
Abstract
This study developed a machine learning model to predict stillbirth using retrospective data from 32,953 singleton pregnancies at multi-centers in South Korea. Variables were collected at baseline, E1 (before 13 weeks of pregnancy), and T0 (before 28 weeks of pregnancy). Each separate cohort (all stillbirths, early stillbirths, late stillbirths) was randomly divided into training and test sets at a 7:3 ratio. Extreme Gradient Boosting Machine algorithm was used to make original models with a full set of variables and simplified models with certain variables from Shapley additive explanations (SHAP) values. The prediction model of whole cohort for all stillbirths achieved an area under the receiver operating characteristic curve (AUC) value of 0.720 (baseline) and 0.740 (E1) with an area under precision-recall curve (AUPR) value of 0.016 (baseline) and 0.019 (E1). The prediction models for early and late stillbirths achieved similar results. For the original model for late stillbirth at T0 achieved AUC of 0.781 and AUPR of 0.015. A simplified model for late stillbirth at T0 using top-ranked SHAP variables demonstrated similar performance with AUC of 0.759 and AUPR of 0.133. Our machine learning model for predicting the late stillbirth in East Asian women in singleton pregnancies with variables before 28 gestational weeks might be helpful for evaluating individual risks.
Similar content being viewed by others


Introduction
Stillbirth is defined as a baby born without signs of life after a threshold 20 weeks of gestation by the American College of Obstetrics and Gynecologists1, which is a desperate event during pregnancy. Risk factors for stillbirth include maternal age, body mass index (BMI), ethnicity, fetal growth restriction, alcohol, smoking, assisted conception, diabetes mellitus, systemic lupus erythematosus/antiphospholipid syndrome, chronic hypertension, low socioeconomic status, and low level of education2,3,4. A systematic review has reported that maternal age, maternal BMI, and diabetes are the most commonly used risk factors in the prediction of stillbirth5. Global stillbirth rate has been estimated to be 0.14%6. In South Korea, stillbirth rate has decreased from 0.2% in 2011 to 0.17% in 20217, although stillbirth rates in twin and triplet pregnancies after 32 weeks of gestation have been reported as 0.48% and 1.26%, respectively8.
Although unexpected stillbirth occurs frequently, early detection of high risk pregnancies for stillbirth might be crucial for its prevention through enhanced monitoring or expedited birth. While various conventional statistical models for predicting risk of stillbirth have shown poor performances4,9,10, recent prediction models using machine learning algorithms have demonstrated better performances11,12. However, most of these studies were performed in Western countries or low-income countries in Asia and Africa12,13,14,15,16. Because ethnicity is considered as an independent influencing factor, a prediction model of stillbirth for East Asians is needed for clinical application. Late-stillbirth ≥ 28 weeks’ gestation in high–income countries is very important because most babies born at ≥ 28 weeks of gestation can survive without showing serious morbidity4,17,18.
Thus, the aim of this study was to develop prediction models for stillbirth, focusing on late stillbirth in singleton pregnancies using a machine learning approach.
Materials and methods
Data source
Data were extracted from a perinatal database for women who delivered between January 2009 and December 2020 at seven hospitals in four areas of South Korea under the authority of The Catholic University of Korea. Data of maternal demographic characteristics, BMI, blood pressure (BP) measurements, blood and urine laboratory tests, diagnoses recorded by physicians, and medications prescribed were collected from the hospitals’ databases via electronic medical records (EMR). These data source were similar as the previous study19. This study was approved by the Institutional Review Board of the Catholic University Medical Centers (XC20WIDI0103). All methods were performed in accordance with the relevant guidelines and regulations. Informed consent was waived due to its retrospective study design.
Definitions of stillbirth
Stillbirth was defined as a baby born without signs of life after a threshold 20 weeks of gestation1. International Classification of Diseases-10 (ICD10) code of O36.4 was used to extract the stillbirth group from the EMR. Early stillbirth was defined as stillbirth between 20+ 0 weeks and 27+ 6 weeks of gestation and late stillbirth was defined as stillbirth after a threshold 28 weeks of gestation20. Multiple pregnancy, maternal age less than 18 years old at delivery, delivery before 20 weeks of gestation, and pregnancy with fetal chromosomal abnormality were excluded to ensure the homogeneity of the study population and reduce confounding factors that could affect the prediction models. Data were confirmed and missing data were abstracted from chart reviews by two obstetricians (J.H.W. and H.S.K.).
Machine learning analysis
Data preparation
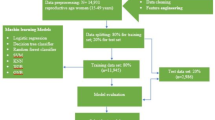
We followed guidelines for Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis for Establishing Prediction models21. Based on these guidelines, all anonymized data from 32,953 subjects were included in the data set used for this study. Subjects were assigned into two groups based on their parity status: nulliparity (n = 17,042) and multiparity (n = 15,911). To ensure a balanced distribution of target variable, a 7:3 stratified split was performed to divide data into training and test sets for each of the three cohorts22: the whole cohort, the nulliparity cohort, and the multiparity cohort. Each cohort of training and test data was analyzed by dividing it into stillbirth and non-stillbirth groups. Because dataset was separated by birth, mothers with multiple births are shared between the training and testing sets.
Variables used to develop stillbirth prediction models
Three sets of variables were used to develop stillbirth prediction models, including variables from different time periods: (1) baseline variables obtained solely from maternal questionnaires completed during the first hospital visits, (2) 1st trimester (E1) variables collected until 13 weeks of gestation, (3) early third trimester (T0) variables collected until 28 weeks of gestation. For predicting all stillbirths and early stillbirths, baseline and E1 variables were used. For predicting late stillbirths, T0 variables were also used. These variables included age, parity, underlying diseases, family history, reproductive history, physical examinations, laboratory results, and obstetric histories of the previous pregnancy for parous women. All sets included age, parity, underlying diseases, reproductive history, obstetric histories of the previous pregnancy, physical examination, and family history. The baseline set included 123 variables for nulliparous women and 145 variables for parous women. The E1 set included variables at baseline and laboratory and ultrasonographic results until E1, which were 175 variables for nulliparous women and 197 variables for parous women. The T0 set included 410 variables for nulliparous women and 432 variables for parous women. The whole cohort used the same sets of variables as those used for the multiparity cohort according to each time point.
Machine learning algorithm and interpretation
XGBoost is a tree-based algorithm that operates based on the Gradient Boosting technique23. In this study, extreme gradient boosting machine (XGBM) algorithm with built-in method for handling missing values was used, making it possible to use data with missing values in the machine learning process24. We further enhanced our model’s performance by employing Optuna for systematic hyperparameter tuning, identifying the optimal settings to maximize predictive accuracy. Optuna is a tool designed for selecting machine learning models or determining hyperparameters, specializing in simplifying and streamlining the optimization process25. Feature selection and hyperparameter tuning were performed using Grid Search with 10-fold cross-validation within the training set (Fig. 1b). An evaluation set was further separated from the training data and used exclusively for early stopping to prevent overfitting. To further address overfitting issues, we reduced the number of early stopping rounds to 10 and adjusted key hyperparameters. The adjusted hyperparameters include n_estimators, colsample_bytree, gamma, learning_rate, max_depth, min_child_weight, random_state, scale_pos_weight, and subsample. These changes were made to enhance the model’s generalization and reduce the performance gap between the training and test sets. The split data set was fed into algorithm and its performance was evaluated using metrics of area under the receiver operating characteristic curve (AUC), area under precision-recall curve (AUPR), specificity, F1 score, precision, and recall.

(a) Participants flow chart. GA gestational age, (b) Machine learning flow chart. CV cross validation.
Confidence intervals (CIs) for these metrics were calculated using a normal approximation based on the assumption of a binomial distribution. The z-value corresponding to the desired confidence level, such as 1.96 for a 95% confidence interval, varies depending on the confidence level and was computed using the scipy.stats.norm.ppf function. The length of the confidence interval (CI length) was then calculated using the following equation: CI length = z * √[m(1 - m) / n], where m is the calculated metric, n is the sample size, and z is the z-value corresponding to the confidence level. Finally, the lower and upper bounds of the confidence interval were determined by subtracting and adding the CI length from the metric value: CI lower bound = m - CI length, CI upper bound = m + CI length.
This approach ensures that the confidence intervals are accurately calculated using the binomial distribution assumption. Shapley values were used to indicate how much influence each variable had in determining model output. The Shapley value was the average value of all contributions of every variable in a coalition according to the presence or absence of each variable26. We used SHapley Additive exPlanations (SHAP) values to calculate and visualize Shapley values of prediction models. This selective focus led to retraining the XGBoost model with these key features to sharpen its predictive capability.
Simplified model evaluation and validation
For clinical application, a simplified model was developed with simplified variables having high ranked SHAP values. The performance of the simplified model of test sets was evaluated by the same parameters evaluated in the original model. The test set was not involved in the feature selection or model tuning process to ensure no data leakage or overfitting. In detail, original train set was divided into train and validation sets, the cross-validation was performed. Based on the AUC values from the each cross-validation fold, paired t-test between original and simplified models was performed. Questionnaires for clinical application for stillbirth prediction were developed based on model performance and convenience.
Results
Data set
The final study cohort included 32,593 pregnancies after subtracting women from 37,078 pregnancies based on exclusion criteria during the study period (Fig. 1). Stillbirth was diagnosed in 299 (0.92%) pregnancies in the entire cohort, which were 209 (0.91%) pregnancies in the training set and 90 (0.91%) pregnancies in the test set. Baseline characteristics are described in Table 1.
Machine learning predictive model for all stillbirths at baseline and E1
For all stillbirths in the whole cohort, a prediction model with original variables achieved an AUC of 0.720 at baseline and 0.740 at E1, and the AUPR values of 0.016 at baseline and 0.019 at E1 (Table 2; Fig. 2). The results in the nulliparous and the multiparous cohorts were shown in Tables 3 and 4, and Fig. 2.

Predictive performance of original prediction models for all stillbirths at baseline and E1 period. (a) AUC at baseline, (b) AUC at E1, (c), AUPR at baseline, (d) AUPR at E1. AUC area under the curve, AUPR area under precision-recall curve.
Machine learning predictive model for early stillbirth at baseline and E1
For early stillbirths, a prediction model with original variables achieved an AUC of 0.728 at baseline and 0.743 at E1 and the AUPR values of 0.010 at baseline and 0.094 at E1 (Table 2).
Machine learning predictive model for late stillbirth at baseline, E1, and T0
The model for late stillbirth achieved an AUC of 0.705 at baseline and 0.719 at E1, with a consistent AUPR of 0.011 at baseline and 0.024 at E1 (Table 2; Fig. 3).

Predictive performance of original prediction models for late stillbirths at T0 period. (a) AUC of whole population, (b) AUC of nulliparous population, (c) AUC of multiparous population. AUC area under the curve.
In the whole cohort, the late stillbirth model using T0 variables achieved an AUC of 0.781 and the AUPR of 0.015. The model showed a specificity of 0.967, and an F1 score of 0.053. (Table 2). The results in the nulliparous and multiparous cohorts were shown in Tables 3 and 4; Fig. 3.
Performances of simplified prediction models for late stillbirth at T0
The simplified model using the top 20 features with high SHAP values (Fig. 4) achieved results with an AUC of 0.873, the AUPR of 0.122 in the train set (Suppl. Tables 1 and Fig. 5). In the test set, the AUC was 0.759 and the AUPR of 0.133 (Fig. 5). This simplified model achieved a specificity of 0.974, and an F1 score of 0.065 (Table 5). In the statistical analysis between original and simplified models, there was no statistical difference in the mean values of cross-validation AUCs between two groups (0.727 and 0.761, p = 0.377), in the prediction of late stillbirth at T0 period (Suppl. Table 2). Weight before pregnancy, maternal height, BMI before pregnancy, maternal occupation, residential area, systolic and diastolic blood pressure at T0 period, number of myoma, laboratory results of hemoglobin, white blood cell, glomerular filtration rate, blood urea nitrogen at E0 period, platelet, triglyceride, total cholesterol, gamma-glutamyl transferase, glucose level at T0 period, C-reactive protein during pregnancy, the shortest cervical length until T0 period, use of nifedipine during pregnancy were identified as the most predictive features for stillbirths at T0 period. Consequently, we developed a simplified questionnaire that corresponded to these variables identified with high SHAP values for clinical use (Table 6).

High SHAP values up to 20 variables in the stillbirths at T0 period. CRP C-reactive protein, SBP systolic blood pressure, DBP diastolic blood pressure, WBC white blood cell, BMI body mass index, GFR glomerular filtration rate, GGT gamma-glutamyl transferase, BUN blood urea nitrogen.

Predictive performance of simplified prediction models for late stillbirths at T0 period. (a) AUC from analysis of train set, (b) AUC from analysis of test set, AUC area under the curve.
Discussion
In this study, the prediction models for all stillbirths, early stillbirth, and late stillbirth, at baseline and E1 showed low prediction performance. However, the prediction model for late stillbirth with T0 variables achieved improved performance. Similarly, a simplified model for predicting stillbirth using high SHAP values at the T0 period demonstrated comparable performance. Based on these findings, a simplified questionnaire was developed at the T0 period for the prediction of stillbirth.
While some authors have suggested biomarkers or specific Doppler findings5,27, application of those markers to all pregnancies is not realistic yet due to cost-effectiveness, feasibility of the healthcare system and resource, acceptance of pregnant women, and rare incidence of stillbirth10. Therefore, baseline estimation of individual risk or early detection of high-risk pregnancies with routinely collected perinatal records and tests including biomarkers during pregnancy might be helpful for more focused antenatal care. Uterine artery Doppler studies are getting more popular in the first pregnancy for the prediction of preeclampsia28. One study has shown that increased first-trimester uterine artery Doppler resistance indices is an independent risk factor for late stillbirth (≥ 34 weeks) but not early stillbirth29. Further research is needed in this regard. In addition, research studies on prediction models using first-trimester uterine artery Doppler are needed.
In this study, prediction of late stillbirth with machine learning approach showed fair to good performances, especially for multiparous women. A recent study from the Stillbirth Collaborative Research Network in United States30 using a machine learning model also demonstrated good performance (AUC of 0.867) for prediction of stillbirth using data prior to viability (22–24 weeks of gestation). However, participants of Black race were oversampled in that study due to increased stillbirth rates at baseline in Black patients. It is well known that Black race has increased risk of stillbirth. Some studies have suggested that Asian/Asian British ethnicity has higher risk for stillbirth compared to the White race31,32. However, those studies were performed in Western countries such as UK or United states. Therefore, socioeconomic disadvantage for minority might have affected results of those studies. There has been no study performed in developed countries of East Asia such as Korea or Japan for the prediction of stillbirth using machine learning model. In this study, the main ethnicity was East Asian, which might be applicable for this population.
This study has several limitations. Firstly, the sample size of stillbirth was small (209 cases in the training set and 90 cases in the test set among 32,593 pregnancies). If we did not exclude multiple pregnancies, fetal chromosomal abnormalities, data imbalance might be improved. However, those risk factors can also make the other bias as a predication model, in singleton pregnancies. Instead, Feature selection and hyperparameter tuning were performed using Grid Search with 10-fold cross-validation within the training set. An evaluation set was further separated from the training data and used exclusively for early stopping to prevent overfitting. To further address overfitting issues, we reduced the number of early stopping rounds to 10 and adjusted key hyperparameters, as we described in the method. Secondly, mothers with multiple births are shared between the training and testing sets. Therefore, there is potential implications, because there can be some risk of information duplication about maternal characteristics between the two sets.
Thirdly, uterine artery Doppler ultrasonography during pregnancy was not included in routine ultrasonography during the study period. In addition, results of uterine artery Doppler ultrasonography were not officially recorded in the EMR. We could not extract results from images, even for women who received Doppler ultrasonography. In addition, because multiples of median values of pregnancy-associated plasma protein-A for the relevant gestational age were taken from routine screening records, which were not from one central lab, there could be some bias. Thirdly, placental growth factor (PLGF), which has shown significant association with placental function and stillbirth5,33,34,35, was not included in the list of biochemical markers of this study. This is because the PLGF test is not accepted as a first trimester screening test for predicting placental insufficiency in Korea. The ratio of soluble Fms-like tyrosine kinase-1/PLGF has been introduced in women after 20 weeks of gestation in South Korea since 2017. It was included as a variable at T0. However, this ratio did not show high SHAP value in the analysis. We speculated that this test has been performed in very limited women until 2020.
The strength of this study was the good performance of the prediction model for late stillbirth using variables from routinely gathered patient information, ultrasonography, vital sign, and laboratory results until 28 weeks of gestation. In addition, because seven hospitals in this study used the same EMR form, bias of information from the EMR was low. In addition, in this study, the simplified model in late stillbirth T0 showed similar performance in the statistical analysis, compared to the original model. We think that feature selection attributed to the improved model performance. When validated in other population, it might be implemented as a risk calculator for East Asian, although further studies are required. Additional studies may be also required to determine whether other biomarkers or ultrasonographic findings can improve the performance of the model.
Conclusions
Based on results of this study, we proposed a machine learning algorithm for reliably predicting late stillbirth in East Asian women at the early third trimester. Although clinical utility of predicting early stillbirths in this model and potential intervention strategies may be limited, this model may be helpful for evaluating individual risks for late stillbirth in singleton pregnancies.
Data availability
All data generated or analyzed during this study are included in this published article (and its Supplementary Information files).
Change history
20 November 2025
The original online version of this Article was revised: In the original version of this Article, Authors Woo Jeng Kim and Sae Kyung Choi were incorrectly indexed as equally contributing authors. The original Article has been corrected.
References
ACOG Practice Bulletin No. 102: management of stillbirth. Obstet. Gynecol. 113, 748–761. https://doi.org/10.1097/AOG.0b013e31819e9ee2 (2009).
Blencowe, H. et al. National, regional, and worldwide estimates of stillbirth rates in 2015, with trends from 2000: a systematic analysis. Lancet Glob Health. 4, e98–e108. https://doi.org/10.1016/s2214-109x(15)00275-2 (2016).
Kim, C. B. et al. Risk of adverse pregnancy outcomes by maternal occupational status: A National population-based study in South Korea. J. Occup. Health. 65, e12380. https://doi.org/10.1002/1348-9585.12380 (2023).
Yerlikaya, G., Akolekar, R., McPherson, K., Syngelaki, A. & Nicolaides, K. H. Prediction of stillbirth from maternal demographic and pregnancy characteristics. Ultrasound Obstet. Gynecol. 48, 607–612. https://doi.org/10.1002/uog.17290 (2016).
Townsend, R. et al. Prediction of stillbirth: an umbrella review of evaluation of prognostic variables. Bjog 128, 238–250. https://doi.org/10.1111/1471-0528.16510 (2021).
Unicef. Monitoring the situation of children and women Global stillbirth rate and number of stillbirths (2000–2021) (2023). https://data.unicef.org/topic/child-survival/stillbirths/
World Health Organization. Stillbirth rate data by country., (2023). https://apps.who.int/gho/data/view.main.STILLBIRTHv?lang=en
Ko, H. S. et al. Optimal timing of delivery based on the risk of stillbirth and infant death associated with each additional week of expectant management in multiple pregnancies: a National cohort study of Koreans. J. Korean Med. Sci. 33, e80. https://doi.org/10.3346/jkms.2018.33.e80 (2018).
Trudell, A. S., Tuuli, M. G., Colditz, G. A., Macones, G. A. & Odibo, A. O. A stillbirth calculator: development and internal validation of a clinical prediction model to quantify stillbirth risk. PLoS One. 12, e0173461. https://doi.org/10.1371/journal.pone.0173461 (2017).
Ishak, M. & Khalil, A. Prediction and prevention of stillbirth: dream or reality. Curr. Opin. Obstet. Gynecol. 33, 405–411. https://doi.org/10.1097/gco.0000000000000744 (2021).
Koivu, A. & Sairanen, M. Predicting risk of stillbirth and preterm pregnancies with machine learning. Health Inf. Sci. Syst. 8, 14. https://doi.org/10.1007/s13755-020-00105-9 (2020).
Cersonsky, T. E. K. et al. Identifying risk of stillbirth using machine learning. Am. J. Obstet. Gynecol. https://doi.org/10.1016/j.ajog.2023.06.017 (2023).
Trudell, A. S., Tuuli, M. G., Cahill, A. G., Macones, G. A. & Odibo, A. O. Balancing the risks of stillbirth and neonatal death in the early preterm small-for-gestational-age fetus. Am. J. Obstet. Gynecol. 211, 295e291–295e297. https://doi.org/10.1016/j.ajog.2014.04.021 (2014).
Berhie, K. A. & Gebresilassie, H. G. Logistic regression analysis on the determinants of stillbirth in Ethiopia. Matern Health Neonatol Perinatol. 2, 10. https://doi.org/10.1186/s40748-016-0038-5 (2016).
Malacova, E. et al. Stillbirth risk prediction using machine learning for a large cohort of births from Western Australia, 1980–2015. Sci. Rep. 10, 5354. https://doi.org/10.1038/s41598-020-62210-9 (2020).
Khatibi, T., Hanifi, E., Sepehri, M. M. & Allahqoli, L. Proposing a machine-learning based method to predict stillbirth before and during delivery and ranking the features: nationwide retrospective cross-sectional study. BMC Pregnancy Childbirth. 21, 202. https://doi.org/10.1186/s12884-021-03658-z (2021).
Manuck, T. A. et al. Preterm neonatal morbidity and mortality by gestational age: a contemporary cohort. Am. J. Obstet. Gynecol. 215, 103. https://doi.org/10.1016/j.ajog.2016.01.004 (2016).
Thompson, R. A. et al. Risk factors for late preterm and term stillbirth: A secondary analysis of an individual participant data meta-analysis. Bjog 130, 1060–1070. https://doi.org/10.1111/1471-0528.17444 (2023).
Kang, B. S. et al. Prediction of gestational diabetes mellitus in Asian women using machine learning algorithms. Sci. Rep. 13, 13356. https://doi.org/10.1038/s41598-023-39680-8 (2023).
Stillbirth Collaborative Research Network Writing Group. Causes of death among stillbirths. Jama 306, 2459–2468. https://doi.org/10.1001/jama.2011.1823 (2011).
Moons, K. G. et al. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): explanation and elaboration. Ann. Intern. Med. 162, W1–73. https://doi.org/10.7326/m14-0698 (2015).
Gholamy, A., Kreinovich, V. & Kosheleva, O. Why 70/30 or 80/20 Relation Between Training and Testing Sets: A Pedagogical Explanation, (2018).
Chen, T. & Guestrin, C. in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 785–794 Association for Computing Machinery, (2016).
Pedregosa, F. et al. Scikit-learn: machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Chintakindi, S., Alsamhan, A. M., Abidi, M. H. & Kumar, M. P. Annealing of Monel 400 alloy using principal component analysis, Hyper-parameter optimization, machine learning techniques, and Multi-objective particle swarm optimization. Int. J. Comput. Intell. Syst. 15 (2022).
Lundberg, S. M. & Lee, S. I. A unified approach to interpreting model predictions. Adv. Neural. Inf. Process. Syst. 30 (2017).
Mastrodima, S., Akolekar, R., Yerlikaya, G., Tzelepis, T. & Nicolaides, K. H. Prediction of stillbirth from biochemical and biophysical markers at 11–13 weeks. Ultrasound Obstet. Gynecol. 48, 613–617. https://doi.org/10.1002/uog.17289 (2016).
Pilalis, A. et al. Screening for pre-eclampsia and fetal growth restriction by uterine artery doppler and PAPP-A at 11–14 weeks’ gestation. Ultrasound Obstet. Gynecol. 29, 135–140. https://doi.org/10.1002/uog.3881 (2007).
Iacovella, C., Franchi, M., Egbor, M., Bhide, A. & Thilaganathan, B. Relationship of first-trimester uterine artery doppler to late stillbirth. Prenat Diagn. 32, 557–561. https://doi.org/10.1002/pd.3855 (2012).
Cersonsky, T. E. K. et al. Identifying risk of stillbirth using machine learning. Am. J. Obstet. Gynecol. 229, 327. https://doi.org/10.1016/j.ajog.2023.06.017 (2023).
Liu, B. et al. Reducing health inequality in black, Asian and other minority ethnic pregnant women: impact of first trimester combined screening for placental dysfunction on perinatal mortality. Bjog 129, 1750–1756. https://doi.org/10.1111/1471-0528.17109 (2022).
Dongarwar, D. et al. Racial and ethnic disparities in stillbirth among pregnant women with obesity. Am. J. Perinatol. https://doi.org/10.1055/a-2099-8494 (2023).
Sherrell, H., Dunn, L., Clifton, V. & Kumar, S. Systematic review of maternal placental growth factor levels in late pregnancy as a predictor of adverse intrapartum and perinatal outcomes. Eur. J. Obstet. Gynecol. Reprod. Biol. 225, 26–34. https://doi.org/10.1016/j.ejogrb.2018.03.059 (2018).
Heazell, A. E. et al. Biochemical tests of placental function versus ultrasound assessment of fetal size for stillbirth and small-for-gestational-age infants. Cochrane Database Syst. Rev. 5, Cd012245. https://doi.org/10.1002/14651858.CD012245.pub2 (2019).
Poon, L. C. et al. Erratum to the international federation of gynecology and obstetrics (FIGO) initiative on pre-eclampsia: A pragmatic guide for first-trimester screening and prevention Int J Gynaecol Obstet 146, 390–391 (2019). https://doi.org/10.1002/ijgo.12892 (2019).
Acknowledgements
This work was financially supported by Korea Health Industry Development Institute, grant number: HI21C1300.
Author information
Authors and Affiliations
Contributions
Author H.S.K. conceived and designed the study. Author S.K.C., Y.S.J., S.M.K., J.E.S., K.C.K., Y.H.K., J.H.W., S.B.H., M.J.L., H.H., and O.K. collected and verified the data. Author M.J.L., H.H., and H.S.C developed the machine learning algorithm. Author W.J.K. and Author H.S.K. wrote the initial draft of the manuscript. All authors reviewed and approved the final version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Kim, W.J., Choi, S.K., Jo, Y.S. et al. Prediction of stillbirth using machine learning methods. Sci Rep 15, 35958 (2025). https://doi.org/10.1038/s41598-025-00335-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-00335-5
