
Abstract
As the amount of labeled data increases, the performance of deep neural networks tends to improve. However, annotating a large volume of data can be expensive. Active learning addresses this challenge by selectively annotating unlabeled data. There have been recent attempts to incorporate self-supervised learning into active learning, but there are issues in utilizing the results of self-supervised learning, i.e., it is uncertain how these should be interpreted in the context of active learning. To address this issue, we propose a multi-armed bandit approach to handle the information provided by self-supervised learning in active learning. Furthermore, we devise a data sampling process so that reinforcement learning can be effectively performed. We evaluate the proposed method on various image classification benchmarks, including CIFAR-10, CIFAR-100, Caltech-101, SVHN, and ImageNet, where the proposed method significantly improves previous approaches.
Similar content being viewed by others

Introduction
Deep learning has made significant advancements in many computer vision tasks, such as image classification1,2, semantic segmentation3, object detection4, and pose estimation5. Besides the rise of deep learning, it was the existence of large-scale labeled datasets, such as ImageNet1 and MS-COCO6, that made this progress possible.
In general, as the amount of annotated data increases, the performance of deep learning models tends to improve. However, in industrial or medical applications, labels are not easily attainable, and the process of annotating data itself requires substantial time and financial resources. To address this issue, active learning (AL)7 is employed as a method to query crucial data that can achieve the higher performance of a model within a limited annotation budget. There have been many recent examples applying AL to several computer vision tasks, such as image classification8, semantic segmentation9, object detection10, pose estimation11.
Recently, self-supervised learning (SSL)12,13 has drawn much attention, and accordingly, many works have attempted to utilize SSL in AL. However, existing approaches have some limitations. There are cases where pretext tasks12,14 lack reliability, and the choice of pretext tasks can lead to varying results in AL. Additionally, using SSL may involve training additional networks15,16, which incurs high computational costs. Moreover, there are cases where SSL operates efficiently but yields lower performance17. Thus, the effective utilization of SSL in AL remains unclear, and it is uncertain whether directly using the results of SSL is the most suitable approach for AL. In this paper, we challenge the limitations of utilizing SSL in AL. Especially, we focus on the utilization of a pretext task in AL, where the interpretation of the task result is uncertain in the context of AL. PT4AL18 is a recent example in this category. It employs a very simplistic data group selection method based on pretext-task outcomes, i.e., dividing and selecting groups based on a monotonic order of the pretext losses, and once a data group is used, it cannot be reused until the end of the AL cycle. Furthermore, improper data groups may be formed depending on the quality of the pretext-task learning, which may lead to performance degradation due to inadequate data sampling. To address these issues, we adopt the multi-armed bandit19 problem, which enables us to select the group with the highest reward and sample data in each AL cycle. By applying this approach, the proposed method provides an effective means to interpret the information from the pretext task.
In order to apply the multi-armed bandit to AL, we devise a new data sampling process. For the multi-armed bandit approach to be effective, a higher number of data sampling cycles is necessary. Therefore, we propose a data sampling process to allow for more data sampling cycles while keeping the computational cost and the total number of labeled data the same as existing approaches.
We validated the proposed approach on various image classification datasets and compared it with existing state-of-the-art methods, including PT4AL18, CoreGCN20, TA-VAAL16 and Learning Loss21. The experiments demonstrate that the proposed method achieves superior or at least competitive performance across various benchmark datasets, i.e., CIFAR-10, CIFAR-10022, SVHN23, Caltech10124, and ImageNet-6425, compared to the existing methods. This indicates that the implication of pretext losses in AL is not as straightforward as claimed in PT4AL, and a better sampling strategy can be learned from these losses.
Our contributions are as follows:
-
We propose a novel approach to learn an effective strategy for utilizing SSL in AL based on multi-armed bandit.
-
For the multi-armed bandit process to be effective, we devise a new data sampling process providing enough sampling cycles while maintaining overall computation costs similar to the existing methods.
The rest of the paper is organized as follows: Related Work covers various existing active learning approaches with an emphasis on those based on representation learning or reinforcement learning, along with a review of the multi-armed bandit. In Method, we briefly review PT4AL and introduce the proposed method. Experiments provides detailed experimental results, as well as some analysis, and finally, the paper is concluded in Conclusion.
Related work
Active learning
Over the past few decades, numerous AL approaches7 have been proposed, such as membership query synthesis methods26,27, stream-based selective sampling methods28,29, and pool-based sampling methods30,31. These approaches were proposed before the rise of deep learning, and recent research trends are quite different from these traditional methods.
Recently proposed AL methods have predominantly been designed for large-scale deep-learning models. In deep learning-based AL, there are two main approaches: the distribution-based approach and the uncertainty-based approach18. The distribution-based approach20,32 considers diversity in the data distribution, while the uncertainty-based approach16,21,33,34 focuses on the decision boundary. In PT4AL18 and PPAL35, both approaches are considered. Sener and Savarese32 use K-means clustering to select a core-set, which covers the feature distribution of the entire unlabeled dataset. Yoo and Kweon21 utilize a loss prediction module is utilized to predict the main-task loss of unlabeled data.
Active learning with representation learning
Representation learning aims to learn meaningful representations from unlabeled data and obtain good pre-trained models that can be used in various downstream tasks. There have been various approaches in the past where representation learning was applied to AL. Pretext-based AL (PAL)15 utilizes SSL techniques such as the rotation task12 and employs a separate scoring network. An active contrastive learning approach36 has been proposed, which enhances the quality of negative samples and exhibits strong performance in tasks like video classification. Yuan et al.37, utilize SSL and pre-trained language models to solve AL. Chaplot et al.38 combine AL and active perception to improve object detection and segmentation by utilizing unlabeled data in a self-supervised manner. Unlike previous AL methods which involve repetitive model training, Xie et al.17 propose a method based on SSL to perform single-pass model inference without training, enabling rapid data sampling. Ma et al.39 solve AL based on representation learning40 and parametric classification. Both VAAL34 and TA-VAAL16 share a common approach of utilizing the latent space feature of a VAE41 to select the data for labeling. In PT4AL18, it is suggested that pretext tasks provide a good initialization for downstream tasks because pretext tasks are highly correlated with semantic data distribution.
However, these approaches are not without issues. For example, directly incorporating SSL results into AL has some potential problems, which can lead to increased computational costs16,34 or performance degradation17. Specifically, there are problems when using the results of pretext tasks in AL. PAL15 employs a scoring network using SSL to assign scores to unlabeled data, but the reliability of the scores can vary depending on the pretext task. For example, the rotation task can be vulnerable to images with rotational symmetries, and it was proposed in PAL15 to use a hybrid score with the classification score. On the other hand, PT4AL18 determines the order of sample annotations based on pretext-task losses, but the relationship between these loss values and the importance of samples in AL is not clear and it is not guaranteed that this is the best order of data sampling.
Active learning with reinforcement learning
Reinforcement learning (RL)42,43 is an approach where an agent learns to take optimal actions in an environment to maximize rewards. There have been various approaches applying RL to AL. Wang et al.8 adopt the actor-critic44 approach and deep deterministic policy gradient algorithm45 for AL on medical image data. Fang et al.46 reframe AL as an RL problem, and a novel method is proposed to explicitly learn a data selection policy. Pang et al.47 treat AL algorithm design as a meta-learning problem, and active query policy networks are trained using deep RL. Liu et al.48 introduce deep RL to address the re-identification task with minimal labeling efforts.
These methods are mainly about incorporating deep RL to solve AL. Unlike these, the main focus of this work is on improving pretext-based AL based on RL. A downside of deep RL is that it may suffer from instability or high computational costs, and we are relatively free of these because we do not rely on deep RL.
Multi-armed bandit
The multi-armed bandit19 problem in RL involves determining the optimal strategy for resource allocation among various choices to maximize reward. The distinctive characteristic that sets the multi-armed bandit apart from other RL methods is that it has no state. Various algorithms49,50 have been developed to solve the multi-armed bandit problem, and among them, we choose Thompson sampling49 algorithm for the proposed method due to its simplicity. It involves sampling from a prior distribution, selecting the arm with the most favorable outcome, observing the reward, and updating the posterior distribution for the next step. The non-stationary bandit algorithm51,52 is used when the reward distribution is non-stationary. In our paper, we employed the discounted Thompson sampling algorithm51, which progressively discounts the effect of past information as the sampling step increases. Due to the nature of AL, where data samples are continuously added, and class regions evolve, using discounted Thompson sampling instead of Thompson sampling can be more appropriate. The discounting mechanism enables the model to prioritize recent data, enhancing its adaptability to shifting decision boundaries. This approach prevents reliance on outdated information which can lead to suboptimal performance. Consequently, discounted Thompson sampling promotes a more effective learning strategy in dynamic AL environments.
The proposed method addresses the issues in using the results of pretext tasks in AL. When utilizing a pretext task in AL, how to interpret the pretext results is somewhat unclear while the performance can be quite dependent on them. To resolve this, the discounted Thompson sampling is employed in this paper to translate the information obtained from the pretext tasks for AL effectively.
Method
In a typical AL scenario, we define the data in the unlabeled pool as \(X_u\). The main process of AL typically involves the following steps. In the beginning, data is randomly sampled from \(X_u\) and labeled by a human oracle to form an initial labeled dataset. The labeled data \(X_l\) and their corresponding labeled annotations \(Y_l\) are then used to train the initial task learner \(\Omega (\cdot )\). Given a sample x, \(\Omega (x)\) predicts its label as \(\hat{y} = \Omega (x)\). Then, K data points \(\textbf{x}_u \subset X_u\) that contribute the most to the model’s improvement are determined based on the task learner so that they can be sampled and annotated by the human oracle. These additional labeled data points \((x_l, y_l)\) are then combined with \((X_l, Y_l)\) and used to further train the task learner \(\Omega (\cdot )\). The process of sampling data, annotation, and training the task learner in each AL cycle is repeated until the limited budget is exhausted.
Review of PT4AL and motivations
In this section, we review PT4AL18 since the proposed method shares the overall framework of PT4AL. PT4AL is a two-stage AL method that involves pretext-task learning for group split and data sampling. In PT4AL, pretext-task learning is performed before the start of AL, utilizing the rotation task12 as the pretext task. The pretext-task learner \(\Omega _p(\cdot )\) is trained based on \(X_u\). Given a sample x, it predicts the probabilities of different rotations as \(p_o = \Omega _p(x)\). There are four different orientations labels \((0^{\circ }, 90^{\circ }, 180^{\circ }, 270^{\circ })\), i.e., \(n_o=4\). During the model training, the model weights \(\theta _s\) are stored at their best performance. After training the pretext-task learner, the pretext-task learner is utilized to calculate the pretext-task losses \(L_{x_k}=(1/n_o)\sum _{l=1}^{n_o}L_{CE}(\Omega _p(g(x_k|o)\, |\,\theta _s),o)\) for each unlabeled training sample \(x_k\) in \(X_u\). Here, \(L_{CE}\) represents the cross-entropy loss, and the rotation operator \(g(\cdot | o)\) rotates the input image based on the orientation label o. Then, the data is sorted in descending order based on \(L_{X_u} = \{ L_{x_k} \}_{k=1}^{n_u}\). Here, \(n_u\) is the number of samples of \(X_u\). The sorted data is then divided into I groups of equal size so that each group contains samples with similar \(L_{x_k}\), where the number I corresponds to the number of AL cycles. For example, if the AL process is conducted for 10 cycles, data is divided into 10 groups \(G = \{G_i\}_{i=1}^{I=10}\).
After the group split, the AL process is executed. In the i-th AL cycle, group \(G_i\) is selected and a sampler \(\phi\) selects K samples from \(G_i\). \(\phi\) utilizes the main-task learner \(\Omega _m(\cdot )\) which predicts the label of the main task given a sample x, i.e., \(\hat{y} = \Omega _m(x)\). In each cycle, the previous cycle’s main-task learner, \(\Omega _m^{i-1}\), is utilized to calculate a confidence score for each unlabeled sample of \(G_i\). The confidence score for each data point is computed as the top-1 posterior probability \(\phi (x) = \max (\Omega ^{i-1}_m(x|\theta _m))\), which corresponds to the least confidence method7 in AL. Here, \(\theta _m\) is the model weights. Based on these scores, data points with lower confidence scores are sampled, which leads to the selection of the top-K data points with higher uncertainty. One exception is the first cycle, i.e., \(i=1\), since the main-task learner has not been trained yet. In the first cycle, the data is sampled from \(G_1\) with a constant interval in descending order of the pretext-task loss. For example, if 1,000 data points are sampled from 5,000 data points, then the first data point will be the first point in the descending order of the pretext-task loss, the second data point will be the sixth, and so on. This process is denoted as \(X_1 = \text {interval}(G_1, L_{X_u})\) hereafter. After labeling the sampled data points, the main-task learner \(\Omega _m\) is trained with the labeled samples. Group selection, data sampling, and main-task learner training together form one AL cycle, and it is repeated until the AL budget is exhausted.
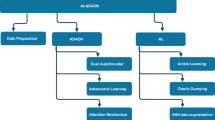
PT4AL has some limitations. Its straightforward group selection approach based on pretext-task loss might not be the optimal choice within this framework. Moreover, PT4AL doesn’t re-explore previously selected groups, potentially missing out on valuable data. To address this, in this paper, we introduce a new group selection process that allows revisiting groups. We propose an RL approach that builds upon the PT4AL framework, using discounted Thompson sampling to select groups at the beginning of each AL cycle. Once the training of the main-task learner is completed, rewards are updated based on the results. The updated rewards are utilized in the next AL cycle to select another group. The overall framework of our method is illustrated in Fig. 1.

The overall framework of the proposed method. Unlabeled training data are sorted based on pretext-task losses and split into groups \(G_1,\ldots ,G_n\). The optimal group \(G_{i^*}\) is selected based on the cumulative rewards, on which the main-task learner is trained. The cumulative rewards are defined by the group’s cumulative success rate S and failure rate F. After training, either the success or failure rate of the optimal group is updated based on the Bernoulli trial determined by \(\rho\). According to the properties of DTS, S and F for groups other than the optimal one are discounted. The details are explained in Algorithm 1.
Discounted Thompson sampling
In this section, we explain how the proposed method selects groups based on discounted Thompson sampling51. First, we initialize the success \(S_i\) and failure \(F_i\) for all groups to zero. As in PT4AL, the groups G are divided based on the pretext-task loss \(L_{X_u}\). At each cycle, a Q-value is sampled for each group using the beta distribution:
For the proposed method, we define t as the timestep of the AL cycle and i as the index of the group. We define the number of groups as \(n_G\). After sampling the Q-values for each group \(G_i\), we select the group with the highest Q-value, i.e., \(i^* = \arg \max _i(Q_t(G_i))\). The samples within the selected group \(G_{i^*}\) are sampled by the sampler \(\phi (\cdot )\). \(\phi (\cdot )\) utilizes the previous cycle’s main-task learner \(\Omega _m^{t-1}(\cdot )\), focusing on data points with low confidence scores7,18, as shown in (2).
which is the same as PT4AL’s sampling method. We then further train the main-task learner using the entire sampled data, including the new ones. After training the main-task learner, the reward value \(r_t\) is received, and a Bernoulli trial with probability \(r_t\) is performed. The outcome \(\rho\) is one if the trial is a success and zero otherwise. Based on the outcome, the selected group’s success and failure are updated as \(S_{i^*} \leftarrow \gamma S_{i^*}+\rho\) and \(F_{i^*} \leftarrow \gamma F_{i^*}+(1-\rho )\), respectively. Similarly, the values for the non-selected groups are updated as \(S_i \leftarrow \gamma S_i\) and \(F_i \leftarrow \gamma F_i\) for \(\forall i \ne i^*\). The parameter \(\gamma\) is the discounted factor. After the values of S and F are updated, this process iteratively continues until the AL budget is exhausted. Note that the proposed method utilizes the not-yet-trained main-task learner \(\Omega _m^0\) to calculate rewards and select groups in the first AL cycle as well, unlike PT4AL.
Reward function details
In this section, we explain the reward function of the discounted Thompson sampling. Let \(L_{\Omega _m^t}\) be the average loss of the main-task learner \({\Omega _m^t}\) over the labeled validation data, which will be explained later. We define \(D_t\) as the discrepancy of the loss \(L_{\Omega _m^t}\) of the main-task learner \(\Omega _m\) between the previous timestep \(t-1\) and the current timestep t, which is described as (3):
The reward function is designed based on \(D_t\) to consider whether the \(\Omega _m\) is sufficiently improving or not. However, a problem arises if we directly use \(D_t\) as a reward function, i.e., the scale of the reward decreases as the step progresses, leading to a situation where there are only successes at the beginning and only failures later on. To mitigate this issue, we introduce a reward function that takes into account the information from the previous time step. For this purpose, we first define an exponential moving average term denoted as \(E_t\) to reduce noise in \(D_t\) during training.
where \(\alpha\) is a hyperparameter. The initial value of \(E_1\) is initialized to zero. Based on \(E_t\), we can define the reward as \(r_t = D_t/E_t\). This represents the ratio of the loss difference, indicating how much the loss has decreased relative to the previous decrement. Note that we use the exponential moving average in the denominator to stabilize the calculation. A higher ratio implies a significant decrease in loss during the current cycle, leading to a higher reward being assigned.
However, if we use \(E_t\) directly, the value of \(E_t\) can be very small during the early stages of training, leading to an inadequate reflection of rewards. To compensate for underestimated values in the early stages, we propose to incorporate a bias correction term as in the Adam optimizer53:
Using the modified \(E'_t\) obtained from (5), we can redefine the reward as \(r_t = D_t/E'_t\). Yet another problem is that, since \(r_t\) should be used as the probability for the Bernoulli trial within discounted Thompson sampling, we need to set \(r_t\) in the range [0, 1]. Accordingly, the final formulation of \(r_t\) is defined by (6) when \(E'_t \ge 0\).
Here, hyperparameters a and b are adopted for determining the effective range of (relative) loss differences and the threshold for sufficient model improvement, respectively. A sigmoid function \(\sigma\) is employed so that the final reward value fits the range of [0, 1]. To achieve good performance, it is crucial to determine the hyperparameters in a way that ensures an appropriate ratio between success and failure outcomes. The details are explained in Experiments.
On the other hand, there are some exceptional cases where we must handle rewards separately: \(E'_t\) becomes less than zero in some cases, especially in the early stage of training, due to the unstable change of the loss value. In this case, we define rewards differently from (6), i.e., \(r_t\) is set to one when \(D_t \ge E^{\prime}_t\) and zero when \(D_t < E^{\prime}_t\) if \(E'_t < 0\).
Validation data
In the proposed method, validation data is utilized for two purposes: calculation of rewards and early stopping of \({\Omega _m^t}\). To ensure a fair comparison with existing methods, this data is taken from the total AL budget we have. Here, we explain how the proposed method samples and utilizes validation data. A small portion of the entire AL budget is reserved as validation data, i.e., samples from the first few AL cycles are dedicated for validation. (Accordingly, we actually have slightly fewer AL cycles for the training of the proposed method.) These samples are selected from the entire unlabeled data at regular intervals in descending order of \(L_{X_u}\), i.e., \(\tilde{X} = \text {interval}(X_u,L_{X_u})\), and they are labeled by a human oracle. \(\tilde{X}\) corresponds to \(V\%\) of the total AL budget. \(\tilde{X}\) is excluded from model training, but is used to calculate the rewards. Additionally, the training of \({\Omega _m^t}\) is early stopped based on \(\tilde{X}\) in each AL cycle as well.
Data sampling for multi-armed bandit
In this section, we propose a new data sampling method to maximize the effectiveness of discounted Thompson sampling51. Discounted Thompson sampling requires repeated trials for each arm to maximize its reward. Accordingly, we propose to revisit groups on multiple cycles.
To enhance the effectiveness of discounted Thompson Sampling while ensuring a fair comparison with existing AL methods, we introduce the notion of “learning amount,” which is a rough measure for determining the appropriate training period. Note that even if the total number of labeled samples is the same, the performance can be worse if the samples are drawn with a larger number of AL cycles, i.e., the number of samples drawn in a single cycle is smaller. This is because the average number of labeled samples is decreased in this case during the training iterations. Accordingly, the learning amount is defined as the product of the total number of iterations and the number of labeled data points, assuming a fixed batch size. If the number of labeled samples is the same, more iterations will increase the performance of a model. On the other hand, if the number of iterations is the same, then having more labeled samples will increase the amount of information fed into the model, increasing the overall performance.
Let \(n_d^t\) be the number of samples newly labeled in the t-th AL cycle, and \(\bar{n}_d^t\) be the cumulative number of labeled samples, i.e., \(\bar{n}_d^t = \sum _{t'=1}^t n_d^{t'}\). Assuming that the batch size B is fixed and \(n_e^t\) denotes the number of epochs in the t-th cycle, the corresponding number of iterations is given as \(n_i^t \triangleq n_e^t \bar{n}_d^t / B\). Accordingly, the learning amount at the t-th cycle becomes \(\nu ^t \triangleq n_i^t \bar{n}_d^t = n_e^t (\bar{n}_d^t)^2/B\) and the total learning amount during the entire AL procedure becomes
where \(n_c\) is the total number of AL cycles. Note that \(\nu ^t\) is proportional to the square of \(\bar{n}_d^t\). Accordingly, fewer labeled samples require more training epochs to match the learning amount.
For example, let us assume that there are two different AL scenarios: one (Scenario 1) performs only a single AL cycle, and the other (Scenario 2) performs ten AL cycles. Here, we assume that \(n_d^t\) and \(n_e^t\) are fixed for all AL cycles, i.e., \(n_{d1}^t=n_{d1}\), \(n_{d2}^t=n_{d2}\), \(n_{e1}^t=n_{e1}\), and \(n_{e2}^t=n_{e2}\), where the subscripts represent the scenarios. We also assume that the total number of labeled samples is the same for both scenarios, i.e., \(\bar{n}_{d1}^1 = \bar{n}_{d2}^{10}\) and accordingly \(n_{d2} = n_{d1} / 10\). If we simply set \(n_{e1}\) and \(n_{e2}\) inversely proportional to the number of AL cycles, i.e., \(n_{e2} = n_{e1} / 10,\) then this is disadvantageous for Scenario 2 due to two reasons: Earlier cycles in Scenario 2 will have fewer iterations in a single epoch, and the number of labeled samples will be fewer at those cycles as well. Considering the learning amount, we can derive an appropriate \(n_{e2}\) assuming \(\nu _1 = \nu _2.\)
The resulting \(n_{e2}\) is somewhat larger than \(n_{e1} / 10,\) compensating for the disadvantages of Scenario 2.
In the experiments, we used the following practice: \(n_c\) is ten for most of the existing methods, but this is too small for discounted Thompson sampling. Hence, the proposed method used \(n_c=100\) for most of the experiments. We set \(n_d^t\) of the proposed method so that each set of ten AL cycles corresponded to a single cycle of the existing methods, i.e., \(n_d^t\) of the proposed method for \({10} \left({t^{\prime}-1}\right) {<} \: t \leq 10t^{\prime} \) was set ten times smaller than \(n_d^{t'}\) of the existing methods. Based on this \(n_d^t,\)\(n_e^t\) was determined so that \(\sum _{t=10t^{\prime} - 9}^{10 t^{\prime}} \nu ^t\) of the proposed method became the same as \(\nu ^{t'}\) of the existing methods. This leads to having more training epochs in the earlier cycles of the proposed method. This is called Scenario A in the experiments, while that of the existing methods is called Scenario B.
Table 1 illustrates how \(n_{d}^t,\)\(n_i^t,\)\(n_e,\) and \(\nu\) were configured for Scenarios A and B on CIFAR-10. The goal was to make the total learning amounts of Scenarios A and B identical. Here, \(n_i^t\) is calculated assuming \(B=128.\)\(n_e\) was set to 200 for Scenario B, following the usual practice in existing methods. For Scenario A, \(n_e\) was determined so that it has the same learning amount as in Scenario B.
Care should be taken here that the learning amount does not directly correspond to the performance of the model. As mentioned earlier, it is simply a rough reference for determining the training epochs. To ensure that this indeed provides a fair comparison, we have also verified the existing methods under Scenario A. Our empirical experience suggests that this gives a similar or slightly worse performance, depending on the characteristics of the method.
In the experiments, we used the following practice: \(n_c\) is ten for most of the existing methods, but this is too small for discounted Thompson sampling. Hence, the proposed method used \(n_c=100\) for most of the experiments. We set \(n_d^t\) of the proposed method so that each set of ten AL cycles corresponded to a single cycle of the existing methods, i.e., \(n_d^t\) of the proposed method for \(10 (t'-1) < t \le 10 t^{\prime}\) was set ten times smaller than \(n_d^{t'}\) of the existing methods. Based on this \(n_d^t,\)\(n_e^t\) was determined so that \(\sum _{t=10t^{\prime} - 9}^{10 t^{\prime}} \nu ^t\) of the proposed method became the same as \(\nu ^{t'}\) of the existing methods. This leads to having more training epochs in the earlier cycles of the proposed method. This is called Scenario A in the experiments, while that of the existing methods is called Scenario B.

Proposed method
Another thing to consider is that the proposed method may require more computational costs in examining the uncertainty of data points due to the increased number of AL cycles. To mitigate this, we draw inspiration from PT4AL18. First, we reduce the number of samples by sampling them at regular intervals in descending order of \(L_{X_u}.\) In other words, a subset \(\tilde{G}_t\) is sampled from \(G_{i^*},\) i.e., \(\tilde{G}_t = \text {interval}(G_{i^*},L_{G_{i^*}}).\) The uncertainty is calculated only for the samples in \(\tilde{G}_t\) using the main-task learner \(\Omega _m.\) This approach significantly reduces computational costs compared to evaluating the entire samples in the group. Moreover, this approach improves the performance significantly compared to when \(\tilde{G}_t\) is randomly sampled, as demonstrated in the experiments. Note that the sampling interval was set to ten, except when \(| \tilde{G}_t |\) becomes smaller than the required number of samples \(n_d^t\) in the current cycle. If this happens, the sampling interval is reduced so that \(| \tilde{G}_t |\) becomes no less than \(n_d^t.\) If we need to revisit a previously visited group, we consider the remaining data in the group and perform interval-wise sampling as described above. The entire process of the proposed method is summarized in Algorithm 1.
Experiments
Experimental settings
We evaluated our method on image classification tasks. All experiments are performed using PyTorch54 on an NVIDIA Geforce RTX 3090 GPU. We used the CIFAR-1022, CIFAR-10022, SVHN23, Caltech-10124, and ImageNet-6425 for the experiments, which a popular benchmark sets used in deep-learning-based AL. We compared the performance of our method with existing AL methods. We also provide ablation experiments to verify the effect of each module in our approach.
Datasets
We evaluated the proposed method on five benchmark image classification datasets with varying sizes and numbers of classes, commonly utilized in recent AL literature. CIFAR-10 consists of 50,000 training images and 10,000 test images. It is composed of 10 classes, with each image having a size of \(32 \times 32\) pixels. CIFAR-100 also contains the same numbers of training and test images, and each image has the same size of pixels. However, it consists of 100 classes. SVHN consists of 73,257 training images and 26,032 test images. It is composed of 10 classes ranging from 0 to 9, and each image has a size of \(32 \times 32\) pixels. Caltech-101 consists of 9,144 images. It comprises a total of 101 classes, with each class containing approximately 40 to 800 images, leading to an imbalanced dataset. The images vary in size, with typical edge lengths ranging from around 200 to 300 pixels. For this dataset, we follow the experimental setup of PT4AL18, splitting the dataset into 8,046 training images and 1,098 test images. ImageNet-64 is a downsampled version of the original ImageNet dataset, comprising a total of 1,281,167 images. ImageNet-64 contains 1,000 classes, and all of its images are resized to a fixed size of \(64 \times 64\) pixels.
Training details
We used ResNet-182 for both the main-task learner \(\Omega _m\) and the pretext-task learner \(\Omega _p.\) The stochastic gradient descent (SGD) optimizer is employed with a weight decay of \(5 \times 10^{-4}\) and a momentum of 0.9. We used the same set of hyper-parameters in all the experiments. The rotation task12 was used as the pretext task in the experiments. All the experiments are repeated ten times and the results are averaged. We did not set any specific random seeds. All the performance was reported in terms of mean accuracy. For all experiments, we set \(n_G=10,\)\(V=1\%,\)\(\alpha =0.1,\)\(\gamma = 0.9,\)\(a=2,\) and \(b=0.4.\) We applied these same hyperparameters for all the datasets, and they provided robust performance across the datasets. This suggests that the results reported in this paper can be broadly applicable and not constrained by dataset-specific tuning. For comparison with other AL methods, we reported the performance of the labeled data by training a separate ResNet-18 network from scratch when a certain amount of data was labeled.
For all datasets, the learning rate for the main-task learner \(\Omega _m\) was set to 0.1. We adjusted the learning rate by a factor of 1/10 at 80% of the training epochs within one AL cycle. The experimental settings for the CIFAR-10 and the Caltech-101 datasets follow those of PT4AL. The batch size for the pretext-task learner \(\Omega _p\) was set to 2 56 for CIFAR-10, CIFAR-100, SVHN, and ImageNet-64, and 64 for Caltech-101. And for the main-task learner \(\Omega _m,\) the batch size was set to 128 for CIFAR-10, CIFAR-100, and SVHN, 64 for Caltech-101, and 512 for ImageNet-64 unless stated otherwise. To report the performance, we trained a model from scratch for 200 epochs using all the labeled samples until that moment. One exception was Caltech-101, where the model was trained for 100 epochs.
For CIFAR-10, CIFAR-100, and SVHN, AL budgets were set according to20, i.e., the total AL budget was set to 10,000 samples for CIFAR-10 and SVHN, and 20,000 samples for CIFAR-100. For these datasets, the number of AL cycles was ten for the existing methods. For the proposed method, this was 100 and the first cycle was reserved as the validation data. We followed the practice of18 for Caltech-101, i.e., the total AL budget was 5,000 samples. For the existing methods, 1,000 points were sampled in the first cycle and 500 points were sampled in each of the following cycles. For the proposed method, 100 points were sampled for the first ten cycles, and then 50 samples were sampled for the remaining cycles. Here, half of the samples in the first cycle were reserved as the validation data. For ImageNet-64, the total AL budget was approximately 33.5% of the total training data. For the existing methods, about 11% of the training data was sampled in the first cycle, and about 2.5% was sampled in each of the following cycles. For the proposed method, about 1.1% was sampled in the first ten cycles, and about 0.25% was sampled in each of the following cycles. Again, some of the samples in the first cycle, corresponding to 1% of the training data, were reserved as the validation data.
Here, we can see that the proposed method generally used ten times more AL cycles (Scenario A) than the existing methods (Scenario B) in the experiments because the RL approach requires a fair amount of trials. We also evaluated the existing methods with more AL cycles as the proposed method, however, this did not improve their performance (in fact, the performance was slightly decreased). The details are provided in Quantitative comparisons.
Compared methods
We compared our method with various existing AL methods, including random sampling, Learning Loss21, CoreGCN20, TA-VAAL16, and PT4AL18. Here, we report that we found a somewhat controversial part in the official codeFootnote 1 of PT4AL. In this code, test data indirectly affects the model through early stopping during training. Accordingly, we excluded the early stopping procedure from PT4AL for a fair comparison. Additionally, unlike the other methods, PT4AL does not train a new model from scratch at each AL cycle. Instead, it performs incremental learning using the previous \(\Omega _m^{i-1}.\) In PT4AL18, this model is also used for performance evaluation. For a fair comparison, we added another version denoted as “PT4AL (from scratch)” in the experiments, where a new model is trained from scratch only for performance evaluation, as the proposed method.
Quantitative comparisons
Figures 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 and 14 provide the results of AL experiments on various datasets. Here, the proposed method performs superior or at least competitive results compared to the existing methods on most datasets. The superiority of the proposed method is generally more evident in the later parts of the AL procedures, which is mainly attributed to the characteristics of RL.
Figures 2, 3 and 4 show the performance on relatively simple datasets such as CIFAR-10, CIFAR-100, and SVHN. For these datasets, the performance is already quite saturated among recent AL methods, and the performance does not significantly differ. Yet, even for these datasets, the proposed method achieves favorable performance most of the time. Figure 2 shows the performance on CIFAR-10 for different numbers of labeled samples. Here, the performance of the proposed and compared methods are not very different in the later parts of the AL cycles, except for CoreGCN and random, which indicates that the performance on CIFAR-10 has already been somewhat saturated in the literature. One downside of the proposed method is that it shows suboptimal performance in the early cycles up to 4k samples, which is mainly due to the characteristics of discounted Thompson sampling where a fair amount of trials are needed to achieve high performance. To confirm this, we conducted another experiment (denoted as Scenario C) in Figs. 11, 12, 13 and 14, of which the details will be explained later. Figure 3 illustrates the performance on CIFAR-100. Our method consistently outperforms other methods across all AL cycles, except for the initial cycle. This is due to the exclusion of validation data in the initial cycle, where only a limited amount of training data is available. Similar trends are observed for SVHN in Fig. 4.

Image classification performance on CIFAR-10.

Image classification performance on CIFAR-100.

Image classification performance on SVHN.

Image classification performance on Caltech-101.

Image classification performance on ImageNet-64.

Comparison between Scenario A (with markers) and Scenario B (without markers) on CIFAR-10.

Comparison between Scenario A (with markers) and Scenario B (without markers) on CIFAR-100.

Comparison between Scenario A (with markers) and Scenario B (without markers) on SVHN.

Comparison between Scenario A (with markers) and Scenario B (without markers) on Caltech-101.

Image classification performance under scenario C on CIFAR-10.

Image classification performance under Scenario C on CIFAR-100.

Image classification performance under Scenario C on SVHN.
Figures 5 and 6 show the performance on challenging datasets such as Caltech-101 and ImageNet-64. For these datasets, we can see clearer patterns. The existing methods show weaker performance in certain regions, i.e., either the early or late stages of AL processes, while the proposed method consistently performs well. Figure 5 presents the performance on Caltech-101. Here, there is no clear winner and each algorithm shows good performance in different intervals. Nevertheless, the proposed method shows competitive performance over all intervals. Most notably, the proposed method significantly outperforms PT4AL in the early cycles. Note that the performance of PT4AL here is different from one reported in the original paper18, which is attributed to the removal of early stopping in our experiments. Figure 6 shows the performance on ImageNet-64. Here, the proposed method outperforms the other methods, especially when the number of labeled samples increases.
In the above experiments, the proposed method and the other methods are based on different AL settings, i.e., Scenarios A and B, respectively, as explained earlier. This might seem unfair, hence we also evaluated the other methods based on Scenario A, i.e., with more AL cycles. Figures 7, 8, 9 and 10 compare the results of the existing methods under Scenarios A and B. Across all datasets, the performance under Scenario A is generally similar to or lower than that under Scenario B for the existing methods. For these experiments, we excluded ImageNet due to the long processing time and since the methods showed consistent trends for all the other datasets.
As explained earlier, the proposed method requires many trials and can show suboptimal performance in early cycles. However, this does not necessarily indicate that the proposed method requires more AL budgets than existing methods. To confirm this, we conducted additional experiments (denoted as Scenario C) in Figs. 11, 12, 13 and 14. For ImageNet, the proposed method performed better than the existing methods even in the early cycles in the original experiments; hence we again excluded ImageNet for these experiments, considering the processing time. In these figures, each point is a result of a separate experiment with 100 AL cycles under various total AL budgets. In other words, they do not represent the results of sequential labeling but only the final results of different experiments with different numbers of total labels. Accordingly, data sampling was performed 100 times for all the experiments but with different numbers of data points sampled in each cycle. For example, 1k indicates that a total of 1k samples have been labeled during 100 AL cycles. For these experiments, the numbers of training epochs were set the same as the proposed method for all the compared methods. Moreover, we reduced the batch size proportionally to the sample size because the number of iterations can be too small, i.e., it was set the same as the number of samples labeled in a single AL cycle. After all AL cycles were completed, a separate ResNet-18 network was trained from scratch with a batch size of 128 for performance evaluation. To make this scenario plausible, the number of groups was set to 100 for PT4AL.
In Fig. 11, the performance of the proposed method is mostly better than the compared methods. Here, the performance of the proposed method for fewer labeled samples is improved compared to Fig. 2, unlike the other methods where the performance is similar or slightly decreased. Figure 12 depicts the performance on CIFAR-100 under Scenario C. Here, our method performs better than the other methods even when the AL budgets are small, unlike in the early cycles of Scenario A. This indicates that having enough AL cycles is crucial for the proposed method. Figure 13 depicts the performance on SVHN under Scenario C, where the proposed method outperforms the other methods when the AL budgets are small. On the other hand, PT4AL performs poorly with small AL budgets. Figure 14 depicts the performance on Caltech-101 under Scenario C. Here, the performance trends for different AL budgets are generally similar to the corresponding cycles in Scenario A or B, for all methods except PT4AL. Interestingly, in this particular experiment, the performance of PT4AL with small AL budgets is better than that in the early cycles under Scenario B.

Image classification performance under Scenario C on Caltech-101.

t-SNE visualization of the CIFAR-100 dataset for PT4AL (left) and ours (right). The light regions in this figure display the t-SNE embeddings of the main-task learner \(\Omega _m\) for the labeled 9,000 data points in CIFAR-100, while the vivid points represent the 1,000 data points sampled by each method’s main-task learner \(\Omega _m\) for labeling.
Qualitative comparisons
To see more detailed characteristics of the proposed method, we compare the t-SNE55 embeddings of PT4AL and the proposed method in Fig. 15. Here, the light regions display the embeddings of the main-task learner \(\Omega _m\) for 9,000 labeled data points in the CIFAR-100 dataset. The vivid points represent the 1,000 data points each method’s main-task learner sampled afterward for labeling. Here, PT4AL tends to focus on the decision boundary of already well-separated regions. On the other hand, the proposed method tends to label not only along the decision boundary but also in areas with relatively unclear and cloudy regions, compared to PT4AL. In AL, the data samples are continuously added, and accordingly, the class regions constantly evolve during training. In this scenario, concentrating on previously identified decision boundaries might not always be the best choice. The proposed method promotes more diversity in this regard, which we conjecture to be the reason for better performance.
Ablation studies
Figures 16, 17 and 18 show the results of various ablation studies. Here, all the values in the figures indicate the decreased performance from the original method. The experiments were conducted on CIFAR-100.

Ablation study on various settings. Curves represent decreased performance from the proposed method.

Performance with various numbers of samples per AL cycle. Curves represent decreased performance from the default setting (100 AL cycles = 200 samp. / cycle).

Performance with various total AL cycles and total AL budgets. Each point on the graph represents the final performance for the respective experiment. Curves represent decreased performance from the default setting (100 AL cycles).
Figure 16 shows an ablation study based on various small changes. Here, “no reward” refers to selecting groups randomly in each AL cycle. “Random uncertainty” selects samples within a group randomly for uncertainty assessment instead of interval-based selection. “Random validation” selects validation data randomly instead of interval-based selection. “Sequential” selects groups sequentially like PT4AL, but with \(n_G=100\). “Round robin” refers to sampling data from groups in a round-robin manner. “No early stopping” indicates that early stopping was not used during the training of \(\Omega _m\) in each AL cycle, i.e., the model weights in the last epoch was used. “No reward,” “sequential,” and “round robin” are configurations where rewards are not considered during group selection. All experiments without rewards exhibited inferior performance compared to the proposed method, which indicates the importance of group selection based on rewards. “Random uncertainty” and “random validation” are configurations in which pretext-task losses are not considered during some detailed sample selection processes. Both of these configurations also displayed inferior performance compared to the proposed method. This highlights that pretext-task losses have significant roles also in the detailed sampling procedure. “No early stopping” also displayed lower performance than the proposed method, indicating that early stopping based on validation data indeed helps.
Figure 17 presents the results of the proposed method with various numbers of samples per AL cycle. As the number of samples per AL cycle decreases (i.e., the number of total AL cycles increases), performance tends to improve. However, if this becomes too low, \(\Omega _m\) may not be learned properly, resulting in lower performance.
Figure 18 shows more results with various total AL cycles and total AL budgets. Each curve represents a different total amount of data used in training, and each point represents the final performance of a different experiment. For all experiments, the batch size was set to 128. The values in the curves represent decreased performance from the default setting, i.e., 100 AL cycles. Except for the 2k experiments, the performance was generally optimal under the default setting. For the 2k experiments, a better performance was observed when the total cycle was smaller than the default setting. In this case, using 100 AL cycles makes the number of samples per cycle too low (20 samples), and we conjecture that this is the main reason for the decreased performance in the default setting. This experiment demonstrates that, in general, a total of 100 AL cycles tends to yield the best results when we have enough AL budget.
Computational complexity
Here, we analyze the computational complexity of the proposed method using the previous notations for analyzing learning amounts. Specifically, we examine the complexity of training iterations, assuming that all methods have the same computational burden in a single iteration. First, we assume that existing methods run \(n_c\) AL cycles, each with \(n_e\) epochs, and \(n_d\) samples are newly labeled in each cycle. The proposed method uses more AL cycles \(n_c^{\prime} = k n_c\) for some \(k \ge 1\), where fewer samples \(n_d^{\prime}=n_d / k\) are labeled in each cycle. Here, the number of epochs is determined based on the learning amount, as explained earlier. Specifically, the number of epochs \(n_e^{\prime s}\) for the s-th cycle is fixed for \((t-1) k < s \le tk\) (which we will call a ‘super cycle’) as in Table 1, and it was set so that the net learning amount in this period matches those of the existing methods in the t-th cycle:
assuming all the methods use the same batch size B. Note here that the number of iterations for the existing methods is given as \(n_i^t = n_e (t n_d) / B\) for the t-th cycle (since the number of training samples is \(\bar{n}_d^t = t n_d\)), while that of the proposed method is \(n_i^{\prime s} = n_e^{\prime s} (s n_d/k) / B\) for the s-th cycle that belongs to the t-th super cycle. Accordingly,
This equation becomes (8) if we set \(t=1\) and \(k=10\).
As described above, the number of iterations for the existing methods is \(n_i^t = n_e (t n_d) / B = O(t)\) in the t-th cycle. For the proposed method, this corresponds to the net iterations \(\bar{n}_i^{\prime t}\) in the t-th super cycle:
where k is canceled in the Big-O notation because the polynomials in the numerator and denominator have the same degrees for k. Interestingly, we can see that the computational complexity of the t-th super cycle in the proposed method is identical to that of the t-th cycle in the existing methods. This indicates that the difference is only in the ignored coefficients of the Big-O notations.
A more detailed analysis is as follows: \(\bar{n}_i^{\prime t}\) is an increasing function for \(k \ge 1\), which can be confirmed by differentiating (11) with k. This means that the upper bound of \(\bar{n}_i^{\prime t}\) is
This upper bound gets very close to \(n_e n_d t / B\) (the number of iterations of the existing methods) if t becomes large. This means that the only meaningful difference in the computational cost is in the early cycles. Indeed, we can confirm that (12) is a decreasing function for \(t \ge 1\), by differentiation. Thus, the largest difference is when \(t=1\), i.e., \(\sup _k\{\bar{n}_i^{\prime 1}\} = 1.5 n_i^1\). Therefore, the proposed method initially has 1.5 times more iterations than the existing methods, and the difference becomes negligible as AL cycles proceed.
Table 2 shows the processing time of each method. For PT4AL and the proposed method, the time taken for the pretext task was also measured and included in the processing time. The CIFAR-100 dataset was used for this experiment, and the time was measured based on Scenarios A and B for the proposed method and the existing methods, respectively. Here, we can see that the processing times of most recent methods, including the proposed method, are generally similar to each other.
Conclusion
In this paper, we proposed a new AL method to address the limitations of existing pretext-task-based AL based on RL. By incorporating discounted Thompson sampling, we enabled a more sophisticated interpretation of pretext results for AL using rewards. We demonstrated that this can significantly improve performance with minimum effort, which proves our main claim and is also practical to use. Additionally, we introduced a new data sampling method to enhance the effectiveness of RL. We validated our method on five datasets for image classification, demonstrating its effectiveness. Exploring various proxy values other than the rotation pretext losses or validation performance to design the groups and rewards in the proposed method is left as future work.
Data availability
All the datasets used in this paper are publicly available and provided by third parties. They can be downloaded as follows: CIFAR-10 and CIFAR-10022 can be downloaded from https://www.cs.toronto.edu/~kriz/cifar.html. SVHN23 can be downloaded from http://ufldl.stanford.edu/housenumbers/ through the link under “Format 1.” Caltech10124 can be downloaded from https://data.caltech.edu/records/mzrjq-6wc02. ImageNet-6425 is available on https://www.image-net.org/download.php through the link under the “Download downsampled image data (32x32, 64x64)” section.
Notes
https://github.com/johnsk95/PT4AL
References
Deng, J. et al. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition (Miami, Florida, 2009).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In 2016 IEEE conference on computer vision and pattern recognition (Las Vegas, Nevada, 2016).
Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K. & Yuille, A. L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 40, 834–848 (2017).
Everingham, M., Van Gool, L., Williams, C. K., Winn, J. & Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 88, 303–338 (2010).
Oberweger, M. & Lepetit, V. Deepprior++: improving fast and accurate 3d hand pose estimation. In 2017 IEEE international conference on computer vision workshops (Venis, Italy, 2017).
Lin, T.-Y. et al. Microsoft coco: Common objects in context. In The European conference on computer vision (Zurich, Switzerland, 2014).
Settles, B. Active learning literature survey. Tech. Rep. University of Wisconsin-Madison Department of Computer Sciences, 2009.
Wang, J. et al. Deep reinforcement active learning for medical image classification. In Medical image computing and computer assisted intervention (Lima, (Peru, 2020).
Xie, B., Yuan, L., Li, S., Liu, C. H. & Cheng, X. Towards fewer annotations: Active learning via region impurity and prediction uncertainty for domain adaptive semantic segmentation. In 2022 IEEE/CVF conference on computer vision and pattern recognition (New Orleans, Louisiana, 2022).
Yuan, T. et al. Multiple instance active learning for object detection. In 2021 IEEE/CVF conference on computer vision and pattern recognition (virtual, 2021).
Caramalau, R., Bhattarai, B. & Kim, T.-K. Active learning for Bayesian 3d hand pose estimation. In Proceedings of the IEEE/CVF winter conference on applications of computer vision (Waikoloa, Hawaii, 2021).
Gidaris, S., Singh, P. & Komodakis, N. Unsupervised representation learning by predicting image rotations. In International conference on learning representations (Vancouver, Canada, 2018).
Chen, X. & He, K. Exploring simple Siamese representation learning. In 2021 IEEE/CVF conference on computer vision and pattern recognition (virtual, 2021).
Zhang, R., Isola, P. & Efros, A. A. Colorful image colorization. In European conference on computer vision (Amsterdam, The Netherlands, 2016).
Bhatnagar, S., Goyal, S., Tank, D. & Sethi, A. Pal. Pretext-based active learning. In The British machine vision conference (virtual, 2021).
Kim, K., Park, D., Kim, K. I. & Chun, S. Y. Task-aware variational adversarial active learning. In 2021 IEEE/CVF conference on computer vision and pattern recognition (virtual, 2021).
Xie, Y., Ding, M., Tomizuka, M. & Zhan, W. Towards free data selection with general-purpose models. In Thirty-seventh conference on neural information processing systems (New Orleans, Louisiana, 2023).
Yi, J. S. K., Seo, M., Park, J. & Choi, D.-G. Pt4al: Using self-supervised pretext tasks for active learning. In European conference on computer vision (Tel Aviv, Israel, 2022).
Katehakis, M. N. & JR, A. F. V.,. The multi-armed bandit problem. Decomposition and computation. Mathematics of Operations Research 12, 262–268 (1987).
Caramalau, R., Bhattarai, B. & Kim, T.-K. Sequential graph convolutional network for active learning. In 2021 IEEE/CVF conference on computer vision and pattern recognition (virtual, 2021).
Yoo, D. & Kweon, I. S. Learning loss for active learning. In 2019 IEEE/CVF conference on computer vision and pattern recognition (Long Beach, California, 2019).
Krizhevsky, A. et al. Learning multiple layers of features from tiny image.s Tech. Rep., University of Toronto (2009).
Netzer, Y. et al. Reading digits in natural images with unsupervised feature learning. In Advances in neural information processing systems workshops (Granada, Spain, 2011).
Fei-Fei, L. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In 2004 IEEE computer society conference on computer vision and pattern recognition workshops (Washington, DC, 2004).
Chrabaszcz, P., Loshchilov, I. & Hutter, F. A downsampled variant of imagenet as an alternative to the cifar datasets (2017). arXiv:1707.08819.
Baum, E. B. & Lang, K. Query learning can work poorly when a human oracle is used. In International joint conference on neural networks (Beijing, China, 1992).
Cohn, D., Ghahramani, Z. & Jordan, M. Active learning with statistical models. In Advances in Neural Information Processing Systems (Denver, Colorado, 1994).
Krishnamurthy, V. Algorithms for optimal scheduling and management of hidden Markov model sensors. IEEE Trans. Signal Process. 50, 1382–1397 (2002).
Yu, H. Svm selective sampling for ranking with application to data retrieval. In Proceedings of the eleventh ACM SIGKDD international conference on Knowledge discovery in data mining (Chicago, Illinois, 2005).
Yang, J. et al. Automatically labeling video data using multi-class active learning. In Proceedings Ninth IEEE international conference on computer vision (Nice, France, 2003).
Hauptmann, A. G., Lin, W.-H., Yan, R., Yang, J. & Chen, M.-Y. Extreme video retrieval: joint maximization of human and computer performance. In Proceedings of the 14th ACM international conference on multimedia (Santa Barbara, California, 2006).
Sener, O. & Savarese, S. Active learning for convolutional neural networks: A core-set approach. In International conference on learning representations (Vancouver, Canada, 2018).
Kye, S. M., Choi, K., Byun, H. & Chang, B. Tidal: Learning training dynamics for active learning. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 22335–22345 (Paris, France, 2023).
Sinha, S., Ebrahimi, S. & Darrell, T. Variational adversarial active learning. In 2019 IEEE/CVF international conference on computer vision (Seoul, Korea (South), 2019).
Yang, C., Huang, L. & Crowley, E. J. Plug and play active learning for object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (Seattle, Washington, 2024).
Ma, S., Zeng, Z., McDuff, D. & Song, Y. Active contrastive learning of audio-visual video representations. In International conference on learning representations (virtual, 2021).
Yuan, M., Lin, H.-T. & Boyd-Graber, J. Cold-start active learning through self-supervised language modeling. In Empirical methods in natural language processing (virtual, 2020).
Chaplot, D. S., Dalal, M., Gupta, S., Malik, J. & Salakhutdinov, R. R. Seal: Self-supervised embodied active learning using exploration and 3d consistency. In Advances in neural information processing systems (virtual, 2021).
Ma, S., Zhu, F., Zhong, Z., Zhang, X.-Y. & Liu, C.-L. Active generalized category discovery. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 16890–16900 (Seattle, Washington, 2024).
Wen, X., Zhao, B. & Qi, X. Parametric classification for generalized category discovery: A baseline study. In Proceedings of the IEEE/CVF international conference on computer vision, 16590–16600 (Paris, France, 2023).
Kingma, D. P. & Welling, M. Auto-encoding variational bayes. In International conference on learning representations (Banff, Canada, 2014).
Guo, J. et al. Trove: A context-awareness trust model for vanets using reinforcement learning. IEEE Internet Things J. 7, 6647–6662 (2020).
Guo, J. et al. Icra: An intelligent clustering routing approach for uav ad hoc networks. IEEE Trans. Intell. Transp. Syst. 24, 2447–2460 (2022).
Haarnoja, T., Zhou, A., Abbeel, P. & Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning (Stockholm, Sweden, 2018).
Lillicrap, T. P. et al. Continuous control with deep reinforcement learning. In International conference on learning representations (Caribe Hilton, San Juan, Puerto Rico, 2016).
Fang, M., Li, Y. & Cohn, T. Learning how to active learn: A deep reinforcement learning approach. In Empirical Methods in Natural Language Processing (Copenhagen, Denmark, 2017).
Pang, K., Dong, M., Wu, Y. & Hospedales, T. Meta-learning transferable active learning policies by deep reinforcement learning. In International conference on machine learning workshops (Stockholm, Sweden, 2018).
Liu, Z., Wang, J., Gong, S., Lu, H. & Tao, D. Deep reinforcement active learning for human-in-the-loop person re-identification. In 2019 IEEE/CVF international conference on computer vision (Seoul, Korea (South), 2019).
Thompson, W. R. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika 25, 285–294 (1933).
Riquelme, C., Tucker, G. & Snoek, J. Deep Bayesian bandits showdown: An empirical comparison of Bayesian deep networks for Thompson sampling. In International conference on learning representations (Vancouver, Canada, 2018).
Raj, V. & Kalyani, S. Taming non-stationary bandits: A Bayesian approach (2017). arXiv:1707.09727.
Agrawal, S. & Goyal, N. Thompson sampling for contextual bandits with linear payoffs. In International conference on machine learning (Atlanta, 2013).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. In International conference on learning representations (San Diego, California, 2015).
Paszke, A. et al. Pytorch: An imperative style, high-performance deep learning library. In Advances in neural information processing systems (Vancouver, Canada, 2019).
van der Maaten, L. & Hinton, G. Visualizing data using t-sne. J. Mach. Learn. Res. 9, 2579–2605 (2008).
Acknowledgements
This work was supported partly by Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korean government (MSIT) (No. 2020-0-00004, Development of Previsional Intelligence based on Long-term Visual Memory Network) (50%), partly by Innovative Human Resource Development for Local Intellectualization program through the Institute of Information & Communications Technology Planning & Evaluation(IITP) grant funded by the Korea government(MSIT) (IITP-2024-2020-0-01741) (25%), and partly by Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government(MSIT) (No.RS-2022-00155885, Artificial Intelligence Convergence Innovation Human Resources Development (Hanyang University ERICA)) (25%).
Author information
Authors and Affiliations
Contributions
Conceptualization, D.K. and M.L.; Data curation, D.K.; Formal analysis, D.K. and M.L.; Investigation, D.K.; Methodology, D.K. and M.L.; Project administration, M.L.; Resources, M.L.; Supervision, M.L.; Validation, D.K. and M.L.; Visualization, D.K.; Writing-original draft, D.K.; Writing-review & editing, M.L.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Kim, D., Lee, M. Interpreting pretext tasks for active learning: a reinforcement learning approach. Sci Rep 14, 25774 (2024). https://doi.org/10.1038/s41598-024-76864-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-76864-2
