
Abstract
Semantic segmentation of high-resolution images from remote sensing is crucial across various sectors. However, due to limitations in computational resources and the complexity of network architectures, many sophisticated semantic segmentation models struggle with efficiency in real-world applications, leading to an interest in developing lightweight model like borders. These models often employ a dual-branch structure, which balances processing speed and performance effectively. Yet, this design typically falls short in leveraging shallow structural information to enrich the dual branches with comprehensive multiscale data. Additionally, the lightweight components struggle to capture the global contextual details of feature sets efficiently. When compared to state-of-the-art models, lightweight semantic segmentation models usually exhibit performance gaps. To address these issues, we introduce a novel approach that incorporates a deep-shallow interaction mechanism with an attention module to improve water body segmentation efficiency. This method spatially adjusts feature representations to better identify water-related data, utilizing a U-Net frame work to enhance the accuracy of edge detection in water zones by providing more precise local positioning information. The attention mechanism processes and merges low and high-level data separately in different dimensions, allowing for the effective distinction of water areas from their surroundings by blending spatial attributes with in-depth context insights. Experimental outcomes demonstrate a remarkable 95% accuracy, showcasing the proposed method’s superiority over existing models.
Similar content being viewed by others
Introduction
Water bodies such as oceans, rivers, lakes, streams, and reservoirs play a crucial role in maintaining and regulating life sources within ecosystems. However, the pace of rapid urbanization is hastening changes and inflicting damage on these vital resources. To protect and derive benefits from existing water resources, continuous monitoring and detailed surveys are essential to gather information about these aquatic environments1. While manual surveys yield reliable data, they are expensive in terms of labor and time-consuming. Recent advancements in remote sensing technology have enabled the use of data collected by various sensors mounted on satellites to obtain timely information. This accurate data is extensively applied in different domains, including the extraction of information about water bodies. Segmentation, a process that labels each pixel in an image with a predefined class name, is a key component of remote sensing and image interpretation, with water body extraction being a prominent use case. The swift evolution of remote sensing technology has allowed for precise observation of Earth’s surface features through remote sensing images, yet this advancement also presents challenges for image processing2. Traditional segmentation techniques for remote sensing images, such as thresholding, region growing, edge detection, clustering, and model-driven methods, often fall short in delivering satisfactory results for high-resolution images. These methods struggle to perform well due to their reliance on manually extracted features and their vulnerability to noise, compromising their robustness3.
The advent of deep learning, particularly convolutional neural networks (CNNs), has led to significant advancements in the segmentation of remote-sensing images. The Fully Convolutional Network (FCN) marked a pivotal shift as the first end-to-end supervised learning approach that utilizes convolutional layers instead of fully connected layers for pixel-wise classification4. Despite its innovations, the FCN is constrained by its localized receptive fields and limited short-range contextual understanding due to its static geometric configuration. This limitation spurred further research into context modelling, including both spatial and relational context modelling techniques, aimed at capturing long-range dependencies within the data. Historically, semantic segmentation employed techniques such as threshold segmentation, edge detection, or traditional machine learning approaches, requiring manually extracted features. These strategies could only grasp a small portion of the existing low-level data, failed to derive significant high-level semantic insights, and had difficulties understanding the contextual links among pixels in an image5.
The advent of deep learning has transformed the landscape of semantic segmentation. With the debut of the Fully Convolutional Network (FCN) marking the first model designed for end-to-end learning in this domain, a variety of CNN-based semantic segmentation models such as SegNet, UNet, Pyramid Scene Parsing Network (PSPNet), and the DeepLabV3 series have since been introduced, significantly advancing the field6. These models have outperformed considerably traditional algorithms by employing specialized encoding-decoding structures or pyramid multiscale modules to extract more detailed spatial features at varying scales, thereby enhancing the sophistication of segmentation results. These successes highlight the critical importance of capturing rich spatial details and inter-pixel contextual correlations in semantic segmentation tasks, necessitating models with the ability to perceive information across multiple scales and extract features from extensive sensory fields7. However, despite the impressive performance of these models, the complexity and computational demands of their architectures pose challenges for real-world applications, especially in scenarios with limited computational resources or requirements for rapid processing.
In this letter, we unveil the DSIA UNet, a novel network that incorporates a Deep-Shallow Interaction with an attention mechanism, specifically designed to tackle two major challenges in the segmentation of remote sensing images. First, our approach emphasizes the extraction of multi-confidence scale class representations within the semantic domain. By using category confidence as a scaling factor, this method bridges the gap between pixels and their corresponding classes, effectively addressing the problem of intra-class variance8,9. In the spatial domain, we’ve developed a Nested Attention Module (NAM) that capitalizes on the inherent pixel-class relationships as queries. This module aims to achieve consensus, enhancing relevant correlations and diminishing incorrect ones. Through the integration of a dual-domain optimization strategy with class-awareness, our approach ensures precise and efficient class-level context modeling.
Our primary contributions can be summarized as follows:
In order to facilitate unique interactions between information in the shallow and deep regions of the network, we have recently suggested an architectural framework for semantic segmentation.
-
By enriching the detail and semantic branches with complementing information, this architecture increases the segmentation accuracy of the model. Shallow Interaction (SI) modules have been added in the shallow layers of the network.
-
In order to increase the complementarity between the semantic and detail branches, these modules are straightforward yet effective. Lightweight fusion modules capable of gathering spatial data and high-level feature channels have been designed for the deeper levels of the network. Further, as a component of the Lightweight Attention Module (LAM), we present a new Lightweight Linear Mobile Attention (LMA) mechanism.
-
When local convolution is combined with this method, a hybrid architecture is produced that effectively collects information about global features as well as local details while managing computational complexity.
Related work
After the Fully Convolutional Network (FCN) model’s10 notable success in establishing new benchmarks, there has been a notable increase in the development of advanced models that utilize convolutional neural networks for addressing segmentation tasks across diverse natural images. Specifically, SegNet improved upon FCN’s upsampling process by employing an encoder-decoder structure to rebuild high-resolution feature maps. Through both top-down and lateral residual connections, UNet’s advanced U-shaped encoder-decoder design enhances the restoration of high-resolution feature information, further refining this method. Through the integration of a multipath refining structure, RefineNet improved forecast accuracy. In order to efficiently gather multiscale contextual information, the atrous spatial pyramid pooling module was introduced in the DeepLabV3 series11. Simultaneously, PSPNet created a multiscale pyramid pooling module with the goal of comprehending the local and global context significantly across the network center. To set itself apart, the Dual Attention Network (DANet) collected rich contextual dependencies by using a self-attention mechanism that makes precise scene segmentation possible. The aforementioned developments highlight the ongoing development and enhancement of semantic segmentation methods, with each person offering distinct approaches to enhancing the accuracy and effectiveness of image segmentation assignments12.
Remote sensing imagery often exhibits significant intraclass variance, exemplified by the substantial differences in shape, color, and texture among buildings across various regions and perspectives. Traditional approaches to class context modeling, which typically extract a global class center for each class, struggle to adequately address this variance. This limitation has motivated our exploration into the semantic domain, where we employ class confidence as a scaling criterion to derive multi-confidence scale class representations for the first time13. This approach involves creating class representations that range from small-scale semantics, which include only pixels with high confidence levels, to large-scale semantics, encompassing all confidence levels. Small-scale semantic representations focus on capturing the salient features of a class, enhancing the modeling of distinct class characteristics. In contrast, large-scale semantic representations aim to capture the class’s global features, providing a comprehensive understanding of the class14. By facilitating interactions between pixels and these multi-confidence scale class representations, we aim to improve the pixels’ ability to accurately perceive different classes. This methodology not only reduces the impact of noise but also strengthens the extraction of robust pixel-class relationships, offering a novel approach to addressing the challenges posed by intraclass variance in remote sensing images.
The research landscape in remote sensing and specifically in the segmentation of water bodies presents a variety of approaches, each with its own set of advantages and limitations. The deep stacked ensemble method referenced in15 requires high processing speeds, indicating a demand for significant computational resources which may not always be feasible. The MC-WBDN model mentioned in16 showcases superior results, yet its application seems limited to specific hydrological studies, reducing its versatility for broader research needs. The Deep U-Net model discussed in17 stands out for its performance but is noted to have some inaccuracies when labelling water images, which could compromise the precision of water body mapping. Meanwhile, the MRSE-Net method in18 improves results but tends to blur the boundaries of water bodies and overlooks small details, potentially leading to less accurate delineations of water extents. The approach involving feature pyramid enhancement and pixel pair matching in19 is commendable for its performance; however, it does not contribute to enhancing the dataset used for segmentation, which could limit improvements in model training and generalization. Goldblatt20 introduced Synthetic Aperture Radar (SAR) images, which provide useful data for segmentation tasks but face the significant challenge of speckle noise. This type of multiplicative noise greatly impacts the image quality, and the limited availability of sufficient training data further complicates their effective use.
These findings highlight the continued difficulties in remote sensing picture segmentation, especially in the area of water body recognition, where problems with noise interference, computing needs, model accuracy, and data quality continue to spur research efforts to find novel solutions. The ground-breaking benchmark ATLANTIS was presented by Seyed et al.21 and is especially intended for the semantic segmentation of water bodies and related items. This benchmark dataset consists of 5,195 photos of bodies of water that have been painstakingly pixel-by-pixel tagged to identify 56 object classes. These classes offer a complete resource for creating and evaluating semantic segmentation models, and are separated into 17 man-made items, 18 natural objects, and 21 broad categories. A simple single-band threshold technique enhanced with bilateral filtering was the method Surekha et al.22 suggested to extract water bodies from satellite data. The idea was to use affordable software to analyze raw picture data so that photographs from various sensors and timings could be analyzed more easily. Unlike other land cover features, this method’s ability to detect water accurately and efficiently is based on the use of free and open-source software platforms. Water bodies in satellite photos can be quickly and accurately identified thanks to this technique23.
A hybrid methodology that combines object-based analysis with pixel-based index techniques is presented by Tambe et al.24. Sentinel-2, a satellite image with 13 multispectral bands and a 10-meter resolution, was used to test this method. Several indices, such as the Normalized Difference Water Index (NDWI), were used in the procedure to identify water bodies. The study concentrated on two very different areas of Macedonia, one with mountains and the other with an urban environment, each with its own set of difficulties. Water bodies in these diverse environments were accurately and thoroughly assessed thanks to the fusion of object-based and pixel-based techniques. In view of these advancements, the current study fills in the gaps found in earlier research by introducing a novel technique to improve water body segmentation25. The novel method, which is described in Table 1, represents a substantial development in the field of remote sensing image processing for the detection and segmentation of water bodies.
Methodology
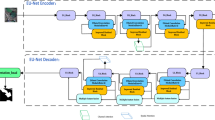
An attention mechanism is included in the U-Net architecture, which serves as the basis of our network. Figure 1 shows the block diagram of our approach and illustrates the architecture of our proposed method. Using the U-Net encoder, which is made up of different convolution and down-sampling components that are common in these kinds of models, feature representations are produced. Within the encoder pathway, two 3 × 3 convolution layers are applied sequentially in each conventional convolution module. The feature processing is further refined by applying a series of layers after each convolution layer. To aid in stabilizing and speeding up the training process, a Batch Normalization (BN) layer is specifically utilized to normalize the inputs to each layer. To lessen overfitting, a Dropout layer is added, which randomly removes a portion of the features during training. The model is then able to learn intricate patterns in the data by introducing non-linearity through the use of a Rectified Linear Unit (ReLU) activation function.
The Nested Attention Module (NAM) plays a crucial role in enhancing the model’s ability to effectively extract and utilize hierarchical features, particularly for tasks like semantic segmentation, where precise localization and contextual understanding are essential.
-
1.
Hierarchical attention mechanism.
-
Nested attention layers within the framework allow the model to focus on both fine-grained (local) and coarse-grained (global) features simultaneously.
-
At each level of the U-Net (encoder, bottleneck, and decoder), NAM prioritizes important spatial or feature-map regions relevant to the task.
-
-
2.
Improved skip connections.
-
U-Net heavily relies on skip connections to transfer features from the encoder to the decoder. NAM can enhance these skip connections by applying attention mechanisms to filter out irrelevant information and highlight critical features.
-
This ensures that the decoder receives refined, contextually significant information, leading to more accurate reconstruction of the target output.
-
-
3.
Spatial and channel-wise feature enhancement.
-
NAM typically includes spatial attention (identifying where to focus) and channel attention (identifying what features to focus on).
-
By combining these two forms of attention, it enables the network to adaptively weight feature maps based on their relevance at each level.
-
-
4.
Multi-scale contextual understanding.
-
The nested structure within the attention module supports multi-scale feature aggregation:
-
At shallow layers (near the input), NAM captures fine details like edges or textures.
-
At deeper layers, it captures global context like object relationships or broader patterns.
-
-
This multi-scale focus is particularly beneficial for segmentation tasks that require balancing fine boundary details with overall contextual awareness.
-
The Nested Attention Module functions as a powerful mechanism to selectively refine and propagate features across the encoder-decoder pathway. Its nested nature enhances hierarchical feature extraction, multi-scale understanding, and contextual integration, leading to significant improvements in tasks like image segmentation, medical imaging, and other dense prediction problems.
An attention mechanism is then given the feature representations that were extracted at each layer of the encoder. To direct the network’s attention toward the features that are most pertinent to the current job, this process reweights across both the channel and pixel dimensions. The attention mechanism improves the model’s capacity to acquire crucial information by highlighting significant traits and suppressing less important ones, producing segmentation results that are more reliable and accurate. In the domain of semantic segmentation, the encoder-decoder architecture, which encompasses both down-sampling and up-sampling processes, is commonly employed to execute the segmentation task comprehensively. However, this architecture faces a significant challenge: the repeated down-sampling processes tend to result in the loss of original spatial information, which is not fully recoverable during the up-sampling phase. Consequently, maintaining rich spatial detail is imperative for achieving accurate semantic segmentation outcomes. Drawing inspiration from the BiSeNet model, our newly developed Net also emphasizes the importance of a detailed branch for capturing low-level spatial information. To effectively harness this low-level information, we adopt a straightforward yet effective shallow structure that prioritizes the extraction of detailed features more so than the semantic branch does. This is accomplished through the implementation of three layers of feature extraction blocks, each employing a 3 × 3 Convolution-Batch Normalization-SiLU (CBS) operator. The SiLU (Sigmoid Linear Unit) function, in particular, provides a non-linear activation that aids in the detailed processing of spatial information.
As we progress through these three layers, we incrementally increase the number of channels in the feature output (64, 128, and 256, respectively) to enrich the representation capacity of the extracted features. This lightweight, shallow design allows for the generation of feature maps at 1/2, 1/4, and 1/8 the size of the original image at each respective layer. The resultant feature representations boast a wide channel bandwidth and high resolution, encapsulating a wealth of spatial detail information that is crucial for the accurate delineation of various objects and regions within the semantic segmentation task26. To ensure a sufficiently expansive receptive field essential for capturing contextual details over larger spatial extents, the semantic branch of our network is designed to be deeper and more complex than the detail branch. Our approach contrasts with the method used by BiSeNet, which directly employs a lightweight backbone to extract contextual information. In our case, the semantic branch is designed with a lightweight hybrid architecture that merges convolutional neural networks (CNNs) and Transformer technologies. This integration involves combining the convolutional layers from ResNet-18 with our newly introduced Linear Mobile Attention (LMA) Module. This combination aims to craft a model that is not only more efficient but also more effective in its performance.
The Lightweight Linear Mobile Attention (LMA) improves computational efficiency and maintains strong feature extraction capabilities, making it particularly suitable for mobile and resource-constrained devices.
-
1.
Efficient feature attention.
-
LMA applies a lightweight attention mechanism that reduces the computational complexity of standard attention methods (e.g., self-attention).
-
By approximating or simplifying attention computations (often replacing quadratic complexity with linear complexity), it ensures that the model remains fast and efficient without compromising attention’s effectiveness.
-
-
2.
Spatial and channel-wise attention.
-
LMA often employs a combination of:
-
Spatial attention: Identifies which regions of the feature map are most important for the task.
-
Channel attention: Focuses on the most critical feature channels, enabling the network to prioritize discriminative features while ignoring irrelevant ones.
-
-
This dual attention mechanism ensures a compact yet effective representation at each layer.
-
-
3.
Lightweight design.
-
Traditional attention mechanisms can be computationally intensive, especially in high-resolution images. LMA:
-
Reduces the attention map size or simplifies attention computation (e.g., using separable convolutions, low-rank approximations, or efficient kernels).
-
Ensures that the attention mechanism is feasible for edge devices while retaining performance close to that of full-fledged attention modules.
-
-
-
4.
Multi-scale context integration.
-
LMA supports multi-scale feature integration:
-
It processes information across different scales in the encoder and decoder to ensure both fine-grained details and global context are captured efficiently.
-
This is particularly important for tasks like segmentation, where precision at boundaries and contextual awareness are both critical.
-
-
-
5.
Enhancing skip connections.
-
U-Net relies heavily on skip connections to transfer features between the encoder and decoder. LMA can refine these connections by selectively emphasizing important spatial and channel-level information.
-
This reduces noise and ensures that only the most relevant features are propagated through the network.
-
The Lightweight Linear Mobile Attention module enhances the U-Net architecture by offering efficient spatial and channel-wise attention mechanisms while maintaining computational feasibility. Its role is to selectively focus on critical features at each stage of the encoder-decoder pipeline, ensuring accurate segmentation with reduced computational overhead. This makes LMA an ideal choice for real-time and resource-constrained applications.

Flow Chart of DSIA U-Net.
Linear attention mechanism
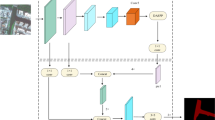
Figure 2 shows impressive achievements in numerous vision-centric tasks, primarily due to its fundamental reliance on the self-attention mechanism. This mechanism facilitates effective long-range interactions and the acquisition of global information, presenting benefits compared to conventional local convolutional approaches. Nevertheless, despite its efficiency, the self-attention process is computationally demanding, particularly for tasks involving high resolution. This is because of its quadratic computational complexity, which substantially elevates both the computational expenses and memory demands. In the context of semantic segmentation, where global contextual understanding is crucial, the self-attention mechanism facilitates the model’s ability to integrate information across the entire image. This is particularly valuable for distinguishing between classes and understanding the broader context within which specific objects or features are situated. However, the challenge lies in optimizing this mechanism to reduce its computational demands without sacrificing the benefits it brings to the task27.

Spatial Attention Module.
The softmax attention, for example, can be expressed mathematically for an input
showcasing the mechanism’s approach to weighting and aggregating information across different positions in the input data. This formulation underscores the balance that must be struck between leveraging the powerful global information processing capabilities of self-attention and managing the computational overhead it entails.
A represents the softmax attention
By multiplying the number of queries (Q) by the transposed keys (K^T), one can obtain the similarity attention map, as defined by Eq. (3). It suffices to meet this condition to ensure that the attention matrix A stays Nonnegative. To further offer flexibility in selecting how similarity is quantified within the attention mechanism, any similarity function Sim can be chosen to calculate the attention matrix A. Not all of the characteristics that the encoder derives are advantageous for the segmentation process in the architecture of U-net-shaped networks used for it. The importance of features can vary across different spatial locations within each channel, leading to a diverse weighting of feature representations for segmentation and, consequently, varying contributions from different channels. However, neglecting the diversity of features and the broader context information may result in inadequate detailing of edges and essential features. In this study, we offer an efficient yet straightforward “Spatial Attention Module” to overcome these issues.

Basic Block Diagram of DSIA U-Net. Here, (1) Encoder (2) Multi-scale Images (3) Global Pixel (4) Global Segmented Water (5) Local Pixel (6) Local Segmented Water (7) Hidden layer (8) Clustering Layer (9) Pre-segmented Image (10) Down-sampling 11. Adaptive Attention 12. Decoder.
This module is intended to remove superfluous information, such as characteristics associated with dams, rivers, fogs, and saline-alkaline lands, while highlighting important data, such as spatial locations and colored pixel values, especially near the borders of bodies of water to their surroundings. Both low-level encoder characteristics and high-level features that have not yet undergone upsampling can be incorporated into the Spatial Attention Module’s architecture, as shown in Fig. 3.
Using global context information from feature mappings in the network, the Spatial Attention Module functions as an auxiliary module and chooses inter-feature representations according to their significance. This makes it possible for the module to consider the wider context information necessary for precise segmentation by utilizing global average pooling throughout the whole advanced feature layer. In the specific case of water segmentation, the complexity of river tributaries and surrounding features necessitates a more nuanced approach than simply relying on pixel values. The global average pooling within the attention module facilitates this by incorporating global context information, thus enhancing the segmentation accuracy without significantly increasing the network parameters.
A given feature map in this context is represented by the formula
where hei and wei denote the height and width of the feature map, respectively, and fea represents the number of channels. This formulation underscores the attention module’s capacity to process and refine feature maps by prioritizing spatially relevant and contextually significant information, thereby improving the segmentation outcome.
Experiments
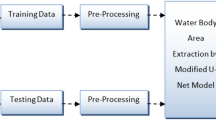
Data set description
The proposed approach is evaluated using a dataset of satellite images of water bodies available on Kaggle shown in Table 1, which comprises Sentinel-2 satellite imagery capturing various water bodies. Each image in this dataset is accompanied by a black-and-white mask, where black represents non-water elements and white indicates water bodies. The masks were generated using the Normalized Difference Water Index (NDWI), a common index for identifying and quantifying vegetation in satellite imagery, albeit with an adjusted higher threshold specifically for water body detection. The dataset was acquired using the Sentinel-2 API and processed using Rasterio, with the NDWI calculated from bands 8 and 3 of the satellite’s data. The dataset contains a total of 5,682 images, evenly split between actual images and their corresponding masks, with 2,841 images in each directory. For model training, evaluation, and validation, the dataset is partitioned as follows: 2,290 images are designated for training, 300 images from the training set are reserved for testing, and an additional 250 images are allocated for validation. Moreover, to assess the model’s performance in real-world scenarios, 12 images from a real-time dataset are specifically used for testing. This comprehensive dataset not only provides a rich variety of water bodies captured under different conditions but also allows for a robust evaluation of the proposed segmentation approach. The inclusion of real-time data for testing further ensures that the approach is tested against current and potentially challenging conditions, offering insights into its practical applicability and effectiveness in identifying water bodies from satellite imagery.
The inclusion of real-time data for testing further ensures that the approach is tested against current and potentially challenging conditions, offering insights into its practical applicability and effectiveness in identifying water bodies from satellite imagery.
Ablation study
Figure 4 shows comparison models with existing models. In the process of fine-tuning our DOCNet model, we carried out ablation studies focusing on two critical parameters: the number of scales in the SEDO (Scale-Enhanced Detail-Oriented) module and the range size in the SPDO (Spatial-Pyramid Detail-Oriented) module30,31,32,33,34. These parameters are pivotal in determining the effectiveness of their respective modules in the context of the LoveDA dataset, a resource chosen for its relevance to our segmentation objectives. Number of Scales in the SEDO Module: In this experiment, we maintained a constant range size of 16 × 16 for the SPDO module to isolate the effects of varying the number of scales, denoted as M, in the SEDO module. The SEDO module is instrumental in our model for capturing multi-confidence scale class representations, which are essential for achieving nuanced segmentation results. It’s important to note that when M is reduced to 1, the multi-scale capability of the SEDO module simplifies to a single-scale case, essentially bypassing the scale enhancement feature of the module.

Comparision with existing models.
Table 2 shows the results of these experiments, as compiled illustrating that the segmentation performance of our model reaches its peak when M is set to 8. We observed this optimal performance as M was incrementally adjusted from 1 to 16. Based on these findings, we chose to configure the SEDO module with M = 8 for the final iteration of our DOCNet model. This configuration allows us to leverage the full potential of multi-confidence scale class representations in enhancing the segmentation accuracy of our network, thereby affirming the significance of the SEDO module in our overall segmentation approach. For the development of deep learning models, a suite of tools and libraries is available, with Keras being the preferred choice for its ease of use and flexibility. In this study, TensorFlow served as the backend for Keras, primarily due to its compatibility with GPU acceleration, which significantly speeds up model training and experimentation35,36. The experiments were conducted using specific computer specifications, including an NVIDIA Titan-V GPU, which is known for its robust performance in deep learning tasks. The software environment comprised Python 3.6 and TensorFlow 1.9.0, running on an Ubuntu 16.04 operating system.
Ablation studies were conducted using Kaggle datasets to showcase the improved performance of individual components within the proposed DSIA-UNet for waterbody segmentation. The results, summarized in Table 1, demonstrate the segmentation efficiency in a step-by-step progression: beginning with the baseline U-Net, transitioning to U-Net enhanced with spatial attention (SA), and culminating in the fully.
Table 3 shows the findings revealed several valuable insights:
-
1.
When employing the U-Net architecture, the metrics of precision, recall, F1-Score, and IoU were calculated as 0.862, 0.843, 0.863, and 0.867, respectively.
-
2.
The combination of U-Net with Attention resulted in notable enhancements. The precision, recall, F1-Score, and IoU values were observed to be 0.891, 0.894, 0.889, 0.895, respectively.
-
3.
By further incorporating Deep Shallow U-Net with Spatial Attention (SA) mechanisms, the model identified crucial parameters while eliminating unnecessary ones. Consequently, the precision, recall, F1-Score, and IoU metrics saw improvements, reaching 0.95, 0.951, 0.953, and 0.954, respectively.
From the outcomes of Table 4, a number of valuable observations were derived:
-
1.
For U-Net with a depth of n = 3 (where n represents the U-Net’s depth), the precision, recall, F1-Score, and IoU metrics yielded values of 0.831, 0.834, 0.837, and 0.839, respectively. Slight variances were observed for n = 4 and n = 5. Considering parameters and complexity, opting for n = 4 is a preferable choice.
-
2.
When incorporating U-Net with Attention Mechanism were evident. Precision, recall, F1-Score, and IoU were calculated as 0.891, 0.894, 0.889, 0.895, respectively.
-
3.
Introducing Deep Shallow U-Net alongside Spatial Attention (SA) led to the identification of essential parameters while removing unnecessary ones. As a result, precision, recall, F1-Score, and IoU were enhanced to 0.95, 0.951, 0.953, and 0.954, respectively.
Table 5 explains the Layer-wise parameters of DSIA U-Net and Table 6 explains the performance Metrics of Precision, Recall. This model underwent training for a total of 100 epochs, starting with a learning rate of 0.001. Remarkably, the training process was efficient, with a total runtime of approximately 2 min per epoch. Python programming was utilized to design and train the model, showcasing the versatility and power of Python in handling deep learning projects. To evaluate the performance of the developed system, a comprehensive set of metrics was employed, including accuracy, precision, recall, F1 score, Inter-section over Union (IoU), Mean Absolute Difference (MAD), and Structural Similarity Index Measure (SSIM). Among these, accuracy was chosen as the primary measure for comparing the proposed model’s performance against existing systems. This decision underscores the importance of accurately classifying each pixel in semantic segmentation tasks, particularly when dealing with complex and varied landscapes.
During the pre-processing phase, the mean value was subtracted from each image in the single channel, a common practice to normalize data and improve model performance. The dataset encompassed a broad spectrum of ground features and landscapes, including urban, suburban, and rural areas, providing a rich and challenging dataset for model training and validation. The training and validation datasets were utilized to optimize the network, while the testing dataset served to evaluate and present the final results of the study. This methodical approach to training and evaluating the deep learning model ensures a thorough assessment of its capabilities and potential applicability in real-world scenarios.
Results and discussion
Visual results
When utilizing the Normalized Difference Water Index (NDWI) in its standard application, distinguishing building areas, clouds, and their shadows from water bodies poses a significant challenge. This difficulty arises because NDWI primarily focuses on highlighting water features, leading to potential confusion with other dark or reflective surfaces. Moreover, the need to set different threshold values for various scenarios complicates the process further, as these thresholds can vary greatly depending on the specific characteristics of the images and the geographic context. In contrast, the proposed DSIA U-Net is designed to overcome these limitations by effectively segmenting water regions in satellite images. This capability is particularly important in remote sensing applications where accurate water body delineation is crucial for environmental monitoring, urban planning, and disaster management. Extensive comparative studies were conducted to demonstrate the effectiveness of DSIA U-Net and showcase the segmentation results achieved by this method.
Real-time dataset of water bodies
The evaluation incorporated two multispectral Landsat datasets to analyze real-time imagery, focusing on the Bhopal region in Madhya Pradesh. These datasets were captured by the Landsat 5 Thematic Mapper (TM) and comprised multispectral images with dimensions of 206 × 424 × 3, representing the Red (R), Green (G), and Blue (B) spectral bands. The images were acquired on two distinct dates—May 29, 2009, and November 9, 2011—covering an upstream lake near Bhopal (approximately 23.2532° N, 77.3382° E).
During this period, significant changes in the lake were observed due to a lack of rainfall in 2009, leading to the lake drying up. The datasets were specifically chosen to study the region’s water bodies and assess the proposed approach’s effectiveness in detecting such changes.

Real-Time Dataset in Bhopal, Madhya Pradesh.

Real-time Dataset with Proposed Model.
Figures 5 and 6 likely present sample multispectral images from the Landsat 5 TM datasets for the Bhopal region, providing visual context for the geographic study area and the temporal changes in the waterbody and proposed output.
The studies utilized two multispectral Landsat datasets for real-time images, with radiometric correction processes applied to normalize the datasets and enhance image quality. Despite the challenges associated with real-time dataset quality, the Intersection over Union (IoU) values achieved for these images ranged between 0.6 and 0.7, indicating considerable accuracy in water body segmentation. To provide a comprehensive evaluation of DSIA U-Net’s performance, several metrics were employed, including the F1-score (F1), mean Intersection over Union (mIoU), and overall accuracy (OA). These metrics collectively offer a detailed view of the model’s capabilities, measuring not only its precision and recall (as reflected in the F1-score) but also the extent of overlap between the predicted and actual water body areas (mIoU) and the model’s overall correctness (OA) shown in Table 6.
Evaluation criteria
The outcomes of these evaluations, depicted in Figs. 7, 8 and 9, and 10, highlight the potential of DSIA U-Net as a robust tool for water body segmentation in satellite imagery. By effectively addressing the limitations of traditional NDWI applications and providing accurate segmentation results, SAU-Net represents a significant advancement in the field of remote sensing image analysis.
where, TP = True positive, TN = True negative,
FP = False positive, FN = False negative.
TP –True positive, TN -True negative,
FP - false positive, FN -false negative.

Proposed F1-Score with other techniques.

Proposed Precision with other techniques.

Proposed Recall with other techniques.

Visual Results with Original Image, Mask, and Predicted Output of DSIA U-Net.
Conclusion
In this work, we report a unique and efficient network architecture that attempts to address the imprecision problems with current simplified networks in terms of high-definition picture segmentation from remote sensing. This approach comprises two primary parts: a detail-oriented branch that captures fine spatial details and a semantic branch that aims to understand the broader context. We build our DSIA U-Net model by enhancing the semantic branch by combining a linear attention mechanism with traditional CNN structures. Apart from enhancing the extraction of detailed local information, this model also investigates methods to reduce computation requirements and enhances fundamental convolution algorithms. Testing extensively and visualizing the results, we show that these improvements result in significant gains in the model’s feature representation ability as well as in the network’s segmentation performance, all while preserving quick inference times.
Data availability
The datasets generated and/or analysed during the current study are available in the kaggle repository, and real time dataset from37 https://www.kaggle.com/franciscoescobar/satellite-images-of-water-bodies.
References
Miao, Z. et al. Automatic water-body segmentation from high-resolution satellite images via deep networks. IEEE Geosci. Remote Sens. Lett. 15(4), 602–606. https://doi.org/10.1109/LGRS.2018.2794545] (2018).
Tambe, R. G., Talbar, S. N. & Chavan, S. S. Deep multi-feature learning architecture for water body segmentation from satellite images. J. Vis. Commun. Image Represent. 77, 103141. https://doi.org/10.1016/j.jvcir.2021.103141 (2021).
Vasantrao, C. P. & Neha, G. A high-performance, Equus Jubatus-optimized deep learning model for satellite image-based change detection. Traitement du Signal https://doi.org/10.18280/ts.400605 (2023).
Aalan Babu, A. & Mary Anita Rajam, V. Water-body segmentation from satellite images using Kapur’s entropy-based thresholding method. Comput. Intell. 36(3), 1242–1260. https://doi.org/10.1111/coin.12339 (2020).
Xia, M. et al. DAU-Net: A novel water areas segmentation structure for remote sensing image. Int. J. Remote Sens. 42(7), 2594–2621. https://doi.org/10.1080/01431161.2020.1856964 (2021).
Duan, L. & Hu, X. Multiscale refinement network for water-body segmentation in high-resolution satellite imagery. IEEE Geosci. Remote Sens. Lett. https://doi.org/10.1109/LGRS.2019.2926412 (2019).
Zhou, Y. N., Luo, J., Shen, Z., Hu, X. & Yang, H. Multiscale water body extraction in urban environ-ments from satellite images. IEEE J. sel. Top. Appl. Earth Observ. Remote Sens. 7(10), 4301–4312. https://doi.org/10.1109/JSTARS.2014.2360436 (2014).
Wang, J. et al. FWENet: A deep con-volutional neural network for flood water body extraction based on SAR images. Int. J. Digit. Earth 15(1), 345–361. https://doi.org/10.1080/17538947.2021.1995513 (2022).
Jonnala, N. S. & Neha, G. SAR U-Net: Spatial attention residual U-Net structure for water body segmentation from remote sensing satellite images. Multimed. Tools Appl. https://doi.org/10.1007/s11042-023-16965-8 (2023).
Zhang, X. et al. ESDINet: Efficient shallow-deep interaction network for semantic segmentation of high-resolution aerial images. IEEE Trans. Geosci. Remote Sens. https://doi.org/10.1109/TGRS.2024.3351437 (2024).
Chen, Y., Tang, L., Kan, Z., Bilal, M. & Li, Q. A novel water body extraction neural network (WBE-NN) for optical high-resolution multispectral imagery. J. Hydrol. 588, 125092. https://doi.org/10.1016/j.jhydrol.2020.125092 (2020).
Aroma, R. J. & Raimond, K. Investigation on spectral indices and soft classifiers-based water body segmentation approaches for satellite image analysis. J. Indian Soc. Remote Sens. 49(2), 341–356. https://doi.org/10.1007/s12524-020-01194-5 (2021).
Jonnala, N. S., et al. BCD-Unet: A novel water areas segmentation structure for remote sensing image. In 2023 7th International Conference on Intelligent Computing and Control Systems (ICICCS). IEEE. https://doi.org/10.1109/ICICCS56967.2023.10142694. (2023).
Yang, Z. et al. A segmentation method based on the deep fuzzy segmentation model in combined with SCANDLE clustering. Pattern Recogn. 146, 110027. https://doi.org/10.1016/j.patcog.2023.110027 (2024).
Ma, X. et al. DOCNet: Dual-domain optimized class-aware network for remote sensing image segmentation. IEEE Geosci. Remote Sens. Lett. 21, 1–5. https://doi.org/10.1109/LGRS.2024.3350211 (2024).
Kaplan, G. & Avdan, U. Object-based water body extraction model using Sentinel-2 satellite imagery. Eur. J. Remote Sens. 50(1), 137–143. https://doi.org/10.1080/22797254.2017.1297540 (2017).
Vasantrao, C. P., et al. Dual adaptive model for change detection in multispectral images. In 2023 Second International Conference on Electrical, Electronics, Information and Communication Technologies (ICEEICT). IEEE. https://doi.org/10.1109/ICEEICT56924.2023.10156920. (2023).
Zhao, Z. et al. Uncertainty-driven trustworthy defect detection for high-resolution powder bed images in selective laser melting. J. Manuf. Syst. 72, 59–73. https://doi.org/10.1016/j.jmsy.2023.11.006 (2024).
Yang, X., Qin, Q., Grussenmeyer, P. & Koehl, M. Urban surface water body detection with sup-pressed built-up noise based on water indices from Sentinel-2 MSI imagery. Remote Sens. Environ. 219, 259–270. https://doi.org/10.1016/j.rse.2018.09.016 (2018).
Goldblatt, R. et al. Using Landsat and nighttime lights for supervised pixel-based image classification of urban land cover. Remote Sens. Environ. 205, 253–275. https://doi.org/10.1016/j.rse.2017.11.026 (2018).
Singh, S. & Girase, S. Semantic segmentation of satellite images for water body detection. In Data Intelligence and Cognitive Informatics: Proceedings of ICDICI 2021 (eds Jeena Jacob, I. et al.) 831–840 (Springer Nature Singapore, Singapore, 2022). https://doi.org/10.1007/978-981-16-6460-1_64.
Jonnala, N. S. & Gupta, N. NDR U-Net: segmentation of water bodies in remote sensing satellite images using nested dense residual U-Net. Revue d’Intelligence Artificielle https://doi.org/10.18280/ria.380324 (2024).
Chong, Q. et al. Pos-DANet: A dual-branch awareness network for small object segmentation within high-resolution remote sensing images. Eng. Appl. Artif. Intell. 133, 107960. https://doi.org/10.1016/j.engappai.2024.107960 (2024).
Zhang, C. et al. A multi-level context-guided classification method with object-based convolutional neural network for land cover classification using very high-resolution remote sensing images. Int. J. Appl. Earth Observ. Geoinform. 88, 102086. https://doi.org/10.1016/j.jag.2020.102086 (2020).
Yuan, K. et al. Deep-learning-based multispectral satellite image segmentation for water body detection. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 14, 7422–7434. https://doi.org/10.1109/JSTARS.2021.3098678 (2021).
Tambe, R. G., Talbar, S. N. & Chavan, S. S. Deep multi-feature learning architecture for water body segmentation from satellite images. J. Vis. Commun. Image Represent. 77, 103141. https://doi.org/10.1016/j.jvcir.2021.103141 (2021).
Shi, W. & Sui, H. An effective superpixel-based graph convolutional network for small waterbody extraction from remotely sensed imagery. Int. J. Appl. Earth Observ. Geoinf. 109, 102777. https://doi.org/10.1016/j.jag.2022.102777 (2022).
Krosuri, L. R. & Aravapalli, R. S. Novel heuristic bidirectional-recurrent neural network framework for multiclass sentiment analysis classification using coot optimization. Multimed. Tools Appl. https://doi.org/10.1007/s11042-023-16133-y (2023).
Yedukondalu, J. & Sharma, L. D. Cognitive load detection using circulant singular spectrum analysis and binary Harris Hawks optimization based feature selection. Biomed. Signal Process. Control 79, 104006. https://doi.org/10.1016/j.bspc.2022.104006 (2023).
Zhang, L. et al. Towards interpretability lightweight semantic segmentation model for waterbody extraction in large-scale high resolution remote sensing images. Int. J. Remote Sens. 45(8), 2721–2738. https://doi.org/10.1080/01431161.2024.2334812 (2024).
Peña, F. J. et al. DeepAqua: Semantic segmentation of wetland water surfaces with SAR imagery using deep neural networks without manually annotated data. Int. J. Appl. Earth Observ. Geoinf. 126, 103624. https://doi.org/10.1016/j.jag.2023.103624 (2024).
Bansal, S., Chauhan, R. & Kumar, P. A Cuckoo search based WDM channel allocation algorithm. Int. J. Comput. Appl. 96(20), 6–12 (2014).
Bansal, S., Kumar, S., & Bhalla, P. A novel approach to WDM channel allocation: Big bang–big crunch optimization. In The Proceeding of Zonal Seminar on Emerging Trends in Embedded System Technologies (ETECH) organized by The Institution of Electronics and Telecommunication Engineers (IETE), Chandigarh Centre, Chandigarh, India, pp. 80–81, August 23–24, (2013).
Liu, M., Liu, J. & Hua, Hu. A novel deep learning network model for extracting lake water bodies from remote sensing images. Appl. Sci. 14(4), 1344. https://doi.org/10.3390/app14041344 (2024).
Nagaraj, R. & Lakshmi, S. K. LWAMNNet: A novel deep learning framework for surface water body extraction from LISS-III satellite images. Earth Sci. Inf. 17(1), 561–592. https://doi.org/10.1007/s12145-023-01187-1 (2024).
Lwin, T. M. M., & Zin, M. W. Attention-based CNN model for semantic segmentation of remote sensing images. In 2024 5th International Conference on Advanced Information Technologies (ICAIT). IEEE, 2024. https://doi.org/10.1109/ICAIT65209.2024.10754920
Gupta, N., Ari, S. & Panigrahi, N. Change detection in landsat images using unsupervised learning and RBF-based clustering. IEEE Trans. Emerg. Top. Comput. Intell. 5(2), 284–297. https://doi.org/10.1109/TETCI.2019.2932087 (2021).
Acknowledgements
This research acknowledged by the Fundamental Research Grant Scheme (FRGS), MOE, Malaysia, Code: FRGS/1/2022/TK07/UKM/02/22. Moreover, this research acknowledges Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R10), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
N S Jonnala, R C Bheemana, K Prakash made substantial contributions to design, analysis and characterization. S Bansal, A Jain, V Pandey, participated in the conception, application and critical revision of the article for important intellectual content. M R I Faruque and K S A Mugren provided necessary instructions for analytical expression, data analysis for practical use and critical revision of the article purposes.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Jonnala, N.S., Bheemana, R.C., Prakash, K. et al. DSIA U-Net: deep shallow interaction with attention mechanism UNet for remote sensing satellite images. Sci Rep 15, 549 (2025). https://doi.org/10.1038/s41598-024-84134-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-84134-4
Keywords
This article is cited by
-
Path-based dominant sets integrating region and boundary cues for image segmentation
The Visual Computer (2026)
-
AER U-Net: attention-enhanced multi-scale residual U-Net structure for water body segmentation using Sentinel-2 satellite images
Scientific Reports (2025)
-
MyWear revolutionizes real-time health monitoring with comparative analysis of machine learning
Scientific Reports (2025)
-
A hybrid deep learning approach for accurate water body segmentation in satellite imagery
Earth Science Informatics (2025)
