
Abstract
With the recent increase in traffic accidents, pelvic fractures are increasing, second only to skull fractures, in terms of mortality and risk of complications. Research is actively being conducted on the treatment of intra-abdominal bleeding, the primary cause of death related to pelvic fractures. Considerable preliminary research has also been performed on segmenting tumors and organs. However, studies on clinically useful algorithms for bone and pelvic segmentation, based on developed models, are limited. In this study, we explored the potential of deep-learning models presented in previous studies to accurately segment pelvic regions in X-ray images. Data were collected from X-ray images of 940 patients aged 18 or older at Gachon University Gil Hospital from January 2015 to December 2022. To segment the pelvis, Attention U-Net, Swin U-Net, and U-Net were trained, thereby comparing and analyzing the results using five-fold cross-validation. The Swin U-Net model displayed relatively high performance compared to Attention U-Net and U-Net models, achieving an average sensitivity, specificity, accuracy, and dice similarity coefficient of 96.77%, of 98.50%, 98.03%, and 96.32%, respectively.
Similar content being viewed by others
Introduction
Pelvic fractures, second only to skull fractures in terms of mortality and complication risk, are becoming more frequent because of the recent increase in traffic accidents1. Interest in pelvic fractures has increased since the 1960s, primarily due to intra-abdominal hemorrhage, the leading cause of death related to pelvic fractures. Since the 1970s, advancements in computed tomography (CT) imaging, external fixation, and pelvic packing have significantly improved the management, diagnosis, and treatment of pelvic fractures2. However, an accurate diagnosis of pelvic fractures remains challenging owing to the complex three-dimensional (3D) nature of the pelvic structure, making it difficult to assess using conventional radiographic techniques3. Simple radiographic examinations may suggest the possibility of a fracture, whereas attempting to confirm it through CT often results in either no fracture or overestimation of the fracture extent4. This indicates the limitations of conventional radiography in precisely assessing the presence or extent of fractures5.
Recent research on medical imaging has demonstrated the potential for various segmentation tasks, such as bone6, pulmonary vessels 7, and pelvic and sacral bones 8. Wang et al.9 attempted to segment the pelvis using a deep learning method and achieved a relatively high detection performance, with an accuracy of 91% and a sensitivity of 84%. Liu et al.10 used a 3D U-Net model to segment the pelvis, demonstrating high accuracy with a dice similarity coefficient (DSC) of 84%. Yuan conducted another study on pelvic segmentation using 11 models and verified their performances. The dataset comprised 14,487 images obtained from 42 patients. In three experiments, BiseNet and LedNet achieved accuracies of 99.49% and 99.41%, respectively11.
Recently, several studies have been performed to detect organ/bone fragmentation and lung nodules. Wu et al.12 used Attention U-Net to attempt organ segmentation in abdominal CT images and achieved high accuracy. Noguchi et al.13 performed bone segmentation on whole-body CT images using a U-Net based architecture. Recently, Wasserthal et al.14 automatically segmented all anatomical structures identifiable in the CT images of each body using no-new-U-Net (nnU-Net).
Considerable research has been conducted on deep-learning models to diagnose lesions and fractures. Kai et al.15 utilized the Swin U-Net for tumor segmentation in breast cancer to enable rapid diagnosis. Gao et al.16 proposed a lightweight Swin U-Net model for segmenting COVID-19 lesions in CT images, achieving excellent segmentation results in multiple lesion regions. Urakawa et al.17 used the VGG model to classify pelvic fractures, focusing on straightforward lesion classification.
Although numerous attempts have been made to segment tumors and organs, studies aiming to develop clinically useful algorithms for bone and pelvis segmentation using these models are limited.
In this study, we examined previous research to explore the potential of deep learning to achieve accurate pelvic region segmentation in X-ray images. When diagnosing pelvic fractures on radiographs, the extent of the fracture in the pubic bone, ilium, or ischium is crucial. Most fractures can be detected on radiographs; however, rapid diagnosis is challenging, particularly for fractures in the pubic and ischial bones or fragmented bone pieces18. Therefore, in this study, the pelvic bone region in X-ray images was segmented using Attention U-Net, Swin U-Net, and U-Net in normal patients as well as those with fractures. In patients with severe fractures, medical experts may not be able to identify all the broken bones. In this case, the deep learning model can segment the fine bone fragments. Even in patients with minor fractures, a fracture diagnosis can be quickly made by first finding and showing the pelvic bone area to a medical professional. To improve the segmentation performance of the pelvic bone region in X-ray images, preprocessing was followed by the adjustment of deep learning model hyperparameter.
Methods
Research environment
The experiments in this study used a system comprising an NVIDIA TESLA P40 graphics processing unit (NVIDIA, Santa Clara, CA, USA), an Intel Xeon E5-2630 v4 CPU (Intel, Santa Clara, CA, USA), 32 GB of RAM, and the Ubuntu 20.04.6 LTS operating system. The programming language used for the experiment was Python (version 3.7.16). The libraries used for preprocessing and training the deep learning models were TensorFlow software (version. 2.6.0), Keras (version. 2.6.0) for various functions supporting deep learning model design and training, unified device architecture (version. 11.2.0) for massive computational processing as a graphics processing device development tool, open computer vision (version. 4.6.0.66) providing various functions for image processing, and matplotlib (version. 3.5.2) for data visualization.
Data
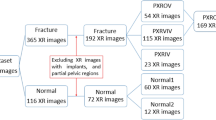
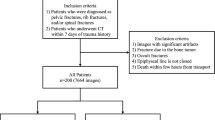
The X-ray images were collected from Gachon University Gil Hospital between January 2015 and December 2022. The dataset comprised X-ray images from 773 adults aged 18 and above diagnosed with pelvic fractures and 167 individuals without pelvic fractures. This study received approval from the Gachon University Gil Hospital Clinical Research Ethics Review Committee, and the need for informed consent was waived due to the retrospective nature of the study (GAIRB2022-153). All experimental protocols were performed in accordance with the relevant guidelines and regulations of the Declaration of Helsinki. The location of the pelvic region was determined by referencing the pelvic AP radiographic findings of radiologists and CT scans. Two trauma surgeons with more than ten years of experience confirmed all fracture sites on the pelvic AP X-ray radiographs. Subsequently, regions of interest (ROIs) were delineated along the boundaries of the pelvic ring for pelvic segmentation (Fig. 1). The ROIs in polygon form were determined using ImageJ software (version. 1.53t, National Institutes of Health, Bethesda, MD, USA).

Pelvic ring segmentation.
Data preprocessing
The variations in the imaging environment of some collected pelvic AP radiographs pose difficulties in adequately identifying the pelvic region. Such images can potentially hinder the effective training of deep-learning algorithms. Thus, data preprocessing becomes a fundamental task for automated pelvic bone segmentation, serving as a crucial step in enhancing the learning capabilities and predictive performance of the model while extracting pertinent information from the data.
Therefore, before the analysis, a histogram equalization preprocessing step was applied to all the image data. In addition, efficient training of convolutional neural networks in deep learning requires consistent dimensions of the input and output images. Hence, in this study, a preprocessing step involving zero padding of the original images was performed to ensure uniform dimensions in terms of both width and height. Subsequently, the images were resized to a uniform size of 512 pixels, with both width and height set to 512 pixels.
Convolutional neural network model for deep learning
In this study, the Attention U-Net, Swin U-Net, and U-Net models were employed for pelvic segmentation training. The Attention U-Net model is an adaptation of the U-Net architecture that integrates attention gates, as shown in Fig. 2. Despite sharing a similar architecture to that of U-Net, it incorporates attention gates in the decoder section to adjust the weights of regions that are not of interest. These aspects are distinguished by omitting regions deemed inconsequential or irrelevant to the prediction or classification outcomes. This process enhances the emphasis on critical areas, leading to more precise segmentation results. The Swin U-Net model combines Swin Transformer blocks with the U-Net architecture, as shown in Fig. 3. Swin transformers have demonstrated excellent performances in image classification and visual tasks, employing the self-attention structure of transformers to model the relationships between pixels, thereby enabling the capture of global contextual information. Moreover, the design includes an encoder-decoder structure specialized for medical image segmentation tasks. For optimization, the Adam optimizer was utilized with a batch size of one and learning rate of 0.001, training for 100 epochs, with model weights updated in each epoch. Figure 4 shows the flowchart proposed in this study. An early stopping function was incorporated to terminate the learning process early and prevent overfitting. When the validation loss did not improve, the patience was set to 30 for training. In addition, to continuously observe validation loss and dynamically adjust the learning rate, the ReduceLROnPlateau function was added to modify the model learning by reducing the learning rate when no change was observed in a certain epoch. To evaluate and compare the performance of both models, we divided the dataset into five segments and conducted a five-fold cross-validation. By comparing the visual analysis results of the medical experts with the prediction results of the deep learning model, the true positive (TP), false negative (FN), true negative (TN), and false positive (FP) were obtained. We assessed and compared the pelvic segmentation performances of the models using sensitivity, specificity, accuracy, and DSC as metrics, defined as follows: sensitivity: TP/(TP + FP); specificity: TN/(TN + FP); and accuracy: (TP + TN)/(TP + TN + FP + FN). Sensitivity measures the effectiveness of the model in detecting the actual pelvic region in ROI images. Specificity measures how well the model detects non-pelvic areas and indicates the ratio of correctly predicted areas outside the pelvic region. Accuracy measures the ratio of pixels predicted as the pelvis among all pixels, whereas DSC measures the similarity between the predicted and actual pelvic regions in the ROI images19. Higher values for each metric indicate better performance in pelvic region segmentation.

Architecture of Attention U-Net model.

Architecture of Swin U-Net model.

Flowchart of the proposed method.
Results
In this study, we trained segmentation models using Attention U-Net, Swin U-Net, and U-Net models on pelvic X-ray images. Figure 5 shows a comparison between the pelvic regions segmented by trauma surgeons and those obtained using Attention U-Net, Swin U-Net, and U-Net models.

Comparison of pelvic segmentation based on Attention U-Net and Swin U-Net. (a) Original, (b) Gold standard, (c) Attention U-Net, (d) Swin U-Net, (e) U-Net.
The results for ROIs are summarized in Table 1. Attention U-Net achieves an average sensitivity, specificity, and accuracy of 88.22%, 92.07%, and 90.80%, respectively. In contrast, Swin U-Net demonstrates an average sensitivity of 96.77%, a specificity of 98.50%, and accuracy of 98.03%, whereas U-Net achieves an average sensitivity of 88.40%, specificity of 91.24%, and accuracy of 84.46%. Table 2 shows the DSC changes associated with the three split models in the presence and absence of fractures. Following the analysis, Attention U-Net obtains a DSC of 83.66% for images with fractures and 83.78% for images without fractures. Swin U-Net achieves a DSC of 96.31% for images with fractures and 96.36% for images without fractures. U-Net achieves a DSC of 84.64% for images with fractures and 83.42% for images without fractures. The presence or absence of fractures does not result in a significant change in DSC.
Figure 6 illustrates the performance differences among Attention U-Net, Swin U-Net, and U-Net. The Bland–Altman plots compare the test set prediction area of each model with the gold standard obtained from medical experts. The comparison results show that Swin U-Net outperforms the Attention U-Net and U-Net models in various evaluation metrics, with a significant difference observed for the DSC metric.

Performance comparison of the three models.
The pelvic segmentation results between the ROIs obtained from Attention U-Net, Swin U-Net, and U-Net were further compared using Bland–Altman graphs (Fig. 7). The rationale behind selecting the Bland–Altman plot for comparing the Swin U-Net, U-Net, and Attention U-Net models lies in its ability to visually assess the agreement of the prediction results among the three models. This allowed us to determine the prediction consistency of the three models when applied to the same data. Additionally, examining the differences between the three models enabled us to understand how each model's predictions diverged, valuable for comparing the biases or consistencies in the predicted values between models. For differences in values clustered around the mean, indicating a strong agreement, the upper and lower limits of the Bland–Altman graph represent the standard deviation of the difference values, typically 1.96. This suggests that the differences were mostly within the range of 1.96 standard deviations. Hence, the differences between the ROI and segmentation results of the models were statistically significant, indicating the reliability of the model predictions.

Bland–Altman plots comparing pelvic area from manual and deep-learning models.
Figure 8 shows the prediction results of each of the three segmentation models on an X-ray image with a fracture. The Swin U-Net demonstrates relatively greater accuracy in segmenting pelvic fracture images compared to Attention U-Net and U-Net. However, Swin U-Net has limitations in segmenting the left ilium, including the fractured area.

Comparison of fracture area within the segmentation results of Attention U-Net and Swin U-Net (a) Gold standard, (b) Attention U-Net, (c) Swin U-Net, and (d) U-Net.
Discussion
In this study, the trained models for pelvic region segmentation in X-ray images were evaluated and compared. Attention U-Net utilizes the attention technique to ignore or allocate less attention to areas unrelated to the gold standard, thereby reducing computational costs. In contrast, Swin U-Net learns by dividing the image into patches, facilitating a comprehensive understanding of the overall structure of the image and enabling identification of detailed features. Overall, both models used in the experiments exhibited excellent performance. From the experimental results, Swin U-Net was confirmed to exhibit higher sensitivity, specificity, accuracy, and DSC, compared to Attention U-Net. Regarding overall performance indicators, Swin U-Net demonstrated approximately 8% higher sensitivity, 6% higher specificity, and 8% higher accuracy than those of Attention U-Net. Among the performance indicators of the segmentation model, the most significant improvement was observed in DSC, which was approximately 13% higher for Swin U-Net. This suggested that Swin U-Net maintained stability and reliability across different input data compared to Attention U-Net, as its sensitivity did not change significantly with variations in input data. In terms of specificity, this implied that Swin U-Net outperformed Attention U-Net in accurately distinguishing the background of the image, excluding the pelvic bone region. Regarding accuracy, Swin U-Net achieved a higher accuracy rate than both Attention U-Net and U-Net in correctly classifying pelvic bone pixels in the image. Furthermore, in terms of DSC, the pelvic bone area predicted by Swin U-Net exhibited greater similarity to the actual pelvic bone area and was more accurate than those predicted by Attention U-Net and U-Net. In all experimental results, Swin U-Net outperformed Attention U-Net and U-Net. This superiority might be attributed to the efficiency of the Transformer series feature extraction function of Swin U-Net and reconstruction structure model. Swin U-Net simultaneously considered global and local features, allowing it to extract features that clearly segmented the detailed structure and boundaries of the pelvic region. In addition, extracting image features on a patch basis likely contributed significantly to segmenting the pelvic bone area using meaningful patch features. However, Attention U-Net tends to rely heavily on the efficiency of the attention mechanism. If the attention mechanism fails to extract appropriate features, the overall performance of the model may degrade. We speculate that the computational complexity of the attention mechanism might have led to overfitting during model learning and posed challenges in hyperparameter adjustment.
In a previous study, a DSC of 95.7% was achieved from CT images using a model with U-Net as the backbone of EfficientNet-B020. Applying the Mask R-CNN model to X-ray images21 resulted in a DSC of 96%, whereas applying a 3D CNN model to multiparametric magnetic resonance imaging. mpMRI yielded a DSC of 85%10. In this study, the average DSC of 96.32% obtained using the Swin U-Net model indicated a performance improvement compared to previous studies.
However, the experimental results differed from those in the coccyx and sacral regions. This discrepancy may stem from the fact that the coccyx and sacrum have fused structures that differ from the ilium. The Bland–Altman graph shown in the experiment was used to compare the segmentation results of the three models. While both models exhibited cases exceeding the standard deviation, the distributions were relatively consistent. This implied that both models exhibited similar segmentation performance levels. However, the presence of outliers exceeding the standard deviation highlighted the need of improving the reliability and stability of model predictions. To achieve this, methods such as acquiring additional datasets and adjusting hyperparameters can be considered. In the experiments conducted in this study, Swin U-Net segmented the pelvic fracture images more accurately than Attention U-Net and U-Net. Given the complex shapes of pelvic fractures in images, accurate localization was crucial. Swin U-Net contributed to accurate localization by effectively segmenting the detailed structure and boundaries of the fracture site. However, it exhibited poor performance in segmenting the left ilium, including the fractured region, which could be attributed to the diversity of the images used for pelvic region segmentation training. The dataset included both normal images and images with pelvic fractures, leading to the pelvic region appearing fragmented rather than as a single cohesive structure. Including more pelvic fracture data in future studies could potentially enhance the segmentation performance of pelvic fracture images.
In conclusion, this study developed a deep learning model for pelvic region segmentation using X-ray images and compared it with other models. The results indicated that Swin U-Net achieved higher performance than Attention U-Net and U-Net. Further research based on these findings and subsequent improvements could potentially facilitate the application of this method in actual clinical practice.
Data availability
The data used to support the findings of this study are available upon request from the corresponding authors.
References
Kim, K. H., Kim, S. J. & Sung, C. S. A clinical study on fractures of the pelvic bone. J. Korean Orthop. Assoc. 17, 485–491 (1982).
Park, K.-C. Pelvic fracture issues. J. Korean Fract. Soc. 23, 341–345 (2010).
Kim, B. H., Im, J. I., Kim, D. J. & Park, J. Y. Diagnostic values of bone scan followed by CT scan in undetected pelvic bone fracture. J. Korean Orthop. Assoc. 32, 523–529 (1997).
Kim, S. Y., Park, B.-H.P. & Ihn, J.-C. Diagnostic value of computed tomography in acetabular fracture. J. Yeungnam Med. Sci. 5, 43–48 (1988).
Han, H.-J. Diagnosis of pelvic bone fractures. J. Korean Fract Soc. 7, 5–11 (1994).
Ho, L., Dong-seong, K. & Heung-sik, K. Bone segmentation method of visible human using multimodal registration. J. KIISE Softw. Appl. 30, 719–726 (2003).
Min-Jun, S. & Do-Yeon, K. Pulmonary vascular segmentation and refinement on the CT scans. J. Korea Inst. Inf. Commun. Eng. 16, 591–597 (2012).
Kim, Y. J., Park, S. J., Kim, K. R. & Kim, K. G. Automated ulna and radius segmentation model based on deep learning on DEXA. J. Korea Multimed. Soc. 21, 1407–1416 (2018).
Wang, Y. et al. Weakly supervised universal fracture detection in pelvic x-rays in Med. In Image Comput. Comput. Assist. Interv. MICCAI. Proceedings of the Part VI: 22nd International Conference, Shenzhen, China, October 13–17, vol. 22 459–467 (Springer, 2019).
Liu, X. et al. Fully automated pelvic bone segmentation in multiparameteric MRI using a 3D convolutional neural network. Insights Imaging 12, 93 (2021).
Yuan, S. et al. Rethinking computer-aided pelvis segmentation. In ICASSP IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 451–1455 (IEEE, 2022).
Wu, J. et al. U-Net combined with multi-scale attention mechanism for liver segmentation in CT images. BMC Med. Inform. Decis. Mak. 21, 283 (2021).
Noguchi, S., Nishio, M., Yakami, M., Nakagomi, K. & Togashi, K. Bone segmentation on whole-body CT using convolutional neural network with novel data augmentation techniques. Comput. Biol. Med. 121, 103767 (2020).
Wasserthal, J. et al. Totalsegmentator: Robust segmentation of 104 anatomic structures in ct images. Rad. Artif. Intell. 5, 5 (2023).
Kai, H., Feng, Z. Y., Meng, H., Baoping, F. Y. & Han, Y. R. Ultrasound image segmentation of breast tumors based on Swin-transformerv2. In Proceedings of the 2022 10th International Conference on Information Technology: IoT and SMART City 106–111 (2022).
Gao, Z.-J., He, Y. & Li, Y. A novel lightweight Swin-unet network for semantic segmentation of COVID-19 lesion in CT images. IEEE Access 11, 950–962 (2022).
Urakawa, T. et al. Detecting intertrochanteric hip fractures with orthopedist-level accuracy using a deep convolutional neural network. Skelet. Rad. 48, 239–244 (2019).
Lee, C. G., Kwon, J. W., Sohn, K. T., Shin, S. H. & Park, J. W. Combined injuries of pubic ramus fracture: The role of computerized tomography. J. Korean Soc. Fract. 12, 40–46 (1999).
Popovic, A., de la Fuente, M., Engelhardt, M. & Radermacher, K. Statistical validation metric for accuracy assessment in medical image segmentation. Int. J. Comput. Assist. Rad. Surg. 2, 169–181 (2007).
Jois, P. S., Manjunath, A. & Fevens, T. Boosting segmentation performance across datasets using histogram specification with application to pelvic bone segmentation. In IEEE International Conference on Bioinformatics and Biomedicine (BIBM) 1364–1369 (IEEE, 2021).
Jodeiri, A. et al. Region-based convolution neural network approach for accurate segmentation of pelvic radiograph. In 26th National and 4th International Iranian Conference on Biomedical Engineering (ICBME) 152–157 (IEEE, 2019).
Acknowledgements
This work was supported by the GRRC program of Gyeonggi Province. [GRRC-Gachon2023(B01), Development of AI-based medical imaging technology], and by Gachon University (GCU-202300500001) and by the Technology Innovation Program (K_G0120011856, Building Data Sets for Artificial Intelligence Learning) funded By the Ministry of Trade, Industry & Energy (MOTIE, Korea).
Author information
Authors and Affiliations
Contributions
Jung Min Lee wrote the overall paper, Kwang Gi Kim designed the study, and Jun Young Park and Young Jae Kim helped write the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lee, J.M., Park, J.Y., Kim, Y.J. et al. Deep-learning-based pelvic automatic segmentation in pelvic fractures. Sci Rep 14, 12258 (2024). https://doi.org/10.1038/s41598-024-63093-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-63093-w
Keywords
This article is cited by
-
Transformer-based and CNN-based models for clinically effective 2D and 3D pelvic bone segmentation in CT imaging
BMC Musculoskeletal Disorders (2025)
-
An automated hip fracture detection, classification system on pelvic radiographs and comparison with 35 clinicians
Scientific Reports (2025)
-
Diagnostic performance of artificial intelligence for facial fracture detection: a systematic review
Oral Radiology (2025)
