
Abstract
q-ROPFLS, including numeric and linguistic data, has a wide range of applications in handling uncertain information. This article aims to investigate q-ROPFL correlation coefficient based on the proposed information energy and covariance formulas. Moreover, considering that different q-ROPFL elements may have varying criteria weights, the weighted correlation coefficient is further explored. Some desirable characteristics of the presented correlation coefficients are also discussed and proven. In addition, some theoretical development is provided, including the concept of composition matrix, correlation matrix, and equivalent correlation matrix via the proposed correlation coefficients. Then, a clustering algorithm is expanded where data is expressed in q-ROPFL form with unknown weight information and is explained through an illustrative example. Besides, detailed parameter analysis and comparative study are performed with the existing approaches to reveal the effectiveness of the framed algorithm.
Similar content being viewed by others

Introduction
MCGDM problem is one of the most significant everyday activities1,2,3,4,5,6. At first, the assessment information is often represented in terms of real numbers. In many complicated MCGDM scenarios, however, it is preferable to ascribe values using fuzzy numbers or linguistic phrases due to the uncertainty and ambiguity of human comprehension. Therefore, Zadeh7 concocted the LVR to characterize the qualitative data in decision-making situations. LVRs may cope with situations when it is difficult to quantify the evaluation values of criteria. For instance, a student’s examination results may be represented exactly using numerical numbers, yet his or her morals are often assessed using verbal phrases such as “bad, fair, and good.” Moreover, Herrera and Martinez8 suggested a model of 2TL representation composed of a linguistic term and a real number in the range \([- 0.5, 0.5)\). The framework can exemplify any computing results throughout the aggregation procedure, so it successfully prevents information loss. Various studies on the scope of 2-tuple linguistic terms9,10,11,12 have been done in recent years. These additions enable the efficient expression of ill-defined and fuzzy data while solving the MCGDM issue. Later, Wei et al.13 expanded the 2TL model to the P2TLN, which may convey a linguistic term’s membership grade \(\mu\) and non-membership grade \(\nu\). Some conventional MCGM approaches, such as Taxonomy method14, VIKOR method14, and TODIM method15, are expanded to Pythagorean 2TL information based on this concept. However, the assignment of membership grades and non-membership grades in P2TLNs is subject to certain constraints. P2TLNs have a requirement that \(\mu ^2+\nu ^2\le 1\), yet there are several instances in which the assessment information given by DMs in the form of P2TLNs cannot satisfy the requirement. For instance, if the membership and non-membership grades are given as \(\left\langle 0.7, 0.8\right\rangle\), P2TLNs are unable to successfully process it because \(0.7^2+0.8^2>1\). Wei et al.16 brought forward the q-ROPFLSs based on the q-rung orthopair fuzzy sets17, in which the total of the qth power of membership grade and non-membership grade should be less than 1, i.e., \(\mu ^q+\nu ^q\le 1\). And when \(q=2\), the q-ROPFLN can be reduced to P2TLN. The q-ROPFLN is hence a more generic and adaptable type of information representation. It has an exceptionally vast expression domain and can prevent data loss. Wei et al.16 presented various q-ROPFL Heronian mean operators as well as their weighted versions. Ju et al.18 investigated some Muirhead mean operators with q-ROPFLNs for MCGDM challenges. Recently, Li et al.19 devised q-ROPFL PROMETHEE II model for MCGDM with unknown weight information.
In recent decades, the correlation coefficient, which is a key for studying the link between any two parameters or variables, has garnered considerable attention. The correlation coefficient developed by Karl Pearsons20 has been utilized in several statistical research, including data analysis and classification, pattern identification, clustering, medical diagnosis, and decision-making. It has been determined that conventional correlation is unsuitable for handling data pertaining to situations of a fuzzy character. To address such issues, several writers have expanded the concept of statistical correlation to include fuzzy correlation21,22,23. In24, Gerstenkon and Manko developed the notion of the intuitionistic fuzzy correlation coefficient. Hong and Hwang25 analyzed the correlation measure and correlation coefficient for IFSs in probabilistic spaces. Zeng and Li26 presented the correlation coefficient of IFSs, which is analogous to the cosine of the intersectional angle in finite sets and probability spaces. Another study27 demonstrated the applicability of IFS correlation coefficients to pattern recognition issues. Chen et al.28 developed correlation coefficients for hesitant fuzzy sets and used these concepts to clustering analysis. The authors in29 explored multilevel analysis methodologies and applications. Garg30 developed a novel correlation coefficient for Pythagorean fuzzy sets and used them for decision making. Park et al.31 propounded the correlation coefficient of interval-valued IFSs and highlighted their applicability by applying them to the challenges of MCGDM. Nguyen32 devised the similarity or dissimilarity measure for IFSs with its applications in pattern recognition, whereas Du33 produced the correlation and correlation coefficients of q-ROFSs. Recently, Li and his coworkers34 studied two \(\zeta\)-correlation coefficients for q-rung orthopair fuzzy setting and addressed an example of clustering analysis to justify the superiority of the suggested approach.
The advancement of the theory and the practical uses of correlation coefficients motivated us to investigate these concepts. Following that, this article explores the correlation coefficients and clustering technique for q-ROPFLSs. Unlike the aforesaid fuzzy sets, q-ROPFLS is constituted by a linguistic 2-tuple and a q-ROFS. Concerning the linguistic 2-tuple, it is a model that prevents the loss of information during computations of discrete linguistic values. The intuitionistic 2TL sets and the Pythagorean 2TL sets are likewise composed of a linguistic 2-tuple, but they include limits on the selection of membership and non-membership grades, whereas q-ROPFLS do not. In the context of intuitionistic 2TL sets, we cannot award 0.5 and 0.6 as membership and non-membership grades since their total exceeds 1. Similarly, in the context of Pythagorean 2TL sets, we cannot select 0.7 and 0.8 as membership and non-membership grades due to the limitation that the sum of their squares exceeds 1. In q-ROFS, however, the range of numbers that can be allocated as membership and non-membership grades is so broad, i.e., we can assign membership and non-membership grades any value between 0 and 1. Thus, the structure of q-ROPFLS is superior compared to other existing frameworks.
The factors listed inspired us to perform this study:
-
(I)
The q-ROPFLS is a useful tool for conveying MCGM problem assessment information. The type of information itself reveals that it mainly contains the following key advantages: (i) information distortion during linguistic information processing can be reduced; (ii) information loss through incorporating parameter q to convey evaluation results can be effectively avoided, and a significantly large range can be used to represent membership grades and non-membership grades for a linguistic evaluation; and (iii) the problems associated with two-dimensional information can be effectively addressed in real-world applications. Currently, there are several techniques in the literature that work in information energy and develop a formula for calculating the correlation coefficient; but, there is a need to expand the methodology for measuring the correlation coefficient in the context of q-ROPFLS.
-
(II)
The significance of criteria in decision analysis is of the utmost relevance for making rational choices. Typically, these weights are unavailable in advance. However, the majority of available clustering methods only account for the situation of known weights and disregard the case of unknown weights. To get more precise findings, it is required to develop a clustering model based on unknown criteria weights.
According to the aforementioned motivations, the following are the novel aspects of this research study:
-
(I)
Information energy, covariance, correlation coefficient, and their corresponding weighted forms for q-ROPFTLSs are formulated. Also, the required properties of the proffered formulation are verified.
-
(II)
Based on the developed theory, the conventional clustering algorithm is extended for q-ROPFLSs with unknown criteria weight information.
-
(III)
A case concerning the classification of CIM software is provided to demonstrate the application of the framed algorithm. Then, a case concerning the clustering of construction materials is studied to compare the proposed method with the prevailing methods.
The remaining sections of the paper are prepared as follows. In Section “Preliminaries”, a brief introduction to fundamental ideas is supplied. Section “Correlation coefficient for q-ROPFLSs” gives the notion of q-ROPFL correlation coefficient and weighted correlation coefficient along with their important properties. In Section “Clustering algorithm under q-ROPFL environment”, clustering algorithm is described to handle the clustering problems with q-ROPFL data. Section “Applications and analysis” analyze the presented algorithm via examples, experiments, and comparisons. At last, Section “Concluding remarks” concludes the article.
The main theme of this study is visualized in Fig. 1.

Graphical illustration of the proposed work.
Preliminaries
In what follows, we make a brief review of LTS, IFLS and q-ROPFLS.
Let \(S=\left\{ s_{\theta }|\theta =1,2,...,\ell \right\}\) be a linguistic term set with odd cardinality. Any label, \(s_{\theta }\) indicates a possible value for a linguistic variable, and it must meet the following requirements8,35:
-
1.
Ordered set: \({{s_{\theta }}_1}\le {{s_{\theta }}_2} \Leftrightarrow \theta _1\le \theta _2;\)
-
2.
Negation operator: \(Neg\left( {{s_{\theta }}_1} \right) ={{s_{\theta }}_2}\), such that \(\theta _1+ \theta _2=\ell ;\)
-
3.
Max operator: \(\max \left( {{s_{\theta }}_1},{{s_{\theta }}_2}\right) ={{s_{\theta }}_1}\) if \({{s_{\theta }}_1}\ge {{s_{\theta }}_2};\)
-
4.
Min operator: Min operator: \(\min \left( {{s_{\theta }}_1},{{s_{\theta }}_2}\right) ={{s_{\theta }}_1}\) if \({{s_{\theta }}_1}\le {{s_{\theta }}_2}.\)
For instance, S can be defined as
Based on the notion of symbolic translation, Herrera and Martinez8,35 created the 2-tuple fuzzy linguistic representation model. It is used to express linguistic evaluation information as a 2-tuple \(\left( s_{\theta },\varkappa _{} \right)\) where \(s_{\theta }\) is a linguistic label from the predefined linguistic term set S, \(\varkappa _{}\) is the value of symbolic translation, and \(\varkappa _{}\in [-0.5, 0.5)\).
Definition 1
8,35 Let \(\vartheta\) be the result of an aggregation of the indices of a set of labels evaluated in a linguistic term set S, i.e., the outcome of a symbolic aggregation operation, \(\vartheta \in \left[ 1,\ell \right]\), with \(\ell\) being the cardinality of S. If \(r = round(\vartheta )\) and \(\varkappa _{}=\vartheta -r\) are two numbers such that \(r\in \left[ 1,\ell \right]\) and \(\varkappa _{} \in [-0.5, 0.5)\), then \(\varkappa _{}\) is called a symbolic translation.
Definition 2
8,35 Let \(S=\left\{ s_{\theta }|\theta =1,2,...,\ell \right\}\) be a linguistic term set and \(\vartheta \in \left[ 1,\ell \right]\) be a numerical value indicating the linguistic symbolic aggregation outcome. Then, the function \(\curlywedge\) used to retrieve the 2-tuple linguistic information equivalent to \(\vartheta\) is then defined as
where round \(\left( .\right)\) is the conventional round function, \(s_r\) is the index label closest to \(\vartheta\), and \(\varkappa _{}\) is the symbolic translation value.
Definition 3
8,35 Let \(S=\left\{ s_{\theta }|\theta =1,2,...,\ell \right\}\) be a linguistic term set and \(\left( s_r, \varkappa \right)\) be a 2-tuple. There is always a function \(\curlyvee\) can be defined, such that, from a 2-tuple \(\left( s_r, \varkappa \right)\) it return its equivalent numerical value \(\vartheta \in \left[ 1, \ell \right]\), which is
Definition 4
16 A q-ROPFLS \({\mathcal {F}}\) on a fixed set \(\texttt {Z}\) is defined as
where \(s_{r(t_i)} \in S\), \(\varkappa (t_i) \in [-0.5,0.5)\), \(\mu (t_i),\nu (t_i) \in [0,1]\), with the condition \(0\le \mu ^q(t_i)+\nu ^q(t_i)\le 1\) \(\left( q\ge 1 \right)\) \(\forall \; t_i\in \texttt {Z}\). The numbers \(\mu (t_i),\nu (t_i)\) present the grade of membership and grade of nonmembership of the element \(t_i\) to linguistic variable \(\left( s_{r(t_i)},\varkappa (t_i)\right)\), respectively. Moreover, \(\pi _{{\mathcal {F}}}\left( t_i \right) =1-\left( \mu ^q(t_i)+\nu ^q(t_i) \right) ^{1/q}\) is called refusal grade, and the q-rung orthopair fuzzy 2-tuple linguistic number (q-ROPFLN) is symbolized by \(\partial =\left( \left( s_{r},\varkappa \right) ,\left\langle \mu , \nu \right\rangle \right) .\)
Definition 5
16 Let \(\partial _1=\left( \left( s_{{r}_1},{\varkappa }_1\right) ,\left\langle {\mu }_1, {\nu }_1\right\rangle \right)\) and \(\partial _2=\left( \left( s_{{r}_2},{\varkappa }_2\right) ,\left\langle {\mu }_2, {\nu }_2\right\rangle \right)\) be two q-ROPFLNs. Then their basic operational laws are given as follows:
-
1.
\(\partial _1\oplus \partial _2=\left( \curlywedge \left( \curlyvee \left( s_{{r}_1},{\varkappa }_1\right) +\curlyvee \left( s_{{r}_2},{\varkappa }_2\right) \right) , \left\langle \left( {\mu }^q_1+{\mu }^q_2-{\mu }^q_1{\mu }^q_2\right) ^{1/q},{\nu }_1{\nu }_2\right\rangle \right) ;\)
-
2.
\(\partial _1\otimes \partial _2=\left( \curlywedge \left( \curlyvee \left( s_{{r}_1},{\varkappa }_1\right) \cdot \curlyvee \left( s_{{r}_2},{\varkappa }_2\right) \right) , \left\langle {\mu }_1{\mu }_2,\left( {\nu }^q_1+{\nu }^q_2-{\nu }^q_1{\nu }^q_2\right) ^{1/q}\right\rangle \right) ;\)
-
3.
\(\eta \partial _1=\left( \curlywedge \left( \eta \curlyvee \left( s_{{r}_1},{\varkappa }_1\right) \right) ,\left\langle \left( 1-\left( 1-{\mu }^q_1\right) ^\eta \right) ^{1/q},{\nu }^{\eta }_1 \right\rangle \right) \; \; \eta > 0;\)
-
4.
\(\partial ^{\eta }_1=\left( \curlywedge \left( \left( \curlyvee \left( s_{{r}_1},{\varkappa }_1\right) \right) ^{\eta }\right) ,\left\langle {\mu }^{\eta }_1,\left( 1-\left( 1-{\nu }^q_1\right) ^\eta \right) ^{1/q}\right\rangle \right) \; \; \eta > 0.\)
Definition 6
18 Let \(\partial _{\iota }= \left( \left( s_{{r}_i},{\varkappa }_i\right) ,\left\langle {\mu }_i, {\nu }_i\right\rangle \right) \left( i=1,2,...,m \right)\) be a family of q-ROPFLNs, then q-ROPFLWA operator is:
where \(w=\left( w_1,w_2,...,w_\flat \right) ^T\) is the weight vector of \(\partial _i\left( \iota =1,2,...,m \right)\) such that \(w_{i}>0\) and \(\sum _{i=1}^{m}w_i=1.\) Especially, if \(w=\left( \frac{1}{\flat },\frac{1}{\flat },...,\frac{1}{\flat } \right) ^T\), then the q-ROPFLWA operator reduces to q-ROPFLA operator of dimension m, which is described as follows:
Definition 7
19 Let \(\partial _1=\left( \left( s_{{r}_1},{\varkappa }_1\right) ,\left\langle {\mu }_1, {\nu }_1\right\rangle \right)\) and \(\partial _2=\left( \left( s_{{r}_2},{\varkappa }_2\right) ,\left\langle {\mu }_2, {\nu }_2\right\rangle \right)\) be two q-ROPFLNs. Then the Hamming distance between \(\partial _1\) and \(\partial _2\) is given by
Correlation coefficient for q-ROPFLSs
Covariance and correlation coefficient of q-ROPFLSs
Definition 8
Let \(\texttt {Z}\) be a fixed set, \(S=\left\{ s_{\theta }|\theta =1,2,...,\ell \right\}\) be a linguistic term set, for q-ROPFLS \({\mathcal {F}}=\left\{ \left( \left( s_{r(t_i)},\varkappa (t_i)\right) ,\left\langle \mu (t_i), \nu (t_i)\right\rangle \right) \right\}\) on \(\texttt {Z}\), the information energy is given by:
The suggested information energy meets the fuzzy interval requirement, i.e., is \(0\le \textit{E}\left( {\mathcal {F}}\right) \le 1\).
Definition 9
Let \(\texttt {Z}\) be a fixed set, \(S=\left\{ s_{\theta }|\theta =1,2,...,\ell \right\}\) be a linguistic term set, for q-ROPFLSs \({\mathcal {F}}=\left\{ \left( \left( s_{r(t_i)},\varkappa (t_i)\right) ,\left\langle \mu (t_i), \nu (t_i)\right\rangle \right) \right\}\) and \(\breve{{\mathcal {F}}}=\left\{ \left( \left( s_{\breve{r}(t_i)},\breve{\varkappa }(t_i)\right) ,\left\langle \breve{\mu }(t_i), \breve{\nu }(t_i)\right\rangle \right) \right\}\) on \(\texttt {Z}\), the covariance of \({\mathcal {F}}\) and \(\breve{{\mathcal {F}}}\) is presented by the following formula:
Theorem 1
The covariance of two q-ROPFLSs \({\mathcal {F}}\) and \(\breve{{\mathcal {F}}}\) holds the following properties:
-
1.
\(\textit{K}\left( {\mathcal {F}},{\mathcal {F}}\right) =\textit{E}\left( {\mathcal {F}}\right) ;\)
-
2.
\(\textit{K}\left( {\mathcal {F}},\breve{{\mathcal {F}}}\right) =\textit{K}\left( \breve{{\mathcal {F}}},{\mathcal {F}}\right)\).
Proof
1. From Eq. (10), the covariance of \({\mathcal {F}}\) with \({\mathcal {F}}\) is given as
2. By using Eq. (10), the covariance of \({\mathcal {F}}\) and \(\breve{{\mathcal {F}}}\) is given as
\(\square\)
Definition 10
Let \(\texttt {Z}\) be a fixed set, \(S=\left\{ s_{\theta }|\theta =1,2,...,\ell \right\}\) be a linguistic term set, for q-ROPFLSs \({\mathcal {F}}=\left\{ \left( \left( s_{r(t_i)},\varkappa (t_i)\right) ,\left\langle \mu (t_i), \nu (t_i)\right\rangle \right) \right\}\) and \(\breve{{\mathcal {F}}}=\left\{ \left( \left( s_{\breve{r}(t_i)},\breve{\varkappa }(t_i)\right) ,\left\langle \breve{\mu }(t_i), \breve{\nu }(t_i)\right\rangle \right) \right\}\) on \(\texttt {Z}\), the correlation coefficient of \({\mathcal {F}}\) and \(\breve{{\mathcal {F}}}\) is presented by the following formula:
Theorem 2
The correlation coefficient between q-ROPFLSs \({\mathcal {F}}\) and \(\breve{{\mathcal {F}}}\) holds the following properties:
-
1.
\(\rho \left( {\mathcal {F}},\breve{{\mathcal {F}}}\right) =\rho \left( \breve{{\mathcal {F}}},{\mathcal {F}}\right)\);
-
2.
\(\rho \left( {\mathcal {F}},{\mathcal {F}}\right) =1\);
-
3.
\(0\le \rho \left( {\mathcal {F}},\breve{{\mathcal {F}}}\right) \le 1\).
Proof
1. It is obvious, so we omit the proof.
2.
3. The inequality \(0\le \rho \left( {\mathcal {F}},\breve{{\mathcal {F}}}\right)\) is obvious. Below let us prove \(\rho \left( {\mathcal {F}},\breve{{\mathcal {F}}}\right) \le 1.\)
According to the Cauchy-Schwarz inequality: \(\left( a_1b_1+a_2b_2+\cdots +a_nb_n \right) ^2\le \left( a^2_1+a^2_2+\cdots +a^2_n \right) \left( b^2_1+b^2_2+\cdots +b^2_n \right)\) where \(a_i, \; b_i \in R, \; i=1,2,...,n.\)
Therefore, \(\textit{K}\left( {\mathcal {F}},\breve{{\mathcal {F}}}\right) \le \sqrt{\textit{E}\left( {\mathcal {F}}\right) } \sqrt{\textit{E}\left( \breve{{\mathcal {F}}}\right) },\) \(0\le \rho \left( {\mathcal {F}},\breve{{\mathcal {F}}}\right) \le 1\) which means the correlation coefficient of two q-ROPFLSs lies between \(\left[ 0,1 \right]\). \(\square\)
Example 1
Let \({\mathcal {F}}_1= \left\{ \left( \left( s_{4},0.0000\right) ,\left\langle 0.5853 ,0.3037 \right\rangle \right) , \left( \left( s_{5},0.0000\right) ,\left\langle 0.6810,0.1913 \right\rangle \right) ,\right. \left. \left( \left( s_{1},0.3333\right) ,\left\langle 0.6388,0.4380 \right\rangle \right) ,\left( \left( s_{2},-0.3333\right) ,\left\langle 0.3405,0.2520 \right\rangle \right) \right\}\) and \({\mathcal {F}}_2=\left\{ \left( \left( s_{3},0.0000\right) ,\left\langle 0.4059 ,0.2714 \right\rangle \right) , \left( \left( s_{6},0.3333\right) , \left\langle 0.2431, 0.5313\right\rangle \right) ,\left( \left( s_{5},0.0000\right) ,\left\langle 0.4059, 0.4000\right\rangle \right) ,\left( \left( s_{6},0.3333\right) ,\left\langle 0.6718 , 0.6316\right\rangle \right) \right\}\) be two q-ROPFTLSs in \(\texttt {Z}=\left\{ t_1,t_2,t_3,t_4 \right\} .\) Then, from Eq. (11), we get \(\rho \left( {\mathcal {F}}_1,{\mathcal {F}}_2\right) =0.2103.\)
Weighted covariance and correlation coefficient of q-ROPFLSs
The weighted correlation measure links the use of subject-assigned weights to the calculation of a correlation measure between two variables. The weights might either be readily available or selected by the researcher to meet a specific demand. For instance, if the number of estimates for each topic varies, it is customary to use these numbers as weights and calculate the correlation between the two variables. It has been shown that sporadic disagreements about distinct items may be associated with different weights. Consequently, while calculating the correlation coefficient between q-ROPFLSs, we shall consider the weighted impact. Within the framework of q-ROPFLS, we build a weighted correlation coefficient in the present part.
Suppose that the weight associated with each element \(t_i\) is \(\varpi _i\), where \(\varpi _i \in [0,1](i=1,2,...,n)\) and \(\sum \limits _{i=1}^{n}\varpi _i =1.\) Then
-
1.
The weighted information energy of \({\mathcal {F}}\) is given by:
$$\begin{aligned} {\textit{E}}_{\varpi }\left( {\mathcal {F}}\right) =\sum _{i=1}^{n}\varpi _i\left( \left( \frac{\curlyvee \left( s_{r(t_i)},\varkappa (t_i)\right) }{\ell } \right) ^2\mu (t_i)^{2q}+\left( \frac{\curlyvee \left( s_{r(t_i)},\varkappa (t_i)\right) }{\ell } \right) ^2\nu (t_i)^{2q}\right) . \end{aligned}$$(12) -
2.
The weighted covariance of \({\mathcal {F}}\) and \(\breve{{\mathcal {F}}}\) is presented by:
$$\begin{aligned} {\textit{K}}_{\varpi }\left( {\mathcal {F}},\breve{{\mathcal {F}}}\right) =\sum _{i=1}^{n}{\varpi }_{i}\left[ \frac{1}{\ell ^2}\left( \curlyvee \left( s_{r(t_i)}, \varkappa (t_i)\right) \cdot \curlyvee \left( s_{\breve{r(t_i)}},\breve{\varkappa }(t_i)\right) \right) \left\{ \left( \mu (t_i)^{q}\cdot \breve{\mu (t_i)^{q}}\right) +\left( \nu (t_i)^{q}\cdot \breve{\nu (t_i)^{q}}\right) \right\} \right] . \end{aligned}$$(13) -
3.
The weighted correlation coefficient of \({\mathcal {F}}\) and \(\breve{{\mathcal {F}}}\) is given by:
$$\begin{aligned} \begin{aligned}{}&\rho _{\varpi }\left( {\mathcal {F}},\breve{{\mathcal {F}}}\right) =\frac{{\textit{K}}_{\varpi } \left( {\mathcal {F}},\breve{{\mathcal {F}}}\right) }{\sqrt{{\textit{E}}_{\varpi }\left( {\mathcal {F}}\right) }\sqrt{{\textit{E}}_{\varpi }\left( \breve{{\mathcal {F}}}\right) }}\\&\quad = \frac{\sum \nolimits _{i=1}^{n}{\varpi }_{i}\left[ \left( \curlyvee \left( s_{r(t_i)}, \varkappa (t_i)\right) \cdot \curlyvee \left( s_{\breve{r(t_i)}},\breve{\varkappa }(t_i)\right) \right) \left\{ \left( \mu (t_i)^{q}\cdot \breve{\mu }(t_i)^{q}\right) +\left( \nu (t_i)^{q}\cdot \breve{\nu }(t_i)^{q}\right) \right\} \right] }{\sqrt{\sum \nolimits _{i=1}^{n}{\varpi }_{i}\left( \left( \curlyvee \left( s_{r(t_i)}, \varkappa (t_i)\right) \right) ^2\mu (t_i)^{2q}+\left( \curlyvee \left( s_{r(t_i)},\varkappa (t_i) \right) \right) ^2\nu (t_i)^{2q}\right) } \sqrt{\sum \nolimits _{i=1}^{n}{\varpi }_{i}\left( \left( \curlyvee \left( s_{\breve{r}(t_i)}, \breve{\varkappa }(t_i)\right) \right) ^2\breve{\mu }(t_i)^{2q}+\left( \curlyvee \left( s_{\breve{r}(t_i)}, \breve{\varkappa } (t_i)\right) \right) ^2\breve{\nu }(t_i)^{2q}\right) }} \end{aligned} \end{aligned}$$(14)
Remark 3
For \({\varpi }=\left( \frac{1}{n},\frac{1}{n},\cdots \frac{1}{n} \right) ^T\), the weighted correlation coefficient reduces to correlation coefficient i.e., \(\rho _{\varpi }\left( {\mathcal {F}},\breve{{\mathcal {F}}}\right) =\rho \left( {\mathcal {F}},\breve{{\mathcal {F}}}\right)\).
Theorem 4
The weighted correlation coefficient between q-ROPFLSs \({\mathcal {F}}\) and \(\breve{{\mathcal {F}}}\) contains the following properties:
-
1.
\(\rho _{\varpi }\left( {\mathcal {F}},\breve{{\mathcal {F}}}\right) =\rho _{\varpi } \left( \breve{{\mathcal {F}}},{\mathcal {F}}\right)\);
-
2.
\(\rho _{\varpi }\left( {\mathcal {F}},{\mathcal {F}}\right) =1\);
-
3.
\(0\le \rho _{\varpi }\left( {\mathcal {F}},\breve{{\mathcal {F}}}\right) \le 1\).
Proof
1. It is obvious, so we omit the proof.
2.
3. The inequality \(0\le \rho _{\varpi }\left( {\mathcal {F}},\breve{{\mathcal {F}}}\right)\) is obvious. Therefore, we need only to prove \(\rho _{\varpi }\left( {\mathcal {F}},\breve{{\mathcal {F}}}\right) \le 1.\)
According to the Cauchy-Schwarz inequality: \(\left( a_1b_1+a_2b_2+\cdots +a_nb_n \right) ^2\le \left( a^2_1+a^2_2+\cdots +a^2_n \right) \left( b^2_1+b^2_2+\cdots +b^2_n \right)\) where \(a_i, \; b_i \in R, \; i=1,2,...,n.\)
Therefore, \({\textit{K}}_{\varpi }\left( {\mathcal {F}},\breve{{\mathcal {F}}}\right) \le \sqrt{{\textit{E}}_{\varpi }\left( {\mathcal {F}}\right) } \sqrt{{\textit{E}}_{\varpi }\left( \breve{{\mathcal {F}}}\right) },\) \(0\le {\rho }_{\varpi }\left( {\mathcal {F}},\breve{{\mathcal {F}}}\right) \le 1\) which means the correlation coefficient of two q-ROPFLSs lies between \(\left[ 0,1 \right]\). \(\square\)
Example 2
Let \({\mathcal {F}}_1= \left\{ \left( \left( s_{4},0.0000\right) ,\left\langle 0.5853 ,0.3037 \right\rangle \right) , \left( \left( s_{5},0.0000\right) ,\left\langle 0.6810,0.1913 \right\rangle \right) ,\right. \left. \left( \left( s_{1},0.3333\right) ,\left\langle 0.6388,0.4380 \right\rangle \right) ,\left( \left( s_{2},-0.3333\right) ,\left\langle 0.3405,0.2520 \right\rangle \right) \right\}\) and \({\mathcal {F}}_2=\left\{ \left( \left( s_{3},0.0000\right) ,\left\langle 0.4059 ,0.2714 \right\rangle \right) ,\right. \left. \left( \left( s_{6},0.3333\right) , \left\langle 0.2431, 0.5313\right\rangle \right) ,\left( \left( s_{5},0.0000\right) ,\left\langle 0.4059, 0.4000\right\rangle \right) ,\left( \left( s_{6},0.3333\right) ,\left\langle 0.6718 , 0.6316\right\rangle \right) \right\}\) be two QROPFTLSs in \(\texttt {Z}=\left\{ t_1,t_2,t_3,t_4 \right\} ,\) \(w=\left\{ 0.2353, 0.2727, 0.1912, 0.3008\right\}\) be the weight vector of \(t_i(i=1,2,3,4)\). Then, from Eq. (14), we get \(\rho _{\varpi }\left( {\mathcal {F}}_1,{\mathcal {F}}_2\right) =0.1224.\)
Clustering algorithm under q-ROPFL environment
Based on the q-rung orthopair fuzzy clustering method36 and the previously designed correlation coefficient formulas for q-ROPFLSs, we construct an approach for clustering in q-ROPFL environment. Firstly, the following ideas are introduced:
Theoretical development
Definition 11
Let \({{\mathcal {F}}}_j\left( j=1,2,...,m \right)\) be m q-ROPFLSs, then \(C=\left( \rho _{ij} \right) _{m \times m}\) is called a correlation matrix, where \(\rho _{ij}=\rho \left( {\mathcal {F}}_i,{\mathcal {F}}_j\right)\) denotes the correlation coefficient of \({{\mathcal {F}}}_i\) and \({{\mathcal {F}}}_j\), which meets the following characteristics:
-
1.
\(0\le \rho _{ij}\le 1 \; \forall \; i,j=1,2,...,m;\)
-
2.
\(\rho _{ij}=1\) if and only if \({{\mathcal {F}}}_i={{\mathcal {F}}}_j\);
-
3.
\(\rho _{ij}=\rho _{ji}\; \forall \; i,j=1,2,...,m.\)
Definition 12
Let \(C=\left( \rho _{ij} \right) _{m \times m}\) be a correlation matrix, if \(C^2=C\circ C=\left( \ddot{\rho _{ij}}\right) _{m \times m}\) is called a composition matrix of C, where
Based on Definition 12, we have
Theorem 5
Let \(C=\left( \rho _{ij} \right) _{m \times m}\) be a correlation matrix, then the composition matrix \(C^2\) is also a correlation matrix.
Proof
-
1.
Since C is a correlation matrix, then \(0\le \rho _{ij}\le 1 \; \forall \; i,j=1,2,...,m.\) Thus \(0\le \ddot{\rho _{ij}}=\max \limits _{k}\left\{ \min \left\{ \rho _{ik},\rho _{kj}\right\} \right\} \le 1\; \forall \; i,j=1,2,...,m.\)
-
2.
Since \(\rho _{ij}=1\) if and only if \({{\mathcal {F}}}_i={{\mathcal {F}}}_j\), then \(\ddot{\rho _{ij}}=\max \limits _{k}\left\{ \min \left\{ \rho _{ik},\rho _{kj}\right\} \right\} =1\) if and only if \({{\mathcal {F}}}_i={{\mathcal {F}}}_k={{\mathcal {F}}}_j\) for some k.
-
3.
Since \(\rho _{ij}=\rho _{ji}\; \forall \; i,j=1,2,...,m,\) then \(\ddot{\rho _{ij}}=\max \limits _{k}\left\{ \min \left\{ \rho _{ik},\rho _{kj}\right\} \right\} = \ddot{\rho _{ij}}=\max \limits _{k}\left\{ \min \left\{ \rho _{ki},\rho _{jk}\right\} \right\} = \ddot{\rho _{ij}}=\max \limits _{k}\left\{ \min \left\{ \rho _{jk},\rho _{ki}\right\} \right\} =\ddot{\rho _{ji}}\; \forall \; i,j=1,2,...,m.\)
Thus, we complete the proof of Theorem 5. \(\square\)
Theorem 6
Let \(C=\left( \rho _{ij} \right) _{m \times m}\) be a correlation matrix, then for any non-negative integer k, the composition matrix \({C^{2}}^{k+1}\) acquired from
is also a correlation matrix.
Proof
We prove this by using mathematical induction method.
If \(k=0\), then \(C^2=C \circ C,\) thus, by Theorem 5, \(C^2\) is a correlation matrix.
Suppose for \(k=\acute{k}\) Eq. (16) holds, i.e., \({C^{2}}^{\acute{k}+1}={C^{2}}^{\acute{k}} \circ {C^{2}}^{\acute{k}}\) and \({C^{2}}^{\acute{k}+1}\) is a correlation matrix.
For \(k=\acute{k}+1\) , we have
\({C^{2}}^{k+1}={C^{2}}^{(\acute{k}+1)+1}=\left( {C^{2}}^{\acute{k}+1}\right) ^2={C^{2}}^{\acute{k}+1}\circ {C^{2}}^{\acute{k}+1}\).
Thus, by Theorem 5, \({C^{2}}^{(\acute{k}+1)+1}\) is also a correlation matrix. \(\square\)
Definition 13
Let \(C=\left( \rho _{ij} \right) _{m \times m}\) be a correlation matrix, if \(C^2\subseteq C,\) i.e.,
then C is called an equivalent correlation matrix.
Lemma 1
37 Let \(C=\left( \rho _{ij} \right) _{m \times m}\) be a correlation matrix, then after the finite times of composition:
There exists a positive integer k such that \({C^2}^k={C^2}^{k+1},\) and \({C^2}^k\) is also an equivalent correlation matrix.
Theorem 7
An equivalent correlation matrix can be derived after the finite times of composition from the correlation matrix \(C=\left( \rho _{ij} \right) _{m \times m}.\)
Proof
If \(C=\left( \rho _{ij} \right) _{m \times m}\) is equivalent correlation matrix. Then the theorem is true obviously. If not, then by Lemma 1, there must exist some positive integer k such that \({C^2}^k={C^2}^{k+1},\) and \({C^2}^k\) is also an equivalent correlation matrix. Since, \({C^2}^k={C^2}^{k+1},\) then \(\left( {C^2}^k\right) ^2 \subseteq {C^2}^{k+1},\) i.e., \({C^2}^k\) is an equivalent correlation matrix. \(\square\)
Definition 14
Let \(C=\left( \rho _{ij} \right) _{m \times m}\) be a correlation matrix, then \(C_{\zeta }=\left( \zeta \rho _{ij} \right) _{m \times m}\) is called \(\zeta -\)cutting matrix of C, where
and \(\zeta\) is the confidence level with \(\zeta \in [0,1]\).
Clustering algorithm
This segment is devoted to put forward the MCGDM model on the basis of propounding theory.
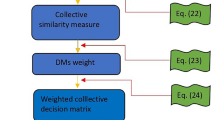
Let \({\mathcal {O}}=\left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,...,{\mathcal {O}}_m \right\}\) be the alternatives set, \({\mathcal {C}}=\left\{ {\mathcal {C}}_1,{\mathcal {C}}_2,...,{\mathcal {C}}_n \right\}\) be the criteria set for each alternative and \(\varpi =\left\{ \varpi _1,\varpi _2,...,\varpi _n \right\}\) be the weight vector of criteria set \({\mathcal {C}}\). The weight vector \(\varpi\) is utilized to depict the importance of different criteria in the process of decision making, where \(\sum \limits _{j=1}^{n}\varpi _j=1\) and \(\varpi _j \in \left[ 0,1 \right]\). The invited ‘p’ DMs \({\mathcal {D}}=\left\{ {\mathcal {D}}_1,{\mathcal {D}}_2,...,{\mathcal {D}}_p \right\}\) evaluate each alternative \({\mathcal {O}}_i\) under the criteria \({\mathcal {C}}_j\) in terms of q-ROPFLNs \(\partial ^k_{ij}\). The main steps involved in the proposed model are manifested as below:
Step 1: Collect the q-ROPFL experimental data set provided by each \({\mathcal {D}}_k\) \((k=1,2,...,p)\) using the LTS S, which includes information about the alternatives described by their relevant characteristics/ criteria. The assessment information of \({\mathcal {D}}_k\) can be described in the form of a decision matrix as

where \(\partial ^k_{ij}\) is the ijth q-ROPFLN provided by kth DM to which alternative \({\mathcal {O}}_i\) satisfies the criteria \({\mathcal {C}}_j\).
Step 2: Apply the q-ROPFLA operator Eq. (6) to aggregate the individual matrices into collective decision matrix \(M=\left[ \partial _{ij} \right] _{m \times n}\),

where \(\partial _{ij}\) can be determined as follows:
Step 3: Based on maximizing deviation model19, determine the weights of criteria \(\varpi =\left( \varpi _1,\varpi _2,...,\varpi _n \right) .\)
Step 4: According to Eq. (14), compute the weighted correlation coefficient between \({{\mathcal {F}}}_i\) and \({{\mathcal {F}}}_j\), and then build the correlation matrix \(C=\left( \rho _{ij} \right) _{m \times m}\) where \(\rho _{ij} =\rho \left( {{\mathcal {F}}}_i,{{\mathcal {F}}}_j\right)\) \(\left( i,j=1,2,...,m\right) .\)
Step 5: Check whether \(C=\left( \rho _{ij} \right) _{m \times m}\) is an equivalent correlation matrix, i.e., \(C^2\subseteq C\), where
If it does not hold, we construct the equivalent correlation matrix \({C^2}^k:\)
Step 6: To categorise the q-ROPFLSs \({{\mathcal {F}}}_i\left( i=1,2,...,m \right)\), we create a \(\zeta\)-cutting matrix \(C_{\zeta }=\left( \zeta \rho _{ij} \right) _{m \times m}\) according to Definition 14 with a confidence level \(\zeta\). If all components of the ith line (column) in \(C_{\zeta }\) match those of the jth line (column) in \(C_{\zeta }\), then the q-ROPFLSs \({{\mathcal {F}}}_i\) and \({{\mathcal {F}}}_j\) are of the same type. This practice enables us to categorise these m q-ROPLSs \({{\mathcal {F}}}_i (i= 1,2,...,m)\).
Figure 2 provides a flowchart depiction of the method for easier comprehension.

Flow chart of the developed clustering algorithm.
Applications and analysis
This section provides some examples to explain the applicability and validity of the proposed clustering algorithm.
Illustrated example
Software assessment and categorization is becoming increasingly essential issue in all areas of human activity. Industrial production, service delivery, and corporate administration are all strongly reliant on software, which is becoming more sophisticated and costly38. A CASE tool to help software development in a CIM context must be chosen among those available on the market. CIM software is often in charge of production planning, control, and monitoring39.
We do clustering for various kinds of CIM software \({\mathcal {O}}_i(i = 1,2,..., 7)\) on the market to better assess them based on four criteria: \({{\mathcal {C}}}_1\): functionality, \({{\mathcal {C}}}_2\): usability, \({{\mathcal {C}}}_3\): portability, and \({{\mathcal {C}}}_4\): maturity. Given that the specialists who do such an examination have varying backgrounds and degrees of knowledge, abilities, experience, personality, and so on, the evaluation information may differ. The experts are provided with the LTS
The assessment information is represented by the q-ROPLSs and enlisted in Tables 1, 2 and 3 to clearly indicate the disparities in the judgments of experts.
Now we proceed to follow the steps of the established algorithm as:
Step 1: The q-ROPFL decision matrices \(M^{k}_{7 \times 4} (k = 1,2,3)\) are shown in Tables 1-3.
Step 2: Employ the q-ROPFLA operator Eq. (20) (taking \(q=3\)) to aggregate all the matrices into collective decision matrix (see Table 4).
Step 3: Based on maximizing deviation model19, criteria weights are determined as:
Step 4: Determine the correlation coefficients of the q-ROPFLSs \({\mathcal {O}}_i(i=1,2,...,7)\) utilizing Eq. (14) and the weight vector \(\varpi = \left( 0.2353, 0.2727, 0.1912, 0.3008\right)\). The resulting correlation matrix is:
Step 5: Find out the equivalent correlation matrix:
Hence, \(C^4\) is an equivalent correlation matrix.
Step 6: In the light of Eq. (19) to generate a \(\zeta\)-cutting matrix \(C_{\zeta }=\left( \zeta \rho _{ij} \right) _{7 \times 7}\) from which all plausible classes of the softwares \({\mathcal {O}}_i(i = 1,2,..., 7)\) can be derived:
-
(i)
If \(0\le \zeta \le 0.6220\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are of the same type:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5, {\mathcal {O}}_6,{\mathcal {O}}_7 \right\} . \end{aligned}$$ -
(ii)
If \(0.6220< \zeta \le 0.7030\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into two types:
$$\begin{aligned} \left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5,{\mathcal {O}}_6,{\mathcal {O}}_7 \right\} . \end{aligned}$$ -
(iii)
If \(0.7030< \zeta \le 0.7590\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into three types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5,{\mathcal {O}}_6,{\mathcal {O}}_7 \right\} . \end{aligned}$$ -
(iv)
If \(0.7590< \zeta \le 0.7634\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into four types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5,{\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(v)
If \(0.7634< \zeta \le 0.8005\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into five types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3,{\mathcal {O}}_4, {\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(vi)
If \(0.8005< \zeta \le 0.8206\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into six types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3,{\mathcal {O}}_4 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} ,\left\{ {\mathcal {O}}_7\right\} . \end{aligned}$$ -
(vii)
If \(0.8206< \zeta \le 1\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into seven types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3, \right\} ,\left\{ {\mathcal {O}}_4\right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} ,\left\{ {\mathcal {O}}_7\right\} . \end{aligned}$$
How to choose the optimal value of \(\zeta\) ?
The framed method categorizes the q-ROPTLSs under the provided confidence levels by utilizing the \(\zeta\)-cutting matrix of the corresponding correlation matrix. Given that confidence levels have a close relationship with the elements of equivalent correlation matrices, people can properly specify the confidence levels in practical applications based on the elements of the equivalent correlation matrices and the actual situations, and thus the framed algorithm has desirable flexibility and practicality.
Parameter analysis
This section discusses option clustering when the parameter q values fluctuate. In the deployed algorithm, several values of q are used for this, as demonstrated below.
Case 1: Clustering analysis using \(q=3:\)
In the preceding section, the clustering method for q=3 has already been executed. Thus, we proceed to the subsequent cases.
Using the obtained weight vector \(\varpi = \left( 0.2353, 0.2727, 0.1912, 0.3008\right)\) ( for q=3), and following the Steps 4-6 of clustering algorithm outlined in the preceding section, the case-by-case computations are performed as follows.
Case 2: Clustering analysis using \(q=5:\)
Step 4: Based on Eq. (14) the correlation matrix of the q-ROPFLSs \({\mathcal {O}}_i(i=1,2,...,7)\) is obtained as:
Step 5: Determine the equivalent correlation matrix:
Step 6: In the light of Eq. (19) to generate a \(\zeta\)-cutting matrix \(C_{\zeta }=\left( \zeta \rho _{ij} \right) _{7 \times 7}\) from which all plausible classes of the softwares \({\mathcal {O}}_i(i = 1,2,..., 7)\) can be derived:
-
(i)
If \(0\le \zeta \le 0.5425\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are of the same type:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5,{\mathcal {O}}_6,{\mathcal {O}}_7 \right\} . \end{aligned}$$ -
(ii)
If \(0.5425< \zeta \le 0.5862\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into two types:
$$\begin{aligned} \left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5,{\mathcal {O}}_6,{\mathcal {O}}_7 \right\} . \end{aligned}$$ -
(iii)
If \(0.5862< \zeta \le 0.5964\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into three types:
$$\begin{aligned} \left\{ {\mathcal {O}}_2\right\} ,\left\{ {\mathcal {O}}_6\right\} , \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5,{\mathcal {O}}_7 \right\} . \end{aligned}$$ -
(iv)
If \(0.5964< \zeta \le 0.7173\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into four types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_7\right\} ,\left\{ {\mathcal {O}}_2\right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(v)
If \(0.7173< \zeta \le 0.7221\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into five types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3,{\mathcal {O}}_4, {\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(vi)
If \(0.7221< \zeta \le 0.7997\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into six types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3,{\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_4\right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(vii)
If \(0.7997< \zeta \le 1\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into seven types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3\right\} ,\left\{ {\mathcal {O}}_4 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} ,\left\{ {\mathcal {O}}_7\right\} . \end{aligned}$$
Case 3: Clustering analysis using \(q=7:\)
Step 4: According to Eq. (14) the correlation matrix of the q-ROPFLSs \({\mathcal {O}}_i(i=1,2,...,7)\) is obtained as:
Step 5: Calculate the equivalent correlation matrix:
Step 6: In the light of Eq. (19) to generate a \(\zeta\)-cutting matrix \(C_{\zeta }=\left( \zeta \rho _{ij} \right) _{7 \times 7}\) from which all plausible classes of the softwares \({\mathcal {O}}_i(i = 1,2,..., 7)\) can be derived:
-
(i)
If \(0\le \zeta \le 0.4026\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are of the same type:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5, {\mathcal {O}}_6,{\mathcal {O}}_7 \right\} . \end{aligned}$$ -
(ii)
If \(0.4026< \zeta \le 0.4693\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into two types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_6,{\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_5\right\} . \end{aligned}$$ -
(iii)
If \(0.4693< \zeta \le 0.4863\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into three types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_6,{\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_2\right\} ,\left\{ {\mathcal {O}}_5\right\} . \end{aligned}$$ -
(iv)
If \(0.4863< \zeta \le 0.6485\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into four types:
$$\begin{aligned} \left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_5\right\} , \left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(v)
If \(0.6485< \zeta \le 0.7596\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into five types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3,{\mathcal {O}}_7\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ ,{\mathcal {O}}_4, \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(vi)
If \(0.7596< \zeta \le 0.7857\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into six types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3, {\mathcal {O}}_7\right\} ,\left\{ {\mathcal {O}}_4 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(vii)
If \(0.7857< \zeta \le 1\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into seven types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3\right\} ,\left\{ {\mathcal {O}}_4 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} ,\left\{ {\mathcal {O}}_7\right\} . \end{aligned}$$
Case 4: Clustering analysis using \(q=9:\)
Step 4: On the basis of Eq. (14) the correlation matrix of the q-ROPFLSs \({\mathcal {O}}_i(i=1,2,...,7)\) is derived as:
Step 5: Work out the equivalent correlation matrix:
Step 6: In the light of Eq. (19) to generate a \(\zeta\)-cutting matrix \(C_{\zeta }=\left( \zeta \rho _{ij} \right) _{7 \times 7}\) from which all plausible classes of the softwares \({\mathcal {O}}_i(i = 1,2,..., 7)\) can be derived:
-
(i)
If \(0\le \zeta \le 0.2425\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are of the same type:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5, {\mathcal {O}}_6,{\mathcal {O}}_7 \right\} . \end{aligned}$$ -
(ii)
If \(0.2425< \zeta \le 0.4015\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into two types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_6,{\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_5\right\} \end{aligned}$$ -
(iii)
If \(0.4015< \zeta \le 0.4621\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into three types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(iv)
If \(0.4621< \zeta \le 0.5874\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into four types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_2\right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(v)
If \(0.5874< \zeta \le 0.7556\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into five types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3,{\mathcal {O}}_7\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_4 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(vi)
If \(0.7556< \zeta \le 0.7573\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into six types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_4 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} ,\left\{ {\mathcal {O}}_7\right\} . \end{aligned}$$ -
(vii)
If \(0.7573< \zeta \le 1\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into seven types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3\right\} ,\left\{ {\mathcal {O}}_4 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} ,\left\{ {\mathcal {O}}_7\right\} . \end{aligned}$$
Case 5: Clustering analysis using \(q=11:\)
Step 4: In the light of Eq. (14) the correlation matrix of the q-ROPFLSs \({\mathcal {O}}_i(i=1,2,...,7)\) is calculated as:
Step 5: Formulate the equivalent correlation matrix:
Step 6: In the light of Eq. (19) to generate a \(\zeta\)-cutting matrix \(C_{\zeta }=\left( \zeta \rho _{ij} \right) _{7 \times 7}\) from which all plausible classes of the softwares \({\mathcal {O}}_i(i = 1,2,..., 7)\) can be derived:
-
(i)
If \(0\le \zeta \le 0.1623\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are of the same type:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5,{\mathcal {O}}_6,{\mathcal {O}}_7 \right\} . \end{aligned}$$ -
(ii)
If \(0.1623< \zeta \le 0.3308\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into two types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_6,{\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_5\right\} . \end{aligned}$$ -
(iii)
If \(0.3308< \zeta \le 0.4347\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into three types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(iv)
If \(0.4347< \zeta \le 0.5302\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into four types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3,{\mathcal {O}}_4, {\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_2\right\} ,\left\{ {\mathcal {O}}_5\right\} , \left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(v)
If \(0.5302< \zeta \le 0.7138\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into five types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3,{\mathcal {O}}_7\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_4 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(vi)
If \(0.7138< \zeta \le 0.7142\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into six types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3,{\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_4\right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(vii)
If \(0.7142< \zeta \le 1\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into seven types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3\right\} ,\left\{ {\mathcal {O}}_4 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} ,\left\{ {\mathcal {O}}_7\right\} . \end{aligned}$$
Case 6: Clustering analysis using \(q=15:\)
Step 4: Utilizing Eq. (14) the correlation matrix of the q-ROPFLSs \({\mathcal {O}}_i(i=1,2,...,7)\) is figure out as:
Step 5: Compute the equivalent correlation matrix:
Step 6: In the light of Eq. (19) to generate a \(\zeta\)-cutting matrix \(C_{\zeta }=\left( \zeta \rho _{ij} \right) _{7 \times 7}\) from which all plausible classes of the softwares \({\mathcal {O}}_i(i = 1,2,..., 7)\) can be derived:
-
(i)
If \(0\le \zeta \le 0.09632\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are of the same type:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5, {\mathcal {O}}_6,{\mathcal {O}}_7 \right\} . \end{aligned}$$ -
(ii)
If \(0.09632< \zeta \le 0.2232\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into two types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_6,{\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_5\right\} . \end{aligned}$$ -
(iii)
If \(0.2232< \zeta \le 0.3629\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into three types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(iv)
If \(0.3629< \zeta \le 0.4231\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into four types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_7\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_5 \right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(v)
If \(0.4231< \zeta \le 0.6104\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into five types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3,{\mathcal {O}}_7\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_4 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(vi)
If \(0.6104< \zeta \le 0.6105\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into six types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_4 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} ,\left\{ {\mathcal {O}}_7\right\} . \end{aligned}$$ -
(vii)
If \(0.6105< \zeta \le 1\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into seven types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3\right\} ,\left\{ {\mathcal {O}}_4 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} ,\left\{ {\mathcal {O}}_7\right\} . \end{aligned}$$
From Case 1 through Case 6, we can notice that the corresponding correlation matrix is \(C^4\) in each case, requiring three iterations in each instance. Therefore, the framed method is stable from the aspect of the number of iterations, since changing the value of q has no impact on its iterations.
From the above experimental results, we can further find that the softwares \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorised into a single class in Cases 1, 2,..., 6 if \(\zeta \le 0.6220\), \(\zeta \le 0.5425\), \(\zeta \le 0.4026\), \(\zeta \le 0.2425\), \(\zeta \le 0.1623\),\(\zeta \le 0.09632\), respectively. Secondly, these softwares categorize into two classes in Case 1, 2,....,6 if \(\zeta \le 0.7030\), \(\zeta \le 0.5862\),\(\zeta \le 0.4693\), \(\zeta \le 0.4015\),\(\zeta \le 0.3308\), \(\zeta \le 0.2232\), respectively. Similarly, the bound of \(\zeta\) can be seen for the next four scenarios. These results indicate that increase in the value of q decrease the upper bound of \(\zeta\) for classifications.
What’s more, in Cases 1 and 2 (two categorization scenario), we find that \({\mathcal {O}}_2\) belongs to a separate class than the other softwares. While Cases 3-6 classify \({\mathcal {O}}_5\) as a distinct category from the others. Next, in the six categorization scenario, the results of Cases 4 and 6 do not match those of Cases 1, 2, 3, and 5. There are significant variances across the remaining situations. Therefore, the framed method is extremely sensitive to ‘q’ from a classification point.
How to choose the optimal value of q ?
To obtain a reasonable value for the parameter q, it must be determined based on the evaluation values provided by the DMs, and it may pick the lowest integer q meeting the inequality \({\mu }^q+{\nu }^q\le 1\). For instance, if the evaluating value provided by the DM is \(\left\langle 0.8, 0.7\right\rangle\), we may set the parameter q to 3 since \(0.8^2 + 0.7^2 > 1\) and \(0.8^3 + 0.7^3< 1\), where \(q=3\) is the smallest integer. If the DM wants to make a judgment based on complicated data, just increase q to enlarge the information representation space of q-ROPFLSs.
Criteria weight analysis
The present part performs sensitivity analysis by varying several criteria weights to ensure the robustness of the created approach. To accomplish this, we switch the weights of any two criteria while maintaining the weights of the other criteria constant. In the case of four criteria, there are six possible cases: \({\mathcal {C}}_1-{\mathcal {C}}_4\), \({\mathcal {C}}_1-{\mathcal {C}}_3\), \({\mathcal {C}}_1-{\mathcal {C}}_2\), \({\mathcal {C}}_2-{\mathcal {C}}_4\), \({\mathcal {C}}_2-{\mathcal {C}}_3\), \({\mathcal {C}}_3-{\mathcal {C}}_4\).
Case 1: Interchanging \({\mathcal {C}}_1\) and \({\mathcal {C}}_4\):
Utilizing Eq. (14) the resulting correlation matrix is obtained as:
Step 5: Find out the equivalent correlation matrix:
Step 6: In the light of Eq. (19) to generate a \(\zeta\)-cutting matrix \(C_{\zeta }=\left( \zeta \rho _{ij} \right) _{7 \times 7}\) from which all plausible classes of the softwares \({\mathcal {O}}_i(i = 1,2,..., 7)\) can be derived:
-
(i)
If \(0\le \zeta \le 0.5889\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are of the same type:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5, {\mathcal {O}}_6,{\mathcal {O}}_7 \right\} . \end{aligned}$$ -
(ii)
If \(0.5889< \zeta \le 0.7074\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into two types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5,{\mathcal {O}}_6,{\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_2\right\} . \end{aligned}$$ -
(iii)
If \(0.7074< \zeta \le 0.7193\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into three types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5,{\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_2\right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(iv)
If \(0.7193< \zeta \le 0.7602\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into four types:
$$\begin{aligned} \left\{ {\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5,{\mathcal {O}}_7\right\} ,\left\{ {\mathcal {O}}_1\right\} , \left\{ {\mathcal {O}}_2 \right\} ,\left\{ {\mathcal {O}}_6\right\} . \end{aligned}$$ -
(v)
If \(0.77602< \zeta \le 0.7763\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into five types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} , \left\{ {\mathcal {O}}_2 \right\} ,\left\{ {\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} ,\left\{ {\mathcal {O}}_7\right\} . \end{aligned}$$ -
(vi)
If \(0.7763< \zeta \le 0.8337\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into six types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} , \left\{ {\mathcal {O}}_2 \right\} ,\left\{ {\mathcal {O}}_3,{\mathcal {O}}_4\right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} ,\left\{ {\mathcal {O}}_7\right\} . \end{aligned}$$ -
(vii)
If \(0.8337< \zeta \le 1\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into seven types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3\right\} ,\left\{ {\mathcal {O}}_4 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} ,\left\{ {\mathcal {O}}_7\right\} . \end{aligned}$$
Case 2: Interchanging \({\mathcal {C}}_1\) and \({\mathcal {C}}_3\):
Step 4: Utilizing Eq. (14) the resulting correlation matrix is obtained as:
Step 5: Find out the equivalent correlation matrix:
Step 6: In the light of Eq. (19) to generate a \(\zeta\)-cutting matrix \(C_{\zeta }=\left( \zeta \rho _{ij} \right) _{7 \times 7}\) from which all plausible classes of the softwares \({\mathcal {O}}_i(i = 1,2,..., 7)\) can be derived:
-
(i)
If \(0\le \zeta \le 0.6381\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are of the same type:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5, {\mathcal {O}}_6,{\mathcal {O}}_7 \right\} . \end{aligned}$$ -
(ii)
If \(0.6381< \zeta \le 0.7083\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into two types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5,{\mathcal {O}}_6,{\mathcal {O}}_7 \right\} ,\left\{ {\mathcal {O}}_2\right\} . \end{aligned}$$ -
(iii)
If \(0.7083< \zeta \le 0.7502\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into three types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} ,\left\{ {\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_5,{\mathcal {O}}_6,{\mathcal {O}}_7 \right\} . \end{aligned}$$ -
(iv)
If \(0.7502< \zeta \le 0.7553\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into four types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} , \left\{ {\mathcal {O}}_2\right\} ,\left\{ {\mathcal {O}}_3,{\mathcal {O}}_4\right\} , \left\{ {\mathcal {O}}_5 \right\} ,\left\{ {\mathcal {O}}_6,{\mathcal {O}}_7\right\} . \end{aligned}$$ -
(v)
If \(0.7553< \zeta \le 0.8074\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into five types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} , \left\{ {\mathcal {O}}_2\right\} ,\left\{ {\mathcal {O}}_3,{\mathcal {O}}_4,{\mathcal {O}}_7\right\} ,\left\{ {\mathcal {O}}_5\right\} , \left\{ {\mathcal {O}}_6 \right\} . \end{aligned}$$ -
(vi)
If \(0.8074< \zeta \le 0.8089\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into six types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_4 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} ,\left\{ {\mathcal {O}}_3,{\mathcal {O}}_7\right\} . \end{aligned}$$ -
(vii)
If \(0.8089< \zeta \le 1\), then \({\mathcal {O}}_i(i = 1,2,..., 7)\) are categorized into seven types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3\right\} ,\left\{ {\mathcal {O}}_4 \right\} ,\left\{ {\mathcal {O}}_5\right\} ,\left\{ {\mathcal {O}}_6\right\} ,\left\{ {\mathcal {O}}_7\right\} . \end{aligned}$$
Similarly, the proposed approach can be used to solve the other cases. In Cases 3, 4, 5, and 6, we will find that the software is of the same type for \(0< \zeta \le 0.6121\), \(0< \zeta \le 0.6145\), \(0< \zeta \le 0.6301\), and \(0< \zeta \le 0.6031\), respectively. It is evident from this that the upper bounds of the intervals are quite close to each other, indicating that the introduced algorithm is stable with respect to criteria weight fluctuations.
Comparative Illustration
This section compares the devised clustering algorithm with previous methods, including intuitionistic fuzzy and q-rung orthopair fuzzy clustering algorithms36,40.
Consider the Jiang et al. clustering of four construction materials problem41. Let \(\left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4 \right\}\) represent the four types of construction materials: sealant, floor varnish, wall paint, and carpet. Assume each of these materials has four criteria \({\mathcal {C}}_1\), \({\mathcal {C}}_2\), \({\mathcal {C}}_3\), and \({\mathcal {C}}_4\) with the weight vector \(\varpi =\left( 0.2,0.2,0.3,0.3\right)\). DMs give their views based on the LTS, S (as taken previously).
The data collected for the four materials by three professionals according to each criterion is recorded in Tables 5, 6 and 7.
Here, we cluster the customers based on the appropriate degree of confidence. Note that in a clustering method, a broad range of confidence level results in the formation of viable clusters. We first employ the proposed algorithm for various values of parameter \(\zeta\) as follows:
Step 1: The q-ROPFL decision matrices \(M^{k}_{4 \times 4} (k = 1,2,3)\) are depicted in Tables 5-7.
Step 2: Employ the q-ROPFLA operator Eq. (6) (taking \(q=1\)) to aggregate all the matrices into collective decision matrix (see Table 8).
Step 3: Since the weight vector is given by DMs, so we omit this step.
Step 4: The weighted correlation matrix of the q-ROPFLSs \({\mathcal {O}}_i(i=1,2,...,4)\) with respect to their given weight is computed as follows:
Step 5: Determine the equivalent correlation matrix:
Step 6: In the light of Eq. (19) to generate a \(\zeta\)-cutting matrix \(C_{\zeta }=\left( \zeta \rho _{ij} \right) _{4 \times 4}\) from which all plausible classes of the softwares \({\mathcal {O}}_i(i = 1,2,..., 4)\) can be derived:
-
(i)
If \(0\le \zeta \le 0.9215\), then \({\mathcal {O}}_i(i = 1,2,..., 4)\) are of the same type:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4 \right\} . \end{aligned}$$ -
(ii)
If \(0.9215< \zeta \le 0.9468\), then \({\mathcal {O}}_i(i = 1,2,..., 4)\) are categorized into two types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_4 \right\} ,\left\{ {\mathcal {O}}_3\right\} \end{aligned}$$ -
(iii)
If \(0.9468< \zeta \le 0.9712\), then \({\mathcal {O}}_i(i = 1,2,..., 4)\) are categorized into three types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1, {\mathcal {O}}_4\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3\right\} \end{aligned}$$ -
(iv)
If \(0.9712< \zeta \le 1\), then \({\mathcal {O}}_i(i = 1,2,..., 4)\) are categorized into four types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3\right\} , \left\{ {\mathcal {O}}_4\right\} \end{aligned}$$
Example 2 data can not be modeled by applying intuitionistic and q-rung orthopair fuzzy correlations36,40. To make the Table 8 legitimate for the implication of40 and36, we exclude the 2-tuple linguistic data from Table 8. By doing so, the resultant data are reduced to a q-rung orthopair fuzzy context (q=1) and are displayed in Table 9.
The stepwise computations are performed by adhering to the method outlined in Ref.36.
Step 1: The weighted correlation matrix of the q-ROFSs \({\mathcal {O}}_i(i=1,2,...,4)\) with respect to their given weight is carried out as follows:
Step 2: Formulate the equivalent correlation matrix:
Step 3: Generate a \(\zeta\)-cutting matrix \(C_{\zeta }=\left( \zeta \rho _{ij} \right) _{4 \times 4}\) from which all plausible classes of the softwares \({\mathcal {O}}_i(i = 1,2,..., 4)\) can be derived:
-
(i)
If \(0\le \zeta \le 0.9648\), then \({\mathcal {O}}_i(i = 1,2,..., 4)\) are of the same type:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4\right\} . \end{aligned}$$ -
(ii)
If \(0.9648< \zeta \le 0.9650\), then \({\mathcal {O}}_i(i = 1,2,..., 4)\) are categorized into two types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_4\right\} , \left\{ {\mathcal {O}}_2,{\mathcal {O}}_3 \right\} \end{aligned}$$ -
(iii)
If \(0.9650< \zeta \le 0.9831\), then \({\mathcal {O}}_i(i = 1,2,..., 4)\) are categorized into three types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_4\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3 \right\} \end{aligned}$$ -
(iv)
If \(0.9831< \zeta \le 1\), then \({\mathcal {O}}_i(i = 1,2,..., 4)\) are categorized into four types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3\right\} , \left\{ {\mathcal {O}}_4 \right\} \end{aligned}$$
Next, the stepwise computations are carried out by following the procedures of Ref.40 (fixing \(\alpha =0.5\)).
Step 1: The correlation matrix of the IFSs \({\mathcal {O}}_i(i=1,2,...,4)\) is determined as follows:
Step 2: Frame the equivalent correlation matrix:
Step 3: Generate a \(\zeta\)-cutting matrix \(C_{\zeta }=\left( \zeta \rho _{ij} \right) _{7 \times 7}\) from which all plausible classes of the softwares \({\mathcal {O}}_i(i = 1,2,..., 4)\) can be derived:
-
(i)
If \(0\le \zeta \le 0.9975\), then \({\mathcal {O}}_i(i = 1,2,..., 4)\) are of the same type:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_3,{\mathcal {O}}_4 \right\} . \end{aligned}$$ -
(ii)
If \(0.9975< \zeta \le 0.9979\), then \({\mathcal {O}}_i(i = 1,2,..., 4)\) are categorized into two types:
$$\begin{aligned} \left\{ {\mathcal {O}}_3\right\} , \left\{ {\mathcal {O}}_1,{\mathcal {O}}_2,{\mathcal {O}}_4 \right\} \end{aligned}$$ -
(iii)
If \(0.9979< \zeta \le 0.9989\), then \({\mathcal {O}}_i(i = 1,2,..., 4)\) are categorized into three types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1,{\mathcal {O}}_4\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3 \right\} \end{aligned}$$ -
(iv)
If \(0.9989< \zeta \le 1\), then \({\mathcal {O}}_i(i = 1,2,..., 4)\) are categorized into four types:
$$\begin{aligned} \left\{ {\mathcal {O}}_1\right\} ,\left\{ {\mathcal {O}}_2\right\} , \left\{ {\mathcal {O}}_3\right\} ,\left\{ {\mathcal {O}}_4 \right\} \end{aligned}$$
By analyzing the results generated by the Bashir et al. approach36, we can find out that when the number of classes is two, the alternatives \({\mathcal {O}}_2\) and \({\mathcal {O}}_3\) are clustered into a single class, but accordingly to the results derived by the suggested and40 method, \({\mathcal {O}}_2\) is clustered into the class of \({\mathcal {O}}_1\) and \({\mathcal {O}}_4\). Further , we can see that our developed methodology has started classification when \(\zeta = 0.9215\). However, the method of36 and40 do not start classification until \(\zeta =0.9648\) and 0.9975, respectively. Our clustering results have a quicker convergence rate than36,40, therefore they can more accurately depict the distinction between groups. Notice that the present techniques36,40 can only process numeric data. Their failure to cope with linguistic arguments has resulted in significant information loss. Whereas the framed algorithm is capable for a linguistic preference structure with symbolic translation parameters of linguistic arguments of solving the MCGDM problems with completely unknown weight information.
Singh et al.40 has used a two-parametric correlation coefficient in his work, so expanding the range of confidence level, and by modifying the values of these two parameters, we can produce the equivalent matrix with less iterations. Despite this advantage, their model fails in the most of complicated problems due to the high constraints on its characteristic functions. For example, it cannot manage the information for the value \(\left\langle 0.5,0.6 \right\rangle\), but the created approach provides an adaptable parameter that enables the easy development of this kind of data. In addition, the approach of Basir et al.36 is based on known weights, and the method40 is based on correlation coefficient rather than weighted correlation coefficient; thus pay no attention to criteria weights. This ignorance may result in some incorrect clusters.
The main benefits of the described clustering algorithm over the past ones are talked over:
-
(i)
The proposed method is suitable for a linguistic preference structure with symbolic translation parameters of linguistic arguments that are highly effective in dealing with ambiguity in the MCGDM problem. While using q-ROPFLSs, the DMs remain easier for data collection and avoid any information loss.
-
(ii)
Unlike the prevailing techniques36,40, the framed algorithm aims to ascertain the weights of the evaluation criteria.
-
(iii)
The presented method is capable for solving the group decision making problems in the context of q-ROPTLSs. Whereas the existing methods36,40 work only for individual decision matrix and fail to model the multi-experts problem. Also the rate of convergence of the developed clustering model is faster than36,40, can be analyzed from the above comparison.
The presented structure also has disadvantages, which are outlined below:
-
(i)
In practice, DMs have different knowledge, proficiency and experiences and therefore the importance of each DM may not be equal. In present study this difference of knowledge and experiences (relative weight) of each DM is not considered and equal weight has been assigned to each DM.
-
(ii)
The formulated correlation coefficients are information energy-based measures, whose results lie inside the interval [0, 1], and hence cannot be used to indicate the negative correlation between two variables.
Concluding remarks
In this article, an intriguing study based on q-ROPFL clustering algorithm employed for classification problems in decision making was presented. For this, we explored the ideas of the information energy and covariance of q-ROPFLSs, and then presented a correlation coefficient. We additionally defined the weighted covariance and correlation coefficient of the q-ROPFLSs. Also, some desired properties and results of the proposed information energy and correlation coefficients were argued. Furthermore, some theoretical development, including the notion of composition matrix, correlation matrix, and equivalent correlation matrix via the proposed correlation coefficients, was given, and then proposed an algorithm for clustering q-ROPTLSs. The presented method works well with symbolic translation parameters of linguistic arguments in a linguistic preference structure. As opposed to conventional decision-making techniques, our suggested clustering algorithm uses q-ROPFLSs, which consistently prevent any loss of information. A practical problem concerning the clustering of construction materials was addressed, and a detailed sensitivity analysis was also performed. It was noticed the parameters q and \(\zeta\) indeed have an impact on the clustering of alternatives. Finally, a comparison example was provided, and it was found that the results of the framed algorithm have more rapid convergence, which confirms the practicality and superiority of the developed approach.
When employing the proposed clustering algorithm based on q-ROPFLSs, further work is still required. To broaden the application range of the present clustering algorithm, it needs to assign weights for different DMs19. Secondly, the introduced concepts can be explored for other extensions of fuzzy theory, which will develop many interesting structures, results, and applications. In addition, it is also a worthy research topic to expand the range of the devised correlation coefficients to the interval \([-1,1]\)42.
Data availability
All data generated or analysed during this study are included in this published article.
Change history
06 March 2023
A Correction to this paper has been published: https://doi.org/10.1038/s41598-023-30738-1
Abbreviations
- q-ROPFLS:
-
q-rung orthopair fuzzy 2-tuple linguistic set
- q-ROPFL:
-
q-rung orthopair fuzzy 2-tuple linguistic
- MCGDM:
-
Multi-Criteria Group Decision-Making
- LVR:
-
Linguistic variable
- 2TL:
-
2-Tuple linguistic
- P2TLN:
-
Pythagorean 2TL number
- DMs:
-
Decision makers
- q-ROPFLN:
-
q-rung orthopair 2-tuple linguistic number
- IFSs:
-
Intuitionistic fuzzy sets
- CIM:
-
Computer-integrated manufacturing
- q-ROPFLWA:
-
q-rung orthopair fuzzy 2-tuple linguistic weighted averaging
- q-ROPFLA:
-
q-rung orthopair fuzzy 2-tuple linguistic averaging
References
Merigó, J. M. & Gil-Lafuente, A. M. New decision-making techniques and their application in the selection of financial products. Inf. Sci. 180(11), 2085–2094 (2010).
Ali, J., Bashir, Z. & Rashid, T. A multi-criteria group decision-making approach based on revised distance measures under dual hesitant fuzzy setting with unknown weight information. Soft. Comput. 26, 8387–8401 (2022).
Ali, J. & Naeem, M. Distance and similarity measures for normal wiggly dual hesitant fuzzy sets and their application in medical diagnosis. Sci. Rep. 12(1), 13784 (2022).
Ali, J. & Naeem, M. Complex q-rung orthopair fuzzy Aczel-Alsina aggregation operators and its application to multiple criteria decision-making with unknown weight information. IEEE Access 10, 85315–85342 (2022).
Saham, A., Garg, H. & Dutta, D. Probabilistic linguistic q-rung orthopair fuzzy generalized Dombi and Bonferroni mean operators for group decision-making with unknown weights of experts. Int. J. Intell. Syst. 36(12), 7770–7804 (2021).
Saham, A., Majumder, P., Dutta, D. & Debnath, B. K. Multi-attribute decision making using q-rung orthopair fuzzy weighted fairly aggregation operators. J. Ambient. Intell. Humaniz. Comput. 12(7), 8149–8171 (2021).
Zadeh, L. A. Fuzzy sets. Inf. Control 8, 338–353 (1965).
Herrera, F. & Martínez, L. A 2-tuple fuzzy linguistic representation model for computing with words. IEEE Trans. Fuzzy Syst. 8(6), 746–752 (2000).
Faizi, S., Nawaz, S. & Ur-Rehman, A. Intuitionistic 2-tuple linguistic aggregation information based on Einstein operations and their applications in group decision making. Artif. Intell. Rev. 53(6), 4625–4650 (2020).
Rong, Y., Liu, Y. & Pei, Z. Complex q-rung orthopair fuzzy 2-tuple linguistic Maclaurin symmetric mean operators and its application to emergency program selection. Int. J. Intell. Syst. 35(11), 1749–1790 (2020).
Lu, J., He, T., Wei, G., Wu, J. & Wei, C. Cumulative prospect theory: performance evaluation of government purchases of home-based elderly-care services using the Pythagorean 2-tuple linguistic TODIM method. Int. J. Environ. Res. Public Health 17(6), 1939 (2020).
Wang, L., Garg, H. & Li, N. Interval-valued \(q\)-rung orthopair 2-tuple linguistic aggregation operators and their applications to decision making process. IEEE Access 7, 131962–131977 (2019).
Wei, G., Lu, M., Alsaadi, F. E., Hayat, T. & Alsaedi, A. Pythagorean 2-tuple linguistic aggregation operators in multiple attribute decision making. J. Intell. Fuzzy Syst. 33(2), 1129–1142 (2017).
He, T., Wei, G., Lu, J., Wei, C. & Lin, R. Pythagorean 2-tuple linguistic taxonomy method for supplier selection in medical instrument industries. Int. J. Environ. Res. Public Health 16(23), 4875 (2019).
Huang, Y.-H. & Wei, G.-W. TODIM method for pythagorean 2-tuple linguistic multiple attribute decision making. J. Intell. Fuzzy Syst. 35(1), 901–915 (2018).
Wei, G., Gao, H. & Wei, Y. Some q-rung orthopair fuzzy Heronian mean operators in multiple attribute decision making. Int. J. Intell. Syst. 33(7), 1426–1458 (2018).
Yager, R. R. Generalized orthopair fuzzy sets. IEEE Trans. Fuzzy Syst. 25(5), 1222–1230 (2016).
Ju, Y., Wang, A., Ma, J., Gao, H. & Santibanez Gonzalez, E. D. Some q-rung orthopair fuzzy 2-tuple linguistic Muirhead mean aggregation operators and their applications to multiple-attribute group decision making. Int. J. Intell. Syst. 35(1), 184–213 (2020).
Li, Z., Pan, Q., Wang, D. & Liu, P. An extended PROMETHEE II method for multi-attribute group decision-making under q-rung orthopair 2-tuple linguistic environment. Int. J. Fuzzy Syst. 24, 3039–3056 (2022).
Pearson, K. Notes on regression and inheritance in the case of two parents. Proceedings of the Royal Society of London 58, 240–242 (K Pearson, 1895).
Chiang, D.-A. & Lin, N. P. Correlation of fuzzy sets. Fuzzy Sets Syst. 102(2), 221–226 (1999).
Murthy, C., Pal, S. & Majumder, D. D. Correlation between two fuzzy membership functions. Fuzzy Sets Syst. 17(1), 23–38 (1985).
Yu, C. Correlation of fuzzy numbers. Fuzzy Sets Syst. 55(3), 303–307 (1993).
Gerstenkorn, T. & Mańko, J. Correlation of intuitionistic fuzzy sets. Fuzzy Sets Syst. 44(1), 39–43 (1991).
Hong, D. H. & Hwang, S. Y. Correlation of intuitionistic fuzzy sets in probability spaces. Fuzzy Sets Syst. 75(1), 77–81 (1995).
Zeng, W. & Li, H. Correlation coefficient of intuitionistic fuzzy sets. J. Ind. Eng. Int. 3(5), 33–40 (2007).
Xuan Thao, N. A new correlation coefficient of the intuitionistic fuzzy sets and its application. J. Intell. Fuzzy Syst. 35(2), 1959–1968 (2018).
Chen, N., Xu, Z. & Xia, M. Correlation coefficients of hesitant fuzzy sets and their applications to clustering analysis. Appl. Math. Model. 37(4), 2197–2211 (2013).
Hox, J. J., Moerbeek, M. & Van de Schoot, R. Multilevel Analysis: Techniques and Applications (Routledge, 2017).
Garg, H. A novel correlation coefficients between Pythagorean fuzzy sets and its applications to decision-making processes. Int. J. Intell. Syst. 31(12), 1234–1252 (2016).
Park, D. G., Kwun, Y. C., Park, J. H. & Park, I. Y. Correlation coefficient of interval-valued intuitionistic fuzzy sets and its application to multiple attribute group decision making problems. Math. Comput. Model. 50(9–10), 1279–1293 (2009).
Nguyen, H. A novel similarity/dissimilarity measure for intuitionistic fuzzy sets and its application in pattern recognition. Expert Syst. Appl. 45, 97–107 (2016).
Du, W. S. Correlation and correlation coefficient of generalized orthopair fuzzy sets. Int. J. Intell. Syst. 34(4), 564–583 (2019).
Li, H., Yang, Y. & Yin, S. Two \(\lambda\)-correlation coefficients of q-rung orthopair fuzzy sets and their application to clustering analysis. J. Intell. Fuzzy Syst. 39(1), 581–591 (2020).
Herrera, F. & Martinez, L. An approach for combining linguistic and numerical information based on the 2-tuple fuzzy linguistic representation model in decision-making. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 8(05), 539–562 (2000).
Bashir, H. et al. Some improved correlation coefficients for q-rung orthopair fuzzy sets and their applications in cluster analysis. Math. Probl. Eng. 2021, 745068 (2021).
Izakian, H. & Abraham, A. Fuzzy c-means and fuzzy swarm for fuzzy clustering problem. Expert Syst. Appl. 38(3), 1835–1838 (2011).
Stamelos, I. & Tsoukias, A. Software evaluation problem situations. Eur. J. Oper. Res. 145(2), 273–286 (2003).
Morisio, M. & Tsoukias, A. A Methodology for the Evaluation and Selection of Software Products (Dipartimento di Automatica e Informatica, 1997).
Singh, S., Sharma, S. & Lalotra, S. Generalized correlation coefficients of intuitionistic fuzzy sets with application to MAGDM and clustering analysis. Int. J. Fuzzy Syst. 22(5), 1582–1595 (2020).
Jiang, Q., Jin, X., Lee, S.-J. & Yao, S. A new similarity/distance measure between intuitionistic fuzzy sets based on the transformed isosceles triangles and its applications to pattern recognition. Expert Syst. Appl. 116, 439–453 (2019).
Sajjad, M., Sałabun, W., Faizi, S. & Ismail, M. Hesitant 2-tuple fuzzy linguistic multi-criteria decision-making method based on correlation measures. PLoS ONE 17(8), e0270414 (2022).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this Article was revised: In the original version of this Article, Wali Khan Mashwani was incorrectly affiliated with “Department of Mathematical Sciences, United Arab Emirates University, P. O. Box 15551 Al-Ain, UAE”. The correct affiliation is: “Institute of Numerical Sciences, Kohat University of Science and Technology, Kohat, KPK, Pakistan ''.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Abbas, F., Ali, J., Mashwani, W.K. et al. q-rung orthopair fuzzy 2-tuple linguistic clustering algorithm and its applications to clustering analysis. Sci Rep 13, 2789 (2023). https://doi.org/10.1038/s41598-023-29932-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-023-29932-y
This article is cited by
-
A 2-dimension linguistic Pythagorean fuzzy decision-making method with application to unmanned aerial vehicle contribution assessment
Scientific Reports (2025)
-
Bipolar Linguistic q-Rung Orthopair Fuzzy Modeling for Sustainable Tourism Development and Decision-Making in Tourism Cities
International Journal of Fuzzy Systems (2025)
-
Correlation coefficients between normal wiggly hesitant fuzzy sets and their applications
Scientific Reports (2024)
-
q-Rung orthopair fuzzy 2-tuple linguistic WASPAS algorithm for patients’ prioritization based on prioritized Maclaurin symmetric mean aggregation operators
Scientific Reports (2024)
-
Interval-valued q-rung orthopair fuzzy Aczel–Alsina operations-based Bonferroni mean aggregation operators and their applications
Computational and Applied Mathematics (2024)
