
Abstract
The Span-based model can effectively capture the complex entity structure in the text, thus becoming the mainstream model for nested named entity recognition (Nested NER) tasks. However, traditional Span-based models decode each entity span independently. They do not consider the semantic connections between spans or the entities’ positional information, which limits their performance. To address these issues, we propose a Bi-Directional Context-Aware Network (Bi-DCAN) for the Nested NER. Specifically, we first design a new span-level semantic relation model. Then, the Bi-DCAN is implemented to capture this semantic relationship. Furthermore, we incorporate Rotary Position Embedding into the bi-affine mechanism to capture the relative positional information between the head and tail tokens, enabling the model to more accurately determine the position of each entity. Experimental results show that compared to the latest model Diffusion-NER, our model reduces 20M parameters and increases the F1 scores by 0.24 and 0.09 on the ACE2005 and GENIA datasets respectively, which proves that our model has an excellent ability to recognise nested entities.
Similar content being viewed by others


Introduction
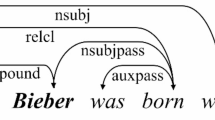
Named Entity Recognition (NER) is a sub-task of information extraction that aims to locate and classify named entities within text sequences. These entities are typically categorized into predefined groups, such as people’s names, organizations, and locations. NER is fundamental for applications like Relation Extraction1, Building Knowledge Graphs2, and Question Answering System3. The prevalent approach treats NER as a sequence annotation task4,5, where each word associated with an entity is labelled with a specific category. However, this approach has difficulties with nested entities, where a word may fall under multiple categories. As shown in Fig. 1, “IL-2R alpha transcripts” is tagged as “protein”, while “IL-2R alpha” is classified as “DNA”. This adds complexity to the NER process.

Example diagram of nest named entity.
To tackle the challenge of nested entities, various studies have introduced span-based models6. Unlike traditional sequence labeling models, span-based models are better suited for handling cases where entities are nested within each other. Span-based models first convert input sentences into abstract representations, subsequently identifying and characterizing potential entity spans by capturing crucial features. These features help a classifier recognize and categorize nested named entities. However, these models often struggle with accurately defining entity boundaries. To improve this, some researches has included the bi-affine mechanism to enhancing boundary clarity in the span representations.
Despite these advancements, many models still overlook the semantic relationships between spans. Yan et al.7 have addressed the issue by employing convolutional neural network (CNN) to analyze score matrices. However, CNN primarily focus on local feature interactions and frequently miss the broader semantic relationships among distant spans. Additionally, these methods commonly ignore the positioning of head and tail tokens within a span. This oversight can result in inaccuracies in determining a span’s length and importance, ultimately leading to incorrect entity recognition.

All valid spans in the sentence.
Therefore, we propose a novel model that focuses on inter-span semantic relations. As illustrated in Fig. 2, the model recognizes specific spatial relationships between the position of each span and its neighbors in a planarized sentence representation. Unlike traditional models, the approach facilitates simultaneous consideration of both localized and long-distance semantic relations. Given that the new semantic relationship model displays a cruciform pattern on the plane matrix, we have developed a Bi-Directional Context-Aware Network (Bi-DCAN) to effectively learn and interpret these patterns. The Bi-DCAN is equipped with a multi-granularity cross-attention mechanism. The mechanism effectively tackles the complex dependencies of semantic relationships between spans by capturing both horizontal and longitudinal relationships. Additionally, we have integrated Rotary Position Embedding (RoPE) into the biaffine component. This integration enables the model to effectively capture the relative positional information between the head and tail tokens of entities. Our comprehensive experiments on three publicly accessible nested datasets clearly demonstrate the effectiveness of our proposed model.
The key contributions of this research can be summarized as follows:
-
We design a novel relational representation between neighbouring spans. The relation representation has advantages over traditional span-based models in learning information about semantic relationships between spans.
-
We propose a Bi-DCAN model based on a self-created multi-granularity cross-focusing mechanism. This mechanism can simultaneously learn the global and local inter-span semantic features, and get rich feature information.
-
We propose an improved bi-affine mechanism. This mechanism is used in conjunction with RoPE to efficiently capture the relative location information of entity head and tail tokens.
Related work
In recent years, many research methods have emerged for the task of nested named entity recognition (Nested NER). These methods can be primarily classified into three categories: Layer-based models, Hypergraph-based models, and Span-based models.
Layer-based models employ hierarchical approaches to identify nested entities across multiple levels. In early research, Ju et al.8 utilized a multi-layer neural network for this purpose. The network features neuron layers stacked from the innermost to the outermost, with each layer functioning as a sequential tagging model. On this basis, Fei et al.9 introduced a scheduling attention mechanism based on multitask learning that uses different tasks to identify entities with different nested layers. Furthermore, Fisher et al.10 developed a novel neural network model that groups annotated entities into a nested structure, assigning a unique label to each entity. In addition to this, some researchers prefer single decoder designs. For example, Wang et al.11 devised a neural hierarchical model named “Pyramid,” which processes Nested NER tasks from the innermost to the outermost layers. Shibuya et al.12 designed a CRF-based decoding strategy that starts from the outermost entities and progresses inward. This method employs separate CRF layers for each entity category, simplifying the decoding process and eliminating the need for re-encoding.
Hypergraph-based models use a hypergraph structure to describe nested structures in sentences, labelling different named entity tokens via hyperarcs. Initial studies employed directed hypergraphs13 to enhance boundary detection and category prediction. These studies emphasized that hyperarcs delineate the relationships among nested entities by connecting multiple nodes, thereby forming paths that lead to distinct subhypergraphs. To tackle the issue of structural ambiguity, Wang et al.14 developed a neural segmented hypergraph model. The model combines neural network to generate distributed feature representations and integrates hypergraphs to address structural ambiguities. In a different approach, Katiyar et al.15 adopted the BILOU labeling method and introduced a hypergraph structure based on a standard LSTM. The method fully leverages the capabilities of the LSTM technique, enhancing the representation and processing of complex entity relationships within hypergraphs.
Span-based models achieve nested entity recognition by enumerating and classifying spans within a sentence. Initial studies16 conducted a comprehensive categorization of all possible spans, utilizing information on both the interiors and boundaries of entities to generate span representations. To minimize the computational complexity associated with span enumeration, subsequent research primarily focused on utilizing entity boundary information for span generation. Zheng et al.17 added a boundary detection task to improve span representations. This adjustment overcomes the shortcomings of traditional methods that focus on learning fragmentary representations without explicit boundary supervision. Another study18 introduced a boundary detection method that employs token-level classifiers to determine the start and end positions of an entity. These positions are then combined and fed into another classifier for final entity classification.In a different approach, Yu et al.19 applied the bi-affine mechanism to classify spans based on their boundary information. Meanwhile, Liu et al.20 proposed dividing the NER task into two subtasks: entity recognition and entity classification. To address the oversight of semantic relationships between spans, Yan et al.7 introduced a planarized sentence representation. This method merges the head and tail entity representations into a 3D feature matrix and uses a convolutional neural network to enable semantic interactions between spans.
Although the aforementioned method facilitates span interaction to some extent, it predominantly focuses on interactions within locally adjacent regions. We suggest that in a planarized layout, a span has a deeper semantic link with its horizontal and vertical neighbors than with adjacent spans. As illustrated in Fig. 2, spans that are horizontally or vertically aligned typically exhibit shared boundaries or containment relationships within the sentence structure. To explore these connections, we developed a Bi-DCAN based on a multi-granularity cross-attention mechanism to thoroughly understand these semantic relationships. In addition, we add RoPE to the MLP layer of the bi-affine mechanism. This enhancement enables the model to accurately learn the relative position information between head and tail markers through RoPE, thus significantly improving its recognition capabilities.
Methodology
Our model’s workflow is shown in Fig. 3, which consists of two main parts: the boundary information extraction module and the entity semantic perception module. The boundary module adopts an improved bi-affine mechanism to obtain entity boundary information by combining with RoPE. The semantic module uses a Bi-DCAN to gather span representations with contextual semantic details. These representations are combined with the feature matrix from the boundary module. Finally, we use a classifier to classify the entities.

Model structure.
Encoder layer
At the start of our model, we use the BERT pre-trained model as a sentence encoder. This encoder converts each token in the sentence into an embedding vector, as shown in Eq. (1).
where, D represents the embedding vector acquired for each sentence, The n denotes the number of tokens in the input sentence, \(d_i \in \mathbb {R}^l\) denotes the embedding vector of each token, and l denotes the dimensionality of the embedded feature.
Bi-affine attention mechanism augmented with location information
Current span-based models often use the bi-affine mechanism to create a 3D feature matrix that represents semantic relationships within a sentence. However, these models usually ignore the positional information that indicates the exact length of the entity’s span. This includes the relative positions of the sentence’s head and tail tokens. We believe ignoring this detail can lead to a mismatch between the predicted and actual positions of entity heads and tails. The problem ultimately leads to a compromised entity identification capability of the model, especially for long entities.
Therefore, we enable the bi-affine mechanism to capture the relative positions of head and tail tokens by integrating the RoPE module. Specifically, we utilise the MLP layer to process sentence embedding vectors. This produces a head-tail vector representation as shown in Eqs. (2, 3).
where \(W_s\in R^{n\times l}\) and \(W_t\in R^{n\times l}\) are two trainable weight matrices, \(b_s\) and \(b_t\) are the corresponding bias vectors. \(D_s\in R^{n\times l}\) and \(D_s\in R^{n\times l}\) are the sequence representations of the head and tail spans, G denotes the word vector dimension of the head-tail tokens.
However, the basic MLP layer used to derive the head and tail vectors lacks the capability to incorporate relative position information. This limitation arises from the independent computation of head and tail vectors within the MLP layer during projection. Consequently, we address this issue by introducing a position encoding module, which enables us to compute the relative position of the head and tail vectors. This computation yields the relative position information \(R_s\) and \(R_t\), with dimensions identical to those of \(D_s\) and \(D_t\) respectively. Drawing inspiration from the approach outlined in21, we integrate the relative position information into the bi-affine mechanism as follows:
According to the geometrical significance of complex multiplication, the relative position transformation corresponds to the rotation of the vectors, in the case of a two-dimensional matrix, as shown in Eq. (4).
where \(q_m^{(1)},\hspace{5.0pt}q_m^{(2)}\) is the representation of \(q_m\) in 2-dimensional coordinates, and \(f(q_m, m)\) can represent the positional information embedding of \(q_m\). Therefore, based on this principle, it is generalized to a general form, using the header tag vector as an example.
where, \(m\in \left[ 0, m\right)\) represents the position of the token in the sentence, while \(\theta _i=10000^{-2i/l},\hspace{5.0pt}i\in \left[ 0,l/2\right)\) signifies the token embedding dimension of the input sequence. Rotary Position Embedding achieves relative positional encoding by incorporating absolute positional encoding, thus merging the benefits of both absolute and relative positional encoding methods.
Finally, we add the relative position information of the head and tail to their respective vectors and input them into the biaffine function for processing. This step yields a position information-enhanced 3D sentence representation matrix, \(R_0\in R^{l\times n\times n}\), as shown in Eq. (6), where ’Biaffine’ refers to the biaffine function.
Bi-directional context-aware network
In order to obtain the semantic relationship between a target span and its horizontal or vertical spans, we design a Bi-DCAN. Specifically, we first decompose the obtained 3D matrix is decomposed and divided into \(H=\left[ H^1, H^2,..., H^n\right]\) and \(V=\left[ v^1, v^2,..., v^n\right]\) according to the horizontal and vertical directions respectively. We set the decomposition width as 1, and since the matrix is a square matrix, the resulting \(H^i\) and \(V^i\) are standardized as \(H^i,\hspace{5.0pt}V^i\in R^{n\times l}\) and \(i\in \left[ 0, n\right)\).
After obtaining the horizontal and vertical feature matrices, we put them into the local and extended attention mechanisms of the multi-granularity attention network for learning. In this way, we were able to efficiently obtain the local semantic dependencies and long-distance dependencies between the spans. A comparison between the local attention mechanism and the dilation attention mechanism with the standard attention mechanism is shown in Fig. 4.

Schematic representation of different attention mechanisms: (A) is the ordinary self-attention mechanism, (B) is the localized attention mechanism, and (C) is the null attention mechanism.
The local attention mechanism targets localized regions near the span in the sequence. To start, we expand the input feature matrix \(X\in R^{n\times l}\) to \(X^q\in R^{n\times 1\times l}\). We then adjust this according to the local length to get \(X^a\in R^{n\times p_s\times l}\), where \(p_s=2n+1\). Finally, we compute the local attention using Eqs. (7, 8, 9).
where \(W_{lo}^Q\in R^{n\times 1\times l}\), \(W_{lo}^K\in R^{n\times p_s\times l}\) and \(W_{lo}^V\in R^{n\times p_s\times l}\) are three learnable weight matrices.
The dilation attention mechanism calculates the attention relationships between a span and its neighboring spans within a specific distance, known as the Dilation Rate. This approach helps us understand the semantic relationships between spans that are far apart. Specifically, we reshape the input matrix. Then, according to the Dilation Rate dl, we select one word every dl positions. This creates \(X^d\in R^{(n/dl)\times l}\). Finally, we perform the dilation attention calculation as outlined in Eqs. (10, 11).
where \(\left\{ W_{a}^Q, W_{a}^K, W_{a}^V\right\} \in R^{(n/dl)\times l}\) are three learnable weight matrices.
We take the horizontal vector as an example. According to the above formula, we can get a horizontal vector representation \(H_a^i\) after the multi-granularity cross-attention mechanism. The specific calculation process is shown as follows:
where \(\text {attention}_h()\) denotes the horizontal attention mechanism module, and similarly, the vertical attention computation can be derived as \(V_a = \text {attention}_v(V) = \left[ V_a^i, V_a^2, ..., V_a^n\right]\).
We argue that local attention mechanisms help overcome certain limitations of dilation attention mechanisms. Conversely, dilation attention addresses issues in local attention mechanisms that might overlook long-range correlations. Consequently, the multi-granularity cross-attention mechanism provides a balanced solution. It conserves computational memory while effectively capturing both strong local correlations and sparse long-range correlations.
Finally we sum the obtained horizontal and vertical outputs and improve the generalization of the model by one MLP layer. The final 3D matrix with enhanced span context-aware information is obtained \(R_a\in R^{n\times n\times l}\).
Training strategies
Our decoding process is adopted as shown in the paper7. Specifically, we use the perceptron to obtain the predicted logits as shown in Eq. (18).
where \(W_o\in R^{T\times l}\), \(b\in R^T\), \(P\in R^{n\times n\times T}\). T is the number of entity categories. Subsequently we use binary cross entropy to calculate the loss as shown in Eq. (19).
Since the upper and lower triangles of the scoring matrix are symmetrically related, we calculate the scores of the upper triangular portion of the scoring matrix as in our reasoning:
where \(i\le j\). To decode the scores, we initially eliminate non-entity spans, as none of them possess scores exceeding 0.5. Subsequently, we arrange the remaining spans based on their highest entity scores. We choose spans in accordance with this order and disregard spans in situations where their boundaries are in conflict.
Experimental results and analysis
Dataset
Our model was evaluated on three publicly available Nest NER datasets: ACE200422, ACE200523, and GENIA24. Table 1 lists the statistics of the datasets. Here, ’Total’ refers to the total number of entities, ’Nested’ indicates the number of nested entities, and ’Ratio’ shows the percentage of nested entities in the dataset.
We processed the ACE2004 and ACE2005 datasets using the same method described in paper19, dividing the data into training, validation, and testing sets.
Likewise, we applied the method from paper14 to preprocess the GENIA dataset. It was split into training, validation, and test sets in an 8:1:1 ratio for our experiments.
Assessment of indicators
We use precision, recall, and F1 scores to evaluate our model and compare it to related works.
Experimental setup
In the experiments, we utilized a single RTX 4090 GPU for training the model on Windows 10. The experimental setups for the GENIA dataset and ACE dataset are presented in Tables 2 and 3.
Hyperparametric analysis
In this section, we aim to evaluate the appropriateness of the hyperparameter settings by conducting a series of experiments on two datasets, GENIA and ACE2004. Specifically, we focus on analyzing the impact of two key hyperparameters: the biaffine size and the number of attention heads in our model. This analysis involves treating these hyperparameters as control variables to systematically explore their effects on the model’s performance. Detailed results from these experiments are depicted in Figs. 5 and 6, which illustrate the outcomes and trends derived from varying these parameters.

Experimental results on the GENIA dataset: (A) is the number of; (B) is biaffine_size.

Experimental results on the ACE2004 dataset: (A) is the number of attention mechanism heads; (B) is biaffine_size.
Through our analysis, we observed that the GENIA dataset is characterized by an abundance of technical terms and complex vocabulary. This complexity demands that the model possess an enhanced feature learning capability. Consequently, a larger number of attention mechanism heads and an increased biaffine_size are necessary to adequately capture the intricate patterns within this dataset. In contrast, the ACE2004 dataset presents simpler content and a smaller volume of data, which could potentially lead to overfitting if larger parameter values are used. Therefore, it is prudent to opt for smaller hyperparameter settings for this dataset to avoid overfitting and ensure that the model generalizes well across different types of textual data.
Comparison experiment
In this section, we perform experiments with the ACE2004, ACE2005, and GENIA datasets to compare our model with span-based models from related works. The results are presented in Table 4. The best results are highlighted in bold.
Notably, on the ACE2005 and GENIA datasets, our model demonstrates superior performance in terms of F1 scores, surpassing the 87% threshold on the ACE2005 dataset and exceeding 81% on the GENIA dataset. Moreover, concerning the ACE2004 dataset, our model exhibits marginal deviation from the optimal Diffusion-NER by a mere 0.11. These findings underscore the efficacy of our proposed model.
Ablation experiment
In this section, we perform ablation experiments to analyze the effect of different modules on the model performance by removing the module. As shown in the Table 5, all the modules contribute to the improvement of the model performance.
Firstly, the RoPE enables the head and tail tokens obtained by the Biaffine mechanism to carry relative position information, which effectively alleviates the entity boundary recognition ambiguity problem. Second, the Bi-DCAN enriches the feature information by learning the semantic dependencies between spans in the planarised sentence features, which improves the model performance. This suggests semantic relationships between spans that share horizontal and vertical coordinates with the target span. Learning this semantic information enriches the semantic representation of spans.
Semantic dependency strength analysis between span
In this section, we use the GENIA dataset to investigate the strength of semantic dependencies between different distances spans. We conduct studies with different dilation rates and local lengths. To highlight the results, we remove the local attention layer in experiments with varying dilation rates, and likewise, we remove the dilation attention layer in experiments with varying local lengths. The results are presented in Fig. 7.

Experimental results on the GENIA dataset: (A) are for different dilation rates; (B) are for different local lengths.
From (A), we notice that the dilation rate reaches its peak at 3 before decreasing. This indicates that the attention mechanism performs best when the relative distance between spans is 3, where the semantic dependency strength is highest.
From (B), we observe that the performance is optimal when the local length is 3, indicating the strongest semantic dependency between a span and its neighboring spans within a distance of 3.
These experiments illustrate that semantic dependencies between target spans are stronger when they are closer to spans located on the same horizontal and vertical coordinates, and weaken as the distance increases.
Experimental comparison of different entity lengths
In this section, we evaluate the model’s performance in recognizing entities of different lengths, with a focus on its ability to identify entity boundaries and types for long entities. We performed experiments using the GENIA dataset and selected entities of length 4, 5, and greater than 5 from the test set to calculate F1 values. To demonstrate the effectiveness of the RoRE module in identifying long entities, we compare our model with CNN-NER, Diffusion-NER, W2NER, and w/o RoPE. The CNN-NER utilizes convolutional modules to capture local positional information. The Diffusion-NER employs diffusion models to identify entity boundaries by generating and optimizing noise. The W2NER uses traditional positional encoding to obtain positional information. Experimental results are presented in Table 6.
As shown in Table 6, when the entity length is 3, our model exhibits comparable performance to other baseline models. And as the entity length increases, the advantage of our model gradually comes out. Experimental results demonstrate that introducing RoPE into Biaffine to enhance positional information guidance significantly improves the accurate representation of the head and tail tokens of long entities by the model.
Experimental results for different nested models
In order to comprehensively analyze the performance of our model in identifying nested entities, we conducted experiments following the experimental setup outlined in reference37. In this setup, nested entities are structured into tuples, where each tuple comprises an outer entity (i.e., the longest entity) along with several inner entities (entities nested within the outer entity). We selected the five most representative entity types for experimentation on the GENIA dataset and calculate their F1 values. The experimental results are presented in the Table 7. Here, “Flat” denotes statistics for non-nested entity recognition, “Nested” indicates statistics for the recognition of each nested entity, “Inner” and “Outer” respectively represent statistics for the recognition of inner and outer entities within the tuple, and finally, “Nesting” denotes statistics for the simultaneous recognition of the entire tuple.
The Table 7 indicates that our model performs well in all the complex nested environment experiments. The analysis suggests that “flat” entities are less difficult to recognise and have larger data volumes, thus narrowing the performance differences between models. The “outer” entities have smaller data volumes, and the diffusion model has some advantages for small sample experiments. Nevertheless, our model still shows strong overall performance. These experimental results effectively validate the competitive advantage of our model in the Nest NER task.
Analysis of the model training process
In this section, we study the training process of the model using the GENIA dataset as an example and training the model using BioBERT-base. We compare the computational efficiency of our model with related works, as illustrated in Table 8.
As can be seen from the Table 8, the Diffusion-NER employs a diffusion model for entity boundary recognition, which results in a higher number of parameters due to the complexity of the denoising step. The Triaffine model utilises a triple affine attention mechanism for entity recognition, which involves more levels of affine transformations to obtain richer features. In contrast, our model utilises semantically dependent information related to span location relationships to enhance span semantic representations. Since only the attention mechanism is used to compute the 3D feature matrix, the number of parameters of our model is small. These results demonstrate that our model is competitive in terms of computational efficiency.
Then, we collect the training results of our model on the ACE2004 dataset with the benchmark models CNN-NER and Diffusion-NER. The training performance of the model is analyzed by comparing the curve fit with 50 epochs. The comparison results are shown in Fig. 8.

Changes in F1 curves for the validation set during training for the ACE2004 dataset.
We run 50 epochs on the ACE2005 dataset and collect the F1 scores for each epoch in the training set, as depicted in Fig. 8. The curves show that our model fits rapidly in the initial training phase, steadily increases around the 3th epoch, and plateaus approximately at the 10th epoch. We retain the best-performing model for test set evaluation.
As illustrated in the Fig. 8, Diffusion-NER exhibits a slower learning fitting speed due to the increased complexity of the network resulting from the introduction and handling of noise during its generation and optimization processes. In contrast, CNN-NER, W2NER, and our model demonstrate lower complexities, thereby facilitating a faster learning fitting rate. Specifically, both CNN-NER and W2NER use simple CNN architectures, which leads them to be relatively poor at capturing long-range dependencies. As a result, they have a slightly slower learning fit compared to our model. consequently leading to a slightly slower learning fitting pace when juxtaposed with our model. The comparison results of the curves confirm the superior convergence speed and stronger learning performance of our model.
Impact of different pre-training models
To verify the scalability of our method, we select four different pre-training models: BERT-Small, BERT-base, BERT-large, and RoBERTa-base. We conducted experiments on the ACE2004 dataset. As shown in Table 9, our model achieves an F1 value of over 85% across different pre-training models, indicating superior performance. This confirms the scalability of our method.
Conclusion
Aiming at the problem that traditional spanning models cannot effectively obtain the semantic relationship information between spans and the location information of entities, we introduce a Bi-Directional Context-Aware Network for nested named entity recognition. Initially, we propose a novel span-level semantic relation model to represent both local and long-range semantic relations between spans. Subsequently, we present a Bi-DCAN that utilizes a multi-granularity cross-attention mechanism to capture and learn the semantic relation information. Additionally, we utilize RoPE to optimize the bi-affine mechanism, enabling it to effectively leverage positional information. We evaluated our model on three nested datasets. The experimental findings show that our model has fewer parameters, high computational efficiency, and achieved the highest F1 scores on the ACE2005 and GENIA datasets. This demonstrates our model’s excellent capability in nested entity recognition. In future work, we aim to further research the semantic relations between spans in the span model and explore more effective ways to integrate local dependencies and boundary information to enhance the model’s performance even further.
Data availability
The datasets analyzed during this study are available at ACE2004 (https://catalog.ldc.upenn.edu/LDC2005T09), ACE2005 (https://catalog.ldc.upenn.edu/LDC2006T06) and GENIA (http://www.geniaproject.org/genia-corpus).
References
Cheng, Q. et al. HacRED: A large-scale relation extraction dataset toward hard cases in practical applications. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2819–2831 (2021).
Liu, Q., Li, Y., Duan, H., Liu, Y. & Qin, Z. A survey of knowledge mapping construction techniques. J. Comput. Res. Dev. 53, 582–600 (2016).
Dwivedi, S. K. & Singh, V. Research and reviews in question answering system. Procedia Technol. 10, 417–424 (2013).
Lafferty, J. D., McCallum, A. & Pereira, F. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In International Conference on Machine Learning (2001).
Lample, G., Ballesteros, M., Subramanian, S., Kawakami, K. & Dyer, C. Neural architectures for named entity recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies 260–270 (2016).
Eberts, M. & Ulges, A. Span-based joint entity and relation extraction with transformer pre-training. In ECAI 2020 2006–2013 (IOS Press, 2020).
Yu, J., Bohnet, B. & Poesio, M. Named entity recognition as dependency parsing. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics 6470–6476 (2020).
Yan, H., Sun, Y., Li, X. & Qiu, X. An embarrassingly easy but strong baseline for nested named entity recognition. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) 1442–1452 (2023).
Ju, M., Miwa, M. & Ananiadou, S. A neural layered model for nested named entity recognition. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) 1446–1459 (2018).
Fei, H., Ren, Y. & Ji, D. Dispatched attention with multi-task learning for nested mention recognition. Inf. Sci. 513, 241–251 (2020).
Fisher, J. & Vlachos, A. Merge and label: A novel neural network architecture for nested NER. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics 5840–5850 (2019).
Wang, J., Shou, L., Chen, K. & Chen, G. Pyramid: A layered model for nested named entity recognition. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics 5918–5928 (2020).
Shibuya, T. & Hovy, E. Nested named entity recognition via second-best sequence learning and decoding. Trans. Assoc. Comput. Linguist. 8, 605–620 (2020).
Lu, W. & Roth, D. Joint mention extraction and classification with mention hypergraphs. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing 857–867 (2015).
Wang, B. & Lu, W. Neural segmental hypergraphs for overlapping mention recognition. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing 204–214 (2018).
Katiyar, A. & Cardie, C. Nested named entity recognition revisited. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies Vol. 1 (2018).
Sohrab, M. G. & Miwa, M. Deep exhaustive model for nested named entity recognition. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing 2843–2849 (2018).
Zheng, C., Cai, Y., Xu, J., Leung, H. & Xu, G. A boundary-aware neural model for nested named entity recognition. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (Association for Computational Linguistics, 2019).
Tan, C., Qiu, W., Chen, M., Wang, R. & Huang, F. Boundary enhanced neural span classification for nested named entity recognition. In Proceedings of the AAAI Conference on Artificial Intelligence Vol. 34 9016–9023 (2020).
Liu, C., Fan, H. & Liu, J. Handling negative samples problems in span-based nested named entity recognition. Neurocomputing 505, 353–361 (2022).
Su, J. et al. Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:2104.09864 (2021).
Mitchell, A. The automatic content extraction (ACE) program-tasks, data, and evaluation.
Walker, C., Strassel, S., Medero, J. & Maeda, K. Ace 2005 multilingual training corpus-linguistic data consortium. https://catalog.ldc.upenn.edu/LDC2006T06 (2005).
Kim, J.-D., Ohta, T., Tateisi, Y. & Tsujii, J. Genia corpus-a semantically annotated corpus for bio-textmining. Bioinformatics 19, i180–i182 (2003).
Lee, J. et al. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 36, 1234–1240 (2020).
Li, X. et al. A unified MRC framework for named entity recognition. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics 5849–5859 (2020).
Shen, Y. et al. Locate and label: A two-stage identifier for nested named entity recognition. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) 2782–2794 (2021).
Wan, J., Ru, D., Zhang, W. & Yu, Y. Nested named entity recognition with span-level graphs. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) 892–903 (2022).
Lou, C., Yang, S. & Tu, K. Nested named entity recognition as latent lexicalized constituency parsing. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) 6183–6198 (2022).
Zhu, E. & Li, J. Boundary smoothing for named entity recognition. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) 7096–7108 (2022).
Yuan, Z., Tan, C., Huang, S. & Huang, F. Fusing heterogeneous factors with Triaffine mechanism for nested named entity recognition. In Findings of the Association for Computational Linguistics: ACL 3174–3186 (2022).
Li, J. et al. Unified named entity recognition as word-word relation classification. In Proceedings of the AAAI Conference on Artificial Intelligence Vol. 36 10965–10973 (2022).
Chen, Y. et al. A boundary regression model for nested named entity recognition. Cogn. Comput. 15, 534–551 (2023).
Shen, Y. et al. Diffusionner: Boundary diffusion for named entity recognition. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) 3875–3890 (2023).
Mu, J., Ouyang, J., Yao, Y. & Ren, Z. Span-prototype graph based on graph attention network for nested named entity recognition. Electronics 12, 4753. https://doi.org/10.3390/electronics12234753 (2023).
Zheng, Q. et al. Exploring interactive and contrastive relations for nested named entity recognition. IEEE ACM Trans. Audio Speech Lang. Process. 31, 2899–2909. https://doi.org/10.1109/TASLP.2023.3293047 (2023).
Rojas, M., Bravo-Marquez, F. & Dunstan, J. Simple yet powerful: An overlooked architecture for nested named entity recognition. In Proceedings of the 29th International Conference on Computational Linguistics 2108–2117 (2022).
Acknowledgements
We gratefully acknowledge this research is supported by the China Postdoctoral Science Foundation under Grant Number 2024MD754245, Natural Science Foundation of Chongqing, China (CSTB2024NSCQ-MSX0110), the Science and Technology Research Program of Chongqing Municipal Education Commission (Grant No. KJQN202101127), NSFC Cultivation Program of Chongqing University of Technology (2022PYZ031).
Author information
Authors and Affiliations
Contributions
Y.L.: Conceptualization, Methodology, Software, Validation, Data Curation, Writing—Original Draft, Writing—Review and Editing. N.L.: Methodology, Formal analysis, Validation, Data Curation, Writing—Review and Editing. H.Y., Y.Z. and X.W.: Formal analysis, Validation, Writing—Review and Editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, Y., Liao, N., Yan, H. et al. Bi-directional context-aware network for the nested named entity recognition. Sci Rep 14, 16106 (2024). https://doi.org/10.1038/s41598-024-67114-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-67114-6
Keywords
This article is cited by
-
SSAM: a span spatial attention model for recognizing named entities
Scientific Reports (2025)
-
Transformer-based prototype network for Chinese nested named entity recognition
Scientific Reports (2025)
