
Abstract
This study explores the thermal conductivity and viscosity of water-based nanofluids containing silicon dioxide, graphene oxide, titanium dioxide, and their hybrids across various concentrations (0 to 1 vol%) and temperatures (30 to 60 °C). The nanofluids, characterized using multiple methods, exhibited increased viscosity and thermal conductivity compared to water, with hybrid nanofluids showing superior performance. Graphene oxide nanofluids displayed the highest thermal conductivity and viscosity ratios, with increases of 52% and 177% at 60 °C and 30 °C, respectively, for a concentration of 1 vol% compared to base fluid. Similarly, graphene oxide-TiO2 hybrid nanofluids achieved thermal conductivity and viscosity ratios exceeding 43% and 144% compared to the base fluid at similar conditions. This data highlights the significance of nanofluid concentration in influencing thermal conductivity, while temperature was found to have a more pronounced effect on viscosity. To tackle the challenge of modeling the thermophysical properties of these hybrid nanofluids, advanced machine learning models were applied. The Random Forest (RF) model outperformed others (Gradient Boosting and Decision Tree) in both the cases of thermal conductivity and viscosity with greater adaptability to handle fresh data during model testing. Further analysis using shapely additive explanations based on cooperative game theory revealed that relative to temperature, nanofluid concentration contributes more to the predictions of the thermal conductivity ratio model. However, the effect of nanofluid concentration was more dominant in the case of viscosity ratio model.
Similar content being viewed by others
Introduction
Nanofluids, composed of nanoparticles dispersed within a base fluid, have gained prominence in thermal system research due to their exceptional capability to enhance heat transfer properties, particularly through greater thermal conductivity1. These advanced colloidal mixtures have captured the interest of researchers for their potential to significantly boost thermal performance, making them suitable for a wider range of industrial thermal applications2. The nanoparticles suspended in the fluid matrix play a significant role in improving heat transfer efficiency. Moreover, the flexibility to tailor nanofluid properties by adjusting concentration and temperature allows for precise customization to meet the demands of specific applications3. This flexibility highlights the potential of nanofluids to improve system efficiency and contribute to more sustainable thermal management technologies, opening new avenues for innovation in heat transfer systems and energy-saving initiatives4.
Hybrid nanofluids represent a cutting-edge development in thermal management systems, consisting of a combination of different nanoparticles suspended in a base fluid. This innovative strategy merges the distinct properties of various nanoparticles, creating a synergistic effect that leads to superior thermal performance compared to traditional single-component nanofluids5,6. The primary advantage of hybrid nanofluids lies in their ability to capitalize on the complementary attributes of diverse nanoparticles. By strategically selecting materials with varying shapes, sizes, and thermal characteristics, researchers can design fluids with enhanced heat transfer properties and increased stability. This combination often results in non-linear improvements in specific heat capacity, thermal conductivity, and viscosity, outperforming single-component nanofluids7,8.
The adaptability of hybrid nanofluids enables them to be tailored for specific application needs. For example, combining metallic and non-metallic nanoparticles can help achieve a balance between high thermal conductivity and long-term stability9,10. Likewise, integrating carbon-based nanostructures with ceramic particles could produce a nanofluid with superior heat transfer capabilities and improved mechanical strength. Optimizing the performance of hybrid nanofluids in thermal management applications requires a thorough understanding of their transport phenomena11. This involves a detailed analysis of their rheological properties, thermal conductivity, viscosity, convective heat transfer, stability and dispersion, along with the effects of Brownian motion and thermophoresis.
By examining these properties and their interactions, researchers can create predictive models for the behavior of hybrid nanofluids. This understanding is crucial for designing more efficient cooling systems for electronics, enhancing industrial heat exchangers, improving solar thermal collectors, and advancing energy storage solutions12,13,14. Additionally, studying hybrid nanofluids expands our fundamental knowledge of nanoscale fluid dynamics and interfacial phenomena. This deeper comprehension not only helps refine current technologies but also encourages innovation in areas like nanofluidics, colloidal science, and advanced materials engineering15,16. As research continues, hybrid nanofluids are expected to play a key role in overcoming thermal management challenges in next-generation technologies, potentially resulting in more energy-efficient and compact cooling solutions for various industries. Recently, many researchers have been exploring ternary nanofluids for thermal management applications17,18,19.
When combined, graphene oxide (GO), metal oxides such as silicon dioxide (SiO2), and titanium dioxide (TiO2) create an effective solution for advanced heat transfer applications. GO’s outstanding TC and greater surface area promote efficient heat conduction and enhance surface contact. TiO2, with its high refractive index and excellent thermal stability, effectively scatters and absorbs light, especially in ultraviolet-based systems, improving heat transfer efficiency. SiO2, renowned for its superior insulation and chemical resistance, helps reduce heat loss and ensures the long-term stability of the system. This synergistic combination provides considerable advantages in different domains of applications, including heat exchangers, thermal management systems, and insulation materials. By harnessing the distinct properties of these materials, researchers and engineers can develop cutting-edge solutions to meet the increasing demand for efficient and sustainable thermal management. Table 1 highlights recent investigations on the thermophysical characteristics of GO-based nanofluids.
This research delves into the thermophysical properties of water-based nanofluids containing GO, SiO2, TiO2, and their hybrid combinations (50:50) across various concentrations and temperatures. Unlike previous studies focused on individual nanomaterial’s, this investigation uniquely examines hybrid nanofluids, illuminating their potential to enhance both thermal conductivity and viscosity. The study employs cutting-edge modeling techniques, particularly machine learning algorithms, to accurately predict these intricate properties. Key questions addressed include the comparative performance of hybrid nanofluids versus single-component alternatives, the precision of advanced machine learning models like extreme gradient boosting and deep neural networks in predicting thermophysical characteristics, and the crucial factors influencing nanofluid behavior, as revealed through analytical methods such as SHAP. This work bridges a significant research gap by elucidating the superior performance of hybrid nanofluids and leveraging sophisticated machine learning models to gain profound insights into the determinants of their thermophysical properties.
As a first step, the study involved synthesizing and characterizing GO, SiO2, and TiO2 nanoparticles, followed by the formulation of nanofluids with concentrations ranging from 0 to 1 vol%. The stability of these nanofluids was assessed, and their thermal conductivity and viscosity were determined at temperatures ranging from 30 to 60 °C. Furthermore, machine learning approaches were used to characterize the behavior of nanofluids based on thermal conductivity and viscosity data from all tested nanofluids.
Methodology
Synthesis of nanoparticles, characterization, and Nanofluid Preparation
The chemical reagents used in this study were obtained from Merck and employed without additional purification. Deionized water had been used consistently throughout the test process. Details on the synthesis of the required nanoparticles can be found in the associated paper32. To evaluate the stability of the nanofluids, a Malvern Instruments, UK make Nano-ZS apparatus was utilized. The structural and morphological characteristics of the nanoparticles were analyzed using X-ray diffraction and field emission scanning electron microscopy. Water-based mono and hybrid nanofluids in a 50:50 ratio were produced using a two-step method. For information on the preparation of the nanofluids, please refer to our published article32.
Thermal conductivity and viscosity
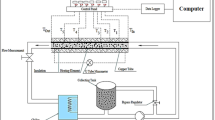
The thermal conductivity of the nanofluids was measured using a KD2 Pro Thermal Properties Analyzer from Decagon Devices Inc. This device, featuring a single KS-1 sensor, employs the transient hot-wire method. The sensor, which is 60 mm long and 1.3 mm in diameter, is immersed in the test fluid and functions as both a heat source and a temperature sensor. The transient hot-wire method minimizes issues with free convection by producing a small amount of heat. The instrument has a maximum error margin of ± 5%. Before starting the experiments, the KD2 Pro was calibrated with a glycerol standard provided by the manufacturer.
The viscosity of the nanofluids was assessed employing a Brookfield DV-II + Pro viscometer with maximum uncertainty of ± 2%. This instrument measures fluid resistance by evaluating the torque exerted by a spindle submerged in the fluid. To ensure accurate readings, a controlled water bath was used alongside the viscometer to maintain temperature stability and assess the impact of temperature on viscosity. Viscosity measurements were taken at temperatures ranging from 30 to 60 °C in 5 °C increments. Each measurement was repeated five times for all concentrations and temperatures to ensure consistency and reliability, with a 15-minute interval between each measurement. Please refer our published article32 for the validation of both the instruments.
Prognostic analysis with machine learning
Random forest
Random Forest (RF) is an ensemble learning method that operates by constructing multiple decision trees during training and outputting either the mode of classification or the mean prediction for regression tasks. Within the framework of regression, the model averages the outputs of individual decision trees33,34,35. Every decision tree reduces overfitting and variance by being constructed using a random subset of the data and a random subset of the features at every node. The technique randomly chooses samples with replacement—bootstrapping—during training to ensure that each tree is trained on another subset. Random feature splitting guarantees that every tree is decorrelated, therefore strengthening the whole ensemble model36,37. Computed as the average of all tree forecasts, the final prediction simultaneously reduces bias and variation. Especially in datasets where decision trees by themselves may show great variance, this approach usually proves strong against overfitting. Because of the averaging of several trees, the training error is typically minimal; nonetheless, overfitting on training data subsets can cause a modest increase in the test error, but less clearly than in single decision trees38,39.
Gradient boosting regression
Gradient Boosting (GB) Regression builds models sequentially, where each new model corrects the errors of the previous one. Usually mean squared error for regression problems, it is a stage-wise additive model adding new trees to minimize the loss function. The procedure begins with training an original data-based decision tree, then computes residuals or errors from this tree40,41. One then trains a fresh tree to forecast these residuals. This tree is included into the model and its forecasts are merged with the past trees to change the general prediction of the model. This procedure is repeated for a designated number of times, with every next tree fixing the errors of the last one42,43. Gradient descent helps to minimize a differentiable loss function, hence updating the model parameters. Though it can be prone to overfitting, especially when too many iterations are carried out, gradient boosting is renowned for its great predictive ability. Its iterative character of concentrating on the most challenging samples at each stage makes it usually more accurate than decision trees and random forests44,45.
Decision tree
Decision trees (DT) operate by recursively partitioning the data into subsets based on the values of input features, creating a tree-like model of decisions. At every node, the method chooses the feature and threshold that reduces a given loss function, like mean squared error in regression problems. Until the data is sufficiently partitioned or a stopping criterion—like the maximum depth—this method iteratively generates branches in the tree. Without feature scaling or data normalizing, decision trees can record intricate relationships among characteristics46. Average of the target values in every leaf node generates the last forecast. Since the framework of decision trees reflects human decision-making procedures, they are straightforward to understand47,48. They do, however, overfit easily, particularly in cases whereby the trees grow deep and capture noise in the training data. Pruning helps to minimize the overfitting issue by simplifying the model by eliminating branches with minimal predictive capability. Although decision trees are strong, their single-tree architecture increases their sensitivity to high variance relative to ensemble techniques like random forests or gradient boosting49,50.
SHAP-based explainable machine learning
SHapley Additive exPlanations (SHAP) values are a game-theory-based approach to interpreting machine learning models by quantifying the contribution of each feature to the model’s output. SHAP values are especially helpful in clarifying how thermal conductivity and viscosity of water-based graphene oxide nanofluids are influenced by variables like nanoparticle concentration, temperature, and other experimental circumstances51,52. By computing the contribution of every characteristic to every individual prediction, SHAP provides insights on the internal dynamics of complicated machine learning models, hence explaining their output. Using random forest (best performing in this study), the researchers would train machine learning models in this work to predict the TC and viscosity employing experimental data. SHAP values for every feature would be computed following training so that the researchers may observe how factors such as temperature or concentration of nanoparticles affect the expected thermal characteristics53,54. Summary plots help one see SHAP values; each point in these graphs represents a prediction and the size of the SHAP values indicates the contribution of a feature. This makes it possible to clearly grasp the fundamental physics and data patterns, including whether and by what degree raising nanoparticle concentration affects heat conductivity or viscosity. SHAP values’ explainability gives the machine learning predictions a fresh layer of transparency, therefore enabling domain experts to better understand the outcomes55,56.
Result and discussion
Characterization
Figure 1a to c show field emission SEM images of the nanoparticles (Fig. 2). Analysis of Fig. 3a and b indicates that both SiO2 and TiO2 nanoparticles have a spherical shape and tend to aggregate due to Van der Waals forces. This spherical form is beneficial because it improves the contact surface area between the nanoparticles and the base fluid, hence improving heat transfer efficiency. Additionally, the uniformity of spherical particles helps reduce fluid resistance, promoting smoother flow dynamics in nanofluids. In contrast, Fig. 1c illustrates that GO nanoparticles have a layered or sheet-like structure. Unlike spherical particles, the sheet-like structure of GO may increase the viscosity of the nanofluid, potentially affecting its flow characteristics. However, the high surface area of these GO nanosheets can enhance the stability and thermal conductivity of the nanofluid, offsetting the potential viscosity increase. Furthermore, the spherical shape of metal oxide nanoparticles helps lower the viscosity of the nanofluids in comparison with irregular structures like GO. This makes SiO2 and TiO2 more suitable for applications where it is crucial to maintain low viscosity while improving heat transfer. Combining these materials can provide a balance between enhanced thermal conductivity and manageable viscosity levels in hybrid nanofluid systems.

FESEM images for (a) SiO2 (b) TiO2 and (c) GO.
The nanoparticles were characterized using a Bruker Advance diffractometer with Cu-Kα radiation over a 2θ range of 10° to 60°, at a 0.02° step size. The crystallite size was calculated using the Scherrer formula. XRD analysis of TiO2 (Fig. 3a) shows pure anatase phases, confirming no impurities and a mean nanoparticle size of 40 nm. In XRD analysis presented in Fig. 3b, GO typically shows a peak around 2θ = 10–15° due to the increased interlayer spacing caused by oxygen functional groups. This peak confirms the successful oxidation of graphite into GO.

XRD for (a) TiO2 and (b) GO nanoparticle.
Nanofluid stability
The zeta potential is an important parameter in determining the dispersed nanoparticles stability in nanofluids. A zeta potential value exceeding ± 30 mV indicates stable colloidal dispersions.
In this study, the mass ratio of Polyvinyl pyrrolidone (PVP) to GO, and to hybrid nanofluids, was kept constant and matched the weight of GO to ensure consistent experimental conditions for accurate comparisons. Stability analysis using the Zetasizer (Malvern Instruments, UK) revealed that zeta potential values were consistent both immediately after preparation and after 25 days, demonstrating the high stability of the nanofluids shown in Fig. 3. These results highlight the effective dispersion of nanoparticles, which is essential for enhancing heat transfer and ensuring long-term stability and performance.

Zeta potential values for considered nanofluids.
Viscosity
Figure 4a–d illustrate how the viscosity of nanofluids varies with concentration and temperature. Viscosity rises with increased concentration but decreases as temperature increases. The highest and lowest viscosity ratio (µ nf/µ bf) observed for GO nanofluid is 2.77 and 1.38 at 30 and 60 °C for 1 and 0.1 vol%, correspondingly. The relationship between temperature and viscosity in nanofluids is governed by a complex interplay of molecular dynamics and nanoparticle behavior. As thermal energy increases, it catalyzes more vigorous molecular motion, weakening the cohesive forces between fluid molecules. This diminution of intermolecular attraction facilitates easier relative movement, manifesting as reduced viscosity and enhanced flow characteristics. Concurrently, elevated temperatures amplify the Brownian motion of suspended nanoparticles, causing them to collide more frequently with fluid molecules and disrupt local fluid structures. This disruption further attenuates fluid viscosity by impeding the formation of transient molecular networks that contribute to flow resistance.
However, the influence of nanoparticles on viscosity is concentration-dependent and non-linear. At higher concentrations, nanoparticles exhibit increased propensity for inter-particle interactions, potentially leading to the formation of temporary or permanent agglomerates. These larger structures can significantly impede fluid flow, counteracting the viscosity-reducing effects of temperature. Moreover, the surface properties of nanoparticles, such as charge distribution and functional groups, play a crucial role in determining their aggregation behavior and subsequent impact on fluid dynamics.
The presence of nanoparticles also introduces additional mechanisms that modulate viscosity. For instance, the formation of a nanolayer of fluid molecules around each particle can alter local fluid properties, creating regions of modified viscosity that influence bulk fluid behavior. Furthermore, the shape anisotropy of certain nanoparticles, such as GO flakes, can induce orientation-dependent effects on fluid flow, adding another layer of complexity to the viscosity profile of nanofluids at varying temperatures and shear rates.
Figure 4d contrasts at various concentrations and temperatures the viscosity of hybrid and mono nanofluids. Whereas SiO2 nanofluids display the lowest viscosity, GO nanofluids have the greatest. The plate-like structure and large surface area of GO hinder fluid movement, increasing its viscosity. On the other hand, the smaller surface area and the spherical shape of SiO2 facilitate easier fluid flow, resulting in lower viscosity. TiO2 nanofluids have higher viscosity than SiO2, likely due to their smaller particle size and higher density. GO-TiO2 nanofluids display higher viscosity compared to GO-SiO2, as TiO2’s smaller particles and SiO2’s shape promote smoother flow. Hybrid nanofluids, such as GO-SiO2 or GO-TiO2, generally exhibit higher viscosity than mono nanofluids due to increased particle interactions, larger particle clusters, and potential synergistic effects between different nanoparticles, leading to greater flow resistance. While adding GO raises viscosity, mixing it with SiO2 or TiO2, which have lower surface areas, reduces the viscosity of GO in hybrid formulations.

Depiction of dynamic viscosity ration in the case of (a) GO (b) GO-TiO2 (c) GO-SiO2 hybrid NF, (d). Comparative depiction of considered nanofluids dynamic viscosity ratio.
Thermal conductivity
Figure 5 (a–c) illustrate the thermal conductivity of both hybrid and mono nanofluids, which increases with temperature and concentration. The maximum and minimum thermal conductivity amplification of 1.52 and 1.09 noticed for GO nanofluid at 60 and 30 °C for 1 and 0.1 vol%, respectively, compared to the water.
The thermal conductivity of nanofluids exhibits a complex relationship with temperature and nanoparticle concentration, driven by several interacting mechanisms. As temperature rises, the intensified Brownian motion of nanoparticles leads to improved dispersion and reduced agglomeration, creating a more uniform distribution of heat-conducting elements throughout the fluid. This enhanced particle mobility facilitates more frequent and energetic collisions between nanoparticles and fluid molecules, establishing numerous transient nanoscale heat transfer bridges that significantly boost overall thermal conductivity. The augmented thermal energy at elevated temperatures also promotes the formation of more robust and extensive percolation networks among nanoparticles, particularly in fluids with higher concentrations. These networks serve as preferential pathways for rapid heat propagation, markedly enhancing the fluid’s thermal transport capabilities. Furthermore, the temperature-induced reduction in fluid viscosity allows for more efficient heat transfer at the nanoparticle-fluid interface, as the decreased resistance to molecular motion enables swifter energy exchange.
Increasing nanoparticle concentration introduces additional heat conduction pathways, amplifying the fluid’s thermal conductivity. However, this relationship is non-linear and exhibits a critical threshold. Beyond a certain concentration, particle crowding can lead to the formation of larger aggregates, which paradoxically may impede heat flow by reducing the effective surface area for heat exchange and disrupting the continuity of thermal pathways. The synergistic interplay between temperature and concentration effects on thermal conductivity is particularly noteworthy. Higher temperatures can mitigate the negative impacts of increased concentration by enhancing particle dispersion and preventing excessive agglomeration, thus maintaining optimal heat transfer conditions even at elevated particle loadings.
It’s crucial to consider the role of nanoparticle material properties in this context. Materials with high intrinsic thermal conductivity, such as graphene or carbon nanotubes, can yield disproportionate increases in fluid thermal conductivity even at relatively low concentrations. The aspect ratio and surface chemistry of nanoparticles also significantly influence their dispersion behavior and interfacial thermal resistance, further modulating the temperature and concentration-dependent thermal conductivity enhancements in nanofluids.

TC in the case of (a) GO (b) GO-TiO2 (c) GO-SiO2 hybrid NF, (d) Thermal conductivity of the nanofluids for 1 vol%.
Figure 5d compares the TC of hybrid and mono NFs. At 1.0 vol% and 60 °C, the highest thermal conductivity ratios for SiO2, TiO2, GO-SiO2, GO-TiO2, and GO nanofluids are 1.17, 1.23, 1.39, 1.43, and 1.52 respectively.
GO demonstrates the most significant TC enhancement owing to its inherent higher TC and layered structure, while SiO2, with lower thermal conductivity and surface area, shows the least. Hybrid nanofluids generally outperform mono nanofluids (except for GO) due to synergistic effects that combine the properties of different nanoparticles to create more efficient heat transfer pathways. Various nanoparticles improve thermal conductivity through enhanced phonon transport, better dispersion, and reduced agglomeration. Additives also help improve dispersion, which enhances the thermal conductivity of hybrids. GO-TiO2 exhibits higher thermal conductivity than GO-SiO2, due to TiO2’s smaller size and higher thermal conductivity. The improvement in thermal conductivity for nanofluids depends on particle size, shape, dispersion, and inter-particle interactions, which are essential for effective thermal management.
Data pre-analysis
The data gathered in lab-based testin phase was evaluated for correlation among the data columns. The correlation matrix offers important new perspectives on the interactions among the variables. Beginning with nanoparticle concentration, it shows a quite significant positive association with the viscosity ratio (0.97), meaning that the viscosity ratio also grows practically proportionately as the nanoparticle concentration rises (Fig. 6a). This makes sense as the inclusion of nanoparticles usually raises the viscosity of the nanofluid. Likewise, the concentration displays a strong positive association with the thermal conductivity ratio (0.82), implying that increasing nanoparticle concentrations enhance the thermal conductivity of the fluid. Conversely, temperature (T) has no effect on concentration (0) since in this scenario the concentration of nanoparticles is independent of temperature. With the TC ratio (0.54), it does, however, exhibit a modest positive correlation, meaning that higher temperatures usually improve the TC of the nanofluids. By contrast, the temperature exhibits a mild negative association with the viscosity ratio (-0.13), meaning that rising temperature somewhat lowers viscosity, a normal behavior for fluids where viscosity drops with heating.
At last, the viscosity ratio and TC ratio show a quite strong positive connection (0.74), implying that in the nanofluid these two characteristics are connected. A rise in one generally follows a rise in the other as the nanoparticles raise both viscosity and heat conductivity. Understanding how changing one feature could affect the total thermal performance of the nanofluid depends on this interdependence. The scatter plot (pair plot) depicted in Fig. 6b visually shows the associations between several dataset variables. Whereas the off-diagonal parts display scatter plots, indicating the correlations between pairs of variables, each diagonal element provides a histogram for a single variable. This plot supports the results of the correlation matrix shown in Fig. 6a. While temperature has a secondary influence on thermal conductivity more than viscosity, the concentration of nanoparticles has a very significant effect on both thermal conductivity and viscosity ratios. The image demonstrates that concentration drives the behavior of the system mostly; temperature has a relatively moderate influence.

Correlations (a) Heatmap (b) pair plots developed using open access python libraries (pandas, matplotlib.pyplot, numpy).
Thermal conductivity ratio models
The TC ratio prediction models were developed by employing three modern ML approaches namely Random Forest (RF), Gradient Boosting (GB), and Decision Tree (DT). The models were then used for statistic-based evaluation and comparison. Table 2 shows the values of mean squared error (MSE), coefficient of determinants (R2), and mean absolute percentage error (MAPE) in each case. With a low Train MSE of 0.0001 and Test MSE of 0.0002 the RF model (Fig. 7a) exhibits good predictive ability. Train R² of 0.9860 and Test R² of 0.9575 show that the model generalizes effectively to unknown data, therefore attesting to great accuracy. Reflecting little prediction errors, the MAPE is likewise rather low, with 0.90% for training and 1.04% for testing. With a Train MSE of 0.0001 and Train R² of 0.9874 indicating outstanding fit the GB model (Fig. 7b) performs similarly on the training set. On the other hand, the Test MSE is somewhat higher at 0.0003 and the Test R² falls to 0.9202, therefore indicating less generalization than the Random Forest. With a MAPE for the test set of 1.42%, greater than that of Random Forest, this model clearly generates more prediction errors in unseen data. Reflecting a quite strong match to the training data, the DT model has a similar Train MSE of 0.0001 and a high Train R² of 0.9876. With a higher Test MSE of 0.0006 and Test R² of 0.8500, its performance on the test set does, however, clearly deteriorates. This suggests that the model suffers with generalizing. Furthermore, supporting that this model generates more errors while testing than Random Forest and Gradient Boosting is the test MAPE of 1.91%. While Decision Tree (Fig. 7c) displays symptoms of overfitting and less dependable predictions on the test data, Random Forest offers the best balance between training and test performance followed by Gradient Boosting.

Model comparison in case of TC ratio model using (a) RF (b) GB (c) DT.
VST model prediction
Three contemporary ML techniques RF, GB, and DT were used in development of the VST ratio prediction models. After that, statistical-based assessment and comparison made advantage of the models. Table 3 lists in each scenario MAPE, R2, and MSE. With their identical Train MSE values and high Train R² values of about 0.97, the performance metrics for the VST ratio models reveal consistent outcomes across all three models: Random Forest, Gradient Boosting, and Decision Tree during training. This implies that every model may reasonably capture the fundamental trends in the training data. The test R² values of the models on the test data expose some variations in their generalizing capacity. With Test R² values of 0.9405 and 0.9637 respectively, the Random Forest and Gradient Boosting models show equivalent generalization. This suggests great forecasting ability despite on unavailability of data. Conversely, the Decision Tree model exhibits a somewhat lower Test R² of 0.9217, which reflects a decreased capacity to sustain accuracy on the test set, thereby maybe indicating a higher vulnerability to overfitting in compared to the ensemble-based models.
These trends are supported by the test data’s Mean Absolute Percentage Error (MAPE). While Gradient Boosting and Decision Tree show better error percentages, Random Forest has the lowest Test MAPE, indicating more exact predictions. This trend implies that, presumably because they have lower overfitting relative to the single-tree Decision Tree model, ensemble models especially Random Forest, handlers the volatility in the data better. Finally, all models perform well during training; with Gradient Boosting closely behind, the Random Forest model offers the best trade-off between training performance and generalization to test data. Though still useful, the Decision Tree model shows more overfitting and poor accuracy in test data predictions (Fig. 8).

Model comparison in case of VST ratio model using (a) RF (b) GB (c) DT.
eXplainable machine learning using SHapley additive exPlanations analysis
The ML approached employed in last section provided excellent results. However, these are black box methods and stakeholders may not how these models predicted or how much was the contribution of each feature involved. By pointing out the most important factors influencing TC and VST ratio predictions, explainable machine learning can offer understanding of the decision-making process of the model. Understanding feature importance and interpreting model outputs helps researchers identify causes of overfitting or errors, therefore strengthening model dependability and guiding optimization for maximum performance.
Employing SHAP values, the Fig. 9a offers a thorough examination of the relative significance of two predictors—nanoparticle concentration (Conc., Vol.%) and temperature (T, °C) on the output of the model. The first plot a bar chart of mean SHAP values showcases how mean SHAP value of nanoparticle concentration exceeds that of temperature (0.0452). This implies that, relative to temperature, concentration contributes more generally to the predictions of the model. The output shows a more significant influence from the SHAP values for concentration, so changes in concentration greatly affect the response of the model.
The bee swarm plot (Fig. 9b) expands on the distribution and range of SHAP values for every predictor. With a higher concentration of SHAP values in the positive range, nanoparticle concentration exhibits a wider distribution whereby both high and low values can either positively or negatively affect the model result. This suggests that generally the expected value rises with increasing concentration. On the other hand, temperature shows a smaller range of SHAP values; most of the values are near zero, thereby suggesting it has a more restricted influence on the prediction of the model. Though less significantly than concentration, high-temperature values nevertheless help the output in some beneficial manner. This implies that, with temperature having a minor but still significant impact, concentration dominates in determining the predictions of the model.
In the case of viscosity ration model, the effects of nanoparticle concentration (Conc., Vol.%) and temperature is depicted in the Fig. 10a. The bar chart shows that concentration, with a substantially higher mean SHAP value (0.3125) than temperature (0.0439), clearly influences the projections of the model. The size of the SHAP value of concentration suggests that variations in this variable cause more significant variations in the viscosity ratio prediction. With a general trend demonstrating that larger concentrations (shown by the red dots) greatly improve the model output, nanoparticle concentration shows a wide range of SHAP values both positive and negative in the bee swarm plot (Fig. 10b). On the other hand, the small range of the SHAP values for temperature indicates their reduced influence on the model since they cluster at zero. High temperatures still somewhat influence the results of the model, but less clearly. Consequently, in this model the concentration of nanoparticles still mostly determines the viscosity ratio.

SHAP values for TC ratio model (a) mean values plot (b) bee swarm plot.

SHAP values for VST ratio model (a) mean values plot (b) bee swarm plot.
Conclusion
This study explored how temperature and concentration affect the thermal properties of various nanofluids, including GO, GO-TiO2, GO-SiO2, TiO2, and SiO2, within a concentration range of 0 to 1 vol% and temperatures from 30 to 60 °C. Using extensive experimental data, accurate prediction models were developed with RF, GB, and DT techniques. To enhance the interpretability of these complex models the SHAP (Shapley Additive Explanations) was utilized. The findings of this study offer valuable insights into the behavior of nanofluids, facilitating the creation of more effective predictive models and a deeper understanding of their thermal performance. The key conclusions are:
-
1.
GO nanofluids showed the highest thermal conductivity enhancement among all tested fluids, achieving a maximum thermal conductivity ratio of 1.52 at 1 vol% and 60 °C. This enhancement is due to GO’s high thermal conductivity, surface area, and layered structure, which improve heat transfer efficiency.
-
2.
Hybrid nanofluids, especially GO-TiO2, exhibited better thermal conductivity enhancement compared to mono nanofluids (except GO). At 1 vol% and 60 °C, GO-TiO2 achieved a TC ratio of 1.43, outperforming GO-SiO2 (1.39), TiO2 (1.23), and SiO2 (1.17). This improvement is attributed to synergistic effects and better nanoparticle dispersion.
-
3.
The viscosity of hybrid nanofluids increases with nanoparticle concentration. Viscosity ratio for GO-TiO2 nanofluid at 1 vol% reached 2.45 at 30 °C, compared to 1.40 at 0.1 vol%. This increase is due to increased particle interactions and larger agglomerates that hinder fluid flow.
-
4.
For GO-SiO2 nanofluid at 1 vol%, the viscosity ratio dropped from 2.30 at 30 °C to 2.07 at 60 °C. Higher temperatures enhance molecular motion, allowing the fluid to flow more freely and reducing internal resistance.
-
5.
The Random Forest (RF) model outperformed others (Gradient Boosting and Decision Tree) in both the cases of thermal conductivity and viscosity with greater adaptability to handle fresh data during model testing.
-
6.
Further analysis using shapely additive explanations based on cooperative game theory revealed that relative to temperature, nanofluid concentration contributes more to the predictions of the thermal conductivity ratio model. However, the effect of nanofluid concentration was more dominant in the case of viscosity ratio model.
Data availability
The data is available within the manuscript.
References
Wang, X., Xu, X. & Choi, S. U. S. Thermal conductivity of nanoparticle-fluid mixture. J. Thermophys. Heat. Trans. 13 https://doi.org/10.2514/2.6486 (1999).
Choi, S. U. S. & Eastman, J. Enhancing Thermal Conductivity of Fluids with Nanoparticles, Developments and Applications of non-newtonian Flows38 (ASME, 1995).
Abdelaziz, A. H., El-Maghlany, W. M., Alaa El-Din, A. & Alnakeeb, M. A. Mixed convection heat transfer utilizing nanofluids, ionic nanofluids, and hybrid nanofluids in a horizontal tube. Alexandria Eng. J. 61 https://doi.org/10.1016/j.aej.2022.03.001 (2022).
Okonkwo, E. C., Wole-Osho, I., Almanassra, I. W., Abdullatif, Y. M. & Al-Ansari, T. An Updated Review of Nanofluids in Various heat Transfer Devicesvol. 145 (Springer International Publishing, 2021). https://doi.org/10.1007/s10973-020-09760-2
Babar, H. & Ali, H. M. Towards hybrid nanofluids: Preparation, thermophysical properties, applications, and challenges. J. Mol. Liq. 281 https://doi.org/10.1016/j.molliq.2019.02.102 (2019).
Sarkar, J., Ghosh, P. & Adil, A. A review on hybrid nanofluids: recent research, development and applications. Renew. Sustain. Energy Rev. 43 https://doi.org/10.1016/j.rser.2014.11.023 (2015).
Vărdaru, A. et al. Synthesis, characterization and thermal conductivity of water based graphene oxide–silicon hybrid nanofluids: an experimental approach. Alexandria Eng. J. 61, 12111–12122. https://doi.org/10.1016/j.aej.2022.06.012 (2022).
Huminic, G., Huminic, A., Dumitrache, F., Fleacă, C. & Morjan, I. Study of the thermal conductivity of hybrid nanofluids: recent research and experimental study. Powder Technol. 367, 347–357. https://doi.org/10.1016/j.powtec.2020.03.052 (2020).
Ranga Babu, J. A., Kumar, K. K. & Srinivasa Rao, S. State-of-art review on hybrid nanofluids. Renew. Sustain. Energy Rev. 77, 551–565. https://doi.org/10.1016/j.rser.2017.04.040 (2017).
Moldoveanu, G. M., Minea, A. A., Huminic, G. & Huminic, A. Al2O3/TiO2 hybrid nanofluids thermal conductivity: an experimental approach. J. Therm. Anal. Calorim. 137, 583–592. https://doi.org/10.1007/s10973-018-7974-4 (2019).
Pourrajab, R., Ahmadianfar, I., Jamei, M. & Behbahani, M. A meticulous intelligent approach to predict thermal conductivity ratio of hybrid nanofluids for heat transfer applications. J. Therm. Anal. Calorim. 146, 611–628. https://doi.org/10.1007/s10973-020-10047-9 (2021).
Alphonse, P. & Muthukumarasamy, K. Synergistic advancements in thermal management: hybrid nanofluids and heat pipes. J. Therm. Anal. Calorim. 149 https://doi.org/10.1007/s10973-023-12805-x (2024).
Somanchi, N. S., Gugulothu, R. & Tejeswar, S. V. Experimental investigations on heat transfer enhancement in a double pipe heat exchanger using hybrid nanofluids. Energy Harvesting Syst. 11 https://doi.org/10.1515/ehs-2023-0065 (2024).
Alklaibi, A. M., Mouli, K. V. V. C. & Sundar, L. S. Heat transfer, and friction factor of Fe3O4–SiO2/Water hybrid nanofluids in a plate heat exchanger: experimental and ANN predictions. Int. J. Therm. Sci. 195 https://doi.org/10.1016/j.ijthermalsci.2023.108608 (2024).
Nordin, N. S. et al. Exploration of recent developments of Hybrid Nanofluids. J. Adv. Res. Fluid Mech. Therm. Sci. 114 https://doi.org/10.37934/arfmts.114.2.130154 (2024).
Skouras, E. D., Karagiannakis, N. P. & Burganos, V. N. Thermal conduction in Hybrid nanofluids and aggregates. Nanomaterials 14 https://doi.org/10.3390/nano14030282 (2024).
Adnan, Abbas, W., Eldin, S. M. & Bani-Fwaz, M. Z. Numerical investigation of non-transient comparative heat transport mechanism in ternary nanofluid under various physical constraints. AIMS Math. 8 https://doi.org/10.3934/math.2023813 (2023).
Alharbi, K. A. M., Adnan, Bani-Fwaz, M. Z., Eldin, S. M. & Akgul, A. Thermal management in annular fin using ternary nanomaterials influenced by magneto-radiative phenomenon and natural convection. Sci. Rep. 13 https://doi.org/10.1038/s41598-023-36418-4 (2023).
Abbasi, A. & Ashraf, W. Analysis of heat transfer performance for ternary nanofluid flow in radiated channel under different physical parameters using GFEM. J. Taiwan. Inst. Chem. Eng. 146 https://doi.org/10.1016/j.jtice.2023.104887 (2023).
Mei, X., Sha, X., Jing, D. & Ma, L. Thermal conductivity and rheology of Graphene Oxide nanofluids and a modified predication model. Appl. Sci. (Switzerland). 12 https://doi.org/10.3390/app12073567 (2022).
Selvam, C., Mohan Lal, D. & Harish, S. Thermal conductivity and specific heat capacity of water–ethylene glycol mixture-based nanofluids with graphene nanoplatelets. J. Therm. Anal. Calorim. 129 https://doi.org/10.1007/s10973-017-6276-6 (2017).
Yadav, S. K., Roy, D., Yadav, A. K., Sagar, P. & Avinashi, S. K. Synthesis and characterization of graphene oxide-based nanofluids and study of their thermal conductivity. J. Therm. Anal. Calorim. 147 https://doi.org/10.1007/s10973-022-11388-3 (2022).
Esfahani, M. R. & Languri, E. M. Exergy analysis of a shell-and-tube heat exchanger using graphene oxide nanofluids. Exp. Therm. Fluid Sci. 83, 100–106. https://doi.org/10.1016/j.expthermflusci.2016.12.004 (2017).
Ranjbarzadeh, R., Akhgar, A., Musivand, S. & Afrand, M. Effects of graphene oxidesilicon oxide hybrid nanomaterials on rheological behavior of water at various time durations and temperatures: synthesis, preparation and stability. Powder Technol. 335, 375–387. https://doi.org/10.1016/j.powtec.2018.05.036 (2018).
Kanti, P. K., Sharma, P., Maiya, M. P. & Sharma, K. V. The stability and thermophysical properties of Al2O3-graphene oxide hybrid nanofluids for solar energy applications: application of robust autoregressive modern machine learning technique. Sol. Energy Mater. Sol. Cells. 253, 112207. https://doi.org/10.1016/J.SOLMAT.2023.112207 (2023).
Kumar Kanti, P., Sharma, P., Sharma, K. V. & Maiya, M. P. The effect of pH on stability and thermal performance of graphene oxide and copper oxide hybrid nanofluids for heat transfer applications: application of novel machine learning technique. J. Energy Chem. https://doi.org/10.1016/J.JECHEM.2023.04.001 (2023).
Kanti, P. K., Sharma, P., Koneru, B., Banerjee, P. & Jayan, K. D. Thermophysical profile of graphene oxide and MXene hybrid nanofluids for sustainable energy applications: Model prediction with a bayesian optimized neural network with K-cross fold validation. FlatChem 39, 100501. https://doi.org/10.1016/J.FLATC.2023.100501 (2023).
Selvarajoo, K., Wanatasanappan, V. V. & Luon, N. Y. Experimental measurement of thermal conductivity and viscosity of Al2O3-GO (80:20) hybrid and mono nanofluids: a new correlation. Diam. Relat. Mater. 144 https://doi.org/10.1016/j.diamond.2024.111018 (2024).
Huminic, G. et al. Water-based Graphene Oxide–Silicon Hybrid Nanofluids—Experimental and Theoretical Approach. Int. J. Mol. Sci. 23, 3056. https://doi.org/10.3390/ijms23063056 (2022).
Çolak, A. B. et al. Experimental study on the Specific Heat Capacity Measurement of Water- based Al2O3-Cu hybrid nanofluid by using Differential Thermal Analysis Method. Curr. Nanosci. 16 https://doi.org/10.2174/1573413715666191118105331 (2019).
Çolak, A. B., Yıldız, O., Bayrak, M. & Tezekici, B. S. Experimental study for predicting the specific heat of water based Cu-Al2O3 hybrid nanofluid using artificial neural network and proposing new correlation. Int. J. Energy Res. 44, 7198–7215. https://doi.org/10.1002/er.5417 (2020).
Kanti, P., Sharma, K. V., Khedkar, R. S. & Rehman, T. Synthesis, characterization, stability, and thermal properties of graphene oxide based hybrid nanofluids for thermal applications: experimental approach. Diam. Relat. Mater. 128, 109265. https://doi.org/10.1016/j.diamond.2022.109265 (2022).
Chen, J. H., Wang, X. L. & Lei, F. Data-driven multinomial random forest: a new random forest variant with strong consistency. J. Big Data. 11 https://doi.org/10.1186/s40537-023-00874-6 (2024).
Breiman, L. Random forests. Mach. Learn. 45 https://doi.org/10.1023/A:1010933404324 (2001).
Biau, G. & Scornet, E. A random forest guided tour. Test 25 https://doi.org/10.1007/s11749-016-0481-7 (2016).
Schonlau, M. & Zou, R. Y. The random forest algorithm for statistical learning. Stata J. 20 https://doi.org/10.1177/1536867X20909688 (2020).
Chen, P. et al. Air pollutant prediction: comparisons between LSTM, light GBM and random forests. J. Environ. Prot. Ecol., 20. (2019).
Gholizadeh, M., Jamei, M., Ahmadianfar, I. & Pourrajab, R. Prediction of nanofluids viscosity using random forest (RF) approach. Chemometr. Intell. Lab. Syst. 201, 104010. https://doi.org/10.1016/j.chemolab.2020.104010 (2020).
Villegas-Mier, C. G., Rodriguez-Resendiz, J., Álvarez-Alvarado, J. M., Jiménez-Hernández, H. & Odry, Á. Optimized Random Forest for Solar Radiation Prediction using Sunshine hours. Micromachines (Basel). 13 https://doi.org/10.3390/mi13091406 (2022).
Kumar, K. P., Alruqi, M., Hanafi, H. A., Sharma, P. & Wanatasanappan, V. V. Effect of particle size on second law of thermodynamics analysis of Al2O3 nanofluid: application of XGBoost and gradient boosting regression for prognostic analysis. Int. J. Therm. Sci. 197, 108825. https://doi.org/10.1016/j.ijthermalsci.2023.108825 (2024).
Bentéjac, C., Csörgő, A. & Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 54 https://doi.org/10.1007/s10462-020-09896-5 (2021).
Wang, F-K. & Mamo, T. Gradient boosted regression model for the degradation analysis of prismatic cells. Comput. Ind. Eng. 144, 106494. https://doi.org/10.1016/j.cie.2020.106494 (2020).
Persson, C., Bacher, P., Shiga, T. & Madsen, H. Multi-site solar power forecasting using gradient boosted regression trees. Sol. Energy. 150, 423–436. https://doi.org/10.1016/J.SOLENER.2017.04.066 (2017).
Aksoy, N. & Genc, I. Predictive models development using gradient boosting based methods for solar power plants. J. Comput. Sci. 67 https://doi.org/10.1016/j.jocs.2023.101958 (2023).
Kefalas, A. et al. Estimation of Combustion parameters from Engine vibrations based on Discrete Wavelet transform and Gradient Boosting. Sensors 22 https://doi.org/10.3390/s22114235 (2022).
Kotsiantis, S. B. Decision trees: a recent overview. Artif. Intell. Rev. 39 https://doi.org/10.1007/s10462-011-9272-4 (2013).
Custode, L. L. & Iacca, G. Evolutionary learning of interpretable decision trees. IEEE Access. 11 https://doi.org/10.1109/ACCESS.2023.3236260 (2023).
Hafeez, M. A. et al. Performance improvement of decision tree: a robust classifier using Tabu Search Algorithm. Appl. Sci. 11, 6728. https://doi.org/10.3390/app11156728 (2021).
Song, Y. Y. & Lu, Y. Decision tree methods: applications for classification and prediction. Shanghai Arch. Psychiatry. 27 https://doi.org/10.11919/j.issn.1002-0829.215044 (2015).
Shehadeh, A., Alshboul, O., Al Mamlook, R. E. & Hamedat, O. Machine learning models for predicting the residual value of heavy construction equipment: an evaluation of modified decision tree, LightGBM, and XGBoost regression. Autom. Constr. 129 https://doi.org/10.1016/j.autcon.2021.103827 (2021).
Wojtuch, A., Jankowski, R. & Podlewska, S. How can SHAP values help to shape metabolic stability of chemical compounds? J. Cheminform. 13 https://doi.org/10.1186/s13321-021-00542-y (2021).
Dataman Dr. Explain Your Model with the SHAP Values (Towards Data Science, 2019).
Futagami, K., Fukazawa, Y., Kapoor, N. & Kito, T. Pairwise acquisition prediction with SHAP value interpretation. J. Finance Data Sci. 7, 22–44. https://doi.org/10.1016/J.JFDS.2021.02.001 (2021).
Fryer, D., Strümke, I. & Nguyen, H. Shapley values for feature selection: the Good, the bad, and the axioms. IEEE Access. 9 https://doi.org/10.1109/ACCESS.2021.3119110 (2021).
Wang, N. et al. On the use of explainable AI for susceptibility modeling: examining the spatial pattern of SHAP values. Geosci. Front. 15 https://doi.org/10.1016/j.gsf.2024.101800 (2024).
Zhong, L. et al. SHAP values accurately explain the difference in modeling accuracy of convolution neural network between soil full-spectrum and feature-spectrum. Comput. Electron. Agric. 217 https://doi.org/10.1016/j.compag.2024.108627 (2024).
Acknowledgements
The authors extend their appreciation to their respective institution for their extended support throughout this research work.
Funding
There are no funding bodies / agencies involved in this research work, and the authors solely contribute to it.
Author information
Authors and Affiliations
Contributions
PKK: conceptualization, methodology, data curation, writing – original draft. PP: Software, resources, supervision. VVW: writing – review and editing, resources, methodology. SD: Former Analysis, Validation, writing –review and editing. PS: writing – review and editing , Project Administration, supervision, Validation.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kanti, P.K., Paramasivam, P., Wanatasanappan, V.V. et al. Experimental and explainable machine learning approach on thermal conductivity and viscosity of water based graphene oxide based mono and hybrid nanofluids. Sci Rep 14, 30967 (2024). https://doi.org/10.1038/s41598-024-81955-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-81955-1
Keywords
This article is cited by
-
Machine and deep learning models for predicting high pressure density of heterocyclic thiophenic compounds based on critical properties
Scientific Reports (2025)
-
Thermal and Flow Properties of Graphene/Fe3O4 Water-Based Hybrid Nanofluids
International Journal of Thermophysics (2025)
