
Abstract
Hyperspectral data and machine learning offer great potential for identifying valuable open ecosystems. Due to the large volume of data, preprocessing of hyperspectral images must involve dimensionality reduction. The main goal of this study was to test the effectiveness of various types of feature reduction (feature selection and feature extraction) when performing classification using the Random Forest algorithm. A comparison was conducted between two ecosystems - heathlands and mires protected as Natura 2000 habitats. Two transformations of feature extraction were chosen, namely Minimum Noise Fraction (MNF) and Principal Component Analysis (PCA), while Linear Discriminant Analysis (LDA) was used as a feature selection method. It was proven that irrespective of the class type, accuracy is higher with the feature extraction method (mean F1 accuracy of 0.922) than with feature selection (mean F1 accuracy of 0.787). At the same time, no significant differences in accuracies were found between the MNF and PCA methods. Although LDA resulted in lower accuracies (0.816 for heathland and 0.750 for mires), the method could also be used due to relatively high F1 values. The effectiveness of the LDA method for feature reduction in open ecosystem identification was confirmed for the first time for open natural vegetation.
Similar content being viewed by others

Introduction
Aerial hyperspectral (HS) data analysed using machine learning (ML) techniques are one of the best sources of highly accurate information on valuable ecosystems. The high accuracy of these methods results in the vegetation in large, protected areas already being mapped using remote sensing1. Heathlands and mires are one of the areas often identified by remote sensing techniques. According to studies published in recent years, the accuracies for mapping of these ecosystems can be predicted1,2,3,4,5.
Current hyperspectral images consist of hundreds of spectral bands, which result in a spectrally continuous reflectance curve. The scanners are characterised by a very high radiometric resolution to record the differences between objects in very narrow spectral bands. The result of narrow bands is a lower signal-to-noise ratio compared with multispectral images, and high spectral and radiometric resolutions. These indicate a large volume of data, which increases processing time and limits the operational use of the data. In addition, information in adjacent spectral bands is repetitive. Ongoing analysis, evaluation of strategies and approaches to dimensionality reduction or automatic band selection remain an open question6,7. Therefore, before the ML analyses, a feature reduction process is usually carried out.
In the case of implementation works in areas covering several hundred square kilometres, such as national parks, the dimensionality reduction is especially important to analyse the data effectively. Currently, two approaches are used to reduce the volume and extract the necessary information: feature extraction (FE) and feature selection (FS)8. The algorithm of FE uses transformations to extract information from spectral bands, creating new components that are independent of wavelength, while FS selects only the most useful information from all input bands for analysis, without any transformations in the input bands6,7. The choice of method depends on the specific requirements of the application, such as computational efficiency, classification accuracy, and interpretability. In practice, hybrid approaches that combine both FE and FS are often employed to achieve optimal results in hyperspectral data analysis.
The FE methods reduce the volume to several dozen transformation bands and increase the informativeness of these layers, which can result in higher classification accuracy. The selection of the most useful bands for further analysis is based on the analysis of the calculated eigenvalues and the visual assessment of the acquired components, and up to dozens of bands are selected. Principal Component Analysis (PCA) and Minimum Noise Fraction (MNF) are well-established and effective methods for FE in hyperspectral data, particularly for reducing dimensionality and eliminating information redundancy6. PCA is useful for reducing the dimensionality of data while retaining the most important information9. It is a statistical method of linear transformation, based on the variance of the images which creates a new set of bands from the highest to the lowest variance. Among others, PCA has been used to reduce the data dimensionality for the identification of various plant species10,11, land cover12,13,14, and crop types15.
MNF, in particular, accounts for the signal-to-noise ratio, which is critical for analyzing highly complex data, such as hyperspectral imaging. The MNF transformation uses two PCA transformations—first to decorrelate the noise and then to compress the information. Based on the results of classification using spectral bands and selected MNF components, a higher classification accuracy was noted for the compressed data5. MNF was previously used for classifying plant species11 and land use/land cover14. In addition to PCA and MNF, more complex data reduction methods can be used, including linear segmented-PCA, folded-PCA, and its nonlinear approaches such as kernel-PCA14. Kernel methods are effectively used for classification, but classifying large areas may be limited due to processing time16.
Another limitation of the FE procedure is the need to perform the transformation every time after data acquisition and before classification, which increases the data preparation time. Both PCA and MNF methods are based on statistics calculated from an image, and it is not possible to transfer the created classification model to an image acquired in another area or time17. It is only possible to transfer the procedure. As a result, the FE method does not allow the application of the currently popular transfer of models18.
The FS methods involve selecting useful spectral bands for the classification while maintaining the original reflectance values in the bands. The idea is to select only the bands that differentiate between the classified objects, based on reference polygons. This eliminates excess information, enabling higher accuracies to be achieved. The designated spectral ranges can be applied to a different area or dataset, or even to a different sensor with a similar spectral resolution19. The methods can be used on spectral bands and on bands after transformation—for example, MNF or PCA. Previously, Fisher’s Linear Discriminant Analysis was proven to improve classification results20,21,22. Linear Discriminant Analysis (LDA) is useful for maximising separation between classes and improving classification accuracy23. The mutual information method was used to identify land cover12,24 and vegetation classes10. Also, the recursive feature elimination method was used to identify vegetation species25 and other vegetation classes26. Classification of datasets, created using different band selection methods, was carried out for montane communities (using the backward elimination algorithm27) and for land use/land cover classes at ecotope level (out-of-bag and wrapper method, using the best-first search as the search algorithm)28. Additionally, reduction methods were used for the classification, such as continuous wavelet analysis29 and cross-cumulative residual entropy13. LDA was used to identify bands useful for habitat identification on Natura 2000 sites30. Feature extraction and feature selection methods can also be combined. Images are transformed using FE methods; then, bands are selected using FS methods. In numerous studies, various combinations of feature reduction methods were tested for identifying vegetation – for example, invasive species or land use forms29,31,32.
Studies show that it is difficult to determine which method of feature reduction of HS data (FE or FS) is more suitable for the classification of heathlands and mires. There are numerous studies on heathland identification, but the accuracies vary greatly: F1-score for the class (F1) ranged from 0.28 (FS was performed using Sequential Forward Feature Selection on AHS sensor data)33 to 0.95 (30 MNF bands, calculated from the HySpex image)4. The classifications were performed on spectral bands, or MNF and PCA bands2,4,27, but methods combining both approaches were rarely used33. In the case of mires, high accuracies (from 0.919 to 0.951) were achieved using HS, or HS and Airborne Laser Scanning (ALS) data fusion, with FE, using the MNF algorithm2,5. The MNF bands were also used as one kind of data to classify wetland vegetation in Poland34,35. The spectral bands and FE and FS methods were also used to identify mires, and the results were dependent on the dataset, but the classification method was also used, with the best results emerging for 30 PCA bands27. Tests were also conducted for spectral bands, MNF bands and a combination of FE and FS and, generally, the best results were noted for the combination of FE and FS, but the difference did not exceed 0.05.
Previous studies suggest that Random Forest (RF) has the highest accuracy and shortest processing time for hyperspectral data9, and is widely validated in the literature as a reliable classifier for hyperspectral data36,37. It was used in our study as it is capable of handling large datasets and high-dimensional spaces efficiently without extensive parameter tuning, which makes it particularly suitable for hyperspectral data. Its robustness and high classification performance stem from combining multiple decision trees to reduce overfitting and variance, making it highly effective in a wide range of classification tasks38,39.
In summary, the accuracies obtained in the studies vary greatly and it is not possible to decide which feature reduction methods are the most effective for heathlands and mires identification. Also, the methods have not been compared sufficiently to draw meaningful conclusions. Therefore, it is worth testing feature reduction methods to appropriately match the data to the purpose of the analysis.
Based on the abovementioned studies, the accuracies that were possible to achieve using various feature reduction methods were estimated. In the case of FE techniques, the limitation is the inability to directly apply the developed classification models to other images because the calculations are based on image statistics. If the method is to be easily transferable, it is better to use the original spectral bands, but the classification accuracies in this case are generally lower4.
The study aims to evaluate methods of dimensionality reduction for the identification of two different types of Natura 2000 habitats: European dry heaths (code 4030) and transition mires and quaking bogs (code 7140) and answer the following questions:
-
Which FE method is better for heathlands and mires identification? (PCA and MNF methods are compared)
-
Is it necessary to conduct the FS for class identification on the classified area or can it be developed from other data? This question is answered through checking for any statistically significant differences in accuracy between the datasets chosen using analysed area and data and pre-designated universal bands.
-
Which approach (FE or FS) should be used to achieve high classification accuracies?
-
What is better for vegetation identification: combination of FE and FS or using FS and FE separately?
Study area
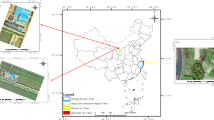
The study area is located in the eastern part of the Uroczyska Lasów Janowskich (Poland) Natura 2000 site (code of area PLH060031), which protects twenty-one habitat types listed in the Habitats Directive (Council Directive 92/43/EEC of 21 May 1992). The area covers 42 km2 and is located on a flat terrain with small, sandy dunes and plains (Fig. 1).The terrain is relatively flat, rising from 150 to 188 m above sea level. The average daily air temperature for this region (Sandomierz station) registered between 1991 and 2020 is 8.8॰C and the average annual precipitation is 551.3 mm40. The study site is located in the catchment area of the Vistula River.

Location with hyperspectral data and images from the study area. Figure generated by the authors using ArcGIS Desktop 10.8.2 (https://www.esri.com/en-us/arcgis/products/arcgis-desktop/resources) and Inkscape (https://inkscape.org). In the background OpenStreetMap (www.openstreetmap.org/). Photos of the habitats were taken by the authors.
Two out of the twenty-one habitats are present in this location: transition mires and quaking bogs (code 7140) and European dry heaths (code 4030). The area is one of the best-preserved sites for both habitats of all the Natura 2000 habitats in Poland. The two habitats selected for analysis are an essential part of the natural landscapes of Europe and are a biodiversity hotspot. At the same time, they differ from each other in many features, which allows us to test the universality of the results on different open ecosystems in terms of structure, species composition and biodiversity. At the same time, both heathlands and peatlands are among the habitats that can be identified on HS data with high accuracy (see “Introduction”). Therefore, the aim of our analysis was to determine whether there is a significant decrease in accuracy when the dimensionality reduction method is simplified (from FE to FS).
European dry heaths (code 4030)
The heathlands in the study area developed on a sand and gravel substrate. The plant community forming this Natura 2000 habitat is Pohlio-Callunetum. The Calluna vulgaris species dominate in all habitat patches, with cover ranging from 70 to 100%. The patches have very little internal floristic variability. Among other herbaceous species, Calamagrostis epigejos, Molinia caerulea, Corynephorus canescens, Festuca ovina, Hypericum perforatum and Solidago virg-aurea occur. A large part of the heath patches in the study area are encroaching on trees and shrubs such as Pinus sylvestris, Populus tremula, Betula pendula and Quercus robur.
Transition mires and quaking bogs (code 7140)
This habitat developed on organic soil with a consistently high water level throughout the year. In the study area, there is high internal floristic diversity. Six different plant communities were noted: Caricetum lasiocarpae, Eriophoro angustifoliii-Sphagnetum recourvi, Caricetum rostratae, Rynchosporetum albae, Eriophorum vaginatum-Sphagnum fallax and Carici-Agrostietum caninae. The dominant vascular plant species in these communities are Carex rostrata, Eriophorum angustifolium and Carex lasiocarpa. The preservation state of the mires in the study area varies, with well-preserved patches as well as significant dry patches, where the expansion of Phragmites australis was observed.
Data and methods
Data
Two types of data were acquired for the analysis: airborne hyperspectral images and ground truth data (the location of the analysed heathlands and mires and other types of vegetation and land cover forms were named ‘background’).
The ground truth data were acquired on 5–7 June 2017: collected were 106 polygons of heathlands, 112 of mires and 404 of the background (Fig. 2). The reference polygons were circles with a radius of 3 m. The location of each ground truth polygon was recorded using a GNSS Mobile Mapper 120 (with real-time differential correction). Each polygon was internally homogeneous and the polygons were distributed as evenly as possible within the study area. Both the polygons of the studied habitats and backgrounds were a representative sample that actually reflected the diversity of vegetation in the study area. Reference data in the field were collected by experienced botanists who are specialists in Natura 2000 habitat monitoring. The details of the on-ground measurements can be found in Jarocinska et al.30.

The study area with ground truth polygons, areas chosen for results visualisation and hyperspectral image. Figure generated by the authors using ArcMap 10.6.1 (https://www.esri.com/en-us/arcgis/products/arcgis-desktop/resources).
Hyperspectral images with 1-metre spatial resolution were collected at approximately the same time as the field survey (1 June 2017) using a Cessna CT206H aeroplane. The data were acquired using two HySpex scanners from the NEO: VNIR-1800 (0.4–0.9 μm) with 182 spectral bands, and SWIR-384 (0.9–2.5 μm) with 288 bands41. The images were combined and corrected radiometrically using HySpex RAD and geometrically (based on Airborne Laser Scanner data) with PARGE. The atmospheric compensation was performed with ATCOR-4 (ReSe Apps) software42 and the bands longer than 2.35 μm were removed due to high noise. The prepared images were mosaicked. As a result, images with 430 bands were analysed. Details on the data preparation can be found in Sławik et al.41.
Methods
In order to answer the research questions, the analysis was divided into three stages. Stage 1 involved preparation of hyperspectral data for classification of individual ecosystems (section “Processing hyperspectral datasets for classification”). This stage produced ten HS datasets (Fig. 3). Stage 2 focused on performing heathlands and mires classification using Random Forest (RF) algorithm (section “Assessing the effectiveness of the classification of heathlands and mires”). The classification of each class was carried out using six scenarios, which differed only in the dataset prepared in Stage 1. The output was maps with classification results and fifty calculated accuracy measures for each scenario. The aim of Stage 3 was to statistically compare the accuracies for each classification scenario (section “Statistical analysis”). The outcome of this stage was to see which classification scenarios differed in the individual accuracy measures. These analyses were carried out separately for both classes.

The scheme of the scenario preparation. Figure generated by the authors using Inkscape (https://inkscape.org).
Processing hyperspectral datasets for classification
Based on the hyperspectral image, ten datasets in total were determined for both heathlands and mires (Fig. 3). Two datasets were determined using feature extraction methods (PCA and MNF) and were the same for both vegetation classes (PCA_30 and MNF_30). Four of the datasets were based on spectral bands and FS analysis using Linear Discriminant Analysis (LDA) method: LDA_universal and LDA_area, for heathlands and mires separately. The last four datasets were also done individually for heathlands and mires, and were a combination of FE algorithms (MNF or PCA) and LDA feature selection analysis—PCA_LDA and MNF_LDA.
Datasets based on feature selection
Four of the datasets created were based on spectral bands selected using Linear Discriminant Analysis. The LDA analysis was performed in a previous study30. The LDA method is a supervised dimensionality reduction method. It is based on FS to determine the ranges and parameters necessary to distinguish the classes under study from the background—in this case, the classes of heathlands and mires vegetation. It is a linear approach to FS that reduces the number of variables while selecting the most differentiating variables that describe the features. The LDA analysis was conducted in an iterative mode—one hundred iterations with random sampling. Analyses were performed in the R software environment43 using the caret44, klaR45, MASS46 and vegan47 libraries. In the study mentioned, spectral bands that separate heathlands and mires from the background were selected30. The separability analysis was carried out with LDA analysis performed on ten randomly selected polygons with a radius of 3 m for each vegetation class. The vegetation classes were acquired based on the vegetation communities mentioned in section “Study area”. The first two datasets—LDA_universal—were analysed for heathlands and mires based on two study areas (heathlands – Bug River Valley and Uroczyska Lasów Janowskich; mires – Biebrza River Valley and Uroczyska Lasów Janowskich). The bands were defined as universal because they were defined as the most separative for the vegetation class regardless of the study area. The amount of data was reduced more than forty times compared with the original dataset of 430 bands: for heathlands there were ten spectral bands, and for mires there were six (Table 1).
The other two datasets—LDA_area—were defined based on one study area. These datasets consist of the bands that separated the analysed vegetation type from the background on the Uroczyska Lasów Janowskich: forty-one spectral bands for heathlands and eleven for mires. In both cases, the volume was reduced by 90% compared with the original hyperspectral image.
Using these two types of datasets (LDA_universal and LDA_area), we checked whether it is necessary to perform FS before the classification of heathlands or mires in each area or if is it possible to use a set of bands previously defined in another area, to reduce the analysis time.
Datasets based on feature extraction
In this case, two datasets were prepared using Principal Component Analysis and Minimum Noise Fraction. Both transformations aimed at dimensionality reduction with information extraction. This is one of the most widely used methods and has long been applied to extract information from remote sensing data48. It is a multivariate statistical technique used for image enhancement, information extraction and dimensionality reduction. The method selects a combination of uncorrelated values so that each variable (principal component) has the smallest possible variance. Calculated components are uncorrelated in contrast to adjacent spectral bands49. In hyperspectral image denoising, MNF transformation is often used17. The algorithm has two steps: the first one is denoising using a covariance matrix to decorrelate and rescale the noise, and the second is the standard PCA transformation50. Both transformations result in uncorrelated bands ranked from most to least informative. Selected bands can be used for classification, so the analysis time can be reduced.
The number of selected variables depends on the purpose of the analysis. A value of the first 30 bands was often used for vegetation identification2,30,34,51 because subsequent bands were not very informative. For the present analysis, PCA and MNF transformations were performed and the first 30 bands were selected based on the literature sources cited and the informativeness measured by the eigenvalues, which began to decline around the 30th band. The percentage of data variance explained by the first 30 components for PCA was 99.994%, and for MNF it was 99.969%. The results were two datasets, PCA_30 and MNF_30, with the same bands for both heathlands and mires. The transformation reduced the data volume by 86% compared with the HS image (5.56 GB compared with 39.88 GB of spectral bands) (Table 1).
Datasets based on feature extraction and feature selection
The last method tested for preprocessing HS data for classification combines the FE and FS approaches. MNF and PCA data were analysed using the LDA algorithm to create two scenarios: PCA_LDA and MNF_LDA, for heathlands and mires separately. Polygons used to determine the LDA_universal and LDA_area datasets were analysed to define the most differentiating PCA and MNF components for both classes. The values of the first 30 MNF and PCA bands were collected for each polygon pixel. Linear Discriminant Analysis was performed in an iterative mode (100 iterations) to count how many times each band was defined as important in the analysis. The correctness value for the analysis was checked. In the case of high mean values (above 0.95), the separation of the bands is good. Based on the frequency of occurrence above 50, the differentiating bands were selected for vegetation types, creating two datasets for heathlands and mires: PCA_LDA and MNF_LDA. For the heathlands, 28 MNF and 22 PCA components were selected, whereas for mires the figures were 11 PCA and 19 MNF bands (Fig. 4). In both cases, the volume was reduced to 87–95% of the original data. The analyses did not test the datasets where 30 layers would be selected from a larger number of PCA or MNF bands using LDA. Creating such a scenario significantly increases processing time, while the aim of the study was to reduce the time of analysis.

LDA results for both vegetation classes based on MNF and PCA data. Figure generated by the authors using Microsoft Office 2016 Excel (https://www.microsoft.com) and Inkscape (https://inkscape.org).
Assessing the effectiveness of the classification of heathlands and mires
The ten datasets were used to create ten different scenarios for Random Forest classification. The algorithm was carried out in an iterative mode for each habitat separately to determine whether differences in results were statistically significant. Random Forest is a machine learning method based on multiple decision trees52. It means that ultimately each object (or pixel in the case of data) is assigned to one specific class. In the case of Random Forest, the classification result is determined based on the voting of multiple decision trees. Each tree votes for a given class, and the final decision is made based on the majority of votes. The algorithm can also be used to estimate the importance of used layers, which was also done to analyse the usefulness of each band.
Validation and prediction were carried out separately for each dataset using the same scheme (Fig. 5). The validation was performed in an iteration mode (50 iterations) to ensure the randomness of training and validation polygons. For heathlands and mires, classifications were done as binary—one vegetation class was analysed at a time. There were always two classes in the reference data—for example, for heathlands: a heath class and a background class consisting of mires and other background polygons. Using this approach means that if there is more than one vegetation class in the area, the analysis time may be longer if LDA analysis is used. The exceptions to this are two scenarios without LDA analysis (PCA_30 and MNF_30), where it is possible to validate and predict both classes at the same time using the same dataset.

Scheme of classification performed for each of six datasets: LDA_universal, LDA_area, PCA_30, MNF_30, PCA_LDA and MNF_LDA. Figure generated by the authors using Inkscape (https://inkscape.org).
The Random Forest validation was performed 50 times, with stratified random sampling of ground truth polygons for each scenario. In each iteration, sampling was performed to divide the polygons into 50% training and 50% validation polygons for heathlands or mires and background class; for example for heathlands: the vegetation class and background containing mires and other classes. Then, the RF algorithm was used to train the model and predict the map with class distribution. For RF, the number of trees was set to 500, and out-of-bag (OOB) error analysis was performed to select the mtry parameter—optimal mtry = 3 was selected for the classification. Based on validation polygons, the accuracy assessment process was carried out. The accuracy was based on the F1-score, Producer Accuracy (PA) and User Accuracy (UA) for vegetation type: PA is the ratio of correctly classified pixels to the number of pixels that should be in that class, based on the validation data; UA is the ratio of correctly classified pixels to that class’s total number of pixels on the classified image. The F1-score is the harmonic mean of PA and UA. As a result of validation, 50 values of F1-score, PA and UA were acquired in 50 iterations. For each model, the map was predicted, and the majority voting was performed to acquire one map for each scenario. The analysis was performed in the R environment using Random Forest53, raster54 and caret libraries44. As a result, the variability of accuracy and habitat map were acquired for each dataset separately for two habitats and based on that the efficiency of classification for six datasets was compared.
Additionally, the values of importance were acquired from the Random Forest algorithm, and graphs were created to analyse which bands were the most useful for classification.
Statistical analysis
The values of PA, UA and F1-score for each scenario were analysed to estimate the statistical significance of the difference between the results. The distribution of F1 values, producer accuracy and user accuracy was analysed using a violin graph. For the parameters for each dataset, the normality of the distribution and the variance were checked. For normal distribution, an ANOVA and post-hoc Tukey test were applied to determine whether statistically significant differences existed between scenarios. For PA values for heathlands, and F1, PA and UA for mires, no normal distribution was noted and Kruskal-Wallis tests were applied in this case. Analyses were carried out at a statistical significance level of 0.05. The analyses were performed using Statistica 13.3 software55.
Results
Comparison of feature extraction methods
The first aim of the analyses was to check whether there is any difference in the achieved accuracy (F1, PA and UA) between two different methods of FE: PCA and MNF. For this purpose, two scenarios were compared: PCA_30 and MNF_30. The average F1 accuracy calculated for heathlands and mires combined for PCA_30 was higher – at 0.925 compared with the MNF_30 of 0.918, but the difference is minimal (0.007). Similar differences were noted for PA (0.007) and UA (0.006), so overall differences are very small.
For heathlands, the average F1 value for both scenarios was 0.940 and the differences between accuracies were rather small and not statistically significant for any of the accuracy measures (Fig. 6). The average F1 accuracy was almost the same for PCA_30 at 0.939 (σ = 0.015) and for MNF_30 at 0.940 (σ = 0.012). Higher differences (0.004) between averages, compared with F1 values, were noted for UA values: 0.949 for PCA_30 and 0.954 for MNF_30. In the case of PA, the differences were smaller – 0.002 (0.930 for PCA_30 and 0.928 for MNF_30). The prediction maps for both scenarios were quite similar; however, based on the MNF_30 scenario, the area covered by the vegetation class was larger by 5.45 ha compared with PCA_30 (Fig. 7).

Distribution of accuracy for the heathlands calculated based on six scenarios with the statistical significance of the difference in accuracies on significance level 0.05. ANOVA was used to test the significance of the difference between the scenarios. Based on the post-hoc Tukey tests, scenarios with no difference were labelled with the same letter. Figure generated by the authors using website Statskingdom (https://www.statskingdom.com/) and Inkscape (https://inkscape.org).

Heathlands map prediction for a part of the study area. Figure generated by the authors usingArcMap 10.6.1 (https://www.esri.com/en-us/arcgis/products/arcgis-desktop/resources) and Inkscape (https://inkscape.org).

Distribution of accuracy for the mires calculated based on six scenarios with the statistical significance of the difference in accuracies on significance level 0.05. ANOVA was used to test the significance of the difference between the scenarios. Based on the post-hoc Tukey tests, scenarios with no difference were labelled with the same letter. Figure generated by the authors using website Statskingdom (https://www.statskingdom.com/) and Inkscape (https://inkscape.org).

Mires map prediction for a part of the study area. Figure generated by the authors using ArcMap 10.6.1 (https://www.esri.com/en-us/arcgis/products/arcgis-desktop/resources) and Inkscape (https://inkscape.org).
For mires, the average F1 value for both transformations was 0.904 and the differences between MNF_30 and PCA_30 were a bit higher compared with heathlands, but still not statistically significant for any of the accuracy metrics. The average F1 value was almost the same for PCA_30 at 0.911 (σ = 0.020) and MNF_30 at 0.897 (σ = 0.022) (Fig. 8). Also, the differences between the two FE scenarios were higher for PA (0.955 for PCA_30 and 0.943 for MNF_30) and UA (0.873 for PCA_30 and 0.855 for MNF_30) compared with those for heathlands. The prediction results shown on the maps for mires for both scenarios were very similar (Fig. 9). In conclusion, it can be stated that the identification accuracy is quite high and there is little difference between these two scenarios, so both can be used to achieve correct results.
The accuracies for heathlands are a little higher compared with mires: the average F1 value was higher in the case of PCA_30 (difference up to 0.028) and MNF_30 (difference up to 0.044). Only in the case of PA was the accuracy better for mires in both scenarios; the difference was higher based on PCA_30 (average 0.024).
Results of feature selection methods
The second analysis aimed at finding the difference between the two scenarios using FS based on spectral bands. The statistical significance differences in accuracy between datasets, chosen using analysed area and data and pre-designated universal bands were checked. The average F1, PA and UA values were higher for the LDA_area scenario. The F1 value for LDA_area was 0.795; for LDA_universal it was 0.778. The differences were higher (0.021) for PA values: 8.45 for LDA_area and 0.824 for LDA_universal. Smaller differences (0.015) were noted for UA.
For heathlands, the average F1 value for both scenarios was 0.818, using LDA_universal of 0.805 (σ = 0.018), whereas for LDA_area it was 0.830 (σ = 0.020), the difference of 0.026 being statistically significant (Fig. 5). The difference (0.027) was also statistically significant for UA, and the accuracy was also higher for LDA_area (0.778 for LDA_univeral and 0.802 for LDA_area). The differences (0.024) were not significant for PA (0.864 for LDA_area and 0.836 for LDA_universal). In conclusion, it can be stated that for the LDA_area scenario, higher accuracies were achieved compared with LDA_universal. The maps produced based on the two scenarios were quite similar, but the heath class covers a slightly larger (0.61 ha) area on the map produced with the LDA_area scenario (Fig. 6). On both maps, the heath patches are very fragmented and there is a visible ‘salt and pepper effect’.
For mires, the average F1 value for both scenarios was 0.756 and accuracies were also higher for LDA_area, but the differences (0.010) between scenarios were not statistically significant: the average F1 value was 0.751 (σ = 0.020) for LDA_universal and 0.761 (σ = 0.020) for LDA_area (Fig. 7). For mires, both results maps were quite similar. The salt and pepper effect was present in both maps, especially for the LDA_universal scenario (Fig. 8).
To sum up, the accuracies for LDA_area were higher compared with LDA_universal. For both scenarios, the F1, PA and UA accuracies were better for heathlands compared with mires—the average difference of F1 for LDA_area was 0.070; for LDA-universal it was 0.053.
The feature importance values for analysed bands acquired from the Random Forest algorithm were compared for two scenarios (Fig. 10). The values of feature importance for the spectral bands were not similar for the two scenarios: LDA_area and LDA_universal; for example, for heathlands, the most important band for LDA_area was the 1.068 nm band, while for LDA_universal it was the 1.138 nm spectral band. For mires, the conclusions were similar—high importance values are not recorded for the same spectral bands.

Importance results acquired during Random Forest classifications. Figure generated by the authors using Microsoft Office 2016 Excel (https://www.microsoft.com/) and Inkscape (https://inkscape.org).
Comparison of the types of feature reduction approaches
This section determines which feature reduction approach (FS or FE) results in higher classification accuracy. Generally, based on the combined results for both habitats, it can be stated that the FE approach was more successful compared with FS based on each accuracy (F1, PA and UA). The F1 average value for FE methods for both classes was 0.922, whereas for FS it was 0.787. For PA the differences were smaller (around 0.104), whereas for UA the difference was higher (0.161). The average for FE was 0.908 and for FS it was 0.747.
To compare the two methods, the significantly better scenario was chosen for each class. From the pair of MNF_30 and PCA_30 scenarios, the one with higher accuracies was selected, and a similar approach was used for LDA_universal and LDA_area scenarios. If a better scenario could not be selected (there were no statistically significant differences), both scenarios were analysed. The results of FE (PCA_30 and MNF_30 scenarios) were presented in section “Comparison of feature extraction methods”, and the results of FS (LDA_universal and LDA_area) are provided in section “Results of feature selection methods”.
In the case of heathlands, three scenarios were compared: LDA_area and two scenarios of FE (PCA_30 and MNF_30). The difference between the average F1 value calculated for both FE scenarios and the FS scenario was around 0.122: better results were noted for FE, where the average value was 0.940, whereas for LDA_area it was 0.830 (Fig. 6). A similar result was noted in the case of producer and user accuracy—the values are similar for both FE scenarios. The biggest difference was noted for UA: in the case of FS (LDA_area scenario), there was the biggest overestimation—the UA was 0.802, and the average difference was 0.160.
In the case of mires, four scenarios were compared: for FS mean from LDA_universal and LDA_area and mean from FE PCA_30 and MNF_30 (Fig. 8). The average differences between the FE and FS scenarios were 0.148 for F1, 0.130 for PA and 0.160 for UA. The accuracies were higher for FE and were statistically significant in each case of F1 (average difference of 0.148), PA (average difference of 0.130) and UA (average difference of 0.160). The average F1 (calculated from the pairs of scenarios) for FS was 0.756; the values of FE were much higher at 0.904. Using FS scenarios, there is also a bigger overestimation, and an even bigger underestimation compared with the FE methods.
To sum up, the FE scenarios were much more successful compared with FS for both mires and heathlands, regardless of the transformation method (PCA or MNF) and the differences were statistically significant: 0.122 for heathlands and 0.148 for mires.
Results of the combination of feature reduction with feature selection
The last step was the comparison between the one feature reduction method and the combination of FE (PCA_30 and MNF_30) and FS (scenarios PCA_LDA and MNF_LDA). The idea was to determine whether carrying out two procedures significantly improves the classification accuracy compared with a single FE algorithm. For these analyses, PCA_30 with PCA_LDA and MNF_30 with MNF_LDA were compared. As an average for both heath and mire classes, slightly better results were achieved using FS scenarios compared with the combination of methods: the average F1 value for FE was 0.922, whereas for the combination it was 0.914. The values were also higher for PA (difference of 0.010) and UA (difference of 0.006). On the other hand, the differences were very small.
Based on the results from section “Comparison of feature extraction methods”, the best scenarios, that used only one feature reduction method, were two FE scenarios: PCA_30 and MNF_30. For each accuracy measure, the average value was higher for PCA_30 compared with PCA_LDA, but the differences were very small and not statically significant (Fig. 5). The average F1 value for heathlands was 0.939 (σ = 0.015) for PCA_30 and 0.937 (σ = 0.015) for PCA_LDA; the differences were smaller than 0.010 for F1, PA and UA. The differences for mires were slightly higher: 0.911 for PCA_30 and 0.899 for PCA_LDA (Fig. 8). The highest difference (around 0.02) was noted for PA. Overall, the differences were small and not statistically significant.
In the case of the MNF_30 and MNF_LDA comparison, the differences were small and not statistically significant. For mires, the accuracy measures are generally slightly higher for the MNF_30 scenario—the difference is around 0.02 for F1 and PA, and 0.01 for UA. For heathlands, the differences are even smaller, with the same values for both scenarios at 0.940 (σ = 0.012 for MNF_30 and σ = 0.011 for MNF_LDA) for F1. PA accuracies are higher for MNF_LDA than MNF_30, and UA accuracies are higher for MNF_30, but both are very small (around 0.002).
The distribution of classes for heathlands is quite similar for the scenarios (Fig. 7). In the case of mires it is also very similar, but a fragmentation of patches related to the salt and pepper effect is apparent for the PCA_LDA scenario compared with PCA_30 (Fig. 9). This is less apparent in the MNF_LDA scenario compared with MNF_30. In this case both maps are very similar.
The feature importance values were quite comparable between scenarios PCA_30 and PCA_LDA, and MNF_30 and MNF_LDA – both for heathlands (Fig. 10). There was a similar trend noted for mires, but here the similarity of feature importance values was somewhat smaller; for example, band 8 MNF had a high value (0.3) importance in the MNF_30 scenario and 0 in MNF_LDA.
Discussion
The accuracies of vegetation class identification observed in this study are generally high. In the case of different scenarios for heathlands, the F1 accuracies varied from 0.805 (using FS) to 0.940 (using FE) (Fig. 6). The F1 accuracies acquired in previous studies, also using hyperspectral airborne images, varied from small values of 0.2833 to high values of more than 0.92,4,56. For mires, accuracies acquired in this study are lower compared with heathlands, but still quite high with average values for FE – 0.904, and for FS – 0.750. The accuracies based on hyperspectral images acquired in other studies are also comparable – from 0.6257 to 0.952. It suggests that the vegetation classes were identified with accuracy that is better or comparable to those mentioned in the literature. Overall, these classes can be effectively identified, but the accuracies vary. Lower accuracies for mires compared with heathlands are caused by the greater heterogeneity of mires and lower spectral distinctiveness from the background. This was also confirmed by the literature2.
For both classes, similar conclusions were reached regarding the use of feature reduction methods – significantly better accuracies were obtained with the FE method (MNF or PCA) compared with FS (LDA method). For both classes, the differences were statistically significant. The analyses were carried out on two different open vegetation types: dry heaths with a single species dominance (low α- and β-diversity) and mires with high α- and β-diversity; however the conclusions regarding differences in accuracies from different scenarios are similar. Furthermore, both classes are quite well studied, and the results are similar to those obtained in this work. Therefore, the conclusions will be universal for open natural ecosystems, although the accuracies may differ between vegetation classes. As a result, in the following sections of the discussion, the accuracies will be considered as an average for both classes.
Based on previous studies, conclusions regarding differences in accuracy between feature reduction methods are similar for each of the analysed vegetation classes24. FE methods were previously compared for different classes: PCA and MNF bands were compared for natural montane vegetation, including heathlands27. In this case, the overall accuracy (OA) was 0.81 and 0.84 for 40 PCA bands, whereas for 30 MNF bands, the OA was 0.81 and 0.82, depending on the classification algorithm (Fig. 11). On the other hand, higher accuracies for MNF outperforming PCA data were acquired—for mineral classification, the OA varied from 0.65 to 0.89 for PCA and from 0.86 to 0.88 for MNF14. The MNF data also proved to be more effective at classifying land cover classes, compared with PCA58. However, the differences in this case were not high (up to 0.04) for the overall accuracies above 0.90. In the case of land cover classification, the comparison between MNF and PCA data gives similar results to this study: the average F1 scores were similar for both datasets (from 0.78 to 0.92, depending on sensor, classifier and number of used components)24. Also, no difference in accuracies (OA above 0.96) between PCA and MNF bands was noted for land cover classification when at least 10 bands were used for classification59.

The average F1 accuracy for each scenario calculated for both vegetation classes. Figure generated by the authors using Microsoft Office 2016 Excel (https://www.microsoft.com/) and Inkscape (https://inkscape.org).
The accuracy results obtained in this study using FE methods are similar to or higher than those reported in the literature. The use of FE allows for the correct identification of classes, similar to those studied – namely, open, natural vegetation. Based on the results, it is not possible to conclude that one of the FE methods is significantly better, as mentioned in previous studies. The mean F1 values for the PCA_30 scenario were 0.925, while those for MNF_30 were 0.918 (Fig. 11). The difference of 0.007 is small, and no statistically significant differences were recorded. Also, it cannot be clearly stated, based on previous studies, which transformation is more efficient14,24,27,59. Similar conclusions can be based on the differences between user and producer accuracies (Figs. 6 and 8) – the results for MNF and PCA are similar.
The results obtained with MNF were slightly more stable – the majority vote in mapping was more likely to indicate 100% class (Figs. 7 and 9). This may be related to the fact that MNF has a noise removal step and in PCA only information extraction is carried out. This may suggest that despite the lack of statistically significant differences it is better to use MNF than PCA for these classes, when identification is carried out as a single classification, not in an iterative mode.
At the same time, with high accuracies, the time required to process the data is important, especially when the classification is done in an iterative mode. Both transformations can be performed with publicly available tools60, but the execution time of the transformation may differ, as MNF performs additional noise removal17. As the differences are not statistically significant, it is the operational aspects (availability of software, time needed for transformations) that should determine the choice of FE method when the classification is done in an iterative mode.
To the best of the authors’ knowledge, the LDA algorithm had not been used previously on open natural vegetation, but it had been tested with hyperspectral data as a FS method in the classification of other classes. In the case of classes that are easy to identify and vary considerably—for example, land cover class, OA accuracies were 0.8661 or 0.95, 0.87 and 0.83, depending on the study area62. Other FS methods were also tested on different hyperspectral sensors, and the F1 accuracies were also in the region of 0.6–0.85, depending on the sensor, FS algorithm, class (land cover, crops and land cover on urban areas) and classifier24. Three methods were compared: mutual information, cross-cumulative residual entropy and normalised cross-cumulative residual entropy, and it cannot be concluded that one of these methods is better. In the studies mentioned above, FS was performed on the classified data but in this study, two different scenarios were analysed: LDA_area and LDA_universal, which were developed in the previous study30. These datasets can be defined as universal for identifying the analysed vegetation classes on different study sites and using other hyperspectral sensors. This procedure offers the possibility of significant time reduction. To date, no such studies have been conducted using FS methods.
The accuracies achieved using the FS procedure were much lower compared with FE. Bands for identification were determined previously30. The accuracy of the LDA_universal scenario is the lowest (F1 = 0.778) compared with the others, but still acceptable for the general identification of habitat patches. In this case, once selected, spectral bands can be used in other areas for class identification. The accuracy for LDA_area was higher (F1 = 0.796), and the differences for heathlands and mires between these two scenarios were statistically significant. This scenario could be applied to general identification. These conclusions are also confirmed by the differences for producer and user accuracies (Figs. 7 and 9).
In the case of F1 accuracy the results are significantly better (by about 0.135) when FE methods rather than FS are used (Fig. 11). For user and producer accuracies, the differences were also above 0.1 (Figs. 6 and 8). Based on LDA_universal and LDA_area, the high fragmentation of vegetation patches related to the salt and pepper effect is evident, whereas for MNF_30 and PCA_30, the fragmentation is smaller and the patches have clearer boundaries. The 0.135 difference is quite large but similar results can be found in other studies. The accuracies for land cover classification were also high, at around 0.10 to 0.1524. For the identification of montane open communities, differences regarding overall accuracy were approximately 0.127. On the other hand, studies were reported where the difference between FS and FE was not present60 or was quite small (up to 0.025)62. For the analysed classes (heathlands and mires), there were no direct comparisons but, based on previous studies, generally higher accuracies were obtained using FE. For example, in the case of heathlands, the highest F1 accuracy was acquired using 30 MNF bands (F1 was 0.902 or 0.954), rather than using methods based on spectral bands (F1 = 0.70)63 or FS methods (performed with Sequential Forward Feature Selection on AHS sensor bands, where F1 = 0.28)33. Similar conclusions can be drawn regarding mire classification – the highest results were acquired using 30 PCA bands27. One limitation of using the FE procedure is the need to build the classification model again for another area or other data. The transformations must be performed each time and for this reason, the models are not universal; in contrast, FS methods can in some cases be performed on another dataset. At the same time, it is worth noting that the development of the model transfer method is advancing rapidly64.
The difference in classification accuracies between FS and FE may be mainly due to the type of analysed classes. Natural vegetation is quite complicated to classify, and the preprocessing method should extract information from the spectral data while reducing noise. Using another FS method might produce higher accuracies; however, FS does not remove noise in the images which may be crucial. In addition, a relationship between biodiversity and spectral variation has been documented for open vegetation, and the analysed vegetation classes are quite diverse65. Therefore, band selection may remove too much information, whereas using FE it is possible to maintain high informativeness.
The limitations of our findings may be due to the fact that the study was conducted in one area and on one data set. Thus, it is not known whether a study repeated in a different geographic location using a different data set (acquired, for example, on a different date) would lead to identical conclusions. However, a model area was chosen for the study in terms of the structure and species composition of the habitats studied and the timing of data acquisition was phenologically optimal, minimising this risk5. Another limitation of our study was the focus on the analysis of two selected habitats. There is no certainty that the conclusions would not have been different for other open habitats. However, in an effort to minimise this limitation, two extremely different open habitats were chosen for the study, both in terms of structure, species composition and biodiversity at the alpha and beta levels. The last limitation of our analysis was the narrowness of the methods tested to reduce the dimensionality of the data. Many other methods are described in the literature (see “Introduction”). An issue worthy of further research is the comparison of other methods for reducing the dimensionality of hyperspectral data to analyse a large dataset14. The data dimensionality reduction methods tested in this study (MNF, PCA, LDA) are possible and relatively simple to use operationally.
In summary, FE methods extract the necessary information for identification, and compress it into a few bands, enabling correct classification. Although FS results in significantly lower accuracies, it still allows for the general identification of classes.
We checked if the combination of the two feature reduction approaches would significantly increase classification accuracy. It is obvious that two procedures are much more time-consuming than one. In addition, the combined use of the procedures did not significantly increase accuracy measures (Fig. 11). Finally, the most successful scenarios, based on accuracies, are PCA_30 and MNF_30. The removal of a few transformation bands did not result in more accurate classification. The transformation bands that were selected with the LDA method are similar to the bands with the highest values of feature importance, and the execution of the LDA is not cost-effective in terms of time (Fig. 10). The maps of class distribution for FE and FE_FS are almost the same, and both can be used in further analysis, namely in environmental protection, but the combination of the procedures is not justified in terms of time and economy.
Comparisons of combined feature reduction methods with single reduction methods are rarely analysed and results are dependent on the method and classes. In the case of land cover classes, the addition of the FS method to FE increased the accuracy of F1 by approximately 0.02 to 0.0710,16. The lack of differences in this study may be caused also by the use of classification from the decision tree group. The Random Forest algorithm selects the bands that separate the classes with the highest confidence39. The results of FE_FS could have been better if LDA procedure had been applied on more than 30 transformation bands (for example, 50) and FS had reduced the number of the most useful bands (to a maximum of 30).
Conclusions
It is necessary to use feature reduction methods for hyperspectral data in ML. The idea is to reduce the amount of data and time necessary for acquiring, preprocessing and classifying, while maintaining accurate classification results. Each feature reduction method is time-consuming, but in the case of multiple classifications it is profitable, and the selection or extraction based on the transformation of appropriate information increases classification accuracy. In the study, a comparison between accuracies acquired using different feature reduction methods was performed under controlled conditions, reducing other factors. Based on the results, it was possible to define which feature reduction methods should be used to achieve the best accuracy in identifying natural open vegetation classes, represented by heathlands and mires. The conclusions are universal for open natural ecosystems, although the accuracies may differ between vegetation classes.
The main findings are:
-
The LDA algorithm was adapted for the first time as an FS method for open natural vegetation, and its effectiveness for the selection of spectral bands for classification was confirmed. The acquired results were high enough to be a useful method for identifying general class distribution; the average F1 was 0.816 for heathlands and 0.750 for mires.
-
The FS method considerably reduces processing time, but to ensure good results the classification images should be generalised to remove the salt and pepper effect (very small patches of vegetation). FS methods can be convenient tools for selecting useful bands and combining them with other types of data, such as Airborne Laser Scanning data.
-
There were no significant differences between the two FE transformations: PCA and MNF, so we recommend that the operational aspects determine the choice of FE method, especially for an iterative classification.
-
The classifications were significantly more successful (0.135) using FE methods compared with FS. The average F1 for FE was 0.992; for FS it was 0.787.
-
The combinations of FE and FS methods give very similar results to single FE scenarios and are more cost-effective in terms of time.
-
The next step in the study of data dimensionality reduction may be to test other new emerging dimensionality reduction methods such as kernel-PCA.
Data availability
The datasets generated and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Wang, Y., Lu, Z., Sheng, Y. & Zhou, Y. Remote sensing applications in monitoring of protected areas. Remote Sens. 12, 1370 (2020).
Jarocinska, A. et al. The utility of airborne hyperspectral and satellite multispectral images in identifying Natura 2000 non-forest habitats for conservation purposes. Sci. Rep. 2023, 13 (2023).
Zagajewski, B. et al. Comparison of Random Forest, Support Vector machines, and neural networks for Post-disaster Forest species Mapping of the Krkonoše/Karkonosze Transboundary Biosphere Reserve. Remote Sens. 13, 2581 (2021).
Halladin-Dabrowska, A., Kania, A. & Kopeć, D. The t-SNE algorithm as a tool to improve the quality of reference data used in accurate mapping of heterogeneous non-forest vegetation. Remote Sens. 12, 145 (2020).
Szporak-Wasilewska, S. et al. Mapping Alkaline fens, transition mires and quaking bogs using Airborne Hyperspectral and laser scanning data. Remote Sens. 13, 1504 (2021).
Jia, W., Sun, M., Lian, J. & Hou, S. Feature dimensionality reduction: a review. Complex. Intell. Syst. 8, 2663–2693 (2022).
Vaddi, R., Kumar, P., Manoharan, B. L. N., Agilandeeswari, P. & Sangeetha, V., Strategies for dimensionality reduction in hyperspectral remote sensing: a comprehensive overview. Egypt. J. Remote Sens. Space Sci. 27, 82–92 (2024).
Nimbalkar, P., Jarocinska, A. & Zagajewski, B. Optimal band configuration for the roof surface characterization using hyperspectral and LiDAR imaging. J. Spectrosc. 2018, 6460518 (2018).
Dash, S., Chakravarty, S., Giri, N. C., Agyekum, E. B. & AboRas, K. M. Minimum noise fraction and long short-term memory model for hyperspectral imaging. Int. J. Comput. Intell. Syst. 17, 16 (2024).
Champa, A. I., Rabbi, M. F., Hasan, M., Zaman, S. M. & Kabir, M. H. A. Tree-Based Classifier for Hyperspectral Image Classification via Hybrid Technique of Feature Reduction 115–119 (2021). https://doi.org/10.1109/ICICT4SD50815.2021.9396809.
Gimenez, R. et al. Mapping plant species in a former industrial site using airborne hyperspectral and time series of Sentinel-2 data sets. Remote Sens. 14, 3633 (2022).
Hossain, M. A., Hasin-E-Jannat, Ahmed, B. & Mamun, M. A. Feature Mining for Effective Subspace Detection and Classification of Hyperspectral Images 544–547 (2017). https://doi.org/10.1109/ECACE.2017.7912965.
Mishu, S. Z., Ahmed, B., Hossain, M. A. & Uddin, M. P. Effective subspace detection based on the measurement of both the spectral and spatial information for hyperspectral image classification. Int. J. Remote Sens. 41, 7541–7564 (2020).
Ali, U. A. M. E., Hossain, M. A. & Islam, M. R. Analysis of PCA based feature extraction methods for classification of Hyperspectral Image. In 2019 2nd Int. Conf. Innov. Eng. Technol. (ICIET) 1–6 (2019).https://doi.org/10.1109/ICIET48527.2019.9290629.
Ruiz Hidalgo, D., Bacca Cortés, B. & Caicedo Bravo, E. Dimensionality reduction of hyperspectral images of vegetation and crops based on self-organized maps. Inform. Process. Agric. 8, 310–327 (2021).
Pilario, K. E., Shafiee, M., Cao, Y., Lao, L. & Yang, S. H. A review of Kernel methods for feature extraction in nonlinear process monitoring. Processes 8, 24 (2020).
Luo, G., Chen, G., Tian, L., Qin, K. & Qian, S. E. Minimum noise fraction versus principal component analysis as a preprocessing step for hyperspectral imagery denoising. Can. J. Remote. Sens. 42, 106–116 (2016).
Zhao, Z., Alzubaidi, L., Zhang, J., Duan, Y. & Gu, Y. A comparison review of transfer learning and self-supervised learning: definitions, applications, advantages and limitations. Expert Syst. Appl. 242, 122807 (2024).
Ramezan, C. A. Transferability of recursive feature elimination (RFE)-Derived feature sets for support Vector Machine Land Cover classification. Remote Sens. 14, 6218 (2022).
Zhou, M., Samiappan, S., Worch, E. & Ball, J. E. Hyperspectral Image Classification Using Fisher’s linear Discriminant Analysis Feature Reduction with Gabor Filtering and CNN 493–496. https://doi.org/10.1109/IGARSS39084.2020.9323727 (2020).
Jayaprakash, C., Damodaran, B. B., Viswanathan, S. & Soman, K. P. Randomized independent component analysis and linear discriminant analysis dimensionality reduction methods for hyperspectral image classification. J. Appl. Rem. Sens. 14, 1 (2018).
Gite, H. R., Solankar, M. M., Surase, R. R. & Kale, K. V. Comparative study and analysis of dimensionality reduction techniques for Hyperspectral Data. In Recent Trends in Image Processing and Pattern Recognition (eds. Santosh, K. C. & Hegadi, R. S.) 534–546 (Springer, 2019). https://doi.org/10.1007/978-981-13-9181-1_47 .
Jarocińska, A., Kopeć, D., Tokarska-Guzik, B. & Raczko, E. Intra-annual variabilities of Rubus caesius L. discrimination on Hyperspectral and LiDAR Data. Remote Sens. 13, 107 (2021).
Islam, M. R., Siddiqa, A., Ibn Afjal, M., Uddin, M. P. & Ulhaq, A. Hyperspectral image classification via information theoretic dimension reduction. Remote Sens. 15, 1147 (2023).
Song, G. & Wang, Q. Species classification from hyperspectral leaf information using machine learning approaches. Ecol. Inf. 76, 102141 (2023).
Li, Q., Kit Wong, F. K. & Fung, T. Comparison Feature Selection Methods for Subtropical Vegetation Classification with Hyperspectral Data. In IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium 3693–3696. https://doi.org/10.1109/IGARSS.2019.8898541 (2019).
Marcinkowska-Ochtyra, A., Zagajewski, B., Raczko, E., Ochtyra, A. & Jarocińska, A. Classification of high-mountain vegetation communities within a Diverse Giant mountains ecosystem using Airborne APEX hyperspectral imagery. Remote Sens. 10, 570 (2018).
Chan, J. C. W. & Paelinckx, D. Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Environ. 112, 2999–3011 (2008).
Omeer, A. A. & Deshmukh, R. R. Improving the classification of invasive plant species by using continuous wavelet analysis and feature reduction techniques. Ecol. Inf. 61, 101181 (2021).
Jarocińska, A., Kopeć, D., Kycko, M., Piórkowski, H. & Błońska, A. Hyperspectral vs. multispectral data: comparison of the spectral differentiation capabilities of Natura 2000 non-forest habitats. ISPRS J. Photogrammetry Remote Sens. 184, 148–164 (2022).
Uddin, M. P., Mamun, M. A., Afjal, M. I. & Hossain Md. A. Information-theoretic feature selection with segmentation-based folded principal component analysis (PCA) for hyperspectral image classification. Int. J. Remote Sens. 42, 286–321 (2021).
Du, B. et al. Mapping Wetland Plant communities using unmanned aerial vehicle hyperspectral imagery by comparing Object/Pixel-Based classifications combining multiple machine-learning algorithms. IEEE J. Sel. Top. Appl. Earth Observations Remote Sens. 14, 8249–8258 (2021).
Haest, B. et al. An object-based approach to quantity and quality assessment of heathland habitats in the framework of natura 2000 using hyperspectral airborne ahs images. Int. Archives Photogrammetry Remote Sens. Spat. Inform. Sci. ISPRS Archives 38, 458 (2010).
Jarocińska, A. et al. Testing textural information base on LiDAR and hyperspectral data for mapping wetland vegetation: a case study of Warta River Mouth National Park (Poland). Remote Sens. 15, 3055 (2023).
Zieliński, H. & Jarocińska, A. The application of AISA hyperspectral Images to the Classification of Vegetation Communities and Natura 2000 habitats of Lower Narew Valley. In Proceedings of SPIE - The International Society for Optical Engineering. 11581 (2020).
Rissati, J. V., Molina, P. C. & Anjos, C. S. Hyperspectral image classification using random Forest and deep learning algorithms. In IEEE Latin American GRSS & ISPRS Remote Sensing Conference (LAGIRS) 132–132. https://doi.org/10.1109/LAGIRS48042.2020.9165588 (2020).
Jarocińska, A., Marcinkowska-Ochtyra, A. & Ochtyra, A. An overview of the Special Issue Remote sensing applications in vegetation classification. Remote Sens. 15, 2278 (2023).
van Jaarsveld, B., Hauswirth, S. M. & Wanders, N. Machine learning and global vegetation: random forests for downscaling and gap filling. Hydrol. Earth Syst. Sci. 28, 2357–2374 (2024).
Belgiu, M. & Drăguţ, L. Random forest in remote sensing: a review of applications and future directions. ISPRS J. Photogrammetry Remote Sens. 114, 24–31 (2016).
Normy klimatyczne 1991–2020—Portal Klimat IMGW-PiB. https://klimat.imgw.pl/pl/climate-normals/TSR_AVE (2022).
Sławik, Ł., Niedzielko, J., Kania, A., Piórkowski, H. & Kopeć, D. Multiple flights or single flight instrument fusion of hyperspectral and ALS data? A comparison of their performance for vegetation mapping. Remote Sens. 11, 970 (2019).
Richter, R. & Schlapfer, D. Atmospheric / Topographic Correction for Airborne Imagery 196 (2020).
Gareth, J., Witten, D., Hastie, T. & Tibshirani, R. An Introduction to Statistical Learning: with Applications in R (Springer, 2014).
Kuhn, M. et al. Package ‘Caret’ Classification and Regression Training (2021).
Roever, C. et al. klaR: Classification and Visualization (2020).
Venables, W. N., Ripley, B. D. & Venables, W. N. Modern Applied Statistics with S (Springer, 2002).
Oksanen, J. et al. Vegan: Community Ecology Package. R package version 2.5-6 (2019).
Ready, P. & Wintz, P. Information extraction SNR improvement, and data compression in multispectral imagery. IEEE Trans. Commun. 21, 1123–1131 (1973).
Singh, A. & Harrison, A. Standardized principal components. Int. J. Remote Sens. 6, 883–896 (1985).
Lee, J. B., Woodyatt, A. S. & Berman, M. Enhancement of high spectral resolution remote-sensing data by a noise-adjusted principal components transform. IEEE Trans. Geosci. Remote Sens. 28, 295–304 (1990).
Sabat-Tomala, A., Raczko, E. & Zagajewski, B. Airborne hyperspectral images and machine learning algorithms for the Identification of Lupine Invasive Species in Natura 2000 Meadows. Remote Sens. 16, 580 (2024).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Liaw, A. & Wiener, M. Classification and regression by randomForest. R News 2, 145 (2002).
Hijmans, R. J. et al. raster: Geographic Data Analysis and Modeling (Springer, 2023).
StatSoft Polska—Lider w analityce danych. https://www.statsoft.pl/ (2022).
Kluczek, M., Zagajewski, B. & Kycko, M. Airborne hySpex hyperspectral versus multitemporal Sentinel-2 images for mountain plant communities mapping. Remote Sens. 14, 1209 (2022).
Feilhauer, H. et al. Mapping the local variability of Natura 2000 habitats with remote sensing. Appl. Veg. Sci. 17, 765–779 (2014).
Arslan, O., Akyürek, Ö. & Kaya, Ş. A comparative analysis of classification methods for hyperspectral images generated with conventional dimension reduction methods. Turkish J. Electr. Eng. Comput. Sci. 25, 58–72 (2017).
Ibarrola-Ulzurrun, E., Marcello, J. & Gonzalo-Martin, C. Assessment of component selection strategies in hyperspectral imagery. Entropy 19, 666 (2017).
MNF/MAF, P. C. A. and EOFs of time series, spatial and spatio-temporal data. https://r-spatial.org/r/2016/03/09/MNF-PCA-EOF.html (2022).
Afjal, M. I., Mondal, M. N. I. & Mamun, M. A. Segmented linear discriminant analysis for hyperspectral image classification. In 12th International Conference on Electrical and Computer Engineering (ICECE) 204–207. https://doi.org/10.1109/ICECE57408.2022.10088677 (2022).
Zhang, M. et al. Hyperspectral remote sensing image feature classification algorithm based on attention U2net. In Third International Conference on Optics and Communication Technology (ICOCT), vol. 12971 211–223 (SPIE, 2023).
Haest, B. et al. Habitat mapping and quality assessment of NATURA 2000 Heathland using airborne imaging spectroscopy. Remote Sens. 9, 266 (2017).
Ma, Y., Chen, S., Ermon, S. & Lobell, D. B. Transfer learning in environmental remote sensing. Remote Sens. Environ. 301, 113924 (2024).
Thornley, R. H., Gerard, F. F., White, K. & Verhoef, A. Prediction of Grassland Biodiversity using measures of spectral variance: a meta-analytical review. Remote Sens. 15, 668 (2023).
Funding
The Acquisition of aerial hyperspectral and ground truth data was co-financed by the Polish National Centre for Research and Development (NCBR) and MGGP Aero under the programme “Natural Environment, Agriculture and Forestry” BIOSTRATEG II.: The innovative approach supporting monitoring of non-forest Natura 2000 habitats, using remote sensing methods (HabitARS), project number: BIOSTRATEG2/297915/3/NCBR/2016. The Consortium Leader is MGGP Aero. The project partners include the University of Lodz, the University of Warsaw, Warsaw University of Life Sciences, the Institute of Technology and Life Sciences, the University of Silesia in Katowice, Warsaw University of Technology.
Author information
Authors and Affiliations
Contributions
A.J.: Conceptualization, investigation, methodology, data curation, writing original draft, visualization, validation, responses to reviewD.K.: Conceptualization, investigation, supervision, field survey, methodology, writing original draft, validation, responses to reviewM.K.: Methodology, software, statistical analysis, writing original draft, responses to review.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Jarocińska, A., Kopeć, D. & Kycko, M. Comparison of dimensionality reduction methods on hyperspectral images for the identification of heathlands and mires. Sci Rep 14, 27662 (2024). https://doi.org/10.1038/s41598-024-79209-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-79209-1
Keywords
This article is cited by
-
Dimensionality reduction in hyperspectral imaging using standard deviation-based band selection for efficient classification
Scientific Reports (2025)
-
Optimizing chemometric spectral preprocessing profiles for hyperspectral non-destructive prediction of mango total soluble solids
Journal of Food Measurement and Characterization (2025)
