
Abstract
Breast ultrasound segmentation remains challenging because of the blurred boundaries, irregular shapes, and the presence of shadowing and speckle noise. The majority of approaches stack convolutional layers to extract advanced semantic information, which makes it difficult to handle multiscale issues. To address those issues, we propose a three-path U-structure network (TPUNet) that consists of a three-path encoder and an attention-based feature fusion block (AFF Block). Specifically, instead of simply stacking convolutional layers, we design a three-path encoder to capture multiscale features through three independent encoding paths. Additionally, we design an attention-based feature fusion block to weight and fuse feature maps in spatial and channel dimensions. The AFF Block encourages different paths to compete with each other in order to synthesize more salient feature maps. We also investigate a hybrid loss function for reducing false negative regions and refining the boundary segmentation, as well as the deep supervision to guide different paths to capture the effective features under the corresponding receptive field sizes. According to experimental findings, our proposed TPUNet achieves more excellent results in terms of quantitative analysis and visual quality than other rival approaches.
Similar content being viewed by others
Introduction
Breast cancer is a disease that poses a huge danger to women’s lives and health1,2. In most cases, breast cancer may typically be prevented by early screening and timely diagnosis3,4,5. Breast ultrasound (BUS) has become a popular breast screening technology due to its low cost and low risk6,7. Breast tumors are manually delineated by radiologists, which is challenging since it consumes time and requires specialized knowledge. Therefore, automatic breast segmentation methods based on machine learning are of great significance. Besides, the diagnosis of BUS images is extremely dependent on physician experience, which is prone to inter- and intra-rater differences8,9. Computer-aided diagnostic (CAD) technologies are widely used to increase the system’s dependability and help radiologists identify and diagnose breast tumors.
Machine learning methods are a burgeoning field that has been extensively employed for classification and segmentation10. By stacking convolutional layers, Convolutional Neural Networks (CNNs) can extract complex semantic features, producing outstanding outcomes in medical image segmentation. Long et al.11 replaced the fully connected layers in the traditional CNNs with \(1 \times 1\) convolution, which significantly reduces computational expense. Kaiming et al.12 proposed a residual learning framework that improves gradient flow and information flow effectively through residual mapping. Huang et al.13 proposed a network with dense connections that encourages feature reuse to stimulate the potential of the network. UNet introduced a symmetrical encoder–decoder framework, which enhances the delivery of spatial information effectively14. Guan et al.15 introduced dense convolution operations to UNet and achieved excellent results in their work on removing artifacts from 2D photoacoustic tomography images. Similarly, Li et al.16 designed a dense convolutional network that combines 2D and 3D segmentation, which achieved high-quality 3D liver and tumor segmentation with fewer parameters.

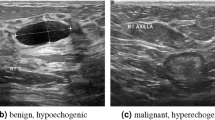
Examples show the heterogeneity in breast tumors. The green line outlines the boundary of the tumor. (a,b) Show the interference of normal benign tissue with the tumor. (c,d) Show the blurring of the boundary due to low contrast, which makes it difficult to segment.
The classical encoder–decoder network offers various benefits for medical image segmentation. For example, it contains plenty of convolutional and pooling operations, which filter noise effectively by repeatedly extracting features. The symmetrical structure enhances the transmission of spatial information, which increases the accuracy of prediction. In addition, multichannel feature extraction shows excellent performance in removing artifacts. However, the architecture of a single encoder makes it hard to extract multiscale features. In breast ultrasound segmentation, as shown in Fig. 1, the size, shape, location, and grayscale intensity of breast tumors vary greatly due to individual variances and breast tissue deformation, which requires a high level of multiscale feature extraction capability. In addition, some benign lesions and normal tissue structures resemble breast tumors, which may lead to segmentation errors. Low contrast between breast cancer and normal tissue causes indistinct borders and makes it difficult to segment breast tissue17,18. Besides, the ultrasound artifacts from speckle noise and shadows can also interfere with segmentation. Regarding the above issues, we propose a three-path U-structure network (TPUNet) for breast tumor segmentation. Specifically, we design a three-path encoder to extract multiscale features, and an attention-based feature fusion block (AFF Block) to fuse features extracted from different encoding paths. Moreover, we introduce a hybrid loss for reducing false negative areas and refining the segmentation boundary.
Our contributions are summarized as follows:
-
We design a three-path U-structure network (TPUNet) for breast ultrasound segmentation. Different from traditional convolutional frameworks with only a single encoder, we design three independent encoding paths. Each path has a different number of convolutional and pooling layers, corresponding to the extraction of features at different scales, respectively. The model can efficiently deal with objects of various scales thanks to this structure.
-
We design an attention-based feature fusion block (AFF Block) to fuse feature maps extracted from different paths. The AFF Block contains two sub-modules: the spatial attention sub-module helps to focus on small targets that are easily overlooked, while the channel attention sub-module learns the importance between different channels. The AFF Block encourages competition between different paths to merge into more salient features.
-
We further introduce deep supervision to guide different paths to capture the effective features under the corresponding receptive field, and a hybrid loss for reducing false negative regions and refining boundary segmentation.
The remaining parts of the paper are divided into the following sections: Section “Related works” assesses the related work of medical image segmentation. Section “Methods” interprets specific details of our Three-Path U-structure Network (TPUNet). Section “Experimental setup” describes the experimental details and settings. The experiment’s results are presented in section “Results and discussion”, along with a discussion of important findings and observations. Section “Conclusion” summarizes the contributions and findings of this study.
Related works
Encoder–decoder structure
Most segmentation models are inspired by the encoder–decoder structure. Ronneberger et al.14 retained abundant feature channels during upsampling, making it a symmetric encoder–decoder structure, which makes UNet transfer advanced semantic features to higher-resolution layers. Zhou et al.19 redesigned the skip pathways to have a nested and dense structure. Feature maps in the encoder are upsampled at different stages and transmit contextual information to each other through dense connections in an effort to gradually close the enormous semantic gap between deep and shallow feature maps through a variety of decoding paths. Huang et al.20 proposed a modified U-structure to capture abundant contextual information from full scales. Unlike UNet, which directly concatenates feature maps on the identical scale, UNet3+ integrates feature maps in the decoder with feature maps of various scales in the encoder. This structure allows UNet3+ to capture abundant contextual information from full scales. Gu et al.21 constructed a dense module to expand the corresponding receptive field sizes by using dilated convolution, and a multiscale pooling operation to integrate contextual information. Jia et al.22 proposed a densely connected multiscale residual module to extract and fuse information, and a pixel-based attention module to produce a weighted map for the extracted feature map. Ibtehaz et al.23 replaced the larger convolution with a succession of \(3\times 3\) convolutions, which can achieve a larger receptive field without requiring additional computation. However, while each of these approaches proposes its own scheme to deal with the multiscale problem, the majority of them are unable to deliver a satisfactory outcome. We suggest a three-path encoder in this study to capture multiscale contextual information. The structure with multiple encoding paths allows our model to easily cope with objects at different scales.
Attention mechanism
Channel attention, spatial attention, and self-attention are the three primary types of attention mechanisms. Channel attention weights different channels according to their respective importance24,25. Spatial attention guides the network to concentrate on the objects that are small and easily overlooked, such as boundaries and small targets26,27,28. Self-attention focuses on information from a long distance, which is difficult for CNNs29,30,31,32,33. Oktay et al.28 introduced an attention-based gating system that can focus on targets of varying shapes and sizes. Woo et al.26 proposed an attention module that progressively infers attention mappings over the channel and spatial dimensions. Chen et al.27 introduced a hybrid adaptive attention module that generates corresponding attention maps under different receptive fields. Vaswani et al.29 first proposed Transformer, which obtains self-attention between different sequences by encoding operations. Dosovitskiy et al.30 designed the Vision Transformer, which cuts the image into small chunks and encodes them to be fed into the Transformer. Based on this, Chen et al.31 designed TransUnet to put the underlying features extracted by CNNs into Transformer to enhance the relationship from a long distance. Liu et al.32 proposed the swin-Transformer, which calculates self-attention within the windows and shifts the window in order to interact with the information in different windows. Cao et al.33 designed a UNet-like symmetric structure by replacing convolutional operations with the swin-Transformer, which achieves excellent performance with less computational expense. In this study, we build an attention-based feature fusion block (AFF Block) to weight and combine the features extracted from different paths. This allows different encoding paths to form competing relationships, which helps to extract more salient features.
Methods
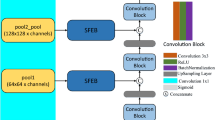
Breast cancer prevention and therapy greatly benefit from breast ultrasound segmentation. In this section, we show the main architecture and details of our TPUNet. As shown in Fig. 2, the suggested version consists of a three-path encoder, the attention-based feature fusion block (AFF Block), and deep supervision. The method extracts multiscale features by using multiple independent encoding paths with different depths, and achieves multiscale feature fusion through the AFF blocks. Deep supervision and a hybrid loss are used to further guide and refine the segmentation.

The description of the three-path U-structure network (TPUNet). Three-path encoder extracts multiscale features from different paths and fuses them through the attention-based feature fusion block (AFF Block). The deep supervision is further introduced to guide the model.
Three-path encoder
The lesion areas of breast ultrasound images often vary greatly in size, shape, and location, requiring the capacity of the model to extract multiscale features. Traditional CNNs extract features by stacking numerous convolutional and pooling layers. However, repeated stacking of convolutional and pooling layers will destroy spatial information. As illustrated in extensive literature34,35,36, shallow feature maps contain low-level semantic features but detailed texture information, while deep feature maps contain high-level semantic features but abstract signal information. The deeper structure is helpful for segmentation tasks, but spatial information is gradually diluted in the top-down encoder. Therefore, the decoder needs to acquire enough information from the encoder to reconstruct the high-resolution segmentation maps. This single encoder–decoder structure makes it difficult for these models to explore advanced semantic and spatial information at different scales simultaneously, which is not conducive to multiscale feature fusion.
Different from those methods, we design a three-path encoder with three independent encoding paths to deal with multiscale problems in BUS images. Specifically, the images are fed into three independent encoding paths and share the same decoder. As depicted in Fig. 2, the inner path has the fewest convolutional layers, which enables it to effectively preserve texture and spatial information. We contend that small targets are easily lost in continuous convolutional and pooling layers, and the inner path can help preserve the information of small targets. In our method, from inner to outer paths, the number of convolution and pooling layers rises gradually. The inner path stores detailed texture features, while the outer path extracts feature information with advanced semantics. The decoding path starts with the outermost encoding path. The features extracted from all encoder paths are fused through the AFF block and gradually supplied to the decoder.
Attention-based features fusion block
As illustrated in Fig. 3, the feature maps extracted from different paths are fed into the attention-based features fusion block (AFF Block) to produce more salient feature maps by weighted fusion. The AFF Block is consisted of two sub-modules: the channel attention sub-module and the spatial attention sub-module.

The description of the attention-based feature fusion block (AFF Block) for two inputs.
In the channel attention sub-module, as shown in Fig. 4a, we perform global average pooling (GAP) for two inputs A and B, and concatenate them together. Then we use 1D convolution with the stride of C+1 and a Sigmoid activation function to produce the attention weights:

After the Sigmoid activation function, \(\alpha \) is a vector with the value from 0 to 1, which has the same number of channels as the inputs. We let \(\alpha \) multiply the input A to represent the channel-weighted maps of A. Similarly, \(1-\alpha \) represents the importance of input B between each channel, which increases the competition between A and B. We use the combination of A and B as the output, and the output is described as follows:
The channel attention sub-module can help us to weight the feature maps extracted from different paths according to their importance and fuse them into more salient feature maps.

The description of (a) the channel attention sub-module and (b) the spatial attention sub-module.
In the spatial attention sub-module, as shown in Fig. 4b, we also start with average pooling (AP) and maximum pooling (MP), but the difference is that this time the pooling operation is done on the channel axis. We concatenate two outputs and use \(1 \times 1\) convolution to change channels to 1. We concatenate the results from inputs A and B, and use a Softmax activation function to produce the attention weights:

where Conv1 and Conv2 represent two independent convolutions. We let \(\alpha \) and \(\beta \) represent the spatially weighted maps of A and B, respectively. As a result of the Softmax activation function, the sum of the values of each pixel point between \(\alpha \) and \(\beta \) is 1, which represents the importance of each pixel point information between A and B. Similarly, this makes A and B compete with each other. We let the combination of A and B be the output, and the output is described as follows:
The spatial attention sub-module can help us concentrate on objects that are easy to overlook.
AFF Block integrates the advantages of the above sub-modules, which weight the feature maps in the spatial and channel dimensions at the same time, and the output is described as follows:
\(\alpha \) is computed from the channel attention sub-module. \(\alpha '\) and \(\beta '\) are computed from the spatial attention sub-module. Similarly, for stages with three inputs, we calculate the output as depicted in Fig. 5, and the output is described as follows:
where \(\alpha , \beta , \gamma \) are computed by concatenating different feature maps and feeding them into the channel attention sub-module, and \(\alpha ', \beta '\), \(\gamma '\) are computed by the spatial attention sub-module.

The description of the attention-based feature fusion block (AFF Block) for three inputs.
Deep supervision and loss function
Deep supervision is further used in the TPUNet to guide the model to direct effective contextual information from full scales. The deep supervision connects the intermediate layer directly to the loss function, which effectively improves the information flow and gradient flow, and provides powerful guidance. The feature maps are fed into a \(3 \times 3\) convolution at each level of the decoder and upsampled to the original image size. To determine the loss for the output of each deep supervision, we employ the cross-entropy loss function, which is described as follows:
\(p_i\) is the output of deep supervisions in different stages and upsampled to the original image size. \(g_t\) is the ground truth. N is the number of pixels and \(\sum \) is the sum for all pixels. \(\lambda _i\) is the weight between deep supervisions in different stages. As illustrated in Fig. 2, the deep supervision loss in each stage of the network has the same importance, so we set each \(\lambda _i\) to 0.1.
For segmentation tasks, cross-entropy and dice loss are frequently employed as loss functions. Cross-entropy loss describes the difference between the prediction and the ground truth. However, in medical segmentation, the background typically makes up a much larger portion of the target, which leads to an imbalance between the background and targets. Small targets make this more obvious because loss functions will focus on a larger portion of the background while disregarding targets. Dice loss describes the overlap region between the prediction and the ground truth. In general, Dice loss is typically more concerned with the target than the background since the gradient of targets is typically greater than the gradient of backgrounds. Current methods always combine Cross-Entropy loss and Dice loss to balance the attention between the target and background, but those methods usually ignore the false negative (FN) regions. As for most medical image segmentation tasks, FN regions are typically associated with undiagnosed lesions, which frequently results in incorrect diagnoses and illness recurrence.
In this work, we introduce Focal loss37 to balance attention between targets and background, as well as simple and hard samples. Focal loss is described as:
where N is the number of pixels and \(\sum \) is the sum for all pixels. \(p_t\) is the output of the network and \(g_t\) is the ground truth. \(\alpha _t\) is used to balance attention between targets and background. In this paper, \(\alpha _t\) is set to 0.8. \(\gamma \) is used to balance easy samples and hard samples and we set \(\gamma \) to 2.
To further reduce medical accidents, we use Focal Tversky loss38,39. Focal Tversky loss is described as:
where T(A, B) is defined as :
where \(p_{0i}\) and \(g_{0i}\) are the output of the network and ground truth. \(p_{1i}=1-p_{0i}\) and \(g_{1i}=1-g_{0i}\). \(\sum \) is the sum for all pixels. \(\alpha \) and \(\beta \) are used to balance FP and FN, we set \(\alpha \) to 0.3 and \(\beta \) to 0.7 in this paper. \(\gamma \) is used to balance easy samples and hard samples, and we set \(\gamma \) to 2 in this paper.
We find that current methods rarely have a loss function that focuses exclusively on the boundary. Therefore, we introduce Hausdorff Distance loss40,41,42 to enhance the boundary of tumors. Hausdorff Distance loss is described as:
where p is the output of the network and g is the ground truth. N is the number of pixels and \(\sum \) is the sum for all pixels. \(d(*)\) is the function to compute the distance map.
In conclusion, we develop a segmentation loss to refine breast ultrasound segmentation. The segmentation loss is defined as:
where \(\alpha \) is used to balance attention between regions and boundaries. Because the Hausdorff Distance loss is unstable in the early epochs of training, the initial value of \(\alpha \) is set to 0 and increases by 0.005 after each epoch but not more than 1, which turns attention from regions to boundaries gradually.
In summary, the hybrid loss function we designed is as follows:
where \(\lambda \) is used to balance deep supervision and segmentation loss. We set \(\lambda \) to 0.6 to ensure that the network pays more attention to the segmentation loss. The deep supervision loss is used to guide the training of the internal modules and to improve gradient flow. The segmentation loss makes the network learn the regional features of breast tumors in the early epochs and refine the boundaries gradually in the later epochs.
Experimental setup
Dataset and pre-processing
We put our method to the test on the Breast Ultrasound Images Dataset (Dataset BUSI43). The data consisted of breast ultrasound scans performed on people from 25 to 75 years old, which were gathered from 600 female patients in 2018. Due to the protection of patient privacy, this dataset does not provide specific age distributions, but this does not affect the main points and conclusions of our study. All images were pre-processed by radiologists and screened for classification as normal (n = 133), benign (n = 437), and malignant (n = 210) datasets, provided by Baheya Hospital, Cairo, Egypt.
We exclude 16 samples from the benign tumor dataset that require multiple segmentation objectives. The remaining 421 pictures are randomly divided into a train set (n = 253), a validation set (n = 84), and a test set (n = 84). In the malignant tumor dataset, we also remove 1 sample that requires multiple segmentation objectives and use all remaining 209 images, dividing them into a train set (n = 125), a validation set (n = 42), and a test set (n = 42) randomly.
We can’t directly feed them into the model because the size between different pictures is inconsistent. We take the longer side of the picture as the edge length and fill the picture with black to make it square. Then we resize the pictures to \(224 \times 224\). We apply data augmentation, including random flip, random rotation, and normalization, to further improve the generalization performance and robustness of our model.
Implementation details
We train our framework on the RTX A6000 48G and the Ubuntu operating system. We train models on benign and malignant tumor datasets. We monitor the mean Intersection over Union (mIoU) and the mean 95% Hausdorff Distance (HD95) on respective validation sets, saving model parameters when mIoU is promoted. Additionally, we employ the Adam optimizer with a 0.003 starting learning rate, halving the learning rate when there is no promotion within 30 epochs on the validation set. All results are scored on the respective test sets.
Evaluation metrics
We evaluate the segmentation performance of the methods by calculating the Intersection over Union (IoU) and 95% Hausdorff Distance (HD95), which are defined as follows:
where A and B are two regions and \(\partial A\) and \(\partial B\) are their boundary curves. \(h(\partial A,\partial B)\) and \(h(\partial B,\partial A)\) are the distance functions between the two curves, which is defined as:
where a and b are points in the boundary curves \(\partial A\) and \(\partial B\), respectively.
Results and discussion
Ablation study
To confirm the validity of each module in our proposed method, we conduct an ablation experiment. We run the experiment with the same setting for a fair comparison. The first line is our primitive TPUNet, with no added any modules and no deep supervision. In the second line, we add deep supervision to the model. In the third line, we add the deep supervision and channel attention sub-modules to the model. In the fourth line, we add the deep supervision and spatial attention sub-modules to the model. In the fifth line, we add the deep supervision and AFF modules to the model. In the last line, we use the hybrid loss function Eq. (13) to train. The results are illustrated in Table 1, while all results are selected with the largest common domain by post-processing. As illustrated in Table 1, the original model has multiple encoding paths, which makes it difficult to optimize. However, the accuracy was dramatically improved after adding deep supervision, which proves the superiority of our model. Besides, the performance of the model can be further improved with the addition of the channel and spatial attention sub-modules. Our AFF Block combines the advantages of the channel and spatial attention sub-modules, and achieves better results than both. On top of this, to improve the segmentation even further, our final suggested model also includes a hybrid loss function. The results of the experiments show that our final strategy produces the best outcomes.
Comparisons with the state of the art
We compare our TPUNet with several state-of-the-art methods: UNet14, Attention U-Net28, UNet++19, UNet3+20, UNeXt44 and Swin-UNet33. All methods are optimized by the training environment suggested in their own paper. The results are illustrated in Table 2, and the segmentation maps are depicted in Fig. 6. As illustrated in Table 2, our TPUNet outperforms other approaches on both mIoU and HD95, which suggests that it can clearly outline the boundaries of the tumor, which is challenging for other methods to do. Moreover, as can be observed in Fig. 6, for benign tumors of varying sizes, shapes, and locations, our model handles them brilliantly and stably, while for malignant tumors with blurred boundaries that are difficult to segment, our method can segment the smoothest and most coherent boundaries. Besides, our method can produce the smallest FP and FN regions, which can effectively reduce medical accidents.

Comparison between different methods for benign tumor and malignant tumor segmentation on the BUSI dataset. Green areas: the true positive (TP); Blue areas: the false positive (FP); Red areas: the false negative (FN). The combination of the green and red areas is the ground truth. The combination of the green and blue areas is the prediction.
Numerous segmentation methods have been developed recently to address multiscale issues. However, most of them only attach some specially designed modules or skip connections. Despite achieving excellent results, those approaches are still limited by the single encoder. In this work, we design a three-path U-structure network (TPUNet) to solve multiscale problems. The three independent encoding paths with different depths correspond to the extraction of features at different scales. In addition, we design the attention-based feature fusion block (AFF Block) to further facilitate the competition and fusion of features. The AFF Block integrates the advantages of the spatial and channel attention sub-modules. The AFF Block encourages different paths to compete with each other and makes a weighted fusion of feature maps from different paths in the channel and spatial dimension to obtain more salient features. Thanks to this structure, our method can extract abundant contextual information on different scales.
Most existing models ignore the importance of boundaries and FN regions, which increases the risk of medical accidents. Subtle differences in boundaries can make an extreme impact on radiologists’ policy decisions, while FN regions imply undetected nidus, which usually leads to misdiagnosis and disease recurrence. We propose a hybrid loss function to further refine segmentation to meet those problems. As shown in Fig. 6, the segmentation maps generated using our method have the smoothest boundary and the smallest FN regions compared to using other competing methods. Besides, we discover that our technique performs better in small organ segmentation across a vast number of studies. We argue it benefits from the structure of multiple coding paths. In the classic encoder–decoder structures, small targets are easy to lose in continuous convolutional and pooling layers. Different from those methods, the three-path encoder architecture proposed in our TPUNet allows us to retain sufficient detailed information in the inner path and to recall and fuse it in the decoder.
Conclusion
In this paper, we propose a three-path U-structure Network named TPUNet to improve multiscale problems in BUS segmentation. The structure of multiple encoding paths shows a new way to deal with multiscale problems in segmentation tasks. Our approach also provides outstanding performance in the segmentation of tiny targets thanks to the structure of multiple coding paths. The AFF Block we designed can filter and weight multiscale feature maps extracted from different encoding paths, and fuse them into a more representative feature map. Moreover, we further propose a hybrid loss function by introducing Focal loss, Focal Tversky loss, and Hausdorff Distance loss, which can reduce the false negative areas and refine segmentation boundaries gradually. Experimental results show that our suggested strategy produces greater accuracy and smoother borders when compared with previous approaches.
Data availability
This study did not include any human clinical images or patient data from restricted datasets. The experiments in this study have been performed in a publicly available dataset (Dataset of Breast Ultrasound Images43 figshare https://doi.org/10.1016/j.dib.2019.104863). All data generated and analysed during this study are available from the corresponding author.
References
Sung, H. et al. Global cancer statistics 2020: Globocan estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 71, 209–249 (2021).
Cao, W., Hong-da, C., Yi-wen, Y., Li, N. & Wan-qing, C. Changing profiles of cancer burden worldwide and in china: A secondary analysis of the global cancer statistics 2020. Chin. Med. J. 134, 783–791 (2021).
Yi-sheng, S. et al. Risk factors and preventions of breast cancer. Int. J. Biol. Sci. 13, 1387 (2017).
Lauby-Secretan, B. et al. Breast-cancer screening-viewpoint of the IARC Working Group. N. Engl. J. Med. 372, 2353–2358 (2015).
Qaseem, A. et al. Screening for breast cancer in average-risk women: A guidance statement from the American College of Physicians. Ann. Intern. Med. 170, 547–560 (2019).
Pauwels, E. K., Foray, N. & Bourguignon, M. H. Breast cancer induced by X-ray mammography screening? A review based on recent understanding of low-dose radiobiology. Med. Princ. Pract. 25, 101–109 (2016).
Seely, J. & Alhassan, T. Screening for breast cancer in 2018—What should we be doing today?. Curr. Oncol. 25, 115–124 (2018).
Ye-jiao, M. et al. Breast tumour classification using ultrasound elastography with machine learning: A systematic scoping review. Cancers 14, 367 (2022).
Singh, V. K. et al. Breast tumor segmentation and shape classification in mammograms using generative adversarial and convolutional neural network. Expert Syst. Appl. 139, 112855 (2020).
Fakoor, R., Ladhak, F., Nazi, A. & Huber, M. Using deep learning to enhance cancer diagnosis and classification. In Proceedings of the International Conference on Machine Learning (ICML), 3937–3949 (2013).
Long, J., Shelhamer, E. & Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 3431–3440 (2015).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778 (2016).
Huang, G., Liu, Z., Van Der Maaten, L. & Weinberger, K. Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 4700–4708 (2017).
Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 234–241 (2015).
Guan, S., Khan, A. A., Sikdar, S. & Chitnis, P. V. Fully dense UNet for 2-D sparse photoacoustic tomography artifact removal. IEEE J. Biomed. Health Inform. 24, 568–576 (2019).
Li, X. et al. H-DenseUNet: Hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE Trans. Med. Imaging 37, 2663–2674 (2018).
Ma, Q., Zeng, T., Kong, D. & Zhang, J. Weighted area constraints-based breast lesion segmentation in ultrasound image analysis. Inverse Probl. Imaging 16, 451–466 (2022).
Yu, Y., Xiao, Y., Cheng, J. & Chiu, B. Breast lesion classification based on supersonic shear-wave elastography and automated lesion segmentation from b-mode ultrasound images. Comput. Biol. Med. 93, 31–46 (2018).
Zhou, Z., Rahman Siddiquee, M. M., Tajbakhsh, N. & Liang, J. Unet++: A nested U-Net architecture for medical image segmentation. In International Workshop on Deep Learning in Medical Image Analysis (DLMIA) and International Workshop on Multimodal Learning for Clinical Decision Support (ML-CDS), 3–11 (2018).
Huang, H. et al. Unet 3+: A full-scale connected UNet for medical image segmentation. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1055–1059 (2020).
Gu, Z. et al. CE-Net: Context encoder network for 2D medical image segmentation. IEEE Trans. Med. Imaging 38, 2281–2292 (2019).
Jia, F., Ma, L., Yang, Y. & Zeng, T. Pixel-attention CNN with color correlation loss for color image denoising. IEEE Signal Process. Lett. 28, 1600–1604 (2021).
Ibtehaz, N. & Rahman, M. S. MultiResUNet: Rethinking the u-net architecture for multimodal biomedical image segmentation. Neural Netw. 121, 74–87 (2020).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 7132–7141 (2018).
Wang, Q. et al. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 11534–11542 (2020).
Woo, S., Park, J., Lee, J. Y. & Kweon, I. S. CBAM: Convolutional block attention module. In European Conference on Computer Vision (ECCV), 3–19 (2018).
Chen, G., Li, L., Dai, Y., Zhang, J. & Yap, M. H. AAU-Net: An adaptive attention u-net for breast lesions segmentation in ultrasound images. IEEE Trans. Med. Imaging 42, 1289–1300 (2023).
Oktay, O. et al. Attention U-Net: Learning where to look for the pancreas. arXiv preprint arXiv:1804.03999 (2018).
Vaswani, A. et al. Attention is all you need. In Advances in Neural Information Processing Systems 30 (NIPS), 6000–6010 (2017).
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
Chen, J. et al. TransUNet: Transformers make strong encoders for medical image segmentation. arXiv preprint arXiv:2102.04306 (2021).
Liu, Z. et al. SWIN transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 10012–10022 (2021).
Cao, H. et al. Swin-UNet: UNet-like pure transformer for medical image segmentation. In European Conference on Computer Vision (ECCV), 205–218 (2022).
Luo, W., Li, Y., Urtasun, R. & Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. In Advances in Neural Information Processing Systems 29 (NIPS), 4905–4913 (2016).
He, K., Zhang, X., Ren, S. & Sun, J. Identity mappings in deep residual networks. In European Conference on Computer Vision (ECCV), 630–645 (2016).
Xiao, X., Lian, S., Luo, Z. & Li, S. Weighted Res-UNet for high-quality retina vessel segmentation. In 9th International Conference on Information Technology in Medicine and Education (ITME), 327–331 (2018).
Lin, T. Y., Goyal, P., Girshick, R., He, K. & Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2980–2988 (2017).
Salehi, S. S. M., Erdogmus, D. & Gholipour, A. Tversky loss function for image segmentation using 3D fully convolutional deep networks. In International Workshop on Machine Learning in Medical Imaging (MLMI), 379–387 (2017).
Abraham, N. & Khan, N. M. A novel focal Tversky loss function with improved attention U-Net for lesion segmentation. In IEEE 16th International Symposium on Biomedical Imaging (ISBI), 683–687 (2019).
Karimi, D. & Salcudean, S. E. Reducing the Hausdorff distance in medical image segmentation with convolutional neural networks. IEEE Trans. Med. Imaging 39, 499–513 (2019).
Kervadec, H. et al. Boundary loss for highly unbalanced segmentation. In International Conference on Medical Imaging with Deep Learning (MIDL), 285–296 (2019).
Liu, Y., Duan, Y. & Zeng, T. Learning multi-level structural information for small organ segmentation. Signal Process. 193, 108418 (2022).
Al-Dhabyani, W., Gomaa, M., Khaled, H. & Fahmy, A. Dataset of breast ultrasound images. figsharehttps://doi.org/10.1016/j.dib.2019.104863 (2020).
Valanarasu, J. M. J. & Patel, V. M. UNeXt: MLP-based rapid medical image segmentation network. In International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 23–33 (2022).
Acknowledgements
This work is supported by the National Natural Science Foundation of China (Grant No. 61902192) and the High-Level Innovative and entrepreneurial project in Jiangsu Province, China (Jiangsu Personnel Office Document, No. [2019]20).
Author information
Authors and Affiliations
Contributions
H.Z. conducted numerical experiments and paper writing, Q.M. improved the presentation of this paper and supervised the study. Y.C. provided advice and guidance on technical matters. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, H., Ma, Q. & Chen, Y. U structured network with three encoding paths for breast tumor segmentation. Sci Rep 13, 21597 (2023). https://doi.org/10.1038/s41598-023-48883-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-023-48883-y
