
Abstract
Pump sizing is the process of dimensional matching of an impeller and stator to provide a satisfactory performance test result and good service life during the operation of progressive cavity pumps. In this process, historical data analysis and dimensional monitoring are done manually, consuming a large number of man-hours and requiring a deep knowledge of progressive cavity pump behavior. This paper proposes the use of graph neural networks in the construction of a prototype to recommend interference during the pump sizing process in a progressive cavity pump. For this, data from different applications is used in addition to individual control spreadsheets to build the database used in the prototype. From the pre-processed data, complex network techniques and the betweenness centrality metric are used to calculate the degree of importance of each order confirmation, as well as to calculate the dimensionality of the rotors. Using the proposed method a mean squared error of 0.28 is obtained for the cases where there are recommendations for order confirmations. Based on the results achieved, it is noticeable that there is a similarity of the dimensions defined by the project engineers during the pump sizing process, and this outcome can be used to validate the new design definitions.
Similar content being viewed by others

Introduction
In 1933, the French mathematician and researcher René Moineau idealized the principle of progressive cavities. However, not having the financial resources to develop his project, Moineau sold his patents to some companies. His principles resulted in the progressive cavity pumping (PCP) lifting system, which is nowadays the main technology for oil well production in the world1.
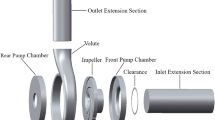
The PCP artificial lift method consists of a progressive cavity pump installed inside the well at the lower end of the production column through which fluid is pumped1. In Fig. 1 (left), it can be seen that the progressive cavity pump basically consists of two components, a stator, and an impeller, and is driven by the rotation of the impeller through the rod column. In addition, it can be noted in Fig. 1 (right) the dimensions that are called major diameter (D) and minor diameter (d), both in the rotor and in the stator.

Rotor and stator with their dimensions: (a) Rotor and stator; (b) Pump dimensions. Source: Netzsch internal specifications manual (modified).
There are several works focused on designing electrical machines with better efficiency and development of fault diagnostics2, with applications optimizing the machine design through the finite element method (FEM)3 and artificial intelligence4. Increasingly, FEM-based approaches are being successfully applied for the development of equipment that is more robust5,6,7. Even simple solutions can be used to improve the performance of electric motors by simply changing the way they are used8. On the other hand, artificial intelligence methods are being improved to obtain models with greater capacity9. In this context, fault diagnosis can be performed by means of time series analysis10,11,12, computer vision13, or general pattern recognition14.
During the rotation movement of the rotor, voids are formed and sealed in the cavity (Fig. 1) of the stator, which is filled by the fluid to be pumped. With the rotation of the rotor, these voids move continuously and progressively in the direction of the helicoid pitch, dragging the fluid in the direction of the pump discharge. It is noteworthy that the ability to generate pressure difference of the PCP is controlled by a combination of the maximum pressure of each cavity and the number of cavities. How much pressure difference each cavity can generate is related to the ability to create seal lines between the rotor and stator and the properties of the pumped fluid. This seal line is improved according to the interference between the rotor and stator, that is, the smaller the space created between them15.
The creation of the seal line between the rotor and the stator happens by combining their dimensions (D and d), with this it is possible to obtain greater success in the result of the performance test on the bench, ensuring a good useful life of the pump in the well. This combination is called pump sizing. The lifetime of a PCP is determined by the interaction between the rotor and stator in the sealing lines (interference) that are controlled by the pump sizing. The pump sizing process is very complex and requires rigorous studies on pump behavior on test benches, fluid composition, and characteristics of the well where the pump will operate, among others. To simplify this process, many PCP manufacturers usually manufacture rotors with different dimensional ranges in the smallest diameter (d) and largest diameter (D) of the rotor for each pump model. These ranges are categorized as standard, single, double oversized, or undersized16.
Based on the arguments exposed above, this paper presents the construction of a prototype based on graph neural networks (GNNs) that performs the interference recommendation and, as a result, calculates the rotor size so that it, combined with the stator can achieve the acceptance criteria obtained during the bench performance test. In addition, it is intended to simplify all the steps performed during pump sizing by increasing the number of examples that can be used as reference, resulting in a more assertive definition.
The use of GNNs is becoming increasingly popular due to their high capability in dealing with data that has inter-sample connections. From this property, it is possible to classify and/or predict the conditions of a sample and its class, based on its interaction with other samples. These interactions are the connections that generate the graphs, when samples are connected with other samples they are called nodes in the graphs. Several graph-based structures have been explored and many variations in their nomenclature and application are presented17.
The great advantage of using GNN is that models based on this concept have the ability to be trained with respect to the relationships between connections to other samples18. GNNs predict higher chances of a node belonging to a class in relation to the connections that this node has with nodes of the same class. Since there are variations in the structure of the GNNs next section presents a discussion about related works considering these variations.
Related works
The development of deep learning models is growing due to improved processing capabilities in hardware nowadays. The use of data represented in the Euclidean space is common to evaluate using these models, however, new approaches are being used from data from non-Euclidean domains19. These data-represented graphs have high complexity because they have connections beyond the basic features that are evaluated in classification problems. The use of deep learning for GNNs is a promising alternative for solving tasks in several fields such as biomedical20, transportation21, energy22, and security23.
According to Wu et al.17, GNNs can be divided into 4 categories, being recurrent GNNs, convolutional GNNs, graph autoencoders, and spatial-temporal. To improve the semantics extraction capability of convolutional neural networks (CNNs), which are currently widely used for image processing in computer vision24, 25, Jiang et al.26 proposed a method that combines CNNs and GNNs for fusing multi-level features, and this combination is shown to outperform well-established methods.
In graph convolutional networks (GCNs) there are many ways to employ convolutional layer operators. Based on these variations alternative models are proposed such as the graph transformer network27, graph isomorphism network28, multi-attention label relation learning CNN29, causal incremental GCN30, principal neighborhood aggregation-based GCN31, among other approaches. Since GCNs do not assign different weights to neighboring nodes, graph attention network (GAT) gains ground as it takes different neighboring nodes into account32.
Several models require all nodes of the graph to be present in the training process of the embeddings, approaches that do not generalize invisible nodes. According to Hamilton, Ying, and Leskovec33, the GraphSAGE (SAmple and aggreGatE) model uses the node feature information to generate the node embeddings for previously unknown data. Thus, instead of learning a function, GraphSAGE generates embeddings by sampling and aggregating features from the local neighborhood of a node.
Models that combine techniques such as graph convolutional recurrent neural networks (GCRNN) have been explored. According to Ruiz, Gama, and Ribeiro34 when compared to GNN models GCRNNs perform better because they use fewer parameters. These models use convolutional filters to keep the number of trainable parameters independent of the size of the graph. In addition to the classification evaluated in this paper, also prediction35 and semantic segmentation26 using GCRNN are becoming popular.
Besides the convolutional layers GCN, GAT, and GraphSAGE, other types are proposed and can be used to create the GNN models. Table 1 shows examples of studies involving GNNs in different applications, for comparative purposes, prediction and forecasting are considered equivalent. All these approaches discussed about convolutional layers, in addition to the GCRNN, can be used for both classification and prediction as can be seen in Table 1.
Proposed method
This paper has been established in accordance with the steps of the CRoss Industry Standard Process for Data Mining (CRISP-DM) model67, starting with the phase of understanding the problem and its data, the selection and treatment of data until a solid and reliable database is achieved, the definition of possible techniques to be used in the construction of the interference recommendation, and finally the evaluation of the results.
In the stages of business understanding and data understanding, it is necessary to follow up with the engineers who design progressive cavity pumps that perform the pump sizing process. In this step, an understanding of the process and why it is important during the manufacturing of progressive cavity pumps is obtained. In addition, all the tasks that are evaluated during the process are documented. Table 2 shows the 8 main tasks that are performed with each new input.
During the process documentation stage, the variables that directly, and indirectly influence the test results of progressive cavity pumps are relevant to pump sizing, and also are cataloged. With this, a total of 38 variables are obtained, among them are variables such as the pump model, test results, test criteria performed, and the complete dimensionality of the rotor and stator assembly that are linked to the test results obtained.
Currently, most of the variables are available in expert systems (non-integrated) with their own database, and another part is in spreadsheets used by the design engineers. Given this scenario, it is decided as a starting point to select data from the system that stores all performance tests of progressive cavity pumps, called performance curves. In this selection the pump serial number, order confirmation number, rotor code, test date, stator surface temperature, test fluid temperature, and stator part code from the year 2019 are considered resulting in 8,714 test records.
The data obtained from this selection went through the cleaning process, as they presented typing errors and a lack of specific fields within the system. In addition, data related to the stators underwent a transformation in its original structure, because stators can be built from one or more welded parts. In this case, the information stored for each complete stator had to be replicated, where each line represents a stator part that makes up the complete stator.
Once the data had been organized and processed, it is used to make a new selection, adding data regarding the test conditions of each order confirmation that are stored in the enterprise resource planning (ERP)68. In this selection, information is added to the data, such as the fluid used in the test, the rotation and pressure by which the test results will be evaluated for the pump acceptance, and the limits of volumetric efficiency defined by the customer, which the pump must have to obtain acceptance. Finally, a dataset with 48,276 records and 37 columns is obtained, representing the entire path from the conception of the sales order for the pump to the final test on the test bench.
To use an approach similar to the process done manually, in which historical data is used to perform pump sizing, in this paper it is chosen to use complex networks to evaluate the influence that an order confirmation (OC) has in relation to the others. In modeling the network, it is considered it non-directed, because both vertices connected by edges are considered similar, and both can be used as a reference to each other. Figure 2 shows a sample network in which each vertex represents an OC and each edge represents one or more reference(s) to other order confirmations. From the relation of each OC a graph is built.

Network representation. Source: Drawn by the author.
Graph neural networks
Graph-based problems have a large application because of the connections between nodes that can improve the classification ability of the model, as they are additional information that can be learned and help in the classification task. GNNs capture the dependency of graphs by passing messages between graph nodes. These techniques become more popular as information becomes more connected, especially among Internet users. In addition to Internet applications, GNNs can be used in many fields where there are connections between samples that may help in the classification task69.
Graph neural networks have generalization capabilities and because of their underlying relationships, they can be applied in various fields of science and engineering70. A graph (\(G_i\)) is a pair of nodes (\(N_i\)) and edges (\(E_i\)) that may have related features that result in information that can be used to classify or predict conditions. Learning in GNNs consists of estimating the weight parameter, such that it approximates the data from the learning data set (\({{\mathcal {L}}}\)):
where \(n_{i,j}\) denotes the \(j_{th}\) node, \(t_{i,j}\) is the desired target associated to \(n_{i,j}\), and \(q_i\) is the number of supervised nodes in the graph71.
The use of graph-based approaches is growing in many applications, there are several models that have been successfully presented for the classification task. Among these models, the GCN proposed by Kipf and Welling72 and the GAT presented by Veličković et al.73 are standing out due to their performance compared to other classifiers.
In GCN there are several ways to use operators in convolutional layers. The GCN model is based on convolutional networks which through a scalable approach is efficient for solving graph problems. In GCNs each node creates a feature vector, which represents the message that should be sent to its neighbors72. Messages are sent in a way that a node receives one message per adjacent node, this passing of the message between connections is represented in Fig. 3.

Nodes receiving the message per adjacent node. Source: Drawn by the author.
According to Kipf and Welling72, the GCN is promising because it is based on the number of graph edges and the features of each node. This method is validated in several benchmarks for classifying nodes in very popular citation datasets, like Cora, Citeseer, and Pubmed. The GNC can be extended to other applications such as remote sensing74, fault diagnosis75, emotional action recognition76, traffic prediction38, and image classification77.
Several frameworks have been used to solve graph-based problems, such as graph attention networks78, graph convolutional networks79, heterogeneous graph neural network80, heterogeneous graph attention network81, and so on. As well as classic neural network models82 or models based on deep learning83,84,85, the choice of the appropriate framework is critical for successful application.
With the network modeled, the algorithms are applied for identifying connected components and calculating the betweenness centrality metric. A graph G (Fig. 4a) is connected if there is a path connecting each pair of vertices of G, otherwise G is said to be disconnected. Thus, a disconnected graph has at least two connected subgraphs, called connected components (Fig. 4b).
The GNNs are being most widely used for their ability to extract additional information from the data70, in addition to GNNs, deep learning-based models are constantly being explored for their ability to learn nonlinear patterns86. Models that use ensemble aggregating weaker learners also have their place within this context87.

Graph: (a) Connected components; (b) Disconnected components. Source: Drawn by the author.
The search for connected components returns a SET Generator with the OC of the connected component. Identifying the connected components in this context is important for clustering OCs that are used as a reference to perform pump sizing. Also, consequently, these connected components have a similarity in their technical characteristics, test criteria, and test results in their OCs and can bring additional information to the analysis. In Fig. 5 it is presented a plot of ten OCs of the graph (each OC has a different color).

Connected components. Source: Author’s simulation results using Python.
With the related components defined, the betweenness centrality metric are calculated, determined by Eq. (2).
where V is the set of vertices of the graph, \(\sigma (s,t)\) is the number of paths between vertices (s, t), and \(\sigma (s,t\mid v)\) is the number of these paths that pass through some vertex v other than (s, t), if \(s=t,\sigma (s,t)=1\) and if \(v \in s,t,\sigma (s,t\mid v)=0\).
This metric is used to measure which OC has the most influence on the connected component it is part of. The highest values of this metric are used as a recommendation and its data is used for pump sizing. The return is a dictionary where the key identifies the OC number.
At the end of this process, there is a list of dictionaries where each dictionary is a connected component containing the OC number as a key and the betweenness centrality value. With the related components defined and each OC having its betweenness centrality calculated, the step that performs the interference recommendation for the incoming OC begins. Figure 6 shows the main actions performed to make the interference recommendation.

Steps for interference recommendation. Source: Drawn by the author.
Initially, a search for OCs is applied to the data set considering the pump model, stator rubber, and pump test parameters, and then the related components to which each OCs is part are located, such connected components are grouped and ordered by the value of the betweenness centrality metric. With this, there is an ordered group of connected components that have similarity with the input. From this, the first 5 OCs with the highest value of betweenness centrality, that is, with the greatest influence, are selected.
Based on the five recommended OCs, their clashes are used to define the new clash. It is chosen to use the median central tendency measure for this definition, because it is known that there may still be outliers between the recommended cases and they can negatively influence the value of the new interference when the average is used.
To calculate the rotor dimensions, measurements D and d of the stator are necessary. In the current process, the stator dimensions are monitored to ensure that the dimensions are close to the stator dimensions of the recommended cases. This monitoring is necessary because changes in the process, and changes in the rubber formulation, among others, can cause changes in the stator dimensional. It is noteworthy that the dimensions of the last thirty stators manufactured are used, calculating the average of the d of these cases.
To search for these stators, parts of the data that make up the pump model and the type of stator rubber are used. The pump pressure is disregarded because it is not a variable that influences the stator dimensional change. Finally, the rotor dimensions are calculated, applying the stator dimension found and the recommended interference.
It is worth mentioning that, to calculate the rotor measurements, the most relevant dimensions and the ones that most influence the result of the bench test for each type of geometry are considered. The rotor diameter measurement (dr) of Single-lobe pumps are calculated using only the smallest diameter of the stator (d), according to:
where i is the interference. For Multi-lobe geometries the largest diameter (D) is also considered, and then the dr is:
where msd is the mean stator diameter, given by:
Results analysis
To test the proposed model, the data set with 48,276 records and 37 columns, resulting from the data selection and cleaning steps, is used. From these data, only the tests where the acceptance rotation is equal to the test rotation are considered, because the pump is tested in several rotations, in this case, only the data of the rotation of interest to which the pump will be evaluated is desired. Therefore, there is a reduction in the data set to 11,673 records.
These data, in turn, are divided into two parts, a part called training, with 80% of the records, which is used to build the network, and the second part called test, with 30% of the records, which are used as input for the recommendation. With the network constructed from the training data, the tests for the recommendation can be performed using the test data as input. In this step variables described in Table 1 categorized as input are considered.
To evaluate the recommendations, it is decided to compare the average dimension d of the impeller in pumps with single-lobe geometry or the average dimension d of the impeller in pumps with multi-lobe geometry with their respective real average dimension. In Table 3 there is a sample of the input variables as well as the target variable y_true which is the real rotor dimensional and which will be compared with the recommended rotor dimensional y_rec defined by the recommendation.
A total of 2,972 tests are performed involving different pump models and test criteria. The first evaluation made on the recommendation is to quantify the number of cases in which it is successful in making recommendations. Within the 2,972 tests, 69% of the cases had recommendations, this happens because the recommendation did not find any OC similar to the given inputs.
Next, the quality of the recommendation is checked, for this, the mean squared error (MSE) metric is used, which calculates the difference between the real rotor measure and the recommended rotor measure, high MSE values, indicate that the recommendation did not perform well in relation to the recommendations. Applying this metric to the recommended data obtained a score of 0.28. It is worth noting that, to calculate the MSE metric, the cases in which there are no recommendations are removed from the recommendation dataset, i.e., the MSE is calculated using 69% of the cases that had recommendations.
In addition to the MSE metric, a check is made on recommendations that had a dimensional difference between y_true and y_rec greater than 0.5mm. With an error less than or equal to 0.5mm it is still possible to do rework on the rotor helicoid, this rework consists of adding a layer of hard chrome over the helicoid or removing it by sanding. Recommendations with differentials greater than 0.5mm affect the profile of the rotor helicoid, which in turn affects the sealing between the cavities. In this context, 6% of the cases tested showed a dimensional difference between y_true and y_rec greater than 0.5mm and 94% less than 0.5mm.
Lastly, visual sample checks are performed by grouping the test results by pump model, except for pump pressure. Figure 7 shows in graph form 20 samples of different pump models comparing their real dimensions with the recommended dimensions.

Real vs. recommended dimensional comparison. Source: Author’s simulation results using Python.
It is possible to see a similarity between the real dimension and the dimension recommended by the recommendation. The dimension of the rotor represented by the y axis shows a decimal variation between the dimensions, in some cases, the precision is even lower, and in others the recommendation is identical to the real dimension.
Although there is a variation between the real dimension and the recommended dimension, it is worth pointing out that this variation is very small and considered acceptable for this context, since to calculate the dimensions of the rotors the stator measures are used, which can suffer dimensional variations that are reflected in the calculated dimensions of the rotor. Besides this, in the current process, there is a cycle time of approximately 62 minutes to perform the pump sizing of each OC. With the implementation of the proposed method, it is estimated the reduction of this time, for cases in which there are recommendations, is about 50% for each OC for which the pump sizing is done.
Comparison to results of other authors
In the work of Zhu et al.88 an MSE of 0.016 was achieved in a communication-related problem, in which a GNN-based model was proposed for improving network performance by utilizing multiple paths simultaneously. By leveraging the power of GNNs, their model optimizes network performance, ultimately enhancing the user experience and the overall efficiency of multipath communication protocols.
In the research of Numcharoenpinij et al.89 using embedding-GNN they had an MSE of 174.952 for predicting drug interaction. This shows that there are cases where the challenge is more complex, and thus the results of MSE may be higher.
Comparatively, in90 an MSE value of 3.38 was obtained for the estimation of traffic speed. Using the GNN, Zuo et al.91 had an MSE of 0.9804, and Wang, Hu, and Zhang92 had an MSE of 0.217, both considering an evaluation of drug response prediction.
In this paper the MSE of 0.28 was achieved, this result has a great influence on the characteristics of the data, which in some cases may have fewer related and non-linear patterns, which means that the results may be inferior or in some cases superior when the task is simpler to solve.
Conclusions
This work presented a method for building an interference recommender, helping users in decision-making and accelerating steps performed during the pump sizing process. Besides the interference recommended, it is possible to diagnose the data used by the recommender, so that an evaluation can be done by experts to try to explain the recommendation, even in cases where the recommendation is not aligned with the user’s definition. Thus, with the help of the recommender, besides delivering a recommendation, the amount of data analyzed by it is much larger if compared to the amount of data that is manually analyzed by the user in the current process.
During the data selection and cleaning stage, several problems related to data quality are identified, due to some legacy systems, which have not been updated during the change of processes over the years, and the use of Excel tables where, both scenarios, give users the freedom to register information without any kind of standardization. In this context, it is decided to eliminate the doubtful records or those with empty fields, impoverishing the database used in this work.
The use of complex networks proved to be very assertive; the construction of a graph represented very well the current analysis model where, during the pump sizing process, previous OCs are used as a reference. In this scenario, OCs are represented by vertices and edges indicating references to other OCs. This allows you to identify the connected components that helped you find similar OCs among the data. In addition to the connected components, the betweenness centrality metric can be used to measure the importance of each vertex in the graph, using this measure to recommend the most important OCs to the user and that consequently are the most used in past definitions.
With this, in the tests performed, the method proved to be very efficient. The recommendation index close to 70% already represents a considerable reduction of user time when performing pump sizing, even if the result does not agree with the user’s opinion, the user can use the data selected by the recommendation to evaluate the results. In addition, the MSE metric reached a value of 0.28 validating the closeness of the recommended dimensional to the real dimensional measured on the rotor.
A sample comparison of the recommended and real dimensional values showed acceptable recommendations to start testing in a production environment with experts following up to perform a final evaluation. Despite achieving good results in a test environment, it is worth mentioning that it is possible to achieve better recommendation levels by enriching the database, including new variables for verification, implementing new pump model similarity algorithms, and performing a seasonal decomposition on the data, among others.
Data availability
The data will be made available upon request to Leandro Starke.
References
Assmann, B.W. Estudo de estratégias de otimização para poços de petróleo com elevação por bombeio de cavidades progressivas. Phd thesis, Universidade Federal do Rio Grande do Norte, Natal, Brazil (2008).
Ewert, P., Kowalski, C. T. & Jaworski, M. Comparison of the effectiveness of selected vibration signal analysis methods in the rotor unbalance detection of pmsm drive system. Electronics 11(11), 1748. https://doi.org/10.3390/electronics11111748 (2022).
Yadollahi, M. & Lesani, H. Power transformer optimal design (PTOD) using an innovative heuristic method combined with fem technique. Electr. Eng. 100(2), 823–838. https://doi.org/10.1007/s00202-017-0537-z (2018).
Frizzo Stefenon, S. et al. Electric field evaluation using the finite element method and proxy models for the design of stator slots in a permanent magnet synchronous motor. Electronics 9(11), 1975. https://doi.org/10.3390/electronics9111975 (2020).
Ghiasi, Z., Faghihi, F., Shayegani-Akmal, A. A., Moradi CheshmehBeigi, H. & Rouzbehi, K. Fem analysis of electric field distribution for polymeric insulator under different configuration of non-uniform pollution. Electr. Eng. 103(6), 2799–2808. https://doi.org/10.1007/s00202-021-01252-2 (2021).
Stefenon, S. F., Seman, L. O., Pavan, B. A., Ovejero, R. G. & Leithardt, V. R. Q. Optimal design of electrical power distribution grid spacers using finite element method. IET Gener. Transm. Distrib. 16(9), 1865–1876. https://doi.org/10.1049/gtd2.12425 (2022).
Heidary, M., Naderi, P. & Shiri, A. Modeling and analysis of a multi-segmented linear permanent-magnet synchronous machine using a parametric magnetic equivalent circuit. Electr. Eng. 104(2), 705–715. https://doi.org/10.1007/s00202-021-01334-1 (2022).
Itajiba, J. A. et al. Experimental comparison of preferential vs, common delta connections for the star-delta starting of induction motors. Energies 14(5), 1318. https://doi.org/10.3390/en14051318 (2021).
Souza, B. J., Stefenon, S. F., Singh, G. & Freire, R. Z. Hybrid-YOLO for classification of insulators defects in transmission lines based on UAV. Int. J. Electr. Power Energy Syst. 148, 108982. https://doi.org/10.1016/j.ijepes.2023.108982 (2023).
Sopelsa Neto, N. F., Stefenon, S. F., Meyer, L. H., Ovejero, R. G. & Leithardt, V. R. Q. Fault prediction based on leakage current in contaminated insulators using enhanced time series forecasting models. Sensors 22(16), 6121. https://doi.org/10.3390/s22166121 (2022).
Seman, L. O., Stefenon, S. F., Mariani, V. C. & dos Santos Coelho, L. Ensemble learning methods using the Hodrick-Prescott filter for fault forecasting in insulators of the electrical power grids. Int. J. Electr. Power Energy Syst. 152, 109269. https://doi.org/10.1016/j.ijepes.2023.109269 (2023).
Medeiros, A., Sartori, A., Stefenon, S. F., Meyer, L. H. & Nied, A. Comparison of artificial intelligence techniques to failure prediction in contaminated insulators based on leakage current. J. Intell. Fuzzy Syst. 42(4), 3285–3298. https://doi.org/10.3233/JIFS-211126 (2022).
Haj, Y. E., El-Hag, A. H. & Ghunem, R. A. Application of deep-learning via transfer learning to evaluate silicone rubber material surface erosion. IEEE Trans. Dielectr. Electr. Insul. 28(4), 1465–1467. https://doi.org/10.1109/TDEI.2021.009617 (2021).
Corso, M. P. et al. Classification of contaminated insulators using k-nearest neighbors based on computer vision. Computers 10(9), 112. https://doi.org/10.3390/computers10090112 (2021).
Duarte, L.B. Cálculo do rendimento energético global do sistema de bombas de cavidades progressivas com acionamento hidráulico. PhD thesis, Centro de Educação Superior da Foz do Itajaí, Balneário Camboriú, Brazil (2017).
Petrowiki: PCP sizing practices. http://petrowiki.org/PCP_sizing_practices/ (accessed on September 1, 2022).
Wu, Z. et al. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 32(1), 4–24. https://doi.org/10.1109/TNNLS.2020.2978386 (2021).
Wu, Z., Pan, S., Long, G., Jiang, J., Chang, X., & Zhang, C. Connecting the dots: Multivariate time series forecasting with graph neural networks. In: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. KDD 20, pp. 753–763. Association for Computing Machinery, New York, USA. https://doi.org/10.1145/3394486.3403118 (2020).
Asif, N. A. et al. Graph neural network: A comprehensive review on non-Euclidean space. IEEE Access 9, 60588–60606. https://doi.org/10.1109/ACCESS.2021.3071274 (2021).
Han, P., Yang, P., Zhao, P., Shang, S., Liu, Y., Zhou, J., Gao, X., & Kalnis, P. Gcn-mf: Disease-gene association identification by graph convolutional networks and matrix factorization. KDD ’19. Association for Computing Machinery, New York, USA. https://doi.org/10.1145/3292500.3330912 (2019).
Wang, H.-W. et al. Evaluation and prediction of transportation resilience under extreme weather events: A diffusion graph convolutional approach. Transp. Res. Part C: Emerging Technol. 115, 102619. https://doi.org/10.1016/j.trc.2020.102619 (2020).
Wang, T. & Tang, Y. Comprehensive evaluation of power flow and adjustment method to restore solvability based on GCRNN and DDQN. Int. J. Electr. Power Energy Syst. 133, 107160. https://doi.org/10.1016/j.ijepes.2021.107160 (2021).
Abou Rida, A., Amhaz, R., & Parrend, P. Evaluation of anomaly detection for cybersecurity using inductive node embedding with convolutional graph neural networks. In: Benito, R.M., Cherifi, C., Cherifi, H., Moro, E., Rocha, L.M., Sales-Pardo, M. (eds.) Complex Networks & Their Applications X, pp. 563–574. Springer, Cham. https://doi.org/10.1007/978-3-030-93413-2_47 (2022).
Stefenon, S. F. et al. Classification of insulators using neural network based on computer vision. IET Gener. Transm. Distrib. 16(6), 1096–1107. https://doi.org/10.1049/gtd2.12353 (2021).
Singh, G., Stefenon, S. F. & Yow, K.-C. Interpretable visual transmission lines inspections using pseudo-prototypical part network. Mach. Vis. Appl. 34(3), 41. https://doi.org/10.1007/s00138-023-01390-6 (2023).
Jiang, D., Qu, H., Zhao, J., Zhao, J. & Liang, W. Multi-level graph convolutional recurrent neural network for semantic image segmentation. Telecommun. Syst. 77(3), 563–576. https://doi.org/10.1007/s11235-021-00769-y (2021).
Liu, Y., Zhang, H., Xu, D. & He, K. Graph transformer network with temporal kernel attention for skeleton-based action recognition. Knowl.-Based Syst. 240, 108146. https://doi.org/10.1016/j.knosys.2022.108146 (2022).
Atserias, A. et al. Quantum and non-signalling graph isomorphisms. J. Comb. Theory Ser. B 136, 289–328. https://doi.org/10.1016/j.jctb.2018.11.002 (2019).
Li, X., Wu, H., Li, M. & Liu, H. Multi-label video classification via coupling attentional multiple instance learning with label relation graph. Pattern Recogn. Lett. 156, 53–59. https://doi.org/10.1016/j.patrec.2022.01.003 (2022).
Ding, S. et al. Causal incremental graph convolution for recommender system retraining. IEEE Trans. Neural Netw. Learn. Syst.https://doi.org/10.1109/TNNLS.2022.3156066 (2022).
Guail, A. A. A., Jinsong, G., Oloulade, B. M. & Al-Sabri, R. A principal neighborhood aggregation-based graph convolutional network for pneumonia detection. Sensors 22(8), 3049. https://doi.org/10.3390/s22083049 (2022).
He, H., Ye, K., & Xu, C.-Z. Multi-feature urban traffic prediction based on unconstrained graph attention network. In: 2021 IEEE International Conference on Big Data, vol. 1. Orlando, USA, pp. 1409–1417. https://doi.org/10.1109/BigData52589.2021.9671619 (2021).
Hamilton, W.L., Ying, R., & Leskovec, J. Inductive representation learning on large graphs. In: Advances in Neural Information Processing Systems, vol. 31, pp. 1–11. NIPS, Long Beach, USA (2017).
Ruiz, L., Gama, F., & Ribeiro, A. Gated graph convolutional recurrent neural networks. In: 2019 27th European Signal Processing Conference (EUSIPCO), pp. 1–5. https://doi.org/10.23919/EUSIPCO.2019.8902995 (2019).
Liu, L. et al. Physical-virtual collaboration modeling for intra- and inter-station metro ridership prediction. IEEE Trans. Intell. Transp. Syst. 23(4), 3377–3391. https://doi.org/10.1109/TITS.2020.3036057 (2022).
Li, Z., Xiong, G., Chen, Y., Lv, Y., Hu, B., Zhu, F., & Wang, F.-Y. A hybrid deep learning approach with gcn and lstm for traffic flow prediction. In: 2019 IEEE Intelligent Transportation Systems Conference (ITSC), pp. 1929–1933. https://doi.org/10.1109/ITSC.2019.8916778 (2019).
Bai, J. et al. A3t-GCN: Attention temporal graph convolutional network for traffic forecasting. ISPRS Int. J. Geo Inf. 10(7), 485. https://doi.org/10.3390/ijgi10070485 (2021).
Zhao, L. et al. T-GCN: A temporal graph convolutional network for traffic prediction. IEEE Trans. Intell. Transp. Syst. 21(9), 3848–3858. https://doi.org/10.1109/TITS.2019.2935152 (2020).
Li, J. et al. Neural inductive matrix completion with graph convolutional networks for miRNA-disease association prediction. Bioinformatics 36(8), 2538–2546. https://doi.org/10.1093/bioinformatics/btz965 (2020).
Jiang, H., Cao, P., Xu, M., Yang, J. & Zaiane, O. Hi-GCN: A hierarchical graph convolution network for graph embedding learning of brain network and brain disorders prediction. Comput. Biol. Med. 127, 104096. https://doi.org/10.1016/j.compbiomed.2020.104096 (2020).
Parisot, S. et al. Disease prediction using graph convolutional networks: Application to autism spectrum disorder and Alzheimer’s disease. Med. Image Anal. 48, 117–130. https://doi.org/10.1016/j.media.2018.06.001 (2018).
Zhou, J., Huang, J. X., Hu, Q. V. & He, L. Sk-GCN: Modeling syntax and knowledge via graph convolutional network for aspect-level sentiment classification. Knowl.-Based Syst. 205, 106292. https://doi.org/10.1016/j.knosys.2020.106292 (2020).
Zhu, X., Zhu, L., Guo, J., Liang, S. & Dietze, S. Gl-GCN: Global and local dependency guided graph convolutional networks for aspect-based sentiment classification. Expert Syst. Appl. 186, 115712. https://doi.org/10.1016/j.eswa.2021.115712 (2021).
Zhao, P., Hou, L. & Wu, O. Modeling sentiment dependencies with graph convolutional networks for aspect-level sentiment classification. Knowl.-Based Syst. 193, 105443. https://doi.org/10.1016/j.knosys.2019.105443 (2020).
Jiao, Y., Xiong, Y., Zhang, J., & Zhu, Y. Collective link prediction oriented network embedding with hierarchical graph attention. In: Proceedings of the 28th ACM International Conference on Information and Knowledge Management. CIKM ’19, pp. 419–428. Association for Computing Machinery, New York, USA. https://doi.org/10.1145/3357384.3357990 (2019).
Li, X., Shang, Y., Cao, Y., Li, Y., Tan, J., & Liu, Y. Type-aware anchor link prediction across heterogeneous networks based on graph attention network. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34. New York, USA, pp. 147–155. https://doi.org/10.1609/aaai.v34i01.5345 (2020).
Grassia, M., & Mangioni, G. wsgat: wsgat: Weighted and signed graph attention networks for link prediction. In: Complex Networks & Their Applications X, pp. 369–375. Springer, Cham. https://doi.org/10.1007/978-3-030-93409-5_31 (2022).
Yu, X., Shi, S. & Xu, L. A spatial-temporal graph attention network approach for air temperature forecasting. Appl. Soft Comput. 113, 107888. https://doi.org/10.1016/j.asoc.2021.107888 (2021).
Aykas, D., & Mehrkanoon, S. Multistream graph attention networks for wind speed forecasting. In: 2021 IEEE Symposium Series on Computational Intelligence (SSCI), Orlando, USA, pp. 1–8. https://doi.org/10.1109/SSCI50451.2021.9660040 (2021).
Yang, T. et al. Hgat: Heterogeneous graph attention networks for semi-supervised short text classification. ACM Trans. Inf. Syst. 39(3), 1–29. https://doi.org/10.1145/3450352 (2021).
Linmei, H., Yang, T., Shi, C., Ji, H., & Li, X. Heterogeneous graph attention networks for semi-supervised short text classification. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4821–4830. Association for Computational Linguistics, Hong Kong, China. https://doi.org/10.18653/v1/D19-1488 (2019).
Liu, Y., & Gou, X. A text classification method based on graph attention networks. In: 2021 International Conference on Information Technology and Biomedical Engineering (ICITBE), Nanchang, China, pp. 35–39. https://doi.org/10.1109/ICITBE54178.2021.00017 (2021).
Chen, Z. et al. A new energy consumption prediction method for chillers based on graphsage by combining empirical knowledge and operating data. Appl. Energy 310, 118410. https://doi.org/10.1016/j.apenergy.2021.118410 (2022).
Chen, Z. et al. Energy consumption prediction of cold source system based on graphsage. IFAC-PapersOnLine 54(11), 37–42. https://doi.org/10.1016/j.ifacol.2021.10.047 (2021).
Liu, G., Tang, J., Tian, Y., & Wang, J. Graph neural network for credit card fraud detection. In: 2021 International Conference on Cyber-Physical Social Intelligence (ICCSI), vol. 1. Beijing, China, pp. 1–6. https://doi.org/10.1109/ICCSI53130.2021.9736204 (2021).
Van Belle, R., Van Damme, C., Tytgat, H. & De Weerdt, J. Inductive graph representation learning for fraud detection. Expert Syst. Appl. 193, 116463. https://doi.org/10.1016/j.eswa.2021.116463 (2022).
Jing, R., Zheng, X., Tian, H., Zhang, X., Chen, W., Wu, D.D., & Zeng, D.D. A graph-based semi-supervised fraud detection framework. In: IEEE International Conference on Cybernetics (Cybconf), vol. 4. Beijing, China, pp. 1–5. https://doi.org/10.1109/Cybconf47073.2019.9436573 (2019).
Yao, D. et al. Deep hybrid: Multi-graph neural network collaboration for hyperspectral image classification. Defence Technol.https://doi.org/10.1016/j.dt.2022.02.007 (2022).
Ding, Y., Zhao, X., Zhang, Z., Cai, W. & Yang, N. Graph sample and aggregate-attention network for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 19, 1–5. https://doi.org/10.1109/LGRS.2021.3062944 (2022).
Zhou, Y., Graham, S., Alemi Koohbanani, N., Shaban, M., Heng, P.-A., & Rajpoot, N. Cgc-net: Cell graph convolutional network for grading of colorectal cancer histology images. In: 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), vol. 1. Seoul, Korea, pp. 388–398. https://doi.org/10.1109/ICCVW.2019.00050 (2019).
Elbasani, E. et al. Gcrnn: Graph convolutional recurrent neural network for compound-protein interaction prediction. BMC Bioinform. 22(5), 1–14. https://doi.org/10.1186/s12859-022-04560-x (2021).
Elbasani, E., & Kim, J.-D. Graph and convolution recurrent neural networks for protein-compound interaction prediction. In: Advanced Multimedia and Ubiquitous Engineering, pp. 91–97. Springer, Singapore. https://doi.org/10.1007/978-981-15-9309-3_13 (2021).
Zhang, N., Guan, X., Cao, J., Wang, X. & Wu, H. Wavelet-HST: A wavelet-based higher-order Spatio-temporal framework for urban traffic speed prediction. IEEE Access 7, 118446–118458. https://doi.org/10.1109/ACCESS.2019.2936938 (2019).
Xu, D., Dai, H., & Xuan, Q. In: Xuan, Q., Ruan, Z., Min, Y. (eds.) Graph Convolutional Recurrent Neural Networks: A Deep Learning Framework for Traffic Prediction, Springer. pp. 189–204 (2021) .
Zhang, Y., Lu, M. & Li, H. Urban traffic flow forecast based on FastGCRNN. J. Adv. Transp. 2020, 8859538. https://doi.org/10.1155/2020/8859538 (2020).
Le, V.-D., Bui, T.-C., & Cha, S.-K. Spatiotemporal graph convolutional recurrent neural network model for citywide air pollution forecasting. TechRxiv, 1–10. https://doi.org/10.36227/techrxiv.14958552.v1 (2021).
Schröer, C., Kruse, F. & Gómez, J. M. A systematic literature review on applying crisp-dm process model. Procedia Comput. Sci. 181, 526–534. https://doi.org/10.1016/j.procs.2021.01.199 (2021).
de Oliveira, J. R. et al. Enterprise resource planning and customer relationship management through management of the supply chain. Interciencia 43(11), 784–791 (2018).
Zhou, J. et al. Graph neural networks: A review of methods and applications. AI Open 1, 57–81. https://doi.org/10.1016/j.aiopen.2021.01.001 (2020).
Scarselli, F., Gori, M., Tsoi, A. C., Hagenbuchner, M. & Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 20(1), 61–80. https://doi.org/10.1109/TNN.2008.2005605 (2009).
Scarselli, F., Gori, M., Tsoi, A. C., Hagenbuchner, M. & Monfardini, G. Computational capabilities of graph neural networks. IEEE Trans. Neural Netw. 20(1), 81–102. https://doi.org/10.1109/TNN.2008.2005141 (2009).
Kipf, T.N., & Welling, M. Semi-supervised classification with graph convolutional networks. 4 1–14. https://doi.org/10.48550/arXiv.1609.02907 (2017).
Veličković, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., & Bengio, Y. Graph attention networks. 3 1–12. https://doi.org/10.48550/arXiv.1710.10903 (2018).
Liang, J., Deng, Y. & Zeng, D. A deep neural network combined CNN and GCN for remote sensing scene classification. IEEE J. Selected Topic. Appl. Earth Obs. Remote Sens. 13, 4325–4338. https://doi.org/10.1109/JSTARS.2020.3011333 (2020).
Li, C., Mo, L. & Yan, R. Fault diagnosis of rolling bearing based on WHVG and GCN. IEEE Trans. Instrum. Meas. 70, 1–11. https://doi.org/10.1109/TIM.2021.3087834 (2021).
Tsai, M.-F. & Chen, C.-H. Spatial temporal variation graph convolutional networks (STV-GCN) for skeleton-based emotional action recognition. IEEE Access 9, 13870–13877. https://doi.org/10.1109/ACCESS.2021.3052246 (2021).
Wan, S. et al. Dual interactive graph convolutional networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 60, 1–14. https://doi.org/10.1109/TGRS.2021.3075223 (2022).
Schmidt, J., Pettersson, L., Verdozzi, C., Botti, S. & Marques, M. A. Crystal graph attention networks for the prediction of stable materials. Sci. Adv. 7(49), 7948. https://doi.org/10.1126/sciadv.abi7948 (2021).
Zhang, S., Tong, H., Xu, J. & Maciejewski, R. Graph convolutional networks: A comprehensive review. Comput. Soc. Netw. 6(1), 1–23. https://doi.org/10.1186/s40649-019-0069-y (2019).
Zhang, C., Song, D., Huang, C., Swami, A., & Chawla, N.V. Heterogeneous graph neural network. In: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 793–803. https://doi.org/10.1145/3292500.3330961 (2019).
Wang, X., Ji, H., Shi, C., Wang, B., Ye, Y., Cui, P., & Yu, P.S. Heterogeneous graph attention network. In: The World Wide Web Conference, pp. 2022–2032. https://doi.org/10.1145/3308558.3313562 (2019).
Fernandes, F. et al. Long short-term memory stacking model to predict the number of cases and deaths caused by Covid-19. J. Intell. Fuzzy Syst. 6(42), 6221–6234. https://doi.org/10.3233/JIFS-212788 (2022).
Eristi, B. & Eristi, H. A new deep learning method for the classification of power quality disturbances in hybrid power system. Electr. Eng.https://doi.org/10.1007/s00202-022-01581-w (2022).
Kiruthiga, D. & Manikandan, V. Intraday time series load forecasting using Bayesian deep learning method-a new approach. Electr. Eng. 104(3), 1697–1709. https://doi.org/10.1007/s00202-021-01411-5 (2022).
Mukherjee, D., Chakraborty, S. & Ghosh, S. Deep learning-based multilabel classification for locational detection of false data injection attack in smart grids. Electr. Eng. 104(1), 259–282. https://doi.org/10.1007/s00202-021-01278-6 (2022).
Kundačina, O. B., Vidović, P. M. & Petković, M. R. Solving dynamic distribution network reconfiguration using deep reinforcement learning. Electr. Eng. 104(3), 1487–1501. https://doi.org/10.1007/s00202-021-01399-y (2022).
Stefenon, S. F. et al. Time series forecasting using ensemble learning methods for emergency prevention in hydroelectric power plants with dam. Electr. Power Syst. Res. 202, 107584. https://doi.org/10.1016/j.epsr.2021.107584 (2022).
Zhu, T., Chen, X., Chen, L., Wang, W. & Wei, G. GCLR: GNN-based cross layer optimization for multipath TCP by routing. IEEE Access 8, 17060–17070. https://doi.org/10.1109/ACCESS.2020.2966045 (2020).
Numcharoenpinij, N., Termsaithong, T., Phunchongharn, P., & Piyayotai, S. Predicting synergistic drug interaction with dnn and gat. In: 2022 IEEE 5th International Conference on Knowledge Innovation and Invention (ICKII), Hualien, Taiwan, pp. 24–29. https://doi.org/10.1109/ICKII55100.2022.9983579 (2022).
Sharma, A. et al. A graph neural network (GNN)-based approach for real-time estimation of traffic speed in sustainable smart cities. Sustainability 15(15), 11893. https://doi.org/10.3390/su151511893 (2023).
Zuo, Z. et al. Swnet: A deep learning model for drug response prediction from cancer genomic signatures and compound chemical structures. BMC Bioinform. 22(1), 1–16. https://doi.org/10.1186/s12859-021-04352-9 (2021).
Wang, X., Hu, J., & Zhang, X. Drug-target affinity prediction based on self-attention graph pooling and mutual interaction neural network. In: International Conference on Intelligent Computing, Singapore, pp. 776–790. https://doi.org/10.1007/978-981-99-4749-2_66. Springer (2023).
Funding
This work was supported in part by the Spanish Agencia Estatal de Investigación, and in part by the Project Monitoring and Tracking Systems for the Improvement of Intelligent Mobility and Behavior Analysis (SiMoMIAC) under Grant PID2019-108883RB-C21/AEI/10.13039/501100011033.
Author information
Authors and Affiliations
Contributions
L.S. - wrote the original draft and computation; A.F.H. - test management; supervision; A.S. - final version review; supervision; S.F.S. - proofreading; J.F.S. - proofreading; supervision; V.R.Q.L. - final version review; proofreading; project administration.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Starke, L., Hoppe, A.F., Sartori, A. et al. Interference recommendation for the pump sizing process in progressive cavity pumps using graph neural networks. Sci Rep 13, 16884 (2023). https://doi.org/10.1038/s41598-023-43972-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-023-43972-4
This article is cited by
-
Optimized hybrid neural hierarchical interpolation time series with STL for flow forecasting in hydroelectric power plants
Scientific Reports (2026)
-
Hybrid group method of data handling for time-series forecasting of thermal generation dispatch in electrical power systems
Electrical Engineering (2025)
-
A deep learning-based approach for axle counter in free-flow tolling systems
Scientific Reports (2024)
-
Bootstrap aggregation with Christiano–Fitzgerald random walk filter for fault prediction in power systems
Electrical Engineering (2024)
