapes of CT and MRI using nonlinear image registration, whereas prepared such data for the chest is difficult. Although there have been reports on MRI–CT transformation in the head and pelvis, which are relatively unchanged by body posture22,23, it is difficult to obtain an aligned pair of corresponding images of the chest and other regions because of breathing and differences in body posture between MRI and CT. Thus, inter-modality image conversion in the chest has been considered challenging to accomplish.
CycleGAN, which enables unpaired image conversion without the need for directly corresponding images, has attracted attention. It has performed well in various fields, such as the generation of synthesised CT from cone-beam CT17, CT segmentation24, and X-ray angiography image generation25. Generally, CycleGAN is employed to perform transformations between two types of image domains. However, no direct constraint exists on the structure of the input and output images, and the structural alignment between the input and output images is not guaranteed. In medical images, the transforms of the anatomical structures are critical. To overcome this problem, several studies have been performed; CycleGAN has been extended to three-dimensional medical images26,27,28, and loss of CycleGAN was changed to set constraints on anatomical structural change27,29,30. In addition, various approaches have been attempted such as a deformation-invariant CycleGAN (DicycleGAN)29, an extension of CycleGAN by adding the gradient consistency loss to improve the accuracy at the boundaries31, and the use of CycleGAN for the paired data32.
Contributions
The contributions of this study are summarised as follows. First, this paper presents a method for performing chest MRI–CT (ZTE to synthesised CT) transformation using unsupervised learning methods such as U-GAT-IT and CycleGAN, which enable unpaired image transformations. Second, the proposed allows constraints to be applied to U-GAT-IT and CycleGAN to overcome the effect of changes in anatomical structures when transforming chest MRI–CT images. For this purpose, we added MIND to the losses of U-GAT-IT and CycleGAN and attempted to suppress the irregular changes in anatomical structures. Third, the combined use of U-GAT-IT and MIND made it possible to generate clinically acceptable synthesised CT images with less structural changes compared with CycleGAN with and without MIND. Fourth, without using any human annotations, the unsupervised learning methods of U-GAT-IT and CycleGAN allowed us to generate synthesised CT.
The remainder of this paper proceeds as follows. “Materials and methods” describes the details of Cycle GAN and U-GAT-IT and the loss of these networks using MIND. “Experiments” describes the details of PET/MRI and CT imaging and experimental studies used for the performance comparison. “Results” describes the experimental results. “Discussion” discusses the results and compares them with previous studies; finally, the study is concluded in “Conclusions”.
Materials and methods
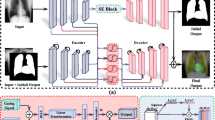
In this study, CycleGAN and U-GAT-IT were used to perform MRI–CT conversion using unpaired data. In addition, we applied MIND, which was proposed in a previous study, to these networks to prevent misalignment between MRI and synthesised CT images. Please refer to Fig. 1 for an outline of the proposed U-GAT-IT + MIND process.

Outline of proposed U-GAT-IT + MIND process (G, D, and \(\upeta \) denote generator, discriminator, and auxiliary classifier, respectively). We introduce Cycle loss, which is a comparison within the same domain after two rounds of transformation; this is in addition to MIND loss, which is a comparison between different domains after one round of transformation.
To compare the performance of U-GAT-IT + MIND loss, we evaluated the performance of CycleGAN alone, U-GAT-IT alone, and the CycleGAN + MIND loss.
CycleGAN
CycleGAN, developed in 2016, is a method that allows transformations between two different image domains. CycleGAN involves competing networks of an image generator (generator) and an adversarial network (discriminator) that attempt to distinguish the generated synthetic image from the real image. Taking the transformation between MRI and CT images as an example, there is a loss (G loss) to make the synthesised CT image closer to the real CT image for the generator, and a loss (D loss) to distinguish the synthesised CT image from the real CT image for the discriminator. In addition, there are two types of losses in CycleGAN: cycle loss and identity loss. Cycle loss is the difference between the original image and the double-synthesised MRI, which is further synthesised from the synthesised CT based on MRI. Identity loss is the difference between the output image and the input image (CT image and synthesised CT image) when the CT image is input to the CT generator. The same four types of losses are calculated for CT-MRI conversion (when synthesised MRI is generated from real CT). Please refer to the original paper on the conceptual diagram. The three types of losses are as follows—Eqs. (1)–(4).
Generator and discriminator loss (Generator and discriminator losses are employed to match the distribution of the translated images to the distribution of the target image):
Cycle loss (To alleviate the mode collapse problem, we applied a cycle consistency constraint to the generator):
Identity loss (To ensure that the distributions of input image and output image are similar, we applied an identity consistency constraint to the generator):
Sum of losses (finally, we jointly trained the generators, and discriminators to optimize the final objective):
where \({I}_{CT}\) denotes the CT image, \({I}_{MRI}\) denotes the MRI image, \({G}_{CT\to MRI}\) denotes the generator that generates MRI from CT, \({G}_{MRI\to CT}\) denotes the generator that generates CT from MRI, \({D}_{CT}\) denotes the discriminator that discriminates between \({G}_{MRI\to CT}\left(mri\right)\) and \(ct\), \({D}_{MRI}\) denotes the discriminator that discriminates between \({G}_{CT\to MRI}\left(ct\right)\) and \(mri\), and \({L}_{GAN}\) denotes the loss that includes G loss and D loss. \({L}_{cyc}\) is the cycle loss, and \({L}_{identitiy}\) is the identity loss. \({\lambda }_{1}\) and \({\lambda }_{2}\) denote coefficients of losses.
Finally, the model was trained by reducing the losses using Eq. (5):
U-GAT-IT
U-GAT-IT is an unsupervised generative attentional network with adaptive layer-instance normalisation for image-to-image translation, which was developed in 2019. Similar to CycleGAN, U-GAT-IT uses the encoder–decoder method for image generation but incorporates the attention module in the discriminator and generator and combines them with the adaptive layer-instance normalisation function (AdaLIN) to focus on the more important parts of the image. AdaLIN is a normalization method introduced along with U-GAT-IT. It allows adaptive selection of the ratio between the commonly used Layer Normalization and Instance Normalization, which is known to be more effective in removing style changes. Combined with the attention-guided module, AdaLIN enables flexible control of the amount of change in shape and texture20.
Generator loss and discriminator loss (Generator and discriminator losses are employed to match the distribution of the translated images to the distribution of the target images.):
CAM loss represents the loss that is important for the conversion from MRI and CT based on the information of auxiliary classifiers \({\upeta }_{\mathrm{MRI}}\) and \({\upeta }_{\mathrm{CT}}\).
CAM losses (By exploiting the information from the auxiliary classifiers \({\upeta }_{CT}\), \({\upeta }_{MRI}\), \(\upeta {D}_{CT}\), and \(\upeta {D}_{MRI}\), given an image from \({I}_{CT} {I}_{MRI}\). \({G}_{MRI\to CT}\) and \({D}_{CT}\) identify where they need to improve in terms of what makes the most difference between two domains.) :
Sum of losses Finally, we jointly trained the encoders, decoders, discriminators, and auxiliary classifiers to optimize the final objective:
where \({L}_{GAN}^{^{\prime}}\) denotes the loss that includes G loss and D loss. \({L}_{cam}^{{G}_{MRI\to CT}}\) is the CAM loss of \({G}_{MRI\to CT}\), \({L}_{cam}^{{D}_{CT}}\) is the CAM loss of \({D}_{CT}\), \({L}_{cyc}\) is the cycle loss, and \({L}_{identitiy}\) is the identity loss. \({\lambda }_{1}, {\lambda }_{2},\mathrm{ and }{\lambda }_{3}\) denote coefficients of losses. Finally, the model was trained by reducing the losses using Eq. (10):
MIND
MIND is a modality-independent neighbourhood descriptor for multi-modal deformable registration reported by Heinrich et al. in 201221. MIND can extract numerical descriptors preserved across modalities by extracting local feature structures.
where I denotes the image, n denotes the normalisation constant (so that the maximum value equals 1), and r ϵ R defines the region to be calculated; \({D}_{p}\left(I,x,x+r\right)\) denotes the distance metric between the positions \(x\) and \(x+r\); it is expressed by Eq. (12). In this study, we considered r = 9. Calculations were performed by convolution, as in previous studies30. P represents a collection of quantities that shifts the image. In this case, there exist 81 sets that shift the image from −4 to 4 along the X- and Y-axis directions.
The denominator \(V\left(I,x\right)\) represents an estimation of the local variance, and it can be expressed as
where N denotes the 3-neighbourhood of voxel x. The left image in Fig. 2 presents the original ZTE MRI while the corresponding right image presents MIND. The outlines of the body surface, lungs, bones, and blood vessels in the lungs were extracted.

MRI and the corresponding MIND image.
MIND loss
By calculating the MIND on two different images and taking the difference between them, MIND can be used as a loss that adds constraints to the change in position between them. For CycleGAN and U-GAT-IT, the difference between the MIND of the image before and after conversion is used as the loss. The MIND loss is represented by Eq. (14). In the equation, \({I}_{MIND}(CT,r)\) is the result of adapting MIND to a CT image pixel by pixel.
By incorporating \({L}_{MIND}\) into the loss of CycleGAN and U-GAT-IT, constraints can be added to the change in structure can be added. The loss of CycleGAN and U-GAT-IT with the addition of MIND is expressed by Eqs. (15) and (16):
where \({\lambda }_{MIND}\) denotes a coefficient of MIND loss. Finally, the models were trained by reducing the loss in Eqs. (17) and (18):
Experiments
This study conformed to the Declaration of Helsinki and the Ethical Guidelines for Medical and Health Research Involving Human Subjects in Japan (https://www.mhlw.go.jp/file/06-Seisakujouhou-10600000-Daijinkanboukouseikagakuka/0000080278.pdf). This study was approved by The Ethics Committee at Kobe University Graduate School of Medicine (Approval number: 170032) and was carried out according to the guidelines of the committee. The Ethics Committee at Kobe University Graduate School of Medicine has waived the need for an informed consent.
In-phase ZTE acquisition on PET/MRI
All PET/MRI examinations (n = 150; mean age, 65.9 ± 13.0 years ; range 19 to 90 years) were performed on an integrated PET/MRI scanner (SIGNA PET/MR, GE Healthcare, Waukesha, WI, USA) at 3.0 T magnetic field strength. MR imaging of the thoracic bed position was performed with the ZTE sequence and was simultaneously acquired with a PET emission scan. No contrast-enhancing material was used. Free-breathing ZTE was acquired by three-dimensional (3D) centre-out radial sampling to provide an isotropic resolution of 2 mm3, large field of view of 50 cm3, and a minimal TE of zero with the following parameters: TR, ~ 1.4 ms; FA, 1°; 250,000 radial centre-out spokes; matrix size, 250 × 250; FOV, 50.0 cm3; resolution, 2 mm3; number of spokes per segment, 512; and approximate acquisition time, 5 min. To minimise fat–water chemical shift effects (i.e. destructive interference at fat–water tissue boundaries), a high imaging bandwidth of ± 62.5 kHz was used. Furthermore, the imaging centre frequency was adjusted to be between fat and water resulting in clean in-phase ZTE images with uniform soft-tissue signal response and minimal fat–water interference disturbances33,34.
CT component of PET/CT
The CT component of PET/CT (Discovery PET/CT 690 (GE Healthcare), number of scans = 150; mean age, 64.4 ± 13.9 years; range, 12–86 years) was utilised for training the CT data. The training data of ZTE and CT were acquired from different patients (unpaired datasets); however, ZTE and CT were performed in the same body position (arms down) on the respective scanners. CT was acquired during shallow expiratory breath-holding for attenuation correction of PET and acquisition of anatomical details with the following parameters: X-ray tube peak voltage (kVp), 120 kV; tube current, 20 mA; section thickness, 3.27 mm; reconstructed diameter, 500 mm; reconstructed convolutional kernel, soft.
Dataset splitting
Data of thirty cases (20%) were used as the validation dataset, and data of the remaining 120 cases (80%) were used as the training dataset. For each case, unpaired CT and ZTE were used, and no manual annotations were performed.
Image postprocessing
ZTE images were semi-automatically processed to remove the background signals by using a thresholding and filling-in technique on a commercially available workstation (Advantage workstation, GE Healthcare) and converted into a matrix size of 640 × 400. To correct the variations in sensitivity and normalise the images of ZTE to the median tissue value, the nonparametric N4ITK method was applied35,36. CT images were also modified to remove the scanner beds on the workstation and were converted into the same matrix size. The MRI was maintained at the window width and window level stored in DICOM images, whereas the CT image was adjusted to a window width of 2000 Hounsfield Unit (HU) and a window level of 350 HU. The CT images were then scaled down to an image resolution of 256 × 256 pixels owing to GPU memory limitations.
Model training
All processing was performed using a workstation (CPU: Core i7-9800X at 3.80 GHz, RAM 64 GB, GPU: TITAN RTX) in all cases of CycleGAN, CycleGAN + MIND, U-GAT-IT, and U-GAT-IT + MIND.
CycleGAN/CycleGAN + MIND
We used a program based on the PyTorch implementation of CycleGAN37, which was modified for DICOM images and MIND calculations. We used values of 10, 0.5, and 20 for \({\lambda }_{1}\), \({\lambda }_{2}\), and \({\lambda }_{MIND}\), respectively, in CycleGAN + MIND with Adam as the optimiser and a learning rate of 0.0002 up to 1000 epochs. A radiologist (4 years of experience) visually evaluated the results when the loss reached equilibrium. If no corruption of synthesised CT was confirmed for the training and validation datasets, the trained network was used for the main visual evaluation described below. Except for \({\lambda }_{MIND}\), the hyperparameters of CycleGAN and CycleGAN + MIND were the same.
U-GAT-IT/U-GAT-IT + MIND
We used a program based on the PyTorch implementation of U-GAT-IT20, which was modified for DICOM images and MIND calculations. We used 100 for \({\lambda }_{1}\), 100 for \({\lambda }_{2}\), 100 for \({\lambda }_{3}\), and 5000 for \({\lambda }_{MIND}\) in U-GAT-IT + MIND, with Adam as the optimiser and a learning rate of 0.0001 up to 100 epochs. The results when the loss reached equilibrium and the training data were not corrupted by visual confirmation by the radiologist were used for evaluation. Except for \({\lambda }_{MIND}\), the hyperparameters of U-GAT-IT and U-GAT-IT + MIND were the same.
Visual evaluation
Twenty-one cases of chest ZTE unused for the training and validation datasets were prepared as the test dataset. The test dataset did not contain any CT images. The synthesised CTs were calculated using CycleGAN, CycleGAN + MIND, U-GAT-IT, and U-GAT-IT + MIND based on axial cross-sectional ZTE images of the supraclavicular fossa, central humeral head, sternoclavicular joint, aortic arch, tracheal bifurcation, and right pulmonary vein levels in each case. In this study, the main purpose was the application of PET/MRI attenuation-correction maps; therefore, it was particularly important to suppress the difference in anatomical structure during the conversion. For this purpose, four radiologists evaluated the synthesised CT visually, as shown below. Before evaluation by the four radiologists, a radiologist (15-year experiments) evaluated the synthesised CT images, and almost all of them were rated as CT-like for CycleGAN, CycleGAN + MIND, U-GAT-IT, and U-GAT-IT + MIND.
Evaluation of image misalignment after conversion
Visual evaluation was performed by four radiologists (Dr A, B, C, and D with 4, 22, 15, and 4 years of experience, respectively). The alignment between the synthesised CTs and the original images of the ZTE was visually evaluated for bone structures. When a relatively large defect, large displacement, or large deformation of the shape of the bone structures was observed, they were classified as having a severe misalignment. When a relatively small defect, small displacement, or small deformation of the shape of the bone structures was observed, they were classified as having a minor misalignment. One point was given when a total of 10 or more major misalignments were found in six images; two points when a total of five or more major misalignments were found; 3 points when a total of three or more major misalignments or 15 or more minor misalignments were found; 4 points when a total of 1 or more major misalignments or 10 or more minor misalignments were found; and 5 points for the others.
Statistics
The U-GAT-IT + MIND and other groups were compared using the Wilcoxon signed-rank test to evaluate the visual evaluation scores of the four radiologists. The Bonferroni method was used to correct multiple comparisons, and statistical significance was set at p < 0.001.
Results
Synthesised CT
In Figs. 3 and 4, the top images are MRI images, and those in the second to fifth rows are the synthesised CTs. Figures 3b and 4b show the fused images obtained from MRI and synthesised CT. The original ZTE images were synthesised in grey, and the synthesised CT image was in colour. Figures 3c and 4c show cropped images around the humerus in the original MR and fused images obtained from MR and synthesised CT. The displacement between the original ZTE images and the synthesised CT, especially in the body contour and the bone area, is improved by U-GAT-IT + MIND.

Original MR and synthesised CT images along with visual evaluation scores for Patient 1. (a) Original MR and synthesised CT images. (b) Original MR and fused images obtained from MR and synthesised CT. (c) Cropped images around the humerus in the original MR and fused images obtained from MR and synthesised CT.

Original MR and synthesised CT images along with visual evaluation scores for Patient 2. (a) Original MR and synthesised CT images. (b) Original MR and fused images obtained from MR and synthesised CT. (c) Cropped images around the humerus in the original MR and fused images obtained from MR and synthesised CT.
Figure 5 shows the 3D VR bone images of the front and side views composited from the synthesised CT. In general, it is extremely difficult or impossible to synthesise these kinds of VR images of bone from MR images.

Three-dimensional VR images of bones obtained via synthesised CT; in general, it is extremely difficult or almost impossible to synthesise these kinds of VR images of bone from MR images. The 3D animation movie is attached as the Supplementary material.
The upper row of Fig. 6 shows the synthesised CT based on the combination of the proposed method and conventional four-tissue segmentation, and the lower row shows the synthesised CT based on conventional four-tissue segmentation. The lower row images are clinically used for attenuation correction of PET/MRI. The upper row shows bone structures, which could not be synthesised using the conventional synthetic method (the lower row).

Synthesised CTs using U-GAT-IT + MIND and the conventional method.

Distribution of evaluation scores for four groups by Dr. A.

Distribution of evaluation scores for four groups by Dr. B.

Distribution of evaluation scores for four groups by Dr. C.

Distribution of evaluation scores for four groups by Dr. D.
The upper row shows the combination of U-GAT-IT + MIND and conventional four-tissue segmentation. The lower row shows the synthesised CT based on the conventional four-tissue segmentation.
Visual evaluation
The results of the visual evaluation scores are summarised as follows.
-
CycleGAN: maximum = 4, minimum = 1, and median = 2 by Dr. A and maximum = 4, minimum = 2, and median = 3 by Dr. B, maximum = 2, minimum = 1, and median = 2 by Dr. C, and maximum = 3, minimum = 2, and median = 2 by Dr. D
-
CycleGAN + MIND: maximum = 4, minimum = 1, and median = 2 by Dr. A and maximum = 4, minimum = 2, and median = 3 by Dr. B, maximum = 2, minimum = 2, and median = 2 by Dr. C, and maximum = 3, minimum = 1, and median = 2 by Dr. D
-
U-GAT-IT: maximum = 3, minimum = 1, and median = 1 by Dr. A and maximum = 4, minimum = 1, and median = 3 by Dr. B, maximum = 2, minimum = 1, and median = 1 by Dr. C, and maximum = 3, minimum = 1, and median = 2 by Dr. D
-
U-GAT-IT + MIND: maximum = 5, minimum = 3, and median = 5 by Dr. A and maximum = 5, minimum = 3, and median = 5 by Dr. B, maximum = 5, minimum = 4, and median = 2 by Dr. C, and maximum = 5, minimum = 4, and median = 5 by Dr. D
Figures 7, 8, 9 and 10 show the distribution of visual evaluation scores by radiologists for CycleGAN, CycleGAN + MIND, U-GAT-IT, and U-GAT-IT + MIND. The boxplot of the scores of the four groups is shown in Fig. 11, and the pair-plot is shown in Sup. Figs. 1–4.

Boxplot of visual evaluation scores (note: small squares indicate the median score). As can be seen, the U-GAT-IT + MIND approach demonstrates higher scores by all Drs.
The results of the Wilcoxon signed-rank test show that U-GAT-IT + MIND was significantly better than CycleGAN, CycleGAN + MIND, and U-GAT-IT. (Dr. A, p < 0.00001, p < 0.00001, p < 0.00001; Dr. B, p = 0.00008, p = 0.00008, p < 0.00001; Dr. C, p < 0.00001, p = 0.00008, p = 0.00008; Dr. D, p < 0.00001, p < 0.00001, p < 0.00001, respectively). The square indicates the median score. U-GAT-IT + MIND shows a tendency of higher scores from all radiologists.
CycleGAN + MIND with high coefficient of MIND loss
The larger the coefficient of MIND loss in CycleGAN + MIND, the more collapsed the synthesised CT became, thus distorting its contrast. Figure 12 shows the synthesised CTs from CycleGAN + MIND with a high coefficient of MIND loss (\({\lambda }_{MIND}\) = 60), which were apparently different from those of a normal CT. Thus, the coefficients of MIND loss of CycleGAN + MIND could not be increased to the same value as the coefficients of MIND loss of U-GAT-IT + MIND.

CT images synthesised using CycleGAN + MIND with high MIND loss coefficient.
Discussion
The combination of U-GAT-IT and MIND can help in image conversion between MRI and CT images with smaller misregistration compared to conventional unpaired image transfer (CycleGAN) using unpaired datasets. The generation of paired datasets for training is simple for the head, neck, and pelvis regions because changes in body position and deformation of organs between different scans are anatomically small, which allows simple non-rigid registrations to adjust the paired data in the hand, neck, or pelvis regions. However, in the chest region, manual annotations or registrations are required to generate the paired datasets, which makes the process extremely time-consuming; furthermore, such models lack robustness because of the anatomically complicated structures of the chest and significant changes and deformation of the images between scans due to different respiratory motions, different scanner-bed shapes, and different body positions, which were the strong motivators to develop an unsupervised method for image conversion with unpaired datasets in this study. Because the annotation of bone structures is not practically possible for the chest region, it is difficult to perform quantitative evaluation; hence, visual evaluations were performed.
In this work, we also tried the combination of CycleGAN and MIND; however, the generated images were apparently different in contrast to a normal CT when the coefficient of loss by MIND (\({\lambda }_{MIND}\)) was increased to the same range as that used for U-GAT-IT + MIND. the CAM loss introduced in U-GAT-IT prevents inconsistencies caused by the increase in MIND loss. When the coefficients of CAM loss were reduced without changing the other coefficients, the generated images seemed not to be CT-like in contrast, suggesting that the effect of CAM loss on the conversion between images was important.
There are some limitations to our study. First, we did not evaluate the effect of the synthesised CT on PET accumulation (e.g., changes in SUV) in this study. Further studies are required to confirm this hypothesis. Second, our study was conducted with a single PET/MRI scanner at a single institution, and external validation was not performed. Because the number of distributed PET/MRI scanners is limited, external validation with multiple PET/MRI scanners is difficult. Because both CycleGAN and U-GAT-IT are image conversion techniques based on unsupervised learning, the effect of overfitting is expected to be low. Fourth, it was difficult to obtain the ground truth after conversion due to the different positions and breathing conditions during PET/MRI and CT imaging, and therefore it was difficult to quantitatively evaluate the effect of the synthesised CT on PET. Further studies are required to confirm this hypothesis.
Conclusions
The combination of U-GAT-IT and MIND was effective in preventing anatomical inconsistencies between ZTE and synthesised CT and enabled the generation of clinically acceptable synthesised CT images. Our method also enables inter-modality image conversion in the chest region, which has been challenging to accomplish up until now without using human annotations.
Data availability
Japanese privacy protection laws and related regulations prohibit us from revealing any health-related private information such as medical images to the public without written consent, although the laws and related regulations allow researchers to use such health-related private information for research purpose under opt-out consent. We utilized the images under acceptance of the ethical committee of Kobe University Hospital under opt-out consent. It is almost impossible to take written consent to open the data to the public from all patients. For data access of our de-identified health-related private information, please contact Kobe University Hospital. The request for data access can be sent to the following e-mail addresses : hidetoshi.matsuo@bear.kobe-u.ac.jp. The other data are available from the corresponding author.
Abbreviations
- DCNNs:
-
Deep convolutional neural networks
- GANs:
-
Generative adversarial networks
- ZTE:
-
Zero echo time
- MIND:
-
Modality-independent neighbourhood descriptor
- PET/MRI:
-
Positron emission tomography/magnetic resonance imaging
References
Zhu, J. -Y., Park, T., Isola, P. & Efros, A. A. Unpaired image-to-image translation using cycle-consistent adversarial networks. in Proceedings of the IEEE international Conference on Computer Vision. 2223–2232. (2017).
Goodfellow, I. J. et al. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 27, 2830 (2014).
Wollenweber, S. D. et al. Comparison of 4-class and continuous fat/water methods for whole-body, MR-based PET attenuation correction. IEEE Trans. Nucl. Sci. 60, 3391–3398. https://doi.org/10.1109/TNS.2013.2278759 (2013).
Gibiino, F., Sacolick, L., Menini, A., Landini, L. & Wiesinger, F. Free-breathing, zero-TE MR lung imaging. Magn. Reson. Mater. Phys. Biol. Med. 28, 207–215. https://doi.org/10.1007/s10334-014-0459-y (2015).
Grodzki, D. M., Jakob, P. M. & Heismann, B. Correcting slice selectivity in hard pulse sequences. J. Magn. Reson. 214, 61–67. https://doi.org/10.1016/j.jmr.2011.10.005 (2012).
Madio, D. P. & Lowe, I. J. Ultra-fast imaging using low flip angles and fids. Magn. Reason. Med. 34, 525–529. https://doi.org/10.1002/mrm.1910340407 (1995).
Weiger, M., Pruessmann, K. P. & Hennel, F. MRI with zero echo time: Hard versus sweep pulse excitation. Magn. Reason. Med. 66, 379–389. https://doi.org/10.1002/mrm.22799 (2011).
Wiesinger, F. et al. Zero TE MR bone imaging in the head. Magn. Reson. Med. 75, 107–114. https://doi.org/10.1002/mrm.25545 (2016).
Wu, Y. et al. Density of organic matrix of native mineralized bone measured by water- and fat-suppressed proton projection MRI. Magn. Reason. Med. 50, 59–68. https://doi.org/10.1002/mrm.10512 (2003).
Aasheim, L. B. et al. PET/MR brain imaging: Evaluation of clinical UTE-based attenuation correction. Eur. J. Nucl. Med. Mol. Imaging. 42, 1439–1446. https://doi.org/10.1007/s00259-015-3060-3 (2015).
Delso, G. et al. Clinical evaluation of zero-echo-time MR imaging for the segmentation of the skull. J. Nucl. Med. 56, 417–422. https://doi.org/10.2967/jnumed.114.149997 (2015).
Sekine, T. et al. Clinical evaluation of zero-echo-time attenuation correction for brain 18F-FDG PET/MRI: Comparison with atlas attenuation correction. J. Nucl. Med. 57, 1927–1932. https://doi.org/10.2967/jnumed.116.175398 (2016).
Sgard, B. et al. ZTE MR-based attenuation correction in brain FDG-PET/MR: Performance in patients with cognitive impairment. Eur. Radiol. 30, 1770–1779. https://doi.org/10.1007/s00330-019-06514-z (2020).
Bradshaw, T. J., Zhao, G., Jang, H., Liu, F. & McMillan, A. B. Feasibility of deep learning-based PET/MR attenuation correction in the pelvis using only diagnostic MR images. Tomography 4, 138–147. https://doi.org/10.18383/j.tom.2018.00016 (2018).
Leynes, A. P. et al. Zero-echo-time and dixon deep pseudo-CT (ZeDD CT): Direct generation of pseudo-CT images for pelvic PET/MRI attenuation correction using deep convolutional neural networks with multiparametric MRI. J. Nucl. Med. 59, 852–858. https://doi.org/10.2967/jnumed.117.198051 (2018).
Torrado-Carvajal, A. et al. Dixon-vibe deep learning (DIVIDE) pseudo-CT synthesis for pelvis PET/MR attenuation correction. J. Nucl. Med. 60, 429–435. https://doi.org/10.2967/jnumed.118.209288 (2019).
Liang, X. et al. Generating synthesized computed tomography (CT) from cone-beam computed tomography (CBCT) using CycleGAN for adaptive radiation therapy. Phys. Med. Biol. 64, 125002. https://doi.org/10.1088/1361-6560/ab22f9 (2019).
Lei, Y. et al. MRI-only based synthetic CT generation using dense cycle consistent generative adversarial networks. Med. Phys. 46, 3565–3581. https://doi.org/10.1002/mp.13617 (2019).
Tang, Y., Tang, Y., Xiao, J., & Summers, R. M. XLSor: A robust and accurate lung segmentor on chest X-Rays using criss-cross attention and customized radiorealistic abnormalities generation. in International Conference on Medical Imaging with Deep Learning. 457–467. (2019).
Kim, J., Kim, M., Kang, H., & Lee, K. U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation. arXiv preprint arXiv:1907.10830 (2019).
Heinrich, M. P. et al. AMIND: Modality independent neighbourhood descriptor for multi-modal deformable registration. Med. Image Anal. 16, 1423–1435. https://doi.org/10.1016/j.media.2012.05.008 (2012).
Lei, Y., Jeong, J. J. & Wang, T. MRI-based pseudo CT synthesis using anatomical signature and alternating random forest with iterative refinement model. J. Med. Imaging 5, 1. https://doi.org/10.1117/1.jmi.5.4.043504 (2018).
Torrado-Carvajal, A. et al. Fast patch-based pseudo-CT synthesis from T1-weighted MR images for PET/MR attenuation correction in brain studies. J. Nucl. Med. 57, 136–143. https://doi.org/10.2967/jnumed.115.156299 (2016).
Sandfort, V., Yan, K., Pickhardt, P. J. & Summers, R. M. Data augmentation using generative adversarial networks (CycleGAN) to improve generalizability in CT segmentation tasks. Sci. Rep. 9, 16884. https://doi.org/10.1038/s41598-019-52737-x (2019).
Tmenova, O., Martin, R. & Duong, L. CycleGAN for style transfer in X-ray angiography. Int. J. Comput. Assist. Rad. Surg. 14, 1785–1794. https://doi.org/10.1007/s11548-019-02022-z (2019).
Abramian, D. & Eklund, A. Generating fMRI Volumes from T1-Weighted Volumes Using 3D CycleGAN. arXiv preprint arXiv:1907.08533 (2019).
Cai, J., Zhang, Z., Cui, L., Zheng, Y. & Yang, L. Towards cross-modal organ translation and segmentation: A cycle- and shape-consistent generative adversarial network. Med. Image Anal. 52, 174–184. https://doi.org/10.1016/j.media.2018.12.002 (2019).
Pan, Y. et al. Synthesizing missing PET from MRI with cycle-consistent generative adversarial networks for Alzheimer’s disease diagnosis. in Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). 455–463. https://doi.org/10.1007/978-3-030-00931-1_52 (Springer, 2018).
Wang, C., Macnaught, G., Papanastasiou, G., MacGillivray, T. & Newby, D. Unsupervised learning for cross-domain medical image synthesis using deformation invariant cycle consistency networks. in Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). 52–60. https://doi.org/10.1007/978-3-030-00536-8_6 (Springer, 2018).
Yang, H. et al. Unpaired brain MR-to-CT synthesis using a structure-constrained CycleGAN. in Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). 174–182. https://doi.org/10.1007/978-3-030-00889-5_20 (Springer, 2018).
Hiasa, Y. et al. Cross-modality image synthesis from unpaired data using CycleGAN: Effects of gradient consistency loss and training data size. in Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). 31–41. https://doi.org/10.1007/978-3-030-00536-8_4 (Springer, 2018).
Harms, J. et al. Paired cycle-GAN-based image correction for quantitative cone-beam computed tomography. Med. Phys. 46, 3998–4009. https://doi.org/10.1002/mp.13656 (2019).
Brodsky, E. K., Holmes, J. H., Yu, H. & Reeder, S. B. Generalized K-space decomposition with chemical shift correction for non-Cartesian water-fat imaging. Magn. Reason. Med. 59, 1151–1164. https://doi.org/10.1002/mrm.21580 (2008).
Engström, M., McKinnon, G., Cozzini, C. & Wiesinger, F. In-phase zero TE musculoskeletal imaging. Magn. Reason. Med. 83, 195–202. https://doi.org/10.1002/mrm.27928 (2020).
Sled, J. G., Zijdenbos, A. P. & Evans, A. C. A nonparametric method for automatic correction of intensity nonuniformity in MRI data. IEEE Trans. Med. Imaging. 17, 87–97. https://doi.org/10.1109/42.668698 (1998).
Tustison, N. J. et al. N4ITK: Improved N3 bias correction. IEEE Trans. Med. Imaging. 29, 1310–1320. https://doi.org/10.1109/TMI.2010.2046908 (2010).
Zhu, J.-Y., Park, T., Isola, P. & Efros, A. A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. (2017).
Acknowledgements
This work was supported by JSPS KAKENHI (Grant Number JP20K16758 and JP19H03599).
Author information
Authors and Affiliations
Contributions
Conceptualization: H.M., M.Ni. and M.No. Data curation: M.No. Formal analysis: H.M. and M.Ni. Funding acquisition: F.Z. and M.No. Investigation: H.M., M.Ni. and M.No. Methodology: H.M., N.Mi., M.No., T.K., S.K. and F.W. Project administration: M.Ni., M.No. and A.K.K. Resources: H.M. Supervision: T.M. Validation: H.M. Visualization: H.M. Writing—original draft: H.M., and M.Ni. Writing—review & editing: M.No., F.Z., T.K., S.K., F.W., A.K.K. and T.M. All authors approved the manuscript to be published and agree to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved.
Corresponding author
Ethics declarations
Competing interests
TK, SK and FW are employees of GE Healthcare. Other authors have no competing financial interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Matsuo, H., Nishio, M., Nogami, M. et al. Unsupervised-learning-based method for chest MRI–CT transformation using structure constrained unsupervised generative attention networks. Sci Rep 12, 11090 (2022). https://doi.org/10.1038/s41598-022-14677-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-022-14677-x
This article is cited by
-
Unsupervised translation of vascular masks to NIR-II fluorescence images using Attention-Guided generative adversarial networks
Scientific Reports (2025)
-
A novel structure preserving generative adversarial network for CT to MR modality translation of spine
Neural Computing and Applications (2024)

{kind=link}
{kind=link}
{kind=link}
{kind=link}