
Abstract
Accurate and rapid prediction of water quality is crucial for the protection of aquatic ecosystems. This study aims to enhance the prediction of total phosphorus (TP) concentrations in the middle reaches of the Yangtze River by integrating advanced modeling techniques. Using operational and discharge data from the Three Gorges Reservoir (TGR), along with water quality parameters from downstream sections, we used Grey Relational Analysis (GRA) to rank the factors contributing to TP concentrations. The analysis identified turbidity, permanganate index (CODMn), total nitrogen (TN), water temperature, chlorophyll a, upstream water level variation, and discharge from the Three Gorges Dam (TGD) as the top contributors. Subsequently, a coupled neural network model was established, incorporating these key contributors, to predict TP concentrations under the dynamic water level control during flood periods in the TGR. The proposed GRA-CEEMDAN-CN1D-LSTM-DBO model was compared with conventional models, including BP, LSTM, and GRU. The results indicated that the GRA-CEEMDAN-CN1D-LSTM-DBO model significantly outperformed the others, achieving a correlation coefficient (R) of 0.784 and a root mean square error (RMSE) of 0.004, compared to 0.58 (R) and 0.007 (RMSE) for the LSTM model, 0.576 (R) and 0.007 (RMSE) for the BP model, and 0.623 (R) and 0.006 (RMSE) for the GRU model. The model's accuracy and applicability further validated in two sections: YC (Yunchi) in Yichang City and LK (Liukou) in Jingzhou City, where it performed satisfactorily in predicting TP in YC (R = 0.776, RMSE = 0.007) and LK (R = 0.718, RMSE = 0.007). Additionally, deep learning analysis revealed that as the distance away from dam increased, prediction accuracy gradually decreased, indicating a reduced impact of TGR operations on downstream TP concentrations. In conclusion, the GRA-CEEMDAN-CN1D-LSTM-DBO model demonstrates superior performance in predicting TP concentration in the middle reaches of the Yangtze River, offering valuable insights for dynamic water level control during flood seasons and contributing of smart to the advancement of water management in the Yangtze River.
Similar content being viewed by others
Introduction
Freshwater is an essential component of the Earth's ecosystem, providing necessary ecosystem services and serving as a unique habitat for various aquatic organisms. Since the opening of the United Nations Water Conference in 2023, global water resources have faced unprecedented crises, particularly in terms of freshwater demand and water pollution issues. As a result, the aquatic environment has become an important topic in both theoretical and practical spheres. Human activities, such as the input of nutrients and harmful substances, have posed serious threats to river ecosystems1. For instance, these harmful substances may endanger the ecological and biological populations. Organic waste, inorganic trace elements such as phosphorus and heavy metals, nitrogen, and emerging pollutants like microplastics, all pose threats to the ecological health of water bodies2. Therefore, understanding the development of river ecosystems and identifying potential driving factors is crucial for protecting their ecological health and services1. Additionally, water, as a necessity for life, is closely related to public health and safety. Understanding the concentration levels of contaminants in drinking water and associated risks is essential for protecting public health and safety3.
Phosphorus, as an important natural nutrient element, is a necessary component for all living organisms, including plants, animals, and microorganisms. In aquatic ecosystems, phosphorus is a growth-limiting factor for primary production and a major contributor to water nutrient levels. The level of phosphorus in water directly affects the level of primary productivity, which in turn affects the structure and species composition of aquatic communities4,5. Therefore, understanding the trend of phosphorus in water can provide assistance in water quality protection. Water quality prediction, as an important means of aquatic environmental protection, plays a significant role in ecological conservation and assessment. In this study, we aimed to predict TP concentrations in typical sections of the middle reaches of the Yangtze River, in order to provide references for the protection of water bodies in this region.
In water quality prediction studies, scholars mainly use mechanistic models (such as MIKE11, EPDRiv1, MIKE21, WASP6, EFDC) and non-mechanistic models (such as utilizing historical monitoring data and analyzing and learning data using mathematical and computer techniques to explore water quality changes). Mechanistic models often require detailed engineering measurement data, have long run times, and high simulation costs. On the contrary, non-mechanistic models rely on historical data to predict water quality and have become powerful tools for solving complex engineering problems. Meanwhile, in the field of water quality prediction, scholars widely use linear distribution-based models to predict various water quality parameters, aiming to solve various unpredictable water quality issues6,7,8,9 However, previous studies have found that due to the influence of multiple complex factors such as physics, chemistry, and biology, different water environmental indicators exhibit strong non-linear characteristics in statistical aspects. As linear distribution-based models cannot comprehensively consider these factors, their simulation results are often unsatisfactory. In recent years, with the emergence of artificial intelligence (AI) technologies such as artificial neural networks (ANNs), support vector machines (SVM), gene expression programming (GEP), linear gene expression, evolutionary polynomial regression (EPR), random forests (RF), and multivariate adaptive regression splines (MARS)10,11, they have been widely used by scholars to simulate water quality indicators and solve water quality problems. For example, Najafzadeh et al.12 applied MARS and LS-SVM to evaluate water quality indicators and demonstrated that LS-SVM and MARS models can provide relatively accurate approximate values in water quality indicator evaluation. Najafzadeh & Ghaemi11 used gene expression programming (GEP), evolutionary polynomial regression (EPR), and model tree (MT) to estimate three indicators, namely biochemical oxygen demand (BOD), dissolved oxygen (DO), and chemical oxygen demand (COD), and concluded that the aforementioned AI models can provide linear and nonlinear multivariate equations for prediction. Najafzadeh & Niazmardi13 predicted the WQI of the Karun River using evolutionary polynomial regression (EPR), M5 model tree (MT), gene expression programming (GEP), and multivariate adaptive regression splines (MARS), and found that FS-MARS and GT-MARS were the most accurate models during the training phase, while FS-M5MT and GT-GEP had lower complexity with linear and polynomial regression during the testing phase. Najafzadeh et al.14 used five intelligentmodels, including artificial neural networks (ANN), support vector machines (SVM), random forests (RF), multivariate adaptive regression splines (MARS), and gene expression programming (GEP), to predict water quality index (WQI) in a river basin. The results showed that all five models performed well, with ANN achieving the highest accuracy. These studies demonstrate the effectiveness of AI models in water quality prediction.
The use of neural networks has gained significant attention in recent research due to their strong predictive capabilities15 In the field of water quality prediction, an increasing number of scholars are employing neural network-based prediction models. Neural networks utilize multiple layers and non-linear relationships to simulate complex phenomena in nature, enabling learning and prediction. Typical neural network models include the backpropagation (BP) neural network, artificial neural network (ANN), long short-term memory (LSTM) neural network, gated recurrent unit (GRU) neural network model, and deep learning models with attention mechanisms such as Transformers. Among them, the BP neural network is renowned for its powerful fitting ability and backpropagation capability, ensuring satisfactory prediction results. Hence, it has been widely applied in water quality prediction. However, with increasing demands for model accuracy, shallow BP neural networks are no longer suitable for complex prediction models, leading to the gradual dominance of deep learning models. For example, Liu et al.16 applied the LSTM network to predict water quality parameters in the Yangtze River Basin, demonstrating its effectiveness in predicting pH, dissolved oxygen (DO), chemical oxygen demand (COD), and NH3-N. Ghiasi et al.17 developed an artificial intelligence-based prediction model combining granular computing and neural network models (GrC-ANN) to provide robust estimates of Dx and its uncertainty in a range of flow geometries with high spatiotemporal variability, finding that the developed GrC-ANN model exhibited robust performance in assessing pollutant mixing (Dx) in turbulent environmental flow systems. Mei et al.18 proposed a CNN-GRU-Attention model (CGA) and predicted turbidity and CODcr in mildly polluted source water, finding that the optimized performance of the combined model exceeded that of individual models, with better optimization effects observed for lower data correlation. Kim et al.19 employed four machine learning models (LSTM, SVM, RF, ANN) to estimate the water quality index (BCWQI) of Lake Päijänne in Finland, finding that the long short-term memory model (LSTM) outperformed other machine learning models. This approach assists decision-makers in estimating BCWQI with limited datasets and reduces challenges in water quality monitoring capabilities.
Moreover, with the development of intelligent algorithms, decision-makers can solve complex problems and select optimal hyperparameters for existing deep learning prediction models. For instance13, coupled the multi-kernel support vector regression (MKSVR) algorithm with the particle swarm optimization (PSO) algorithm and evaluated the proposed algorithm based on WQPs of the Karun River in Iran, revealing the superiority of the newly developed SVM technique in estimating WQPs in natural streams. Jafari-Asl et al.20 used the NCHBA algorithm combined with the EPANET model to study the optimization problem of pump scheduling in WDS, finding that the use of this optimization algorithm significantly saved energy costs and improved efficiency. Intelligent algorithms are increasingly being employed in machine learning to select the best hyperparameters for deep learning models21.
The aforementioned machine learning and deep learning models have played a significant role in addressing water quality issues worldwide. Similar to data-driven models, they rely on analyzing and learning from datasets to explore water quality variations. Furthermore, with the development of technology, an increasing number of rivers have established water quality monitoring stations, reducing the difficulty of collecting data through manual sampling. This convenience facilitates the use of machine learning in water quality prediction, enabling the estimation of overall water quality and future trends in river spatial distribution. Therefore, there is an urgent need to develop a modern technology that can capture the future water quality trends of each section in the context of real-time monitoring systems and data collection. However, through the literature review, it is found that existing research still has the following three shortcomings: Firstly, most studies tend to select basic water quality parameters without fully considering the characteristics of the study area and the impact of the correlation between input parameters on the prediction indicators. This results in room for improvement in the accuracy of the models. Secondly, previous prediction models often lack data preprocessing for the prediction indicators, and it is expected that the prediction accuracy of the models can be improved through data preprocessing. Thirdly, although machine learning models have been proven to be suitable for water quality prediction, how to improve the prediction accuracy of the models remains an important topic in this field.
In summary, for the TP concentration data of the middle reaches of the Yangtze River during the flood season, this study selects the CNN1D model and couples it with the advanced LSTM neural network prediction model to propose a GRA-CEEMDAN-CN1DLSTM-DBO coupled model for predicting water quality in typical sections of the middle reaches of the Yangtze River during the flood season. Additionally, this technique isexpected to address the aforementioned shortcomings in existing research and improve the accuracy of water quality prediction models. By incorporating advanced techniques such as data preprocessing, feature selection, and intelligent algorithms, the GRA-CEEMDAN-CN1DLSTM-DBO coupled model aims to provide more accurate and reliable predictions of water quality parameters in the middle reaches of the Yangtze River during the flood season. This research contributes to the field of water quality prediction by proposing an improved model that can assist decision-makers in managing and protecting water resources more effectively.
Materials and methods
Study area
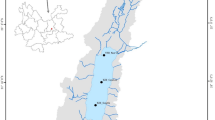
The selected research area is the Three Gorges—Ge Zhou dam cascade Reservoir and the downstream section of the cascade reservoir of the Yangtze River. The water quality data of three typical section water quality hydrological stations at Yichang and Jing Zhou under the TGD are selected as the original data, including 18 indexes such as dissolved oxygen concentration, ammonia nitrogen concentration, and section flow. The research area of this experiment is shown in the Fig. 1.

Study area map.
Considering the limitation of space, the following experiments in this paper take the NJG as a typical display. The model is established and used in the other two sites (Yun Chi (YC) and Liu Kou(LK)) for verification, to explore the applicability and accuracy of the model.
Data sources
In this research work, the hydrological data from the Three Gorges-Gezhouba cascade reservoir and the water quality data from three national control sections downstream of the cascade reservoir were selected as the research objects. The data were collected from the China Environmental Monitoring Station (https://szzdjc.cnemc.cn:8070/GJZ/Business/Publish/Main.html) and the Yangtze River Hydrological Network (http://www.cjh.com.cn/). The main hydrological indicators include the water level upstream of the There Gorges Dam, the discharge downstream of the There Gorges Dam, the daily variation range of the water level upstream of the There Gorges Dam, the water level at the national control sections, the flow rate at the national control sections, and the daily variation range of the water level at the national control sections. The main water quality indicators are based on the "Surface Water Environmental Quality Standards" (GB3838-2002), including water temperature, pH, dissolved oxygen, conductivity, turbidity, permanganate index, ammonia nitrogen, TP, and TN, totaling 9 monitoring indicators. The data collection period is from April 23, 2023, to September 6, 2023, with a collection frequency of once every 24 h, resulting in a total of 1638 data sets. These data reflect the periodic variations in the regulation process of the cascade reservoirs during the flood season and the water quality at the downstream national control sections. Statistical analysis was conducted on the data series, including mean values, standard deviation values, maximum values, and minimum values. The section NJG is taken as an example, and the downstream section YC is taken as an example. The statistical results are shown in Table 1.
In this study, TP was selected as the predicted indicator. To improve the prediction accuracy, the Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN) method was used to decompose TP into several signal sequences that are easier to predict. Additionally, gray correlation analysis (GRA) was employed to statistically analyze the 18 data series mentioned earlier. Finally, the parameters with high contribution rates to the predicted indicator were chosen, including turbidity, permanganate index, total nitrogen, water temperature, chlorophyll a, water level upstream of the TGD, discharge downstream of the TGD, and daily variation range of the water level upstream of the TGD. These parameters were selected as input parameters for the model. The predicted signal sequences were then superimposed to obtain the final prediction results for TP.
Data preprocessing
Correlation analysis
Considering the multivariate correlations and interdependencies in water quality information, it is important to analyze the correlations among various indicators to improve prediction accuracy. Common methods for correlation analysis, such as Pearson correlation analysis, Granger causality analysis (GCA), and GRA, have been used. Among these, GRA is advantageous for addressing the nonlinear nature of water quality information and the presence of numerous local indicators. This study utilizes GRA to analyze the statistical regularities among water quality data.
Grey relational analysis is based on the theory of grey systems and measures the correlation between factors based on their similarity. It provides a measure of the degree of influence of individual factors on the target value in a system. One of its advantages is that it does not have strict requirements regarding sample size and statistical rules, making it a commonly used method for studying the relationship between variables.
Training set, verification set partition
The allocation ratio of the training set and verification set is 0.8:0.2, that is, the first 80% of data is used for training, and the last 20% of data is compared with the original data to verify the accuracy of the model.
Experimental methods and theories
EMD, EEMD, CEEMDAN
Empirical Mode Decomposition (EMD)22 is an adaptive algorithm used to decompose nonlinear and non-stationary time series into high-frequency components (Intrinsic Mode Functions, IMF) and low-frequency components (residuals, R). However, EMD suffers from mode mixing issues, where different features of the time series signal are mixed within the IMFs. To address this, an enhanced version called Ensemble Empirical Mode Decomposition (EEMD)23 was introduced. EEMD eliminates mode mixing but retains some noise in the IMFs. To overcome the limitations of EEMD, CEEMDAN24 was proposed. This approach effectively eliminates mode mixing and residual noise in the decomposition.
The combination of data decomposition methods with prediction models is widely used in water quality prediction analysis. Preprocessing with EEMD and CEEMDAN has been shown to improve the predictive performance of deep learning models in water quality prediction studies. For example, For example, CEEMDAN coupled with LSTM models have been proposed for predictive tasks25.
Long short-term memory neural networks
As a type of feedforward neural network that includes both forward connections and internal feedback connections, the recurrent neural network (RNN) can preserve the state information from the previous time step in the hidden layer. Its inherent structure makes it advantageous in handling time series tasks. However, traditional RNNs often suffer from the vanishing gradient and exploding gradient problems during training, causing the network gradients to diminish. In such cases, RNNs fail to learn effectively.
Long Short-Term Memory (LSTM) networks, a subtype of RNNs, are designed to overcome the limitations of traditional RNNs, especially in capturing and retaining long-term dependencies in sequential data. LSTM networks, as recurrent artificial neural networks, possess a short-term memory known as the "lookback window" that allows them to recall patterns from specific time periods1. The goal of LSTM is to address the problem of capturing long-term dependencies by introducing gate structures (as shown in Fig. 2) that facilitate long-term memory. These gates include a forget gate, which discards redundant information, an input gate, which selects and stores crucial information in the internal state, and an output gate, which determines the output information.

LSTM model frame diagram.
LSTM networks are specifically designed to address the challenges faced by traditional RNNs and excel in capturing and retaining long-term dependencies in sequential data. By incorporating gate structures, LSTM networks can effectively learn and process time series data while avoiding the issues of vanishing or exploding gradients during training.
In addition, this study utilized the PyTorch library in Python to build the LSTM model. The parameter settings for the LSTM model include learning rate, number of neurons, batch size, dropout rate, hidden size, and activation function. Research has shown that optimizing these parameters can lead to more accurate prediction results26,27. Therefore, selecting appropriate parameters is a crucial factor that affects the final prediction accuracy of the model.
Furthermore, one key advantage of LSTM as a black-box model is that it not only predicts the future but also estimates the impact of variables28. For example1, conducted feature importance analysis using the LSTM model to determine the relative importance of driving factors in wetland shrinkage. Based on this, in our study, we will use this black-box model to predict the water quality of three sections and quantify the impact of dynamic predicted operating water levels during the cascade flood season on TP concentration in downstream sections. However, LSTM models also have limitations. When dealing with long-term dependent degraded data, they often face the problems of vanishing or exploding gradients, which result in the loss of information from previous sequences. Even with the improved LSTM model, these problems cannot be completely avoided. Additionally, the model outputs point estimates, making it difficult to evaluate the confidence level of the prediction results.
One-dimensional convolutional neural networks
Convolutional neural networks (CNNs) are a type of feedforward neural network that includes convolutional operations and deep structures. They reduce the complexity of the model through three characteristics: local connections, weight sharing, and downsampling29. Compared to RNNs, CNNs avoid the complex feature extraction process and effectively mitigate issues such as capacity regeneration and overfitting caused by limited data30
Furthermore, CNNs can extract abstract visual features, such as points, lines, and planes, from input data, and they have three dimensions. Among them, 1D-CNN is commonly used for sequence data processing, 2D-CNN is suitable for image and text processing, and 3D-CNN is often used for video processing31 Existing research has shown that using 1D-CNN with vector-based input can effectively learn patterns generated from the input data, making it advantageous for data processing32. Therefore, in this study, we will use 1D-CNN to efficiently extract features from the data. To address the low correlation of feature information positions in the prediction of phosphorus concentration during the flood season in the middle reaches of the Yangtze River, using CNN can obtain more useful information from fewer segments of the overall water quality dataset. Specifically, 1D-CNN treats the convolution kernel as a window, moves the window over the time series data to extract local sequential segments, multiplies them with weights, computes the features of the sequence, and then performs downsampling to further filter out information from noisy data that may bias the prediction results, ultimately leading to more accurate predictions.
Compared to other deep learning models, CNNs can handle high-dimensional raw data more effectively, automatically extract degraded feature information, and have noise reduction capabilities. However, water quality data is time-dependent, and CNNs have limited ability to extract temporal features, leading to the loss of important temporal information. Therefore, CNNs are often used in combination with other models.
CN1D-LSTM
Coupled prediction methods are a major focus in current research on deep learning for prediction. The general approach is to combine multiple models to compensate for the limitations of individual models and fully exploit the advantages of different algorithms, thereby achieving improved performance33. The combination of CNN and LSTM, known as the CNN-LSTM model, allows for the utilization of CNN's feature extraction capabilities and LSTM's sensitivity to time series data, leading to enhanced water quality prediction34.
The CNN-LSTM model consists of convolutional layers and max pooling layers. The convolutional layers scan the input water quality information and perform convolutional operations on local sequential segments using convolutional kernel weights, resulting in an initial feature matrix. This feature matrix exhibits stronger representation capabilities compared to the original water quality time series. The max pooling layers take the feature matrix from the preceding convolutional layer as input and slide a pooling window over the matrix, selecting the maximum value within the window for pooling. This process generates a more expressive feature matrix. By employing CNN to filter out noisy data and subsequently utilizing LSTM for further prediction, biases in the prediction results can be avoided, ultimately enhancing prediction accuracy. In this study, the input water quality sequences are convolved in the convolutional layers and subsequently fed into LSTM for training. Specifically, CN1D-LSTM is employed to predict the IMF1-IMFn components obtained after CEEMDAN decomposition.
However, it is important to acknowledge that such models and other deep learning methods possess certain limitations. For instance, they often lack the ability for uncertainty quantification, as they rely on data-driven approaches rather than explicitly representing the underlying physical and chemical processes associated with Biogenic substance transport and transformation, as mechanistic models do.
Dung beetle optimizer
The Dung Beetle Optimizer (DBO)35 is a novel swarm intelligence optimization algorithm proposed by Professor Shen Bo's team at Dong Hua University. It primarily simulates five behaviors of dung beetles: rolling a ball, dancing, reproducing, foraging, and stealing. This algorithm is characterized by its strong optimization ability and fast convergence speed, In this study, the DBO optimization algorithm was utilized to perform hyperparameter tuning for the model. The selected parameters for tuning were the learning rate and hidden size. The learning rate is a crucial parameter that affects the training speed and convergence performance of the model. A learning rate that is too large may prevent the model from converging, while a learning rate that is too small can result in a slow training process. A larger hidden size can provide more parameters and non-linear transformation capabilities, enabling the model to better fit complex data patterns. However, an excessively large hidden size may lead to overfitting, whereas a small hidden size may result in underfitting. By utilizing this method, the uncertainty in the final model results caused by manually selecting parameters can be avoided.
Model building
In this experiment, BP, GRU, LSTM, CNN-LSTM, CEEMDAN-LSTM, and CEEMDAN-CNN-LSTM were selected respectively and the dung beetle optimization algorithm was used to optimize the model. After a comparison of experimental results, GRA-CEEMDAN-CN1DLSTM-DBO had the best effect. The GRA-CEEMDAN-CN1DLSTM-DBO model framework is shown in Fig. 3 below:

GRA-CEEMDAN-CN1DLSTM-DBO model frame diagram.
The model can be divided into three parts. The first part involves data processing, including the selection and manipulation of the training dataset. Initially, the grey relational analysis method is used to rank and select the relevant data types concerning the target variable for prediction. Then, by combining the influencing mechanisms with the target variable for prediction, an analysis is conducted to choose the relevant variables that rank higher and have a close relationship with the influencing mechanisms. These selected variables, along with the IMF data from the second part, are combined to form the complete training dataset.
In the second part, the input sequence is decomposed using CEEMDAN, resulting in a set of IMFs and a residual component. The high-frequency IMFs are considered as noise, while the low-frequency sequences represent fluctuations. The decomposition allows the original data to be transformed into more stable and regular sub-sequences, facilitating better pattern learning and improved prediction accuracy. Feature Modulation Decomposition is also commonly used in recurrent neural network prediction36. In this study, the phosphorus data from three water-quality hydrological stations in the middle reaches of the Yangtze River were decomposed.
In the NJG (Name of a specific area or section), after decomposing the data using CEEMDAN, four sets of IMF data and one residual component (RES) were obtained. IMF1 exhibits the strongest nonlinearity, highest amplitude, and highest frequency, while IMF2-IMF4 are more stable. The residual component's influence on the numerical values is neglected in this study.
After decomposition using CEEMDAN, the original data is transformed into more regular and stable sub-sequences, which are easier for the LSTM model to learn and predict compared to the original data. Each IMF is individually normalized and input into the CN1D-LSTM model for prediction. The Dung Beetle Optimizer is used to find the optimal solution for each IMF in the CN1D-LSTM model. Finally, the predicted results of all IMFs are combined to obtain the final predicted sequence of phosphorus concentration data in the NJG section.
In formula 1, "prediction(t)" represents the output of the prediction model, and "n" represents the number of IMF components. Since the residual obtained from model decomposition is negligible in numerical value, its influence can be disregarded. Therefore, the prediction model's output is obtained by directly adding the residual to the predicted IMF components.
The third part focuses on model optimization using the DBO. This algorithm optimizes the learning rate and the number of neurons in the CN1D-LSTM model to find the global optimum solution for the model's fitness function. The optimization steps in this study are as follows: define the fitness function as the Mean Squared Error (MSE) loss of the CN1D-LSTM model, initialize the population size, set the parameter search boundaries, and define the proportion of different dung beetles in the model. In each update iteration, the optimal fitness is calculated as the position is updated, leading to the discovery of the global optimum solution.
To validate the feasibility of the CEEMDAN-CN1DLSTM-DBO model, four comparative models (BP, GRU, LSTM, CN1DLSTM) were established in this study. The Dung Beetle Optimization algorithm was used to optimize the last two models. To evaluate the model's feasibility during the flood season in the middle reaches of the Yangtze River, three hydrological and water quality stations in the middle reaches of the Yangtze River were selected for validation. Additionally, the input phosphorus concentration data varied among the mentioned models. In the CEEMDN-CN1DLSTM model, the predicted sequences are the IMF data obtained from the CEEMDAN decomposition. In the other models, the TP concentration index of the section is directly used as the predicted sequence.
Prediction of phosphorus concentration
Data processing procedure
This experiment utilized data from three water quality stations in the Yangtze River Basin during the flood season (April to September) of 2023. The data included variables such as cascade reservoir flow, cascade reservoir water level and water level difference, daily water level, water level difference and flow rate between stations and downstream stations, dissolved oxygen concentration, turbidity, permanganate index, TN concentration, ammonia nitrogen concentration, downstream water level, daily variation of downstream water level, downstream section flow rate, and TP concentration. The water quality information exhibited complex correlations among multiple factors. The phosphorus content in the middle reaches of the Yangtze River was found to have non-linear correlations with indicators such as sediment, water level, and flow rate. In order to enhance the predictive accuracy of the model, the correlations among these indicators were analyzed to identify the parameters strongly associated with the research objective. In the following example using the NJG cross-section, the specific steps involved preprocessing the data through dimensionless processing. Grey relational analysis was then used to calculate the relationships between 18 variables and phosphorus content. The ranking of correlations resulted in turbidity, permanganate index, TN, water temperature, chlorophyll a, Three Gorges Dam upstream water level, Three Gorges Dam outflow rate, and daily variation of Three Gorges Dam upstream water level. The results indicated that the TP concentration in the water at the outlet of the Three Gorges Dam was not only related to water quality parameters, but also greatly influenced by the dynamic control of water levels in the downstream river section during the flood season. Finally, eight variables with significant correlations to TP were selected as the initial input sequence data. The grey relational analysis heatmap is shown in Fig. 4.

Heat map of grey correlation analysis.
The reasons for the training data set are detailed below especially during the flood season, the dynamic control of upstream inflow and the operation water level of cascade reservoirs have altered the hydrological characteristics of the original river channel. Scholars have conducted relevant studies on the impact of dam construction and operation on downstream ecology, focusing mostly on the effects of reservoir construction on downstream organisms and the patterns of nutrient retention and conversion in cascade reservoirs. For instance37, revealed the phenomenon of phosphorus retention and sedimentation caused by reservoir construction. This study focuses on the TP concentration in the surface water of the middle reaches of the Yangtze River. Taking the NJG section as an example, its geographical location determines that its water quality is significantly influenced by the TGD. During the flood season, the TGD dynamically controls the water level and flow in the reservoir area through scheduling procedures and hydrological forecasts. Considering the geographical context of the research object located downstream of a cascade reservoir, the factors influencing the water quality in the downstream of the Yangtze River are subdivided based on the dynamic control of the operating water level in the upstream cascade reservoir during the flood season. The cascade reservoir controls the discharge flow by regulating the inflow flow combined with scheduling regulations, indirectly affecting the water level variation in the reservoir area through water level elevation or reduction. This dynamic control of the operating water level during the flood season has an impact on the TP concentration in the reservoir area, which in turn affects the TP concentration in the downstream discharge water. Additionally, the rise or fall of the water level in front of the dam also affects the retention time of source materials in the reservoir area, thereby influencing their transformation, retention, and sedimentation. As shown in Fig. 4 shows the grey correlation coefficients of the TP concentration in the NJG water and the water level and its daily variation amplitude in the reservoir area, which are 0.65 and 0.75, respectively. This indicates that, compared to dilution of the TP concentration in the reservoir area, the inflow carrying capacity of TP from the upstream cascade reservoir and the retention time in the reservoir area are the main factors influencing the TP concentration in the downstream section. Moreover, different flow rates from the TGD also affect the TP flux in the downstream. As shown in Fig. 5, the water flow trend of typical sections in the middle reaches of the Yangtze River is generally consistent with the water flow trend downstream of the TGR. This indicates that the dynamic control of the operating water level during the flood season in the Gezhouba cascade reservoir has an equal impact on the downstream water flow of the middle reaches of the Yangtze River. As shown in Fig. 4, the grey correlation coefficient between the Three Gorges discharge flow rate and the TP concentration in the NJG section is 0.78, indicating that the dynamic control of the operating water level in the cascade reservoir influences the TP concentration in the downstream water by changing the discharge flow rate. However, as shown in Fig. 4, the TP concentration in the NJG section decreases with increasing distance from the dam, with grey correlation coefficients of 0.78, 0.77, and 0.73, indicating a decreasing level of influence with increasing distance from the dam. Therefore, during the flood season with frequent scheduling, the dynamic control of the operating water level in the cascade reservoir can affect the change of the TP concentration in the downstream under the influence of various complex factors. It is extremely difficult to predict changes in downstream source element concentrations through mechanistic research. Therefore, this study innovatively introduces water level and flow rate indicators as training factors to analyze the relationship between the TP concentration in the surface water of the middle reaches of the Yangtze River during the flood season and reservoir operations. Although the water level has the lowest GRA score in relation to the TP concentration in the NJG section, considering the completeness of the influencing mechanisms of the cascade reservoir, the water level is included in the sequence of training factors. The ability to predict the TP concentration in the downstream section of the cascade reservoir based on factors such as the water level in front of the dam, the daily variation range of the water level, and the reservoir discharge flow is discussed through figure four and the aforementioned analysis. In the grey system, there is a strong correlation between the TP concentration in the middle reaches of the Yangtze River and the water level and flow rate influenced by the dynamic control of the cascade reservoir upstream. The water level difference reflects the operation of the upstream cascade reservoir and the process of dynamic control during the flood season. Grey correlation analysis shows a strong correlation between the daily water level difference and the phosphorus concentration in this section among the 18 indicators. Dissolved oxygen content, turbidity, CODMn, TN, daily water level in front of the dam, daily water level difference, and reservoir discharge flow rate are selected as the original dataset, forming a complete training dataset for the TP concentration in the river section (Fig. 5).

Typical section discharge of Yangtze River.
Main program
In the preprocessing stage, four sets of IMF sequences and one set of residual (RES) were obtained. Only the four sets of IMF sequences were considered for prediction. The CN-LSTM model was chosen to predict the IMF data using the Pytorch library in Python. The dataset was divided into a training set (80%) and a test set (20%) using the parameters train_size = int(len(y) * 0.8) and test_size = len(y)—train_size. The input variables included turbidity, permanganate index, total nitrogen, water temperature, chlorophyll a, Three Gorges Dam upstream water level, Three Gorges Dam outflow rate, and daily variation of Three Gorges Dam upstream water level. The model structure and parameter information are displayed in the Table 2:
The five layers are sequentially connected to form the entire CNNLSTM model. The input data first undergoes feature extraction through two convolutional layers, conv1 and conv2. Subsequently, spatial dimension reduction is performed using the max pooling layer, pool. Finally, time series prediction modeling is carried out through the LSTM layer. In the process of setting the LSTM parameters, the DBO optimization algorithm was employed to select the hyperparameters for the learning rate and hidden size. The optimization process was as follows: (1) Initialize the population, X, based on the given parameters and boundaries; (2) Calculate the fitness values for the initial population; (3) Iterate a specified number of times (maximum iteration, MaxIter); (4) In each iteration, update the positions of the population based on a certain probability and rules; (5) Update the best solution, GbestScore, and its corresponding position, GbestPosition; (6) Record the best fitness value at each iteration, stored in the Curve; (7) Return the final best fitness value, optimal position, and fitness curve. The selection of DBO optimization parameters are displayed in the Table 3:
The DBO optimization algorithm was utilized for iterative optimization, and the optimal solution was obtained from GbestPosition. Specifically, the first element of GbestPosition was assigned to the learning_rate, while the second element was converted to an integer and assigned to the hidden_size. This indicates that the results of the firefly optimization algorithm were used for selecting the learning rate and hidden layer size. Subsequently, a CNNLSTM model was created and moved to the designated device (CUDA or CPU) as determined earlier. The mean squared error (MSE) loss function and the Adam optimizer were defined. The model generated predictions for the corresponding IMF components and the predictions for each IMF component were summed to obtain the TP concentration of the study section's water. Additionally, this study applied the model to two other sections, Yichang (YC) and Jingzhou (LK), which are farther from the TGD outflow section compared to the previous section. The model's performance was evaluated for these two sections to analyze the importance of cascade reservoir operation scheduling on TP concentration in the middle reaches of the Yangtze River.
Model evaluation
To objectively evaluate the predictive accuracy of the aforementioned models, it is important to employ robust methods for assessing the performance of ML-based models that quantify uncertainty and evaluate systematic and random errors, ensuring accurate and reliable predictions38. In this study, the root mean square error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE), and coefficient of determination (R2) were chosen as evaluation metrics to assess the prediction accuracy of the BP, LSTM, GRU, and CN1DLSTM models for predicting TP data after CEMMDAN decomposition.
R2 is determined as the measure of the proportion of the variance explained, while RMSE represents the square root of the mean of the squared distances between each predicted value and the actual value, measuring the deviation between predicted and actual values. A higher RMSE indicates a larger error. RMSE is sensitive to significant errors in the experimental data. On the other hand, MAE, similar to RMSE, represents the mean of the absolute values of the distances between each predicted value and the actual value, measuring the average absolute error between predicted and actual values. MAE reflects the true prediction error status of the model. MAPE compares the difference between predicted and actual values to the actual value itself, measuring the average relative error between predicted values and actual values. MAPE is highly influenced by outliers. The values of RMSE, MAE, and MAPE range from 0 to + ∞, with values closer to 0 indicating more accurate predictions. The coefficient of determination, R2, ranges from 0 to 1, with values closer to 1 indicating better predictive ability of the regression.
The specific calculation formulas for each loss function are as follows:
where N represents the total amount of data, \({y}_{i}\) represents the true value, and \({{y}_{i}}^{*}\) represents the predicted value.
Results
Modal decomposition and its prediction results
In this study, the phosphorus data from three water-quality hydrological stations in the middle reaches of the Yangtze River were decomposed. The decomposition of the phosphorus data from the NJG after applying CEEMDAN is shown in the Fig. 6.

CEEMDAN decomposition results.
As shown in Fig. 6, in the NJG section, CEEMDAN decomposition yielded four sets of Intrinsic Mode Functions (IMFs) and one residual component (RES). The high-frequency IMFs are generally considered as noise in the phosphorus concentration, while the low-frequency IMFs represent fluctuations. IMF1 exhibits the strongest nonlinearity, highest amplitude, and highest frequency, while IMF2-IMF4 are more stable. The residual component has negligible influence on the numerical values and is excluded from further analysis and prediction calculations.
The advantage of the CEEMDAN decomposition method is that it transforms the original data into more regular and stable sub-sequences, which are easier for the LSTM model to learn and predict compared to the original data. Each IMF is individually normalized and input into the CN1D-LSTM model for prediction. The Dung Beetle Optimizer is employed to find optimal solutions for each IMF in the CN1D-LSTM model. The predicted results of all IMFs are then combined to obtain the final predicted sequence of phosphorus concentration in the NJG section.
As shown in Fig. 7, (a) the predicted results of IMF1-IMF4 are consistent with the aforementioned analysis. High-frequency IMFs exhibit stronger nonlinearity, higher amplitude, and frequency, resulting in lower prediction performance. Conversely, (b-d) IMF2-IMF4 display greater stability, leading to improved prediction effectiveness of the model.

The prediction results for each individual IMF (a) IMF1_Prediction, (b) IMF2_Prediction, (c) IMF3_Prediction, (d) IMF4_Prediction.
According to Eq. 1, the IMF1-4 components are summed up to obtain the final prediction results for the NJG section, as shown in Fig. 8. The evaluation results, including MAPE (Mean Absolute Percentage Error), RMSE (Root Mean Square Error), MAE (Mean Absolute Error), and R2 (Coefficient of Determination), are 0.045, 0.03, 0.002, and 0.955, respectively. These results indicate that the model performs well in terms of prediction accuracy. As shown in Fig. 8, the model successfully addresses the issue of lag in the prediction results. However, similar to other deep learning frameworks, it also exhibits a tendency to underestimate certain peak values.

The results of GRA-CEEMDAN-CN1DLSTM-DBO models for phosphorus concentration in NJG.
Results of different prediction models
Taking the phosphorus concentration in the NJG section during the flood season as an example, to compare the GRA-CEEMDAN-LSTM-DBO model with other types of models. to verify the accuracy of the model predictions, the final validation datasets for each model were selected for comparison. The line graphs and scatter plots of the validation datasets for each model are shown in the Fig. 9. The evaluation metrics obtained after applying the evaluation function were compared with the output results from running all the models. The summarized evaluation results are presented in the table below.

The results of different prediction models of phosphorus concentration in NJG were tested (a) LSTM, (b) BP, (c) GRU, (d) CNLSTM, (e) LSTM-DBO, (f) CN1DLSTM-DBO, (g) IGRA-CEEMDAN-CN1DLSTM-DBO.
Table 4 shows the statistics of the predictive effect of phosphorus concentration on each model test dataset of the NJG cross-section, through the predicted effect of the phosphorus concentration in the NJG, we can easily find:
-
The combined model and the improved coupled model have higher accuracy than single prediction models;
-
The performance of the three single prediction models on the test dataset is similar, with the predictive accuracy of the R2 indicator approximately around 0.6.
-
Using one-dimensional convolutional neural networks to extract time series features and then using long short-term memory neural networks can improve the predictive accuracy of the model. By segmenting the data, the predictive accuracy of the model can be significantly improved;
-
The use of DBO can improve the predictive accuracy of the model. Compared to the LSTM model, both the LSTM-DBO and CN1DLSTM-DBO models show improved predictive accuracy. In the case of the CN1DLSTM-DBO model compared to CN1DLSTM, MAE is reduced by 12.5%, MAPE is reduced by 10.8%, and R2 is improved by 10.3%. Compared to the single LSTM model, RMSE is reduced by 11.6%, MAPE is reduced by 10.8%, and R2 is improved by 14.5%;
-
After decomposing the time series using CEEMDAN and training the prediction model, predicting the decomposed time series separately and adding them together can effectively improve the predictive accuracy of the model. Compared to the DBO-CN1DLSTM model, the CEEMDAN-DBO-CN1DLSTM model shows improved lagging of the predicted results. The evaluation indicators show that MAPE is reduced by 61.2%, RMSE is reduced by 100%, MAE is reduced by 100%, and R2 is improved by 33% compared to the DBO-CN1DLSTM model. Compared to the single LSTM model, MAPE is reduced by 67%, RMSE and MAE are reduced by 133% and 67% respectively, and R2 is improved by 49.4%.
Relationship between prediction results of different stations and response of cascade reservoir
To explore the applicability and feasibility of the model in the middle reaches of the Yangtze River under the influence of scheduling during the flood season, this study used the model to perform prediction simulations on three sections (NJG, YC, and LK). The prediction results of the YC cross-section and LK cross-section are shown in the Fig. 10.

Site model verification (a) Complete picture of YC, (b) Test set of YC, (c) Complete picture of LK, (d) Test set of LK.
Table 5 presents the model accuracy of GRA-CEEMDAN-CN1DLSTM-DBO in YC and LK. This study aims to validate the feasibility and accuracy of this model in the middle reaches of the Yangtze River. Additionally, it aims to examine the relationship between the model parameters and the accuracy concerning the distance from the cascade reservoir. The objective is to explore how the selection of model parameters reflects the impact on the TP concentration in water bodies based on the distance from the cascade reservoir. According to the results shown in the Tables 4 and 5, the CEEMDAN-DBO-CN1DLSTM model performs well in predicting phosphorus concentrations in the downstream sections of cascade reservoirs, compared to single models and combined models. The model shows good fitting performance across all three sections, indicating its applicability and feasibility in the middle reaches of the Yangtze River under the influence of scheduling during the flood season. However, as the model is used for downstream section prediction simulations, the results indicate that the predictive accuracy for the target section decreases with the distance from the cascade reservoir.
For example, the R2 value for the NJG section is 0.784, which is higher than the R2 value of 0.776 for the YC section and 0.718 for the LK section. This suggests that the NJG section, located downstream of the TGD and upstream of the Ge Zhou Dam, achieves better fitting performance. It is speculated that this difference in model accuracy may be due to the weakening of the frequency synchronization between the flow and water level of the target section and the cascade reservoir as the distance increases. Sections closer to the cascade reservoir are more likely to be affected by factors such as flow, leading to differences in model accuracy.
Discussion
This study employed deep learning methods to predict the TP concentration in the typical sections of the middle reaches of the Yangtze River. Previous studies often select a few typical water quality indicators as training datasets for parameter selection, without fully considering the unique geographical factors in different regions. However, using only a few typical water quality indicators may not be sufficient to meet the requirements of prediction accuracy. In this study, we investigated a section located in the middle reaches of the Yangtze River, where the TGR in the upstream undergoes artificial interventions. During the flood season, the operation and scheduling of the TGR are more frequent, leading to changes in the original hydroecological characteristics of the river and affecting the concentration of nutrients in the downstream water. Previous studies have not considered the impact of cascade reservoirs' artificial interventions on river water quality. Therefore, this study fully considers the influence of cascade reservoir operations and selects water quality indicators and cascade reservoir operation scheduling indicators. Based on the grey relational analysis (GRA), we ranked the contribution rates of TP concentration in downstream sections and finally selected eight indicators, including turbidity, permanganate index, TN, water temperature, chlorophyll a, Three Gorges Dam water level, Three Gorges discharge flow, and daily variation range of Three Gorges Dam water level, as input parameters for the model training, learning, and validation processes. The results of this study can provide assistance for water quality prediction work worldwide.
With the development of machine learning and deep learning models, they have been widely applied in hydrological runoff prediction. In recent years, more and more environmental researchers have used machine learning and deep learning models to predict water quality in various rivers. However, there are few studies on time series prediction of TP concentration in downstream water bodies of cascade reservoirs during the flood season. The water quality during the flood season exhibits the largest fluctuations and is the most difficult to predict. Therefore, in this study, taking the dynamic control of water levels in the TGR during the flood season as the background, the GRA-CEEMDAN-CNLSTM-DBO model was used to predict the TP concentration at the outlet section. This provides reference for the ecological and environmental impacts caused by the dynamic control of water levels in large-scale cascade reservoirs. Existing machine learning and deep learning models still face challenges in improving prediction accuracy and reducing prediction lag. However, it has been proven that data preprocessing using signal decomposition methods can improve the above issues36. Therefore, in this study, the Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN) method was used to decompose the prediction indicators, eliminating modal mixing and residual noise in the decomposition and discarding the noise prediction part. The results of this study showed that the coupled model using signal decomposition for data preprocessing improved the overall prediction accuracy and successfully addressed the issue of prediction lag. However, similar to other deep learning frameworks, it also exhibited a tendency to underestimate certain peak values. In addition, previous studies have demonstrated that model accuracy and prediction efficiency can be improved by selecting and optimizing parameters. In this study, a relatively new optimization algorithm, the Dung Beetle Optimization (DBO), was adopted in the water quality prediction field to optimize the parameter selection of the parallel CNN1D-LSTM network35. The results showed that DBO has been proven effective in accelerating model training and improving the accuracy of machine learning models21.
Compared to mechanistic models, the GRA-CEEMDAN-CNLSTM-DBO model does not require detailed engineering data but relies on analysis and learning from the dataset to explore water quality variations. Its prediction accuracy has been improved with the development of deep learning models, and it greatly reduces the modeling cost compared to mechanistic models for water quality simulation. In addition, in response to the construction of smart water conservancy, the model developed in this study can quickly predict and warn future water quality changes based on the monitoring data from the national surface water quality automatic monitoring stations in the middle and lower reaches of the Yangtze River and the existing database. It can also be used to predict other water quality indicators and grasp the overall development trend of water quality in monitoring sections in the future, which can be extended to the entire middle and lower reaches of the Yangtze River and rivers with similar backgrounds. As a predictive tool, non-mechanistic models can help relevant environmental researchers and cascade reservoir managers quickly understand the trend of water quality development and carry out reasonable management. Combined with the mechanistic model's typical regional water quality deduction, a mechanism-data-driven model is formed, thereby creating a digital twin system for the Three Gorges water conservancy and providing suggestions and assistance for similar river water environmental management.
The research results demonstrate that preprocessing has been proven to improve the predictive performance of deep learning models in water quality prediction studies. Although preprocessing was also conducted in this study, it cannot guaranteethe absolute accuracy of the predictions. There are still limitations and uncertainties in the model, such as the selection of input parameters, the choice of decomposition methods, and the optimization of parameters. Further research is needed to address these limitations and improve the model's performance. Additionally, the model's applicability to other rivers and water bodies needs to be validated. Overall, this study provides valuable insights into predicting TP concentration in the middle reaches of the Yangtze River and lays the foundation for future research in water quality prediction and management.
Conclusion
This study aimed to predict the TP concentration in the middle reaches of the Yangtze River using deep learning methods. The research process consisted of three main stages: preprocessing, model program, and hyperparameter optimization. In the preprocessing stage, the Grey Relational Analysis (GRA) was used to select eight water quality indicators and cascade reservoir operation scheduling indicators as input parameters. The TP concentration in the middle reaches of the Yangtze River was chosen as the target variable. The dataset collected during the 2023 flood season was divided into training and testing sets. To improve prediction accuracy, the Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN) algorithm was employed to decompose the TP concentration time series into several intrinsic mode functions (IMFs). The IMFs were then used as the output parameters for the model prediction. In the model program stage, various machine learning and deep learning models, including BP, LSTM, GRU, and CN1D-LSTM, were used to predict the IMFs obtained from the CEEMDAN decomposition. Lastly, in the hyperparameter optimization stage, the Dung Beetle Optimization (DBO) algorithm was utilized to optimize the learning rate and hidden size of the model. The performance of different regression algorithms and deep learning methods was quantified using statistical metrics such as R, RMSE, MAPE, and NSE. Additionally, the rationality and applicability of the GRA-CEEMDAN-CNLSTM-DBO model were verified using two sections in Yichang and Jingzhou. The key findings of this study are as follows: first, the TP concentration is not only highly correlated with certain water quality parameters but also influenced by hydrological parameters related to the dynamic control of water levels in upstream cascade reservoirs. Second, the integration of time series decomposition and prediction results significantly improves the performance of time series prediction. Third, compared to basic machine learning and deep learning models, the proposed GRA-CEEMDAN-CNLSTM-DBO model demonstrates relatively successful performance in predicting TP data in the middle reaches of the Yangtze River. The CNN feature extraction captures important data characteristics that are stored and utilized by LSTM for long-term memory, thereby improving the accuracy of the model. Fourth, the use of the DBO optimization algorithm enhances the prediction accuracy of the model. Finally, the applicability of the GRA-CEEMDAN-CNLSTM-DBO model was demonstrated through the validation on three typical sections in the middle reaches of the Yangtze River. However, the model has limitations in terms of decreasing prediction accuracy with increasing distance between the section and cascade reservoirs, indicating a weakening impact of cascade reservoirs on downstream areas.
Data availability
Data and materials are available from the corresponding author upon request.
References
Mahdian, M. et al. Anzali wetland crisis: Unraveling the decline of Iran’s ecological gem. J. Geophys. Res.-Atmos. 129(4), e2023JD039538 (2024).
Stride, B. et al. Microplastic transport dynamics in surcharging and overflowing manholes. Sci. Total Environ. 899, 165683 (2023).
Noori, R. et al. A non-threshold model to estimate carcinogenic risk of nitrate-nitrite in drinking water. J. Clean. Prod. 363, 132432 (2022).
Ryther, J. H. & Dunstan, W. M. Nitrogen, phosphorus, and eutrophication in the coastal marine environment. Science. 171(3975), 1008–1013 (1971).
Benitez-Nelson, C. R. The biogeochemical cycling of phosphorus in marine systems. Earth Sci. Rev. 51(1–4), 109–135 (2000).
Faruk, D. Ö. A hybrid neural network and ARIMA model for water quality time series prediction. Eng. Appl. Artif. Intell. 23(4), 586–594 (2010).
Wu, E. M. Y., Kuo, S. L. & Liu, W. C. Generalized autoregressive conditional heteroskedastic model for water quality analyses and time series investigation in reservoir watersheds. Environ. Eng. Sci. 29(4), 227–237 (2012).
Kadam, A. K. et al. Prediction of water quality index using artificial neural network and multiple linear regression modelling approach in Shivganga River basin India. Model. Earth Syst. Environ. 5, 951–962 (2019).
Valentini, M., dos Santos, G. B. & Muller, V. B. Multiple linear regression analysis (MLR) applied for modeling a new WQI equation for monitoring the water quality of Mirim Lagoon, in the state of Rio Grande do Sul—Brazil. SN Appl. Sci. 3, 1–11 (2021).
Heddam, S. & Kisi, O. Modelling daily dissolved oxygen concentration using least square support vector machine, multivariate adaptive regression splines and M5 model tree. J. Hydrol. 559, 499–509 (2018).
Najafzadeh, M. & Ghaemi, A. Prediction of the five-day biochemical oxygen demand and chemical oxygen demand in natural streams using machine learning methods. Environ. Monit. Assess. 191, 1–21 (2019).
Najafzadeh, M., Ghaemi, A. & Emamgholizadeh, S. Prediction of water quality parameters using evolutionary computing-based formulations. Int. J. Environ. Sci. Technol. 16, 6377–6396 (2019).
Najafzadeh, M. & Niazmardi, S. A novel multiple-kernel support vector regression algorithm for estimation of water quality parameters. Nat. Resour. Res. 30(5), 3761–3775 (2021).
Najafzadeh, M. et al. A comprehensive uncertainty analysis of model-estimated longitudinal and lateral dispersion coefficients in open channels. J. Hydrol. 603, 126850 (2021).
Ostad-Ali-Askari, K. & Shayannejad, M. Computation of subsurface drain spacing in the unsteady conditions using artificial neural networks (ANN). Appl. Water Sci. 11(2), 21 (2021).
Liu, P. et al. Analysis and prediction of water quality using LSTM deep neural networks in IoT environment. Sustain. -Basel. 11(7), 2058 (2019).
Ghiasi, B. et al. Uncertainty quantification of granular computing-neural network model for prediction of pollutant longitudinal dispersion coefficient in aquatic streams. Sci. Rep. 12(1), 4610 (2022).
Mei, P., Li, M., Zhang, Q. & Li, G. Prediction model of drinking water source quality with potential industrial-agricultural pollution based on CNN-GRU-Attention. J. Hydrol. 610, 127934 (2022).
Kim, H. I. et al. Incorporation of water quality index models with machine learning-based techniques for real-time assessment of aquatic ecosystems. Environ. Pollut. 355, 124242 (2024).
Jafari-Asl, J., Hashemi Monfared, S. A. & Abolfathi, S. Reducing water conveyance footprint through an advanced optimization framework. Water-SUI. 16(6), 874 (2024).
Alamgeer, M. et al. Dung beetle optimization with deep feature fusion model for lung cancer detection and classification. Cancers 15(15), 3982 (2023).
Huang, N. E. et al. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. P Roy. Soc. A-Math. Phy. 454(1971), 903–995 (1998).
Wu, Z. & Huang, N. E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt Data Anal. 1(01), 1–41 (2009).
Cao, J., Li, Z. & Li, J. Financial time series forecasting model based on CEEMDAN and LSTM. Physica A. 519, 127–139 (2019).
Li, H. et al. Daily flow prediction of the Huayuankou hydrometeorological station based on the coupled CEEMDAN–SE–BiLSTM model. Sci. Rep. 13(1), 18915 (2023).
Ahmadi, S. M., Balahang, S. & Abolfathi, S. Predicting the hydraulic response of critical transport infrastructures during extreme flood events. Eng. Appl. Artif. Intell. 133, 108573 (2024).
Khosravi, K. et al. Soil water erosion susceptibility assessment using deep learning algorithms. J. Hydrol. 618, 129229 (2023).
Noori, R. et al. Active and online prediction of BOD 5 in river systems using reduced-order support vector machine. Environ. Earth Sci. 67, 141–149 (2012).
Wang, F. K., Amogne, Z. E., Chou, J. H. & Tseng, C. Online remaining useful life prediction of lithium-ion batteries using bidirectional long short-term memory with attention mechanism. Energy. 254, 124344 (2022).
Shen, S. et al. Deep convolutional neural networks with ensemble learning and transfer learning for capacity estimation of lithium-ion batteries. Appl. Energy. 260, 114296 (2020).
Guo, S., Wen, Y., Zhang, X. & Chen, H. Runoff prediction of lower yellow river based on CEEMDAN–LSSVM–GM (1, 1) model. Sci. Rep. 13(1), 1511 (2023).
Donnelly, J., Daneshkhah, A. & Abolfathi, S. Physics-informed neural networks as surrogate models of hydrodynamic simulators. Sci. Total Environ. 912, 168814 (2024).
Ge, M. F., Liu, Y., Jiang, X. & Liu, J. A review on state of health estimations and remaining useful life prognostics of lithium-ion batteries. Measurement. 174, 109057 (2021).
Tan, W. et al. Application of CNN and long short-term memory network in water quality predicting. Intell. Autom. Soft Comput. 34(3), 1943–1958 (2022).
Xue, J. & Shen, B. Dung beetle optimizer: A new meta-heuristic algorithm for global optimization. J Supercomput. 79(7), 7305–7336 (2023).
Luo, L. et al. Ensemble empirical mode decomposition and a long short-term memory neural network for surface water quality prediction of the Xiaofu River China. Water-SUI. 15(8), 1625 (2023).
Mao, Y. C. et al. Caries and restoration detection using bitewing film based on transfer learning with CNNs. Sens.-Basel 21(13), 4613 (2021).
Yeganeh-Bakhtiary, A., EyvazOghli, H., Shabakhty, N. & Abolfathi, S. Machine learning prediction of wave characteristics: Comparison between semi-empirical approaches and DT model. Ocean Eng. 286, 115583 (2023).
Funding
This work is supported by the National Key R&D Program of China (Grant No. 2022YFC3202804).
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Writing and editing: H Y and Y H ; chart editing: H L.; preliminary data collection: P L .All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yao, H., Huang, Y., Lv, P. et al. Phosphorus prediction in the middle reaches of the Yangtze river based on GRA-CEEMDAN-CNLSTM-DBO. Sci Rep 14, 19442 (2024). https://doi.org/10.1038/s41598-024-70262-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-70262-4
