
Abstract
Detection of printed circuit board assembly (PCBA) defects is crucial for improving the efficiency of PCBA manufacturing. This paper proposes PCBA-YOLO, a YOLOv5-based method that can effectively increase the accuracy of PCBA defect detection. First, the spatial pyramid pooling module with cross-stage partial structure is replaced in the neck network of YOLOv5 to capture the resolution features at multiple scales. Second, large kernel convolution is introduced in the backbone network to obtain larger effective receptive fields while reducing computational overhead. Finally, an SIoU loss function that considers the angular cost is utilized to enhance the convergence speed of the model. In addition, an assembled PCBA defect detection dataset named PCBA-DET is created in this paper, containing the corresponding defect categories and annotations of defect locations. The experimental results on the PCB defect dataset demonstrate that the improved method has lower loss values and higher accuracy. Evaluated on the PCBA-DET dataset, the mean average precision reaches 97.3\(\%\), achieving a real-time detection performance of 322.6 frames per second, which considers both the detection accuracy and the model size compared to the YOLO series of detection networks. The source code and PCBA-DET dataset can be accessed at https://github.com/ismh16/PCBA-Dataset.
Similar content being viewed by others
Introduction
Given the growing complexity of printed circuit board assembly (PCBA) design due to the growing number of functional modules, the PCBA inspection deserves to be prioritized as a way to guarantee product quality1. Intelligent inspection technologies, such as automated optical inspection (AOI), are frequently used for surface inspection of PCBAs during the production process2,3,4. Inspecting PCBAs after manufacturing and assembly helps facilitate rework and reduce material waste. However, this inspection is typically performed by human inspectors5, which demands significant manpower and time and is prone to errors such as missed or incorrect inspections. Therefore, an automated detection method that tackles these challenges is of great significance for the PCBA production process quality inspection.
Convolutional neural network (CNN) technology6 has been primarily credited for the significant advancements in deep learning that have been made in recent years in a variety of fields, including image recognition, object detection, and semantic segmentation7. CNN-based object identification techniques are being widely used in a variety of industries, such as intelligent security, autonomous driving, and medical image analysis8. These CNN-based algorithms are mainly divided into two types: one-stage and two-stage object detection methods. While the latter is defined by high accuracy but slow detection speed, the former is distinguished by fast detection speed but low precision. Common two-stage methods are represented by R-CNN9, Fast R-CNN10, Faster R-CNN11, and Mask R-CNN12, other various methods and their representative networks include R-FCN13, Cascade R-CNN14 and VFNet15. To detect surface defects on flexible printed circuit boards (FPCBs) in integrated circuit (IC) packaging, Luo et al. suggested a decoupled two-stage object detection framework that separates the localization and classification tasks through two distinct modules16. Although these two-stage methods have their unique advantages in tackling tasks in high-precision and multi-scale scenarios, their intricate structure and lengthy inspection times prevent them from matching the real-time standards of the PCBA quality inspection procedure.
For the detection of product surface defects on high-speed assembly lines, one-stage algorithms have become one of the widely used algorithms in the field of target inspection, such as the You Only Look Once (YOLO)17, Single Shot multi-box Detector (SSD), because of their fast and accurate detection performance. To enhance the performance of YOLO, relevant improvements have been made to the algorithm. Based on the YOLO model, YOLOv218 uses Darknet-19 to enhance the algorithm performance and adopts various methods such as batch normalization19 and anchor boxes to improve recall. YOLOv320 adds a feature pyramid network (FPN)21 to the network to recognize objects at various scales, deepens the network substantially, and utilizes Darknet-53 as its backbone. YOLOv422 replaces the backbone with CSPDarknet53 and uses a path aggregation network (PANet)23 as the neck to improve its feature representation. The YOLOv5 algorithm proposed by Glenn Jocher, with a neck network using the structure of FPN and pixel aggregation network (PAN), exhibits outstanding accuracy and robustness in the object detection task.
However, directly applying the YOLOv5 algorithm to PCBA defect detection encounters several issues, including low accuracy in detecting defects on small PCBA targets and a high rate of false positives and omissions24. YOLOv5 has been widely adopted for object detection tasks across various fields, and numerous improved models have emerged that could serve as valuable references for enhancing PCBA defect detection. Intending to improve the accuracy of the network’s target localization, Guo et al. opted to replace the YOLOv5 basic network with MobileNetV325, a new backbone feature extraction network that has fewer parameters and GFLOPs and introduced coordinate attention lightweight attention modules26. Xiong et al. added an attention module that combines ECA-net and CBAM27,28 to enhance the tiny-scale object detection; meanwhile, they adopted a simpler module of BottleneckCSP to lower the parameter count and improve the speed of the model29. Liu et al. used ghost bottleneck lightweight deep convolution, asymptotic feature pyramid network, and decoupling header layer to reduce the number of parameters of the model based on the YOLOv5s detection algorithm, which facilitates the detection of bolts in factories30,31. Wu et al.32 based on the YOLOv5 detection algorithm, reduced the dimensionality of the convolutional layer by integrating the Ghost module and introduced the channel focusing mechanism in the backbone network of feature extraction, which addressed the drawbacks of the cumbersome process of manually detecting the grotto murals with low accuracy rate. Zhou et al.33 used CSPlayer and Global Attention Mechanism (GAM) to improve the flexibility of the YOLOv5 model for detecting defects on the surface of metallic materials. To be able to detect loose bolts, Sun et al. combined deep learning with computer vision and developed a method called YOLOv5-based loose bolt detection. Specifically, they used YOLOv5 to recognize two unique circular markers that were added to the bolt and nut, respectively. This allowed for the detection of loose bolts by determining the rotation angle of the nut against the bolt based on the central coordinate for each prediction bounding box34. Abhiroop et al. integrated YOLOv5 with Transformer into an end-to-end model designed for detecting and identifying PCB defects. This approach utilizes a CNN network to extract feature maps and leverages Transformer to acquire multilevel features enriched with global information35. Park et al.36 analyzed the characteristics of PCB image data, classifying PCB defect detection into three distinct methodologies. They utilized ResNet50 and YOLOv7 for the classification and detection of these defects. These algorithms have significant reference value for PCBA quality inspection, but given the requirements of the inspection process for real-time and accuracy, there are still the following problems that need to be further improved. (1) Although there are numerous lightweight techniques that lower FLOPs and model file size, improving detection accuracy remains challenging. (2) Large model parameters are present in some algorithms with higher detection accuracy, which makes it hard to meet the real-time detection requirement.
This work proposes an improved PCBA defect detection method based on YOLOv5s to address these issues. Furthermore, for PCBA assembly defect identification, a dataset called PCBA-DET includes the prevalent kinds of faults in the PCBA production process. The following are this article’s primary contributions: (1) A PCBA defect detection dataset (PCBA-DET) with precise manual annotations was constructed, which includes the common categories of defects after PCBA assembly. Compared to all open-source PCBA datasets, PCBA-DET adds the detection of different devices such as fan screws, fan group wires, motherboard screws, etc., so the number of defect categories is also higher. (2) The spatial pyramid pooling cross stage partial convolution (SPPCSPC) is utilized in place of the spatial pyramid pooling fast (SPPF) of the original model to capture features at multiple scales and resolutions, effectively improving the precision of the model. (3) Large convolutional kernels are used in the backbone of YOLOv5, which significantly improves the effective receptive fields while lowering the number of parameters in the model and the algorithmic complexity. (4) SIoU_Loss is adopted to replace CIoU_Loss in the loss calculation to enhance both the inference accuracy and convergence speed. The rest of the paper is structured as follows. The dataset that was used for the study is described in Section 2. The recently developed YOLOv5 model is described in Section 3. In Section 4, we conduct experiments on the method proposed in this study and a discussion of the findings. The presented work is summed up in Section 5.
Dataset
PCB defect dataset
The PCB defect dataset was released by the Open Lab on Human Robot Interaction at Peking University37,38. This dataset classifies defects into two categories: functional defects and cosmetic defects. It includes six common defect types: short, spur, spurious copper, missing hole, mouse bite, and open circuit. Figure 1 illustrates the types of defects included in the PCB dataset. Various data augmentation algorithms were applied to these images, resulting in a total of 10,668 images and their corresponding annotation files.

Six different PCB defects.
The PCB defects dataset utilize an XML file in PASCAL VOC39 format as the annotation file. This file format needs to be converted to a TXT file in YOLO format, employing the following conversion formula:
where \({{d}_{w}}\) and \({{d}_{h}}\)stand for the width and height of the original label, respectively, \(({{x}_{c}},{{y}_{c}})\) represents the center point of the normalized bounding box, and w and h indicate the width and height of the normalized label. The upper left and lower right coordinates of the bounding box are expressed by \(({{x}_{\min }},{{y}_{\min }})\), \(({{x}_{\max }},{{y}_{\max }})\). The converted labels are available on website along with PCBA-DET.
PCBA-DET dataset
Defect detection of PCBAs after manufacturing and assembly ensures that the components are correctly positioned on the board and that both the board and components are free from scratches40,41. To ensure the dataset is representative of real-world applications, different types of PCBAs collected from a real production are manually photographed from above, from the side, and from a tilted angle to simulate image acquisition on a live manufacturing pipeline. A dataset of 4000 images containing 8 defect categories and 18,100 ROI-labeled defects is then constructed and accurately labeled manually, which is called PCBA-DET. Unlike the PASCAL VOC dataset, the annotations are formatted as txt files in YOLO format, although the PCBA-DET annotations also include the category of each defect and the coordinates of the bounding box. The eight defect categories of PCBA-DET are shown in Fig. 2.

Types of defects. The 8 defect types included in the dataset are: (a) loose fan screw, (b) missing fan screw, (c) loose motherboard screw, (d) missing motherboard screw, (e) loose fan wiring, (f) missing fan wiring, (g) fan scratch, and (h) motherboard scratch.

Basic information regarding the PCBA-DET. (a) Number of instances per class. (b) Distribution of defect center point locations. (c) Distribution of the size of the height and width of the defects. (d) Number of instances per image. (e) Number of classes per image.
Figure 3a shows the number of instances in each category, and the proportion of these instances is consistent with the frequency with which defects appear in practical production. Figure 3b,c show the distribution of the coordinates of the center point of the defect label and the distribution of the ratio of the height and width relative to the whole image, respectively, and many tiny defects are relatively evenly distributed in the image, which is consistent with the defects that will occur in the actual PCBA production. Figure 3d shows the number of instances per image, which is the same as VOC in that having more than 8 instances in a single image is rare. The difference is that the number of instances in each image of PCBA-DET is more evenly distributed below 7 instances, which takes into account the production process of image acquisition for PCBA as a whole, which will have multiple defects appearing on one image at the same time. Figure 3e shows the number of species in each image. Same as VOC almost no image appears to have more than 4 categories, although more than 90% of the images of PCBA-DET have multiple categories, which reflects the complexity of the image semantics.
To increase the diversity and quality of the training data, PCBA-DET employs three different types of data augmentation techniques to obtain samples that closely resemble real-world data distributions. Figure 4 illustrates the effects of these various data augmentation methods. Motion blur is used to simulate the jitter that occurs during camera acquisition in real-world scenarios. Color temperature adjustment is applied to mimic the effects of illumination changes on image acquisition. Additionally, Gaussian noise is introduced to replicate the interference that occurs during image collection. We also combine these three data augmentation operations to simulate more complex PCBA pipeline image acquisition scenarios.
It is evident that the PCBA-DET dataset of this work has a comprehensive variety of defects, a sufficient number of instances, and clear imaging, especially with the high cost of manual labeling.

Data augmentation in PCBA-DET: (a) Original image. (b) Motion blur. (c) Color temperature change. (d) Gaussian noise. (e) Motion blur and color temperature change. (f) Motion blur and Gaussian noise. (g) Color temperature change and Gaussian noise. (h) Motion blur, color temperature change and Gaussian noise.
Methods
This section will outline the general PCBA-YOLO network layout before providing more detail on the enhancements made to the YOLOv5 method’s neck, backbone, and loss functions.
PCBA-YOLO network structure
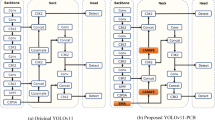
Based on the width of the feature map and the depth of the network, YOLOv5 is split into five models: YOLOv5n, YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x. YOLOv5x has the highest accuracy and YOLOv5n is the lightest of them all. YOLOv5s is selected as the baseline model for enhancement in light of the accuracy and speed requirements of real-time PCBA inspection. The four parts of YOLOv5s are input, neck, backbone, and prediction. By enhancing the neck, backbone network, and loss function, the PCBA-YOLO network model is put out in this study. Figure 5 displays the structural schematic of the upgraded YOLOv5s.
Adaptive image scaling, adaptive anchor box calculation, and mosaic data augmentation are applied to the input images in the input module in order to minimize overfitting and boost the accuracy and generalization performance of the model. The mosaic data enhancement findings on the PCB defect and PCBA-DET are displayed in Fig. 6.
The neck network makes use of the feature pyramid structure of PAN and FPN. Spatial pyramid pooling (SPP) with the Cross Stage Partial (CSP) structure42, known as SPPCSPC, is employed to enhance the feature fusion capabilities within Neck networks43. SPPCSPC optimizes the characterization of PCBA defective features by integrating feature information from different scales, thus enhancing the model’s proficiency in handling multi-scale tasks44. A weighted fusion of feature maps at different scales is performed using an upsampling module and multiple downsampling modules to produce a more robust and accurate feature representation. The upsampling module upsamples the low-resolution feature maps to the same resolution as the high-resolution feature maps by interpolation, while the downsampling module downsamples the high-resolution feature maps to the same resolution as the low-resolution feature maps by convolution.
In the backbone network, YOLOv5 uses the CSPDarknet53 structure to transform the original input image into a multilayer feature map for feature extraction of the image, which mainly consists of Conv and C3 modules. In this paper, the RepLKNet45 module, a large convolutional kernel network, is used instead of the C3 module in the backbone, which consists of a bottleneck residual structure module. This lowers the number of model parameters that are increased by using SPPCSPC in the neck and enhances the effective receptive fields (ERFS)46 of the model.
In the detect module, a \(1\times 1\) convolution is used in channel fusion on feature maps, and three output tensors that correspond to three different-sized detection boxes are obtained. Related to the input data, the output tensor size, namely the feature map size, for the adopted datasets is calculated as batch_size \(\times\) num_anchors \(\times\) grid_size \(\times\) grid_size \(\times\) (num_classes + 5). Specifically, the batch size is 32; the predicted number of anchors is 3; the grid sizes of the three feature maps are 20, 40, and 80 respectively; num_classes is the total class value of the PCBA-DET as 14.

PCBA-YOLO network structure.

Mosaic data enhancement on PCB defect and PCBA-DET. (a, b) are the results of mosaic data enhancement on PCB defect, (c) and (d) are the results of mosaic data enhancement on PCBA-DET.
Improvements of the neck network
The network structure of SPP, a feature fusion module47, is depicted in Fig. 7. The input image is split up into multiple grids of varying sizes in this module, and features are pooled from each grid separately. The outputs of each grid are then concatenated into a single vector, which is used as input for subsequent layers of the neural network. By these grids of different sizes, SPP is able to capture features at different scales, thus improving its robustness to changes in the input image size.
SPP Fast (SPPF) is used in the YOLOv5 network to acquire features at multiple spatial scales at a faster speed. Its network structure is displayed in Fig. 8a. SPPF can quickly combine features at multiple scales to provide fused input for subsequent layers. To gain stronger feature fusion capability, the proposed model replaces the SPPF module with SPPCSPC in YOLOv5. Figure 8b shows the network structure of SPPCSPC. The initial usage of SPP in this module is the extraction of features across multiple scales and resolutions. The pooled features are concatenated and passed through a series of convolution layers to generate high-dimensional feature maps. The cross-stage partial is then used to connect the SPP output with the input of the subsequent layer.
SPPCSPC splits the high-dimensional feature maps to follow two paths: one path processes the features through a sequence of convolution layers, while the other path is connected directly to the output. These two paths are then concatenated and passed through additional convolution layers before being fed to the next layer. By combining SPP and CSP, SPPCSPC is able to capture features of multiple scales and resolutions while facilitating information flow and improving gradients throughout the network.

SPP network structure.

SPPF and SPPCSPC network structure.
Improvements of the backbone network
The primary convolution kernel size of the backbone network in the YOLOv5 is \(3\times 3\), but the \(3\times 3\) kernel in the deep layer will lead to small effective receptive fields. This can be improved by introducing a few large convolution kernels. As shown in previous studies, a depthwise (DW)48 large convolution doesn’t bring much increase to the computational costs; instead, with its design of shortcut and reparameterization, YOLOv5 can benefit from a large kernel size that brings higher detection accuracy and larger effective receptive fields. This study replaces the fourth C3 layer in the YOLOv5 backbone with a large convolutional kernel using RepLKNet, which reduces the number of parameters and computation increase caused by the introduction of the SPPCSPC structure in the neck network. Figure 9 shows the network structure of RepLKNet.
RepLKNet is composed of Stem, four Stages, and three Transitions. Figure 10a is Stem, or the beginning layers, where a \(3\times 3\) convolution layer that moves with a stride of 2 is first used for downsampling, a DW \(3\times 3\) convolution is then used to capture low-level patterns, and another convolution layer and DW layer are used for downsampling at last.
After capturing more details, the tensor output by Stem goes through the four Stages and the Transitions in between. Each Stage consists of several RepLK blocks and a similar CNN-style block, namely a ConvFFN block. Figure 10b is the RepLK block where a \(5\times 5\) kernel is used in each DW convolution for reparameterization. The convolution kernel size of the large kernel convolution can be modified by adjusting the value of K in the DW convolution, experiments have been carried out in this work when K = 13, 17, and 27 respectively. Figure 10c is the ConvFFN block where batch normalization is adopted to replace layer normalization which is often used in FFN and typically applied before the fully connected layer. By this practice, the RepLK block and the FNN block are interleaved while the inference becomes more efficient. Figure 10d shows the Transition block where the channel size is increased by a \(1\times 1\) convolution and then downsampled by a DW \(3\times 3\) convolution.

Network structure of RepLKNet.

Components of the RepLKNet network. (a) Stem network structure. (b) RepLK Block network structure. (c) ConvFFN network structure. (d) Transition network structure.
Loss function improvement
The effectiveness of the PCBA detection model largely relies on the choice of the loss function. Three major types of losses are included in the YOLOv5 model training: the confidence loss \({{l}_{obj}}\), the classification loss \({{l}_{cls}}\), and the position loss of the prediction box and the target box \({{l}_{box}}\). The weighted sum of the three losses is the total loss value of the network, which is calculated as follows:
The confidence loss \({{l}_{obj}}\) is a binary cross-entropy loss that penalizes the model for false positive predictions and false negative predictions. The following is the definition of confidence loss:
The classification loss \({{l}_{cls}}\) measures the degree to which the predicted class label for the object matches the ground truth class label. It is also a binary cross-entropy loss and penalizes the model for misclassifying an object. The classification loss is defined as follows:
The bounding box regression loss \({{l}_{box}}\) measures the degree to which the predicted bounding box coordinates match the ground truth bounding box coordinates. YOLOv5 employs CIoU_Loss49 as the loss function for \({{l}_{box}}\), which is described as follows:
where \(\varphi\) is a positive trade-off parameter and v measures the consistency of the aspect ratio:
CIoU_Loss considers the overlap area, the distance between the centers of the boxes, and the aspect ratio of bounding box regression. However, it overlooks the direction of the mismatch, thus slowing down the model’s convergence rate50. Consequently, the proposed approach introduces the SIoU_Loss51 to address this limitation of the CIoU_Loss. The calculation method is as follows:
Four cost functions make up SIoU_Loss: Angle, Distance, Shape, and IoU costs. Angle cost is one of them and is described as follows:
When defining Distance cost, Angle cost is taken into consideration and is computed as follows:
where
Shape cost is computed as follows:
IoU is calculated as follows:
The contribution of each IoU component is shown in Fig. 11.
SIoU_Loss redefines the penalty metrics and considers the vector angle between regressions in comparison to CIoU_Loss. This reduces the overall number of degrees of freedom while increasing training speed and inference accuracy.

The contribution of IoU components is depicted schematically.
Experiments and discussions
Experimental environment and training parameters
Using the PyTorch framework and Ubuntu 20.04 operating system, the model was trained. The GPU is an NVIDIA GeForce RTX 3080, and the CPU is an Intel(R) Xeon(R) Platinum 8255C CPU running at 2.50 GHz. Python 3.8 and CUDA11.3 make up the software environment. The image datasets used include the publicly available datasets PCB defect and PCBA-DET, annotated as txt files in YOLO format.
The following are the specific parameters that are set for the model training process: The image dimensions are 640x640x3, the batch size is 32, the learning rate is 0.01; the momentum parameter is 0.937; the weight attenuation factor is 0.0005; there are 260 training epochs; the learning rate is updated through the cosine annealing algorithm, the learning rate is updated using the cosine annealing algorithm, and the optimizer SGD is chosen to compute the adaptive learning rate.
Measurement indicators
Precision, recall, mAP@0.5, mAP@0.5:0.95, parameter amount, floating-point operations (FLOPs), and frames per second (FPS) are taken into consideration as the measurement indicators of the experiments to assess the performance of the improved model. Precision represents the model’s ability to identify the objects, and recall represents its ability to find the true regression box. They are computed in the manner described below:
True positives (TP) in the equations stand for the number of correctly predicted positives, false positives (FP) for the number of incorrectly predicted positives, true negatives (TN) for the number of correctly predicted negatives, and false negatives (FN) for the number of incorrectly predicted negatives.
Within all data, the area under the PR curve for a given class indicates the average precision (AP) value. The average AP for all classes is called mean average precision, or mAP. mAP assesses the effectiveness of detecting multiple classes, whereas AP evaluates the detection of a single class. When IoU is set to 0.5, the mAP is known as mAP@0.5. It is necessary to compute the model’s mAP@0.5:0.95, or mAP with an IoU ranging from 0.5 to 0.95, in order to assess the accuracy of the model more accurately. The following are the calculation formulas:
Experiments on the PCB defect dataset
Results and discussions
In this paper, we first conduct experiments on the PCB defect dataset to verify the effectiveness of the proposed model in defect detection. Figure 12 shows the changes in each evaluation metric throughout the training process of PCBA-YOLO. It can be seen that the model converges rapidly and basically converges completely after 300 rounds. Notably, the K-value of the DW convolution kernel in the RepLKNet module of the improved model is 13.

Changes in each evaluation metric during the PCBA-YOLO training process.
To evaluate the improvements of the proposed model, we conducted experiments using YOLOv5s on the PCB defects dataset. Figure 13a compares the mAP@0.5 values of PCBA-YOLO and YOLOv5s throughout the training process. Initially, both models exhibit similar mAP@0.5 values. However, after 100 epochs, the proposed model clearly outperforms the original. Figure 13b shows the changes in total loss values for both methods during training. The proposed model consistently has a lower total loss, demonstrating that PCBA-YOLO converges more rapidly.

Comparison of PCBA-YOLO and YOLOv5s training processes. (a) Change in mAP@0.5. (b) Change in total loss value.
The results of the comparison experiments are presented in Table 1. The CDI-YOLO model, proposed by G.X. et al., demonstrates the lowest number of parameters and GFLOPs, whereas YOLOv5s achieves the highest recall. Despite having greater model complexity, our proposed model attains the highest mAP@0.5, indicating superior mean average detection precision. Overall, PCBA-YOLO exhibits strong precision and rapid convergence in defect detection.
Experiments on the PCBA-DET dataset
Results and discussions
Experiments are conducted on the PCBA-DET dataset to confirm the efficacy of the suggested improved model in PCBA detection. Given that distinct DW convolution kernel sizes within the large kernel convolutional network RepLKNet may result in disparate model performances, \(13\times 13\), \(17\times 17\), and \(27\times 27\) convolutions are selected to undergo experiments respectively.
The PCBA-DET training procedure for various models is depicted in Fig. 14, and Table 2 demonstrates the specific results. Table 2 shows that, for K = 13, the suggested model in this work has the best precision and mAP@0.5, which are enhanced by 1.3% and 0.5% in comparison to YOLOv5s. In comparison to YOLOv5s, PCBA-YOLO has the best recall and mAP@0.5:0.95 at K = 17, which are improved by 1.5% and 1.4%, respectively. When K = 13, the mAP@0.5:0.95 of the model is very close to that of K=17 and the parameters are slightly reduced. Therefore, this study uses K = 13 as the convolutional kernel size for the large kernel convolutional network of PCBA-YOLO. Summing box_loss, cls_loss, and obj_loss during model training yields the total loss function. The convergence curves of the total loss function for PCBA-YOLO and the baseline model during model training are displayed in Fig. 15. It is evident that PCBA-YOLO performs better at convergence and retains lower loss levels during model training.

Experimental results of different RepLKNet convolution kernel sizes on the PCBA dataset.

Convergence curves of YOLOv5s and PCBA-YOLO for PCBA-DET datasets.
The training results of the approach described in this paper with additional YOLO series models on PCBA-DET are shown in Table 3. It is evident that when compared to YOLOv3, the enhanced model has higher accuracy, fewer parameters, and fewer FLOPs. ompared to the YOLOv5m architecture, which is both deeper and wider than YOLOv5s, the proposed method achieves similar accuracy but has significantly fewer parameters and FLOPs. This reduction makes the proposed method more suitable for practical deployment and application. Compared to YOLOv7, which is more novel than YOLOv5, although mAP@0.5 is slightly lower, mAP@0.5:0.95 is improved by 0.3% and the parameters and FLOPs are much lower. Meanwhile, PCBA-YOLO has real-time detection performance similar to YOLOv5s and outperforms YOLOv3, YOLOv5m and YOLOv7.
The results of the single class AP comparison on PCBA-DET between YOLOv5s, YOLOv7, and PCBA-YOLO are displayed in Table 4. The efficiency of PCBA-YOLO in the field of PCBA defect detection is demonstrated by the fact that, out of the eight different faults, six of the single class APs of the approach used in this research are not lower than the baseline model and five of them are better than the YOLOv7 model.
In summary, the PCBA-YOLO defect detection model, which is based on YOLOv5s, is shown to achieve superior detection accuracy and lower training loss values. Furthermore, when compared to the more novel YOLOv7 model, it is able to considerably reduce the number of parameters and FLOPs while maintaining comparable accuracy. It is evident that the method suggested in this study for PCBA flaw detection can satisfy the demands of accuracy and speed of detection in actual manufacturing.
Comparisons
Figure 16 displays the performance comparison between PCBA-YOLO and YOLOv5s in different detection scenarios. As shown in Fig. 16a, in contrast to the proposed model, YOLOv5 fails to detect two out of the four similar missing fan screws. As shown in Fig. 16b, YOLOv5 mistakes the fixed motherboard screw for a missing one, while no misjudgment is made by PCBA-YOLO whose confidence in the defect detection in question is lower than the set threshold of 0.25. As shown in Fig. 16c, when it comes to large-scale objects, both models manage to detect the corresponding defects, but PCBA-YOLO has higher confidence in the detection. Overall, PCBA-YOLO performs better than the baseline model.

Comparison of model detection results in different scenarios.
Ablation experiments
Ablation experiments are conducted on the PCBA-DET dataset to study the influence of each improved module on the overall algorithm performance and a DW 13\(\times\)13 convolution is chosen for RepLKNet.
Table 5 gives the results of the ablation experiments of the model after the introduction of the various modules. It can be seen that the addition of the SPPCSPC structure improves the precision of the model by 0.8%, but also brings larger parameters and FLOPs.The introduction of RepLKNet improves the precision of the model by 0.9% and reduces part of the computational expense. Simultaneous introduction of the SPPCSPC and RepLKNet networks leads to higher detection accuracy and smaller model size relative to the introduction of only the SPPCSPC network. Replacing the loss function with SIoU brings about an increase in detection accuracy without affecting the model’s parameters and FLOPs.
Conclusion
This paper proposes a PCBA inspection method based on an improved YOLOv5 model to increase the assembled PCBA defect detection efficiency in industrial manufacturing scenarios. The following are the principal results:
-
(1)
A PCBA defect detection dataset called PCBA-DET with 4000 images and manual annotations of 8 defect types and 18100 ROI labeled objects is proposed.
-
(2)
The SPPCSPC and RepLKNet structures are added to the neck and backbone networks of YOLOv5, respectively, improving the detection accuracy of the model.
-
(3)
The CIoU loss function is substituted by SIoU, which effectively reduces the loss value of the improved model.
-
(4)
Experiments were conducted on different datasets and compared with related methods, the method in this work has superior performance.
The results of the experiments demonstrate that the improved method can meet the speed and accuracy requirements of practical production while also having a higher detection accuracy than the original method. Furthermore, it has similar detection accuracy and lower computational cost than YOLOv7, which is more novel than the baseline model. The proposed model shows better detection performance in both general object inspection datasets and PCBA inspection datasets, which is highly generalizable. In future research, we will focus on addressing the following issues: Although experiments have been conducted using the novel YOLOv9 method, the real-time performance for PCBA detection has not met our expectations. Therefore, further optimization of YOLOv9 is essential. Additionally, deploying the improved model to embedded devices and continuing to optimize our proposed method in practical PCBA detection applications will be crucial.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Zhang, H. & Li, Y.-F. Integrated optimization of test case selection and sequencing for reliability testing of the mainboard of internet backbone routers. Eur. J. Oper. Res. 299, 183–194 (2022).
Werner, F. T., Yilmaz, B. B., Prvulovic, M. & Zajić, A. Leveraging em side-channels for recognizing components on a motherboard. IEEE Trans. Electromagn. Compat. 63, 502–515 (2020).
Cheng, T. et al. A practical micro fringe projection profilometry for 3-d automated optical inspection. IEEE Trans. Instrum. Meas. 71, 1–13 (2022).
Runji, J. M. & Lin, C.-Y. Markerless cooperative augmented reality-based smart manufacturing double-check system: Case of safe pcba inspection following automatic optical inspection. Robot. Comput. Integr. Manuf. 64, 101957 (2020).
Runji, J. M. & Lin, C.-Y. Switchable glass enabled contextualization for a cyber-physical safe and interactive spatial augmented reality pcba manufacturing inspection system. Sensors 20, 4286 (2020).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 25 (2012).
Long, J., Shelhamer, E. & Darrell, T. Fully convolutional networks for semantic segmentation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3431–3440 (2015).
Wu, M., Awasthi, N., Rad, N. M., Pluim, J. P. & Lopata, R. G. Advanced ultrasound and photoacoustic imaging in cardiology. Sensors 21, 7947 (2021).
Girshick, R., Donahue, J., Darrell, T. & Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 580–587 (2014).
Girshick, R. Fast r-cnn, in Proceedings of the IEEE International Conference on Computer Vision, 1440–1448 (2015).
Ren, S., He, K., Girshick, R. & Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 8 (2015).
He, K., Gkioxari, G., Dollár, P. & Girshick, R. Mask r-cnn, in Proceedings of the IEEE International Conference on Computer Vision, 2961–2969 (2017).
Dai, J., Li, Y., He, K. & Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 29 (2016).
Cai, Z. & Vasconcelos, N. Cascade r-cnn: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 43, 1483–1498 (2019).
Zhang, H., Wang, Y., Dayoub, F. & Sunderhauf, N. Varifocalnet: An iou-aware dense object detector, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8514–8523 (2021).
Luo, J., Yang, Z., Li, S. & Wu, Y. Fpcb surface defect detection: A decoupled two-stage object detection framework. IEEE Trans. Instrum. Meas. 70, 1–11 (2021).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: Unified, real-time object detection, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 779–788 (2016).
Redmon, J. & Farhadi, A. Yolo9000: Better, faster, stronger, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7263–7271 (2017).
Ioffe, S. & Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift, in International Conference on Machine Learning, 448–456 (pmlr, 2015).
Redmon, J. & Farhadi, A. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767 (2018).
Lin, T.-Y. et al. Feature pyramid networks for object detection, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2117–2125 (2017).
Bochkovskiy, A., Wang, C.-Y. & Liao, H.-Y. M. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934 (2020).
Liu, S., Qi, L., Qin, H., Shi, J. & Jia, J. Path aggregation network for instance segmentation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 8759–8768 (2018).
Tu, G., Qin, J. & Xiong, N. N. Algorithm of computer mainboard quality detection for real-time based on qd-yolo. Electronics 11, 2424 (2022).
Guo, G. & Zhang, Z. Road damage detection algorithm for improved yolov5. Sci. Rep. 12, 15523 (2022).
Howard, A. et al. Searching for mobilenetv3, in Proceedings of the IEEE/CVF International Conference on Computer Vision, 1314–1324 ( 2019).
Wang, Q. et al. Eca-net: Efficient channel attention for deep convolutional neural networks, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11534–11542 (2020).
Woo, S., Park, J., Lee, J.-Y. & Kweon, I. S. Cbam: Convolutional block attention module, in Proceedings of the European Conference on Computer Vision (ECCV), 3–19 (2018).
Xiong, C., Hu, S. & Fang, Z. Application of improved yolov5 in plate defect detection. Int. J. Adv. Manuf. Technol. 1–13 (2022).
Han, K. et al. Ghostnet: More features from cheap operations, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1580–1589 (2020).
Liu, Z. & Lv, H. Yolo_bolt: A lightweight network model for bolt detection. Sci. Rep. 14, 656 (2024).
Wu, L., Zhang, L., Shi, J., Zhang, Y. & Wan, J. Damage detection of grotto murals based on lightweight neural network. Comput. Electr. Eng. 102, 108237 (2022).
Zhou, C. et al. Metal surface defect detection based on improved yolov5. Sci. Rep. 13, 20803 (2023).
Sun, Y., Li, M., Dong, R., Chen, W. & Jiang, D. Vision-based detection of bolt loosening using yolov5. Sensors 22, 5184 (2022).
Bhattacharya, A. & Cloutier, S. G. End-to-end deep learning framework for printed circuit board manufacturing defect classification. Sci. Rep. 12, 12559 (2022).
Park, J.-H., Kim, Y.-S., Seo, H. & Cho, Y.-J. Analysis of training deep learning models for pcb defect detection. Sensors 23, 2766 (2023).
Huang, W. & Wei, P. A pcb dataset for defects detection and classification. arXiv preprint arXiv:1901.08204 (2019).
Ding, R., Dai, L., Li, G. & Liu, H. Tdd-net: A tiny defect detection network for printed circuit boards. CAAI Trans. Intell. Technol. 4, 110–116 (2019).
Everingham, M. et al. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 111, 98–136 (2015).
Simmons, R. S. Optical Inspection System for Printed Circuit Board or the Like. US Patent 10527559 (2020).
Wang, Y., Wang, J., Cao, Y., Li, S. & Kwan, O. Integrated inspection on pcb manufacturing in cyber-physical-social systems. IEEE Trans. Syst. Man Cybern. Syst. 53, 2098–2106. https://doi.org/10.1109/TSMC.2022.3229096 (2023).
Wang, C.-Y. et al. Cspnet: A new backbone that can enhance learning capability of cnn, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 390–391 (2020).
Zhu, P. et al. Object detection for hazardous material vehicles based on improved yolov5 algorithm. Electronics 12, 1257 (2023).
Liang, J., Kong, R., Ma, R., Zhang, J. & Bian, X. Aluminum surface defect detection algorithm based on improved yolov5. Adv. Theory Simul. 7, 2300695 (2023).
Ding, X., Zhang, X., Han, J. & Ding, G. Scaling up your kernels to 31 \(\times\) 31: Revisiting large kernel design in cnns, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11963–11975 (2022).
Luo, W., Li, Y., Urtasun, R. & Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 29 (2016).
He, K., Zhang, X., Ren, S. & Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 37, 1904–1916 (2015).
Chollet, F. Xception: Deep learning with depthwise separable convolutions, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1251–1258 (2017).
Zheng, Z. et al. Distance-iou loss: Faster and better learning for bounding box regression, in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34, 12993–13000 (2020).
Yu, J., Shi, X., Wang, W. & Zheng, Y. Lcg-yolo: A real-time surface defect detection method for metal components. IEEE Access 12, 41436–41451 (2024).
Gevorgyan, Z. Siou loss: More powerful learning for bounding box regression. arXiv preprint arXiv:2205.12740 (2022).
Xiao, G., Hou, S. & Zhou, H. Pcb defect detection algorithm based on cdi-yolo. Sci. Rep. 14, 7351 (2024).
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China (No. JZ2019GJQN0385, 61906057, 61703306), Program B of Academic Newcomer Promotion Plan (JZ2022HGTB0274), Natural Science Research Project of Colleges and Universities in Anhui Province (No. 2022AH051889), the Fundamental Research Funds for the Central Universities, the Fundamental Research Funds for the Central Universities of China, and Natural Science Foundation of Anhui Province (2308085QF227).
Author information
Authors and Affiliations
Contributions
M.S. wrote the main manuscript, developed the model, and conducted the experiments. Y.L. performed the statistical analysis and graph generation. J.C. conducted the literature survey and comparative experiments with the model. H.G., K.Y., and J.C. photographed, constructed, and annotated the printed circuit board assembly dataset. J.L., Y.J. and H.H. revised and advised on the paper and helped with formatting review and editing. Q.W. and Y.W. performed the data collection. All authors participated in writing and reviewing the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Shen, M., Liu, Y., Chen, J. et al. Defect detection of printed circuit board assembly based on YOLOv5. Sci Rep 14, 19287 (2024). https://doi.org/10.1038/s41598-024-70176-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-70176-1
This article is cited by
-
Lightweight Small-Object surface defect detection method based on improved YOLOv11
The International Journal of Advanced Manufacturing Technology (2026)
-
Yolo-cd: a lightweight real-time PCB defect detection model for edge deployments
Journal of Real-Time Image Processing (2026)
-
Enhanced YOLOv11 framework for high precision defect detection in printed circuit boards
Scientific Reports (2025)
-
A texture enhanced attention model for defect detection in thermal protection materials
Scientific Reports (2025)
-
An improved EAE-DETR model for defect detection of server motherboard
Scientific Reports (2025)
