
Abstract
Quantum algorithms for solving noisy linear problems are reexamined, under the same assumptions taken from the existing literature. The findings of this work include on the one hand extended applicability of the quantum Fourier transform to the ring learning with errors problem which has been left open by Grilo et al., who first devised a polynomial-time quantum algorithm for solving noisy linear problems with quantum samples. On the other hand, this paper also shows there exist efficient classical algorithms for short integer solution and size-reduced learning with errors problems if the quantum samples used by the previous studies are given.
Similar content being viewed by others
Introduction
In designing algorithms, setting underlying assumptions on what one can and cannot do is a crucial starting point. Indeed in a study of quantum algorithms, seemingly innocent assumptions sometimes become the center of controversies, for example one in a blackbox query1,2, in a state preparation3, or on quantum random access memory4. Considering that the field is not in the mere proof-of-concept stage, it is a necessary task to examine such an assumption and evaluate its plausibility.
One of the rapidly growing fields in quantum technology is machine learning where researchers try to make the best use of physical phenomena in studying the patterns in data. Following the pioneering work on the quantum approach to learning parity with noise (LPN) problem by Cross et al5., an important milestone was achieved in 2019 by Grilo et al6. where the authors have proven that learning with errors (LWE) problem is efficiently solvable by using Bernstein-Vazirani (BV) algorithm7, if a certain form of a superposed data sample is available. The paper also investigated the applicability of the learning algorithm to LPN, ring learning with errors (RLWE), learning with rounding, and short integer solution (SIS) problems, although not all were successful. The algorithm was further revised in 2022 by utilizing the divide-and-conquer strategy, basically dealing with component-wise problems8.
As clearly noted by the authors of the paper6, it does not directly mean the end of some lattice based cryptography, as it is not clear how such a sample can be prepared. At the time of writing, there has been no known way to efficiently prepare such samples, but on the other hand, there has been no mathematical proof that an efficient way is nonexistent. To sum up, it is too early to be optimistic (or pessimistic) on the plausibility of the learning algorithms along the line.
Nevertheless, we have noticed in some occasions specific to two papers6,8, certain assumptions allow polynomial-time classical algorithms questioning their soundness, or the negative prospect given by the authors turns out to be feasible. This work is summarized as follows:
-
The LWE algorithm with quantum samples is extended to solve RLWE problem, which has been deemed to be infeasible under the error model by Bshouty and Jackson6,9.
-
It is shown that the quantum sample assumption in the SIS algorithm is stronger than that in LWE in the sense that a polynomial-time classical algorithm can be devised given the same sample introduced by the previous work.
-
Divide-and-conquer algorithm takes advantage of the component-wise approach to the secret vector, assuming size-reduced quantum samples8. We develop classical algorithms for the LWE problem given the same samples.
In the following, background information is covered prioritizing introduction to the LWE algorithm with quantum samples. New findings are then followed.
Preliminaries
This section first introduces cryptographic hard problems related with noisy linear learning, and reviews the (generalized) Bernstein-Vazirani (BV) algorithm7 for solving the LWE problem with quantum samples. Readers are assumed to be familiar with Bra-ket notation and the elementary quantum computation.
The following notation is used throughout the paper.
-
For \(q> 2\), \(\mathbb {Z}_q:= [-\frac{q}{2},\frac{q}{2}) \cap \mathbb {Z}\). For \(q=2\), \(\mathbb {Z}_2:= \{0,1\}\). We also define \(\mathbb {Z}^+ = \{ a \in \mathbb {Z}: a> 0\}\).
-
An inner product of two vectors \({\varvec{a}} = (a_0, a_1, \ldots , a_{n-1})\), \({\varvec{b}} = (b_0, b_1, \ldots , b_{n-1})\) is defined as follows:
$$\begin{aligned} \left<{\varvec{a}},{\varvec{b}}\right> = a_0 b_0 + a_1 b_1 + \cdots + a_{n-1} b_{n-1} \hspace{5.0pt}. \end{aligned}$$ -
Let \(x \leftarrow \chi\) denote a variable x taking a value according to the probability distribution \(\chi\), and let \(x_0,\ldots ,x_{l-1}{\mathop {\longleftarrow }\limits ^{i.i.d.}} \chi\) denote that \(x_0,\ldots ,x_{l-1}\) are sampled independently according to the probability distribution \(\chi\). Let \(\mathscr {U}(S)\) denote the uniform distribution on a set S. Let \(\mathscr {B}_\eta\) denote the Bernoulli distribution with parameter \(\eta \in [0,1/2)\) so that \(\Pr [x = b: x \leftarrow \mathscr {B}_\eta ] = b \!\cdot \! \eta + (1-b) \!\cdot \! (1-\eta )\) for \(b \in \{0,1\}\).
-
Let \(\textsf{poly}(x_1,\ldots ,x_m) = O(x_1^{c_1} \cdots x_m^{c_m})\) for some constants \(c_1,\ldots ,c_m\).
Hard problems
Here we describe cryptographic hard problems such as LPN, LWE, RLWE, and SIS. The hardness of these problems are guaranteed in the following sense: LPN problem can be seen as the average-case analogue of the decoding random linear codes which is NP-complete10, and LWE, RLWE, SIS problems are known to be at least as hard as certain lattice problems in worst-case11,12,13,14,15 when they are properly parameterized.
Learning parity with noise. Let \({\varvec{s}} \in \{0,1\}^n\) be a secret vector and let \(\eta \in [0,1/2)\) be a noise parameter. An LPN sample is given by
where \({\varvec{x}} \leftarrow \mathscr {U}(\{0,1\}^n)\) and \(e \leftarrow \mathscr {B}_\eta\). The (search) LPN problem asks to find the secret vector \({\varvec{s}} \in \{0,1\}^n\), given such LPN samples.
Learning with errors. The LWE problem is a generalization of the LPN problem. Let \({\varvec{s}} \in \mathbb {Z}_q^n\) be a secret vector where \(q \in \mathbb {Z}^+\), and let \(\chi _{\tiny lwe }\) be a probability distribution on \(\mathbb {Z}\), called error distribution. An LWE sample is given by
where \({\varvec{a}} \leftarrow \mathscr {U}(\mathbb {Z}_q^n)\) and \(e \leftarrow \chi _{\tiny lwe }\). The (search) LWE problem asks to find \({\varvec{s}}\), given such LWE samples.
Ring learning with errors.The RLWE problem is in general defined on a ring of integers of a number field, but for simplicity only polynomial rings are considered in this work. It is well-known that these two definitions are equivalent16.
The RLWE problem is similar to the LWE problem, but it deals with elements in the ring \(\mathscr {R}:= \mathbb {Z}[X]/\langle \phi (X)\rangle\) instead of a vector in \(\mathbb {Z}_q^n\), where \(\phi (X) \in \mathbb {Z}[X]\) is a monic irreducible polynomial of degree n. Let \(s(X) \in \mathscr {R}_q:= \mathscr {R} / q\mathscr {R}\) be a secret polynomial where \(q \in \mathbb {Z}^+\). Let \(\chi _{\tiny rlwe }\) be a probability distribution on \(\mathscr {R}\) which samples \(e(X) = \sum _{i=0}^{n-1} e_i X^i \in \mathscr {R}\) as \(e_0,\ldots ,e_{n-1} {\mathop {\longleftarrow }\limits ^{i.i.d.}} \chi\) using a probability distribution \(\chi\) on \(\mathbb {Z}\). An RLWE sample is given by
where \(a(X) \leftarrow \mathscr {U}(\mathscr {R}_q)\), \(e(X) \leftarrow \chi _{\tiny rlwe }\), and \(\cdot\), \(+\) denote multiplication and addition in \(\mathscr {R}\), respectively. The (search) RLWE problem asks to find s(X), given such RLWE samples.
Short integer solution. The SIS problem is defined as follows: given n uniformly selected random vectors \({\varvec{a}}_1,\ldots , {\varvec{a}}_n \in \mathbb {Z}_q^m\) for \(q \in \mathbb {Z}^+\), find a nonzero \({\varvec{v}} = (v_1,\ldots ,v_n) \in \mathbb {Z}^n\) such that
where \(\sqrt{n} q^{m/n} \le \beta < q\). The inhomogeneous version of SIS problem is to find a short \({\varvec{v}}\) such that \(\sum _{i=1}^n v_i {\varvec{a}}_i \equiv {\varvec{z}} \bmod q\) for given \({\varvec{z}} \in \mathbb {Z}_q^m\) where \(m < n\).
Bernstein-Vazirani algorithm

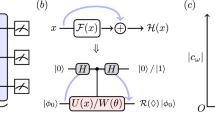
(a) A circuit description of BV algorithm and (b) its variant.
Binary case. Consider a vector \({\varvec{s}} \in \{0,1\}^n\) and a function \(f_{\varvec{s}}: \{0,1\}^n \rightarrow \{0,1\}\), \(f_{\varvec{s}}({\varvec{x}}) = \left<{\varvec{s}},{\varvec{x}}\right> \bmod 2\). The problem is, for given quantum oracle access to the unitary \(U_{f_{\varvec{s}}}:\left| {\varvec{x}} \,\right\rangle \left| 0 \,\right\rangle \mapsto \left| {\varvec{x}} \,\right\rangle \left| f_{\varvec{s}} ({\varvec{x}}) \,\right\rangle\), to find \({\varvec{s}}\).
Figure 1(a) describes a quantum circuit for the BV algorithm7,17. The initial state is \(\left| {\varvec{0}} \,\right\rangle \left| 1 \,\right\rangle\), and then applying the gates as shown in Figure 1 (a) achieves the goal. Details are not covered here, but the quantum state just before the measurement in Figure 1 (a) reads,
where \(\left| - \,\right\rangle = \frac{1}{\sqrt{2}}(\left| 0 \,\right\rangle - \left| 1 \,\right\rangle )\). As can be seen from Equation (1), when measuring \(\left| {\varvec{y}} \,\right\rangle\) register, the only non-trivial amplitude occurs for \({\varvec{y}} = {\varvec{s}}\), and there does not exist any chance of measuring a string other than \({\varvec{s}}\). Assuming single qubit gates are simultaneously executable and the query is efficient, the time complexity of the algorithm is O(1).
Slightly different circuit is introduced in Figure 1 (b). Using this circuit, the state before the measurement reads,
Notice that the Hadamard gate acting on the bottom wire is redundant, but only there to make Equation (2) simple. It can be seen from Equation (2) that measuring the first register gives \({\varvec{s}}\) with probability 1/2. The procedure can simply be repeated until we get \({\varvec{s}}\).
Generalized BV algorithm. Instead of qubits, consider q-dimensional qudits. Each wire in Figure 1 represents q-dimensional complex vectors and Hadamard gate is accordingly generalized18. Recall that generalized Hadamard operation can be understood as quantum Fourier transform on \(\mathbb {Z}_q\)19 such as
We are ready to describe the generalized BV algorithm. Notice that after the query in Figure 1 (b), we would have \(\frac{1}{\sqrt{q^n}} \sum _{{\varvec{x}} \in \mathbb {Z}_q^n} \left| {\varvec{x}} \,\right\rangle \left| f_{{\varvec{s}}}({\varvec{x}}) \,\right\rangle\) where \(f_{{\varvec{s}}}: \mathbb {Z}_q^n \rightarrow \mathbb {Z}_q\), \(f_{{\varvec{s}}}({\varvec{x}}) = \left<{\varvec{s}},{\varvec{x}}\right> \bmod q\). Instead of specifying a circuit for preparing such states, we simply define a quantum sample \(\left| \psi \,\right\rangle \in (\mathbb {C}^q)^{n+1}\), and take it as an input to the BV algorithm as follows:

\(\textsf{BV}_{q,n}\).
One may think of the input \(\left| \psi \,\right\rangle\) as what we get by querying an oracle \(\mathscr {O}_{\varvec{s}}\). This algorithm will be the core subroutine in the learning algorithms.
At this point, it will be a natural question to ask if the algorithm still works for noisy input samples. The main contribution of the previous work6 is to answer the question as briefly reviewed below.
LWE algorithm with quantum samples
Let \({\varvec{s}} \in \mathbb {Z}_q^n\) be a secret vector and let \(\mathscr {V} \subseteq \mathbb {Z}_q^n\). A quantum LWE sample for \({\varvec{s}}\) and \(\mathscr {V}\), denoted by \(\displaystyle \left| \psi ^{\tiny lwe }_{{\varvec{s}},\mathscr {V}} \,\right\rangle\), is defined as follows:
where \(\chi _{\tiny lwe }\) is a probability distribution on \(\mathbb {Z}\). We assume that the support of \(\chi _{\tiny lwe }\) is \([-k,k] \cap \mathbb {Z}\) for some small positive integer k, i.e. \(|e_{{\varvec{a}}}| \le k\). Define a quantum oracle \(\mathscr {O}^{\tiny lwe }_{{\varvec{s}},\mathscr {V}}\) which outputs \(\displaystyle \left| \psi ^{\tiny lwe }_{{\varvec{s}},\mathscr {V}} \,\right\rangle\) when queried.
Given access to the quantum oracle \(\mathscr {O}^{\tiny lwe }_{{\varvec{s}},\mathscr {V}}\), one can find the secret vector \({\varvec{s}}\) by using the \(\textsf{qLWE}- \textsf{Solver}\) described in Algorithm 2 (see below). The subroutine \(\textsf{Test}\) in Algorithm 2 is designed to check if the candidate \(\tilde{{\varvec{s}}}\) is indeed the secret vector \({\varvec{s}}\) by using additional LWE samples. Note that in Algorithm 3 the oracle \(\mathscr {O}^{\tiny lwe }_{{\varvec{s}}, \mathscr {V}}\)can be quantum or classical. Detailed analysis on Algorithm 2 is not covered here. Interested readers are encouraged to refer to Section IV B in the previous paper6. Results and parameter choices are summarized as follows. Probability that \(\textsf{BV}_{q,n}(\displaystyle \left| \psi ^{\tiny lwe }_{{\varvec{s}},\mathscr {V}} \,\right\rangle )\) returns the correct secret \({\varvec{s}}\) is lower bounded by \(\mathrm {\Omega }\! \left( {|\mathscr {V}|}/({kq^n}) \right)\). If \(\tilde{{\varvec{s}}} = {\varvec{s}}\), \(\textsf{Test}\) returns 1 (pass) with certainty. If \(\tilde{{\varvec{s}}} \ne {\varvec{s}}\), the probability that 1 is returned is at most \(\left( ({2k \!+\! 1}) / {q} \right) ^{\! \ell _2}\). By setting \(\mathscr {V} = \mathbb {Z}_q^n\), \(\ell _1 = O(k \log (1/\eta ))\), and \(\ell _2 = 1\), we have
-
success probability: \(1 - \eta\)
-
sample complexity: \(O(k \log (1/\eta ))\)
-
time complexity: \(O( k \log (1/\eta ) \cdot \textsf{poly}(n,\log q))\).
In the last item, the time complexities of sample preparation (i.e. oracle query), \(\textsf{BV}_{q,n}\), and \(\textsf{Test}\) are assumed to be O(1), \(\textsf{poly}(n,\log q)\), and \(\textsf{poly}(n,\log q)\), respectively.

\(\textsf{qLWE}- \textsf{Solver}\).

\(\textsf{Test.}\)
Revisiting previous works
This section presents new results. The first finding is about the solvability of the RLWE problem by reducing it to LWE. The second and third findings involve the development of efficient classical algorithms for SIS and size-reduced LWE problems under certain assumptions.
The purpose of the second and the third results is to show the following: if the assumptions on quantum samples taken in the previous works do hold, and then there also exist polynomial-time classical algorithms. A handful of classical algorithms are introduced below, but before presenting the results, we are urged to clarify the meaning of the word ‘classical’ here. In Result 2 and Result 3, we begin with quantumsamples assumed in respective previous works6,8. We do not question or evaluate the practicality of preparing quantum samples, but rather immediately carry out the measurement in computational basis. Each measurement gives rise to one classical sample that is put as an input to classical algorithms we develop. Therefore in estimating the complexity of classical algorithms, the number of samples used should be read as the number of quantum samples assumed.
Result 1: RLWE algorithm with quantum samples
The goal of this subsection is to solve the RLWE problem given that the LWE problem is solvable by Algorithm 2. Applying Algorithm 2 to RLWE problem was originally unsuccessful by the authors of6, Section V. Below the RLWE problem with quantum samples is reduced to LWE by efficiently transforming a RLWE sample to an LWE sample. The reduction utilizes linearity of operations in \(\mathscr {R}\). To be more specific, a RLWE sample is transformed to an LWE sample in a way that the coefficients of a polynomial become a vector. The LWE algorithm described in the previous section is then applied to recover s(X).
Let \({\varvec{s}}(X)\) be a secret polynomial and let \(\mathscr {V} \subseteq \mathscr {R}_q\). A quantum RLWE sample for \({\varvec{s}}\) and \(\mathscr {V}\), denoted by \(\displaystyle \left| \psi ^{\tiny rlwe }_{{\varvec{s}},\mathscr {V}} \,\right\rangle\) is defined as follows:
where \(\chi _{\tiny rlwe }\) is a probability distribution on \(\mathscr {R}\) which samples \(e_a(X) = \sum _{i=0}^{n-1} e_{a,i} X^i\) as \(e_{a,0},\ldots ,e_{a,n-1} {\mathop {\longleftarrow }\limits ^{i.i.d.}} \chi\) using a probability distribution \(\chi\) on \(\mathbb {Z}\).
Transform from \(\mathscr {R}_q\) to \(\mathbb {Z}_q^n\). Recall that the polynomial ring \(\mathscr {R}\) is defined as \(\mathscr {R} = \mathbb {Z}[X]/\langle \phi (X) \rangle\). Let us consider a (row) vector and a matrix constructed from a polynomial \(a(X) = \sum _{i=0}^{n-1} a_i X^i\) as follows:
where \(\cdot\) is a multiplication of polynomials. Let \(\phi (X) = X^n - \sum _{i=0}^{n-1} \phi _i X^i\) and define
We then have a useful lemma.
Lemma 1
For any \(a(X), b(X) \in \mathscr {R}\), the following relations hold:
Proof
Straightforwardly,
which verifies the first equation.
Next, from \(\phi (X) = X^n - \sum _{i=0}^{n-1} \phi _i X^i\), we have \(X^n \equiv \sum _{i=0}^{n-1} \phi _i X^i \bmod \phi\), and thus
Therefore,
the second equation holds. \(\square\)
Let \(\textbf{M}^T\) denote the transpose of \(\textbf{M} \in \mathbb {R}^{l \times m}\). Let \((j+1)\)-th column vector of \(\textbf{M} \in \mathbb {R}^{l \times m}\) be denoted by \(\textbf{M}_j \in \mathbb {R}^{l \times 1}\) so that \(\textbf{M}\) can be written as \(\textbf{M} = \left( \textbf{M}_0 \,\vert \, \cdots \,\vert \, \textbf{M}_{m-1} \right)\). In particular, when \(l = 1\), \(\textbf{M}_j\) denotes the \((j+1)\)-th coordinate of the row vector \(\textbf{M}\). From Lemma 1, the matrix \(\textsf{M}_\phi (b)\) can be written as
which shows that
RLWE to LWE. Let \({\varvec{a}} = \textsf{V}(a)\) for \(a\in \mathscr {R}\). Define a unitary operation,
where,
We see that the operation is efficiently computable as any power of \(\textbf{P}\) can be classically pre-computed by knowing the fixed polynomial \(\phi (X)\).
Now let \({\varvec{s}} = \textsf{V}(s)\) and \({\varvec{e}}_a = (e_{a,0},\ldots ,e_{a,n-1}) = \textsf{V}(e_a)\). By Lemma 1, Equation (4), and the linearity of \(\textsf{V}\), we have
For a given quantum RLWE sample, we apply the following transformations:
where \(\bmod \;q\) is omitted in the third register. Uncomputing irrelevant information, we have a quantum sample with secret \({\varvec{s}}\):
Alternatively, interchanging the role of a(X) and s(X) in the transformation, we have a quantum sample with secret \({\varvec{s}}_j\):
where,
In either case, the LWE algorithm is then applied to solve the problem.
Result 2: a classical algorithm for SIS problem
We develop an efficient classical algorithm for solving SIS given that the following quantum sample is provided. In6, Appendix B, a quantum sample for SIS is defined by,
where \({\varvec{v}}\in \mathbb {Z}^n\) is a short secret vector such that \(0<\Vert {\varvec{v}} \Vert \le \beta\). The authors have developed a polynomial time quantum algorithm for finding \({\varvec{v}}\) by using \(O(2n\beta )\) quantum samples. The detailed description of the algorithm is not covered here. Instead, let us focus on the problem itself. From the definition of the SIS problem, we are given an under-determined system of equations (\(m < n\)). Hardness of the SIS problem comes from the fact that among the exponentially many solutions (\(\Omega (q^{n-m})\)), there exists no known way to choose a short one within polynomial time.
Assuming the SIS quantum sample in Equation (5) is obtainable, an efficient classical algorithm can be designed. Notice that by measuring a quantum sample, one obtains a classical sample \((\textbf{A},\textbf{A} {{\varvec{v}}}) \in \mathbb {Z}_q^{m \times n} \times \mathbb {Z}_q^m\). Prepare \(t = \Omega (n/m)\) classical samples of the form \(({\varvec{A}}^{(i)},{\varvec{z}}^{(i)}) \in \mathbb {Z}_q^{m\times n} \times \mathbb {Z}_q^m\) which satisfies \({\varvec{A}}^{(i)} {\varvec{v}} \equiv {\varvec{z}}^{(i)} \bmod q\) for some nonzero vector \({\varvec{v}} \in \mathbb {Z}^n\) with \(\Vert {\varvec{v}} \Vert \le \beta\). Each classical sample leads to m linear equations (be reminded that one quantum sample leads to one classical sample, and one classical sample here corresponds to m linear equations),
where \(A^{(i)}_{kl}\) is the kth row, lth column element of \(\textbf{A}^{(i)}\), and \(v_k\), \(z_k^{(i)}\) are the kth elements of \({\varvec{v}}\) and \({\varvec{z}}^{(i)}\), respectively. Therefore the total number of linear equations reads \(mt = \Omega (n)\). Since there are n unknowns while we have \(\Omega (n)\) equations, we can find the secret vector \({\varvec{v}}\) by solving the system of equations using Gaussian elimination within \(O(n^3)\) time. The total number of (quantum) samples used is \(\Theta (n/m)\).
Result 3: classical algorithms for size-reduced LWE problem
Song et al. have published a paper in 2022 which improved the result of Grilo et al. assuming a resized sample8. In a nutshell, the improved algorithm and Algorithm 2 work similarly except for the resized samples. Therefore, here we drop the details on the algorithm and jump right into the discussion on the resized sample. Recall first that an LWE sample is \(({\varvec{a}}, b = \left<{\varvec{s}},{\varvec{a}}\right> + e \bmod q) \in \mathbb {Z}_q^{n} \times \mathbb {Z}_q\), \(\vert e \vert \le k\).
Let \(\mathscr {V}_j \subseteq \mathbb {Z}_q\), \({\varvec{s}} = (s_0,\ldots , s_{n-1}) \in \mathbb {Z}_q^n\), and consider the noise model \(\chi _{\tiny lwe }\) as a discrete uniform or a bounded Gaussian distribution in the interval \([-\xi ,\xi ]\) around zero with \(\xi \ll q\). Assume a resized quantum sample examined by8, Equation (9) is given,
where \(e_j'\)is derived according to8, Equation (4)-(8) satisfying,
Below two classical algorithms are introduced assuming the resized samples are given.
Search on the error
We first introduce an algorithm that exhaustively searches the ‘correct error’. Given a resized sample, an immediate (classical) strategy would be to exhaustively search \(s_j\) with O(qn) complexity (in which the scenario is indeed discussed in8, Discussion), but a more sophisticated search would be to examine the error.
Consider an oracle \(\mathscr {O}^{\tiny resized }_{s_j, \mathscr {V}_j}\) which on query returns the (measured) resized sample of the jth component \((a_j', b_j')\), where \(b_j' = a_j' s_j + e_j' \bmod q\). Given access to the oracle, Algorithm 4 is developed.

\(\textsf{SearchError.}\)

\(\mathsf {e-\! Test.}\)
If \(\tilde{e}_j' = e_j'\), then replacing \(b_j'\) in Line 5 by \(a_j' s_j + e_j' \bmod q\) affirms \(\tilde{s}_j = s_j\). Since the error is exhaustively searched within the range \(-\xi ' \le e_j' \le \xi '\), Algorithm 4 eventually outputs the correct \(\tilde{s}_j (= s_j)\) with time complexity \(O(\xi ')\), as long as the probability that wrong \(\tilde{s}_j (\ne s_j)\) passes the test is low enough. If \(\tilde{s}_j \ne s_j\), for a random sample \((a_j'', b_j'')\), the probability that \(|b_j'' - a_j'' \tilde{s}_j \bmod q| \le \xi '\) holds is \((2 \xi ' + 1 )/ q\). Therefore, such \(\tilde{s}_j \ne s_j\) will pass \(\mathsf {e\text {-}Test}\) with the probability \(((2\xi '+1) / q)^M\).
In the previous work8, the probability that the BV subroutine outputs \(\tilde{s}_j = s_j\) is \(\Omega (1/\xi ')\)(8, Equation (17) with \(|v_j| \approx q\)), thus \(O(\xi ')\) repetitions of the subroutine would give the correct \(\tilde{s}_j( = s_j)\). The probability that their M-trial test accepts an incorrect answer is at most \(((2\xi ' + 1)/q)^M\)as in8, Equation (12).
One may notice that the two algorithms have similar upper bounds on the number of repetitions (of error guessing in Algorithm 4 and BV subroutine in8, Section 3). Moreover, the probability that an incorrect candidate passes the \(\mathsf {e\text {-}Test}\) and M-trial test is exactly the same. Direct comparison of the two algorithms is not immediate due to the differences in approaches (e.g., exhaustive or else) and unit computations (quantum or classical), but it is plausible to assess the two as similar in performance. Except for the query, Algorithm 4 works classically.
Lattice reduction
There is another way to find \(s_j'\) using techniques in lattice theory. Given two classical samples \((a_{j,k}', b_{j,k}' = a_{j,k}' s_j + e_{j,k}' \bmod q)\) for \(k = 1, 2\), consider two-dimensional vectors \({\varvec{a}}_j' = (a_{j,1}', a_{j,2}')\), \({\varvec{b}}_j' = (b_{j,1}', b_{j,2}')\), \({\varvec{e}}_j' = (e_{j,1}', e_{j,2}')\). Then by the construction, we know there is a vector \({\varvec{v}} \in \mathbb {Z}^2\) such that \({\varvec{v}} \equiv s_j {\varvec{a}}_j' \bmod q\) and \(\Vert {\varvec{b}}_j' - {\varvec{v}} \Vert = \Vert {\varvec{e}}_j' \Vert\). In particular, the vector \({\varvec{v}}\) is very close to \({\varvec{b}}_j'\) since \(\Vert {\varvec{e}}_j' \Vert \le \sqrt{2} \xi '\) is small. Furthermore, notice that a set \(\{ {\varvec{w}} \in \mathbb {Z}^2: {\varvec{w}} \equiv x {\varvec{a}}_j' \bmod q, x \in \mathbb {Z}\}\) constitutes a lattice in which \({\varvec{v}}\) is included. In other words, for given \({\varvec{b}}_j'\), finding \(s_j\) can be solved by looking for a lattice vector that is closest to \({\varvec{b}}_j'\), known as the closest vector problem (CVP).
In general, the CVP is hard to solve, that is, it takes time exponential in the lattice dimension. However in our case, it is sufficient to solve the CVP over a two-dimensional lattice, which is tractable by using the Babai’s nearest plane algorithm with a short basis computed by the Lagrange-Gauss algorithm.
Lagrange-Gauss algorithm. This algorithm is useful for finding a shortest basis of a lattice in two-dimension. We say that an ordered basis \({\varvec{g}}_1, {\varvec{g}}_2\) of a lattice L is Lagrange-Gauss reduced if \(\Vert {\varvec{g}}_1 \Vert \le \Vert {\varvec{g}}_2 \Vert \le \Vert {\varvec{g}}_2 + z {\varvec{g}}_1 \Vert\) for all \(z \in \mathbb {Z}\). It can be shown that if a basis \({\varvec{g}}_1, {\varvec{g}}_2\) of a lattice L is Lagrange-Gauss reduced, then \(\Vert {\varvec{g}}_i \Vert = \lambda _i(L)\), where \(\lambda _i(L)\) is the ith successive minimum of L20, Chapter 17. This basis can be computed efficiently by Algorithm 6.

\(\textsf{LagrangeGauss.}\)
Detailed analysis of the algorithm can be found in20, Chapter 17. The time complexity of the algorithm is known to be \(O(\log ^3 (\max _i{\Vert {\varvec{g}}_i \Vert ^2}) )\), where \({\varvec{g}}_i\) are inputs.
Nearest plane algorithm. The algorithm is for solving CVP. Let \({\varvec{g}}_1, \ldots , {\varvec{g}}_n \in \mathbb {R}^n\) be basis vectors of a lattice L. Given a target vector \({\varvec{t}} \in \mathbb {R}^n\), we are asked to find a vector \({\varvec{v}} \in L\) such that \(\Vert {\varvec{t}} - {\varvec{v}} \Vert\) is minimized.
Babai’s nearest plane algorithm gives an approximate solution to CVP21 in general dimension. Intuitively, what it does is to fix some basis vectors and then find a linear combination of remaining vectors such that it is closest to the projected \({\varvec{u}}\)onto the hyperplane spanned by the fixed basis. Algorithm 7 describes the nearest plane algorithm in dimension 2. We refer to20, Chapter 18 for general dimension.

\(\textsf{NearestPlane.}\)
Proposition 1
Let \({\varvec{g}}_1, {\varvec{g}}_2 \in L\), and \({\varvec{t}} \in \mathbb {R}^2\) be inputs to Algorithm 7 and let \(\textbf{g}_1^*, \textbf{g}_2^*\) be Gram-Schmidt orthogonalized vectors of \({\varvec{g}}_1,{\varvec{g}}_2\). If there exists \({\varvec{w}} \in L\) such that \(\Vert {\varvec{t}} - {\varvec{w}} \Vert < \frac{1}{2} \min _{i\in \{1,2\}}(\Vert \textbf{g}_i^* \Vert )\), then Algorithm 7outputs \({\varvec{w}}\).
Proof
Let \({\varvec{v}} = z_1 {\varvec{g}}_1 + z_2 {\varvec{g}}_2\) be the output of Algorithm 7, and let \({\varvec{t}}_1, {\varvec{t}}_2\) be vectors as in the algorithm. Assume there exists \({\varvec{w}}\) such that \({\varvec{w}} = w_1 {\varvec{g}}_1 + w_2 {\varvec{g}}_2 = {\varvec{t}} - {\varvec{e}}\) for some \(w_1, w_2 \in \mathbb {Z}\) and \(\Vert {\varvec{e}} \Vert < \frac{1}{2} \min _{i\in \{1,2\}}(\Vert \textbf{g}_i^* \Vert )\). Then we have a useful bound on \(\vert \langle {\varvec{e}}, \textbf{g}_i^*\rangle \vert / \Vert \textbf{g}_i^* \Vert ^2\) for \(i=1,2\),
Recall that \({\varvec{t}}_2 = {\varvec{t}} = {\varvec{w}} + {\varvec{e}}\). From
we see that \(z_2 = \bigg \lfloor \frac{\langle {\varvec{t}}_2, \textbf{g}_2^*\rangle }{\Vert \textbf{g}_2^* \Vert ^2} \bigg \rceil = w_2\) due to Equation (7). Similarly, recalling \({\varvec{t}}_1 = {\varvec{t}} - z_2 {\varvec{g}}_2\) and from
we have \(z_1 = \bigg \lfloor \frac{\langle {\varvec{t}}_1, \textbf{g}_1^*\rangle }{\Vert \textbf{g}_1^* \Vert ^2} \bigg \rceil = w_1\), proving \({\varvec{v}} = {\varvec{w}}\). \(\square\)
The time complexity of Algorithm 7 is \(O(\log ^2 B )\) where \(B = \max \{\Vert {\varvec{g}}_1 \Vert ,\Vert {\varvec{g}}_2 \Vert \}\).
Finding \(s_j\) by lattice reduction. In addition to the above algorithms, we adopt Gaussian heuristic which predicts that the number of lattice points inside a measurable set \(\mathscr {B} \subset \mathbb {R}^n\) is approximately equal to \({\text {Vol}}(\mathscr {B}) / {\text {Vol}}(L)\) where L is a full-rank lattice in \(\mathbb {R}^n\) and \({\text {Vol}}(L):= \det (L)\). Gaussian heuristic is widely used in analyzing the performance of lattice-related algorithms. Applied to Euclidean ball in dimension n, we expect the length of a nonzero shortest vector in a random lattice L to be approximately,
We are now ready to describe the method. Suppose we are given two classical samples \((a_{j,k}', b_{j,k}' = a_{j,k}' s_j + e_{j,k}' \bmod q)\) for \(k = 1, 2\), by measuring the resized quantum samples. Assume that \(a_{j,1}'\) is invertible in \(\mathbb {Z}_q\). Let \({\varvec{a}} = (a_{j,1}',a_{j,2}')\) and consider the following lattice:
where \(\bmod ~ q\) applies to each component. Notice that by letting \({\varvec{v}} = (v_1, v_2) \equiv x {\varvec{a}}\) for some \(x \in \mathbb {Z}\), we have \(x \equiv (a_{j,1}')^{-1} v_1 \bmod q\). This shows that two vectors \(\textbf{b}_1 = (1, (a_{j,1}')^{-1} a_{j,2}' \bmod q)\) and \(\textbf{b}_2 = (0, q)\) form a basis of \(\mathscr {L}\), that is,
and thus \(\dim (\mathscr {L}) = 2\), \(\det (\mathscr {L}) = \det \!\big (\big [{\begin{array}{c} {\textbf{b}_1} \\ {\textbf{b}_2} \end{array}}\big ]\big ) = q\). As explained earlier, the purpose of introducing \(\mathscr {L}\) is to reduce finding \(s_j\) to solving CVP: if one manages to find \({\varvec{v}} \in \mathscr {L}\) that is close to \({\varvec{b}} = (b_{j,1}', b_{j,2}')\), then the error is obtained by \({\varvec{e}} = {\varvec{b}} - {\varvec{v}}\).
By using Lagrange-Gauss algorithm with inputs \(\textbf{b}_1, \textbf{b}_2\), we have basis vectors \({\varvec{g}}_1, {\varvec{g}}_2 \in \mathscr {L}\) such that \(\Vert {\varvec{g}}_i \Vert = \lambda _i(\mathscr {L})\) for \(i = 1, 2\). Assuming the Gaussian heuristic holds, \(\lambda _1(\mathscr {L}) = \Vert {\varvec{g}}_1 \Vert \approx \sqrt{\det (\mathscr {L})} = \sqrt{q}\). Let \(\textbf{g}_1^*, \textbf{g}_2^*\) be Gram-Schmidt orthogonalized vectors of \({\varvec{g}}_1,{\varvec{g}}_2\). Due to the properties of Gram-Schmidt orthogonalized vectors, we know that \({\varvec{g}}_1 = \textbf{g}_1^*\) and \(\det (\mathscr {L}) = \det \!\big (\big [{\begin{array}{c} {\textbf{b}_1} \\ {\textbf{b}_2} \end{array}}\big ]\big ) = \det \!\big (\big [{\begin{array}{c} {\textbf{g}_1^*} \\ {\textbf{g}_2^*} \end{array}}\big ]\big ) = \Vert \textbf{g}_1^* \Vert \Vert \textbf{g}_2^* \Vert\). Therefore, \(\Vert \textbf{g}_2^* \Vert \approx \sqrt{q}\).
Since \({\varvec{b}} \equiv s_j {\varvec{a}} + {\varvec{e}} \bmod q\), we have \({\varvec{b}} = s_j {\varvec{a}} + {\varvec{e}} + q {\varvec{l}}\) for some \({\varvec{l}} \in \mathbb {Z}^2\) and \(\Vert {\varvec{b}} - (s_j {\varvec{a}} + q{\varvec{l}}) \Vert = \Vert {\varvec{e}} \Vert\). Thus, if \(\Vert {\varvec{e}} \Vert < \frac{1}{2}\min \{\Vert \textbf{g}_1^* \Vert , \Vert \textbf{g}_2^* \Vert \} \approx \frac{1}{2}\sqrt{q}\), then taking \({\varvec{g}}_1, {\varvec{g}}_2\) and \({\varvec{b}}\) as inputs, Babai’s algorithm outputs the vector \({\varvec{w}} = s_j {\varvec{a}} + q {\varvec{l}}\) by Proposition 1. Computing \({\varvec{w}} \bmod q\) then yields \(s_j {\varvec{a}} \bmod q\), from which we recover \(s_j\). Indeed, since \(|e_{j,i}'| \le \xi '\) (i.e., \(\Vert {\varvec{e}} \Vert \le \sqrt{2} \xi '\)), a condition for the algorithm to work is
In the previous paper, the authors assume \(\xi ' \ll q\), thus Equation (8) likely holds. Considering the complexity of each subroutine algorithm, the total running time is \(\textsf{poly}(\log (q))\).

Success rate of the proposed algorithm as a function of the error bound for (a) \(q=3329\) (Kyber) and for (b) \(q=2^{23} -2^{13} + 1\) (Dilithium). In each figure, the condition given by Equation (8) is around 20 and 1023, respectively. In (b), the interval in the horizontal axis is 10.
The above analysis relies on Gaussian heuristic which is not guaranteed to work beneficially on every instance. To verify the validity of the approach, numerical tests are carried out summarized in Figure 2. Each subfigure shows the success rate of the lattice reduction method for chosen modulus qfrom Kyber22and Dilithium23, respectively. For each error bound \(\xi '\), the following procedure is conducted 1000 times: a pair of resized samples is produced randomly (including the secret) and the algorithm is applied to output a candidate for the secret. The success rate is the number of times the algorithm correctly outputs the secret divided by 1000. As can be seen from the figure, the algorithm succeeds better as the bound gets smaller. There is a chance that the algorithm fails for small \(\Vert {\varvec{e}} \Vert\) due to unusually short Gram-Schmidt vectors, but such cases can be overcome by getting another sample and trying a different lattice.
Conclusion
A definitive conclusion on whether the linear learning algorithms will be immediately useful once a powerful quantum computer is ready is not yet drawn from this work, but we have shown that the RLWE problem can be tackled if LWE is indeed solvable quantumly. In addition, it is also shown that assumptions taken in solving SIS and size-reduced LWE problems lead to efficient classical algorithms, implying that the previously claimed quantum advantages need to be reexamined. A further multidisciplinary study on the subject may estimate the true feasibility of the algorithms.
Data availibility
All data generated or analysed during this study are included in this published article.
References
Brassard, G., Høyer, P. & Tapp, A. Quantum cryptanalysis of hash and claw-free functions. In LATIN’98: Theoretical Informatics, 163–169 (Springer (eds Lucchesi, C. L. & Moura, A. V.) (Berlin Heidelberg, Berlin, Heidelberg, 1998).
Chailloux, A., Naya-Plasencia, M. & Schrottenloher, A. An efficient quantum collision search algorithm and implications on symmetric cryptography. In Takagi, T. & Peyrin, T. (eds.) Advances in Cryptology – ASIACRYPT 2017, 211–240 (Springer International Publishing, Cham,) (2017).
Aaronson, S. Read the fine print. Nature Physics 11, 291–293. https://doi.org/10.1038/nphys3272 (2015).
Jaques, S. & Rattew, A. G. Qram: A survey and critique. arXiv preprint arXiv:2305.10310 (2023).
Cross, A. W., Smith, G. & Smolin, J. A. Quantum learning robust against noise. Phys. Rev. A 92, 012327. https://doi.org/10.1103/PhysRevA.92.012327 (2015).
Grilo, A. B., Kerenidis, I. & Zijlstra, T. Learning-with-errors problem is easy with quantum samples. Phys. Rev. A 99, 032314. https://doi.org/10.1103/PhysRevA.99.032314 (2019).
Bernstein, E. & Vazirani, U. Quantum complexity theory. In Proceedings of the Twenty-Fifth Annual ACM Symposium on Theory of Computing, STOC ’93, 11–20, https://doi.org/10.1145/167088.167097 (Association for Computing Machinery, New York, NY, USA,) (1993).
Song, W. et al. Quantum solvability of noisy linear problems by divide-and-conquer strategy. Quantum Science and Technology 7, 025009. https://doi.org/10.1088/2058-9565/ac51b0 (2022).
Bshouty, N. H. & Jackson, J. C. Learning dnf over the uniform distribution using a quantum example oracle. In Proceedings of the Eighth Annual Conference on Computational Learning Theory, COLT ’95, 118–127, https://doi.org/10.1145/225298.225312 (Association for Computing Machinery, New York, NY, USA,) (1995).
Berlekamp, E., McEliece, R. & van Tilborg, H. On the inherent intractability of certain coding problems (corresp.). IEEE Transactions on Information Theory 24, 384–386 (1978).
Regev, O. On lattices, learning with errors, random linear codes, and cryptography. In Proceedings of the Thirty-Seventh Annual ACM Symposium on Theory of Computing, STOC ’05, 84–93, https://doi.org/10.1145/1060590.1060603 (Association for Computing Machinery, New York, NY, USA,) (2005).
Brakerski, Z., Langlois, A., Peikert, C., Regev, O. & Stehlé, D. Classical hardness of learning with errors. In Boneh, D., Roughgarden, T. & Feigenbaum, J. (eds.) Symposium on Theory of Computing Conference, STOC’13, Palo Alto, CA, USA, June 1-4, 2013, 575–584, https://doi.org/10.1145/2488608.2488680 (ACM, 2013).
Lyubashevsky, V., Peikert, C. & Regev, O. On ideal lattices and learning with errors over rings. In Advances in Cryptology - EUROCRYPT 2010, 1–23 (Springer (ed. Gilbert, H.) (Berlin Heidelberg, Berlin, Heidelberg,) (2010).
Ajtai, M. Generating hard instances of lattice problems (extended abstract). In Miller, G. L. (ed.) Proceedings of the Twenty-Eighth Annual ACM Symposium on the Theory of Computing, Philadelphia, Pennsylvania, USA, May 22-24, 1996, 99–108, https://doi.org/10.1145/237814.237838 (ACM, 1996).
Micciancio, D. & Regev, O. Worst-case to average-case reductions based on gaussian measures. SIAM J. Comput. 37, 267–302. https://doi.org/10.1137/S0097539705447360 (2007).
Rosca, M., Stehleé, D. & Wallet, A. On the ring-lwe and polynomial-lwe problems. In Nielsen, J. B. & Rijmen, V. (eds.) Advances in Cryptology - EUROCRYPT 2018 - 37th Annual International Conference on the Theory and Applications of Cryptographic Techniqeus, Tel Aviv, Israel, April 29 - may 3, 2018 Proceedings, Part I, vol. 10820 of Lecture Notes in Computer Science, 146–173 (Springer, 2018).
Deutsch, D. & Jozsa, R. Rapid solution of problems by quantum computation. Proceedings of the Royal Society of London. Series A: Mathematical and Physical Sciences 439, 553–558, https://doi.org/10.1098/rspa.1992.0167 (1992). https://royalsocietypublishing.org/doi/pdf/10.1098/rspa.1992.0167.
Wang, Y., Hu, Z., Sanders, B. C. & Kais, S. Qudits and high-dimensional quantum computing. Frontiers in Physics 8, https://doi.org/10.3389/fphy.2020.589504 (2020).
Kaye, P., Laflamme, R. & Mosca, M. An Introduction to Quantum Computing (Oxford University Press Inc, USA, 2007).
Galbraith, S. Mathematics of Public Key Cryptography (Cambridge University Press,) (2012).
Babai, L. On lovász’ lattice reduction and the nearest lattice point problem. Combinatorica 6, 1–13. https://doi.org/10.1007/BF02579403 (1986).
Avanzi, R. et al. Crystals-kyber algorithm specifications and supporting documentation. NIST PQC Round 3 (2021).
Bai, S. et al. Crystals-dilithium algorithm specifications and supporting documentation. NIST PQC Round 3 (2021).
Author information
Authors and Affiliations
Contributions
M.K. conceived ideas, M.K. and P.K. participated in analysis and writing the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Kim, M., Kim, P. Assessing the feasibility of quantum learning algorithms for noisy linear problems. Sci Rep 14, 29160 (2024). https://doi.org/10.1038/s41598-024-78386-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-78386-3
