
Abstract
The latest advancements of deep learning have resulted in a new era of natural language processing. The machines now possess an unparallel ability to interpret and engage with various tasks such as text classification, content generation and natural language understanding. This development extended to the analysis of human behavior, where deep learning models are used to decode human personality. Due to the rise of social media, generating huge amounts of textual data that reshaped communication patterns. Understanding personality traits is a challenging topic which helps us to explore the patterns of thoughts, feelings and behaviors which are helpful for recruitment, career counselling and consumers’ behavior for marketing, etc. In this research study, the main aim is to predict the human personality trait of agreeableness showing whether a person is emotional who feels a lot or thinker who is logical and has rational thinking. This behavior leads to analyzing them as cooperative, friendly and respecting difference of views. For comprehensive empirical analysis, shallow machine learning models, ensemble models, and deep learning technique including state of the art transformer-based models are applied on real-world dataset of MBTI. For feature engineering, textual features of TF-IDF and POS tagging and word embeddings such as word2vec, glove and sentence embeddings are explored. The results analysis shows the highest performance 91.57% with sentence embeddings utilizing Bi-LSTM algorithm that highlights the power of this study as compared to existing studies in the relevant literature.
Similar content being viewed by others

Introduction
Deep learning has become a cornerstone in the evolution of Natural Language Processing (NLP), significantly impacting how we interact and analyze with Users Generated Content (UGC) in the digital age. The advent of Web 2.0 brought a unique transformation in internet usage, that shows how users interact with the internet by creating vast amounts of unstructured data that traditional methods struggled to process effectively. Social media provides a base-ground for diverse text content serving as a primary source of communication among users1 to share their feelings, thinking and emotions on different platforms like blogs, Facebook, Instagram, Twitter, reddit etc.2. This evolution has laid the foundation for web 3.0 where the integration of Artificial Intelligence (AI) particularly in NLP technologies become more powerful tool to analyze how vast repository of UGC extracting valuable insights into user personalities and behaviors in language use, sentiment, and interaction style of human personality in the form of textual posts that reflect the individual behaviors towards social interaction3. This capability not only enhances personalized user experience but also refines communication patterns4. This interdisciplinary approach not only advances the understanding approach of personality but also has practical applications in fields such as psychology, sociology, anthropology, marketing, recruitments5, human–computer interaction, and personalized recommendation systems6.
Personality traits are classified into broad dimensions that encapsulate different traits of individual’s behaviors and emotional capability. The personality model, also called five-factor model, widely used in the psychological personality theory to predict the traits7 such as preferences are extroversion categorized by high socially expanded and energetic, often paired with agreeableness, marked by consideration and cooperativeness in maintaining their relationships8. Moreover, Conscientiousness traits follow the attributes of disciplined and manageability. Lastly, openness with its rational and curiosity nature, boosts the flexibility and open mindedness visions that power the dynamic aspects of all traits9. Together all these traits provide a detailed map of personality, highlighting the different ways that how people interact with others through social circles including measures of posts, comments, reviews and user content10. To evaluate the individuals’ personality differences, the Myers-Briggs Type Indicator (MBTI) framework provides a valuable insight into how people perceive the world digitally using different social media platform11, process information and make decisions in various contexts, including personal development, career counseling, communication and team building, to help individuals understand their strengths, weaknesses, and communication abilities 12. Among all, the MBTI model has faced critique regarding its reliability and dependability in capturing the complexities of personality due to too noisy and complex data in nature. MBTI framework is a widely utilized psychological tool that categorizes individuals into sixteen unique personality types based on four parameters. Our focus in this study is to explore agreeableness trait with feeling and thinking measures. Agreeableness, one of the major dimensions in big five personality trait, describes individuals’ nature to be compassionate, cooperative, politeness, and harmonious in their interactions and communication with others13. Highly tendency of agreeable shows the Feeling preference are most empathetic, considerate, and willing to compromise, making them effective in supportive and collaborative roles. Such users seem warm, kind, trustworthy, consider the values, needs and feeling of other. Moreover, they emotionally impact their decisions and have positive relationships14. Conversely, individuals with low agreeable feature capacity have thinking preference, may be more competitive, critical, and less concerned with others’ feelings, which can lead to conflicts in interpersonal settings. Thinking dimension shows the preference of individuals that tend to prefer prioritize logic, objectivity, rational analysis, when making decision. They value fairness, consistency and impartiality by relying on data and facts to guide their choices. Understanding agreeableness is crucial for predicting social behavior and enhancing teamwork, as it influences how individuals manage conflicts, build relationships, and contribute to group dynamics. Table 1 shows the behaviors of related preferences by analyzing UGC15.
In this research study, the main aim is to predict agreeable personality trait using MBTI framework. The integration of AI and advanced computational models utilized to significantly enhance the accuracy and efficiency of personality prediction models. NLP techniques allow for the extraction of meaningful features from textual data, In this regard, we applied shallow ML models with textual features and state-of-the-art DL models and transformer-based model called BERT model also carried out using word embeddings and advanced sentence embeddings, are evaluated using standard measures. These algorithms facilitate the modeling of complex relationships between these features and personality traits. From the obtained results, the proposed models with features more effective to classify the personality trait detection from text data show the roadmap to researcher in the domain of AI and NLP as an active research area.
Our main research contributions in this research study are as follows:
-
Investigating various textual features including TF-IDF and POS tagging for syntactic meaning patterns and word embeddings including word2vec, GloVe, and advanced sentence embeddings to capture the semantics relationship between words and sentences as well.
-
Exploration of diverse conventional machine learning models, ensemble models, deep learning models, and state-of-the-art transformer-based model for the accurate prediction patterns of personality trait agreeableness.
-
Conducting detailed empirical analysis to predict the highest accuracy measure of 91.57% with Bi-LSTM + advanced sentence embeddings that show highest performance in term of accuracy as compared to existing literature.
The goal of structuring this study is to present the data in a way that makes sense and permits readers to comprehend the methodology and results. Section 2 discusses a literature review with an emphasis on the overall methodologies of machine learning and deep learning, Sect. 3 provides the details of research methodology sharing steps of applied framework, Sect. 4 presents experimental set-up sharing datasets and performance evaluation measures, Sect. 5 shares results and discussions. Lastly, Sect. 6 presents the conclusion and future work in psychology domain with AI methodologies.
Related work
Personality trait detection is a trending research area which defines human personality and behavior differences. Literature on the detection of personality traits in psychology literature has been studied for analyzing the individual with the help of online platforms. Due to various social media platform, there is a vast amount of literature using computation models16, in this study, we examine the literature, as display in Table 2 conducted on the base of computational models including ML and DL for meta-analysis.
Machine learning algorithms
The research focused on whether age-related changes in functional network features could still accurately represent personality traits, with particular attention to the agreeableness trait. One approach to improving e-recruitment involves predicting candidates’ personalities using resumes and social media profiles. This framework applied NLP with algorithms like SVM, NB, and LR leveraging models such as Big Five and MBTI to enhance job-person fit and hiring efficienc5. Another study explored the personality trait of extroversion individual using various machines and ensemble learning models with textual features of TF-IDF and POS tagging for syntactic features, achieving an accuracy of 86% using MBTI dataset8. By investigating personality using social media textual data, applying preprocessing techniques like tokenization and vectorization, this approach combined with NB and ANN achieving 90% accuracy. However, limitations in data scarcity, model complexity, linear assumption constraints, and a single-model approach, all which may affect the robustness and generalization of prediction results14. The role of ML in personality assessments using MBTI framework, individuals can gain deep awareness and meaningful relationships, develop personal growth and enhance the communication modes for building and training, including LR, GB and SVM models17. Selection features PCA and Chi-square aimed at predicting personality dimensions with their corresponding preferences by analyzing social media subjects in Arabic tweets of 110 participant with the TF-IDF and bow focusing on the role of personality traits in self-reported twitter accounts applying conventional ML models18. The intersection of psychology and data mining by analyzing how users’ online behaviors in social networks reflect their personality trait, primarily focused on individual trait using random forest model to differentiate personalities of regular users and opinion leaders based on their psychological profiles19. While brand personality on social media employed hybrid approach using LGA2Vec algorithm integrated with shallow machine learning models to automate brand trait extraction, by comparing competitors, and assessing brand-consumer personality alignment for strategic brand management20.Another approach demonstrated how matching advertising messages to consumer personality traits, inferred from contextual data, to enhance the persuasives and purchasing behavior for marketing rate. This study reveals that neurotic and extroverted personalities, identified as moderating factors that explain variations in consumer response across various traits21. However, eWOM text also utilized to infer personality optimizing advertisement messaging followed the methodology that involves topic modeling, ensemble classification, and explainable AI on reviews to tailored advertising scheme22.
Another approach using regression models for data analysis and prediction of trait, MBTI dataset utilized by handling inconsistent and impurity in dataset with mean value of 49.58%23. Analysis of SVM and MNB model using self-reported twitter dataset focused on subject matter personalities achieve accuracy of 80% and 82% respectively applying word weightage IF-IDF technique24. The performance of various classification algorithms in predicting human behavior in health social networks. Machine learning algorithms are utilized to extract evaluations from the net and categorize these into five classes. The study is limited to the analysis of speech and gestures25. Data-centric approach to predicting MBTI personality types using NLP enriches text representation by generating features based on sentimental, grammatical, and aspect analysis for each classifier26. Another primitive approach was introduced using binary transformer with feature extraction Term Frequency & Inverse Gravity Moment using three datasets including Facebook, twitter and Instagram. Maximum entropy classifier achieving accuracy of 83% to predict personality trait27.
Deep learning models
The extensive use of DL models like CNN, LSTM, and RNN in the context of predicting personality traits by using social media platforms integrated with psychological domain, provides a deeper analysis into current trends and future directions in text-based personality trait classification. The psychopathic study was investigated to classify the traits from social media text using various deep learning techniques on labeled and unlabeled data28 combined with word2vec and to deal with imbalance data using synthetic minority over-sampling technique utilized predict and classify MBTI personality types well, achieving a relatively 80% to handle imbalanced data29. GRU and LSTM algorithms carried out to predict five factor personality models using supervised learning models embedded with word2vec CBoW, analyzing the uploaded text on website30. Application of LSTM for selection of career using trait predictions31, hybrid approach utilizing LSTM-CNN32,33 and Bi-LSTM model for personality trait classification from textual content incorporation of word embeddings for text representation enhances the model’s performance using MBTI dataset with accuracy of 61%34.
The RNN-PRS model uses an RNN-LSTM framework to recommend professional careers by predicting personality types from social media activities, leveraging type indicators for personalized suggestion35, also human robot interaction using transformer-based model utilizing LSTM layers embeddings of tf-idf and word2vec approach36. An innovative method to detect learners’ personalities through facial expressions analyzed by CNN algorithm shaping the emotions to judge users’ personality types37. Multimodal data employed using hybrid deep models of CNN + Bi-LSTM integrate with GloVe embeddings and state-of-the-art BERT models using social media posts and network features, addressing the limitations of static word embeddings by incorporating dynamic embeddings for contextual adaptability3839. Moreover, From traditional to advanced word embeddings including Word2Vec, GloVe, Fasttext, and Keras combined with deep learning models such as CNN, LSTM, BI-LSTM, BI-GRU, GRU and Hybrid approach CNN with LSTM enhanced the personality classification using MBTI dataset achieving accuracy of 82%40. Furthermore, by combining emoji information from textual data using Bi-LSTM model with baseline methods of LIWC and Doc2Vec, highlighting emojis’ value in personality analysis41. Temporal aspects of users-generated content introduced hierarchical hybrid HMAttn-ECBiL model integrated with CNN model that led to semantic loss when extracting personality information from textual data. The model emphasized the importance of encoding the most valuable information from posts, as not all texts significantly influence personality classification42. Integrating generative AI with DenseNet and NLP technique, combining user profiles images with text to enhance identification accuracy over 97% on MBTI dataset in personality analysis43. Analysis of DL approaches used for personality detection from social network text postings, utilizing a hierarchical neural network with the ATTRCNN architecture and inception variant to extract deep semantic features tested on data my personality, regression algorithms yielding the lowest prediction error. Also, the Neural network model incorporates Word2Vec and LSTM layers to analyze textual data and identify personality types44.
Limitations of existing studies
Despite extensive research on personality traits, there is a notable gap in literature specifically addressing agreeableness trait. Existing studies primarily rely on traditional psychometrics assessment and self-reported measures using conventional models and features, which may not fully capture the deep expressions of agreeableness trait in natural language. Furthermore, the integration of cutting-edge models, such as deep learning-based sentence embeddings, remains underexplored. This limitation highlights the need for innovative methodologies that leverage these advanced models to provide a deeper and more accurate understanding of agreeableness.
Proposed research methodology
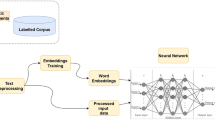
Our proposed methodology integrates a combination of textual features and word embeddings to predict personality trait prediction using text data. Figure 1 illustrates the following framework of methodology applied to conduct this study, employs MBTI dataset, aimed at predicting personality types through textual data. The initial preprocessing involves several stages including removal of stop words, URLs, symbols, digits, tokenization, lemmatization and character normalization to ensure the textual data is clean, retain only meaningful linguistic elements and to standardize the data for further analysis In the feature extraction phase, both traditional and modern techniques are applied. Traditional textual features such as TF-IDF and POS tagging, offering insights into sentence structure and linguistic patterns. Further, various word embedding techniques are integrated for more advanced representations such as GloVe, Word2Vec, and sentence embedding to capture meaningful patterns of text. Then data is split into 80–20 ratio into two main training pipelines including traditional machine learning, ensemble learning models and advanced deep learning algorithm including transformer-based models providing a comprehensive approach to classification. For classification, a diverse range of applied models is trained, ML classifiers include SVM, DT, LR, KNN, ensemble learning includes GB, RF, XGB, and Adaboost. In addition, DL algorithms such as LSTM, and Bi-LSTM and state-of-the-art transformer-based model BERT also applied to capture the long-range dependencies and contextual patterns in the text. For optimal configuration of model training is further fine-tuned using hyperparameters tuning for the prediction of personality dimensions of thinking and feeling based on MBTI axes sensing and intuitive respectively, evaluated using standard performance metrics. This comprehensive proposed methodology for this study enables a robust and effective assessment of prediction of personality using textual data, leveraging both conventional machine learning, ensemble learning and advanced deep learning techniques including state-of-the-art transformer-based model for optimal prediction results.

Proposed framework showing steps of research methodology.
Data preprocessing
In the data preprocessing phase, several steps are performed to ensure the text data is clean and suitable for further analysis.
-
Firstly, Unwanted information is removed such as stop-words, digits, punctuations, URLs and special characters from the data.
-
Following the process of noise removal, to lessen the redundancy and boost the consistency of the text to their base or root form to present a word into single representations, lemmatization is applied.
-
Moreover, tokenization is performed to handle the text data by converting it into a structured format by splitting the text into tokens form, where the text is segmented into individual words.
-
Additionally, character normalization is carried out to ensure uniformity in the text by converting all characters into a standard format, particularly lowercase to handle variations in text encoding.
Textual features
The process of demonstrating words as compact vectors in a high dimensional space from NLP, refers to as text embedding, used to capture the contextual and semantic data about text, by enabling ML models to process and predict the language words more effectively. In this proposed methodology TF-IDF and POS tagging is carried out using formulated equations.
Term frequency-inverse document frequency (TF-IDF)
TF-IDF is a numerical parameter used to evaluate the significance of a word in a document comparative to a corpus. Term Frequency (TF) indicates the repetition of each word in a document, while Inverse Document Frequency (IDF) manifests the presence of documents containing a specific word across a corpus, thereby providing a weighted representation that highlights significant words while downplaying common terms45. The core functionality of TF-IDF is calculated as in Eq. 1.
where \(T\) represents Term frequency, \(D\) as Document, \(v\left(t,d\right)\) used to show the Total frequency of t in d, \({\sum }_{x\epsilon d}v\left(x,d\right)\) as Total count of all terms in document, \(\Delta\) as Total number of documents, and \(\sigma\) Document frequency of the term.
Part of Speech (POS) tagging
POS tagging is the process of labeling each word by assigning matching part of speech such as noun, verb, adjective etc. to words in a text data corpus. This helps in understanding the grammatical structure and syntactic relationships within the context of the text, which can be informative for personality prediction46. Words represented as \({w}_{1}, {w}_{2}, {w}_{3}, \dots \dots .{, w}_{n}\) in a sentence, corresponding tags \({t}_{1}, {t}_{2}, {t}_{3}, \dots \dots .{, t}_{n}\), the joint probability of words and tags \({P(w}_{1}, {w}_{2}, {w}_{3}, \dots \dots .{, w}_{n}\), \({t}_{1}, {t}_{2}, {t}_{3}, \dots \dots .{, t}_{n})\) is given by using chain rule computed as in Eq. (2).
where \({{\varvec{w}}}_{{\varvec{i}}}\), \({{\varvec{w}}}_{{\varvec{c}}}\), \({{\varvec{w}}}_{{\varvec{t}}}\) represents Input, Context, and Target words in a vocabulary respectively and \({{\varvec{P}}({\varvec{t}}}_{1})\), \({\varvec{P}}\left({{\varvec{t}}}_{{\varvec{i}}}|{{\varvec{t}}}_{{\varvec{i}}-1}\right)\), \({\varvec{P}}\left({{\varvec{w}}}_{{\varvec{i}}}|{{\varvec{t}}}_{{\varvec{i}}}\right)\) used to presents the probability of the first POS tag, probability of transitioning from POS \({t}_{i-1}\) Tag to \({t}_{i}\), probability of observing word \({w}_{i}\) Given its pos tag \({t}_{i}\), respectively.
Word embedding features
Word embeddings capture semantic links between words by replacing them in a space where similar words are closer together. Embedding approach allows for the finding of semantic similarities and contextual information within words, converting raw text data into organized and representations that facilitate more understandable language47. Word embeddings are generated using algorithms like Word2Vec, GloVe, and Sentence Embeddings.
Word2Vec
Word2Vec is widely used NLP techniques for creating word embeddings, which are vector notation of words in a continuous vector space. that learns vector notations of words by predicting neighboring words in a text. The embedding captures the semantic similarities between words, allowing the model to understand contextual meaning from large corpus in a text. Equation 3 represents the embedding of the word w in the vocabulary using objective function.
where \({\mathbb{C}}\) denotes Objective function, \({{\varvec{\varepsilon}}}^{\boldsymbol{^{\prime}}}\left({{\varvec{w}}}_{{\varvec{t}}}\right)\) and \({\varvec{\varepsilon}}\left({{\varvec{w}}}_{{\varvec{c}}}\right)\) represents the embedding of target and context word \({w}_{t}\) and \({w}_{c}\) respectively.
Global vectorization (GloVe)
Its aim is to learn word depiction by considering global word repetition stats. It is based on word vectors by factorizing a matrix of word repetition counts. GloVe embeddings use both global and local information of text, enhancing the model’s understanding of word semantic, is defined as in Eq. 4.
where, \(|{\varvec{V}}|\) as vocabulary size, \(\overrightarrow{{\varvec{V}}}\) matrix of word vectors, \({\overline{\overrightarrow{{\varvec{V}}\boldsymbol{ }}} }^{{\varvec{T}}}\) shows the matrix of context word vectors, \({\overrightarrow{{\varvec{B}}}}_{{\varvec{i}}}\) and \(\overline{\overrightarrow{{{\varvec{B}} }_{{\varvec{j}}}}}\) Bias vectors, \({{\varvec{X}}}_{{\varvec{i}}{\varvec{j}}}\) Co-occurrence count of words i and j.
Sentence embeddings
Sentence embeddings refer to a numeric representation of a sentence in the form of vector notation of whole sentences from real numbers, depicting the semantic meaning and syntactic structure. It represents the entire sentences as fixed-length vectors, capturing the overall meaning and context of the sentence with semantics similarities at the sentence stage. To enable effective sentence similarity and comparison by measuring the distance between vectors. as defined in Eq. 5.
where \(\overrightarrow{{\varvec{E}}}\) as embedding of the words, \(\overrightarrow{{\varvec{C}}}\left({\varvec{S}}\right)\) as Context word of the sentence S, \({\overrightarrow{\mathbb{N}}}_{{\varvec{\omega}}}\) shows the new embedding of sentence, \(\overrightarrow{{\varvec{A}}}\) and \(\overrightarrow{{\varvec{U}}}\) presents the Matrix notations.
Applied algorithms
To evaluate and predict the personality trait through text, conduct a comprehensive approach using computational models for predicting agreeableness linked with thinking and feeling axes using MBTI framework. Exploring with ML and DL models shows how different methods categorize text classification by focusing on language. These models range from ML models to ensemble models like LR and DT to advanced ones like SVM and XGB. Similarly, in DL, models like LSTM, Bi-LSTM, and state-of-the-art transformer models, like BERT, have categorized the language to enable applications as text summarization, and dialogue systems. Here is the brief methodology of algorithms conducted in this research.
Shallow machine learning models
Shallow Machine Learning models refer to traditional algorithms characterized by their relatively simple architectures and fewer layers of computation. Shallow ML models operate by learning patterns from data through a training process, to capture the relationship between dataset input features and the target variables. Models like SVM, NB, KBB, LT and DT are widely used in various tasks such as classification, regression and clustering, providing robust and effective solutions for predicting tasks 48.
Support vector machine (SVM)
SVM is a supervised learning model, works by detecting the hyperplane that separates different classes which are best in the feature space. The optimal hyperplane exploits the margin between the nearest points of the targeted classes, SVM excels in capturing complex relationships within data, that openness exhibits intricate interdependencies with other factors, computed as in Eq. 6 and 7.
Subject to
where \({{\varvec{\gamma}}}_{{\varvec{i}}}\) as slack variables, \(\boldsymbol{\alpha }\) acquire weight vector, and \({\varvec{C}}\) shows the regularization parameter.
K-Nearest Neighbor (KNN)
KNN, is a simple, non-parametric algorithm categorizes a data point based on the edge wise class among its closest neighbors in the feature space, computed as in Eq. 8. It’s mainly efficient for capturing complex relationships in data and conducting non-linear decision boundaries.
where \({{\varvec{y}}}\) and \({{\varvec{y}}}_{{\varvec{i}}}\) as predictive variable and labels of the k-nearest neighbors.
Logistic Regression (LR)
LR is used for binary classification tasks, where the objective is to predict using two possible outcomes. The probability of predictive class belongs to target class using objective function between range of [0,1] as in Eq. 9.
Naïve Bayes (NB)
Naïve bayes is the probabilistic classifier based on Baye’s theorem, assuming that features are temporarily independent given the input class label. NB shows the occurrence of a particular word in a text is independent existence of another word. This is achieved by combining the prior probability of each class with the observed words appearing in the text, defined in Eq. 10.
where, \({\varvec{p}}({\varvec{y}}\boldsymbol{ }|\boldsymbol{ }{{\varvec{x}}}_{1},.,{{\varvec{x}}}_{{\varvec{n}}})\) as posterior probability of class—y given the feature vector \({x}_{1}\) and \({\varvec{P}}({\varvec{y}})\) as prior probability of class—y, and \({\varvec{P}}({{\varvec{x}}}_{{\varvec{i}}}|{\varvec{y}})\) as feature of \({x}_{i}\) of given class y.
Decision Tree (DT)
Decision Tree works by recursively splitting the feature space into target areas on feature values, resulting in the form of tree-like architecture of decisions. It breaks down the data into nodes based on the value of the input features. Each node shows a feature, each branch shows a decision, and the leaf indicates a result. The working of decision tree computed as in Eq. 11, involves selecting the best feature to split the data at each node.
where, \(G\left({Q}_{m}\right)\) represent the impurity for node m, \({N}_{mk}\) as the number of samples of class k in node m, and \({N}_{m}\) shows the number of samples in node m.
Ensemble learning models
Ensemble learning is a ML technique that joins multiple distinct models to develop a stronger, more accurate predictive model. By integrating multiple models, ensemble methods can often achieve better results than any single model alone. Ensemble models like GB, RF, XGB and AdaBoost are utilized for prediction of personality trait.
Gradient Boosting (GB)
GB is a boosting ensemble method that builds a sequence of weak learners where each tree corrects the errors of its antecedent. GB iteratively fits the new model to predict a more accurate estimate of target variable. The output of prediction is evaluated by summing the predictions of all weak learners, weighted by a learning rate.
Random Forest (RF)
RF is operated by composing a collection of decision trees during training and target the specific class that is base mode of other classes for classification concern using individual trees. Each tree uses a random subset of attributes and training data. The final prediction is based on the average prediction of all th trees in the forest.
Xtreme Gradient Boosting (XGB)
XGB is an optimized and efficient implementation of GB algorithm. It is known for its speed and performance. It optimizes the objective function by adding new trees that predict the residuals of previous trees. The final predictions are the sum of prediction from all the trees, weighted by a learning rate.
Adaptive Boosting (AdaBoost)
AdaBoost is a boosting ensemble algorithm that combines multiple weak learners to build a stronger learner. It focuses more on the data points that are misclassified by the previous models, thereby gradually improving the overall prediction accuracy. AdaBoost assigns weight to each data point based on its classification accuracy in the previous iteration. The output prediction is based on total a weighted of the predictions from all the weak latent.
Sequential deep learning algorithms
Sequential Deep Learning models refer to architecture that leverages multiple neural networks to process input data simultaneously. These models are designed to enhance the learning, training and feature extraction capabilities of traditional DL architecture by using multilayered neural network to analyze and interpret complex patterns of data 49,50. Such models can automatically learn representations and features from large and complex raw data and handle effectively through optimization process 51. Deep algorithms such as LSTM and Bi-LSTM are used in this study.
Long Short-Term Memory (LSTM)
LSTM is a type of RNN designed to handle the limitations of conventional models in acquiring long-range dependencies in subsequent data. It is effective in predicting data in a sequential form with long-term dependencies handling various multimodal data, by identifying contextual information and modifying complex patterns in personality dynamics over time. LSTM consists of three gates to overcome the wide range of information into and out of the memory cell. Ate each step t, LSTM executes following operation to predict trait as in Eq. 12.
where, \({{\varvec{f}}}_{{\varvec{t}}}\) and \({{\varvec{i}}}_{{\varvec{t}}}\) used as forget gate output and the input gate output, \({{\varvec{C}}}_{{\varvec{t}}}\) and \({{\varvec{C}}}_{{\varvec{t}}-1}\) as cell state at time t and the cell state from the previous time step, \({\widehat{{\varvec{C}}}}_{{\varvec{t}}}\) candidate cell state, and \(\boldsymbol{\varnothing }\) as activation function.
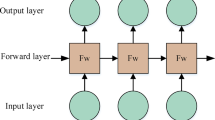
Bidirectional Long Short-Term Memory (Bi-LSTM)
Bi-LSTM is an enhanced version of LSTM algorithm that handles input data in both forward and backward directions, to capture contextual information. This bidirectional processing enables better understanding of the analysis of the entire input sequence. Bi-LSTM combines two LSTM, one is handling the processing in sequence of forward direction and the other is in backward position. At each step t, the forward LSTM \(\left(\overrightarrow{LSTM}\right)\) and the backward LSTM \(\left(\overleftarrow{LSTM}\right)\) produce hidden states \(\overrightarrow{{h}_{t}}\) and \(\overleftarrow{{h}_{t}}\) respectively as in Eq. (13, 14).
The final output is obtained by concatenating these hidden states as in Eq. 16.
By combining Eq. 13 and 14, we get,
where \({{\varvec{h}}}_{{\varvec{t}}}\) represents the output of Bi-LSTM at time t with concatenation of forward and backward hidden state.
Transformer-based learning algorithms
A transformer-based model is a deep learning architecture designed for NLP tasks. Unlike conventional models that process text sequentially, transformer used self-attention mechanisms to consider the entire context of a word in a sentence simultaneously. This allows for capturing complex dependencies and relationships within the text. Advanced models like GPT, BERT, and T5 significantly improve tasks such as sentiment analysis and question answering techniques 52.
Bidirectional Encoder Representations from Transformers (BERT)
BERT introducing a bidirectional approach to language modeling, allowing the model to consider the context from both the left and right sides of words to interpret natural language processing task efficiently 53. Transformers use the self-attention mechanism to weigh the influence of different words in a sentence on each other. BERT consists of multiple layers of encoders, each composed of self-attention and feed forward neural networks. It allows to capture complex dependencies and relationships within the text effectively, computed as in Eq. 16.
where, \({{\varvec{B}}{\varvec{E}}{\varvec{R}}{\varvec{T}}}_{{\varvec{C}}{\varvec{L}}{\varvec{S}}}\) shows the output vector for [CLS] token and \({{\varvec{B}}{\varvec{E}}{\varvec{R}}{\varvec{T}}}_{{\varvec{p}}{\varvec{o}}{\varvec{o}}{\varvec{l}}{\varvec{e}}{\varvec{r}}}\) as pooled output of the BERT model.
Experimental setup
This section proposes the method of data selection and shows the mapping of personality trait agreeableness to directly feeling and oppositely to thinking relation. Data is gathered using an open-source library called Kaggle. After gathering the data, the text is examined for selection of targeted label. Feature engineering approaches are conducted for selected labels. For the next step, models are trained to predict personality traits.
Description of dataset
The dataset used in this study, named as MBTI datasetFootnote 1, sourced from Kaggle, comprises a collection of personality type data. This data includes various posts from individuals on a social media platform, labeled with their respective type. The MBTI typology categorizes individuals into sixteen distinct dimensions based on four axes. It consists of 8674 rows of data, each row representing an individual type along with text posts. This dataset created with the help of textual data in the form of survey responses, tweets, Youtube links, and emojis, where an individual’s response based on the MBTI personality type such as INFP, ESTJ, etc., rely on the individual’s replies or textual analysis. In research, FT labels focus on exploring personality trait of attribute agreeableness from MBTI dataset.
Exploratory data analysis
Integrating the visualizations and statistics for posts labeled with thinking and feeling shows that how individuals differ in their online communication. The media post of feeling is longer than thinking label. Both labels have outliers, with some users posting significantly longer texts, but the range of outliers and interquartile is broader for feeling type personality. Detailed view of distribution of posts over words as shown in Fig. 2, shows the significant difference in verbosity between two types. Feelers write longer posts to express their thoughts, views, and more elaborate as compared to thinker.

Distribution of number of words per post by label.
Overall summary statistics are analyzed as shown in Table 3. There are 4694 posts labeled as feeling and 3981 posts labeled as thinking. Both labels encompasseseight unique MBTI types, with INFP among feeling posts and INTP with thinking posts. These statistic provide a understanding of dataset composition and highlight the individual personality tends in online environment between the two groups.
At the end, The most common words used by correspondnig labels using wordcloud as shown in Fig. 3, offers a qualitative analysis into the content and thematic differences between labels, like ‘feel’, ‘love’, ‘really’, and ‘think’ highlight the tendency relation of words with labels into distinct behavioral patterns and cognitive orientations of individuals to identify personality with these labels. In the Feeling (F) trait wordcloud, prominent words such as ‘people’, ‘feel’, ‘love’ and ‘friend’ indicate a strong emphasis on emotions and perosnal connections. The word ‘people’ underscores individuals interpersonal focus, highlighting the importance place on fostering and maintaing meaningful relationships. Words like ‘good’ and ‘friend’ suggest that judgemnets are often based on perosnal values and quality of their social bonds. In contrast, The Thinking (T) trait wordcloud features words such as ‘think’, ‘know’, ‘one’, ‘time’, ‘way’ and ‘make’. These words reflect a logical and analytical approach to processing information and making decisions. ‘Think’ and ‘Know’ indicates that these individuals rely on logical reasoning and objective analysis to navigate their interactions and decsions. Words like ‘make’ and ‘way’ suggest a methodological and productivity-oriented mindset, emphasizing the importance of planning and achieving tangible outcomes. Both wordclouds highlight the signficance of individuals “people” but for different behaviors and reasons.

Word cloud visualization of (a) for both FT (b) F for Feeling content only, and (c) T for Thinking content only.
Performance evaluation measures
When evaluating classification models for predicting personality traits, several performance metrics are commonly used, to find the overall performance of model, that how much they predict the rate of true and false positive and negative prediction of instances based on dataset, by applying accuracy, precision, recall, f1-measure and Receiver Operating Characteristics (ROC) and Area Under the Cure (AUC) are computed, as shown in Table 4 Where TP, TN FP, and FN stand for True Positive, True Negative, False Positive and False Negative, respectively.
Results and discussion
To predict the results of personality traits with the given MBTI label TF mapped to personality trait openness. For analyzing this pattern, the model is trained to distinguish between thinking or feeling. The experiment was conducted using high-performance computing resources, including NVIDIA Tesla V100 GPU with 128 GB memory for model training. The system also featured an Intel Xeon E5-2698 v4 CPU with 20 cores and 256 GB of DDR4 RAM, providing substantial processing power and memory for data pre-processing and model execution. The model was then trained and evaluated using standard metrics to measure the performance of applied experiment techniques.
Machine learning results
The comparison between TF-IDF and POS tagging as feature selection technique for predicting the traits of thinking or feeling, generally achieve higher accuracy and performance metrics compared to those trained on POS tagging features SVM, LR, DT add XGB models utilizing TF-IDF, consistently demonstrate accuracy scores of 84% or above with precision, recall, and F1-score values also consistently high. This suggests that TF-IDF features effectively capture relevant information for distinguishing between thinking and feeling traits. The distribution of words and their importance, as captured by TF-IDF, effectively encodes information pertinent to the trait. In contrast, model train on POS features exhibit lower accuracy and performance matrices while 68% for SVM and 61% for AdaBoost models achieve high accuracy with POS features, which capture the syntactic structure of the text, contribute to the prediction, they still fall short compared to TF-IDF base models. The lower performance metrics for POS features suggest that syntactic patterns alone are not as strongly indicative of agreeableness trait as the semantic content captured by TF-IDF. Results with shallow machine learning are shown in Table 5.
Overall, these results indicate that TF-IDF feature captured more meaningful information for predicting thinking and feeling traits, due to their ability to represent the importance of words in context. Conversely, POS does not adequately capture the linguistic with these traits, leading to lower predictive performance. By applying ML, the highest prediction rate is 84% to classify personality traits. When employing TF-IDF with SVM, DT and LR obtained highest accuracy and f1-measure as well. This demonstrates that from textual features, TF-IDF captures the information more effectively for distinguishing between intuitive personality trait or sensitive personality-based individuals. However, POS tagging showing lower accuracies and f1-measures also with ML models, overall SVM model obtained highest score of accuracy at 63%. These performance highlights the ability measures of features based on dataset to capture the patterns more accurately, as comparative analysis of TF-IDF and POS tagging feature with ML and ensemble models using ROC-AUC curve is shown in Fig. 4 and 5 respectively.

Comparative analysis of ROC Curve of ML with TF-IDF.

Comparative analysis of ROC Curve of ML with POS tagging.
Deep learning results
By applying word embeddings with models’ LSTM, and Bi-LSTM are applied on the selected feature set to train the test data, significantly enhance the prediction accuracy of the trait. The model employs three different types of embbedings: word2vec, glove and sentence transformer embeddings with LSTM to predict traits across different epochs. As the number of training epochs increases, there is constant upward trend in all key metric, and get the optimal result at epoch 30. The model predicted the results by using performance metrics to evaluate the accuracy of these techniques on personality traits, hyperparameters are defined, as in Table 6. Such parameters are chosen for deep models to balance model performance, computational and efficiency. An input size of 2000 allows model to process sufficiently long sequences, capturing meaningful patterns over extended contexts, which is necessary for text classification. The vocabulary size of 1000 ensures that the model focuses on the most frequent and relevant terms, reducing complexity and memory requirements while maintaining coverage of language used. Embeddings with size of 128 provide a dense representation of words, balancing between expressiveness and computational efficiency. A unit size of 100 for each LSTM unit helps the model learn a rich set of features without overfitting, given a reasonably sized dataset. Using 4 hidden layers increases the model’s depth, enabling us to learn more complex representation and hierarchies within the data. The Sigmoid function is chosen for its ability to handle nonlinear relationships and its role in gating mechanisms within LSTM cells, helping to control the flow of information. The Adam optimizer is selected for its robustness and efficiency, particularly in handling sparse gradients and adapting learning rates during training, which often leads to faster convergence and better performance. Training the model over 35 epochs gives the optimal results at 30, to verify model ability 35 epochs sets the iteration for learning complex patterns without excessive overfitting. Batch Size 64 strikes a balance between computational load and training stability, ensuring that gradient updates are neither too noisy with very small batches nor too smooth as with very large batches.
These parameters collectively aim to optimize the model’s learning process, enhance its performance, and ensure it generalizes to dataset. Using LSTM and Bi-LSTM models and pre-trained word embeddings like word2vec, glove, and sentence transformer, highly effective in predicting personality traits from the text data. The models can leverage rich linguistic information encoded in these embeddings to better understand the traits from text. LSTM and Bi-LSTM model with Word2Vec, GloVe, and Sentence Transformers embeddings results shown in Table 7.
Word2vec with LSTM exhibit promising performance in classifying personality traits as thinking and feeling with the accuracy rate of 86%. GloVe with LSTM exhibit promising performance in classifying personality traits as thinking and feeling with the accuracy rate of 89.39%. Sentence Transformer with LSTM exhibit promising performance in classifying personality traits as thinking and feeling with the accuracy rate of 90.17%. This suggests that sentence embeddings, which capture the contextual information within a sentence, provide a richer representation of textual content to agreeableness trait. Similarly, Word2vec with Bi-LSTM exhibit promising performance in classifying personality traits as thinking and feeling with the accuracy rate of 85.37%. GloVe with Bi-LSTM exhibit promising performance in classifying personality traits as thinking and feeling with the accuracy rate of 91.34%. Sentence Transformer with Bi-LSTM exhibits promising performance in classifying personality traits as thinking and feeling with the accuracy rate of 91.57%.
Overall, these findings highlight the potential role of context and semnatic richness captured by sentence embeddings in predicting the trait. The superiror performance of sentence embedding over traditional word embeddings (word2vec, glove) in both LSTM and Bi-LSTM models underscores the importance of capturing thr vroader context within sentence to accuractely assess personality trait either sentence shows the behavior of thinking and feeling, this combined analysis of results are shown in Fig. 6 and 7.

LSTM accuracy with deep embeddings.

Bi-LSTM accuracy with deep embeddings.
Transformer-based models utilized to anticipate personality prediction task to generate relevant text data using attention mechanism that provides high quality of coherence and contextual representation of text. The computed results from utilizing BERT for personality traits prediction with an accuracy of 82.37% to classify traits based on encoded text representation, highlight the competitive lower results as compared to another deep model such as Bi-LSTM when integrating with advanced sentence embedding.
To detect other personality trait in comparison of targeted agreeableness trait with advanced deep learning models, we also employed three more dimensions from MBTI data based on big five personality models such as extroversion, openness, and conscientiousness using advanced sentence embeddings, as shown in Table 8. Among the models, the Bi-LSTM model demonstrates the highest performance across most traits, achieving the highest accuracy for extroversion (92.52%), openness (89.23%), and conscientiousness (90.50%). This suggests that Bi-LSTM effectively captures the sequential dependencies and patterns in text that relate to personality trait. High accuracy generally indicates that Bi-LSTM makes fewer overall errors. Using LSTM model, which shows competitive accuracy with extroversion with a maximum accuracy score of 91.50%, openness with 88.23% and conscientiousness accuracy with 89.56% are slightly lower compared to Bi-LSTM model. This indicates that while LSTM can capture some personality-related patterns in sentence embeddings, it lacks the bi-directional ability to capture both past and future context more effectively. On the other hand, BERT exhibits relatively lower performance across all traits, especially in capturing trait conscientiousness with 77.90%, significantly below the other models. BERT’s highest score is openness (88.24%) but it still does not surpass the Bi-LSTM model. This result implies that BERT, though known for its powerful contextual embeddings, not as effective as LSTM -based models for personality trait classification in this dataset.
The comparison of proposed models with existing studies highlights significant advancements in the prediction accuracy of agreeableness. Previous studies using models LSTM, XGB including other ML classifiers, and BERT achieved results from 70 to 85% between. In contrast, the proposed models demonstrate superior performance. The ML classifiers using TF-IDF achieve accuracy of 84%, BERT encoder with word embedding reaches 82%, and notably, the Bi-LSTM model utilizing sentence embeddings achieves a remarkable accuracy of 91.57%. These results indicate that the proposed methods, particularly the Bi-LSTM model with sentence embeddings, offer substantial improvements over traditional and existing approaches. Overall, this significant improvement in results demonstrates the superiority of the proposed approaches over existing methodologies as shown in Table 9 and highlights its potential for advancing research in the field of personality trait prediction from social media content.
We also have computed the average computational efficiency of all models evaluated on dataset as shown in Fig. 8. Based on the results obtained from training and evaluating the various classifiers, it is evident that there is a significant variation in both training and predicting time across models. Overall, SVM and XGB exhibit the highest accuracy scores, but the SVM time is higher than compared to other classifiers. KNN unexpectedly long prediction time raises concern due to its scalability for larger dataset. Furthermore, deep models are advanced and have embedding layers, and attention mechanism to detect the semantic meaning and relationship between words and whole sentence also, such models require higher computation time as compared to traditional machine learning models.

Best average computational time of classifiers.
Conclusion and future research directions
Personality trait is pivotal in unraveling the consequences of human behavior and interactions. The significance of predicting personality traits within MBTI framework is paramount in interpreting individual motivations and predicting behavioral patterns, highlighting their dimensions including how they think, feel and act in different circumstances. This study presents the remarkable potential of psychological domain by applying advanced computational models of AI. These integrations of various AI methodologies and leveraging a dataset based on the MBTI framework, we demonstrated the effectiveness of shallow ML models and ensemble models with textual features, DL models and state-of-the-art transformer-based model with deep features in predicting personality trait agreeableness. The main findings in this research compare the execution of various models from traditional to advanced level for predicting personality trait. From textual feature, TF-IDF continuously showing the highest results in term of accuracy, precision, recall and f1-score among agreeableness trait, highlighting efficacy of ML models SVM with accuracy of 84% to capture the features from data. Notably, ensemble learning also comparable accuracy of 83% with TFIDF + XGB. Along with other features, POS tagging achieves accuracy of 63% with SVM and 62% with GB. Both textual features show comparable results for predicting the trait. On the other hand, deep results, LSTM achieved 86% accuracy with word2vec feature, Bi-LSTM with advanced word embedding feature sentence embeddings achieve accuracy of 91.57% highlights the effectiveness of model capability. While the Transformer based model, BERT with its encoder architecture, yielded slightly lower accuracy at 82%, highlights the significant exploration in prediction tasks. However, DL models surpassed these performances for capturing intricate linguistic context in personality trait. Our research shed light on the intricate interplay between human behavior, personality, and the digital landscape, providing valuable insight into how individuals present themselves and interact within the online ecosystem. Potential future research direction may include exploring additional personality traits and psychological theoretical frameworks integrated with AI methodologies to enhance the accuracy of personality prediction. Moreover, investigating the multimodalities of data such as image, video, audio with applications of advance meta-learning techniques, GANs, advance versions transformer-based models such as Roberta, SpanBERT, LLMs including GPT, and transfer learning techniques to leverage the models and adapt them to the task of prediction. This research not only advances the field of AI but also underscores the potential for integrating psychological theories with AI methodologies of human behavior in the digital age.
Data availability
The datasets generated and/or analysed during the current study are available in the Kaggle repository, https://www.kaggle.com/datasets/datasnaek/mbti-type.
Notes
https://www.kaggle.com/datasets/datasnaek/mbti-type \ Last-accessed 9 Feb 2024.
References
C. Guinn, “Assessing Author Personality Types Using ChatGPT,” in 2023 Congress in Computer Science, Computer Engineering, & Applied Computing (CSCE), 2023, pp. 96–101. https://doi.org/10.1109/CSCE60160.2023.00021.
Ishfaq, U., Khan, H. U., Iqbal, S. & Alghobiri, M. Finding influential users in microblogs: state-of-the-art methods and open research challenges. Behaviour and Information Technology https://doi.org/10.1080/0144929X.2021.1915384 (2021).
Ishfaq, U., Khan, H. U. & Iqbal, S. Identifying the influential nodes in complex social networks using centrality-based approach. Journal of King Saud University - Computer and Information Sciences 34(10), 9376–9392. https://doi.org/10.1016/j.jksuci.2022.09.016 (2022).
Mahmood, A., Khan, H. U. & Ramzan, M. On modelling for bias-aware sentiment analysis and its impact in twitter. Journal of Web Engineering 19(1), 1–28. https://doi.org/10.13052/jwe1540-9589.1911 (2020).
L. Thapa, A. Pandey, D. Gupta, A. Deep, and R. Garg, “A Framework for Personality Prediction for E-Recruitment Using Machine Learning Algorithms,” in 2024 14th International Conference on Cloud Computing, Data Science & Engineering (Confluence), 2024, pp. 1–5. https://doi.org/10.1109/Confluence60223.2024.10463354.
Tindall, D., McLevey, J., Koop-Monteiro, Y. & Graham, A. Big data, computational social science, and other recent innovations in social network analysis. Canadian Review of Sociology/Revue canadienne de sociologie 59(2), 271–288. https://doi.org/10.1111/cars.12377 (2022).
M. Kuchhal, P. Jangid, M. Saini, and R. Jindal, “Personality Prediction And Group Detection Using Social Media Posts,” in 2022 IEEE 7th International conference for Convergence in Technology, I2CT 2022, Institute of Electrical and Electronics Engineers Inc., 2022. https://doi.org/10.1109/I2CT54291.2022.9825280.
A. Naz, H. U. Khan, S. Alesawi, O. I. Abouola, A. Daud, and M. Ramzan, “AI Knows You: Deep Learning Model for Prediction of Extroversion Personality Trait,” IEEE Access, p. 1, 2024, https://doi.org/10.1109/ACCESS.2024.3486578.
Bashkirova, A., Compagner, A., Henningsen, D. M. & Treur, J. An adaptive modelling approach to employee burnout in the context of the big five personality traits. Cogn Syst Res 79, 109–125. https://doi.org/10.1016/j.cogsys.2022.12.010 (2023).
Faisal, Ch. M. S., Daud, A., Imran, F. & Rho, S. A novel framework for social web forums’ thread ranking based on semantics and post quality features. J Supercomput 72(11), 4276–4295. https://doi.org/10.1007/s11227-016-1839-z (2016).
M. Goyal and P. Tawde, “A research attempt to predict and model personalities through users’ social media details,” in IBSSC 2022 - IEEE Bombay Section Signature Conference, Institute of Electrical and Electronics Engineers Inc., 2022. https://doi.org/10.1109/IBSSC56953.2022.10037272.
K. N. Pavan Kumar and M. L. Gavrilova, “Latent Personality Traits Assessment From Social Network Activity Using Contextual Language Embedding,” IEEE Trans Comput Soc Syst, vol. 9, no. 2, pp. 638–649, Apr. 2022, https://doi.org/10.1109/TCSS.2021.3108810.
A. R. Feizi-Derakhshi et al., “Text-based automatic personality prediction: a bibliographic review,” Nov. 01, 2022, Springer. https://doi.org/10.1007/s42001-022-00178-4.
P. Sánchez-Fernández, L. G. Baca Ruiz, and M. del Carmen Pegalajar Jiménez, “Application of classical and advanced machine learning models to predict personality on social media,” Expert Syst Appl, vol. 216, p. 119498, 2023, https://doi.org/10.1016/j.eswa.2022.119498.
Safari, F. & Chalechale, A. Emotion and personality analysis and detection using natural language processing, advances, challenges and future scope. Artif Intell Rev 56, 3273–3297. https://doi.org/10.1007/s10462-023-10603-3 (2023).
Hayat, M. K. et al. Towards Deep Learning Prospects: Insights for Social Media Analytics. IEEE Access 7, 36958–36979. https://doi.org/10.1109/ACCESS.2019.2905101 (2019).
S. Chen, Y. Liu, T. Meng, and S. Wang, “The enhancement of Personality Assessment and Detection using Machine Learning Techniques,” 2023, pp. 110–121. https://doi.org/10.2991/978-94-6463-300-9_12.
Alsubhi, S. M., Alhothali, A. M. & Almansour, A. A. AraBig5: The Big Five Personality Traits Prediction Using Machine Learning Algorithm on Arabic Tweets. IEEE Access 11, 112526–112534. https://doi.org/10.1109/ACCESS.2023.3297981 (2023).
D. Karanatsiou, P. Sermpezis, D. Gruda, K. Kafetsios, I. Dimitriadis, and A. Vakali, “My Tweets Bring All the Traits to the Yard: Predicting Personality and Relational Traits in Online Social Networks,” ACM Transactions on the Web, vol. 16, no. 2, May 2022, https://doi.org/10.1145/3523749.
Pamuksuz, U., Yun, J. T. & Humphreys, A. A Brand-New Look at You: Predicting Brand Personality in Social Media Networks with Machine Learning. Journal of Interactive Marketing 56(1), 1–15. https://doi.org/10.1016/j.intmar.2021.05.001 (2021).
Shumanov, M., Cooper, H. & Ewing, M. Using AI predicted personality to enhance advertising effectiveness. Eur J Mark 56(6), 1590–1609. https://doi.org/10.1108/EJM-12-2019-0941 (2022).
Christodoulou, E. & Gregoriades, A. “Applying Machine Learning in Personality-based Persuasion Marketing”, in. IEEE International Conference on Data Mining Workshops (ICDMW) 2023, 16–23. https://doi.org/10.1109/ICDMW60847.2023.00010 (2023).
G. V. Mohan Krishna and M. Vijay Anand, “Analyzing Personality Insights Through Machine Learning,” in IEEE 9th International Conference on Smart Structures and Systems, ICSSS 2023, Institute of Electrical and Electronics Engineers Inc., 2023. https://doi.org/10.1109/ICSSS58085.2023.10407083.
Universitas Diponegoro. Department of Electrical Engineering, Universitas Diponegoro. Program Studi Sistem Komputer, Institute of Electrical and Electronics Engineers. Indonesia Section, and Institute of Electrical and Electronics Engineers., ICITACEE 2020 : the 7th International Conference on Information Technology, Computer and Electrical Engineering : proceedings : Electrical engineering & information technology research toward eco-friendly technology and humanity.
Jupalle, H. et al. Automation of human behaviors and its prediction using machine learning. Microsystem Technologies 28(8), 1879–1887. https://doi.org/10.1007/s00542-022-05326-4 (2022).
C. Basto, “Extending the Abstraction of Personality Types based on MBTI with Machine Learning & Natural Language Processing (NLP).”
M. D. Kamalesh and B. B, “Personality prediction model for social media using machine learning Technique,” Computers and Electrical Engineering, vol. 100, May 2022, https://doi.org/10.1016/j.compeleceng.2022.107852.
A. Iqbal and F. Siddiqui, “Predicting Personality Using Deep Learning Techniques,” in Lecture Notes on Data Engineering and Communications Technologies, vol. 26, Springer Science and Business Media Deutschland GmbH, 2019, pp. 168–179. https://doi.org/10.1007/978-3-030-03146-6_17.
G. Ryan, P. Katarina, and D. Suhartono, “MBTI Personality Prediction Using Machine Learning and SMOTE for Balancing Data Based on Statement Sentences,” Information (Switzerland), vol. 14, no. 4, Apr. 2023, https://doi.org/10.3390/info14040217.
M. Anusha, C. R. Yoshitha, D. S. Namratha, B. S. Manoj, T. P. Kausalya Nandan, and P. S. Raju, “Text-Based Personality Assessment Using Deep Learning Techniques,” in 2024 International Conference on Emerging Technologies in Computer Science for Interdisciplinary Applications (ICETCS), 2024, pp. 1–6. https://doi.org/10.1109/ICETCS61022.2024.10543333.
H. Naik, S. Dedhia, A. Dubbewar, M. Joshi, and V. Patil, “Myers Briggs Type Indicator (MBTI) - Personality Prediction using Deep Learning,” in 2022 2nd Asian Conference on Innovation in Technology, ASIANCON 2022, Institute of Electrical and Electronics Engineers Inc., 2022. https://doi.org/10.1109/ASIANCON55314.2022.9909077.
N. Sujatha, S. Pramod, S. Bhatla, T. Thulasimani, R. Kant, and A. Chauhan, “Efficient Method for Personality Prediction using Hybrid Method of Convolutional Neural Network and LSTM,” in 2023 4th International Conference on Electronics and Sustainable Communication Systems, ICESC 2023 - Proceedings, Institute of Electrical and Electronics Engineers Inc., 2023, pp. 959–964. https://doi.org/10.1109/ICESC57686.2023.10193058.
Ahmad, H., Asghar, M. U., Asghar, M. Z., Khan, A. & Mosavi, A. H. A Hybrid Deep Learning Technique for Personality Trait Classification from Text. IEEE Access 9, 146214–146232. https://doi.org/10.1109/ACCESS.2021.3121791 (2021).
Khattak, A., Jellani, N., Asghar, M. Z. & Asghar, U. Personality classification from text using bidirectional long short-term memory model. Multimed Tools Appl 83(10), 28849–28873. https://doi.org/10.1007/s11042-023-16661-7 (2024).
V. V. R. Maheswara Rao, N. Silpa, M. Gadiraju, S. S. Reddy, S. Bonthu, and R. R. Kurada, “A Plausible RNN-LSTM based Profession Recommendation System by Predicting Human Personality Types on Social Media Forums,” in Proceedings - 7th International Conference on Computing Methodologies and Communication, ICCMC 2023, Institute of Electrical and Electronics Engineers Inc., 2023, pp. 850–855. https://doi.org/10.1109/ICCMC56507.2023.10083557.
G. B. Mohan, R. P. Kumar, E. R, and S. Gorantla, “Enhancing Personality Classification through Textual Analysis: A Deep Learning Approach Utilizing MBTI and Social Media Data,” in 2023 International Conference on Network, Multimedia and Information Technology (NMITCON), 2023, pp. 1–6. https://doi.org/10.1109/NMITCON58196.2023.10276193.
N. El Bahri, Z. Itahriouan, A. Abtoy, and S. Brahim Belhaouari, “Using convolutional neural networks to detect learner’s personality based on the Five Factor Model,” Computers and Education: Artificial Intelligence, vol. 5, p. 100163, 2023, https://doi.org/10.1016/j.caeai.2023.100163.
S. Chaurasia, K. K. Bharti, and A. Gupta, “A multi-model attention-based CNN-BiLSTM model for personality traits prediction based on user behavior on social media,” Knowl Based Syst, vol. 300, Sep. 2024, https://doi.org/10.1016/j.knosys.2024.112252.
Saeidi, S. Identifying personality traits of WhatsApp users based on frequently used emojis using deep learning. Multimed Tools Appl 83(5), 13873–13886. https://doi.org/10.1007/s11042-023-15209-z (2024).
Shanmukha, A. G., Shamyuktha, R. S., Karan, S., Gupta, D. & Palaniswamy, S. “Advancing Personality Detection through Word Embedments and Deep Learning: An Examination Using the MBTI Dataset”, in. IEEE Recent Advances in Intelligent Computational Systems (RAICS) 2024, 1–6. https://doi.org/10.1109/RAICS61201.2024.10689948 (2024).
Zhou, L., Zhang, Z., Zhao, L. & Yang, P. Attention-based BiLSTM models for personality recognition from user-generated content. Inf Sci (N Y) 596, 460–471. https://doi.org/10.1016/j.ins.2022.03.038 (2022).
X. Wang, Y. Sui, K. Zheng, Y. Shi, and S. Cao, “Personality classification of social users based on feature fusion,” Sensors, vol. 21, no. 20, Oct. 2021, https://doi.org/10.3390/s21206758.
G. Jenifa, K. Padmapriya, P. Sevanthi, K. Karthika, V. S. Pandi, and D. Arumugam, “An Effective Personality Recognition Model Design using Generative Artificial Intelligence based Learning Principles,” in ICCDS 2024 - International Conference on Computing and Data Science, Institute of Electrical and Electronics Engineers Inc., 2024. https://doi.org/10.1109/ICCDS60734.2024.10560368.
Xue, D. et al. Deep learning-based personality recognition from text posts of online social networks. Applied Intelligence 48(11), 4232–4246. https://doi.org/10.1007/s10489-018-1212-4 (2018).
M. Ahmed, H. U. Khan, S. Iqbal, and Q. Althebyan, “Automated Question Answering based on Improved TF-IDF and Cosine Similarity,” in 2022 Ninth International Conference on Social Networks Analysis, Management and Security (SNAMS), 2022, pp. 1–6. https://doi.org/10.1109/SNAMS58071.2022.10062839.
Daud, A. et al. Latent dirichlet allocation and POS tags based method for external plagiarism detection: LDA and POS tags based plagiarism detection. International Journal on Semantic Web and Information Systems (IJSWIS) 14(3), 53–69 (2018).
M. Kowsher et al., “An Enhanced Neural Word Embedding Model for Transfer Learning,” Applied Sciences (Switzerland), vol. 12, no. 6, Mar. 2022, https://doi.org/10.3390/app12062848.
U. Ishfaq et al., “Empirical Analysis of Machine Learning Algorithms for Multiclass Prediction,” Wirel Commun Mob Comput, vol. 2022, 2022, https://doi.org/10.1155/2022/7451152.
M. Kowsher et al., “LSTM-ANN & BiLSTM-ANN: Hybrid deep learning models for enhanced classification accuracy,” in Procedia Computer Science, Elsevier B.V., 2021, pp. 131–140. https://doi.org/10.1016/j.procs.2021.10.013.
Kazi, S., Khoja, S. & Daud, A. A survey of deep learning techniques for machine reading comprehension. Artif Intell Rev 56, 2509–2569. https://doi.org/10.1007/s10462-023-10583-4 (2023).
A. Urooj, H. U. Khan, S. Iqbal, and Q. Althebyan, “On Prediction of Research Excellence using Data Mining and Deep Learning Techniques,” in 2021 8th International Conference on Social Network Analysis, Management and Security, SNAMS 2021, Institute of Electrical and Electronics Engineers Inc., 2021. https://doi.org/10.1109/SNAMS53716.2021.9732153.
A. Rahali and M. A. Akhloufi, “End-to-End Transformer-Based Models in Textual-Based NLP,” Mar. 01, 2023, Multidisciplinary Digital Publishing Institute (MDPI). https://doi.org/10.3390/ai4010004.
Khan, W., Daud, A., Khan, K., Muhammad, S. & Haq, R. Exploring the frontiers of deep learning and natural language processing: A comprehensive overview of key challenges and emerging trends. Natural Language Processing Journal 4, 100026. https://doi.org/10.1016/j.nlp.2023.100026 (2023).
M. H. Amirhosseini and H. Kazemian, “Machine Learning Approach to Personality Type Prediction Based on the Myers–Briggs Type Indicator®,” Multimodal Technologies and Interaction, vol. 4, no. 1, 2020, https://doi.org/10.3390/mti4010009.
R. Bin Tareaf, “MBTI BERT: A Transformer-Based Machine Learning Approach Using MBTI Model For Textual Inputs,” in 2022 IEEE 24th Int Conf on High Performance Computing & Communications; 8th Int Conf on Data Science & Systems; 20th Int Conf on Smart City; 8th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), IEEE, Dec. 2022, pp. 2285–2292. https://doi.org/10.1109/HPCC-DSS-SmartCity-DependSys57074.2022.00338.
P. Kumar R, B. Mohan G, and G. D. Sai, “Ensemble Machine Learning Models in Predicting Personality Traits and Insights using Myers-Briggs Dataset,” in Proceedings of the 2nd IEEE International Conference on Advances in Computing, Communication and Applied Informatics, ACCAI 2023, Institute of Electrical and Electronics Engineers Inc., 2023. https://doi.org/10.1109/ACCAI58221.2023.10199294.
H. Kandpal, D. Gupta, and R. Bathla, “Enhanced Personality Profiling: Unveiling MBTI Traits Through Machine Learning Analysis,” in 2024 11th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), 2024, pp. 1–5. https://doi.org/10.1109/ICRITO61523.2024.10522158.
Author information
Authors and Affiliations
Contributions
Raed Alsini: Visualization, Resources, Investigation, Writing—Original Draft Anam Naz: Investigation, Formal Analysis, Supervision Hikmat Ullah Khan: Supervision, Conceptualization, Data Curation Amal Bukhari:Visualization and Validation Ali Daud: Project Administration, Conceptualization Muahammad Ramzan: Formal Analysis, Data Curation.
Corresponding authors
Ethics declarations
Completing interest
The authors declare no competing interests.
Ethics approval
Ethical Approval was not required as no humans were involved in the study. The dataset for the experimentation was downloaded from KAGGLE which is freely available for research purpose. The dataset was anonymized by removing the identity of the users who generated content and now the dataset only contains text and no information about the humans/users involved in generating the content.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Alsini, R., Naz, A., Khan, H.U. et al. Using deep learning and word embeddings for predicting human agreeableness behavior. Sci Rep 14, 29875 (2024). https://doi.org/10.1038/s41598-024-81506-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-81506-8
Keywords
This article is cited by
-
Research on English text scoring technology based on deep learning in English teaching
Discover Artificial Intelligence (2026)
-
A novel deep transformer based CvT model for sign language recognition in visual communication
Scientific Reports (2025)
-
A multi-factor data mining and transformer-based predictive modeling approach for career success using educational and behavioral traits
Scientific Reports (2025)
-
A hybrid deep learning and fuzzy logic framework for feature-based evaluation of english Language learners
Scientific Reports (2025)
-
Deep learning and sentence embeddings for detection of clickbait news from online content
Scientific Reports (2025)
