
Abstract
Accurate estimation of the soil resilient modulus (MR) is essential for designing and monitoring pavements. However, experimental methods tend to be time-consuming and costly; regression equations and constitutive models usually have limited applications, while the predictive accuracy of some machine learning studies still has room for improvement. To forecast MR efficiently and accurately, a new model named black-winged kite algorithm-extreme gradient boosting (BKA-XGBOOST) is proposed. In BKA-XGBOOST, XGBOOST captures the many-to-one nonlinear relationship between geotechnical factors and MR, while BKA provides the optimal hyperparameters for XGBOOST. By combining them, XGBOOST has stable and accurate predictive capabilities for different combinations of soil data. Comparisons with nine models show that the proposed model outperforms other models in terms of MR prediction accuracy, with a determination coefficient (R2) of 0.995 and a mean absolute error (MAE) of 0.975 MPa. In addition, an efficient MR prediction software is developed based on the model to improve its practicality and interactivity, which is promising for assisting engineers in evaluating pavement properties.
Similar content being viewed by others

Introduction
The advent of modern transportation systems has led to an increase in the construction of roads. The elastic modulus of recoverable strain under repeated stress is called resilient modulus (MR). It is defined as the ratio of the deviator stress (σd) to the recoverable strain (εr). As one of the essential characteristics of soil, MR has been found to depend on several factors such as the weighted plasticity index (wPI), dry unit weight (γd), confining stress (σc), deviator stress (σd), moisture content (w) and the number of FT cycles (NFT)1,2,3,4. The prediction of MR is of paramount importance to the safe and sustainable design of flexible pavement systems5,6. Traditional forecasting methods for MR can be classified into three primary categories: experimental methods, regression equation methods, and principal modeling methods (as illustrated in Table 1). Owing to their complexity and time consumption, these technologies are challenging to implement in engineering.
On the other hand, developing intelligent computing technologies, including support vector machines, long-short-term neural networks, random forests, and artificial neural networks, has enabled the rapid, effective, and cost-effective resolution of some civil engineering problems36,37,38,39,40,41,42,43,44,45. As illustrated in Table 2, some researchers have employed various machine learning techniques to predict the MR, either by utilizing single or combinatorial algorithms. These studies demonstrate that machine learning methods are proficient at predicting MR.
Research gap
However, there is room for improvement in some of these machine learning studies. The accuracy of the models presented in the article can be improved. Fewer soil types were used in the experiments, making it difficult to demonstrate the generalizability of the models. Moreover, non-computer individuals have difficulties in using the models. Therefore, there is a need for more research in machine learning for predicting MR.
Research objective
This paper aims to develop an efficient, generalizable and user-friendly MR prediction model. For that purpose, this study proposed the black-winged kite algorithm-extreme gradient boosting model (BKA-XGBOOST) and collected 12 types of soil data from multiple studies to verify the feasibility and generalizability of the model. The model was based on XGBOOST, well-suited for capturing many-to-one nonlinear relationships66,67,68,69,70. Moreover, BKA, with powerful optimization capabilities71, was employed to optimize the parameters of XGBOOST, ensuring that XGBOOST maintains optimal performance. In addition, an application program based on BKA-XGBOOST has been developed to facilitate its use by engineers.
Research significance
This study addresses the problem of MR being difficult to assess in the geotechnical field. Traditional methods for predicting MR are complex and time-consuming, and some machine learning models exhibit low accuracy and inadequate generalizability. By proposing the BKA-XGBOOST model, this study introduces a novel approach to accurately and efficiently assess various types of MR. The application developed based on the proposed model is user-friendly and can assist engineers in geotechnical engineering.
Research methodology
The BKA-XGBOOST model proposed in this paper employs BKA to search for the three best parameters of XGBOOST to improve its prediction accuracy for various soil data. The dataset utilized for the experiment was collected from Ding, Rahman, Solanki and Ren2,3,4,72, encompassing 2813 soil data points. To evaluate the performance of the proposed model, it was compared with nine single models and four hybrid models utilized in previous studies from a range of evaluation metrics. In addition, a BKA-XGBOOST-based application was developed to improve the model’s usability. Figure 1 illustrates the structure of the research methodology for this study.

The structure of the research methodology.
Experimental environment
The training and testing were conducted using a hardware setup that consists of a 12th Gen Intel (R) Core i5-12500 H processor, 32.0 GB of RAM, and an NVIDIA GeForce RTX 3060 graphics card. The utilized software is MATLAB 2023b. Furthermore, the proposed model requires an average of 0.5247 s to predict 563 samples within the specific hardware setting.
Data analysis
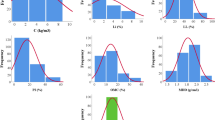
Several factors affect MR. Choosing the wrong factors as inputs to XGBOOST would lead to imprecise forecasts and unnecessary computations. Some researchers have demonstrated that the wPI, γd, σc, σd, w and NFT exert a more pronounced influence on MR1,2,3,4 ; hence, this study employs these factors as inputs. To validate the feasibility of the proposed model, this study gathered 2,813 sets of soil data from earlier studies as experimental data2,3,4,72. The dataset comprises six inputs and one output. wPI equals the plasticity index measured by the standard plasticity test multiplied by the percent passing 0.425 mm sieve; γd is the dry weight of the soil divided by the soil’s volume; σc, σd and MR are obtained from the triaxial test; w is typically calculated by determining the mass difference after drying the soil; NFT is derived from cyclic freeze-thaw experiments. Twelve soil types were included in the dataset, with two originating from China, five from the United States, and five from Canada. According to the statistical analysis in Table 3, it can be seen that the value distribution of γd is relatively concentrated, while the distribution of other inputs is relatively scattered. In particular, a larger standard deviation for σc, σd, and MR implies more significant fluctuations in their values. From Fig. 2, all the variables soil data variables exhibit a non-positive distribution, and the relationship between the two variables is complicated, encompassing negative, positive, and weak correlations. For instance, the sub-graphs in the first column of the fifth row and the second column of the fifth row illustrate that w tends to increase with wPI, contrary to γd. On the other hand, σd remains constant as σc escalates. It is essential to analyze the relationship between the variables further.

Soil data statistics.
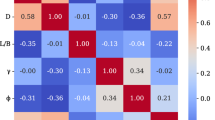
Correlation analysis was employed to investigate the relationship between these variables further. Pearson, Spearman, and Kendall are three standard methods for analyzing the correlations between two variables. The Pearson method is suitable for normally distributed continuous variables. In contrast, the Spearman method is suitable for non-normally distributed continuous variables, and the Kendall method is suitable for categorical variables. Because all variables in the data were non-normally distributed, the Spearman correlation coefficient was employed73. If the correlation coefficients between two variables range from ± 0.81 to ± 1.0, ± 0.61 to ± 0.80, ± 0.41 to ± 0.60, ± 0.21 to ± 0.40, and ± 0.00 to ± 0.20, respectively, then they may show a very strong, strong, moderate, weak, and no relationship74. From Fig. 3, it shows that γd and w present a very strong negative correlation, wPI and w exhibit a strong positive correlation, while wPI and γd, as well as w and MR, show moderate negative correlations. The remaining variables display either weak correlation or no correlation with one another. Although γd and w, as well as wPI and w, exhibit a strong correlation, the rest of the variables have a weak correlation. Consequently, it was unnecessary to assess the data for multicollinearity.

Correlations between variables.
Soft computing approaches
Extreme gradient boosting
XGBOOST, the foundation of the proposed model, was initially introduced by Chen in 201675. It represents an improvement upon the gradient-boosting decision tree (GBDT). Compared to GBDT, XGBOOST exhibits the following principal advantages: (1) The CART tree produced by XGBOOST takes into account the intricacy of the tree. (2) XGBOOST is a second-order derivative expansion that fits the previous round of loss function. In contrast, GDBT is a first-order derivative expansion that fits the previous round of loss function. Hence, XGBOOST exhibits higher accuracy and necessitates a reduced number of iterations. (3) XGBOOST can utilize multi-threading throughout the process of selecting the optimal split point, resulting in a significant enhancement in the speed of execution. (4) XGBOOST integrates regularization terms into the loss function, which helps control the complexity of the model and prevents overfitting. (5) XGBOOST permits the utilization of custom objective functions and evaluation functions, provided that the objective function is second-order differentiable76. (6) XGBOOST can automatically learn the trend of missing feature values in sample77. Regarding regression problems, the fundamental algorithm of XGBOOST mainly involves determining expected MR and objective functions. The specific contents of this algorithm are as follows:
For soil data \(\:\left\{\left({x}_{1},{\text{y}}_{1}\right),\dots\:,\left({x}_{n},{y}_{n}\right)\right\}\), containing n samples, the predicted value of MR can be expressed as:
where \(\:{x}_{i}\) is the impact factor of MR containing m features, and \(\:{\hat{y}}_{i}\) is the predicted value of MR. k is the number of the classification and regression tree (CART), F is the set of regression trees, and \(\:{f}_{k}\left({x}_{i}\right)\) is the predicted value of CART.
For real values \(\:{y}_{i}\) the objective function is defined as follows:
where \(\:l\left({y}_{i},{\hat{y}}_{i}\right)\) is the loss function used to evaluate the accuracy of \(\:{\hat{y}}_{i}\), and \(\:{\Omega\:}\left({f}_{k}\right)\) represents the regularization term to avoid overfitting.
Substitute \(\:{\hat{y}}_{i}={\sum\limits}_{k=1}^{K}\:{f}_{k}\left({x}_{i}\right)={\hat{y}}_{i}^{(t-1)}+{f}_{t}\left({x}_{i}\right)\) into formula 2, the objective function after k iterations is defined as follows:
Use the second-order Taylor expansion of Eq. 3 and delete the constant, the following formula is obtained:
where \(\:{g}_{i}={l}^{{\prime\:}}\left({y}_{i},{\hat{y}}_{i}^{k-1}\right)\), and \(\:{h}_{i}={l}^{{\prime\:}{\prime\:}}\left({y}_{i},{\hat{y}}_{i}^{k-1}\right)\). \(\:{g}_{i}\) and \(\:{h}_{i}\) represent the first-order and second-order gradient statistics of the loss function respectively.
For a tree containing L leaves, which contain j sample sets, and the weight of the leaves is \(\:\omega\:\), the regularization term \(\:{\Omega\:}\left({f}_{k}\right)\) can be expressed as:
where λ and µ are constants.
Further simplify the objective function, the following formula is obtained:
Black-winged kite algorithm
BKA is a biologically inspired algorithm proposed by Wang in 202471. The algorithm replicates black-winged kites’ predation and migration patterns, known for their remarkable ability to adjust to environmental fluctuations in their natural habitat. This simulation strategy enables the method to efficiently adapt to dynamic optimization situations. BKA exhibits an optimal balance between global and local search, a rich population diversity, and simple computational complexity. Furthermore, it demonstrated satisfactory performance in a comparative analysis of 59 test functions with 17 optimization algorithms, including particle swarm optimization, whale optimization algorithm, grey wolf optimization, and sparrow search algorithm71. Therefore, BKA is utilized to determine the most suitable settings for XGBOOST, which allows XGBOOST to achieve its highest level of performance. The primary computation of BKA consists of three phases: initialization, predation, and migration. The specifics of this algorithm are as follows:
Initialization
As the initial stage of the algorithm, this stage mainly involves the definition of individuals and optimal positions.
Use a matrix to represent the position of black-winged kites.
where pop is the number of individuals, dim is the dimension of the problem being asked, and BKi, j represents the i-th black-winged kite in the j-th dimension.
Use the following formula to represent the position of i-th black-winged kite:
where \(\:B{K}_{lb}\) and \(\:B{K}_{ub}\) are the lower and upper bounds of the black wing kite in the j-th dimension respectively, and rand is a random number between 0 and 1.
Use the root mean square error as the adjustment value and represent the leader (\(\:{X}_{\text{L}}\)) of the population with the individual with the smallest fitness value, and its position is expressed by the following formula:
where \(\:{f}_{\text{best\:}}=min\left(f\left({X}_{i}\right)\right.\).
Predation
The second stage represents the global exploration and search process of the algorithm by simulating the hunting and searching behavior of black-winged kites on small grassland mammals. The following is the mathematical expression that describes the attacking behavior of black-winged kites.
where \(\:{y}_{t}^{ij}\) and \(\:{y}_{t+1}^{ij}\) respectively represent the position of the i-th black-wing kite in the j-th dimension in the t and t + 1 iterations. r is a random number between 0 and 1, and p is a constant with a value of 0.9. T is the maximum number of iterations and t is the number of iterations completed so far.
Migration
When the climate and food resources are inadequate to support black-winged kites, they will relocate to a different habitat under the direction of a leader in pursuit of more favorable living conditions and increased food availability. In this stage, the leader’s fitness value is utilized to assess their suitability for guiding the populace in migration. If the fitness value of the leader’s current position is lower than that of a randomly selected individual, the leader will relinquish its leadership. In contrast, the leader will guide the populace towards the destination. The subsequent mathematical formula delineates the migratory patterns exhibited by black-winged kites.
where \(\:{L}_{t}^{j}\) represents the leader of the black-winged kites in the j-th dimension of the t-th iteration. \(\:{y}_{t}^{i,j}\) and \(\:{y}_{i+1}^{i,j}\) respectively represent the position of the i-th black-winged kite in the j-th dimension in the t and t+1 iterations. \(\:{F}_{i}\) represents the position of any black-winged kite in the j-th dimension in t iteration. \(\:{F}_{ri}\) represents the fitness value of a random position in the j-th dimension obtained by any black-winged kite in t iterations. \(\:C\left(\text{0,1}\right)\) represents Cauchy mutation78, and its standard formula is \(\:f\left(x\right)=\frac{1}{\pi\:}\frac{1}{{x}^{2}+1},\:-{\infty\:}<x<{\infty\:}\).
Black-winged kite algorithm-extreme gradient boosting
The BKA-XGBOOST model combines BKA and XGBOOST (Fig. 4). XGBOOST serves as the foundation of the model, processing the input and output data of the soil. Although XGBOOST is proficient in managing nonlinear many-to-one relationships, its performance is most significantly influenced by the depth of the tree, the learning rate, and the maximum number of iterations79,80. It is challenging to predict MR using XGBOOST with inappropriate parameter settings accurately81. Furthermore, manually identifying optimal parameters necessitates a certain degree of expertise, is also inherently time-consuming, and frequently yields suboptimal outcomes82. Consequently, BKA is employed here to ascertain the optimal tree depth, learning rate, and maximum number of iterations for XGBOOST, thereby contributing to the accurate prediction of MR. Upon reaching the maximum number of iterations or when the fitness value no longer decreases, BKA will provide an optimal tree depth, learning rate, and maximum number of iterations. Otherwise, BKA will continue to determine the optimal parameters.
Using raw data with disparate magnitudes and sizes along different dimensions for direct training and prediction may result in prolonged training periods and suboptimal training outcomes83. Consequently, all the data are transformed using the max-min normalization approach to ensure they fall within the range of 0 to 1. Moreover, the ratio of the training set to the test set significantly influences the predictive performance of XGBOOST. 80% of the data are randomly selected for model training and the remaining data are used for prediction67,84. Moreover, a 5-fold cross-validation procedure is employed to mitigate overfitting during training85,86. The training data are divided into five distinct subsets in the cross-validation process. One of these subsets is the validation data set, while the other four subsets are used to train the model68.

The structure of BKA-XGBOOST.
Performance evaluation
Model performance was assessed using the mean absolute error (MAE), root mean square error (RMSE), determination coefficient (R2), mean absolute percentage error (MAPE), and relative percent deviation (RPD). The ideal values of MAE, RMSE, R2, and MAPE are 0, 0, 1, and 0, respectively, and an RPD above 1.4 indicates that the model is reliable87,88,89,90. The formulas are as follows:
where \(\:{y}_{i}\) represents the actual value, \(\:{\hat{y}}_{i}\) represents the estimated value, and \(\:\bar{y}\) represents the average of the actual values.
Results and discussion
Predictions of the proposed model
The parameter settings of BKA-XGBOOST are primarily determined by the parameters of BKA and the optimization range. The number of populations and the maximum number of iterations of BKA are set to 10 and 20, respectively, to balance the optimization time and effect. The three critical parameters of XGBOOST optimized by BKA are the depth of CART, the learning rate, and the number of iterations of XGBOOST. BKA searches for the optimal parameter within the set range and determines whether the resulting parameter is optimal by the magnitude of the RMSE, which ultimately yields the parameter combination with the smallest RMSE after 20 iterations. The optimization ranges of the three parameters should be set moderately to avoid suboptimal solutions and waste computing resources. Based on previous studies67,80,91,92,93,94, the optimization ranges of these three parameters are set as follows: the depth of CART is set to 3 to 30, the learning rate is set to 0.001 to 0.1, and the number of iterations of XGBOOST is set to 100 to 1000.
To determine the reliability of BKA-XGBOOST, the original data were randomly and nonrepetitively reassembled ten times. BKA-XGBOOST was employed to predict ten distinct data combinations. The optimization process of BKA and the corresponding optimal parameters are illustrated in Fig. 5; Table 4, respectively. The corresponding parameter combinations obtained from Table 4 indicate that the optimal parameter settings consist of parameter combinations with different values, and there is no apparent linear trend in the parameter settings. Manually determining parameters is a challenging and time-consuming task. Furthermore, the prediction results illustrated in Fig. 6 indicate that the prediction curve aligns well with the actual value curve overall. BKA-XGBOOST, with this parameter configuration, demonstrates great predictive accuracy. This is further substantiated by the indicators shown in Table 5.

The XGBOOST parameters optimization process.

BKA-XGBOOST predictions.
Sensitivity analysis
Sensitivity analysis aims to determine the relative importance of inputs to outputs. Since the contributions of wPI, γd, σc, σd, w and NFT to the prediction of MR are unknown, the proposed model is still a black box model. Therefore, it is necessary to conduct sensitivity analysis to explore the impact of each variable on MR. To further explore the impact of each input on MR, the maximum information coefficient (MIC) method was employed. The notion of MIC is derived from mutual information theory and is utilized to quantify the level of mutual effect between two variables95. MIC is a method that is universally applicable and provides a fair assessment of the relationships between variables, in contrast to methods such as Pearson, Spearman, and Kendall, which lack these qualities96,97,98. As illustrated in Fig. 7, the influence of w on MR is pronounced, whereas the impacts of NFT, σd, and σc on MR are relatively modest. This suggests that MR depends heavily on w, γd, and wPI.

The degree of influence of inputs on MR.
Comparison of various models
To ascertain the effectiveness of the proposed model, the models in Table 2 are employed for comparison, including the extreme learning machine (ELM), the K-nearest neighbor (KNN), the support vector machine (SVM), the extreme gradient boosting (XGBOOST), the random forest (RF), the least square support vector machine (LSSVM), the radial basis function neural network (RBFNN), the back propagation neural network (BPNN), and the generalized regression neural network (GRNN). Table 6 presents the parameter settings employed in the comparison models.
The dataset used for the comparison model is the 4th dataset in Table 4 (BKA-XGBOOST’s performance on this dataset is closest to its average performance, and the feasibility of the proposed model can be fairly evaluated by comparing its performance on this dataset). Figure 8 shows the predictions of different models for the same dataset. According to Fig. 8, the prediction curve of KNN is far from the actual value curve, and the absolute prediction error for most samples is the largest. On the other hand, the prediction curve of BKA-XGBOOST is closer to the actual value, and the error is the smallest in all samples except the 407th sample. Based on the model performance comparison shown in Fig. 9, XGBOOST outperforms the other single models, indicating that using XGBOOST to predict MR is reasonable. In addition, the performance of XGBOOST optimized by BKA has improved. The proposed model accomplishes the objective of precisely forecasting MR.

Predictions from different models.

Performance of various models.
Score analysis
Score analyze is a method for evaluating model performance99,100. In score analysis, models are allocated scores based on various evaluation metrics, and the model with the performance metrics closest to the desired values requires the highest score101,102,103. This study evaluates ten models from five error metrics with a maximum score of 10 and a minimum score of 1. The scores obtained by the models are presented in Table 7. From Table 7, it can be seen that BKA-XGBOOST has received the highest score and is the best-performing model. XGBOOST follows.
Regression error characteristics curve
Regression error characteristic (REC) curve visually depicts a regression model’s predictive performance. REC curve contrasts with conventional merits by emphasizing the cumulative distribution function of the absolute error104. The area over the REC curve (AOC) represents a biased estimate of the predicted error105, with the lowest AOC value signifying the most effective model106. To evaluate the models’ performance, the REC curves were generated (Fig. 10) and the AOC was computed (Table 8). Table 8 demonstrates that the AOC of BKA-XGBOOST is the lowest, signifying it as the most effective model.

The models’ REC curves.
Anderson–Darling test
The Anderson-Darling (AD) test is a nonparametric test typically used to assess data’s normality and analyze the dispersion of predictions. If the model’s AD value is close to the AD value of the actual value, the model demonstrates a reliable capacity to evaluate the MR107. The AD test was employed to evaluate the fit of the models’ predictions to the actual value. As shown in Table 9, the P of the actual value and all predictions are below 0.005, indicating that they are non-normally distributed. Moreover, the AD value of BKA-XGBOOST is closest to the AD value of the actual value, which indicates that BKA-XGBOOST has the best performance.
Comparison models in the literature
Table 10 shows the comparison with previous studies using different models, including genetic algorithm-adaptive layered population structure (GA-ALPS), symbiotic organisms search-least square support vector machine (SOS-LSSVM), jellyfish swarm optimizer- extreme gradient boosting (JSO-XGBOOST) and genetic algorithm-artificial neural network (GA-ANN). As the previous research utilizes a different dataset than the one employed in this work, direct performance comparisons are unconvincing. The proposed model retains the same parameters as previously stated and predicts the dataset, including 283 data points utilized by Ghorbani (Additional data 2), and 891 data points employed by Sadik, Azam, and He (Additional data 1). According to Table 10, the proposed model demonstrated the highest level of accuracy in predicting outcomes. The RMSE of the proposed model is reduced by 13.72% and 24.82% compared to GA-ANN and JSO-XGBOOST, respectively. The proposed model improves the prediction accuracy to a certain extent, and this research contributes to the accurate prediction of MR.
Model programing
To increase the practicality of the model, MATLAB App Designer is employed to create the MR prediction program. The program is divided into two interfaces: the login interface and the main program (illustrated in Fig. 11). Prior to accessing the main program, users are required to enter their accounts and passwords on the login interface. Upon successful verification, users are permitted to enter the main program. The main program is divided into three sections: the setting area, the functional area, and the output area. The setting area reserves the default BKA basic parameters and the optimization range of XGBOOST parameters, which users have the option to adjust. The ribbon contains Input, Analyze, Predict, Output, and Quit buttons. By clicking the Input button, the data are imported into the program, which supports files in the formats xls, csv, and xlsx. If the user wants to explore the sensitivity of different input factors to MR, the importance of the inputs calculated by the MIC method (the inputs are represented by numbers in order) will be shown by clicking the Analyze button. Subsequently, clicking the Predict button initiates the random selection of 80% of the data for training, with the objective of identifying the optimal XGBOOST parameters. The remaining data are then predicted on the basis of the obtained parameters. The prediction performance of the model is displayed in the form of a line chart, and the prediction accuracy of the model is evaluated with five evaluation indicators. In addition, the program also displays the optimal number of iterations, tree depth, and learning rate obtained through BKA. After clicking the Output button to obtain the prediction results, the user can click the Quit button to exit the program.

Soil resilient modulus prediction program.
Summary and conclusions
Forecasting MR is an important part of assessing road safety and sustainability. Traditional methods, including experimental, regression equation, and constitutive model methods, are difficult to implement in engineering due to their time-consuming and complex characteristics. The generality and accuracy of some machine learning methods for predicting MR also need to be further improved. In this situation, this study proposes BKA-XGBOOST as a novel approach for predicting MR. The performance of the proposed model is compared with nine individual models and four literature models using several metrics. The conclusions drawn from this study are as follows:
-
Influence of geotechnical factors: Among the six geotechnical factors utilized as inputs, the one that has the most impact on MR is w, which is influenced by γd.
-
Effect of optimization algorithm: For different combinations of soil data, BKA can provide the optimal parameters to XGBOOST to ensure its outstanding performance. Moreover, the AOC of XGBOOST following BKA optimization is reduced significantly and further improved in accuracy.
-
The best performance model: Performance metrics (MAE = 0.975 MPa, RMSE = 1.7719 MPa, R2 = 0.995, RPD = 15.3902, MAPE = 0.0354), score analysis (score = 50), REC curve (AOC = 14.3497), AD test (model’s AD = 42.056, a difference of 0.232 from the AD of the actual value) indicate that BKA-XGBOOST is the best model. It also proved to be the best model in comparison with four literature models (MAE = 2.8754 MPa, RMSE = 4.1266 MPa, R2 = 0.9769 for additional dataset 1; MAE = 3.1306 MPa, RMSE = 4.4862 MPa, R2 = 0.9816 for additional dataset 2).
In conclusion, this study introduced a new model, BKA-XGBOOST, for evaluating MR. The proposed model exhibits great accuracy, generalizability, and user-friendliness. It has potential for application in geotechnical engineering. However, the soil types employed in the experiments are inadequate. Consequently, more types of soil data will be used in subsequent experiments to test the model’s generalizability and precision further.
Data availability
All data generated or analyzed during this study are included in this manuscript.
Abbreviations
- AD:
-
Anderson-Darling
- AOC:
-
Area over the REC curve
- BKA:
-
Black black-winged kite algorithm
- BPNN:
-
Back propagation neural network
- ELM:
-
Extreme learning machine
- GA-ALPS:
-
Genetic algorithm-adaptive layered population structure
- GA-ANN:
-
Genetic algorithm-artificial neural network
- GBDT:
-
Gradient boosting decision tree
- GRNN:
-
Generalized regression neural network
- JSO-XGBOOST:
-
Jellyfish swarm optimizer- extreme gradient boosting
- KNN:
-
K-nearest neighbor
- LSSVM:
-
Least square support vector machine
- MAE:
-
Mean absolute error
- MAPE:
-
Mean absolute percentage error
- MIC:
-
Maximum information coefficient
- MR :
-
Soil resilient modulus
- NFT :
-
Number of FT cycles
- R2 :
-
Determination coefficient
- RBFNN:
-
Radial basis function neural network
- REC:
-
Regression error characteristics curve
- RF:
-
Random forest
- RMSE:
-
Root mean square error
- RPD:
-
Relative percent deviation
- SOS-LSSVM:
-
Symbiotic organisms search-least square support vector machine
- SVM:
-
Support vector machine
- w:
-
Moisture content
- wPI:
-
Weighted plasticity index
- XGBOOST:
-
Extreme gradient boosting
- γd :
-
Dry unit weight
- εr :
-
Recoverable strain
- σc :
-
Confining stress
- σd :
-
Ratio of deviator stress
References
Ren, Y., Zhang, L. & Suganthan, P. N. Ensemble classification and regression-recent developments, applications and future directions. IEEE Comput. Intell. Mag. 11, 41–53. https://doi.org/10.1109/MCI.2015.2471235 (2016).
Ding, L., Han, Z., Zou, W. & Wang, X. Characterizing hydro-mechanical behaviours of compacted subgrade soils considering effects of freeze-thaw cycles. Transp. Geotech. 24, 100392. https://doi.org/10.1016/j.trgeo.2020.100392 (2020).
Rahman, M. T. Evaluation of Moisture, Suction Effects and Durability Performance of Lime Stabilized Clayey Subgrade Soils (2013).
Solanki, P., Zaman, M. & Khalife, R. Effect of Freeze-Thaw Cycles on Performance of Stabilized Subgrade, Vol. 230 (2013).
Kardani, N. et al. Prediction of the resilient modulus of compacted subgrade soils using ensemble machine learning methods. Transp. Geotech. 36, 100827. https://doi.org/10.1016/j.trgeo.2022.100827 (2022).
Heidarabadizadeh, N., Ghanizadeh, A. R. & Behnood, A. Prediction of the resilient modulus of non-cohesive subgrade soils and unbound subbase materials using a hybrid support vector machine method and colliding bodies optimization algorithm. Constr. Build. Mater. 275, 122140. https://doi.org/10.1016/j.conbuildmat.2020.122140 (2021).
Andrei, D., Witczak, M., Schwartz, C. & Uzan, J. Harmonized resilient modulus test method for unbound pavement materials. Transp. Res. Rec. 1874, 29–37. https://doi.org/10.3141/1874-04 (2004).
Drumm, E. C., Boateng-Poku, Y. & Johnson Pierce, T. Estimation of subgrade resilient modulus from standard tests. J. Geotech. Eng. 116, 774–789., https://doi.org/10.1061/(ASCE)0733-9410(1990)116:5(774) (1990).
American Association of State, H. & & Transportation, O. AASHTO guide for design of pavement structures, 1993. 1 volume (various pagings): illustrations; 28 cmThe Association (1993).
Mazari, M., Navarro, E., Abdallah, I. & Nazarian, S. Comparison of numerical and experimental responses of pavement systems using various resilient modulus models. Soils Found. 54, 36–44. https://doi.org/10.1016/j.sandf.2013.12.004 (2014).
Kim, D. G. Engineering Properties Affecting the Resilient Modulus of Fine-Grained Soils as Subgrade (The Ohio State University, 1999).
George, K. P. Prediction of resilient modulus from soil index properties (2004).
Kim, D. & Kim, J. R. Resilient behavior of compacted subgrade soils under the repeated triaxial test. Constr. Build. Mater. 21, 1470–1479. https://doi.org/10.1016/j.conbuildmat.2006.07.006 (2007).
Park, H. I., Kweon, G. C. & Lee, S. R. Prediction of resilient modulus of granular subgrade soils and subbase materials using artificial neural network. Road. Mater. Pavement Des. 10, 647–665. https://doi.org/10.1080/14680629.2009.9690218 (2009).
Kim D.-G.
Hanittinan, W. Resilient modulus Prediction Using Neural Network Algorithm (The Ohio State University, 2007).
Pezo, R. & Hudson, W. Prediction models of resilient modulus for nongranular materials. Geotech. Test. J. 17, 349–355 (1994).
Sadrossadat, E., Heidaripanah, A. & Osouli, S. Prediction of the resilient modulus of flexible pavement subgrade soils using adaptive neuro-fuzzy inference systems. Constr. Build. Mater. 123, 235–247. https://doi.org/10.1016/j.conbuildmat.2016.07.008 (2016).
Seed, H. B. Prediction of flexible pavement deflections from laboratory repeated-load tests. 117 pages illustrations 28 cm (Highway Research Board, National Research Council, National Academy of Sciences-National Academy of Engineering, 1967).
National Research Council & Research, T. B. Layered Pavement Systems. Iv, 79 Pages: Illustrations ; 28 cm (National Academy of Sciences, 1981).
Uzan, J. Characterization of granular material. Transp. Res. Rec. 1022, 52–59 (1985).
Kolisoja, P. Resilient Deformation Characteristics of Granular Materials (Tampere University of Technology Finland, 1997).
Ng, C. W. W., Zhou, C., Yuan, Q. & Xu, J. Resilient modulus of unsaturated subgrade soil: experimental and theoretical investigations. Can. Geotech. J. 50, 223–232. https://doi.org/10.1139/cgj-2012-0052 (2013).
Yang, S. R., Huang, W. H. & Tai, Y. T. Variation of resilient modulus with soil suction for compacted subgrade soils. Transportation Research Record 1913, 99–106. https://doi.org/10.1177/0361198105191300110 (2005).
Liang Robert, Y., Rabab’ah, S. & Khasawneh, M. Predicting moisture-dependent resilient modulus of cohesive soils using soil suction concept. J. Transp. Eng. 134, 34–40. https://doi.org/10.1061/(ASCE)0733-947X(2008)134:1(34) (2008).
Han, Z. & Vanapalli, S. K. Model for predicting resilient modulus of unsaturated subgrade soil using soil-water characteristic curve. Can. Geotech. J. 52, 1605–1619. https://doi.org/10.1139/cgj-2014-0339 (2015).
Khoury, N., Brooks, R., Boeni Santhoshini, Y. & Yada, D. Variation of resilient modulus, strength, and modulus of elasticity of stabilized soils with postcompaction moisture contents. J. Mater. Civ. Eng. 25, 160–166. https://doi.org/10.1061/(ASCE)MT.1943-5533.0000574 (2013).
Li, D. & Selig Ernest, T. Resilient modulus for fine-grained subgrade soils. J. Geotech. Eng. 120, 939–957. https://doi.org/10.1061/(ASCE)0733-9410(1994)120:6(939) (1994).
ARA, I. T. & Council, N. R. Washington, DC. Guide for mechanistic-empirical design of new and rehabilitated pavement structures: NCHRP 1-37A Final Report (2004).
Johnson, T. C. Frost action predictive techniques for roads and airfields: A comprehensive survey of research findings (1986).
Azam, A. M., Cameron, D. A. & Rahman, M. M. Model for prediction of resilient modulus incorporating matric suction for recycled unbound granular materials. Can. Geotech. J. 50, 1143–1158. https://doi.org/10.1139/cgj-2012-0406 (2013).
Zhang, J., Peng, J., Liu, W. & Lu, W. Predicting resilient modulus of fine-grained subgrade soils considering relative compaction and matric suction. Road. Mater. Pavement Des. 22, 703–715. https://doi.org/10.1080/14680629.2019.1651756 (2021).
Cary, C. E. & Zapata, C. E. Enhanced model for resilient response of soils resulting from seasonal changes as implemented in mechanistic–empirical pavement design guide. Transp. Res. Rec. 2170, 36–44. https://doi.org/10.3141/2170-05 (2010).
Khoury, N. & Maalouf, M. Prediction of resilient modulus from post-compaction moisture content and physical properties using support vector regression. Geotech. Geol. Eng. 36, 2881–2892. https://doi.org/10.1007/s10706-018-0510-2 (2018).
Chu, X., Dawson, A. & Thom, N. Prediction of resilient modulus with consistency index for fine-grained soils. Transp. Geotech. 31, 100650. https://doi.org/10.1016/j.trgeo.2021.100650 (2021).
Gandomi, A., Alavi, A., Mirzahosseini, M. & Moghadas Nejad, F. Nonlinear genetic-based models for prediction of flow number of asphalt mixtures. J. Mater. Civ. Eng. 23, 248–263. https://doi.org/10.1061/(Asce)Mt.1943-5533.0000154 (2011).
Shahin, M., Jaksa, M. & Maier, H. Recent advances and future challenges for artificial neural systems in geotechnical engineering applications. Adv. Artif. Neural Syst. 2009. https://doi.org/10.1155/2009/308239 (2009).
Singh, R., Kainthola, A. & Singh, T. N. Estimation of elastic constant of rocks using an ANFIS approach. Appl. Soft Comput. 12, 40–45. https://doi.org/10.1016/j.asoc.2011.09.010 (2012).
Shahin, M. A. State-of-the-art review of some artificial intelligence applications in pile foundations. Geosci. Front. 7, 33–44. https://doi.org/10.1016/j.gsf.2014.10.002 (2016).
Alavi, A. H., Hasni, H., Lajnef, N., Chatti, K. & Faridazar, F. An intelligent structural damage detection approach based on self-powered wireless sensor data. Autom. Constr. 62, 24–44. https://doi.org/10.1016/j.autcon.2015.10.001 (2016).
Alavi, A. H. & Gandomi, A. H. Energy-based numerical models for assessment of soil liquefaction. Geosci. Front. 3, 541–555. https://doi.org/10.1016/j.gsf.2011.12.008 (2012).
Ding, X., Amiri, M. & Hasanipanah, M. Enhancing shear strength predictions of rocks using a hierarchical ensemble model. Sci. Rep. 14, 20268. https://doi.org/10.1038/s41598-024-71367-6 (2024).
Ding, X., Hasanipanah, M. & Ulrikh, D. V. Hybrid metaheuristic optimization algorithms with least-squares support vector machine and boosted regression tree models for prediction of air-blast due to mine blasting. Nat. Resour. Res. 33, 1349–1363. https://doi.org/10.1007/s11053-024-10329-1 (2024).
Wang, Y., Rezaei, M., Abdullah, R. A. & Hasanipanah, M. Developing two hybrid algorithms for predicting the elastic modulus of intact rocks. 15, 4230 (2023).
Hasanipanah, M. et al. Intelligent prediction of rock mass deformation modulus through three optimized cascaded forward neural network models. Earth Sci. Inf. 15, 1659–1669. https://doi.org/10.1007/s12145-022-00823-6 (2022).
Solanki, P. Artificial neural network models to estimate resilient modulus of cementitiously stabilized subgrade soils. Int. J. Pavement Res. Technol. 6 (3), 155–164. https://doi.org/10.6135/ijprt.org.tw/2013 (2013).
Kim, S. H., Yang, J. & Jeong, J. H. Prediction of subgrade resilient modulus using artificial neural network. KSCE J. Civ. Eng. 18, 1372–1379. https://doi.org/10.1007/s12205-014-0316-6 (2014).
Ghanizadeh, A. & Rahrovan, M. Application of artificial neural network to predict the resilient modulus of stabilized base subjected to wet-dry cycles. 1, 37–47 (2016).
Saha, S., Gu, F., Luo, X. & Lytton, R. Use of an artificial neural network approach for the prediction of resilient modulus for unbound granular material. Transp. Res. Rec. J. Transp. Res. Board. 1 https://doi.org/10.1177/0361198118756881 (2018).
Bastola, N. R., Vechione, M. M., Elshaer, M. & Souliman, M. I. Artificial neural network prediction model for in situ resilient modulus of subgrade soils for pavement design applications. Innov. Infrastruct. Solut. 7, 54. https://doi.org/10.1007/s41062-021-00659-x (2021).
Ikeagwuani, C. C. & Nwonu, D. C. Statistical analysis and prediction of spatial resilient modulus of coarse-grained soils for pavement subbase and base layers using MLR, ANN and Ensemble techniques. Innov. Infrastruct. Solut. 7, 273. https://doi.org/10.1007/s41062-022-00875-z (2022).
Oskooei, P. R., Mohammadinia, A., Arulrajah, A. & Horpibulsuk, S. Application of artificial neural network models for predicting the resilient modulus of recycled aggregates. Int. J. Pavement Eng. 23, 1121–1133. https://doi.org/10.1080/10298436.2020.1791863 (2022).
Pal, M. & Deswal, S. Extreme learning machine based modeling of resilient modulus of subgrade soils. Geotech. Geol. Eng. 32, 287–296. https://doi.org/10.1007/s10706-013-9710-y (2014).
Hao, S. & Pabst, T. Prediction of CBR and resilient modulus of crushed waste rocks using machine learning models. Acta Geotech. 17, 1383–1402. https://doi.org/10.1007/s11440-022-01472-1 (2022).
Ikeagwuani, C. C., Nweke, C. C. & Onah, H. N. Prediction of resilient modulus of fine-grained soil for pavement design using KNN, MARS, and random forest techniques. Arab. J. Geosci. 16, 388. https://doi.org/10.1007/s12517-023-11469-z (2023).
Ikeagwuani, C. C. Determination of unbound granular material resilient modulus with MARS, PLSR, KNN and SVM. Int. J. Pavement Res. Technol. 15, 803–820. https://doi.org/10.1007/s42947-021-00054-w (2022).
Khan, A. et al. An ensemble tree-based prediction of Marshall mix design parameters and resilient modulus in stabilized base materials. Constr. Build. Mater. 401, 132833. https://doi.org/10.1016/j.conbuildmat.2023.132833 (2023).
Kayadelen, C., Altay, G. & Önal, Y. Numerical simulation and novel methodology on resilient modulus for traffic loading on road embankment. Int. J. Pavement Eng. 23, 3212–3221. https://doi.org/10.1080/10298436.2021.1886296 (2022).
Kaloop, M. R. et al. Predicting resilient modulus of recycled concrete and clay masonry blends for pavement applications using soft computing techniques. Front. Struct. Civil Eng. 13, 1379–1392. https://doi.org/10.1007/s11709-019-0562-2 (2019).
Sarkhani Benemaran, R., Esmaeili-Falak, M. & Javadi, A. Predicting resilient modulus of flexible pavement foundation using extreme gradient boosting based optimised models. Int. J. Pavement Eng. 24, 2095385. https://doi.org/10.1080/10298436.2022.2095385 (2023).
Sadik, L. Developing prediction equations for soil resilient modulus using evolutionary machine learning. Transp. Infrastruct. Geotechnol. https://doi.org/10.1007/s40515-023-00342-x (2023).
Azam, A. et al. Modeling resilient modulus of subgrade soils using LSSVM optimized with swarm intelligence algorithms. Sci. Rep. 12, 14454. https://doi.org/10.1038/s41598-022-17429-z (2022).
He, B. et al. A case study of resilient modulus prediction leveraging an explainable metaheuristic-based XGBoost. Transp. Geotech. 45, 101216. https://doi.org/10.1016/j.trgeo.2024.101216 (2024).
Nazzal, M. D. & Tatari, O. Evaluating the use of neural networks and genetic algorithms for prediction of subgrade resilient modulus. Int. J. Pavement Eng. 14, 364–373. https://doi.org/10.1080/10298436.2012.671944 (2013).
Ghorbani, B., Arulrajah, A., Narsilio, G., Horpibulsuk, S. & Bo, M. W. Development of genetic-based models for predicting the resilient modulus of cohesive pavement subgrade soils. Soils Found. 60, 398–412. https://doi.org/10.1016/j.sandf.2020.02.010 (2020).
Bione, F. R. A. et al. Estimating total organic carbon of potential source rocks in the Espírito Santo Basin, SE Brazil, using XGBoost. Mar. Pet. Geol. 162, 106765. https://doi.org/10.1016/j.marpetgeo.2024.106765 (2024).
Shehab, M., Taherdangkoo, R. & Butscher, C. Towards reliable barrier systems: a constrained XGBoost model coupled with gray wolf optimization for maximum swelling pressure of bentonite. Comput. Geotech. 168, 106132. https://doi.org/10.1016/j.compgeo.2024.106132 (2024).
Sun, L. et al. Fusing daily snow water equivalent from 1980 to 2020 in China using a spatiotemporal XGBoost model. J. Hydrol. 632, 130876. https://doi.org/10.1016/j.jhydrol.2024.130876 (2024).
Huu Nguyen, M., Nguyen, T. A. & Ly, H. B. Ensemble XGBoost schemes for improved compressive strength prediction of UHPC. Structures 57, 105062. https://doi.org/10.1016/j.istruc.2023.105062 (2023).
Li, X. et al. Dynamic bond stress-slip relationship of steel reinforcing bars in concrete based on XGBoost algorithm. J. Build. Eng. 84, 108368. https://doi.org/10.1016/j.jobe.2023.108368 (2024).
Wang, J., Wang, W., Hu, X., Qiu, L. & Zang, H. -f. black-winged kite algorithm: a nature-inspired meta-heuristic for solving benchmark functions and engineering problems. Artif. Intell. Rev. 57, 98. https://doi.org/10.1007/s10462-024-10723-4 (2024).
Ren, J., Vanapalli, S. K., Han, Z., Omenogor, K. O. & Bai, Y. The resilient moduli of five Canadian soils under wetting and freeze-thaw conditions and their estimation by using an artificial neural network model. Cold Reg. Sci. Technol. 168, 102894. https://doi.org/10.1016/j.coldregions.2019.102894 (2019).
Zhang, L. & Wang, L. Optimization of site investigation program for reliability assessment of undrained slope using Spearman rank correlation coefficient. Comput. Geotech. 155, 105208. https://doi.org/10.1016/j.compgeo.2022.105208 (2023).
Khatti, J. & Grover, K. S. Estimation of intact rock uniaxial compressive strength using advanced machine learning. Transp. Infrastruct. Geotechnol. 11, 1989–2022. https://doi.org/10.1007/s40515-023-00357-4 (2024).
Chen, T. & Guestrin, C. In Proc. of the 22nd acm Sigkdd International Conference on Knowledge Discovery and Data Mining, 785–794.
Hong, Z., Tao, M., Liu, L., Zhao, M. & Wu, C. An intelligent approach for predicting overbreak in underground blasting operation based on an optimized XGBoost model. Eng. Appl. Artif. Intell. 126, 107097. https://doi.org/10.1016/j.engappai.2023.107097 (2023).
Rahman, M., Cao, Y., Sun, X., Li, B. & Hao, Y. Deep pre-trained networks as a feature extractor with XGBoost to detect tuberculosis from chest X-ray. Comput. Electr. Eng. 93, 107252. https://doi.org/10.1016/j.compeleceng.2021.107252 (2021).
Jiang, M., Feng, X., Wang, C., Fan, X. & Zhang, H. Robust color image watermarking algorithm based on synchronization correction with multi-layer perceptron and Cauchy distribution model. Appl. Soft Comput. 140, 110271. https://doi.org/10.1016/j.asoc.2023.110271 (2023).
Sun, Z., Li, Y., Yang, Y., Su, L. & Xie, S. Splitting tensile strength of basalt fiber reinforced coral aggregate concrete: optimized XGBoost models and experimental validation. Constr. Build. Mater. 416, 135133. https://doi.org/10.1016/j.conbuildmat.2024.135133 (2024).
Sun, Z., Wang, X., Huang, H., Yang, Y. & Wu, Z. Predicting compressive strength of fiber-reinforced coral aggregate concrete: interpretable optimized XGBoost model and experimental validation. Structures 64, 106516. https://doi.org/10.1016/j.istruc.2024.106516 (2024).
Dhanya, L. & Chitra, R. A novel autoencoder based feature independent GA optimised XGBoost classifier for IoMT malware detection. Expert Syst. Appl. 237, 121618. https://doi.org/10.1016/j.eswa.2023.121618 (2024).
Sun, M. et al. Research on prediction of PPV in open-pit mine used RUN-XGBoost model. Heliyon 10, e28246. https://doi.org/10.1016/j.heliyon.2024.e28246 (2024).
Thai, D. K., Le, D. N., Doan, Q. H., Pham, T. H. & Nguyen, D. N. A hybrid model for classifying the impact damage modes of fiber reinforced concrete panels based on XGBoost and Horse Herd optimization algorithm. Structures 60, 105872. https://doi.org/10.1016/j.istruc.2024.105872 (2024).
Kıyak, B., Öztop, H. F., Ertam, F. & Aksoy, İ. G. An intelligent approach to investigate the effects of container orientation for PCM melting based on an XGBoost regression model. Eng. Anal. Bound. Elem. 161, 202–213. https://doi.org/10.1016/j.enganabound.2024.01.018 (2024).
Lin, L. et al. A new FCM-XGBoost system for predicting pavement condition index. Expert Syst. Appl. 249, 123696. https://doi.org/10.1016/j.eswa.2024.123696 (2024).
Zheng, J. et al. Metabolic syndrome prediction model using bayesian optimization and XGBoost based on traditional Chinese medicine features. Heliyon 9, e22727. https://doi.org/10.1016/j.heliyon.2023.e22727 (2023).
Khatti, J. & Grover, K. Prediction of compaction parameters of soil using GA and PSO optimized relevance vector machine (RVM). ICTACT J. Soft Comput. 13, 2890–2903. https://doi.org/10.21917/ijsc.2023.0399 (2023).
Mahabub, M. S., Hasan, M. R., Khatti, J. & Hossain, A. T. M. S. Assessing the effects of influencing parameters on field strength of soft coastal soil stabilized by deep mixing method. Bull. Eng. Geol. Environ. 83, 9. https://doi.org/10.1007/s10064-023-03502-y (2023).
Khatti, J. & Grover, K. S. Prediction of uniaxial strength of rocks using relevance vector machine improved with dual kernels and metaheuristic algorithms. Rock Mech. Rock Eng. 57, 6227–6258. https://doi.org/10.1007/s00603-024-03849-y (2024).
Kumar, M. & Samui, P. Reliability analysis of settlement of pile group in clay using LSSVM, GMDH, GPR. Geotech. Geol. Eng. 38, 6717–6730. https://doi.org/10.1007/s10706-020-01464-6 (2020).
Bo, Y. et al. Prediction of tunnel deformation using PSO variant integrated with XGBoost and its TBM jamming application. Tunn. Undergr. Space Technol. 150, 105842. https://doi.org/10.1016/j.tust.2024.105842 (2024).
Guo, X., Yang, Q., Wang, Q., Sun, Y. & Tan, A. Electromagnetic torque modeling and validation for a permanent magnet spherical motor based on XGBoost. Simul. Model. Pract. Theory 102989 https://doi.org/10.1016/j.simpat.2024.102989 (2024).
Wu, C., Pan, H., Luo, Z., Liu, C. & Huang, H. Multi-objective optimization of residential building energy consumption, daylighting, and thermal comfort based on BO-XGBoost-NSGA-II. Build. Environ. 254, 111386. https://doi.org/10.1016/j.buildenv.2024.111386 (2024).
Sheikhi, S. & Kostakos, P. Safeguarding cyberspace: enhancing malicious website detection with PSOoptimized XGBoost and firefly-based feature selection. Comput. Secur. 142, 103885. https://doi.org/10.1016/j.cose.2024.103885 (2024).
Reshef, D. N. et al. Detecting Novel associations in large data sets. Science 334, 1518–1524. https://doi.org/10.1126/science.1205438 (2011).
Zhang, Y. & Shang, P. KM-MIC: an improved maximum information coefficient based on K-Medoids clustering. Commun. Nonlinear Sci. Numer. Simul. 111, 106418. https://doi.org/10.1016/j.cnsns.2022.106418 (2022).
Chen, C., Zhang, G., Liang, Y. & Wang, H. Impacts of Locust feeding on interspecific relationships and niche of the major plants in Inner Mongolia grasslands. Glob. Ecol. Conserv. 51, e02913. https://doi.org/10.1016/j.gecco.2024.e02913 (2024).
Zhang, Y., Zhu, D., Wang, M., Li, J. & Zhang, J. A comparative study of cyber security intrusion detection in healthcare systems. Int. J. Crit. Infrastruct. Prot. 44, 100658. https://doi.org/10.1016/j.ijcip.2023.100658 (2024).
Kocak, B., Pınarcı, İ., Güvenç, U. & Kocak, Y. Prediction of compressive strengths of pumice-and diatomite-containing cement mortars with artificial intelligence-based applications. Constr. Build. Mater. 385, 131516. https://doi.org/10.1016/j.conbuildmat.2023.131516 (2023).
Thamboo, J., Sathurshan, M. & Zahra, T. Reliable unit strength correlations to predict the compressive strength of grouted concrete masonry. Mater. Struct. 57, 151. https://doi.org/10.1617/s11527-024-02417-8 (2024).
Alkayem, N. F. et al. Prediction of concrete and FRC properties at high temperature using machine and deep learning: a review of recent advances and future perspectives. J. Build. Eng. 83, 108369. https://doi.org/10.1016/j.jobe.2023.108369 (2024).
Bahmed, I. T., Khatti, J. & Grover, K. S. Hybrid soft computing models for predicting unconfined compressive strength of lime stabilized soil using strength property of virgin cohesive soil. Bull. Eng. Geol. Environ. 83, 46. https://doi.org/10.1007/s10064-023-03537-1 (2024).
Khatti, J., Grover, K. S., Kim, H. J., Mawuntu, K. B. A. & Park, T. W. Prediction of ultimate bearing capacity of shallow foundations on cohesionless soil using hybrid LSTM and RVM approaches: an extended investigation of multicollinearity. Comput. Geotech. 165, 105912. https://doi.org/10.1016/j.compgeo.2023.105912 (2024).
Fissha, Y. et al. Predicting ground vibration during rock blasting using relevance vector machine improved with dual kernels and metaheuristic algorithms. Sci. Rep. 14, 20026. https://doi.org/10.1038/s41598-024-70939-w (2024).
Bi, J. & Bennett, K. Regression Error Characteristic Curves, Vol. 1 (2003).
Khatti, J. & Polat, B. Y. Assessment of short and long-term pozzolanic activity of natural pozzolans using machine learning approaches. Structures 68, 107159. https://doi.org/10.1016/j.istruc.2024.107159 (2024).
Khatti, J. & Grover, K. S. Assessment of hydraulic conductivity of compacted clayey soil using artificial neural network: an investigation on structural and database multicollinearity. Earth Sci. Inf. 17, 3287–3332. https://doi.org/10.1007/s12145-024-01336-0 (2024).
Author information
Authors and Affiliations
Contributions
All the work in this study was completed by Xiangfeng Duan.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Duan, X. Assessment of resilient modulus of soil using hybrid extreme gradient boosting models. Sci Rep 14, 31706 (2024). https://doi.org/10.1038/s41598-024-81311-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-81311-3
