
Abstract
To mitigate the safety risks and economic losses caused by wheel damage, this paper proposes an interval valued fuzzy inference-based sound analysis method for wheel damage detection. Firstly, interval valued fuzzy sets are defined to represent various levels of damage severity. A similarity calculation method is then designed, based on the defined interval valued fuzzy sets, to assess the damage level of wheel components. Moreover, the OWA operator is employed to assign higher weights to key features while reducing the influence of noise or redundant features. Finally, a double-threshold interval valued fuzzy inference approach is proposed for comprehensive decision-making regarding the wheel damage degree. The proposed method is applied to wheel damage sound analysis, and a corresponding detection system is developed. Experimental results demonstrate that the proposed method outperforms existing techniques in detection accuracy, response speed, and robustness, and it is adaptable to various wheel operating environments.
Similar content being viewed by others

Introduction
Collisions between external objects and wheels may cause damage, leading to potential safety risks and economic losses. Therefore, researching wheel damage detection methods has significant theoretical value, economic benefits, and safety implications. Traditional methods for detecting damage in railway and motor vehicle wheels rely primarily on manual inspection, which suffers from high labor intensity and subjective results. When a large vehicle is driving smoothly, the wheel vibration waveform may be irregular, but the amplitude of sound vibrations usually remains below a fixed threshold. However, when a wheel is damaged by a foreign object, the sound vibration amplitude will spike significantly. This phenomenon forms the theoretical basis for developing a wheel damage detection system. By detecting sound signals during wheel operation, wheel damage can be effectively identified, allowing for timely early warnings. Additionally, the damage location and the foreign object responsible can be pinpointed. Our previous research has demonstrated the significant potential of fuzzy inference in wheel damage detection, fault diagnosis, and early warning systems.
Fuzzy inference has been widely applied in control systems and artificial intelligence. Closed intervals and fuzzy sets offer similar advantages in representing uncertain data. In the early 1980s, the Polish school introduced interval analysis as a complementary tool to fuzzy set methods1,2. Due to the improved results from combining interval analysis with fuzzy set methods, the concept of interval valued fuzzy sets was introduced and applied in fuzzy inference.
In practical applications, especially in decision-making and evaluation, determining single-valued membership is often difficult, whereas interval valued membership is easier to establish due to the complexity of dynamic processes. Additionally, interval valued fuzzy inference helps reduce information loss during the inference process. Zeng et al.3 examined simple and multiple interval valued fuzzy inference based on fuzzy relations, but did not address cases involving deterministic factors or weights. During the inference process, factors with greater influence should be assigned higher weights, to align with human cognitive reasoning. Yager’s OWA (ordered weighted averaging) operator theory4,5 effectively embodies this principle. Liu et al.6 introduces several commonly used OWA operators, while wang et al.7 discusses the weighting method for OWA operators involving combination numbers. To compare two interval valued fuzzy sets8, quantitative indicators such as distance and norm are required. Distance measures the difference between two sets, while norm evaluates their similarity9. Gitinavard et al.10 proposed a decision model based on complex proportional evaluation and final aggregation in a hesitant fuzzy environment, which reduces information loss and accounts for unequal weight distribution among decision-makers. Gitinavard et al.11 also introduced a ranking method within an interval valued hesitant fuzzy set (IVHFS) environment, aiming to reduce data loss and better manage uncertainty, with its feasibility demonstrated in green supplier selection. However, these studies primarily focus on theoretical derivation and methodological exploration, with limited application to specific practical problems.
In numerous application areas, especially in decision-making and inference, the ambiguity and lack of information make it difficult to describe object characteristics using single-valued membership. In such cases, it is more appropriate to use interval valued membership instead. In the 1970s, Zadeh12, Jahn13, Sambuc14, and Grattan-Guinness15 independently introduced the concept of interval valued fuzzy sets, which are considered a generalization of Zadeh’s fuzzy sets. In many instances, interval valued fuzzy set theory better fits real-world decision-making and inference processes. Turksen’s work on interval valued fuzzy set paradigms16, M.B. Gorzafczany’s research on approximate inference with interval valued fuzzy sets17,18, and contributions from Zeng et al. to decomposition, representation, and extension theorems19,20 have significantly advanced the field.
Interval valued fuzzy sets have demonstrated notable success in cluster analysis21, comprehensive evaluation22, decision analysis23, and fuzzy inference24,25, among other fields. Mousavi et al.26 explored the application of the interval valued hesitant fuzzy group decision-making (IVHF-GDM) method in evaluating the relationships between candidate robots and their attributes. They demonstrated the method’s effectiveness in handling complex decision-making processes. However, research on the application of fuzzy inference in wheel damage detection remains limited, despite its proven success in other domains. Furthermore, traditional fuzzy inference methods typically use single-weight inference, which fails to account for the multidimensional differences between influencing factors.
Mosleh et al.27 proposed an unsupervised method based on track acceleration data to detect wheel abrasions, but it is susceptible to noise and lacks fine-grained distinction of damage types. Moreover, its reliance on track acceleration data makes it vulnerable to noise interference in complex environments, reducing accuracy. Mosleh et al.28 proposed an envelope spectrum analysis method for detecting wheel flat defects, but it struggles to differentiate defects in complex damage scenarios and depends heavily on speed and track conditions. These limitations restrict its broader applicability in real-world environments.
To address the problem of wheel damage detection, this paper proposes a sound analysis method based on interval valued fuzzy inference, as shown in Fig. 1. The method consists of four main steps: First, interval valued fuzzy sets are defined to represent different levels of damage severity. Next, the sound signal of a normal wheel and the data collected by the pickup are input into the similarity calculation module. The results are then mapped to interval valued fuzzy sets to evaluate the damage level of each wheel component. Subsequently, the OWA operator is used to assign weights to different damage levels. Since the same wheel may produce different sounds in various scenarios, targeted evaluations are necessary for different conditions. Finally, the double-threshold interval valued fuzzy inference method is applied to determine the comprehensive damage level of the wheel.

The pipeline of interval valued fuzzy inference method.
The contributions of this paper are as follows:
-
(1)
An interval valued fuzzy set is defined to represent different levels of damage severity, and a similarity calculation method is developed to assess the damage levels of various wheel components.
-
(2)
An OWA operator weighting method is designed to assign higher weights to key features and lower weights to noise or redundant features.
-
(3)
A double-threshold interval valued fuzzy inference method is proposed to make comprehensive decisions on the overall wheel damage level.
-
(4)
Experimental results demonstrate that the proposed method outperforms existing approaches in detection accuracy, response speed, and robustness, and is adaptable to various wheel operating environments.
Define interval valued fuzzy sets
Based on the definition rules in fuzzy sets29, this paper provides the following definition based on the problem under investigation:
Definition 1
Let \(U=\{u_1,u_2,\cdots ,u_n\}\) be a domain of discourse. An interval valued fuzzy set \(A:U \rightarrow I[0,1]\) assigns each element in U to a closed subinterval of [0,1], where I[0, 1] denotes the set of all closed subintervals within [0, 1]. For \(\forall u_i \in U\), the interval valued fuzzy set A is defined as \(A=\{[A^-(u_i),A^+(u_i)]\vert ,u_i\in U\}\) where \(A^-:U\rightarrow [0,1]\) and \(A^+:U\rightarrow [0,1]\), with \(A^-(u_i) \le A^+(u_i)\) for all \(u_i\in U\). The collection of all interval valued fuzzy sets defined on the domain U is denoted by IF(U).
Definition 2
\(A,B\in IF(U)\), and the operations of the intersection and union of A and B are as follows:
Similarity degree calculation
When measuring the difference between defects and normal parts, appropriate metrics must be introduced. In the study of wheel damage detection using interval valued fuzzy sets, this paper adopts the similarity of interval valued fuzzy sets as the metric. Below, we define the similarity of interval valued fuzzy sets.
Definition 3
Let an \(A(A\in IF(X))\) membership function represented as A(x), where \(A(x) = [A^-(X), A^+(X)]\), suppose there is a mapping \(N:IF(X)\times IF(X)\rightarrow I,A,B,\in IF(X)\), if:
-
(1)
\(N(A,A)=1\)
-
(2)
\(N(X,\varnothing )=0,X=(1,1),\varnothing =(0,0)\)
-
(3)
\(N(A,B)=N(B,A)\)
-
(4)
\(A\subseteq B\subseteq C\Rightarrow N(A,C) \le N(B,C) \wedge N(A,B)\)
Then, N(A, B) is defined as the similarity between A and B.
Considering the different impacts of the upper and lower bounds of the interval values on the similarity calculation, as well as the varying importance of each factor or attribute in the domain, this paper assigns different weights based on the actual situation. The resulting similarity calculation formula is as follows:
Theorem 1
If \(A,B\in IF(X)\), when \(X=\{x_1,x_2,\cdots ,x_n\}\) is a finite set, \(p\in N^*\), take \(\lambda _i,\mu _i \in [0,1]\) and \(\lambda _i+\mu _i=1, \omega =(\omega _1,\omega _2,\cdots ,\omega _n)\) is the weighted vector associated with the domain of discourse X, where \(\omega _i \in [0,1],\sum \limits _{i=1}^{n}\omega _i=1,i=1,2,\cdots ,n\), define:
Then, N(A, B) represents the similarity degree of interval valued fuzzy sets A and B.
(b) if \(A(x_i)=[1,1]\), then \(A^C(x_i)=[0,0],i=1,2,\cdots ,n\), there is
Similarly: if \(A(x_i)=[0,0]\), then \(A^C(x_i)=[1,1], i=1,2,\cdots ,n\), then \(N(A,A^C)=0\);
(c) \(N(A,B)=N(B,A)\) is obviously true.
(d) \(\because A\subseteq B\subseteq C\)
\(\therefore A^-(x_i) \le B^-(x_i) \le C^-(x_i), A^+(x_i) \le B^+(x_i) \le C^+(x_i),\quad i=1,2,\cdots ,n,\)
then
\(\vert A^-(x_i) - C^-(x_i) \vert \ge \vert A^-(x_i) - B^-(x_i) \vert , \vert A^+(x_i) - C^+(x_i) \vert \ge \vert A^+(x_i) - B^+(x_i) \vert\)
that
\(\lambda _i\vert A^-(x_i) - C^-(x_i) \vert ^p \ge \lambda _i\vert A^-(x_i) - B^-(x_i) \vert ^p\), \(\mu _i\vert A^+(x_i) - C^+(x_i) \vert ^p \ge \mu _i\vert A^+(x_i) - B^+(x_i) \vert ^p\)
\(\sum \limits _{i=1}^{n}\omega _i (\lambda _i\vert A^-(x_i)-C^-(x_i)\vert ^p + \mu _i\vert A^+(x_i)-C^+(x_i)\vert ^p) \ge \sum \limits _{i=1}^{n}\omega _i (\lambda _i\vert A^-(x_i)-B^-(x_i)\vert ^p + \mu _i\vert A^+(x_i)-B^+(x_i)\vert ^p)\)\(\ge \sum \limits _{i=1}^{n}\omega _i (\lambda _i\vert A^-(x_i)-B^-(x_i)\vert ^p + \mu _i\vert A^+(x_i)-B^+(x_i)\vert ^p)\)
so
Similarly \(N(A,C) \le N(B,C)\).
\(\therefore N(A,B)\) is the similarity degree of interval valued fuzzy sets A and B.
When \(p=1\) or 2, the following inference can be drawn from the theorem mentioned above:
Corollary 1
If \(A,B\in IF(X)\), when \(X=\{x_1,x_2,\cdots ,x_n\}\) is a finite set, take \(\lambda _i,\mu _i \in [0,1]\) and \(\lambda _i+\mu _i=1, \omega =(\omega _1,\omega _2,\cdots ,\omega _n)\) is the weighted vector associated with the domain of discourse X, where \(\omega _i \in [0,1],\sum \limits _{i=1}^{n}\omega _i=1,i=1,2,\cdots ,n\), defined
Then \(N_1(A,B)\) is the similarity degree of interval valued fuzzy sets A and B.
Corollary 2
If \(A,B\in IF(X)\), when \(X=\{x_1,x_2,\cdots ,x_n\}\) is a finite set, take \(\lambda _i,\mu _i \in [0,1]\) and \(\lambda _i+\mu _i=1, \omega =(\omega _1,\omega _2,\cdots ,\omega _n)\) is the weighted vector associated with the domain of discourse X, where \(\omega _i \in [0,1],\sum \limits _{i=1}^{n}\omega _i=1,i=1,2,\cdots ,n\), defined
Then \(N_2(A,B)\) is the similarity degree of interval valued fuzzy sets A and B.
OWA operator weighting method
OWA operator: Let \((a_1,a_2,\cdots ,a_n\in R^n)\), R is the sets of real numbers. Let \(F:R^n \rightarrow R\), if \(F(a_1,a_2,\cdots ,a_n=\sum \limits _{j=1}^{n}\omega _jb_j)\), F is an n-dimensional ordered weighted average operator (OWA operator). Here, \(\omega _j \in [0,1],j \in \{1,2,\cdots ,n\},\) \(\omega =(\omega _1,\omega _2,\cdots ,\omega _n)\) are n-dimensional weighted vectors associated with the function F, and \(\sum \limits _{j=1}^{n}\omega _j=1\), let \(b_j\) be the j-th number after \(a_n\) is sorted from largest to smallest.
A key feature of the OWA operator is that it first reorders the decision data \((a_1,a_2,\cdots ,a_n)\) in descending order to produce a new sequence \((b_1,b_2,\cdots ,b_n)\), which is then aggregated using a weighted vector. The weight \(w_j\) is unrelated to the element \(a_j\) but is determined by the j-th position during aggregation.
The OWA operator performs aggregation multi-attribute decision information between the maximum and minimum operators. When the weight vector w takes special values, the operator exhibits specific behavior, as follows:
-
(1)
When \(\omega =(1,0,0,\cdots ,0)\), \(F(a_1,a_2,\cdots ,a_n)=\sum \limits _{j=1}^{n}\omega _jb_j=b_1\). In this case, the OWA operator is equivalent to the \(\vee\) operator in fuzzy operations.
-
(2)
When \(\omega =(0,0,0,\cdots ,1)\), \(F(a_1,a_2,\cdots ,a_n)=\sum \limits _{j=1}^{n}\omega _jb_j=b_n\). In this case, the OWA operator is equivalent to the \(\wedge\) operator in fuzzy operations.
-
(3)
When \(\omega =(\frac{1}{n},\frac{1}{n},\cdots ,\frac{1}{n})\), \(F(a_1,a_2,\cdots ,a_n)=\sum \limits _{j=1}^{n}\omega _jb_j=\frac{1}{n}\sum \limits _{i=1}^{n}a_i\). In this case, the OWA operator is equivalent to the arithmetic average operator.
In decision-making and inference processes, experts may sometimes provide biased evaluations due to personal preferences or aversions. To ensure fairness and objectivity in the evaluation process, the influence of such emotional factors should be minimized when collecting experimental data. Considering these factors, the weight design proposed in this paper is relatively reasonable. Whether an expert assigns a high score due to preference or a low score due to aversion, the corresponding weight will be reduced, effectively mitigating the negative impact of emotional bias. Following this principle, this paper proposes an OWA operator weighting method based on differentiated weights.
Weight Acquisition Method: Assuming the components of the vector \(\omega (\omega _1,\omega _2,\cdots ,\omega _n)\) are defined according to the combination number formula (4), and the conditions of Definition 4 are satisfied, then the weights obtained are ordered weighted weights.
Obviously, \(\sum \limits _{j=1}^{n}\omega _j=1\) is true.
\(\sum \limits _{k=0}^{n-1}C_{n-1}^{k}=2^{n-1}\) is known by the properties of combination numbers, then
The Eq. (4), defined based on the random sequence of nature, is arranged in accordance with objective phenomena, aligning with the natural law governing the development of things.
Double threshold multiple multi-dimensional fuzzy inference method
The performance of wheel damage is influenced by various factors, including the working environment, road conditions, load, and vehicle type. Therefore, it is necessary to evaluate the similarity among these factors and provide multiple decision-making inferences. Using multi-dimensional inference as an basis, this paper proposes an interval valued fuzzy inference method based on weighted similarity degrees. To enhance the practicality and generality of the method, the following three conditions are established:
-
(1)
Assign an appropriate threshold, denoted as \(\tau _i\), where \(\tau _i \in [0,1]\), and \(i=1,2,\cdots ,n\), to the i-th rule. This threshold determines the validity of the rule. If the rule meets or exceeds this threshold, it will be activated; otherwise, it will not be activated.
-
(2)
Associate each antecedent of the i-th rule with a threshold vector \(\gamma _i=(\gamma _{i1},\gamma _{i2},\cdots ,\gamma _{im})\), where \(\gamma _{ij}\) represents the threshold for the i-th rule’s antecedent \(A_{ij}\), and \(\gamma _{ij}\in [0,1], \quad i=1,2,\cdots ,n,\) and \(\quad j=1,2,\cdots ,m\). When the given fact \(A_j^*\) has a similarity degree \(N(A_j^*,A_{ij}\ge \gamma _{ij})\) with \(A_{ij}\), further calculations are performed based on this similarity degree. if \(N(A_j^*,A_{ij} < \gamma _{ij})\), then set \(N(A_j^*,A_{ij} = 0\) and proceed with additional calculations. This approach is practical because when the similarity degree \(N(A_j^*,A_{ij})\) between is too small, the fact is considered to have no significant effect on the result.
-
(3)
Depending on the situation, each antecedent has a different impact on the outcome. The antecedent of the i rule is assigned a weight vector \(\omega _i=(\omega _{i1},\omega _{i2},\cdots ,\omega _{im})\), where \(\omega _{ij}\in [0,1]\), with \(i=1,2,\cdots ,n\), and \(j=1,2,\cdots ,m,\) and \(\sum \limits _{j=1}^{m}\omega _{ij}=1\). Here, \(\omega _{ij}\) represents the influence of the antecedent \(A_{ij}\) of rule i on the consequence \(B_i\) of the rule.
After introducing the threshold, the general form of interval valued fuzzy inference is:
Known \(R_1: A_{11}\) and \(A_{12}\) and \(\cdots\) and \(A_{1m} \rightarrow B_1, \gamma _1,\tau _1\)
\(R_2: A_{21}\) and \(A_{22}\) and \(\cdots\) and \(A_{2m} \rightarrow B_2, \gamma _2,\tau _2\)
\(\cdots \cdots\)
\(R_n: A_{n1}\) and \(A_{n2}\) and \(\cdots\) and \(A_{nm} \rightarrow B_n, \gamma _n,\tau _n\)
Given \(A_1^*\) and \(A_2^*\) and \(\cdots\) and \(A_m^*\)
Find \(B^*\)
Here, \(R_i\) represents the rules we defined, which include premise \(A_i\) and corresponding conclusions \(B_i\), \(\gamma _i\), \(\tau _i\). \(A_{ij}\) represents the quantitative value of the wheel attribute, \(B_i\) represents the membership value of the sound amplitude, \(\gamma _i\) represents the membership value of the sound wavelength, and \(\tau _i\) represents the membership value of the sound frequency. These are used to judge the degree of wheel damage. \(A_i^*\) represents our input, and \(B^*\) represents the output corresponding to \(A_i^*\).
Next, the new interval valued fuzzy inference algorithm based on similarity is:
Step 1: Calculate the similarity between each antecedent of each rule and the antecedent corresponding to the given fact:
First, the obtained similarity degree \(\alpha _{ij}\) is compared with the corresponding threshold \(\gamma _{ij}\). If \(\alpha _{ij} \ge \gamma _{ij}\), then set \(\alpha _{ij}^* = \alpha _{ij}\); if \(\alpha _{ij} < \gamma _{ij}\), then set \(\alpha _{ij}^* = 0\). The resulting similarity degree vector after comparison is denoted as \(\alpha _i^* = (\alpha _{i1}^*,\alpha _{i2}^*,\cdots ,\alpha _{im}^*)\).
Next, let \(w_i=(w_{i1},w_{i2},\cdots ,w_{im})\), where \(i=1,2,\cdots ,n\), represent the OWA operator based on combination numbe. The comprehensive similarity degree of the i-th rule, denoted as \(\pi _i\), then
Where \((\varepsilon _{i1},\varepsilon _{i2},\cdots ,\varepsilon _{im})\) is the component vector of \(\alpha _i^*=(\alpha _{i1}^*,\alpha _{i2}^*,\cdots ,\alpha _{im}^*)\) sorted in descending order.
Based on the provided threshold \(\tau _i\), the following can be inferred:
If \(\pi _i \ge \tau _i\), this rule will be activated.
If \(\pi _i < \tau _i\), this rule will not be activated.
Step 2: When only i-th Rule is activated, the output is calculated as follows:
When p rules (where \(p>1\)) are activated, the conclusions from these rules are combined with appropriate weights to reach the final conclusion. To determine the weights, the parameter \(\beta\) is involved in determining the weights, the comprehensive similarity degree \(\pi _i\) is used to establish the weight vector. Here \(\beta\) is defined as \(\beta =\mathop {max}\limits _{i\text {-th rule is activated}}(\pi _i)\), and s represents the number of activated rules with the maximum comprehensive similarity degree.
Let \(I=\{i\vert i-th\, rule\, is\, activated ,\pi _i=\beta ,1 \le i \le n\}\), and assign the weight \(\frac{1+\beta }{2s}\) to \(B_i\). The conclusion of the rules with the largest comprehensive similarity degree is denoted as \(B_1^* = \mathop {\cup }\limits _{i\in I}\frac{1+\beta }{2s}B_i\).
For the remaining activated rules, assign the weight \(\frac{1-\beta }{2(p-s)}\). The conclusions of these rules are then denoted as \(B_2^* = \mathop {\cup }\limits _{i\notin I}\frac{1-\beta }{2(p-s)}B_i\).
Step 3: Merge the conclusions from both steps to obtain the actual output \(B^*=B_1^* \cup B_2^*\).
Application of interval valued fuzzy inference method in wheel damage detection
In this section, we present a specific case to demonstrate the detailed implementation process of the interval valued fuzzy inference method for wheel defect detection.
Case definition
Since wheel damage can occur in different environments, affect different parts, and vary in severity, multiple multidimensional interval values must be considered when calculating similarity. For wheel defect detection, it is necessary to adopt multidimensional fuzzy inference methods. To address this, we define a set of multidimensional interval valued fuzzy production rules, as follows:
Known \(R_1: A_{11}\) and \(A_{12}\) and \(A_{13} \rightarrow B_1, \gamma _1,\tau _1\)
\(R_2: A_{21}\) and \(A_{22}\) and \(A_{23} \rightarrow B_2, \gamma _2,\tau _2\)
\(R_3: A_{31}\) and \(A_{32}\) and \(A_{33} \rightarrow B_3, \gamma _3,\tau _3\)
Given \(A_1^*\) and \(A_2^*\) and \(A_3^*\)
Find \(B^*\)
Where \(A_{1\_}\): slight damage, \(A_{2\_}\): moderate damage, \(A_{3\_}\): severe damage
Wheel: \(A_{\_1}\)[left wheel damage membership, right wheel damage membership]
Bogie: \(A_{\_2}\)[horizontal deformation membership, vertical deformation membership, diagonal deformation membership]
Rail: \(A_{\_3}\)[left rail damage membership, right rail damage membership, rail width, rail height]
\(B_{\_}\): sound amplitude, \(\gamma _{\_}\): sound wavelength, \(\tau _{\_}\): sound frequency
Case calculation process
Assume the membership values for each component of a certain interval of wheel damage are calculated as follows:
\(A_{11}\)={[0.1,0.2],[0.1,0.3]}, \(A_{12}\)={[0.1,0.3],[0.4,0.5],[0.7,0.8]}, \(A_{13}\)={[0.2,0.3],[0.1,0.3],[0.4,0.6],[0.8,0.9]};
\(A_{21}\)={[0.4,0.6],[0.6,0.7]}, \(A_{22}\)={[0.2,0.4],[0.7,0.9],[0.4,0.5]}, \(A_{23}\)={[0.4,0.6],[0.5,0.6],[0.7,0.8],[0.3,0.5]};
\(A_{31}\)={[0.7,0.9],[0.8,0.9]}, \(A_{32}\)={[0.6,0.8],[0.1,0.3],[0.5,0.7]}, \(A_{33}\)={[0.7,0.8],[0.6,0.8],[0.2,0.4],[0.5,0.7]};
\(B_{1}\)={[0.2,0.4],[0.5,0.6]}, \(B_{2}\)={[0.5,0.7],[0.1,0.3]}, \(B_{3}\)={[0.6,0.8],[0.9,0.95]};
The membership value for a normal wheel is assumed to be:
\(A_1^*\)={[0.6,0.8],[0.4,0.6]}, \(A_2^*\)={[0.1,0.3],[0.4,0.6],[0.6,0.8]}, \(A_3^*\)={[0.5,0.7],[0.4,0.5],[0.3,0.5],[0.4,0.6]}.
For simplicity, let \(\gamma _1=\gamma _2=\gamma _3=(0.6,0.6,0.6),\tau _1=0.65,\tau _2=0.65\), and \(\tau _3=0.70\).
Based on the inference steps outlined above, we proceed to infer the systematic results.
Firstly, the similarity degree \(\alpha _{ij}\) between the given fact \(A_j^*\) and the i-th rule is calculated using the similarity degree Eq. (2) as mentioned in corollary 1, where \(\lambda _i\)=0.4,\(\mu _i=0.6\), and the value of \(\omega _i\) is determined by the OWA operator Eq. (5) based on the combination number. The computed similarity degree are \(\alpha _1\)=(0.57,0.965,0.74),\(\alpha _2\)=(0.83,0.77,0.78),\(\alpha _3\)=(0.78,0.675,0.865). These are then compared with \(\gamma _j\)=(0.6,0.6,0.6), resulting in \(\alpha _1^*\)=(0,0.965,0.74),\(\alpha _2^*\)=(0.83,0.77,0.78), \(\alpha _3^*\)=(0.78,0.675,0.865).
Next, the weight vector \(\omega _i=(\omega _{i1},\omega _{i2},\cdots ,\omega _{im})\), where \(i=1,2,\cdots ,n\), represents the degree of influence of the antecedent on the conclusion of the i-th rule, These weights are obtained using the OWA operator based on combination numbers. The similarity degree \(\pi _i\) between the given fact \(A^*\) and the i-th rule are as follows: \(\pi _1=0.61125, \pi _2=0.79, \pi _3=0.775\). Based on the given threshold \(\tau _i\), the fuzzy inference system can generate multiple multi-dimensional interval valued fuzzy production rules:
\(\pi _1=0.61125<\tau _1=0.62\), the first rule is not activated;
\(\pi _2=0.79>\tau _2=0.65\), the second rule is activated;
\(\pi _3=0.775>\tau _3=0.70\), the third rule is activated.
Since more than one rule is activated, we follow the method outlined in Step 2 to calculate the final result. It is known that \(\beta = \mathop {max}\limits _{i\text {-th rule is activated}}(\pi _i)=\pi _2=0.79\),
Then, the final result \(B^*=B_1^* \cup B_2^*=\{[0.4475,0.6265],[0.0945,0.2685]\}\).
If in the above example, the threshold \(\gamma _i\)(for \(i=1,2,3\)) is removed and no other changes are made, then
\(\pi _1=0.75375>\tau _1=0.65\), the first rule is activated, too.
All the three rules will be activated, then
Therefore, the final result \(B^*=B_1^* \cup B_2^*=\{[0.4475,0.6265],[0.0845,0.2685]\}\).
Case results
Comparing the two final output results above, it is clear that there are differences between them. The thresholds \(\gamma _i,i=1,2,3\) are valid, as they filter out unnecessary rules, thereby influencing the final output.
To validate the feasibility and reliability of the interval valued similarity degree defined in this paper, we compare the membership degree provided by the expert system for real wheel damage with the calculations from Eq. (1)–(3), as shown in Fig. 2.

The computed interval valued similarity degree is compared with the membership values from the actual expert system.
As shown in Fig. 2, the values calculated using (1)–(3) closely approximates the true values, demonstrating the validity and feasibility of the defined interval valued fuzzy similarity degree.
Dataset
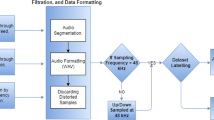
The dataset construction pipeline is shown in Fig. 3.

The pipeline of dataset construction.
Data acquisition
In the construction route, the experimental design is based on a bogie equipped with three wheelsets (six wheels), with pickups installed near the wheels on both sides of each wheelset. The pickup heads are positioned close to and facing the wheels, and the wires from the 6 pickups are bundled together and connected to a small host device inside the vehicle through the side of the car for data transmission, as shown in Fig. 4.

Installation of relevant equipment and the software system.
On the test route, simulated damage objects are set, and the vehicle runs back and forth along the route in the experimental area to collect data under various damage conditions. The collected data is transmitted in real-time to a small data server, as illustrated in Fig. 5.

The pipeline of data acquisition.
Establishment of expert knowledge base
Using the collected data, fuzzy interval values are calculated for bruises and normal sounds. Then, classify and analyze the data based on these interval values to identify the different characteristics of bruised and normal sounds. Additionally, a difference analysis algorithm is developed to compare the normal standard library data with the test data.
Part of the collected data will be used as a standard library for model training. Once the training reaches the desired accuracy, the remaining data will be imported into the trained model for testing. Through the analysis and training of bruised and normal sound data, an expert knowledge base of different sound characteristics can be established.
Data calibration
-
(1)
Damage Time
By analyzing the amplitude or frequency data of sound waves collected under normal and damaged conditions, fuzzy interval values are calculated to determine whether a damage has occurred, and an identification algorithm model is established. Subsequently, a fuzzy interval value algorithm program is written to build a damage detection system. When the system is running, it records the exact time of the damage based on the internal clock. Using this algorithm model, the system automatically identifies the specific damaged wheel when a damage is detected.
-
(2)
Damage Location
Using the fuzzy interval value algorithm, along with the vehicle’s speed and the recorded damage time, the system calculates the exact location on the track where the damage occurred, i.e., the vehicle’s position at the time of damage.
-
(3)
Identification of the Damaged Object
Prior to data analysis, a data collection experiment is conducted to simulate different types of wheel damage caused by various obstacles. The sound wave data from these tests is used to calculate fuzzy interval values for each type of damage. These values help extract the sound wave characteristics for various types of wheel damage, establishing an expert database of sound signatures. When a wheel is damaged, the system automatically matches the current sound wave with those in the expert database to identify the specific type of damage.
Experiment
Problem definition
The data is collected in real-time by pickups installed on the inner side of the EMU bogie. The captured audio signals are analyzed and processed to assess the comprehensive damage status of the wheel. The input includes the sound wave signal \(X(t)={\lambda (t),F(t),\omega (t)}\) collected by the pickup and the azimuth angle \(\phi (t)\). The output includes the frequency and amplitude of the sound wave.
Here \(\lambda (t)\) represents the wavelength at time t, F(t) represents the amplitude at time t, \(\omega (t)\) represents the sound frequency at time t.
Interval value fuzzy inference detection system
Based on the interval valued fuzzy inference method, this paper establishes an interval valued fuzzy inference detection system, as shown in Fig. 6.

The interval Value Fuzzy Inference Detection System(IVFIS).
First, the developed system was installed in the wheel running environment shown in Fig. 7 for preliminary testing. It was then integrated into the control system of the train test section, where 150 tests were conducted under different conditions. During train operation, the system detects the damage degree d of the wheelset components and compares it with the membership degree \(d_0\) from the expert standard library. If the difference \(e=|d-d_0|\) is less than \(\delta\), the detection result is considered accurate. As the number of experiments increases, the error e approaches 0, as shown in Fig. 8.

The Wheel driving environment.

Stability of the interval Value Fuzzy Inference Detection System.
Experimental results show that the inference detection system demonstrates strong robustness when facing interferences such as road surface bumps, slight track deformations, and minor rail looseness. This robustness can be attributed to two main factors: (1) The signal acquisition device is installed on the bogie rather than directly on the wheel, making it less sensitive to noise and improving the algorithm’s robustness. (2) Key parameters, such as the weight vector and dual thresholds in the similarity calculation, are automatically selected, reducing the system’s dependence on these parameters.
Quantitative results
The method proposed in this paper is compared with existing detection methods, including the GAN network30, Yolox31, STC89C51 processor of MCU unit32, and the fuzzy inference method19. The results are shown in Fig. 9.

Comparison results of the interval valued fuzzy inference method proposed in this paper with other methods.
As shown in the experimental process and Fig. 9, the detection accuracy of the proposed method exceeds 90% with 200 samples, while the accuracy of GAN, Yolox, the STC89C51 processor, and the fuzzy inference method are all below 90%. This demonstrates that the method in this paper has significant advantages in detection accuracy.
Since the interval valued fuzzy inference method in this paper performs inference based on similarity calculations, it not only aligns more closely with the natural properties of objects but also reflects objective facts more accurately. Additionally, this method offers fast detection speeds and is minimally affected by external interference. Furthermore, it can accurately locate the damaged wheel, determine the time of damage, identify the damage location, and calibrate the damaged object.
Qualitative results
The waveform of the simulated wheel bruise in the environment shown in Fig. 7 is shown in Fig. 10. By observing the sound waveform, it is evident that when the wheel is bruised, the waveform amplitude shows a significant jump. Multiple experimental results further confirm the presence of wheel bruising, demonstrating that the system can effectively perform the alarm function for wheel bruises.

The Waveform When the wheel is damaged.
Conclusion
This paper proposes a wheel damage detection method based on interval valued fuzzy inference by analyzing sound during wheel operation. It effectively addresses the challenge of detecting wheel damage. First, interval valued fuzzy sets are defined to represent different levels of damage severity. Then, the sound signals from normal wheels and the data collected by the pickup are processed through a similarity calculation method, with results mapped to the interval valued fuzzy set to evaluate the damage level of each wheel component. The OWA operator is then used to assign weights to different damage degrees. Finally, a double-threshold interval valued fuzzy inference method is applied to make a final decision on the wheel’s overall damage level. This method was validated in wheel scratch sound analysis experiments, demonstrating its effectiveness. Compared to other detection methods, it offers significant advantages in detection accuracy, aligning more closely with natural object properties, reflecting objective facts, delivering fast detection, and being less affected by external interference. Additionally, it can accurately locate the damaged wheel, determine the time of damage, identify the damage location, and calibrate the damaged object.
The application of the research method in this paper offers valuable insights insights for railway operation management. First, by enabling automatic detection of sound signals, managers can identify abnormal conditions of train components at an early stage, thereby effectively reducing the incidence of equipment failures, thereby reducing operating costs and ensuring safety. Secondly, the robustness of the algorithm demonstrates that the system can operate stably in different environments, which means that reliable condition monitoring can be achieved in different regions and weather conditions, providing a wide range of application possibilities for railway management departments. Finally, the automated threshold and weight selection significantly reduces reliance on professionals, thereby enhancing railway operation management more efficient and reduce labor costs.
However, this paper also identifies several limitations: (1) some parameter adjustments rely on randomness; (2) model correction efficiency is low; and (3) the method’s applicability in non-ground driving scenarios remains unverified. Sensitivity analysis showed that automated parameter assignment reduces the model’s sensitivity to key parameters. Future work will focus on improving the controllability and correction efficiency of parameter adjustments, expanding the application scenarios, and developing universal parameter adaptive adjustment mechanisms to enhance the model’s robustness and generalization in practical applications.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author QingE Wu (qewu@sspu.edu.cn) on reasonable request.
References
Albrycht, J. & Wišniewski, H. Proceedings of the Polish Symposium on Interval & Fuzzy Mathematics: August 26-29, 1983 (Wydawnictwo Politechniki Poznaňskiej, 1985).
Turksen, I. & Yao, D. D. Representations of connectives in fuzzy reasoning: The view through normal forms. IEEE Trans. Syst. Man Cybern. 146–151 (1984).
Zeng, W., Yu, F. & Li, H. Interval-valued fuzzy inference (in chinese). Fuzzy Syst. Math. 21, 68–74 (2007).
Yager, R. R. Families of owa operators. Fuzzy Sets Syst. 59, 125–148 (1993).
Sun, X. & Wang, N. Interval valued weighted fuzzy reasoning based on owa operator (in chinese). Comput. Eng. Appl. 48, 156–159 (2012).
Liu, Y., Gao, X., Lu, G. & Wang, Y. Weighted attribute information fusion based on owa aggregation operator (in chinese). Chin. J. Sci. Instrum. 27, 322–325 (2006).
Wang, Y. & Xu, Z. A new method of giving owa weights. Math. Pract. Theory 38, 51–61 (2008).
Deschrijver, G. & Kerre, E. E. On the relationship between some extensions of fuzzy set theory. Fuzzy Sets Syst. 133, 227–235 (2003).
Zeng, W. & Li, H. Relationship between similarity measure and entropy of interval valued fuzzy sets. Fuzzy Sets Syst. 157, 1477–1484 (2006).
Gitinavard, H., Mousavi, S., Vahdani, B. & Siadat, A. Project safety evaluation by a new soft computing approach-based last aggregation hesitant fuzzy complex proportional assessment in construction industry. Sci. Iranica 27, 983–1000 (2020).
Gitinavard, H. & Zarandi, M. H. F. A mixed expert evaluation system and dynamic interval-valued hesitant fuzzy selection approach. Int. J. Math. Comput. Sci. 10, 341–349 (2016).
Zadeh, L. A. Outline of a new approach to the analysis of complex systems and decision processes. IEEE Trans. Syst. Man Cybern. 28–44 (1973).
Jahn, K.-U. Intervall-wertige mengen. Math. Nachr. 68, 115–132. https://doi.org/10.1002/mana.19750680109 (1975).
Sambuc, R. & Fonctions, F. Application l’aide au diagnostic en pathologie thyroidienne (Faculté de Médecine de Marseille, Aix-Marseille Université, Marseille, France, 1975).
Grattan-Guinness, I. Fuzzy membership mapped onto intervals and many-valued quantities. Math. Log. Q. 22, 149–160 (1976).
Turksen, I. B. Interval valued fuzzy sets based on normal forms. Fuzzy Sets Syst. 20, 191–210 (1986).
Gorzałczany, M. B. A method of inference in approximate reasoning based on interval-valued fuzzy sets. Fuzzy Sets Syst. 21, 1–17 (1987).
Gorzałczany, M. B. Interval-valued fuzzy controller based on verbal model of object. Fuzzy Sets Syst. 28, 45–53 (1988).
Zeng, W. & Shi, Y. Note on interval-valued fuzzy set. In Fuzzy Systems and Knowledge Discovery, 20–25 (Springer (eds Wang, L. & Jin, Y.) (Berlin Heidelberg, Berlin, Heidelberg, 2005).
Zeng, W., Shi, Y. & Li, H. Representation theorem of interval-valued fuzzy set. Internat. J. Uncertain. Fuzziness Knowl.-Based Syst. 14, 259–269 (2006).
Rico, N., Huidobro, P., Bouchet, A. & Díaz, I. Similarity measures for interval-valued fuzzy sets based on average embeddings and its application to hierarchical clustering. Inf. Sci. 615, 794–812 (2022).
Ma, Q., Chen, Z., Tan, Y. & Wei, J. An integrated design concept evaluation model based on interval valued picture fuzzy set and improved grp method. Sci. Rep. 14, 8433 (2024).
Salimian, S. & Mousavi, S. M. A multi-criteria decision-making model with interval-valued intuitionistic fuzzy sets for evaluating digital technology strategies in covid-19 pandemic under uncertainty. Arab. J. Sci. Eng. 48, 7005–7017 (2023).
Luo, M., Li, W. & Shi, H. The relationship between fuzzy reasoning methods based on intuitionistic fuzzy sets and interval-valued fuzzy sets. Axioms 11, 419 (2022).
Zeng, S., Tang, M., Sun, Q. & Lei, L. Robustness of interval-valued intuitionistic fuzzy reasoning quintuple implication method. IEEE Access 10, 8328–8338 (2022).
Mousavi, S. M., Vahdani, B., Gitinavard, H. & Hashemi, H. Solving robot selection problem by a new interval-valued hesitant fuzzy multi-attributes group decision method. Int. J. Indus. Math. 8, 231–240 (2016).
Mosleh, A., Meixedo, A., Ribeiro, D., Montenegro, P. & Calçada, R. Automatic clustering-based approach for train wheels condition monitoring. Int. J. Rail Transp. 11, 639–664 (2023).
Mosleh, A., Montenegro, P., Alves Costa, P. & Calçada, R. An approach for wheel flat detection of railway train wheels using envelope spectrum analysis. Struct. Infrastruct. Eng. 17, 1710–1729 (2021).
Zadeh, L. A. Fuzzy sets. Information and Control (1965).
Vega-Márquez, B., Rubio-Escudero, C. & Nepomuceno-Chamorro, I. Generation of synthetic data with conditional generative adversarial networks. Logic J. IGPL 30, 252–262 (2022).
Jiang, P., Ergu, D., Liu, F., Cai, Y. & Ma, B. A review of yolo algorithm developments. Procedia Comput. Sci. 199, 1066–1073 (2022).
Chen, Y. et al. Submarine cable detection method based on multisensor communication. J. Sens. 2021, 1176347 (2021).
Acknowledgements
This work is supported by the Key Science and Technology Program of Henan Province (222102210084); Key Science and Technology Project of Henan Province University (23A413007), respectively.
Author information
Authors and Affiliations
Contributions
Q.W. and F.W. designed the methodology. Q.W. and S.S. conceived the experiment(s). Q.W. and B.Z. validated the experiment(s). Q.W. and F.W. performed the formal analysis. B.Z. and S.S. created the visualizations. Q.W. and S.S. conducted the investigation. Q.W. and B.Z. prepared the original draft. Q.W. and F.W. reviewed and edited the manuscript. Q.W. supervised the project. Q.W. administered the project. All authors reviewed the manuscript.
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wu, Q., Wu, F., Zhang, B. et al. A weighted fuzzy inference method and application on wheel damage analysis. Sci Rep 14, 31351 (2024). https://doi.org/10.1038/s41598-024-82792-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-82792-y
