
Abstract
In this study, the Xgboost method is employed for TOC estimation in mixed carbonate and siliciclastic shale from the Hashan area, Junggar Basin. The results show that this approach is effective for TOC estimation in this area although the model performance is not very excellent with a correlation coefficient of 0.54 between measured TOC and predicted TOC values, likely due to a small samples dataset. Therefore, the PCA method is applied to debase dimension of well log data from five dimensional to two-dimensional data, which enhances the correlation coefficient between the predicted and measured TOC from 0.54 to 0.68. Based on the model, the isopleth maps of TOC distributions in Fengcheng Formation were redrawn showing two shale oil exploration targets, which likely correspond to two depositional centers of this strata. All the same, the model in this work provides reliable data for shale oil evaluation in the study area and a good example under similar geological setting.
Similar content being viewed by others
Introduction
With the rapid growth of energy demand and the sharp decrease of conventional petroleum resources, the unconventional resources, e.g., tight oil and gas, shale oil and gas, heavy oil, are gradually coming into focus1,2,3. Among those, shale oil is one of the most important unconventional resources and occur widely in sedimentary basins4,5,6. Shale is characterized by the abundant organic matter and acts as the source rock for conventional petroleum accumulations7,8,9. Shale plays have been found around the globe, including the Latin America, the Middle East, Russia and China3,10. TOC content is the assessment of the amount of total hydrocarbon occurring in the studied strata and is generally used to survey the quality of a shale play. TOC content depends on the hydrocarbon saturation and porosity of shale. Therefore, TOC are considered to be one of the significant parameters for shale oil assessment. Generally, TOC data can be available by laboratory measurement for rock samples11, which are burned to convert to carbon dioxide. However, TOC datasets are limited due to the time and experimental cost and core samples amounts, which cannot meet fine evaluation of shale oil.
To address this problem, the relationships between TOC and well logging parameter have been established by numerous authors due to the vertically successive well logging data12,13,14. For example, Schmokers and Hester (1983) showed that TOC content of sediments heads a positive linear correlation with the corresponding density13. Passey et al.12 showed that the ΔlogR got by the porosity and resistivity well logging (baseline) can be used to calculate the TOC content. Prior to using this approach, it is key to determine baselines for the sonic and resistivity logs defined as the interval transit time and resistivity of non-hydrocarbon-bearing beds (sandstones), which likely vary in different strata and geological setting. Besides these concerns, this method should be calibrated when it is used in unconventional plays. Moreover, in a complex geological setting, this method is unavailable due to the rapid change of lithology. A 3D surface fitting method has been developed to applied for TOC content estimation15. The above methods employ limited logging data leading to the inaccuracy results. With the development of artificial intelligence and big data technology, many machine learning models have been applied for source rock organic richness evaluation16,17,18,19,20,21, thermal maturity prediction22,23, organic matter kerogen type definition24,25,26, reservoirs pore-pressure estimation27,28, reservoir oil saturation estimation29, oil and gas distribution prediction27,30,31, lithology identification32,33,34,35, reservoir porosity and permeability estimation36,37. Various machine learning methods have been used to predict the TOC content by the combine of laboratory measurement data and well logging data38,39,40,41,42. For instance, Neural networks, e.g., artificial neural network and BP neural network, have been widely employed to estimate TOC values due to their powerful flexibility to handling the complex and nonlinear problems43,44. The support vector regression is a critical learning model for solving the small sample size problems, which have been applied for TOC content prediction under small sample conditions45,46. The gaussian process regression model, an ensemble learning model, have been successfully used to estimate TOC content attributed to its ability for dealing with complex problems (e.g., high dimensions, small samples, and non-linearity)47,48,49. Xgboost method were employed to predicte TOC of source rock from the Espírito Santo Basin, SE Brazil50. However, those methods have been attempted in conventional clastic rock and carbonate reservoirs deposited under stable deposition conditions. Less work has been done on the shale reservoirs composed of a mixture of siliceous and carbonate rocks deposited under a tectonic complex setting.
In this work, a sample set from Hashan area, Junggar Basin provides an excellent opportunity to focus on the TOC content of shale reservoirs and well logging data by machine learning methods. Subsequently, this understanding can be expanded to shale reservoirs deposited in the similar structural and sedimentary setting.
Geological settings
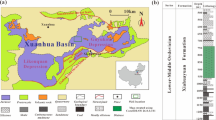
The Junggar Basin is one of the most petroliferous basins in the northwestern China51. It can be divided into Southern Piedmont Thrust Zone, Central Depression, Western Uplift, Eastern Uplift, Luliang Uplift and Wulungu Depression from south to north52. The Hashan area, located in the northwestern margin of Junggar Basin, is adjacent to Hala’alate Mountains (Fig. 1a). This area has undergone multistage tectonic movements and is mainly influenced by compressional tectonic regimes53,54, which results in the formation of many large-scale thrust nappe structures55,56 (Fig. 1b).

(a) Location of the study area in the Junggar Basin, (b) structural overview of the Hashan area, and (c) transverse section in the study area showing the strata distribution and lithology (location of section shown in b).
The stratigraphic framework is comprised of a series of depositions from Carboniferous to Quaternary57. Overlying the Carboniferous basement are the Permian depositions, including the Jiamuhe Formation, Fengcheng Formation, Xiazijie Formation, Lower Wuerhe Formation and Upper Wuerhe Formation. The Triassic strata contain the Baikouquan, Kelamayi, Baijiantan Formations (Fig. 2). The P1f. consists of organic-rich shale, mudstone and dolomitic mudstone and is an entirely hydrocarbon-abundant formation58,59, which is an important target for shale oil exploration60,61. A diversity of lithologies, including mudstone, dolomitic mudstone, silty fine sandstone, muddy siltstone, dolomitic siltstone and siltstone as well as silty fine sandstone, were identified based on careful core observations62,63,64,65. Moreover, very frequent lithological variations with meter–centimeter scale also present in the well profiles62,65.

Stratigraphic chart for the Hashan area in the Junggar Basin.
Samples and methods
Samples
A total of 82 core samples of the Fengcheng Formation were collected from five wells, i.e., HQ101, HQ6, HS1, HS2 and HSX1, in the Hashan area. The locations of those wells have been shown in Fig. 1a. The basic information of the core samples, indicating the sampling depth and main lithology, has been listed in Table S1 (in Supplementary material).
TOC measure
The selected rock samples were ground into power with particle diameters of less than 0.2 mm. And then, 100 mg of power samples were washed by diluted HCl and deionized water, respectively to remove the inorganic carbon and other contaminants in cores. All samples were dried in an oven at 80 °C for one day. The samples were heated to 900 °C using a LECO CS-230 analyzer so that organic carbon was fully combusted and converted into carbon dioxide.
Model data
In this study, the collected TOC datasets of core samples together with corresponding log data were randomly subdivided into training subset and testing subset, where the former was made from 70% of the data and the latter was consisted of left 30%. Prior to data input, all of the datasets were normalized in 0–1 using a min–max normalization pre-processing method in order to remove the effect of the different log with different units.
The relationships between measured TOC and well log data, including GR (Gamma-ray), RT (Resistivity), AC (Acoustic logging), DEN (Density) and CNL (Compensated neutron logging), have been shown in previous reports13,18,19,20,21,66. Therefore, the aforementioned data were selected as input for TOC values estimation in this study. GR log measures the radioactivity of different formations, where organic-rich strata are characterized by relatively extreme radioactivity with high GR values. DEN tool measures the bulk formation density affected by matrix and fluids compositions. Organic matter in rocks showing a low density decreases the density of source beds. Neutron log allows for the response of concentration of hydrogen atoms in rocks. The contents of hydrogen atoms and porosity in sedimentary rocks are related to the contents of organic matter. Consequently, organic-rich intervals have a high neutron porosity. RT log aims to measure the fluid conductivity in strata, whereby mature source rocks contain an enhanced resistivity due to the abundant generated hydrocarbons. AC log similar with CNL log also measures the contents of hydrogen atoms and porosity.
Several key steps are as follows (Fig. 3): Firstly, emending the depth of core sample by core observation and well log analysis; Next, establishing the relation between TOC values and corresponding well log data by statistical and visualization method to remove the abnormal data point; Then, subdividing the dataset into training and test subset; After that, debasing dimension of well log data from five dimensional to two-dimensional data with PCA method; Finally training, saving and applying the model. Table 1 lists the main parameters about the Xgboost model. Among those, the parameter for “min_child_weight” is equivalent to “minimum leaf size”.

A flowchart showing the general work process in this study.
Xgboost algorithm
Xgboost algorithm, one of important ensemble learning algorithms, was firstly developed by Chen and Guestrin67 and has been applied in various fields due to its great ability to deal with non-linearity problems. The basic structure and main idea of the algorithm is to assemble multiple simple tree models to iteratively generate a new tree, which can significantly enhance the accuracy of the model. It can be thought to be an optimization problem. The objective function is as follow:
where \(l\left({\widehat{y}}_{i}, {y}_{i}\right)\) is a loss function to determine the difference between the observed values \({y}_{i}\) and predicted values \({\widehat{y}}_{i}\) and \(\Omega \left({f}_{k}\right)\) is the regularization term to use to simplify the model and avoids overfitting problems. The function expression is as follows:
where T is the number of trees, and ω is number of Nodes.
The objective function is derived by expanding loss function using a Taylor Series:
where gi is the first order derivative and hi is the second derivative.
Define \({I}_{j}\) as the instance of node j. The function can be rewrite as follow:
where \({\text{G}}_{j}= {\Sigma }_{i\epsilon {I}_{j}}{g}_{i}\) and \({\text{H}}_{j}= {\Sigma }_{i\epsilon {I}_{j}}{h}_{i}\)
For a fixed structure q(x), the optimal wright \({{\upomega }^{*}}_{j}\) of node j can be expressed by:
and the corresponding optimal value can be calculated by:
Results and discussions
Petrological features
The thin section observations show the lithology of the Fengcheng Formation in the study area. The results show that Fengcheng Formation are characterized by carbonate, siltstone and mudstone and generally comprise either interbedded carbonatite and mudstone or interbedded siltstone and mudstone68 (Fig. 4). Figure 5 illustrates the relative content of calcareous minerals, felsic minerals and clay minerals. The results indicate that Fengcheng Formation shales in the study area are dominated by brittle minerals, i.e., quartz, feldspar, calcite and dolomite. The relative content of clay minerals ranges from 5.10 to 27.10%, with a mean of 15.30%. In general, based on the ternary diagram of mineral compositions, Fengcheng Formation shales belong to mixed shales69,70.

The representative microscope photographs showing the lithology characteristics of the Fengcheng Formation in the study area. (a) well HS1, 2100.30 m, silty mudstone interbedded with calcite; (b) well HS1, 2103.00 m, mudstone interbedded with siltstone; (c) well HQ6, 2702.20 m, micrite dolomite; (d) well HQ6, 2698.50 m, dolomite; (e) well HSX1, 3683.00 m, mudstone interbedded with organic matter; (f) well HSX1, 3302.10 m, dolomite.

Ternary diagram of mineral compositions of shale of Fengcheng Formation in Hashan area (modified from Zeng et al.69).
Correlation analysis
Figure 6 shows the relationships between the well logging and TOC values. The well logging data and correlated TOC values of selected samples are all conformed to a Gaussian distribution. The scatter plots show no significant correlation between the TOC values and the well log parameters. The TOC content was the only predicted attributes used in the Xgboost model. A conventional normalization approach was used to remove the influences of different units of different well log parameters prior to the Xgboost prediction model.

Cross plots of TOC and well log parameters.
TOC prediction
As shown in Fig. 7, the R2 of the measured TOC and estimated TOC values is 0.54 using Xgboost model. A significant relationship occurs between some well log parameters leads to the bad performance of the model in the test set. For example, the AC have a clearly negative linear relationship with DEN and a positive linear relationship with CNL, which may lead to an inaccurate prediction model. Therefore, a principal component analysis method was applied for the removal of overfitting16,29. The results show that the correlation of determination increase between measured TOC and estimated TOC values by a Xgboost model with principal component analysis. Other evaluation indicator including mean squared error (MSE), root mean squared error (RMSE) and mean absolute error (MAE) for the model are calculated to comprehensively assess the model. The MSE, RMSE and MAE in the model with PCA values are 0.05, 0.39 and 0.28 respectively, which are clearly lower than that in the model without PCA with values of 0.14, 0.63 and 0.39 respectively. Moreover, the R2 of the measured TOC and estimated TOC values for test data subset involved PCA method (0.57) is much higher than that without PCA method (0.12). Therefore, it indicates that PCA analysis can decrease the influence of overfitting on the model to a certain extent and then increase generalization ability.

Cross plots of measured TOC and estimated TOC values by combination (a) with PCA analysis and (b) without PCA analysis.
Implication for shale oil exploration
Profile distribution features
A visual comparison of the final output of estimated TOC values compared to the measured results can be seen in Figs. 8 and 9. The TOC prediction curves can predict the organic richness of each well where there were no samples taken. The sediments from the second member of Fengcheng Formation and top of the third member of Fengcheng Formation have high TOC content. In the well HSX1, the sediments are mainly mudstone at the depth of 3325–3375, which is characterized by high TOC values. The second member of Fengcheng Formation is dominated by calcareous dolomite. The volcanic ash has abundant magnesium and iron-rich materials, which can fertilise the algae and bacteria. Therefore, the second member of Fengcheng Formation sediments contain rich organic matter and have high TOC values. In the well HS1 from the northern study area, the second and third members of Fengcheng Formation were eroded due to massive thrust (Fig. 1b). The organic matter of the first member of Fengcheng Formation sediments were well preserved in the thrust nappe, leading to the high TOC content (Fig. 9). Therefore, the first member of Fengcheng Formation in the thrust nappe, second member of Fengcheng Formation and top of third member of Fengcheng Formation and may be shale oil potential layers in the Fengcheng Formation in the study area, which are characterized by higher contents of TOC.

Well-logging curves and TOC distribution for the well HSX1. GR: Gamma-Ray logging; SP: Spontaneous Potential logging; CNL: Compensated Neutron logging; DEN: Density logging; AC: Acoustic logging; RT: Resistivity logging.

Profile of wells HSX1-HQ101-HQ6-HS1 showing the TOC distribution. GR: Gamma-Ray logging; D: Depth; Litho: Lithology; RT: Resistivity logging; Md TOC: Measured TOC; Ed TOC: Estimated TOC.
Plane distribution features
The planar distribution characteristics of dark mudstone in the Fengcheng Formation show that the dark mudstone is mainly distributed in the HS11 well block of the western area and the HQ23 well block of central area (Fig. 10a). However, based on the data from CNPC, the occurrence of Fengcheng Formation shale in the Hashan area is very limited, which is only distributed in the margin of the Mahu Sag (Fig. 10b)71,72. In areas where no assay data were available, on basis of the above established prediction model, the geophysical logs were used to estimate the TOC content. The TOC contours of Fengcheng Formation in the study area have been illustrated in Fig. 10c. The TOC values are more than 3.00% around the well HS11 and more than 2.00% in the HQ23 well block, which is consisted with the distribution characteristics of dark mudstone. The Fengcheng shale with TOC > 5.00%, covering about 300 m2, is more than 200 m thick closed to wells HS11 and HQ23 (Fig. 10d). It also reflects that the central of paleolake during Early Permian Fengcheng Formation depositional stage may be in the well HQ23 zone in Hashan area and Fengnan area in Mahu Sag, where the confined water body were separated from the seawater regressing toward eastsouth. It leads to those sediments formed under a saline and reducing environment favorite for the prevailing of aquatic organisms, which can contribute amount of organic matter for source rock. Therefore, the well HQ23 and HS1 blocks can be the shale oil target for future exploration in this area. However, strong fault movements resulted in the shale reservoirs heterogeneity, which brings about the engineering problem and a relatively lower oil production compared with the Mahu Sag.

Isopleth maps of (a) thickness of dark mudstone of Fengcheng Formation (m) in this work; (b) thickness of dark mudstone of Fengcheng Formation (m) drawn by CNPC; (c) total organic carbon content of Fengcheng Formation (%) and (d) thickness of dark mudstone of Fengcheng Formation with TOC > 1.5% (m).
Comprehensive assessment
Table S1 also shows the lithology for the selected samples in this study. By compared the siliceous with carbonate rocks data, it is clearly observed that a similar performance of the prediction model on those samples. Several authors have shown the relationship between lithology and well log data, and lithology predictions model using well log data have been proved to be effective. Actually, the effects of lithology relying on just that relation have been considered. Therefore, the influence of lithology on the TOC values estimation is minor due to the input of multi-petrophysical data and considerable relationship between those data and lithology.
As shown in Fig. 6b, it can be observed that the predicted TOC values have a linearly positive correlation with the measured TOC values with a coefficient of association of 0.68. The model performance is not very excellent due to the limited dataset and the most of core samples with a relatively lower TOC values. Even so, the results of model behavior in the samples with high TOC values are clear, indicating the model still can be used for TOC values estimation.
To enhance the reliability for TOC estimation from the well log data, the quality of original materials should be sufficient, which was determined by compared with the difference between the observed well data and inspection log. The tolerable errors of GR, RT, AC, DEN and CNL log data are 5%, 10%, 5%, 5% and 10%, respectively. The depth error between the original observation well and the inspection well is less than ± 20 cm/200 m. The input data with a skewed distribution would be decrease the generalization of model and results in misleading MSE values of the trained data, where the values appear to be very low but the true values may be high. Therefore, standardization of the data should be performed.
As reviewed in the introduction part, some machine learning methods including Xgboost have been widely used to predict TOC contents and other physicochemical properties of rocks in the subsurface. However, the selected samples in previous studies mainly were pure shales and/or mudstones with high TOC contents deposited under a stable water body such as deep-lacustrine and marine (e.g., Yu et al.41, Mahmoud et al.44, Rui et al.45), which appear to provide a conceptual study frame. Whereas, in this study, the samples are mixed lithology with shales and carbonates deposited under a sharply changed environment and distributed in a tectonic complex geological setting, which would pose challenges for the depth emendation of the core sample and data processing. Meanwhile, a small set of data were obtained due to the limited exploration in the study area. In addition, the PCA method were employed to decrease the effect of overfitting issue likely leading by the narrow dataset, which were rarely reported. Therefore, this work presents a case study for the TOC contents estimation in the similar geological background. The distributions of the Fengcheng Formation shales in this area are updated based on the predicted data in this study and the constraint of geological model, which provides more detailed information for further shale oil exploration.
Conclusions
In this paper, the validity of using a xgboost machine learning algorithm was tested to predict TOC values using wireline logs. The results showed that xgboost algorithm has a good performance to deal with a nonlinear relationship between TOC values and well log parameters, which performed very well on TOC estimation with acceptable correlation. The correlation coefficient between measured TOC and predicted TOC values is 0.54, which is not very excellent likely relevant to a small core samples dataset. For this issue, the principal component analysis (PCA) method was used to transform the dimension (D) of data from 5 to 2D. By combination with Xgboost algorithm and PCA approach, the correlation coefficient between the predicted and measured TOC increases from 0.54 to 0.68, indicating PCA method can be applied for the decrease of overfitting. The model in this work provides reliable data for shale oil evaluation in the study area and a good example under similar geological setting. Based on the data and model, the second member of Fengcheng Formation contains tremendous potential in exploration of shale oil in the Hashan area. The present method in this study can help to save study time and avoid the difficulty to identify the “base line” corresponding the non-source rock segment due to a complex lithology mixed with carbonate and siliceous rocks. In the future, more sample data should be considered and a combinatorial method is involved to solve the overfitting problem.
Data availability
All data analysed during this study are included in the supplementary information files.
References
Wang, S., Qin, C., Feng, Q., Javadpour, F. & Rui, Z. A framework for predicting the production performance of unconventional resources using deep learning. Appl. Energy 295, 117016 (2021).
Xia, W. et al. Conversion of petroleum to methane by the indigenous methanogenic consortia for oil recovery in heavy oil reservoir. Appl. Energy 171, 646–655 (2016).
Zou, C. Unconventional Petroleum Geology (Elsevier, 2013).
Hughes, J. D. A reality check on the shale revolution. Nature 494, 307–308 (2013).
Pang, X. et al. Main controlling factors and movability evaluation of continental shale oil. Earth-Sci. Rev. 243, 104472 (2023).
Smith, J. L. Estimating the future supply of shale oil: A Bakken case study. Energy Econ. 69, 395–403 (2018).
Ougier-Simonin, A., Renard, F., Boehm, C. & Vidal-Gilbert, S. Microfracturing and microporosity in shales. Earth-Sci. Rev. 162, 198–226 (2016).
Zou, C. et al. Formation mechanism, geological characteristics and development strategy of nonmarine shale oil in China. Pet. Explor. Dev. 40, 15–27 (2013).
Zou, C. et al. Organic-matter-rich shales of China. Earth-Sci. Rev. 189, 51–78 (2019).
Mustafa, A. et al. Shale brittleness prediction using machine learning—A Middle East basin case study. AAPG Bull. 106, 2275–2296 (2022).
Peters, K. E. & Cassa, M. R. Applied source rock geochemistry: Chapter 5: Part II. Essential elements. In The Petroleum System—From Source to Trap. Aapg Bull (eds Lb, M. & Wg, D) 93-120 (1994).
Passey, Q. R., Creaney, S., Kulla, J. B., Moretti, F. J. & Stroud, J. D. A practical model for organic richness from porosity and resistivity logs. AAPG Bull. 74, 1777–1794 (1990).
Schmoker, J. W. & Hester, T. C. Total organic carbon in Bakken formation, United States portion of Williston Basin. AAPG Bull. 67, 2165–2174 (1983).
Zhao, P., Mao, Z., Huang, Z. & Zhang, C. A new method for estimating total organic carbon content from well logs. AAPG Bull. 100, 1311–1327 (2016).
Zeng, B. et al. Selective methods of toc content estimation for organic-rich interbedded mudstone source rocks. J. Nat. Gas Sci. Eng. 93, 104064 (2021).
Bolandi, V., Kadkhodaie, A. & Farzi, R. Analyzing organic richness of source rocks from well log data by using SVM and ANN classifiers: A case study from the Kazhdumi formation, the Persian Gulf basin, Offshore Iran. J. Pet. Sci. Eng. 151, 224–234 (2017).
Goliatt, L., Saporetti, C. M. & Pereira, E. Super learner approach to predict total organic carbon using stacking machine learning models based on well logs. Fuel 353, 128682 (2023).
Khan, M. R., Kalam, S., Asad, A. & Abu-khamsin, S. A. Development of a Deterministic total organic carbon (Toc) predictor for shale reservoirs. In SPE Middle East Oil and Gas Show and Conference (Abu Dhabi, UAE: SPE, 2023).
Jia, W., Zong, Z., Qin, D. & Lan, T. A method for predicting the toc in source rocks using a machine learning-based joint analysis of seismic multi-attributes. J. Appl. Geophys. 216, 105143 (2023).
Sun, J. et al. Prediction of toc content in organic-rich shale using machine learning algorithms: Comparative study of random forest, support vector machine, and Xgboost. Energies 16, 4159 (2023).
Liu, X., Tian, Z. & Chen, C. Total organic carbon content prediction in lacustrine shale using extreme gradient boosting machine learning based on Bayesian optimization. Geofluids 2021, 1–18 (2021).
Ma, J., Kang, D., Wang, X. & Zhao, Y. Defining kerogen maturity from orbital hybridization by machine learning. Fuel 310, 122250 (2022).
Shalaby, M. R., Malik, O. A., Lai, D., Jumat, N. & Islam, M. A. Thermal maturity and toc prediction using machine learning techniques: Case study from the cretaceous-paleocene source rock, Taranaki Basin, New Zealand. J. Pet. Explor. Prod. Technol. 10, 2175–2193 (2020).
Gordon, J. B., Sanei, H. & Pedersen, P. K. Predicting hydrogen and oxygen indices (HI, OI) from conventional well logs using a random forest machine learning algorithm. Int. J. Coal Geol. 249, 103903 (2022).
Kang, D., Wang, X., Zheng, X. & Zhao, Y. Predicting the components and types of kerogen in shale by combining machine learning with Nmr spectra. Fuel 290, 120006 (2021).
Safaei-Farouji, M. & Kadkhodaie, A. Application of ensemble machine learning methods for kerogen type estimation from petrophysical well logs. J. Pet. Sci. Eng. 208, 109455 (2022).
Rabbani, A. & Babaei, M. Image-based modeling of carbon storage in fractured organic-rich shale with deep learning acceleration. Fuel 299, 120795 (2021).
Yu, H., Chen, G. & Gu, H. A machine learning methodology for multivariate pore-pressure prediction. Comput. Geosci. 143, 104548 (2020).
Asante-Okyere, S., Shen, C., Ziggah, Y. Y., Rulegeya, M. M. & Zhu, X. Principal component analysis (PCA) based hybrid models for the accurate estimation of reservoir water saturation. Comput. Geosci. 145, 104555 (2020).
Ma, K. et al. A novel method for favorable zone prediction of conventional hydrocarbon accumulations based on rusboosted tree machine learning algorithm. Appl. Energy 326, 119983 (2022).
Ren, H., Wang, X., Guo, Q., Guo, X. & Zhang, R. Spatial prediction of oil and gas distribution using tree augmented Bayesian network. Comput. Geosci. 142, 104518 (2020).
Ao, Y., Zhu, L., Guo, S. & Yang, Z. Probabilistic logging lithology characterization with random forest probability estimation. Comput. Geosci. 144, 104556 (2020).
Hackley, P. C., Jubb, A. M., McAleer, R. J., Valentine, B. J. & Birdwell, J. E. A review of spatially resolved techniques and applications of organic petrography in shale petroleum systems. Int. J. Coal Geol. 241, 103745 (2021).
Lan, X., Zou, C., Kang, Z. & Wu, X. Log facies identification in carbonate reservoirs using multiclass semi-supervised learning strategy. Fuel 302, 121145 (2021).
Zou, Y., Chen, Y. & Deng, H. Gradient boosting decision tree for lithology identification with well logs: A case study of Zhaoxian gold deposit, Shandong Peninsula, China. Nat. Resour. Res. 30, 3197–3217 (2021).
Al Khalifah, H., Glover, P. W. J. & Lorinczi, P. Permeability prediction and diagenesis in tight carbonates using machine learning techniques. Mar. Pet. Geol. 112, 104096 (2020).
Ishola, O. & Vilcáez, J. Machine learning modeling of permeability in 3D heterogeneous porous media using a novel stochastic pore-scale simulation approach. Fuel 321, 124044 (2022).
Bai, Y. & Tan, M. Dynamic committee machine with Fuzzy-C-means clustering for total organic carbon content prediction from wireline logs. Comput. Geosci. 146, 104626 (2021).
Handhal, A. M., Al-Abadi, A. M., Chafeet, H. E. & Ismail, M. J. Prediction of total organic carbon at Rumaila oil field, Southern Iraq using conventional well logs and machine learning algorithms. Mar. Pet. Geol. 116, 104347 (2020).
Shalaby, M. R., Jumat, N., Lai, D. & Malik, O. Integrated toc prediction and source rock characterization using machine learning, well logs and geochemical analysis: Case study from the Jurassic source rocks in Shams Field, Nw Desert, Egypt. J. Pet. Sci. Eng. 176, 369–380 (2019).
Yu, H. et al. A new method for toc estimation in tight shale gas reservoirs. Int. J. Coal Geol. 179, 269–277 (2017).
Rong, J. et al. Machine learning method for toc prediction: Taking Wufeng and Longmaxi shales in the Sichuan basin, Southwest China as an example. Geofluids 2021, 1–13 (2021).
Elkatatny, S. A self-adaptive artificial neural network technique to predict total organic carbon (TOC) based on well logs. Arab. J. Sci. Eng. 44, 6127–6137 (2019).
Mahmoud, A. A. A. et al. Determination of the total organic carbon (TOC) based on conventional well logs using artificial neural network. Int. J. Coal Geol. 179, 72–80 (2017).
Rui, J., Zhang, H., Zhang, D., Han, F. & Guo, Q. Total organic carbon content prediction based on support-vector-regression machine with particle swarm optimization. J. Pet. Sci. Eng. 180, 699–706 (2019).
Tan, M., Song, X., Yang, X. & Wu, Q. Support-vector-regression machine technology for total organic carbon content prediction from wireline logs in organic shale: A comparative study. J. Nat. Gas Sci. Eng. 26, 792–802 (2015).
Rui, J. et al. Toc content prediction based on a combined gaussian process regression model. Mar. Pet. Geol. 118, 104429 (2020).
Shi, X. et al. Application of Extreme learning machine and neural networks in total organic carbon content prediction in organic shale with wire line logs. J. Nat. Gas Sci. Eng. 33, 687–702 (2016).
Zheng, D., Wu, S. & Hou, M. Fully connected deep network: An improved method to predict toc of shale reservoirs from well logs. Mar. Pet. Geol. 132, 105205 (2021).
Bione, F. R. A. et al. Estimating total organic carbon of potential source rocks in the Espírito Santo basin, Se Brazil, Using Xgboost. Mar. Pet. Geol. 162, 106765 (2024).
Zhang, Z. M., Liou, G. & Coleman, G. An outline of the plate tectonics of China. Gsa Bull. 95, 295–312 (1984).
Li, D., He, D., Santosh, M. & Ma, D. Tectonic framework of the Northern Junggar Basin part II: The Island Arc basin system of the Western Luliang uplift and its link with the West Junggar Terrane. Gondwana Res. 27, 1110–1130 (2015).
Liang, Y., Zhang, Y., Chen, S., Guo, Z. & Tang, W. Controls of a strike-slip fault system on the tectonic inversion of the mahu depression at the Northwestern margin of the Junggar Basin, Nw China. J. Asian Earth Sci. 198, 104229 (2020).
Ma, D., He, D., Li, D., Tang, J. & Liu, Z. Kinematics of syn-tectonic unconformities and implications for the tectonic evolution of the Hala’alat Mountains at the Northwestern margin of the Junggar Basin Central Asian Orogenic Belt. Geosci. Front. 6, 247–264 (2015).
Li, D., He, D., Sun, M. & Zhang, L. The Role of arc‐arc collision in accretionary orogenesis: Insights from∼ 320 Ma tectono‐sedimentary transition in the Karamaili Area, Nw China. Tectonics 39, 5623 (2020).
Ma, D., He, D., Li, D., Tang, J. & Liu, Z. Kinematics of syn-tectonic unconformities and implications for the tectonic evolution of the Hala’alat Mountains at the Northwestern margin of the Junggar Basin, Central Asian Orogenic Belt. Geosci. Front. 6, 247–264 (2015).
Chen, Z. et al. Origin and mixing of crude oils in triassic reservoirs of Mahu Slope Area in Junggar Basin, Nw China: Implication for control on oil distribution in basin having multiple source rocks. Mar. Pet. Geol. 78, 373–389 (2016).
Cao, J. et al. An alkaline lake in the late Paleozoic ice age (LPIA): A review and new insights into paleoenvironment and petroleum geology. Earth-Sci. Rev. 202, 103091 (2020).
Wang, T. et al. Spatiotemporal evolution of a late Paleozoic alkaline lake in the Junggar Basin. China. Mar. Pet. Geol. 124, 104799 (2021).
Tang, Y. et al. Discovery of shale oil in alkaline Lacustrine Basins: The late Paleozoic Fengcheng formation, Mahu Sag, Junggar Basin, China. Pet. Sci. 18, 1281–1293 (2021).
Zhang, K. et al. Shale dominant lithofacies and shale oil enrichment model of Lower Permian Fengcheng formation in Hashan area, Junggar Basin. Pet. Geol. Exp. 45, 593–605 (2023).
Liu, C., Liu, K., Wang, X., Wu, L. & Fan, Y. Chemostratigraphy and sedimentary facies analysis of the permian Lucaogou formation in the Jimusaer Sag, Junggar Basin, Nw China: Implications for tight oil exploration. J. Asian Earth Sci. 178, 96–111 (2019).
Cao, Z. et al. Lacustrine tight oil accumulation characteristics: Permian Lucaogou formation in Jimusaer Sag, Junggar Basin. Int. J. Coal Geol. 153, 37–51 (2016).
Cao, Z. et al. Geochemical characteristics of crude oil from a tight oil reservoir in the Lucaogou formation, Jimusar Sag, Junggar Basin. AAPG Bull. 101, 39–72 (2017).
Wu, H. et al. A unique lacustrine mixed dolomitic-clastic sequence for tight oil reservoir within the Middle Permian Lucaogou formation of the Junggar Basin, Nw China: Reservoir characteristics and origin. Mar. Pet. Geol. 76, 115–132 (2016).
Kamali, M. R. & Allah Mirshady, A. Total organic carbon content determined from well logs using Δlogr and neuro fuzzy techniques. J. Pet. Sci. Eng. 45, 141–148 (2004).
Chen, T. & Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd International conference on knowledge discovery and data mining 785–794 (2016).
Wang, Y. et al. Occurrence state and oil content evaluation of permian Fengcheng formation in the Hashan area as constrained by Nmr and multistage rock-eval. Pet. Sci. 20, 1363–1378 (2023).
Zeng, Z. et al. Shale oil reservoir characteristics and controlling factors of Permian Fengcheng Formation in Hashan area, northwestern margin of Junggar Basin. Lithol. Reserv. 35, 25–35 (2023).
Li, Z. et al. Fine-grained sedimentary characteristics and evolution model of Permian Fengcheng Formation in Hashan area, Junggar Basin. Pet. Geol. Exp. 45, 693–704 (2023).
Zhi, D. et al. Orderly coexistence and accumulation models of conventional and unconventional hydrocarbons in lower permian Fengcheng formation, Mahu Sag, Junggar Basin. Pet. Explor. Dev. 48, 43–59 (2021).
Hu, T. et al. Hydrocarbon generation and expulsion characteristics of P1f source rocks and tight oil accumulation potential of Fengcheng area on northwest margin of Junggar Basin, Northwest China. J. Central South Univ. (Sci. Technol.) 48, 427–439 (2017).
Acknowledgements
This work was supported by Funds for International Cooperation and Exchange of the National Natural Science Foundation of China (Grant No. S2021-JC-QN-0121). Thanks to the Exploration and Development Research Institute, Shengli Oilfield Company for providing the data and cores, as well as permitting publishing. We want to express our appreciation to Dr. Heather Bedle, In-house Editor, and two anonymous reviewers whose comments significantly improve the quality of manuscript.
Author information
Authors and Affiliations
Contributions
YZ: Conceptualization, Investigation, Methodology, Formal analysis, Writing—Original Draft; GZ: Conceptualization, Formal analysis, Writing—Original Draft, Funding acquisition; WZ: Conceptualization, Resources, Review & Editing; JZ: Conceptualization, Resources, Review & Editing; KL: Methodology, Supervision; ZC: Resources, Investigation, Writing—Review & Editing. All author reviewed the manuscript and approved to publish.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, Y., Zhang, G., Zhao, W. et al. Total organic carbon content estimation for mixed shale using Xgboost method and implication for shale oil exploration. Sci Rep 14, 20860 (2024). https://doi.org/10.1038/s41598-024-71504-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-71504-1
