
Abstract
Appointment scheduling (AS) plays a crucial role in outpatient clinic management. Traditional methods involve patient grouping using pre-defined rules and scheduling based on these groups. However, pre-defined rules may not adequately capture the heterogeneity in patients’ service times (i.e., consultation duration). Advanced machine learning (ML) methods can address individual-level heterogeneity but pose challenges for practical scheduling. To strike a balance, we propose a data-driven AS decision support system, Cluster-Predict-Schedule (CPS), integrating both supervised and unsupervised ML for efficient patient grouping and scheduling. The novelty of CPS lies in its adaptability to service time heterogeneity through a data-driven approach, determining patient groups based on data rather than pre-defined rules. Additionally, CPS includes a generic and efficient algorithm for generating appointment templates adaptable to any number of patient groups. Our system’s efficacy is demonstrated using a real-world dataset. Evaluated by the weighted sum of patient wait times, physician idle time, and overtime, CPS achieves up to 15.0% cost reduction compared to the FCFA (first-call, first-appointment) scheme and over 4.7% savings against the common New/Return classification with traditional sequencing candidate (TSC) rules. In addition, CPS enhances outpatient operational efficiency without compromising fairness.
Similar content being viewed by others
Introduction
Medical services are valuable and limited resources. According to CDC statistics, the United States spent approximately $772.9 billion on outpatient services in 20191. However, about 12.0% of individuals under age 65 still could not access timely medical care due to the high cost2,3. Inefficiencies in outpatient clinics, reflected in long patient wait times, physician idle time, and overtime, stem from a mismatch between medical service demand and available capacity, further complicated by heterogeneous service times (i.e., consultation duration)4. Appointment scheduling (AS) involves deciding the sequence of patients for a physician’s service and allocating time slots for each patient5,6, which is widely used in outpatient clinics to match healthcare demand with providers’ capacity7. A well-designed and adaptable AS decision support system is vital to healthcare provider resource allocation and patient care quality8,9.
Since the pioneering work of Bailey10 in the 1950s, numerous vital aspects of outpatient AS have been investigated7,11,12. Most extant studies on outpatient AS model the patient service time as a homogeneous population, assuming either deterministic or independent and identically distributed (i.i.d.) consultation service time7. Such a simplified modeling choice allows researchers to study essential phenomena affecting the scheduling system, such as no-shows13,14,15,16,17,18, walk-ins19,20,21, and same-day re-entries22,23,24. However, such studies often overlook the heterogeneity of service times in real outpatient management practices. On the other hand, the performance of outpatient AS can be sensitive to patient heterogeneity, and therefore, it is beneficial to take patient heterogeneity information into account when developing AS systems25,26.
Categorizing patients based on their heterogeneity is essential for enhancing outpatient AS efficiency25,27. The heterogeneity in patient service times is addressed in various approaches in the literature, which can be divided into two distinct streams: (1) research modeling service times on an individual patient basis, acknowledging patient-specific heterogeneity28,29,30,31, and (2) studies considering groups of patients with different service time requirements24,25,32,33. The first stream of research considers the differences in service time at the individual patient’s level. However, implementing these strategies practically presents challenges. This is due to the need for high-quality historical data to accurately predict service times and no-show risk, along with a complicated AS system capable of adjusting allotted service time for individual patients. The second stream considers the differences in service time at the patient’s group level, in which the method of grouping patients is usually set a priori. For example, Cayirli et al.32 group patients based on whether they visit a facility for the first time for a condition. This is referred to as New/Return hereafter. The pre-defined classification simplifies scheduling implementation. Studies show that AS systems using simple pre-defined classification schemes can noticeably improve productivity34,35,36. However, pre-defined rules may not adequately capture the heterogeneity in patients’ service times.
One promising approach to addressing the above grouping issue is to utilize machine learning (ML) techniques, which bring benefits to improving outpatient operational efficiency37,38. ML excels at analyzing extensive data, uncovering relationships, and identifying patterns, making it valuable in medical and healthcare applications39,40,41,42. Additionally, ML allows computers to learn patterns autonomously without being explicitly programmed43, facilitating the exploration of a more promising outpatient AS scheme, particularly suited for contexts with heterogeneous service times. However, the classification scheme in the ML-related literature assumes that the grouping is given a priori or obtained through subjective experience, thus missing the opportunity to leverage ML to explore the value of historical data fully.
The limitations of existing research have driven us to develop an ML-based scheduling decision support system that balances implementation convenience and service time heterogeneity. Are there better ways to group patients regarding the number of groups used and how each group is defined? If yes, how can one find them, and how would one sequence patients based on these groups? To answer these questions, we propose a data-driven decision support system for outpatient AS in which the heterogeneity in patients’ service times is derived from empirical data. Such a system consists of three components, namely, Cluster, Predict, and Schedule (CPS). Initially, we cluster patients in historical data based on service times using unsupervised ML (i.e., K-median). Following the clustering process, we obtain each patient’s group label. We utilize service times from historical data alongside patient category labels and train a decision tree, a supervised ML model, to map each patient’s service time to their respective group. This decision tree will be employed as a classifier for incoming patient categorization. Next, we train a predictive model (i.e., XGBoost) to predict the incoming patients’ service time using existing patients’ data. The predicted service time is input into the decision tree to obtain the patient’s group label. Finally, upon obtaining category labels for all upcoming patients, scheduling ensues by implementing our proposed cost-minimizing sequence template based on patient groups.
We compare the proposed CPS to existing methods in the literature and practice and find that CPS is more cost-effective than competing methods. Compared to commonly used scheduling methods like FCFA (first-call, first-appointment) and New/Return-based approaches, our CPS method demonstrates cost reductions of approximately 15.0% and 4.7%, respectively. Moreover, our approach, CPS, demonstrates superior service fairness compared to FCFA. Specifically, our method results in smaller disparities in expected waiting times for patients scheduled across various time slots, in contrast to FCFA. The results and ensuing discussion offer valuable insights for healthcare institution administrators. They aid in improving AS decisions and applying ML techniques to reduce the operational costs of outpatient clinics.
Our study considers patient/service heterogeneity by utilizing data to balance too few groups (homogeneous assumption) and too much heterogeneity (individual-level differentiation). Classifying patients into manageable groups is realistic and easy to implement in medical practice25. The main contributions of our study are as follows:
-
To address the problems of low outpatient operational efficiency due to the heterogeneity of patient service times, this paper proposes a new data-driven method of patient classification based on service time clustering and prediction, using both unsupervised and supervised learning.
-
The general candidate sequencing rules, generated by our candidate rules generator (CRG) algorithm, yield significant efficiency improvement in numerical experiments using real-world data. Simple rules can perform close to the optimal appointment sequencing decision obtained by exhaustive enumeration in various clinical environments.
-
CPS is developed to determine the classification of patients using ML and to schedule patients based on the heterogeneity of their service times at the patient group level, thereby enhancing outpatient operational efficiency from these two perspectives.
The remainder of this paper is organized as follows. Section “Problem definition and methodology” describes our problem context, and outlines the proposed AS system, CPS. In Section “Results and discussion”, we delineate the implementation steps of CPS using real data from a clinical setting and derive its optimal schedule. Then, we present the numerical experiments, results, and derived insights. Finally, Section “Conclusions and future works” concludes and discusses our limitations and future research.
Problem definition and methodology
In this section, we describe the problem context and the proposed CPS system, including the mathematical formulation of the optimization problem and the workflow of the CPS.
The outpatient AS problem context
We consider the outpatient AS problem in the following general clinical setting. A clinic session of planned length \(\mathcal {T}\) (e.g., four hours) is divided into n equal-length slots. Each patient’s appointment is assigned to one slot. Scheduled patients arrive punctually at appointment times, and a single physician serves them with stochastic consultation times (i.e., the single-stage single-server setting). While a clinic may have multiple physicians, physicians usually have their own panels of patients. Therefore, one can schedule appointments for each physician independently. We assume the demand for service is large enough to fill all slots within each session consistently. This is supported by literature and by practice11,26,44. The n slots in a session are labeled 1 through n, indicating the chronological order. We label the appointments in a session according to their slot labels; thus, the \(i^{th}\) appointment is assigned to slot i. Hereafter, the \(i^{th}\) appointment and the \(i^{th}\) slot are used interchangeably.
To capture the cost of outpatient scheduling in our model, we adopt the notation (whenever applicable) from Chen and Robinson44 to define the following for slot i:
-
\(A_{i}\) is the appointment time. We set \(A_1=0\) by convention.
-
\(X_i \triangleq A_{i+1} - A_{i}\) is the service time allowance.
-
\(\xi _{i}\) is the random service time (whose distribution will be specified later).
-
\(Y_{i}\) is the realized start time of the \(i^{th}\) appointment with the physician. \(Y_1 = A_1 = 0\), and \(Y_{i+1} = \max (A_{i+1}, Y_{i}+\xi _{i}),\ i=1,...,n-1\).
-
\(W_{i}=Y_{i}-A_{i}\) is patient i’s waiting time.
We obtain the expression of the waiting using the famous Lindley recursion45:
where, \((x)^+ \triangleq max(x,0)\) is the non-negative part of any given x. \(W=\sum _{i=1}^{n} W_i\) is the total waiting time of all patients in the session.
I and O are the physician’s idle time and overtime, respectively. They can be determined as follows44:
Note that the appointment times \(\{A_{i}\}'s\) and thus \(\{X_i\}\)’s are fixed according to our assumption that the session is divided into n slots with fixed length. This is called individual-block fixed-interval AS in literature25,30,46.
Given a set of n patients to be scheduled for a session, we can assume that each one of them can be classified into one of the K classes for K being generic without loss of generality. This implies that if no classification is available, then \(K=1\); on the other hand, if each of the n patients has their own class, then \(K=n\). Let \(n_k\) be the number of patients of the \(k^{th}\) class for the session in question, \(k\in \{1,...,K\}\). Therefore, \(\sum _{k=1}^{K} n_k = n\).
An appointment schedule for a given session is the assignment of patients to each of the n available slots within that session. Our scheduling decision is to decide how to assign different patients to these n slots, and this is modeled by the decision variables \(\{x_{i,k}\}'s\). Each \(x_{i,k}\), for \(i\in \{1,...,n\}\) and \(k\in \{1,...,K\}\), is binary such that \(x_{i,k} = 1\) if the appointment assigned to slot i is a patient of class k; otherwise, \(x_{i,k} = 0\). Furthermore, as each patient from every class among these n patients needs to be scheduled, we have \(\sum _{i=1}^n x_{i,k} = n_k\) for each class k. Also, since each slot can accommodate only one patient; hence, \(\sum _{k=1}^K x_{i,k} = 1\).
Define \(\Xi _k\) as the random service time of class-k with the cumulative distribution function (CDF) \(\Phi _{k}(\cdot )\). The random service time of the appointment i, \(\xi _i \triangleq \sum _{k=1}^K \Xi _k\cdot x_{i,k}\) by definition, since the appointment i will be of a class-k for some \(k\in \{1,...,K\}\).
The optimization model
The objective function we used to evaluate any schedule is formulated as Eq. (3).
where, \(c_W\), \(c_I\), and \(c_O\) are the unit cost of patients’ waiting time (\(W_{i}\)), the physician idle time (I), and overtime (O), respectively. They can also be interpreted as the clinic’s perspective on the disutility of unproductive time. Furthermore, using \(W_{i}\), I, and O as key performance indicators (KPIs) for outpatient scheduling optimization is a common practice in the literature47,48,49.
With the problem setup stated in the previous section, the optimization model could be formulated as Model I.
Note that \(\{\Xi _k\}\)’s and hence \(\{\xi _i\}\)’s are random variables. Therefore, Model I is a stochastic programming problem. We further index the random variables using \(\omega\) where each \(\omega\) is a point from the probability space \(\tilde{\Omega }\). Model II is the ensuing formalization.
This is a stochastic programming problem with binary decision variables. Solving for the exact solution is computationally challenging. A common solution approach is Sample Average Approximation (SAA), i.e., randomly generating a sufficient number of samples and then optimizing the average cost of these samples19,50,51. So, we can take a large random sample of \(\omega 's\) from \(\tilde{\Omega }\) and replace the expectation operation above with the corresponding sample average. Let \(\Omega\) be the N sampled values of \(\omega\) (i.e., the number of sample instances \(|\Omega | = N\)), and the objective function becomes
Our appointment scheduling problem is then to optimize Eq. (18) with the constraints outlined in Eqs. (11) to (17), which is a mixed-integer programming (MIP) problem, and we call this Model III.
For given \(c_W\), \(c_I\), and \(c_O\), the optimal schedule is the sequence of different groups of patients (represented by \(\{x_{i,k}\}\)) that minimizes total cost z. If the whole patient population is treated as a homogeneous group, i.e., \(\{\xi _i\}_{i=1}^n\) are i.i.d., then there is no need to sequence them, which makes the computational problem trivial but compromises scheduling productivity. The other extreme is considering heterogeneity at the individual level, i.e., \(K=n\). This may fully utilize the heterogeneity in service time and maximize the scheduling benefit, but the computational effort needed to sequence all n patient classes will become forbidding since there will be n! different sequences. Our approach is to strike a balance between these two extremes. We classify patients into a few groups and model the service times of patients within each group as i.i.d. random variables. The proposed decision support system will make our scheduling problem computationally more tractable and practically more manageable. The proposed framework for classifying and scheduling patients will be discussed in the next section.
The CPS framework
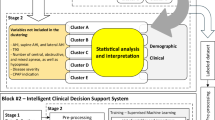
CPS’s workflow is illustrated in Fig. 1. In Stage 1, leveraging historical data, we utilize unsupervised ML to cluster patients based on their service times. To explicitly capture the clustering mechanism, we train a decision tree to learn the mapping from a patient’s service time to the corresponding cluster. We could derive the cutoff point(s) from the resulting decision tree. In Stage 2, we train the supervised ML model that predicts a patient’s service time based on the patient’s characteristics. The predicted service time is input into the decision tree in the first stage, and the patient’s group is the output. Then, in Stage 3, we first propose a scheme to generate candidate schedule templates. A schedule template is the assignment of patients of different groups to the slots of a clinic session. We then use empirical data to conduct Monte Carlo simulations to pick the best templates (i.e., the output of the CPS) for various clinic settings. In the rest of this section, we detail the processes in CPS.

A flowchart of the CPS system. A rectangular represents a process. A hexagon represents some form of data. Moreover, a hexagon with a filled background signifies the input or output within this schematic representation. Stage 1: Cluster. Leveraging historical data, we utilize unsupervised ML to cluster patients based on their service times. To explicitly capture the clustering mechanism, we train a decision tree to learn the mapping from a patient’s service time to the corresponding cluster. Stage 2: Predict. We need the service time of each incoming patient to use the cluster. So, we train the supervised ML model that predicts a patient’s service time based on the patient’s characteristics. Stage 3: Schedule. We first propose a scheme to generate candidate schedule templates. A schedule template is the assignment of patients of different groups to the slots of a clinic session. We then use empirical data to conduct Monte Carlo simulations to pick the best templates (i.e., the output of the CPS) for various clinic settings.
Cluster patients based on historical service times
The initial stage of CPS involves employing unsupervised ML techniques to cluster patients, capturing the heterogeneity in their service times. We cluster based on patient service times (i.e., \(\xi _i\)’s) because they directly influence AS’s effectiveness and the objective value z, as indicated in Eqs. 1 to 3, rather than patient characteristics. To obtain patients’ cluster labels, we apply K-median clustering, less outlier-sensitive than K-means, to historical patients’ service times, indicated by the purple components in Fig. 1. We then utilize a decision tree to learn the clustering rules, i.e., the unsupervised learning results, indicated by the orange components in Fig. 1.
Predict incoming patients’ service times
Clustering in CPS requires the knowledge of the incoming patient’s service time, which is the future information we would not have when scheduling the appointment. As such, we use the predicted service time as a proxy. Specifically, we utilize historical data on patients’ characteristics and the corresponding service times to train a supervised ML model for predicting incoming patients’ service times. The patients to be scheduled (i.e., incoming patients) are then classified using their predicted service times as the input to the fine-tuned decision tree obtained in the previous section. These processes are illustrated by the dark blue and light blue components in Fig. 1, respectively.
Schedule incoming patients groups
Then, we design the sequencing rules to schedule the acquired patient groups. These processes are illustrated by the red components in Fig. 1. Generally, the design of sequencing rules is considered one of the most important aspects of AS. There are well-known sequencing rules when K, the number of patient groups, is 2 (e.g., Type A and Type B) in the literature25,30; and we call these rules the traditional sequencing candidate (TSC) rules. The following five scheduling rules are frequently employed in such cases.
-
ABG: assigning Type A patients to the beginning slots and Type B the remaining slots25,30,32,52,53,54,55.
-
ABND: assigning Type B to the middle slots and leaving both the beginning and the ending slots to Type A25,30.
-
BBND: assigning Type A to the middle slots and leaving both the beginning and the ending slots to Type B25,30.
These TSC rules are easy to implement in practice but cannot be directly generalized to handle cases beyond two patient types. To the best of our knowledge, for \(K \ge 3\), the literature provides no generic sequencing schemes beyond sorting the appointments by the expectation or the variance of patient groups’ service times26.
To address this, we develop a generic algorithmic scheme, named CRG, to generate candidate schedule sequences for any K. We use \(\texttt {TYPES} =(T_1, T_2,\ldots , T_K)\) to denote the K types of patients, and \(\textbf{c}=(n_1,n_2,\ldots ,n_K)\) is called a composition, indicating that there are \(n_k\) patients of type \(T_k,\ k=1,2,\ldots ,K\), to be scheduled. Given \(\texttt {TYPES}\) and \(\textbf{c}\), the candidate templates set \(\texttt {Templates}\) can be derived using the CRG algorithm. We can further evaluate the candidate templates and pick the best one for a clinic. More details about CRG are provided in the following section.
The CRG algorithm
The main idea of CRG is to concatenate two types of sub-sequences: the one with repeating patterns and the one with remaining patients not included in the repeating patterns. The precise meaning of repeating patterns and the definition of other necessary terms are given below.
As mentioned above, let \(\texttt {TYPES} =(T_1, T_2,\ldots , T_K)\) denotes the K types of patients. Let \(\mathbb {Z}_+\) and \(\mathbb {N}\) be the set of non-negative and positive integers, respectively. \(\textbf{c}=(i_1,i_2,\ldots ,i_K)\in \mathbb {Z}^K_+\) is called a composition of patients, which represents \(i_k\) patients of type \(T_k\) for \(k=1,2,\ldots ,K\). A composition \(\textbf{c}\) such that \(\textbf{c}\in \mathbb {N}^K\) is called a positive composition. We do not further differentiate patients beyond patient types, and thus \(\texttt {TYPES}\) together with a composition \(\textbf{c}\), i.e., \((\texttt {TYPES},\textbf{c})\), defines a set of patients. A sequence of \((\texttt {TYPES},\textbf{c})\) is to put all the patients of the set into some order.
Suppose we originally have the patient set \((\texttt {TYPES}, \textbf{c})\), and \(\mathbf {c'}\) is another composition such that \(\mathbf {c'}\le \textbf{c}\) in the vector sense, then \(\textbf{c}-\mathbf {c'}\) also denotes a composition, which represents the patients in \((\texttt {TYPES}, \textbf{c})\) but not in \((\texttt {TYPES}, \mathbf {c'})\). Note \(\textbf{c}-\textbf{c}\equiv \textbf{0}\) represents an empty set of patients by definition. We say a sequence is Type-Bundled if patients of the same type are arranged next to each other in this sequence. Given the patient set \((\texttt {TYPES},\textbf{c})\), we use \(\texttt {TypeBundles}(\texttt {TYPES},\textbf{c})\) to denote the collection of all Type-Bundled sequences of this patient set.
By definition, if \(\textbf{c}\) is a composition, so is \(r\cdot \textbf{c}\), \(\forall r\in \mathbb {N}\). If \(\textbf{p}\) is a sequence of patients in the patient set defined by \((\texttt {TYPES},\textbf{c})\), we use \(r\otimes \textbf{p}\) to denote the sequence that repeats \(\textbf{p}\) for r times; therefore \(r\otimes \textbf{p}\) is a sequence of patients in the set \((\texttt {TYPES},r\cdot \textbf{c})\). For the trivial case of \(r=1\), \(1\otimes \textbf{p}\equiv \textbf{p}\). For a sequence \(r\otimes \textbf{p}\), we call \(\textbf{p}\) a repeating pattern.

Candidate Rules Generator (CRG).
With the terms defined above, Algorithm 1 describes our scheme that generates the candidate appointment sequences for the session of \(\sum n_k\) slots with the set of patients \((\texttt {TYPES},\textbf{c})\) such that \(\textbf{c}=(n_1,\ldots ,n_K)\). Here is the explanation of the algorithm. For each positive composition \(\mathbf {c'} \le \textbf{c}\):
-
Step 1. Generate Type-Bundled sequences to form \(\texttt {Patterns}\), the set of pattern sub-sequences (line 4).
-
Step 2. Determine \(r = \min _{k} \lfloor \frac{n_k}{i_k}\rfloor\) (line 5), the maximum times a pattern can be repeated.
-
Step 3. Construct \(\texttt {RepeatingPatterns}\), the collection of sub-sequences that repeat the sub-sequences of \(\texttt {Patterns}\) for r times (line 6).
-
Step 4. For the remaining patients represented by the composition \(\textbf{c}-r\cdot \mathbf {c'}\), construct the corresponding collection of sequences \(\texttt {Remainders} {\mathop {=}\limits ^{\text {def}}}\texttt {TypeBundles}(\texttt {TYPES}, \textbf{c}-r\cdot \mathbf {c'})\) (line 7).
-
Step 5. Obtain a new collection of schedule sequences for the session, \(\texttt {NewRules}\). Each sequence in it is the concatenation of one sub-sequence from the repeating pattern collection \(\texttt {RepeatingPatterns}\) and a sub-sequence from the remaining patients’ collection \(\texttt {Remainders}\). We use \(\oplus\) to denote the concatenation of two sub-sequences (line 8).
-
Step 6. Update the candidate rules set \(\texttt {Templates}\) by adding \(\texttt {NewRules}\) (line 9).
We also provide an illustrative example to demonstrate the functionality of CRG in Supplementary Appendix A.
Templates evaluation
Lastly, the candidate templates can be evaluated using the associated cost z, as defined in Eq. (18), considering different clinic preferences represented by \(c_W\), \(c_I\), and \(c_O\). In literature, a frequently used technique is approximating expectation by sample average, also known as Monte Carlo simulation. We adopt the idea of SAA but sample the service times \(\{\xi _i\}'s\) from the historical data to evaluate the candidate templates and pick the best one. Once the sample service times are given, we can use the Eqs. (11) to (17) to compute \(W_i\), I and O for a given template (with its sequencing decision represented by \(\{x_{i,k}\}'s\)).
Results and discussion
This section presents the numerical results and discusses the important findings.
Case study
To showcase how CPS works, we conducted numerical experiments using a real dataset from our partner clinic and its operational context, with \(n=16\) (i.e., a session comprising 16 slots over four hours). The same approach and principles can be applied in other clinics using their specific data sets.
The real-world problem
Hangu is our partnered clinic in Guangzhou, China. At Hangu, patients make appointments either by phone or online, and they receive one appointment slot for each consultation. The clinic currently adopts a FCFA approach for scheduling. FCFA, while straightforward, is widely implemented across various clinics and hospitals26,32,56. Nonetheless, FCFA overlooks the heterogeneity in patient service times, potentially leading to operational inefficiencies.
The publicly available dataset57 used in our study contains 6637 consultation records collected from 381 half-day sessions of its stellar physician between 2018 and 2019. The dataset is evenly divided based on the entry date: the training set comprises records from January 2018 to January 2019 (50% of the dataset, totaling 3319 records), which is appropriate to train the model and meets the requirements for achieving satisfactory performance58,59. The test set includes records from January to December 2019 (50% of the dataset, totaling 3318 records).
We performed the feature pre-processing before using the data to construct the CPS model used for Hangu. All continuous variables undergo standardization, while categorical variables undergo one-hot encoding. The feature preprocessing steps occur after splitting the dataset into training and testing sets. This ensures that scaling parameters only come from the training set, preventing information leakage from the test set. While the details of the data can be found in the data article, Feng et al.56, Table 1 presents the feature variables’ meaning and statistical descriptions of the data. Besides the features, there is a response variable for the supervised ML model to predict, which is ServTime, the service time recorded. Note that there are 2392 missing values in the Address feature, attributed to patient preferences, which carries information related to patient characteristics. Additionally, the regression analysis indicates that Address_NA coefficients strongly predict ServTime (\(p<0.001\), two-tailed t-test) via linear regression56. Thus, we retain these missing values as a distinct category within the feature, refraining from imputation or exclusion.
The data will be used as the input of the CPS model. We first use the training set to train the clustering and service time prediction models. These models are then applied to the test set to determine each patient’s type in the test set. We then generate schedule templates and evaluate them using the test set. The details are given in the following subsections.
Clustering patients
We employ the Python package pyclustering61 on the training set with the default parameters for the clustering. The quality of the clustering is measured by the sum of absolute error (SAE) and the silhouette coefficient (SC)62, as shown in Figures 2a and 2b respectively. Both \(K=2\) and \(K=3\) exhibit an inflection point in their SAE values, as shown in Fig. 2c (elbow plot). Moreover, \(K=3\)’s SAE is lower, indicating better clustering in terms of SAE. \(K=2\)’s SC is higher, indicating better clustering in terms of SC.

Clustering quality metrics: (a) sum of absolute errors (SAEs) and (b) silhouette coefficients (SCs). (a) and (b) are the plots of the SAEs and the SCs, respectively, against the number of clusters K. The SC quantifies the compactness and separation of clusters based on the distance between data points within and between clusters. It ranges from -1 to 1. Higher values indicate better clustering.
We further compute the 95% confidence intervals of SAE and SC for a closer examination; see Table 2. The result shows that both differences are statistically significant. Since both \(K=2\) and \(K=3\) have merits, we include both in our study. The decision trees we built to capture the clustering rules are shown in Fig. 3.

Decision trees: (a) \(K=2\) and (b) \(K=3\). The service classification decision tree is based on K-median clustering. When \(K=2\), without loss of generality, we label the cluster with the larger mean service time A. Figure 3a shows the resulting tree structure. The cut-off point of the service times of patients in the two clusters is 811.5 seconds. When \(K=3\), we label the clusters A, B, and C in descending order of the mean service time of these patients. The decision tree for this clustering rule is shown in Fig. 3b, whose cut-off points are 630.5 and 975.5.
Predicting service times
In this section, we build predictive models using the training set for predicting incoming patients’ service time in the test set to put them into groups we obtained in the previous step. We employ linear regression (LR), support vector regression (SVR), extreme gradient boosting (XGBoost), and deep neural network regression (DNNR) to predict patients’ service time. These methods are widely adopted and robust in predicting uncertainties associated with outpatient scheduling30. Our implementation relies on the scikitlearn framework (for LR, SVR, XGBoost) and keras (for neural networks). All ML components are implemented with Python. Table 1 presents the input features utilized by these models. We employ 10-fold cross-validation for training and validation purposes. Bayesian optimization is used for tuning the hyperparameters. A comprehensive list of all hyperparameters explored and their respective search ranges can be found in Table 3.
We use root mean squared error (RMSE), and \(R^2\) to evaluate the performance of each model, and results in Table 4 show that XGBoost generally outperforms others. Consequently, XGBoost is selected as the predictive model, with its feature importance values (%) ranked in descending order: His.ServTime (32.7), Visit.No (25.1), M.Cancer (15.2), Address (13.5), Return (9.2), S.Cancer (2.7), and Gender (1.6).
Patient classification and schedule evaluation
After we predict the incoming patients’ service times, we use the decision trees in Fig. 3 to obtain patients’ cluster labels. Next, we generate candidate schedule sequences using CRG under a specific classification scheme. We then select the best sequence for each chosen setting through simulations conducted with the test set. Besides the proposed classification scheme, two popular alternatives from the literature are also adopted for comparison to gain management insights. These two alternatives are FCFA and New/Return. Notably, FCFA represents the current practice at Hangu and serves as our baseline.
To generate schedule sequences for comparison, we need to determine the set of patients \((\texttt {TYPES},\textbf{c})\) for each session. For each classification scheme (excluding New/Return), \(\texttt {TYPES}\) is given by the decision tree; the patient composition \(\textbf{c}\) is determined in a way that maintains fair access to care for patients regardless of the classifications. This means the long-run percentage of slots for each patient group is proportional to the percentage this group takes up in our patient population. The detailed patients classification is presented in Table 5. We document how to obtain these numbers in each scenario in Supplementary Appendix B.
Given the patient set \((\texttt {TYPES},\textbf{c})\) (of 16 patients), we can use CRG to generate a set of candidate sequences, namely \(\texttt {Templates}\), for their appointment. For each sequence in the \(\texttt {Templates}\), we use the average of 10, 000 replications (sampling from the test set) to evaluate it, as described in Section “Problem definition and methodology”. Due to space limitations, additional details are provided in Supplementary Appendix C. In our simulation, \(c_W\) is normalized to 1 without loss of generality, \(c_I\in \{0, 5,10\}\) and \(c_O\in \{1,2,...,10\}\), resulting in \(3 \times 10=30\) instances. These parameters cover typical clinic settings in the literature and extend beyond specific clinics like Hangu30,63,64. Then, we select the sequence with the lowest cost z as the best sequence in each clinic preference setting. Therefore, each policy’s solution schedule is the collection of sequences, each being the best sequence found by simulation under one scenario. The corresponding objective z is the weighted average of the \(z's\) obtained under different scenarios listed in Table 5. A detailed explanation is available in Supplementary Appendix D.
Experimental setup
This section outlines our experimental setup, comparing CPS’s performance with Hangu’s FCFA, and New/Return+TSC, moment-related (MR) rules, which are from the literature.
As discussed in the previous section, we incorporate both \(K=2\) (referred to as K2) and \(K=3\) (referred to as K3) in our study due to their respective strengths. When patients are classified into two pre-defined categories, such as New/Return, there are well-known TSC rules. When using our data-driven classification scheme with K2, we use TSC as an alternative sequencing method and compare its performance with the one of the proposed CRG. When K3, TSC is unavailable as it only applies to two-type classifications.
In addition to TSC rules, three other promising sequencing algorithms for AS are mentioned in the literature50,65. These rules, defined by the first and/or the second moment of service duration, are collectively referred to as MR.
-
Smallest-mean-first (SMF). Sequence patients in order of increasing mean of service durations50,55,66.
-
Smallest-variance-first (SVF). Sequence patients in order of increasing variance of service durations67,68,69.
-
Smallest-coefficient-of-variations-first (SCVF). Sequence patients in order of increasing coefficient of variation (CV) of service durations. The CV is defined as the ratio of the standard deviation to the mean, namely \(CV=\sigma /\mu\)64,65,70.
Previous studies show no single sequencing method is superior across all potential settings. While some research suggests that sequencing by increasing processing times yields the best results65,66, other studies propose that scheduling longer appointments first can be more effective5,32. Furthermore,71 find that, in certain cases, prioritizing patients with higher service duration variability can surpass the SVF rule’s performance. Therefore, we conducted experiments that included SMF, SVF, SCVF, and their respective reverse forms. The MR rules for these comparative experiments were derived from the training set data of our study, as detailed in Table 6.
In the meantime, one may also exhaustively enumerate all the sequences for a specific set of patients with a given classification (Enum) for K2 and K3, respectively. This is essential to solve Model III to the optimum by enumerating all the possible \({x_{i,k}}'s\) and pick the one with the best z in Eq. (18) for any given combination of \(c_W\), \(c_I\), and \(c_O\). While this approach could be time-consuming and result in excessive candidate sequences, we still choose to include Enum for K2 and K3 in our experiment for benchmarking purposes. Note that we can also solve Model III to the optimum by popular commercial solvers, such as Gurobi, and interested readers are referred to Supplementary Appendix E for the detailed discussion about the computational efforts as well as solution quality.
As a result, to investigate the effects of classification and sequencing, we evaluate the following policies (combinations of classification and sequencing schemes) besides the baseline FCFA: (1) New/Return+TSC; (2) K2+TSC; (3) K2/K3+CRG; (4) K2/K3+Enum; (5) New/Return+MR; and (6) K2/K3+MR.
The proposed CRG algorithm, TSC, and MR rules were implemented using R 4.2.3 on the Windows 11 platform. The experiments were conducted on a laptop with an AMD Ryzen 7 6800H CPU running at 3.20 GHz and equipped with 16 GB of RAM. In the computational experiments, all the Model III instances were solved by calling Gurobi 11.0.0 on R 4.2.3. When using Gurobi, we employed its default termination parameters (i.e., TimeLimit = Infinity, MIPGap = 1e-4, MIPGapAbs = 1e-10, NodeLimit = Infinity).
Performance evaluation
For each scheme of interest, we report the relative performance measure with respect to FCFA’s, \(\frac{z}{z_{F}}\), where z represents the simulated performance measure of each scheduling scheme (excluding FCFA) of Eq. (3), and \(z_{F}\) is the FCFA counterpart serving as the baseline. \(\frac{z}{z_{F}} < 1\) indicates that the current scheme outperforms FCFA, and methods with lower values of \(\frac{z}{z_{F}}\) are favorable. Figures 4 and 5 show the comparisons in schemes considered with various combinations of \((c_I,c_O)\) while \(c_W\) is normalized to 1.
Overall, all methods mentioned in this paper, except MR, outperform FCFA (i.e., their \(\frac{z}{z_{F}}<1\)), regardless of the clinic’s preferences concerning the disutility of physician idling and overtime. MR also outperforms FCFA most of the time, with a few exceptions when physician idling cost is set to zero and physician overtime cost is at a moderate level. In particular, CPS exhibits a significant cost reduction compared to FCFA, the current practice at Hangu as well as many other clinics. Savings of nearly \(15.0\%\) can be achieved using K2+CRG at \((c_I,c_O)=(0,1)\) compared to FCFA, as shown in Fig. 4a; similarly, savings of nearly \(14.0\%\) are observed with K3+CRG at \((c_I,c_O)=(10,10)\), as shown in Fig. 4b. In addition, both K2+CRG and K3+CRG’s solutions are close to the optimal solution provided by K2+Enum and K3+Enum, respectively. In the following, we compare CPS to New/Return+TSC, MR, and a commercial solver, Gurobi’s solution.

Cost comparison of CPS and New/Return+TSC methods: (a) Comparing New/Return+TSC with K2, (b) Comparing New/Return+TSC with K3 and (c) Comparing K2+CRG and K3+CRG.
CPS vs. New/Return+TSC
When compared against the widely-used New/Return+TSC in literature, the savings of CPS can be more than \(4.7\%\) (when using K3+CRG at \((c_I,c_O)=(5,10)\)) , as shown in Fig. 4b. If we fix the number of patient types at two, K2+CRG can save 4.12% compared to New/Return+TSC, as shown in Fig. 4a at \((c_I,c_O)=(0,2)\). We provide a detailed discussion in the following.
Figure 4a compares the best solution found by New/Return +TSC and the ones found by using our classification for K2 combined with different sequencing schemes. K2+TSC outperforms New/Return+TSC in most \(c_I\) and \(c_O\) configurations; the savings can reach 3.06% at \((c_I,c_O)=(0,6)\). The implication is that a better classification scheme using data (i.e., K2) yields a better scheduling performance than the pre-defined New/Return. In addition, K2+CRG outperforms K2+TSC, indicating that searching over the better sequencing candidates obtained by CRG yields further improvement; the savings can reach 5.73% at \((c_I,c_O)=(0,1)\). The costs of K2+CRG’s solutions are the closest to the optimal ones obtained by K2+Enum. The cost gap can range from 0.22% to 1.20%.
Figure 4b compares our method of \(K\textit{3}\)+CRG with New/Return+TSC. As mentioned in Section “Problem definition and methodology”, when the number of patient categories is three or more, the scheduling method of TSC is no longer applicable, whereas CRG remains capable of addressing this issue. Therefore, we compare K3+CRG to New/Return+TSC and observe a notable reduction in costs, with savings reaching \(4.71\%\) at \((c_I,c_O)=(5,10)\). The costs of K3+CRG’s solutions are the closest to the optimal ones obtained by K3+Enum. The cost gap can range from 0 to 0.68%.
Another observation drawn from Figs. 4a and 4b is that, for both K2 and K3, one only needs to search over the candidate templates generated by CRG to achieve a performance close to that of enumerating all conceivable sequence templates (Enum). This is particularly true in K3, as K3+CRG performs nearly as well as K3+Enum. This highlights the advantage of CRG for practitioners since a full enumeration of all possible templates is computationally forbidding and practically cumbersome.
Figure 4c compares a simpler classification (K2) scheme with the one using an additional category (K3). The results show that an increased number of categories in patient classification generally reduces overall costs by up to 2.61%. However, such nominal cost savings come at the expense of increased management complexity.
CPS vs. Moment-related methods
Figure 5 shows that CPS is also superior to MR. Figure 5a indicates that CRG outperforms or equals MR when using advanced patient classification methods (K2 and K3). Specifically, when K2 is used, CRG significantly outperforms MR in all instances; when K3 is used, CRG significantly outperforms MR when \(c_I=0\), while performance is identical with MR in the remaining \(c_I\) cases. Figure 5b suggests that in cases where patient classification relies on New/Return, CRG demonstrates enhanced performance in patient sequencing compared to MR across all instances. Figure 5c indicates that, across all instances tested, CPS outperforms New/Return+MR, which is the combination of popular patient classification scheme New/Return together with MR for appointment sequencing. Specifically, K2+CRG outperforms New/Return+MR in all \(c_I\) and \(c_O\) configurations, with savings reaching 8.37% at \((c_I,c_O)=(0,5)\). Similarly, K3+CRG dominates New/Return+MR in all \(c_I\) and \(c_O\) configurations, with maximum savings up to 9.44% achieved at \((c_I,c_O)=(0,5)\). This suggests that CPS has a significant advantage over state-of-the-art methods in reducing outpatient scheduling costs.

Cost comparison of CPS and MR: (a) Comparing CPS with K2+MR and K3+MR, (b) Comparing New/Return+CRG with New/Return+MR and (c) Comparing CPS with New/Return+MR.
Fairness analysis
Besides the costs, the fairness of patient service interests practitioners and researchers72. It is well-known in literature and practice that patients assigned to later appointment times of the session generally experience longer waiting times due to the congestion that tends to build up over time7. One metric to measure this disparity is the standard deviation of the average waiting time throughout a clinic session32,73, and we denote it by STD(W). Scheduling policies of small STD(W) are considered more equitable. Figure 6 plots the relative performance of each policy in terms of STD(W) using FCFA’s as the benchmark (\(\textit{STD}_F(W)\)). It shows that the schedules obtained by CPS aiming to optimize the overall costs are also desirable in terms of STD(W). In particular, the solution found by K3+CRG performs consistently well in terms of STD(W) across all clinic cost preferences. Furthermore, as shown in Fig. 6a, K3+CRG exhibits greater stability in fairness compared to K2+CRG and New/Return+TSC, consistently maintaining a higher level of fairness (low STD(W)). Regardless of the patient classification method used, the fairness of MR falls short compared to CRG, with K3+CRG exhibiting the highest level of fairness among these strategies, as illustrated in Fig. 6b.

The disparity in patient waiting times: (a) The disparity in patient waiting times of CPS and TSC and (b) The disparity in patient waiting times of CPS and MR.
Additionally, we evaluate fairness among various genders and address groups, which is an essential demographic characteristic in our study (as shown in Table 1). The experimental results show that our CPS system does not show favoritism towards any particular gender or address group, thereby meeting the fairness requirements in healthcare services. Detailed results can be found in Supplementary Appendix F.
Managerial implications
This research provides valuable managerial insights tailored for outpatient management practitioners. It aims to support them in reducing operational costs while improving the patient experience.
First, outpatient practice managers can leverage CPS to trim operational patient classification and scheduling costs. These cumulative benefits allow a phased implementation of CPS to mitigate complexity. For instance, if adjusting the scheduling system poses challenges, adopting CP (Cluster and Predict) components of CPS independently from S (Schedule) can enhance patient classification, followed by using the existing TSC scheduling method. Furthermore, the simulation results can guide a partial CPS implementation based on cost settings, curbing unnecessary management expenses. For example, excluding physician idle time costs and with moderate overtime expenses (5 to 6 times the patient wait cost), implementing K2+TSC can yield results similar to K2+CRG without altering the scheduling scheme.
Second, CPS demonstrates favorable performance regarding equity of patient visits, enhancing patient satisfaction. Since CPS does not differentiate among patients of the same category, it can, to a certain extent, accommodate patient preferences for different time slots in outpatient practice. Simulation results indicate that, in most instances, the fairness of CPS is superior to the traditional New/Return+TSC method. Notably, as classifications become more detailed, the fairness performance of CPS consistently outperforms FCFA across various outpatient settings.
Lastly, increasing the number of patient categories may not always lead to reduced operational costs. Specifically, when the cost of physician idle time is disregarded, and overtime expenses remain low (less than four times the patient unit wait time cost), in particular settings that prioritize patient experience, such as boutique clinics or concierge medicine, the utilization of the K2+CRG approach appears more advantageous than K3+CRG in reducing outpatient operational costs. However, within healthcare institutions that prioritize reducing physician idle time and overtime expenses (e.g., specialist clinics), a more detailed classification can reduce outpatient operational costs but add complexity to outpatient management. Thus, achieving an optimal balance requires careful consideration of the context within outpatient management.
Conclusions and future works
This study provides a novel data-driven decision support system for redesigning scheduling templates at the patient group level. Patients are first grouped and then scheduled in slots based on their group labels. The simulation results show a significant reduction in the clinic’s cost, considering the patient waiting times, physician idle time, and overtime, while improving patient equity in terms of waiting time disparity. The proposed templates are also easy to implement and interpretable. They could assist hospital or clinic administrators in refining and optimizing AS decision-making processes through adaptive strategies that maximize the utilization of medical resources. Moreover, CPS could periodically update its models to learn from updated historical data, enabling dynamic adaptation to changing circumstances.
Compared to existing scheduling methods, CPS has clear advantages. It uses data-driven patient classification to improve scheduling over traditional methods like New/Return while reducing operational costs and ensuring equitable access to healthcare resources. In terms of sequencing, the benefits from patient classification allow CRG to efficiently generate optimal or close-to-optimal schedule templates compared to commercial solvers, delivering comparable performance. However, CPS has limitations. It requires ML for patient classification, making the classification less intuitive than the traditional ones (e.g., New/Return). The templates produced by CRG, though containing repetitive patterns, may be more sophisticated than those intuitive rules (e.g., FCFA, TSC), demanding refined management capabilities for outpatient scheduling.
To the best of our knowledge, this research represents the first attempt to combine supervised and unsupervised ML techniques to create patient classifications and develop a novel CRG algorithm for more efficient patient scheduling with heterogeneous service times. While this study focuses on outpatient clinics, the proposed AS decision support system, namely CPS, also applies to other medical services with appointment-based arrivals and heterogeneous duration, such as day surgeries and psychological counseling. Our study excludes patient no-shows due to unavailable records in the showcase clinic. Future research can enhance CPS by considering more complex settings, such as no-shows and re-entrance. While our case study utilizes a real dataset from a collaborative clinic, our CPS system is designed to be adaptive and thus not confined to any specific dataset or clinic environment. Any clinic can readily implement it with access to historical data on service durations and associated patient information such as demographics, reasons for visits, and past appointment history. Additionally, our numerical studies accommodate a broad spectrum of clinic preferences concerning patient and physician productivity, as demonstrated by the varied values of \(c_W\), \(c_I\), and \(c_O\). Future research could further enhance the productivity improvements of the CPS by incorporating datasets that include more comprehensive patient information, should such datasets become available.
Data availability
We use a public dataset in our numerical studies to demonstrate the efficacy of the proposed framework. The datasets analyzed during the current study are available in the Zenodo repository at https://zenodo.org/record/7484205. The details of the dataset can be found in the data descriptor, see Feng et al.56. All the data included in this study are also available upon reasonable request by contacting the corresponding or first authors.
References
Centers for Disease Control and Prevention (CDC). Health care expenditures. https://www.cdc.gov/nchs/hus/topics/health-care-expenditures.htm. Last Reviewed: [January 16, 2024].
Centers for Disease Control and Prevention (CDC). Health insurance coverage. https://www.cdc.gov/nchs/hus/topics/health-insurance-coverage.htm. Last Reviewed: [January 16, 2024].
Sommers, B. D. et al. Health insurance coverage and health-what the recent evidence tells us. N. Engl. J. Med. 377, 586–593. https://doi.org/10.1056/NEJMsb1706645 (2017).
Klassen, K. J. & Yoogalingam, R. Appointment scheduling in multi-stage outpatient clinics. Health Care Manag. Sci. 22, 229–244. https://doi.org/10.1007/s10729-018-9434-x (2019).
Vanden Bosch, P. M. & Dietz, D. C. Minimizing expected waiting in a medical appointment system. IISE Trans. 32, 841–848, https://doi.org/10.1023/A:1007635012421 (2000).
Mak, H.-Y., Rong, Y. & Zhang, J. Sequencing appointments for service systems using inventory approximations. Manuf. Serv. Oper. Manag. 16, 251–262. https://doi.org/10.1287/msom.2013.0470 (2014).
Cayirli, T. & Veral, E. Outpatient scheduling in health care: a review of literature. Prod. Oper. Manag. 12, 519–549. https://doi.org/10.1111/j.1937-5956.2003.tb00218.x (2003).
Topuz, K., Urban, T. L., Russell, R. A. & Yildirim, M. B. Decision support system for appointment scheduling and overbooking under patient no-show behavior. Annals of Operations Research 1–29, https://doi.org/10.1007/s10479-023-05799-0 (2024).
Mahes, R., Mandjes, M., Boon, M. & Taylor, P. Adaptive scheduling in service systems: a dynamic programming approach. European Journal of Operational Research 312, 605–626. https://doi.org/10.1016/j.ejor.2023.06.026 (2024).
Bailey, N. T. A study of queues and appointment systems in hospital out-patient departments, with special reference to waiting-times. J. R. Stat. Soc. Series B Stat. Methodol. 14, 185–199, https://doi.org/10.1111/j.2517-6161.1952.tb00112.x (1952).
Gupta, D. & Denton, B. Appointment scheduling in health care: Challenges and opportunities. IISE Trans. 40, 800–819. https://doi.org/10.1080/07408170802165880 (2008).
Ahmadi-Javid, A., Jalali, Z. & Klassen, K. J. Outpatient appointment systems in healthcare: A review of optimization studies. Eur. J. Oper. Res. 258, 3–34. https://doi.org/10.1016/j.ejor.2016.06.064 (2017).
Kaandorp, G. & Koole, G. Optimal outpatient appointment scheduling. Health Care Manag. Sci. 10, 217–229. https://doi.org/10.1007/s10729-007-9015-x (2007).
Muthuraman, K. & Lawley, M. A stochastic overbooking model for outpatient clinical scheduling with no-shows. IISE Trans. 40, 820–837. https://doi.org/10.1080/07408170802165823 (2008).
Zacharias, C. & Pinedo, M. Appointment scheduling with no-shows and overbooking. Prod. Oper. Manag. 23, 788–801. https://doi.org/10.1111/poms.12065 (2014).
Chen, Y., Kuo, Y.-H., Fan, P. & Balasubramanian, H. Appointment overbooking with different time slot structures. Comput. Ind. Eng. 124, 237–248. https://doi.org/10.1016/j.cie.2018.07.021 (2018).
Hassin, R. & Mendel, S. Scheduling arrivals to queues: A single-server model with no-shows. Manage. Sci. 54, 565–572. https://doi.org/10.1287/mnsc.1070.0802 (2008).
LaGanga, L. R. & Lawrence, S. R. Appointment overbooking in health care clinics to improve patient service and clinic performance. Prod. Oper. Manag. 21, 874–888. https://doi.org/10.1111/j.1937-5956.2011.01308.x (2012).
Wang, S., Liu, N. & Wan, G. Managing appointment-based services in the presence of walk-in customers. Manage. Sci. 66, 667–686. https://doi.org/10.1287/mnsc.2018.3239 (2020).
Liu, N., van Jaarsveld, W., Wang, S. & Xiao, G. Managing outpatient service with strategic walk-ins. Manage. Sci.[SPACE]https://doi.org/10.1287/mnsc.2023.4676 (2023).
Kuiper, A., Mandjes, M., de Mast, J. & Brokkelkamp, R. A flexible and optimal approach for appointment scheduling in healthcare. Decis. Sci. 54, 85–100. https://doi.org/10.1111/deci.12517 (2023).
Feng, H., Alvarado, M., Li, Z. & Colón-Morales, C. A simulation study of outpatient surgery clinic with stochastic re-entrance. In 2020 Winter Simulation Conference (WSC), 1–12, https://doi.org/10.1109/WSC48552.2020.9384110 (2020).
Zhou, M., Loke, G. G., Bandi, C., Liau, Z. Q. G. & Wang, W. Intraday scheduling with patient re-entries and variability in behaviours. Manuf. Serv. Oper. Manag. 24, 561–579. https://doi.org/10.1287/msom.2020.0959 (2022).
Feng, H., Alvarado, M. M., Konda, S. & Lawley, M. Sequential clinical scheduling with stochastic patient re-entrance: Case of mohs micrographic surgery. Comput. Ind. Eng. 184, 109589. https://doi.org/10.1016/j.cie.2023.109589 (2023).
Cayirli, T., Veral, E. & Rosen, H. Designing appointment scheduling systems for ambulatory care services. Health Care Manag. Sci. 9, 47–58. https://doi.org/10.1007/s10729-006-6279-5 (2006).
Lee, S. J., Heim, G. R., Sriskandarajah, C. & Zhu, Y. Outpatient appointment block scheduling under patient heterogeneity and patient no-shows. Prod. Oper. Manag. 27, 28–48. https://doi.org/10.1111/poms.12791 (2018).
Rohleder, T. R. & Klassen, K. J. Using client-variance information to improve dynamic appointment scheduling performance. Omega 28, 293–302. https://doi.org/10.1016/S0305-0483(99)00040-7 (2000).
Golmohammadi, D. A decision-making tool based on historical data for service time prediction in outpatient scheduling. Int. J. Med. Inform. 156, 104591. https://doi.org/10.1016/j.ijmedinf.2021.104591 (2021).
Srinivas, S. & Salah, H. Consultation length and no-show prediction for improving appointment scheduling efficiency at a cardiology clinic: a data analytics approach. Int. J. Med. Inform. 145, 104290. https://doi.org/10.1016/j.ijmedinf.2020.104290 (2021).
Salah, H. & Srinivas, S. Predict, then schedule: Prescriptive analytics approach for machine learning-enabled sequential clinical scheduling. Comput. Ind. Eng. 108270, https://doi.org/10.1016/j.cie.2022.108270 (2022).
Samorani, M., Harris, S. L., Blount, L. G., Lu, H. & Santoro, M. A. Overbooked and overlooked: machine learning and racial bias in medical appointment scheduling. Manuf. Serv. Oper. Manag. 24, 2825–2842. https://doi.org/10.1287/msom.2021.0999 (2022).
Cayirli, T., Veral, E. & Rosen, H. Assessment of patient classification in appointment system design. Prod. Oper. Manag. 17, 338–353. https://doi.org/10.3401/poms.1080.0031 (2008).
Klassen, K. J. & Rohleder, T. R. Scheduling outpatient appointments in a dynamic environment. J. Oper. Manag. 14, 83–101. https://doi.org/10.1016/0272-6963(95)00044-5 (1996).
Walter, S. A comparison of appointment schedules in a hospital radiology department. Br. J. Prev. Soc. Med. 27, 160. https://doi.org/10.1136/jech.27.3.160 (1973).
Sickinger, S. & Kolisch, R. The performance of a generalized bailey-welch rule for outpatient appointment scheduling under inpatient and emergency demand. Health Care Manag. Sci. 12, 408–419. https://doi.org/10.1007/s10729-009-9098-7 (2009).
Deceuninck, M., Fiems, D. & De Vuyst, S. Outpatient scheduling with unpunctual patients and no-shows. Eur. J. Oper. Res. 265, 195–207. https://doi.org/10.1016/j.ejor.2017.07.006 (2018).
Bolaji, A. L. et al. A room-oriented artificial bee colony algorithm for optimizing the patient admission scheduling problem. Comput. Biol. Med. 148, 105850. https://doi.org/10.1016/j.compbiomed.2022.105850 (2022).
Pham, T. S., Legrain, A., De Causmaecker, P. & Rousseau, L.-M. A prediction-based approach for online dynamic appointment scheduling: A case study in radiotherapy treatment. INFORMS J. Comput.[SPACE]https://doi.org/10.1287/ijoc.2023.1289 (2023).
Shehab, M. et al. Machine learning in medical applications: A review of state-of-the-art methods. Comput. Biol. Med. 145, 105458. https://doi.org/10.1016/j.compbiomed.2022.105458 (2022).
Gupta, N. S. & Kumar, P. Perspective of artificial intelligence in healthcare data management: A journey towards precision medicine. Comput. Biol. Med. 107051, https://doi.org/10.1016/j.compbiomed.2023.107051 (2023).
Pianykh, O. S. et al. Improving healthcare operations management with machine learning. Nat. Mach. Intell. 2, 266–273. https://doi.org/10.1038/s42256-020-0176-3 (2020).
Ala, A., Chen, F. et al. Appointment scheduling problem in complexity systems of the healthcare services: A comprehensive review. J. Healthc. Eng. 2022, https://doi.org/10.1155/2022/5819813 (2022).
Srinivas, S. & Ravindran, A. R. Optimizing outpatient appointment system using machine learning algorithms and scheduling rules: A prescriptive analytics framework. Expert Syst. Appl. 102, 245–261. https://doi.org/10.1016/j.eswa.2018.02.022 (2018).
Chen, R. R. & Robinson, L. W. Sequencing and scheduling appointments with potential call-in patients. Prod. Oper. Manag. 23, 1522–1538. https://doi.org/10.1111/poms.12168 (2014).
Lindley, D. V. The theory of queues with a single server. In Mathematical Proceedings of the Cambridge Philosophical Society 48, 277–289. DOI: https://doi.org/10.1017/S0305004100027638 (Cambridge University Press (1952).
Cayirli, T., Yang, K. K. & Quek, S. A. A universal appointment rule in the presence of no-shows and walk-ins. Prod. Oper. Manag. 21, 682–697. https://doi.org/10.1111/j.1937-5956.2011.01297.x (2012).
Zhou, S. & Yue, Q. Appointment scheduling for multi-stage sequential service systems with stochastic service durations. Comput. Oper. Res. 112, 104757. https://doi.org/10.1016/j.cor.2019.07.015 (2019).
Kuo, Y.-H., Balasubramanian, H. & Chen, Y. Medical appointment overbooking and optimal scheduling: tradeoffs between schedule efficiency and accessibility to service. Flex. Serv. Manuf. J. 32, 72–101. https://doi.org/10.1007/s10696-019-09340-z (2020).
Zhou, S., Li, D. & Yin, Y. Coordinated appointment scheduling with multiple providers and patient-and-physician matching cost in specialty care. Omega 101, 102285. https://doi.org/10.1016/j.omega.2020.102285 (2021).
Denton, B., Viapiano, J. & Vogl, A. Optimization of surgery sequencing and scheduling decisions under uncertainty. Health Care Manag. Sci. 10, 13–24. https://doi.org/10.1007/s10729-006-9005-4 (2007).
Srinivas, S. & Choi, S. S. Designing variable-sized block appointment system under time-varying no-shows. Comput. Ind. Eng. 172, 108596. https://doi.org/10.1016/j.cie.2022.108596 (2022).
Jerbi, B. & Kamoun, H. Multiobjective study to implement outpatient appointment system at hedi chaker hospital. Simul. Model. Pract. Theory 19, 1363–1370. https://doi.org/10.1016/j.simpat.2011.02.003 (2011).
Millhiser, W. P., Veral, E. A. & Valenti, B. C. Assessing appointment systems’ operational performance with policy targets. IIE. Trans. Healthc. Syst. Eng. 2, 274–289. https://doi.org/10.1080/19488300.2012.736121 (2012).
Sun, Y. et al. Stochastic programming for outpatient scheduling with flexible inpatient exam accommodation. Health Care Manag. Sci. 1–22, https://doi.org/10.1007/s10729-020-09527-z (2021).
Salzarulo, P. A., Mahar, S. & Modi, S. Beyond patient classification: using individual patient characteristics in appointment scheduling. Prod. Oper. Manag. 25, 1056–1072. https://doi.org/10.1111/poms.12528 (2016).
Feng, H., Jia, Y., Zhou, S., Chen, H. & Huang, T. A dataset of service time and related patient characteristics from an outpatient clinic. Data 8, 47. https://doi.org/10.3390/data8030047 (2023).
Feng, H., Jia, Y., Zhou, S., Chen, H. & Huang, T. A dataset of service time and related patient characteristics from an outpatient clinic. Zenodo https://zenodo.org/record/7484205 (2022).
Joseph, V. R. Optimal ratio for data splitting. Stat. Anal. Data Min. 15, 531–538. https://doi.org/10.1002/sam.11583 (2022).
Attia, Z. I. et al. Screening for cardiac contractile dysfunction using an artificial intelligence-enabled electrocardiogram. Nat. Med. 25, 70–74. https://doi.org/10.1038/s41591-018-0240-2 (2019).
Huang, Y. & Verduzco, S. Appointment template redesign in a women’s health clinic using clinical constraints to improve service quality and efficiency. Appl. Clin. Inform. 6, 271–287. https://doi.org/10.4338/ACI-2014-10-RA-0094 (2015).
Novikov, A. PyClustering: Data mining library. J. Open Source Softw. 4, 1230, https://doi.org/10.21105/joss.01230 (2019).
Rousseeuw, P. J. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 20, 53–65. https://doi.org/10.1016/0377-0427(87)90125-7 (1987).
Denton, B. & Gupta, D. A sequential bounding approach for optimal appointment scheduling. IISE Trans. 35, 1003–1016. https://doi.org/10.1080/07408170304395 (2003).
Klassen, K. J. & Yoogalingam, R. Improving performance in outpatient appointment services with a simulation optimization approach. Prod. Oper. Manag. 18, 447–458. https://doi.org/10.1111/j.1937-5956.2009.01021.x (2009).
Gul, S., Denton, B. T., Fowler, J. W. & Huschka, T. Bi-criteria scheduling of surgical services for an outpatient procedure center. Prod. Oper. Manag. 20, 406–417. https://doi.org/10.1111/j.1937-5956.2011.01232.x (2011).
Marcon, E. & Dexter, F. Impact of surgical sequencing on post anesthesia care unit staffing. Health Care Manag. Sci. 9, 87–98. https://doi.org/10.1007/s10729-006-6282-x (2006).
Kemper, B., Klaassen, C. A. & Mandjes, M. Optimized appointment scheduling. Eur. J. Oper. Res. 239, 243–255. https://doi.org/10.1016/j.ejor.2014.05.027 (2014).
Mak, H.-Y., Rong, Y. & Zhang, J. Appointment scheduling with limited distributional information. Manage. Sci. 61, 316–334. https://doi.org/10.1287/mnsc.2013.1881 (2015).
Bentayeb, D., Lahrichi, N. & Rousseau, L.-M. Patient scheduling based on a service-time prediction model: a data-driven study for a radiotherapy center. Health Care Manag. Sci. 22, 768–782. https://doi.org/10.1007/s10729-018-9459-1 (2019).
Anderson, K., Zheng, B., Yoon, S. W. & Khasawneh, M. T. An analysis of overlapping appointment scheduling model in an outpatient clinic. Oper. Res. Health Care 4, 5–14. https://doi.org/10.1016/j.orhc.2014.12.001 (2015).
Kong, Q., Lee, C.-Y., Teo, C.-P. & Zheng, Z. Appointment sequencing: Why the smallest-variance-first rule may not be optimal. Eur. J. Oper. Res. 255, 809–821. https://doi.org/10.1016/j.ejor.2016.06.004 (2016).
Ala, A., Alsaadi, F. E., Ahmadi, M. & Mirjalili, S. Optimization of an appointment scheduling problem for healthcare systems based on the quality of fairness service using whale optimization algorithm and nsga-ii. Scientific Reports 11, 19816. https://doi.org/10.1038/s41598-021-98851-7 (2021).
Bertsimas, D., Farias, V. F. & Trichakis, N. On the efficiency-fairness trade-off. Manage. Sci. 58, 2234–2250. https://doi.org/10.1287/mnsc.1120.1549 (2012).
Funding
Haolin Feng’s work is partially supported by the National Natural Science Foundation of China (Grant No. 72071217, 71991474) and the Natural Science Foundation of Guangdong Province, China (Grant No. 2015A030313088). Teng Huang’s work is supported by the National Natural Science Foundation of China (Grant No. 72101277) and the China Postdoctoral Science Foundation (Grant No. 2021M703664).
Author information
Authors and Affiliations
Contributions
H.F.: Conceptualization, Supervision, Investigation, Formal analysis, Writing - original draft. Y.J.: Conceptualization, Data curation, Writing - original draft. T.H.: Project administration, Conceptualization, Investigation, Formal analysis, Writing - original draft, Writing - review & editing. S.Z.: Data curation, Software, Writing - original draft. H.C.: Investigation, Data curation. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Feng, H., Jia, Y., Huang, T. et al. An adaptive decision support system for outpatient appointment scheduling with heterogeneous service times. Sci Rep 14, 27731 (2024). https://doi.org/10.1038/s41598-024-77873-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-77873-x
Keywords
This article is cited by
-
Reinforcement learning for healthcare operations management: methodological framework, recent developments, and future research directions
Health Care Management Science (2025)
