
Abstract
Previous studies have proposed that heat shock proteins 27 (HSP27) and its anti-HSP27 antibody titers may play a crucial role in several diseases including cardiovascular disease. However, available studies has been used simple analytical methods. This study aimed to determine the factors that associate serum anti-HSP27 antibody titers using ensemble machine learning methods and to demonstrate the magnitude and direction of the predictors using PFI and SHAP methods. The study employed Python 3 to apply various machine learning models, including LightGBM, CatBoost, XGBoost, AdaBoost, SVR, MLP, and MLR. The best models were selected using model evaluation metrics during the K-Fold cross-validation strategy. The LightGBM model (with RMSE: 0.1900 ± 0.0124; MAE: 0.1471 ± 0.0044; MAPE: 0.8027 ± 0.064 as the mean ± sd) and the SHAP method revealed that several factors, including pro-oxidant-antioxidant balance (PAB), physical activity level (PAL), platelet distribution width, mid-upper arm circumference, systolic blood pressure, age, red cell distribution width, waist-to-hip ratio, neutrophils to lymphocytes ratio, platelet count, serum glucose, serum cholesterol, red blood cells were associated with anti-HSP27, respectively. The study found that PAB and PAL were strongly associated with serum anti-HSP27 antibody titers, indicating a direct and indirect relationship, respectively. These findings can help improve our understanding of the factors that determine anti-HSP27 antibody titers and their potential role in disease development.
Similar content being viewed by others

Introduction
Intracellular protective proteins known as heat shock proteins (HSPs) are expressed in response to stressful situations within cells and enable the cells to overcome these conditions1. These stressful conditions include environmental, physical, and chemical stressors such as high temperature, viral infections, oxidative stress, ischemia, toxins, and reactive oxygen species1.
Heat shock proteins play a molecular chaperone role in the body and are found in most cells in the body. These molecular chaperones are used in the refolding of damaged cell proteins and prevent the accumulation of fat in certain pathways2. HSP27 is a small HSPs with a molecular mass of 27 kDa3. A high serum concentration of several HSPs has been reported in individuals with cardiovascular disease (CVD)1. The overexpression of HSPs, including HSP27 in the body is not good and it causes the immune system to recognize it as an auto-antigen and thus release an antibody called anti-HSP27 against it4. Therefore, an increase in HSP27 and consequently an increase in antibodies produced against it (anti-HSP27) has been expressed as an inflammatory marker in the body1. Identify the factors associated with serum anti-HSP27 antibody titers is important.
Recent studies have investigated this topic. For instance, in5 the authors investigated the association between the serum anti-HSP27 antibody level and the presence of the metabolic syndrome. In6 the results showed a significant correlation between vitamin D and anti-HSP27 antibody titers. Moreover, they found that serum pro-oxidant-antioxidant balance was positively associated with serum anti-HSP27 antibody titers. The relationship between the serum anti-HSP27 antibody titers and diabetes was not significant in7. A significant direct relationship has been observed between some factors such as hypertension8, obesity, body mass index, age, height, serum LDL-C, serum triglycerides, and serum total cholesterol1, hypertriglyceridemia9 with serum anti-HSP27 antibody titers.
The real-world data in many fields of health, education, and the social sciences yield values of skewness and kurtosis that clearly deviate from the normal distribution. Bono et al. mentioned some of non-normal variables that were listed by Arnau et al. such as, reaction times or response latency in cognitive studies, survival data from clinical trials, clinical assessment indexes in drug abuse research, physical and verbal violence in couples, divorced parents’ satisfaction with co-parenting relationships in family studies, and labor income or health care costs in sociological studies. More recent examples involving non-normal data include neuropsychological data, data about paranoid ideation, fatigue symptoms of breast cancer patients, data on violence or sexual aggression, and numerous studies on the cost of health care, such as costs among patients with depression or anxiety, costs following brief cognitive behavioral treatment for insomnia, and costs of anorexia nervosa10. Hence, an useful algorithm must be used to construct the model to take this into account11. Machine learning methods can be used for these problems. The process of applying new methods to discover knowledge behind data using a computer is called data mining which uses machine learning techniques. Generally, we face two types of machine learning methods, supervised and unsupervised12.
Today, machine learning techniques have become increasingly popular in medical research. There is growing evidence that these methods can be effectively applied to a wide range of real-world problems in the field13,14,15.
Jing et al.16 used machine learning classification algorithms to predict and categorized HSPs into six different families, HSP20, HSP40, HSP60, HSP70, HSP90, and HSP100. They applied a support vector machine (SVM) to achieve this purpose. Another published study that has conducted by Meher et al. has the same goal with Jing’s study17.
Min et al. proposed a convolutional neural network (CNN) that classifies both non-HSPs and six HSP families simultaneously. Their algorithm was trained on raw protein sequences and also on top of pre-trained protein representations18. Moreover, Chen et al. also used the two benchmark datasets of HSPs and their goal was the classification of HSPs and then prediction them using machine learning algorithms19.
We did not find any studies that used machine learning techniques for the prediction of serum anti-HSP27 antibody levels using related factors such as demographic factors, chronic diseases, social factors, chemical parameters, etc. In previous studies, simple methods such as general linear models, case–control studies1,20, logistic regression, and simple statistical tests such as correlation tests, analysis of variance, Kruskal–Wallis test1,5,6,7,8,9 were used.
The strengths of this study can be mentioned as follows: I) This study has been done on a larger scale with a population of 4181, II) Some of the attributes studied in this study have not been studied in previous studies, III) Using the advanced machine learning methods, V) So far, no study has been done in this area using machine learning techniques.
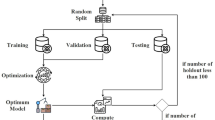
This paper is organized as follows. In section “Introduction”, we discussed HSPs, anti-HSP27, and a brief review of the related conducted studies in this area. Section “Material and methods”, i.e. material and methods, we expressed a brief demonstration of machine learning methods and their application. In section “Results”, the results of the research are reported. Section “Discussion” discusses the results obtained and compare them to other related studies. Finally, section “Conclusion” concludes this study. The graphical abstract is shown in Fig. 1.

Graphical Abstarct.
Material and methods
Study design, data collection, and data processing
The present study recruited participants from the Mashhad stroke and heart atherosclerotic disorder (MASHAD) cohort study at baseline21. Inclusion criteria required participants to be between the ages of 35 and 65, while exclusion criteria involved being outside this age range or declining to participate in the study. A total of 9,074 individuals who met the inclusion and exclusion criteria were enrolled in the study.
In the pre-processing phase, after removing the missing values, the 4,181 complete data records remained. Moreover, the data were normalized using the normalization formula as follows:
where, \({X}_{i}\) refer to the actual value and \({X}_{normalized}\) contains the normalized values of the X variable. Some used algorithms in this study such as SVM, MLP, and MLR need to be normalized, but the LightGBM does not. To develop the desired set of machine learning models, we used the K-Fold cross-validation (CV) methods on data. The required hyperparameters of models were determined during the fivefold CV method according to Table 3.
All analyses related to the pre-processing and modelling were implemented using Python 3 programming language.
Predictive techniques
Multiple linear regression (MLR)
Linear regression is one of the most common predictive models so it is the basis of regression-based machine learning models as well as, is so popular, simple, and widely used. In fact, this model tries to predict the outcome values using some predictors. In other words, it studies the relationship between predictor variables and outcome22.
Multilayer perceptron (MLP)
One of the most used and popular methods in machine learning is Multilayer perceptron (MLP) which is almost simple and has clear architecture. MLPs are neural networks that include at least three layers. This model consists of inputs, weights, biases, and an activation function that yields the output. The neurons of a certain layer feed the neurons of the next layer with their outputs. The connection power between neurons is determined by the adaptive coefficient weights, which are multiplied by each input to neurons. After that, a non-linear function i.e. activation function (usually applying sigmoid or hyperbolic tangent function) is used. The training process consists of adjusting the coefficients (weights) of the MLP. With calculating the error function (mean value of the difference between the actual target (T) and the forecasted output) and updating weights based on the learning rate and the error in each epoch and at the end repeating steps until reaching the number of epochs, the training process is completed and the final weights are determined23.
Support vector machine (SVM)
SVMs are one of the supervised learning methods and they are used for classification and regression problems24 and recently have been successfully acted in solving these problems25. In classification problems, SVMs create optimal decision boundaries between observations of two or more classes, and in Regression or approximation function problems, SVMs approximate optimal function to data. In both approaches, SVMs are found the optimal solution for solving a quadratic optimization problem. The SVMs for classification are called Support Vector Classification (SVC) and the SVMs for regression are called Support Vector Regression (SVR)11. Also, SVMs use various kernel functions to choose optimal non-linear decision boundaries in classification and optimal non-linear functions in regression11,26,27. Unlike common statistical methods, SVMs do not need to know the probability distribution of observations and also, unlike Neural networks, SVMs have an optimal and global solution. On the other, in SVMs, the complexity of the calculations does not depend on the number of input variables11,28. SVMs based on the structural risk minimization principle try to minimize the upper bound of generalization error and this is the final goal of SVM11,12,26.
Ensemble methods
One of the branches of machine learning is ensemble methods. Ensemble methods combine some weak learners to build a reliable model. The main goal of ensemble learning is to improve predictability in models. In other words, converting weak learners to strong learners, increase the accuracy of the results significantly. As well, ensemble learning can handle classification and regression problems well and are ideal. The popularity of it is due to reducing the bias and variance to boost the accuracy of models29.
Weak base learners in ensemble learning can be homogenous (base weak learners of the same types) or heterogeneous (base weak learners of the different types). Ensemble learning methods are mainly divided into categories of boosting and bagging. Bagging stands for bootstrap aggregating such as random forest (RF). Boosting has various forms such as gradient boosting, adaptive boosting (AdaBoost), categorical boosting (CatBoost), light gradient boosting machine (LightGBM), and extreme gradient boosting (XGBoost) algorithms29.
An improved version of the gradient boosting algorithm is called XGBoost and is one of the popular machine learning algorithms. This algorithm works based on the decision tree approach and the gradient boosting decision tree algorithm is the base it exactly. This algorithm has powerful predictive power and its implementation is simple30.
Ke et al. proposed an ensemble model in 201731. This model works based on a decision tree algorithm as a weak learner that was called LightGBM. It uses a novel technique called histogram-based binning and learns more efficiently than other algorithms. Tree-based models such as XGBoost produce the trees by level-wise growth method. While LightGBM applies the leaf-wise growth strategy rather than the level-wise growth method to generate the tree (Fig. 2).

Presentation of level-wise versus leaf-wise growth strategy.
Applying the leaf-wise growth strategy rather than the level-wise growth method can reduce the errors and then leads to high accuracy. In addition, LightGBM can handle high-dimensional problems. The generated decision tree with XGBoost is made using a level-wise growth method30,32. CatBoost is a supervised machine learning method based on gradient boosting on decision trees that is a powerful method and appropriate for the classification and regression problem with a dataset consisting of many categorical variables. AdaBoost is another ensemble method. The most common weak learner in adaBoost is the decision tree. It is the first successful algorithm to boost binary classification32.
Model evaluation
For evaluating the performance of models, we employed five performance metrics. The formula of these metrics is expressed as follows:
-
Root Mean Square Error
$$RMSE=\sqrt{\frac{1}{N}\sum_{i=1}^{N}{({y}_{i}-{\widehat{y}}_{i})}^{2}}$$ -
Mean Absolute Error
$$MAE=\frac{1}{N}\sum_{i=1}^{N}|{y}_{i}-{\widehat{y}}_{i}|$$ -
Coefficient of Determination
$${R}^{2}=1-\frac{\sum_{i=1}^{N}{({y}_{i}-{\widehat{y}}_{i})}^{2}}{\sum_{i=1}^{N}{({y}_{i}-{\overline{y} }_{i})}^{2}}$$
Explanation techniques
Explanations using SHAP
With respect to most of the machine learning methods are black boxes, therefore, it leads to difficult interpretation. Hence, we need Explainable Machine Learning methods. SHAP stands for "SHapley Additive exPlanations". Shapley values are a widely used approach based on a game theory to explain the output of machine learning models. It technique provides global interpretability, i.e., SHAP values not only show feature importance but also show whether the feature has a positive or negative impact on predictions. In other words, this method approximates the individual contribution of each feature, for each row of data. It approximates the contribution of that feature by estimating the model output without using it versus all the models that do include it30,33.
Feature importance using PFI
Fisher et al. proposed the Permutation Feature Importance for the random forest. After that, this extended and can be applied to all machine learning methods. The values of a variable are permuted to assess prediction error increases or decreases via permutation. In this method, the relationship between the desired variable and outcome is broken and then the decrease in the evaluation metrics shows how much the model depends on the feature. In fact, this method shows how important this feature is for a desired machine learning method30,34.
Ethics approval and consent of participant
The study protocol was given approval by the Ethics Committee of Mashhad University of Medical Sciences and written informed consent was obtained from participants. All methods were conducted in accordance with relevant guidelines and regulations. Ethic approval code: IR.MUMS.MEDICAL.REC.1399.558.
Results
We included 55 attributes from the database. Descriptive statistics and the bivariate analysis for evaluating the initial association between the target variable and all of the independent variables are reported in Tables 1 and 2. We used the Kolmogorov–Smirnov (Lilliefors correction) test to check the normality of the distribution. Due to the non-normal distribution of variables, we used the non-parametric Spearman correlation coefficient test, the Mann–Whitney U test, and the Kruskal–Wallis H test. The mean and standard deviation of the anti-HSP27 variable are 0.246 and 0.177, respectively.
The hyperparameters tuning to achieve the optimal models was performed using fivefold CV and the optimal values of hyperparameters were summarized in Table 3. The obtained evaluation metrics values by MLR, SVM, MLP, LightGBM, XGBoost, CatBoost, and AdaBoost during the training and test phases were shown in Table 4 as mean ± standard deviation.
According to these results, the performance of LightGBM was assessed as RMSE = 0.1914, MAE = 0.1461, and MAPE = 0.9237 on the training and RMSE = 0.1900, MAE = 0.1471, and MAPE = 0.8027 on the test dataset. This model outperformed other models on unseen data (test dataset) significantly.
The XGBoost model (RMSE = 0.1752, MAE = 0.1322, MAPE = 1.3979) performed better than other models, after that, the CatBoost (RMSE = 0.1787, MAE = 0.1346, MAPE = 1.3992) was performed superior to those of AdaBoost (RMSE = 0.1945, MAE = 0.1461, MAPE = 1.5437), SVR (RMSE = 0.1828, MAE = 0.1386, MAPE = 1.2952), MLP (RMSE = 0.1961, MAE = 0.1433, MAPE = 0.7828), and MLR (RMSE = 0.1806, MAE = 0.1409, MAPE = 1.4872) models in the training.
In the test phase, the other models such as the XGBoost (RMSE = 0.1977, MAE = 0.1485, MAPE = 1.5565), CatBoost (RMSE = 0.1991, MAE = 0.1473, MAPE = 1.5212), AdaBoost (RMSE = 0.1957, MAE = 0.1504, MAPE = 1.5510), SVR (RMSE = 0.1954, MAE = 0.1475, MAPE = 1.6571), MLP (RMSE = 0.1975, MAE = 0.1499, MAPE = 0.9246), and MLR (RMSE = 0.1955, MAE = 0.1479, MAPE = 1.6607) were evaluated (See the Table 4). These values also are visualized in the bar chart in Fig. 3.

Barplot for model evaluation (RMSE and MAE are multiplied by 10 for better visualization).
During the model evaluation, the LightGBM was recognized as the most accurate model. Then, we explained the predictions of the most accurate model using two model-agnostic explanation techniques: permutation feature importance (PFI) and shapley additive explanations (SHAP).
The plotted bar chart in Fig. 3, shows the feature importance (for each feature) in the estimation of antibody titers using the PFI technique. Among all features, the PAB, HS-CRP, PAL, and TG were identified as the four most important features. The importance order of other features are shown in Fig. 4.

PFI scores of the studied features.
The base value in Fig. 5 indicates the mean LightGBM model prediction. Some features were presented in red and some in blue. The red (blue) features move the estimation higher (lower) than the base value. The LightGBM model’s output value is 0.26.

Explanation of the LightGBM model’s output value of 0.26 using SHAP.
The global explanation was offered via the PFI score. We used the SHAP summary plot (Fig. 6) to explain both local and global explanations and show whether the feature has a positive or negative impact on predictions. Using this plot, we can measure the magnitude and direction. The PAB and PAL were identified as the most effective variables in serum anti-HSP27 antibody titer prediction using PFI and SHAP.

SHAP summary plot of the LightGBM model.
The low values of the PAB variable have a high negative contribution to the prediction, while high values have a high positive contribution. The high values of the PAL variable have a high negative contribution to the prediction, while low values have a high positive contribution.
The PDW, MUAC, SBP, age, RDW, WHR, NL, PLT, Glocuse, and RBC variables have a negative contribution when their values are low, and a positive contribution on high values. While, high values of the Chol have a negative contribution to the prediction and also, low values have a positive contribution. The RBC has an almost modest contribution. HC and the 27 other features have almost no contribution to the prediction.
Discussion
Data mining and the use of machine learning methods in various scientific fields have made significant progress in their methodologies. The field of data mining research includes powerful processes and tools that lead to the effective analysis and knowledge discovery. Data mining aims are to discover patterns and unknown correlations and predict data trends and behaviors35. Ensemble methods are powerful data mining tools24.
Elevated serum levels of several heat shock proteins (HSPs), including HSP27, have been observed in individuals with cardiovascular disease (CVD). However, excessive expression of HSP27 can have detrimental effects, leading to increased inflammation in the body. Identifying the associated variables with serum anti-HSP27 antibody levels can serve as a potential biomarker of inflammation in individuals with CVD. Understanding the underlying mechanisms of CVD and identifying such biomarkers can aid in the development of new therapeutic strategies for treating and managing CVD. Overall, this study has important implications for improving our understanding of CVD pathogenesis and advancing the development of effective treatments.
In the present study, the LightGBM model that it is a combination of decision trees as the weak learners was applied. Using a data mining approach, this study represents the first attempt to identify the demographic, clinical, and biochemical characteristics associated with anti-HSP27. The study's strengths include the use of advanced and novel methods, as well as a large sample size.
Our results showed that variables pro-oxidant-antioxidant balance (PAB), physical activity level (PAL), platelet distribution width (PDW), mid-upper arm circumference (MUAC), systolic blood pressure (SBP), age, red cell distribution width (RDW), waist-to-hip ratio (WHR), neutrophils to lymphocytes ratio (NL), platelet count (PLT), glucose, cholesterol, red blood cells (RBC) were associated to anti-HSP27.
The relative importance of variables showed that the PAB was the most important and related variable to serum anti-HSP27 antibody titers with a direct effect on the prediction of serum anti-HSP27 antibody titers. Ghazizadeh et al.6 for investigating the relationship between serum anti-HSP27 antibody titers and RDW, PAB conducted a cross-sectional study on 852 participants from the cohort study based on the Mashhad stroke and heart atherosclerotic disorders (MASHAD study). This study showed a significant correlation between serum anti-HSP27 antibody titers and PAB as well as RDW using Spearman correlation analysis. In addition, the univariate and multivariate logistic regression analyses after adjustment for confounder factors including sex, age, physical activity, and smoking status, showed that the level of anti-hsp27 increased 1.83 fold in line with increasing of 1 unit of PAB in subjects with level of PAB 36.31–82.63 (H2O2%) in comparison to the reference group (PAB level 36.31gt). Our model’s results have shown that PAB was strongly related to serum anti-HSP27 antibody titers.
Our results showed that age was an important and related variables with serum anti-HSP27 antibody titers. Our data showed that serum anti-HSP27 antibody titer did not relate to gender which is consistent with the results of Zilaee et al., and also Rea et al. study36,37. Zilaee et al. study was conducted on a total of 106 subjects with metabolic syndrome aged 18–65 years, with and without diabetes based on a case–control study. Rea et al. study was conducted on four age groups (less than 40, between 40 and 69, between 70 and 89, and 90 or larger than 90). No significant differences were observed in anti-HSP antibodies based on gender and age changes. But the results of the regression analysis revealed a significant relation between anti-HSP antibody levels and age36,37. In addition, the results of the Kargari et al.1 study had similar results to Zilaee et al. and Rea et al. studies about the relationship between age and gender with serum anti-HSP27 antibody titers.
In addition, we observed a strong association with an indirect effect between serum anti-HSP27 antibody titer and the PAL, while Sadabadi et al. found the PAL was not significant. One reason for the discrepancy could be that they performed their study on participants with MetS disease.
Kargari et al. in their study on 933 subjects showed a significant relationship between diabetes mellitus and serum anti-HSP27 antibody titer1 that their results were not similar to the results of our research. Azarpazhooh et al.8, and Tavana et al.20 in their studies reported that diabetes mellitus is not associated with serum anti-HSP27 antibody titer. Azarpazhooh et al.’s study was carried out on 168 patients in the first 24 h after the onset of stroke in a case–control study and the patients were matched in terms of age and gender. Hence, our findings were consistent with their findings. The study of Tavana et al. was conducted based on a case–control study on 106 subjects with metabolic syndrome and 6447 subjects with diabetes mellitus. These differences may be due to the target population, other patient conditions, and time periods for each study.
A study38 showed the relationship between BMI and antibody titers to HSP60, 65, and 70 is significant. Kargari et al. found a significant relationship between BMI and HTN with serum anti-HSP27 antibody titer. Also, Azarpazhooh et al. concluded that serum anti-HSP27 antibody titer was significantly higher in hypertensive patients compared with non-hypertensive patients (p < 0.001). But, our results showed that BMI and HTN were not associated with serum anti-HSP27 antibody titer. In both studies Kargari et al. and Azarpazhooh et al., no significant difference was observed between smoking status and serum anti-HSP27 antibody titer and was consistent to our conclusion.
Also, we explored the educational level of individuals that was not related to serum anti-HSP27 antibody titer and our result was different from the study of Victora et al.39.
In addition to the items mentioned so far, obesity, height, LDL, TG, Chol, WHR, and Hs-CRP were positively associated with serum anti-HSP27 antibody titer in Kargari et al. study. In another study that was conducted by Sadabadi et al., PAL and HC were not significant, and the serum HSP27 antibody titers were different (p-value = 0.05) between the subjects with high WC, HDL, TG, BPS, and BPD compared to participants with low WC, HDL, BPS, BPD, and glucose5. In our study, PAL was related and consistent with the study of Sadabadi et al.
In addition to all of the above, our finding revealed that there was a relationship between other variables such as MAUC and PLT with serum anti-HSP27 antibody titer. These variables were not studied in previous studies.
In summary, there are differences in the results of this study with other studies mentioned. The previous studies have been conducted using common statistical methods that require special assumptions or case–control studies but in the present study, a non-parametric method that does not require special assumptions has been used as well as it can predict and model the linear and nonlinear relationships between input and output patterns, well. These differences could be due to the cross-sectional study design and sample size in case and control groups20. Another reason that can cause these discrepancies is the sample size, which can be influential in the bivariate analysis stage for feature selection in our selection and other studies. Also, the presence of other influential factors or conditions of the subjects, the special patients under study that have been considered in previous studies can be effective. The limitation of this study was the exclusion of important variables such as drug use and vitamin D due to missing values exceeding 70 percent.
Conclusion
The LightGBM method was effective in elucidating the relationship between PAB and PAL and serum anti-HSP27 antibody titers with a direct and indirect effect on the prediction of serum anti-HSP27 antibody titers, respectively. The PDW, MUAC, SBP, age, RDW, WHR, NL, PLT, glucose, cholesterol, and RBC were also associated with anti-HSP27 antibody titers. In addition, we aim to investigate this topic as a longitudinal study in the future.
Data availability
The data that support the findings of this study are available from [Mashhad University of Medical Sciences], but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are however available from the authors upon reasonable request and with permission of [Mashhad University of Medical Sciences].
References
Kargari, M. et al. Relationship between serum anti-heat shock protein 27 antibody levels and obesity. Clin. Biochem. 50(12), 690–695 (2017).
Wu, J. et al. Role of heat shock protein 27 in cardiovascular disease. J. Biochem. Pharmacol. Res. 1(1), 43–50 (2013).
Mohammadpour, A. H. et al. Correlation between heat-shock protein 27 serum concentration and common carotid intima-media thickness in hemodialysis patients. Iran J. Kidney Dis. 5(4), 260–266 (2011).
Mohammadi, F. et al. The effects of curcumin on serum heat shock protein 27 antibody titers in patients with metabolic syndrome. J. Diet. Suppl. 1–10 (2018).
Sadabadi, F. et al. Is there any association between Serum anti-HSP27 antibody level and the presence of metabolic syndrome; population based case-control study. Revista Romana de Medicina de Laborator 27(2), 179–187 (2019).
Ghazizadeh, H. et al. Prognostic factors associating with pro-oxidant-antioxidant balance; neutrophils to lymphocytes ratio, vitamin D, heat shock protein 27, and red cell distribution width. Arch. Med. Res. 51(3), 261–267 (2020).
Tavana, M. et al. Serum anti-hsp27 antibodies concentration in diabetes mellitus; population based case-control study. Arch. Med. Lab. Sci. 5(1), 12–17 (2020).
Azarpazhooh, M. R. et al. Serum high-sensitivity C-reactive protein and heat shock protein 27 antibody titers in patients with stroke and 6-month prognosis. Angiology 61(6), 607–612 (2010).
Taheri-Bonakdar, M. et al. The association between serum anti-HSP27 levels with hypertriglyceridemia. Transl. Metab. Syndr. Res. 3, 12–16 (2020).
Bono, R. et al. Non-normal distributions commonly used in health, education, and social sciences: A systematic review. Front. Psychol. 8, 1602 (2017).
Wang, L., Support Vector Machines: Theory and Applications. Vol. 177. (Springer, 2005).
Jothi, N., Rashid, N. A. & Husain, W. Data mining in healthcare–a Review. Procedia Comput. Sci. 72, 306–313 (2015).
Kolachalama, V. B. & Garg, P. S. Machine learning and medical education. npj Digital Med. 1(1), 54 (2018).
Mansoori, A. et al. Prediction of type 2 diabetes mellitus using hematological factors based on machine learning approaches: A cohort study analysis. Sci. Rep. 13(1), 663. https://doi.org/10.1038/s41598-022-27340-2 (2023).
Saberi-Karimian, M. et al. Data mining approaches for type 2 diabetes mellitus prediction using anthropometric measurements. J. Clin. Lab. Anal. 37(1), e24798. https://doi.org/10.1002/jcla.24798 (2023).
Jing, X. Y. & Li, F. M. Identifying heat shock protein families from imbalanced data by using combined features. Comput. Math. Methods Med. 2020, 8894478 (2020).
Meher, P. K., et al. ir-HSP: Improved Recognition of Heat Shock Proteins, Their Families and Sub-types Based On g-Spaced Di-peptide Features and Support Vector Machine. 8 (2018).
Min, S. et al. Protein transfer learning improves identification of heat shock protein families. PLoS ONE 16(5), e0251865 (2021).
Chen, W. et al. Recent advances in machine learning methods for predicting heat shock proteins. Curr. Drug. Metab. 20(3), 224–228 (2019).
Burt, D. et al. Anti-heat shock protein 27 antibody levels and diabetes complications in the EURODIAB study. Diabetes Care 32(7), 1269–1271 (2009).
Ghayour-Mobarhan, M. et al. Mashhad stroke and heart atherosclerotic disorder (MASHAD) study: Design, baseline characteristics and 10-year cardiovascular risk estimation. Int. J. Public Health 60(5), 561–572 (2015).
Niu, W.-J. et al. Comparison of multiple linear regression, artificial neural network, extreme learning machine, and support vector machine in deriving operation rule of hydropower reservoir. Water 11(1), 88 (2019).
Parhizkari, L., Najafi, A. & Golshan, M. Medium term electricity price forecasting using extreme learning machine. J. Energy Manag. Technol. 4(2), 20–27 (2020).
Mitra, V., Wang, C. J. & Banerjee, S. Text classification: A least square support vector machine approach. Appl. Soft Comput. 7(3), 908–914 (2007).
Chuang, C. C. & Lee, Z. J. Hybrid robust support vector machines for regression with outliers. Appl. Soft Comput. 11(1), 64–72 (2011).
Suykens, J. A. et al. Least squares support vector machines. 2002: World Scientific Publishing Company.
Lee, M. C. & To, C. Comparison of support vector machine and back propagation neural network in evaluating the enterprise financial distress. IJAIA 1(3), 31–43 (2010).
Suykens, J. A. K. & Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 9, 293–300 (1999).
Luo, M. et al. Combination of feature selection and catboost for prediction: The first application to the estimation of aboveground biomass. Forests 12(2), 216 (2021).
Chaibi, M. et al. An interpretable machine learning model for daily global solar radiation prediction. Energies 14(21), 7367 (2021).
Ke, G., et al. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inform. Process. Syst. 30 (2017)
Wang, Y. & Wang, T. Application of improved LightGBM model in blood glucose prediction. Appl. Sci. 10(9), 3227 (2020).
Trevisan, V. Using SHAP Values to Explain How Your Machine Learning Model Works. 2022; Available from: https://towardsdatascience.com/using-shap-values-to-explain-how-your-machine-learning-model-works-732b3f40e137.
Fisher, A., Rudin, C. & Dominici, F. All models are wrong, but many are useful: Learning a variable’s importance by studying an entire class of prediction models simultaneously. J. Mach. Learn. Res. 20(177), 1–81 (2019).
Giannopoulou, E.G., Data Mining in Medical and Biological Research. 2008: In-Teh.
Zilaee, M. et al. Barberry treatment reduces serum anti-heat shock protein 27 and 60 antibody titres and high-sensitivity c-reactive protein in patients with metabolic syndrome: A double-blind, randomized placebo-controlled trial. Phytother. Res. 28(8), 1211–1215 (2014).
Rea, I. M., McNerlan, S. & Pockley, A. G. Serum heat shock protein and anti-heat shock protein antibody levels in aging. Exp. Gerontol. 36(2), 341–352 (2001).
Ghayour-Mobarhan, M. et al. Association between indices of body mass and antibody titres to heat-shock protein-60, -65 and -70 in healthy Caucasians. Int. J. Obes. (Lond) 31(1), 197–200 (2007).
Victora, G. D. et al. Mother–child immunological interactions in early life affect long-term humoral autoreactivity to heat shock protein 60 at age 18 years. J. Autoimmun. 29(1), 38–43 (2007).
Acknowledgements
We would like to thank Mashhad University of Medical Sciences for supporting this study.
Funding
The collection of clinical data was financially supported by Mashhad University of Medical Sciences.
Author information
Authors and Affiliations
Contributions
All authors have read and approved the manuscript. N.T.: Formal analysis; Investigation; Methodology; Software; Writing—original draft. M.J.N.: Formal analysis; Methodology; Validation. Habibollah Esmaeili: Writing—review & editing; Validation. S.M.: Data curation; Writing—review & editing. M.H.: Data curation; Writing—review & editing. G.A.F.: Review & editing. M.G.-M.: Resources; Supervision; Data curation.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Talkhi, N., Nooghabi, M.J., Esmaily, H. et al. Prediction of serum anti-HSP27 antibody titers changes using a light gradient boosting machine (LightGBM) technique. Sci Rep 13, 12775 (2023). https://doi.org/10.1038/s41598-023-39724-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-023-39724-z
This article is cited by
-
Machine learning model development and validation using SHAP: predicting 28-day mortality risk in pulmonary fibrosis patients
BMC Medical Informatics and Decision Making (2025)
