
Abstract
The accurate detection of tunnel lining cracks and prompt identification of their primary causes are critical for maintaining tunnel availability. The advancement of deep learning, particularly in the domain of convolutional neural network (CNN) for image segmentation, has made tunnel lining crack detection more feasible. However, the CNN-based technique for tunnel lining crack detection commonly prioritizes increasing algorithmic complexity to enhance detection accuracy, posing a challenge in balancing the accuracy of detection and the efficiency of the algorithm. Motivated by the superior performance of Unet in image segmentation, this paper proposes a lightweight tunnel lining crack detection model named Mini-Unet, which refined the Unet architecture and utilized depthwise separable convolutions (DSConv) to replace some standard convolution layers. In the optimization of the proposed model parameters, applying a hybrid loss function that integrated dice loss and cross-entropy loss effectively tackled the imbalance between crack and background categories. Several models were set up to contrast with Mini-Unet and the experimental results were analyzed. Mini-Unet achieves a mean intersection over union (MIoU) of 60.76%, a mean precision of 84.18%, and a frame per second (FPS) of 5.635, respectively. Mini-Unet outperforms several mainstream models, enabling rapid detection while maintaining identified accuracy and facilitating the practical application of AI power for real-time tunnel lining crack detection.
Similar content being viewed by others


Introduction
Numerous geologically intricate tunnels and urban subways have been, or are currently being, constructed globally. Ensuring the safe operation of tunnels necessitates prompt inspection and treatment of tunnel distress, which has garnered increasing attention1. Crack, the most prevalent form of tunnel defect, frequently appears on tunnel lining during construction or in-service stages due to aging or continuous external impact2. The cracks in the tunnel impact the structural stability of tunnels3 and continued propagation of these cracks may exacerbate damage to the tunnel structure, potentially leading to an accident2. Consequently, the timely and precise detection of cracks is crucial for maintaining the structural stability of tunnels.
Traditional tunnel lining crack detection predominantly relies on human visual inspection. Inspectors traverse the tunnel line, recording the observations of cracks. Therefore, manual crack inspection is a labor-intensive and time-consuming process4, and its results are usually influenced by the subjectivity of inspectors5. With the rapid development of digital image processing technology, automatic identification algorithms have been gradually employed in crack detection. Image-based identification algorithms can quickly segment cracks from other noise and background, such as edge-detection-based method6, thresholding method7, and pattern recognition method8. However, the generalization capability of these algorithms is limited and the detection accuracy of tunnel lining cracks is significantly impacted by complex backgrounds and changeable tunnel illumination9. Recently, deep learning-based theories and applications have been developed, which are capable of automatically extracting requisite features for tunnel lining crack identification, presenting a viable avenue for image-based crack detection. Numerous deep learning-based neural networks, such as CrackNet10, FraSegNet11, DeepCrack12, Unet13,14,15,16, faster region-based convolutional neural network (Faster R-CNN)17 and mask region-based convolutional neural network (Mask R-CNN)18, have been utilized in civil engineering. Compared with traditional digital image processing, tunnel lining crack detection by deep learning exhibits superior generalization performance and higher accuracy5. Nevertheless, the majority of algorithms based on deep learning prioritize increasing algorithmic complexity to enhance detection accuracy, neglecting the balance between detection accuracy and algorithmic efficiency in practical tunnel engineering. Aiming at this challenge, this paper proposes a lightweight model for tunnel lining crack detection to enhance detected speed while maintaining detection accuracy.
The remainder sections of this paper are organized as follows. Section 2 furnishes an overview of pertinent literature, encompassing automatic crack detection methods and lightweight CNNs. Section 3 presents the techniques of DSConv, the hybrid loss function, and the proposed model. The analysis and comparison of the experimental results are delineated in Sect. 4. Section 5 provides a brief discussion regarding the effect of cracks’ width on detected results and limitations of this paper, while Sect. 6 serves as the conclusion of the paper, offering insights into future research directions.
Related work
This section presents an overview of automatic crack detection methods and introduces the design of the lightweight CNN.
Automatic crack detection methods
Presently, there has been a notable increase in research focused on the intelligent detection of cracks, which can be broadly categorized into several techniques, including digital image processing5,19,20,21, machine learning22,23, and deep learning10,24,25,26,27,28,29,30.
Utilizing digital image processing techniques, N Otsu et al.19 proposed a nonparametric and unsupervised method for image segmentation, employing zeroth and first-order cumulative moments to optimal threshold automatic selection. Furthermore, the authors extended this method to address multi-threshold problems straightforwardly. Edge detection algorithms, such as the Canny operator20, have also been employed to detect cracks by monitoring changes in pixel brightness at the intersection of cracks and the background5. However, the detection performance of crack edge fractures frequently appears to be limited. Talab et al.21 addressed this challenge by applying Sobel’s filtering to eliminate image noise and then detecting cracks using Otsu’s method, attaining continuous and accurate crack identification performance. Li et al.22 utilized a backpropagation neural network (BPNN) for pavement crack detection. Meanwhile, Chen et al.23 extracted the local binary patterns (LBP) of pavement crack and then reduced the dimensionality of the LBP feature spaces using principal component analysis (PCA). Finally, they employed simplified samples to train a support vector machine (SVM) for crack detection.
Deep learning techniques automatically learn hierarchical representations from raw data, thereby reducing the reliance on handcrafted features and manual rule design. Consequently, deep learning, particularly CNNs, has demonstrated scalability and adaptability across a diverse array of crack detection. Li et al.24 employed a Faster R-CNN for automatic tunnel surface defect detection in harsh environments. Doshi et al.26 incorporated You Only Look Once (YOLOv4) for efficient detection and classification of pavement distress. To refine segmentation, Zhang et al.10 proposed CrackNet, comprising a five-layer CNN without any pooling layer, for pixel-wise crack segmentation on 3D asphalt pavement images. Zou et al.25 developed an end-to-end trainable deep CNN (DeepCrack) for crack identification, which fused multi-scale crack representations from various convolutional stages. This paper proposes a highly efficient tunnel lining crack detection model (Mini-Unet) that enhances the inference speed of the model while maintaining the accuracy of tunnel lining crack identification.
Lightweight CNNs
Due to computational complexity, CNNs with intricate architectures may exhibit significant response latency when deployed on conventional computers31. Consequently, there has been a burgeoning trend towards developing lightweight CNN variants in response to this challenge. These lightweight models are engineered to mitigate computational intensity while maintaining prediction accuracy32. With fewer computational hyperparameters, models efficiently guarantee rapid reaction and real-time object detection33.
Two principal techniques exist for acquiring lightweight CNNs, including directly training tiny networks and compressing pre-trained CNNs33. MobileNetV1, the first lightweight network, was based on DSConv, which transformed standard convolution into depthwise convolution (DWConv) and pointwise convolution(PWConv)34. In contrast to MobileNetV1, MobileNetV2 proposed two modifications: linear bottlenecks and inverted residuals, significantly increasing the model’s efficiency35. Furthermore, MobileNetV3 was constructed with a unique architectural design and a combination of complementary search methods36. The construction of the Xception model primarily involved replacing the original convolution process in InceptionV337 with DSConv38. In the ShuffleNetV1 network, a ShuffleNet unit was proposed to substantially decrease computation costs while maintaining predicted accuracy, comprising two main operations: pointwise group convolution (PGConv) and channel shuffle39. However, as discussed in the ShuffleNetV2, both PGConv and bottleneck structures increased memory access cost (MAC), which was non-negligible, especially for lightweight models. Thus, the real-time speed of the target hardware in the compact model design was took into account and a fundamental operator of channel split was introduced40. Unlike the aforementioned models that mostly relied on DWConv, GhostNet was a lightweight CNN structure41. It incorporated a label confusion model (LCM) module, named the Ghost module, which aimed to generate feature maps through linear transformation methods42.
Model implementation and basic setting
This section begins with an exploration of various theories related to DSConv. Next, a hybrid loss function integrating cross-entropy and dice loss functions is constructed for model training. Lastly, the architecture of the proposed model (Mini-Unet) is elucidated.
Depthwise separable convolution
The DSConv is extensively employed in various CNN architectures34,38, significantly reducing the computational burden during the inference process43. Compared to standard convolution, DSConv minimizes the number of multiplication operations and parameters needed for the convolution filter, leading to reduced processing time through fewer arithmetic operations44.
The standard convolution procedure entails the utilization of convolutional kernels to extract and fuse features, deriving a distinctive representation34. Nevertheless, the process of DSConv can be divided into two stages using factorized convolutions: DWConv and PWConv. In DWConv, each input channel is associated with a single convolutional filter, while PWConv applies a 1 × 1 convolutional kernel to iterate over the output channels.
The DWConv kernel processes one input channel at a time and aggregates the outputs of each channel. Specifically, it takes a feature map as input and applies a series of 2D filters along the width and height dimensions to iterate through all channels. An instance of the DWConv is depicted in Fig. 1a, where three 3 × 3 2D filters convolve with the associated channel of a 3 × 8 × 8 feature map, generating a single 3 × 6 × 6 output. The output of DWConv kernel is then passed into a PWConv kernel, which iterates over every feature map using a 1 × 1 filter. Figure 1b illustrates the PWConv process, where four 3 × 1 × 1 filters iteratively convolve with the 3 × 6 × 6 feature map and then produce four outputs of one channel sized 6 × 6, corresponding to the filter.

Demonstration of the DWConv and PWConv.
Hybrid loss function
The cross-entropy (CE) loss is a commonly utilized loss function for classification owing to its ability to accurately assess predicted results, effectively capturing the differences between two probability distributions y and p. In the context of image segmentation, y and p represent individual pixels of annotations and predictions within categories, respectively. The CE loss is defined as follows:
where i iterates over each pixel; C is the number of categories; c is the current category; N is the total number of instances; \(p_{{i,c}}\) is the predicted result derived from the model associated with every category; \(y_{{i,c}}\) employs a one-hot encoding strategy to represent the ground-truth labels. Since all training instances contribute equally to the ultimate objective, as demonstrated by Eq. (1), the CE loss remains a highly accurate evaluation strategy, providing consistent statistical predictions45.
The CE loss primarily evaluates the pixel-wise difference between the model’s predicted result and the annotated label. However, in unbalanced scenarios, it potentially results in the under-segmentation of small objects due to excessive attention to larger objects. This frequently causes the learning process to be stuck in the local minima of the loss function, leading to the predictions that are excessively biased toward the background46. Compared to the image size, the segmentation of the tunnel lining crack typically occupies relatively small areas. However, dice loss, based on the Sørensen-Dice coefficient47, is robust to class imbalance, assigning false positives and false negatives equally, which can be described as follows:
The dice loss can be defined from Eq. (2) as follows:
Dice loss delivers higher quality segmentations while CE loss yields well-calibrated segmentations48. Consequently, the hybrid loss function is constructed by integrating both dice loss and CE loss, and is denoted as follows:
Network architecture
Unet, a CNN developed by Olaf Ronneberger et al.49, was initially designed for biomedical image segmentation. Over time, it has found widespread applications in various domains, including satellite image recognition50,51 and civil engineering52,53. Its architecture maintains the output image size, achieved by combining downsampling (encoder) with convolutional layers and upsampling (decoder) to generate the segmentation output. The encoder part captures the context of the image by generating feature maps, while the decoder ensures precise localization using transposed convolutions. These structures are interconnected via skip connections, enabling Unet to deliver an output of the same size as the input, along with the corresponding categories.
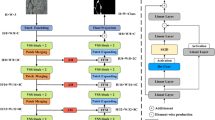
This study was motivated by Unet model to propose the lightweight tunnel lining crack segmentation model. This entailed decreasing the number of downsampling steps from four to three and substituting the standard convolution with DSConv at the fifth and sixth convolutional layers. Additionally, the transposed convolutions were replaced with bilinear interpolation during the upsampling process. These refinements culminated in developing a lightweight Unet model (Mini-Unet), as depicted in Fig. 2. Subsequent to these enhancements, the model exhibits enhanced resilience and faster inference speed.

Mini-Unet architecture.
Evaluation
This section commences with an introduction to the tunnel lining crack dataset utilized in this study. Following this, the evaluation metrics for model are presented. Finally, an ablation study is conducted to compare the performance of the proposed model with other models.
Tunnel lining crack dataset
The dataset of tunnel lining crack (Fig. 3) consists of 2,000 images. The width of the cracks is fine and it bears many complex similarities with surface textures. To ensure practicality, the dataset was constructed by collecting images from actual tunnel scenes, focusing on cracks in arch and sidewall linings. Initially, the original images were cropped to a resolution of 512 × 512 pixels, and only those containing visible cracks were retained for the dataset. The cracks were manually labeled in red. Training samples were randomly chosen from this dataset, with 90% allocated for training and the remaining images for validation set. To ensure objectivity, establishing the ground truth through the creation of a benchmark is essential to conducting any experiments. Specifically, each potential correspondence in every image pair was manually verified.

Tunnel lining crack pixel-level annotation.
To ensure the precision and consistency of experiments, all studies are implemented in the same equipment and are trained on a GPU. The details of hardware and software are shown in Table 1. During the process of experiments, the Adam optimizer and an adaptive learning rate were employed. Specifically, the hyperparameters of Adam were set to their defaults, the initial learning rate was 1e-3 and decreased by 0.9 every 5 epochs. The remainder of experiment details were as follows: the image size was 512 × 512 pixels, the minimum batch was 16, and the trained epoch was 150.
Performance evaluation
Commonly utilized metrics for assessing the performance of deep learning models encompass accuracy, precision, recall, and other relevant measures. This paper employs IoU, precision, and FPS to evaluate the performance of experimental models.
IoU, widely acknowledged in object detection and semantic segmentation, quantifies the overlap between the predicted and annotated masks54. It is formally calculated as the ratio of the intersection to the union of the two areas, as shown in Eq. 5. Where label is the manually annotated ground-truth image, while prediction represents the predicted result of the model. In pixel-wise detection, prediction corresponds to the number of pixels allocated within the predicted mask, whereas the label represents the number of pixels derived from manual annotated label.
Precision is the ratio of correctly classified pixels to the total number of pixels classified by the model in a specific category. True positive (TP) denotes the pixels accurately identified as belonging to the object or region of interest in the predicted mask, following the manual annotation. False Positive (FP) denotes the pixels erroneously identified as part of the object or region of interest in the predicted mask, despite not being manually annotated. As delineated in Eq. 6.
FPS is a crucial speed metric for assessing the performance of models in real-time applications55. It represents the number of the model’s processed operations per second and evaluates how the lightweight enhancement of the model benefits prediction speed. The equation of FPS can be expressed as follows:
where Num is the number of predicted images, and Time denotes the prediction time.
Model performance analysis
To analyze the performance of Mini-Unet, several variations of Unet model were tested, including Unet(tiny), which resamples only three times and uses bilinear interpolation for upsampling; Unet(DSC), in which the fifth and sixth standard convolutions of Unet(tiny) architecture are replaced with DSConv; and Mini-Unet, which incorporates the hybrid loss function into Unet(DSC). Table 2 showcases the performance metrics for each model, including MIoU, mean precision (abbreviated as Precision), the number of model parameters (abbreviated as Parameter), floating point operations (FLOPs), and FPS.
In Table 2, as the model progressively becomes lighter, several evaluation metrics present a decrease compared to the Unet49 model, including MIoU and Precision. Specifically, Unet(tiny) shows a reduction of 1.65% and 1.32% in MIoU and Precision, respectively, Unet(DSC) decreases by 2.22% and 2.03% in MIoU and Precision, respectively. Nevertheless, the application of the hybrid loss function during training improves the model’s performance. Compared to the Unet model, Mini-Unet exhibits a decrease of 0.67% in MIoU and 1.30% in Precision, respectively. Notably, there exists a significant reduction of 92.53% and 57.33% in the number of model parameters and FLOPs, while inference speed is significantly enhanced by 11.47%.
To validate the advancement of the proposed Mini-Unet model, several models were compared against it, including Unet + + 56 with supervision (abbreviated as Unet++(w/)), Unet + + without supervision (abbreviated as Unet++), deeplabv357 based on resnet50, deeplabv3 based on resnet101, PSPnet58, Segnet59, and EGE-UNet60. Unet + + introduces dense skip connections to capture multi-scale features more effectively and enables finer fusion of feature maps at different scales to supervise model training, providing richer feature representations for capturing complex shapes and boundaries. This study constructed Unet + + with fusion multi-stage feature maps as prediction (Unet++(w/)) and predicted cracks using the last feature map (Unet++), respectively. Model deeplabv3 is a state-of-the-art deep learning model designed for semantic segmentation tasks, which heavily utilizes atrous (or dilated) convolution to control the feature maps resolution within the network. And atrous spatial pyramid pooling (ASPP) is one of the core innovations in deeplabv3, consisting of multiple parallel atrous convolution layers with different dilation rates. This paper uses restnet5061 and restnet10161 as its backbone, enhancing its ability to extract rich and high-level semantic features. PSPnet is particularly known for its ability to capture global context and handle large-scale variations in image content, which is developed to achieve superior performance in scene parsing. Segnet, known for its encoder-decoder structure, particularly excels in computational efficiency and memory usage, performing well in pixel-wise classification. Aim at validating the inference speed alongside prediction accuracy, the efficient group enhanced UNet (EGE-UNet) was trained to be compared against the proposed model (Mini-Unet), which is a lightweight network with just 50KB parameters and achieves superior performance in skin lesion image segmentation.
The metrics of these models are displayed in Table 3. As seen, Mini-Unet outperforms many mainstream models except the Unet, Unet++, and Unet++(w/)) in term of MIoU and Precision, while being much more lightweight than those three models. Additionally, the Parameter outperforms other models except for the EGE-UNet model and FLOPs are much lower than other models except EGE-UNet and deeplabv3(resnet50). However, the inference speed is significantly faster than others. Compared with Unet model, the number of parameters and FLOPs has decreased to 2.319 M and 93.304G, respectively, and inference speed has increased by 11.47%. Consequently, primary strength of Mini-Unet lies in its optimal balance between prediction speed and accuracy, rendering it a compelling choice for tunnel lining crack segmentation tasks, particularly in scenarios where computational resources are limited or real-time processing is essential.
To delve into an analysis of the Mini-Unet model, image segmentation results from the Unet, Unet++(w/), and EGE-UNet are utilized as exemplars for further examination. Since the proposed network is motivated by Unet model, the goal aims to evaluate the changes in prediction performance. Additionally, the identification accuracy of Unet++(w/) is higher than that of other models in our study, as shown by MIoU and Precision metrics in Table 3, while EGE-UNet demonstrates fast inference speed and is more lightweight than other models in term of Parameter and FLOPs. The visual prediction results are displayed in Fig. 4. The width of tunnel lining cracks is fine. Compared to the image size, the proportion of the tunnel lining crack pixels relative to the entire image is relatively small, which means EGE-UNet model may learn more background details. As seen in the EGE-UNet prediction in Fig. 4, it misidentifies numerous pixels near crack targets as background noises. Though EGE-UNet is an excellent lightweight network, it does not optimally balance between prediction speed and accuracy for crack identification. Specifically, the metrics for EGE-UNet on MIoU, Precision, and FPS are 59.36%, 79.51%, and 5.597, respectively. Compared with Mini-Unet model, though the number of parameters and FLOPs has decreased to 0.053 M and 0.072G, respectively, inference speed is 0.67% slower and identification accuracy decreases by 2.30% and 5.55% in term of MIoU and Precision, respectively. Thus, there is no doubt that Mini-Unet outperforms EGE-UNet in tunnel lining crack identification.

Performance of models on tunnel lining crack dataset.
In image (a) of Fig. 4, the background noise is relatively minimal, causing little interference during crack detection. In this situation, Unet, Unet++(w/) and Mini-Unet accurately segment cracks while maintaining consistency with the annotated label image. Upon observing the image (b) of Fig. 4, slight background interference is evident, primarily caused by minor detachment of the tunnel lining wall and paint coating damage. Under this condition, Unet++(w/) performs optimally, whereas the performances of Unet and Mini-Unet are poorer, misidentifying grooves as cracks. This can be confirmed by examining the annotated regions in the image. In image (c) of Fig. 4, the image background is severely disturbed by noise, mainly originating from the tunnel’s fireproof coating. The uneven surface of the fireproof coating closely resembles a crack in this two-dimensional image. Under the current complex noise interference, the Unet++(w/) model accurately identifies the edges and overall details of cracks. In comparison, the prediction result of Unet displays discontinuous detail recognition in curved sections of the crack, while the Mini-Unet’s prediction result exhibits multiple discontinuity segmentation. Examination of the image (d) in Fig. 4 reveals that Unet, Unet++(w/), and Mini-Unet accurately identify the edge information of discontinuous cracks and achieve precise segmentation. This demonstrates that Mini-Unet model possesses the capability to detect the overall integrity of cracks. Furthermore, Mini-Unet shows competence in identifying multi-branch tunnel lining cracks, as evidenced by image (e) in Fig. 4. However, in the presence of noise interference caused by other ancillary facilities in the background, all three models exhibit misidentification, mistakenly identifying tunnel pipelines as cracks, as presented in image (f) of Fig. 4.
Evaluation using public dataset
To further validate the efficiency of the proposed Mini-Unet, a public dataset “bridge crack image dataset”62 is used to retrain Unet, Unet++(w/), EGE-UNet, and the proposed Mini-Unet. The dataset consists of 1873 concrete crack images, which are randomly divided into 1363 training images, 340 validation images, and 170 testing images. This dataset is highly challenging due to the complex similarities between concrete cracks and surface textures. The sizes of the original concrete crack images are mostly 1,024 × 1,024 pixels, and images are resized to 512 × 512 pixels for training, valuation, and testing. All four models are treated with 100-epoch training, the remainder of experiment details remain the same. Table 4 shows the segmentation metrics of all networks on testing images.
It can be observed that Unet and Unet++(w/) both attain higher detection accuracy than EGE-UNet and Mini-Unet in the concrete crack detection task using the bridge crack image dataset. The Precision and MIoU achieved by the proposed Mini-Unet on testing images are 89.78% and 77.86%, respectively. Specifically, compared with Unet, Mini-Unet decreases by 0.49% and 0.97% on MIoU and Precision, respectively, but inference speed has increased by 9.47%. Though the prediction accuracy is slightly lower than Unet and Unet++(w/), the proposed Mini-Unet still yields the fastest inference speed compared with all four networks. This experiment further demonstrates the efficiency of the proposed Mini-Unet in concrete crack detection.
Figure 5 reveals the typical identification outputs of Unet, Unet++(w/), EGE-UNet, and the proposed Mini-Unet. It can be observed that the proposed Mini-Unet has a strong capability of comprehending global contexts as well as learning concrete crack target details. The performance of image segmentation is almost on par with Unet, Unet++(w/) and outperforms EGE-UNet model.

Performance of models on bridge crack image dataset.
Discussion
During the image acquisition process, the camera is configured with a subject distance of 3700 millimeters (abbreviated as mm) and equipped with a 50 mm focal length lens. The acquired tunnel lining images exhibit a resolution of 2000 × 4096 pixels. Enlarging the image to a magnification level of 15 allows for the acquisition of crack width using a specialized crack comparison card, achieving a precision of up to 0.2 mm. To investigate the impact of crack width on detection effectiveness, an image depicting cracks with a width greater than 0.5 mm (Fig. 6) and an image featuring width less than 0.5 mm (Fig. 7) are selected for comparative analysis.

Comparison of the crack’s width (greater than 0.5 mm) effect on model detection performance.
In Fig. 6, although the Mini-Unet model exhibits discontinuities in crack segmentation within the upper-right corner of the image, it accurately delineates the overall contour of the crack. Furthermore, the crack segmentation performance in other areas of the image is equally outstanding when compared to Unet and Unet++(w/).

Comparison of the crack’s width (less than 0.5 mm) effect on model detection performance.
Figure 7 illustrates that Unet++(w/) model identifies the overall profile of the tunnel lining crack, however, its identification also displays discontinuities. Conversely, the segmentation performances of Unet and Mini-Unet are poor, as evidenced in the enlarged area of Fig. 7. The segmented result of both models remains numerous discontinuous regions. This indicates that, while there exists a gap compared to Unet++(w/), Mini-Unet and Unet show similar crack identification performance. Mini-Unet, being a lightweight network, is designed to balance detection accuracy and speed. Analyzing the model’s segmentation performance, Mini-Unet has made significant progress toward this goal.
As shown in Table 2, there is no doubt that the Parameter and FLOPs of Mini-Unet are obviously lower than those of the Unet model by nearly 92.53% and 57.33%, respectively. However, the image processing speed increases by 11.47%, which is not thoroughly discussed in the paper. Additionally, the optimization of hyperparameters, such as learning rate, number of epochs, batch size, image size, coefficient of loss function, and so on, is also not discussed. Furthermore, overfitting remains a fundamental issue in deep learning due to image background noise, the limited image size of the training set, and the fewer hyperparameters in Mini-Unet. Therefore, the selection of an appropriate regularization technique for Mini-Unet needs to be explored in future experiments.
Conclusions
Tunnel lining cracks influence the stability of the tunnel structure and the safety of their operation. Aiming at facilitating prompt identification of tunnel lining cracks, this paper proposes a highly efficient tunnel lining crack detection model (Mini-Unet) by integrating DSConv technology. Additionally, a hybrid loss function is employed to mitigate the categories imbalance between crack and image background during model training.
The proposed Mini-Unet model achieves high efficiency in detecting tunnel lining cracks with an FPS of 5.635, a Precision of 84.18% and an MIoU of 60.76%, respectively. Compared with Unet, Unet++, Unet++(w/), deeplabv3(resnet50), deeplabv3(resnet101), PSPnet, Segnet, and EGE-UNet, the proposed Mini-Unet is significantly more efficient in tunnel lining crack detection. Though the identification accuracy of the Mini-Unet is slightly lower than U-net, Unet++, and Unet++(w/), it outperforms other models. The proposed model’s Parameters and FLOPs are reduced to 2.319 M and 93.304G, respectively, and its processing speed is the fastest among all models. The high efficiency reflects the potential of the proposed Mini-Unet model for real-time tunnel lining distress pixel-level detection.
Compared with the other three state-of-the-art models using a public concrete crack dataset, the proposed Mini-Unet model still shows competitive performance. Despite sacrificing some accuracy, the proposed Mini-Unet demonstrates faster inference speed. The proposed Mini-Unet is not trained to simultaneously detect all types of distress on tunnel lining. However, the success of the proposed Mini-Unet model might imply that advanced deep-learning technologies will promote real-time tunnel lining distress detection.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Liu, C. et al. A state-of-the-practice review of three-dimensional laser scanning technology for tunnel distress monitoring. J. Perform. Constr. Facil. 37, 03123001 (2023).
Zhao, S., Zhang, D., Xue, Y., Zhou, M. & Huang, H. A deep learning-based approach for refined crack evaluation from shield tunnel lining images. Autom. Constr. 132, 103934 (2021).
Zhang, J. Z. et al. Effect of ground surface surcharge on deformational performance of tunnel in spatially variable soil. Comput. Geotech. 136, 104229 (2021).
Ren, Y. et al. Image-based concrete crack detection in tunnels using deep fully convolutional networks. Constr. Build. Mater. 234, 117367 (2020).
Zhou, Z., Zhang, J., Gong, C. & Wu, W. Automatic tunnel lining crack detection via deep learning with generative adversarial network-based data augmentation. Undergr. Space 9, 140–154 (2023).
Abdel-Qader, I., Abudayyeh, O. & Kelly, M. E. Analysis of edge-detection techniques for crack identification in bridges. J. Comput. Civil Eng. 17, 255–263 (2003).
Shen, B., Zhang, W. Y., Qi, D. P. & Wu, X. Y. Wireless multimedia sensor network based subway tunnel crack detection method. Int. J. Distrib. Sens. Netw. 11, 184639 (2015).
Zhang, W., Zhang, Z., Qi, D. & Liu, Y. Automatic crack detection and classification method for subway tunnel safety monitoring. Sensors 14, 19307–19328 (2014).
Ye, X. W., Jin, T. & Chen, P. Y. Structural crack detection using deep learning–based fully convolutional networks. Adv. Struct. Eng. 22, 3412–3419 (2019).
Zhang, A. et al. Automated pixel-level pavement crack detection on 3D asphalt surfaces using a deep‐learning network. Computer-Aided Civil Infrastructure Eng. 32, 805–819 (2017).
Chen, J., Zhou, M., Huang, H., Zhang, D. & Peng, Z. Automated extraction and evaluation of fracture trace maps from rock tunnel face images via deep learning. Int. J. Rock Mech. Min. Sci. 142, 104745 (2021).
Liu, Y. et al. A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing 338, 139–153 (2019).
Ali, L. et al. Performance evaluation of deep CNN-based crack detection and localization techniques for concrete structures. Sensors 21, 1688 (2021).
Andrushia, A., Lubloy, E. & D., N, A. & Deep learning based thermal crack detection on structural concrete exposed to elevated temperature. Adv. Struct. Eng. 24, 1896–1909 (2021).
Jenkins, M. D., Carr, T. A., Iglesias, M. I., Buggy, T. & Morison, G. A deep convolutional neural network for semantic pixel-wise segmentation of road and pavement surface cracks. In 2018 26th European signal processing conference (EUSIPCO) 2120–2124 (2018).
Huyan, J., Li, W., Tighe, S., Xu, Z. & Zhai, J. CrackU-net: a novel deep convolutional neural network for pixelwise pavement crack detection. Struct. Control Health Monit. 27, e2551 (2020).
Deng, J., Lu, Y. & Lee, V. C. S. Concrete crack detection with handwriting script interferences using faster region-based convolutional neural network. Computer-Aided Civil Infrastructure Eng. 35, 373–388 (2020).
Kim, B. & Cho, S. Image-based concrete crack assessment using mask and region‐based convolutional neural network. Struct. Control Health Monit. 26, e2381 (2019).
Otsu, N. A threshold selection method from gray-level histograms. Automatica 11, 23–27 (1975).
Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell., 679–698 (1986).
Talab, A. M. A., Huang, Z., Xi, F. & HaiMing, L. Detection crack in image using Otsu method and multiple filtering in image processing techniques. Optik 127, 1030–1033 (2016).
Li, L., Sun, L., Ning, G. & Tan, S. Automatic pavement crack recognition based on BP neural network. PROMET-Traffic&Transportation 26, 11–22 (2014).
Chen, C., Seo, H., Jun, C. H. & Zhao, Y. Pavement crack detection and classification based on fusion feature of LBP and PCA with SVM. Int. J. Pavement Eng. 23, 3274–3283 (2022).
Li, D. et al. Automatic defect detection of metro tunnel surfaces using a vision-based inspection system. Adv. Eng. Inform. 47, 101206 (2021).
Zou, Q. et al. Deepcrack: learning hierarchical convolutional features for crack detection. IEEE Trans. Image Process. 28, 1498–1512 (2018).
Doshi, K. & Yilmaz, Y. Road damage detection using deep ensemble learning. In IEEE International Conference on Big Data (Big Data) pp. 5540–5544 (2020). (2020).
Zhai, G., Xu, Y. & Spencer, B. F. Bidirectional graphics-based digital twin framework for quantifying seismic damage of structures using deep learning networks. Struct. Health Monit., 14759217241231299 (2024).
Guo, G. & Zhang, Z. Road damage detection algorithm for improved YOLOv5. Sci. Rep. 12, 15523 (2022).
Li, J., He, Z., Li, D. & Zheng, A. Research on water seepage detection technology of tunnel asphalt pavement based on deep learning and digital image processing. Sci. Rep. 12, 11519 (2022).
Ye, G. et al. An improved transformer-based concrete crack classification method. Sci. Rep. 14, 6226 (2024).
Bouguettaya, A., Kechıda, A. & Taberkıt, A. M. A survey on lightweight CNN-based object detection algorithms for platforms with limited computational resources. Int. J. Inf. Appl. Math. 2, 28–44 (2019).
Xue, H. & Ren, K. Recent research trends on Model Compression and Knowledge Transfer in CNNs. In IEEE International Conference on Computer Science, Artificial Intelligence and Electronic Engineering (CSAIEE) pp. 136–142 (2021). (2021).
Chang, S. & Zheng, B. A lightweight convolutional neural network for automated crack inspection. Constr. Build. Mater. 416, 135151 (2024).
Howard, A. G. et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861 (2017).
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A. & Chen, L. C. Mobilenetv2: Inverted residuals and linear bottlenecks. In: Proc. IEEE conference on computer vision and pattern recognition. 4510–4520 (2018).
Cao, Y., Xu, J., Lin, S., Wei, F. & Hu, H. Proceedings of the IEEE/CVF international conference on computer vision workshops. (2019).
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. & Wojna, Z. Rethinking the inception architecture for computer vision. In: Proc. IEEE conference on computer vision and pattern recognition. 2818–2826 (2016).
Chollet, F. & Xception Deep learning with depthwise separable convolutions. In: Proc. IEEE conference on computer vision and pattern recognition. 1251–1258 (2017).
Zhang, X., Zhou, X., Lin, M., Sun, J. & Shufflenet An extremely efficient convolutional neural network for mobile devices. In: Proc. IEEE conference on computer vision and pattern recognition. 6848–6856 (2018).
Ma, N., Zhang, X., Zheng, H. T. & Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In: Proc. European conference on computer vision (ECCV). 116–131 (2018).
Nie, Y. et al. Learning ghost features for efficient image super-resolution. arXiv preprint arXiv:2101.08525. (2021).
Liang, Y., Li, M., Jiang, C. & Liu, G. CEModule: a computation efficient module for lightweight convolutional neural networks. IEEE Trans. Neural Networks Learn. Syst. 34(9), 6069–6080 (2021).
Srivastava, H. & Sarawadekar, K. A depthwise separable convolution architecture for CNN accelerator. In: 2020 IEEE Applied Signal Processing Conference (ASPCON). 1–5 (2020).
Lu, G., Zhang, W. & Wang, Z. Optimizing depthwise separable convolution operations on gpus. IEEE Trans. Parallel Distrib. Syst. 33(1), 70–87 (2021).
Gneiting, T. & Raftery, A. E. Strictly proper scoring rules, prediction, and estimation. J. Am. Stat. Assoc. 102(477), 359–378 (2007).
Milletari, F., Navab, N. & Ahmadi, S. A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In: fourth international conference on 3D vision (3DV). 565–571 (2016). (2016).
Li, X. et al. Dice loss for data-imbalanced NLP tasks. arXiv preprint arXiv:1911.02855 (2019).
Yeung, M. et al. Calibrating the dice loss to handle neural network overconfidence for biomedical image segmentation. J. Digit. Imaging 36(2), 739–752 (2023).
Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In: Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5–9, 2015, , proceedings, part III 18. 234–241 (Springer International Publishing, 2015).
Alsabhan, W. & Alotaiby, T. Automatic building extraction on satellite images using unet and ResNet50. Comput. Intell. Neurosci. 2022(1), 5008854 (2022).
Ch, A. et al. B. ECDSA-based water bodies prediction from satellite images with UNet. Water. 14(14), 2234 (2022).
Liu, F., Liu, J. & Wang, L. Asphalt pavement crack detection based on convolutional neural network and infrared thermography. IEEE Trans. Intell. Transp. Syst. 23(11), 22145–22155 (2022).
Qiu, Z., Martínez-Sánchez, J., Arias, P. & Datcu, M. A novel low-cost multi-sensor solution for pavement distress segmentation and characterization at night. Int. J. Appl. Earth Obs. Geoinf. 120, 103331 (2023).
Garcia-Garcia, A., Orts-Escolano, S., Oprea, S. & Villena-Martinez, V. & Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv preprint arXiv:1704.06857 (2017).
Zhou, Z., Zheng, Y., Zhang, J. & Yang, H. Fast detection algorithm for cracks on tunnel linings based on deep semantic segmentation. Front. Struct. Civil Eng. 17, 732–744 (2023).
Zhou, Z., Rahman Siddiquee, M. M., Tajbakhsh, N. & Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, September 20, 2018, Proceedings 4 3–11 (2018). (2018).
Chen, L. C., Papandreou, G., Schroff, F. & Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv. arXiv preprint arXiv:1706.05587 5 (2017).
Zhao, H., Shi, J., Qi, X., Wang, X. & Jia, J. Pyramid scene parsing network. In: Proc. IEEE conference on computer vision and pattern recognition 2881–2890 (2017).
Badrinarayanan, V., Kendall, A., Cipolla, R. & Segnet A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 39, 2481–2495 (2017).
Ruan, J., Xie, M., Gao, J., Liu, T. & Fu, Y. Ege-unet: an efficient group enhanced unet for skin lesion segmentation. In International conference on medical image computing and computer-assisted intervention 481–490 (2023).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In: Proc. IEEE conference on computer vision and pattern recognition 770–778 (2016).
Li, L. F., Ma, W. F., Li, L. & Lu, C. Research on detection algorithm for bridge cracks based on deep learning. Acta Automatica Sinica 45, 1727–1742 (2019).
Funding
The research was supported by the Foundation of Liaoning Province Education Administration (JYTQN2023380), China Postdoctoral Science Foundation (2022M722224) and Doctoral Start-up Foundation of Liaoning Province (2022-BS-189). The writers thank the funding body for their support.
Author information
Authors and Affiliations
Contributions
Conceptualization, Formal Analysis, Resources, Writing–review and editing, B.L.; Methodology, Writing original draft, X.C.; Data curation, Writing–review and editing, F.L.; Project administration, Supervision, Writing–review and editing, F.W.; Validation, Software, Writing–review and editing, S.J.; Data curation, Writing–review and editing, K.Z.; All authors have agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, B., Chu, X., Lin, F. et al. A highly efficient tunnel lining crack detection model based on Mini-Unet. Sci Rep 14, 28234 (2024). https://doi.org/10.1038/s41598-024-79919-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-79919-6
