
Abstract
With the rapid advancement of technology, aerial interaction patterns have become increasingly complex, making intelligent air combat a prominent and cutting-edge research area in multi-agent systems. In this context, the dynamic and uncertain nature of large-scale air combat scenarios poses significant challenges, including scalability issues, computational complexity, and decision-making difficulties in multi-agent collaborative decision-making. To address these challenges, we propose a novel multi-aircraft autonomous decision-making approach based on graphs and multi-agent reinforcement learning (MADRL) under zero-order optimization, implemented through the GraphZero-PPO algorithm. This method innovatively integrates GraphSAGE and zero-order optimization into the MADRL framework. By leveraging the graph structure to adapt to the high dynamics and high-dimensional characteristics of multi-agent systems, the proposed approach enables rapid decision-making for missile launches through an efficient sampling strategy while employing zero-order optimization to explore global optima effectively. Finally, we present simulation experiments conducted in both 1v1 and 8v8 air combat scenarios, along with comparative results. The findings demonstrate that the proposed method can effectively adapt to large-scale air combat environments while achieving high win rates and rapid decision-making performance.
Similar content being viewed by others

Introduction
With the rapid advancement of technology, aerial interaction patterns have grown increasingly complex, establishing intelligent air combat as both a hotspot and a frontier in multi-agent systems research. In this context, the dynamic and uncertain nature of air combat scenarios has intensified, underscoring the critical importance of multi-agent collaborative decision-making. Enabling agents to achieve efficient collaboration in high-dimensional and dynamic interaction environments is not only a pivotal challenge in the field of artificial intelligence but also a key to bridging theoretical research on multi-agent systems with practical applications. Consequently, the investigation of decision-making technologies for aircraft in complex air combat environments is of profound significance.
Related works
Currently, methods for solving decision-making problems in intelligent air combat can be broadly categorized into three types: game theory-based approaches1,2,3,4, prior data-driven approaches5,6,7, and autonomous learning-based approaches8,9. However, traditional methods face certain limitations when addressing large-scale complex game problems. For instance, in game theory-based methods, solving differential games requires complex mathematical derivations and computations, which are time-consuming and often fail to achieve global optimal solutions. Meanwhile, matrix games, as static models, struggle to effectively model multi-agent cooperative strategies. In addition, prior data-driven approaches, such as expert systems, have high construction and maintenance costs due to the difficulty of building and updating rule bases. Although deep learning-based methods exhibit strong learning capabilities, their decision-making performance is constrained by the quality of pilot data, making it difficult to surpass human pilot expertise10.
In contrast, autonomous learning-based decision-making methods offer an intelligent learning approach that does not rely on prior knowledge, enabling continuous learning and adaptation in dynamic environments. Through repeated exploration of different collaborative strategies (such as formations and firepower allocation), agents can learn optimal strategies, thereby overcoming the limitations of traditional game-theoretic methods and expert systems. Autonomous learning-based decision-making methods can be broadly categorized into two main approaches: adaptive dynamic programming and deep reinforcement learning10. Adaptive dynamic programming combines dynamic programming with adaptive control, enabling the resolution of complex dynamic decision-making problems through learning and optimization. However, it requires substantial computational resources and depends heavily on accurate models. On the other hand, deep reinforcement learning integrates perception and decision-making capabilities, allowing agents to autonomously explore and learn optimal strategies through interactions with the environment. This approach adapts to different opponents and environments, demonstrating significant potential. By interacting with the environment, agents can autonomously learn optimal air combat strategies without human intervention, resulting in trained aircraft capable of continuously adapting to various adversaries and battlefield scenarios.
Currently, intelligent air combat decision-making methods based on deep reinforcement learning can be categorized into two main types: (1) value-based methods, with the Deep Q-Network (DQN)11being a representative algorithm, and (2) policy-based methods, represented by algorithms such as REINFORCE13and Actor-Critic14. Among these, most deep reinforcement learning approaches adopt Actor-Critic-based algorithms. Representative stochastic policy methods include Trust Region Policy Optimization (TRPO)15and Proximal Policy Optimization (PPO)16. On the other hand, deterministic policy methods are represented by the Deep Deterministic Policy Gradient (DDPG) algorithm17.
Shengzhe Dan et al.18 investigated single-agent self-play deep reinforcement learning techniques to address intelligent decision-making problems in air combat scenarios. Luo et al.19 proposed a cooperative UAV maneuvering method based on improved multi-agent deep reinforcement learning (MADRL) to solve the classic two-versus-one pursuit problem in air combat. Yan Ruichi et al.20 developed a heterogeneous UAV team consisting of one leader and two wingmen, utilizing self-play reinforcement learning methods to study cooperative decision-making for the team. Ouyang et al.21 combined graph convolutional networks (GCNs) with deep reinforcement learning in a two-versus-one cooperative air combat scenario to address multi-UAV cooperative maneuvering decisions. These studies have explored air combat decision-making in small-scale heterogeneous scenarios, demonstrating effectiveness in setups with a limited number of agents (e.g., 1v1 or 2v2). However, when scaling up to larger interactions (e.g., 3v3 or beyond), challenges such as the exponential growth of the strategy space, susceptibility to local optima, and strategy cycling in self-play emerge. To address these issues, Wang et al.22 introduced the E-MATD3 algorithm, which integrates evolutionary algorithms with multi-agent reinforcement learning (MARL), successfully mitigating strategy cycling in 5v5 air combat scenarios. Additionally, Lei Yangqi et al.23 proposed a competitive reinforcement learning pigeon optimization algorithm for 4v4 and 4v2 scenarios, addressing the problem of local optima in multi-UAV decision-making. While these studies have expanded the scale of air combat scenarios, the optimization algorithms employed tend to have high computational complexity. This often results in significant computational resource consumption, particularly in large-scale, highly dynamic environments, where the high-dimensional strategy space still incurs substantial computational costs.
In large-scale air combat scenarios, intricate dependencies and interactions exist among multiple aircraft, involving dynamic games and cooperative behavior between opposing sides. Fundamentally, this constitutes a dynamic, high-dimensional, multi-agent distributed control problem. Graph Neural Networks (GNNs) offer natural advantages in multi-agent systems by representing each agent as a node and the interactions between agents as edges in a graph. Among GNNs, GraphSAGE (Graph Sample and Aggregation) stands out as an efficient variant, designed to handle large-scale graph data while mitigating computational complexity through a sampling mechanism. By aggregating information from a sampled subset of neighboring nodes during each update (rather than from the entire graph), GraphSAGE achieves linear or near-linear time complexity, making it particularly well-suited for solving collaborative decision-making problems in large-scale multi-agent systems.
Regarding optimization, traditional gradient-based methods encounter significant challenges. Objectives in air combat scenarios are typically non-convex, and gradient-based approaches often get trapped in local optima, especially when opposing agents’ strategies exert mutual influence. In such cases, gradients frequently fail to guide optimization towards the global optimum. Conversely, zero-order optimization methods, which do not rely on explicit gradient information, can explore a broader strategy space, thereby avoiding local optima and enhancing the robustness of decision-making in dynamic environments.
To address the challenges of scale explosion and computational complexity caused by an increasing number of agents in large-scale, highly dynamic, and uncertain intelligent air combat scenarios, this paper introduces the GraphZero-PPO algorithm. The proposed method effectively balances scalability and decision-making efficiency while maintaining a high win rate in complex air combat scenarios.
Contribution and structure of the paper
The primary contributions of this research are as follows:
(1) To address the challenges of scalability, computational complexity, and decision-making difficulties caused by the increasing number of agents in large-scale intelligent aerial combat, this study innovatively integrates Graph Neural Networks (specifically GraphSAGE) and zeroth-order optimization into Multi-Agent Deep Reinforcement Learning (MADRL). A novel algorithm, GraphZero-PPO, is proposed to address the problem of multi-aircraft collaborative autonomous decision-making in large-scale aerial combat scenarios.
(2) The GraphZero-PPO algorithm employs a multi-tiered control architecture, which includes global decision-making, high-level strategy generation, and specific tactical execution. At the high-level decision-making stage, the GraphZero module is utilized to model large-scale aerial combat environments. By leveraging the neighbor-sampling mechanism of GraphSAGE, the algorithm can rapidly extract global information, thereby reducing computational complexity and decision-making pressure. Moreover, the integration of zeroth-order optimization significantly enhances the efficiency of global search during policy optimization, effectively reducing time costs.
(3) In 8-vs-8 aerial combat testing, the proposed strategy demonstrated a significant advantage in both win rate and exploration speed compared to other strategies against the same opponent, with an average win rate exceeding 80%. The experiments also validated the effectiveness of the GraphZero module, showcasing the generation of complex and effective tactics, such as coordinated attacks and interference avoidance. These results highlight the enhanced decision-making capabilities and tactical diversity of the agents.
The structure of this paper is organized as follows: In Sect. 2, we define the problem addressed in this study, introduce the system modeling, and provide an overview of the observation space, action space, and reward function used in the experiments. Section 3 presents a detailed explanation of the GraphZero-PPO algorithm framework adopted in this study, along with its specific implementation process. Subsequently, Sect. 4 provides a comprehensive description of the simulation experiments conducted and an analysis of the experimental results obtained. Finally, in Sect. 5, we summarize the key findings and contributions of this research, offer suggestions for future work, and discuss the potential applications of the proposed method, thereby concluding the paper.
Problem description and modeling analysis
Problem description
In this study, we focus on decision-making problems in intelligent air combat scenarios, starting with a 1v1 single-aircraft combat as the initial research focus and gradually expanding the scope to include more complex 8v8 large-scale multi-aircraft combat decision-making scenarios.
The specific scenario involves an air combat setup where the red team (our side) controls 8 aircraft, and the blue team (opponent side) also controls 8 aircraft. The engagement begins from fixed initial positions. Figure 1is a schematic diagram of the multi-aircraft game scenario.

llustration of the Multi-Aircraft Combat Scenario.
Flight kinematics model
The traditional dynamic models of aircraft are usually based on three degrees of freedom (roll, pitch and yaw), which mainly describe the attitude changes of the aircraft and are applicable to scenarios with relatively low requirements for attitude control. However, they cannot comprehensively simulate the positional movements in three-dimensional space. On this basis, the six-degree-of-freedom model can describe the spatial motion of the aircraft more accurately by introducing three translational degrees of freedom (in the directions of the X, Y, and Z axes of the body coordinate system), and it is suitable for complex trajectory planning and high-precision navigation tasks. In this paper, the six-degree-of-freedom model is adopted. The aircraft is regarded as a rigid body with left-right symmetry, and it is simplistically assumed that the airspace conditions are constant (gravity, air density and the mass of the aircraft remain unchanged) to reduce the computational complexity. The dynamic equations of the aircraft are shown as follows:
Equations of positional kinematics
Where, \(\:\overrightarrow{r}=\left(x,y,z\right)\) denotes the position vector of the aircraft, where \(\:x,y,z\) are the coordinates of the aircraft along the X, Y, and Z axes in three-dimensional space, used to determine the location of the aircraft. \(\:\overrightarrow{v}=\left(u,v,w\right)\)represents the velocity vector of the aircraft, where \(\:u,v,w\) are the components of the aircraft’s velocity along the X, Y, and Z axes in the body coordinate system, describing the speed and direction of the aircraft’s movement \(\:\overrightarrow{F},\overrightarrow{T},\overrightarrow{A},\overrightarrow{G}\) represent the resultant external force, thrust, aerodynamic force and gravity\(\:\overrightarrow{a}\)、\(\:m\) denote the acceleration and the mass of the aircraft.
Equations of attitude kinematics
Where,\(\:\theta\:,\varphi\:,\phi\:\)represent the pitch angle, roll angle and yaw angle respectively;\(\:p,q,r\) represent the roll rate, pitch rate and yaw rate around the body coordinate axes respectively\(\:\overrightarrow{M},{\overrightarrow{M}}_{A},{\overrightarrow{M}}_{T},{\overrightarrow{M}}_{gr}\) represent the resultant moment, aerodynamic moment, engine thrust moment and landing gear moment respectively\(\:\overrightarrow{\alpha\:},I\) denote the angular acceleration and the moment of inertia of the aircraft.

Schematic diagram of the three-dimensional coordinates of the aircraft.
As shown in Fig. 2, a three-dimensional coordinate system of the aircraft is established, where the X-axis points directly to the north, the Y-axis points to the east, and the Z-axis points directly upward.
Where, \(\:{\overrightarrow{r}}_{(a,b)}^{\left(i\right)},{\overrightarrow{v}}_{(a,b)}^{\left(i\right)}\) denote the position and velocity vectors of our side (a) and the opposing side (b) aircraft,; \(\:{x}_{(a,b)}^{\left(i\right)},{y}_{(a,b)}^{\left(i\right)},{z}_{(a,b)}^{\left(i\right)}\) represent the coordinates of both sides’ aircraft along the X, Y, and Z axes in three-dimensional space; \(\:{u}_{(a,b)}^{\left(i\right)},{v}_{(a,b)}^{\left(i\right)},{w}_{(a,b)}^{\left(i\right)}\) represent the components of the velocity of both sides’ aircraft along the X, Y, and Z axes in the coordinate system. (These will be abbreviated in subsequent text.)
Where, \(\:{v}_{a},{v}_{b}\) denote the magnitudes of the velocities of our side and the opposing side
Where, \(\:\overrightarrow{R},R\) represent the relative position vector (from our aircraft to the opposing aircraft) and its magnitude.
Where, \(\:\alpha\:,\beta\:\:\)denote the relative heading angle and the relative threat angle.
Observation features and action space
The state set includes the flight parameters of all aircraft and missiles, as well as information regarding their relative motions. The agent obtains our side’s information and the situation information of both sides from the state set as observed features, as shown in Table 1.
Aileron: It controls the roll (banking) motion of the aircraft, and its value range is [−1, 1].
Elevator: It controls the pitch motion of the aircraft, and its value range is [−1, 1].
Rudder command: It controls the yaw motion of the aircraft, and its value range is [−1, 1].
Throttle command: It controls the engine thrust of the aircraft, and its value range is [0.4, 0.9].
Missile launch command: It controls whether the aircraft launches a missile or not (0 indicates not launching a missile, and 1 indicates launching a missile).
Reward function
In order to make the aircraft better adapt to the battlefield situation and possess stronger capabilities of evading missiles and hitting targets, the reward function adopts the sparse reward and internal reward and punishment mechanism.
To ensure the safe flight of the aircraft, it is necessary to impose constraints on its flight altitude and speed to avoid low-altitude flight and excessive descent speed. When the aircraft is below the safe altitude and its speed is too fast, it will receive a severe punishment. When the altitude of the aircraft is lower than the dangerous altitude threshold (\(\:{h}_{d}\)), it will receive an even more severe punishment.
Where,\(\:{P}_{v}\), represents the velocity punishmen
\(\:w\), represents the descent velocity of the aircraft.
\(\:{k}_{v}\),.presents the punishment coefficient, which is used to adjust the intensity of the punishment and is set to 0.2 in this paper.
\(\:{h}_{s}\),sents the safe altitude threshold, which is set to 5 km in this paper.
\(\:{P}_{h}\), represents the altitude punishment
\(\:{h}_{d}\), represents the dangerous altitude threshold, which is set to 3.5 km in this paper.
R, represents the total reward.
During the flight process, control the heading, altitude, speed and roll of the aircraft to keep them within the normal range. If they exceed the range, penalties will be imposed. The definition of the angle reward is as follows:
Where,\(\:{r}_{a},{r}_{h},{r}_{r},{r}_{v}\) They respectively represent the heading reward, altitude reward, roll angle reward and speed reward.
K represents the error scaling factor.
\(\:\varDelta\:\) represents the difference between the current value and its target value.
During the game process, in order to better execute tactical maneuvers and avoid being locked by opponents, it is necessary to maintain a favorable altitude. The altitude difference between our aircraft and the blue aircraft should be less than \(\:{k}_{H}\), Based on the altitude difference from the blue aircraft, the reward function is set.
Where,\(\:{h}_{a},{h}_{b}\) represent the altitude of our aircraft and that of the blue aircraft respectively.
While maintaining the altitude, it is also necessary to pay attention to the threat of the opponent’s missiles and take corresponding actions. The reward function is set based on the velocity attenuation of the missile and the relative angle with the target aircraft.
Where,\(\overrightarrow {{v_t}}\overrightarrow {{v_{t^{\prime}}}}\) respectively represent the velocity of the missile at the previous time, the current velocity of the missile and the missile velocity attenuation amount. \(\overrightarrow {{v_m}} \overrightarrow {{v_a}} ~and~\gamma\) are respectively the missile velocity, the aircraft velocity and the angle between them.
In order to avoid the radical behavior of the aircraft launching multiple missiles simultaneously during the game process, a reward function based on the number of missiles is set.
Meanwhile, in order to prevent the aircraft from being destroyed too quickly, a reward function is set based on the survival time of the aircraft.
During the training, through the rewards of events, the aircraft is motivated and guided to actively take actions to seek opportunities for attacks, improving the accuracy and efficiency of attacks. Meanwhile, when the aircraft is hit or crashes, penalties are given to motivate it to take actions for evasion.
GraphZero-PPO algorithm design
Overview of the overall framework
In this paper, in order to solve the problems of high complexity, dimensional expansion and computational efficiency caused by multi-agents, high dynamics and high uncertainty in the 8v8 air game environment, a multi-layer control structure is designed targeted. Among them, the high-level control: GraphSAGE and zero-order optimization are adopted for macroscopic decision-making to determine the missile launch strategy. The middle-level control: The self-play PPO algorithm (FSP-PPO) is used to generate maneuvering strategies to adapt to the dynamic air game environment. The low-level control: It executes specific actions, including details such as aileron adjustment and throttle control. The framework structure is shown in Fig. 3.

Overall framework diagram.
Hierarchical control framework
In the 8v8 air combat scenario, a total of 16 agents (8 red aircraft and 8 blue aircraft) participate in dynamic engagements. Each agent must not only make decisions based on its own objectives but also consider the behaviors of all other agents. This introduces both competitive and cooperative dynamics between the red and blue teams. In such an environment, the decision-making process becomes a highly dynamic and complex game, with inherent unpredictability. Additionally, the state and action spaces in the air combat scenario grow exponentially.
Each agent’s state includes its position, velocity, attitude, and relative position and distance with respect to other agents, while its actions involve maneuvering and weapon deployment decisions. As the number of agents increases, the exponential growth in state and action spaces leads to an immense search space, further complicating the decision-making process.
To address these challenges, we adopt a hierarchical control architecture, dividing the complex decision-making task into multiple subtasks, each optimized at different levels of control. This decomposition enables the system to effectively adapt to the multi-agent, highly dynamic, and uncertain environment.
High-Level Control: The air combat environment is abstracted into a graph structure, where the GraphSAGE model is employed to efficiently sample and aggregate information from neighboring nodes. This allows the system to capture a large amount of global and dynamically changing information, enabling optimal target assignments for each agent. This approach not only mitigates the exponential growth of the state space but also separates missile launch decisions from other action controls, thereby reducing the computational burden for individual agents. Additionally, a zero-order optimization algorithm is employed at this level, leveraging its gradient-free nature to rapidly identify global optima.
Middle-Level Control: Using the high-level global decisions as input, this level employs proximal policy optimization (PPO), which is a well - known algorithm in the field of reinforcement learning. PPO aims to optimize the policy by directly adjusting the policy parameters to maximize the expected return. Here, we enhance PPO with self - play and term it as Fully Stochastic Self - Play Proximal Policy Optimization (FSP - PPO). FSP - PPO allows agents to learn more effective strategies by competing against themselves or different versions of themselves during the training process. The narrowed decision-making scope provided by the high-level inputs reduces computational complexity, allowing the middle-level control to focus on refining tactical maneuvers.
Low-Level Control: At the lowest level, action decisions generated by the middle level are executed in real time using pre-trained maneuver strategies. This ensures that agents can quickly respond to dynamic changes in their current states, providing immediate and precise control during engagements.
This hierarchical architecture effectively addresses the challenges of large-scale air combat scenarios, balancing global coordination with local adaptability while reducing computational overhead at each decision-making layer. The schematic diagram of the framework is shown in Fig. 4.

Hierarchical control framework diagram.
GraphZero-PPO algorithm
High-level control: graphsage and zero-order optimization in missile launch decision-making
We initially construct a graph by abstracting the aerial combat scenario into a graph structure, where aircraft are represented as nodes and the relationships between aircraft are represented as edges. The state information of the aircraft, including position, velocity, attitude, and armament, is encoded as the initial feature vectors of the nodes. Subsequently, we employ GraphSAGE for information aggregation to update the node features. After the aggregation by GraphSAGE, zeroth-order optimization algorithms are utilized for decision-making.
We initiate the process by constructing a graph\(G=\left( {V,E} \right)\)from the aerial combat scenario. The set of aircraft \(A\) corresponds to the vertex set, i.e.,\(V = A\), and the relationships between aircraft define the edge set \(\varepsilon\). For each aircraft \({a_i} \in A\), its state information\({s_i}=\left( {{p_i},{v_i},{\alpha _i},{\omega _i}} \right)\)is encoded as the initial feature vector\(x_{i}^{0}\)of the corresponding vertex\({v_i} \in V\), where\({p_i},{v_i},{\alpha _i}and{\omega _i}\)represent position, velocity, attitude, and armament respectively.
In our air - combat graph, for an 8 × 8 scenario,\(V=\left\{ {{v_1}, \cdots ,{v_8}} \right\}\). The features of vertex\({v_i}\)are\({x_i}=\left( {d_{i}^{{blue}},po{s_i}} \right)\), where\(d_{i}^{{blue}}\)is the distance from the blue aircraft and\(po{s_i}\) is the position encoding of the local aircraft. The adjacency matrix \(A \in {\left\{ {0,1} \right\}^{8 \times 8}}\) represents the graph connectivity, with\({A_{ij}}=1\)if\(\left( {{v_i},{v_j}} \right) \in \varepsilon\) and\({A_{ij}}=0\) otherwise. The weighted matrix\({A_W}\)is determined by a function\(V\) of the distance between agents, i.e.,\(A_{{ij}}^{W}=f\left( {{d_{ij}}} \right)\), as shown in Fig. 5.

Generation process diagram of the weighted adjacency matrix.

GraphSAGE network structure diagram.
In the selection of graph neural networks for our research, we have chosen GraphSAGE due to its efficient neighbor sampling mechanism, which aggregates local information and avoids the computationally intensive global calculations typical of traditional graph neural networks. This approach significantly mitigates computational complexity. Specifically, in a graph comprising n nodes (representing the number of aircraft), conventional graph neural networks often exhibit a computational complexity that scales exponentially with the number of nodes, denoted as \(O\left( {{2^n}} \right)\) GraphSAGE, however, by selectively sampling neighboring nodes, confines its computations to a subset of local neighbors, thereby reducing the computational complexity to a linear or near-linear scale, \(O\left( n \right)\). This characteristic renders GraphSAGE particularly well-suited for handling large-scale multi-aircraft scenarios, where it can efficiently process and rapidly extract global information, thus enhancing the overall performance and scalability of the system. Our network structure includes two convolutional layers (SAGEConv) and a batch normalization layer (BatchNorm). The specific structure is shown in Fig. 6.
The first convolutional layer (conv1): The input feature dimension is 8, and the output feature dimension is 128. It uses the mean aggregation method to aggregate the information of neighbor nodes and performs nonlinear transformation through batch normalization and the ReLU activation function.
The second convolutional layer (conv2): The input feature dimension is 128, and the output feature dimension is 8. It adopts the max pooling aggregation strategy to aggregate the information of neighbor nodes. This layer further updates the feature representation of nodes through batch normalization and the ReLU activation function.
Figure 6 GraphSAGE network structure diagram.
In order to enable the GraphSAGE network to assign the optimal attack targets for agents and make the overall algorithm achieve the best results, the parameter optimization of the model plays a crucial role. Its core lies in adjusting the internal parameters of the model to prompt the model to exhibit more excellent performance in the system’s decision-making tasks. Specifically, it is committed to finding the optimal parameter configuration so that the model can achieve the best decision-making results under the given objective function.
This paper adopts zero - order RACOS (Randomized Adaptive Constrained Optimization Strategy), initially proposed by Yu Yang et al.23. In optimization problems, especially those characterized by non - convexity and high - dimensionality, the selection of an appropriate optimization algorithm is decisive. Traditional gradient - based optimization methods, while elegant in theory and relatively straightforward in implementation, encounter substantial difficulties in non - convex scenarios.
In aerial combat scenarios, the objective function is highly complex and non - convex. The interaction among diverse aircraft strategies, the dynamic nature of the battlefield, and numerous constraints render it extremely challenging for traditional gradient - based methods to identify the global optimal solution. These methods rely on the gradient information of the objective function to direct the search. However, in non - convex functions, the gradient can mislead the algorithm into local optima, causing it to stagnate and fail to explore other potentially superior regions of the strategy space.
Conversely, zero - order optimization algorithms like RACOS offer a distinct approach. Although they entail some computational overhead during sampling, their advantage lies in their ability to effectively circumvent local optima within non - convex, high - dimensional strategy spaces. The zero - order RACOS algorithm, through its random sampling and probabilistic selection mechanisms, searches the strategy space with a time complexity of \(O\left( N \right)\), where N represents the number of samples. This implies that as the number of samples increases linearly, the algorithm comprehensively explores the strategy space. Despite the potential increase in the number of samples with problem complexity, the overall time - cost reduction achieved by avoiding repeated gradient calculations and entrapment in local optima is significant.
Let \(\theta\) denote the parameter vector of the GraphSAGE network, and define the parameter space \(\Theta\) as\(\Theta =\prod _{{k=1}}^{d}\left[ {{l_k},{u_k}} \right]\). Here, \(d\) represents the dimension of the parameter vector, and\(\left[ {{l_k},{u_k}} \right]\)designates the range of the \(k\) - th parameter.
The probability density function of the initial sampling distribution is
This initial sampling distribution follows a uniform distribution across the parameter space. As a result, each point within the parameter space has an equal probability of being sampled initially. This provides a fair starting point for the algorithm to commence exploring the entire strategy space.
In the 8v8 scenario of this paper, the objective function is set based on the overall performance of the agents. The objective is to ensure that our side (the red side) wins while maintaining a larger number of surviving agents. To this end, the objective function is defined as
In this equation, B represents the number of surviving blue agents, R represents the number of surviving red agents, k is a constant (set to 1 in this paper), and T represents the total number of surviving agents. The objective function \(J\left( \theta \right)\) is designed to balance two key aspects: the difference in the number of surviving agents between the two sides and the proportion of blue agents among all survivors. By incorporating both factors, a more comprehensive evaluation of the agents’ performance in various combat situations becomes possible.
To prevent agents from over - emphasizing the number of survivors, encourage them to actively seek higher rewards, and avoid over - concentration on specific behaviors, a dispersion reward is added to the objective function.
Where,\({R_a}\) represents the average reward and t represents the current step number. The addition of the dispersion reward prompts the agents to explore a broader range of strategies, preventing them from being overly fixated on maximizing the number of survivors. This diversification of agent behavior potentially leads to enhanced overall performance.
The optimization process is as follows:
-
1.
Let \({\theta ^0}\) be the initial parameter vector obtained by flattening the model parameters. This step simplifies the parameter representation and makes it easier for the algorithm to handle.
-
2.
At iteration m, sample a parameter vector\({\theta ^m}\) from the sampling distribution\({p_m}\left( \theta \right)\) (initially \({p_0}\left( \theta \right)=p\left( \theta \right)\)). he sampling distribution updates based on the principle of exploring regions in the parameter space that are more likely to yield better objective - function values. In RACOS, this update is guided by a probability - based mechanism that considers the objective - function values of previously sampled points. Points associated with better objective - function values are assigned higher probabilities of being in the vicinity of the next sample. This adaptive sampling mechanism enables the algorithm to gradually concentrate on more promising regions of the parameter space.
-
3.
The objective function \(J^{\prime}({\theta ^m})\) is evaluated\(N=5\) times, and the average value \(\bar {J^{\prime}}({\theta ^m})\)is calculated. Conducting multiple evaluations and computing the average mitigates noise in the objective - function evaluation, providing a more reliable estimate of the parameter vector’s performance.
-
4.
Update the sampling distribution \({p_{m+1}}(\theta )\)based on\(\{ {\theta ^i},\bar {J^{\prime}}({\theta ^i})\} _{{i=0}}^{m}\)and select the parameter vector\({\theta ^{m*}}\) with the best performance so far. Repeat until convergence. Convergence is determined either when the change in the best - found objective - function value over a specific number of iterations falls below a predefined threshold or when the maximum number of iterations (such as that set by a budget parameter) is reached. The optimization process is illustrated in Fig. 7.

Zero-order optimization flow chart.
Middle-level control: PPO algorithm based on self-play (FSP-PPO)
To promote the development of effective strategies for agents, we integrate the self - play algorithm into the Proximal Policy Optimization (PPO) framework. Self - play, a key technique in machine learning and optimization, allows agents to improve their performance by competing against their current or previous versions.
In the air combat context, agents engage in repeated competitions. These can be between an agent’s present form and its past iterations. After each competition, agents update their strategies based on the outcomes. This iterative process of competition and strategy adjustment is crucial for agents to gradually enhance their performance over time.
Within the PPO framework, consider a set of agents\(\mathcal{A}=\{ {a_1}, \cdots ,{a_n}\}\). For an agent\({a_i}\), at training step \(t\), the probability of selecting agent\({a_j}(j \ne i)\)as an opponent is defined as::
This probability distribution is formulated to ensure equal pairing opportunities for all agents during training. By enabling each agent to be paired with any other agent with the same probability, it leads to diverse experiences. Such diversity encourages agents to explore a broad range of the strategy space. Through this exploration, agents are more likely to find efficient and adaptable strategies, better equipping them to handle the complex and dynamic multi - agent air combat scenarios. The detailed algorithmic flow of this process is shown in Fig. 8.

Flow chart of the FSP-PPO algorithm.
The Actor - Critic network architecture is fundamental to the FSP - PPO framework. The Actor and Critic networks have similar structural designs. The Actor network consists of three main components: a feature extraction module, a recurrent module, and an action selection module. The Critic network, likewise, is composed of a feature extraction module, a recurrent module, and a value evaluation module.
The feature extraction module of the Actor network uses a multi - layer perceptron (MLP) to convert raw observations into hidden feature representations. It then normalizes these features to standardize the input for subsequent processing, enhancing the stability and efficiency of the learning process. The recurrent module, employing a gated recurrent unit (GRU), processes these features while effectively capturing temporal dependencies in the air combat environment. Based on the processed features, the action module generates actions and their corresponding logarithmic probabilities. It then outputs state values through a combination of multi - layer perceptron and linear layer operations. The value evaluation module of the Critic network, using MLP and linear layers, generates the value of the state. The overall architecture of the Actor - Critic network is presented in Fig. 9.

Actor-Critic network framework diagram.
Let\({\pi _{{\theta _a}}}({\mathbf{s}},{\mathbf{a}})\)be the policy of the Actor network parameterized by\({\theta _a}\), and \({V_{{\theta _c}}}({\mathbf{s}})\)be the value function of the Critic network parameterized by\({\theta _c}\).
When an observation\({\mathbf{s}}\) is input into the feature extraction module of the Actor network, it generates a feature vector \({{\mathbf{z}}_a}\). The GRU - based recurrent module updates the hidden state\(h_{a}^{t}\) according to the following equations:
Where \(\sigma\)is the sigmoid function, and \({{\mathbf{W}}_r}\),\({{\mathbf{W}}_z}\),\({{\mathbf{W}}_h}\)are learnable weight matrices. The Gated Recurrent Unit (GRU), a simplified version of the Long Short - Term Memory (LSTM) unit, combines the input, forget, and output gates of the LSTM into an update gate and a reset gate. This structural simplification, along with the use of a single update gate for control, enables the neural network to perform forgetting and selective memory functions more efficiently, significantly reducing the number of parameters.
Subsequently, the action module generates an action\({{\mathbf{a}}^t}\) and its log - probability \(\log {\pi _{{\theta _a}}}({{\mathbf{s}}^t},{{\mathbf{a}}^t})\) based on the updated hidden state \({\mathbf{h}}_{a}^{t}\).
The Critic network, with a similar feature extraction and recurrent module structure as the Actor network, has a value evaluation module that outputs\({V_{{\theta _c}}}({{\mathbf{s}}^t})\) based on the output of its recurrent module. This state value estimate is essential for guiding the learning process within the FSP - PPO framework, facilitating the optimization of agent strategies in the complex air combat environment.
Experiments and analysis
1v1 single aircraft game
Parameter settings
In this paper, a 1v1 experiment was set up. There was one aircraft on each of the red and blue sides, and they started the game from the specified initial positions. All aircraft have the same initial state.
For the hardware environment of the experiment, Dell-PowerEdge-R730, Linux-5.4.0–150-generic-x86_64-with-glibc2.17, and Tesla P100-PCIE-16GB are used. For the software environment, the Python language and the PyTorch software package are adopted. The experimental parameter settings and initial information are shown in Tables 2 and 3.
Analysis of simulation results
At the initial moment, the red and blue sides are moving towards each other. The blue side adopts the basic Proximal Policy Optimization (PPO) algorithm, while the red side uses the Fully Stochastic Self-Play PPO (FSP-PPO) algorithm as the decision-making core.
The experiment set the maximum number of steps to 108. To display the final result conveniently, the rewards of one round are accumulated to obtain the round accumulated rewards. In order to better observe the changing trend of the curves, the curves are smoothed. The curves of strategy loss, value loss, and reward variation are shown in the figure.

Curve of strategy loss variation.

Curve of value loss variation.

Curve of average reward variation.
As can be seen from Fig. 10, in the initial stage, the Policy Loss fluctuates significantly and then gradually stabilizes. The Policy Loss represents the error between the policy network and the target policy. In the early stage of training, the model needs to learn from random policies, resulting in a relatively large and unstable loss. As the constraining effect of the Clipping update in PPO becomes stronger, the fluctuations in the Policy Loss decrease, and the updates of the policy network gradually approach the target policy.
From Fig. 11, it can be observed that the Value Loss is also relatively large in the early stage of training and then drops rapidly after a certain number of training steps, and subsequently remains at a relatively low level. The Value Loss reflects the error between the state value function estimated by the model and the real target value. The relatively large Value Loss in the initial stage is mainly due to the model’s insufficient understanding of the environmental dynamics and rewards. After a large amount of interaction data has been accumulated, the model can evaluate the state values more accurately, and the loss decreases rapidly.
From Fig. 12, the Total Reward curve grows slowly in the early stage of training, gradually increases as the training progresses, and finally stabilizes. The reward curve directly reflects the performance changes of the policy during the PPO algorithm training process. The low rewards in the early stage indicate that the policy is still in the exploration stage and the model has not yet learned effective action strategies. As the training proceeds, the model gradually optimizes the action strategies and can obtain higher cumulative rewards. The gradual entry into the stable period indicates that the policy is close to the optimal state and the model’s learning of the environment tends to be saturated.
In this paper, the Tacview simulation software is used to replay the combat scenes and trajectories of each round. Tacview is a powerful flight data visualization and analysis software that can display and replay in real time parameters such as the flight trajectories, attitudes, speeds, and altitudes of aircraft, reproduce combat scenes, and show the positions and actions of participating aircraft, missiles and other weapons. The 1v1 simulation trajectory diagram is shown in Fig. 13. From the figure, it can be observed that the two aircraft initially fly towards each other. As time progresses, they engage in mutual attacks and successfully evade missiles by adopting strategies, while simultaneously adjusting their trajectories to prepare for counterattacks.

1v1 simulation trajectory diagram.
On this basis, the scale is expanded to 2v2 and 4v4. Under the same parameter settings, only the number of agents is changed for training. The training duration and the size of the strategy space are shown in the following table.

Comparison table of training with different scales.
As shown in Fig. 14, the training in the 1v1 scenario took 3394 min. However, after expanding to the 4v4 scenario, the training time increased to 15,603 min, which is approximately five times longer. The size of the strategy space grows exponentially. The interactions among agents will lead to nonlinear complexity in the combination of strategies, causing the growth of the strategy space to far exceed the linear scale. Multi-agent reinforcement learning usually needs to simulate complex environments and conduct large-scale parallel computations simultaneously. This imposes higher requirements on hardware resources. Especially in high-dimensional strategy spaces, the number of model parameters and the amount of computation increase exponentially.
8v8 Multi-aircraft game
Parameter settings
In order to evaluate the decision-making ability of the algorithm in this paper in the multi-aircraft air game problem, the following comparative experiments are carried out. In this experiment, it is assumed that our eight aircraft are on the red side and the eight encountered aircraft are on the blue side. At the start of the battle, both sides have already detected each other, and all aircraft have the same initial states, including initial speed, altitude, etc. Each aircraft carries 4 missiles, and the aircraft execute tactics such as tracking the blue side, evading missiles, and launching missiles to shoot down the blue side’s aircraft. When all the aircraft on one side are shot down, the other side wins. The experimental parameters are detailed in Table 4.
Analysis of simulation results
Our side uses the multi-layer control algorithm as the maneuvering strategy, and the average win rate and failure rate are shown in the figure. The comparison of the average win rates of the three maneuvering strategies is shown in the figure, and the comparison of the average rewards is also shown in the figure.

Comparison diagram of the variation of the average objective function with three networks as the top-level control.

Comparison diagram of the variation of the average reward with three networks as the top-level control.

Comparison diagram of the variation of the win rate with three networks as the top-level control.

Comparison diagram of the variation of the optimal solution with three networks as the top-level control.

Comparison of training time among different networks.
Judging from the experimental results in Fig. 15, the average objective function of the top-level control using the GraphSAGE network gradually stabilizes between 0 and − 4 after a brief exploration and optimization. This indicates that through exploration and optimization, our side has learned effective strategies and can continuously achieve victories.
Judging from Fig. 16, the changes in rewards are not significant. This is because we trained it on the basis of expanding the 1v1 model into an 8v8 one. However, it can still be clearly seen from the figure that the rewards obtained using the GraphSAGE network are higher than those of other networks.
From the experimental results in Fig. 17, the win rates of the three networks are not high in the early stage of training. As the optimization and exploration progress, the win rates of the three networks gradually increase. Among them, when the top-level control using the GraphSAGE network is adopted, the win rate curve rises the fastest and gradually stabilizes and tends to 80%. This shows that our side has gradually formed effective winning strategies after the early exploration and has gained an overwhelming advantage over the blue side.
From the experimental results in Fig. 18, the optimization objectives of the three networks all tend to be stable in the early stage of training. Comparatively speaking, the MLP and GraphSAGE networks have better performance than the GCN network. The former two basically maintain all negative values and relatively quickly explore the optimal optimization objectives and continue to optimize stably. When the GCN network is adopted, the exploration is slower, and it takes multiple stages of optimization to explore the optimal optimization objective, and the effect is poorer.
In terms of training duration, as shown in Fig. 19, the training speed of the MLP network is the fastest, followed by that of the GraphSAGE network, and the GCN network is the slowest. Based on the above comprehensive analysis and comparison, although the MLP network has advantages in training speed and exploration speed, its win rate is not high. The GCN network is not only slow in training speed and exploration speed but also has the lowest win rate. In contrast, the GraphSAGE network is only slightly inferior in training speed, and it has advantages in both exploration speed and win rate. Overall, it has the best performance.
In order to observe the combat effect more intuitively, we will demonstrate the game process, use Tacview to display the dynamic trajectories of the game, and judge the rationality of the trajectories.
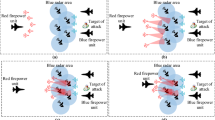
At the beginning of the battle, under the threat of the blue side’s missiles, the red side launches missiles to counterattack. All the red side’s aircraft are locked by missiles and adopt maneuvering strategies to avoid the missiles. Some of the blue side’s aircraft are locked by missiles and avoid the missiles, while some are not locked and pursue the red side. While both sides are avoiding missiles, they change their headings, climb in altitude, and occupy favorable attack angles.
As shown in Fig. 20, at the beginning of the battle, the blue side’s aircraft launched a rapid attack and fired multiple missiles at the red side, forcing the red side into an emergency response state. The red side’s aircraft were locked by missiles, so they urgently launched counterattack missiles and simultaneously adopted maneuvering strategies to evade the incoming missiles. These strategies included making sharp turns, diving or climbing to change their own trajectories and reduce the probability of being hit. The red side’s aircraft showed a high degree of coordination, maintaining a relatively safe distance from each other and making rapid tactical movements.
At the same time, some of the blue side’s aircraft were also locked by missiles and took evasive actions. They tried to avoid missile attacks by making sharp lateral maneuvers, rapid climbs or dives. For those blue side’s aircraft that were not locked by missiles, they quickly changed their headings and used flexible maneuvering strategies to pursue the red side, attempting to find suitable attack angles.
As shown in Fig. 21, as the battle progressed, the altitudes and headings of the aircraft on both sides were constantly changing. While evading missiles, the red side’s aircraft flexibly adjusted their headings and altitudes to find more favorable attack angles. Some aircraft chose to increase their altitudes, attempting to occupy the commanding heights so that they could have a larger field of vision and attack range in subsequent counterattacks. Meanwhile, another part of the red side’s aircraft lowered their flight altitudes, using the terrain for cover and attempting to launch surprise attacks in the blind spots of the blue side’s aircraft.
The aircraft of the red side and the blue side began to engage in a fierce aerial game in the air, and the distance between them gradually narrowed. As shown in Fig. 22, when facing being surrounded by multiple missiles, the red side’s aircraft chose to fly away from the formation and use single aircraft as decoys. As shown in Fig. 23, when evading missiles, the red side’s aircraft adopted the sideslip - dive - turn strategy. When detecting the incoming missiles, they first performed a sideslip, that is, the aircraft fuselage tilted to one side while keeping the flight direction basically unchanged. Then, they quickly dived to increase the distance from the missiles. After diving for a certain distance, they changed the flight direction to further get rid of the missile tracking.
Finally, while evading missiles, the red side’s aircraft gradually narrowed the distance with the blue side, seized the opportunity to launch missiles and shot down all the blue side’s aircraft to achieve the final victory.

Simulation trajectory diagram at the initial stage of the battle.

Simulation trajectory diagram in the middle stage of the battle.

Single aircraft decoy missile.

Missile evasion.
Conclusion
In the field of intelligent aerial games, the autonomous decision-making problem in large-scale multi-aircraft engagements has consistently been a hotspot and a challenging area of research. To address the critical issue of adapting to the scale explosion and computational complexity caused by the increasing number of agents in highly dynamic and uncertain large-scale intelligent aerial combat scenarios while maintaining a high win rate, this paper constructs simulation environments for 1v1 and 8v8 red-versus-blue engagements.
We decompose the problem and propose a hierarchical decision-making framework, dividing the strategies into missile-firing strategies and maneuver-generation strategies, and implement this framework using a novel GraphZero-PPO algorithm. The GraphZero module abstracts the complex aerial combat scenarios into graph structures, where a GraphSAGE network is utilized for missile-firing decision-making, effectively reducing decision-making pressure. Additionally, a zero-order optimization algorithm is employed to rapidly search for global optimal solutions.
A reward function tailored to the complex requirements of aerial combat tasks is designed, taking into account multidimensional factors such as attack accuracy, survival status, and tactical execution. This design accurately evaluates the performance of aircraft during engagements, providing precise guidance for the decision-making algorithm.
To comprehensively evaluate the decision-making capabilities of the proposed GraphZero-PPO algorithm, multiple simulation experiments are conducted. These include simulations of different scales (1v1 and 8v8) and comparative simulations using different algorithms as top-level controllers. The experimental results demonstrate that the proposed method not only exhibits outstanding performance in large-scale aerial engagements but also achieves a high win rate. The generated strategies include complex and effective tactics such as coordinated attacks and deception maneuvers, which work seamlessly to significantly enhance the decision-making capabilities of the aircraft.
Despite these achievements, the current research has limitations. The focus on the 8v8 scenario may hinder its direct application to larger - scale air combat. As the number of aircraft increases, the exponential growth of state and action spaces, along with more complex agent relationships, poses challenges to the existing algorithm’s architecture and information - processing mechanisms.
Looking ahead, we plan to optimize the algorithmic framework. This involves enhancing the performance of graph - based models to better handle large - scale multi - agent systems and improving the zero - order optimization algorithm to balance computational cost and optimization effectiveness. We will also integrate dynamic airspace conditions into the model to make it more realistic. Additionally, we aim to conduct in - depth comparative studies with mainstream multi - agent algorithms such as QMIX and MATD3 in a unified experimental environment. These efforts are expected to further improve the algorithm’s performance and contribute to the development of intelligent aerial combat technology.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Garcia, E. et al. Multiple pursuer multiple evader differential games[J]. IEEE Trans. Autom. Control. 66 (5), 2345–2350 (2020).
Mishley, A. & Shaferman, V. Linear quadratic guidance laws with intercept angle constraints and varying speed adversaries[J]. J. Guidance Control Dynamics. 45 (11), 2091–2106 (2022).
Ruan, W., Duan, H. & Deng, Y. Autonomous maneuver decisions via transfer learning pigeon-inspired optimization for UCAVs in dogfight engagements[J]. IEEE/CAA J. Automatica Sinica. 9 (9), 1639–1657 (2022).
Li, S. et al. Threat sequencing of multiple UCAVs with incomplete information based on game theory[J]. J. Syst. Eng. Electron. 33 (4), 986–996 (2022).
Burgin, G. H., Fogel, L. J. & Phelps, J. P. An Adaptive Maneuvering Logic Computer Program for the Simulation of one-on-one air-to-air Combatvolume 1 (General description[R]. NASA, 1975).
Bloom, P. C. & Chung, Q. B. Lessons learned from develo** a mission-critical expert system with multiple experts through rapid prototy**[J]. Expert Syst. Appl. 20 (2), 217–227 (2001).
Geng, W. & Ma, D. Study on tactical decision of UAV medium-range air combat[C]//The 26th Chinese Control and Decision Conference (2014 CCDC). IEEE, : 135–139. (2014).
Crumpacker, J. B., Robbins, M. J. & Jenkins, P. R. An approximate dynamic programming approach for solving an air combat maneuvering problem[J]. Expert Syst. Appl. 203, 117448 (2022).
Wang Xing, H. & Zelong, Z. Y. Architecture and technologies of the U.S. Intelligent missile air combat system [J]. Aerodynamic Missile J. (11), 91–97. https://doi.org/10.16338/j.issn.1009-1319.20200311 (2021).
He Jiafan, W. et al. Application of deep reinforcement learning technology in intelligent air combat [J]. Command Inform. Syst. Technol. 2021, 12(05):6–13 .https://doi.org/10.15908/j.cnki.cist.2021.05.002
Zhang Ye, T. et al. Current Situation and Prospect of Deep Reinforcement Decision-making Methods in Intelligent Air Combat [J]. Aero Weaponry,2024,31(03):21–31.
Mnih, V. et al. Human-level control through deep reinforcement learning[J]. Nature 518 (7540), 529–533 (2015).
Williams, R. J. On the use of backpropagation in associative reinforcement learning[C]//ICNN. : 263–270. (1988).
Barto, A. G., Sutton, R. S. & Anderson, C. W. Neuronlike adaptive elements that can solve difficult learning control problems[J]. IEEE Trans. Syst. Man. Cybernetics, (5): 834–846. (1983).
Schulman, J. Trust Region Policy Optimization[J]. arxiv preprint arxiv:1502.05477, (2015).
Schulman, J. et al. Proximal policy optimization algorithms[J]. arxiv preprint arxiv:1707.06347, (2017).
Lillicrap, T. P. Continuous control with deep reinforcement learning[J]. arxiv preprint arxiv:1509.02971, (2015).
Shan Shengzhe, Z. Weiwei. An intelligent Decision-making method for air combat based on Self-play deep reinforcement learning [J]. Acta Aeronautica Et Astronaut. Sinica 2024, 45(04):206–218 .
Luo, D. et al. Multi-UAV cooperative maneuver decision-making for pursuit-evasion using improved MADRL[J]. Def. Technol. 35, 187–197 (2024).
Ruichi, Y. et al. A collaborative countermeasure Decision-making method for heterogeneous UAV swarms based on Self-play reinforcement learning [J]. Scientia Sinica Informationis 2024, 54(07):1709–1729 .
Ou Yang, G. et al. A collaborative air combat maneuver Decision-making method based on graph convolutional deep reinforcement learning [J]. J. Univ. Sci. Technol. Beijing 2024, 46(07):1227–1236 .https://doi.org/10.13374/j.issn2095-9389.2023.09.25.004
Baolai Wang, X. & Gao Tao Xie,An evolutionary multi-agent reinforcement learning algorithm for multi-UAV air combat,Knowledge-Based Systems,Volume 299,2024,112000,ISSN 0950–7051,https://doi.org/10.1016/j.knosys.2024.112000
Yangqi, L. Duan Haibin. Multi-UAV game Decision-making based on reinforced competitive learning and pigeon swarm optimization [J]. Scientia Sinica Technologica 2024, 54(01):136–148 .
Yu, Y., Qian, H. & Hu, Y. Q. Derivative-free optimization via classification[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 30(1). (2016).
Author information
Authors and Affiliations
Contributions
Lin Huo: Conceptualization, methodology, software, validation, formal analysis, investigation, resources, writing—review and editing; Chudi Wang: writing—original draft preparation; Yue Han: visualization, supervision, project administration, funding acquisition.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Huo, L., Wang, C. & Han, Y. Autonomous air combat decision making via graph neural networks and reinforcement learning. Sci Rep 15, 16169 (2025). https://doi.org/10.1038/s41598-025-00463-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-00463-y
Keywords
This article is cited by
-
Cooperative Air Combat between High-Performance Manned Fighters and Low-Performance UAVs
International Journal of Aeronautical and Space Sciences (2026)
