
Abstract
The segmentation accuracy of the lung images is affected by the occlusion of the front background objects. To address this problem, we propose a full-scale lung image segmentation algorithm based on hybrid skip connection and attention mechanism (HAFS). The algorithm uses yolov8 as the underlying network and enhancement of multi-layer feature fusion by incorporating dense and sparse skip connections into the network structure, and increased weighting of important features through attention gates. Finally the proposed algorithm was applied to the lung datasets Montgomery County chest X-ray and Shenzhen chest X-ray. The experimental results show that the proposed algorithm improves the precision, recall, pixel accuracy, Dice, mIoU, mAP and GFLOPs metrics compared to the comparison algorithms, which proves the advancement and effectiveness of the proposed algorithm.
Similar content being viewed by others

Introduction
As a traditional disease in China, the proportion of people suffering from lung cancer has been increasing year by year, seriously affecting the health of the nation1. Medical imaging techniques, such as Magnetic Resonance Imaging (MRI), CT scans, and Positron Emission Tomography (PET) scans, which are used to locate and assess the progression of lung cancer before and after treatment, play a crucial role in the diagnosis of lung cancer2. With the development of computer vision technology, the segmentation of lung cancer images assists doctors to quickly diagnose the type of lung cancer and give later treatment plans, providing a new direction for the diagnostic research of lung cancer3. According to the lung cancer segmentation techniques can be classified into traditional image segmentation methods and deep learning image segmentation methods. Traditional lung cancer image segmentation methods mainly contain threshold-based segmentation methods, region-based image segmentation methods, edge detection-based segmentation methods, and image segmentation methods combined with specific tools. Deep learning segmentation methods mainly contain semantic segmentation and instance segmentation in two ways. Among the semantic segmentation methods include such as FCN4, SegNet5, U-Net6, UNet++7, PSPNet8, LinkNet9, DeepLab V310,11. Instance segmentation methods include the R-CNN series algorithms12,13 and the Yolo series algorithms14. Such as, Hooda et al.15 proposed a study on segmentation of lungs in chest images using fully convolutional networks to solve the problem of dense estimation during segmentation and to achieve end-to-end training, but the method suffers from semantic divide and feature loss in different layers. To solve the above problems, Das16 proposed a U-Net based adaptive lung segmentation method for automatic segmentation of COVID-19, which solves the problem of semantic divide existing in different layers by skip connection, but the method needs to design different layers of the network structure in order to achieve good segmentation results for different input size images. To solve the above problem, LIU et al.17 proposed a UNet + + -based automatic segmentation method of COVID-19 lesions in CT slices. This method can be adapted to the input of images of different sizes, but the method has a large number of parameters and a long training time. To solve the above problems, Samudrala et al.18 proposed a hybrid network structure using the DenseNet-121 model with an attention pyramid scene parsing network. The method can improve the efficiency of decision-making, but the segmentation accuracy of this network is low and the model can only be used for semantic segmentation, which lacks more application scenarios. Aiming at the above problems, Kâmil Doğan et al.19 proposed an enhanced Mask RCNN network structure for pulmonary embolism detection and segmentation. The method improves the detection and segmentation of the network by improving the loss function. However, the method does not solve the problem of low efficiency in two stages. Kang et al.20 proposed an attention and multi-scale fusion Yolo instance segmentation algorithm, which belongs to the one-stage algorithm with high execution efficiency but low execution accuracy. Based on the problems of the above methods in the process of image segmentation, we take Yolov8 as the basic method model. Drawing on the skip connection in Giraffedet Network21, we use the hybrid skip connection to integrate the feature maps of different layer scales, and at the same time, integrate the attention mechanism into the network structure to strengthen the protection of the important subtle features and improve the segmentation accuracy of the network. The main contribution points of this paper are: (1) We use a hybrid skip-connection approach to fuse different layers of scale features to enhance the information transfer; (2) Incorporating attention gates22 into the network to weight tiny features and prevent the loss of tiny features; (3) Improving the output structure of the network for instance segmentation and semantic segmentation of images.
Methodology
Overall network structure
Yolov8, another major update from ultralytics, has a wide range of applications in image classification23, object detection24, image segmentation25, pose estimation and tracking26. The following changes exist in Yolov8 compared to previous versions: In the backbone network, the C3 structure of Yolov5 is replaced by the C2f. structure, which is richer in gradient flow, and the number of different channels is adjusted for different scale models. In the head, compared to Yolov5, the changes are larger, switching to the current mainstream decoupled head structure, separating the classification and detection heads, and also switching from Anchor-Based to Anchor-Free. The TaskAligedAssigner positive sample allocation strategy is used for loss function computation and the Distribution Focal Loss function is introduced. Therefore, based on the above features of Yolov8, and according to the problems of lung medical image segmentation, this paper proposes a lung image segmentation network based on hybrid skip connection and attention mechanism. The network uses C2f. as the feature extraction algorithm, which is the lightweight structure to reduce the computational parameters and ensure the performance of the network well for lung medical image data. In the backbone network, to improve the feature fusion capability, Add = True in the C2f. module. In Neck network, Add = False in C2f. module for feature extraction of different layers. The hybrid skip connection network structure is used in the network to enhance the fusion of image features by using multi-scale feature information, and the attention gate structure is integrated into the network structure to improve the accuracy of image segmentation. The overall network structure is shown in Fig. 1.

Overall network structure diagram.
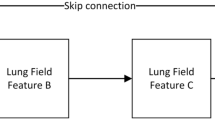
Hybrid skip connection
A study on the improvement of the Neck part of yolov8 by hybrid skip connection. Hybrid skip connection is an improved study based on BiFPN27. Since BiFPN focuses only on feature fusion and lacks internal block connectivity, hybrid skip connection design a new path fusion that includes cross-layer and cross-scale connectivity. Network structure is shown in Fig. 2a,b shows the BiFPN network structure.

(a) BiFPN (b) Hybrid skip connections.
In BiFPN, the emphasis is on same-layer feature fusion and the lack of connectivity of features in different layers. Hybrid skip connection proposes two feature connection methods, one is Dense-link for same layer feature connection and one is log2n-link for different layer feature connection. Structure is illustrated in Fig. 3a and b.

(a) Dense-link (b) log2n-link.
Dense-link connects all layers above and log2n-link takes a power of 2 skip connection. Dense-link: for each scale feature P of the k layer, the lth feature receives all the above layer feature matrices and as shown in Eq. (1).
Where the Concat() function refers to all layers above the feature matrix connection and the Conv() function denotes the 3 × 3 convolution operation.
log2n-link is a power of 2 jump connection inspired by the “Giraffedet” Network21. The derivation is as follows: for k layers the lth are of the form l-20, l-21,…, l-2n-1, l-2n forms. According to the rule, when l-2n is the n + 1st node, hence l-2n = n + 1, converts to l-1 = 2n + n. when 2n > > n, similarly l-1 = 2n, result is n = log2(l-1). So, in each level k, the lth layer receives the feature-map from at most log2(l-1) number of preceding layers, and these input layers are exponentially apart from depth l with base 2, as denoted in Eq. (2):
Where l-2n ≥ 0, compare to dense-link at depth l, the time complexity of log2n-link only cost Ο(l·log2l). Moreover, log2n-link only increase the short distances among layers during backpropagation from 1 to 1 + log2(l-1). Hence, log2n-link can scale to deeper networks. Based on Dense-link and log2n-link, two hybrid skip connections, our full-scale network structure is depicted in Fig. 4.

Current Layer Output Structure Diagram.
According to the Neck in Fig. 1, the T4, T5 and T6 are generated by P4, P5, P6 through a hybrid skip connection network. The concatenation in P6’ consists previous layer T4 down-sampling, previous layer T6 up-sampling, previous layer T5 and current layer P5’. In this work, we apply bilinear interpolation and max-pooling as our up-sampling and down-sampling functions respectively.
Improved network header structure
In order to better achieve the segmentation effect, the model can achieve semantic segmentation and instance segmentation. In this paper, we improve the structure of the network header, change the original target detection header into segmentation header, and implement semantic segmentation and instance segmentation function. The internal modification structure is shown in Fig. 5. This structure uses an improved attention gate approach to weight the output important feature information, suppress irrelevant feature information, and strengthen the data effect of important features.

Improved Neck network structure.
The principle is to concatenate the feature matrices \({\text{P}}_{5}^{^{\prime\prime}} ,P_{6}^{^{\prime\prime}} ,P_{7}^{^{\prime\prime}}\), and the concatenated feature matrix is filtered and normalized. Finally, the results are multiplied with the underlying features \({\text{P}}_{4}^{^{\prime\prime}}\). The method enhances high-level correlated feature data and suppresses low-level uncorrelated feature data. As shown in Eqs. (3) and (4).
Where \({\text{P}}_{5}^{^{\prime\prime}} ,P_{6}^{^{\prime\prime}} ,P_{7}^{^{\prime\prime}}\) is the input feature matrix, \(\sigma_{1}\) is the ReLU function, \(\sigma_{2}\) is the sigmoid activation function, and the offset term \(b_{\psi } \in {\mathbb{R}}\).
Experimental results and analysis
Experimental configuration
The configuration environment for this study was a Windows 11 workstation with an AMD Ryzen 7 5800H processor and Radeon Graphics (3.20 GHz). It also had 16 GB of RAM and an NVIDIA GeForce RTX 3050 Laptop GPU (4 GB VRAM). The development environment used was PyCharm 2022, with the PyTorch 1.12.1 framework. In model training, the loss function uses the TaskAligedAssigner positive sample allocation strategy and introduces the Distribution Focal Loss function, the batch size was 64, the number of model iterations was epochs = 100 and select the optimal checkpoint as the model validation parameters, and the initial learning rate of the model was 0.001. The stochastic gradient descent method was selected as the optimizer to update the model parameters.
Evaluation metrics
In order to verify the validity of the method proposed in this paper, quantitative evaluation indicators are used. Precision is a measure of the accuracy with which the model predicts positive cases, the higher the value, the better the algorithm’s predictive performance. Recall is used as a measure of the coverage of positive examples by the model, and a higher value indicates a better predictive performance of the algorithm. Pixel accuracy (PA) is the ratio of the number of correctly classified pixels to the total number of pixels in the image segmentation result, which is used to measure the accuracy of the image segmentation algorithm, and the higher the value indicates the better performance of the algorithm. Mean Intersection Over Union (mIoU), which represents the ratio of the intersection and merger of the true labels and the predicted values of the class, the greater the value, the better the algorithm’s segmentation effect and the higher the accuracy. Dice coefficient a measure of the similarity between the real and predicted samples, the higher the value the better the prediction of the model. The meaning of mAP value is the average area enclosed by the Precision-Recall curve, the higher the value, the better the performance of the algorithm. GFLOPs denote the number of floating point operations, which measures the computational complexity of the model, the larger the value of GFLOPs, the higher the complexity of the model and the lower the computational efficiency. The formulae are shown in Eqs. (5–11).
Where k denotes the number of classifications, NTP represents the number of positive samples predicted to be positive by true positive, NFP represents the number of negative samples predicted to be positive by false positive, NFN represents the number of positive samples predicted to be negative by false negative, and NTN represents the number of negative samples predicted to be negative by true negative.
Datasets
Montgomery County chest X-ray set28, This dataset was collected in collaboration with the Department of Health and Human Services, Montgomery County, Maryland, USA. Contains 138 frontal chest x-rays from the Montgomery County Tuberculosis Screening Project, of which 80 are normal cases and 58 are cases with tuberculosis manifestations. This dataset can be used as a segmentation and classification task and some of the results of the data are shown in Fig. 6. In order to increase the number of samples, we use the data enhancement method of 180 degree rotation and image flipping. The data can be downloaded via the URL: https://openi.nlm.nih.gov/imgs/collections/NLM-MontgomeryCXRSet.zip.

Montgomery County chest X-ray Lung dataset images.
Shenzhen chest X-ray set29 is a digital image database of tuberculosis created by the Third People’s Hospital of Shenzhen, China, in collaboration with Guangdong Medical College. This dataset contains 336 radiographs exhibiting tuberculosis and 326 normal cases. The dataset contains two parts, the original image and the segmented image, and part of the data is displayed as shown in Fig. 7, and the data can be downloaded via URL: https://openi.nlm.nih.gov/imgs/collections/ChinaSet_AllFiles.zip.

Shenzhen chest X-ray lung dataset images.
Since the Montgomery County chest X-ray set and the Shenzhen chest X-ray set datasets are the same modal data, these two datasets are combined in the experiments in this paper. The number of samples after data preprocessing is 1896, and we randomly divide them according to 70% of the training set, 20% of the testing set, and 10% of the validation set.
Ablation experiment
In order to prove the effectiveness of the proposed method on the data set, different combinations are used to check the experimental effect of the improved algorithm. In this paper, Yolov8 is used as the base network, by incorporating hybrid skip connection and attention into the structure of the base network. The results of the ablation experiments are shown in Table 1.
Through the experimental results in Table 1, we can see that method 4, which incorporates hybrid skip connection and attention gate into the underlying network, shows optimal results in Precision, Recall and mAP@0.5 metrics compared to the other different combinations of methods, so it can be concluded that the effectiveness of the algorithms proposed in this paper.
Figure 8 shows the heat map of different models on the dataset. method 1 is the basic approach, method 2 is the approach with the addition of an attention gate, method 3 is the approach with hybrid skip connection, and method 4 is the approach with a combination of hybrid skip connection and attention gate. Through the analysis of experimental results in Fig. 8, the heat map of method 2 is more obvious than that of method 1, with segmentation features, proving the validity of attention gate. The heat map of method 3 is more pronounced and more convergent than method 1, proving the effectiveness of hybrid skip connection. The heat map of method 4 is more prominent and convergent than those of method 1, 2, and 3, proving that this improvement of method 4 is the optimal method.

Heat map of ablation experiment.
Comparison experiment
Meanwhile, in order to verify the performance of the algorithm proposed in this paper compared to other methods, Table 2 Comparison experiments of semantic segmentation methods and Table 3 Comparison experiments of instance segmentation methods are carried out. Tables 2 and 3 show the mean values calculated from the results of the three operations as well as the margin of error.
According to the experimental results in Table 2, The algorithm in this paper has the advantages of Precision, Recall, Pixel Accuracy (PA), Dice and Mean Intersection Over Union(mIoU) improved by 0.5%, 0.7%, 0.3%, − 0.4% and 1.4%, respectively, compared with the optimal results of other algorithms. On the evaluation metric of Dice, there is a decrease compared to the optimal value, but the proposed algorithm can be proved to be advanced as a whole.
The experimental results in Table 3 can be analyzed that the algorithm proposed in this paper improves by 2%, 7.7%, 2.9%, 2.1% and reduces by 3.2 compared to Mask RCNN19 and improves by 1.2%, 4.3%, 2.3%, 1% and reduces by 0.1 compared to Yolo v820 in Precision, Recall, mAP@0.5, mAP@0.5–0.95 and GFLOPs evaluation metrics, respectively. It is proved that the algorithm proposed in this paper is the optimal effect in terms of computing performance and algorithm complexity.
Figure 9 shows the semantic segmentation effect diagram, we enlarge the error map and discharge it from top to bottom according to the sequence numbers 1, 2, 3, and 4 corresponding to the numbers in the larger figure. Through the experimental results, it can be analyzed that the algorithm proposed in this paper has a good segmentation effect on the subtle features of the image. Compared to other semantic segmentation algorithms, the proposed algorithm in this paper has better performance in image feature retention. As shown in the red box in the figure, there is a loss of subtle features in different methods, while our proposed method is closest to the standard segmentation effect, so it can prove the sophistication of the algorithm proposed in this paper.

Semantic segmentation effect diagram.
Figure 10 represents the comparison experiments conducted on the dataset by selecting representative instance segmentation algorithms, and it can be seen through the running effect that the algorithm proposed in this paper improves compared to the Mask RCNN19 and Yolo v820 algorithms in the calculation of instance segmentation confidence, which proves the advancement of the algorithm proposed in this paper.

Instance segmentation effect diagram.
In order to further evaluate the advantages and disadvantages of the algorithm, we will use the method of loss function to verify the convergence of different algorithms and the training termination position of the algorithm in the iterative process. The curves in Fig. 11 and Fig. 12 are the results of the average loss curves obtained through three 100-round training.

Semantic segmentation method loss curve.

Instance segmentation algorithm loss function.
Through the analysis of the loss curve in Fig. 11, we can see that the convergence of our method has been lower loss values than that of other comparison methods during the iteration process, and tends to be stable after 70 epochs. Therefore, it can be proved that the proposed method has faster convergence speed and better stability in semantic segmentation.
In Fig. 12, our method converges in a faster way at the initial position, while the loss values are lower than the other compared methods. After 40 epochs, our loss values change slowly in a stable way. Thus it can be proved that our method converges better and the model is more stable during instance segmentation.
Discussion
In this paper, we propose a full-scale lung segmentation algorithm based on a hybrid skip connections and attention mechanism. The algorithm performs dense and sparse skip connections for different layers of feature data to improve the multi-scale feature fusion capability of the algorithm. The segmentation accuracy of the algorithm is improved through the improvement of the algorithm head by adding an attention mechanism to prevent the loss of important features. Through comparative experiments, we find that the algorithm proposed in this paper shows better results in both semantic segmentation and instance segmentation of images, and thus the effectiveness of the algorithm proposed in this paper can be proved. However, the algorithm also has some limitations, for example, due to different sizes or different resolutions of the input images, the feature granularity is different usually does not contribute equally to the output features, and the feature granularity is not matched in the hybrid skip connection, which affects the image segmentation effect in the later stage.
Ethical statement
All experiments performed in the study involving human participants were in accordance with the ethical standards of the institutional research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards. This study was performed on the public subject datasets. Ethical approval was confirmed by the license attached with their open access data.
Data availability
The data that support the findings of this study are openly available at the following URL: https://openi.nlm.nih.gov/imgs/collections/NLM-MontgomeryCXRSet.zip. and https://openi.nlm.nih.gov/imgs/collections/ChinaSet_AllFiles.zip.
References
Leiter, A., Veluswamy, R. R. & Wisnivesky, J. P. The global burden of lung cancer: Current status and future trends. Nat. Rev. Clin. Oncol. 20(9), 624–639 (2023).
Fu, X. et al. Multimodal spatial attention module for targeting multimodal PET-CT lung tumor segmentation. IEEE J. Biomed. Health Inform. 25(9), 3507–3516 (2021).
de Margerie-Mellon, C. & Chassagnon, G. Artificial intelligence: A critical review of applications for lung nodule and lung cancer. Diagn. Interv. Imaging 104(1), 11–17 (2023).
Long, J., Shelhamer, E. & Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 39(4), 640–651 (2015).
Badrinarayanan, V., Kendall, A. & Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 39(12), 2481–2495 (2017).
Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5–9, 2015, proceedings, part III 18 (eds Ronneberger, O. et al.) (Springer International Publishing, 2015).
Zhou Z, Rahman Siddiquee M M, Tajbakhsh N, et al. Unet++: A nested u-net architecture for medical image segmentation[C]//Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, September 20, 2018, Proceedings 4. Springer International Publishing, 2018: 3-11.
Zhao H, Shi J, Qi X, et al. Pyramid scene parsing network[C]. In Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2881–2890 (IEEE, 2017).
Chaurasia, A. & Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In 2017 IEEE visual communications and image processing (VCIP) (eds Chaurasia, A. & Culurciello, E.) (IEEE, 2017).
Chen, L. C. et al. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs[J]. IEEE Trans. Pattern Anal. Mach. Intell. 40(4), 834–848 (2018).
Chen, L. C. et al. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV) (eds Chen, L. C. et al.) (Springer, 2018).
Bharati P, Pramanik A. Deep learning techniques—R-CNN to mask R-CNN: a survey[J]. Computational Intelligence in Pattern Recognition: Proceedings of CIPR 2019, 2020: 657-668 (Springer)
Girshick R. Fast r-cnn[C]. In Proceedings of the IEEE international conference on computer vision. pp. 1440–1448 (IEEE, 2015).
Terven, J., Córdova-Esparza, D.-M. & Romero-González, J.-A. A comprehensive review of YOLO architectures in computer vision: From YOLOv1 to YOLOv8 and YOLO-NAS[J]. Mach. Learn. Knowl. Extr. 5, 1680–1716 (2023).
Hooda, R., Mittal, A. & Sofat, S. Lung segmentation in chest radiographs using fully convolutional networks. Turk. J. Electr. Eng. Comput. Sci. 27(2), 710–722 (2019).
Das, A. Adaptive UNet-based lung segmentation and ensemble learning with CNN-based deep features for automated COVID-19 diagnosis. Multimed. Tools Appl. 81(4), 5407–5441 (2022).
Liu, L. et al. Application of UNet++-based automatic segmentation model of COVID-19 lesions in CT slices. Microelectron. Comput. 40(4), 47–55 (2023).
Samudrala, S. & Mohan, C. K. Semantic segmentation of breast cancer images using DenseNet with proposed PSPNet[J]. Multimed. Tools Appl. 83(15), 46037–46063 (2024).
Doğan, K., Selçuk, T. & Alkan, A. An enhanced mask R-CNN approach for pulmonary embolism detection and segmentation. Diagnostics 14(11), 1102–1113 (2024).
Kang, M. et al. ASF-YOLO: A novel YOLO model with attentional scale sequence fusion for cell instance segmentation. Image Vis. Comput. 147, 105057 (2024).
Tan Z, Wang J, Sun X, et al. Giraffedet: A heavy-neck paradigm for object detection[C]. In International conference on learning representations. pp. 1–17, (MIT Press publisher2021).
Oktay O, Schlemper J, Le Folgoc L, et al. Attention U-Net: Learning Where to Look for the Pancreas[C]. In Medical Imaging with Deep Learning. pp.1–10, (Springer, 2018).
Wang, P., Fan, E. & Wang, P. Comparative analysis of image classification algorithms based on traditional machine learning and deep learning. Patt. Recognit. Lett. 141, 61–67 (2021).
Zou, Z. et al. Object detection in 20 years: A survey. Proc. IEEE 111(3), 257–276 (2023).
Minaee, S. et al. Image segmentation using deep learning: A survey. IEEE Trans. pattern Anal. Mach. Intell. 44(7), 3523–3542 (2021).
Naya-Varela, M., Faina, A. & Duro, R. J. Morphological Development in robotic learning: A survey. IEEE Trans. Cognit. Dev. Syst. 13(4), 750–768 (2021).
Tan M, Pang R, Le Q V. 2021 Efficientdet: Scalable and efficient object detection[C]. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10781–10790 (IEEE, 2020).
Candemir, S. et al. Lung segmentation in chest radiographs using anatomical atlases with nonrigid registration. IEEE Trans. Med. Imag. 33(2), 577–590 (2013).
Jaeger, S. et al. Two public chest X-ray datasets for computer-aided screening of pulmonary diseases[J]. Quantitative imaging in medicine and surgery 4(6), 475–477 (2014).
Acknowledgements
This research was funded by the program of the Natural Science Research of Jiangsu Province Higher Education Institutions in 2023 under Grant No.23KJD520011, the General Program of Nantong Science and Technology Bureau in 2020 under Grant No. JCZ2022108 and MSZ2020072, the Program of The Nantong Institute of Technology Young and Middle-aged Backbone Teacher in 2022 under Grant No. ZQNGGJS202237 and ZQNGGJS202234. We would like to thank everyone who has contributed to this article. We also would like to thank the anonymous reviewers and editors for their helpful suggestions and comments.
Author information
Authors and Affiliations
Contributions
Conceptualization: Qiong Zhang, Jianlin Qiu Data curation: Qiong Zhang, Hao Chen Software: Qiong Zhang Supervision: Byungwon Min Validation: Yiliu Hang, Jianlin Qiu Visualization: Qiong Zhang Writing-original: Qiong Zhang Writing-review: Qiong Zhang, Byungwon Min Methodology: Qiong Zhang, Byungwon Min Project administration: Qiong Zhang Investigation: Yiliu Hang Formal analysis: Byungwon Min Funding acquisition: Qiong Zhang, Jianlin Qiu Resources: Qiong Zhang, Jianlin Qiu.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, Q., Min, B., Hang, Y. et al. A full-scale lung image segmentation algorithm based on hybrid skip connection and attention mechanism. Sci Rep 14, 23233 (2024). https://doi.org/10.1038/s41598-024-74365-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-74365-w
Keywords
This article is cited by
-
Aggregate global features into separable hierarchical lane detection transformer
Scientific Reports (2025)
