
Abstract
This study addresses the growing importance of hand gesture recognition across diverse fields, such as industry, education, and healthcare, targeting the often-neglected needs of the deaf and dumb community. The primary objective is to improve communication between individuals, thereby enhancing the overall quality of life, particularly in the context of advanced healthcare. This paper presents a novel approach for real-time hand gesture recognition using bio-impedance techniques. The developed device, powered by a Raspberry Pi and connected to electrodes for impedance data acquisition, employs an impedance chip for data collection. To categorize hand gestures, Convolutional Neuron Network (CNN), XGBoost, and Random Forest were used. The model successfully recognized up to nine distinct gestures, achieving an average accuracy of 97.24% across ten subjects using a subject-dependent strategy, showcasing the efficacy of the bioimpedance-based system in hand gesture recognition. The promising results lay a foundation for future developments in nonverbal communication between humans and machines as it contributes to the advancement of technology for the benefit of individuals with hearing impairments, addressing a critical social need.
Similar content being viewed by others


Introduction
Body language plays a crucial role in non-verbal communication, whether between humans or between humans and machines. It encompasses a variety of forms, such as hand gestures, arm movements, posture, walking, running, facial expressions, and eye movements. As human-machine communication evolves rapidly, it is essential to develop systems that facilitate simple and natural interactions for humans1,2,3,4. By gathering data from the sensors, these smart devices can interpret human intentions and translate them into corresponding commands executed by machines.
Furthermore, automated systems are becoming increasingly essential in the manufacturing industry due to their accuracy, speed, fatigue-free operation, better repetition of tasks, and much higher productivity than human labor. However, they lack the flexibility of humans. Therefore, good communication between humans and machines will create the best work efficiency5.
Recognizing gestures is also an important part of communication between people and systems in the healthcare industry, such as using robots in the operating room, physical therapy, or prosthetics for disabled people.
The deaf and mute community is a significant and growing group, yet they often do not receive the attention and support they deserve from society. A survey conducted by the General Statistics Office (GSO) in 2016 and 2017 with UNICEF’s technical assistance revealed that over 6.2 million individuals in Vietnam are either deaf or have significant hearing problems, which accounts for nearly 7% of the country’s total population aged 2 years and older, and an additional 13% - nearly 12 million, live in a household with a person with a disability6,7. They rely on sign language to communicate with one another, which primarily involves arm and hand movements. Words are expressed through morphology and fingerspelling. However, the grammar of sign language differs from that of Vietnamese, making it difficult to learn. As a result, many individuals who lose their hearing later in life choose not to learn it, leading to only a small portion of the deaf community being proficient. This underscores a significant communication barrier within the deaf community.
For decades, various research institutions and researchers have explored different methods to understand sign language, with the most common solution being the use of advanced image recognition technologies to analyze hand and arm movements8,9,10,11,12. Hu and colleagues proposed a hybrid CNN-RNN model for sEMG-based hand gesture recognition, combining spatial and temporal feature extraction. Their model incorporates attention mechanisms to enhance the recognition of gestures from often noisy EMG signals13. In another study, Wang et al. employed deep learning techniques to capture both spatial and temporal dependencies in EMG signal patterns, enhancing the accuracy and generalization of sEMG-based hand gesture recognition systems14. Additionally, cost-effective methods using accelerometers, gyroscopes, and flex sensors have demonstrated great success in enabling machines to interpret hand gestures. More recently, Liu et al. utilized bioimpedance as the primary technology to decode human postures into emotional states, achieving an impressive Macro F1 Score of 82.58% for six hand-over-face gestures15. While image-based systems can achieve high accuracy in controlled environments, they face challenges in dynamic settings, can be costly, and raise privacy concerns due to their reliance on cameras to capture visual data. Users may feel uncomfortable with video recordings, and there are security concerns related to the storage of image data. EMG-based systems, though accurate, require meticulous setup and calibration, limiting their scalability for widespread use. In contrast, bioimpedance offers a well-balanced solution, excelling in user-friendliness, portability, cost-effectiveness, and robustness to environmental conditions.
Building on this foundation, this project aims to develop a hand gesture recognition system using bioimpedance technology to facilitate seamless communication, especially for individuals in the deaf and mute community. The focus is on designing a practical and user-friendly sign language interpretation application that addresses the limitations of current technologies by offering improved accuracy, robustness to environmental factors, and greater accessibility for a wider range of applications. This article will provide an in-depth exploration of the design context, background research, and design methods, culminating in the presentation of deliverables that introduce an innovative solution to the field. Specifically, this project seeks to address communication challenges faced by the deaf and mute community in Vietnam.

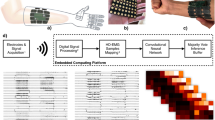
The simplified functional block diagram of the hardware implementation for the proposed bioimpedance-based gesture recognition system.
Methods
System design
A bioimpedance measurement circuit is typically divided into three stages considering operational efficiency and safety concerns16: control, signal generation, and signal distribution and acquisition. A simplified functional block diagram of the system is illustrated in Fig. 1.
For the control system, Raspberry Pi 3 model B (Raspberry Pi Ltd., Cambridge, England) was chosen for this system due to its wide availability in the market, as well as its strong computational ability. In this work, Raspberry Pi computer was coded with Python to not only control the AD5933 chip (Analog Devices, Norwood, MA, USA) but also for real-time model deployment of hand-gesture recognition. The AD5933, known for its precision in measuring electrical impedance, integrates a range of functionalities such as a signal generator, digital-to-analog converter, digital signal processor, and analog-to-digital converter on a single chip and it was widely used for electrical impedance for decades16,17,18.
The Raspberry Pi communicates with the AD5933 through the I2C bus, sending commands to manage its operation and control the frequency. During this process, the AD5933 generates a fixed voltage output at the specified frequency of 50 kHz for bio-impedance measurements. The alternating voltage source from the chip is controlled with both amplitude and frequency. Due to the safety purpose, a constant amplitude of the injection voltage is maintained at 1 V peak-to-peak19. The AD5933 chip supports a stimulation frequency range typically between 1 kHz and 100 kHz, making it highly suitable for bio-impedance applications, including hand gesture recognition20,21,22. For instance, bio-impedance measurements for physiological parameters like respiration and heart rate have been successfully conducted with optimal stimulation frequencies between 70 and 80 kHz23. Additionally, previous studies have established that the typical frequency range for stimulation signals in hand gesture recognition applications lies between 20 and 60 kHz24,25. Based on this research, 50 kHz was chosen for the present study, as it provides an ideal balance between signal quality and performance.
One of the important requirements in electrical circuits used on the human body is the control of frequency and current amplitude applied to the tissue, which should be standardized according to IEC-60601 and dependent on frequency. However, the AD5933 provides a sine wave voltage with a constant amplitude in a bipolar configuration, which is not recommended for human applications18. Therefore, an additional stable voltage-controlled current source (VCCS) is needed when using the AD5933 chip. The load-in-the-loop circuit and Howland pump circuit, or improved versions such as the Double Howland or Mirrored Howland, have been compared in some studies, showing that the improved Howland circuits are more effective in stabilizing the current of the power source without being affected by the load components. However, the load-in-the-loop circuit still provides a certain level of efficiency19 and is simpler, which is why it is currently employed in this work.
For this research, instead of a complete electrical impedance tomography (EIT) system, the focus was solely on the raw signals received from the AD5933 to construct the device. The final design has a multiplexer act as a channel divider in the receiving stage, and without changing the transmitting stage altogether. After receiving raw data from each channel, the AD5933 converts it to real and imaginary data and then transmits it to the Raspberry Pi for calculation of impedance using the following equations:
where the “Gain factor” is calculated with a calibration procedure, using a known input impedance with the same system26.
When the AD5933 was activated along with the Raspberry Pi, it would also be controlled via I2C protocol for frequency sweeps, by sourcing an AC voltage with a frequency of 50 kHz at its “Vout” pin. This voltage source will then be converted into a current source via a load-in-the-loop circuit and divided into 2 emitting sites at the hand, through 2 electrodes. The other 6 electrodes are for the receiving stage, with 5 electrodes at each finger (thumb, index, middle, ring, and pinky finger, respectively) and another one in the middle as the reference. The voltage signals are measured by the AD5933 through its “Vin” pin one after another. The signals are sampled by the chip and then sent to Raspberry Pi. The data finally arrived at the computer for further processing.

Block diagram illustrating the software implementation of the proposed hand gesture recognition system, showcasing both the offline training process and the real-time deployment phase.
Various materials and designs have been investigated for the electrodes used in this system. Electrocardiogram (ECG) electrodes are commonly employed in many bioimpedance applications due to their high conductivity and ease of use. These electrodes typically feature silver/silver chloride (Ag/AgCl) material, which ensures stable electrical contact with the skin and minimizes impedance27,28. However, the final material used for the contact electrodes was dry conductive fabric due to its lightweight, stable signal, and can be reusable29,30.
Software implementation
The software implementation process is divided into two main categories, as shown in Fig. 2. The first category is offline analysis, where gesture-induced data is collected while users perform gestures to train machine learning models. The well-trained model, including its structure and optimal weights, is saved in a lite format to facilitate its transfer to the embedded system for deployment. These steps on data processing and training are performed on an Intel Core i7-powered personal computer (PC) with 16 GB of RAM, utilizing the CPU for computation. The second component is the online deployment of the pre-trained model, where new impedance data is used for real-time gesture prediction. The real-time gesture recognition process runs continuously until the user turns off the device with the on/off switch. Python and its libraries were exclusively used to code all procedures.
To begin an impedance measurement, the AD5933 is placed in standby mode and initialized with a starting frequency. Typically, it performs a frequency sweep to calculate impedance across a range of frequencies, but in this study, the device is configured to operate at a fixed frequency of 50 kHz for measurements instead of sweeping through multiple frequencies. As a result, both the number of increments and the increment frequency are set to 0, ensuring the AD5933 remains in a constant repeat mode at 50 kHz. After each measurement, the real and imaginary components of the impedance are stored within the AD5933 and later retrieved for impedance calculation. Additionally, the system was optimized to enhance the data acquisition sampling frequency from AD5933 to 317 Hz in an effort to obtain more detailed information on impedance changes during gesture performance.
As shown in Eq. (1) and (2), for the calculation of an impedance, aside from the magnitude (calculated from the real and imaginary value of AD5933), a gain factor is also needed. To get this value, the calibration process must be taken in place. This process for calibration is similar to that of the main impedance measurement, which would also require a frequency sweep for getting the real and imaginary values. However, instead of measuring an unknown impedance, the calibration process would measure an already known impedance to get its real and imaginary values from the AD5933. This gain factor will later be used for the main impedance measurement process. A 1 k\(\Omega\) resistor was used as the calibrating resistor for obtaining the gain factor, as human skin impedance is typically less than 1 k\(\Omega\)31,32, and the gain factor needs to be close to the measured load. The resistor was calibrated outside of the hardware design, set up using eight alligator clip connectors, and returned a closely accurate impedance value.

Performing gestures during experiments: (a) from left to right: relaxing, finger spelling of letter “A”, “B”, and “C”, respectively; (b) “Agree”.
Experiments and data acquisition
Data was collected via impedance measurements while users performed gestures. Following each frequency sweep and current injection, signals were sequentially measured through five electrodes placed on the fingers, managed by the multiplexer: “Thumb,” “Index,” “Middle,” “Ring,” and “Pinky” (Fig. 3a).
The study protocol was approved by the Ethics Committee of Ho Chi Minh City University of Technology, Vietnam National University, and was conducted in accordance with the Declaration of Helsinki. Informed consent was obtained from all subjects before their participation. All volunteers were healthy, right-hand dominant, aged between 20 and 35, consisting of 6 males and 4 females, and were deaf individuals without any other disabilities. During the measurement process, subjects were instructed to wear the electrodes on the back of their hands as illustrated in Fig. 3. The electrodes were placed at the second joint of the fingers, as this location provided the necessary flexibility for hand gesture execution.
Experiments were conducted with all ten individuals as they performed gestures, during which impedance data was collected. Each person was tested across 9 different labels: “A”, “B”, “C”, “Eat”, “Thanks”, “Agree”, “Sleep”, “Drink”, and “Sorry”. Among these, 6 labels “Agree”, “Eat”, “Drink”, “Sleep”, “Sorry”, and “Thanks” are dynamic, while 3 labels “A”, “B”, and “C” are static. Each gesture was measured for impedance changes over approximately 1.5 seconds, with the multiplexer scanning the five fingers, yielding 95 impedance values per finger. The training data for each gesture was meticulously labeled during the impedance measurement process based on the corresponding postures. On average, 80 gestures were recorded per class, organized into 4 sets of 20 gestures each. Each set lasted approximately 60 seconds, with a 2-min rest period between sets to ensure consistency. All collected data was recorded and pre-processed before further analysis. The hand gesture recognition procedure is based on machine learning algorithms using the TensorFlow library with the Python programming language on a PC for training and the TensorFlow Lite library on a Raspberry Pi for real-time deployment. TensorFlow and Keras libraries were used to train the processed data and create a machine learning model. This model was then created and evaluated multiple times to select the optimal one for real-time deployment.
Training and deployment of machine learning models
The current study evaluates the system with three different strategies including subject-dependent, subject-independent, and mixed-subject. In a subject-dependent strategy, the model is trained and tested on data from the same subject. Each subject has a personalized model, often fine-tuned to their specific bio-impedance patterns. Since the model only needs to generalize to the specific bio-impedance signals of the same subject, it can achieve high accuracy by learning subject-specific patterns but requiring re-training or adaptation for each individual user, which can be time-consuming for new subjects. The subject-independent, on the other hand, requires the model to be trained on data from a group of subjects and tested on unseen subjects. This approach aims to generalize across different individuals without needing subject-specific calibration. It requires a large and diverse training dataset to capture a wide variety of bio-impedance patterns but generalizing across subjects can lead to a drop in accuracy due to inter-subject variability. In the mixed-subject strategy, the model is trained on multiple subjects, partially fine-tune on the new subject and it requires some data from the new user for partial training or fine-tuning before using it. Thus it balanced accuracy and generalization between subject-dependent and subject-independent.
The dataset contains a total of 7444 gestures from all subjects. However, it is imbalanced due to certain limitations. Subject 1 contributed the most gestures, averaging 150 gestures per class, whereas Subject 10 performed approximately 50 gestures per class.
In the subject-dependent strategy, a separate model was trained and tested for each individual subject, with 80% of the data allocated for training and 20% for testing. Additionally, five-fold cross-validation was applied to ensure robust model evaluation. In the mixed-subject strategy, data from all subjects was combined and divided into five folds for cross-validation, where four folds (80% of the data) were used for training, and the remaining fold (20%) for testing. In both approaches, the impedance data was normalized for each subject, rescaling the values between 0 and 1 to ensure equal contribution of all features to the machine learning model. Finally, in the subject-independent strategy, the model was trained on data from 9 subjects and tested on the remaining subject. To reduce variations between subjects, normalization was applied to each gesture.
In this study, a CNN model is used to automatically learn and extract relevant features from impedance data for gesture classification. CNNs are widely regarded as one of the most powerful deep learning algorithms, particularly for tasks such as image recognition, object detection, and processing other forms of visual data33. The input layer of the CNN model comprises two 2D convolutional layers, each performing convolution operations with 64 filters of size \(2\times 2\). ReLU activation is applied after each convolution to introduce non-linearity, enabling the network to learn more complex patterns. The output from these convolutional layers is then flattened and passed into a fully connected layer with 32 neurons. A 50% dropout rate is applied after the final hidden layer to reduce overfitting, and the signal is then passed to the output layer, which consists of 9 neurons with softmax activation to classify the 9 gestures.
In addition to the CNN deep learning model, traditional machine learning approaches such as XGBoost34 and Random Forest35 were employed to learn gesture-induced impedance data for comparison. Both of these robust algorithms are based on decision trees: XGBoost employs gradient boosting to build models sequentially, with each new tree correcting the errors of the previous ones, while Random Forest constructs multiple decision trees in parallel during training and combines their predictions for a final output.
Since the CNN model relies on the resource-intensive TensorFlow library for execution, TensorFlow Lite (TFLite) was chosen for the real-time deployment on the Raspberry Pi due to its limited CPU processing power and memory capacity. TFLite is a lightweight, optimized framework tailored for running TensorFlow pre-trained models on embedded devices like the Raspberry Pi, which helps significantly reduce recognition time. To enable this, the pre-trained Keras model was converted to the TFLite format before being deployed to the Raspberry Pi for inference36. After transferring the final TFLite model to the Raspberry Pi, it was able to predict incoming gesture-induced impedance values and classify them into 9 corresponding hand gestures: “A”, “B”, “C”, “Agree”, “Drink”, “Eat”, “Sleep”, “Sorry”, and “Thanks.

(a) The complete hand gesture recognition system; (b) Graphical user interface (GUI) for hand gesture recognition system.
The real-time testing assesses the performance of a hand gesture recognition system using bioimpedance in a practical setting, evaluating its effectiveness under various real-world conditions. Six participants took part in the experiment, performing a series of predefined hand gestures while the system recognized them in real-time. Each participant performed 45 gestures (9 distinct pre-trained gestures, repeated five times each) to gather sufficient data, using a mixed-subject strategy for evaluation.
Results
Complete system
The final hardware design for the device achieved stable impedance measurement. Since the impedance of human skin is under 1 k\(\Omega\), the device was tested by measuring resistors ranging from 400 \(\Omega\) to 1.5 k\(\Omega\). As a result, the system returned accurate values consistently.
The printed circuit board (PCB) design was compact and efficiently organized, featuring a multitask push button, power on/off switches, and test pins for monitoring the AD5933 output voltage as well as the MUX. As depicted in Fig. 4a, the complete gesture recognition system comprises an analog board connected to a digital control board with the Raspberry Pi integrated.
A GUI was developed using the PyQt5 library and integrated into the device to enhance user interaction, making it easier to handle and control the system (Fig. 4b). The intuitive GUI allows users to manage various settings, including gain, amplitude, and the frequency of the injected voltage. Additionally, the system’s predicted gesture is also displayed in real-time for the user.

Visualization of raw impedance data for 9 gestures performed by Subject 6.

Impedance data visualization with t-SNE in 2-dimensional space for: (a) Subject 6 alone and (b) all subjects.
Gesture decoding
Figure 5 shows the impedance measured across five fingers during the gesture performance of Subject 6. The gesture “Thanks” exhibits the highest impedance for all fingers, ranging from 850 to 1000 \(\Omega\), while the gestures “A” and “Sleep” are among those with the lowest impedance values. In most gestures, the pinky shows the highest impedance, whereas the thumb and ring fingers have the lowest. The gesture “Sleep” displays the most variation in impedance, with the index and middle fingers showing the greatest fluctuations.
Figure 6 presents a 2D visualization of the impedance using the t-SNE (t-distributed Stochastic Neighbor Embedding) algorithm37, providing insights into the high-dimensional data. By preserving local structure, the algorithm ensures that points close in the high-dimensional space remain close in the low-dimensional representation. The visualization reveals distinct clusters corresponding to 9 gesture groups, highlighting the potential for gesture recognition using a subject-dependent strategy (Fig. 6a). In contrast, Fig. 6b shows less distinct clustering of the 9 gestures across all subjects, suggesting that training a model across multiple subjects is challenging due to variations between individuals.

Subject-dependent strategy: confusion matrix for Subject 6 using: (a) CNN and Random Forest and (b) XGBoost algorithms.

Classification accuracy of CNN, XGBoost, and Random Forest models across 10 subjects using a subject-dependent strategy.
Figure 7 presents the classification results of the model built on Subject 6 data using a subject-dependent strategy, displayed as confusion matrices. Both the CNN and Random Forest algorithms achieved perfect recognition with 100% accuracy and no misclassifications. In contrast, the XGBoost model achieved a classification accuracy of 92.86%, with several gestures being misclassified.

Classification accuracy of CNN, XGBoost, and Random Forest models across 10 subjects using a subject-independent strategy.
The classification results for all subjects using the subject-dependent strategy for the CNN, XGBoost, and Random Forest algorithms are shown in Fig. 8. All three models performed well on the test dataset after training. Notably, the Random Forest and CNN models delivered the best results, with average accuracies of 97.24% and 95.12%, respectively, outperforming XGBoost, which achieved 90.73%. For both Random Forest and CNN, 7 out of 10 subjects achieved an accuracy above 95% on the test set. Subjects 2 and 3 were among those with the lowest classification accuracy.
In contrast to the subject-dependent strategy, the subject-independent approach produced poor results, as shown in Fig. 9. The overall average accuracies were 34.63%, 29.22%, and 31.92% for the CNN, XGBoost, and Random Forest models, respectively. The best performance was observed for Subject 9, with an average accuracy of 46.22% across all three models. Subjects 1, 2, and 3 had the lowest recognition accuracy. This may be due to the fact that the pre-trained model was based on a smaller dataset (half of the total data), which limited its ability to generalize to the first three subjects, who contributed a disproportionately large portion of the dataset (comprising half of the 7,444 gestures).
Figure 10 depicts the classification results for the CNN, XGBoost, and Random Forest models, obtained using five-fold cross-validation in a mixed-subject strategy. As shown, CNN outperforms the other algorithms in this evaluation. Specifically, it achieves an average accuracy of 87.1%, while XGBoost and Random Forest attain 82.2% and 76.1%, respectively. The superior performance of CNN may be attributed to its ability to automatically learn complex features from the data, which proves beneficial in tasks like gesture classification. Meanwhile, although XGBoost and Random Forest also perform well, their lower accuracies suggest that they may not capture the intricate patterns as effectively as CNN in this context.
In real-world scenarios, the system takes an average of 400 ms to recognize each gesture using the CNN model. However, a significant decrease in accuracy is observed, with the system correctly identifying gestures 77.8% of the time during real-time testing. This decline is likely due to the model encountering previously unseen data, emphasizing the need for improved generalization across a broader range of gestures and environments. Training the model on a more diverse dataset, including various environmental conditions, could enhance its accuracy in practical applications.

Five-fold cross-validation results using the mixed-subject strategy for the CNN, XGBoost, and Random Forest algorithms.
Discussions
The experimental analysis revealed that the subject-dependent setup achieved significantly higher accuracy in gesture recognition compared to the other two strategies. This underscores the difficulty bio-impedance-based models face in generalizing across users, likely due to substantial variations in bio-impedance signals from one individual to another. As the results highlight, subject-independent models are less effective because they struggle to identify consistent, generalized features from bio-impedance data. While subject-dependent setups require calibration before use, involving user-specific training which can be time-consuming and somewhat costly, this approach remains highly practical for applications that prioritize accuracy. When compared to subject-independent and mixed-subject methods, the subject-dependent strategy offers a compelling balance between precision and feasibility for certain specialized use cases.
Recent studies have demonstrated that the accuracy of bio-impedance-based gesture recognition systems tends to be lower than other methods, such as image-based techniques, EMG, and others13,14,38. However, bioimpedance provides distinct advantages, including lower power consumption, simpler computational requirements, and enhanced privacy. In our study, the proposed system successfully recognized up to 9 gestures, achieving higher accuracy compared to several recent works. For instance, Khushaba et al.39 reported 90% accuracy in recognizing 10 gestures using an EMG-based system in a subject-dependent setup. Similarly, Tenore et al.40 achieved an average accuracy of 90% for decoding 10 gestures using EMG. Our results also exceeded those of Li et al.41, who attained 85% accuracy in decoding 10 movements using EMG. However, our system’s performance was lower than that of Simonyan et al.42, who reported an impressive 91.4% accuracy for 20 dynamic gestures using an image-based technique in a cross-subject scenario. Likewise, Wan et al.43 achieved 94.6% accuracy in recognizing 10 dynamic gestures using image-based methods in cross-subject evaluations.
While image-based techniques generally offer superior performance by effectively capturing gesture-related visual features, they come with notable limitations, such as privacy concerns and high computational demands. In contrast, our bioimpedance-based approach provides a more balanced solution, offering a strong trade-off between performance and privacy. This makes it an attractive and practical option for hand gesture recognition, particularly in privacy-sensitive environments, where visual tracking may not be feasible or desirable due to privacy and security concerns.
There are several limitations with this device, particularly in impedance measurement and gesture recognition. The skin’s impedance is less than 1 k\(\Omega\), so even with a buffer, the variation during gestures remains minimal, leading to poor recognition. Calibration is also complicated, as multiple components, such as resistors and capacitors, must be considered. Additionally, users must remove electrodes during calibration, which is time-consuming and uncomfortable. The current electrode design lacks stability and requires adhesive tape. Furthermore, factors like sweat and temperature fluctuations can impact skin conductivity, affecting impedance and recognition accuracy26.
The device, using only raw bio-impedance data, can recognize up to nine distinct hand gestures with satisfactory accuracy. However, integrating complementary sensors like accelerometers or EMG could significantly improve both accuracy and robustness. Converting bio-impedance data into EIT images may also enhance spatial information, boosting gesture differentiation. Additionally, incorporating robust preprocessing techniques and adaptive algorithms would help the system handle real-world conditions more efficiently. Expanding the training dataset would improve generalization across diverse users and scenarios, making the system more adaptable. Given that bio-impedance data is highly subject-specific, future work should focus on subject-independent models and environmentally adaptive systems to reduce the impact of factors like temperature, sweat, and user characteristics (age, gender, BMI), improving the system’s overall reliability in real-world applications.
In summary, the device was designed to achieve two primary objectives. First, it accurately measured bioimpedance signals using a well-integrated hardware system powered by Python on a Raspberry Pi processor. Second, it successfully recognized up to 9 distinct Vietnamese hand gestures, both static and dynamic, achieving a notable accuracy of 97.24% on average, using the Random Forest algorithm in a subject-dependent strategy, despite the time-consuming calibration required before use. Even with limited training data, the pre-trained gesture recognition model was deployed in real-time, providing acceptable performance in practical applications.
Data availability
All the data are available within the article or available from the authors upon reasonable request.
References
Czuszynski, K., Ruminski, J. & Wtorek, J. The passive operating mode of the linear optical gesture sensor. vol. 18, pp. 145–156 arXiv:1712.04260https://doi.org/10.48550/arXiv.1712.04260 (2017).
Greussing, E. et al. Researching interactions between humans and machines: Methodological challenges. Publizistik 67, 531–554. https://doi.org/10.1007/s11616-022-00759-3 (2022).
Guo, L., Lu, Z. & Yao, L. Human-machine interaction sensing technology based on hand gesture recognition: A review. IEEE Trans. Human-Mach. Syst. 51, 300–309. https://doi.org/10.1109/THMS.2021.3086003 (2021).
Gupta, H., Chudgar, H., Mukherjee, S., Dutta, T. & Sharma, K. A continuous hand gestures recognition technique for human-machine interaction using accelerometer and gyroscope sensors. IEEE Sens. J. 16, 6425–6432. https://doi.org/10.1109/JSEN.2016.2581023 (2016).
Liu, H. & Wang, L. Gesture recognition for human-robot collaboration: A review. Int. J. Ind. Ergon. 68, 355–367. https://doi.org/10.1016/j.ergon.2017.02.004 (2018).
Unicef. Children with disabilities in Viet Nam. Unicef (2018).
GSO. The national survey on people with disabilities 2016 (vds2016). General Statistics Office of Vietnam (2016).
Kuznetsova, A., Leal-Taixé, L. & Rosenhahn, B. Real-time sign language recognition using a consumer depth camera. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops 83–90 (2013).
Starner, T., Weaver, J. & Pentland, A. Real-time American sign language recognition using desk and wearable computer based video. IEEE Trans. Pattern Anal. Mach. Intell. 20, 1371–1375. https://doi.org/10.1109/34.735811 (1998).
Imagawa, I. et al. Recognition of local features for camera-based sign language recognition system. In Proceedings 15th International Conference on Pattern Recognition. ICPR-2000 vol. 4, pp. 849–853. https://doi.org/10.1109/ICPR.2000.903050 (2000).
Wadhawan, A. & Kumar, P. Sign language recognition systems: A decade systematic literature review. Arch. Comput. Methods Eng. 28, 785–813. https://doi.org/10.1007/s11831-019-09384-2 (2021).
Mejía-Peréz, K. et al. Automatic recognition of Mexican sign language using a depth camera and recurrent neural networks. Appl. Sci. 12, 5523. https://doi.org/10.3390/app12115523 (2022).
Hu, Y. et al. A novel attention-based hybrid CNN-RNN architecture for SEMG-based gesture recognition. PLoS ONE 13, e0206049. https://doi.org/10.1371/journal.pone.0206049 (2018).
Wang, L., Fu, J., Chen, H. & Zheng, B. Hand gesture recognition using smooth wavelet packet transformation and hybrid CNN based on surface EMG and accelerometer signal. Biomed. Signal Process. Control 86, 105141. https://doi.org/10.1016/j.bspc.2023.105141 (2023).
Liu, M., Bello, H., Zhou, B., Lukowicz, P. & Karolus, J. iface: Hand-over-face gesture recognition leveraging impedance sensing. In Proceedings of the Augmented Humans International Conference 131–137 https://doi.org/10.1145/3652920.3652923 (2024).
Wang, L. et al. Assessment of alterations in the electrical impedance of muscle after experimental nerve injury via finite-element analysis. IEEE Trans. Biomed. Eng. 58, 1585–1591. https://doi.org/10.1109/TBME.2011.2104957 (2011).
Al-Ali, A., Maundy, B. & Elwakil, A. Design and Implementation of Portable Impedance Analyzers. 1–14 (Springer International Publishing, 2019) https://doi.org/10.1007/978-3-030-11784-9.
Pliquett, U. & Barthel, A. Interfacing the ad5933 for bio-impedance measurements with front ends providing galvanostatic or potentiostatic excitation. J. Phys. Conf. Ser. 012019 https://doi.org/10.1088/1742-6596/407/1/012019 (2012).
Potdar, S., Panditrao, A. & Khambete, N. Monitoring breathing rate using bio-impedance technique. In 2016 International Conference on Computing Communication Control and automation (ICCUBEA) 1–3 https://doi.org/10.1109/ICCUBEA.2016.7860143 (2016).
Ward, L. et al. Muiti-frequency bioelectrical impedance augments the diagnosis and management of lymphoedema in post-mastectomy patients. Eur. J. Clin. Invest. 22(11), 751–754. https://doi.org/10.1111/j.1365-2362.1992.tb01440.x (1992).
Hannan, W. et al. Evaluation of multi-frequency bio-impedance analysis for the assessment of extracellular and total body water in surgical patients. Clin. Sci. (Lond. England: 1979) 86(4), 479–485. https://doi.org/10.1042/cs0860479 (1992).
Lehnert, M. et al. Estimation of body water compartments in cirrhosis by multiple-frequency bioelectrical-impedance analysis. Nutrition 17(1), 31–34. https://doi.org/10.1016/S0899-9007(00)00473-1 (2001).
Ferreira, J., Pau, I., Lindecrantz, K. & Seoane, F. A handheld and textile-enabled bioimpedance system for ubiquitous body composition analysis. An initial functional validation. IEEE J. Biomed. Health Inform. 21, 1224–1232. https://doi.org/10.1109/JBHI.2016.2628766 (2016).
Zhang, Y. & Harrison, C. Tomo: Wearable, low-cost electrical impedance tomography for hand gesture recognition. In Proceedings of the 28th Annual ACM Symposium on User Interface Software and Technology 167–173 https://doi.org/10.1145/2807442.2807480 (2015).
Ma, G., Chen, H., Wang, P., Dong, S. & Wang, X. A two-electrode frequency-scan system for gesture recognition. Mechatronics 94, 103039. https://doi.org/10.1016/j.mechatronics.2023.103039 (2023).
Devices, A. Ad5933: 1 MSPS, 12-bit impedance converter, network analyzer. http://www.analog.com/en/rfif-components/direct-digital-synthesis-dds/ad5933/products/product.html (2013).
Groenendaal, W., Lee, S. & Van Hoof, C. Wearable bioimpedance monitoring: Viewpoint for application in chronic conditions. JMIR Biomed. Eng. 6, e22911. https://doi.org/10.2196/22911 (2021).
Ferreira, J., Seoane, F. & Lindecrantz, K. Portable bioimpedance monitor evaluation for continuous impedance measurements. towards wearable plethysmography applications. In 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) 559–562 https://doi.org/10.1109/EMBC.2013.6609561 (2013).
Choi, Y., Lee, J. & Kong, S. Driver ECG measuring system with a conductive fabric-based dry electrode. IEEE Access 6, 415–427. https://doi.org/10.1109/ACCESS.2017.2766098 (2017).
Taji, B., Shirmohammadi, S., Groza, V. & Bolic, M. An ecg monitoring system using conductive fabric. In 2013 IEEE International Symposium on Medical Measurements and Applications (MeMeA) 309–314 https://doi.org/10.1109/MeMeA.2013.6549758 (2013).
Rosell, J., Colominas, J., Riu, P., Pallas-Areny, R. & Webster, J. Skin impedance from 1 Hz to 1 MHz. IEEE Trans. Biomed. Eng. 35(8), 649–651. https://doi.org/10.1109/10.4599 (1988).
Gabriel, S., Lau, R. & Gabriel, C. The dielectric properties of biological tissues: II. Measurements in the frequency range 10 Hz to 20 GHz. Phys. Med. Biol. 41(11), 2251. https://doi.org/10.1088/0031-9155/41/11/002 (1996).
O’Shea, K. An introduction to convolutional neural networks. arXiv:1511.08458https://doi.org/10.2196/22911 (2015).
Chen, T. & Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 785–794, https://doi.org/10.1145/2939672.2939785 (2016).
Breiman, L. Random forests. Mach. Learn. 45(1), 5–32. https://doi.org/10.1007/s42979-021-00827-x (2001).
TensorFlow. Model conversion overview | tensorflow lite. https://www.tensorflow.org/lite/models/convert (2023).
Van der Maaten, L. & Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 9, 2579–2605 (2008).
Sarma, D. & Bhuyan, M. Methods, databases and recent advancement of vision-based hand gesture recognition for HCI systems: A review. SN Comput. Sci. 2, 436. https://doi.org/10.1007/s42979-021-00827-x (2021).
Khushaba, R. N., Kodagoda, S., Takruri, M. & Dissanayake, G. Toward improved control of prosthetic fingers using surface electromyogram (EMG) signals. Expert Syst. Appl. 39(12), 10731–10738. https://doi.org/10.1016/j.eswa.2012.02.192 (2012).
Tenore, F. V. et al. Decoding of individuated finger movements using surface electromyography. IEEE Trans. Biomed. Eng. 56(5), 1427–1434. https://doi.org/10.1016/j.eswa.2012.02.192 (2008).
Li, G., Schultz, A. E. & Kuiken, T. A. Quantifying pattern recognition-based myoelectric control of multifunctional transradial prostheses. IEEE Trans. Neural Syst. Rehabil. Eng. 18(2), 185–192. https://doi.org/10.1109/TNSRE.2009.2039619 (2010).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556 (2014).
Wan, J. et al. Chalearn looking at people: ISOGD and CONGD large-scale RGB-d gesture recognition. IEEE Trans. Cybern. 52(5), 3422–3433. https://doi.org/10.1109/TCYB.2020.3012092 (2020).
Acknowledgements
This research is funded by Vietnam National University HoChiMinh City (VNU-HCM) under grant number: C2022-20-04.
Author information
Authors and Affiliations
Contributions
N.M.T., Q.L.H., T.T.P, and T.H.N. conceived the experiments, N.M.T., T.N.T., N.K.L., and D.N.H. conducted the experiments, N.M.T. and T.H.N. analysed the results, N.M.T. and T.H.N wrote the manuscript. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Consent for publication
All subjects provided informed consent for the publication of identifying information and/or images in this open-access publication, in accordance with ethical standards.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Than, NM., Nguyen, ST., Huynh, DN. et al. A multi-channel bioimpedance-based device for Vietnamese hand gesture recognition. Sci Rep 14, 31830 (2024). https://doi.org/10.1038/s41598-024-83108-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-83108-w
