
Abstract
Addressing the issue of low recognition accuracy in human motion detection when relying on a single feature, a novel approach integrating Frequency Modulated Continuous Wave (FMCW) radar technology with a Residual Network (ResNet) architecture has been proposed. This method commences by capturing the echo signals of six distinct human motions using an FMCW radar. These signals undergo preprocessing, followed by the application of a two-dimensional Fourier transform to derive the Range-time Map (RTM) and Doppler-time Map (DTM) representations of the human motions. To enhance the extraction and precise identification of human motion features, the conventional single-channel input structure of convolutional neural networks has been refined. Specifically, the ResNet18 residuals have been upgraded by incorporating Inception V1 modules. Furthermore, the Convolutional Block Attention Module (CBAM) has been integrated to engineer a dual-channel fusion residual network capable of recognizing and classifying human motions effectively. Empirical results demonstrate that the recognition accuracy of human motion detection has been enhanced by 1–4% when employing this dual-feature fusion structure, as compared to single-feature domain recognition. This improvement attests to the robust recognition capabilities of the proposed model.
Similar content being viewed by others


Introduction
With the development of science and technology, human motion recognition, as an important auxiliary technology in smart home, has important application value in many fields such as security monitoring, medical monitoring and human-computer interaction, and has become a research hotspot at home and abroad in recent years1,2,3. According to the type of sensor, there are two main types of human action recognition: contact type and non-contact type. Common contact devices include smart phones, watches or human motion detection devices composed of sensors such as accelerometers and vibrating gyroscopes4,5,6. According to the type of sensor, there are two main categories of human motion recognition: wearable and non-contact. Commonly used wearable sensors include wristbands, ankle monitors, etc. Such sensors must be worn closely, and have problems such as poor portability, easy damage, high false alarm rate and low recognition accuracy7. Non-contact sensors based on computer vision have been popularized in many public places, but such sensors have high requirements for storage space and information processing capacity, and have shortcomings such as blind areas, sensitivity to lighting conditions and easy disclosure of personal privacy8. Radar, as an environmental sensing sensor, is insensitive to illumination, temperature and other conditions and can better protect user privacy. It has been extensively utilized in the study of human behavior and gait in recent years9.
Literature10 proposes to introduce the CBAM into the residual block of the residual network to build a human motion recognition model, and extract the micro-Doppler time-domain spectrum of radar echo data as a classification feature for recognition. Literature11 proposed a radar human action recognition method based on asymmetric convolutional residual network. By using a strategy combining asymmetric convolution and Mish activation function in the residual block of ResNet18 network, the limitations of linear and nonlinear transformations in the residual block in micro-Doppler spectrum recognition were solved. In literature12, distance Doppler spectrum and azimuth-based spectrum were put into the convolutional neural network as inputs for feature extraction, which was learned by cascade long short-term memory (LSTM), and finally the two networks were fused to recognize gestures. Literature13 proposes a hybrid neural network model to explore the multi-domain fusion of radar echo data. By using this hybrid model, more abundant features can be obtained through multi-domain feature fusion, and better recognition accuracy can be obtained. Literature14 proposes a recognition method based on multi-spectral graph and hybrid convolutional neural network, which performs different time-frequency analysis on radar echo data, generates time-spectral graph with different features, and fuses different features to improve recognition accuracy. Literature15 proposes a feature fusion convolutional neural network structure that integrates range-time graphs and micro-Doppler spectra, and the results show that the recognition ability of feature fusion network is superior to that of single feature recognition method. Literature16 inputs the obtained range-time matrix, Doppler-time matrix and the range-Doppler-frame three-dimensional matrix of fixed frame time length into three-channel Convolutional Neural Networks (CNN) for gesture feature extraction. To obtain the gesture classification result, the feature vectors taken from each data domain are fused using a trainable weight matrix. In literature17, the 2D data time-range, time-Doppler and range-Doppler features of millimeter wave radar are jointly expanded into a 3D data model and then human motion recognition is carried out. Literature18 designed a three-branch convolutional neural network with feature adaptive fusion to realize high-dimensional abstract feature extraction and multi-dimensional adaptive feature fusion of human motion distance, Doppler and Angle 3D feature data sets. The above studies have realized the recognition and classification of different motions, and achieved relatively good results, but there is still room for further improvement. For example, the available information of radar data set is not fully applied, and the designed convolutional neural network has a shallow level and a single structure, resulting in low recognition accuracy.
This research examines millimeter wave radar-based human motion recognition. Firstly, human motion signals are collected by radar hardware equipment, and then the echo data is preprocessed. Secondly, the range-time and Doppler-time map of human motion are obtained by using two-dimensional Fourier transform. Finally, an improved dual-channel fusion residual network based on ResNet18 is designed to recognize and classify human motion. The model is verified by using the small data set collected by FMCW radar. The results show that the recognition ability of different features extracted from the radar echo signal is better than that of single features.
Radar signal processing
FMCW radar echo signal model
When the FMCW radar is working, the transmitter and receiver of the system are kept on synchronously, and during the scanning phase, the transmitted signal’s central frequency rises linearly19,20, which can be expressed by the formula
Where\(A_T\) is the transmitting power; \(\sigma (t)\) is the phase noise; \(f_c\) is the starting frequency of the linear FM signal. \(B\) is the frequency modulation bandwidth, \(T_c\) is the duration of Chirp, and the received signal \(x_R(t)\)of the radar contains the information of the moving target located at a specific range which can be expressed by the formula
Where \(\alpha\) is affected by target distance and radar cross-sectional area; \(t_d =2R(t)/c\) is the range-dependent round-trip propagation delay of the radar signal. The target and radar’s radial distances are denoted by \(R(t)\), and \(c\) is the speed of light in vacuum. Generally speaking, the FMCW radar system uses the mixed calculation of the transmitted signal and the received signal to estimate the target distance, and the mixing signal generates the signal whose frequency is proportional to the target distance through the low-pass filter, which can be expressed as
Where \(A_R\) is the received signal power and \(f_b=2BR(t)/cT_c\) represents the beat frequency. In the close-range measurement scenario. Because of the range-dependent impact, the residual phase noise \((\Delta \sigma(t)=\sigma(t)-\sigma(t-2R/c))\)can be disregarded. \(\pi Bt_{d}^{2}/T_C\) can also be approximately ignored in the actual scenario because the value is too small.
Ultimately, following I/Q sampling, the beat signal can be written as
Where \(T_f\) represents the fast timeline sampling interval; \(T_s\)represents the slow timeline sampling interval.
Acquisition of range-time features and doppler-time features
The FMCW radar records echo data in binary format, which is then rearranged into a matrix with each row denoting a Chirp and each point in the row representing a sample point for the mixing signal. The rows of the matrix are also known as the fast time dimension, and the columns as the slow time dimension. This is because the interval of sampling points in a Chirp is significantly smaller than the interval between each Chirp. In other words, the time interval of the left and right points in the matrix is less than the time interval of the upper and lower points. Firstly, In the human motion radar echo signal data set, the Moving Target Indication (MTI) filter is employed to remove static clutter from the radar echo signal. The clutter is generated by static objects in the test environment or targets unrelated to human behavior. The MTI filter can obtain an output by weighted summation of the same range unit of multiple pulse echoes, which can suppress static targets and slow clutter. Figure 1 shows the comparison effect of the two spectra of human walking motions before and after passing through the MTI filter. Then, the range distribution information is obtained by Fast Fourier Transform (FFT) along the fast time dimension and hamming window. The range distribution information accumulates into the range-time feature, that is the RTM. Then, the FFT of the range-time distribution matrix along the slow time dimension and the Hamming window is applied again to obtain the Doppler distribution information, which is accumulated into the DTM over time. Figures 2 and 3 show schematic diagrams of RTM and DTM for the six motions.

MTI filter input and output comparison result. (a) RTM before MTI filter input. (b) RTM after MTI filter input. (c) DTM before MTI filter input. (d) DTM after MTI filter input.

RTM for six human motions. (a) clap. (b) jump. (c) punch. (d) run. (e) squat. (f) walk.

DTM for six human motions. (a) clap. (b) jump. (c) punch. (d) run. (e) squat. (f) walk.
Residual network design based on feature fusion
Convolutional neural networks and residual networks
CNN is a commonly used model for image feature extraction in deep learning. Compared with traditional manual feature extraction methods, CNN has simple steps and better performance in the stability of feature extraction, adaptability to target changes and recognition rate21. CNN obtains abstract information, such as color, corner, edge, spot, endpoint and so on, by convolution of input feature graphs, which is the key to feature learning. For RTM and DTM, their spectral shapes are quite different, because the two contain the human space range feature and the human micro-Doppler feature respectively. The two features reflect different levels of different human motions, and the recognition ability of the two features will also be different. In order to enable CNN to have a better recognition ability of human motion, it is necessary to consider not only the more comprehensive feature extraction of RTM and DTM respectively, but also the integration of RTM and DTM features to make a comprehensive discrimination.
In traditional convolutional neural networks, each layer directly convolves the output of the previous layer, which will result in a strong correlation between high-level features and low-level features, which will have a negative impact on the model’s decision-making. Each layer in a residual network22 not only convolves the output of the layer before it, but also residually joins that layer’s output to the current layer’s input. To get a more representative feature vector as the current layer’s output, residual concatenation can combine the output and input of the current layer. It is possible to effectively separate high-level features from low-level features via residual connections, which facilitates the network’s ability to understand the internal structure of the data. Using residual network as feature extraction network can not only extract more comprehensive features of RTM and DTM respectively, but also effectively solve the problem of inadequate feature extraction due to the loss of original information as the depth of neural network increases.

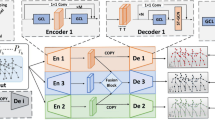
Dual channel feature fusion residual network structure diagram.

Improved residual block structure diagram.
ResNet model based on feature fusion
Figure 4 displays the dual-channel feature fusion residual network created for this paper, which is an improved neural network architecture based on the ResNet18 network architecture. To simplify the process of network training, the input of the model is cut to 224 × 224 range-time feature graph and Doppler-time feature graph. The feature extraction part of the spectral graph consists of two convolution blocks with convolution kernel 7, the maximum pooling layer, eight improved residual blocks and two global average pooling layers. Each convolution block is computed through 3 × 3 convolution, batch normalization layers, and ReLU activation function operations. After the feature learning of the two channels, the features extracted from the two channels are cascaded and fused through the feature cascade. Finally, the extracted features are sent to the two fully connected layers for identification and classification, and the probability values of the 6 actions are obtained by the Softmax function. Then, dropout is added after the full connection layer, with the Dropout ratio set to 0.5, to prevent overfitting brought on by tiny data sets and a too deep network. To allow the network to acquire more granular features, the CBAM is added before the maximum pooling layer and the global average pooling layer. CBAM is a lightweight Attention mechanism Module that combines the Channel Attention Module (CAM) and the Spatial Attention Module.
(SAM). Here, the CAM pays attention to the color changes of the input spectrum, and the SAM pays attention to the position information of each color in the spectrum. The CAM and the SAM are combined to establish the connection between the motion information of each behavior, so as to make the extracted features more effective and fulfill the goal of enhancing the model’s performance.
The modified residual block is the replacement of the residual block structure in ResNet18 with the Inception V1 block. Since ResNet18 has two basic residual block structures, the improved residual block is to replace the two 3 × 3 convolution blocks in the basic residual block with the Inception V1 module, while retaining the original residual connections in the basic residual block and the 1 × 1 convolution kernel for channel number matching. The two improved residual blocks are shown in Fig. 5. The improved network architecture can use Inception V1 module with 4 branch channels in the original ResNet18 residual block position, and use convolution kernels of different sizes of 5 × 5, 1 × 1 or 3 × 3 on the four branch channels to extract features of action images of different dimensions. The improved network model can not only reduce the number of parameters, but also improve the running speed.
Identify model parameter settings
The simulation was performed on NVIDIA GeForce RTX 1080, using the deep learning framework PyTorch and Python 3.8. Using the cross-entropy loss function and the Adam optimizer, the initial learning rate was set to 0.0005, and the StepLR learning rate update strategy was used, the Batch size was set to 32, and the model trained 100 epochs.
Experimental verification
Experimental setup and data acquisition
In this experiment, TI’s IWR1642 millimeter wave radar and DCA1000 data acquisition card are used. IWR1642 is a FMCW millimeter wave radar operating in the 77 GHz ~ 81 GHz band, with two antennas transmitting linear frequency modulation signals and four antennas receiving echo signals. The IF signal obtained in the mixer is sampled by AD and then transmitted to PC by DCA1000 acquisition card and analyzed and preprocessed on CPU to generate feature map, and then sent to network for training.
During the experiment, the whole set of radar acquisition equipment was fixed on a tripod, about 1 m away from the ground, and there was no other moving target interference except the experimental object, and no static object was placed in the linear range between the radar and the experimenter. Each subject completes the motion within 2.5 m directly in front of the radar. In order to collect the complete gesture signal, radar parameters need to be configured to a certain extent. Table 1 shows the configuration parameters of the radar system.
For each motion, each experimenter collected 50 times, and the acquisition time of radar echo signal corresponding to each motion was 2s. There were 10 experimenter, and the collected motions were clapping, jumping, punching, running, squatting and walking. We ended up with 3000 samples. After the radar echo signal is preprocessed, RTM and DTM are obtained. The sample size of both RTM and DTM is 3000. In a ratio of 8:2, the obtained RTM and DTM are split into training and test sets.
Experimental results and analysis
The created model is assessed using the classification algorithm evaluation indexes and confusion matrix. The classification algorithm evaluation indexes mainly include the following:
(1) accuracy: The proportion of correctly classified samples to total samples, defined as:
(2) precision: The proportion of samples predicted by the classifier to be positive cases that are actually positive cases, expressed as:
(3) recall: The proportion of samples that are actually positive examples predicted by the classifier to be positive examples, expressed as:
(4) F1 Score: the harmonic average of accuracy rate and recall rate. The model’s equilibrium between accuracy and recall rates is assessed, and the expression is:
Where, TP refers to the number of positive cases that the model correctly predicts as positive cases, TN refers to the number of negative cases that the model correctly predicts as negative cases, FP refers to the number of negative cases that the model incorrectly predicts as positive cases, and FN refers to the number of positive cases that the model incorrectly predicts as negative cases.
In order to evaluate the recognition ability of human motion based on range-time feature, Doppler-time feature and fusion feature, the following three sets of experiments were conducted:
(1) Use a single RTM for human motion recognition;
(2) Use a single DTM for human motion recognition;
(3) Integrate RTM and DTM for human motion recognition.
Figures 6 and 7 illustrate the changes of recognition accuracy and training loss value with the number of iterations in the three groups of experiments. The accuracy comparison outcomes for the three feature maps are displayed in Table 2. The picture illustrates how, following 20 iterations, the recognition accuracy of the three experimental groups all tended to stabilize., and the loss function value declined slowly. By comparing the change curves of the recognition accuracy and loss function value of the three groups of experiments, it can be seen that the recognition ability of the six human motions by different features was highest in the range-time and Doppler-time fusion feature maps The lowest is the range-time feature. Table 2 shows that the RTM and DTM fusion feature map’s recognition accuracy for human motions is 99%., while RTM can only achieve 95.17% identification accuracy, DTM can get 97.5% recognition accuracy.

The accuracy curve of three groups of experiments.

Loss change curves of three groups of experiments.
Therefore, it can be concluded that: Compared with single feature, the fusion feature of RTM and DTM has better recognition ability for human motion, and DTM has higher confidence than RTM in the recognition of single feature human motion.
In order to analyze the positive and false error rates of each motion in the three groups of experiments, the test confusion matrix after input of RTM, DTM, and fusion feature maps is presented in Figs. 8, 9 and 10, respectively. Tables 3, 4 and 5 give the evaluation indexes of RTM, DTM and fusion feature map respectively. Through the analysis of the confusion matrix and evaluation index information of the above two single feature maps and fusion feature maps, it is evident from the range-time confusion matrix that the recognition accuracy of running and walking is relatively low, and they are prone to misjudgment. Meanwhile, running is also prone to misjudgment as clapping and punching. In the Doppler-time confusion matrix, squatting is easily mistaken for clapping and punching, and walking is easily mistaken for running.

RTM confusion matrix.

DTM confusion matrix.

Fusion feature map confusion matrix.
Overall, the recognition accuracy of most motions in the Doppler-time feature is slightly higher than that of the range-time feature. As Fig. 10; Table 5 demonstrate, the recognition accuracy of jumping, punching, squatting and walking all reached 100%, and only clapping and running still had a few misjudgments, but compared with RTM and DTM, the misjudgment rate had been significantly reduced. Based on the examination of the supplied feature map, there are local similarities between range-time feature and Doppler-time feature, which leads to high error rate of recognition. By comparing the confusion matrix and evaluation index of the three feature maps, it can be seen that the fusion feature improves the misjudgment between squatting and clapping, squatting and punching, running and walking, and the recognition accuracy of other human movements is improved after the fusion feature discrimination, except clapping. It shows that feature fusion not only obtains the key feature points of range-time feature and Doppler-time feature respectively, but also promotes the recognition ability of the two features. After feature fusion, the overall recognition rate increases. It can be proved that the fusion of range-time feature and Doppler-time feature can make up for the deficiency of single feature recognition.
The visual scatterplots of the three feature graphs based on T-distributed Stochastic Neighbor Embedding (t-SNE) are shown in Fig. 11(a) to Fig. 11(c). By converting the feature vector of each data into two-dimensional coordinates, the coordinate points corresponding to each data can be obtained, and the colors of the corresponding points for each type of action are different. As can be seen from the figure, there is less overlap between various colors in the scatter plot of the fusion feature map, and only a little overlap exists between the two groups of movements: running and walking, clapping and squatting. There is a large overlap between actions in the RTM scatter plot, and the overlap between colors in the DTM scatter plot is less than that in the RTM scatter plot, but the overlap between the two is higher than that in the fusion feature plot, indicating that the feature vectors after the fusion of RTM and DTM have the highest degree of separation, that is, the classification effect is better than that of RTM and DTM.

Scatter plot. (a) RTM scatter plot. (b) DTM scatter plot. (c) Scatter plot of fusion feature plot.

Recognition accuracy of six motions under different variants.
.
Model performance analysis
In order to verify the effect of the improved part based on ResNet18 in this paper, three variants are set up: Variant one is no CBAM attention module; Variant two is the residual block using the normal residual block in ResNet18; Variant three is a fully connected layer with only one layer and no dropout. Figure 12 displays the recognition accuracy of each approach in relation to each action. As illustrated in the figure, the recognition accuracy of the two movements of punching and squatting in the four methods has reached 100%, and the recognition accuracy of jumping and walking movements with ordinary residual blocks and the proposed model has also reached 100%.Only the recognition accuracy of the proposed model of clapping and running is slightly lower than that of the model without CBAM and the model with ordinary residual blocks.
The number of parameters in the network and the amount of floating point computation determine the performance of the model. Network floating point arithmetic and parameter quantity can be expressed as:
Where, M represents the side length of each convolutional output feature, K represents the convolution kernel size, \({C_{l - 1}}\) represents the number of output channels of \({{l - 1}}\) convolutional layer, and \({C_l}\) represents the number of output channels of l each convolutional layer.
Table 6 Shows the comparison results of the parameters, the FLOPs and the recognition accuracy of each model. The table shows that there is not much of a difference in the recognition accuracy between the model employed in this paper and the model that uses the ordinary residual block., but the parameters and the FLOPs of the model using the ordinary residual block are more than 6 times that of the model in this paper. The main reason is that Inception V1 contains multiple branches, and each branch path shares input features, reducing the number of parameters required for independent learning features. At the same time, a large number of 1 × 1 convolution kernels are used for dimensionality reduction, reducing the computational load of subsequent convolution operations. Although the model without CBAM and with only one layer of full connection layer is smaller than the model in this paper, CBAM can improve the capability of feature extraction because it pays attention to the color change of the spectral graph and the position information of each color in the spectral graph. Meanwhile, the fully connected layer of ResNet18 network is changed from the original single layer to two layers. The learning ability and expression ability of the model are enhanced, so the recognition accuracy of the model in this paper is higher than that of the model without CBAM and the model with only one layer of full connection layer. It demonstrates the strong performance of the model this study presents.
Compare with other behavior recognition models
To confirm that the model works as intended, this paper conducts comparative tests on recent models using the HAR radar public dataset23 of the University of Glasgow, and conducts experiments on the model proposed in this paper on the HAR dataset. Table 7 displays the comparative experimental results for each model. The table indicates that literature24 uses Bi-LSTM network architecture to use radar data in the form of continuous time series of micro-Doppler information, and achieves nearly 90% accuracy. The CNN-LSTM mixed network is used as the classification model in Literature25, which integrates the three domain features of RTM, RDM and DTM, obtaining 94.25% accuracy. The model in this paper takes range-time and Doppler-time spectrum as input features. Using the improved ResNet18 as a classification model, the recognition accuracy on the public data set is 95.16%. Since the feature extraction ability of residual blocks is stronger than that of ordinary convolutional layers, the recognition accuracy rate is 1.23% higher than that of the ordinary double-channel convolutional neural network proposed in literature25. Meanwhile, because convolution has a stronger ability to extract global features of images, it is also more complete than SSAE in learning block neighborhood features in images. Therefore, the recognition accuracy of the model proposed in this paper is higher than the SSAE method proposed in literature26. It shows that the model proposed in this paper has better recognition effect than other models in the table, and is a choice better than other motion recognition methods.
Conclusion
In this paper, a human motion recognition method based on feature fusion and residual network is proposed for small data sets. First, a data acquisition system based on FMCW radar was built to collect the echo signal of human motion, and then the range-time and Doppler-time spectra of human motion were extracted by using two FFTS and related algorithms. Finally, for a variety of human motion features, a modified ResNet18 dual-channel feature fusion residual network was designed to replace the ResNet18 residuals with Inception V1 and an improved ResNet18 dual-channel feature fusion residuals network containing CBAM attention module. The RTM and DTM were simultaneously input into the network for training. Experiments show that the human motion recognition accuracy of the fusion feature proposed in this paper is higher than that of the single feature. At the same time, after replacing the residual block, the parameter number of the model is reduced by more than 6 times, and the calculation amount is reduced by 4 times, which indicates that the classification model in this paper has a good performance in human motion recognition of FMCW radar. Although the model in this paper can obtain an ideal recognition accuracy rate, this paper only uses human motion recognition for one type of motion, and has not been involved in the recognition of continuous motion or multiple motions in practical application. Therefore, in order to achieve the recognition of continuous motion or numerous motions, we will also investigate the human motion segmentation problem in future work.
Data availability
The datasets used and analyzed during the current study are available from the corresponding author on reasonable request.
References
Huang, J., Qin, L., Jiang, X., Cai, H. & Chen, Y. Multi person behavior recognition based on scene and interactive features. J. Sichuan Univ. (Natural Sci. Edition). 59 (6), 77–88. https://doi.org/10.19907/j.0490-6756.2022.063001 (2022).
Li, J., Zhang, Q. & Zheng, G. Overview of human posture recognition by Ultra-wideband radar. Comput. Eng. Appl. 57 (3), 14–23. https://doi.org/10.3778/j.issn.1002-8331.2009-0444 (2021).
Ray, A. & Kolekar, M. H. Transfer learning and its extensive appositeness in human activity recognition: a Survey. Expert Syst. Appl. 65 (6), 122538–122570. https://doi.org/10.1016/j.eswa.2023.122538 (2023).
Bodhe, R., Sivakumar, S., Sakarkar, G., Juwono, G. H. & Apriono, C. Outdoor activity classification using smartphone based Inertial Sensor measurements. Multimedia Tools Appl. 15 (1), 1–27. https://doi.org/10.1007/s11042-024-18599-w (2024).
Alexan, A. I., Alexan, A. R. & Oniga, S. Real-time machine learning for Human activities Recognition based on wrist-worn Wearable devices. Appl. Sci. 14 (1), 329–349. https://doi.org/10.3390/app14010329 (2024).
Zhang, H., Xu, L. & Multi-STMT Multi-level Network for Human Activity Recognition Based on Wearable Sensors. IEEE Trans. Instrum. Meas. 73 (3), 1–12. https://doi.org/10.1109/TIM.2024.3365155 (2024).
Li, X., Wang, Y., Zhang, B., Ma, J. & Psdrnn An efficient and effective HAR scheme based on feature extraction and deep learning. IEEE Trans. Industr. Inf. 16 (10), 6703–6713. https://doi.org/10.1109/TII.2020.2968920 (2020).
Chin-Shyurng, F., Lee, S. E. & Wu, M. L. Real-time musical conducting gesture recognition based on a dynamic time warping classifier using a single-depth camera. Appl. Sci. 9 (3), 528–538. https://doi.org/10.3390/app9030528 (2019).
Le, H. T., Phung, S. L. & Bouzerdoum, A. A fast and compact deep gabor network for Micro-doppler signal processing and human motion classification. IEEE Sens. J. 21 (20), 23085–23097. https://doi.org/10.1109/JSEN.2021.3106300 (2021).
Luo, J., Chang, J., Wu, P., Xu, Y. & Lu, Z. FMCW radar human behavior recognition based on residual network. Comput. Sci. 50 (11A), 174–179. https://doi.org/10.11896/jsjkx.220800247 (2023).
Zhang, Y., Tang, H., Wu, Y., Wang, B. & Yang, D. F. M. C. W. Radar Human Action Recognition Based on asymmetric convolutional residual blocks. Sensors 24 (14), 4570. https://doi.org/10.3390/S24144570 (2024).
Yu, J., Tseng, Y., Tseng, P. & & A mmWave MIMO Radar-based Gesture Recognition Using Fusion of Range, Velocity, and angular information. IEEE Sens. J. 24 (6), 9124–9134. https://doi.org/10.1109/JSEN.2024.3355395 (2024).
Ding, W., Guo, X. & Wang, G. Rader-Based Human Activity Recognition using hybrid neural network Model with Multidomain Fusion. IEEE Trans. Aerosp. Electron. Syst. 57 (5), 2889–2898. https://doi.org/10.1109/TAES.2021.3068436 (2021).
Qing, Y., Chen, C., Tang, L., Jai, Y. & Cui, G. Parallel LSTM-CNN network with radar multispectrogram for human activity recognition. IEEE Sens. J. 23 (2), 1308–1317. https://doi.org/10.1109/JSEN.2022.3224083 (2023).
Zhang, L., Liu, B., Qu, L. & Liu, Y. Human activity recognition with FMCW radar based on fusion feature convolutional neural network. Telecommunication Eng. 62 (2), 147–154. https://doi.org/10.3969/j.issn.1001-893x.2022.02.001 (2022).
Zhao, Y., Yang, T., Wu, H. & Qu, L. Hand gesture recognition method using FMCW radar based on multi-domain fusion. J. China Acad. Electron. Inform. Technol. 18 (6), 495–502. https://doi.org/10.3969/j.issn.1673-5692.2023.06.002 (2023).
Zhao, Y., Zhang, Z. & Zhang, Z. Multi-angle data cube action recognition based on millimeter wave radar. In Chinese Control And Decision Conference (CCDC), pp. 749–753. China. (2020). https://doi.org/10.1109/CCDC49329.2020.9164448
Li, C., Jiang, J. & Zhou, F. Human Motion Recognition Algorithm with Three⁃Dimensional Feature Adaptive Fusion based on Millimeter-Wave Radar. Radar Sci. Technol. 22 (5), 569–578. https://doi.org/10.3969/j.issn.1672-2337.2024.05.012 (2024).
Ahmad, J., Roh, J. C., Wang, D. & Dubey, A. Vital signs monitoring of multiple people using a FMCW millimeter-wave sensor. In IEEE Radar Conference (RadarConf18), pp. 1450–1455. USA. (2018). https://doi.org/10.1109/RADAR.2018.8378778
Gurbuz, S. Z. & Amin, M. G. Radar-based human-motion recognition with deep learning: promising applications for indoor monitoring. IEEE. Signal. Process. Mag. 36 (4), 16–28. https://doi.org/10.1109/MSP.2018.2890128 (2019).
Yin, H. & Guo, Z. Radar HRRP target recognition with one-dimensional CNN. Telecommunication Eng. 58 (10), 1121–1126. https://doi.org/10.3969/j.issn.1001-893x.2018.10.002 (2018).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778. (2016). https://doi.org/10.1109/CVPR.2016.90
Imran, M. A. Radar sensing for activity classification in elderly people exploiting micro-doppler signatures using machine learning. Sensors 21 (11), 3881. https://doi.org/10.3390/s21113881 (2021).
Shrestha, A., Li, H., Kernec, J. L. & Fioranelli, F. Continuous human activity classification from FMCW radar with Bi-LSTM networks. IEEE Sens. J. 20 (22), 13607–13619. https://doi.org/10.1109/JSEN.2020.3006386 (2020).
Ding, W., Guo, X. & Wang, G. Radar-based human activity Recognition using hybrid neural network Model with Multidomain Fusion. lEEE Trans. Aerosp. Electron. Syst. 57 (5), 2889–2898. https://doi.org/10.1109/TAES.2021.3068436 (2021).
Jokanović, B. & Amin, M. Fall detection using deep learning in range-doppler radar. IEEE Trans. Aerosp. Electron. Syst. 54 (1), 180–189. https://doi.org/10.1109/TAES.2017.2740098 (2017).
Acknowledgements
This work was supported by the Provincial Natural Science Foundation of Jiangxi (Grant: 20242BAB25052) and the Jiangxi Graduate Student Innovation Fund Project (Grant: YC2023-S843).
Author information
Authors and Affiliations
Contributions
Xiaoyu Luo: Formal analysis, Investigation, Methodology, software, Writing-original draft. Qiusheng Li: Conceptualisation, Resources; Supervision; Writing - review & editing.All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Luo, X., Li, Q. Human motion recognition based on feature fusion and residual networks. Sci Rep 14, 29097 (2024). https://doi.org/10.1038/s41598-024-80783-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-80783-7
