
Abstract
Automatic Modulation Classification (AMC) is crucial in non-cooperative communication systems as it facilitates the identification of interference signals with minimal prior knowledge. Although there have been significant advancements in Deep Learning (DL) within the field of AMC, leveraging the inherent relationships between In-phase (I) and Quadrature-phase (Q) components, and enhance recognition accuracy under low signal-to-noise ratio (SNR) conditions remains a challenge. This study introduces a complex-valued convolutional fusion-type multi-stream spatiotemporal network (CC-MSNet) for AMC, which combines spatial and temporal feature extraction modules for modulation recognition. Experimental results demonstrate that the CC-MSNet performs well on three benchmark datasets, RML2016.10a, RML2016.10b, and RML2016.04c, with average recognition accuracy of 62.86%, 65.08%, and 71.12%. It also performs excellently in low SNR environments below 0dB, significantly outperforming other networks.
Similar content being viewed by others
Introduction
In the realm of wireless communication systems, signal analysis and processing techniques encompass a complex sequence of procedures, including signal detection, identification, and recovery, these techniques often operate under conditions where channel and signal parameters are not fully known. As an integral part of this sequence, AMC is crucial not only for signal demodulation and parameter extraction but also playing a pivotal role in guiding the selection of appropriate technical parameters during communication interference efforts. It is particularly true in the practical setting of non-cooperative communications, where research on AMC holds substantial theoretical significance as well as considerable practical value1,2.
In 2016, T. O’Shea et al.3 demonstrated the potential of DL in AMC by directly processing IQ signals using a Convolutional Neural Network (CNN) model, and released the RML2016.10a dataset, sparking a research boom on DL applications within the field of AMC. In 2017, T. O’Shea and colleagues combined the ability of CNN to process frequency features with the advantage of Recurrent Neural Network (RNN) in capturing temporal information to create the CLDNN model4, this model successfully extracted key features that enhanced classification accuracy. In 2018, T. O’Shea and colleagues5 proposed a modulation recognition model based on the Residual Network (ResNet) and the RML 2018.01a communication signal dataset, using a deeper network model to achieve modulation recognition for 24 types of communication signals. Subsequently, based on the above benchmark datasets and models, a large number of deep learning-based AMC methods were proposed6,7,8,9,10.Xu et al. innovatively extracted IQ signal features from both the time and frequency domains and processed them using a CNN-LSTM fusion network, proposing a space-time multi-channel MCLDNN11 model, this model combined multi-channel inputs, spatial feature mapping, temporal feature extraction, and a fully connected classification layer to enhance the model’s understanding of complex signals and further improve classification accuracy. Following closely, Cui et al. proposed the IQCLNet12 model, which further optimized the number, size of convolution kernels, and the depth of convolutional layers to extract IQ timing and phase features more finely, demonstrating the superiority of the network.In 2020, J. Krzyston et al.13 introduced the concept of complex convolution by constructing a numerical convolution module that implemented a process similar to two-dimensional real convolution. This method required only minor modifications to the network parameters to improve recognition accuracy, performing well especially under low SNR conditions. It is evident that DL-AMC techniques have evolved from preliminary signal processing to sophisticated multi-network models, addressing the issues of traditional methods that rely on manual expertise and heavy computation.
Although the above algorithms have achieved certain results in the field of AMC, challenges such as improving average network recognition rates in low SNR environments and distinguishing between commonly confused signals still further research. To fully exploit the intrinsic relationship between IQ data and enhance the feature extraction capability of the DL-AMC model to improve the accuracy of model identification, based on the complex convolution model in literature13, this paper proposes a new model named improved CC-MSNet. The main contributions of this paper are as follows:
-
The use of a complex convolution module as one branch of the IQ data stream input allows for a more comprehensive mining of the phase information of the signal through complex convolution, so that the features of signal can be extracted more comprehensively and the precision of signal recognition can be improved.
-
The network adopts a dual-module collaborative approach that processes spatial and temporal features, feeding the input IQ signals into both spatial and temporal feature extraction modules. This fully considers the fusion of features across spatial and temporal dimensions, capturing IQ data characteristics more effectively and aiding in the differentiation of easily confused signals.
-
Multiplicative Gaussian noise is introduced as a weight regularization parameter between LSTM and Bi-LSTM, as well as between the temporal feature extraction module and the fully connected output module. The method with this noise not only improves accuracy but also eliminates overfitting in the model, enhancing its robustness.
IQ signal representation model
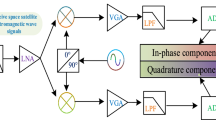
In modern communication systems, to transmit more information within the limited spectrum resources, most analog or digital signals are transmitted using IQ modulation. The principles of modulation and demodulation are illustrated in Fig. 1.

The modulation and demodulation process.
During transmission, the I-channel signal and Q-channel signal is respectively modulated onto the carrier wave to form the transmitter signal\(Z(t)\), whose expression is:
Where\(\omega {\text{c}}\)represents the carrier frequency.
At the receiving end, the received signal is denote at the receiving end, the received signal is denote\(y(t)\), and its expression is:
Where A represents the channel gain,\(\omega\)represents the angular frequency, \(\varphi\)represents the phase, and j represents the imaginary number. The I-channel signal and Q-channel signal is separated through orthogonal carrier components by low-pass filters, corresponding to the data stream format preserved as a matrix in AMC, detailed as follows:
The proposed AMC method
The overall network structure of CC-MSNet
This article proposes a CC-MSNet network, as shown in Fig. 2. It consists of two modules: the first is the multi-stream spatial feature extraction module (MSSM), and the second is the time feature extraction module(TM). In the following subsections, we will detail each module.

CC-MSNet network architecture.
Multi-stream spatial feature extraction module
Complex convolution data stream
In processing IQ signals, traditional methods often feed the I-channel signal (real part) and Q-channel signal (imaginary part) as separate channels into a neural network to extract information features independently. This approach neglects the inherent physical correlation between the real and imaginary parts. To more comprehensively process IQ data and effectively capture the rich features between them, this study employs a complex convolution module. This module can delve deeper into the intrinsic connections of IQ signals, thereby helping the model to understand the complex nature of the signals more accurately. This paper references the concept of complex convolution proposed in literature14,15, which is based on the principle that two-dimensional real convolution is equivalent to one-dimensional complex convolution through linear transformation. This approach enables a neural network to compute complex convolutions within the standard framework of real-number deep learning, ensuring that the correlation between the real and imaginary parts of the complex signal is preserved after the real convolution operation. In this way, we can not only leverage DL techniques existing but also ensure the accuracy and integrity of signal processing.
The expression of the complex convolution kernel is introduced as:
Its matrix expression is as follows:
Convolution operation is performed on the input complex data\({Z_{\text{n}}}\)with the complex convolution kernel \({V_m}\)to get the following result:
The graphical representation is shown in Fig. 3:

Complex number convolution process.
Zero padding the top and bottom of the\(Zn\) matrix.
Convolution operation with \({V_m}\)yields the expression of the two-dimensional matrix form X as:
The convolution of real-valued functions \(Zn*Vm\)is expressed as \({X_{{\text{DL}}}}\) :
When\({X_{{\text{DL}}}}\)does\(\left[ {\begin{array}{*{20}{c}} 1&0 \\ 0&1 \\ { - 1}&0 \end{array}} \right]\) linearly transformed to be equivalent to X the process of equating a one-dimensional complex convolution with a linearly transformed two-dimensional real convolution is realized.
Multi-stream spatial feature extraction (MSSM)
In AMC systems, the size of IQ sample signals is 128 × 2, indicating that there are 128 samples, each containing I and Q component. To effectively extract features from these signals, the MSSM divides the signal into four channels. Channel 1 corresponds to the I component of the IQ signal, while channel 2 corresponds to the Q component, each channel independently undergoes three layers of small convolution operations, which is then combined in parallel to further extract features, this feature extraction method is inspired by the VGG network with its use of smaller convolution kernels in to increase the depth of the network, enabling the model to learn more complex features. Channel 3 is the IQ channel, which specifically addresses the correlation between the I and Q components, it uses a sequence of convolution kernels (2,1), (1,3), (1,3) to extract features, this approach not only reduces the data dimensionality but also minimizes subsequent variations in the frequency domain of the data. Channel 4 is the complex convolution channel, this channel performs (2,3) convolution operations on zero-padded (1,1) IQ components followed by a linear transformation to achieve complex IQ convolution. The complex convolution module can more comprehensively process IQ data, capturing richer features between IQ signals and exploring their intrinsic relationships. With its four-branch structure, the MSSM module employs small convolution kernels, dimensionality reduction, and complex convolution techniques to thoroughly extract spatial features from IQ signals. These features are further processed by a (9,5) convolution kernel before being passed to the time feature extraction module for temporal analysis, providing key information for modulation recognition. In short, the MSSM module as Fig. 4 shows that deepens feature extraction, enhancing the performance of the AMC system.

Multi-stream spatial feature extraction module.
Time feature extraction module
LSTM and Bi-LSTM network architectures
The advantage of the RNN9 lies in its more comprehensive extraction of the overall temporal state features, utilizing hidden layers to fully exploit the effective information at the current and previous time nodes. As classical networks of the RNN model, Long Short Term Memory (LSTM) and Bi-directional Long Short-Term Memory (Bi-LSTM) can adequately capture the dynamic changes over time in sequential data and effectively learn and remember the data associations within a long time span. The specific recognition framework is shown in Fig. 5:

Recognition framework of LSTM.
Utilizing the Bi-LSTM, with its forward and backward inputs, allows for a more effective perception of “context” information and a deeper exploration of sequential features.The framework is shown in Fig. 6:

Recognition framework of Bi-LSTM.
Multiplicative gaussian noise
In AMC task, noise is usually added to eliminate the effect of the isolated feature on the whole training model. The common noises are additive noise and multiplicative noise. In this paper, Gaussian dropout is chosen as a hyperparameter, which can be used as a regularization method to limit the complexity and improve the generalization ability of the model, and can prevent overfitting directly by introducing randomness. The specific principle is as follows:
Gaussian dropout is a regularization technique where the noise is multiplicatively related to the signal, meaning that the noise value is multiplied by the signal sample value rather than setting it to zero. The standard deviation is usually set to a small value to avoid destroying the original signal. This strategy can simulate to some extent real-world signal transmission environments (such as fading, doppler effects, or nonlinearities), this helps to understand and process the characteristics and variations of the signal more comprehensively.
The multiplicative Gaussian noise is normally distributed with a probability density expression:
Where \(\sigma\)denotes the standard deviation of the noise level, \({\sigma ^2}\)is its variance, and 1 is the mean of the noise level. Let the original input signal expression be\(s(t)\), then the expression of the output signal after the introduction of multiplicative Gaussian noise is:
The above formula, multiplicative Gaussian noise is multiplied by the original signal, introducing additional variability into model training. This variability helps model learning by reducing excessive dependence on specific noise or details in the training data. it enhances the model’s ability to make more accurate predictions on new and unseen data. furthermore, it can increase the robustness of the model while preserving signal characteristics. Literature16,17,18,verifies the effectiveness of multiplicative noise in neural networks.
Robust temporal feature extraction
The spatial feature extraction module thoroughly explores the intrinsic relationships within IQ data through multi-stream branches, while the temporal feature extraction module leverages the strengths of LSTM and Bi-LSTM networks in extracting sequential features, fully capturing the dynamic changes and dependencies over time in sequential data. After passing through the MSMM module, the input form of the data is (124, 100), which then enters the LSTM network before moving to the next moment’s Bi-LSTM network for the extraction of “context” information. To enhance the model’s robustness, this paper introduces multiplicative Gaussian noise between the LSTM and Bi-LSTM, as well as between the temporal feature extraction module and the fully connected output module, with the specific model details are shown in Fig. 7.

Time feature extraction module.
Experiment and result analysis
The experiments in this paper were conducted on the public datasets3,4,5, RML 2016.10a, RML 2016.10b, and RML 2016.04c. The specific data sample size and modulation characteristics are shown in Table 1. The dataset generated by O’Shea and others through GNU Radio. In order to simulate the real-world data characteristics of modulated signals and take into account the time-varying random channel effects common in most wireless systems, including center frequency offset, sampling rate offset, Additive white Gaussian noise, multipath, and fading, provides the validation base data for many network models.
Ablation comparison experiments based on spatial feature extraction module
To conduct ablation experiments by changing the number of input channels and different input data, the advantages of the MSSM module were verified. Three different modules, A, B, and C, were selected to carry the same temporal features for the experiment: Model A used a 3-channel approach to process I, Q independent data, and IQ data; Model B used a 3-channel approach to process I, Q independent data, and processed IQ data using complex convolution; Model C used 4 channels to individually handle I, Q independent data, IQ data, and IQ data processed through complex convolution. Specific parameters are shown in Table 2.
The RML 2016.10a dataset was chosen, split into training, testing, and validation sets at a ratio of 6:2:2. The training configuration included 50 epochs, a batch size of 128, using the Adam optimizer and cross-entropy loss function, with an initial learning rate of 0.001, decreasing every 10 Epochs to promote model convergence.

Comparison experiment of CC-MSNet spatial feature extraction module network.
The Fig. 8 shows that Model C outperforms Model A and Model B in all performance indicators. Specifically, at SNR above 0dB, Model C achieves an average precision improvement of 6.27% and 0.41% over Model A and Model B, respectively. Below 0dB, the average precision is improved by 0.91% and 0.31% compared to Model A and Model B, respectively. In terms of overall average precision, Model C surpasses Model A by 3.59% and Model B by 0.35%. These data indicate that Model C significantly outperforms Model A and slightly outperforms Model B in overall performance. This demonstrates that adopting a complex convolution approach as a branch to simultaneously process both the amplitude and phase information of signals helps capture more subtle features within the IQ data. It exploits and utilizes a greater range of signal attributes, which is more conducive to improving the network’s recognition accuracy.
Comparison experiment of ablation based on temporal feature extraction module
To verify the effectiveness of the temporal feature extraction model, we constructed comparative models to perform ablation experiments on whether to choose LSTM, Bi-LSTM etc., as well as the number of network layers and whether to introduce multiplicative Gaussian noise among other differences.The model details are shown in Table 3.

Comparison experiment of CC-MSNet time feature extraction module network.
From Fig. 9, it can be concluded that Network 5 has a better recognition accuracy. Comparing Network 1 with Network 2, which only replaces one layer of Bi-LSTM, the recognition accuracy is improved by 1.47%. This indicates that as the number of input features increases, the Bi-LSTM network can better exploit the features of the data. When comparing Network 3 with Network 2, an additional FC layer is added, but the accuracy below 0dB and the overall recognition accuracy is not as good as Network 2. This suggests that increasing the FC layers does not enhance the recognition accuracy; instead, reducing the FC layers can effectively alleviate overfitting in the network. When comparing Network 4 with Network 2, an extra layer of Gaussian noise is added, and all four indicators are improved, indicating that Gaussian noise contributes to enhancing the recognition accuracy. Upon comparing Network 5 with Network 4, the average recognition accuracy improves by 0.32%, the highest recognition accuracy by 0.31%, the accuracy above 0dB by 0.5%, and the accuracy below 0dB by 0.16%. This further verifiy that Gaussian noise can indeed enhance the model’s recognition accuracy.
To obtain appropriate parameters for multiplicative Gaussian noise, ablation experiments were conducted distinctively. Gaussian dropout is a regularization technique that prevents overfitting by adjusting the output of neurons with noise instead of setting them to zero. This enables the model to make more accurate predictions on new, unseen data.The Table 4 shows that the optimal value for Gaussian dropout is 0.5.
Comparative experiments of different network models
In Sect. 4.2 and 4.3, the effectiveness of the two modules of the CC-MSNet network was verified through comparative experiments. In this section, the network is compared with existing advanced modulation signal recognition networks, namely CNN219, CLDNN220,ResNET5, LSTM9, PET-CGDNN21, and MCLDNN11. Comparative experiments are conducted on three benchmark datasets: RML 2016.10a, RML 2016.10b, and RML 2016.04c.The model details are shown in Table 5.
Comparison of model structures
Model recognition accuracy comparison

Classification accuracy of different networks on RML2016.10a.

Classification accuracy of different networks on RML2016.10b.

Classification accuracy of different networks on RML2016.04c.
From Table 6; Figs. 10, 11 and 12, it can be seen that on the benchmark datasets RML 2016.10a, RML 2016.10b, and RML 2016.04c, the CC-MSNet demonstrates superior average recognition accuracy under both low SNR ([-20dB, -2dB]) and high SNR ([0dB, 18dB]) compared to other networks. Further comparison with the MCLDNN model shows that the average accuracy is improved by 0.75%, 0.95%, and 0.63% respectively. When the SNR is less than 0dB, the average accuracy is improved by 0.28%, 1.21%, and 1.02% respectively. Additionally, the CC-MSNet network achieves a recognition precision of over 93% at SNR of 4dB, 8dB, 10dB, and 12dB on the RML 2016.10a dataset.
Comparison of model training accuracy, training loss, validation accuracy, and validation loss
During the training process, the network weights are updated continuously in real-time, and the weights that yield the best validation accuracy (val-accuracy) are saved for testing. Using MCLDNN as a comparison model, Fig. 13 shows the comparison curves of training accuracy, training loss, validation accuracy, and validation loss between the CC-MSNet network and the MCLDNN network on three benchmark datasets.

Comparison of the training/validation curves for CC-MSNet and MCLDNN.
From Fig. 13, it can be observed that on three public datasets, the CC-MSNet network demonstrates significantly better training accuracy and training loss compared to the MCLDNN network, confirming the conclusion that the increase in the number of extracted features due to the introduction of complex convolution for IQ signals leads to improved training accuracy. As seen from the comparison of validation accuracy, the CC-MSNet network performs slightly better than the MCLDNN network, especially on the RML2016.10a dataset, where the CC-MSNet network achieves a commendable level after only 20 training iterations, indicating that this network converges more rapidly. From the validation loss graph, it is evident that on the RML2016.10a dataset, the CC-MSNet network has a lower validation loss compared to the MCLDNN network, and it reaches a lower level of validation loss with a relatively fewer number of training iterations, further validating the faster convergence rate of this network.
Comparison of confusion matrices


(a1–f1) is confusion matrices of the proposed and benchmark models on RML2016.10a; (a2–f2) is confusion matrices on RML2016.10b; (a3–f3) is confusion matrices on RML2016.04c.
Selecting the confusion matrices of the MCLDNN and CC-MSNet networks at -6dB, -2dB, and 0dB SNR for comparison, it can be seen from Fig. 14 that under the three SNR conditions, the average recognition rate of the CC-MSNet network has improved compared to the MCLDNN network across the three benchmark datasets. It can also be seen that the CC-MSNet network has made relative improvements in distinguishing easily confused modulations such as 16-QAM and 64-QAM, AM-DSB and WBFM, and BPSK and QPSK. Among these, the confusion between BPSK and QPSK is mainly concentrated under low SNR conditions, for example, on the RML2016.10a dataset at -2dB SNR, QPSK achieved an 82% recognition accuracy rate, a 14% improvement over the MCLDNN network; the confusion between 16QAM and 64QAM is due to their similar constellation structures, which leads to significant overlap of constellation points after signal interference by noise, causing difficulty in recognition, as on the RML2016.10a dataset at -2dB SNR, the recognition accuracy rates for 16-QAM and 64-QAM signals reached 82% and 94%, respectively, both improving by 4% compared to the MCLDNN network. As for WBFM and AM-DSB, since both modulation types originate from voice signals with a few interruptions and periods of silence, during the silent periods, the collected analog modulation signal contains only the carrier signal, making the features distinguishing them very weak. Even under higher SNR conditions, there is still a large amount of WBFM being misclassified as AM-DSB modulated signals. However, experimental results show that on the RML2016.10a and RML2016.04c datasets, the CC-MSNet network has recognition accuracy rate improved on both WBFM and AM-DSB.
Conclusion
This paper proposes a CC-MSNet network for AMC. The efficacy of the spatial and temporal feature extraction modules of the CC-MSNet was determined through ablation experiments, and the CC-MSNet model was compared with six commonly used benchmark models for modulation recognition. The model was validated on three benchmark datasets: RML 2016.10a, RML 2016.10b, and RML 2016.04c, and the test results of the model were analyzed. The comparison revealed that the CC-MSNet model has a higher recognition accuracy and faster convergence speed, confirming the model’s advancement and robustness.In light of the experimental results and conclusions, the next steps in the research direction are clarified:
-
Although the introduction of complex convolution branches in this paper has played a certain role and effect in improving the average recognition rate, this technology still has some limitations: For example, dealing with large datasets often results in high computational complexity. This complexity makes it difficult to meet real-time requirements for applications such as wireless communication and radar systems. Additionally, there are challenges related to hardware performance, cost, and power consumption.
-
There are also limitations and challenges of different modulation schemes, such as, WBFM and AM-DSB, since they both originate from a speech signal with a small number of discontinuities and quiet periods, during the quiet periods, the collected analog modulation signals contain only carrier signals, and the features that can distinguish them are very weak. For example 16-QAM and 64-QAM, even under high SNR conditions, there may be a large overlap of constellation points, leading to difficulties in identification.
-
Comparative experiments have shown that the CC-MSNet has improved recognition performance under low SNR conditions compared to other networks, but the performance is generally lower. How to improve the recognition accuracy under low SNR conditions becomes another direction for future research. Considerations might include preprocessing steps such as noise reduction for low SNR signals before inputting them into the network model to enhance recognition accuracy.
-
The network model proposed in this paper demonstrates advantages in modulation recognition based on a large dataset with labels. However, in real-world scenarios, the collected datasets often consist of far more unlabeled samples than labeled ones. It is practically significant to build a network that can correctly map, distinguish, and identify modulation signals under conditions of small sample size, open set environment, or spectral overlap. The literature22,23,24 also provides corresponding model algorithms and verifies their effectiveness in these three situations, pointing out directions for our research and expanding our ideas. The next step could be to study modulation recognition techniques from the perspective of different real-world signal sample scenarios.
Data availability
The experimental datasets RadioML2016.10a, RadioML2016.10b, and RadioML2016.04c can be found at https://www.deepsig.ai/datasets. And The experiment code can be contacting the corresponding author@wangyuying870908@163.com.
References
Guo, K., Dong, C. & An, K.NOMA-based cognitive satellite terrestrial relay network: secrecy performance under channel estimation errors and hardware impairments.IEEE Internet Things J.9(18), 17334–17347. https://doi.org/10.1109/JIOT.2022.3157673 (2022).
Guo, K., Li, X., Alazab, M., Jhaveri, R. H. & An, K. Integrated satellite multiple two-way relay networks: secrecy performance under multiple eves and vehicles with non-ideal hardware. IEEE Trans. Intell. Veh.https://doi.org/10.1109/TIV.2022.3215011 (2022).
O’Shea, T. J., Corgan, J. & Clancy, T. C. Convolutional radio modulation recognition networks. In Engineering Applications of Neural Networks: 17th International Conference, EANN, Aberdeen, UK, September 2–5, 2016, Proceedings 17, 213–226 https://doi.org/10.1007/978-3-319-44188-7_16 (Springer, 2016).
West, N. E. & O’shea, T. Deep architectures for modulation recognition. In 2017 IEEE International Symposium on Dynamic Spectrum Access Networks (Dy SPAN), Piscataway, NJ, 2017, 1–6. https://doi.org/10.1109/DySPAN.2017.7920754 (2017).
O’Shea, T. J., Roy, T. & Clancy, T. C. Over-the-air deep learning based radio signal classification. IEEE J. Sel. Top. Signal Process.12, 168–179. https://doi.org/10.1109/JSTSP.2018.2797022 (2018).
Zhang, W. T., Cui, D. & Lou, S. T. Training images generation for CNN based automatic modulation classification. IEEE Access. 9, 62916–62925. https://doi.org/10.1109/ACCESS.2021.3073845 (2021).
Li, L., Dong, Z., Zhu, Z. & Jiang, Q. Deep-learning hopping capture model for automatic modulation classification of wireless communication signals. IEEE Trans. Aerosp. Electron. Syst.59, 772–783. https://doi.org/10.1109/TAES.2022.3189335(2023) (2023).
Hong, D., Zhang, Z. & Xu, X. IEEE Automaticmodulation classification using recurrent neural networks. In Proceedings of the 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 Decemberhttps://doi.org/10.1109/CompComm.2017.8322633(2017).
Rajendran, S., Meert, W., Giustiniano, D., Lenders, V. & Pollin, S. Deep learning models for wireless signal classification with distributed low-cost spectrum sensors. IEEE Trans. Cogn. Commun. Netw.4, 433–445. https://doi.org/10.1109/TCCN.2018.2835460 (2018).
Peng, Y. et al. Automatic modulation classification using deep residual neural network with masked modeling for wireless communications. Drones 7. 390. https://doi.org/10.3390/drones7060390 (2023).
Xu, J., Luo, C., Parr, G. & Luo, Y. A spatiotemporal multi-channel learning framework for automatic modulation recognition. IEEE Wirel. Commun. Lett.9, 1629–1632. https://doi.org/10.1109/LWC.2020.2999453 (2020).
Cui, T., Wang, D., Ji, L., Han, J. & Huang, Z. Time and phase features network model for automatic modulation classification. Comput. Electr. Eng.111https://doi.org/10.1016/j.compeleceng.2023.108948 (2023).
Krzyston, J., Bhattacharjea, R. & Stark, A. Complex-valued convolutions for modulation recognition using deep learning. In IEEE International Conference on Communications Workshops (ICC Workshops), Dublin, Ireland, 2020, , 1–6. https://doi.org/10.1109/ICCWorkshops49005.2020.9145469 (2020).
Krzyston, J., Bhattacharjea, R. & Stark, A. Modulation pattern detection using complex convolutions in deep learning. In 25th International Conference on Pattern Recognition, 2021 2233–2239 https://doi.org/10.1109/ICPR48806.2021.9412382 (2020).
Zeng, Z., Sun, J., Han, Z. & Hong, W. SAR automatic target recognition method based on multi-stream complex-valued networks. IEEE Trans. Geosci. Remote Sens.60, 5228618. https://doi.org/10.1109/TGRS.2022.3177323(2022) (2022).
Karthik, R., Menaka, R. & Kathiresan, G. S. Gaussian dropout based stacked ensemble CNN for classification of breast tumor in ultrasound images. IRBM, 43(6), 715–733 https://doi.org/10.1016/j.irbm.2021.10.002 (2022).
Hron, J., Matthews, A. G. & Ghahramani Z. Variational Gaussian dropout is not Bayesian. https://doi.org/10.48550/arXiv.1711.02989 (2017).
Liu, Z., Cheng, L. & Liu, A. Multiview and multimodal pervasive indoor localization. In Proc. 25th ACM Int. Conf. Multimedia. 109–117. https://doi.org/10.1145/3123266.3123436 (2017).
Tekbıyık, K., Ekti, A. R., Görçin, A., Kurt, G. K. & Keçeci, C. Robust and fast automatic modulation classification with CNN under multipath fading channels. In 2020 IEEE 91st Vehicular Technology Conference (VTC) Antwerp, Belgium, 1–6. https://doi.org/10.1109/VTC2020-Spring48590.2020.9128408 (2020).
Liu, X., Yang, D. & Gamal, A. E. Deep neural network architectures for modulation classification. In 51st Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 2017, 915–919 https://doi.org/10.1109/ACSSC.2017.8335483 (2017).
Zhang, F., Luo, C., Xu, J. & Luo, Y. An efficient deep learning model for automatic modulation recognition based on parameter estimation and transformation. IEEE Commun. Lett.25, 3287–3290. https://doi.org/10.1109/LCOMM.2021.3102656 (2021).
Zhang, X. et al. Few-shot automatic modulation classification using architecture search and knowledge transfer in radar-communication coexistence scenarios. IEEE Internet Things J.https://doi.org/10.1109/JIOT.2024.3423018 (2024).
Chen, K., Zhang, J., Chen, S. & Zhang, S. Deep metric learning for robust radar signal recognition. Digit. Signal Process.https://doi.org/10.1016/j.dsp.2023.104017 (2023).
Pan, Z., Wang, S., Zhu, M. & Li, Y. Automatic waveform recognition of overlapping lpi radar signals based on multi-instance multi-label learning. IEEE Signal Process. Lett., 27, 1275–1279 https://doi.org/10.1109/LSP.2020.3009195 (2020).
Author information
Authors and Affiliations
Contributions
conceptualization, Y.W. and M.W.; methodology, Y.W.; software, Y.W. and S.H.; validation, Y.W., S.H. and Z.X.; formal analysis, Y.W.; investigation, Y.W.; resources, S.F.; data curation, Y.W.; writing—original draft preparation, Y.W.; writing—review and editing, Y.W.; visualization, Y.W. and M.W.; supervision, Y.C.; funding acquisition, S.F. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, Y., Fang, S., Fan, Y. et al. A complex-valued convolutional fusion-type multi-stream spatiotemporal network for automatic modulation classification. Sci Rep 14, 22401 (2024). https://doi.org/10.1038/s41598-024-73547-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-73547-w
This article is cited by
-
SCALNet: A lightweight attention-enhanced convolutional network for robust modulation classification using constellation diagrams
Signal, Image and Video Processing (2026)
-
Optimization of deep learning architecture based on multi-path convolutional neural network algorithm
Scientific Reports (2025)
