
Abstract
Emojis, utilizing visual means, mimic human facial expressions and postures to convey emotions and opinions. They are widely used in social media platforms such as Sina Weibo, and have become a crucial feature for sentiment analysis. However, existing approaches often treat emojis as special symbols or convert them into text labels, thereby neglecting the rich visual information of emojis. We propose a novel multimodal information integration model for emoji microblog sentiment analysis. To effectively leverage the emoji visual information, the model employs a text-emoji visual mutual attention mechanism. Experiments on a manually annotated microblog dataset show that compared to the baseline models without incorporating emoji visual information, the proposed model achieves improvements of 1.37% in macro F1 score and 2.30% in accuracy, respectively. To facilitate the related research, our corpus will be publicly available at https://github.com/yx100/Emojis/blob/main/weibo-emojis-annotation.
Similar content being viewed by others
Introduction
Sentiment analysis, also known as sentiment classification, aims to identify and extract opinions from large amounts of unstructured text and categorize these opinions into different sentiment polarities, such as positive, neutral, or negative1. By analyzing the sentiment of online user-generated data, it is possible to understand people’s attitudes or opinions towards certain events or topics. For example, companies are interested in understanding customer perceptions of their products or brands2. Sentiment analysis has significant applications in fields such as political election prediction3, stock market prediction4, product evaluation5, and movie box office prediction6.
Emojis have gradually become the most popular non-textual symbols on social media and an indispensable chat tool in today’s online communication7,8. They are composed of various pictographs (pictorial symbols), such as smiling faces  and keep it up
and keep it up , they simulate human facial expressions and gestures. Studies show that over 50% of Instagram posts contain one or more emojis. Emojis provide important information about users’ emotions9, which are intuitive visual supplements to textual information and are very helpful for understanding the sentiment contained in text. For example, the sentence “Why is it like this? Even soap operas aren’t this dramatic
, they simulate human facial expressions and gestures. Studies show that over 50% of Instagram posts contain one or more emojis. Emojis provide important information about users’ emotions9, which are intuitive visual supplements to textual information and are very helpful for understanding the sentiment contained in text. For example, the sentence “Why is it like this? Even soap operas aren’t this dramatic .”, with three emojis at the end can more intuitively convey emotional characteristics on the microblog post. How to leverage emojis to detect sentiment polarity in social media dataset has increasingly attracted attention from both academia and industry.
.”, with three emojis at the end can more intuitively convey emotional characteristics on the microblog post. How to leverage emojis to detect sentiment polarity in social media dataset has increasingly attracted attention from both academia and industry.
Traditional methods usually convert emojis into special symbols or corresponding texts, and then use them as a whole with microblog text to apply text-based uni-modal sentiment analysis models7,10. However, from a visual perspective, emoji images inherently carry more intuitive emotional information11, which is both different from and complementary to the emotional information conveyed by text. Compared to unimodal text or visual data, multimodal data integrates information from different sources, providing a more comprehensive and accurate reflection of users’ true feelings. Nevertheless, multimodal sentiment analysis remains a highly challenging task. Firstly, since the emotional information in different modal data is diverse, it is necessary to effectively extract and represent the emotional features of these modalities during sentiment analysis. From the perspective of cognitive science, different words in text have varying degrees of importance in sentiment analysis. Similarly, not all emoji images have the same contribution to emotional expression. Therefore, in the feature extraction stage, this paper not only needs to eliminate noise interference in the text data, but also needs to identify and highlight emoji images that play a crucial role in emotional expression. Secondly, since different modal data may contain potential features of different dimensions and attributes, this paper needs to develop corresponding techniques and methods to ensure that these features can be correctly fused and interpreted in the sentiment analysis process.

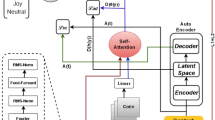
The Architecture of Emoji multimodal microblog sentiment analysis based on mutual attention mechanism.
To address the aforementioned challenges, this paper proposes an Emoji Multimodal Microblog Sentiment Analysis model based on a Mutual Attention Mechanism (MAM-EMMSA). The overall architecture is shown in Fig. 1. This model considers not only the textual information of emojis but also their visual information. In encoding textual semantic information, the model first converts emojis into their corresponding names, then utilizes a pre-trained language model, Bidirectional Encoder Representations from Transformers (BERT)12, combined with the positional information of emojis to obtain vector representations for each word. Next, a Bi-directional Long Short-Term Memory (Bi-LSTM) network is employed to learn the dependencies of contextual semantics, and a multi-head self-attention mechanism is used to focus on important parts of the sequence. For encoding the visual information of emojis, the model adopts a residual convolutional network ResNet-50 model and an image transformer encoder to preserve more relevant information13. To better integrate the visual information of emojis, the proposed model employs a mutual attention mechanism to model the interactions between emoji images and text, thereby maximizing the contribution of each modality to sentiment conveyance. Finally, the multimodal representations are combined with the original semantic representations and fed into a sentiment classifier for classification.
To validate the effectiveness of the proposed model, we manually annotate a microblog dataset with emojis and conducte experiments. The experimental results demonstrate that the proposed model is highly effective compared to several powerful baseline models, including previous neural network models.
The main contributions of this paper are summarized as follows:
-
(1)
We propose a novel emoji multimodal microblog sentiment analysis method based on a mutual attention mechanism (MAM-EMMSA). This method combines the visual information of emojis with textual information, effectively integrating features from different modalities to provide a more effective and accurate basis for sentiment classification.
-
(2)
We utilize the pre-trained model BERT, combined with the positional information of emojis in text. Through BiLSTM and a multi-head self-attention mechanism, it extract richer textual semantic features. Simultaneously, the paper uses ResNet and transformer models to extract more accurate visual features.
-
(3)
To verify the effectiveness of the model, we construct a microblog dataset containing one or more emojis and validate the proposed model (MAM-EMMSA) on this dataset. The experimental results demonstrate the feasibility and effectiveness of the proposed model.
The remainder of this paper is structured as follows: “Related work” section briefly reviews recent research advancements in the field of sentiment analysis. “Methodology” section provides a detailed description of the multimodal sentiment classification model based on the mutual attention mechanism (MAM-EMMSA). “Sentiment classification” section presents the classification function and model training. “Experiments” section presents relevant experimental results and offers an in-depth discussion.
Related work
Sentiment analysis, particularly text-based sentiment analysis, has long been a prominent topic in natural language processing (NLP)14. Traditional lexicon-based methods leverage resources like sentiment lexicons and linguistic rules to determine the sentiment orientation of text15,16. However, these methods rely heavily on the development of sentiment lexicons, and thus, the sole use of lexicons for sentiment analysis is becoming less common. Traditional machine learning approaches for sentiment analysis focus on manually designing features suitable for classifiers. These methods first extract textual features using techniques such as bag-of-words or N-grams16, and then classify the sentiment polarity using machine learning algorithms like Support Vector Machines (SVM), Naive Bayes, or Maximum Entropy17,18,19.
With the rise of deep learning techniques, neural networks like convolutional neural networks (CNNs)20, LSTMs21, and attention mechanisms22 have been introduced into sentiment analysis tasks, demonstrating remarkable performance. In recent years, the emergence of text pre-training models based on transformers such as BERT and RoBERTa, has further advanced text sentiment analysis12,23. However, these text sentiment analysis models often overlook the emotional information conveyed by emojis.
Emojis are considered as one of the significant features in text sentiment analysis, providing additional cues for sentiment recognition. Some pioneering works have attempted to use emojis as auxiliary sentiment labels to train classifiers. For instance, Liu et al. used emojis to smooth noisy sentiment labels24. Novak et al. were among the first to treat emojis as part of the lexical features for sentiment analysis25. However, compared to methods based on vocabulary and lexicons, these approaches have a relatively limited understanding of the complex semantics of emojis. Inspired by the success of word embedding algorithms, Eisner et al. proposed the emoji2vec model for pre-training emojis, obtaining semantic word embeddings for each emoji. Their research demonstrated that using emoji embeddings significantly improved the performance of Twitter sentiment analysis tasks26. Zhao adopted a CNN and recurrent neural network (RNN) based on an attention mechanism to extract semantic features and weight the sentiment orientation values of text and emojis, thereby predicting the sentiment orientation of microblog comments27.
However, these studies primarily focus on improving the accuracy of sentiment analysis for short texts, often treating emojis as independent inputs to predict sentiment labels. This approach overlooks the potential impact of emojis on the overall text sentiment. To gain a more comprehensive understanding of text sentiment, further research needs to explore the interaction and relationship between emojis and text more deeply.
Lou et al. measured the contribution of each word to the sentiment polarity based on emojis by incorporating an attention mechanism7. Yuan proposed a co-attention network based on emojis to learn the interactive emotional semantics between text and emojis for predicting the sentiment polarity of microblog texts10. Chen combined more powerful and fine-grained dual emoji embeddings to accurately represent complex semantic and emotional information2. However, these models have not fully utilized the visual information of emojis.
Multimodal sentiment analysis (MSA) is an emerging research field that integrates linguistic and non-linguistic behaviors to detect user emotions. Early multimodal fusion work mainly focused on geometric operations in the feature space28. However, recent studies have developed methods such as reconstruction loss29or hierarchical mutual information maximization30 to optimize multimodal representations. Yu et al. successfully achieved consistency and diversity across modalities through multi-task joint learning31. Additionally, Poria et al. proposed a recurrent model with multi-level attention to capture contextual information in text32. These studies have brought new perspectives and methods to the field of multimodal sentiment analysis.
Methodology
Problem definition
This paper focuses on the task of multimodal sentiment analysis of microblogs with emojis. Let there be N multimodal samples \(S=\{(T_1,E_1),...,(T_N,E_N)\}\), where T represents the textual modality, E represents the emoji visual modality, and N denotes the number of microblog posts containing emojis. Sentiment labels are computed by the \(f(T_k,E_k) \rightarrow G_k\), with the possible values for sentiment label \(G_k\) including {positive, neutral, negative}.
Feature extracting
Users not only focus on the overall presentation of a post but also on specific parts that interest them. In the textual modality, we denote a microblog post as \(T=\{w_C,w_1,...,w_i,...,w_l,e_1,e_1,...,e_m,w_S\}\), utilizing special tokens [CLS] and [SEP] to denote the beginning and end of the sequence. For the i-th word and the j-th emoji in the post, their corresponding text representations are denoted as \(T=\{w_i\}\) and \(T=\{e_j\}\) respectively. We use BERT12, specifically the 12-layer uncased version, to encode input sentences to obtain the hidden representations of textual modality. The embedding from the last Transformer layer’s output can be represented as:
where \(W^t=\{w^t_C,w^t_1,...,w^t_i,...,w^t_l,e^t_1,e^t_1,...,e^t_m,w^t_S\}\), \(W^t \in \mathbb {R}^{n^t\times d^t}\); \(n^t\) denotes the length of the text sequence (including emoji texts), \(d^t=768\) denotes dimension of the text, \(\theta ^{t}_{BERT}\) refers to the parameters of the BERT.
Context representation
In addition to semantic information, the proposed method also considers the positional information of emojis in text. The method calculates the relative distance between each word and each emoji, and utilizes the result as positional embeddings. By employing a Bi-LSTM and a Multi-Head Self-Attention mechanism (MHSA), the concatenation of word embeddings and position embeddings is transformed into a contextual representation of text. The main procedure is formulated as follows:
The contextual representation method maximally retains the original semantic information and syntactic structure of the context. We get \(H^t_{avg}\) after average pooling of \(H^t\), which is utilized as the textual feature for feature fusion in the final sentiment analysis:
Visual representation
To fully utilize the visual information of emojis, we use the last convolutional layer of the pre-trained ResNet50 (Residual Networks) model to extract initial image features33, as the image feature vector \(H^v\) can be:
where ResNet is a convolutional neural network that is 50 layers deep. \(H^v=\{r_1,...,r_j,...,r_l^v\}\), \(H^v \in \mathbb {R}^{l^v\times d^v}\); \(l^v=7\times 7\) is the number of feature regions, and \(d^v=2048\) is the dimension of each region, \(\theta ^{v}_{Res}\) refers to the parameters of the ResNet50.
To capture the coherence information of the emoji image, we further employ an Image Transformer Encoder (Trans) based on a vanilla transformer34 to get emoji features \(V^l_{\mathbb {L}^v} \in \mathbb {R}^{l^v\times d^t}\).
where Trans denotes the Transformer encoding operation for images, \(V^l_0 = H^vW^l_v+b^l_v\), \(W^l_v \in \mathbb {R}^{d^v\times d^t}\), \(b^l_v \in \mathbb {R}^{d^t}\), \(\mathbb {L}^v=1,...,L_{v}\) is the layers in the image Transformer encoder, \(\theta ^{v}_{\mathbb {L}^v-1}\) denotes the parameters of Trans.
Multimodal fusion
The feature representation of one modality can enhance the representation of another modality. In the multimodal fusion layer, we use a mutual attention mechanism (MAM) to model the interaction between emoji images and text, thereby extracting key information from the multimodal input.
For the input text \(H^t\), we set text as the query (Q), and the emoji image \(V^l\) as the key (K) and value (V), \(K=V\). The emoji-enhanced text can be expressed
For the emoji images, we set the emoji images as the query (Q) and text as the keys (K) and values (V). The images enriched with textual information can be represented by the following formulas.
where \(H^{vt}_0=H^{vt}\) is a visual representation that captures text-enhanced emoji expressions.
Based on the multimodal representations \(H^{tv}\) and \(H^{vt}_{\mathbb {L}^n}\), we first calculate their respective representations \(H^{tv}_{avg}\)and \(H^{vt}_{avg}\) through average pooling operations. Then, by concatenating the contextual representations \(H^{t}_{avg}\), \(H^{tv}_{avg}\), and \(H^{vt}_{avg}\), we obtain a microblog representation containing more information. This process can be represented using the following formulas.
where F represents the final representation that integrates multimodal information, \(V^l_{\mathbb {L}^v}\) denotes emoji image features.
Sentiment classification
The fused multimodal representation F is fed into a fully connected layer to map it to the target space of C classes, followed by using the softmax function to C the probability distribution of sentiment for the microblog post.
where \(W_c\) and \(b_c\) denote the trainable weight matrix and bias vector, respectively.C is the number of sentiment polarities, and \(p_c\) represents the probability of sentiment label c.
Model training
The model training process utilizes categorical cross-entropy as the loss function, aiming to minimize the cross-entropy loss between the true sentiment distribution and the predicted sentiment distribution. The expression for the loss function is:
where the parameter \(p_d^c\) represents the true probability of sentiment label c for the d-th post, and \(\widetilde{p_d^c}\) represents the predicted probability of sentiment label c of the d-th post. D denotes the set of posts. \(\lambda\) is the weight of \(L_2\) regularization, used to prevent overfitting.
Experiments
We first introduce the process of constructing the dataset, followed by a detailed explanation of the evaluation metrics and hyperparameter settings used in this experiment. Next, we list a series of comparable baseline methods and provide brief descriptions for each. Finally, we present the experimental results and corresponding analysis.
Dataset
We utilize the Weibo API to collect 50,000 microblog posts from Sina Weibo (https://weibo.com), a widely popular microblogging platform in China. Subsequently, 20,000 posts containing emojis are filtered out. To ensure data representativeness, the microblog posts are sorted based on the frequency of emoji occurrences, and a collection of emojis that appeared at least 10 times is selected. Then, the microblog posts are filtered based on these emojis, retaining only those containing at least one emoji. To clean the data, URLs, usernames, tags, and special characters are filter out. Additionally, only microblogs with a text length greater than 3 are retained. After these processing steps, a total of 12,278 microblogs are selected for subsequent annotation work. During the tokenization stage, the Harbin Institute of Technology Language Technology Platform (LTP) (https://ltp.ai/) is used as the tokenization tool to accurately segment the microblog text.
We invite three annotators to construct the dataset, including two senior students majoring in linguistics and one student majoring in computer science. The sentiment polarity is divided into positive, neutral, and negative, represented by 2, 1, and 0 respectively, and labels appearing at least twice are accepted. Each microblog post retains at least one emoji. The annotation work is mainly divided into two parts. First, annotators annotate the polarity of each post based solely on the text. In other words, emojis were removed from text, and only the pure text of each microblog post is used as the basis for polarity. Secondly, annotators consider both text and emojis, and annotate the sentiment polarity of each microblog. Finally, sentiment polarity annotations are obtained for 12,278 microblogs with emojis. The statistics of this corpus are shown in Table 1.
Experimental setting
All the deep learning models used in this paper are based on the Pytorch framework, and fivefold cross-validation is applied to the dataset. In the experiments of the proposed model, for textual semantic information of a microblog post, the model first replaces all emojis in the original corpus with corresponding textual representations (https://www.emojiall.com/zh-hans/platform-weibo). For example, the microblog “Today is the last day of work, tomorrow officially starts the best” is replaced with “Today is the last day of work [applause] , tomorrow officially starts the best [love you]
, tomorrow officially starts the best [love you] ”. Next, a BERT pre-trained model with a dimension of 768 is employed to extract text vector representations for words and emojis. Specifically, the position vector dimension of emojis is set to 20. In the model architecture, the number of neurons in the BiLSTM layer is set to 256,and the number of attention heads is 4. For the visual information of emojis, a residual neural network ResNet50 with 50 layers is chosen as the basic structure. During training, to enhance the diversity of the data, random cropping of images with a size of 224 \(\times\) 224 pixels is applied, along with random horizontal flipping and scaling. In the image transformer encoding stage, \(L^v\) is 1.The Adam optimization method is used to estimate the model parameters, with a learning rate of 0.001, a dropout value of 0.3, a regularization coefficient of \(10^{-5}\), and a batch size of 64. Additionally, to ensure the stability and reliability of the results, each experiment is repeated 5 times, and the average values are reported.
”. Next, a BERT pre-trained model with a dimension of 768 is employed to extract text vector representations for words and emojis. Specifically, the position vector dimension of emojis is set to 20. In the model architecture, the number of neurons in the BiLSTM layer is set to 256,and the number of attention heads is 4. For the visual information of emojis, a residual neural network ResNet50 with 50 layers is chosen as the basic structure. During training, to enhance the diversity of the data, random cropping of images with a size of 224 \(\times\) 224 pixels is applied, along with random horizontal flipping and scaling. In the image transformer encoding stage, \(L^v\) is 1.The Adam optimization method is used to estimate the model parameters, with a learning rate of 0.001, a dropout value of 0.3, a regularization coefficient of \(10^{-5}\), and a batch size of 64. Additionally, to ensure the stability and reliability of the results, each experiment is repeated 5 times, and the average values are reported.
Evaluation method
In the experiment, we use accuracy and macro F1 as evaluation metrics to assess the performance of the MAM-EMMSA model. Accuracy is one of the most commonly used evaluation metrics in classification tasks, and its definition is as follows:
where T and N represent the numbers of samples predicted correctly and incorrectly, respectively.
Due to the potential issue of class imbalance in multi-class tasks, we utilize the macro F1 for a more fair comparison. Unlike accuracy, the macro F1 first calculates the precision and recall for each class separately. Then, the average of precision and recall for all classes is computed as macro precision (\(P_{Macro}\)) and macro recall (\(R_{Macro}\)) respectively. Finally, the macro F1 (\(F1_{Macro}\)) is calculated using \(P_{Macro}\) and \(R_{Macro}\). The calculation formulas are as follows:
where C represents the number of classes in sentiment analysis, and \(\textit{TP}_\textit{i}\), \(\textit{FP}_\textit{i}\), and \(\textit{FN}_\textit{i}\) represent the numbers of true positives, false positives, and false negatives respectively.
Baseline models
To evaluate the performance of the MAM-EMMSA model, we compare it with several baseline models, including SVM, Bi-LSTM (text), Bi-LSTM (text+emoji), EA-Bi-LSTM, and ECN. Regarding the experimental setup for neural network models, all models are ensured to follow the same configurations and parameters as the proposed model. Below are the detailed descriptions of these baseline models:
-
SVM17 This is a classical binary classification statistical method that does not consider the impact of emojis on the sentiment polarity of text, but merely treats emojis as independent emoji words. Various features such as bag-of-words and punctuation marks are utilized are utilized to train the SVM classifier.
-
Bi-LSTM(word) This model takes only the word embeddings in the microblog as input and utilizes a bidirectional long short-term memory (Bi-LSTM) network for sentiment analysis.
-
Bi-LSTM (word+emoji) In this model, both the word vectors from microblog posts and the corresponding text vectors of emojis are used as inputs to the Bi-LSTM for sentiment analysis.
-
EA-Bi-LSTM 7 This model introduces an emoji-based attention network on top of Bi-LSTM, aiming to enhance the accuracy of sentiment analysis by focusing on crucial emojis. The input of the model also includes word vectors and emoji text vectors.
-
ECN 10 This is an Emoji-based Co-attention Network (ECN) for sentiment analysis. Similar to other models, it takes word vectors and emoji text vectors as input.
Results
Table 2 presents the experimental results of sentiment analysis for all models on the Microblog corpus. Given the significant class imbalance issue resulting in a notably smaller number of neutral microblogs compared to positive or negative ones, to fairly evaluate each model, this paper employs both macro F1 score and accuracy, achieving consistent performance across the annotated corpus.
In Table 2, We see that compared to the discrete SVM model, the neural network model Bi-LSTM (word) demonstrates superior performance in the experiment. It demonstrates the strong capability of neural network models in feature extraction and sequence information capturing. Compared to the sparsity of metrics in discrete models, Bi-LSTM (word) model can more accurately capture the sentiment tendencies in text.
Compared with the Bi-LSTM (word) model that only uses text features, the Bi-LSTM (word+emoji) model that combines word and emoji text features achieves an improvement of 9.17% and 8.37% in macro F1 score and accuracy, respectively. It demonstrates that the impact of emoji-corresponding text information on sentiment polarity of a microblog post is stronger than that of text.
Furthermore, compared to the Bi-LSTM (word+emoji) model, the EA-Bi-LSTM model shows an increase of 3.04% in macro F1 score and an improvement of 1.44% in accuracy. This is attributed to the EA-Bi-LSTM model not only utilizing text and emoji features but also considering the additional feature of emojis’ influence on text.
Compared to the EA-Bi-LSTM model, the ECN model shows improvements in both F1 score and accuracy. The ECN model utilizes a more comprehensive set of features, including text, emojis, the impact of emojis on text, the impact of text on emojis, and the information features among multiple emojis. The use of these features further validates the significant roles that text and emojis play in sentiment prediction on microblogs. The interaction information based on emojis and text can effectively capture the mutual influence of sentiment polarity between emojis and text. A multi-feature fusion model based on emojis and text can more effectively capture the sentiment information in microblogs.
As shown in Table 2, the proposed MAM-EMMSA model significantly outperforms previous benchmark models on the Chinese microblog dataset, achieving macro P (Precision) of 83.85%, macro R (Recall) of 77.26%, macro F1 of 80.42%, and Acc (Accuracy) of 87.95%. On one hand, this model combines textual and visual information of emojis to obtain rich feature information of emojis. On the other hand, it introduces a mutual attention mechanism to capture fine-grained interactions between emoji images and text, thereby obtaining additional valuable information.
Analysis
The role of emojis
To further investigate the importance of emojis in sentiment analysis on Microblogs. We evaluate their impact on model performance by removing or simplifying emoji inputs from the model. The NE-MAM-EMMSA model represents the complete removal of emoji inputs. The NEV-MAM-EMMSA model indicates the removal of only the visual information of emojis, while the NET-MAM-EMMSA model represents the removal of only the textual information related to emojis. Table 3 details the performance of three models in terms of Macro F1 and accuracy.
As can be seen from Table 3, the performance of the MAM-EMMSA model is significantly better than the NE-MAM-EMMSA model, likely due to the fact that the NE-MAM-EMMSA model only considers textual features while ignoring emoji information. This result indicates that emojis contain crucial emotional information in sentiment analysis, which is consistent with previous experimental analyses. Compared to the NEV-MAM-EMMSA model, the NET-MAM-EMMSA model shows improved macro F1 score and accuracy, suggesting that the emoji visual information may contain richer emotional features than their textual counterparts.
The effectiveness of mutual attention mechanism
To further explore the effectiveness of the mutual attention mechanism in the model, we compares the original MAM-EMMSA model architecture with several modified variants. Table 4 demonstrates the impact of the mutual attention mechanism on MAM-EMMSA. MAM-EMMSA-V1 removes the attention module from text to the emoji image and uses the average value of the emoji image vectors after being transformed as the representation of the emoji. MAM-EMMSA-V2 removes the attention module from the emoji image to text and uses the average value of the text vectors after being processed by MHSA (Multi-Head Self-Attention) as the representation of text. While MAM-EMMSA-V3 completely removes the mutual attention module, it calculates the average value of the text vectors after being processed by MHSA and the average value of the emoji image vectors after being transformed, and then concatenates these two vectors as the input for the fully connected layer.
As can be seen from Table 4, when the mutual attention mechanism is removed, and only the text vector and emoji image vector are concatenated, the F1 score and accuracy of MAM-EMMSA-V3 drop significantly. It fully demonstrates that the mutual attention module plays a critical role in the proposed MAM-EMMSA model. Compared to MAM-EMMSA-V2, the MAM-EMMSA-V1 model has slightly lower macro F1 and accuracy. This might be because the model replaces the attention mechanism on emoji images with the average value of all emoji image vectors. This change indicates that the model’s accuracy decreases in sentiment analysis when it cannot accurately identify the emojis that dominate the sentiment of text.
The impact of dataset size on experimental performance
In our model, we fine-tune pre-trained models BERT-uncased base and ResNet50 on the Weibo dataset to extract text and visual features, respectively. Some studies indicate that pre-trained models have a certain capability for few-shot learning35,36,37. To investigate the impact of dataset size on experimental performance, we compare the results of experiments with datasets of different sizes, as shown in Fig. 2. From Fig. 2, we can see that when the dataset size increases from 6000 to 8000, the macro F1 increases by 1.23%; when it increases from 8000 to 10,000, the macro F1 increases by 0.65%; and when it increases from 10,000 to 12000, the macro F1 only increases by 0.03%. These results indicate that as the data size increases, the improvement in the macro F1 becomes progressively stable, validating the effectiveness of pre-trained models in few-shot learning. In the future, we plan to expand the dataset to further enhance the model’s performance.

The impact of dataset size on experimental performance.
Impact of different pre-trained vision models
To investigate the impact of different pre-trained vision models on sentiment analysis, we replace ResNet50 in the MAM-EMMSA model with VGG1638 and DenseNet12139. The experimental results are presented in Table 5. Here, MAM-EMMSA-VGG16 refers to the visual information extracted using VGG16 for emoji analysis, while MAM-EMMSA-DenseNet121 refers to the visual information extracted using DenseNet121, with the other parts of the model remaining unchanged. The third column of the table shows the training time for each epoch. We observed that the macro F1 score of MAM-EMMSA is 1.81% higher than that of MAM-EMMSA-VGG16, and the accuracy is 2.12% higher, with each epoch taking 33 seconds less than MAM-EMMSA-VGG16. Compared to MAM-EMMSA-DenseNet121, MAM-EMMSA has slightly lower macro F1 scores and accuracy but requires 28 seconds less of running time. Considering both performance and efficiency, we decided to use ResNet50 as the visual information extraction model for emoji images.
Analysis of imbalanced classes
In our dataset, neutral data is relatively scarce. To achieve balance among the classes, we adopt an oversampling method to augment the neutral data. Specifically, we first use the “Modern Chinese Synonym Dictionary” to perform synonym replacement on neutral Weibo sentences, increasing the number of neutral data instances to 5225, which matches the number of both positive and negative data instances. Subsequently, we use this augment dataset to validate the performance of our proposed model. The experimental results are shown in Table 6. MAM-EMMSA (augment) indicates the experiment of our proposed model on the augment dataset.
In Table 6, we can observe that simple data augmentation, due to its inability to obtain diverse data, may not effectively alleviate the class imbalance problem. Data augmentation is a complex knowledge engineering task. To remain consistent with other baselines, our final model did not adopt data augmentation methods. In the future, we will conduct further research on the issue of data imbalance.
Analysis of the time complexity and space complexity of the models
All experiments are conducted on the Ubuntu 20.04 operating system using a machine equipped with a NVIDIA GeForce RTX 3090 24G GPU and 128G of memory, along with the PyTorch 1.7 framework. We perform a detailed analysis of the time and space complexity for our proposed model MAM-EMMSA compared to the baseline model using BERT. The results, shown in the Table 7, show that MAM-EMMSA has a lower time complexity than ECN, likely due to the longer computation time required by CNNs compared to attention mechanisms. Additionally, compared to EA-Bi-LSTM, MAM-EMMSA requires more computational resources when processing emoji images and implementing multi-head attention mechanisms, which accounts for the increased time and space complexity.
It is important to note that previous studies on sentiment analysis of microblog posts did not consider the impact of emoji images. Our manuscript primarily focuses on exploring this crucial aspect, highlighting its importance in sentiment analysis. In the future, we will explore other models to further enhance performance and address the concerns regarding the contribution of our work.
Case study
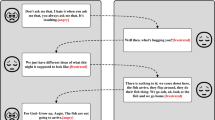
To highlight the role of the text-to-emoji image attention module in the MAM-EMMSA model, we compared the original MAM-EMMSA model with the NEV-MAM-EMMSA model, which removed the text-to-emoji image attention module. We randomly sampled some examples as shown in Fig. 3, columns 2 through 4 represent the standard polarity, NEV-MAM-EMMSA predicted polarity, and MAM-EMMSA predicted polarity, respectively. We can see that both NEV-MAM-EMMSA and MAM-EMMSA provided correct predictions for example (1) through (3). One likely reason is that each microblog post contains one emoji, and both models can learn the semantic information from text and emojis.

Microblog samples of MAM-EMMSA and NEV-MAM-EMMSA predicts results.
In Fig. 3, we can also observe that NEV-MAM-EMMSA made incorrect predictions while the MAM-EMMSA model with the text-to-emoji attention module performed well for examples 4 through 5. Which may be due to each microblog contains multiple emojis, and NEV-MAM-EMMSA failed to sufficiently distinguish between the emojis and text. However, the MAM-EMMSA model was able to identify and focus on important emoji information. This design enables the MAM-EMMSA model to achieve higher accuracy when handling microblog posts containing multiple emojis.
To explore the impact of the attention mechanism on the ambiguity of emojis, we visualized the attention weights of two Weibo sentences. Fig. 4 illustrates the weight distribution of each word after processing through the attention mechanism. In Fig. 4 (1), the model primarily allocates more weight to the words “ ” (couldn’t continue watching) and “
” (couldn’t continue watching) and “ ” (left), which directly express dissatisfaction with the movie. The
” (left), which directly express dissatisfaction with the movie. The  (crying) typically conveys strong emotions and, in this context, is likely associated with negative feelings such as disappointment or pain, hence it obtains the higher weight assigned. In Fig. 4, the weights of “
(crying) typically conveys strong emotions and, in this context, is likely associated with negative feelings such as disappointment or pain, hence it obtains the higher weight assigned. In Fig. 4, the weights of “ ” (too) and “
” (too) and “ ” (beautiful) are higher, indicating the user’s satisfaction and praise for the ordered clothes. Although the
” (beautiful) are higher, indicating the user’s satisfaction and praise for the ordered clothes. Although the  appears to represent negative emotions on the surface, in this context, it is often used to express strong positive emotions, such as surprise or being touched, which also results in a higher weight. From Fig. 4, we can see that the attention mechanism can allocate more weight to words and emoticons that are more important for emotional judgment and select the emoticon meanings most relevant to the current context, thereby distinguishing between different meanings or emotional layers of emoji and reducing the interference caused by their ambiguity.
appears to represent negative emotions on the surface, in this context, it is often used to express strong positive emotions, such as surprise or being touched, which also results in a higher weight. From Fig. 4, we can see that the attention mechanism can allocate more weight to words and emoticons that are more important for emotional judgment and select the emoticon meanings most relevant to the current context, thereby distinguishing between different meanings or emotional layers of emoji and reducing the interference caused by their ambiguity.

The impact of attention on emoji bi-sense.
Conclusions and future work
In response to the abundance of emoji in Microblogs, we propose a novel multimodal sentiment analysis model, termed Mutual Attention Mechanism-based Emoji-Multimodal Microblog Sentiment Analysis (MAM-EMMSA). This model integrates textual context semantic information with emoji visual information using mutual attention mechanism to achieve sentiment classification. To validate the effectiveness of this model, we constructed a microblog corpus that contains both plain text polarities and text-emojis polarities, and each microblog post contains at least one emoji. Experimental results demonstrate that combining textual and emoji representations effectively enhances the accuracy of Microblog sentiment analysis.
In the future, we will improve sentiment information extraction algorithms and optimize the fusion methods between different modalities, aiming to further enhance sentiment analysis accuracy. Additionally, by leveraging more diverse annotated resources for model training and optimization, our MAM-EMMSA model is expected to achieve further refinement and improvement.
Data availability
Our dataset access is open. Details of the dataset can be found online at: https://github.com/yx100/Emojis/blob/main/weibo-emojis-annotation. If anyone wishes to request the data from this study, please contact the author Yinxia Lou at yinxia@whu.edu.cn.
References
Neri, F., Aliprandi, C., Capeci, F. & Cuadros, M. Sentiment analysis on social media. In 2012 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 919–926 (IEEE, 2012).
Chen, H., Sun, M., Tu, C., Lin, Y. & Liu, Z. Neural sentiment classification with user and product attention. In Proc. 2016 Conference on Empirical Methods in Natural Language Processing 1650–1659 (2016).
Matalon, Y., Magdaci, O., Almozlino, A. & Yamin, D. Using sentiment analysis to predict opinion inversion in tweets of political communication. Sci. Rep. 11(1), 7250 (2021).
Mehta, P., Pandya, S. & Kotecha, K. Harvesting social media sentiment analysis to enhance stock market prediction using deep learning. PeerJ Comput. Sci. 7, e476 (2021).
Park, S., Cho, J., Park, K. & Shin, H. Customer sentiment analysis with more sensibility. Eng. Appl. Artif. Intell. 104, 104356 (2021).
Kumar, S., De, K. & Roy, P. P. Movie recommendation system using sentiment analysis from microblogging data. IEEE Trans. Comput. Soc. Syst. 7(4), 915–923 (2020).
Lou, Y., Zhang, Y., Li, F., Qian, T. & Ji, D. Emoji-based sentiment analysis using attention networks. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 19(5), 1–13 (2020).
Miller, H., Kluver, D., Thebault-Spieker, J., Terveen, L. & Hecht, B. Understanding emoji ambiguity in context: The role of text in emoji-related miscommunication. In Proc. International AAAI Conference on Web and Social Media, vol. 11, 152–161 (2017).
Hogenboom, A. et al. Exploiting emoticons in polarity classification of text. J. Web Eng. 14(1 &2), 22–40 (2015).
Yuan, X., Hu, J., Zhang, X., Lv, H. & Liu, H. Emoji-based co-attention network for microblog sentiment analysis. In Neural Information Processing: 28th International Conference, ICONIP 2021, Sanur, Bali, Indonesia, December 8–12, 2021, Proceedings, Part V 28 3–11 (Springer, 2021).
Fan, C., Chang, S., Wu, Y. & Wang, Y. An emotion analysis model based on fine-grained emoji attention mechanism for multi-modal. In 2021 IEEE International Conference on Smart Internet of Things (SmartIoT) 89–94 (IEEE, 2021).
Kenton, J. D. M.-W. C. & Toutanova, L. K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of naacL-HLT, vol. 1, 2 (2019).
Wen, L., Li, X. & Gao, L. A transfer convolutional neural network for fault diagnosis based on resnet-50. Neural Comput. Appl. 32(10), 6111–6124 (2020).
Bo Pang, L. L. et al. Opinion mining and sentiment analysis. Found. Trends Inf. Retriev. 2(1–2), 1–135 (2008).
Turney, P. D. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews. Preprint at http://arXiv.org/cs/0212032 (2002).
Taboada, M., Brooke, J., Tofiloski, M., Voll, K. & Stede, M. Lexicon-based methods for sentiment analysis. Comput. Linguist. 37(2), 267–307 (2011).
Ahmad, M., Aftab, S. & Ali, I. Sentiment analysis of tweets using svm. Int. J. Comput. Appl. 177(5), 25–29 (2017).
Dey, L., Chakraborty, S., Biswas, A., Bose, B. & Tiwari, S. Sentiment analysis of review datasets using naive bayes and k-nn classifier. Preprint at http://arxiv.org/abs/1610.09982 (2016).
Lee, H. Y. & Renganathan, H. Chinese sentiment analysis using maximum entropy. In Proc. Workshop on Sentiment Analysis Where AI Meets Psychology (SAAIP 2011) 89–93 (2011).
Dos Santos, C. & Gatti, M. Deep convolutional neural networks for sentiment analysis of short texts. In Proc. COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers 69–78 (2014).
Wang, X., Jiang, W. & Luo, Z. Combination of convolutional and recurrent neural network for sentiment analysis of short texts. In Proc. COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers 2428–2437 (2016).
Long, Y., Lu, Q., Xiang, R., Li, M. & Huang, C.-R. A cognition based attention model for sentiment analysis. In Proc. 2017 Conference on Empirical Methods in Natural Language Processing 462–471 (2017).
Liao, W., Zeng, B., Yin, X. & Wei, P. An improved aspect-category sentiment analysis model for text sentiment analysis based on roberta. Appl. Intell. 51, 3522–3533 (2021).
Liu, K.-L., Li, W.-J. & Guo, M. Emoticon smoothed language models for twitter sentiment analysis. In Proc. AAAI Conference on Artificial Intelligence, vol. 26, 1678–1684 (2012).
Smailović, J. et al. Sentiment of emojis. PLoS ONE 10(12), e0144296 (2015).
Guibon, G., Ochs, M. & Bellot, P. From emojis to sentiment analysis. In WACAI 2016 (2016).
Eisner, B., Rocktäschel, T., Augenstein, I., Bošnjak, M. & Riedel, S. emoji2vec: Learning emoji representations from their description. Preprint at http://arxiv.org/abs/1609.08359 (2016).
Morency, L.-P., Mihalcea, R. & Doshi, P. Towards multimodal sentiment analysis: Harvesting opinions from the web. In Proc. 13th International Conference on Multimodal Interfaces 169–176 (2011).
Hazarika, D., Zimmermann, R. & Poria, S. Misa: Modality-invariant and-specific representations for multimodal sentiment analysis. In Proc. 28th ACM International Conference on Multimedia 1122–1131 (2020).
Han, W., Chen, H. & Poria, S. Improving multimodal fusion with hierarchical mutual information maximization for multimodal sentiment analysis. Preprint at http://arxiv.org/abs/2109.00412 (2021).
Wenmeng, Y., Hua, X., Yuan, Z. & Jiele, W. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis. In Proc. AAAI Conference on Artificial Intelligence, vol. 35, 10790–10797 (2021).
Poria, S. et al. Multi-level multiple attentions for contextual multimodal sentiment analysis. In 2017 IEEE International Conference on Data Mining (ICDM) 1033–1038 (IEEE, 2017).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proc. IEEE Conference on Computer Vision and Pattern Recognition 770–778 (2016).
Vaswani, A. et al. Attention is all you need. Adv. Neural Inf. Process. Syst. 30, 1 (2017).
Hui, B., Liu, L., Chen, J., Zhou, X. & Nian, Y. Few-shot relation classification by context attention-based prototypical networks with bert. EURASIP J. Wirel. Commun. Netw. 1–17, 2020 (2020).
Dodge, J. et al. Fine-tuning pretrained language models: Weight initializations, data orders, and early stopping. Preprint at http://arxiv.org/abs/2002.06305 (2020).
Sung, F. et al. Learning to compare: Relation network for few-shot learning. In Proc. IEEE Conference on Computer Vision and Pattern Recognition 1199–1208 (2018).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. Preprint at http://arxiv.org/abs/1409.1556 (2014).
Huang, G., Liu, Z., Van Der Maaten, L. & Weinberger, K. Q. Densely connected convolutional networks. In Proc. IEEE Conference on Computer Vision and Pattern Recognition 4700–4708 (2017).
Acknowledgements
This work was supported by the Ministry of Education of Humanities and Social Science project, China (No. 23YJE740002). The authors are very thankful to the editor and referees for their valuable comments and suggestions for improving the paper.
Author information
Authors and Affiliations
Contributions
Conceptualization, Y.X. Lou; methodology, Y.X. Lou; software, J.X. Zhou; validation, J.X. Zhou; investigation, J. Zhou; resources, J. Zhou; formal analysis, D.H. Ji and Q. Zhang; writing original draft preparation, Y.X. Lou; writing review and editing, J.X. Zhou; All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Lou, Y., Zhou, J., Zhou, J. et al. Emoji multimodal microblog sentiment analysis based on mutual attention mechanism. Sci Rep 14, 29314 (2024). https://doi.org/10.1038/s41598-024-80167-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-80167-x
