
Abstract
AI-based methods to generate images have seen unprecedented advances in recent years challenging both image forensic and human perceptual capabilities. Accordingly, these methods are expected to play an increasingly important role in the fraudulent fabrication of data. This includes images with complicated intrinsic structures such as histological tissue samples, which are harder to forge manually. Here, we use stable diffusion, one of the most recent generative algorithms, to create such a set of artificial histological samples. In a large study with over 800 participants, we study the ability of human subjects to discriminate between these artificial and genuine histological images. Although they perform better than naive participants, we find that even experts fail to reliably identify fabricated data. While participant performance depends on the amount of training data used, even low quantities are sufficient to create convincing images, necessitating methods and policies to detect fabricated data in scientific publications.
Similar content being viewed by others
Introduction
Recent years have seen a steady increase in papers retracted by scientific journals, both in absolute terms as well as in proportion to papers published1. Last year alone saw a record of more than 10,000 papers retracted, with most cases being due to scientific misconduct1. Metanalyses indicate that on average 2–4% of scientist participating in self-reporting surveys admit to fraudulent fabrication, falsification or modification of data or results, and ~15% of respondents stated that they know of a colleague engaging in such behavior2,3,4. Scientific fraud results in huge follow-up costs: For scientists, funding organizations and companies these take the form of time and resources wasted trying to reproduce fabricated results or the failure of entire projects which were unknowingly based on fraudulent publications5,6,7,8,9. And, in biomedical fields, these costs can mean inadequate or outright harmful treatments for patients during clinical trials or even clinical practice5,8,10,11.
A common form of fraud in publications, which has become more frequent for years, is the manipulative use of images which are supposed to exemplify or represent experimental results6,12,13. Traditionally, these include inadequate duplication and reuse of images, or manipulations such as the addition, replication, removal, or transformation of objects within an image12,14,14,15. Two studies from 2016 and 2018 including 20,621 and 960 scientific articles estimated the prevalence of inappropriate image reuse or duplication to be 3.8 and 6.1%, respectively12,14. Another study from 2018 using an automated detection pipelines of two different data sets of 1,364 and 1546 articles found 5.7 and 8.6% of papers containing suspected image manipulations, respectively6. Finally, a large study from 2018 also using an automated detection pipeline to scan 760,000 articles indicates a rate 0.6% of articles with fraudulent image use16. In contrast to classical forms of image manipulations, modern AI-based methods such as Generative Adversarial Networks (GANs) and Diffusion Models can completely synthesize entire images from scratch17,18,19 and are expected to be much harder to detect than previous forms of manipulation 20,21. This also includes complex images such as histological tissue samples which possess an intricate structure and therefore are harder to manipulate manually.
In the present study, we use the stable diffusion algorithm18, one of the most recent methods of AI-based image generation, to generate artificial images of mouse kidney histological samples; and in a large online survey with more than 800 participants, we test human ability to distinguish between these artificially generated and genuine histological samples.
By specifically recruiting both, participants with and without prior experience with histological images into our study, we show that prior experience with histological images increases the chance of correct classification, but that even with task-specific training, the overall performance is low. Furthermore, using different sets of artificial images, we demonstrate that human ability to detect such images depends on the amount of data used for training of the stable diffusion algorithm and that very small amounts of training data are already sufficient to generate convincing histological images. Finally, we discuss potential first steps to ameliorate the threat which new, generative methods pose to science integrity.
Results
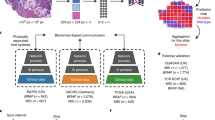
In order to test the influence of specific, task-relevant training on the ability to distinguish between genuine and artificial images we exploited the fact that, in contrast to almost all other image categories, to which most people are exposed to in varying degrees in their daily life, there is a sharp distinction between people who either never have seen a histological image (“naive”) and those who have considerable previous experience (“experts”) due to training in a biomedical field. To construct a stimulus set consisting of genuine and artificial histological images of the same structures, we obtained images of periodic acid–Schiff (PAS) stained samples of mouse kidney tissue with a central glomerulus. We then used these to create two sets of artificial histological images using the stable diffusion method in the DreamBooth framework (Fig. 1). One set of images is based on 3 (A3), and one based on 15 (A15) genuine images as training data. In an online survey using the LimeSurvey software, we presented a selection of 8 genuine and 8 artificial images. The images were presented sequentially and for each image participants were asked to classify them as “AI-generated” or “genuine”, with the additional option to skip images. In order to obtain naive and expert populations with similar age, educational status, and socio-economic background, we recruited a total of 1021 undergraduate students from German universities for our study. Out of these, 816 completed the survey and were included in our analysis. 526 participants were classified as experts (186 male, 329 female, 4 diverse, 7 not specified; age 23.2 ± 5.1 (mean ± SD)), and 290 were classified as naive (136 male, 137 female, 7 diverse, 10 not specified; age 24.5 ± 5.5 (mean ± SD)).

Example images. (a) Artificial image created using 15 training images. (b) Genuine PAS-stained histological mouse kidney samples images. c) Artificial image created using 3 training images. Images were presented without scalebar during the study.
While we find that, in principle, artificial images can be distinguished from genuine images, this distinction is subject to a high degree of uncertainty. In addition, we found a clear difference between naive and expert subjects: whereas naive participants only classified 54.5% images correctly (2531/4640 trials, Exact binominal test vs. chance p < 0.001), experts performed significantly better, classifying 69.3% images correctly (5833/8416 trials, Chi2 test with Yate’s continuity correction: p < 0.001, Fig. 2a).Overall, both naive and expert participants were able to identify artificial images equally well as genuine ones (Naive: genuine 1245/2320, artificial 1286/2320; expert: genuine 2913/4208, artificial 2920/4208; Chi2 test with Yate’s continuity correction: pnaive = 0.94, pexpert = 0.97). Accordingly, both sensitivity and specificity were higher for expert than for naive participants, whereas within each group sensitivity and specificity were almost identical (Naive: sensitivity 0.55, 95% CI [0.53 0.57], specificity 0.54, 95% CI [0.52 0.56]; expert: sensitivity 0.69, 95% CI [0.68 0.71], specificity 0.69, 95% CI [0.68 0.71]; Fig. 2b).

Experts are more successful in discriminating genuine from artificial images. (a) Overall performance of naive and expert participants (ntrials,naive = 4640, ntrials,expert = 8416, Chi2-Test with Yates’ Continuity correction: p < 0.001). (b) Sensitivity and specificity for naive and expert participants (point estimates and 95% confidence intervals (CI)). (c) Participant performance by image type and prior experience (ntrials,naive = 4640, ntrials,expert = 8416). (d) Results for binomial regression on data shown in (c), displayed as odds ratio (OR) point estimate with 95% CI. “::” indicates statistical interactions. (e) CDF of participant-wise performance by prior experience. Red arrow indicates experts who classified all images correctly. Inset shows the same data as boxplot. nparticipants,expert = 525, nparticipants,naive = 288, Wilcoxon rank sum test p < 0.001.
However, when we separated artificial images based on the number of images used for training the diffusion model, we found that both, naive and expert participants, classified A3 images more successfully than genuine images (binomial regression, OR 1.42, 95% CI [1.23 1.64], Fig. 2c,d, Supp. Fig. 2a,b), whereas they classified A15 images less frequently correct than genuine images (OR 0.82, 95% CI [0.71 0.94]). We did not find any significant interactions between participant group and image category (expert::A3 OR 0.97, 95% CI [0.8 1.17], expert::A15 OR 0.93, 95% CI [0.78 1.12]), indicating that the observed effect of image category was not dependent on whether participants had prior experience with histological images.
Importantly, performance was not dependent on stimulus presentation order during the survey (i.e. there was no in- or decrease in performance between classification of those images shown early and those shown late during the study; Pearson’s correlation: R2 = 0.058, p = 0.38), indicating that participants neither lost motivation nor underwent significant training effects during the study. In order to test whether the observed difference in performance is present across participants or driven by a few particularly well-performing individuals in the extremes of the distribution, we calculated the individual performance for each participant. Notably, we do find a small group of expert (n = 10, 1.9% of all experts) but not naive participants who classified all images correctly. While this performance is outstanding (enrichment ratio against all experts 5.5, Exact binomial test p < 0.001, red arrow in Fig. 2e) even compared to mean expert rather than chance performance (~ 70% vs. 50% correct for any image), we observe that experts also perform generally better than naive participants (median participant-wise performance 0.56 vs. 0.75, Wilcoxon rank sum test p < 0.001, Fig. 2e inset). Taken together, our data clearly demonstrates that training enhances the ability to distinguish between genuine and artificial images, but that even experts cannot reliably identify artificial images.
Intriguingly, we found a systematic difference in response times between correct and incorrect classifications, with faster responses for correctly classified images (median 6.99 vs. 7.7 s, Fig. 3a). This effect cannot be explained by differences in response times between the two study groups, as experts—who more often classify an image correctly—actually take on average longer for each classification than naive participants (median 6.98 vs. 7.35 s; Scheirer-Ray-Hare test: pcorrectness < 0.001, pexperience < 0.001, pcorrectness::experience = 0.01; Fig. 3b). Instead, we observe the same direction of effect of faster classifications in correct trials in both, naive and expert participants, with astronger difference in experts (median: naive 6.77 vs. 7.38 s, experts: 7.07 vs. 8.06 s; Wilcoxon rank sum test between correct and incorrect trials with Bonferroni correction for multiple testing: pnaive = 0.0015, pexpert < 0.001; Fig. 3c). Of note, while almost 100% of response times fall within the first 30 s after the trial start, there is an extremely long but thin tail until well over 2000s (Fig. 3a,b). These outliers likely represent cases in which participants started the study, left the browser window and the survey open to do something else, and then finished it at some later time point. Importantly, we observed the same response times effects irrespective of whether outliers were included (Fig. 3a-d) or removed for statistical testing (Supp. Fig. 3a-d). To test whether this effect we found could also be observed on a participant-wise basis, we calculated for every participant average response times for correctly and incorrectly classified images, respectively. This paired comparison similarly yielded faster response times for correct classifications, additionally confirming our results on a within-participant level (Median response time 8.33 vs. 9.17 s, Wilcoxon signed rank test p < 0.001, Fig. 3d, Supp. Fig. 3d). Taken together, we find that participants classified images faster during correct as opposed to incorrect trials, and that this effect cannot be explained by prior experience with histological images.

Response times are shorter for correct classifications. (a) Empirical cumulative density functions (CDFs) of response times for correctly vs. incorrectly classified images (ncorrect = 8364, nincorrect = 4474, Scheirer-Ray-Hare test: pcorrectness < 0.001). Inset displays full distributions. (b) CDFs of response times for naive vs. expert participants (nnaive = 4526, nexpert = 8312, Scheirer-Ray-Hare test: pexperience < 0.001). Inset displays full distributions. (c) CDFs for group wise comparisons (nnaive,correct = 2531, nnaive,incorrect = 1995, nexpert,correct = 5833, nexpert,incorrect = 2479, post-hoc Wilcoxon rank sum test with Bonferroni correction: pn,c-n,i = 0.0015, pn,c-e,c < 0.001, pn,c-e,i < 0.001, pn,i-e,c = 1, pn,i-e,i < 0.001, pe,c-e,i < 0.001). (d) CDFs of within-participant response times for correct and incorrect responses (nparticipants = 803, Wilcoxon signed rank test p < 0.001). Inset shows the same data as boxplots. Data beyond 30 s not shown for display purposes.
Discussion
In the present study we investigated the ability of human expert and naive participants to distinguish genuine histological samples from artificial ones synthesized using the stable diffusion algorithm 19. We find that naive participants, who have never seen histological images before, are able to classify images better than chance in a statistically significant manner. The actual rate of correct classifications (~ 55%), however, was only slightly better than chance (50%). As we did not observe any correlation between stimulus number and performance, it is unlikely that participants learned to distinguish image categories within the study. We assume therefore that the above-chance performance of naive participants results from an overall artificial aspect of synthesized images. While experts performed significantly better than naive participants, overall performance was nevertheless low (70%), demonstrating that distinguishing between real and artificial images is a genuinely hard task.
In addition to these differences in classification performance, we observed that participants were faster when they classified images correctly than when they classified them incorrectly. This effect was not explained by experience with histological images, as it is present within both groups of participants (although more pronounced in experts). In addition, experts, who had a higher rate of correct images, exhibited overall slower response times. As the correctness of a decision is an indicator for its difficulty, faster response times for correct images are in line with canonical models of perceptual decision making, as the drift–diffusion model, in which task difficulty correlates with time allotted to evidence accumulation22. In contrast, the overall slower response times of experts likely reflect a more active and thus more time-consuming evaluation strategy based on their biomedical training. The performance we observe in our study lies within the range of reported human abilities to discriminate between real and manipulated or synthesized faces23,24,25 and natural objects and scenes26,27. However, and not surprisingly, in our study the ability to detect artificial images depended strongly on the amount of training data used during image generation, and thus on the resulting image quality. Consequently, as image quality depends both on the precise algorithm employed and the amount of training data, or, in case of manually manipulated images, on the skill and effort of the manipulator, direct, quantitative comparison of the ability to detect forged images between studies should only be done with caution. Furthermore, both sets of artificial images we employed in our study were created based on relatively few training data, preventing a ceiling effect which would make comparisons between groups challenging.
The fact that, despite this small training sets in our study, detection was difficult suggests that technical hurdles for a forged image to remain undetected in a realistic scenario are low. In a realistic scenario, it would be easy to obtain much larger training sets and to synthesize hundreds of images and just use the most convincing one to include in a publication. In addition, in our study participants were explicitly made aware to expect artificial images, a precondition which likely increases detection probability. Conversely, as our expert group was mainly recruited from undergraduate students with histological experience, we would expect that we underestimate the ability of a more advanced expert as an experienced researcher or pathologist to spot artificial images. However, in a typical real-world scenario, a paper will often contain data obtained from multiple techniques, such that neither reviewers nor readers might actually be experts in the particular technique which supposedly created an artificial image. In addition, once a paper is published, it might take a long time until it is retracted28, and might influence scientific literature even after its retraction29. Finally, the ability of generative algorithms to create realistic images will only increase further in the future. Thus, although our study does not perfectly reflect a real-world scenario, our results clearly demonstrate the difficulty to reliably detect artificial scientific images.
Taken together, this raises practical concerns for the scientific community as fraudulently employed synthesized scientific images might frequently remain undetected. However, though not perfect, viable technical solutions have been proposed, both for scanning scientific publications in particular6,16,30 and for the detection of image manipulation in general15,20,31,32,33. Such forensic solutions allow both a higher throughput and consistently outperform humans if applied on the same data sets25,27. Where applicable, these methods to detect fraudulent data could be complemented with procedures to authenticate the entire digital workflow including data acquisition, processing, and publication via the implementation of technical standards to secure data provenance such as C2PA (https://c2pa.org). In addition to the introduction of technical measures to promote data integrity, accessibility of the original data associated with any publication is of crucial importance for several reasons: (i) It allows access to high-quality, rather than compressed or otherwise distorted data, which removes obstacles for automated forensic methods 23, (ii) it results in images in their original format and being associated with their original meta data, the combination of which is much harder to fake than an image alone 15,31, (iii) it is necessary to actually be able to meaningfully enforce the use of standards as C2PA, and (iv) the requirement to submit original data seems to act as a deterrence against fraudulent misconduct per se34.
A very effective time point to perform such an automated scanning is during editorial review of submitted manuscripts11,14,21. Journals can introduce policies that require authors to submit all original data prior to publication, whereas original data may not be recoverable afterwards13. Similarly, journals can require the application of data provenance standards for scientific data. In addition, methods of image synthesis and manipulation continuously evolve, necessitating a respective development in detection methods15,35,36. Neither reviewers nor readers can be realistically expected to keep up with this development. Similarly, for the particular case of image reuse, journals, but not readers or reviewers can maintain data bases of previously published images for cross-reference11,14,16,37. Crucially, if original data is checked before, rather than at some distant time point after publication, the enormous follow up costs of fraudulent science which arise for fellow scientist, funding organizations, scientific journals, companies and patients alike can be reduced much more effectively1,5,7,8,9,10,11,14. And finally, introduction of screening policies by scientific journals has actually been shown to effectively reduce the number of problematic images in accepted manuscripts14. On a side note, we would like to point out that while in the present study, we focus on fraudulent use of synthesized scientific data, there are promising avenues for beneficial employment of synthesized data in the biomedical context. While the most obvious case is likely data augmentation38,39,40 for machine learning applications, synthetic data furthermore has the potential to protect privacy when sharing or publishing data, to aid explainability of classification algorithms, or for training and education40,41,42. In conclusion, we demonstrate that it is genuinely hard to spot AI-generated scientific images and that training in the specific field is only somewhat effective at improving the ability to do so; and propose a step towards a solution to ameliorate the threat which new, AI-based methods of image generation pose to science.
Materials and Methods
Animals
Male C57BL/6NCrl mice (Charles River Laboratories, age 12–14 weeks, 24-31 g body weight) were used to obtain kidney histologies. Animal care and experiments were approved by local authorities (Landesamt für Gesundheit und Soziales, Berlin, license G0198/18), and carried out in line with the guidelines of the American Physiological Society. Mice were fed standard rodent chow and provided with food and water ad libitum. Reporting on experimental animals adheres to the ARRIVE guidelines where applicable.
Histology
Mice were sacrificed by cervical dislocation under isoflurane anaesthesia. Kidneys were removed and embedded in paraffin. For Periodic acid-Schiff staining, in paraffin embedded kidneys were sliced in 1.5 µm thin sections and incubated on slides for 16 h at 60 °C to melt away excessive paraffin. Deparaffinized slices were rehydrated and incubated with 0.5% periodic acid followed by washing in tab water and incubating with Schiff reagent. After another washing step with tab water, the slices were counterstained with Mayer´s hematoxylin and washed again. The stained slices were dehydrated and mounted with a synthetic mounting medium. Stained kidney slices were recorded using an Eclipse Ti2-A microscope and a DS-Ri2 camera controlled through the NIS-Elements software (Nikon, USA). To obtain large images single images were recorded and stitched afterwards.
Image generation
Images were generated using stable diffusion 1.5 model checkpoint which has been trained with the DreamBooth (https://github.com/huggingface/diffusers) framework (the exact training parameters are provided in our GitHub and zenodo repositories). The model was trained with either 3 or 15 histological kidney sample images (512 × 512 pixels, 0,37 µm/pixel). During the survey, the 3 genuine images used to train the model with 3 images, 5 out of the 15 genuine images used to train the model with 15 images, and 4 artificial images from either approach were used.
Study implementation
The study was conducted online using the LimeSurvey software version 3.25.7 + 210,113 (https://www.limesurvey.org/), hosted at the university Jena and was approved by the local ethics committee (Reference number: 2023–2886-Bef). Participants were recruited from German university undergraduate students. Recruitment was implemented mainly by advertisement of the study via student representations who forwarded the invitation to participate in the study to students in their respective academic department. In addition, participants were recruited by postings in university buildings, or directly in lecture halls. In all cases, participants accessed the study via a QR code in the advertisement, and we did not control the participants’ stage of career (i.e. whether they were e.g. undergraduate or PhD students or faculty). However, as most participants were recruited via student representations, we assume our sample mainly consists of undergraduate university students. Participants were explicitly made aware that data was collected for a scientific study. Participants were not reimbursed for study participation. During the survey, 16 images (8 genuine, 8 artificial) were presented, one image at a time. Participants were not made aware of the likelihood of encountering an artificial image. Images were presented without scale bars. For every image, participants were asked to classify the image as “genuine” or "AI-generated”. Participants were asked whether they are familiar with histological images in order to distinguish between naive and expert participants. In addition, we collected data on participant age, gender and response time for every classification. A total of 1021 participants started the study, out of which 816 participants completed the study.
Data analysis and statistics
All statistical analysis was performed using custom code using RStudio 2023.09.0 + 463 running R version 4.2.0 (2022–04-22). The versions of all R packages used are documented within the code in the associated repository. Only responses from participants who completed the survey were included in the analysis. If participants did not answer whether they had previously seen histological images (2.8% of all included participants), we assumed they did not know the term and thus treated them as naive in the analysis. If participants skipped single images (1.7% of all included responses), we assumed they were not able to distinguish and treated responses as incorrect trials. For analysis of response times these trials were excluded instead. Crucially, as a sanity check for these assumptions, we additionally performed all analysis excluding both participants who did not indicate whether they had prior experience with histological images, as well as excluding all trials that had been skipped by participants, which yielded the same qualitative and quantitative results. To calculate participant-wise performance, correctly and incorrectly classified images were coded as ‘1’ and ‘0’, respectively, and averaged for every participant. The enrichment ratio was calculated as fold change between the observed number of observations and the number expected under a binomial distribution. To calculate within-participant response time, response times were averaged separately for correct and incorrect trials within each participant, and 10 participants who classified all images correctly were excluded from this comparison. For inferential statistics on frequencies, the exact binomial test was used for comparison to chance levels, and the Chi2 test with Yate’s continuity correction was used to test for statistical difference between groups. To test the statistical contribution of prior experience and image category on classification performance, we used a general linear model assuming a binomial distribution and calculated the odds ratio as OR = eEst where ‘Est’ denotes the model point estimates. For inferential statistics on continuous data, data was tested for normal distribution using the Anderson–Darling test. All continuous data sets were non-normally distributed; thus, the Wilcoxon rank sum test was used for non-paired and the Wilcoxon signed rank test for paired data. To test group effects on response times, the Scheirer-Ray-Hare test was used as non-parametric alternative to a multi-way ANOVA, and post-hoc pair-wise comparisons were made using the Wilcoxon rank sum test with Bonferroni’s correction for multiple testing. For calculation of sensitivity, specificity and accuracy, we counted genuine images as negative and artificial images as positive ground truth, and confidence intervals (CI) were calculated using the Wilson score interval method. Statistical levels are indicated in figures as: ‘n.s.’: p ≥ 0.05, ‘*’: p < 0.05, ‘**’: p < 0.01, ‘***’: p < 0.001. ‘::’ indicates statistical interaction between factors. P-Values smaller than 0.001 are abbreviated as ‘p < 0.001’; the exact values can be found in the publicly available analysis markdown document. Boxplots indicate median, 25th-75th percentile (box) and last data point within 1.5*IQR (inter-quartile range) below 25th or above 75th percentile (whiskers). Outliers beyond whisker range are indicated as single data points and were always included in statistical analyses. Boxplot notches indicate the 95% CI of the median and are calculated as median ± 1.58*IQR/sqrt(n), where ‘IQR’ denotes the inter-quartile range, ‘sqrt()’ the square root and ‘n’ the number of data points.
Data and code availability
Original data collected in this study, images used for the survey, and custom code used in this study are publicly available on GitHub at https://github.com/janH-21/AI_histology and zenodo.org at https://doi.org/10.5281/zenodo.13887356.
References
Van Noorden, R. More than 10,000 research papers were retracted in 2023 — a new record. Nature 624, 479–481 (2023).
Fanelli, D. How Many Scientists Fabricate and Falsify Research? A Systematic Review and Meta-Analysis of Survey Data. PLOS ONE 4, e5738 (2009).
Xie, Y., Wang, K. & Kong, Y. Prevalence of Research Misconduct and Questionable Research Practices: A Systematic Review and Meta-Analysis. Sci Eng Ethics 27, 41 (2021).
Gopalakrishna, G. et al. Prevalence of questionable research practices, research misconduct and their potential explanatory factors: A survey among academic researchers in The Netherlands. PLOS ONE 17, e0263023 (2022).
Begley, C. G. & Ellis, L. M. Raise standards for preclinical cancer research. Nature 483, 531–533 (2012).
Bucci, E. M. Automatic detection of image manipulations in the biomedical literature. Cell Death Dis 9, 1–9 (2018).
Freedman, L. P., Cockburn, I. M. & Simcoe, T. S. The Economics of Reproducibility in Preclinical Research. PLOS Biology 13, e1002165 (2015).
Sabel, B. A., Knaack, E., Gigerenzer, G. & Bilc, M. Fake Publications in Biomedical Science: Red-flagging Method Indicates Mass Production. 2023.05.06.23289563 Preprint at https://doi.org/10.1101/2023.05.06.23289563 (2023).
Yamada, K. M. & Hall, A. Reproducibility and cell biology. Journal of Cell Biology 209, 191–193 (2015).
Avenell, A., Stewart, F., Grey, A., Gamble, G. & Bolland, M. An investigation into the impact and implications of published papers from retracted research: systematic search of affected literature. BMJ Open 9, e031909 (2019).
Wager, E. How journals can prevent, detect and respond to misconduct. Notfall Rettungsmed 14, 613–615 (2011).
Bik, E. M., Casadevall, A. & Fang, F. C. The Prevalence of Inappropriate Image Duplication in Biomedical Research Publications. mBio 7, https://doi.org/10.1128/mbio.00809-16 (2016).
Gilbert, N. Science journals crack down on image manipulation. Nature https://doi.org/10.1038/news.2009.991 (2009).
Bik, E. M., Fang, F. C., Kullas, A. L., Davis, R. J. & Casadevall, A. Analysis and Correction of Inappropriate Image Duplication: the Molecular and Cellular Biology Experience. Molecular and Cellular Biology 38, e00309-e318 (2018).
Verdoliva, L. Media Forensics and DeepFakes: An Overview. IEEE Journal of Selected Topics in Signal Processing 14, 910–932 (2020).
Acuna, D. E., Brookes, P. S. & Kording, K. P. Bioscience-scale automated detection of figure element reuse. 269415 Preprint at https://doi.org/10.1101/269415 (2018).
Goodfellow, I. et al. Generative Adversarial Nets. In Advances in Neural Information Processing Systems vol. 27 (Curran Associates, Inc., 2014).
Rombach, R., Blattmann, A., Lorenz, D., Esser, P. & Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 10674–10685 (IEEE, New Orleans, LA, USA, 2022). https://doi.org/10.1109/CVPR52688.2022.01042.
Sohl-Dickstein, J., Weiss, E. A., Maheswaranathan, N. & Ganguli, S. Deep Unsupervised Learning using Nonequilibrium Thermodynamics. Proceedings of the 32 nd International Conference on Machine Learning (2015).
Gu, J. et al. AI-enabled image fraud in scientific publications. PATTER 3, (2022).
Liverpool, L. AI intensifies fight against ‘paper mills’ that churn out fake research. Nature 618, 222–223 (2023).
Hanks, T. D. & Summerfield, C. Perceptual Decision Making in Rodents, Monkeys, and Humans. Neuron 93, 15–31 (2017).
Hulzebosch, N., Ibrahimi, S. & Worring, M. Detecting CNN-Generated Facial Images in Real-World Scenarios. in 642–643 (2020).
Nightingale, S. J. & Farid, H. AI-synthesized faces are indistinguishable from real faces and more trustworthy. Proceedings of the National Academy of Sciences 119, e2120481119 (2022).
Wang, S.-Y., Wang, O., Zhang, R., Owens, A. & Efros, A. Detecting Photoshopped Faces by Scripting Photoshop. in 2019 IEEE/CVF International Conference on Computer Vision (ICCV) 10071–10080 (IEEE, Seoul, Korea (South), 2019). https://doi.org/10.1109/ICCV.2019.01017.
Nightingale, S. J., Wade, K. A. & Watson, D. G. Can people identify original and manipulated photos of real-world scenes?. Cogn. Research 2, 30 (2017).
Schetinger, V., Oliveira, M. M., da Silva, R. & Carvalho, T. J. Humans are easily fooled by digital images. Computers & Graphics 68, 142–151 (2017).
Steen, R. G., Casadevall, A. & Fang, F. C. Why Has the Number of Scientific Retractions Increased?. PLOS ONE 8, e68397 (2013).
Fanelli, D., Wong, J. & Moher, D. What difference might retractions make? An estimate of the potential epistemic cost of retractions on meta-analyses. Accountability in Research 29, 442–459 (2022).
Mandelli, S. et al. Forensic Analysis of Synthetically Generated Western Blot Images. IEEE Access 10, 59919–59932 (2022).
Bhagtani, K. et al. An Overview of Recent Work in Media Forensics: Methods and Threats. Preprint at https://doi.org/10.48550/arXiv.2204.12067 (2022).
Marra, F., Gragnaniello, D., Verdoliva, L. & Poggi, G. Do GANs Leave Artificial Fingerprints? in 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR) 506–511 (2019). https://doi.org/10.1109/MIPR.2019.00103.
McCloskey, S. & Albright, M. Detecting GAN-generated Imagery using Color Cues. Preprint at https://doi.org/10.48550/arXiv.1812.08247 (2018).
Miyakawa, T. No raw data, no science: another possible source of the reproducibility crisis. Molecular Brain 13, 24 (2020).
Ricker, J., Damm, S., Holz, T. & Fischer, A. Towards the Detection of Diffusion Model Deepfakes. Preprint at https://doi.org/10.48550/arXiv.2210.14571 (2023).
Wang, S.-Y., Wang, O., Zhang, R., Owens, A. & Efros, A. A. CNN-Generated Images Are Surprisingly Easy to Spot... for Now. in 8695–8704 (2020).
Wang, L., Zhou, L., Yang, W. & Yu, R. Deepfakes: A new threat to image fabrication in scientific publications?. Patterns 3, 100509 (2022).
Chen, R. J., Lu, M. Y., Chen, T. Y., Williamson, D. F. K. & Mahmood, F. Synthetic data in machine learning for medicine and healthcare. Nat Biomed Eng 5, 493–497 (2021).
Ding, K. et al. A Large-scale Synthetic Pathological Dataset for Deep Learning-enabled Segmentation of Breast Cancer. Sci Data 10, 231 (2023).
Giuffrè, M. & Shung, D. L. Harnessing the power of synthetic data in healthcare: innovation, application, and privacy. npj Digit. Med. 6, 1–8 (2023).
Gonzales, A., Guruswamy, G. & Smith, S. R. Synthetic data in health care: A narrative review. PLOS Digital Health 2, e0000082 (2023).
Dolezal, J. M. et al. Deep learning generates synthetic cancer histology for explainability and education. NPJ Precis Oncol 7, 49 (2023).
Acknowledgements
We would like to thank all members of the Mrowka lab for discussion of the project. This study was supported by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – Project ID 394046635 – SFB 1365, the Free State of Thuringia under the number 2018 IZN 0002 (Thimedop) and the European Union within the framework of the European Regional Development Fund (EFRE).
Funding
Open Access funding enabled and organized by Projekt DEAL. Freistaat Thüringen (2018 IZN 0002), Deutsche Forschungsgemeinschaft (394046635), European Regional Development Fund (EFRE).
Author information
Authors and Affiliations
Contributions
Conceptualization: RM; Methodology (artificial image synthesis, survey design): RM; Methodology (animals, histology): VAK, MF; Formal analysis: JH, CS; Visualization: JH; Investigation (participant recruitment): JH, SR; Writing: JH, RM; Supervision: RM. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hartung, J., Reuter, S., Kulow, V.A. et al. Experts fail to reliably detect AI-generated histological data. Sci Rep 14, 28677 (2024). https://doi.org/10.1038/s41598-024-73913-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-73913-8
Keywords
This article is cited by
-
How good are medical students and researchers in detecting duplications in digital images from research articles: a cross-sectional survey
Research Integrity and Peer Review (2025)
-
Fake AI images will cause headaches for journals
Nature (2025)
-
Image fraud in nuclear medicine research
European Journal of Nuclear Medicine and Molecular Imaging (2025)
