
Abstract
This article aims to suggest an improved estimator for estimation of population median using auxiliary information under simple random sampling. The expression for the bias and mean square error are obtained up to first order approximation. We determine the MLE of the optimal values of the describing scalars. The proficiency of the suggested estimator is evaluated in comparison to the preliminary estimators using the MSE threshold. The suggested estimators are compared numerically to the ones that are currently studied in this study. The performance and novelty of the estimators was evaluated using real data sets and a simulation study. To check the efficiency of estimators empirical and theoretical study has been studied. Based on numerical result it is to be noted that our suggested estimator is more efficient as compared to existing estimators which is considered in this article in terms of least MSE and greater PRE.
Similar content being viewed by others

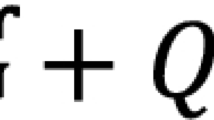
Introduction
In survey sampling, utilization of auxiliary information can improved estimator efficiency whichever at the design or at the estimation stage. Many efforts have been done for the purpose of increasing efficiency of an estimator. The efficient estimators of the population’s median have received comparatively less attention compared to that of its mean, proportion, variance, regression coefficient, etc., which have all been the subject of significant studies. Income, expenditure, taxation, consumption, and production are frequently of interest to researchers; at this point the distributions of these last two variables are extremely skewed. The median is a far better, rather than the mean in these circumstances. It is common for statisticians to be interested in handling variables with extremely skewed distributions, such earnings and consumption, in the sampling literature. In such circumstances, the median is believed to be a well central measure than the mean. The authors in Ref.1 recommended enhanced estimator for median exhausting auxiliary information under simple and stratified random sampling. Reference2 discussed difference type estimator for median estimation. The authors in Refs.3,4,5 discussed estimation of population median using two phase sampling. Reference6 recommended median estimator using auxiliary information. Reference7 suggested improved estimator for population median. References8,9 discussed a novel estimator utilizing auxiliary information. Reference10 recommend ratio and regression type estimator for population median. Reference11 suggested enhanced estimator for population median usig two phase sampling. The authors in Refs.12,13 discussed exponential and ratio type estimator for population median. Reference14 discussed difference type estimator for population median using auxiliary information. The authors in Refs.15,16,17,18,19,20,21,22,23,24 discussed some improved estimator for population parameter under different sampling design using auxiliary information.
Materials and methods
Let a population consists \(\text{W}\) = \(\left({\text{W}}_{1}, {\text{W}}_{2}, \dots , {\text{W}}_{N}\right)\) of N differing units. Let \(Y_{i}\) and \(X_{i}\) be the \(i{\text{th}}\) values of the study variable and the auxiliary variables. Let a sample of n is chosen from \(\text{W}\). The sample and population medians of the study and the auxiliary variable are denoted by \(M_{y}\) and \(M_{x}\), and \(M_{y}\) and \(M_{x}\) with probability density functions of fy \(\left({M}_{y}\right)\) and fx \(\left({M}_{x}\right)\). The correlation coefficienct between the \(M_{y}\) and \(M_{x}\) are represented by \({\rho }_{yx}\) and is defined as \({\rho }_{\left({M}_{y}, {M}_{x}\right)}\) = 4 \({P}_{11}\left(y,x\right) -\) 1, where \({P}_{11}\) = \(P\left(y\le {M}_{y}\cap x\le {M}_{x}\right)\).
To gain the expressions of bias and MSE we used the following error terms:
where
Existing counterparts
This section consists of some well know existing estimators for comparison purpose.
-
(1)
Reference6 discuss usual unbiased median estimator \(\left({\widehat{M}}_{y}\right)\), which is given by:
$${\widehat{M}}_{y}={\widetilde{M}}_{y}.$$(1)The variance of \({\widehat{M}}_{y}\), is given by:
$$ Var\left( {\hat{M}_{y} } \right) = \Lambda M_{y}^{2} C_{My}^{2} = \Lambda \left\{ {f_{y} (M_{y} )} \right\}^{ - 2} . $$(2) -
(2)
Reference9 recommended ratio estimator, which is given by:
$$ \hat{M}_{R} = \hat{M}_{y} \left( {\frac{{M_{x} }}{{M_{x} }}} \right). $$(3)The expressions of \(Bias\left( {\hat{M}_{R} } \right)\) and \(MSE\left( {\hat{M}_{R} } \right)\) are given by:
$$ Bias\left( {\hat{M}_{R} } \right) \cong \Lambda M_{y} \left( {C_{Mx}^{2} - C_{Myx} } \right), $$$$ MSE\left( {\hat{M}_{R} } \right) \cong \Lambda M_{y}^{2} \left( {C_{My}^{2} + C_{Mx}^{2} - 2C_{Myx} } \right). $$(4) -
(3)
The exponential ratio-type estimator is given by:
$$ \hat{M}_{EX} = \hat{M}_{y} \exp \left( {\frac{{M_{x} - \hat{M}_{x} }}{{M_{x} + \hat{M}_{x} }}} \right). $$(5)The expressions of \(Bias\left( {\hat{M}_{EX} } \right)\) and \(MSE\left( {\hat{M}_{EX} } \right)\) are given by
$$ Bias\left( {\hat{M}_{EX} } \right) \cong \Lambda M_{y} \left( {\frac{3}{8}C_{Mx}^{2} - \frac{1}{2}C_{Myx} } \right), $$and
$$ MSE\left( {\hat{M}_{EX} } \right) \cong \Lambda M_{y}^{2} \left( {C_{My}^{2} + \frac{1}{4}C_{Mx}^{2} - 2C_{Myx} } \right){.} $$(6) -
(4)
The difference estimator, is given by:
$$ \hat{M}_{D} = \hat{M}_{y} + d\left( {M_{x} - \hat{M}_{x} } \right){.} $$(7)The optimum value of d is given by:
$$ d_{opt} = \frac{{M_{y} \rho_{yx} C_{My} }}{{M_{x} C_{Mx} }}. $$The minimum \(MSE\left( {\hat{M}_{D} } \right)\) at the optimum value is given by:
$$ MSE\left( {\hat{M}_{D} } \right)_{\min } \cong \Lambda M_{y}^{2} C_{My}^{2} \left( {1 - \rho_{xy}^{2} } \right){.} $$(8) -
(5)
Following5,10,25 respectively, proposed some difference-type estimators \(\hat{M}_{Di} (i = 1,2,3)\), which is given by:
$$ \hat{M}_{D1} = d_{1} \hat{M}_{y} + d_{2} \left( {M_{x} - \hat{M}_{x} } \right){,} $$(9)$$ \hat{M}_{D2} = \left[ {d_{3} \hat{M}_{y} + d_{4} \left( {M_{x} - \hat{M}_{x} } \right)} \right]\left( {\frac{{M_{x} }}{{\hat{M}_{x} }}} \right), $$(10)$$ \hat{M}_{D3} = \left[ {d_{5} \hat{M}_{y} + d_{6} \left( {M_{x} - \hat{M}_{x} } \right)} \right]\exp \left( {\frac{{M_{x} - \hat{M}_{x} }}{{M_{x} + \hat{M}_{x} }}} \right){.} $$(11)At the optimum values of \(d_{i} (i = 1,2,.....,6)\) the bias of \(\hat{M}_{Di} (i = 1,2,3)\) are given by
$$ Bias\left( {\hat{M}_{D1} } \right) \cong M_{y} \left( {d_{1} - 1} \right){,} $$$$ Bias\left( {\hat{M}_{D2} } \right) \cong M_{y} \left( {d_{3} - 1} \right) + d_{3} \Lambda M_{y} \left( {C_{Mx}^{2} - C_{Myx} } \right) + d_{4} \Lambda M_{x} C_{Mx}^{2} {,} $$$$ Bias\left( {\hat{M}_{D3} } \right) \cong M_{y} \left( {d_{5} - 1} \right) + d_{5} \Lambda M_{y} \left\{ {\frac{3}{8}C_{Mx}^{2} - \frac{1}{2}C_{Myx} } \right\} + \frac{1}{2}d_{6} \Lambda M_{x} C_{Mx}^{2} . $$At the optimum values of \(d_{i} (i = 1,2,...,6)\)
$$ d_{1(opt)} = \frac{1}{{1 + \Lambda C_{My}^{2} \left( {1 - \rho_{xy}^{2} } \right)}},\;d_{5(opt)} = \frac{{1 - \left( {{{\Lambda C_{Mx}^{2} } \mathord{\left/ {\vphantom {{\Lambda C_{Mx}^{2} } 8}} \right. \kern-0pt} 8}} \right)}}{{1 + \Lambda C_{My}^{2} \left( {1 - \rho_{xy}^{2} } \right)}}, $$$$ d_{3(opt)} = \frac{{1 - \Lambda C_{Mx}^{2} }}{{1 - \Lambda C_{Mx}^{2} + \Lambda C_{My}^{2} \left( {1 - \rho_{xy}^{2} } \right)}},\;d_{2(opt)} = \frac{{M_{y} }}{{M_{x} }}\left[ {\frac{{\rho_{xy} C_{My} }}{{C_{Mx} \left\{ {1 + \Lambda C_{My}^{2} \left( {1 - \rho_{xy}^{2} } \right)} \right\}}}} \right], $$$$ d_{4(opt)} = \frac{{M_{y} }}{{M_{x} }}\left[ {1 + d_{3(opt)} \left( {\frac{{\rho_{xy} C_{My} }}{{C_{Mx} }} - 2} \right)} \right]\;{\text{and}}\;d_{6(opt)} = \frac{{M_{y} }}{{M_{x} }}\left[ {\frac{1}{2} + d_{5(opt)} \left( {\frac{{\rho_{xy} C_{My} }}{{C_{Mx} }} - 1} \right)} \right]. $$The minimum mean square error of \(\hat{M}_{Di} (i = 1,2,3)\) are given by
$$ MSE\left( {\hat{M}_{D1} } \right)_{\min } \cong \frac{{\Lambda M_{y}^{2} C_{My}^{2} \left( {1 - \rho_{xy}^{2} } \right)}}{{1 + \Lambda C_{My}^{2} \left( {1 - \rho_{xy}^{2} } \right)}}, $$(12)$$ MSE\left( {\hat{M}_{D2} } \right)_{\min } \cong \frac{{\Lambda M_{y}^{2} \left( {1 - \Lambda C_{Mx}^{2} } \right)C_{My}^{2} \left( {1 - \rho_{xy}^{2} } \right)}}{{\left( {1 - \Lambda C_{Mx}^{2} } \right) + \Lambda C_{My}^{2} \left( {1 - \rho_{xy}^{2} } \right)}}{,} $$(13)$$ MSE\left( {\hat{M}_{D3} } \right)_{\min } \cong \frac{{\Lambda M_{y}^{2} \left[ {C_{Mx}^{2} \left( {1 - \rho_{xy}^{2} } \right) - \frac{\Lambda }{4}C_{Mx}^{2} \left\{ {\frac{1}{16}C_{Mx}^{2} + C_{My}^{2} \left( {1 - \rho_{xy}^{2} } \right)} \right\}} \right]}}{{1 + \Lambda C_{My}^{2} \left( {1 - \rho_{xy}^{2} } \right)}}. $$(14) -
(6)
Reference14 suggested the generalized difference-type estimator for population median, which is given by:
$$ \hat{M}^{G}_{pp} = \left[ {m_{1} \hat{M}_{y} + m_{2} \left( {M_{x} - \hat{M}_{x} } \right)} \right]\left[ {\left( {\frac{{aM_{x} + b}}{{a\hat{M}_{x} + b}}} \right)\exp \left\{ {\frac{{\alpha_{2} a\left( {M_{x} - \hat{M}_{x} } \right)}}{{a\left\{ {(\gamma - 1)M_{x} + \hat{M}_{x} } \right\} + 2b}}} \right\}} \right], $$(15)where \(m_{1}\) and \(m_{2}\) are unidentified constants whose values are to be determined, \(a\) and \(b\) defined as unknown population parameters and \(\alpha_{1}\), \(\alpha_{2}\) and \(\gamma\) are scalar quantities which can take different values like \(\alpha_{1} = b = 0\) and \(\alpha_{2} = \gamma = a = 1\).
The \(Bias\left( {\hat{M}^{G}_{pp} } \right)\) is given by
$$ Bias\left( {\hat{M}_{pp}^{G} } \right) \cong (m_{1} - 1)M_{y} + m_{2} M_{y} \Lambda \left\{ {\frac{3}{2}C_{Mx}^{2} - C_{My} } \right\} + m_{2} M_{x} \Lambda C_{Mx}^{2} {.} $$At the optimum values of
$$ m_{1(opt)} = \frac{{1 - 0.5\Lambda C_{Mx}^{2} }}{{1 + \Lambda C_{My}^{2} (1 - \rho_{xy}^{2} )}}, $$and
$$ m_{2(opt)} = \frac{{M_{y} }}{{M_{x} }}\left[ {1 + m_{1(opt)} \left\{ {\frac{{\rho_{xy} C_{My} }}{{C_{Mx} }} - 2} \right\}} \right]. $$The \(\min MSE\left( {\hat{M}^{G}_{pp} } \right)\) is given by
$$ MSE\left( {\hat{M}^{G}_{pp} } \right)_{\min } \cong \frac{{M_{y}^{2} }}{{1 + \Lambda C_{My}^{2} (1 - \rho_{xy}^{2} )}}\left[ {\Lambda C_{My}^{2} (1 - \rho_{xy}^{2} ) - \frac{1}{4}\Lambda^{2} C_{Mx}^{4} - \Lambda^{2} C_{My}^{2} C_{Mx}^{2} (1 - \rho_{xy}^{2} )} \right]{.} $$(16) -
(7)
The author in Ref.2 proposed the following difference type estimator using two-auxiliary variables
$$ \hat{M}_{P}^{I} = \left\{ {\hat{M}_{y} + m_{1} \left( {M_{x} - \hat{M}_{x} } \right)} \right\}\left\{ {m_{2} \exp \left( {\frac{{M_{z} - \hat{M}_{z} }}{{M_{z} + \hat{M}_{z} }}} \right)} \right.\left. { + \left( {1 - m_{2} } \right)\exp \left( {\frac{{\hat{M}_{z} - M_{z} }}{{M_{z} + \hat{M}_{z} }}} \right)} \right\}{.} $$(17)The \(Bias\left( {\hat{M}_{P}^{I} } \right)\) is given by
$$ Bias\left( {\hat{M}_{P}^{I} } \right) = \Lambda \left[ {m_{1} M_{x} C_{Mxz} \left( {m_{2} - 0.5} \right) + M_{y} C_{Myz} \left( {0.5 - m_{2} } \right)} \right]. $$The \(MSE\left( {\hat{M}_{P}^{I} } \right)\) is given by
$$ MSE\left( {\hat{M}_{P}^{I} } \right) = \Lambda \left[ {M_{y}^{2} } \right.\left\{ {\left( {C_{My}^{2} + 0.25C_{Mz}^{2} } \right) + m_{2} C_{Mz} \left( {m_{2} } \right.C_{Mz} - C_{Mz} - 2\rho_{yz} \left. {C_{My} } \right) + \rho_{yz} C_{My} C_{Mz} } \right\} + m_{1} M_{x} C_{Mx} \left( {m_{1} } \right.\,M_{x} C_{Mx} - 2M_{y} \rho_{yx} C_{My} - \rho_{xz} C_{Mz} M_{y} + 2m_{2} \rho_{xz} C_{Mz} \left. {\left. {M_{y} } \right)} \right], $$$$ m_{1(opt)} = \frac{{C_{My} M_{y} \left( {\rho_{xz} \rho_{yz} - \rho_{yx} } \right)}}{{C_{Mx} M_{x} \left( {\rho_{xz}^{2} - 1} \right)}}, $$$$ m_{2(opt)} = \frac{{C_{Mz} \left( {\rho_{xz}^{2} - 1} \right) + 2C_{My} \left( {\rho_{xz} \rho_{yx} - \rho_{yz} } \right)}}{{2C_{Mz} \left( {\rho_{xz}^{2} - 1} \right)}}. $$At the optimum values of, the expression of \(MSE(M_{p}^{I} )_{\min }\) is given by:
$$ MSE(\hat{M}_{p}^{I} )_{\min } = \frac{{\Lambda M_{y}^{2} C_{My}^{2} }}{{\left( {1 - \rho_{xz}^{2} } \right)}}\left( {1 - \rho_{xz}^{2} - \rho_{yx}^{2} - \rho_{yz}^{2} + 2\rho_{yx} \rho_{xz} \rho_{yz} } \right). $$(18) -
(8)
Reference26 proposed the following ratio-cum-product exponential-type median estimator as
$$ \hat{M}_{SM} = \hat{M}_{y} \left\{ {m_{12} \left( {\frac{{M_{x} }}{{\hat{M}_{x} }}} \right)} \right.\left. { + m_{13} \left( {\frac{{\hat{M}_{x} }}{{M_{x} }}} \right)} \right\}\left\{ {\alpha \exp \left( {\frac{{M_{x} - \hat{M}_{x} }}{{M_{x} + \hat{M}_{x} }}} \right)} \right.\left. { + \left( {1 - \alpha } \right)\exp \left( {\frac{{\hat{M}_{x} - M_{x} }}{{M_{x} + \hat{M}_{x} }}} \right)} \right\}{,} $$(19)$$ Bias\left( {\hat{M}_{SM} } \right) = M_{y} \left[ {\left( {m_{12} + m_{13} - 1} \right) + m_{12} \Lambda \left\{ {\left( {\frac{3}{8} + \frac{3\alpha }{2}} \right)C_{Mx}^{2} - \left( {\alpha + \frac{1}{2}} \right)C_{Myx} } \right\}} \right.\left. { + m_{13} \Lambda \left\{ {\left( {\frac{3}{2} - \alpha } \right)C_{Myx} + \left( {\frac{3}{8} - \frac{\alpha }{2}} \right)C_{Mx}^{2} } \right\}} \right]. $$
The optimal values of \(m_{12(opt)} = \left[ {\frac{{A_{2} A_{4} - A_{3} A_{5} }}{{A_{1} A_{2} - A_{3}^{2} }}} \right]\) and \(m_{13(opt)} = \left[ {\frac{{A_{1} A_{5} - A_{3} A_{4} }}{{A_{1} A_{2} - A_{3}^{2} }}} \right]\), the expression of \(MSE\left( {M_{SM} } \right)_{\min }\) is given by:
where \(A_{1} = 1 + \Lambda \left\{ {C_{My}^{2} + \left( {\alpha^{2} + 4\alpha + 1} \right)C_{Mx}^{2} - 2\left( {2\alpha + 1} \right)C_{Myx} } \right\},\) \(A_{2} = 1 + \Lambda \left\{ {C_{My}^{2} + \left( {\alpha^{2} - 4\alpha + 3} \right)C_{Mx}^{2} + 2\left( {3 - 2\alpha } \right)C_{Myx} } \right\},\) \(A_{3} = 1 + \Lambda \left\{ {C_{My}^{2} + 2\left( {1 - 2\alpha } \right)C_{Myx} + \alpha^{2} C_{Mx}^{2} } \right\},\) \(A_{4} = 1 + \Lambda \left\{ {\left( {\frac{3}{8} + \frac{3\alpha }{2}} \right)C_{Mx}^{2} - \left( {\alpha + \frac{1}{2}} \right)C_{Myx} } \right\}\) and \(A_{5} = 1 + \Lambda \left\{ {\left( {\frac{3}{8} - \frac{\alpha }{2}} \right)C_{Mx}^{2} + \left( {\frac{3}{2} - \alpha } \right)C_{Myx} } \right\}\).
Proposed estimator
Estimator performance can be enhanced by making use of auxiliary information during design and estimation stages. We used auxiliary information to determine the population median based on this notion. Taking motivation from Ref.27, we have suggested an improved estimator for population median using single auxiliary variable under simple random sampling. Our suggested estimator under simple random sampling offers several advantages over the existing estimators, the most notable of which are their enhanced adaptability, efficiency, and originality, which is given by:
By expressing the above equation in error terms, we have:
After simplifying we have:
Taking expectation on both sides of Eq. (22), we have:
Squaring Eq. (22), and ignoring higher order terms and taking expectation, we got:
Putting the optimum values of \({\alpha }_{1opt}\) and \({\alpha }_{2opt}\) in Eq. (23), we got the minimum mean square, we have:
Numerical study
In this section, we take three actual data sets to observe the efficiency of an estimators. Here, we consider three actual data sets. The PRE of \({\widehat{M}}_{i}\) with respect to \({\widehat{M}}_{y}\) is carried using below expression.
Population 1: [Source28].
Y = Number of faculty, X = Number of students in 4 diverse schools under 36 districts in Punjab.
N = 144, n = 10, \(\Lambda\) = 0.02327, \({M}_{y}\) = 2023, \({M}_{x}\) = 64,659, fy \(\left({M}_{y}\right)\) = 0.00024, fx \(\left({M}_{x}\right)\) = 0.00001, \({\rho }_{yx}\) = 0.86110, \(C_{My}\) = 2.05965, \(C_{Mx}\) = 1.54658, \(C_{Myx}\) = 2.74295.
Population 2: [Source29].
Y = Oil prices in present week in 2017, X = Oil prices in preceding week from 2017.
N = 51, n = 11, \(\Lambda\) = 0.01782, \({M}_{y}\) = 25.80, \({M}_{x}\) = 25.60, fy \(\left({M}_{y}\right)\) = 0.0728, fx \(\left({M}_{x}\right)\) = 0.1080, \({\rho }_{yx}\) = 0.9956, \(C_{My}\) = 0.53242, \(C_{Mx}\) = 0.36168, \(C_{Myx}\) = 0.19172.
Population 3: [Source3].
Y = Advanced degrees in 2007 of US, X = Advanced degrees in 2006 of US.
N = 1134, n = 210, \(\Lambda\) = 0.00097, \({M}_{y}\) = 48.55, \({M}_{x}\) = 48.49, fy \(\left({M}_{y}\right)\) = 0.0075349, fx \(\left({M}_{x}\right)\) = 0.0075437, \({\rho }_{yx}\) = 0.9953, \(C_{My}\) = 2.73359, \(C_{Mx}\) = 2.7378, \(C_{Myx}\) = 7.43791.
Empirical study
In this section, a simulation study was acknowledged to estimate the performance of the estimators empirically. Three populations are generated of size 1500 from normal population with theoretical means 5, for both Y and X. The variance covariance metrics used for three different populations are given by:
Population 1:
Population 2:
Population 3:
The sample sizes n = 50, 150, 250 are chosen in each population. The population density functions for Y and X are calculated utilizing normal distributions. Tables 3 and 4 comprise the mean square error and percentage relative efficiency based on the simulated data.
Conclusion
In this article, we have suggested an enhanced estimator for estimation of population median under simple random sampling using auxiliary variable. Up to the first order of approximation, we evaluated into the bias and MSE of the suggested estimator. Three different datasets are used to evaluate the proposed generalized class of estimators against existing estimators. To check the novelty of estimator a simulation study is also conducted. The results of mean square error and percentage relative efficiency using actual data sets are given in Tables 1 and 2. Three simulated populations are generated of population size 1500 from normal distribution with theoretical means 5, for both Y and X. The sample sizes n = 50, 150, 250 are chosen in each population. The population density functions for Y and X are calculated utilizing normal distributions. The results based on simulation study include on Tables 3 and 4. Based on outcome of actual data sets and a simulation study, we can observe that the suggested estimator achieved minimum MSE and the higher percentage relative efficiency. This shows that the suggested estimator is more efficient for practical determinations when compared to other estimators. Consequently, regarding the new survey, we highly suggest choosing the suggested estimators discussed in this work for calculating the finite population median under the scenario of simple random sampling. The current work can be easily extended to estimation population mean using predictive approach under stratified and systematic random sampling. Further this work is easily extended to estimate population median under stratified random sampling.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Aladag, S. & Cingi, H. Improvement in estimating the population median in simple random sampling and stratified random sampling using auxiliary information. Commun. Stat. Theory Methods 44(5), 1013–1032 (2015).
Baig, A., Masood, S. & Ahmed Tarray, T. Improved class of difference-type estimators for population median in survey sampling. Commun. Stat. Theory Methods 49(23), 5778–5793 (2020).
Bandyopadhyay, A., Singh, G. N. & Das, P. Estimation of population median in presence of non-response under two-phase sampling. Sri Lankan J. Appl. Stat. 17, 2 (2016).
Enang, E. I., Etuk, S. I., Ekpenyong, E. J. & Akpan, V. M. An alternative exponential estimator of population median. Int. J. Stat. Econ. 17(3), 85–97 (2016).
Gupta, S., Shabbir, J. & Ahmad, S. Estimation of median in two-phase sampling using two auxiliary variables. Commun. Stat. Theory Methods 37(11), 1815–1822 (2008).
Gross, S. Median estimation in sample surveys. In Proc. Section on Survey Research Methods, Vol. 1814184 (American Statistical Association, 1980).
Jhajj, H. S., Kaur, H. & Walia, G. Efficient family of ratio-product type estimators of median. Model Assist. Stat. Appl. 9(4), 277–282 (2014).
Irfan, M., Javed, M., Shongwe, S. C., Zohaib, M. & Haider Bhatti, S. Estimation of population median under robust measures of an auxiliary variable. Math. Probl. Eng. 2021, 1–14 (2021).
Kuk, A. Y. & Mak, T. K. Median estimation in the presence of auxiliary information. J. R. Stat. Soc. Ser. B (Methodol.) 51(2), 261–269 (1989).
Rao, T. J. On certail methods of improving ration and regression estimators. Commun. Stat. Theory Methods 20(10), 3325–3340 (1991).
Shabbir, J., Gupta, S. & Hussain, Z. Improved estimation of finite population median under two-phase sampling when using two auxiliary variables. Sci. Iran. 22(3), 1271–1277 (2015).
Shahzad, U., Al-Noor, N. H., Hanif, M. & Sajjad, I. An exponential family of median based estimators for mean estimation with simple random sampling scheme. Commun. Stat. Theory Methods 50(20), 4890–4899 (2021).
Subzar, M. et al. Efficient class of ratio cum median estimators for estimating the population median. PLoS ONE 18(2), e0274690 (2023).
Shabbir, J. & Gupta, S. A generalized class of difference type estimators for population median in survey sampling. Hacettepe J. Math. Stat. 46(5), 1015–1028 (2017).
Singh, G. N., Pandey, A. K. & Singh, C. Generalized estimation strategy for mean estimation on current occasion in two-occasion rotation patterns. Commun. Stat. Simul. Comput. 51(4), 1661–1684 (2022).
Singh, G. N., Jaiswal, A. K. & Pandey, A. K. Improved imputation methods for missing data in two-occasion successive sampling. Commun. Stat. Theory Methods 52(6), 2010–2029 (2023).
Singh, G. N., Pandey, A. K. & Sharma, A. K. Some improved and alternative imputation methods for finite population mean in presence of missing information. Commun. Stat. Theory Methods 50(19), 4401–4427 (2021).
Ahmad, S. et al. Improved estimation of population distribution function using twofold auxiliary information under simple random sampling. Heliyon 10, 2 (2024).
Hussain, M. A. et al. Estimation of population median using bivariate auxiliary information in simple random sampling. Heliyon 10, 7 (2024).
Subramani, J. & Kumarapandiyan, G. Estimation of population mean using coefficient of variation and median of an auxiliary variable. Int. J. Probab. Stat. 1(4), 111–118 (2012).
Kumar, A. & Siddiqui, A. S. Enhanced estimation of population mean using simple random sampling. Res. Stat. 2(1), 2335949 (2024).
Bhushan, S. & Kumar, A. Ranked set sampling imputation methods in presence of correlated measurement errors. Commun. Stat. Theory Methods 1, 1–22 (2024).
Khan, L., Ahmad, S., Alomair, A. M. & Alomair, M. A. Enhanced exponential ratio-cum-ratio estimator in ranked set sampling using transformed auxiliary information. Heliyon 10, 6 (2024).
Ahmad, S. & Shabbir, J. Proportion estimation using enhanced class of estimators under simple random sampling: Application with real data sets and simulation. In Measurement: Interdisciplinary Research and Perspectives (eds Ahmad, S. & Shabbir, J.) 1–13 (Taylor & Francis, 2024).
Shabbir, J. & Gupta, S. A note on generalized exponential type estimator for population variance in survey sampling. Rev. Colomb. Estadística 38(2), 385–397 (2015).
Muneer, S., Khalil, A., Shabbir, J. & Narjis, G. Efficient estimation of population median using supplementary variable. Sci. Iran. 29(1), 265–274 (2022).
Zakari, Y. & Muhammad, I. Modified estimator of finite population variance under stratified random sampling. Eng. Proc. 56(1), 177 (2023).
Punjab Development Statistics (PDS), Bureau of Statistics, Government of Punjab, Lahore, Pakistan (2012).
Aamir, M., Shabri, A. & Ishaq, M. Improving forecasting accuracy of crude oil prices using decomposition ensemble model with reconstruction of IMFs based on ARIMA model. Malay. J. Fund. Appl. Sci. 14(4), 471–483 (2018).
Acknowledgements
This work was supported by the Deanship of Scientific Research, Vice Presidency for Graduate Studies and Scientific Research, King Faisal University, Saudi Arabia [Grant No. 5736].
Author information
Authors and Affiliations
Contributions
S. A and S.M wrote the main manuscript. A.M.A and M.A.A supervised the overall paper, and give concept.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ahmad, S., Masood, S., Alomair, A.M. et al. Improved modified estimator for estimation of median using auxiliary information under simple random sampling. Sci Rep 14, 16504 (2024). https://doi.org/10.1038/s41598-024-67189-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-67189-1
