
Abstract
Spectrum sensing (SS) technology is essential for cognitive radio (CR) networks to effectively identify and utilize idle spectrum resources. Due to the influence of noise characteristics in the channel, providing accurate sensing results is challenging. In order to improve the performance of SS under non-Gaussian noise and overcome the limitations of existing methods that are mostly based on a single feature, we propose a novel time-frequency cross fusion network (TFCFN). Specifically, we utilize gated recurrent units (GRU) to capture long-term dependencies in the time domain on the original signals, meanwhile, we perform a fast Fourier transform (FFT) on the original signals to obtain the frequency domain information, and subsequently use convolutional neural networks (CNN) to extract the local spatial features in the frequency domain. Ultimately, these time-domain and frequency-domain features are dynamically fused through a cross-attention mechanism to construct more comprehensive and robust features for signal classification. We use generalized Gaussian distribution (GGD) as the noise model and reconstruct the RadioML2016.10a dataset to explore the performance under various noise conditions. The experimental results show that compared with the baseline methods, TFCFN exhibits better detection ability and maintains lower complexity in both Gaussian and non-Gaussian noise environments. Notably, when the shape parameter of GGD is set to 0.5 and the signal-to-noise ratio (SNR) of the received signal is -16dB, it can maintain the probability of false alarm (\(P_f\)) of 10% while still ensuring the probability of detection (\(P_d\)) of over 90%.
Similar content being viewed by others

Introduction
Background
With the explosive growth of wireless communication applications and the continuous innovation and development of wireless communication technology1, the scarcity of spectrum resources and the increasingly complex electromagnetic environment have become great challenges for communication systems. The traditional spectrum management adopts a static allocation strategy, which is the main reason for low spectrum utilization2. The emergence of CR provides a new technological solution to significantly improve the efficiency of spectrum resource utilization3. It can monitor and understand the usage of spectrum in the current environment, allowing secondary users (SU) to access idle spectrum without causing interference to PUs. SS, as the primary component of CR systems, endows the system with the ability to discover spectrum holes. The detection performance of SS directly determines whether it can accurately and real-time discover idle spectrum, and then allocate suitable communication frequency bands for SUs. This key link profoundly affects the operational efficiency and quality of service of the entire wireless communication system4.
The characteristics of channel fading, environmental noise, and dynamic changes in wireless channels can seriously affect the performance of SS5. Among them, noise, as an important interference source, its complexity and diversity lead to a decline in the performance of traditional SS methods. In an ideal situation, many theoretical analyses and algorithm designs tend to assume that noise follows a Gaussian distribution. However, in real-world environments, transient electromagnetic interference caused by thunderstorms and lightning, short voltage spikes or current pulses caused by arcing and switching operations on power lines, do not follow a Gaussian distribution. These non-Gaussian noises have the characteristics of strong suddenness, short duration, and concentrated energy, which pose a serious challenge to SS. Therefore, in order to improve the accuracy and robustness of SS, it is necessary to develop sensing techniques and algorithms that can effectively deal with such noise. When modeling noise, several common empirical models are worth paying attention to. Gaussian mixture model (GMM) and GGD are widely used to fit the pulse phenomena of man-made impulsive noise and ultra wideband interference6,7,8,9,10. The \(\alpha\)-stable distribution has good fitting properties for natural electromagnetic noise environments11.
Research status
Traditional SS algorithms include energy detection (ED)12, matched filter detection (MFD)13, cyclostationary feature detection14 and so on. Specifically, the ED determines whether a particular frequency band is occupied by calculating the energy in that band compared to a threshold value. It is widely used due to the simplicity of its implementation, but it requires a high estimate of the noise power and performs poorly in low SNR conditions. In addition, the calculation of the threshold must be adjusted based on specific noise distributions, as the threshold calculation formulas for different noise distributions are incompatible with each other. Of particular importance is that traditional ED will lose its effectiveness due to the possible absence of second-order moments in the \(\alpha\)-stable distribution15. MDF utilizes known features of the PU signal to design a specific filter to match the received signal. It achieves maximum detection performance under ideal conditions, but requires a priori information about the PU, which is not always applicable in real environment. Cyclostationary feature detection determines the presence of a signal by detecting the periodic changes in the statistical characteristics of the signal. This method improves the performance of SS in low SNR environments, however, it has high computational complexity.
Machine learning and deep learning, as key technologies in the field of artificial intelligence, have been widely researched and applied in areas such as computer vision, natural language processing, and network security16,17,18,19,20. With the continuous maturity of deep learning technology, its application in the field of communication has become an increasingly hot research topic. Deep learning is completely data-driven and can automatically learn and extract the features of complex signals without any priori information, thereby improving the performance of SS. Gao et al.21 proposed DetectNet, a combined model of CNN, Long Short-Term Memory (LSTM), and Deep Neural Network (DNN) for SS. DetectNet capitalizes on the underlying structural information of modulated signals, showcasing state-of-the-art detection performance. Su et al.22 applied a stacked convolutional autoencoder to preprocess signals for noise reduction. They introduced a self-attention mechanism in a combined model named H-CSG, further enhancing detection performance. In references23,24, the authors used short-time Fourier transform and wavelet transform to process signal data into time-frequency matrix data as inputs to CNN, transforming the SS into an image classification problem. Wang et al.25 utilized ConvLSTM to simultaneously extract temporal and spatial features of IQ signals, and then implemented SS at extremely low SNR based on the extracted features. These deep learning based methods are effective in terms of results, which proves that deep learning has enormous potential for development in the field of SS. The above studies were conducted under the assumption of Gaussian white noise background and have not yet explored robustness in non-Gaussian noise environments. Mehrabian et al. proposed a CNN detector for symmetric \(\alpha\)-stable (\(S\alpha S\)) noise26. Compared with the baselines, this detector exhibits stronger robustness in dealing with impulse noise. Subsequently, they further proposed a CNN detector suitable for various noise models in multi antenna systems, including Middle Class A, \(S\alpha S\) distribution, and GGD27.
Motivation and contribution
The above research methods only use information from one domain in the signal as input to the neural network, ignoring the rich information contained in other domains. Therefore, these methods may not achieve optimal performance in non-Gaussian noise environments28. Due to the regularity exhibited by PU signals in the time domain and the transient nature of non-Gaussian noise pulses, using GRU to extract global temporal dependencies is very helpful. Furthermore, it is worth noting that frequency domain information also plays an important role in signal processing. Since frequency domain signals do not contain time series information, CNN is used to focus on local features in the frequency domain. Taking inspiration from the cross attention mechanism’s ability to effectively fuse multimodal features29,30, we have adopted this mechanism as a module for fusing time-domain and frequency-domain features. Through this integration, the TFCFN adapts to various noises and improves performance. The main contributions of this work are as follows:
-
1.
In our experiments, we employ the open-source RadioML2016.10a dataset31 to represent PU signals. We further utilize a GGD noise model to simulate the non-Gaussian noise encountered in real communication environments, thereby training our model.
-
2.
We propose a deep learning-based model that effectively fuses time and frequency features using a cross-attention mechanism to improve the accuracy of SS.
-
3.
We conduct comparative experiments under varying degrees of noise tailing conditions to evaluate the performance differences between our proposed model and other methods such as ED32, DetectNet21, WT-ResNet24, ConvLSTM25, 1D-CNN26, 2D-CNN27, and MASSnet-B33. The experimental results indicate that our model exhibits superior detection performance and robustness, regardless of whether the noise tailing is mild or severe.
Organization
The rest of this paper is organized as follows. The “Related work” section introduces related work. The “System model” section introduces the system model and problem statement of SS. The proposed TFCFN and its training process are presented in the “The proposed TFCFN” section. The “Performance evaluation” section provides simulation results and discussion. Finally, the “Conclusion” section provides a summary of this paper. Table 1 provides the abbreviations and their descriptions used in this paper.
Related work
Traditional spectrum sensing methods
The ED12 algorithm has received widespread attention due to its simple implementation. Chen et al. proposed replacing the amplitude squared operation with an arbitrary positive power operation to improve the energy detector in Gaussian noise34. Fading and noise are key factors affecting the ED algorithm. Digham et al. proposed a closed form expression for the \(P_d\) on multipath channels35. Chatziantiou et al. derived an analytical expression for the average \(P_d\) under two wave with diffusion power fading, and extended it to collaborative SS and square law selection diversity reception to mitigate fading effects36. Gao et al. fully utilized the stochastic characteristics of the GGD and the central limit theorem to derive the \(P_d\) and \(P_f\), and analyzed the impact of noise uncertainty on the system32. The eigenvalue based methods are also popular in the field of SS. Chaurasiya et al. proposed a maximum-minimum-eigenvalue algorithm and a spectrum sensor architecture based on this algorithm37. In order to improve the detection performance under noise uncertainty, Hashim et al. obtained an adaptive threshold based on the absolute covariance value38. The method based on high-order moments is used for SS in satellite communication39. The hybrid SS technology proposed by Ramya et al. automatically selects sensing methods based on energy or eigenvalues according to the range of SNR40. MFD is a better detection algorithm when there is prior information of PU signal. Brito et al. proposed a hybrid method based on existing MFD, which flexibly adjusts the number of MFD used to optimize detection performance under different \(P_f\)41. Obtaining prior information limits the application in certain scenarios. The act of obtaining prior information limits its application in certain scenarios. To address this issue, Zhang et al. developed a new test statistic. This statistic is composed of the correlation between the received signal and its delayed version, as well as the independence of noise at different times. Due to the accumulation of correlation, prior information from PU is no longer required42. Bala et al. proposed an iterative algorithm applied to CR Internet of Things (IoT) devices to optimize sensing threshold and time, greatly improving CR-IoT throughput in low SNR regions43.
Deep learning-based spectrum sensing methods
Data driven deep learning methods have become a hot topic in the field of SS in recent years. An et al. proposed a CNN for digital television terrestrial multimedia broadcasting systems, which can achieve satisfactory \(P_d\) at low SNRs44. Duan et al. used kernel principal component analysis to map the sampled signal to a high-dimensional space, created a covariance matrix, and then obtained the eigenvectors through matrix decomposition. Finally, CNN was used for classification45. Uvaydov et al. implemented real-time wideband SS using CNN46. Based on this work, Mei et al. designed a parallel CNN that reduced latency47. Wang et al. used residual dense network to solve the problem of gradient vanishing in deep network structure, while using convolutional block attention module to improve network performance48. The LSTM model developed by Balwani et al. extracted temporal correlations between spectrum data and achieved high classification accuracy, but at the cost of longer training and execution time49. Subsequently, Soni et al. improved the detection performance by using PU activity statistics as training data for LSTM, at the cost of high time consumption50. Combining various models together can extract multiple features. Xing et al. used CNN and BiLSTM in series, simultaneously extracting local features and global correlations of time-domain data, and then emphasized the importance of features using self-attention51. Denoising the signal and then classifying it is a novel innovation. Due to the two-stage nature of the H-CSG method22, where the denoising and detection stages are trained separately, the results are affected by the denoising performance. Therefore, Su et al. implemented joint learning for denoising and detection.52. Ni et al. did not limit themselves to CNN and LSTM, but used a temporal convolutional network with a special structure that allows it to extract temporal related features from sequence data53. MASSnet adopts a residual network structure, which is specifically optimized for the flexible configuration problem of multi antenna technology33. The most popular transformer model in the natural language processing field is gradually being used to handle SS tasks54,55.
System model
In this work, we consider a single-input single-output (SISO) system influenced by Rayleigh fading channels and non-Gaussian noise. SS is used to detect the presence or absence of PU signals, so it is usually represented as a binary hypothesis problem:
where r(n) denotes the n-th received signal sample in a detection period; s(n) is the signal from the PU; h(n) represents the channel gain in the current detection period, and w(n) represents a random noise sequence that follows the GGD. \({H_0}\) and \({H_1}\) signify the hypotheses that the PU is absent and present, respectively.
The GGD can represent noise distributions with different heavy-tailed characteristics by adjusting its shape parameter, which is an extension of the Gaussian distribution and can adapt to a wider range of noise environments. Its probability density function (PDF) can be expressed as56:
where \({\beta }\) is the shape parameter, \({\Gamma (\cdot )}\) denotes gamma function, and \({\alpha }\) is the scale parameter and the relationship between it and the variance of the random variable can be expressed as: \({\sigma ^2} = \alpha ^2\frac{\Gamma (3/\beta )}{\Gamma (1/\beta )}\). In particular, when \({\beta =2}\), the GGD degenerates to a Gaussian distribution; when \({0<\beta <2}\), the GGD exhibits heavy-tailed properties.
Typically, the performance metrics for evaluating SS are \(P_d\) and \(P_d\) defined as:
where \({P_d}\) is the probability of correctly detecting PU signals in the presence of the PU, and \({P_f}\) is the probability of mistakenly identifying noise as a signal in the absence of the PU.
The proposed TFCFN
To effectively perform SS in a non-Gaussian noise environment, we have utilized a cross-attention mechanism to fuse time-domain and frequency-domain features, enabling the model to adaptively learn the correlations between time-frequency features and dynamically assign corresponding frequency-domain feature weights to each time-domain feature. In the following, we will introduce the generation and preprocessing method of the dataset, followed by the detailed parts of the TFCFN architecture, and finally, the training and testing process will be described.
Dataset generating and preprocessing
The RadioML2016.10a dataset is a publicly available dataset widely used for wireless signal modulation identification. We reconstructed this dataset to meet the needs of the SS task, which is represented as follows:
where \({r_k}\) is the reconstructed signal, \({s_k}\) is the clean modulated signal, \({h_k}\) is the complex Rayleigh decay coefficient, and \({w_k}\) is the GGD noise. Specifically, we use clean QPSK signals with a signal length (L) of 128 and add GGD noise to simulate PU signals at specified SNRs. The SNR range we set spans from -20dB to 0dB, with an increment of 2dB. For each SNR level, we generate 2000 PU signal samples and an equivalent number of GGD noise samples. For the classification task, PU signal samples are labeled as 1, and GGD noise samples are labeled as 0. Therefore, the total number of signal samples in the entire dataset is 44000, with 22000 samples for \(H_0\) and \(H_1\) respectively. In addition, the dataset is divided into training set, validation set and test set in the ratio of 3:1:1. In the GGD, the variance of the noise is fixed to 1, and the shape parameter \({\beta }\) is selected from \(\{0.5, 1, 1.5,2\}\) to examine the effects of different noise trailing phenomena on the SS. Note that each \(\beta\) value builds a separate dataset.
The received signal is an IQ signal consisting of in-phase and quadrature components. As neural networks cannot process complex signals directly, the received IQ signal is decomposed into I-Q components, which can be represented by the \({L \times 2}\)-dimension matrix \({R_T}\) as follows:
where L refers to the number of sampling points for a sample and \({r_I(n)}\), \({r_Q(n)}\) denote the I-Q components of the n-th received signal, respectively. And the dimensions of \(r_I(n)\) and \(r_Q(n)\) are both \(L\times 1\). The TFCFN needs to integrate information from both time and frequency domains to better understand and analyze the data. To obtain the frequency domain features, the TFCFN utilizes the Discrete Fourier Transform (DFT). The DFT converts a signal from the time domain to the frequency domain by decomposing it into a composite of different frequency components. Its formula is expressed as:
where X[f] denotes the complex amplitude in the frequency domain, and f denotes the different frequency components. Note that here r is equivalent to r(n) in Eq. (1) and r[n] represents the n-th sampling point. L refers to the number of sampling points for sample r. Specifically, the FFT is used to accomplish this transformation task. The resulting X[f] is complex vector, which needs to be processed as a matrix with \({L \times 2}\)-dimension:
where L represents the number of X[f] points, and its value is the same as the number of sampling points of r. The \(real(\cdot )\) and \(imag(\cdot )\) functions respectively refer to taking the real and imaginary parts.
In order to improve the performance and stability of the model,we perform max-min normalization on matrices \(R_T\) and \(R_F\) along the column-wise direction. By scaling the original data and mapping the features to the [0,1] interval, max-min normalization can effectively unify the magnitudes of different features, and it also helps to accelerate the learning process and improve the convergence speed of the model. The specific implementation is:
where \({\overline{R}}\) represents the matrix normalized by \(R_T\) or \(R_F\). \(R_{n, j}\) is the n-th element of the original matrix \(R_T\) or \(R_F\) in j-th column, \(min_{j}\) and \(max_{j}\) are the minimum and maximum values in j-th column, respectively. Finally, the normalized matrices of \(R_T\) and \(R_F\) are represented as \({\overline{R}}_T\) and \({\overline{R}}_F\), respectively.
TFCFN architecture
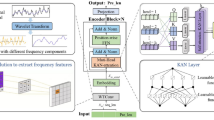
The TFCFN we designed is a multi-feature input model, and its overall architecture is shown in Fig. 1. As can be seen from the figure, the TFCFN is a deep neural network architecture that incorporate one-dimensional Convolutional (Conv1D) layers, GRUs, cross-attention block and Dense layers. The input time-domain and frequency-domain data are subjected to deep feature extraction using network modules appropriate to their characteristics, respectively; specifically, two GRUs are used to extract the time-domain features, and two Conv1D layers are used to extract the frequency features. Subsequently, the extracted features are fused using the cross-attention block to obtain a comprehensive feature representation being used for signal and noise classification. We denote the input time-domain and frequency-domain data as \({{\overline{R}}_T \in R^{L \times 2}}\) and \({{\overline{R}}_F \in R^{L \times 2}}\), respectively, where L denotes the signal length. In addition, Fig. 1 includes the settings of module parameters and changes in feature dimensions.

TFCFN architecture.
Recurrent neural networks (RNN), particularly LSTM network, have been widely applied in SS tasks due to their exceptional ability to handle time-series data57,58,59. However, the structure of LSTM is relatively complex with a large number of parameters, leading to high computational costs. The GRU, as a simplified version of LSTM, merges the hidden state and cell state and contains only update and reset gates, thus simplifying the network structure. This simplification not only reduces the number of parameters in the model but also improves the efficiency of training, while maintaining performance comparable to LSTM60. Therefore, in our work, we have chosen to use two GRUs with 32 units to extract time features from the data, achieving a balance between performance and efficiency. The features extracted from the time-domain data are represented as \(X_t\). Frequency-domain data reveal information about the intensity and phase of the signal at different frequency components, which, although they do not contain underlying temporal information, are equally crucial for understanding the spectral properties of the signal. Conv1D excels at extracting local features of the data, which can help the model to identify the frequency-specific components as well as the interactions between these components. In order to deepen the model’s sensitivity to signal variations and to enhance the level of feature abstraction, we employ two Conv1D layers as the extraction module for frequency-domain features. The parameter configuration for these two Conv1D is “32@3”. This means that each layer contains 32 convolution kernels, with each kernel having a size of 3. After each convolutional layer, the data will undergo ReLU activation function processing to introduce nonlinear characteristics and enhance the feature extraction ability between layers. The features extracted from the frequency-domain data in this way are denoted as \(X_f\).

Cross-attention block.
In recent years, the cross-attention mechanism has received extensive attention in the field of multimodal research. This mechanism is capable of computing the similarity between different modal input information and adaptingively associating and fusing the information based on the similarity scores. In this paper, we regard the frequency-domain and time-domain features as two modalities of the signal, each proving a different perspective on the signal. The application of the cross-attention mechanism in TFCFN is illustrated in the Fig. 2. Specifically, the features \(X_t\) and \(X_f\) are mapped into Query (Q), Key (K) and Value (V) matrices through Dense layer, and the Q and K matrices are dot products to generate an attention weight matrix whose elements represent the similarity between time-domain and frequency-domain features. In order to stabilize the gradient and prevent numerical overestimation, the dot product result is divided by \(\sqrt{d_k}\), where \(d_k\) is the diemnsion of K. Subsequently, the softmax function is applied to normalize these weights, resulting in an attention distribution assigned to the frequency-domain features on each time-domain features. The attention weight matrix is multiplied by the V matrix to obtain a feature representation X that combines time-domain and frequency-domain information. The calculation process is shown below:
where T denotes transpose, and \(d_k\) is the dimension of K. In TFCFN, we combine early time-domain features with enhanced features to improve the model’s feature expression ability, and the final classification feature is represented as:
Subsequently, we further processed \(X'\) through a series of Conv1D and Dense layers to obtain the classification result. In the processing, in order to reduce the number of model parameters, we choose to use a Global Average Pooling layer instead of Flatten layer.
Training and testing phase
To train the TFCFN, we label the processed data according to the states of \({H_0}\) and \({H_1}\) to construct the training dataset:
where each tuple \(({\overline{R}}_u, y_u)\) represents the u-th sample of the labeled training dataset. Here, \({\overline{R}}_u \in \{({\overline{R}}_T, {\overline{R}}_F)_1, \ldots ({\overline{R}}_T, {\overline{R}}_F)_u\}\). The label \({y_u \in \{0,1\}}\) indicates the binary state: \(y_u = 0\) for the noise-only state \({H_0}\), and \(y_u = 1\) for the signal-present state \(H_1\). SS can thus be framed as a binary classification problem, and \(y_u\) is encoded as a one-hot vector to reflect this:
The labeled data \({\mathcal {D}}\) are then fed into the TFCFN for training. The output of the network is a probability vector normalized by the softmax function:
with
here, \({\theta }\) represents the set of parameters of the TFCFN, and \({f_\theta ({\overline{R}}_u)}\) is the vector of probabilities, with \({f_{\theta |H_i}({\overline{R}}_u)}\) denoting the probability that the given sample \({\overline{R}}_u\) is classified as state \(H_i\).
To obtain the optimal parameter \({\theta }\), we accomplished this by minimizing the cross-entropy loss function using an Adam optimizer with a learning rate of 0.0005. The cross-entropy function is defined as follows:
After obtaining a model with optimal parameters by training on the dataset \({{\mathcal {D}}}\), the determination of the PU state can be performed using the new test data. Typically, the result is taken from the category corresponding to the maximum probability in \({f_{\theta }({\overline{R}}_u)}\), which is denoted as follows:
In order to compare the experimental results more accurately, we are keeping a constant \(P_f\) for comparison. The method is to replace the judgment condition of Eq. (16) by a decision threshold \({\gamma }\)61. Concretely, a new dataset \({{\mathcal {D}}_\text {noise}}\) is created by randomly selecting purely noisy samples from dataset \({{\mathcal {D}}}\), where \({{\mathcal {D}}_\text {noise}} = \{({\overline{R}}'_1, 0), ({\overline{R}}'_2, 0),...,({\overline{R}}'_n, 0)\}\). Subsequently, this dataset is subjected to predictions using the trained model, and the probabilities of \(H_1\) states are subsequently ranked:
Finally, the decision threshold \({\gamma }\) can be represented as:
where \({round(\cdot )}\) is rounding function. After obtaining \({\gamma }\), Eq. (16) transforms to the following judgment condition:
Performance evaluation
In this section, we first demonstrate the effectiveness of the cross-attention mechanism in TFCFN through ablation experiments. Next, we will evaluate the performance of TFCFN under constant \(P_f\) and different noise conditions, and compare it with existing SS techniques. At the same time, we will demonstrate the receiver operating characteristic (ROC) curves of TFCFN under different noise tail levels. Subsequently, the results of a series of generalization and robustness experiments will be analyzed. Finally, we will analyze and discuss the complexity of the model.
Ablation experiment
In the ablation experiment, we replace the cross-attention module, denoted as “CA”, with several common feature fusion methods to validate the effectiveness of the module. These methods include “Concat”, “Add”, and “Multiply”. The results are presented in Table 2, where accuracy, a commonly used metric in classification tasks, is employed as the performance indicator to intuitively compare the classification performance under different shape parameters of the GGD. In the experiments, the aforementioned modules and the “CA” were validated using only the X feature, while “CA + skip connection” incorporated the \(X_d\) feature for validation. All results are averaged over multiple runs.
Through the “Concat” operation, features \(X_t\) and \(X_f\) are concatenated in the channel dimension, which increases the number of features. However, experimental results indicate that this fusion strategy is not ideal in overall performance, despite maintaining a moderate level of parameter count and floating-point operations (FLOPs). When using the “Add” operation, the corresponding elements of features \(X_t\) and \(X_f\) are directly added to enhance the information content of the features. When the \(\beta =0.5\), there is a significant improvement in the performance of the model. The “Multiply” operation emphasizes the interaction between \(X_t\) and \(X_f\) features through element level multiplication, and shows good performance at \(\beta =1.5\). Similar to the “Add” operation, the “Multiply” operation also maintains the original dimensions of the features, so their parameter count and FLOPs are relatively low. The “CA” dynamically adjusts the importance of features by calculating the attention score between \(X_t\) and \(X_f\). This mechanism not only considers the interactions between features, but also establishes more complex dependency relationships between different features. The experimental results show that the “CA” performs the best in handling different noise shape parameters. Although its parameter count and FLOPs have increased, this is due to the additional computation required within the attention mechanism. In addition, when we introduce skip connection and add the most primitive feature information into the model, the performance is further improved.
Comparative experiment
In our experiments, we compare the proposed TFCFN model with existing deep learning-based methods and traditional method, which include ED32, DetectNet21, WT-ResNet24, ConvLSTM25, 1D-CNN26, 2D-CNN27, and MASSnet-B33. For a fair comparison, all schemes use the same original dataset and are fine-tuned to obtain optimal hyperparameters. The properties of these methods are presented in the Table 3.
Figure 3 illustrates the \(P_d\) of all schemes at different SNRs when the \(P_f\) is constant at 0.1. Although the threshold calculation of the ED is derived from the GGD, its performance is lower than that of deep learning based methods. As shown in Fig. 3a, the characteristics of GGD noise approximate Gaussian noise when \(\beta =2\). ConvLSTM, WT-ResNet and DetectNet are schemes designed as SS algorithm in a Gaussian white noise environment. Observations show that the performance of TFCFN is similar to that of ConvLSTM when the SNR is below -14 dB. However, when the SNR exceeds -14 dB, TFCFN significantly outperforms the other schemes, and its \(P_d\) improves by about 7.5% compared to ConvLSTM. As the \(\beta\) decreases, the tail of the noise distribution thickens, indicating an increase in the probability of extreme values in the noise. This change has the most significant impact on traditional ED algorithm, whose performance is extremely dependent on accurate estimates of noise energy levels. The CNN and ConvLSTM show similar detection performance when the \(\beta\) is reduced to 1.5. At SNR below -16 dB, the performance of the schemes does not differ much. However, when the SNR is higher than -16dB, the performance of TFCFN is significantly improved compared to CNN and ConvLSTM, with an increase in \(P_d\) ranging from about 5% to 10%. In Fig. 3c, TFCFN outperforms the other schemes in terms of \(P_d\) at all SNRs, and only slightly underperforms in the -20 dB SNR condition. Compared with ConvLSTM, TFCFN improves the \(P_d\) by about 4% to 9%. In particular, TFCFN shows optimal performance at \(\beta =0.5\). Under the condition of -20 dB SNR, the \(P_d\) of TFCFN reaches 57%, which is significantly higher than other schemes by more than 40%. In addition, when the SNR is increased to above -16 dB, the \(P_d\) of TFCFN is more than 90%. From the analysis of the results, it can be seen that the method with GRU or LSTM structures performs better, indicating that long-term dependencies in the time domain play a significant role. On this basis, introducing frequency domain features further improves the \(P_d\). The performance differences between various methods can be more clearly understood through accuracy indicators, as shown in the Table 4.

Probability of detection of different methods at \(P_f = 0.1\)

ROC curves of different noise distribution at SNR = -18 dB.
Figure 4 illustrates the curves of the \(P_d\) as a function of the \(P_f\), where different curves correspond to different GGD noise \(\beta\) values. In this figure, the curve shifts to the left overall as the \(\beta\) value decreases. This trend indicates that when the tail of the noise distribution becomes thicker, i.e., the \(\beta\) value decreases, the TFCFN is able to achieve a higher \(P_d\) while maintaining a low \(P_f\). In the TFCFN, the cross-attention mechanism allows the model to dynamically learn the importance of time-frequency features, which means that the model can automatically assign higher weights to features that are more informative in thick-tailed noise environments. At the same time, the stacking of multiple layers of convolution and recurrent structures increases the expressive power of the model, allowing it to capture more complex signal features. Taken together, the results show that TFCFN has higher \(P_d\) and better adaptability when dealing with non-Gaussian noise, especially noise distributions with thicker tails.
Generalization experiments
The impact of modulation methods
In this experiment, we study the classification of untrained signals with new modulation types by various methods. All models are trained using QPSK signals under the conditions of \(\beta=2\) and \(\beta =1\), respectively. Subsequently, BPSK and 16QAM signals were tested. The experimental results are shown in the Fig. 5, and all results maintain the \(P_f=0.1\). The experimental results revealed that when faced with new BPSK signals, the performance of 1D-CNN, 2D-CNN, WT-ResNet, and DetectNet all showed significant degradation. Compared with the results shown in Fig. 3, the \(P_d\) of TFCFN changes less and still maintains the best performance among all comparison methods. This discovery confirms that a fully trained TFCFN model can effectively detect new signals that have not been encountered before.

Performance of detecting new signals at \(P_f = 0.1\)
The impact of noise uncertainty

Performance results under noise uncertainty at \(P_f = 0.1\)
In real-world SS scenarios, the uncertainty of noise manifests as fluctuations in noise power over time, which may lead to significant performance degradation of certain detectors. In this experiment, the background noise is GGD noise. According to Eq. (2), when the shape parameter \(\beta\) remains fixed, \(\frac{\Gamma (3/\beta )}{\Gamma (1/\beta )}\) becomes a constant. Therefore, in the GGN model, only the parameter \(\alpha\) has an impact on the variance of noise, and its uncertainty can be represented by \(\alpha ^2\in [\frac{1}{\rho }\alpha _0^2, \rho \alpha _0^2]\), where \(\alpha _0^2\) is the nominal \(\alpha ^2\) and \(\rho\) is the uncertainty factor32. In Fig. 6, we use NU to represent uncertainty, and its transformation relationship with \(\rho = 10^{\frac{NU}{10}}\), with NU expressed in dB52. In the experiment, all methods used the trained model shown in Fig. 3, and it can be considered that \(NU=0dB\). We conduct tests on the cases of \(\beta =2\) and \(\beta =1\) respectively to evaluate the changes in model performance at \(NU=0.2 \, {\rm dB}\) and \(NU=0.5\, {\rm dB}\). The experimental results indicate that ED is most affected as it requires a higher estimation of noise power. On the contrary, the results of TFCFN remained stable and were not significantly affected. This indicates that TFCFN has reliability in environments with noise uncertainty.
The impact of shape parameter on GGD
In this section, we aim to estimate the generalization ability of the trained model under different shape parameter conditions of GGD. Specifically, we use the model trained in a GGD noise environment with \(\beta =1.5\) to test its performance on unknown datasets generated under different shape parameters \(\beta =2\) and \(\beta =1\). As shown in Fig. 7a, after training under the condition of \(\beta =1.5\), the performance of the TFCFN model on the test data of \(\beta =2\) is quite similar to that of the model trained and tested directly under the condition of \(\beta =2\) (see Fig. 3a). This indicates that the TFCFN has good robustness in handling the transition from slightly sharp shapes to smoother Gaussian distribution, and can effectively generalize to distributions similar to the training data. However, as shown in Fig. 7b, when the TFCFN is evaluated on the test dataset with \(\beta =1\), its performance decreased compared to the results shown in Fig. 3c. This is because the noise at \(\beta =1\) has sharper peaks and heavier tails, and the model failed to fully capture the specific characteristics of these noises during training. However, the TFCFN still exhibits certain functionality, and its \(P_d\) is still prominent among the compared models.

Generalization experiment results of shape parameter \(\beta\)
Comparison experiment of other noise distributions
To verify the robustness of TFCFN to other noise distributions, we conduct experiments on GMM noise and \(S\alpha S\) noise. The performance comparison and analysis under each noise distribution will be introduced below.
The PDF of a GMM is composed of a weighted sum of PDF of a set of Gaussian distributions. The PDF of a binary GMM is as follows:
where \(\epsilon\) is a mixed parameter, and \(0< \epsilon < 1\). In general, when the variance of the noise satisfies \(\sigma _2^2>> \sigma _1^2\) and \(\epsilon<< 1\), the variance of Gaussian noise \(\sigma _2^2\) is used to describe sudden pulses or interferences with short duration and large amplitude changes. At the same time, the Gaussian distribution with variance of \(\sigma _1^2\) dominates in the background noise. The total noise variance \(\sigma ^2\) is \((1 - \epsilon )\sigma _1^2 + \epsilon \sigma _2^2\). In the experiment, set \(\sigma _1^2 = 1\), \(\sigma _2^2 = 4\), \(\epsilon = 0.5\), and \(P_f=0.1\) to observe the perceptual performance of all models on the GMM5. As shown in Fig. 8, under multiple SNR conditions, the TFCFN model exhibits significantly better detection performance than other models. Specifically, under SNR = -8 dB, the \(P_d\) of TFCFN exceeds 90%. In the SNR range of -16 dB to -8 dB, TFCFN has an \(P_d\) increase of about 5% compared to the other models. The experimental results show that TFCFN can still achieve ideal detection performance under GMM.

Performance results under GMM noise environments.
The PDF of \(\alpha\)-stable distribution does not have a closed expression, so it is defined through the characteristic function:
where \(\alpha (0 < \alpha \le 2)\) denotes the characteristic exponent, \(\beta (-1 \le \beta \le 1)\) represents symmetrical parameter, \(\gamma\) is the proportional parameter, \(\mu\) is the positional parameter, sign(z) is a sign function, and \(\omega (z, \alpha )\) is define as:
When \(\beta =0\), the \(\alpha\)-stable distribution is symmetric about \(\mu\) and degenerates into a \(S\alpha S\) distribution. Specifically, when \(\alpha =2\), the \(S\alpha S\) distribution transforms into a Gaussian distribution; When \(\alpha =1\), it degenerates into a Cauchy distribution62. In the experiment, we mainly focus on the performance of TFCFN under the conditions of \(\alpha =1.5\) and \(\alpha =1.2\)27. In addition, other related parameters were set as follows: \(\beta =0\), \(\mu =0\), \(\gamma =1\), \(P_f=0.1\). Since the \(S\alpha S\) distribution does not possess a finite second-order moments, its variance becomes undefined. Therefore, in scenarios with additive \(S\alpha S\) noise, the generalized signal-to-noise ratio (GSNR) is commonly used as a measurement metric. The definition of GSNR is as follows:
where \(\sigma _s^2\) represents the variance of the signal. Figure 9a shows the detection performance of each model under different GSNR condition when the \(\alpha =1.5\). Overall, the TFCFN performs better than other models. In the range of GSNR from -20 dB to -14dB, the \(P_d\) of the TFCFN is quite similar to other models. However, within the range of GSNR from -12 dB to -6 dB, the \(P_d\) of the TFCFN is about 10% higher than other models. As shown in Figure 9b, when the \(\alpha\) value is adjusted to 1.2, the pulse characteristics of the noise become more prominent. Within the GSNR range of -16 dB to -8 dB, the results are higher than those obtained when \(\alpha =1.5\), while still maintaining a higher level than other models.

Performance results under \(S\alpha S\) noise environments.
Complexity analysis
In deep learning, the number of parameters and the FLOPs are common metrics used to measure the complexity of a model, which can be regarded as the space complexity and time complexity, respectively. In Table 5, we present in detail the computational complexity analysis based on deep learning methods, where l and \(D_l\) represent the index and number of layers of the network layer, respectively. In a Conv1D, \(u_l\), \(k_l\), and \(m_l\) represent the number of channels in the l-th layer, the size of the convolution kernel, and the length of the output sequence, respectively. In LSTM and GRU, \(e_l\) and \(h_l\) represent the size of the embedding layer and the number of hidden units in the l-th layer, respectively. In addition, \(d_l\) represents the number of neurons in the l-th dense layer52. Compared to Conv1D, the convolutional kernels and feature maps in Conv2D are two-dimensional. Therefore, we use \(m_l^h \times m_l^w\) to represent the size of the output feature map, and \(k_l^h \times k_l^w\) to denote the size of the convolutional kernel. ConvLSTM replaces fully connected layers with convolutional layers internally, thereby changing the computational cost of convolution. Compared to LSTM, GRU reduces the number of parameters and FLOPs of the model by reducing the computation of on gating structure. In addition, during the classification stage, we adopted a global pooling layer to reduce data dimensionality, thereby reducing the number of input neurons in the Dense layer, further reducing the overall parameter and computational complexity. Please refer to the Table 5 for specific comparative data. It can be seen that the TFCFN has much fewer parameters than other comparative models, while its FLOPs remain at a slightly lower to moderate level. The actual FLOPs are influenced by the size of features and the number of channels. In both 2D-CNN and MASSnet, pooling operations are used to reduce the size of features, resulting in a decrease in computational complexity. However, their characteristic information may be lost.
Conclusion
In this paper, we studied a multi feature fusion network called TFCFN. This network effectively integrates time-domain and frequency-domain features through cross-attention mechanism, which can better adapt to Gaussian noise and strong impulse noise environments simulated by GGD. The experimental results show that TFCFN performs better than the comparative methods under various shape parameters of GGD, while maintaining lower complexity. In addition, the experiment verified that the network has robustness under new modulation methods, noise models (GMM and \(S \alpha S\)), and noise uncertainty. However, we are still dissatisfied with the results at extremely low SNR, and TFCFN has certain limitations in multi antenna scenarios. Future work will further optimize TFCFN to improve its performance and practicality in practical communication systems.
Data availability
All data generated or analyzed during this study are included in this article.
References
Abdulsalam, A., Al-shami, S., Al-aghbary, A. & Hamam, H. Performance study of an improved version of li-fi and wi-fi networks. CRJ (2023).
Haykin, S. Cognitive radio: Brain-empowered wireless communications. IEEE J. Sel. Areas Commun. 23, 201–220. https://doi.org/10.1109/JSAC.2004.839380 (2005).
Mitola, J. & Maguire, G. Cognitive radio: Making software radios more personal. IEEE Pers. Commun. 6, 13–18. https://doi.org/10.1109/98.788210 (1999).
Mazhar, T. et al. Quality of service (qos) performance analysis in a traffic engineering model for next-generation wireless sensor networks. Symmetry 15. https://doi.org/10.3390/sym15020513 (2023).
Li, J. et al. Spectrum sensing with non-Gaussian noise over multi-path fading channels towards smart cities with iot. IEEE Access 9, 11194–11202. https://doi.org/10.1109/ACCESS.2021.3051719 (2021).
Middleton, D. Statistical-physical models of man-made radio noise, part I. First-order probability models of the instantaneous amplitude (1974).
Zhao, Y., Zhuang, X. & Ting, S.-J. Gaussian mixture density modeling of non-gaussian source for autoregressive process. IEEE Trans. Signal Process. 43, 894–903. https://doi.org/10.1109/78.376842 (1995).
Corral, C., Emami, S. & Rasor, G. Model of multi-band ofdm interference on broadband qpsk receivers. In Proceedings. (ICASSP ’05). IEEE International Conference on Acoustics, Speech, and Signal Processing, 2005.. Vol. 3. iii/629–iii/632. https://doi.org/10.1109/ICASSP.2005.1415788 (2005).
Moghimi, F., Nasri, A. & Schober, R. Adaptive lp norm spectrum sensing for cognitive radio networks. IEEE Trans. Commun. 59, 1934–1945. https://doi.org/10.1109/TCOMM.2011.051311.090588 (2011).
Zhou, Q. & Ma, X. Receiver designs for differential uwb systems with multiple access interference. IEEE Trans. Commun. 62, 126–134. https://doi.org/10.1109/TCOMM.2013.120413.130005 (2014).
Bibalan, M. H. & Amindavar, H. On parameter estimation of symmetric alpha-stable distribution. In 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 4328–4332. https://doi.org/10.1109/ICASSP.2016.7472494 (2016).
Urkowitz, H. Energy detection of unknown deterministic signals. Proc. IEEE 55, 523–531. https://doi.org/10.1109/PROC.1967.5573 (1967).
Salahdine, F., Ghazi, H. E., Kaabouch, N. & Fihri, W. F. Matched filter detection with dynamic threshold for cognitive radio networks. In 2015 International Conference on Wireless Networks and Mobile Communications (WINCOM). 1–6. https://doi.org/10.1109/WINCOM.2015.7381345 (2015).
Sherbin M., K. & Sindhu, V. Cyclostationary feature detection for spectrum sensing in cognitive radio network. In 2019 International Conference on Intelligent Computing and Control Systems (ICCS). 1250–1254. https://doi.org/10.1109/ICCS45141.2019.9065769 (2019).
Liu, M., Zhao, N., Li, J. & Leung, V. C. M. Spectrum sensing based on maximum generalized correntropy under symmetric alpha stable noise. IEEE Trans. Vehic. Technol. 68, 10262–10266. https://doi.org/10.1109/TVT.2019.2931949 (2019).
Torun, O., Yuksel, S. E., Erdem, E., Imamoglu, N. & Erdem, A. Hyperspectral image denoising via self-modulating convolutional neural networks. Signal Process. 214, 109248. https://doi.org/10.1016/j.sigpro.2023.109248 (2024).
Himeur, Y. et al. Video surveillance using deep transfer learning and deep domain adaptation: Towards better generalization. Eng. Appl. Artif. Intell. 119, 105698. https://doi.org/10.1016/j.engappai.2022.105698 (2023).
Kheddar, H., Himeur, Y., Al-Maadeed, S., Amira, A. & Bensaali, F. Deep transfer learning for automatic speech recognition: Towards better generalization. Knowl.-Based Syst. 277, 110851. https://doi.org/10.1016/j.knosys.2023.110851 (2023).
Kheddar, H., Himeur, Y. & Awad, A. I. Deep transfer learning for intrusion detection in industrial control networks: A comprehensive review. J. Netw. Comput. Appl. 220, 103760. https://doi.org/10.1016/j.jnca.2023.103760 (2023).
Mazhar, T. et al. Electric vehicle charging system in the smart grid using different machine learning methods. Sustainability 15, 2603 (2023).
Gao, J., Yi, X., Zhong, C., Chen, X. & Zhang, Z. Deep learning for spectrum sensing. IEEE Wirel. Commun. Lett. 8, 1727–1730. https://doi.org/10.1109/LWC.2019.2939314 (2019).
Su, Z., Teh, K. C., Razul, S. G. & Kot, A. C. Deep non-cooperative spectrum sensing over rayleigh fading channel. IEEE Trans. Vehic. Technol. 71, 4460–4464. https://doi.org/10.1109/TVT.2021.3138593 (2022).
Chen, Z., Xu, Y.-Q., Wang, H. & Guo, D. Deep stft-cnn for spectrum sensing in cognitive radio. IEEE Commun. Lett. 25, 864–868. https://doi.org/10.1109/LCOMM.2020.3037273 (2021).
Zhen, P., Zhang, B., Chen, Z., Guo, D. & Ma, W. Spectrum sensing method based on wavelet transform and residual network. IEEE Wirel. Commun. Lett. 11, 2517–2521. https://doi.org/10.1109/LWC.2022.3207296 (2022).
Wang, Q. et al. Convlstm-based spectrum sensing at very low snr. IEEE Wirel. Commun. Lett. 12, 967–971. https://doi.org/10.1109/LWC.2023.3254048 (2023).
Mehrabian, A., Sabbaghian, M. & Yanikomeroglu, H. Spectrum sensing for symmetric \(\alpha\)-stable noise model with convolutional neural networks. IEEE Trans. Commun. 69, 5121–5135. https://doi.org/10.1109/TCOMM.2021.3070892 (2021).
Mehrabian, A., Sabbaghian, M. & Yanikomeroglu, H. Cnn-based detector for spectrum sensing with general noise models. IEEE Trans. Wirel. Commun. 22, 1235–1249. https://doi.org/10.1109/TWC.2022.3203732 (2023).
Liu, M., Zhang, X., Chen, Y. & Tan, H. Multi-antenna intelligent spectrum sensing in the presence of non-gaussian interference. Digit. Signal Process. 140, 104135. https://doi.org/10.1016/j.dsp.2023.104135 (2023).
Yuan, N., Li, J. & Sun, B. Global cross-attention network for single-sensor multispectral imaging. In IEEE Transactions on Emerging Topics in Computational Intelligence. 1–13. https://doi.org/10.1109/TETCI.2024.3414950 (2024).
Liu, Y. et al. Sca: Streaming cross-attention alignment for echo cancellation. In ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 1–5. https://doi.org/10.1109/ICASSP49357.2023.10096417 (2022).
O’shea, T. J. & West, N. Radio machine learning dataset generation with gnu radio. In Proceedings of the GNU Radio Conference. Vol. 1 (2016).
Gao, R., Qi, P. & Zhang, Z. Performance analysis of spectrum sensing schemes based on energy detector in generalized gaussian noise. Signal Process. 181, 107893. https://doi.org/10.1016/j.sigpro.2020.107893 (2021).
Zhang, L., Zheng, S., Qiu, K., Lou, C. & Yang, X. Massnet: Deep-learning-based multiple-antenna spectrum sensing for cognitive-radio-enabled internet of things. IEEE Internet Things J. 11, 14435–14448. https://doi.org/10.1109/JIOT.2023.3343699 (2024).
Chen, Y. Improved energy detector for random signals in gaussian noise. IEEE Trans. Wirel. Commun. 9, 558–563. https://doi.org/10.1109/TWC.2010.5403535 (2010).
Digham, F. F., Alouini, M.-S. & Simon, M. K. On the energy detection of unknown signals over fading channels. IEEE Trans. Commun. 55, 21–24. https://doi.org/10.1109/TCOMM.2006.887483 (2007).
Chatziantoniou, E., Allen, B., Velisavljevic, V., Karadimas, P. & Coon, J. Energy detection based spectrum sensing over two-wave with diffuse power fading channels. IEEE Trans. Vehic. Technol. 66, 868–874. https://doi.org/10.1109/TVT.2016.2556084 (2017).
Chaurasiya, R. B. & Shrestha, R. Hardware-efficient and fast sensing-time maximum-minimum-eigenvalue-based spectrum sensor for cognitive radio network. IEEE Trans. Circuits Syst. I Regul. Pap 66, 4448–4461. https://doi.org/10.1109/TCSI.2019.2921831 (2019).
Hashim, B. T., Ziboon, H. T. & Abdulsatar, S. M. Covariance absolute values spectrum sensing method based on two adaptive thresholds. Indonesian J. Electric. Eng. Comput. Sci. (IJEECS) 30, 1029–1037 (2023).
Benedetto, F., Giunta, G. & Pallotta, L. Cognitive satellite communications spectrum sensing based on higher order moments. IEEE Commun. Lett. 25, 574–578. https://doi.org/10.1109/LCOMM.2020.3029091 (2021).
Ramya, M. & Rajeswari, A. Improved hybrid spectrum sensing technique in cognitive radio communication system. Signal Image Video Process. 18, 4233–4242 (2024).
Brito, A., Sebastião, P. & Velez, F. J. Hybrid matched filter detection spectrum sensing. IEEE Access 9, 165504–165516. https://doi.org/10.1109/ACCESS.2021.3134796 (2021).
Zhang, C., Li, J., Li, B. & Ma, W. Blind matching filtering algorithm for spectrum sensing under multi-path channel environment. Electronics 12. https://doi.org/10.3390/electronics12112499 (2023).
Bala, I., Sharma, A., Tselykh, A. & Kim, B.-G. Throughput optimization of interference limited cognitive radio-based internet of things (cr-iot) network. J. King Saud Univ.-Comput. Inf. Sci. 34, 4233–4243. https://doi.org/10.1016/j.jksuci.2022.05.019 (2022).
An, N. et al. Spectrum sensing for dtmb system: A cnn approach. IEEE Trans. Broadcast. 68, 271–278. https://doi.org/10.1109/TBC.2021.3108055 (2022).
Duan, Y., Huang, F., Xu, L. & Gulliver, T. A. Intelligent spectrum sensing algorithm for cognitive internet of vehicles based on kpca and improved cnn. Peer-to-Peer Netw. Appl. 16, 2202–2217 (2023).
Uvaydov, D., D’Oro, S., Restuccia, F. & Melodia, T. Deepsense: Fast wideband spectrum sensing through real-time in-the-loop deep learning. In IEEE INFOCOM 2021 - IEEE Conference on Computer Communications. 1–10. https://doi.org/10.1109/INFOCOM42981.2021.9488764 (2021).
Mei, R. & Wang, Z. Deep learning-based wideband spectrum sensing: A low computational complexity approach. IEEE Commun. Lett. 27, 2633–2637. https://doi.org/10.1109/LCOMM.2023.3310715 (2023).
Wang, A., Meng, Q. & Wang, M. Spectrum sensing method based on residual dense network and attention. Sensors 23, 7791 (2023).
Balwani, N., Patel, D. K., Soni, B., López-Benítez, M. Long. & short-term memory based spectrum sensing scheme for cognitive radio. In IEEE 30th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC). 1–6. https://doi.org/10.1109/PIMRC.2019.8904422 (2019).
Soni, B., Patel, D. K. & López-Benítez, M. Long short-term memory based spectrum sensing scheme for cognitive radio using primary activity statistics. IEEE Access 8, 97437–97451. https://doi.org/10.1109/ACCESS.2020.2995633 (2020).
Xing, H. et al. Spectrum sensing in cognitive radio: A deep learning based model. Trans. Emerg. Telecommun. Technol. 33, e4388 (2022).
Su, Z., Teh, K. C., Xie, Y., Razul, S. G. & Kot, A. C. Signal enhancement aided end-to-end deep learning approach for joint denoising and spectrum sensing. IEEE Trans. Vehic. Technol. 73, 4424–4428. https://doi.org/10.1109/TVT.2023.3324826 (2024).
Ni, T. et al. Spectrum sensing via temporal convolutional network. China Communications 18, 37–47, https://doi.org/10.23919/JCC.2021.09.004 (2021).
Zhang, W., Wang, Y., Chen, X., Cai, Z. & Tian, Z. Spectrum transformer: An attention-based wideband spectrum detector. In IEEE Transactions on Wireless Communications. 1–1. https://doi.org/10.1109/TWC.2024.3391515 (2024).
Zhang, W., Wang, Y., Chen, X. & Tian, Z. Spectrum transformer: Wideband spectrum sensing using multi-head self-attention. In 2023 IEEE 24th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC). 101–105. https://doi.org/10.1109/SPAWC53906.2023.10304551 (2023).
Chandra, S. S., Upadhye, A., Saravanan, P., Gurugopinath, S. & Muralishankar, R. Deep neural network architectures for spectrum sensing using signal processing features. In 2021 IEEE International Conference on Distributed Computing, VLSI, Electrical Circuits and Robotics (DISCOVER). 129–134. https://doi.org/10.1109/DISCOVER52564.2021.9663583 (2021).
Balwani, N., Patel, D. K., Soni, B., López-Benítez, M. Long. & short-term memory based spectrum sensing scheme for cognitive radio. In IEEE 30th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC). 1–6. https://doi.org/10.1109/PIMRC.2019.8904422 (2019).
Balwani, N., Patel, D. K., Soni, B., López-Benítez, M. Long. & short-term memory based spectrum sensing scheme for cognitive radio. In IEEE 30th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC). 1–6. https://doi.org/10.1109/PIMRC.2019.8904422 (2019).
Bkassiny, M. A deep learning-based signal classification approach for spectrum sensing using long short-term memory (lstm) networks. In 2022 6th International Conference on Information Technology, Information Systems and Electrical Engineering (ICITISEE). 667–672. https://doi.org/10.1109/ICITISEE57756.2022.10057728 (2022).
Chung, J., Gulcehre, C., Cho, K. & Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555 (2014).
Liu, C., Wang, J., Liu, X. & Liang, Y.-C. Deep cm-cnn for spectrum sensing in cognitive radio. IEEE J. Sel. Areas Commun. 37, 2306–2321. https://doi.org/10.1109/JSAC.2019.2933892 (2019).
Liu, M., Zhao, N., Li, J. & Leung, V. C. M. Spectrum sensing based on maximum generalized correntropy under symmetric alpha stable noise. IEEE Trans. Vehic. Technol. 68, 10262–10266. https://doi.org/10.1109/TVT.2019.2931949 (2019).
Acknowledgements
This research was funded by National Key R&D Program of China, grant number 2021YFC3002103, National Key R&D Program of China, grant number 2023YFC3011505, the Natural Science Project of Xinjiang University Scientific Research Program, grant number XJEDU2021Y003 and major special projects in Xinjiang Uygur Autonomous Region (2022A01007-4).
Author information
Authors and Affiliations
Contributions
W.G., R.Y., and H.M. provided research background and questions, and designed experiments. H.X. and Y.Y. conducted experiments and analyzed and results, and H.X. prepared the original manuscript. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Xi, H., Guo, W., Yang, Y. et al. Cross-attention mechanism-based spectrum sensing in generalized Gaussian noise. Sci Rep 14, 23261 (2024). https://doi.org/10.1038/s41598-024-74341-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-74341-4
